Embed Size (px)
Citation preview

Pergamon Pattern Recognition, Vol. 30, No. 1, pp. 123-140, 1997
Copyright © 1996 Pattern Recognition Society. Published by Elsevier Science Ltd Printed in Great Britain. All rights reserved
0031-3203/97 $17.00+.00
PII:SO031-3203(96)00060-X
MATCHING DELAUNAY GRAPHS
ANDREW M. FINCH, RICHARD C. WILSON and EDWIN R. HANCOCK Department of Computer Science, The University of York, York Y01 5DD, UK
(Received 23 February 1995; in revised form 26 March 1996; received for publication 15 April 1996)
Abstract--This paper describes a Bayesian framework for matching Delaunay triangulations. Relational structures of this sort are ubiquitous in intermediate level computer vision, being used to represent both Voronoi tessellations of the image plane and volumetric surface data. Our matching process is realised in terms of probabilistic relaxation. The novelty of our method stems from its use of a support function specified in terms of face-units of the graphs under match. In this way, we draw on more expressive constraints than is possible at the level of edge-units alone. In order to apply this new relaxation process to the matching of realistic imagery requires a model of the compatibility between faces of the data and model graphs. We present a particularly simple compatibility model that is entirely devoid of free parameters. It requires only knowledge of the numbers of nodes, edges and faces in the model graph. The resulting matching scheme is evaluated on radar images and compared with its edge-based counterpart. We establish the operational limits and noise sensitivity on the matching of random-dot patterns. Copyright © 1996 Pattern Recognition Society. Published by Elsevier Science Ltd.
Graph matching Relaxation labelling Delaunay triangulation
t. INTRODUCTION
Delaunay triangulations pervade computer vision. They not only provide a convenient and robust neighbourhood representation for Voronoi tessellations of the image plane, (1-3) but also provide a powerful geometric representation for volumetric information. (4-7) Ahuja (1- 3) has promoted their use as a device for representing the early perceptual structure of dot patternsJ 8) Some of the computational advantages have been demonstrated by Tuceryan and Chorzempa (9) who show that the Delau- nay graph has optimal stability to noise when compared with a number of alternative 2D neighbourhood graphs. Boissonnat (4) has established their effectiveness as a convenient volumetric surface representation in compu- tational geometry. In the context of 3D vision, Faugeras et alJ 5) have identified the discontinuity preserving properties of Delaunay graphs and exploited them as a surface reconstruction device. More recently, triangula- tions have been exploited in the construction of deformable shape models. (7'6)
Despite their widespread use and attractive computa- tional features, little effort has been devoted to devising effective means for matching Delaunay graphs. This is surprising since the inexact graph matching problem has been the focus of sustained activity in a number of distinct methodological areas for over three decades. ~1°- 17) One of the earliest practical matching techniques was the association graph idea of Barrow et alJ 18) In essence, this allowed subgraph isomorphisms to be located by transforming the matching process into one of searching for maximal cliques in an association graph. This idea was later exploited by Horaud and Skordas °1) for stereo matching. Symbolic scene de- scriptions have also been matched using consistent
labelling techniques (14) and discrete relaxation.(~9) Some of the key contributions to this endeavour have come from the field of syntactic and structural pattern recognition. They have included the definition of a meaningful relational distance metric to measure consistency of match, (15) the idea of exploiting graph- edit operations to overcome structural errors (2°'13) and the definition of entropy associated with a match. (21)
More recently, optimisation ideas have provided an alternative framework for inexact relational matching which draw on the available constraints in a finer way. (t°'22'12'23'17) Basic to this philosophy, is the concept
of iteratively updating matches to optimise a measure of consistency defined over a set of constraint relations provided by the model graph. Algorithms falling into this category can be divided into those that realise the matching process via discrete or configurational opti- misation and those that adopt a continuous evidence combining framework. The former category includes the stochastic relaxation method of Herault et al. (22) and the iterative discrete relaxation method of Wilson and Hancock. (16'17) The evidence combining approach is exemplified by probabilistic relaxation. Concrete ex- amples include the pioneering work of Faugeras and Price (24) together with the more recent idea of exploit- ing binary attribute relations originally introduced by Li (23) and later formally developed by Kittler, Christmas and Petrou. (12) An extensive review of object recogni- tion techniques, including structural matching, can be found in the recent paper of Suetens, Fua and Hanson. (25)
Despite this plethora of alternative matching techni- ques, interrogation of the literature reveals that only Ogawa (26) has attempted to tailor a matching scheme to
123

124 A.M. FINCH et al.
the triangular face structure of the Delaunay graph using a variant of the maximal clique algorithm. (18"11) Viewed from the perspective of the Delaunay triangulation, this means that the majority of the available matching algorithms described above are of limited utility since they overlook the salient triangulated graph structure. In short, they are satisfied with exploiting only the pairwise constraints provided by graph edges. (12'27) This limited use of available relational information not only limits the achievable performance, it may also actually lead to internal inconsistencies in the specification of the matching process. (28) The basic problem stems from the fact that the cyclic ordering of edges is overlooked and this in turn can lead to mis-triangulation of the final match.
It is this observation that motivates the study reported in this paper. Our aim is to develop an effective strategy for the inexact matching of Delaunay graphs. In particular we aim to directly tailor this matching scheme to their triangulated face structure. Because we wish to match under conditions of uncertainty and structural error, we adopt a Bayesian evidence combining approach. This is to be contrasted with the constraint filtering philosophy of Ogawa's maximal clique algo- rithm. (26) In order to meet our aim, we draw on the Bayesian framework for probabilistic relaxation devel- oped by Kittler and Hancock. (28) Application of this optimisation approach to the matching problem requires not only that we develop a support-function that draws on triangulated graph units, but also an associated model of compatibility expressed at the level of consistent graph faces. Our compatibility model is purely symbolic in nature since it is specified only in terms of the numbers of nodes, edges and faces in the model graph. In other words, it does not use any measurement information concerning the detailed geometry of the Delaunay triangulation, being expressed entirely in terms of symbolic relational structures. By directly exploiting the face-triangulation property of Delaunay graphs, we improve the fidelity of match beyond that achievable with edge-based constraints alone. (12'27) Because the compatibility model is parameter-free, the method also offers certain advantages in terms of ease of control.
The outline of this paper is as follows. Section 2 describes our probabilistic relaxation framework which allows us to exploit using face-based cons- traints in the matching of Delaunay triangulations. Section 3 presents an efficient recursive method for computing the support function using face-based compat ibi l i ty coefficients . Sect ion 4 details the error model which deals with constraint corruption. Section 5 illustrates the application of this technique to a graph matching task using data from a synthetic aperture radar image. In Section 6 we describe a sensitivity analysis using random dot patterns. This analysis allows us to assess the operating limits of our method and provide comparison with some alternative matching techniques. Finally, Section 7 offers some concluding remarks.
2. PROBABILISTIC RELAXATION LABELLING
Viewed from a theoretical perspective our aim in this paper is to develop a Bayesian framework for matching Delaunay triangulations. Relational structures of this sort are ubiquitous in intermediate level computer vision, being widely used to represent Voronoi tessella- tions of an image plane (1'2'9) or volumetric surface data. (5'4) Our aim is to realise the matching process in terms of probabilistic relaxation. (28'29) The basic com- putational demand placed upon us by this framework is the availability of a support function that can be specified in terms of face-units of the graphs under match. In this way, we draw on more expressive constraints than is possible at the level of edge-units alone. In particular, it allows us to exploit the constraint provided by the cyclic ordering of nodes in a Delaunay neighbourhood.
2.1. Delaunay graphs
Our aim is to match scenes abstracted in terms of Delaunay triangulations. We denote such graphs by the triple ff=(~z,o¢,~). Here ¢ / is the set of vertices and
c ~ × ~U is the set of edges. The novel ingredient of the work reported here is to exploit constraints provided by the set of triangular faces ~,~ in the matching process. We use the term face to mean a Cartesian triple of node labels, i . e . .~ C ~V" × Y/" × ~F', such that (i,j, k) c ~ (i,j) c g A (j, k) E g A (k, i) C g. In other words, a face represents a first-order cycle in a Delaunay graph.
Previous work on relational matching has concen- trated on finding correspondences between the nodes in a data graph ~d and their counterparts in a model graph ~m using constraints provided by the edge-set 8m. It has been shown (27) that this particular strategy is best suited to matching graphs which are tree-like in form (i.e. graphs in which [ ~V [~] o ~ [). In particular, this method performs poorly when the graphs contain first order cycles. In this paper, we introduce a matching scheme which draws on constraints represented by the face-sets of the data and model graphs.
This approach is motivated by the abundance of intermediate-level processing operations which are abstracted in terms of Delaunay graphs. Such graphs consist of first-order cycles that form triangular faces. Our technique aims to draw on constraints provided by these triangular faces to take advantage of the cyclic ordering of the nodes in the graphs under match. This ordering concept is central to the ideas presented here and is illustrated in Fig. 1. Such an ordering exists if the graph is planar.
We define a data graph ~a on the labels J~ of the objects u , ~ , a = l , . . . , n to be ~d=(~U'd,~d, ffd), where "Ua = {J1 , . . . , Jn} . The model graph ~ m =
(~Um,gm,ffm) where ~/'rn = {J1 . . . . ,JM} is defined on the values J,, attributable to these labels. In order to accommodate entries in the data graph that have no physical match in the model graph, we augment the indexed set of data nodes ~V'm by a null category qk This symbol is used to label unmatchable data entities which

Matching Delaunay graphs 125
Fig. l. Label value J0 together with its contextual neighbours j l . . . . . in .
represent noise or extraneous clutter. We denote the index set of the contextual neighbours of unit us, as I~,. This set includes the index a. For the purpose of notational simplicity and without loss of generality, we re-index the units in the network. This ensures that the object under consideration has index 0 and its neighbours are indexed from 1 , . . . , n (as in Fig. 1).
2.2. Probability update formula
The starting point for the face-based constraint approach is the evidence combining formula of Kittler and Hancock. (2s'29) This scheme allows for the updating of the a posteriori probabilities of the labellings through the interpretation of the relaxation process as a sequence of filtering operations on the available measurements. One filtering operation consists of updating the probability of an object-label assignment with a revised probability which has been derived using the label-assignment probabilities of its contextual neigh- bours.
Suppose the measurement on the object indexed a at iteration i of the relaxation scheme is x (/) and that after probability updating the implicit filtered measurement is x~ (/+1). According to Kittler and Hancock (z8) the label- probability at the ith iteration is interpreted to be the a posteriori probability for the relevant object-label assignment given the filtered observation pertaining to the object in question. The implicit filtering operation corresponds to replacing this probability by its with- context counterpart computed using the observations in the ensemble I~ available from the previous iteration of the relaxation scheme, i.e.
P(JoHjo I x_~ i+1)) ~-- P(Jo~--*jo I x~),w c I0). (1)
In the above expression we have used the notation Jo~--~jo to denote the match of data node Jo c ~//a against model node Jo E ~/'rn- The development of a detailed evidence combining formula from this starting point has been detailed by Kittler and Hancock. (29'28) The resulting probability update formula is, in fact, a generalisation of the Rosenfeld et aL (3°) relaxation scheme. If p(i)(Jo --* jo) is the probability for the match
J0 ~ j0 at iteration i of the relaxation scheme, then the update formula is
p(i+l)(JoF-+jo ) . - P(i)(Jo~-~Jo)Q(O(Jo~'+Jo) Y~j, eV, Uc) p(i) ( jo~_~j,~ ) Q(i) ( jo,_~j~ ) "
(2)
The iteration process is initialised by setting the label-probabilities equal to the non-contextual a poster- iori measurement probabilities, i.e. p(O)(j~_~j)= e ( J ~ j l x } ° l ) . The critical ingredient in the above probability update formula is the support function Q(i)(Jo~Jo) that combines evidence for the match Jo~--~jo over the Delaunay neighbourhood of object uo, i.e. I0. In fact, one of the important features of the Kittler and Hancock (29'28) Bayesian framework for probabilistic relaxation is that rather than using an arithmetic average support function of the type originally described by Rosenfeld eta/. (3°), it delivers a product-form support- function. Specifically, the general purpose support function is of the form
1 a(i) (jo~__~jo) _ P(Jo~-+Jo) J~ ~.m~v ,o" "
. . . ~-~ []-[P(i)(Jc?-'-~Jc~)]p(jc~_.~ja,~/olEio). 11 p ja~_~ "
j.cvmuo L~/0 ( J~)J (3)
The formalism employed in this expression deserves some elucidation. We have used the notation J0~-+j0, J1,-~jl,...,Jn,-~j, to denote the matching of the objects in the re-indexed Delaunay neighbourhood Io onto the configuration of nodes jo , j l , . . . , jn , in the model graph. The quantity P(Ja~--~j~, Va c Io) is the joint prior for this neighbourhood matching configura- tion. The single-object prior P(J~,--~j~), on the other hand, models the probability of matching configurations for individual nodes. It is also worth stressing that the multiple summations extend over the combinatorial space of potential matchings that can be assigned to I0. In other words the support function is of exponential complexity. The expression must therefore be regarded as only the starting point in the development of a more practical relaxation scheme. There are two key issues to which we must turn our attention in pursuing our development of a practical matching scheme for Delaunay graphs. The first of these is the simplification of the joint prior P ( J ~ j ~ , Va E Io) in terms of the triangular face-units which constitute the basic rela- tional structure of the Delaunay graph. Secondly, we must provide a way of curbing the exponential complexity of the support function so that it may be evaluated in polynomial time.
2.3. Factorisation of the joint prior over graph faces
Turning our attention to the first of the goals outlined in the previous subsection, we note that in the support function of equation (3) the joint a priori probability

126 A.M. FINCH et al.
P ( Jo~--~jo, J l ~--+jl . . . . , Jn~-~jn ) characterises the relation- ships between matched objects in the Delaunay neighbourhood. In other words, the joint a pr ior i probability represents the world model for the matching process. Our aim in this section is to introduce the simplifying assumptions required to factorize the joint a pr ior i probability at the face-level. We commence by demanding that the probabilistic interactions between different graph nodes are limited to mutually interacting Delaunay neighbourhoods. This requirement is most easily expressed in terms of the conditional priors, i.e.
P(Jc~HJc~ I J ~ J ; ~ , 3 ~ lo, 3 # O) (4) = P ( J ~ j ~ I J ~ j ~ , 3 ~ Io, 3 ~ I~,3 # 0).
According to this assumption, the probability of a particular match at unit us, ~ ~ I0, given the matches of some other units in the contextual neighbourhood of unit u0, is independent of those units which are not directly
P(Jo~-*jo, . . . , Jn~--~jn)
= p(J~F--~jn I Jo~--+jo,Jl~--~jl,Jn_l~--~j,_l)
x P(J~_IF--~jn_I I Jo~--~jO,Jn_2~--~j,_2)... (6)
. . . × P ( J v H j 2 I Jl~-*jl,Jo~-~jo)
x e ( J l ~ j l [ J o H j o ) e ( J o ~ J o ) .
Inspection of the above equation reveals that, with the exception of the first and last lines, the product is expressed in terms of conditional probabilities of the form P(Jk~--~jklJk--l~--~jk--l,Jo~-'*jo) defined over trian- gular Delaunay faces. In order to have a uniform order of dependence, we must further develop the first term in the product. Rather than being confined to a single face, the first term draws on the quartet of nodes forming two adjacent faces. We lift this quartet dependence by rewriting the first term of the product in equation (6), using the Bayes formula and again applying equa- tion (4) to restrict the order of interaction
P(Jn~---+Jn I J0~--~J0:J1 ~-->jl, Jn-1 ~--~j.-l) = e(JlW-~J 1 I Jo~--~jo,Jn~-+jn)P(Jn_l~--~j,_l I JoHJo, J ~ j , ) P ( J o ~ J o l J ~ j , ) P ( J , ~ j , )
P(JI~-+jl I Jo~--~jo)P(Jn_l~--~jn_l I J o H j o ) P ( J o ~ j o )
(7)
interacting with unit u~. The structure imposed on the a pr ior i point probability by this assumption may be somewhat restrictive. Nevertheless, it is less restrictive and more consistent than the simplifying assumptions which are used in deriving the edge-based support function previously employed by Wilson and Han- cock (27) in their studies of tree-like graphs. Moreover, rather than being tailored to tree-like graphs with low edge densities and few first-order cycles, it is specifi- cally designed to consistently match graphs constructed from triangular faces.
The application of the property of the world model given in equation (4) leads to different factorizations of the a p r i o r i joint probabili ty P(Jo~-~jo, J1 ~--~j~,-.-, Jn~--~jn) in equation (3) depending on the form of the contextual neighbourhood. Kittler et aL (12) have derived a factorization in terms of pairwise transitional probabilities. This paper is primarily con- cerned with matching Delaunay triangulations where the contextual neighbourhood is typified by the example in Fig. 1.
Expressing P(Jo~--~jo, J l~ - -~ j l , . . . , J~--~j,) in terms of conditional probabilities we aim to exploit the cyclic ordering of the nodes in the model graph
P(Jo~--+jo, . . . , JnF--~jn)
= P(Jn~--~jn I J0~-*J0, "'" ,Jn l~--~j,-l)
× e ( J ~ - l ~ j , - 1 I J0~ jo , - . . ,J~-z~j~-2) "" "
• . . × P ( J I H j l I J o ~ j o ) e ( J o ~ j o ) (5)
and using equation (4) to restrict the scope of interac- tion, equation (5) simplifies to:
Substituting from equation (7) into equation (6) and rearranging terms gives the final result:
P ( Jo~-~jo, . . . , Jn~--~j, )
= P ( J I ~ j l I J o ~ j o , J , ~ j , )
x P ( J 2 H j 2 I Jl~-+jl,Jo~-*jo) . . . (8)
. . . x e ( J n - l ~ j n - 1 I J n - 2 H j n - 2 , J o ~ j o )
× P ( J n ~ j ~ I J ~ - l H j n - l , J o ~ j o )
Thus, the joint a pr ior i probability can be expressed in terms of conditional probabilities involving triples of labels matched to the graph faces of the Delaunay triangulation.
3. RECURSIVE EVALUATION OF THE SUPPORT FUNCTION
The support function given by equation (3) represents the basic formulation of the probabilistic relaxation process. It specifies how evidence should be combined over the set of triangular faces forming a Delaunay neighbourhood. Moreover, the product-sum appearing in the support function of equation (3) represents a nested product of summations over the object-labels assigned to the objects included in the Delaunay neighbourhood. Unfortunately expressed in this form, the complexity of the support function Q(Jo~-~jo) is still of order O(Mn) . In other words, our model simplification has not provided any computational advantages, and we have still to meet the second goal outlined in our concluding remarks from Section 2.1. In order to be of practical utility, an efficient method of enumerating the support function is required. By re-organising terms, equation (3) may cast

Matching Delaunay graphs 127
in a form which is amenable to recursive iteration with resulting reduction in computational complexity as:
1 ~-~ P(i)(Jl~-+jl ) Q(i)(Jo~-,jo ) - - p(jo~.+jo) j, evA~uc~ P(JI~-~jl)
× ~ P(J~j~ I J.~j.,Jo~jo) j~EVmL)Cb
× Z P(i)(J2e--~J2) j2ev,.o¢ P(J2~-+J2)
× P(J2~-*j2 I J l ~ j l , J o H j o ) " " p(i) (jk~__,jk)
• . . x Z p(Jk~--+jk) jk E VmUO
x P(Jk~-+jk I Jk l~--~jk-l,Jo~---~jo) p(1) (Jk+l ~---~jk+[)
× ~ p(Jk+l~--,jk+t) J,~+l EVmUO
x / ' ( ~ + 1 ~ j , + 1 I J*~J*, JoHjo) '" •
. . . x ~-~ P(i)(Jn-w~j. 1) j, ,~-'~o¢ P(Jn-l~---~jn-l)
X P(Jn_le--+jn_l I Jn_z~--"~jn_2,Jo~-+jo )
p(i) ( j n ~ j . ) X
P(Jn~--~j,) × P(J, Hj,, I J,,_l~--~j,,_l,Jo~jo).
(9)
This is an important statement of our factorisation of the joint prior. It not only makes clear the role of graph- faces in modelling the constraints operating in the contextual neighbourhood Io, but also illustrates how we draw on cyclic ordering relations. At each nested level in the expression, the calculation depends only on the sum over potential matches for a particular object, the match assigned to the preceding object and the match of the central object. This property together with the cyclic ordering of the indices of the units u,~, a = 1, n, about the central object Uo allows the product-sum to be written as a recursive sum.
To this end, we adopt the convention of initialising the recursion at the node indexed n by setting
e(J,_l*--~jn_l,Jnw--~jn)
__ P(i)(J"~---~Jn) p(jn~__~j" I J,,_p___~jn_l,jo~__~jo). (10)
P(Jn~--~jn )
With this definition, the recursion-kernel employed in the cyclic evaluation of support is
E(Jk_lw-+jk 1,Jn~--+jn) plil (J~A)
= Z p(jk~_+jk) Jk ~j~
× P(JkHjk I Jk l~--*jk-l,Jo~--~jo)e(Jk~--*jk,J,~--~j~). (11)
The support function in equation (3) may be expressed as:
1_ V " p(i)(J1 ~--~jl) Q(i)(jo~.+j7 ) - p(jo~__~jT) j, eVA~mU¢ P(JI~--~jl)
× ~ p(J~j~ [Sn~j.,Jo~jo) j . EVmUO
× e(Jl~--~jl,JnF--~jn). (12)
In the recursion formula (equation (11)), the index JMHjM of the quantity e(JM~--~jM,J,~j,), is needed because the label assigned to each unit enters two levels of summation in a cyclic manner; the index J, Hjn is required since it is necessary to break the cycle of indices at some object in the neighbourhood, in order to perform a recursive evaluation. This two-fold level of summation effectively propagates the face-based con- straints around the periphery of the Delaunay neigh- bourhood. When the quantity Q(i)(j0~__~jT) is expressed in this form, the computational complexity is of order O(nM3).
The Bayesian ingredients of equations (9-12) are the single node prior P(Jk~--*jk) and the conditional prior P(Jk~-~jklKk_W-~jk_?-%Jo~-+ko). It is the conditional prior that measures the consistency between the label match Jk~--+jk and the matches Jk-1 ~--*jk-l and Jo~--~jo on the remaining nodes of the face {Jk, Jk-l, J0} belonging to the data graph. Its counterpart in the more heuristic formulation of Rosenfeld et a/. O°) are the compatibility coefficients which invariably require ad hoc specifica- tion. In our Bayesian framework the compatibility coefficient is specified by the mutual information measure:
R(jk,jk-i ,jo) = P(Jk~--~Jk ] Jk-l~-*Jk-l' J°~--~J°) P(JkHjk)
p(jk~__~jk,Jk_l~__~jk_],jo~__~jo ) (13)
= P(4~jk)e(Jk ]~jk-~,Jo~jo)"
The contextual neighbourhood relating to this equa- tion is illustrated in Fig. 1. We assign values to these compatibility coefficients in accordance with an error model described in Section 4 below.
4. C O M P A T I B I L I T Y M O D E L
Application of the relaxation framework to the correspondence problem requires a probabilistic de- scription of the matching constraints operating between the model and data graphs. In constructing this model of the compatibility coefficients R(jk,jlc-t,jo), we would like to capture some of the uncertainties introduced by different classes of segmentation error. These errors include noise contamination, fragmentation due to over segmentation and accidental merging due to under segmentation.
Our adopted modelling philosophy is that the relaxation operations are aimed at locating correspon- dences between the nodes in graph ffd and those in graph fCm- We take the view that the nodes in graph ffd represent data that must be matched in the light of constraints provided by graph ~m. In order to cope with inconsistencies between the model and data graphs, we

128 A.M. FINCH et al.
employ a system of constraint softening. The Bayesian basis for this constraint softening process is to compute the non-zero probabilities for each of the different combinatorial label configurations. Computation of these probabilities requires a model of the underlying constraint corruption process. In reference (16) we modelled this process in terms of memoryless label corruption; the parameter of this process being the probability of label errors p. Following the methodology described in reference (16), we adopt a binomial distribution of probability. The probabilities for various labelling configurations are listed below:
• Faces of the data graph with all nodes matched to a face in the model graph are uncorrupted and occur with total probability mass (1 _p)3. This is the case where there is a consistent match between a data-graph face and a model-graph face. There are I ~,n [ such feasible matches.
• Faces with two nodes matched to an edge in the model graph and one-node matched to the null label; these have total probability mass p(1 - p ) 2 . This is the case when one of the edges in a data-graph face has a match in the model graph. It should be noted that it is impossible for only two of the three edges to be consistently matched without violating the neighbour- hood ordering relation. There are [O~rn [ such config- urations.
• Faces in which two nodes are null-matched have a probability of p2(1 - p ) . This is the case when none of the edges in the data-graph face are consistently matched, but one of the nodes forms a consistently matched edge or face unit with one or more nodes in an abutting face. There are I "/rm I such configurations. Configurations in which all nodes in the face are null matched take the remaining probability mass, i.e. p3. This is the case if all three nodes in the unit are consistent with being noise. There is one configuration of this type.
• Matches involving non-null label triplets incon- sistent with the above configurations are completely forbidden and therefore account for zero total prob- ability mass.
In each of the cases listed above the available mass of probability is distributed uniformly among the label configurations falling into the relevant constraint class. Using this distribution model, we arrive at a rule which yields the joint probabilities for face and edge configurations:
P( Jk~jk , Jk- l H jk - l , Jo~jo ) (l--p) 3
~ T p(1-p) 2
p2(1 p)
p3
0
if {jk,j~-I ,j0} C ,~m
if {jk,jk-1} C ~m andjo = ¢
if jk C "¢/'m and jk_l = ¢ and j0 = ¢
if jk = ¢ and jk-l = ¢ and j0 = ¢
otherwise.
(14)
The edge-priors may be computed by summing over the face-priors to eliminate the dependence on the match Jo~jo. The summation runs over the labels of all model nodes together with the null-label, i.e.
P( Jk~--+jk , Jk- 1 ~-~jk- I )
(15) = Y ] P (Jk~ jk , Jk - l~ j~ - l , Jo~ jo ) .
j0E3V'mU~b
Upon substitution for the face priors, we arrive at the following probability distribution for the edge-priors
P( Jk~-+jk, Jk-I F--~jk-1)
{ (1-p)~ if {jk,jk-l} E ~m l~ml p(l-p) if jk E ~//'m andjk-I = q~ (16)
= - ] - ¢ 7 -
p2 ifjk = ¢ and jk-1 = c~
0 otherwise.
The single-label priors are obtained in a directly analogous fashion by summing the edge-priors with the following result:
{l~-e- i f j~ iE~ ' ,~ e(JkHjk) = -I (17) if jk = q5
The compatibility coefficients are derived by sub- stituting equations (14), (16) and (17) into equa- tion (13). Their specification is given below in the following rule:
R(jk,jk-1 ,j0)
f 2
1
0
In other words, process is captured
if {jk,jk-l,jO} E ~ m
if {jk_l,j0} Er~m andjk = ¢
if {jk-l,j0} ESm and j0 = ¢
ifj0E~Um andjk-1 =j~ = ¢ (18)
or jk- i E 3e'rn and j0 = jk = ¢
or jk C ¢/'m and j0 = A - I = ¢
or {jk, j0} ESrn andjk_l = ¢
or j0 =A-1 =Jk = 4 ~
otherwise.
the entire graph-based constraint by a model which is entirely devoid
of free parameters; it is specified purely in terms of the number of nodes, edges and faces in the model graph. The valid labelling configurations and their associated coefficients are illustrated in Fig. 2. The pattern of compatibilities clearly grades the different face con- straints according to their overall consistency. Fully consistent faces have higher compatibility values than partially matched faces which feature isolated edges or nodes. It is particularly interesting to note that the isolated edge compatibilities display several subtle features which discourage violation of the neighbour- hood ordering relation. Partially matched faces contain- ing a consistent training edge, i.e. {jk-l , j0} E ~r m or an edge that preserves ordering in the contextual neigh- bourhood, i.e. {jk,jk-1} E gm both receive a higher

Matching Delaunay graphs 129
C
C i
C
l_ O 1 I 1
O / - / - t'KI2 I
O Label in 'V,,, ~ - ) Label = ~ - - Consistent edge
Fig. 2. The valid face labeling configurations.
5. E X P E R I M E N T S
In order to demonstrate some of the performance advantages of our face-based matching scheme, we have taken an application involving synthetic aperture radar data. Here we are interested in matching linear hedge structures from radar images against their cartographic representation in a digital map. The radar data is subject to multiplicative speckle noise and is cluttered with unmapped vegetation features. An example image is shown in Fig. 3.
We establish Delaunay graph representations of data and model by seeding Voronoi tessellations from the midpoints of the linear segments. 1 Delaunay edges signify that linear segments give rise to adjacent Voronoi cells. Fig. 4 illustrates these two stages in establishing a relational description for the lines in the digital map. Figure 4(a) shows the Voronoi cells seeded from the line-centres, while Fig. 4(b) shows the associated Delaunay graph; in both cases the relevant sets of extracted linear segments are superimposed. Fig. 5 shows the corresponding Delaunay graph for the SAR data. In the case of the radar data, the linear segments have been extracted from the raw image shown in Fig. 3 using the dictionary-based relaxation technique de- scribed in reference (31) which draws on an accurate model of speckle noise.
compatibility than the innovation of an isolated leading- edge that could potentially disrupt this ordering, i.e. {jk,J0} ~ gm. In other words, the compatibility pattern favours null matched nodes that are surrounded by a consistently ordered collective neighbourhood over matches that are connected to a plethora of incorrectly ordered yet individually consistent edges. It is this ability to impose ordering relations that enhances the internal consistency of our face-based relaxation scheme and represents the main advantage over purely edge- based compatibility models. (12'27)
To conclude this section it is illuminating to describe the effects of relaxing the neighbourhood ordering constraint. This corresponds to imposing a conditional independence assumption on adjacent peripheral nodes, i.e.
P(Jk~--+jk,Jk l~-+jk_l,Jow-+jo)=
P(Jk~-~jk IJo~-+Jo) " P(Jk l~--~jk-I IJo~j0)" P(JoF--~jo) .
(19)
Under this assumption the face compatibility is equal to:
R({j~,jk l,j0} C Fm) - I Vm [2 (20) IEml
In other words, the face contributes to the computation of support only as a consistent edge. It is under the conditional independence of adjacent edges that our face-based relaxation scheme becomes equivalent to its edge-based counterpart. We will explore this limit in more detail in the next section.
5.1. Initial probabili~ assignment
The initial matches between the linear segments extracted from the SAR data and their map representa- tion are established on the basis of the affinity between the vectors of unary node attributes in the two graphs. We assume a uniform distribution of null-match probability Po for the nodes in the data graph, i.e.
p(O) (Kk ~--~cO) Po (21 )
The matching probabilities are computed from expo- nential distributions of the Mahalanobis distance between attribute-vectors pairs computed using an estimate of the variance-covariance matrix E, i.e.
p(O) (Yk ~ jk)
(l - P~))exp [ - ½ (x S° ) -x_j,(°)'T~) e~ l,t~(o) _ x(°))l~Jk j
~ j ~ , m exp[_ ½,tx_~(0)- x(0)~Tz~_j J l ;x(0) - ~ J~ x_10))] "
(22)
Our assumed model for the matching priors is one of the un i fo rmi ty over the set of matches i.e. P(4~--~Jk) = (I ~-m I" [ ~//'d l) 1.
In keeping with our philosophy of exploiting only the minimal amount of geometric information, in our
1Although we acknowledge that there are proven advantages in adopting the constrained Delaunay triangulation (Sj for line- data, we make use of this simpler method for computational expediency reasons. Our main objective here is primarily to establish an application vehicle to demonstrate our matching method.

130 A.M. FINCH et al.
Fig. 3. The SAR image.
(a)
J J • )
Fig. 4. Voronoi tessellation and resulting Delaunay graph.
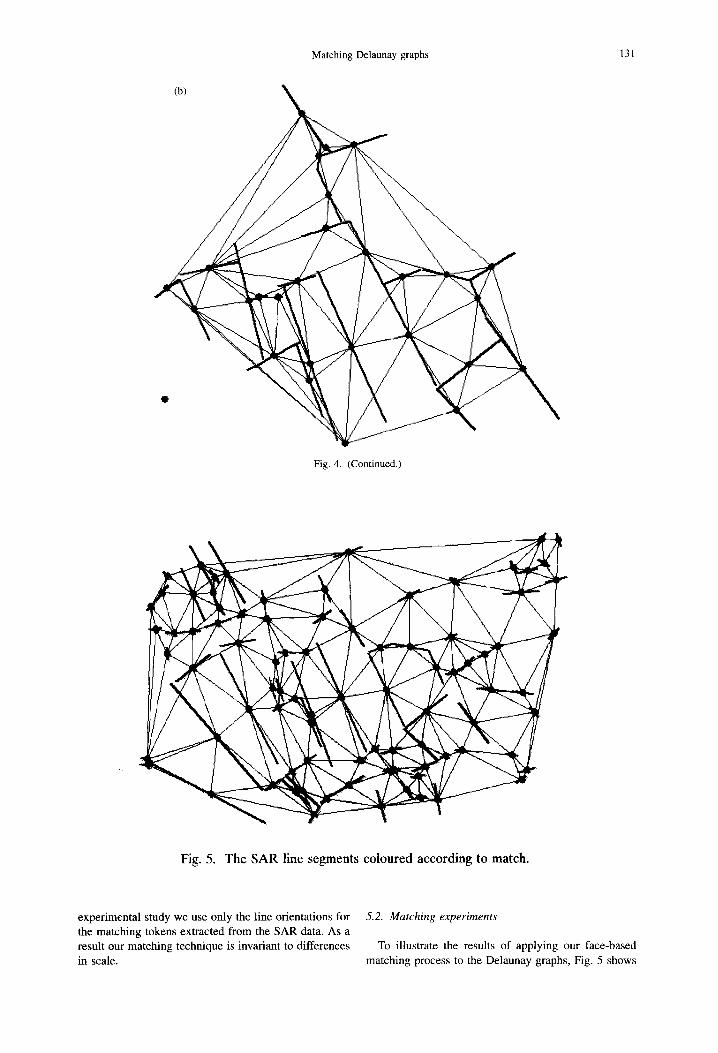
Matching Delaunay graphs 131
Fig. 4. (Continued.)
Fig. 5. The SAR line segments coloured according to match.
experimental study we use only the line orientations for the matching tokens extracted from the SAR data. As a result our matching technique is invariant to differences in scale.
5.2. Matching experiments
To illustrate the results of applying our face-based matching process to the Delaunay graphs, Fig. 5 shows

132 A.M. FINCH et al.
Table 1. Comparative line matching performance between face-based and edge-based approaches
Constraint Correct Incorrect Null
Face (best) 18 5 64 Face (theoretical 16 8 63 parameters) Edge (best) 19 22 46 Theoretical optimal 25 0 62 Weakened edges 15 6 66 Weakened faces 14 l0 63
the final match obtained using the compatibility model prescribed by equation (18). The segments coloured green are correctly matched, the purple segments are assigned to the null category while the red segments represent residual errors. A summary of the matching statistics is given in the first row of Table 1.
Initial probabilities have been computed using equation (22). The effectiveness of matching is critically sensitive neither to the mean orientation parameter nor its variance. The matching scheme converges rapidly. In the majority of cases the matches are unambiguously assigned after just two iterations.
5.3. Exploring the compatibility model
To give some idea of the effectiveness of our compatibility model, there are 28 nodes, 46 faces and 142 edges in the model graph. In consequence, the face compatibility l em II 3U'm l / I~"m I = 86.43, while the edge compatibility I ~m 12 / I em I = 5.52. The graph in Fig. 6 shows the accuracy of match (defined here to be the number of correctly matched line segments, minus the number of incorrectly matched line segments) plotted against the edge and face compatibility values.
The graph shows a broad plateau around the theoretically optimal parameter values. In this region (3-8 edge compatibility and 30-100 face-compatibility) the correct/incorrect surplus is consistently high (i.e. 7-9). This is an encouraging observation, it means that our very simple compatibility model is adequate in
describing the matching errors in a complex experi- mental example without excessive parameter tuning. The matching statistics obtained using face-constraints compare favourably to those obtained using edge- constraints. Using face-constraints produces approxi- mately the same number of correct matches, but with fewer residual errors. As shown in Table l, we can see that the best result for the edge-constraint approach matches 19 line segments correctly as opposed to 18 using faces as additional constraints. However, in the edge case, there are 22 incorrect matches. By contrast, the face-based method is more effective in identifying unmatchable elements and assigning them to the null category; as a result there are just 5 residual errors. This improvement effectively eliminates the need for a post- processing stage to remove inconsistent matches (e.g. the constraint filtering approach employed in reference (17)).
This investigation of our compatibility model has several limiting cases that merit special mention. The first of these is the situation in which the three faces that contain only a single consistent edge are forced to have equal compatibility coefficients. In practice this has been effected by weakening the compatibilities of the training and peripheral edges (i.e. replacing the compatibility [ "//'m 12 / I ~m I with unity) so that they are on parity with the leading edge compatibility. This procedure effectively corresponds to relaxing the neighbourhood ordering constraint. The second inter- esting limit corresponds to relaxing the face-constraint. We do this by invoking the assumption of conditional independence of the peripheral nodes outlined in the previous section.
The results of experiments conducted under these limiting conditions are summarised in the last two rows of Table 1. In both cases the results of matching are inferior to those obtained with the theoretical pattern of compatibilities. These figures underline two important features of the compatibility model. Firstly, they illustrate that face-based constraints actively improve the match. Secondly, they show that the inequality of the edge compatibilities, i.e. the cyclic neighbourhood
Nat o1~
Fig. 6. A graph of the surplus of cor rec t matches p lo t t ed against the face and edge compat ib i l i ty coefficients.

Matching Delaunay graphs 133
Fig. 7. The set of SAR line segments with no corrupting lines added.
ordering relation, plays a critical role in the matching process.
5.4. Distorting and deforming the Delaunay graph
We have conducted some experiments aimed at measuring the robustness of our method to controlled levels of clutter. Our experimental protocol has been as follows. Firstly, we have removed from the SAR data all line segments for which no feasible match exists in the model. The corresponding Delaunay graph which contains 18 line tokens is shown in Fig. 7.
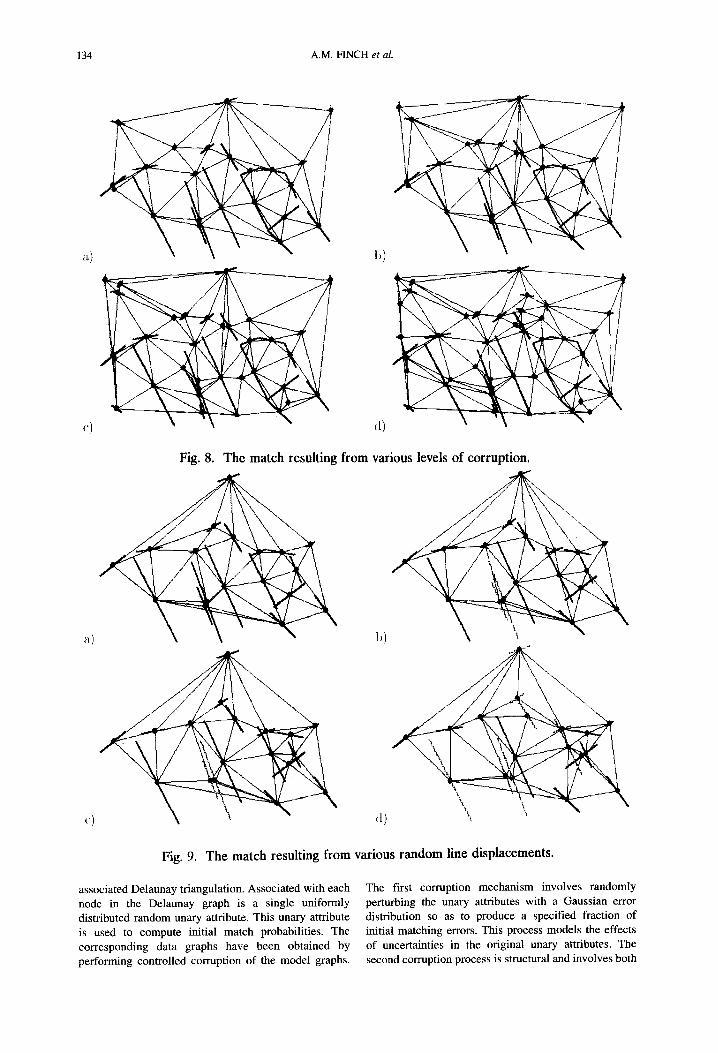
Application of our relaxation scheme to this ideal data graph produces a perfect match. Commencing from this maximally consistent set of real data, we have added controlled numbers of clutter segments with random locations and orientations. Fig. 8(a)-(d) show the matched realisations of the resulting Delaunay graphs when 4, 9, 18 and 27 clutter tokens are added.
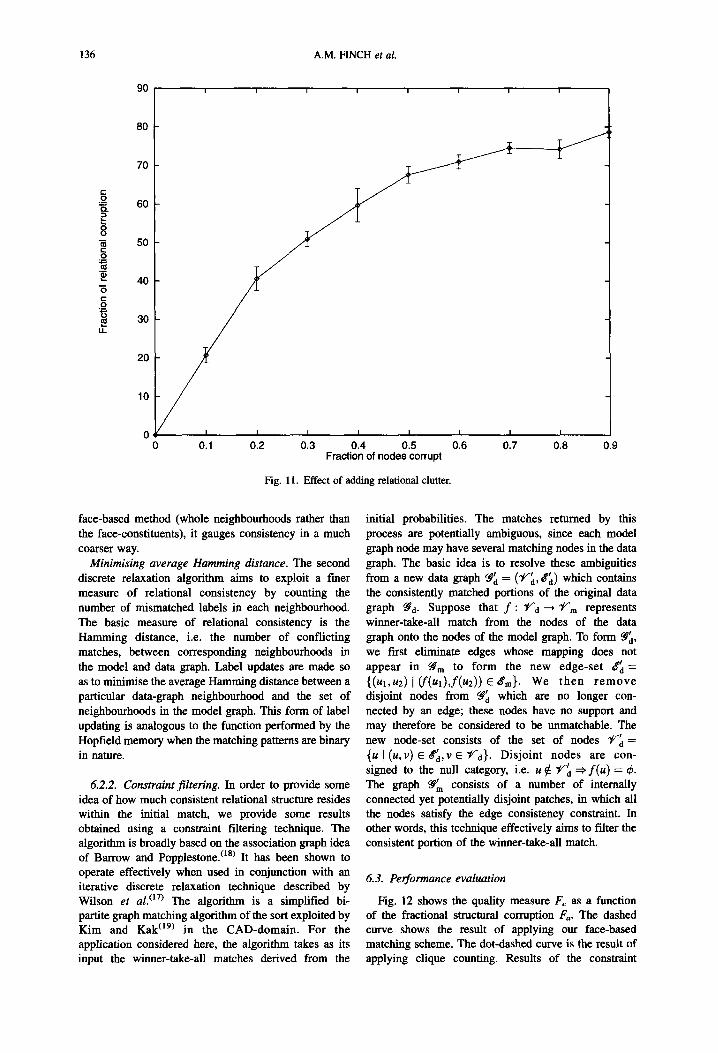
The results of this controlled corruption of the set of the idealised data are summarised in Fig. 10. The solid line shows the fraction of matchable entities which are correctly identified as a function of the fraction of added clutter. By contrast the dashed line shows the fraction of added line-tokens that are matched in error. The accuracy of the match does not fall below 90% until the fractional clutter exceeds 35%. However, it is important to stress that the fraction of incorrectly matched nodes never exceeds 25%. In other words, the majority of the added clutter nodes are correctly assigned to the null category.
The corruption experiments described above demon- strate that our method is effective at controlling noise contamination, However, as we indicated in the introduction, one of the perceived advantages of our largely symbolic approach is the avoidance of a detailed
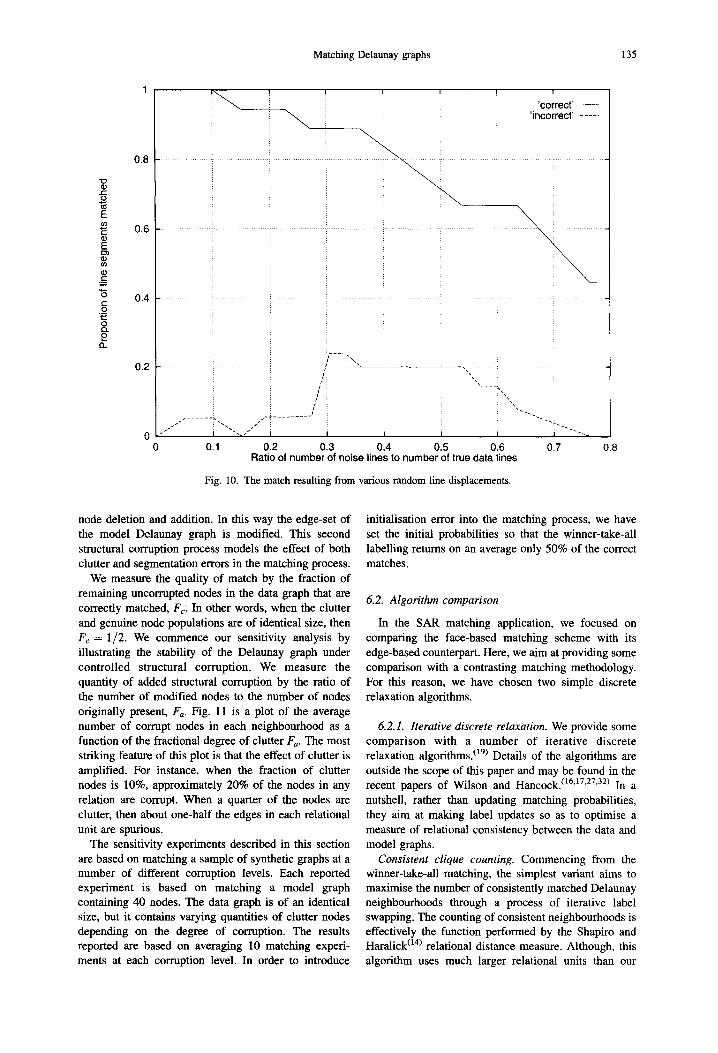
transformational model. In order to investigate the effects of controlled shape deformation, we have randomly perturbed the positions of the line tokens shown in Fig. 7 and evaluated the resulting accuracy of match. This perturbation has been effected by randomly displacing the line-centres according to a Gaussian distribution of known variance. Fig. 9(a)-(d) show the perturbed line segments, when the standard deviations of the random co-ordinate displacements are 5, 10, 15 and 20 pixels. For comparison, typical Voronoi cells have effective radii of approximately 50 pixels. It is not until the average displacement is 20 pixels that the corruption of the graph topology is sufficient to cause a large proportion of the line segments to be mismatched. These results would suggest that our technique has considerable potential in the matching of non-rigid or articulated objects.
6. SENSITIVITY ANALYSIS
In order to provide some controlled evaluation and comparative assessment of our matching technique, we have chosen to investigate the matching of random dot patterns. Our aims here are two-fold. In the first instance, we would like to establish the operating limits of the face-based matching technique under conditions of controlled clutter and structural deformation. Our second aim is to provide some direct comparison with some alternative matching techniques.
6.1. Random graph generation
We conduct the performance evaluation described above by generating random dot patterns. Our model graphs are constructed by seeding Voronoi tessellations from the random dots and computing the edges of the
134 A.M. FINCH et al.
/ f
~) d)
- - - - - - _ _ _ _ _ _
/
h)
Fig. 8. The match resulting from various levels of corruption.
~,) I~)
~) ,1)
Fig. 9. T h e ma t ch resu l t ing from various r a n d o m l ine d i sp lacement s .
associated Delaunay triangulation. Associated with each node in the Delaunay graph is a single uniformly distributed random unary attribute. This unary attribute is used to compute initial match probabilities. The corresponding data graphs have been obtained by performing controlled corruption of the model graphs.
The first corruption mechanism involves randomly perturbing the unary attributes with a Gaussian error distribution so as to produce a specified fraction of initial matching errors. This process models the effects of uncertainties in the original unary attributes. The second corruption process is structural and involves both
Matching Delaunay graphs 135
e -
E c -
E
e -
c o
o e~
O _
0.8
0.6
0.4
0.2
' co r rec t ' - - ' i ncor rec t ' - . . . .
. . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . i . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . _
t i ! ~, !
i i xx
, x
t • •
0.1 0 .2 0 .3 0 .4 0 .5 0 .6 0 .7 Ratio of number of noise lines to number of true data lines
Fig. 10. The match resulting from various random line displacements.
0.8
node deletion and addition. In this way the edge-set of the model Delaunay graph is modified. This second structural corruption process models the effect of both clutter and segmentation errors in the matching process.
We measure the quality of match by the fraction of remaining uncorrupted nodes in the data graph that are correctly matched, Fc: In other words, when the clutter and genuine node populations are of identical size, then Fc = 1/2. We commence our sensitivity analysis by illustrating the stability of the Delaunay graph under controlled structural corruption. We measure the quantity of added structural corruption by the ratio of the number of modified nodes to the number of nodes originally present, Fa. Fig. 11 is a plot of the average number of corrupt nodes in each neighbourhood as a function of the fractional degree of clutter Fa. The most striking feature of this plot is that the effect of clutter is amplified. For instance, when the fraction of clutter nodes is 10%, approximately 20% of the nodes in any relation are corrupt. When a quarter of the nodes are clutter, then about one-half the edges in each relational unit are spurious.
The sensitivity experiments described in this section are based on matching a sample of synthetic graphs at a number of different corruption levels. Each reported experiment is based on matching a model graph containing 40 nodes. The data graph is of an identical size, but it contains varying quantifies of clutter nodes depending on the degree of corruption. The results reported are based on averaging 10 matching experi- ments at each corruption level. In order to introduce
initialisation error into the matching process, we have set the initial probabilities so that the winner-take-all labelling returns on an average only 50% of the correct matches.
6.2. Algorithm comparison
In the SAR matching application, we focused on comparing the face-based matching scheme with its edge-based counterpart. Here, we aim at providing some comparison with a contrasting matching methodology. For this reason, we have chosen two simple discrete relaxation algorithms.
6.2.1. Iterative discrete relaxation. We provide some comparison with a number of iterative discrete relaxation algorithms. (19) Details of the algorithms are outside the scope of this paper and may be found in the recent papers of Wilson and Hancock. (16'17'27'32) In a nutshell, rather than updating matching probabilities, they aim at making label updates so as to optimise a measure of relational consistency between the data and model graphs.
Consistent clique counting. Commencing from the winner-take-all matching, the simplest variant aims to maximise the number of consistently matched Delaunay neighbourhoods through a process of iterative label swapping. The counting of consistent neighbourhoods is effectively the function performed by the Shapiro and Haralick 04) relational distance measure. Although, this algorithm uses much larger relational units than our
136 A.M. FINCH et al.
90
80
c- O
3
O O
E O
"6 c O
LL
70
60
50
40
30
20
10
0 d e t t
0 0.1 0.2 I I I I
0.3 0.4 0.5 0.6 Fra~ionofnodescorrupt
Fig. 11. Effect of adding relational clutter.
I I I 0.7 0.8 0.9
face-based method (whole neighbourhoods rather than the face-constituents), it gauges consistency in a much coarser way.
Minimising average Hamming distance. The second discrete relaxation algorithm aims to exploit a freer measure of relational consistency by counting the number of mismatched labels in each neighbourhood. The basic measure of relational consistency is the Hamming distance, i.e. the number of conflicting matches, between corresponding neighbourhoods in the model and data graph. Label updates are made so as to minimise the average Hamming distance between a particular data-graph neighbourhood and the set of neighbourhoods in the model graph. This form of label updating is analogous to the function performed by the Hopfield memory when the matching patterns are binary in nature.
6.2.2. Constraint filtering. In order to provide some idea of how much consistent relational structure resides within the initial match, we provide some results obtained using a constraint filtering technique. The algorithm is broadly based on the association graph idea of Barrow and Popplestone. (is) It has been shown to operate effectively when used in conjunction with an iterative discrete relaxation technique described by Wilson et al. (17) The algorithm is a simplified bi- partite graph matching algorithm of the sort exploited by Kim and Kak (19) in the CAD-domain. For the application considered here, the algorithm takes as its input the winner-take-all matches derived from the
initial probabilities. The matches returned by this process are potentially ambiguous, since each model graph node may have several matching nodes in the data graph. The basic idea is to resolve these ambiguities
! ¢ from a new data graph f~ = (~e'd, gd) which contains the consistently matched portions of the original data graph (~d. Suppose that f : ~e'd ---* ~e'm represents winner-take-all match from the nodes of the data graph onto the nodes of the model graph. To form ~ , we first eliminate edges whose mapping does not appear in ~m to form the new edge-set 8~ = {(Ul,u2) l (f(ul),f(u2)) E 8m}. We then r emove disjoint nodes from ~ which are no longer con- nected by an edge; these nodes have no support and may therefore be considered to be unmatchable. The new node-set consists of the set of nodes ~ = {U [ (U, V) E ~d, V E ~Pd}" Disjoint nodes are c o n - signed to the null category, i.e. u ~ ~ ~ f ( u ) = c~. The graph f ~ consists of a number of internally connected yet potentially disjoint patches, in which all the nodes satisfy the edge consistency constraint. In other words, this technique effectively aims to filter the consistent portion of the winner-take-all match.
6.3. Performance evaluation
Fig. 12 shows the quality measure Fc as a function of the fractional structural corruption Fa. The dashed curve shows the result of applying our face-based matching scheme. The dot-dasbed curve is the result of applying clique counting. Results of the constraint
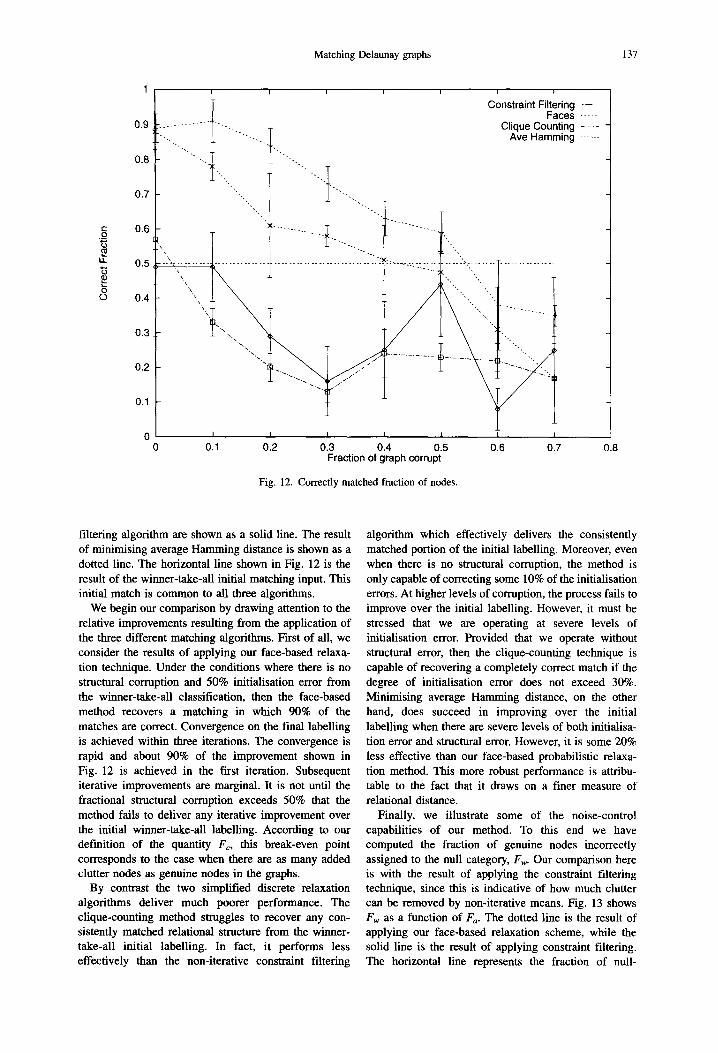
Matching Delaunay graphs 137
"- " - , .
" '" " '" t " " , " ' "
iiiiiii:iii :::::: ii:i iii: .... - \ , \ _
" " " - . X ]; .....
t - O
i i
t~
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2 . . . . . . . . . . . t
0,1
I I I I
0 0.1 0.2 0.3 0.4 0.5 Fraction of graph corrupt
Fig. 12. Correctly matched fraction of nodes.
Constraint Filtering - - Faces -- -
Clique Counting - -, Ave Hamming ......
I I
0.6 0.7 0.8
filtering algorithm are shown as a solid line. The result of minimising average Hamming distance is shown as a dotted line. The horizontal line shown in Fig. 12 is the result of the winner-take-all initial matching input. This initial match is common to all three algorithms.
We begin our comparison by drawing attention to the relative improvements resulting from the application of the three different matching algorithms. First of all, we consider the results of applying our face-based relaxa- tion technique. Under the conditions where there is no structural corruption and 50% initialisation error from the winner-take-all classification, then the face-based method recovers a matching in which 90% of the matches are correct. Convergence on the final labelling is achieved within three iterations. The convergence is rapid and about 90% of the improvement shown in Fig. 12 is achieved in the first iteration. Subsequent iterative improvements are marginal. It is not until the fractional structural corruption exceeds 50% that the method falls to deliver any iterative improvement over the initial winner-take-all labelling. According to our definition of the quantity Fc, this break-even point corresponds to the case when there are as many added clutter nodes as genuine nodes in the graphs.
By contrast the two simplified discrete relaxation algorithms deliver much poorer performance. The clique-counting method struggles to recover any con- sistently matched relational structure from the winner- take-all initial labelling. In fact, it performs less effectively than the non-iterative constraint filtering
algorithm which effectively delivers the consistently matched portion of the initial labelling• Moreover, even when there is no structural corruption, the method is only capable of correcting some 10% of the initialisation errors. At higher levels of corruption, the process falls to improve over the initial labelling. However, it must be stressed that we are operating at severe levels of initialisation error. Provided that we operate without structural error, then the clique-counting technique is capable of recovering a completely correct match if the degree of initialisation error does not exceed 30%. Minimising average Hamming distance, on the other hand, does succeed in improving over the initial labelling when there are severe levels of both initialisa- tion error and structural error. However, it is some 20% less effective than our face-based probabilistic relaxa- tion method. This more robust performance is attribu- table to the fact that it draws on a finer measure of relational distance.
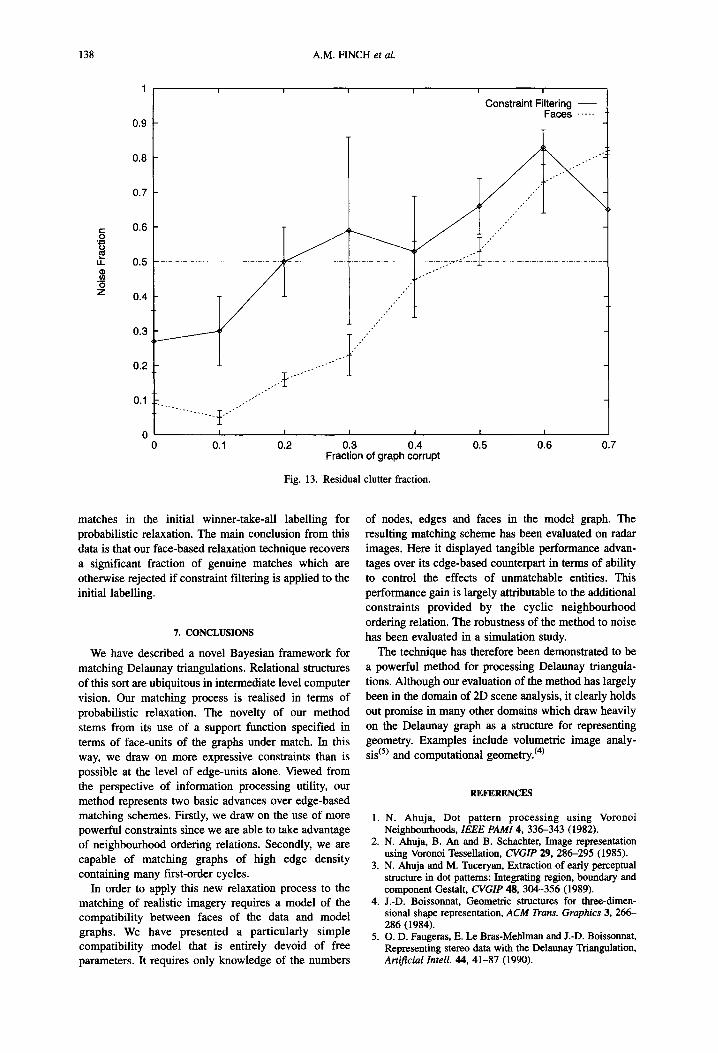
Finally, we illustrate some of the noise-control capabilities of our method. To this end we have computed the fraction of genuine nodes incorrectly assigned to the null category, F~. Our comparison here is with the result of applying the constraint filtering technique, since this is indicative of how much clutter can be removed by non-iterative means. Fig. 13 shows Fw as a function of Fa. The dotted line is the result of applying our face-based relaxation scheme, while the solid line is the result of applying constraint filtering. The horizontal line represents the fraction of null-
138 A.M. FINCH et al.
t- O
LL
"5 Z
1
0.9
0.8
0.7
0.6
0.5
0.4
0.3
0.2
0.1
0
t
°.- °
se ~r~
I I
0.1 0.2
' ' I Constraint Filtering - - Faces ..... 1
I I I
0.3 0.4 0.5 0,6 Fraction of graph corrupt
Fig. 13. Residual clutter fraction.
0.7
matches in the initial winner-take-all labelling for probabilistic relaxation. The main conclusion from this data is that our face-based relaxation technique recovers a significant fraction of genuine matches which are otherwise rejected if constraint filtering is applied to the initial labelling.
7. CONCLUSIONS
We have described a novel Bayesian framework for matching Delaunay triangulations. Relational structures of this sort are ubiquitous in intermediate level computer vision. Our matching process is realised in terms of probabilistic relaxation. The novelty of our method stems from its use of a support function specified in terms of face-units of the graphs under match. In this way, we draw on more expressive constraints than is possible at the level of edge-units alone. Viewed from the perspective of information processing utility, our method represents two basic advances over edge-based matching schemes• Firstly, we draw on the use of more powerful constraints since we are able to take advantage of neighbourhood ordering relations. Secondly, we are capable of matching graphs of high edge density containing many first-order cycles.
In order to apply this new relaxation process to the matching of realistic imagery requires a model of the compatibility between faces of the data and model graphs. We have presented a particularly simple compatibility model that is entirely devoid of free parameters. It requires only knowledge of the numbers
of nodes, edges and faces in the model graph. The resulting matching scheme has been evaluated on radar images. Here it displayed tangible performance advan- tages over its edge-based counterpart in terms of ability to control the effects of unmatchable entities. This performance gain is largely attributable to the additional constraints provided by the cyclic neighbourhood ordering relation. The robustness of the method to noise has been evaluated in a simulation study.
The technique has therefore been demonstrated to be a powerful method for processing Delaunay triangula- tions. Although our evaluation of the method has largely been in the domain of 2D scene analysis, it clearly holds out promise in many other domains which draw heavily on the Delatmay graph as a structure for representing geometry. Examples include volumetric image analy- sis (5) and computational geometry. (4)
REFERENCES
1. N. Ahuja, Dot pattern processing using Voronoi Neighbourhoods, IEEE PAMI 4, 336-343 (1982).
2. N. Ahuja, B. An and B. Schachter, Image representation using Voronoi Tessellation, CVGIP 29, 286-295 (1985).
3. N. Ahuja and M. Tuceryan, Extraction of early perceptual structure in dot patterns: Integrating region, boundary and component Gestalt, CVGIP 48, 304-356 (1989).
4. J.-D. Boissonnat, Geometric structures for three-dimen- sional shape representation, ACM Trans. Graphics 3, 266- 286 (1984).
5. O. D. Faugeras, E. Le Bras-Mehlman and J.-D. Boissonnat, Representing stereo data with the Delaunay Triangulation, Artificial IntelL 44, 41-87 (1990).

Matching Delaunay graphs 139
6. I. A. Essa, T. Darrell and A. Pentland, Tracking facial motion, IEEE Workshop on Motion of Non-rigid and Articulated Objects, Austin, Texas, pp. 36--42 (1994).
7. H. Delingette, Adaptive and deformable models based on simplex meshes, IEEE Workshop on Motion of Non-rigid and Articulated Objects, Austin, Texas, pp. 152-157 (1994).
8. S. Sarker and K.L. Boyer, Perceptual organisation in computer vision: A review and proposal for a classificatory structure, IEEE SMC 23, 382-399 (1993).
9. M. Tuceryan and T. Chorzempa, Relative sensitivity of a family of closest point graphs in computer vision applications, Pattern Recognition 25, 361-373 (1991).
10. K. Boyer and A. Kak, Structural stereopsis for 3D vision, IEEE PAM1 10, 144-166 (1988).
11. R. Horaud and T. Skordas, Stereo correspondence through feature grouping and maximal cliques, IEEE PAMI 11, 1168-1180 (1989).
12. J. Kittler, W. J. Christmas and M. Petrou Probabilistic relaxation for matching problems in machine vision, Proc. Fourth Int. Conf. Computer Vision, Berlin, Germany, 666- 674 (1993).
13. B. T. Messmer and H. Bunke, Efficient error-tolerant subgraph isomorphism detection, Shape, Structure and Pattern Recognition, D. Dori and A. Bruckstein, eds, World Scientific (1995).
14. L. Shapiro and R. M. Haralick, Structural dcscription and inexact matching, IEEE PAMI 3, 504-519 (1981).
15. L. Shapiro and R. M. Haralick, A metric for comparing relational descriptions, IEEE PAMI 7, 90-94 (1985).
16. R. C. Wilson and E. R. Hancock, Graph matching by discrete relaxation, Pattern Recognition in Practice IV'. Multiple Paradigms, Comparative Studies and Hybrid Systems, North Holland, pp. 165-177 (1994) (1985).
17. R. C. Wilson, A. N. Evans and E. R Hancock Relational matching by discrete relaxation, Image and Vision Computing 13, 411-422 (1995).
18. H. G. Barrow and R. J. Popplestone, Relational descriptions in picture processing, Machine Intell. VI, 377-396 (1971).
19. W. Kim and A. C. Kak, 3D Object recognition using Bi- partite graph matching embedded in discrete relaxation, IEEE PAMI 13, 224-251 (1991).
20. A. Sanfeliu and K. S. Fu, A distance measure between attributed relational graphs for pattern recognition, IEEE SMC 13, 353-362 (1983).
21. A. K. C. Wong and M. You, Entropy and distance of random graphs with application to structural pattern recognition, IEEE PAM1 7, 599-609 (1985).
22, L. Herault, R. Horaud, E Veillon and J.-J. Niez Symbolic image matching by simulated annealing, Proc. First British Machine Vision Conf., Oxford , 319-324 (1990).
23. S. Z. Li, Matching invafiant to translations rotations and scale changes, Pattern Recognition 25, 583-594 (1992).
24. O.D. Faugeras and K. E. Price, Semantic labelling of aerial images using stochastic relaxation, IEEE PAMI 3, 633-642 (1981).
25. P. Suetens, P. Fua and A. J. Hanson Computational strategies for object recognition, ACM Computing Surveys 2,4, 5-61 (1992).
26. H. Ogawa, Labelled point pattern matching by Delaunay Triangulation and Maximal Cliques, Pattern Recognition 19, 35-40 (1986).
27. R. C. Wilson and E. R Hancock, A Bayesian Compatibility model for graph matching, Pattern Recognition Lett. 17, 263-276 (1996).
28. J. Kittler and E. R. Hancock, Combining evidence in probabilistic relaxation, Int. J. Pattern Recognition and Artificial Intell. 3, 29-64 (1989).
29. J. Kittler and E. R. Hancock, Contextual decision rule for region analysis, Image and Vision Computing 5, 145-154 (1987).
30. A. Rosenfeld, R. A Hummel and S. W. Zucker Scene labelling by relaxation operations, 1EEE Trans. Systems Man and Cybernetics 6, 420-433 (1976).
31. A. N. Evans, N. G. Sharp and E. R. Hancock, Noise models for linear feature detection in SAR images, Proc. 1994 Int. Conf. Image Process., Austin, Texas, pp. 466-470 (1994).
32. R. C. Wilson and E. R. Hancock, Relational matching with dynamic graph structures, Proce. Fifth Int. Conf. Computer Vision, Boston, pp. 450-456 (1995).
33. D. Geman and S. Geman, Stochastic relaxation, Gibbs distributions and Bayesian restoration of images, 1EEE PAMI 6, 721-741 (1984).
34. D. Geiger and F. Girosi, Parallel and deterministic algorithms from MRF's: Surface reconstruction, IEEE PAM1 13, 401-412 (1991).
35. R. Horaud, E Veilon and T. Skordas, Finding geometric and relational structures in an image, Proc. First European Conf. Computer Vision, Antibes, France, pp. 374-384 (1990).
36. M. Kass, A. Witken and D. Terzopoulos Constraints on deformable models: Recovering 3D shape from non-rigid motions, Artificial lntell. 36, 91-123 (1988).
37. S. Sclaroff and A. Pentland, A modal framework for correspondence and recognition, Proc. Fourth Int. Conf. Computer Vision, Berlin, Germany, pp. 308-331 (1993).
38. S. Zucker, C. David, A. Dobbins and L. Iverson, Coarse tangent fields and fine spline coverings, Proc. Second Int. Conf. Computer Vision, pp. 586-577 (1988).
About the Author--ANDREW FINCH is currently a research associate in the Department of Computer Science at the University of York. He gained a B.Sc degree in mathematics in 1984 and an M.Sc. in psychology in 1989 both from the University of Warwick. Between 1989 and 1993 Dr Finch undertook D.Phil at research the University of York in the area of statistical pattern recognition and neural networks. He also worked for five years in the software industry in the UK, France and Holland. His research interests are in density estimation, probabilistic inference and optimisation methods.
About the Author--RICHARD WILSON is currently a research associate in the Department of Computer Science at the University of York. Dr Wilson was awarded an open scholarship to read physics at St John's College, University of Oxford, graduating with first class honours in 1992. Between 1992 and 1995 he undertook research at the University of York on the topic of relational graph matching for which he was awarded the D.Phil degree. He has published some 30 papers in journals, edited books and refereed conferences. His research interests are in high-level vision, scene understanding and structural pattern recognition.
About the Author--EDWIN HANCOCK gained his B.Sc. in physics in 1977 and Ph.D. in high energy nuclear physics in 1981, both from the University of Durham, UK. After a period of postdoctoral research working on

140 A.M. FINCH et al.
charm-photo-product ion experiments at the Stanford Linear Accelerator Centre, he moved into the fields of computer vision and pat tern recognition in 1985. Between 1981 and 1991, he held posts at the Rutherford-Appleton Laboratory, the Open University and the University of Surrey. Since 1991 Dr Hancock has been a Lecturer in Computer Science at the University of York where he now leads a group of some 15 researchers in the areas of computer vision and pat tern recognition. He has published over 100 refereed papers in the areas of high energy nuclear physics, computer vision, image processing and pat tern recognition. He was awarded the 1990 Pat tern Recognition Society Medal. Dr Hancock serves as an Associate Editor of the journa l Pattern Recognition and has been a guest editor for the Image and Vision Computing Journal. He chaired the 1994 British Machine Vision Conference and has been a p rogramme committee m e m b e r for several national and international conferences.





























