Embed Size (px)
Citation preview

Operating system support for multimedia systems
T. Plagemanna,* , V. Goebela, P. Halvorsena,1, O. Anshusb,2
aUniK-Center for Technology at Kjeller, University of Oslo, NorwaybDepartment of Computer Science, Princeton University, Princeton NJ, USA
Abstract
Distributed multimedia applications will be an important part of tomorrow’s application mix and require appropriate operating system(OS) support. Neither hard real-time solutions nor best-effort solutions are directly well suited for this support. One reason is the co-existenceof real-time and best effort requirements in future systems. Another reason is that the requirements of multimedia applications are not easilypredictable, like variable bit rate coded video data and user interactivity. In this article, we present a survey of new developments in OSsupport for (distributed) multimedia systems, which include: (1) development of new CPU and disk scheduling mechanisms that combinereal-time and best effort in integrated solutions; (2) provision of mechanisms to dynamically adapt resource reservations to current needs; (3)establishment of new system abstractions for resource ownership to account more accurate resource consumption; (4) development of newfile system structures; (5) introduction of memory management mechanisms that utilize knowledge about application behavior; (6) reductionof major performance bottlenecks, like copy operations in I/O subsystems; and (7) user-level control of resources including communication.q 2000 Elsevier Science B.V. All rights reserved.
Keywords: Operating systems; Multimedia; Quality of service; Real-time
1. Introduction
Distributed multimedia systems and applications playalready today an important role and will be one of thecornerstones of the future information society. More speci-fically, we believe that time-dependent data types will be anatural part of most future applications, like time-indepen-dent data types today. Thus, we will not differentiate in thefuture between multimedia and non-multimedia applica-tions, but rather between hard real-time, soft real-time,and best effort requirements for performance aspects likeresponse time, delay jitter, synchronization skew, etc.Obviously, all system elements that are used by applica-tions, like networks, end-to-end protocols, databasesystems, and operating systems (OSs), have to provideappropriate support for these requirements. In this article,we focus on the OS issues on which applications, end-to-endprotocols, and database systems directly rely. For simpli-city, we use in this article the notionmultimedia systems and
applicationswhich comprises alsodistributedmultimediasystems and applications.
The task of traditional OSs can be seen from two perspec-tives. In the top–down view, an OS provides an abstractionover the pure hardware, making programming simpler andprograms more portable. In the bottom–up view, an OS isresponsible for an orderly and controlled allocation ofresources among the various executing programs competingfor them. Main emphasis of resource management incommodity OSs, like UNIX or Windows systems, is todistribute resources to applications to reach fairness andefficiency. These time-sharing approaches work in a best-effort manner, i.e. no guarantees are given for the executionof a program other than to execute it as fast as possible whilepreserving overall throughput, response time, and fairness.
Specialized real-time OSs in turn emphasize on managingresources in such a way that tasks can be finished withinguaranteed deadlines. Multimedia applications are oftencharacterized as soft real-time applications, because theyrequire support for timely correct behavior. However, dead-line misses do not naturally lead to catastrophic conse-quences even though theQuality of Service (QoS)degrades, perhaps making the user annoyed.
Early work in the area of OS support for multimediasystems focussed on the real-time aspect to support theQoS requirements of multimedia applications. Traditionalreal-time scheduling algorithms, likeEarliest Deadline
Computer Communications 23 (2000) 267–289
0140-3664/00/$ - see front matterq 2000 Elsevier Science B.V. All rights reserved.PII: S0140-3664(99)00180-2
www.elsevier.com/locate/comcom
* Corresponding author. Tel.:147-64844733; fax:147-63818146.E-mail addresses:[email protected] (T. Plagemann), [email protected]
(V. Goebel), [email protected] (P. Halvorsen), [email protected] (O. Anshus).1 This research is sponsored by the Norwegian Research Council, DITS
program under contract number 119403/431 (INSTANCE project).2 On leave from Computer Science Department, University of Tromsø,
Norway.

First (EDF) andRate Monotonic(RM), have been adoptedfor CPU (and disk) scheduling. These scheduling mechan-isms are based on a periodic task model [1]. In this model,tasks are characterized by a start times, when the taskrequires the first execution, and a fixed periodp in whichthe task requires execution timee with deadlined (seeFig. 1). Often, the deadline is equal to the end of the period.
An 8 bit, 8 kHz PCM encoded audio stream is a goodexample for such a periodic task: the constant samplingrate and the fixed sample size generate a constant bit stream.In order to handle the stream more efficiently, samples oftypically 20 ms are gathered in a packet. Thus, the systemhas to handle in each period, i.e.,p� 20 ms, a packet beforethe next period. The fixed packet size requires a constantexecution timee per period. This periodic task model isattractive from an engineering point of view, because itmakes it possible to predict the future: in periodk, whichstarts ats1 �k 2 1�p; the task with execution timee has tobe finished befores1 �k 2 1�p 1 d:
However, experiences with multimedia applicationsincluding efficient variable bit rate (VBR) coding schemesfor video, like H.261, H.263, MJPEG, and MPEG, lead tothe conclusion that it is not that easy to foresee futurerequirements. Video frames are generated in a fixedfrequency (or period), but the size of the frames and theexecution times to handle each of these frames is notconstant [2,3]. It varies on a short time scale, between thedifferent frames, e.g. I, B, or P frames in MPEG, and on alarger time scale, e.g. due to scene shifts such as from aconstant view on a landscape to an action scene. Further-more, the degree of user interactivity is much higher inrecent multimedia applications, e.g. interactive distancelearning, than in earlier applications, like video-on-demand(VoD). It is very likely that this trend will continue in thefuture and make resource requirements even harder topredict.
Latest developments in the area of multimedia OSs stillemphasize on QoS support, but integrate often adaptabilityand support both real-time and best effort requirements.Furthermore, new abstractions are introduced, like newtypes of file systems and resource principals that decoupleprocesses from resource ownership. Finally, mainbottlenecks, like paging, copy operations, and disk I/O,have been tackled to fulfill the stringent performancerequirements.
It is the goal of this article to give an overview over recentdevelopments in OS support for multimedia systems. OSsupport for multimedia is an active research area, and there-fore, it is not possible to discuss all particular solutions in
depth. Instead, we introduce for each OS aspect the basicissues and give an overview and a classification of newapproaches. Furthermore, we describe a few examples inmore detail to enable the reader to grasp the idea of somenew solutions. However, for an in-depth understanding, thereader has to refer to the original literature, becausethis article is intended as a survey and to serve as an“entry-point” for further studies.
The rest of this article is structured as follows: Section 2discusses general OS developments, and Section 3summarizes the requirements of multimedia applications.The basic dependency between resource management andQoS is discussed in Section 4. Management of the systemresources, like CPU, disk, main memory, and other systemresources, are discussed in Sections 5–8. New approaches toovercome the I/O bottleneck are presented in Section 9.Section 10 gives some conclusions.
2. Operating system architectures
Traditionally, an OS can be viewed as a resource allocatoror as a virtual machine. The abstractions developed tosupport the virtual machine view include a virtual processorand virtual memory. These abstractions give each processthe illusion that it is running alone on the computer. Eachvirtual machine consumes physical resources like physicalprocessor and memory, data-, instruction-, and I/O buses,data and instruction caches, and I/O ports. However, insteadof allowing a process to access resources directly, it must doso through the OS. This is typically implemented as systemcalls. When a process makes a system call, the call is givento a library routine which executes an instruction sending asoftware interrupt to the OS kernel. In this way, the OS getscontrol in a secure way and can execute the requestedservice. This is a too costly path for some services, becausetrapping to the OS involves the cost of crossing the user–supervisor level boundary at least twice, and possibly cross-ing address spaces also at least twice if a context switch toanother process takes place. In addition, there are costsassociated with the housekeeping activities of the OS.
When several processes are executing, each on its ownvirtual processor, they will implicitly interfere with eachother through their use of physical resources. Primarily,they will affect each other’s performance, because applica-tions are not aware of physical resources and of each other.A multimedia application can face a situation where it doesnot get enough resources, because the OS is not aware ofeach applications’ short and longer term needs. This willtypically happen when the workload increases.
The need to go through the OS to access resources and theway the OS is designed and implemented results in a systemwhere low latency communication is difficult to achieve. Itis also difficult to either have resources available when theyare needed by a process; or have a process ready to execute
T. Plagemann et al. / Computer Communications 23 (2000) 267–289268
Fig. 1. Periodic task model.

when the resources, including cooperating processes onother processors or computers, are available or ready.
A traditional general-purpose OS, like UNIX or WindowsNT, is not a good platform for the common case needs ofmultimedia applications. In these OSs, resource allocationfor each process is based on general purpose schedulingalgorithms, which are developed to provide a balancebetween throughput and response time, and to provide fair-ness. These algorithms get some limited feedback from theapplication processes on what they are doing, but basically,the OS has little or no understanding of what the applica-tions are doing and what their requirements are. Also, thedegree to which an application can directly controlresources in a secure way, or provide the OS with hintsfor its resource requirements, has traditionally been verylimited.
There are several OS architectures in use today of whichthe monolithic kernel and them-kernel architectures, or theirhybrids, are the most common. In a monolithic OS kernel,all components are part of a large kernel, execute in ahardware-protected supervisory mode, and can use theentire instruction set. Consequently, the kernel has totalcontrol over all resources. User processes execute in usermode and can therefore use only a limited instruction setand have only a limited control over resources. A userprocess cannot execute an instruction to switch to super-visory mode, enable or disable interrupts, or directly accessI/O ports. When a user process needs OS services, itrequests the service from the OS, and the kernel performsthe requested service. Two crossings between user- andkernel-level take place, from the user process to the kerneland then back again when the service has finished.
In the m-kernel architecture, the OS is divided into asmaller kernel with many OS services running as processesin user mode. This architecture is flexible, but has tradition-ally resulted in an increased overhead. The kernel sends arequest for service to the correct user-level OS process. Thiscreates extra overhead, because typically four crossingsbetween user- and kernel-level take place, i.e. from theuser process to the kernel, from the kernel to the user-level service, from the user-level service to the kernel, andfinally, from the kernel to the user process. This can alsoresult in memory degradation because of reduced instruc-tion locality giving an increased number of cache misses. InRef. [4], a comparative study of three OSs, includingNetBSD (a monolithic UNIX) and Windows NT (am-kernellike architecture), is presented. The monolithic NetBSD hasthe lowest overhead for accessing services. However, theoverall system performance can significantly be determinedby specific subsystems, e.g. graphics, file system, and diskbuffer cache; and for some cases Windows NT does as wellas NetBSD in spite of the higher overhead associated withits m-kernel architecture.
Library OSs (also referred to as vertically structuredsystems) like the Exokernel architecture [5,6] and Nemesis[7] have been proposed as an alternative to monolithic and
m-kernel OSs. The basic idea is that those parts of an OS thatcan run at user-level are executed as part of the applicationprocesses. The OS is implemented as a set of librariesshared by the applications. The OS kernel can be keptvery small, and it basically protects and exports theresources of the computer to the applications, i.e. leavingit to the applications to use the resources wisely. This allowsfor a high flexibility with respect to the needs of individualapplications. At the same time it gives processes more directcontrol over the resources with better performance as apotential result.
However, the results presented in Refs. [8–10] identifyseveral areas of significance for the performance of an OSincluding the switching overhead between user and kernelmode, switching between address spaces, the cost of inter-process communication (IPC), and the impact of the OSarchitecture upon memory behavior including cache misses.These papers show how am-kernel OS can be designed andimplemented at least as efficient as systems using otherarchitectures. The SUMO OS [11] describes how to improvem-kernels by reducing the number of protection crossingsand context switchings even though it is built on top of theChorus OS.
Threads can be used as a way of reducing OS-inducedoverhead. Basically, threads can be user-level or kernel-level supported. User-level threads have very low overhead[12]. However, they are not always scheduled preemptively,and then the programmer must make sure to resume threadscorrectly. User-level threads can also result in blocking thewhole process if one thread blocks on a system service.Even if user-level threads will reduce the internal overheadfor a process, we still have no resource control betweenvirtual processors. Kernel-supported threads have muchhigher overhead, but are typically scheduled preemptivelyand will not block the whole process when individualthreads block. This makes kernel-level supported threadssimpler to use in order to achieve concurrency and overlapprocessing and communication. Kernel-level supportedthreads can potentially be scheduled according to theprocess requirements, but this is typically not done.Split-level scheduling[13] combines the advantages of user andkernel-level thread scheduling by avoiding kernel-leveltraps when possible.Scheduler activations[12] is a kernelinterface and a user-level thread package that togethercombine the functionality of kernel threads with the perfor-mance and flexibility of user-level threads.
Low-context switching overhead can also be achievedwhen using processes. For example, Nemesis uses a singleaddress space for all processes. This allows for a lowcontext-switching overhead, because only protection rightsmust be changed.
The rapid development of commodity multiprocessorsand clusters of commodity computers provide a scalableapproach to separating virtual machines onto physicalprocessors and memories and thereby reduces the inter-ference between them. However, there are still shared
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 269
resources that must be scheduled, including networks,gateways, routers, servers, file systems, and disks.
3. Multimedia application requirements
In this section, we briefly discuss the requirementsthat multimedia applications impose onto OSs. First, weexemplify typical requirements by introducing a multimediaapplication that is in productive use since 1993 for teachingregular courses at the University of Oslo. Afterwards, wegive a more general characterization of multimediaapplication requirements.
3.1. Example: interactive distance learning
The main goal of the electronic classrooms is to create adistributed teaching environment which comes as close aspossible to a traditional (non-distributed) classroom [14].The classroom system is composed out of three mainparts: electronic whiteboards, audio system, and videosystem. At each site there is at least one large electronicwhiteboard to display transparencies. The lecturer canwrite, draw, and erase comments on displayed transparen-cies by using a light-pen.
The main element of the audio system is a set of micro-phones that are mounted evenly distributed on the ceiling inorder to capture the voice of all the participants. The videosystem comprises in each classroom three cameras and twosets of monitors. One camera focuses on the lecturer, andtwo cameras focus on the students. A video-switch selectsthe camera corresponding to the microphone with the loud-est input signal. Two monitors are placed in the front andtwo monitors are placed in the back of each classroomdisplaying the incoming and outgoing video information.All video data is compressed according to the compressionstandard H.261.
During a lecture, at least two electronic classrooms areconnected. Teacher and students can freely interact witheach other regardless of whether they are in the same or
in different classrooms. Audio, video, and whiteboardevents are distributed in real-time to all sites, allowing allparticipants to see each other, to talk to each other, and touse the shared whiteboard to write, draw, and presentprepared material from each site.
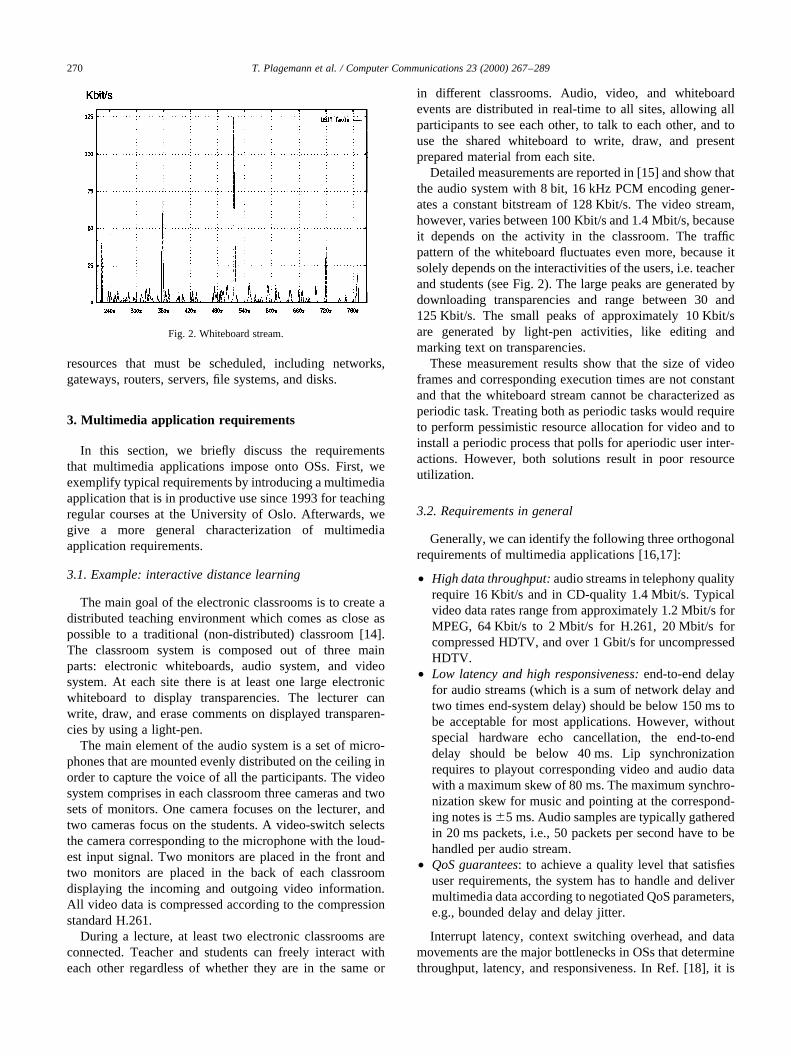
Detailed measurements are reported in [15] and show thatthe audio system with 8 bit, 16 kHz PCM encoding gener-ates a constant bitstream of 128 Kbit/s. The video stream,however, varies between 100 Kbit/s and 1.4 Mbit/s, becauseit depends on the activity in the classroom. The trafficpattern of the whiteboard fluctuates even more, because itsolely depends on the interactivities of the users, i.e. teacherand students (see Fig. 2). The large peaks are generated bydownloading transparencies and range between 30 and125 Kbit/s. The small peaks of approximately 10 Kbit/sare generated by light-pen activities, like editing andmarking text on transparencies.
These measurement results show that the size of videoframes and corresponding execution times are not constantand that the whiteboard stream cannot be characterized asperiodic task. Treating both as periodic tasks would requireto perform pessimistic resource allocation for video and toinstall a periodic process that polls for aperiodic user inter-actions. However, both solutions result in poor resourceutilization.
3.2. Requirements in general
Generally, we can identify the following three orthogonalrequirements of multimedia applications [16,17]:
• High data throughput:audio streams in telephony qualityrequire 16 Kbit/s and in CD-quality 1.4 Mbit/s. Typicalvideo data rates range from approximately 1.2 Mbit/s forMPEG, 64 Kbit/s to 2 Mbit/s for H.261, 20 Mbit/s forcompressed HDTV, and over 1 Gbit/s for uncompressedHDTV.
• Low latency and high responsiveness:end-to-end delayfor audio streams (which is a sum of network delay andtwo times end-system delay) should be below 150 ms tobe acceptable for most applications. However, withoutspecial hardware echo cancellation, the end-to-enddelay should be below 40 ms. Lip synchronizationrequires to playout corresponding video and audio datawith a maximum skew of 80 ms. The maximum synchro-nization skew for music and pointing at the correspond-ing notes is 5 ms. Audio samples are typically gatheredin 20 ms packets, i.e., 50 packets per second have to behandled per audio stream.
• QoS guarantees: to achieve a quality level that satisfiesuser requirements, the system has to handle and delivermultimedia data according to negotiated QoS parameters,e.g., bounded delay and delay jitter.
Interrupt latency, context switching overhead, and datamovements are the major bottlenecks in OSs that determinethroughput, latency, and responsiveness. In Ref. [18], it is
T. Plagemann et al. / Computer Communications 23 (2000) 267–289270
Fig. 2. Whiteboard stream.

documented that especially the interrupt handling is a majoroverhead. To implement QoS guarantees for these perfor-mance aspects, advanced management of all systemresources is required. The need for advanced resourcemanagement has lead to the development of new OSabstractions and structures. In the following sections, wediscuss basic resource management tasks and explain howthe new OS abstractions and structures can reduce contextswitching overhead and data movement costs.
4. Resource management and QoS
A computer system has many resources, which may berequired to solve a problem: CPU, memory at differentlevels, bandwidth of I/O devices, e.g. disk and host–network interface, and bandwidth of the system bus. InFig. 3, the basic resource types CPU, memory, and band-width are partitioned into concrete system resources.
One of the primary functions of an OS is to multiplexthese resources among the users of the system. In the adventof conflicting resource requests, the traditional OS mustdecide which requests are allocated resources to operatethe computer systemfairly and efficiently [19]. Fairnessand efficiency are still the most important goals for resourcemanagement in today’s commodity OSs. However, withrespect to multimedia applications, other goals that arerelated to timeliness become of central importance. Forexample, user interactions and synchronization requireshort response timeswith upper bounds, and multimediastreams require a minimumthroughputfor a certain periodof time. These application requirements are specified asQoS requirements. Typical application-level QoS specifica-tions include parameter types like frame rate, resolution,jitter, end-to-end delay, and synchronization skew [20].These high-level parameters have to be broken down (ormapped) into low-level parameters and resources that arenecessary to support the requested QoS, like CPU time perperiod, amount of memory, and average and peak networkbandwidth. A discussion of this mapping process is beyondthe scope of this paper, but we want to emphasize at thispoint that such a specification of resource requirements isdifficult to achieve. A constant frame rate does not necessa-rily require constant throughput and constant execution timeper period. Furthermore, user interactions can generateunpredictable resource requirements.
In order to meet QoS requirements from applications andusers, it is necessary to manage the system resources in sucha manner that sufficient resources are available at the righttime to perform the task with the requested QoS. In par-ticular, resource management in OS for QoS comprises thefollowing basic tasks:
• Specification and allocation requestfor resources that arerequired to perform the task with the requested QoS.
• Admission control includes a test whether enoughresources are available to satisfy the request withoutinterfering with previously granted requests. The waythis test is performed depends on requirement specifica-tion and allocation mechanism used for this resource.
• Allocation and schedulingmechanisms assure that asufficient share of the resource is available at the righttime. The type of mechanism depends on the resourcetype. Resources that can only exclusively be used by asingle process at a time have to be multiplexed in thetemporal domain. In other words, exclusive resources,like CPU or disk I/O, have to be scheduled. Basically,we can differentiate between fair scheduling, real-timescheduling, and work and non-work conserving schedul-ing mechanisms. So-called shared resources, likememory, basically require multiplexing in the spatialdomain, which can be achieved, e.g. with the help of atable.
• Accountingtracks down the actual amount of resourcesthat is consumed in order to perform the task. Accountinginformation is often used in scheduling mechanisms todetermine the order of waiting requests. Accountinginformation is also necessary to make sure that no taskconsumes more resources than negotiated and steals them(in overload situations) from other tasks. Furthermore,accounting information might trigger system-initiatedadaptation.
• Adaptationmight be initiated by the user/application orthe system and can mean to downgrade QoS and corre-sponding resource requirements, or to upgrade them.Adaptation leads in any case to new allocation para-meters. Accounting information about the actual resourceconsumption might be used to optimize resourceutilization.
• Deallocationfrees the resources.
Specification, admission control, and allocation and sche-duling strongly depend on the particular resource type,while adaptation and resource accounting represent moreresource type independent principles. Thus, the followingtwo subsections introduce adaptation and resource account-ing, before we discuss the different system resources inmore detail.
4.1. Adaptation
There are two motivations for adaptation in multimediasystems: (1) resource requirements are hard to predict, e.g.
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 271
Fig. 3. Operating system resources.

VBR video and interactivity; and (2) resource availabilitycannot be guaranteed if the system includes best-effort sub-systems, e.g. today’s Internet or mobile systems. In best-effort systems, it is only possible to adapt the applicationwith respect to the amount of application data the systemhas to handle. In OSs, both situations might occur, and it ispossible to adapt both application and resource allocations.In Ref. [21], adaptation with feedback and adaptation with-out feedback are distinguished. Adaptation without feed-back means that applications change only the functionalityof the user interface and do not change any resource para-meters. Therefore, we consider in this article only adapta-tion with feedback, i.e. feedback control systems. Fig. 4shows a simplified view of the collaboration betweenresource consumer, e.g. application, and resource provider,e.g. CPU scheduler, in adaptation with feedback [22]:
(A) The resource consumer, or a management entity,estimates its resource requirements and requests the provi-der to allocate the resource according to its specification.(B) After admission control is successfully passed, theresource utilization is monitored. The monitoring resultscan reflect the general resource utilization, e.g. the resourceis under- or over-utilized, and the accuracy of the consu-mers’ resource requirements estimations, e.g. it uses less ormore resources than allocated. The monitoring resultsmight trigger step (C) and/or (D).(C) The provider requests the consumer to adjust itsresource requirements, e.g. by reducing the frame rate ofa video.(D) The consumer requests the provider to adjust the alloca-tion parameters.
Most of the recent results in the area of adaptive resourcemanagement discuss CPU management (see Section 5).Monitoring of actual execution times is supported in mostof these systems. More general approaches for adaptiveresource management include AQUA [22], SWiFT [23],Nemesis [7], Odyssey [24], and QualMan [20]. The crucialaspects of adaptation are the frequency in which feedbackcontrol (and adaptation) is performed and the related over-head. For example, SCOUT uses a coarse-grained feedbackmechanism that operates in the order of several seconds[25]. On the other hand, the work presented in Ref. [26]aims to predict the execution times of single MPEG frames.Whether fine-grained adaptation of allocation parametersresults in better QoS and/or better resource utilization is
still open. However, it is obvious that it requires frequentadjustment of allocation parameters, which must not imposemuch overhead.
4.2. New abstractions for resource principals
Resource accounting represents a fundamental problem,because most OSs treat a process as the “chargeable” entityfor allocation of resources, such as CPU time and memory.In Ref. [27], it is pointed out that “a basic design premise ofsuch process-centric systems is that a process is the unit thatconstitutes an independent activity. This gives the processabstraction a dual function: it serves both as a protectiondomain and as a resource principal.” This situation is insuf-ficient, because there is no inherent one-to-one mappingbetween an application task and a process. A single processmight serve multiple applications, and multiple applicationsmight serve together a single application. For example,protocol processing is in most monolithic kernels performedin the context of software interrupts. The correspondingresource consumption is charged to the unlucky processrunning at that time, or not accounted at all [27].m-kernelsimplement traditional OS services as user-level servers.Applications might invoke multiple user-level servers toperform on its behalf, but the resource consumption ischarged to the application and the user-level servers insteadof charging it to the application only [28]. It is important tonote that ownership of resources is not only important foraccounting reasons, but also for scheduling. The resources aprocess “owns”, e.g. CPU time, define also its schedulingparameter. For example, in commodity OSs with priority-based CPU scheduling, each process is associated with apriority, which in turn determines when it is scheduled,i.e. receives its CPU time. Thus, a server or kernel threadthat is performing a task on behalf of an application withQoS requirements should inherit the corresponding schedul-ing parameters for needed resources, e.g. the priority.
In Ref. [29], the problem of resource ownership and thecorresponding scheduling decisions is partially solved for amonolithic kernel by deriving weights of kernel activitiesfrom user weights. By this, the proportional share schedul-ing, in the extended FreeBSD kernel, is able to provide anappropriate share of CPU bandwidth to the kernel activitysuch that QoS requirements of the user process can be met.
We can identify two basic, orthogonal approaches tohandle this problem: (1) introduction of a new abstractionfor resource ownership; and (2) to provide applications asmuch control as possible over devices, as it is done inso-called library OSs, like Exokernel [5,6] and Nemesis[7]. In these systems, applications can directly controlresource consumption for network I/O and file I/O, becausenetwork device drivers and disk device drivers areaccessible from the application in user-space without kernelinterference. Obviously, resource consumption can be easilycharged to the application.
In Ref. [27], a quite extensive discussion of new
T. Plagemann et al. / Computer Communications 23 (2000) 267–289272
Fig. 4. Feedback control for adaptation.

abstractions for resource ownership can be found. Theseabstractions differ in terms of: (1) which resources areconsidered; (2) which relationships between threads andresource owners are supported; and (3) which resourceconsumptions are actually charged to the owner. InStrideand Lottery scheduling [30], resource rights are encapsu-lated by tickets. Tickets are owned by clients, and tickettransfers allow to transfer resource rights between clients.In Mach [31], AlphaOS [32], and Spring [33],migratingthreads and shuttles, respectively, correspond to threadsand own resources. Migration of threads between protectiondomains enables these systems to account resourceconsumption of independent activities to the correctowner, i.e. thread. In Ref. [34], threads can act as schedulerfor other threads and can donate CPU time to selectedthreads. Thereservation domains[35] of Eclipse, theSoft-ware Performance Units[36], and thescheduling domainsin Nemesis [7] enable the scheduler to consider the resourceconsumption of a group of processes.
Thereserveabstraction is introduced in Real-Time Mach[28]. The main purpose of reserves is to accurately accountCPU time for activities that invoke user-level services, e.g.client threads that invoke various servers (which are runningin user-space, because Real-Time Mach is am-kernel). Eachthread is bound to one reserve, and multiple threads, poten-tially running in different protection domains, can be boundto a single reserve. By this, computations of server threadsthat are performed on behalf of a client can be charged to theclients reserve and scheduling of the server computations isperformed according to the reservations of the reserve. InRef. [37], the concept of reserves is extended to manageadditional resource types such as CPU, disk bandwidth,network bandwidth, and virtual memory.
Resource containers[27] allow explicit and fine-grainedcontrol over resource consumption at all levels in thesystem, because it allows dynamic relationships betweenresource principals and processes. The system providesexplicit operations to create new resource containers, tobind processes to containers and to release these bindings,and to share containers between resources. Resourcecontainers are associated with a set of attributes, likescheduling parameters, memory limitations, and networkQoS values, that can be set by applications and supportthe appropriate scheduling (decoupled from particularprocess information). Furthermore, containers can bebound to files and sockets, such that the kernel resourceconsumption on behalf of these descriptors is charged tothe container.
In the Rialto OS, anactivity objectis the abstraction towhich resources are allocated and against which resourceusage is charged [38,39]. Applications run by default intheir own activity and typically in their own process.Activities may span over address spaces and machines.Multiple threads of control may be associated with anactivity. The threads execute with rights granted by secureduser credentials associated with this activity. The CPU
scheduler treats all threads of an activity equal, becausethe assumption is that they cooperate toward a commongoal.
The path abstraction in the SCOUT OS [40] combineslow-level de-multiplexing of network packets via packetfilter with migrating threads. A path represents an I/O pathand is executed by a thread. One thread can sequentiallyexecute multiple paths. A newly awakened thread inheritsthe scheduling requirements of the path and can adjust themafterwards. The path object is extended in the Escort OSwith a mechanism to account all resource consumptions of apath to defend against denial of service attacks [41].
Compared to the previously discussed approaches forresource accounting, a basically different approach is intro-duced in Ref. [42]. Multiple threads, which may reside indifferent protection domains, are gathered in a job. Insteadof measuring the resource consumption of these threads,Steere et al. [42] monitor the progress of jobs and adapt,i.e. increase or decrease, the allocation of CPU to those jobs.So-called symbiotic interfaces link the notion of progress,which is depending on the application to system metrics,like a buffer’s fill-level.
5. CPU scheduling
Most commodity OSs, like Windows NT and Solaris,perform priority schedulingand provide time-sharing andreal-time priorities. Priorities of threads in the real-timerange are never adjusted from the system. A straightforwardapproach to assure that a time critical multimedia taskreceives sufficient CPU time would be to assign a real-time priority to this task. However, in Ref. [43], it isshown for the SVR4 UNIX scheduler that this approachresults in unacceptable system performance. A highpriority multimedia task, like video, has precedence overall time-sharing tasks and is nearly always active. Starvationof timesharing tasks, e.g. window system and basic systemservices, leads to poor QoS for the multimedia applicationand unacceptable performance for the entire system. Thus,the usage of real-time priorities does not automatically leadto the desired system behavior. However, other implemen-tations, like those described in Refs. [3,44], show that fixedreal-time priorities can be utilized to successfully schedulereal-time and best effort tasks in a general purpose UNIXsystem.
Several new solutions have been recently developed. Thefollowing section gives a general overview and classifica-tion of these solutions, and subsequent sections present twosolutions in more detail.
5.1. Classification of scheduling mechanisms
Two of the most popular paradigms for resource alloca-tion and scheduling to satisfy the contradicting goals offlexibility, fairness, and QoS guarantees areproportionalshare resource allocationandreservation-basedalgorithms
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 273

[45]. In proportional share allocation, resource requirementsare specified by the relative share (or weight) of theresource. In a dynamic system, where tasks dynamicallyenter and leave the system, a share depends on both thecurrent system state and the current time. The resource isalways allocated in proportion to the shares of competingrequests. Thus, in pure proportional share resource alloca-tion, no guarantees can be given, because the share of CPUmight be arbitrary low. The basis for most proportionalshare resource allocation mechanisms are algorithms thathave been developed for packet scheduling in packet-switched networks, likeweighted fair queuing[46], virtualclock [47], and packet-by-packet generalized processorsharing [48]. Examples for systems using proportionalshare CPU allocation includeAdaptive Rate Control(ARC) [49], SMART [50], Earliest Eligible Virtual Dead-line First [45], Lottery and Stride scheduling [30], andMove-to-Rear List(MTR-LS) scheduling in Eclipse [35].
In contrast to proportional share resource allocation,reservation-based algorithms, like RM and EDF scheduling,can be used to implement guaranteed QoS. The minimumshare for each thread is both state and time independent.However, resource reservation sacrifices flexibility and fair-ness [45]. EDF scheduling is used in Nemesis [7], DASH[51], and SUMO [52]. The principles of RM scheduling areapplied, for example, in Real-Time Mach [28], HeiTS [44],AQUA [22] and for theReal-Time Upcallin the MARSsystem [163,164]. To implement a feedback-driven propor-tional allocator for real-rate scheduling, the work presentedin Ref. [42] uses both EDF and RM.
Most modern solutions of CPU scheduling for multimediasystems are based on either proportional share allocation, orare a combination of different allocation paradigms in hierar-chies to support both real-time and best-effort requirements.
For example, the scheduler in the Rialto system [39] and thesoft real-time (SRT) user-level scheduler from [3] combineEDF and round-robin scheduling. The Atropos scheduler inNemesis [7] also applies EDF to sort waiting schedulingdomains in different queues. The proportional shareresource allocationStart-time Fair Queuingin Ref. [53] isused in Ref. [2] to achieve a hierarchical partition of CPUbandwidth in a general framework. For each of these parti-tions, arbitrary scheduling mechanisms can be used. Propor-tional share scheduling is also the primary policy in Ref.[29]. When multiple processes are eligible, they are sched-uled according to EDF. In the context of the Flux project, aCPU inheritance schedulingframework has been devel-oped in which arbitrary threads can act as scheduler forother threads and widely different scheduling policiescan co-exist [34]. The scheduler in SCOUT, calledBERT [25], merges reservation-based and proportionalshare resource allocation in a single policy, instead ofcombining two or more policies in a hierarchicalapproach. Basically, BERT extends the virtual clockalgorithm by considering deadlines for the schedulingdecision and by allowing high-priority real-time tasksto steal CPU cycles from low priority and best efforttasks.
In addition to the resource allocation paradigm,i.e. proportional share (P), reservation-based (R), andhierarchical (H), Table 1 uses the following criteria to clas-sify CPU scheduling approaches: (1) whether admissioncontrol is performed; (2) whether adaptation is supported;(3) whether a new abstraction for resource principal is intro-duced; and (4) what is the context of the scheduler, i.e. is itpart of a new kernel, integrated in an existing kernel, orimplemented on top of an existing kernel in user-space.
In the following subsections, we describe in more detail two
T. Plagemann et al. / Computer Communications 23 (2000) 267–289274
Table 1CPU scheduling approaches
System/project Paradigm Admissioncontrol
Adaptationsupport
Resourceprincipal
Context
AQUA Reservation-based Yes Yes No SolarisARC Proportional share Yes Yes No SolarisAtropos Hierarchical Yes Yes Yes NemesisBERT Merges proportional share
and reservation-basedYes Yes Yes SCOUT
FLUX Hierarchical No No No Prototype in user-spaceRef. [2] Proportional share No Yes No FrameworkHeiTS Reservation-based Yes No No AIXRef. [29] Hierarchical No Yes (only monitoring
of execution times)No (system processes inheritweight from user process)
FreeBSD
Lottery, Stride Proportional share No Yes Yes MachMTR-LS Proportional share Yes No Yes EclipseRialto Hierarchical Yes Yes Yes RialtoRT Mach Reservation-based Yes Yes Yes RT-MachRT Upcalls Reservation-based No No No NetBSDSMART Proportional share No Yes No SolarisSRT Hierarchical Yes Yes No User-level schedulerRef. [42] Reservation-based Yes Yes No Prototype in user-spaceSUMO Hierarchical Yes No No Chorus

distinct approaches, i.e. Rialto scheduler and SMART, thatdiffer in all classification criteria except adaptation support.
5.2. Rialto scheduler
The scheduler of the Rialto OS [38,39,54] is based onthree fundamental abstractions:
• Activitiesare typically an executing program or applica-tion that comprises multiple threads of control.Resources are allocated to activities and their usage ischarged to activities.
• CPU reservationsare made by activities and arerequested in the form: “reservex units of time out ofevery Y units for activity A”. Basically, period lengthand reservations for each period can be of arbitrarylength.
• Time constraintsare dynamic requests from threads tothe scheduler to run a certain code segment within aspecified start time and deadline to completion.
The scheduling decision, i.e. which threads to activatenext, is based on a pre-computed scheduling graph. Eachtime a request for CPU reservation is issued, this schedulinggraph is recomputed. In this scheduling graph, each noderepresents an activity with a CPU reservation, specified astime interval and period, or represents free computationtime. For each base period, i.e. the lowest common denomi-nator of periods from all CPU reservations, the schedulertraverses the tree in a depth-first manner, but backtracksalways to the root after visiting a leaf in the tree. Eachnode, i.e. activity that is crossed during the traversal, isscheduled for the specified amount of time. The executiontime associated with the schedule graph is fixed. Freeexecution times are available for non-time-critical tasks.This fixed schedule graph keeps the number of contextswitches low and keeps the scheduling algorithmscalable.
If threads request time constraints, the scheduler analyzestheir feasibility with the so-calledtime interval assignmentdata structure. This data structure is based on the knowledgerepresented in the schedule graph and checks whetherenough free computation time is available between starttime and deadline (including the already reserved time inthe CPU reserve). Threads are not allowed to define timeconstraints when they might block—except for shortblocking intervals for synchronization or I/O. When duringthe course of a scheduling graph traversal an intervalassignment record for the current time is encountered, athread with an active time constraint is selected accordingto EDF. Otherwise, threads of an activity are scheduledaccording to round-robin. Free time for non-time-criticaltasks is also distributed according to round-robin.
If threads with time constraints block on a synchroniza-tion event, the thread priority (and its reservations) is passedto the holding thread.
5.3. SMART
The SMART scheduler [50] is designed for multimediaand real-time applications and is implemented in Solaris2.5.1. The main idea of SMART is to differentiate betweenimportanceto determine the overall resource allocation foreach task andurgencyto determine when each task is givenits allocation. Importance is valid for real-time and conven-tional tasks and is specified in the system by a tuple ofpriority andbiased virtual finishing time. Here, the virtualfinishing time, as known from fair-queuing schemes, isextended with a bias, which is a bounded offset measuringthe ability of conventional tasks to tolerate longer and morevaried service delays. Application developers can specifytime constraints, i.e. deadlines and execution times, for aparticular block of code, and they can use the system noti-fication. The system notification is an upcall that informs theapplication that a deadline cannot be met and allows theapplication to adapt to the situation. Applications canquery the scheduler for availability, which is an estimateof processor time consumption of an application relativeto its processor allocation. Users of applications can specifypriority and share to bias the allocation of resources for thedifferent applications.
The SMART scheduler separates importance and urgencyconsiderations. First, it identifies all tasks that are importantenough to execute and collects them in a candidate set.Afterwards, it orders the candidate set according to urgencyconsideration. In more detail, the scheduler works asfollows: if the tasks with the highest value-tuple is a conven-tional task, schedule it. The highest value-tuple is eitherdetermined by the highest priority or for equal prioritiesby the earliest biased virtual finishing time. If the taskwith the highest value-tuple is a real-time task, it creates acandidate set of all real-time tasks that have a higher value-tuple than the highest conventional task. The candidate set isscheduled according to the so-called best-effort real-timescheduling algorithm. Basically, this algorithm finds thetask with the earliest deadline that can be executed withoutviolating deadlines of tasks with higher value-tuples.SMART notifies applications if their computation cannotbe completed before its deadline. This enables applicationsto implement downscaling.
There is no admission control implemented in SMART.Thus, SMART can only enforce real-time behavior inunderload situations.
6. Disk management
Magnetic and optical disks enable permanent storage ofdata.3 The file system is the central OS abstraction to handledata on disk. However, in most commodity OSs, it is possi-ble to by-pass the file system and to use raw disks, e.g. for
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 275
3 We focus in this article only on issues related to magnetic disks.

database systems. The two main resources that are of impor-tance for disk management, no matter whether the filesystem of an OS or raw disk is used, are:
• Memory space on disk:allocation of memory space at theright place on disks, i.e. appropriate data placement, canstrongly influence the performance.
• Disk I/O bandwidth:access to disk has to be multiplexedin the temporal domain. CPU scheduling algorithmscannot directly be applied for disks, because of thefollowing reasons [55]: (1) a disk access cannot bepreempted, i.e. it is always necessary to read a wholeblock; (2) access times (which correspond to executiontime for CPU scheduling) are not deterministic, becausethey depend on the position of the disk head and theposition of data on disk; and (3) disk I/O represents themain performance bottleneck in today’s systems.
Multimedia data can be managed on disk in two differentways [57]: (1) the file organization on disk is not changedand the required real-time support is provided by specialdisk scheduling algorithms and large buffers to avoid jitter;or (2) the data placement is optimized for continuous multi-media data in distributed storage hierarchies like disk arrays[56].
In the following subsections, we discuss file management,data placement, and disk scheduling issues of multimediafile systems separately.
6.1. File management
The traditional access and control tasks of file systems,like storing file information in sources, objects, programlibraries and executables, text, and accounting records,have to be extended for multimedia file systems with real-time characteristics, coping with larger file sizes (high diskbandwidth), and with multiple continuous and discrete datastreams in parallel (real-time delivery) [57]. The fact that inthe last years storage devices have become only marginallyfaster compared to the exponentially increased performanceof processors and networks, makes the effect of this dis-crepancy in speed for handling multimedia data by filesystems even more important. This is documented by thelarge research activity to find new storage structures andretrieval techniques. The existing approaches can be cate-gorized along multiple criteria, and we present a brief clas-sification along architectural issues and data characteristics.
From the architectural perspective, multimedia filesystems can be classified as [166]:
• Partitioned file systemsconsist of multiple subfilesystems, each tailored to handle data of a specific datatype. An integration layer may provide transparent accessto the data handled by the different subfile systems. Thereare multiple examples of systems using this approach,e.g. FFS [58],Randomized I/O(RIO) [59], Shark [60],Tiger Shark [61], and the combination of UFS and CMFSin [62].
• Integrated file systemsmultiplex all available resources(storage space, disk bandwidth, and buffer cache) amongall multimedia data. Examples of integrated multimediafile systems are the file system of Nemesis [63], Fellini[64], and Symphony [65].
Another way to classify multimedia file systems is togroup the systems according to the supported multimediadata characteristics:
• General file systems capable of handling multimedia datato a certain extend, e.g. FFS [58], andlog-structured filesystems[66–68].
• Multimedia file systems optimized for continuous multi-media data (video and audio data), e.g. SBVS [69], Mitra[70], CMFS [71], PFS [72], Tiger [73,74], Shark [60],Tiger Shark [61], and CMSS [75].
• Multimedia file systems handling mixed-media work-loads (continuous and discrete multimedia data), e.g.Fellini [64], Symphony [65], MMFS [76], the file systemof Nemesis [63], and RIO [59].
The file system of Nemesis [63] supports QoS guaranteesusing a device driver model. This model realizes a low-levelabstraction providing separation of control and data pathoperations. To enable the file system layers to be executedas unprivileged code within shared libraries, data pathmodules supply translation and protection of I/O requests.QoS guarantees and isolation between clients are providedby scheduling low-level operations within the devicedrivers.
Fellini [64] supports storage and retrieval of continuousand discrete multimedia data. The system provides rateguarantees for active clients by using admission control tolimit the number of concurrent active clients.
Symphony [65] can manage heterogeneous multimediadata supporting the coexistence of multiple data typespecific techniques. Symphony comprises aQoS-awaredisk schedulingalgorithm for real-time and non-real-timerequests, and a storage manager supporting multiple blocksizes and data type specific placement, failure recovery, andcaching policies.
MMFS [76] handles interactive multimedia applica-tions by extending the UNIX file system. MMFS has atwo-dimensional file structure for single-medium editingand multimedia playback: (1) a single-mediumstrandabstraction [165]; and (2) a multimedia file construct,which ties together multiple strands that belong logicallytogether. MMFS uses application-specific information forperformance optimization of interactive playback. Thisincludes intelligent prefetching, state-based caching,prioritized real-time disk scheduling, and synchronizedmulti-stream retrieval.
RIO [59] provides real-time data retrieval with statisticaldelay guarantees for continuous and discrete multimedia data.The system applies random data allocation on heterogeneous
T. Plagemann et al. / Computer Communications 23 (2000) 267–289276

disks and partial data replication to achieve load balancingand high performance.
In addition to the above-mentioned aspects, new mechan-isms for multimedia file organization and metadata handlingare needed. For instance, in MMFS [76], each multimediafile has a uniquemnode, and for every strand in a multi-media file exists a uniqueinode. Mnodes include metadataof multimedia files and multimedia-specific metadata ofeach strand, e.g. recording rate, logical block size, andsize of the application data unit.
Metadata management in Symphony [65] uses atwo-levelmetadata structure(similar to inodes) allowing both datatype specific structure for files and supporting the traditionalbyte stream interface. Like in UNIX, fixed size metadatastructures are stored on a reserved area of the disk. Thefile metadata comprises, in addition to the traditional filemetadata, information about block size used to store thefile, type of data stored in the file, and a two-level index.The first index level maps logical units, e.g., frames, to byteoffsets, and the second index level maps byte offsets to diskblock locations.
Fellini [64] uses the raw disk interface of UNIX to storedata. It maintains the following information: raw disk parti-tion headers containing free space administration informa-tion on the disks, file control blocks similar to UNIX inodesdescribing data layout on disk, and file data.
Minorca [77] divides the file system partition into multiplesections: super block section, cylinder group section, andextent section. Metadata such as inodes and directory blocksare allocated in the cylinder group section in order to maintainthe contiguity of block allocation in the extent section.
6.2. Data placement
Data placement(also often referred to asdisk layoutanddata allocation) anddisk schedulingare responsible for theactual values of seek time, rotation time, and transfer time,which are the three major components determining diskefficiency [78]. There are a few general data placementstrategies for multimedia applications in which readoperations dominate and only few non-concurrent writeoperations occur:
• Scattered placement: blocks are allocated at arbitraryplaces on disk. Thus, sequential access to data willusually cause a large number of intra-file seeks androtations resulting in high disk read times. However, inRIO [59], random data placement is used to supportmixed-media workloads stored on heterogeneous diskconfigurations. In their special scenario, the reportedperformance measurements show similar results asthose for conventional striping schemes [79].
• Contiguous placement: all data blocks of a file aresuccessively stored on disk. Contiguous allocation willmostly result in better performance compared to scatteredallocation. The problem of contiguous allocation is that itcauses external fragmentation.
• Locally contiguous placement(also calledextent-basedallocation): the file is divided into multiple fragments(extents). All blocks of a fragment are stored contiguously,but fragments can be scattered over one or multiple disks.The fragment size is usually determined by the amount ofdata required for one service round. Locally contiguousplacement causes less external fragmentation thancontiguous placement.
• Constrained placement: this strategy restricts the averagedistance measured in tracks, between a finite sequence ofblocks [71,80]. Constrained placement represents acompromise of performance and fragmentation betweenscattered and contiguous placement. However, complexalgorithms are needed to obey the defined constraints[81]. This strategy takes into account only seek timesand not rotation times.
• VBR compressed data placement: conventional fixed-sized clusters correspond to varying amounts of time,depending on the achieved compression [82]. Alter-natively, the system can store data in clusters that corre-spond to a fixed amount of time, with a variable clustersize. Additionally, compressed data might not correspondto an even number of disk sectors, which introduces theproblem ofpackingdata [83].
To optimize write operations,log-structured placementhas been developed to reduce disk seeks for write intensiveapplications [66–68]. When modifying blocks of data, log-structured systems do not store modified blocks in theiroriginal positions. Instead, all writes for all streams areperformed sequentially in a large contiguous free space.Therefore, instead of requiring a seek (and possibly intra-file seeks) for each stream writing, only one seek is requiredprior to a number of write operations. However, this doesnot guarantee any improvement for read operations, and themechanism is more complex to implement.
For systems managing multiple storage devices, thereexist two possibilities of distributing data among disks[78,84]:
• Data striping: to realize a larger logical sector, manyphysical sectors from multiple disks are accessed inparallel.
• Data interleaving: requests of a disk are handled inde-pendent of requests from other disks. All fragments of arequest can be stored on�1 2 n� disks [85].
Some multimedia file systems, e.g. Symphony [65] andTiger Shark [61], usestriping techniques to interleave bothcontinuous and non-continuous multimedia data acrossmultiple disks. There are two factors crucially determiningthe performance of multi-disk systems [78]:
• Efficiency in using each disk. The amount of seek androtation times should be reduced as much as possible inorder to have more time available for data transfer.
• Fairnessin distributing the load over all disks.
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 277

These two factors largely depend on the data distributionstrategy and the application characteristics. They are veryimportant to achievesynchronization, which means thetemporal relationship between different multimedia datastreams [57]. Synchronization is often achieved by storingand transmitting streams interleaved, e.g. by using a MPEGcompression mechanism. Another solution istime-stampingof the multimedia data elements and appropriate buffering atthe presentation system to enable the OS to synchronizerelated data elements of continuous and discrete multimediadata.
6.3. Disk scheduling
Traditional disk scheduling algorithms focused mainly onreducing seek times [86], e.g.Shortest Seek Time First(SSTF) orSCAN. SSTF has high response time variationsand may result in starvation of certain requests. SCANreduces the response time variations and optimizes seektimes by serving the requests in an elevator-like way.There exist many variations and hybrid solutions of theSSTF and SCAN algorithms that are widely used today[87–89].
Modern disk scheduling algorithms [90,91] try to mini-mize the sum of seek and rotational delays by prioritizing,e.g. the request with theSmallest Positioning Time First.
However, disk scheduling algorithms for multimedia datarequests need to optimize, beside the traditional criteria,also other criteria special for multimedia data includingQoS guarantees [57,84]. The following list represents anoverview of recent multimedia data disk scheduling algo-rithms, which are primarily optimized for continuous datastreams [78,92]:
• EDF strategy [1] serves the block request with thenearest deadline first. Strict EDF may cause low through-put and very high seek times. Thus, EDF is often adaptedor combined with other disk scheduling strategies.
• SCAN-EDF strategy[93] combines the seek optimizationof SCAN and the real-time guarantees of EDF. Requestsare served according to their deadline. The request withthe earliest deadline is served first like in EDF. If multi-ple requests have the same (or similar) deadline, SCAN isused to define the order to handle the requests. Theefficiency of SCAN-EDF depends on how often thealgorithm can be applied, i.e. how many requests havethe same (or similar) deadline, because the SCANoptimization is only achieved for requests in the samedeadline class [94].
• Group Sweeping Strategy(GSS) [89,95] optimizes diskarm movement by using a variation of SCAN handlingthe requests in a round-robin fashion. GSS splits therequests of continuous media streams into multiplegroups. The groups are handled in a fixed order. Withina group, SCAN is used to determine time and order ofrequest serving. Thus, in one service round, a requestmay be handled first. In another service round, it may
be the last request served in this group. To guaranteecontinuity of playout, a smoothing buffer is needed.The buffer size is depending on the service round timeand the required data rate. Thus, the playout can first startat the end of the group containing the first retrievalrequests when enough data is buffered. GSS representsa trade-off between optimizations of buffer space anddisk arm movement. GSS is an improvement comparedto SCAN, which requires a buffer for every continuousmedia request. However, GSS may reduce to SCANwhen only one group is built, or in the other extremecase, GSS can behave like round-robin when everygroup contains only one request.
• Scheduling in rounds, e.g. Refs. [79,84,96], splits everycontinuous media request into multipleblocks(so-calledfragments) in a way that the playout duration of eachfragment is of a certain constant time (normally a fewseconds). The length of the round represents an uppertime limit for the system to retrieve the next fragmentfrom disk for all active requests. For each round, theamount of buffered data must not be less than the amountof consumed data avoiding that the amount of buffereddata effectively decreases over the time. Disk schedulingalgorithms with this property are called work-ahead-augmenting [71] or buffer-conserving [97]. Within around, it is possible to use round-robin or SCANscheduling.
However, there has only been done little work on diskscheduling algorithms for mixed multimedia data work-loads, serving discrete and continuous multimedia datarequests at the same time. Some examples are describedin [62,92,93,98–100]. These algorithms have to satisfythree performance goals: (1) display continuous mediastreams with minimal delay jitter; (2) serve discrete requestswith small average response times; and (3) avoid starvationof discrete requests and keep variation of response timeslow. In Ref. [92], disk scheduling algorithms for mixed-media workloads are classified by:
• Number of separate scheduling phases per round: one-phase algorithms produce mixed schedules, containingboth discrete and continuous data requests. Two-phasealgorithms have two, not timely overlapping, schedulingphases serving discrete and continuous data requestsisolated in the corresponding phase.
• Number of scheduling levels: hierarchical schedulingalgorithms for discrete data requests are based on defin-ing clusters. The higher levels of the algorithms areconcerned with the efficient scheduling of clusters ofdiscrete requests. The lower levels are efficientlyscheduling the requests within a cluster. The most impor-tant task to solve in this context is how to schedulediscrete data requests within the rounds of continuousdata requests, which are mostly servedbySCAN variations.
For instance,Cello [101] uses such a two-level disk
T. Plagemann et al. / Computer Communications 23 (2000) 267–289278

scheduling architecture. It combines a class-independentscheduler with a set of class-specific schedulers. Two timescales are considered in the two levels of the framework toallocate disk bandwidth: (1) coarse-grain allocation of band-width to application classes is performed by the class-independent scheduler; and (2) the fine-grain interleavingof requests is managed by the class-specific schedulers. Thisseparation enables the co-existence of multiple diskscheduling mechanisms at a time depending on the applica-tion requirements.
7. Memory management
Memory is an important resource, which has to be care-fully managed. The virtual memory subsystem of com-modity OSs allows processes to run in their own virtualaddress spaces and to use more memory than physicallyavailable. Thus, the memory manager has several complextasks such as bookkeeping available resources and assigningphysical memory to a single process [57,102]. Further keyoperations of the virtual memory system include [103,104]:
• Allocation of each process’ virtual address space andmapping physical pages into a virtual address spacewith appropriate protection.
• The page fault handler manages unmapped and invalidmemory references. Page faults happen when unmappedmemory is accessed, and memory references that areinconsistent with the current protection are invalid.
• Loading data into memory and storing them back to disk.• Duplicating an address space in case of afork call.
Since virtual memory is mapped onto actual availablememory, the memory manager has to do paging or swap-ping, but due to the real-time performance sensitiveness ofmultimedia applications, swapping should not be used in amultimedia OS [57]. Thus, we focus on paging-basedmemory systems. Techniques such as demand-paging andmemory-mapped files have been successfully used incommodity OSs [17,105]. However, these techniques failto support multimedia applications, because they introduceunpredictable memory access times, cause poor resourceutilization, and reduce performance. In the followingsubsections, we present new approaches for memory alloca-tion and utilization, data replacement, and prefetching usingapplication-specific knowledge to solve these problems.Furthermore, we give a brief description of the UVMVirtual Memory System that replaces the traditional virtualmemory system in NetBSD 1.4.
7.1. Memory allocation
Usually, upon process creation, a virtual address space isallocated whichcontainsthe data of the process. Physicalmemory is then allocated and assigned to a process and thenmapped into the virtual address space of the process accord-ing to available resources and a global or local allocation
scheme. This approach is also calleduser-centered alloca-tion. Each process has its own share of the resources.However, traditional memory allocation on a per client(process) basis suffers from a linear increase of requiredmemory with the number of processes.
In order to better utilize the available memory, severalsystems use so-calleddata-centered allocationwherememory is allocated to data objects rather than to a singleprocess. Thus, the data is seen as a resource principal. Thisenables more cost-effective data-sharing techniques[106,107]: (1)batchingstarts the video transmission whenseveral clients request the same movie and allows severalclients to share the same data stream; (2)buffering (orbridging) caches data between consecutive clients omittingnew disk requests for the same data; (3)stream merging(oradaptive piggy-backing) displays the same video clip atdifferent speeds to allow clients to catch up with eachother and then share the same stream; (4)content insertionis a variation of stream merging, but rather than adjustingthe display rate, new content, e.g. commercials, is insertedto align the consecutive playouts temporally; and (5)pero-dic services(or enhanced pay-per-view) assigns each clip aretrieval period where several clients can start at the begin-ning of each period to view the same movie and to shareresources. These data-sharing techniques are used in severalsystems. For example, a per movie memory allocationscheme, i.e. a variant of the buffering scheme, for VoDapplications is described in Ref. [108]. All buffers areshared among the clients watching the same movie andwork like a sliding window on the continuous data. Whenthe first client has consumed nearly all the data in the buffer,it starts to refresh the oldest buffers with new data. Periodicservices are used in pyramid broadcasting [109]. The data issplit in partitions of growing size, because the consumptionrate of one partition is assumed to be lower than the down-loading rate of the subsequent partition. Each partition isthen broadcast in short intervals on separate channels. Aclient does not send a request to the server, but instead ittunes into the channel transmitting the required data. Thedata is cached on the receiver side, and during the playout ofa partition, the next partition is downloaded. In Refs.[110,111], the same broadcasting idea is used. However,to avoid very large partitions at the end of a movie andthus to reduce the client buffer requirement, the partitioningis changed such that not every partition increases in size, butonly eachnth partition. Performance evaluations show thatthe data-centered allocation schemes scale much better withthe numbers of users compared to user-centered allocation.The total buffer space required is reduced, and the averageresponse time is minimized by using a small partition size atthe beginning of a movie.
The memory reservation per storage devicemechanism[78] allocates a fixed, small number of memory buffers perstorage device in a server-push VoD server using a cycle-based scheduler. In the simplest case, only two buffers ofidentical size are allocated per storage device. These buffers
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 279

work co-operatively, and during each cycle, the bufferschange task as data is received from disk. That is, datafrom one process is read into the first buffer, and when allthe data is loaded into the buffer, the system starts totransmit the information to the client. At the same time,the disk starts to load data from the next client into theother buffer. In this way, the buffers change task fromreceiving disk data to transmitting data to the network untilall clients are served. The admission control adjusts thenumber of concurrent users to prevent data loss when thebuffers switch and ensures the maintenance of all clientservices.
In Ref. [112], the traditional allocation and page-wiringmechanism in Real-Time Mach is changed. To avoid thatprivileged users monopolize memory usage by wiringunlimited amount of pages, only real-time threads areallowed to wire pages, though, only within their limitedamount of allocated memory, i.e. if more pages are needed,a request has to be sent to the reservation system. Thus,pages may be wired in a secure way, and the reservationsystem controls the amount of memory allocated to eachprocess.
7.2. Data replacement
When there is need for more buffer space, and there areno available buffers, a buffer has to be replaced. How to bestchoose which buffer to replace depends on the application.However, due to the high data consumption rate in multi-media applications, data is often replaced before it might bereused. The gain of using a complex page replacementalgorithm might be wasted and a traditional algorithm asdescribed in Refs. [113] or [102] might be used. Neverthe-less, in some multimedia applications where data oftenmight be reused, proper replacement algorithms mayincrease performance. Thedistance[114], thegeneralizedinterval caching[115], and the SHR [116] schemes, allreplace buffers after the distance between consecutiveclients playing back the same data and the amount ofavailable buffers.
Usually, data replacement is handled by the OS kernelwhere most applications use the same mechanism. Thus, theOS has full control, but the used mechanism is often tuned tobest overall performance and does not support application-specific requirements. In Nemesis [105],self-paginghasbeen introduced as a technique to provide QoS to multi-media applications. The basic idea of self-paging is to“require every application to deal with all its own memoryfaults using its own concrete resources”. All paging opera-tions are removed from the kernel where the kernel is onlyresponsible for dispatching fault notifications. This gives theapplication flexibility and control, which might be needed inmultimedia systems, at the cost of maintaining its ownvirtual memory operations. However, a major problem ofself-paging is to optimize the global system performance.Allocating resources directly to applications gives them
more control, but that means optimizations for globalperformance improvement are not directly achieved.
7.3. Prefetching
The poor performance of demand-paging is due to thelow disk access speeds. Therefore, prefetching data fromdisk to memory is better suited to support continuous play-back of time-dependent data types. Prefetching is a mechan-ism to preload data from slow, high-latency storage devicessuch as disks to fast, low-latency storage like main memory.This reduces the response time of a data read request drama-tically and increases the disk I/O bandwidth. Prefetchingmechanisms in multimedia systems can take advantage ofthe sequential characteristics of multimedia presentations.For example, in Ref. [117], a read-ahead mechanismretrieves data before it is requested if the system determinesthat the accesses are sequential. In Ref. [118], the utilizationof buffers and disk is optimized by prefetching all the short-est database queries maximizing the number of processesthat can be activated once the running process is finished. InRef. [119], assuming a linear playout of the continuous datastream, the data needed in the next period (determined by atradeoff between the maximum concurrent streams and theinitial delay) is prefetched into a shared buffer. Preloadingdata according to the loading and consuming rate and theavailable amount of buffers is described in Ref. [120].
In addition to the above-mentioned prefetching mechan-isms designed for multimedia applications, more generalpurpose facilities for retrieving data in advance are designedwhich also could be used for certain multimedia applica-tions. Theinformed prefetchingandcachingstrategy [121]preloads a certain amount of data where the buffers areallocated/deallocated according to a global max–min valua-tion. This mechanism is further developed in Ref. [122]where the automatic hint generation, based on speculativepre-executions using mid-execution process states, is usedto prefetch data for possible future read requests. Moreover,the dependent-based prefetching, described in Ref. [123],captures the access patterns of linked data structures. Aprefetch engine runs in parallel with the originalprogram using these patterns to predict future datareferences. Finally, in Ref. [124], an analytic approachto file prefetching is described. During the execution ofa process a semantic data structure is built showing the fileaccesses. When a program is re-executed, the saved accesstrees are compared against the current access tree of theactivity, and if a similarity is found, the stored tree is usedto preload files.
Obviously, knowledge (or estimations) about applicationbehavior might be used for both replacement andprefetching. In Ref. [125], the buffer replacement andpreloading strategyleast/most relevant for presentationdesigned for interactive continuous data streams ispresented. A multimedia object is replaced and prefetchedaccording to its relevance value computed according to the
T. Plagemann et al. / Computer Communications 23 (2000) 267–289280

presentation point/modus of the data playout. In Ref. [126],this algorithm is extended for multiple users and QoSsupport.
7.4. UVM virtual memory system
The UVM Virtual Memory System [103,104] replacesthe virtual memory object, fault handling, and pager of theBSD virtual memory system; and retains only the machinedependent/independent layering and mapping structures.For example, the memory mapping is redesigned to increaseefficiency and security; and the map entry fragmentation isreduced by memory wiring. In BSD, the memory objectstructure is a stand-alone abstraction and under control ofthe virtual memory system. In UVM, the memory objectstructure is considered as a secondary structure designedto be embedded with a handle for memory mapping result-ing in better efficiency, more flexibility, and less conflictswith external kernel subsystems. The new copy-on-writemechanism avoids unnecessary page allocations and datacopying, and grouping or clustering the allocation and useof resources improves performance. Finally, a virtualmemory-based data movement mechanism is introducedwhich allows data sharing with other subsystems, i.e.when combined with the I/O or IPC systems, it can reducethe data copying overhead in the kernel.
8. Management of other resources
This section takes a brief look at management aspects ofOS resources that have not yet been discussed, like schedul-ing of system bus and cache management. Furthermore, wedescribe some mechanisms for speed improvements inmemory access. Packet scheduling mechanisms to sharenetwork bandwidth between multiple streams at the host–network interface are not discussed here due to spaceconsiderations. All solutions for packet scheduling in OSsare adopted from packet scheduling in packet networks.
8.1. Bus scheduling
The SCSI bus is a priority-arbitrated bus. If multipledevices, e.g. disks, want to transfer data, the device withthe highest priority will always get the bus. In systems withmultiple disks, it is possible that real-time streams beingsupported from a low-priority disk get starved from high-priority disks that serve best effort requirements [127].DROPS [128] schedules requests to the SCSI subsystemsuch that the SCSI bandwidth can be fully exploited. Itdivides SCSI time into slots where the size of slots isdetermined by the worst case seek times of disk drives.
SCSI is a relatively old technology, and PCI has becomethe main bus technology for multimedia PCs and work-stations [129]. However, to the best of our knowledge, nowork has been reported on scheduling of PCI bus or otheradvanced bus technologies to support QoS. Probably,
because the bus is no longer regarded as one of the mostlimiting performance bottlenecks, except in massive parallelI/O systems.
8.2. Cache management
All real-time applications rely on predictable scheduling,but the memory cache design makes it hard to forecast andschedule the processor time [10]. Furthermore, memorybandwidth and the general OS performance have notincreased at the same rate as CPU performance. Bench-marked performance can be improved by enlarging andspeeding up static RAM-based cache memory, but thelarge amount of multimedia data that has to be handled byCPU and memory system will likely decrease cache hitratios. If two processes use the same cache lines and areexecuted concurrently, there will not only be an increase incontext switch overheads, but also a cache-interference costthat is more difficult to predict. Thus, the system per-formance may be dominated by slower main memory andI/O accesses. Furthermore, the busier a system is, the morelikely it is that involuntary context switches occur, longerrun queues must be searched by the scheduler, etc. flushingthe caches even more frequently [17].
One approach to improve performance is to partition thesecond-level cache as described in Refs. [10,128]. Workingsets of real-time and time-sharing applications are allowedto be separated into different partitions of the second-levelcache. The time-share applications then cannot disrupt thecached working sets of real-time applications, which leadsto better worst case predictability.
Another approach is discussed in Ref. [130]. A very lowoverhead thread package is used letting the applicationspecify each thread’s use of data. The thread schedulerthen execute in turn all threads using the same data. Inthis way, the data that is already in the cache is used byall threads needing it before it is flushed.
Bershad et al. [131] describe an approach using conflictdetection and resolution to implement a cheap, large, andfast direct-mapped cache. The conflicts are detected byrecording and summarizing a history of cache misses, anda software policy within the OS’s virtual memory systemremoves conflicts by dynamically remapping pages. Thisapproach nearly matches the performance of a two-wayset associative cache, but with lower hardware cost andlower complexity.
8.3. Speed improvements in memory accesses
The term dynamic RAM (DRAM), coined to indicate thatany random access in memory takes the same amount oftime, is slightly misleading. Most modern DRAMs providespecial capabilities that make it possible to perform someaccesses faster than others [132]. For example, consecutiveaccesses to the same row in a pagemode memory are fasterthan random accesses, and consecutive accesses that hitdifferent memory banks in a multi-bank system allow
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 281

concurrency and are thus faster than accesses that hit thesame bank. The key point is that the order of the requestsstrongly affects the performance of the memory devices. Forcertain classes of computations, like those which involvestreams of data where a high degree of spatial locality ispresent and where we, at least in theory, have a perfectknowledge of the future references, a reordering of thememory accesses might give an improvement in memorybandwidth.
The most common method to reduce latency is to increasethe cache line size, i.e. using the memory bandwidth to fillseveral cache locations at the same time for each access.However, if the stream has a non-unit-stride (stride is thedistance between successive stream elements in memory),i.e. the presentation of successive data elements does notfollow each other in memory, the cache will load data whichwill not be used. Thus, lengthening the cache line sizeincreases the effective bandwidth of unit-stride streams,but decreases the cache hit rate for non-streamed accesses.
Another way of improving memory bandwidth inmemory-cache data transfers for streamed access patternsis described in Ref. [132]. First, since streams often have notemporal locality, they provide a separate buffer storage forstreamed data. This means that streamed data elements,which often are replaced before they might be reused, donot affect the replacement of data elements that might bene-fit from caching. Second, to take advantage of the ordersensitivity of the memory system, a memory-schedulingunit is added to reorder the accesses. During compile-time, information about addresses, strides of a stream, andnumber of data elements are collected enabling thememory-scheduling unit to reorder the requests duringrun-time.
9. I/O tuning
Traditionally, there are several different possible data
transfers and copy operations within an end-system asshown in Fig. 5. These often involve several differentcomponents. Using the disk-to-network data path as anexample, a data object is first transferred from disk tomain memory (A). The data object is then managed by themany subsystems within the OS designed with differentobjectives, running in their own domain (either in user orkernel space), and therefore, managing their buffers differ-ently. Due to different buffer representations and protectionmechanisms, data is usually copied, at a high cost, fromdomain to domain ((B), (C), or (D)) to allow the differentsubsystems to manipulate the data. Finally, the data object istransferred to the network interface (E). In addition to allthese data transfers, the data object is loaded into thecache (F) and CPU registers (G) when the data object ismanipulated.
Fig. 5 clearly identifies the reason for the poor perfor-mance of the traditional I/O system. Data is copied severaltimes between different memory address spaces which alsocauses several context switches. Copy operations andcontext switches represent the main performance bottlenecks.Furthermore, different subsystems, e.g. file system andcommunication subsystem, are not integrated. Thus, theyinclude redundant functionality like buffer management,and several identical copies of a data object might be storedin main memory, which in turn reduces the effective size ofthe physical memory. Finally, when concurrent usersrequest the same data, the different subsystems might haveto perform the same operations on the same data severaltimes.
We distinguish three types of copy operations: memory–CPU, direct I/O (i.e. memory–I/O device), and memory–memory. Solutions for these types of copy operations havebeen developed for general purpose and application specificsystems. The two last subsections describe a sampleapproach for each.
9.1. Memory–CPU copy operations
Data manipulations are time consuming and are often partof different, distinct program modules or communicationprotocol layers, which typically access data independentlyof each other. Consequently, each data manipulation mayrequire access to uncached data resulting in loading the datafrom memory to a CPU register, manipulating it, and pos-sibly storing it back to memory. Thus, these repeatedmemory–CPU data transfers, denoted (F) and (G) in Fig.5, can have large impacts on the achieved I/O bandwidth. Todecrease the number of memory–CPU data transfers,inte-grated layer processing[133,134] performs all data manip-ulation steps, e.g. calculating error detection checksums,executing encryption schemes, transforming data forpresentation, and moving data between address spaces, inone or two integrated processing loops instead ofperforming them stepwise as in most systems.
T. Plagemann et al. / Computer Communications 23 (2000) 267–289282
Fig. 5. Data transfers and copy operations.

9.2. Memory–I/O device copy operations
Data is transferred between hardware devices, such asdisks and network adapters, and applications’ physicalmemory. This is often done via an intermediate subsystem,like the file system or the communication system, adding anextra memory copy. A mechanism to transfer data withoutmultiple copying isdirect I/O, which in some form is avail-able in several commodity OSs today, e.g. Solaris andWindows NT. Direct memory access (DMA) orprogrammed I/O(PIO) is used to transfer data directlyinto a frame buffer where, e.g. the file system’s buffercache is omitted in a data transfer from disk to application.Without involving the CPU in the data transfers, DMAcan achieve transfer rates close to the limits of mainmemory and the I/O bus, but DMA increases complex-ity in the device adapters, and caches are often notcoherent with respect to DMA [135]. Using PIO, onthe other hand, the CPU is required to transfer everyword of data between memory and the I/O adapter.Thus, only a fraction of the peak I/O bandwidth is achieved.Due to high transfer rates, DMA is often used for direct I/Odata transfers. However, despite the reduced bandwidth,PIO can sometimes be preferable over DMA. If datamanipulations, e.g. checksum calculations, can be inte-grated with the PIO data transfer, it is possible to save onememory access, and after a programmed data movement,the data may still reside in the cache, reducing furthermemory traffic.
In case of application–disk transfers, direct I/O canoften be applied since the file system usually does nottouch the data itself. However, in case of application–network adapter transfers, the communication systemmust generate packets, calculate checksums, etc. makingit harder to avoid the data transfer through the commu-nication system. Nevertheless, there are several attemptsto avoid data touching and copy operation transfers, i.e.reducing the traditional (B)(E) data path in Fig. 5 to only(E). After burner [136] and Medusa [137] copy datadirectly onto the on-board memory using PIO, with inte-grated checksum and data length calculation, leaving justenough space in front of the cluster to add a packed header.Using DMA and a user-level implementation of thecommunication software, theapplication device channel[138,139] gives restricted but direct access to an ATMnetwork adaptor removing the OS kernel from the criticalnetwork send/receive path. In Ref. [49], no memory-to-memory copying is needed using shared buffers or directmedia streaming by linking the device and networkconnection together. Finally, in Refs. [140,141], zero-copy communication system architectures are reported forTCP and ATM, respectively. Virtual memory page remap-ping (see next subsection) is used to eliminate copyingbetween applications running in user space and the OSkernel, and DMA is used to transfer data between memoryand the network buffer.
9.3. Memory–memory copy operations
Direct I/O is typically used when transferring databetween main memory and a hardware device as describedabove. However, data transfers between different processaddress spaces is done through well-defined channels, likepipes, sockets, files, and special devices, giving eachprocess full control of its own data [142]. Nevertheless,such physical copying is slow and requires at least twosystem calls per transaction, i.e. one on sender and one onreceiver side. One way of reducing the IPC costs is to usevirtual page(re)mapping. That is, the data element is notphysically copied byte by byte, but only the address invirtual memory to the data element in physical memory iscopied into the receiver’s address space. Access rights to thedata object after the data transfer are determined by the usedsemantic:
• The copy modelcopies all data from domain to domaingiving each process full control of its own data at the costof cross domain data copying and maintaining severalidentical copies in memory.
• The move modelremoves the data from the sourcedomain by virtually remapping the data into the destina-tion domain avoiding the multiple-copies problem.However, if the source later needs to re-access themoved data, e.g. when handling a retransmission request,the data must be fetched back.
• The share modelmakes the transferred data visible andaccessible to both the source and the target domain bykeeping pointers in virtual memory to the same physicalpages, i.e. by usingshared memorywhere severalprocesses map the same data into their address space.Thus, all the sharing processes may access the samepiece of memory without any system call overheadother than the initial cost of mapping the memory.
Several general cross-domain data copy avoidance archi-tectures are suggested trying to minimize respectively toeliminate all (C), (B), and (D) copy operations depicted inFig. 5. Tenex [143] was one of the first systems to use virtualcopying, i.e. several pointers in virtual memory refer to onephysical page. Accent [144,145] generalized the concepts ofTenex by integrating virtual memory management and IPCin such a way that large data transfers could use memorymapping techniques rather than physical data copying. TheV distributed system [146] and the DASH IPC mechanism[147] use page remapping, and thecontainer shippingfacility [148,149] uses virtual inter-domain data transfersbased on the move model where all in-memory copying isremoved. Furthermore,fast buffers(fbufs) [138,150] is afacility for I/O buffer management and data transfers acrossprotection domain boundaries primarily designed for hand-ling network streams using shared virtual memory iscombined with virtual page remapping. In Ref. [151],fbufs is extended to a zero-copy I/O framework. Fastin-kernel data paths between I/O objects, increasing
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 283

throughput and reducing context switch operations, aredescribed in Refs. [152,153]. A new system call,splice (),moves data asynchronously and without user–process inter-vention to and from I/O objects specified by file descriptors.These descriptors specify the source and sink of I/O data,respectively. This system call is extended in thestream ()system call of the Roadrunner I/O system [154,155] tosupport kernel data streaming between any pair of I/Oelements without crossing any virtual memory boundariesusing techniques derived from stackable file systems. TheGenie I/O system [156–158] inputs or outputs data to orfrom shared buffers in-place (i.e. directly to or from appli-cation buffers) without touching distinct intermediatesystem buffers. Data is shared by managing reference coun-ters, and a page is only deallocated if there are no processesreferencing this page. The universal continuous media I/Osystem [159,160] combines all types of I/O into a singleabstraction. The buffer management system is allowed toalign data buffers on page boundaries so that data can bemoved without copying which means that the kernel and theapplication are sharing a data buffer rather than maintainingtheir own separate copy. The UVM Virtual Memory System[103,104] data movement mechanism provides new techni-ques that allow processes to exchange and share data inmemory without copying. The page layout and page transferfacilities give support for page loan out and reception ofpages of memory, and the map entry passing enablesexchange chunks of the processes’ virtual address space.
9.4. IO-Lite
IO-Lite [161,162] is an I/O buffering and caching systemfor a general purpose OS inspired by the fbuf mechanism.IO-Lite unifies all buffering in a system. In particular,buffering in all subsystems are integrated, and a singlephysical copy of the data is shared safely and concurrently.This is achieved by storing buffered I/O data in immutablebuffers whose location in memory never change. Accesscontrol and protection is ensured at the granularity ofprocesses by maintaining access control lists to cachedpools of buffers. For cross-domain data transfers, IO-Litecombines page remapping and shared memory.
All data is encapsulated in mutable buffer aggregates,which are then passed among the different subsystemsand applications by reference. The sharing of read-onlyimmutable buffers enables efficient transfers of I/O dataacross protection domain boundaries, i.e. all subsystemsmay safely refer to the same physical copy of the data with-out problems of synchronization, protection, consistency,etc. However, the price to pay is that data cannot be modi-fied in-place. This is solved by the buffer aggregateabstraction. The aggregate is mutable, and a modifiedvalue is stored in a new buffer, and the modified sectionsare logically joined with the unchanged data through pointermanipulation.
9.5. Multimedia mbuf
The multimedia mbuf(mmbuf) [163,164] is speciallydesigned for disk-to-network data transfers. It provides azero-copy data path for networked multimedia applicationsby unifying the buffering structure in file I/O and network I/O.This buffer system looks like a collection of clustered mbufsthat can be dynamically allocated and chained. The mmbufheader includes references to mbuf header and buffer cacheheader. By manipulating the mmbuf header, the mmbuf canbe transformed either into a traditional buffer, that a filesystem and a disk driver can handle, or an mbuf, whichthe network protocols and network drivers can understand.
A new interface is provided to retrieve and send data,which coexist with the old file system interface. The oldbuffer cache is bypassed by reading data from a file intoan mmbuf chain. Both synchronous (blocking) and asyn-chronous (non-blocking) operations are supported, andread and send requests for multiple streams can be bunchedtogether in a single call minimizing system call overhead.At setup time, each stream allocates a ring of buffers, eachof which is an mmbuf chain. The size of each bufferelement, i.e. the mmbuf chain, depends on the size of themultimedia frame it stores, and each buffer element can bein one of four states: empty, reading, full, or sending.Furthermore, to coordinate the data read and send activities,two pointers (read and send) to the ring buffer are main-tained. Then, for each periodic invocation of the streamprocess, these pointers are used to handle data transfers. Ifthe read pointer is pointing to a buffer element in the emptystate, data is read into this chain of mmbufs, and the pointeris advanced to the next succeeding chain on which the nextread is performed. If the send pointer is holding a full bufferelement, the data stored in this buffer element is transmitted.
10. Conclusions
The aim of this article is to give an overview of recentdevelopments in the area of OS support for multimediaapplications. This is an active area, and a lot of valuableresearch results have been published. Thus, we have notdiscussed or citedall recent results, but tried to identifythe major approaches and to present at least one representa-tive for each.
Time-dependent multimedia data types, like audio andvideo, will be a natural part of future applications and inte-grated together with time-independent data types, like text,graphics, and images. Commodity OSs do not presentlysupport all the requirements of multimedia systems. NewOS abstractions need to be developed to support a mix ofapplications with real-time and best-effort requirements andto provide the necessary performance. Thus, management ofall system resources, including processors, main memory,network, disk space, and disk I/O, is an important issue. Themanagement needed encompasses admission control,
T. Plagemann et al. / Computer Communications 23 (2000) 267–289284

allocation and scheduling, accounting, and adaptation.Proposed approaches for better multimedia support include:
• New OS structures and architectures, like the library OSsExokernel and Nemesis.
• New mechanisms that are especially tailored for QoSsupport, like specialized CPU and disk scheduling.
• New system abstractions, like resource principals forresource ownership, inheritance of the associatedpriorities, and accounting of resource utilization.
• Extended system abstractions to additionally support newrequirements, like synchronization support and metadatain file systems.
• Avoiding the major system bottlenecks, like copyoperations avoidance through page remapping.
• Support for user-level control over resources includinguser-level communication.
It is not clear how new OS architectures should look likeor even if they are really needed at all. Monolithic andm-kernel architectures can be developed further, and a care-ful design and implementation of such systems can provideboth good performance and build on time provenapproaches. When proposing new architectures, it becomesvery important to demonstrate both comparable or betterperformance and better functionality than in existing solu-tions. Furthermore, it is important to implement and evalu-ate integrated systems and not only to study one isolatedaspect. In this respect, Nemesis is probably the mostadvanced system.
To evaluate and compare performance and functionalityof new approaches, more detailed performance measure-ments and analysis are necessary. This implies designingand implementing systems, and developing and using acommon set of micro- and application benchmarks forevaluation of multimedia systems. The field is still veryactive, and much work remains to be done before it becomesknown how to design and implement multimedia platforms.
Acknowledgements
We would like to thank Frank Eliassen, Liviu Iftode,Martin Karsten, Ketil Lund, Chuanbao Wang, and LarsWolf for reviewing earlier versions of this paper and theirvaluable comments and suggestions.
References
[1] C.L. Liu, J.W. Layland, Scheduling algorithms for mutliprogram-ming in a hard real-time environment, Journal of the ACM 20 (1)(1973) 46–61.
[2] P. Goyal, X. Guo, H.M. Vin, A hierarchical CPU scheduler formultimedia operating systems, Proc. of 2nd USENIX Symp. onOperating Systems Design and Implementation (OSDI’96), Seattle,WA, USA, October 1996, pp. 107–121.
[3] H.-H. Chu, K. Nahrstedt, CPU service classes for multimedia
applications, Proc. of IEEE Int. Conf. on Multimedia Computingand Systems (ICMCS’99), Florence, Italy, June 1999.
[4] J.B. Chen, Y. Endo, K. Chan, D. Mazie`res, D. Dias, M.I. Seltzer,M.D. Smith, The measured performance of personal computeroperating systems, ACM Transactions on Computer Systems 14(1) (1996) 3–40.
[5] D. Engler, S.K. Gupta, F. Kaashoek, AVM: application-level virtualmemory, Proc. of 5th Workshop on Hot Topics in Operating Systems(HotOS-V), Orcas Island, WA, USA, May 1995.
[6] M.F. Kaaskoek, D.R. Engler, G.R. Ganger, H.M. Briceno, R. Hunt,D. Mazieres, T. Pinckney, R. Grimm, J. Jannotti, K. Mackenzie,Application performance and flexibility on exokernel systems,Proc. of 16th Symp. on Operating Systems Principles (SOSP’97),St. Malo, France, October 1997, pp. 52–65.
[7] I. Leslie, D. McAuley, R. Black, T. Roscoe, P. Barham, D. Evers, R.Fairbairns, E. Hyden, The design and implementation of an operat-ing system to support distributed multimedia applications, IEEEJournal on Selected Areas in Communications 14 (7) (1996)1280–1297.
[8] J. Liedtke, On micro kernel construction, Proc. of 15th ACM Symp.on Operating Systems Principles (SOSP’95), Cooper Mountain,Colorado, USA, December 1995, pp. 237–250.
[9] J. Liedtke, Toward real microkernels, Communication of the ACM39 (9) (1996) 70–77.
[10] H. Hartig, M. Hohmuth, J. Liedtke, S. Scho¨nberg, J. Wolter, Theperformance ofm-kernel-based systems, Proc. of 16th ACM Symp.on Operating System Principles (SOSP’97), October 1997, St. Malo,France, pp. 66–77.
[11] G. Coulson, G. Blair, P. Robin, D. Shepherd, Supporting continuousmedia applications in a micro-kernel environment, in: O. Spaniol(Ed.), Architecture and Protocols for High-Speed Networks, KluwerAcademic, Dordrecht, 1994.
[12] T.E. Anderson, B.N. Bershad, E.D. Lazowska, H.M. Levy, Schedu-ler activations: effective kernel support for the user-level manage-ment of parallelism, ACM Transactions on Computer Systems 10 (1)(1992) 53–79.
[13] R. Govindan, D.P. Anderson, Scheduling and IPC mechanisms forcontinuous media, Proc. of 13th ACM Symp. on Operating SystemsPrinciples (SOSP’91), Pacific Grove, CA, USA, October 1991,pp. 68–80.
[14] K.A. Bringsrud, G. Pedersen, Distributed electronic classrooms withlarge electronic whiteboards, Proc. of 4th Joint European Network-ing Conf. (JENC4), Trondheim, Norway, May 1993, pp. 132–144.
[15] T. Plagemann, V. Goebel, Analysis of quality-of-service in a wide-area interactive distance learning system, L. Wolf (Ed.), EuropeanActivities in Interactive Distributed Multimedia Systems and Tele-communication Services, Telecommunication Systems 11 (1/2)(1999) 139–160.
[16] K. Nahrstedt, R. Steinmetz, Resource management in networkedmultimedia systems, IEEE Computer 28 (5) (1995) 52–63.
[17] H. Schulzrinne, Operating system issues for continuous media,ACM/Springer Multimedia Systems 4 (5) (1996) 269–280.
[18] S. Araki, A. Bilas, C. Dubnicki, J. Edler, K. Konishi, J. Philbin,User–space communication: a quantitative study, Proc. of 10thInt. Conf. of High Performance Computing and Communications(SuperComputing’98), Orlando, FL, USA, November 1998.
[19] J.L. Peterson, A. Silberschatz, Operating System Concepts,Addison-Wesley, New York, 1985.
[20] K. Nahrstedt, H. Chu, S. Narayan, QoS-aware resource managementfor distributed multimedia applications, Journal on High-SpeedNetworking, Special Issue on Multimedia Networking 7 (3/4)(1999) 229–258.
[21] J. Gecsei, Adaptation in distributed multimedia systems, IEEEMultimedia 4 (2) (1997) 58–66.
[22] K. Lakshman, AQUA: an adaptive quality of service architecture fordistributed multimedia applications, PhD thesis, Computer ScienceDepartment, University of Kentucky, Lexington, KY, USA, 1997.
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 285

[23] A. Goel, D. Steere, C. Pu, J. Walpole, SWiFT: A feedback controland dynamic reconfiguration toolkit, Technical Report CSE-98-009,Oregon Graduate Institute, Portland, OR, USA, June 1998.
[24] B. Noble, M. Satyanarayanan, D. Narayanan, J.E. Tilton, J. Flinn, K.Walker, Agile application-aware adaptation for mobility, Proc. ofthe 16th ACM Symp. on Operating System Principles (SOSP’97),St. Malo, France, October 1997, pp. 276–287.
[25] A. Bavier, L. Peterson, D. Mosberger, BERT: a scheduler for best-effort and real-time paths, Technical Report TR 587-98, PrincetonUniversity, Princeton, NJ, USA, August 1998.
[26] A. Bavier, B. Montz, L. Peterson, Predicting MPEG execution times,Proc. of 1998 ACM Int. Conf. on Measurement and Modeling ofComputer Systems (SIGMETRICS’98), Madison, WI, USA, June1998, pp. 131–140.
[27] G. Banga, P. Drutchel, J.C. Mogul, Resource containers: a newfacility for resource management in server systems, Proc. of 3rdUSENIX Symp. on Operating Systems Design and Implementation(OSDI’99) New Orleans, LA, USA, February 1999.
[28] W. Clifford, J.Z. Mercer, R. Ragunathan, On predictable operatingsystem protocol processing, Technical Report CMU-CS-94-165,School of Computer Science, Carnegie Mellon University,Pittsburgh, PA, May 1994.
[29] K. Jeffay, F.D. Smith, A. Moorthy, A. Anderson, Proportional sharescheduling of operating system services for real-time applications,Proc. of 19th IEEE Real-Time System Symp. (RTSS’98), Madrid,Spain, December 1998, pp. 480–491.
[30] C.A. Waldspurger, Lottery and Stride scheduling: flexible propor-tional-share resource management, PhD thesis, Department ofElectrical Engineering and Computer Science, MassachusettsInstitute of Technology, Cambridge, MA, USA, September 1995.
[31] B. Ford, J. Lepreau, Evolving Mach 3.0 to the migrating threadmodel, Proc. of 1994 USENIX Winter Conf., San Francisco, CA,USA, January 1994.
[32] R.K. Clark, E.D. Jensen, F.D. Reynolds, An architectural overviewof the alpha real-time distributed kernel, Workshop on Micro-Kernels and other Kernel Architectures, April 1992.
[33] G. Hamilton, P. Kougiouris, The spring nucleus: a microkernel forobjects, Proc. USENIX Summer Conf., Cincinnati, OH, USA, June1993.
[34] B. Ford, S. Susarla, CPU inheritance scheduling, Proc. of 2ndUSENIX Symp. on Operating Systems Design and Implementation(OSDI’96), Seattle, WA, USA, October 1996, pp. 91–105.
[35] J. Bruno, E. Gabber, B. O¨ zden, A. Silberschatz, The Eclipse operat-ing system: providing quality of service via reservation domains,Proc. of USENIX Annual Technical Conf., New Orleans, LA,June 1998.
[36] B. Vergehese, A. Gupta, M. Rosenblum, Performance isolation:sharing and isolation in shared memory multiprocessors, Proceedingof 8th Int. Conf. on Architectural Support for ProgrammingLanguages and Operating Systems (ASPLOS-VIII), San Jose, CA,USA, October 1998.
[37] R. Rajkumar, K. Juvva, A. Molano, S. Oikawa, Resource kernels: aresource-centric approach to real-time systems, Proc. of SPIE/ACMConf. on Multimedia Computing and Networking (MMCN’98), SanJose, CA, USA, January 1998.
[38] M.B. Jones, P.J. Leach, R.P. Draves, J.S. Barrera, Modular real-timeresource management in the Rialto operating system, Proc. of 5thWorkshop on Hot Topics in Operating Systems (HotOS-V), OrcasIsland, WA, USA, May 1995, pp. 12–17.
[39] M.B. Jones, D. Rosu, M.-C. Rosu, CPU reservations and timeconstraints: efficient, predictable scheduling of independent activ-ities, Proc. of 16th ACM Symp. on Operating Systems Principles(SOSP’97), St. Malo, France, October 1997, pp. 198–211.
[40] D. Mosberger, L.L. Peterson, Making paths explicit in the Scoutoperating system, Proc. of 2nd USENIX Symp. on OperatingSystems Design and Implementation (OSDI’96), Seattle, WA,USA, October 1996.
[41] O. Spatscheck, L.L. Peterson, Defending against denial of serviceattacks in Scout, Proc. of 3rd USENIX Symp. on Operating SystemsDesign and Implementation (OSDI’99), New Orleans, LA, USA,February 1999, pp. 59–72.
[42] D.C. Steere, A. Goel, J. Gruenenberg, D. McNamee, C. Pu,J. Walpole, A feedback-driven proportion allocator for real-ratescheduling, Proc. of 3rd USENIX Symp. on Operating SystemsDesign and Implementation (OSDI’99), New Orleans, LA, USA,February 1999, pp. 145–158.
[43] J. Nieh, J.G. Hanko, J.D. Northcutt, G.A. Wall, SVR4 UNIXscheduler unacceptable for multimedia applications, Proc. of 4thInt. Workshop on Network and Operating System Support for Digi-tal Audio and Video (NOSSDAV’93), Lancaster, UK, November1993.
[44] L.C. Wolf, W. Burke, C. Vogt, Evaluation of a CPU schedulingmechanism for multimedia systems, Software—Practice andExperience 26 (4) (1996) 375–398.
[45] I. Stoica, W. Abdel-Wahab, K. Jeffay, On the duality betweenresource reservation and proportional share resource allocation,Multimedia Computing and Networking 1997, SPIE Proc. Series,Volume 3020, San Jose, CA, USA, February 1997, pp. 207–214.
[46] A. Demers, S. Keshav, S. Shenker, Analysis and simulation of a fairqueueing algorithm, Internet-Working: Research and Experience1 (1) (1990) 3–26.
[47] L. Zhang, Virtual clock: a new traffic control algorithm for packetswitching networks, ACM Transactions on Computer Systems 9 (3)(1991) 101–124.
[48] A.K. Parek, R.G. Gallager, A generalized processor sharingapproach to flow control in integrated services networks: thesingle-node case, IEEE/ACM Transactions on Networking 1 (3)(1993) 344–357.
[49] D.K.Y. Yau, S.S. Lam, Operating system techniques for distributedmultimedia, Technical Report TR-95-36 (revised), Department ofComputer Sciences, University of Texas at Austin, Austin, TX,USA, January 1996.
[50] J. Nieh, M.S. Lam, The design, implementation and evaluation ofSmart: a scheduler for multimedia applications, Proc. of 16th ACMSymp. on Operating System Principles (SOSP’97), St. Malo, France,October 1997, pp. 184–197.
[51] D.P. Anderson, S.Y. Tzou, R. Wahbe, R. Govindan, M. Andrews,Support for Continuous Media in the DASH system, Proc. of 10thInt. Conf. on Distributed Computing Systems (ICDCS’90), Paris,France, May 1990, pp. 54–61.
[52] G. Coulson, A. Campbell, P. Robin, G. Blair, M. Papathomas,D. Hutchinson, The design of a QoS controlled ATM based commu-nication system in Chorus, IEEE Journal on Selected Areas ofCommunications 13 (4) (1995) 686–699.
[53] P. Goyal, H.M. Vin, H. Cheng, Start-time fair queuing: a schedulingalgorithm for integrated services packet switching networks, Proc. ofACM SIGCOMM’96, San Francisco, CA, USA, August 1996,pp. 157–168.
[54] M.B. Jones, J.S. Barrera, A. Forin, P.J. Leach, D. Rosu, M.-C. Rosu,An overview of the Rialto real-time architecture, Proc. of 7th ACMSIGOPS European Workshop, Connemara, Ireland, September1996, pp. 249–256.
[55] A. Molano, K. Juvva, R. Rajkumar, Real-time filesystems guaran-teeing timing constraints for disk accesses in RT-Mach, Proc. of 18thIEEE Real-Time Systems Symp. (RTSS’97), San Francisco, CA,USA, December 1997.
[56] P.M. Chen, E.K. Lee, G.A. Gibson, R.H. Katz, D.A. Patterson,RAID: high-performance, reliable, secondary storage, ACMComputing Surveys 26 (2) (1994) 145–185.
[57] R. Steinmetz, Analyzing the multimedia operating system, IEEEMultimedia 2 (1) (1995) 68–84.
[58] S.J. Leffler, M.K. McKusick, M.J. Karels, J.S. Quarterman, TheDesign and Implementation of the 4.3BSD UNIX Operating System,Addison-Wesley, New York, 1989.
T. Plagemann et al. / Computer Communications 23 (2000) 267–289286

[59] J.R. Santos, R. Muntz, Performance analysis of the RIO multimediastorage system with heterogeneous disk configurations, Proc. of 6thACM Multimedia Conf. (ACM MM’98), Bristol, UK, September1998, pp. 303–308.
[60] R.L. Haskin, The Shark continuous-media file server, Proc. of 38thIEEE Int. Conf.: Technologies for the Information Superhighway(COMPCON’93), San Francisco, CA, USA, February 1993,pp. 12–15.
[61] R.L. Haskin, F.B. Schmuck, The Tiger Shark file system, Proc. of41st IEEE Int. Conf.: Technologies for the Information Superhigh-way (COMPCON’96), Santa Clara, CA, USA, February 1996,pp. 226–231.
[62] K.K. Ramakrishnan, L. Vaitzblit, C. Gray, U. Vahalia, D. Ting,P. Tzelnic, S. Glaser, W. Duso, Operating system support for avideo-on-demand file service, Proc. of 4th Int. Workshop onNetwork and Operating System Support for Digital Audio andVideo (NOSSDAV’93), Lancaster, U.K., 1993, pp. 216–227.
[63] P.R. Barham, A fresh approach to file system quality of service,Proc. of 7th Int. Workshop on Network and Operating SystemSupport for Digital Audio and Video (NOSSDAV’97), St. Louis,MO, USA, May 1997, pp. 119–128.
[64] C. Martin, P.S. Narayanan, B. O¨ zden, R. Rastogi, A. Silberschatz,The Fellini multimedia storage server, in: S.M. Chung (Ed.), Multi-media Information and Storage Management, Kluwer Academic,Dordrecht, 1996, pp. 117–146.
[65] P.J. Shenoy, P. Goyal, S.S. Rao, H.M. Vin, Symphony: an integratedmultimedia file system, Proc. of ACM/SPIE Multimedia Computingand Networking 1998 (MMCN’98), San Jose, CA, USA, January1998, pp. 124–138.
[66] M. Rosenblum, The Design and Implementation of a Log-StructuredFile System, Kluwer Academic, Dordrecht, 1995.
[67] M. Seltzer, K. Bostic, M.K. McKusick, C. Staelin, An implementa-tion of a log-structured file system for UNIX, Proc. of USENIXWinter Conf., San Diego, CA, USA, January 1993.
[68] R.Y. Wang, T.E. Anderson, D.A. Patterson, Virtual log based filesystems for a programmable disk, Proc. of 3rd USENIX Symp. onOperating Systems Design and Implementation (OSDI’99), NewOrleans, LA, USA, February 1999, pp. 29–43.
[69] M. Vernick, C. Venkatramani, T. Chiueh, Adventures in building theStony Brook video server, Proc. of 4th ACM Multimedia Conf.(ACM MM’96), Boston, MA, USA, November 1996, pp. 287–295.
[70] S. Ghandeharizadeh, R. Zimmermann, W. Shi, R. Rejaie, D. Ierardi,T.-W. Li, Mitra: a scalable continuous media server, MultimediaTools and Applications 5 (1) (1997) 79–108.
[71] D. Anderson, Y. Osawa, R. Govindan, A file system for continuousmedia, ACM Transactions on Computer Systems 10 (4) (1992)311–337.
[72] W. Lee, D. Su, D. Wijesekera, J. Srivastava, D.R. Kenchammana-Hosekote, M. Foresti, Experimental evaluation of PFS continuousmedia file system, Proc. of 6th ACM Int. Conf. on Information andKnowledge Management (CIKM’97), Las Vegas, NV, USA,November 1997, pp. 246–253.
[73] W. Bolosky, J. Barrera, R. Draves, R. Fitzgerald, G. Gibson,M. Jones, S. Levi, N. Myhrvold, R. Rashid, The Tiger video fileserver, Proc. of 6th Int. Workshop on Network and OperatingSystem Support for Digital Audio and Video (NOSSDAV’96),Zushi, Japan, April 1996, pp. 212–223.
[74] W.J. Bolosky, R.P. Fitzgerald, J.R. Douceur, Distributed schedulemanagement in the Tiger video file server, Proc. of 16th ACM Symp.on Operating System Principles (SOSP’97). St. Malo, France,October 1997, pp. 212–223.
[75] P. Lougher, D. Shepherd, The design of a storage server forcontinuous media, The Computer Journal 36 (1) (1993) 32–42.
[76] T.N. Niranjan, T. Chiueh, G.A. Schloss, Implementation and evalua-tion of a multimedia file system, Proc. of IEEE Int. Conf. on Multi-media Computing and Systems (ICMCS’97), Ottawa, Canada, June1997.
[77] C. Wang, V. Goebel, T. Plagemann, Techniques to increase diskaccess locality in the Minorca multimedia file system (shortpaper), to be published in Proc. of 7th ACM Multimedia Conf.(ACM MM’99), Orlando, FL, USA, October 1999.
[78] A. Garcia-Martinez, J. Fernadez-Conde, A. Vina, Efficient memorymanagement in VoD servers, Computer Communications, in press.
[79] S. Berson, S. Ghandeharizadeh, R.R. Muntz, X. Ju, Staggered strip-ing in multimedia information systems, Proc. of 1994 ACM Int.Conf. on Management of Data (SIGMOD’94), Minneapolis, MN,USA, May 1994, pp. 70–90.
[80] H.M. Vin, V. Rangan, Admission control algorithm for multimediaon-demand servers, Proc. of 4th Int. Workshop on Network andOperating System Support of Digital Audio and Video (NOSS-DAV’93), La Jolla, CA, USA, 1993, pp. 56–68.
[81] E. Chang, H. Garcia-Molilna, Reducing initial latency in mediaservers, IEEE Multimedia 4 (3) (1997) 50–61.
[82] T.C. Bell, A. Moffat, I.H. Witten, J. Zobel, The MG retrieval system:compressing for space and speed, Communications of the ACM 38(4) (1995) 41–42.
[83] D.J. Gemmell, S. Christodoulakis, Principles of delay sensitivemultimedia data storage and retrieval, ACM Transactions onInformation Systems 10 (1) (1992) 51–90.
[84] D.J. Gemmell, H.M. Vin, D.D. Kandlur, P.V. Rangan, L.A. Rowe,Multimedia storage servers: a tutorial, IEEE Computer 28 (5) (1995)40–49.
[85] C. Abbott, Efficient editing of digital sound on disk, Journal ofAudio Engineering 32 (6) (1984) 394–402.
[86] P.J. Denning, Effects of scheduling on file memory operations, Proc.AFIPS Conf., April 1967, pp. 9–21.
[87] R. Geist, S. Daniel, A continuum of disk scheduling algorithms,ACM Transactions on Computer Systems 5 (1) (1987) 77–92.
[88] J. Coffman, M. Hofri, Queuing models of secondary storage devices,in: H. Takagi (Ed.), Stochastic Analysis of Computer and Com-munication Systems, North-Holland, Amsterdam, 1990.
[89] P.S. Yu, M.S. Chen, D.D. Kandlur, Grouped sweeping schedulingfor DASD-based multimedia storage management, ACM Multi-media Systems 1 (3) (1993) 99–109.
[90] D.M. Jacobson, J. Wilkes, Disk scheduling algorithms based onrotational position, HP Laboratories Technical Report HPL-CSP-91-7, Palo Alto, CA, USA, February 1991.
[91] M. Seltzer, P. Chen, J. Ousterhout, Disk scheduling revisited, Proc.of 1990 USENIX Technical Conf., Washington, D.C., USA, January1990, pp. 313–323.
[92] Y. Rompogiannakis, G. Nerjes, P. Muth, M. Paterakis, P. Trianta-fillou, G. Weikum, Disk scheduling for mixed-media workloads in amultimedia server, Proc. of 6th ACM Multimedia Conf. (ACMMM’98), Bristol, UK, September 1998, pp. 297–302.
[93] A.L.N. Reddy, J.C. Wyllie, I/O issues in a multimedia system, IEEEComputer 27 (3) (1994) 69–74.
[94] A.L.N. Reddy, J. Wyllie, Disk scheduling in a multimedia I/Osystem, Proc. of 1st ACM Multimedia Conf. (ACM MM’93),Anaheim, CA, USA, August 1993, pp. 225–233.
[95] M.-S. Chen, D.D. Kandlur, P.S. Yu, Optimization of the groupsweep scheduling (GSS) with heterogeneous multimedia streams,Proc. of 1st ACM Multimedia Conf. (ACM MM’93), Anaheim,CA, USA, August 1993, pp. 235–241.
[96] B. Ozden, R. Rastogi, A. Silberschatz, Disk striping in video serverenvironments, Proc. of IEEE Int. Conf. on Multimedia Computingand Systems (ICMCS’96), Hiroshima, Japan, June 1996.
[97] D.J. Gemmell, J. Han, Multimedia network file servers: multi-channel delay sensitive data retrieval, Multimedia Systems 1 (6)(1994) 240–252.
[98] T.H. Lin, W. Tarng, Scheduling periodic and aperiodic tasks in hardreal time computing systems, Proc. of 1991 ACM Int. Conf. onMeasurement and Modeling of Computer Systems(SIGMETRICS’91), San Diego, CA, USA, May 1991, pp. 31–38.
[99] G. Nerjes, Y. Rompogiannakis, P. Muth, M. Paterakis,
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 287

P. Triantafillou, G. Weikum, Scheduling strategies for mixed work-loads in multimedia information servers, Proc. of IEEE InternationalWorkshop on Research Issues in Data Engineering (RIDE’98),Orlando, FL, USA, February 1998, pp. 121–128.
[100] R. Wijayaratne, A.L.N. Reddy, Integrated QoS management for diskI/O, Proc. of IEEE Int. Conf. on Multimedia Computing and Systems(ICMCS’99), Florence, Italy, June 1999.
[101] P.J. Shenoy, H.M. Vin, Cello: a disk scheduling framework for nextgeneration operating systems, Proc. of ACM Int. Conf. on Measure-ment and Modeling of Computer Systems (SIGMETRICS’98),Madison, WI, USA, June 1998.
[102] A.S. Tanenbaum, Modern Operating Systems, Prentice Hall, NewYork, 1992.
[103] C.D. Cranor, The design and implementation of the UVM virtualmemory system, PhD thesis, Sever Institute of Technology, Depart-ment of Computer Science, Washington University, St. Louis, MO,USA, August 1998.
[104] C.D. Cranor, G.M. Parulkar, The UVM virtual memory system,Proc. of USENIX Annual Technical Conf., Monterey, CA, USA,June 1999.
[105] S.M. Hand, Self-paging in the Nemesis operating system, Proc. of 3rdUSENIX Symp. on Operating Systems Design and Implementation(OSDI’99), New Orleans, LA, USA, February 1999, pp. 73–86.
[106] M.N. Garofalakis, B. O¨ zden, A. Silberschatz, On periodic resourcescheduling for continuous-media databases, The VLDB Journal 7 (4)(1998) 206–225.
[107] R. Krishnan, D. Venkatesh, T.D.C. Little, A failure and overloadtolerance mechanism for continuous media servers, Proc. of 5thACM Int. Multimedia Conf. (ACM MM’97), Seattle, WA, USA,November 1997, pp. 131–142.
[108] D. Rotem, J.L. Zhao, Buffer management for video databasesystems, Proc. of 11th Int. Conf. on Data Engineering (ICDE’95),Tapei, Taiwan, March 1995, pp. 439–448.
[109] S. Viswanathan, T. Imielinski, Metropolitan area video-on-demandservice using pyramid broadcasting, Multimedia Systems 4 (4)(1996) 197–208.
[110] K.A. Hua, S. Sheu, Skyscraper broadcasting: a new broadcastingscheme for meteropolitan video-on-demand system, Proc. of ACMSIGCOMM’97, Cannes, France, September 1997, pp. 89–100.
[111] L. Gao, J. Kurose, D. Towsley, Efficient schemes for broadcastingpopular videos, Proc. of 8th Int. Workshop on Network and Operat-ing Systems Support for Digital Audio and Video (NOSSDAV’98),Cambridge, UK.
[112] T. Nakajima, H. Tezuka, Virtual memory management for inter-active continuous media applications, Proc. of IEEE Int. Conf. onMultimedia Computing and Systems (ICMCS’97), Ottawa, Canada,June 1997.
[113] W. Effelsberg, T. Ha¨rder, Principles of database buffer management,ACM Transactions on Database Systems 9 (4) (1984) 560–595.
[114] B. Ozden, R. Rastogi, A. Silberschatz, Buffer replacement algo-rithms for multimedia storage systems, Proc. of IEEE Int. Conf.on Multimedia Computing and Systems (ICMCS’96), Hiroshima,Japan, June 1996.
[115] A. Dan, D. Sitaram, Multimedia caching strategies for hetero-geneous application and server environments, Multimedia Toolsand Applications 4 (3) (1997) 279–312.
[116] M. Kamath, K. Ramamritham, D. Towsley, Continuous media shar-ing in multimedia database systems, Proc. of 4th Int. Conf. on Data-base Systems for Advanced Applications (DASFAA’95), Singapore,April 1995, pp. 79–86.
[117] D.C. Anderson, J.S. Chase, S. Gadde, A.J. Gallatin, K.G. Yocum,M.J. Feeley, Cheating the I/O bottleneck: network storage withTrapeze/Myrinet, Proc. of USENIX Annual Technical Conf., NewOrleans, LA, USA, June 1998.
[118] R.T. Ng, J. Yang, Maximizing buffer and disk utilization for news-on-demand, Proc. of 20th IEEE Int. Conf. on Very Large Databases(VLDB’94), Santiago, Chile, 1994, pp. 451–462.
[119] H. Tezuka, T. Nakajima, Simple continuous media storage server onreal-time mach, Proc. of USENIX Annual Technical Conf., SanDiego, CA, USA, January 1996.
[120] A. Zhang, S. Gollapudi, QoS management in educational digitallibrary environments, Technical Report CS-TR-95-53, StateUniversity of New York at Buffalo, New York, NY, USA, 1995.
[121] R.H. Patterson, G.A. Gibson, E. Ginting, D. Stodolsky, J. Zelenka,Informed prefetching and caching, Proc. of 15th ACM Symp. onOperating System Principles (SOSP’95), Cooper Mountain, CO,USA, December 1995, pp. 79–95.
[122] F. Chang, G.A. Gibson, Automatic I/O hint generation through spec-ulative execution, Proc. of 3rd USENIX Symp. on OperatingSystems Design and Implementation (OSDI’99), New Orleans,LA, USA, February 1999, pp. 1–14.
[123] A. Roth, A. Moshovos, G.S. Sohi, Dependence based prefetching forlinked data structures, Proc. of 8th Int. Conf. on ArchitecturalSupport for Programming Languages and Operating Systems(ASPLOS-VIII), San Jose, CA, USA, October 1998, pp. 115–126.
[124] H. Lei, D. Duchamp, An analytical approach to file prefetching,Proc. of USENIX Annual Technical Conf., Anaheim, CA, USA,January 1997.
[125] F. Moser, A. Kraiss, W. Klas, L/MRP: A buffer management strat-egy for interactive continuous data flows in a multimedia DBMS,Proc. of 21st IEEE Int. Conf. on Very Large Databases (VLDB’95),Zurich, Switzerland, 1995, pp. 275–286.
[126] P. Halvorsen, V. Goebel, T. Plagemann, Q-L/MRP: a buffer manage-ment mechanism for QoS support in a multimedia DBMS, Proc. of1998 IEEE Int. Workshop on Multimedia Database ManagementSystems (IWMMDBMS’98), Dayton, OH, USA, August 1998,pp. 162–171.
[127] A.L.N. Reddy, Scheduling in multimedia systems,Design andApplications of Multimedia Systems, Kluwer Academic, Dordrecht,1995.
[128] H. Hartig, R. Baumgartl, M. Borriss, C.-J. Hamann, M.Hohmuth, F. Mehnert, L. Reuther, S. Scho¨nberg, J. Wolter,DROPS—OS support for distributed multimedia applications,Proc. of 8th ACM SIGOPS European Workshop, Sintra, Portugal,September 1998.
[129] J. Nishikawa, I. Okabayashi, Y. Mori, S. Sasaki, M. Migita,Y. Obayashi, S. Furuya, K. Kaneko, Design and implementationof video server for mixed-rate streams, Proc. of 7th Int. Work-shop on Network and Operating System Support for DigitalAudio and Video (NOSSDAV’97), St. Louis, MO, USA, May1997, pp. 3–11.
[130] J. Philbin, J. Edler, O.J. Anshus, C.C. Douglas, K. Li, Thread sche-duling for cache locality, Proc. of 7th Int. Conf. on ArchitecturalSupport for Programming Languages and Operating Systems(ASPLOS-VII), Cambridge, MA, USA, October 1996, pp. 60–71.
[131] B.N. Bershad, D. Lee, T.H. Romer, J.B. Chen, Avoiding conflictmisses dynamically in large direct-mapped caches, Proc. of 6thInt. Conf. on Architectural Support for Programming Languagesand Operating Systems (ASPLOS-VI), San Jose, CA, USA, October1994, pp. 158–170.
[132] S.A. McKee, R.H. Klenke, K.L. Wright, W.A. Wulf, M.H. Salinas,J.H. Aylor, A.P. Barson, Smarter memory: improving bandwidth forstreamed references, IEEE Computer 31 (7) (1998) 54–63.
[133] M.B. Abbott, L.L. Peterson, Increasing network throughput by inte-grating protocol layers, IEEE/ACM Transactions on Networking1 (5) (1993) 600–610.
[134] D.D. Clark, D.L. Tennenhouse, Architectural considerations for anew generation of protocols, Proc. of ACM SIGCOMM’90,Philadelphia, PA, USA, September 1990, pp. 200–208.
[135] P. Druschel, M.B. Abbot, M.A. Pagels, L.L. Peterson, Networksubsystem design, IEEE Network 7 (4) (1993) 8–17.
[136] C. Dalton, G. Watson, D. Banks, C. Calamvokis, A. Edwards,J. Lumley, Afterburner, IEEE Network 7 (4) (1993) 36–43.
[137] D. Banks, M. Prudence, A high-performance network architecture
T. Plagemann et al. / Computer Communications 23 (2000) 267–289288

for a PA-RISC workstation, IEEE Journal on Selected Areas inCommunications 11 (2) (1993) 191–202.
[138] P. Druschel, Operating system support for high-speed communica-tion, Communication of the ACM 39 (9) (1996) 41–51.
[139] P. Druschel, L.L. Peterson, B.S. Davie, Experiences with a high-speed network adaptor: a software perspective, Proc. of ACMSIGCOMM’94, London, UK, September 1994, pp. 2–13.
[140] H.-K.J. Chu, Zero-copy TCP in Solaris, Proc. of 1996 USENIXAnnual Technical Conf., San Diego, CA, USA, January 1996,pp. 253–264.
[141] H. Kitamura, K. Taniguchi, H. Sakamoto, T. Nishida, A new OSarchitecture for high performance communication over ATMnetworks: zero-copy architecture, Proc. of 5th Int. Workshop onNetwork and Operating Systems Support for Digital Audio andVideo (NOSSDAV’95), Durham, NH, USA, April 1995, pp. 87–90.
[142] M.K. McKusick, K. Bostic, M.J. Karels, J.S. Quarterman, TheDesign and Implementation of the 4.4 BSD Operating System,Addison-Wesley, New York, 1996.
[143] D.G. Bobrow, J.D. Burchfiel, D.L. Murphy, R.S. Tomlinson,B. Beranek, Tenex, a paged time sharing system for the PDP-10,Communications of the ACM 15 (3) (1972) 135–143.
[144] R. Fitzgerald, R.F. Rashid, The integration of virtual memorymanagement and interprocess communication in Accent, ACMTransactions on Computer Systems 4 (2) (1986) 147–177.
[145] R. Rashid, G. Robertson, Accent: a communication-orientednetwork operating system kernel, Proc. of 8th ACM Symp. onOperating System Principles (SOSP’81), New York, NY, USA,1981, pp. 64–75.
[146] D.R. Cheriton, The V distributed system, Communications of theACM 31 (3) (1988) 314–333.
[147] S.-Y. Tzou, D.P. Anderson, The performance of message-passingusing restricted virtual memory remapping, Software—Practice andExperience 21 (3) (1991) 251–267.
[148] E.W. Anderson, Container shipping: a uniform interface for fast,efficient, high-bandwidth I/O, PhD thesis, Computer Science andEngineering Department, University of California, San Diego, CA,USA, 1995.
[149] J. Pasquale, E. Anderson, P.K. Muller, Container shipping—operat-ing system support for I/O-intensive applications, IEEE Computer27 (3) (1994) 84–93.
[150] P. Druschel, L.L. Peterson, Fbufs: A high-bandwidth cross-domaintransfer facility, Proc. of 14th ACM Symp. on Operating SystemsPrinciples (SOSP’93), Asheville, NC, USA, December 1993,pp. 189–202.
[151] M.N. Thadani, Y.A. Khalidi, An efficient zero-copy I/O frameworkfor UNIX, Technical Report SMLI TR-95-39, Sun MicrosystemsLaboratories Inc., May 1995.
[152] K.R. Fall, A peer-to-peer I/O system in support of I/O intensiveworkloads, PhD thesis, Computer Science and Engineering Depart-ment, University of California, San Diego, CA, USA, 1994.
[153] K. Fall, J. Pasquale, Improving continuous-media playback perfor-
mance with in-kernel data paths, Proc. of IEEE Int. Conf. on Multi-media Computing and Systems (ICMCS’94), Boston, MA, USA,May 1994, pp. 100–109.
[154] F.W. Miller, P. Keleher, S.K. Tripathi, General data streaming, Proc.of 19th IEEE Real-Time System Symp. (RTSS’98), Madrid, Spain,December 1998.
[155] F.W. Miller, S.K. Tripathi, An integrated input/output system forkernel data streaming, Proc. of SPIE/ACM Multimedia Computingand Networking (MMCN’98), San Jose, CA, USA, January 1998,pp. 57–68.
[156] J.C. Brustoloni, Interoperation of copy avoidance in network and fileI/O, Proc. of 18th IEEE Conf. on Computer Communications(INFOCOM’99), New York, NY, USA, March 1999.
[157] J.C. Brustoloni, P. Steenkiste, Effects of buffering semantics on I/Operformance, Proc. of 2nd USENIX Symp. on Operating SystemsDesign and Implementation (OSDI’96), Seattle, WA, USA, October1996, pp. 227–291.
[158] J.C. Brustoloni, P. Steenkiste, Evaluation of data passing andscheduling avoidance. Proc. of 7th Int. Workshop on Network andOperating System Support for Digital Audio and Video(NOSSDAV’97), St. Louis, MO, USA, May 1997, pp. 101–111.
[159] C.D. Cranor, G.M. Parulkar, Universal continuous media I/O: designand implementation, Technical Report WUCS-94-34, Department ofComputer Science, Washington University, St. Louis, MO, USA,1994.
[160] C.D. Cranor, G.M. Parulkar, Design of universal continuous mediaI/O, Proc. of 5th Int. Workshop on Network and Operating SystemsSupport for Digital Audio and Video (NOSSDAV’95), Durham,NH, USA, April 1995, pp. 83–86.
[161] V.S. Pai, IO-Lite: a copy-free UNIX I/O System, Master of Sciencethesis, Rice University, Houston, TX, USA, January 1997.
[162] V.S. Pai, P. Druschel, W. Zwaenepoel, IO-Lite: a unified I/O buffer-ing and caching system, Proc. of 3rd USENIX Symp. on OperatingSystems Design and Implementation (OSDI’99), New Orleans, LA,USA, February 1999, pp. 15–28.
[163] M.M. Buddhikot, X.J. Chen, D. Wu, G.M. Parulkar, Enhancementsto 4.4BSD UNIX for efficient networked multimedia in projectMARS, Proceeding of IEEE Int. Conf. on Multimedia Computingand Systems (ICMCS’98), Austin, TX, USA, June/July 1998.
[164] M.M. Buddhikot, Project MARS: scalable, high performance, web-based multimedia-on-demand (MOD) services and servers, PhDthesis, Sever Institute of Technology, Department of ComputerScience, Washington University, St. Louis, MO, USA, August 1998.
[165] P.V. Rangan, H. Vin, Designing file systems for digital video andaudio, Proc. of the 13th Symp. on Operating Systems Principles(SOSP’91), Pacific Grove, CA, USA, October 1991, pp. 81–94.
[166] P.J. Shenoy, P. Goyal, H.M. Vin, Architectural considerations fornext generation file systems, to be published in Proc. of 7th ACMMultimedia Conf. (ACM MM’99), Orlando, FL, USA, October1999.
T. Plagemann et al. / Computer Communications 23 (2000) 267–289 289





























