Embed Size (px)
Citation preview

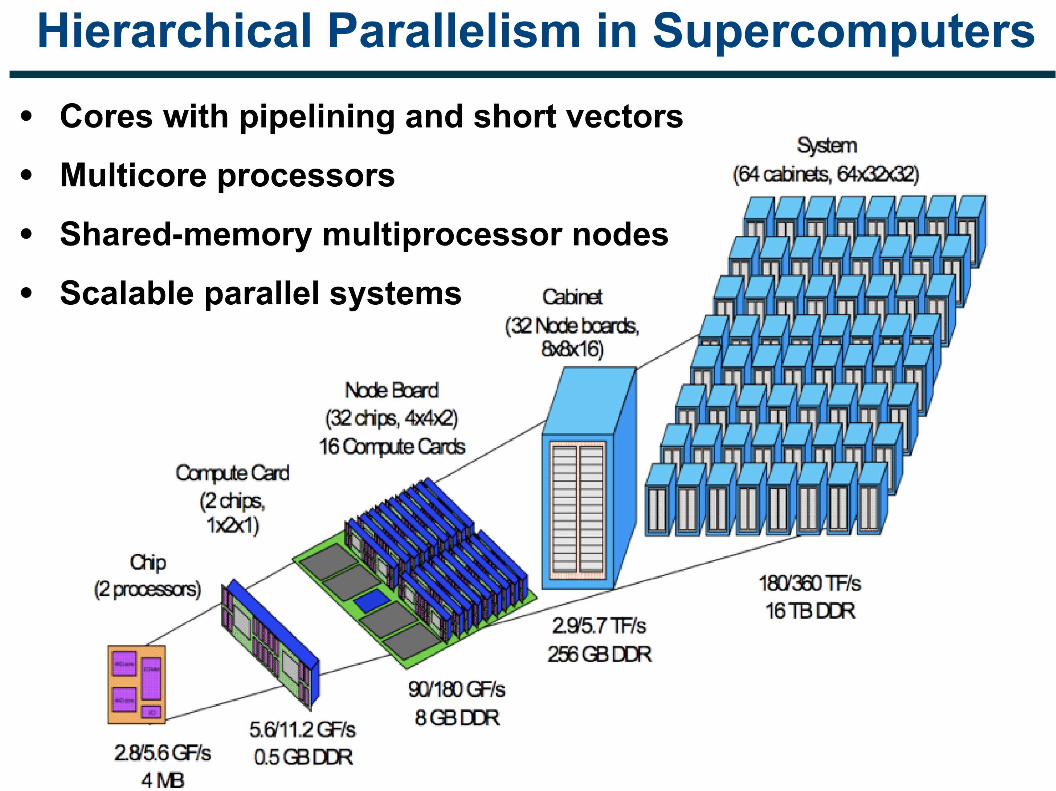
Parallel Architectures

Part 1:
The rise of parallel machines



Early Multicore Processors



SUN UltraSPARC T1/T2
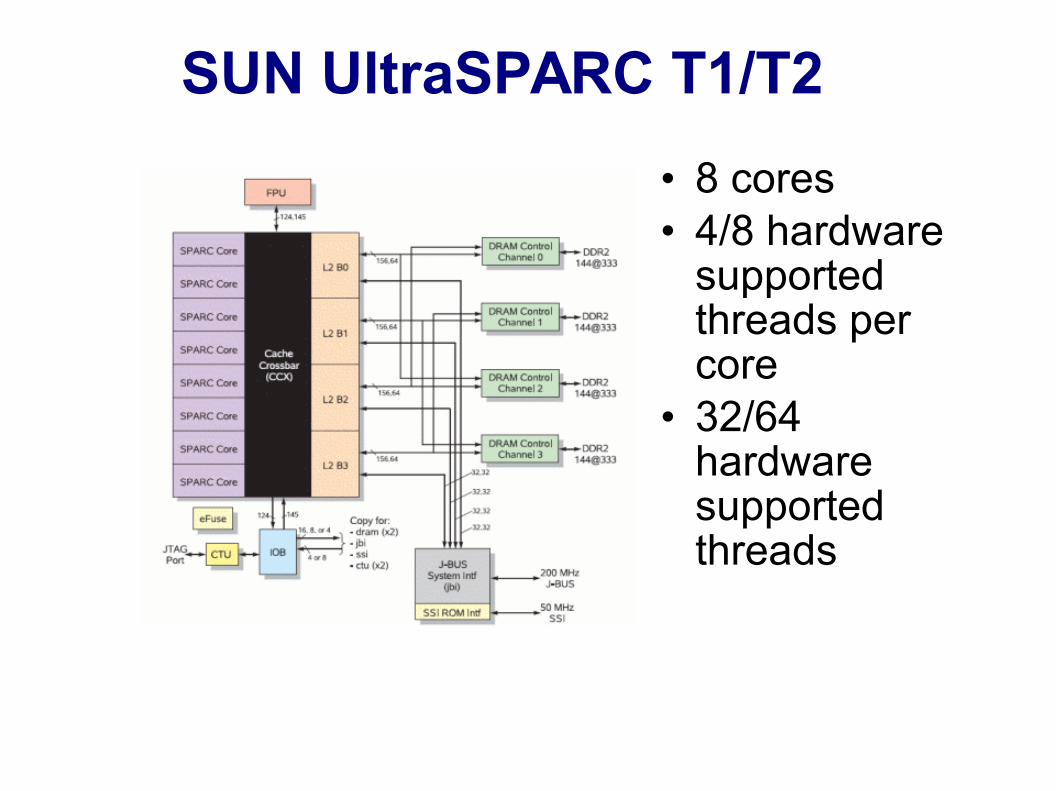
SUN UltraSPARC T1/T2
• 8 cores• 4/8 hardware
supported threads per core
• 32/64 hardware supported threads


IBM Cell processor
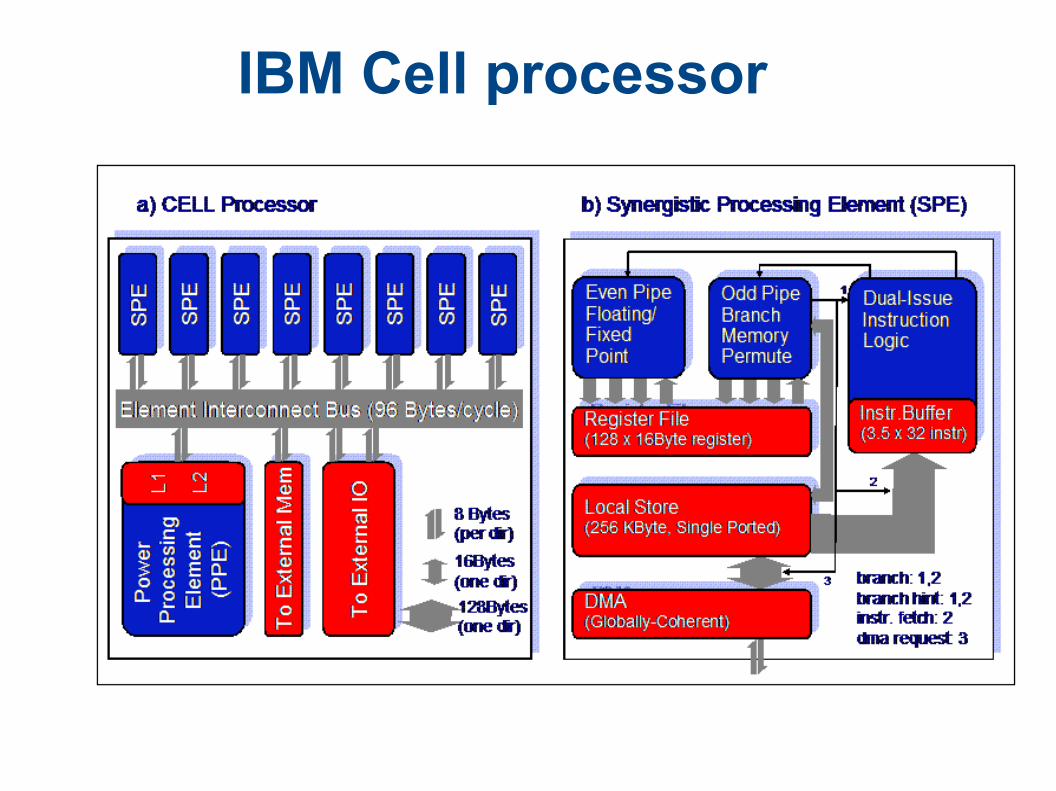
IBM Cell processor

Current Multicore Processors

Intel Core i9
Core i9-7920X: 12 cores/24 threads,16.5MB cache, 140W, 44 PCIe lanes
Core i9-7900X: 10 cores/20 threads, 3.3-4.3GHz, 13.75MB cache, 140W, 44 PCIe lanes
Core i9-7820X: 8 cores/16 threads, 3.6-4.3GHz, 11MB cache, 140W, 28 PCIe lanes
Core i9-7800X: 6 cores/12 threads, 3.5-4GHz, 8.25MB cache, 140W, 28 PCIe lanes

AMD Ryzen 9
Ryzen 9 1998X: 16 cores/32 threads, 3.5-to-3.9GHz, 155W
Ryzen 9 1998: 16 cores/32 threads, 3.2-to-3.6GHz, 155W
Ryzen 9 1977X: 14 cores/28 threads, 3.5-to-4.1GHz, 155W
Ryzen 9 1977: 14 cores/28 threads, 3.2-to-3.7GHz, 140W
Ryzen 9 1976X: 12 cores/24 threads, 3.6-to-4.1GHz, 140W
Ryzen 9 1956X: 12 cores/24 threads, 3.2-to-3.8GHz, 125W
Ryzen 9 1956: 12 cores/24 threads, 3.0-to-3.7GHz, 125W
Ryzen 9 1955X: 10 cores, 3.6-to-4.0GHz, 125W
Ryzen 9 1955: 10 cores, 3.1-to-3.7GHz, 125W

GPUs

NVIDIA Titan XP
3840 NVIDIA CUDA cores
running at 1.6 GHz
12 TFLOPS
12 GB of GDDR5X memory

NVIDIA GeForce GTX
GEFORCE GTX 1080 Ti:
3584 NVIDIA CUDA cores
running at 1.58 GHz.
11 GB of GDDR5X memory.
GEFORCE GTX 1080:
2560 NVIDIA CUDA cores
running at 1.6 GHz.
8 GB of GDDR5X memory.
...
GEFORCE GTX 950:
768 NVIDIA CUDA cores
running at 1 GHz.
2 GB of GDDR5X memory.
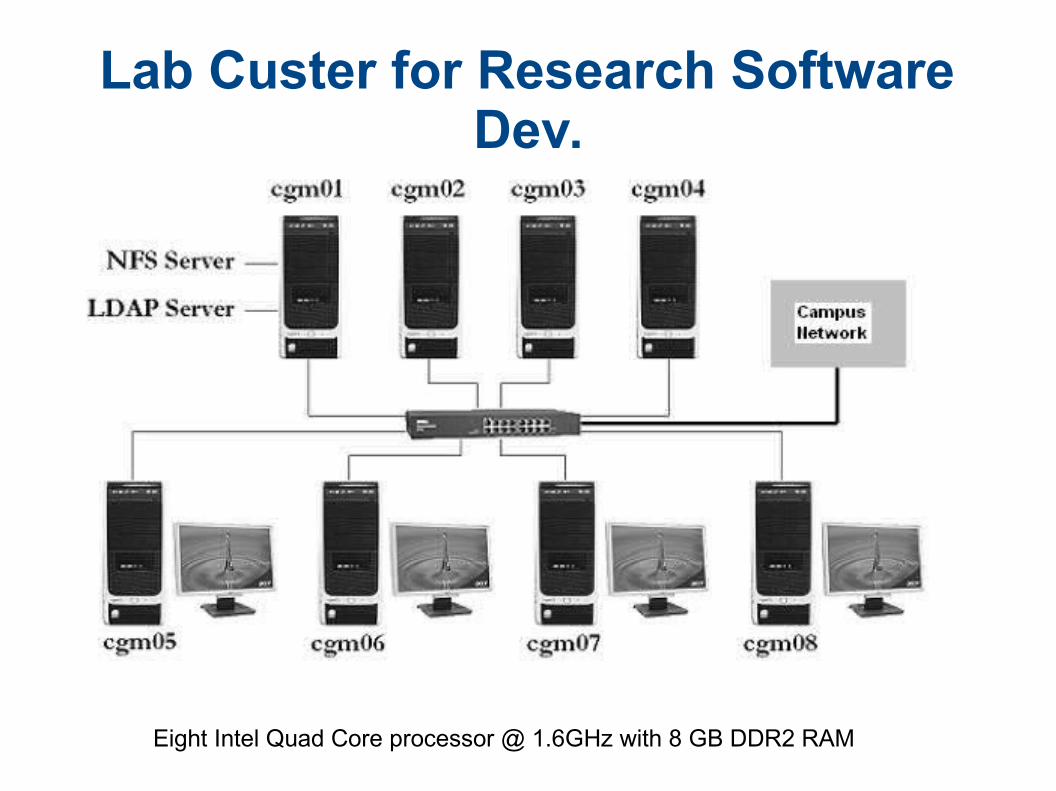
Lab Custer for Research Software Dev.
Eight Intel Quad Core processor @ 1.6GHz with 8 GB DDR2 RAM



Part 2:
Taxonomies for Parallel Architectures

Taxonomies for Parallel Architectures
• Floyd’s Taxonomy - program control and memory access
• Taxonomy Based on Memory Organization• Taxonomy Based on Processor Granularity• Taxonomy Based on Processor
Synchronization• Taxonomy Based on Interconnection
Architecture

Floyd’s Taxonomy
• Computer architectures:– SISD– MISD– SIMD– MIMD
• Based on method of program control and memory access
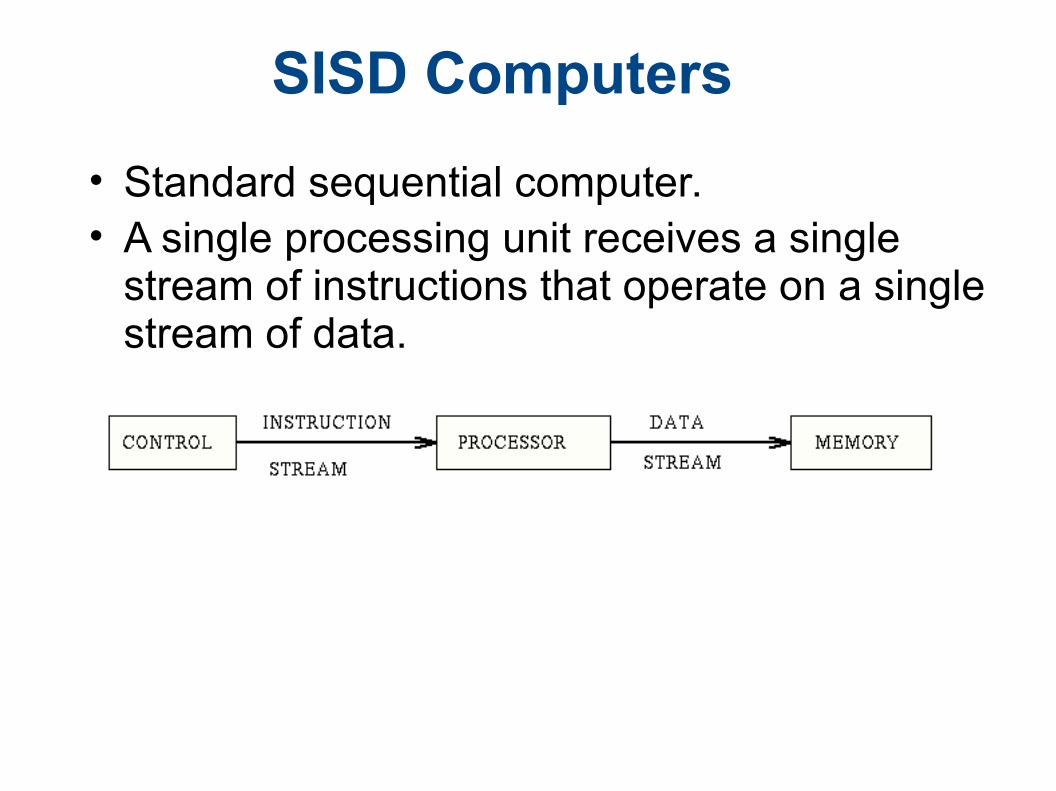
SISD Computers
• Standard sequential computer. • A single processing unit receives a single
stream of instructions that operate on a single stream of data.
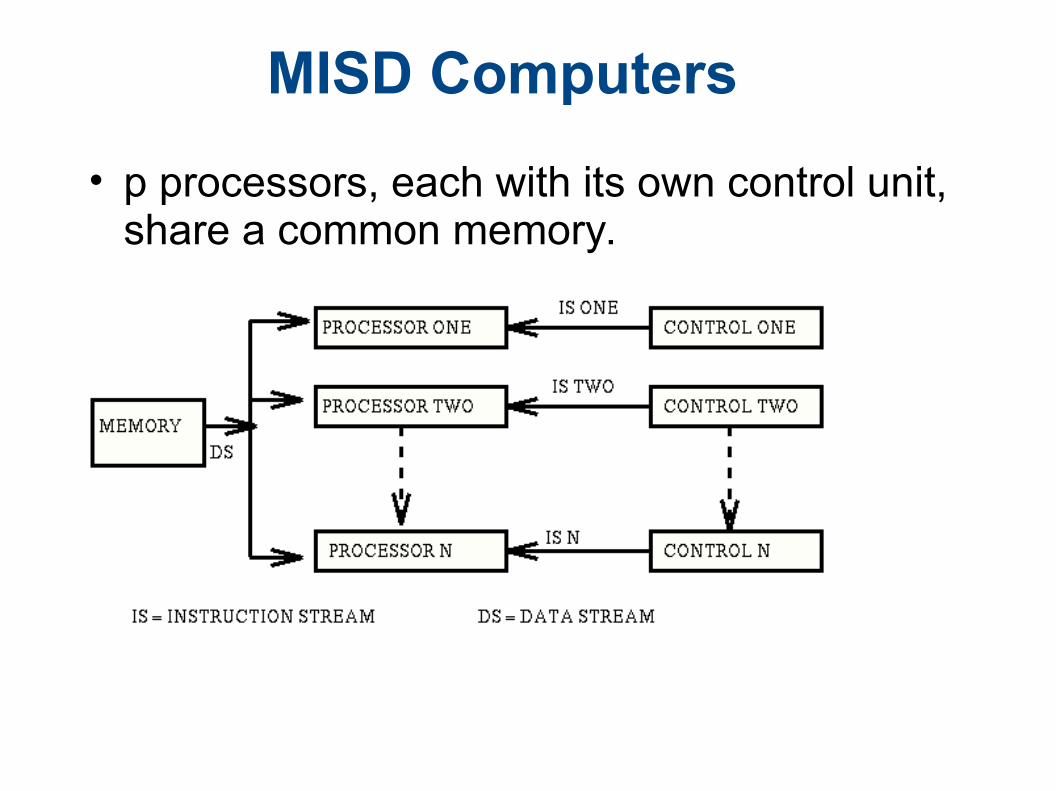
MISD Computers
• p processors, each with its own control unit, share a common memory.
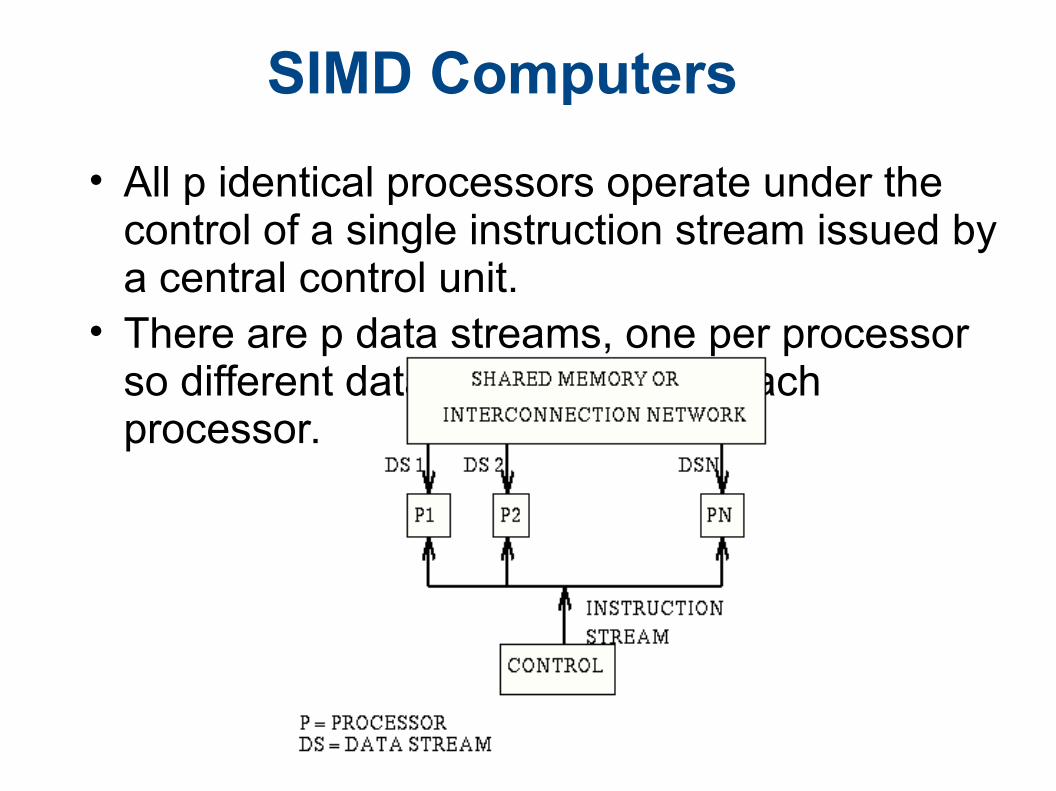
SIMD Computers
• All p identical processors operate under the control of a single instruction stream issued by a central control unit.
• There are p data streams, one per processor so different data can be used in each processor.
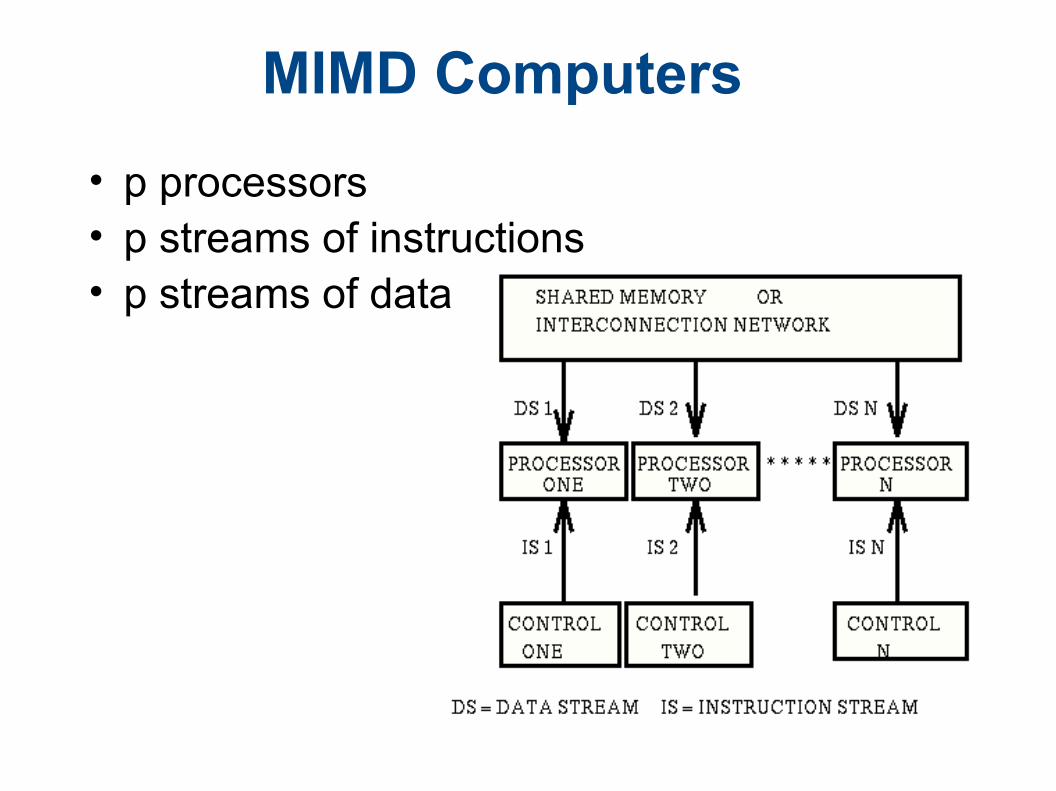
MIMD Computers
• p processors• p streams of instructions• p streams of data

Taxonomy Based on Memory Organization
• Distributed memory • Shared memory– UMA– NUMA
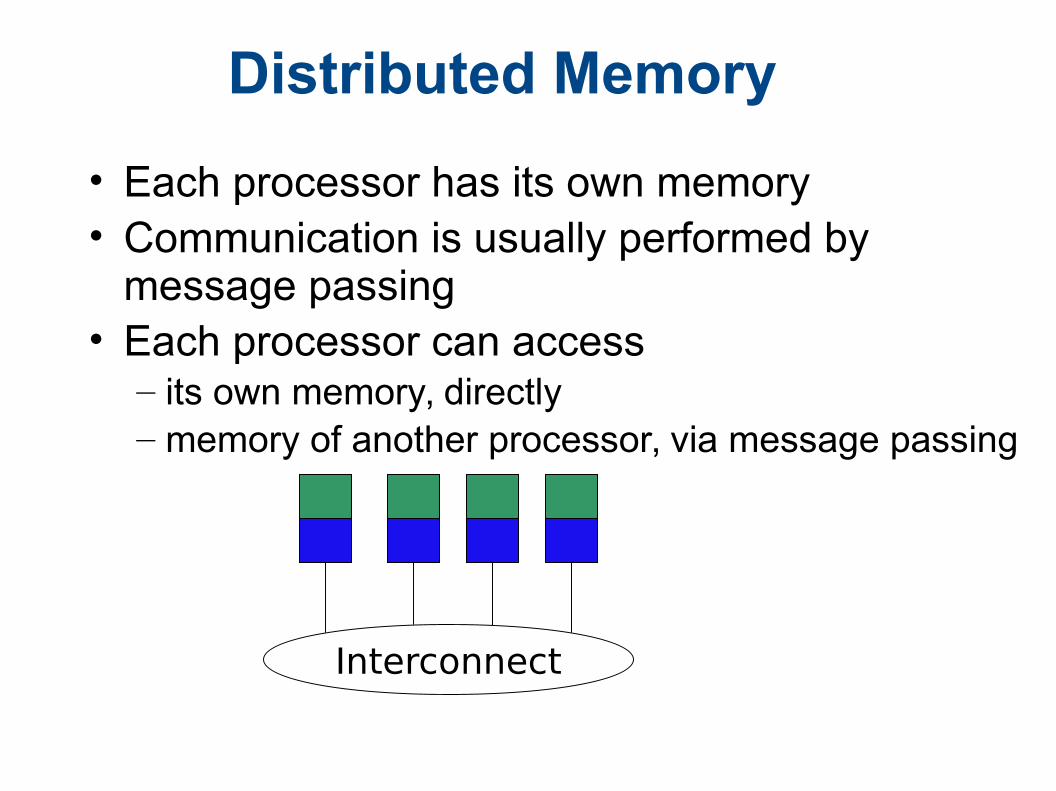
Distributed Memory
• Each processor has its own memory• Communication is usually performed by
message passing• Each processor can access – its own memory, directly – memory of another processor, via message passing
Interconnect
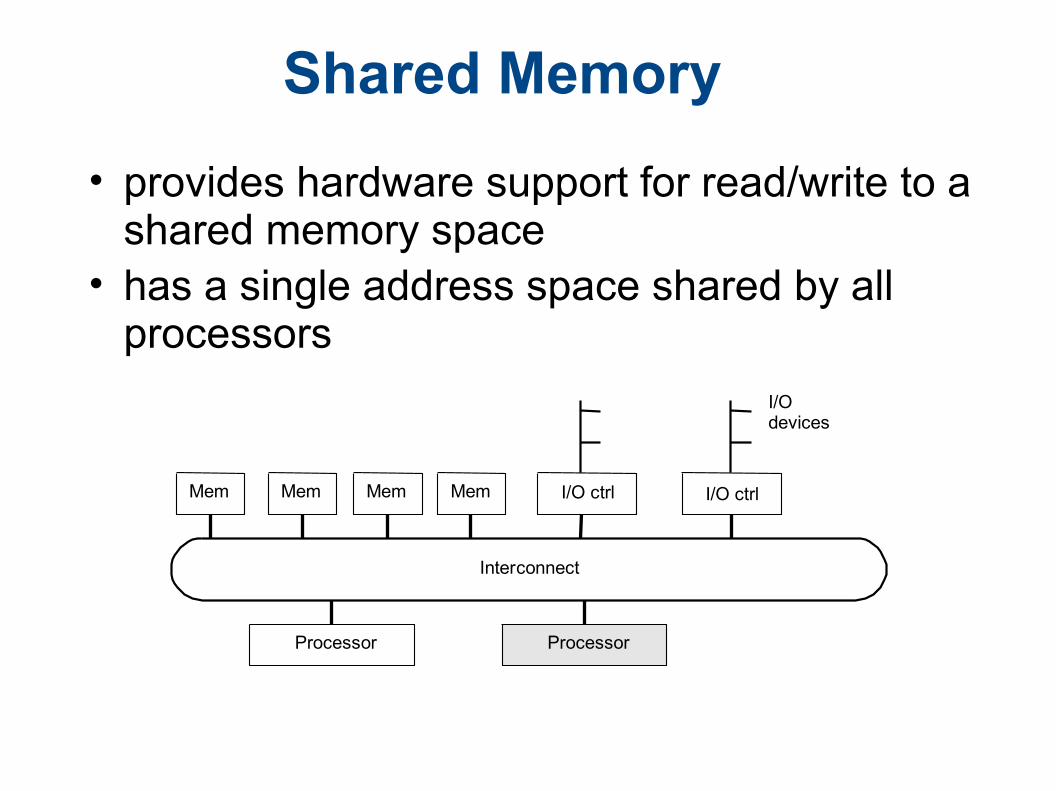
Shared Memory
• provides hardware support for read/write to a shared memory space
• has a single address space shared by all processors
I/O ctrlMem Mem Mem
Interconnect
Mem I/O ctrl
Processor Processor
Interconnect
I/Odevices

Scaling Up…
– Problem is interconnect: cost (crossbar) or bandwidth (bus)
– Dance-hall: bandwidth still scalable, but lower cost than crossbar• latencies to memory uniform, but uniformly large
– Distributed memory or non-uniform memory access (NUMA)• Construct shared address space out of simple message
transactions across a general-purpose network (e.g. read-request, read-response)
– Caching shared (particularly nonlocal) data?

Taxonomy Based on Processor Granularity
• Coarse Grained: Few powerful processors• Fined Grained: Many small processors
(massively parallel)• Medium Grained: …between the two...

Taxonomy Based on Processor Synchronization
• Asynchronous: Processors run on independent clocks. User has synchronize via message passing or shared variable.
• Fully Synchronous: Processors run in sync on one global clock.
• Bulk-synchronous: Hybrid. Processors have independent clocks. Support is provided for global synchronization to be called by the user’s application program.
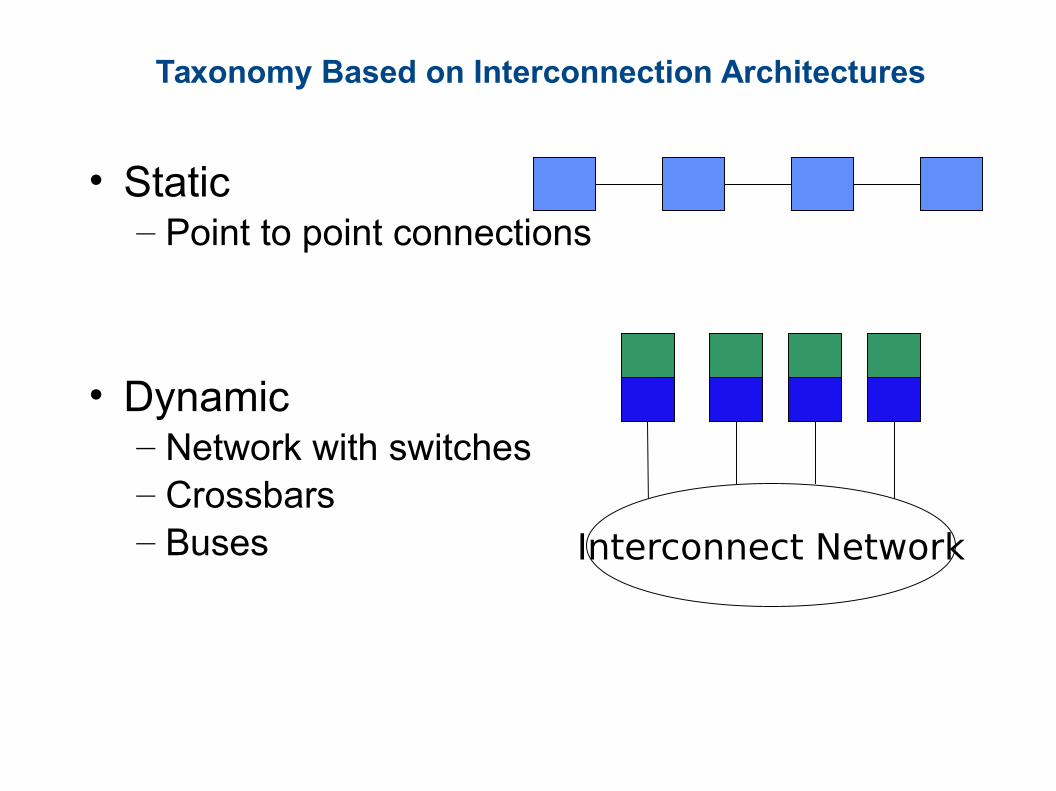
Taxonomy Based on Interconnection Architectures
• Static – Point to point connections
• Dynamic– Network with switches – Crossbars– Buses Interconnect Network
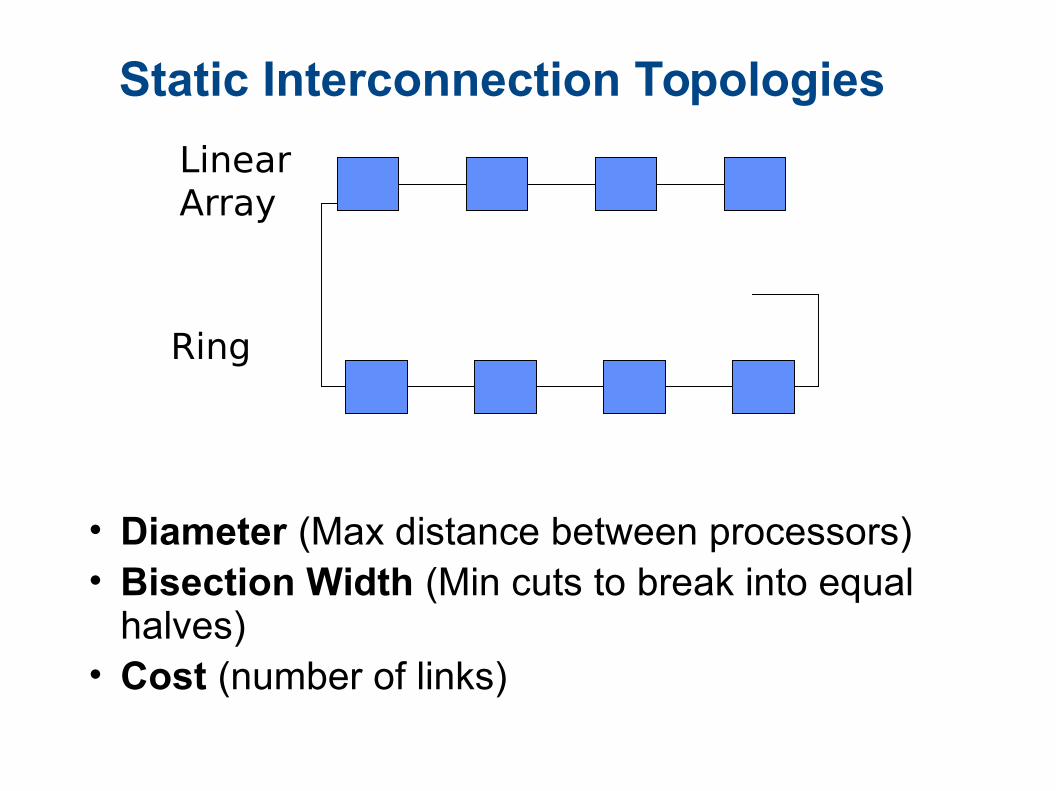
Static Interconnection Topologies
• Diameter (Max distance between processors)• Bisection Width (Min cuts to break into equal
halves)• Cost (number of links)
Linear Array
Ring
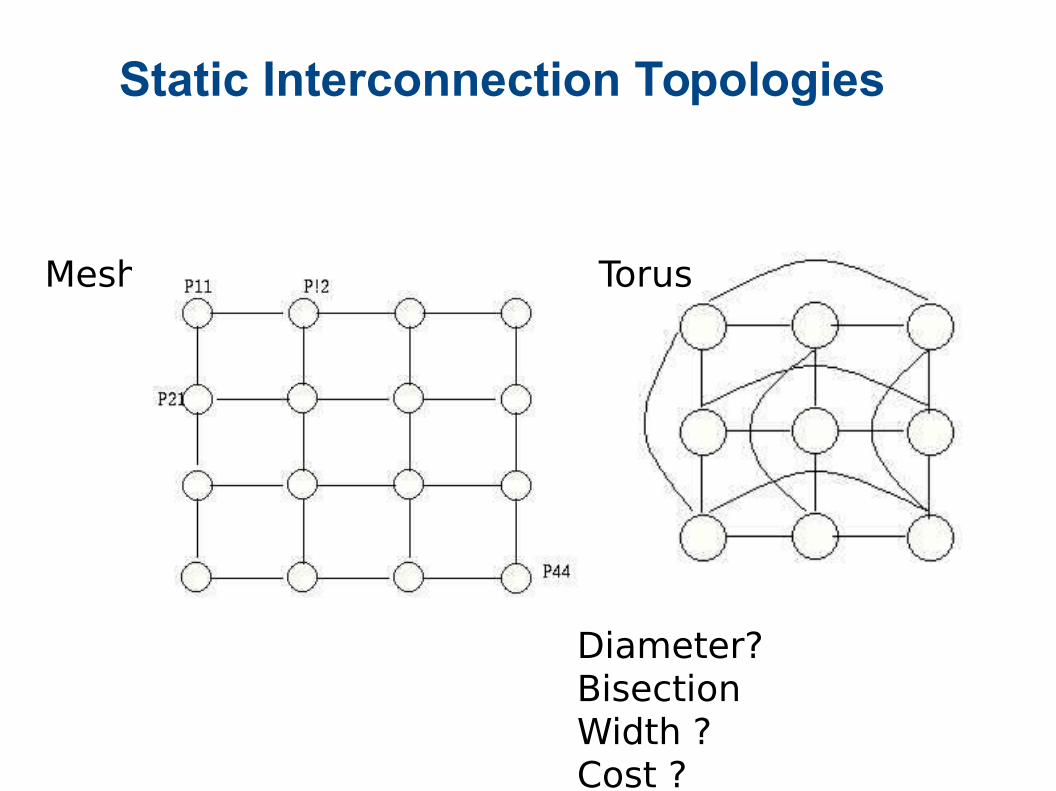
Static Interconnection Topologies
Mesh Torus
Diameter?Bisection Width ?Cost ?
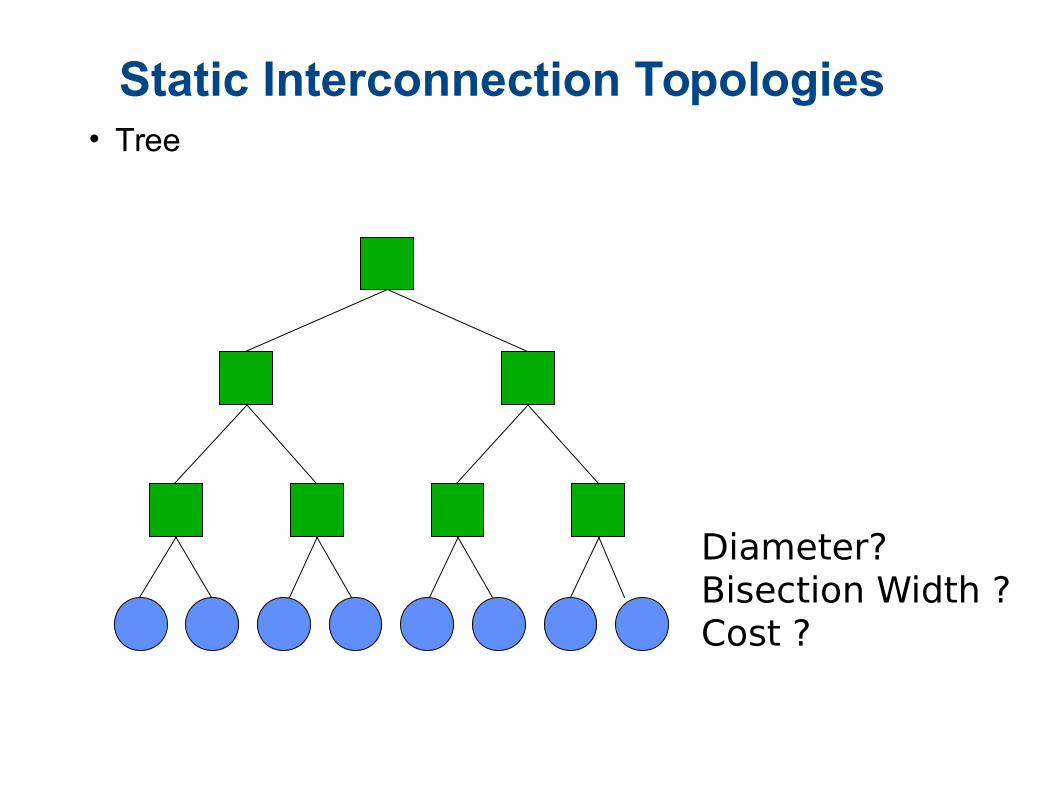
Static Interconnection Topologies• Tree
Diameter?Bisection Width ?Cost ?
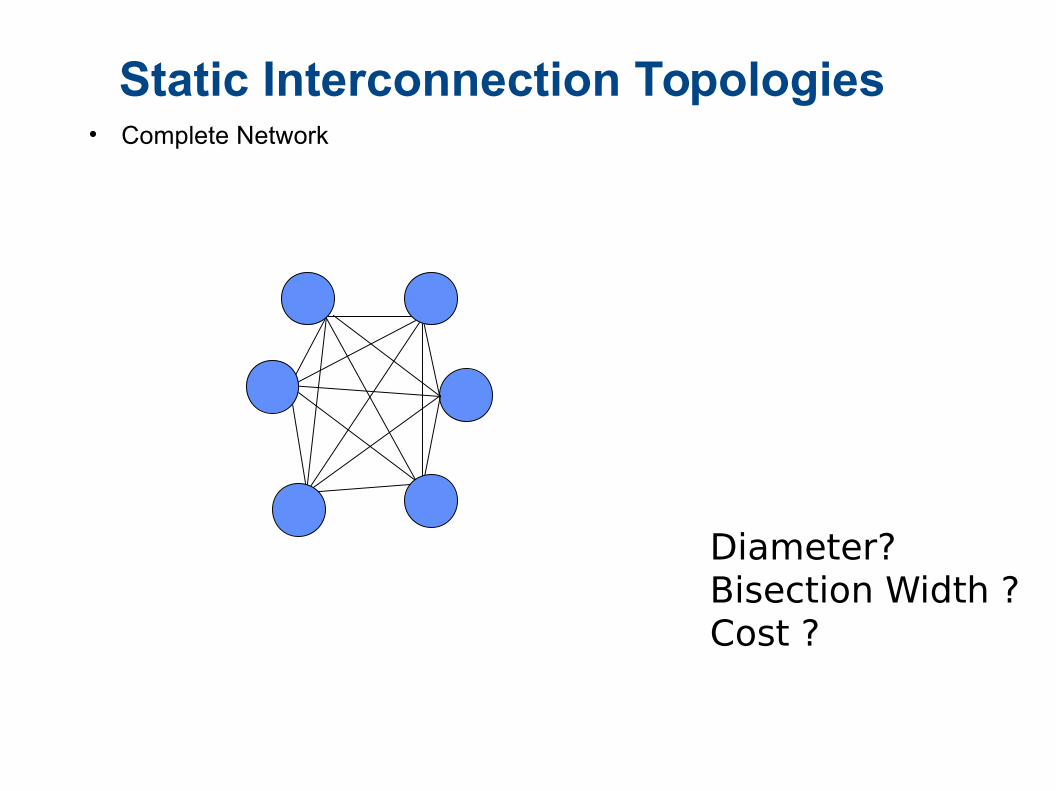
Static Interconnection Topologies• Complete Network
Diameter?Bisection Width ?Cost ?
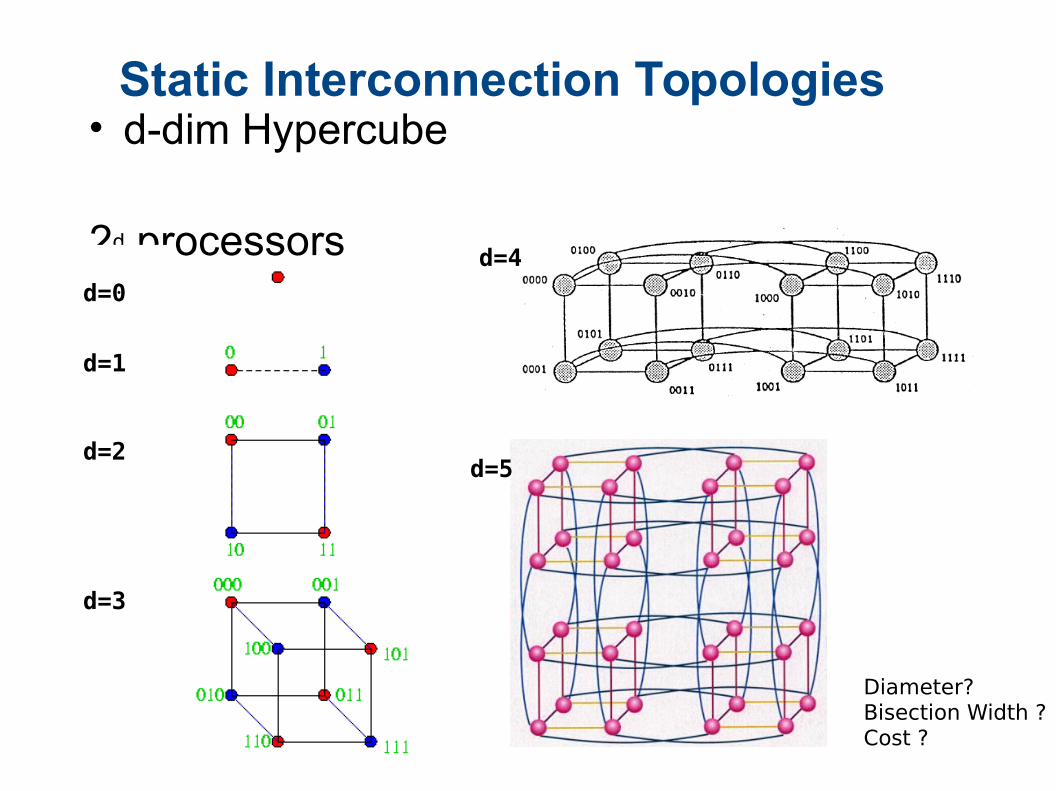
Static Interconnection Topologies• d-dim Hypercube
2d processors
Diameter?Bisection Width ?Cost ?
d=0
d=1
d=2
d=3
d=5
d=4
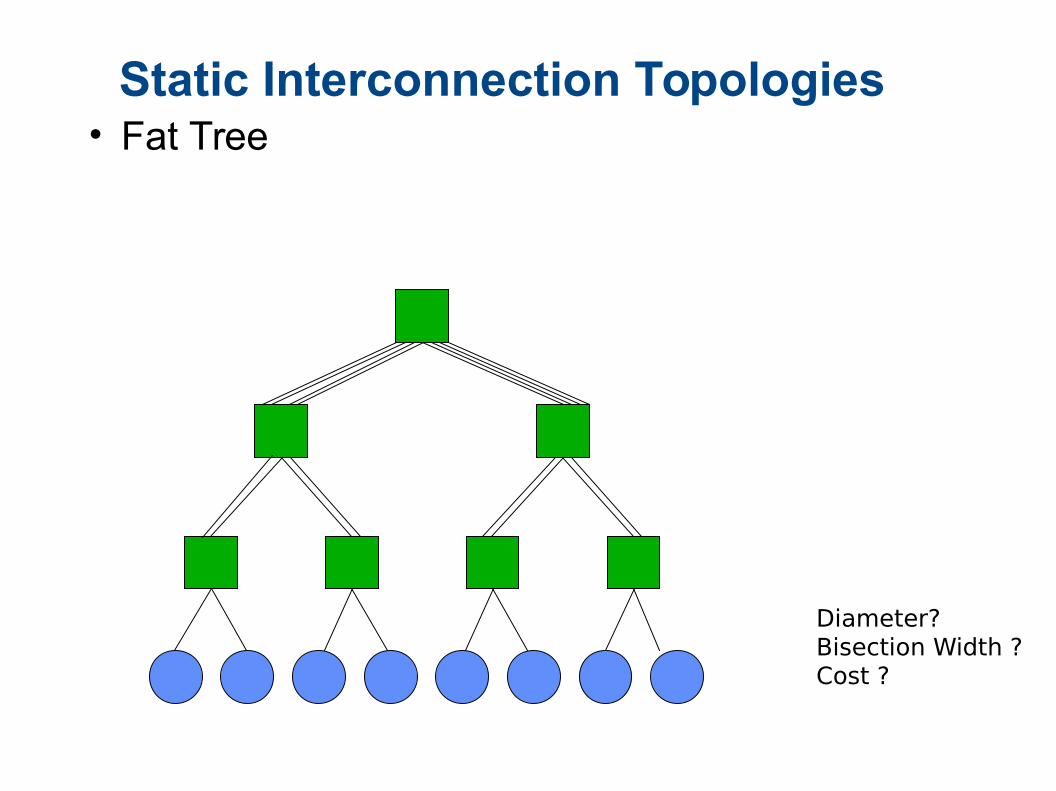
Static Interconnection Topologies• Fat Tree
Diameter?Bisection Width ?Cost ?
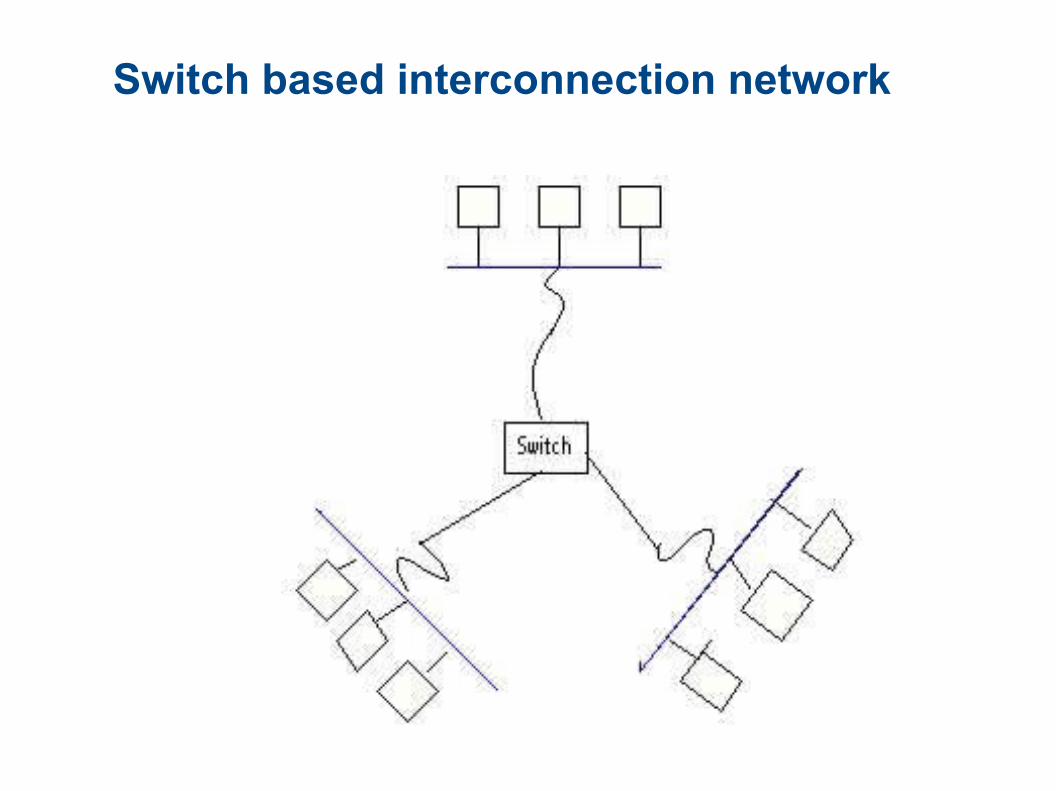
Switch based interconnection network

Summary

massively parallelclusters
Taxanomy of parallel machines
Distributedmemory
Shared memory
MIMD SIMD
coarse grainedclusters
multi-coreGPU
Fine grained
Coarse grained
• Massively parallel cluster (MIMD, distributed memory, fine grained)
• Coarse grained cluster (MIMD, distributed memory, coarse grained)
• Multi-core processor (MIMD, shared memory, coarse grained)
• GPU (SIMD, shared memory, fine grained)





























