Embed Size (px)
Citation preview

1
Learning to Harness Bandwidth with MultipathCongestion Control and Scheduling
Shiva Raj Pokhrel, Senior Member, IEEE and Anwar Walid, Fellow, IEEE
Abstract—Multipath TCP (MPTCP) has emerged as a fa-cilitator for harnessing and pooling available bandwidth inwireless/wireline communication networks and in data centers.Existing implementations of MPTCP such as, Linked IncreaseAlgorithm (LIA), Opportunistic LIA (OLIA) and BAlancedLInked Adaptation (BALIA) include separate algorithms forcongestion control and packet scheduling, with pre-selectedcontrol parameters. We propose a Deep Q-Learning (DQL) basedframework for joint congestion control and packet scheduling forMPTCP. At the heart of the solution is an intelligent agent forinterface, learning and actuation, which learns from experienceoptimal congestion control and scheduling mechanism usingDQL techniques with policy gradients. We provide a rigorousstability analysis of system dynamics which provides importantpractical design insights. In addition, the proposed DQL-MPTCPalgorithm utilizes the ‘recurrent neural network’ and integratesit with ‘long short-term memory’ for continuously i) learningdynamic behavior of subflows (paths) and ii) responding promptlyto their behavior using prioritized experience replay. Withextensive emulations, we show that the proposed DQL-basedMPTCP algorithm outperforms MPTCP LIA, OLIA and BALIAalgorithms. Moreover, the DQL-MPTCP algorithm is robustto time-varying network characteristics, and provides dynamicexploration and exploitation of paths.
Index Terms—Multipath TCP, Deep Q-Learning, StabilityAnalysis.
I. INTRODUCTION
CONGESTION Control design of both TCP and multipathTCP (MPTCP) is a fundamental problem in networking
and has been widely investigated in the literature (see [2]–[9] and references therein). Most of the seminal single-path congestion control protocols proposed are either delay-based (e.g., TCP Vegas), or loss-based (e.g., TCP NewReno),otherwise hybrid (both) (e.g., Compound TCP). All of thesecongestion control protocols use some packet-based events (loss,delay, etc.) as an indication for the congestion and perform theirwindow adjustment (based on some fixed control mechanism)to control the number of outstanding packets in the network.
To take advantage of the increasingly available wirelessand wireline access technologies, and mutlipath and multi-homing capabilities in the Internet and data centers, MultipathTCP (MPTCP) has emerged as an enabler for harnessing andaggregating available bandwidth and improve applications’performance. Raiciu et al. [10] developed the MPTCP LinkedIncrease Algorithm (LIA) congestion control that elegantly uses
S. R. Pokhrel is with the School of Information Technology, DeakinUniversity, Geelong, Australia. A. Walid is with Nokia Bell Labs, MurrayHill, NJ, USA. The revised version of this paper will appear in IEEETransactions in Mobile Computing [1]. Email: [email protected],[email protected]
Fig. 1. 5G Network-assisted MPTCP: An abstract view of ATSSS [16]
their specific window increase function to couple the congestionwindows running on different subflows; however, it suffersfrom throughput inefficiency problem which was addressedby Opportunistic LIA (OLIA) [11]. Packet scheduling inMPTCP determines which path, among available paths withopen windows, to send a packet so that the need for packet re-sequencing at the receiver is minimized. The design of MPTCPpacket scheduling has also been equally challenging [12]–[15].
As shown in Fig. 1, MPTCP has a vital role to play in5G and 6G networks [16]; see the 3rd Generation PartnershipProject (3GPP) 5G Release 17 [16] for further details. SinceRelease 15, the 3GPP introduced a new Access Traffic Steering,Switching, and Splitting (ATSSS) feature [17].1
ATSSS is one of the prevalent use case of network-assistedmultipath data transport. It has two main components (seeFig. 1): User Equipment (UE) and 5G Core. The UE couldnatively use MPTCP while the User Plane Function may have aTCP to MPTCP proxy. The 3GPP has already defined the use ofthe 0-RTT TCP Convert Protocol for the MPTCP proxy, whichaddresses the proxy directly (IETF RFC-8803, July 2020) [18].Another option relying on the activation of a dedicated functiondeveloped MPTCP concentrator [19], where the identity isexplicitly considered on the hosts.
One early very prevalent use of MPTCP is the SIRI digitalassistant of Apple iPhone, which has been using MPTCP since2013 (iOS 7) to allow Siri to use both the Wi-Fi or Cellularwhatever is available and attain the lowest delay and highreliability. In 2019, MPTCP was also introduced by Apple intheir Maps and Music. Samsung is another key player in theMPTCP framework that has been introduced in phones used byKorean Telecom, SK Telecom and LG+ since 2015 in South
1Steering: choosing the best network depending on the user’s location andnetwork conditions; Switching:enabling seamless handovers from 4G/5G toWi-Fi (or vice versa) Splitting: data transport over multiple paths for higherspeeds.
arX
iv:2
105.
1427
1v1
[cs
.NI]
29
May
202
1

2
Korea. The goal here was to merge Wi-Fi and Cellular and usethem to attain Gigabit speeds at the same time. From 2016, oncustomer premises devices such as DSL home gateways and/orLTE/4G modems, Tessares and Swisscom adopted MPTCP,mainly to aggregate the capacities of the fixed and mobilenetworks.
By using fluid-flow model and dynamical system analysis,Peng et al. [20] designed BAlanced LInked Adaptataion(BALIA) to achieve a better balanced performance. However,all of the aforementioned congestion control approaches [6],[10], [11], [20] designed MPTCP on the basis of model-based frameworks, which are challenged in highly dynamicwireless networks (such as 5G2 [21] and beyond3 [22]–[24])as the underlying models do not apply equally well in variousscenarios and the solutions can be in suboptimal regimes andunstable states.
To elaborate, the current MPTCP congestion control designmainly consists of two steps: i) developing mathematicalmodels for resource allocation problem (e.g., fluid and/orqueuing models [6], [20]), ii) designing algorithms to solve themodels (e.g., convex optimization based on its properties [6],[20]). Such models, which are based on the Network UtilityMaximization (NUM) or control-theoretic frameworks, typi-cally lead to algorithms with fixed parameters. Such algorithms,however, may be unable to handle highly fluctuating and time-varying wireless channels and data paths.
Furthermore, in current model-based MPTCP design, a user’sutility is normally a function of its instantaneous rate, yielding‘bandwidth sharing’ networks [25] which fits the case of infinitelength flows. All the main single path TCP algorithms proposedin the literature have strictly concave utility functions, implyinguniqueness and existence of a stable equilibrium and theirconvergence. However, the case of MPTCP is much moredelicate: whether an underlying utility function exists dependson the design choice. It is worth noting that the utility functiondoes not exist for some well-known MPTCP congestion controlalgorithms [6], [10], [11], [20] (see [20, Tab. 1]). Therefore,utility maximization with the standard MPTCP congestioncontrol algorithms has been typically challenging and nontrivial.
Moreover, the current MPTCP design does not provideapplications with full access to the transport layer features(cross-layer)4, making it difficult to configure the transportlayer behavior to take advantage of the available context andnetwork information. Given that the file size is known, anatural alternative is to use, for a path, the optimal ShortestRemaining Processing Time (SRPT) scheduling. However,naively applying SRPT to networks creates starvation formultipath flows. In contrast, one may plan to develop anoptimization framework and/or cross-layer approach with i)precise prediction of future values and ii) accurate mathematicalmodel to quantify the network behaviour precisely. But bothi) and ii) are extremely challenging and unscalable becauseof large state space (combinatorial in the number of packets
2‘Considerations for MPTCP operation in 5G’ https://tools.ietf.org3‘5G ATSSS solution’, https://www.tessares.net4Cross-layer approach refers to sharing information among TCP/IP layers for
efficacious use of network resources and achieving high degree of adaptivity.It is an escape from the established TCP/IP layering of protocols.
in flights) over future wireless networks. Therefore, there isa need for robust experience-driven algorithms that can adaptintelligently to dynamic environments without escaping fromthe TCP/IP layering fundamentals.
A. LiteratureRecently, real momentum has been building up towards
learning-based TCP designs to exploit and handle dynamicnetwork environments [3], [4], [8], [26]–[33]. Winstein etal. [27] proposed Remy, a single path congestion control, whichis capable of generating control rules for several differentnetwork settings. Authors in [26], [34] developed a (singlepath) performance-based congestion control protocol, suchthat the source can continuously track and adopts actionstimely for a higher network performance [35]. Zaki et al.[28] proposed Verus, a congestion control protocol that learnsa correlation between end-to-end delivery delay of packetsto update the congestion window [4], [33]. However, theseworks [4], [26]–[28], [33], [34], are basically for designingsingle path congestion control protocols and are not applicabledirectly for MPTCP.
More recently, advances in machine learning have beenapplied to the design of MPTCP [3], [8], [15], [29]–[32],[36]. Mai et al. [29] applied deterministic policy gradientfor learning the optimal congestion control strategies. Liao etal. [30] proposed a DRL-based multipath scheduler aiming atdecreasing the out-of-order queue sizing under heterogeneouspaths. Silva et al. [32] implemented an adaptive virtualreality with content-aware prioritisation to improve MPTCP’sperformance.
Of particular relevance to this work are the two multipathcongestion control designs [3], [8] using deep reinforcementlearning (DRL). Both of these designs [3], [8] focus oncongestion control and do not address packet scheduling.Indeed, all of the aforementioned MPTCP designs [3], [8],[15], [29]–[32], [36] considered either congestion control orpacket scheduling separately (instead of jointly). It is knownthat the performance of MPTCP is significantly impacted bypacket scheduling which decides what packet to send on whichpath among the available paths that have open window. Sucha decision impacts the goodput (rate of packets delivered tothe receiver in the right order) and the required resquencingdelay. The advantage of the MPTCP controller in [8], however,is shown only when it is applied to a group of sources, ratherthan the usual and versatile case of a controller per source.In addition, the stability of the proposed algorithms [3], [8],[29]–[32] are not addressed, whereas stability is a key desirablegoal in the original MPTCP design philosophy [10]. Authorsin [15], [36] introduced Deep Q Network (DQN) frameworkto enhance the MPTCP congestion control [36] and packetscheduling [15] performance in asymmetric paths.
In this paper, we develop DQL-MPTCP, a Deep Q-Learning(DQL) based framework for joint congestion control andpacket scheduling of MPTCP. At the heart of the solutionis an intelligent agent, which learns from experience optimalcongestion control and scheduling mechanism using DQLtechniques with policy gradients. DQL-MPTCP is a situation-aware learning driven by reward maximization, where the

3
reward is a controllable function representing applicationperformance. Our framework, unlike prior works, employsa DQL agent for joint learning of scheduling and congestioncontrol for each DQL-MPTCP connection. The two controls(congestion and scheduling) jointly and effectively worktogether towards achieving the target reward. Furthermore,our implementation setup is versatile to use, i.e. whether thesender is a device or a server, readily inter-works with thecurrent Linux kernel implementation (and makes comparisonswith standard MPTCP algorithms fair).
Unlike earlier model-driven MPCTP designs [6], [10],[11], [20], our DQL-MPTCP utilizes runtime statistics of theunderlying network environment. We combine the Deep Q-Learning (DQL) based control with policy gradients, as it iscapable of effectively handling complex and dynamic statespaces. DQL-MPTCP learns dynamic system state and makesdecisions without relying on any mathematical formulas orfixed control policies. DQL-MPTCP has to deal with mappingof traffic to multiple paths (subflows) efficiently. One may thinkof a simple approach and attach a DQL agent for each subflowindependently, so as to separately conduct congestion controlacross all of the available paths. However, such approach isnot fair to traditional single path TCP [10], [20] and fails tocapture the necessary and essential coupling of paths. DQL-MPTCP maximizes total performance reward by performingcoupled congestion control and packet scheduling over allactive paths/subflows of a connection. As will be discussed,we adopt a prioritized experience replaying concept to attaindesired performance even with a limited data sets.
B. Novelty and Contributions
In this paper, we exploit a setting where a DQL agent accessdatasets from the history of the system [37]; using prioritizedexperience replay [38] we store experience tuple (current state,current action, reward, next state) in the memory, and thensample most important transitions from the memory morefrequently.5 As the users could be mobile and the numberof available network paths (subflows joining and leaving)changes over time, existing DRL and convolution neuralnetwork approximation framework. To achieve an MPTCPalgorithm that leverages few samples of data to accelerate theonline learning even from relatively small datasets, we exploita recurrent neural network integrated with the long short-termmemory (LSTM) as a replay buffer, and continuously capturepacket flow dynamics. More specifically, our design is capableof automatically assessing and selecting the essential data setsfrom replay during learning.
Our main contributions in this article are as follows:C1 We propose a new approach for designing coupled
multipath congestion control and packet scheduling usingDeep Q-Learning with policy gradients.
In contrast to standard MPTCP designs, this new direction indesigning multipath TCP performs both packet schedulingand congestion control. The two controls (congestion andscheduling) jointly and effectively work together towards
5For scalable design (i.e. memory requirements), we consider deleting thetuples after sampling and maintain only the samples.
maximizing the performance. Moreover, the aggregate rewardcan be selected as a function of packet goodput (rate of in-orderreceived packets) and overall delay.C2 We develop an integrated ‘Policy Gradient with Deep
Q-Learning’ framework for multipath TCP, that usesan intelligent agent with the objective of maximizinga desired performance reward and performing dynamiccongestion control and scheduling across all availablenetwork paths.
Accommodation of accurate state and fine-grained actionsresults in a large state-action space; therefore, we integratepolicy gradient algorithm with an actor-critic mechanism. Torespond to highly dynamic networks, we exploit the agent‘spolicy distribution to average the value function over a set ofactions, rather than only sampled action values.
To elaborate, when a connection is first initiated the endhosts have limited updated knowledge of the characteristics ofthe path. Typically, information is confined to that gleaned fromthe initial connection handshake and also from cached historicalinformation. As the connection proceeds, feedback is obtainedfrom packet transmissions but this feedback is delayed. Thereason being 25-50 ms typical Round-Trip Times (RTTs) overlocal wireless internet paths, which can correspond to hundredsof packets ‘in flight’ (around 150ms for international paths).Forward error correction has been used [24], [39] to amelioratesuch circumstances. Short connections (i.e. small TCP flows),thus have limited information as to the path characteristics.Longer connections, e.g., bulk TCP flows, need to learn the pathcharacteristics on the fly while transmitting packets. Our newdesign is to ameliorate the delay in learning path characteristics.C3 In our design of DQL-MPTCP, we utilize long short-term
memory (LSTM) recurrent neural network for trackingand learning of dynamic behaviour of wireless/wirelinepaths, and appropriately adjusting congestion control andpacket scheduling.
We investigate the design of intelligent schedulers that assignpackets to paths in such a way as to minimise the reorderingdelay at the receiver. Key aspects that we address include adelay-aware scheduling, the impact of connection length of theoptimal scheduler strategy and the need for joint scheduling oftransmissions and learning of path characteristics (see Sec. II-Bfor details).C4 We conduct stability analysis of DQL-MPTCP, which
provides important practical insights for the protocoldesign (Sec. IV).
C5 We evaluate DQL-MPTCP and compare its performancewith the standard MPTCP algorithms. Our comparisondemonstrates significant performance improvements withDQL-MPTCP.
II. PRELIMINARIES AND MOTIVATIONS
Multipath congestion control and packet scheduling mech-anisms require continuous control action. However, it isimpossible to apply Q-learning to continuous control actiondirectly, because in continuous spaces, finding a greedy policyrequires an optimization of control action at at every timestamp. In fact, this type of optimization is sluggish in nature and

4
hard to implement in practice with unconstrained approximatesand large (control action) state spaces. Therefore, we use adeterministic policy gradient algorithm with an actor-criticapproach. Such gradient-based algorithm maintains an actor(function) which can specify the policy by mapping states toa (specific) control action directly. The critic can be learnedby using the Bellman equation (similar to Q-learning). Byapplying the chain rule to the expected utility, the actor canbe modified from an initial distribution with respect to theparameters.
It is well-known that using a nonlinear approximation suchas (deep) neural network for reinforcement learning is notdesirable [3], [8]. In fact, such a nonlinear approximation isunstable and may lead to a diverging state [40]–[42]. Thepioneering work on the Deep Q-networks by Mnih et al. [43]laid the foundations for solving complex decision problems;their idea of combining experience replay with Q-learningand convolutional neural network enabled the framework tolearn and perform intelligently. This approach not only avoidsdivergence and oscillations, but also is comparable to humansin making multilevel decisions. We exploit the ideas underlyingthe success of DQL [35] in our continuous multipath congestioncontrol and scheduling by combing it with policy gradients.
Recurrent neural networks exhibit a high capability ofmodeling nonlinear time series problems in an effectiveway; however, there are some issues to be addressed. Inparticular, they are unable to train time varying networklags that are common in future wireless networks, and relyon a predetermined time duration for learning making theminflexible. To overcome the aforementioned shortcomings ofthe recurrent neural networks, we use LSTM, that act as aprioritized experience replay buffer for continuously trackingthe active subflows and their interactions with the networks.
A. Integrated Learning Framework
We start by employing a Markov Decision Process (MDP),a 5-tuple (S(t), A(t), R(t), T (t), γ), where S(t) is a finiteset of states, A(t) is a finite set of actions, R(t) is a rewardfunction, T (t) is the transition function (T (t) determined fromthe probability state distribution P (t)) and γ is a discount factor.In every state s(t) ∈ S(t), the agent takes an action a(t) ∈ A(t),receives a reward R(a(t), s(t)), and attains new state s(t+ 1)obtained from the probability distribution P (s(t+1)|s(t), a(t)).The important notations used in our design and algorithms aresummarized in Table I.
We have a policy that specifies for every state which actionthe agent can take, where the aim of the agent is to discoverthe policy that potentially maximizes the expected reward. Fortractability [27], we consider 6-tuple (sending rate, throughput,RTT, change in window, schedule, difference in RTT) as thestate of an MPTCP connection.6
Our DQL-MPTCP takes action on each MPTCP subflowand provides what change (window increase, decrease and/or
6In our experiments we have observed that adding more parameters,increasing data sampling complexity with no noticeable improvement in theperformance of the agent.
TABLE ISUMMARY OF NOTATIONS.
Notation DescriptionN(.), E(.), Q(.) Representation N(.), Actor E(.) and Critic Q(.)
N(.), E(.), Q(.) Target Representation, Actor and Critic Networks;Replicate the structure of N(.),E(.) and Q(.)
S(t) Finite set of states, s(t) ∈ S(t), new state s(t+ 1),S(t) = {s(t, n)} indicates subflow on link n
A(t) Finite set of actions, a(t) ∈ A(t)R(t) Reward function, a reward R(a(t), s(t)) from dis-
tribution P (s(t+ 1)|s(t), a(t))T (t) Transition function determined from the probability
state distribution P (t)γ Discount factor.Q?(s, a) Estimate of the expected future rewardΠ? Optimal policy (greedy policy for Q?)F(t) Final state for all subflows of the connection, ultimate
final state fN (t)τ = {τn} RTTs of all active subflowsW(t) = {Wn} Size of the congestion windowsU(t, n) Utility of the subflow n at time ta(t) Control action for the target subflowyi Target for the Critic Q(.)
packet schedule change) needs to be made concurrently to thecongestion windows and packet scheduling for the subflows.
An estimate of the expected future reward that can beobtained from (s(t), a(t)) is given by the value (using Bellmanequation) [37]
Q?(s, a) = Es′∼P
[R(s, a, s′) + γmax
a′Q?(s′, a′)
], (A1)
The optimal policy, denoted by Π? can be obtained as a greedypolicy with respect to Q?:
Π?(s) = arg maxa′
Q?(s, a). (A2)
It has been known that with respect to Q? approximator,algorithm approximates greedy policy as the optimal policy.Our prioritized experience replay technique mandates the DQLagent to sample more frequently the most important statetransitions from the memory. For example, we consider thelikelihood of sampling a transition proportion to its priorityin the spirit of those underlying learning from demonstra-tions [35], [37]. Therefore, with the prioritized experiencereplay [38], we develop a mechanism to attain comparativelybetter performance even with a limited data sets and learningtime.
B. Joint Scheduling and Congestion Control
A real momentum in recent years has been in the develop-ment of packet scheduling and congestion control mechanismswhich aim to maximize the performance of MPTCP. See [5], [6],[11], [20], [24] for multipath congestion control [5], [6], [11],[15], [20], [24], [36] and [12]–[14] for the packet scheduling.Perhaps the most known scheduling policy is the one adoptedby MPTCP scheduler [10], the min–RTT, which assigns packetsto the smallest RTT path and fills its window, and so on to theother smallest RTT paths.
The time taken for a packet to traverse a mobile networkpath is always stochastic and time-varying (variable path delay)as a result of queueing, other flows sharing the path, wirelesslink layer retransmissions etc. When packets are sent viamultiple paths they therefore can easily arrive at the destination

5
reordered in which case they need to be buffered until they canbe delivered in order to higher layers, leading to head-of-lineblocking. Moreover, the resulting buffering delay in MPTCPcan be substantial [6], [24], [39], to the point where it largelyundermines the throughput gain from use of multiple paths.7
In this work, we propose a new intelligent Packet Schedulingpolicy coupled tightly with multipath congestion control, witha notion that for controlled performance there is a potential toefficiently utilize the time-varying wireline and wireless linkseven when per-packet delays are highly fluctuating. To attainthis, we have to move from the usual notion of consideringpackets individually to a new consideration of jointly schedulingcollections of packets subject to an overall minimal deliverydelay from all active subflows.
This new notion of scheduling is driven by our observationthat the QoE (quality of experience) requirement is usually totransmit application layer entities such as video clips, icons,web pages, micro-blogs, etc. with the lowest attainable delay,and it is the overall aggregate delay rather than the per-packetdelay which is critical in such context. This observation hasfundamental implications in our packet scheduler design. Weare scheduling packets in groups; therefore, such schedulingis capable of considering application layer contexts and theirrelationship to path uncertainties.
The packet scheduling policy in this work is coupledtightly with the multipath congestion control mechanism.Our scheduler assigns a number of packages to each pathproportional to their short term average goodput (numberof successful packets per RTT).8 Given the availability inthe windows (specified by the multipath congestion controlprocess), our scheduler always assigns packets to the pathsproportionally, ranging from the largest goodput path to thesmall goodput path. Such a scheduling policy has the effect ofminimizing packet re-sequencing at the receiver [44].
III. THE PROPOSED MPTCP SCHEME
In this section, we present the design of our Deep Q-Learningenabled MPTCP with policy gradients for joint congestioncontrol and packet scheduling across paths of different char-acteristics. At a high level, the interactions between modulesof the proposed DQL-MPTCP are as illustrated in Figure 2.A detailed explanation of actor critic training, representationnetwork and subflow state analysis is provided with algorithmsin Section 3.1-3.3. As discussed in Section 3.3, the DQL agent(submodules inside the dashed portion in Figure 2) of theproposed MPTCP interacts with the links and the user to collectthe freshest information of the state S(t) = {s(t, n)} here, nindicates an MPTCP subflow on the link n. At the beginningof time slot t, the agent computes the reward, R(t) (the sumof utilities of all active subflows from previous actions), by
7In existing works [6], [24], [39], the problem of variable path delaywas partially addressed by employing delay adaptation [6] and forward errorcorrection [24], [39] at the MPTCP source.
8The transient behaviour, i.e., the trajectories through which short termaverage goodputs (θn(t)) approach their steady values, is essential for thecomputation of exact reordering delay. However, we are concerned with thedifference in short term steady goodputs, and our interest lies in designinga solution that can alleviate the severe reordering delay perceived at theapplication layer.
Fig. 2. A abstract view of interrelationship between the DQL-MPTCP modules.The modules inside the dashed region (form a DQL Agent) take packet rates,reward, congestion windows as input and generate control actions as outputs.A module on the left rectangle (is a MPTCP user with source program atthe OS kernel), which provides new packet rates, schedule and congestionwindows.
using the actor-critic network (Sec. III-B). The computation isbased on the representation learned (Sec. III-A) by the LSTMand the current state of the subflows S(t) (final states F(t) anda(t) are used to compute R(t)).
The DQL-agent is queried periodically by the MPTCP source(one query per slot), in order to i) update the size of thewindows (W(t+ 1)), ii) update the RTTs (τ = {τn}) of activesubflows and iii) schedule packets to the subflows (schedule,for next slot, see Figure 2). Rather than using only the actionsthat were actually executed, we consider a policy gradientalgorithm that uses the agent’s explicit representation of allaction values to estimate the gradient of the policy. Therefore,our framework implements the action (via packet schedulingand congestion control at the MPTCP source in the kernel) byobserving the reward R(t). To ensure stability and maintainreplay buffer, we have used target Network Representation N(.)Actor E(.) and Critic Q(.), which replicate the structure oftheir corresponding networks in the state analysis, i.e., NetworkRepresentation N(.), Actor E(.) and Critic Q(.) respectively.
A key feature of DQL is its use of a target network whosepurpose is to stabilize the learning process. In traditional Q-learning, the value of executing an action in the current stateis updated using the values of executing actions in the nextstate. This process can be unstable since the values on bothsides of the update equation can change at the same time. Thetarget network keeps a copy of the estimated value function toserve as a stable target for a few future steps [43]. The mainbuilding blocks in Figure 2 and our algorithms are explainednext.
A. Network Representation
The Network Representation module creates a (representa-tion) vector simply by observing the states of MPTCP subflows

6
(s(t, n) as inputs). However, it is challenging to deal with therepresentation when the number of subflows are time-varying(joining and leaving the MPTCP connection), which will becommon in future wireless networks. Rather than using fixedinput size Deep Neural Network approach (e.g., feed forward),we use LSTM which has the capability to handle variablenumber of inputs over time so as to capture the dynamicsof varying number of MPTCP subflows (corresponding to theconditions of the available network paths and access interfaces).The approach is to provide the states of the subflows one byone into the LSTM for learning the Network (and Delay)Representation in a sequential manner.
The ultimate final state fN (t), the output of this module(we denote F(t) for all subflows of the connection), is thenfed for Actor-Critic training. Furthermore, we propose to trainboth ‘LSTM-based representation’ and ‘Actor-Critic Network’jointly by using backward propagation. We have an inner loopbetween three modules, viz. subflow state analysis → networkrepresentation → actor-critic training. It is worth noting thatjointly training the interrelated modules (by observing thestate of the subflows) yields improved performance rather thantraining them individually.
B. Actor-Critic Training
The actor network consists of completely connected LSTMwith two hidden layers, that consists of 128 neurons in bothlayers. The critic is very similar to the actor except of the outputlayer with a single linear neuron. We use Rectified Linearfunction in hidden layers and hyperbolic tangent function inthe output layer for activation.
The final state F(t) produced by the LSTM-based represen-tation is combined with the state of the corresponding MPTCPsubflow, which is then supplied to the Actor-Critic network.The agent specifies at each time t how to update the size of thecongestion window (W(t)) and changes schedule (if any) foreach subflows of the MPTCP connection in order to maximizethe reward.
The reward in our framework is the sum of the utilitiesof all active subflows belonging to the MPTCP connection,i.e., R(t) :=
∑Nn U(t, n) where, U(t, n) is the utility of the
subflow n at time t. It is worth noting that our frameworkis flexible to define and handle desired utility function (e.g.,fairness-based [25] or, loss, delay, and throughput-based [34])and scheduling policy.
Resources can be allocated amongst the competing flowsaccording to various policies. To perform MPTCP congestioncontrol and scheduling, we aim to facilitate applications withefficiency and fairness. Although there is no global notion offairness, proportional and max-min fair allocations [45], [46]are the two well-known schemes.
Proportional Fairness [47, Eqn.(2.10), pp. 37]: For a set ofusers U = {1, 2, ..., n} the goodput allocation [θ∗1 , θ
∗2 , ..., θ
∗n]
to the set of users U is proportionally fair if and only if forany other feasible scheme [θ1, θ2, ..., θn], such that∑
u∈U
θu − θ∗uθ∗u
≤ 0. (1)
Algorithm 1 Training Algorithm1: procedure TRAINING2: Sample transitions (Si,ai,Ri,Si+1) from priority replay3: Compute fNi+1 using N(Si+1)4: Evaluate target for Q(.), yi = Ri + γQ(fN
i+1, E(fNi+1))
5: Critic parameters min(loss), 1/k∑k
i (yi −Q(ai,fNi ))2
6: Compute Policy Gradient from Critic: 5aQ(ai,fNi )
7: Update actor parameters, 1/k∑k
i 5aQ(ai,fNi ).5k E(fN
i )
8: Compute Policy gradient from Actor: 5kE(fNi )
9: Update network representation (policy gradient),1/k
∑ki 5aQ(ai,f
Ni ).5k E(fN
i ).5RiR(Si+1)
10: end procedure
In (1), when the proportional change in one user’s packetrate is positive, at least another user for which the change inpacket rate is negative.
In our implementation, we have used the well-knownproportional fairness approach for all subflows (active paths)and maximize the function U(t, n) = logθn(t), where θn(t) isthe short-term average goodput along path n in the previousslot perceived by the subflow. For delay minimization, ourscheduling policy (recall Section II-B) implements batchscheduling of packets to the subflows with a rate proportionalto their short-term average goodputs.Remark III.1. Despite its empirical success and advancement,the theoretical perception behind the convergence of theactor-critic algorithm is lagging. Actor-Critic learning can beviewed as an alternating online bilevel optimisation process,the convergence of which is known to be fragile. In Sec. 4,we concentrate on applying DQL agent regulators, a basicbut essential determination in Q-learning with gradients, tounderstand the learning dynamics’ instability. Our aim in thiswork is to design a flexible framework, the stability of whichis independent of the underlying utility function. Therefore, inthis setting, we analyse a non-asymptotic convergence of theDQL-learning and demonstrate how it seeks a linear rate ofconvergence that is globally optimal. Our stability analyses inSec. 4 can be the first step to thoroughly comprehend bileveloptimisation for the utility-based actor-critic problems, whichwill be investigated in future (in the worst case this can beNP-hard, non-convex and is mostly overcome with heuristics).
C. DQL-MPTCP with Policy Gradients
Our DQL-based multipath congestion control and schedulingmechanism is illustrated in Algorithms 1 and 2. Algorithm 1illustrates the training process. Algorithm 2 initializes theparameters of Representation Network N(.), Critic networksQ(.) and Actor networks E(.). In order to ensure stable learning(see step 3, Algorithm 2) , we have used target networks N(.)E(.) Q(.), which replicate the structure of their correspondingnetworks, i.e., N(.), Actor E(.) and Critic Q(.) respectively.
For the convergence of the learning process, the targetnetwork parameters are updated using a smallish controlparameter (0.001, see steps 17-19, Algorithm 2), such that thetarget parameters are adapted slowly in each iteration–recallthat the target network, by design, needs to update slowly for

7
stability.9 Our MPTCP DQL agent runs all the time, listeningfor periodic queries from the MPTCP source (implemented inthe kernel).
To enable exploration, which is useful when training in-experienced DQL agent, we add correlated noise, using theOrnstein-Uhlenbeck stochastic process [35], [37] to controlactions in run-time. Such coupling of prioritized experiencereplay with exploration helps the DQL agent improve its actionsof adjusting subflow window sizes and packet scheduling.10
Recall that the actor and critic networks are completelyconnected LSTM with two hidden layers, that consists of 128neurons in both layers. We use Rectified Linear function inthe hidden layers and hyperbolic tangent function in the outputlayer for activation. The critic and actor networks are trainedjointly using Adam optimizer (we set learning rates to 0.001and 0.01 respectively and discount factor γ = 0.95).
The final state network representation of all active subflowsF(.) is derived from the representation network N(.) (see step8, Algorithm. 2), and the control action for the target MPTCPsubflow a(t) is computed by using the actor E(.) (see step9, Algorithm. 2). First, the generated transition samples arestored into kernel (memory), thereafter they are randomlysampled for training the tuple (network representation N, actorE, critic Q) jointly by using k prioritized samples (step 2,Algorithm. 1). The critic is a Deep Q-Learning Network andits parameters are updated by minimizing the squared error(step 5, Algorithm. 1), i.e., the target for critic yi is evaluated byapplying the Bellman equation (step 4, Algorithm. 1). The Q-function uses the Bellman equation and takes action (a(t)) andstate (S(t)) as inputs. For continuous control, the parametersof the network representation and actor networks are adaptedtogether with the policy gradients using the chain rule [35,Eqn. (6)] by using k samples (steps 6-10, Algorithm. 1). OurDQL framework consisting of the representation, critic andactor networks has key ingredients for training and learningMPTCP packet scheduling and congestion control.
Remark III.2. The complexity analysis of DQL algorithmis another evolving research direction. To the best of ourknowledge, despite the popularity of DQL with policy gradients,we are still investigating to accurately predict the computationalcomplexity to train/learn a DQL network and solve a givenproblem. With the relevant insights from this work and [49],[50], an important future research direction would be a thoroughcomplexity analysis of DQL-MPTCP.
IV. STABILITY ANALYSIS
Peng et al. [20] conducted a detailed study of the variousvariants of the MPTCP using a generalised fluid model andanalyzed their stabilization aspects. In fact, analyzing stabilityhas been an essential first step in designing a congestioncontrol algorithm to guarantee it has a desirable equilibriumand convergence properties. Our DQL-MPTCP algorithm is
9The rationale for selecting smallish control parameter values comes fromour stability analysis in Section IV.
10An effective way to conduct retraining of the agent to adapt for the newnetwork settings will benefits from transfer learning [48] and needs furtherinvestigations in future.
Algorithm 2 DQL-MPTCP Coupled Algorithm1: procedure BEGIN2: Representation Network N(.), Actor E(.) and Critic Q(.)3: Target Networks N(.) E(.) Q(.)4: Ornstein-Uhlenbeck process a for exploration5: end procedure6: procedure SCHEDULING & CONGESTION CONTROL7: While (Schedule Change || Window Adapt) do8: Compute final state F(.) and schedule by N(.)9: Update target a(t) using Actor E(fN (t))
10: Create action a(t) applying a(t) and process a11: Take action a(t), observe R(.) and S(t+ 1)12: Store transitions (a(t),S(t),R(t),S(t+ 1))13: procedure ON-LINE TRAINING14: Call TRAINING15: end procedure16: procedure UPDATE TARGET NETWORK17: N(.) := .001N(.) + .999N(.)18: E(.) := .001E(.) + .999E(.)19: Q(.) := .001C(.) + .999Q(.)20: end procedure21: endWhile22: end procedure
first trained offline (using Algorithm. 1) and then deployed,and goes along to learn online (step 14 in Algorithm. 2 callsAlgorithm. 1). Therefore, we examine whether the learningprocess of DQL-MPTCP will indeed drive the network towardsan equilibrium starting from an arbitrary initial state. Eventhough in reality a network is seldom in equilibrium, a stableonline learning process ensures that it is always pursuing adesirable state, which also makes it easier to understand theglobal protocol behavior of the overall network.
For improving smoothness and responsiveness in the imple-mentation, we indirectly guarantee the stability by imposing fewconstraints in the underlying Q-learning process of our MPTCPalgorithm. Given the convergence of value iteration (the Q-learning process), the policy iteration is guaranteed to converge.Further, at the convergence point, the current policy and itsvalue function are the optimal policy and the optimal valuefunction. Recall (A2), the optimal policy Π? is a greedy policycorresponding to Q?. In fact, any unconstrained policy iterationprocess leverages wider state space and region. Besides, theconvergence of the policy iteration has been proven to benot slower than that of the value iteration, therefore, policyiteration has the potential to improve both smoothness andresponsiveness.Based on above discussion, our focus in thissection is mainly to quantify the convergence conditions ofvalue iteration for the Q-learning process of our DQL-MPTCP.
Divergence is an important challenge in Deep Q Learning;it is not well understood and often arises in implementations.Therefore, it is important to analyze the stability of ourproposed DQL-MPTCP algorithm [40], [42].
With relevant insights from [42], the DQL ideas implementedin Algorithm 1 is to learn an approximate to the optimal valuefunction Q?, which satisfies (A1). With T ?Q(s, a) given bythe right hand side of (A1), after T ? : Q → Q operation on

8
Q functions; then (A1) is given by
Q? = T ?Q?, (A3)
where T ? is the optimal Bellman operator, which with modulusγ is a contraction in the supremum norm. As a result, we havetwo cases.
CASE I. Given that the Q-function is represented by afinite table with (completely) known Ri (reward function)and transition kernel (steps 12 and 14 Algorithm 1), T ? canbe determined and therefore, Q? can be estimated by using thesuccessful method for computing an optimal Markov DecisionProcess policy (and its value), known as value iteration. Forsuch cases, the value iteration starts at the end and then worksbackward, refining the estimate of Q?. Consider Qi be theQ-function assuming there are i stages to go, then, these canbe defined recursively; and the iteration starts with an arbitraryfunction Q0 and uses the following equation to obtain thefunction for i + 1 stages (to move from the function for istages to go):
Qi+1 = T ?Qi. (A4)
The convergence of the value iteration given by (A4) usingQ0 as an initial point is undertaken by the Banach Fixed PointTheorem.
CASE II. Given that Ri and the transition kernel are partiallyknown (not completely known), it is viable to use Q-learningand learn Q? in such settings [41], [42]. In fact, Watkins etal. [41] demonstrated that Q-learning converges to the optimuma? (action-values) with probability 1 so long as all actionsare repeatedly sampled in all stages and the action-valuesare represented discretely (steps 10, Algorithm. 2 and 4-10,Algorithm. 1). The Q-values of the (s, a) pairs are updatedusing reward and next state for estimating T ?Qi(s, a) givenby
T ?Qi(s, a) = Ri + γmaxa
Qi(s, a)
as:
Qi+1(s, a) = Qi(s, a) + αi(T ?Qi(s, a)−Qi(s, a)
). (A5)
(A5) under much relaxed condition, viz., the learning ratesαi ∈ [0, 1} must approaches zero and all state action pairsmust be visited often enough, converges to Q?. One can observethat the Q-learning given by (A5) works on time-varyingdifference as the updates in each stages are based on thetemporal difference (T ?Q(st, at)−Q(st, at)) given by:
∆t = Rt + γmaxa
Q(st, at)−Q(st, at). (A6)
Motivated by the analysis in [42], our DQL-MPTCP is basedon the generalization of (A5) to the approximation setting:
g′ = g + α(T ?Qg(s, a)−Qg(s, a)
)∇gQg(s, a)
], (A7)
where Qg is a continuous function with parameters g. Observethat (A7) becomes (A5) given Qg is a table. On the whole,such DQL representation uses gradient descent and experiencereplay, maintaining the expected update as:
g′ = g+α Es,a∼ρ
[(T ?Qg(s, a)−Qg(s, a)
)∇gQg(s, a)
], (A8)
where ρ, at the time of updates, is the distribution of theprioritized experience in the replay. Typically, to ensure stability,it is acceptable to replace, T ?Qg with the one based on slowly-updating target network, T ?Qh, where h is obtained by Polyakaveraging [35], [40]–[42].11
Using Taylor expansion of Q around g for the pair (s, a) wecan observe the new Q-values based on (A8) as:
Q′g(s, a) = Qg(s, a) +∇gQg(s, a)T (g′ − g) + O(∥∥g′ − g∥∥2),
(A9)Over a finite state action space, we consider matrix vector formin R|S||A|, therefore, combining (A8) and (A9) provides:
Q′g = Qg +αKgDρ
(T ?Qg(s, a)−Qg(s, a)
)+ O
(∥∥g′ − g∥∥2),(A10)
where Dρ is a diagonal matrix obtained from the distributionfrom replay, ρ(s, a) and Kg is |S||A| × |S||A| a matrix givenby
Kg(s, a, s, a) = ∇gQg(s, a)T∇gQg(s, a).
Finally, our formulation (A10) provides us important insightsto analyse the stability of DQL-MPTCP. In particular, the onlycondition essential now for convergence of DQL-MPTCP is toguarantee that the update operator U : Q → Q with
UQg = Qg + αKgDρ
(T ?Qg(s, a)−Qg(s, a)
)(A11)
is a contraction on Q.With relevant insights from [40]–[42],this will be considered next.
A. Practical Design Insights
In this subsection, we investigate the potential conditionsand study how the update U : Q → Q given by (A11) maygive rise to instability in DQL-MPTCP and how to repairsuch instabilities. Next, motivated by the analysis in [42], wedecompose our analysis into following cases.
CASE I. We consider U i, a special case of U where Kg = 1and Dρ = 1, therefore, (A11) becomes
U iQg = Qg + α(T ?Qg −Qg
). (A11.1)
Theorem IV.1. U i defined by (A11.1) is a contraction on Qand Q? is the fixed-point.
Proof. Observe that U i given by (A11.1) satisfies∥∥∥U iQ1 − U iQ2
∥∥∥∞
=∥∥α(T ?Q1 − T ?Q2) + (1− α)(Q1 −Q2)
∥∥∞ ,
≤ α‖T ?Q1 − T ?Q2‖∞ + (1− α)∥∥(Q1 −Q2)
∥∥∞ ,
≤ αγ‖Q1 −Q2‖∞ + (1− α)∥∥(Q1 −Q2)
∥∥∞ ,
= ‖Q1 −Q2‖∞ (1− α(1− γ)),
and since 1 > (1−α(1− γ)), the update U i contracts and Q?
is its fixed-point (follows straightforward using (A3)).
CASE 1 and Theorem IV.1 provide us the following importantdesign insight for stable MPTCP.
11For simplicity and tractability [35], we omit the target network in ourstability analysis.

9
DESIGN INSIGHT 1. Given U of the proposed DQL-MPTCPgets increasingly closer to U i, one can anticipate progressivelymore stable DQL-MPTCP behavior.
CASE II. We consider U ii, a special case of U where Kg = 1,therefore, (A11) becomes
U iiQg = Qg + αDρ
(T ?Qg −Qg
). (A11.2)
Theorem IV.2. U ii defined by (A11.2) is a contraction onQ and Q? is the fixed-point, if ρ(s, a) > 0,∀(s, a) and α ∈(0, 1/ρ) where ρ = maxs,a ρ(s, a).
Proof. One can observe that for any (s, a),
[U iiQ1 − U iiQ2](s, a)
= αρ(s, a)([T ?Q1 − T ?Q2](s, a)
)+(1− αρ(s, a))
(Q1(s, a)−Q2(s, a)
),
≤ αγρ(s, a)‖Q1 −Q2‖∞ + (1− αρ(s, a))∥∥(Q1 −Q2)
∥∥∞
= ‖Q1 −Q2‖∞ (1− αρ(s, a)(1− γ)).
By taking the maxs,a on both sides,∥∥∥U iiQ1 − U iiQ2
∥∥∥∞
≤ maxs,a‖Q1 −Q2‖∞ (1− αρ(s, a)(1− γ)).
= ‖Q1 −Q2‖∞ (1− αρ(1− γ)),
where ρ = mins,a ρ(s, a). Note that the condition, ρ(s, a) >0,∀(s, a), is equivalent to ρ > 0. Therefore, 1 > (1− αρ(1−γ)), which mandates that the update U ii contracts and Q? isits fixed-point (follows straightforward using (A3)). However,observe that when ρ = 0, we simply have an upper bound on∥∥U iiQ1 − U iiQ2
∥∥∞. See [42] for more background.
Considering U ii, we observe that the missing data in thedistribution has adverse impact on the convergence of thelearning process. Given that the (exploration) policy exploresall state action pairs enough, U ii behaves as expected, however,missing data may cause a problem. This observation providesus another important design insight.
DESIGN INSIGHT 2. DQL-MPTCP may struggle to converge,when data is scarce at the beginning of the training, whereinitial conditions matter a lot.
The importance of DESIGN INSIGHT 2 will be discussed inSection IV-B.
CASE 3. We consider U iii, a special case of U where Kg = Kis positive-definite constant symmetric matrix, therefore, (A11)becomes
U iiiQg = Qg + αKDρ
(T ?Qg −Qg
). (A11.3)
Therefore, U iii is the case of linear function approximation,K is constant with respect to g and the Q-values before andafter updates are given by
Qg′ = U iiiQg; where
K(s, a, s, a) = φ(s, a)Tφ(s, a).
Theorem IV.3. U iii defined by (A11.3) is a contraction on Qand Q? is the fixed-point, if and only if i) αρxKxx > 1, ∀xand
ii) (1− γ)ρxKxx ≥ (1 + γ)∑x 6=y
ρy∣∣Kxy∣∣ ,∀x,
where x, y are the indices of state action pairs.
Proof. By using index notation
[U iiiQ1 − U iiiQ2]x
= α∑y
ρyKxy([(T ?Q1 −Q1)− (T ?Q2
−Q2)]y)
+ [Q1 −Q2]x,
= α∑y
ρyKxy[T ?Q1 − T ?Q2]y
+∑y
(∆xy − αρyKxy)[Q1 −Q2]y.
≤∑y
(αγρy
∣∣Kxy∣∣+∣∣∆xy − αρyKxy∣∣ )‖Q1 −Q2‖∞ .
Let
G(K) = maxx
∑y
(αγρy
∣∣Kxy∣∣+∣∣∆xy − αρyKxy∣∣ ).
Then, assuming αρxKxx > 1, condition i),
G(K) = maxx
(α(1 + γ)
∑x 6=y
ρy∣∣Kxy∣∣+
∣∣1− αρyKxy∣∣+γαρyKxy
).
= maxx
(1 + (1 + γ)
∑x 6=y
ρy∣∣Kxy∣∣− (1− γ)ρxKxx
).
Observe that G(K) < 1 if an only if
∀x, (1− γ)ρxKxx ≥ (1 + γ)∑x 6=y
ρy∣∣Kxy∣∣ .
See [42] for other details.
Considering U iii, we observe that the conditions in The-orem IV.1 are quite confining, it not only requires ρ > 0everywhere but also for the choices of γ (eg. γ = 0.999)the (diagonal terms of K)�(off-diagonal terms of K) . Thisobservation provides us another important design insight.
DESIGN INSIGHT 3. The stability of DQL-MPTCP dependson the properties of the Q-approximator; in the sense thatapproximators which are more aggressive (larger off-diagonalterms in K) may not demonstrate stable learning.
Generally, in our DQL-MPTCP learning, both the K andthe ρ change between update stages, thus, each stage can beperceived as applying different updates. On this end, in general,if we sequentially apply different contraction maps with thesame fixed point, then we will atain that fixed point. As aresult, motivated by the findings in [42], we have the followingtheorem.
Theorem IV.4. Assume a sequence of updates {U0,U1,U2,. . . } with each U i : Q → Q being Lipschitz continuous withconstant δi and the existence and uniqueness of the fixed pointQ? = T ?Q? is guaranteed, where all U i share a commonfixed point Q?. Then, starting from any initial point Q0, thetrajectory {Q0, Q1, Q2, . . . } generated by the DQL-MPTCPalgorithm converges to a unique and globally stable fixed
10
point Q?, if and only if the stages produced by Qi+1 = U iQisatisfies (for an iterate k):∥∥∥Q? −Q0
∥∥∥ i−1∏j=0
δj ≥∥∥∥Q? −Qi∥∥∥ such that ∀j ≥ k, δj ∈ [0, 1).
(A11.4)
Proof. Using fixed-point assumption and iterative sequenceof updates,
∥∥Q? −Qi∥∥ =∥∥U i−1Q? − U i−1Qi−1∥∥.
From the definition (and property) of Lipschitzcontinuity
∥∥Q? −Qi∥∥ ≤ δi−1∥∥Q? −Qi−1∥∥. Therefore,∥∥Q? −Q0
∥∥∏i−1j=0 δj ≥
∥∥Q? −Qi∥∥ . Finally, sequence{Q0, Q1, . . . } for ∀j ≥ k, δj ∈ [0, 1) converges to Q? aslimm→∞
∏mj=k δj = 0.
B. Stability by DesignEven though DQL-MPTCP updates vary between stages, the
aforementioned insights from different settings provide usefulguidance for understanding and addressing possible instabilityissues in DQL-MPTCP. With the relevant intuitions from theaforementioned analysis, we next discuss four different possiblecauses of instability and how we address them by design.
CAUSE 1. Consider a scenario with aggressive learning rate(α is very high), then the term O
(∥∥g′ − g∥∥2) in (A9) is quitelarge, as a result DQL-MPTCP updates may not correlate wellwith the Bellman updates thus leading to instability.
CAUSE 2. A scenario when α is small enough for lin-earization, however, quite large that the U in (A11.3) startexpanding rather then contracting, hence, leading to instability(Theorem IV.3).
CAUSE 3. Too aggressive generalization of Q function dueto large off-diagonal matrix of K also may cause U to expand(Theorem IV.3).
CAUSE 4. If the distribution for updates are inadequate, theQ-values for missing state action pairs which are computed bygeneral extrapolation, often incur errors. Such errors, whichpropagate through the Q-values to all other state-action pairs,may lead to unstable learning (Theorem IV.2).
Observe that the three insights from Section IV-A have beenexploited for the convergence and stability in the DQL-MPTCPdesign (Section III-C). Earlier in Section III-C, we adoptedsmooth learning rates in relation to the Bellman updates forguaranteed contraction and linearization. We have also appliedconstructive generalization of the Q function and utilizedlearning from demonstrations to tackle the case of missingvalues.
V. PERFORMANCE EVALUATION
We have executed an extensive set of experiments to evaluateDQL-MPTCP under several network scenarios. The networksettings used in our testbed are discussed next. Thereafter, wepresent our findings and reflections from the obtained results.
We evaluate and compare the performance of our DQL-MPTCP algorithm with the standard MPTCP algorithms whoseimplementation code is accessible: LIA [10], BALIA [20],OLIA [11]. We have used MPTCP v0.93 implemented inLinux.12 We explain the findings from four different experi-
12https://www.multipath-tcp.org
0 10 20 30 40 50 60
Time in seconds1
2
3
4
5
6
7
8
9
10
Thr
ough
put i
n M
bps
DQL-MPTCP
BALIA-MPTCP
OLIA-MPTCP
LIA-MPTCP
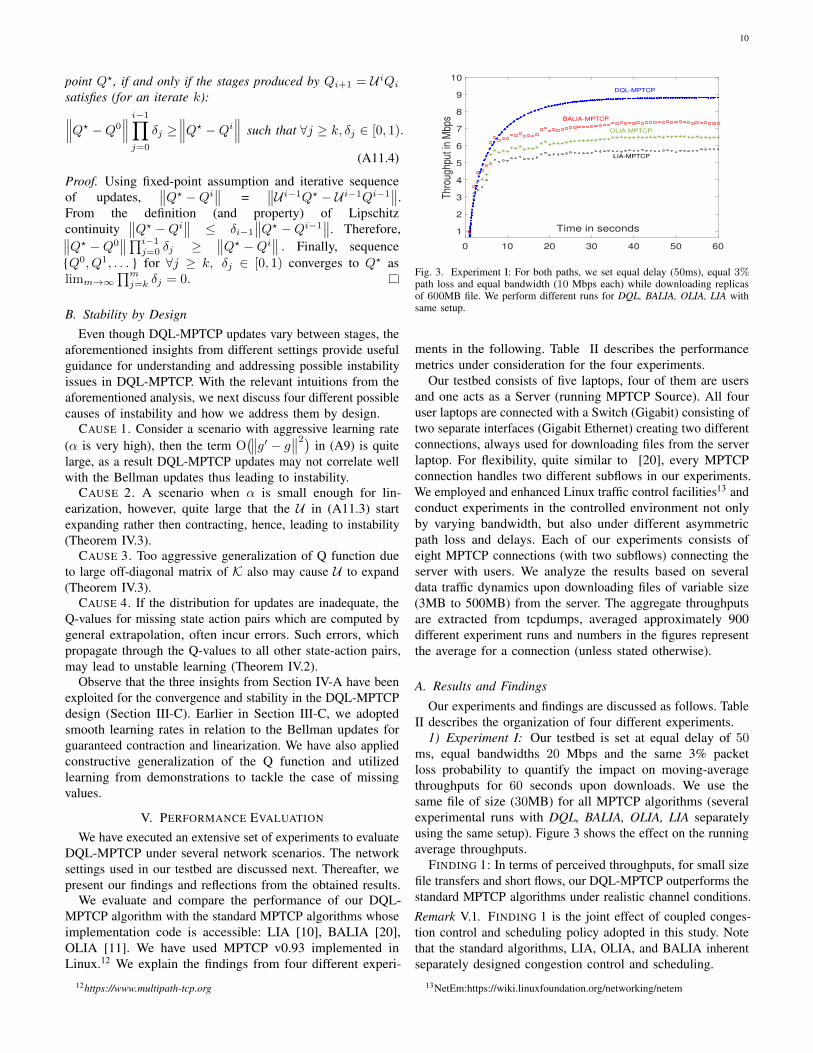
Fig. 3. Experiment I: For both paths, we set equal delay (50ms), equal 3%path loss and equal bandwidth (10 Mbps each) while downloading replicasof 600MB file. We perform different runs for DQL, BALIA, OLIA, LIA withsame setup.
ments in the following. Table II describes the performancemetrics under consideration for the four experiments.
Our testbed consists of five laptops, four of them are usersand one acts as a Server (running MPTCP Source). All fouruser laptops are connected with a Switch (Gigabit) consisting oftwo separate interfaces (Gigabit Ethernet) creating two differentconnections, always used for downloading files from the serverlaptop. For flexibility, quite similar to [20], every MPTCPconnection handles two different subflows in our experiments.We employed and enhanced Linux traffic control facilities13 andconduct experiments in the controlled environment not onlyby varying bandwidth, but also under different asymmetricpath loss and delays. Each of our experiments consists ofeight MPTCP connections (with two subflows) connecting theserver with users. We analyze the results based on severaldata traffic dynamics upon downloading files of variable size(3MB to 500MB) from the server. The aggregate throughputsare extracted from tcpdumps, averaged approximately 900different experiment runs and numbers in the figures representthe average for a connection (unless stated otherwise).
A. Results and Findings
Our experiments and findings are discussed as follows. TableII describes the organization of four different experiments.
1) Experiment I: Our testbed is set at equal delay of 50ms, equal bandwidths 20 Mbps and the same 3% packetloss probability to quantify the impact on moving-averagethroughputs for 60 seconds upon downloads. We use thesame file of size (30MB) for all MPTCP algorithms (severalexperimental runs with DQL, BALIA, OLIA, LIA separatelyusing the same setup). Figure 3 shows the effect on the runningaverage throughputs.
FINDING 1: In terms of perceived throughputs, for small sizefile transfers and short flows, our DQL-MPTCP outperforms thestandard MPTCP algorithms under realistic channel conditions.Remark V.1. FINDING 1 is the joint effect of coupled conges-tion control and scheduling policy adopted in this study. Notethat the standard algorithms, LIA, OLIA, and BALIA inherentseparately designed congestion control and scheduling.
13NetEm:https://wiki.linuxfoundation.org/networking/netem
11
TABLE IIMETRICS USED FOR NETWORK EMULATION EXPERIMENTS
Experiment ID Metrics used in the emulated Network Settings and Scenario RemarksI Moving Average Throughputs: Arithmetic mean of a set of previous Compare DQL-MPTCP with
throughputs until t seconds LIA, OLIA, BALIAII Throughputs vs. Fluctuating Delay: Variation in throughputs with How DQL-MPTCP reacts to
increasing one path delays fluctuating delays in one of the pathIII Throughputs vs. Varying Bandwidth: Average throughputs with How DQL-MPTCP performs
increasing one path capacities with respect to varying capacitiesIV TCP Friendliness : Ability of a new protocol to behave under Degradation of DQL-MPTCP
congestion like the TCP protocol when TCP competes for bandwidth
20 30 40 50 60 70 80 90 100Delay in milliseconds
2
3
4
5
6
7
Thr
ough
put i
n M
bps
BALIA-MPTCP
OLIA-MPTCP
LIA-MPTCP
DQL-MPTCP
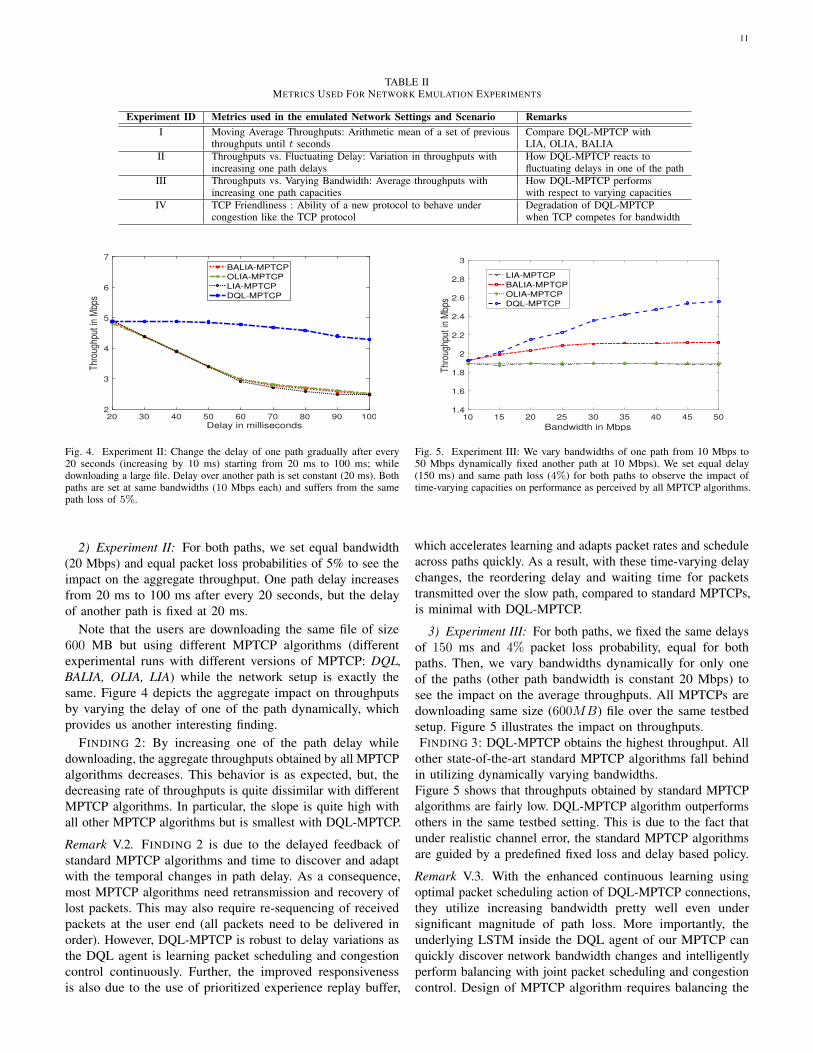
Fig. 4. Experiment II: Change the delay of one path gradually after every20 seconds (increasing by 10 ms) starting from 20 ms to 100 ms; whiledownloading a large file. Delay over another path is set constant (20 ms). Bothpaths are set at same bandwidths (10 Mbps each) and suffers from the samepath loss of 5%.
2) Experiment II: For both paths, we set equal bandwidth(20 Mbps) and equal packet loss probabilities of 5% to see theimpact on the aggregate throughput. One path delay increasesfrom 20 ms to 100 ms after every 20 seconds, but the delayof another path is fixed at 20 ms.
Note that the users are downloading the same file of size600 MB but using different MPTCP algorithms (differentexperimental runs with different versions of MPTCP: DQL,BALIA, OLIA, LIA) while the network setup is exactly thesame. Figure 4 depicts the aggregate impact on throughputsby varying the delay of one of the path dynamically, whichprovides us another interesting finding.
FINDING 2: By increasing one of the path delay whiledownloading, the aggregate throughputs obtained by all MPTCPalgorithms decreases. This behavior is as expected, but, thedecreasing rate of throughputs is quite dissimilar with differentMPTCP algorithms. In particular, the slope is quite high withall other MPTCP algorithms but is smallest with DQL-MPTCP.
Remark V.2. FINDING 2 is due to the delayed feedback ofstandard MPTCP algorithms and time to discover and adaptwith the temporal changes in path delay. As a consequence,most MPTCP algorithms need retransmission and recovery oflost packets. This may also require re-sequencing of receivedpackets at the user end (all packets need to be delivered inorder). However, DQL-MPTCP is robust to delay variations asthe DQL agent is learning packet scheduling and congestioncontrol continuously. Further, the improved responsivenessis also due to the use of prioritized experience replay buffer,
10 15 20 25 30 35 40 45 50
Bandwidth in Mbps
1.4
1.6
1.8
2
2.2
2.4
2.6
2.8
3
Thr
ough
put i
n M
bps
LIA-MPTCP
BALIA-MPTCP
OLIA-MPTCP
DQL-MPTCP
Fig. 5. Experiment III: We vary bandwidths of one path from 10 Mbps to50 Mbps dynamically fixed another path at 10 Mbps). We set equal delay(150 ms) and same path loss (4%) for both paths to observe the impact oftime-varying capacities on performance as perceived by all MPTCP algorithms.
which accelerates learning and adapts packet rates and scheduleacross paths quickly. As a result, with these time-varying delaychanges, the reordering delay and waiting time for packetstransmitted over the slow path, compared to standard MPTCPs,is minimal with DQL-MPTCP.
3) Experiment III: For both paths, we fixed the same delaysof 150 ms and 4% packet loss probability, equal for bothpaths. Then, we vary bandwidths dynamically for only oneof the paths (other path bandwidth is constant 20 Mbps) tosee the impact on the average throughputs. All MPTCPs aredownloading same size (600MB) file over the same testbedsetup. Figure 5 illustrates the impact on throughputs.FINDING 3: DQL-MPTCP obtains the highest throughput. All
other state-of-the-art standard MPTCP algorithms fall behindin utilizing dynamically varying bandwidths.Figure 5 shows that throughputs obtained by standard MPTCPalgorithms are fairly low. DQL-MPTCP algorithm outperformsothers in the same testbed setting. This is due to the fact thatunder realistic channel error, the standard MPTCP algorithmsare guided by a predefined fixed loss and delay based policy.
Remark V.3. With the enhanced continuous learning usingoptimal packet scheduling action of DQL-MPTCP connections,they utilize increasing bandwidth pretty well even undersignificant magnitude of path loss. More importantly, theunderlying LSTM inside the DQL agent of our MPTCP canquickly discover network bandwidth changes and intelligentlyperform balancing with joint packet scheduling and congestioncontrol. Design of MPTCP algorithm requires balancing the
12
BALIADQL LIA
OLIA
TCP BALIA
TCP DQLTCP LIA
TCP OLIA
0
0.5
1
1.5
2
2.5
Thr
ough
put i
n M
bps
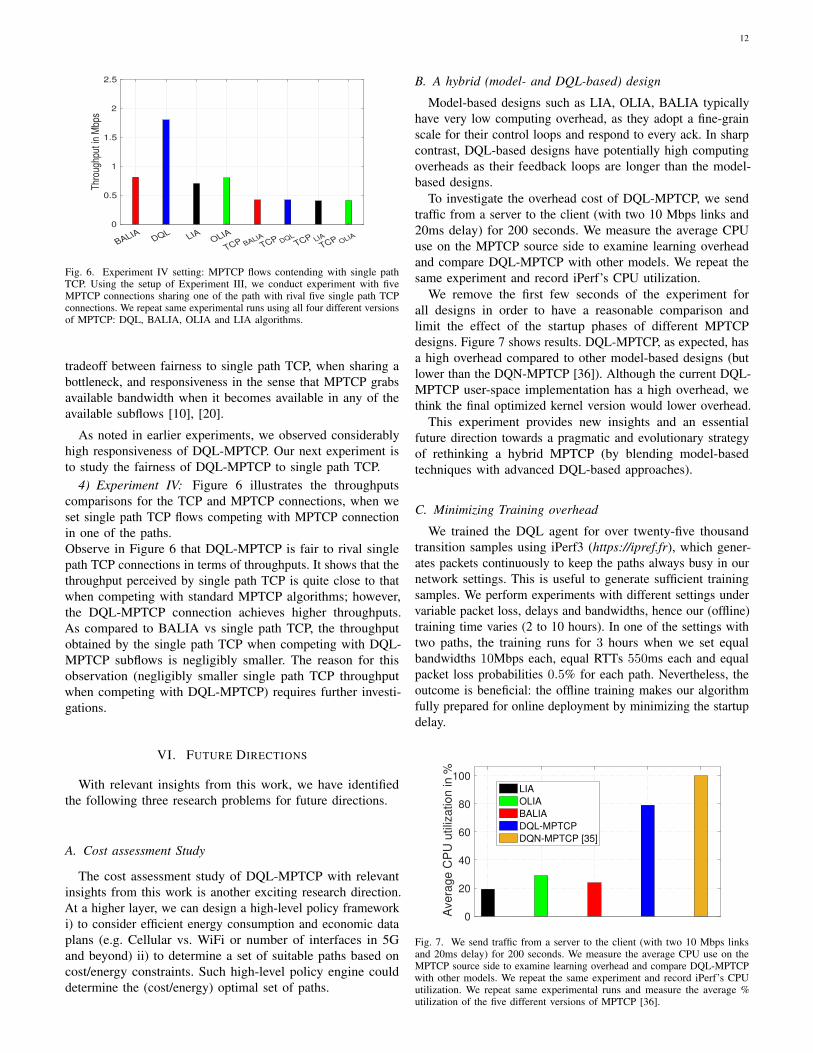
Fig. 6. Experiment IV setting: MPTCP flows contending with single pathTCP. Using the setup of Experiment III, we conduct experiment with fiveMPTCP connections sharing one of the path with rival five single path TCPconnections. We repeat same experimental runs using all four different versionsof MPTCP: DQL, BALIA, OLIA and LIA algorithms.
tradeoff between fairness to single path TCP, when sharing abottleneck, and responsiveness in the sense that MPTCP grabsavailable bandwidth when it becomes available in any of theavailable subflows [10], [20].
As noted in earlier experiments, we observed considerablyhigh responsiveness of DQL-MPTCP. Our next experiment isto study the fairness of DQL-MPTCP to single path TCP.
4) Experiment IV: Figure 6 illustrates the throughputscomparisons for the TCP and MPTCP connections, when weset single path TCP flows competing with MPTCP connectionin one of the paths.Observe in Figure 6 that DQL-MPTCP is fair to rival singlepath TCP connections in terms of throughputs. It shows that thethroughput perceived by single path TCP is quite close to thatwhen competing with standard MPTCP algorithms; however,the DQL-MPTCP connection achieves higher throughputs.As compared to BALIA vs single path TCP, the throughputobtained by the single path TCP when competing with DQL-MPTCP subflows is negligibly smaller. The reason for thisobservation (negligibly smaller single path TCP throughputwhen competing with DQL-MPTCP) requires further investi-gations.
VI. FUTURE DIRECTIONS
With relevant insights from this work, we have identifiedthe following three research problems for future directions.
A. Cost assessment Study
The cost assessment study of DQL-MPTCP with relevantinsights from this work is another exciting research direction.At a higher layer, we can design a high-level policy frameworki) to consider efficient energy consumption and economic dataplans (e.g. Cellular vs. WiFi or number of interfaces in 5Gand beyond) ii) to determine a set of suitable paths based oncost/energy constraints. Such high-level policy engine coulddetermine the (cost/energy) optimal set of paths.
B. A hybrid (model- and DQL-based) design
Model-based designs such as LIA, OLIA, BALIA typicallyhave very low computing overhead, as they adopt a fine-grainscale for their control loops and respond to every ack. In sharpcontrast, DQL-based designs have potentially high computingoverheads as their feedback loops are longer than the model-based designs.
To investigate the overhead cost of DQL-MPTCP, we sendtraffic from a server to the client (with two 10 Mbps links and20ms delay) for 200 seconds. We measure the average CPUuse on the MPTCP source side to examine learning overheadand compare DQL-MPTCP with other models. We repeat thesame experiment and record iPerf’s CPU utilization.
We remove the first few seconds of the experiment forall designs in order to have a reasonable comparison andlimit the effect of the startup phases of different MPTCPdesigns. Figure 7 shows results. DQL-MPTCP, as expected, hasa high overhead compared to other model-based designs (butlower than the DQN-MPTCP [36]). Although the current DQL-MPTCP user-space implementation has a high overhead, wethink the final optimized kernel version would lower overhead.
This experiment provides new insights and an essentialfuture direction towards a pragmatic and evolutionary strategyof rethinking a hybrid MPTCP (by blending model-basedtechniques with advanced DQL-based approaches).
C. Minimizing Training overhead
We trained the DQL agent for over twenty-five thousandtransition samples using iPerf3 (https://ipref.fr), which gener-ates packets continuously to keep the paths always busy in ournetwork settings. This is useful to generate sufficient trainingsamples. We perform experiments with different settings undervariable packet loss, delays and bandwidths, hence our (offline)training time varies (2 to 10 hours). In one of the settings withtwo paths, the training runs for 3 hours when we set equalbandwidths 10Mbps each, equal RTTs 550ms each and equalpacket loss probabilities 0.5% for each path. Nevertheless, theoutcome is beneficial: the offline training makes our algorithmfully prepared for online deployment by minimizing the startupdelay.
1 2 3 4 50
20
40
60
80
100
Avera
ge C
PU
utiliz
ation in %
LIA
OLIA
BALIA
DQL-MPTCP
DQN-MPTCP [35]
Fig. 7. We send traffic from a server to the client (with two 10 Mbps linksand 20ms delay) for 200 seconds. We measure the average CPU use on theMPTCP source side to examine learning overhead and compare DQL-MPTCPwith other models. We repeat the same experiment and record iPerf’s CPUutilization. We repeat same experimental runs and measure the average %utilization of the five different versions of MPTCP [36].

13
It is worth noting that offline training is a one time job. Recallthat we have used Deep Neural Networks (DNNs) for inferencein our DQL-MPTCP implementation, each of which ownsonly two (hidden) layers. The online inference time observedduring our experimentation is just about 0.8ms (which causessmallish overhead for real-time decision process). Retrainingour DQL agent is needed only when the network settingschanges drastically (e.g., from high-bandwidth-delay to low-bandwidth-delay). The cause for this is to collect sufficienttransition samples needed to update (and learn) the DNNsand gain sufficient experience to make better decisions whencomparable conditions occur in a new network environment.An effective way to conduct retraining of a trained DQL agentto adapt for the new network services, such as ultra reliable lowlatency communication, will benefits from transfer learning [48]and needs further investigations [51].
VII. CONCLUSIONS
We developed a novel DQL-based multipath congestioncontrol and packet scheduling scheme using policy gradientsand prioritized replay buffer for the future Internet andwireless technologies. It utilizes a DQL agent with policygradients to jointly perform dynamic packet scheduling andcongestion control, and conduct network reward maximizationfor all active subflows of an MPTCP connection. We providedstability analysis of DQL-MPTCP with relevant practical designinsights. Our design consists of training intelligent agent forinterface and actuation, which possesses a flexible LSTM-basedrepresentation network. The developed architecture appears tobe capable of i) learning an effective representation of allMPTCP subflows, ii) jointly performing intelligible coupledcongestion control and packet scheduling, and iii) dealing withdynamic network characteristics and time-varying flows.
We observed better performance of DQL-MPTCP whencomparing with standard MPTCP algorithms under similarnetwork settings. Essentially, what the DQL policy may amountto is that each MPTCP agent either sends or abstains fromsending based on a set of observables and the policy attemptsto maximize goodput and maintain low delays over the wholenetwork and for all contending agents. Moreover, we anticipatethat the DQL should have accelerated MPTCP in discoveringthe best policy for the underlying partially observable Markovprocess (of the network dynamics), which requires furtherinvestigations and is left for future work.
REFERENCES
[1] S. R. Pokhrel and A. Walid, “Learning to harness bandwidth withmultipath congestion control and scheduling,” IEEE Transactions onMobile Computing, vol. 0, no. 0, p. early access, 2021.
[2] A. Walid, Q. Peng, J. Hwang, and S. Low, “Balanced Linked AdaptationCongestion Control Algorithm for MPTCP,” Internet Engineering TaskForce, Internet-Draft draft-walid-mptcp-congestion-control-04, 2016.
[3] W. Li et al., “SmartCC: A Reinforcement Learning Approach forMultipath TCP Congestion Control in Heterogeneous Networks,” IEEEJournal on Selected Areas in Communications, 2019.
[4] P. Goyal, A. Agarwal, R. Netravali, M. Alizadeh, and H. Balakrishnan,“ABC: A Simple Explicit Congestion Control Protocol for WirelessNetworks,” arXiv preprint arXiv:1905.03429, 2019.
[5] F. Chiariotti et al., “Analysis and Design of a Latency Control Protocol forMulti-Path Data Delivery With Pre-Defined QoS Guarantees,” IEEE/ACMTransactions on Networking, 2019.
[6] S. R. Pokhrel and M. Mandjes, “Improving Multipath TCP Performanceover WiFi and Cellular Networks: an Analytical Approach,” IEEETransactions on Mobile Computing, 2018.
[7] X. Nie et al., “Dynamic TCP Initial Windows and Congestion ControlSchemes through Reinforcement Learning,” IEEE Journal on SelectedAreas in Communications, vol. 37, no. 6, pp. 1231–1247, 2019.
[8] Z. Xu et al., “Experience-driven Congestion Control: When Multi-PathTCP Meets Deep Reinforcement Learning,” IEEE Journal on SelectedAreas in Communications, 2019.
[9] S. R. Pokhrel and C. Williamson, “A rent-seeking framework for multipathTCP,” ACM SIGMETRICS Performance Evaluation Review, vol. 48, no. 3,pp. 63–70, 2021.
[10] C. Raiciu, M. Handley, and D. Wischik, “Coupled Congestion Controlfor Multipath Transport Protocols, IETF RFC 6356,” 2011.
[11] R. Khalili et al., “MPTCP is Not Pareto-optimal: Performance Issues anda Possible Solution,” IEEE/ACM Transactions on Networking, vol. 21,no. 5, pp. 1651–1665, 2013.
[12] P. Hurtig et al., “Low-latency Scheduling in MPTCP,” IEEE/ACMTransactions on Networking, vol. 27, no. 1, pp. 302–315, 2018.
[13] A. Garcia-Saavedra, M. Karzand, and D. J. Leith, “Low Delay Ran-dom Linear Coding and Scheduling over Multiple Interfaces,” IEEETransactions on Mobile Computing, vol. 16, no. 11, pp. 3100–3114,2017.
[14] Y.-S. Lim, E. M. Nahum, D. Towsley, and R. J. Gibbens, “ECF: AnMPTCP Path Scheduler to Manage Heterogeneous Paths,” in Proceedingsof the 13th International Conference on emerging Networking Experi-ments and Technologies, 2017, pp. 147–159.
[15] J. Luo, X. Su, and B. Liu, “A reinforcement learning approach formultipath TCP data scheduling,” in 2019 IEEE 9th Annual Computingand Communication Workshop and Conference (CCWC), 2019, pp. 0276–0280.
[16] 3GPP, “Study on access traffic steering, switch and splitting support inthe 5G system architecture phase 2 (release 17),” 3GPP TS23.700-93,V17.0.0, 2021.
[17] M. Simon, E. Kofi, L. Libin, and M. Aitken, “ATSC 3.0 broadcast 5Gunicast heterogeneous network converged services starting release 16,”IEEE Transactions on Broadcasting, vol. 66, no. 2, pp. 449–458, 2020.
[18] O. Bonaventure, M. Boucadair, B. Peirens, S. Seo, and A. Nandugudi, “0-RTT TCP converters,” Internet-Draft draft-bonaventure-mptcp-converters-01. IETF Secretariat, Tech. Rep., 2017.
[19] M. Boucadair et al., “An MPTCP option for network-assisted MPTCPdeployments: Plain transport mode,” IETF, 2016.
[20] Q. Peng, A. Walid, J. Hwang, and S. H. Low, “Multipath TCP: Analysis,Design, and Implementation,” IEEE/ACM Transactions on Networking,pp. 596–609, 2016.
[21] H. Haile, K.-J. Grinnemo, S. Ferlin, P. Hurtig, and A. Brunstrom, “End-to-End Congestion Control Approaches for High Throughput and LowDelay in 4G/5G Cellular Networks,” Computer Networks, p. 107692,2020.
[22] C. Lee, J. Jung, and J.-M. Chung, “DEFT: Multipath TCP for High SpeedLow Latency Communications in 5G Networks,” IEEE Transactions onMobile Computing, 2020.
[23] M. Polese, R. Jana, and M. Zorzi, “TCP in 5G mmWave Networks:Link Level Retransmissions and MP-TCP,” in 2017 IEEE Conference onComputer Communications Workshops (INFOCOM WKSHPS). IEEE,2017, pp. 343–348.
[24] S. R. Pokhrel and J. Choi, “Low-Delay Scheduling for Internet of Vehicles:Load-Balanced Multipath Communication With FEC,” IEEE Transactionson Communications, vol. 67, no. 12, pp. 8489–8501, 2019.
[25] S. R. Pokhrel et al., “Fair Coexistence of Regular and Multipath TCPover Wireless Last-Miles,” IEEE Transactions on Mobile Computing,vol. 18, no. 3, pp. 574–587, 2019.
[26] M. Dong et al., “PCC: Re-architecting Congestion Control for ConsistentHigh Performance,” in 12th USENIX Symposium on Networked SystemsDesign and Implementation (NSDI 15), 2015, pp. 395–408.
[27] K. Winstein and H. Balakrishnan, “TCP ex machina: Computer-generatedCongestion Control,” ACM SIGCOMM‘13, pp. 123–134, 2013.
[28] Y. Zaki et al., “Adaptive Congestion Control for Unpredictable CellularNetworks,” in ACM SIGCOMM Computer Communication Review,vol. 45, no. 4. ACM, 2015, pp. 509–522.
[29] T. Mai, H. Yao, Y. Jing, X. Xu, X. Wang, and Z. Ji, “Self-learningCongestion Control of MPTCP in Satellites Communications,” in 201915th International Wireless Communications & Mobile ComputingConference (IWCMC). IEEE, 2019, pp. 775–780.
[30] B. Liao, G. Zhang, Z. Diao, and G. Xie, “Precise and Adaptable:Leveraging Deep Reinforcement Learning for GAP-based Multipath

14
Scheduler,” in 2020 IFIP Networking Conference (Networking). IEEE,2020, pp. 154–162.
[31] J. Chung, D. Han, J. Kim, and C.-k. Kim, “Machine Learning BasedPath Management for Mobile Devices Over MPTCP,” in 2017 IEEEInternational Conference on Big Data and Smart Computing (BigComp).IEEE, 2017, pp. 206–209.
[32] F. Silva, M. A. Togou, and G.-M. Muntean, “AVIRA: Enhanced Multipathfor Content-aware Adaptive Virtual Reality,” in 2020 InternationalWireless Communications and Mobile Computing (IWCMC). IEEE,2020, pp. 917–922.
[33] Y. Li et al., “HPCC: High Precision Congestion Control,” in Proceedingsof the ACM Special Interest Group on Data Communication. ACM,2019, pp. 44–58.
[34] M. Dong et al., “PCC Vivace: Online-Learning Congestion Control,” in15th USENIX Symposium on Networked Systems Design and Implemen-tation (NSDI 18), 2018, pp. 343–356.
[35] T. P. Lillicrap et al., “Continuous Control With Deep ReinforcementLearning,” Jan. 26 2017, US Patent App. 15/217,758.
[36] S. R. Pokhrel and S. Garg, “Multipath Communication With DeepQ-Network For Industry 4.0 Automation and Orchestration,” IEEETransactions on Industrial Informatics, pp. 1–1, 2020.
[37] T. Hester et al., “Deep Q-learning From Demonstrations,” in Thirty-Second AAAI Conference on Artificial Intelligence, 2018.
[38] T. Schaul, J. Quan, I. Antonoglou, and D. Silver, “Prioritized ExperienceReplay,” arXiv preprint arXiv:1511.05952, 2015.
[39] S. Ferlin, H. Kucera, Claussen, and O. Alay, “MPTCP meets FEC:Supporting latency-sensitive applications over heterogeneous networks,”IEEE/ACM Transactions on Networking, vol. 26, no. 5, pp. 2005–2018,2018.
[40] T. Haarnoja, A. Zhou, S. Ha, J. Tan, G. Tucker, and S. Levine,“Learning to Walk via Deep Reinforcement Learning,” arXiv preprintarXiv:1812.11103, 2018.
[41] C. J. Watkins and P. Dayan, “Q-Learning,” Machine learning, vol. 8, no.3-4, pp. 279–292, 1992.
[42] J. Achiam, E. Knight, and P. Abbeel, “Towards Characterizing Divergencein Deep Q-Learning,” arXiv preprint arXiv:1903.08894, 2019.
[43] V. Mnih et al., “Human-level Control Through Deep ReinforcementLearning,” Nature, vol. 518, no. 7540, p. 529, 2015.
[44] S. K. Saha et al., “MuSher: An Agile Multipath-TCP Scheduler for Dual-Band 802.11 ad/ac Wireless LANs,” in The 25th Annual InternationalConference on Mobile Computing and Networking, 2019, pp. 1–16.
[45] F. P. Kelly, A. K. Maulloo, and D. K. Tan, “Rate control for commu-nication networks: shadow prices, proportional fairness and stability,”Journal of the Operational Research society, vol. 49, no. 3, pp. 237–252,1998.
[46] R. Mazumdar, L. G. Mason, and C. Douligeris, “Fairness in NetworkOptimal Flow Control: Optimality of Product Forms,” IEEE Transactionson communications, vol. 39, no. 5, pp. 775–782, 1991.
[47] S. R. Pokhrel, “Modeling and performance evaluation of TCP overlast-mile wireless networks,” Ph.D. dissertation, 2017.
[48] S. R. Pokhrel et al., “Multipath TCP meets transfer learning: A noveledge-based learning for industrial IoT,” IEEE Internet of Things Journal,2021.
[49] H. Kumar, A. Koppel, and A. Ribeiro, “On the Sample Complexityof Actor-Critic Method for Reinforcement Learning with FunctionApproximation,” arXiv preprint arXiv:1910.08412, 2019.
[50] T. Degris, M. White, and R. S. Sutton, “Off-Policy Actor-Critic,” arXivpreprint arXiv:1205.4839, 2012.
[51] S. R. Pokhrel et al., “Towards ultra reliable low latency multipath TCPfor connected autonomous vehicles,” IEEE Transactions on VehicularTechnology, 2021.





























