Embed Size (px)
Citation preview

Future Generation Computer Systems 28 (2012) 881–889
Contents lists available at SciVerse ScienceDirect
Future Generation Computer Systems
journal homepage: www.elsevier.com/locate/fgcs
Expanding the volunteer computing scenario: A novel approach to use parallelapplications on volunteer computingAlejandro Calderón ∗, Felix García-Carballeira, Borja Bergua, Luis Miguel Sánchez, Jesús CarreteroComputer Architecture Group, Computer Science Department, Universidad Carlos III de Madrid, Leganés, Madrid, Spain
a r t i c l e i n f o
Article history:Received 28 May 2010Received in revised form15 March 2011Accepted 7 April 2011Available online 16 April 2011
Keywords:Volunteer computingHigh throughput computingHigh performance computingMPIParallel application
a b s t r a c t
Nowadays, high performance computing is being improved thanks to different platforms like clusters,grids, and volunteer computing environments. Volunteer computing is a type of distributed computingparadigm in which a large number of computers, volunteered by members of the general public, providecomputing and storage resources for the execution of scientific projects.
Currently, volunteer computing is used for high throughput computing, but it is not used for parallelapplications based on MPI due to the difficulty in communicating among computing peers. As Sarmentaand Hirano (1999) [2] said, there are several research issues to be solved in volunteer computingplatforms, one of them is ‘implementing other types of applications’. In fact, the BOINC team (thewell known volunteer computing development platform) is requesting ‘MPI-like support’ for volunteercomputing as one of its hot topics.
This paper proposes an extension of the usual capabilities of volunteer computing and desktop gridsystems by allowing the execution of parallel applications, based onMPI, on these types of platforms. Thegoal of this paper is to describe a method to transform and adapt MPI applications in order to allow theexecution of this type of applications on volunteer computing platforms and desktop grids. The proposedapproach does not require anMPI installation on the client’s side, which keeps the software to be installedon the client quite lightweight. The paper describes the prototype built, and also shows the evaluationmade of this prototype, in order to test the viability of the idea proposed in this article, with promisingresults.
© 2011 Elsevier B.V. All rights reserved.
1. Introduction
Nowadays, high performance computing can be foundondiffer-ent platforms: supercomputers, clusters, grids, clouds, volunteercomputing environments, and desktop grids. Volunteer comput-ing and desktop grids are interesting options for high performancecomputing due to the great amount of volunteer resources avail-able in the world.
Volunteer computing [1] is a type of distributed computingparadigm, in which a large number of computers, volunteeredby members of the general public, provides computing andstorage resources for the execution of scientific projects. Currently,volunteer computing is used for high throughput computing, butit is not used for parallel applications based on MPI, due to thedifficulty in communicating among computing peers.
As Sarmenta [2] said, there are several research issues tobe solved in volunteer computing platforms, one of them is‘implementing other types of applications’. In fact, the BOINC team(the well known volunteer computing development platform) is
∗ Corresponding author. Tel.: +34 91 624 9497.E-mail address: [email protected] (A. Calderón).
0167-739X/$ – see front matter© 2011 Elsevier B.V. All rights reserved.doi:10.1016/j.future.2011.04.004
requesting ‘MPI-like support’ for volunteer computing as one of itshot topics [3].
In a volunteer computing scenario, people (volunteers) providecomputing resources to a project, which uses these resources toperform distributed computing. Volunteers are typically based onInternet-connected PCs [4], and many famous projects are worthycauses (medical research, environmental studies, etc.).
The most used platform for volunteer computing is BOINC [5],that hosts many well known projects, like SETI@home [6,1]. Theglobal capacity of current volunteer computing based on BOINCprojects is increasing day by day [7]. The average number offloating point operations per second of all BOINC projects exceeded3,600,000 GigaFLOPS [7] on November 2010, which is larger thanthe 2,570,000 GigaFLOPS of the new fastest supercomputer in theworld (see the November 2010 top 500 list [8]), and this capacityis increasing day by day.
Sarmenta [2] identified some important research issues involunteer computing: user interface design, adaptive parallelism,fault and sabotage tolerance, performance and scalability, andimplementing other types of applications.
Since the work of Sarmenta [2], volunteer computing hasbeen used in the same way. Input data to be processed are

882 A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889
divided into small portions, and all the portions are stored in aserver, together with the application binary for different platformswithin a project. One application binary and one portion of thedata are sent to a volunteer computer. Then, the application isexecuted, and the results are returned to the server. This processis repeated until all work portions are completed. This kind ofbehavior is appropriate for high throughput computing. However,the volunteer computing environment has not been used forparallel applications, such asMPI applications, due to the difficultyin communicating with other computing peers efficiently. Theexecution of parallel applications in volunteer platforms is a veryimportant and hot topic. As is described in the BOINC ‘helpwanted’wiki page [3], one of the proposals for future versions of the BOINCplatform (but still not solved) is to ‘add support for MPI-type [9]applications’.
This paper proposes an extension of the usual capabilities ofvolunteer computing and desktop grid systems by allowing theexecution of parallel applications based on MPI on these typesof platforms. The paper describes a method to transform andadapt MPI applications in order to allow the execution of thistype of applications in volunteer computing platforms and desktopgrids. The proposed approach, called MPIWS, does not require anMPI installation on the client’s side, which keeps the software tobe installed on the client quite lightweight. The paper describesthe prototype built, and also shows the evaluation made of thisprototype in order to test the viability of the idea proposed in thisarticle, with promising results.
The rest of the paper is organized as follows: Section 2 describesthe motivation and goals; Section 3 shows the main details ofthe proposed model; Section 4 describes the main aspects of theprototype developed; Section 5 presents themain results obtainedin the evaluation; Section 6 shows the related work; and, finally,Section 7 summarizes the paper, and shows the expected futurework.
2. Motivation and goals
Typical parallel applications for clusters and supercomputersare written using the MPI standard [9] (Message Passing Interface)as the programming interface. An MPI implementation actslike a middleware, and provides an execution environmentwhere several compute nodes run the processes of the parallelapplication.
Typical volunteer applications use some volunteer computingmiddleware API. The most known middleware is BOINC [4]. Italso provides an execution environment where several volunteercomputers offer their computational resources for a period of timeto run applications. In this case, the execution environment isbased on a pull system [10], where volunteer computers requestthe work to be done.
The input data to be processed are divided into small portions,and all these portions together with the application (that couldbe executed on different platforms) are managed by a scheduler.The application and one portion of data are sent to the volunteercomputer. Then, the application is executed, and the resultsare returned, so the scheduler tracks the work done, and thework still to be done. This model of execution is appropriate forsequential applications, but is not used for the execution of parallelapplications, such as MPI applications.
In this paper, we try to answer the following question: howcan a general MPI application be executed using a set of volunteercomputational resources?
One possible strategy would be executing a virtual machine(for example, Oracle VirtualBox or VMWare that provide supportfor Windows, Linux and MacOS) in each volunteer computer. Thevirtual machine [11] provides the software found in a cluster
node, so it is possible to use an MPI implementation, and build acluster using the virtual machines deployed on different volunteercomputers. The main problem with this option is that not onlydoes the BOINC middleware have to be installed on the volunteercomputers, but also some virtual machine monitor (i.e. OracleVirtualBox or VMWare), which could demand a large amount ofcomputational andmemory resources in the volunteer computers.For example, the size of a virtual machine hard disk could beseveral hundred megabytes in the best case. Furthermore, the MPIimplementation used should be adapted in order to allow thecommunication of the computational peers using the Internet.
Instead, the strategy proposed by the authors is to adapt theMPI application in order to allow the execution of the processes ofa parallel application on different volunteer nodes. The proposedapproach does not require an MPI installation on the client’s sideto keep the software to be installed on the client quite lightweight.
The main goals of the proposed approach are the following.
• To take advantage of volunteer computing and desktop gridplatforms’ power for the execution of MPI parallel applications,allowing the execution of an MPI parallel program throughnodes located even in different administrative domains.
• To re-use the existing software with minimal changes. The ideais to provide a nearly transparent solution for users.
• To use web services to solve connectivity problems amongcomputational resources, due to firewalls, filters, etc.
• To provide a mechanism to deploy the parallel applicationprocesses on different volunteer computers.
The next section introduces the general framework used, andthe proposed model.
3. Proposed model
The objective of this paper is to describe a general frameworkto allow the execution of parallel applications in computationalresources connected to the Internet. In this section we define, ina formal way, the general model behind this approach.
Let C = C1, . . . , Cm be a set of independent computationalresources connected to the Internet, with |Ci| ≥ 1. If |Ci| = 1,then Ci represents a single node. If |Ci| > 1, then Ci representsa cluster with |Ci| nodes. Each cluster may have its own MPI ornative implementation. MPIk is the MPI implementation used inthe cluster Ck, and it can be different from MPIj.
Let P = P1, . . . , Pn be the processes of an MPI program. Thegoal is to execute P on C using a mapping function π : P → C ,where π(Pk) = Cj if Pk executes in Cj. In Fig. 1, we can see threecomputational resources. The first is a clusterwith three nodes andone MPI implementation. The second is a cluster with a differentMPI implementation. The third represents a single node. All theseresources are connected to the Internet. The nodes inside a clustercan communicate through a local network. The figure represents aparallel application with 6 processes deployed on these resources.
Let M = (R, S) be a directed graph that represents a singleMPI communication call, with R ⊂ P and S ∈ R × R. For q =
(Pi, Pj) where q ∈ S, Pi is the MPI source process and Pj is the MPIdestination process of the communication. All MPI communicationcalls (synchronous, asynchronous, point to point, collective, etc.)can be represented by a directed graph.
Any MPI collective primitive needs several arrows (directedarcs) in order to represent the communication that this collectiveprimitive performs.
There are two types of communications. The MPI communica-tionM = (R, S) can be:
• local: π(Pi) = π(Pk)∀Pi, Pk ∈ R,• remote: ∃Pi, Pk ∈ R, and Pi = Pk | π(Pi) = π(Pk).

A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889 883
Fig. 1. Example of an MPI application execution.
Fig. 1 shows an MPI application with six processes. Localcommunication among the processes executing in the samecomputational resource Ck is made using the native MPIkimplementation installed on the Ck cluster, if this implementationis available. The remote communication uses web services.
This general model has been adapted and applied to volunteercomputing platforms. In this case, all computational resources,C = C1, . . . , Cm, are single volunteer computers, and therefore|Ci| = 1. For this scenario, all communications are remote, and anyMPI implementation is available. The implementation developeddoes not take into account local communications among processeslocated in the same computational resource; all communicationshave been considered in this paper as remote.
3.1. MPIWS model
As we defined before, C = C1, . . . , Cm is a set of independentcomputational resources connected to the Internet, and P =
P1, . . . , Pn is an MPI program associated with a volunteer project.In order to deploy P on C , a dedicated cluster associated with thevolunteer project is required.We call this cluster a stub cluster. Thiscluster belongs to the volunteer project, and can be associatedwiththe volunteer project server. On the stub cluster we define a stubMPI as SP = SP1, . . . , SPn, where:• SP is an MPI program too;• |P| = |SP|;• all processes execute on the stub cluster, and therefore ∀Pi, Pk ∈
SP, π(Pi) = π(Pk), and they use the same MPI implementationavailable on this cluster;
• ∀Pi ∈ P, ∃ SPi ∈ SP , where each SPi represents a remote stubprocess for Pi.
The remote communication is used for communication amongprocesses of different computational resources, and for communi-cation among processes of the same computational resource whenan MPI implementation is not available. The remote communica-tion uses Web services and the cooperation of the stub MPI.
Any MPI communication M = (R, S) can be transformed in anMPI remote communication M ′
= (R′, S ′), where R′⊂ P ∪ SP ,
S ′⊂ R′
× R′ and ∀q ∈ S, q = (Px, Py)∃q1, q2, q3 ∈ S ′, withq1 = (Px, SPx), q2 = (SPx, SPy), q3 = (SPy, Py). q1 and q3 are doneby using Web services, whereas q2 uses the MPI implementationavailable on the cluster where the stub MPI executes (see Fig. 2).
Fig. 2 represents an example of a parallel program with fourprocesses. In this example four volunteer computers are used.Each process of the parallel application is executed in a volunteercomputer. The stub cluster executes all MPI stubs by using the MPIimplementation available on this cluster.
3.2. Key aspects of the MPIWS model
Any parallel application consists of a computational part anda communication–synchronization part. The proposed model pro-vides a two level structure in order to support both parts: volunteercomputers provide the resources for the computational part andthe stub cluster provides the non-computational resources (com-munication, synchronization, file access, etc.).
Both the stub cluster and volunteer computers work togetherto provide a new kind of platform that makes use of the extracomputational capacity provided by the volunteer computers. Forexample, a stub cluster that executes the MPI stub could have 100nodes with 16 cores each. This cluster could hold the MPI stub foran MPI program running in 1600 volunteer quad-core nodes. Ascan be seen, in this casewe can use a computational capacity in thevolunteer nodes that is not available in the stub cluster. In thisway,any MPI application with great computational cost could benefitfrom this platform.
This two level configuration reduces costs (compared withhaving a cluster with 1600 nodes), and takes advantage of theexisting infrastructure. From the administration point of view, noextra software is needed on the volunteer computers, for example,virtual machines, MPI implementations, etc. In order to avoid theproblems that firewalls and other security softwaremay introduce,remote communication is based on Web services, so volunteercomputers are able to communicate with the MPI stubs withoutadditional changes.
3.3. Architecture for remote communication
Given an MPI parallel application source code, a simplepreprocessor stage is needed to build the source code for twoprograms: the one to be executed on the volunteer nodes, and theone to be executed on the stub cluster.
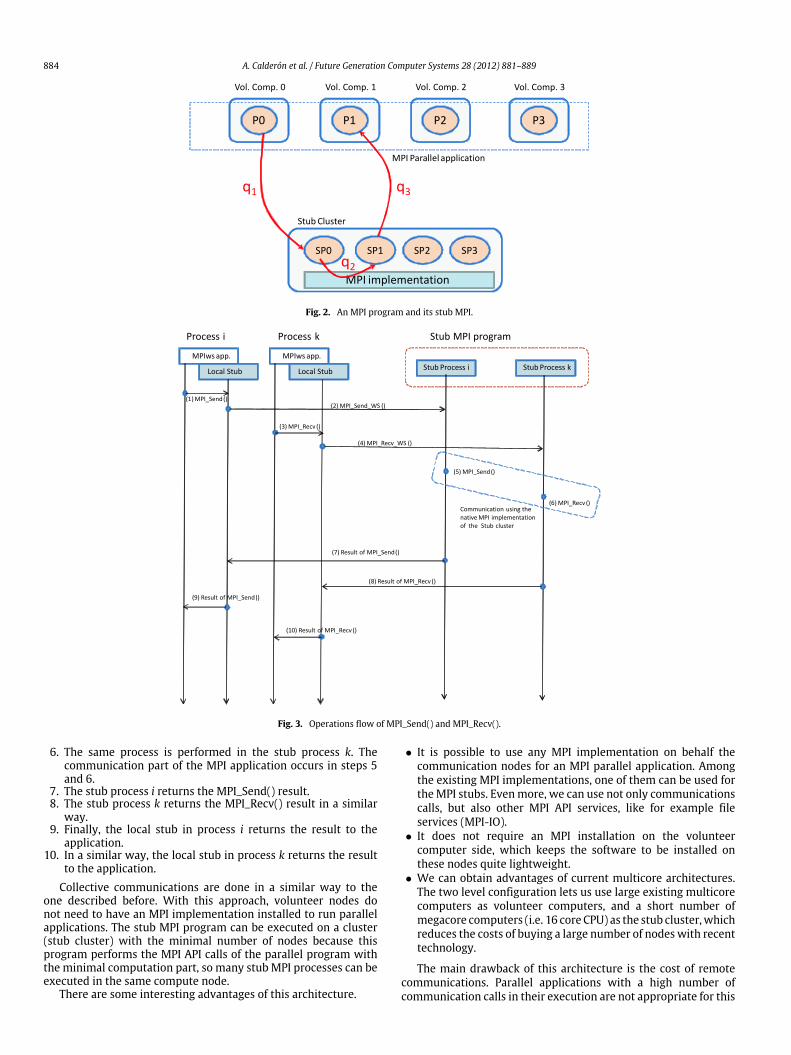
Fig. 3 shows an example of an MPI application with twoprocesses (process k and process i) executed on two volunteernodes. One process requests an MPI_Send and the other one anMPI_Recv respectively.
The preprocessor adds to each MPI process a local stub thatintercepts the MPI calls of this process. Any call to the MPI API willbe issued by the local stub (1 and 3). Furthermore, the preprocessorcreates the MPI stub program to support the communication partof the program. Each process of theMPI stub has a remote stub thatreceives any communication request from the corresponding localstub (2 and 4), using Web services.
With these elements, a point to point communication betweentwo processes (Pi executes an MPI_Send() operation, and processPk executes an MPI_Recv() operation) is made as follows.
1. Process Pi executes an MPI_Send(), and this operation isprocessed by the local stub inside the same process. This is alocal call because the application code and the local stub codebelong to the same process.
2. The local stub in the process Pi requests to the remote stub ithe MPI operation. This communication is done by using Webservices.
3. Process Pk executes an MPI_Recv(), and this operation isprocessed by the local stub inside the same process.
4. The local stub in the process Pk requests to the remote stub kthe MPI operation. This communication is also done by usingWeb services.
5. When the remote stub i receives a request, it also receivesthe parameters of the MPI operation. With these parametersthe remote stub implements the communication by usingthe MPI implementation available in the stub cluster. In thiscase, the stub cluster executes an MPI_Send() call in order tocommunicate with the stub process k.
884 A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889
Fig. 2. An MPI program and its stub MPI.
Fig. 3. Operations flow of MPI_Send() and MPI_Recv().
6. The same process is performed in the stub process k. Thecommunication part of the MPI application occurs in steps 5and 6.
7. The stub process i returns the MPI_Send() result.8. The stub process k returns the MPI_Recv() result in a similar
way.9. Finally, the local stub in process i returns the result to the
application.10. In a similar way, the local stub in process k returns the result
to the application.Collective communications are done in a similar way to the
one described before. With this approach, volunteer nodes donot need to have an MPI implementation installed to run parallelapplications. The stub MPI program can be executed on a cluster(stub cluster) with the minimal number of nodes because thisprogram performs the MPI API calls of the parallel program withthe minimal computation part, so many stub MPI processes can beexecuted in the same compute node.
There are some interesting advantages of this architecture.
• It is possible to use any MPI implementation on behalf thecommunication nodes for an MPI parallel application. Amongthe existing MPI implementations, one of them can be used fortheMPI stubs. Evenmore, we can use not only communicationscalls, but also other MPI API services, like for example fileservices (MPI-IO).
• It does not require an MPI installation on the volunteercomputer side, which keeps the software to be installed onthese nodes quite lightweight.
• We can obtain advantages of current multicore architectures.The two level configuration lets us use large existing multicorecomputers as volunteer computers, and a short number ofmegacore computers (i.e. 16 core CPU) as the stub cluster,whichreduces the costs of buying a large number of nodeswith recenttechnology.
The main drawback of this architecture is the cost of remotecommunications. Parallel applications with a high number ofcommunication calls in their execution are not appropriate for this

A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889 885
Fig. 4. Preprocessing and deployment.
approach. The proposedmodel is appropriate for parallel scientificapplications that spend more time in their computational phasesthan in the communication phases.
However, as is described in [12], almost all successful MPI pro-grams are written in a bulk synchronous style in which the com-putation proceeds in phases. Within each phase, processors firstparticipate in a communication operation. For the remainder of thephase, each processor can perform computation without any com-munication. Virtually all of the highly scalable scientific kernels canbe formulated in this way, including matrix–vector multiplication,explicit time integration, and particle simulation. Important ker-nels that do not fit this model, like sparse factorizations, typicallydo not scale beyond a few hundred processors.
4. MPIWS implementation
We have built a prototype in order to evaluate the viability ofthe proposed model. This prototype consists of a preprocessor anda library that implements the remote communication. Given anMPI application, the preprocessor replaces all MPI references withMPIWS library references, and builds a new application (the initialMPI code is kept without modification). The preprocessor alsobuilds the associated stub MPI. This process, totally transparent tousers, can be seen in Fig. 4.
Later, the MPIWS application may be deployed on differentvolunteer nodes and the stub MPI application on the stub cluster.Communication among local and remote stubs uses Web services,implemented in the prototype using gSOAP 2.7.
In this prototype, an mpirun-like utility is provided in orderto deploy the processes in the corresponding nodes. This mpirun-like utility receives the list of volunteer computers available atthat time and the stub cluster to use. With this list and the stubcluster, the mpirun-like utility launches the stub MPI program inthe stub cluster, and also launches the appropriate MPI processin each volunteer computer. This list could be obtained using, forinstance, an existing volunteer project server like the one used ina BOINC project.
As the performance of Web services is poor for large messages(especially for binary messages), the prototype implementsmessage compression. The compression has been implementedwith two algorithms: GZIP and LZO. GZIP is provided by gSOAPwhile LZO is not, but the latter is the recommended algorithm forquick compression and decompression. The LZO algorithm [13] hasbeen used by authors before in a multithread MPI implementationcalled MiMPI [14,15] with successful results. Compression isactivated when the message size is greater than or equal to twokilobytes (2 KB).
5. Evaluation
In this section we want to demonstrate that the proposedarchitecture can be used in terms of high performance computingin a scenario composed of a set of volunteer computers withoutany MPI implementation installed on them. In order to performthe evaluation, the prototype described in the previous section hasbeen used.
For this evaluation, two aspects have been evaluated: themaximum bandwidth that can be obtained, and the throughputobtained with a typical MPI application.
5.1. Platforms used
The evaluation has been made using two hardware environ-ments.
• The first one is a typical cluster with 8 Intel dual core processorsat 2.2 GHz, with 2 GB of RAM, and interconnected to aFastEthernet network. This cluster uses OpenMPI [16] as theMPI native implementation.
• The second one consists of 40 independent PCs (the volunteercomputers) located in laboratory rooms placed in two differ-ent campuses of the university (Colmenarejo and Leganes cam-puses), with an approximate distance between them of 45 km.These PCs are not configured as a cluster, and they do not haveany MPI implementation installed. All machines use DebianGNU/Linux 4.0, and they are interconnected to a FastEthernetnetwork. All these PCs are different. Some of them are dual core,some others are single core, and the frequency varies from 1.8to 2.2 GHz. The memory varies from 1 to 2 GB.
We want to compare unmodified MPI programs against thesame MPI programs transformed following the proposal of thispaper. For this purpose we will use the hardware environmentsdescribed above.
• When we evaluate unmodified MPI programs, we will use thefirst hardware environment (cluster).
• When we evaluate MPI programs transformed following theproposal of this paper, we will use only one node of the firsthardware environment to execute the stub MPI program, andthe second hardware environment will execute the volunteerprocesses.
Communication between the stub node and the volunteerprocesses takes place over a FastEthernet network. As describedbefore, the Web services communication among the processes inthe second platform and the processes in the stub node (located inone node of the first platform) is made by using gSOAP version 2.7.
We know that this environment is not fully representative of areal-life situation in volunteer computing. However, this scenariois appropriate to obtain initial conclusions about the benefits of theproposal. The only main difference with a real-life scenario is thevolatility of the nodes, that will be addressed in future works.
5.2. Evaluation software and results
For the evaluation,wehaveused a benchmark and a real parallelapplication. Both of them have been executed in the platformsdescribed above. The results for the first scenario are shown asCluster-OpenMPI, and the results for the second one are shown asPCs-MPIWS.
The results presented here are the average values obtainedafter executing the tests 25 times. The results obtained in everytest were almost the same; that is the reason why the standarddeviation is very low. The standard deviation found in the secondtest (the one with more differences among the values obtained)was less than 5% of the average value.
886 A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889
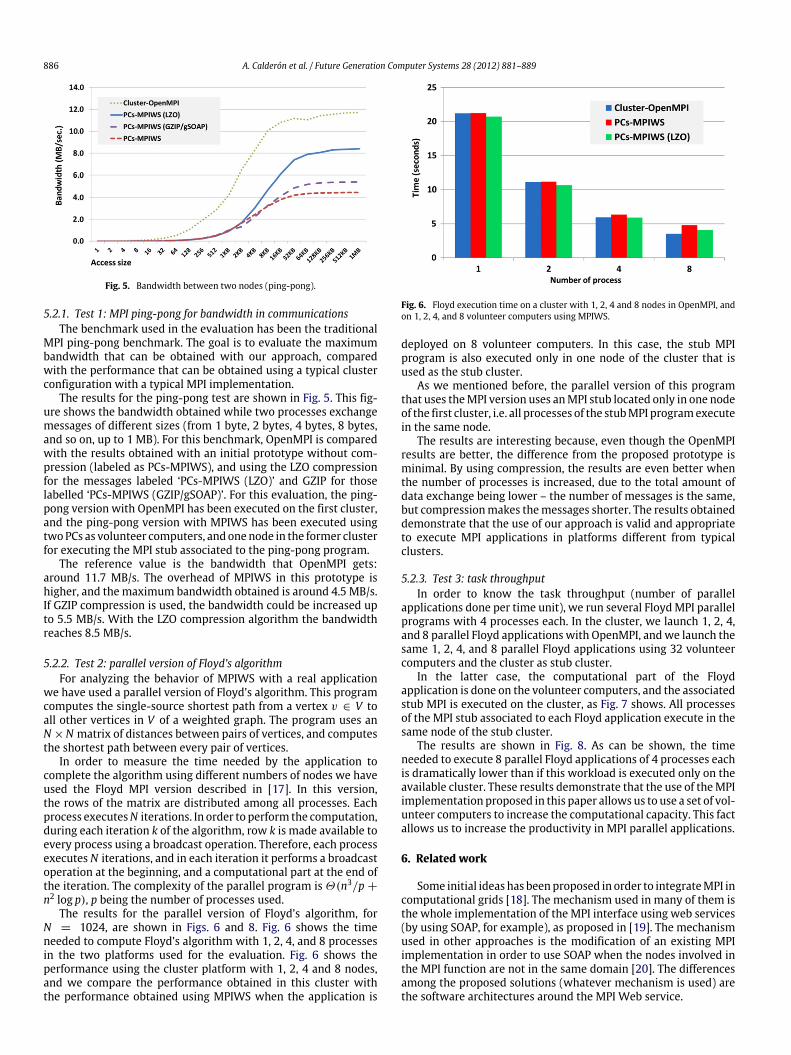
Fig. 5. Bandwidth between two nodes (ping-pong).
5.2.1. Test 1: MPI ping-pong for bandwidth in communicationsThe benchmark used in the evaluation has been the traditional
MPI ping-pong benchmark. The goal is to evaluate the maximumbandwidth that can be obtained with our approach, comparedwith the performance that can be obtained using a typical clusterconfiguration with a typical MPI implementation.
The results for the ping-pong test are shown in Fig. 5. This fig-ure shows the bandwidth obtained while two processes exchangemessages of different sizes (from 1 byte, 2 bytes, 4 bytes, 8 bytes,and so on, up to 1 MB). For this benchmark, OpenMPI is comparedwith the results obtained with an initial prototype without com-pression (labeled as PCs-MPIWS), and using the LZO compressionfor the messages labeled ‘PCs-MPIWS (LZO)’ and GZIP for thoselabelled ‘PCs-MPIWS (GZIP/gSOAP)’. For this evaluation, the ping-pong version with OpenMPI has been executed on the first cluster,and the ping-pong version with MPIWS has been executed usingtwoPCs as volunteer computers, and onenode in the former clusterfor executing the MPI stub associated to the ping-pong program.
The reference value is the bandwidth that OpenMPI gets:around 11.7 MB/s. The overhead of MPIWS in this prototype ishigher, and the maximum bandwidth obtained is around 4.5 MB/s.If GZIP compression is used, the bandwidth could be increased upto 5.5 MB/s. With the LZO compression algorithm the bandwidthreaches 8.5 MB/s.
5.2.2. Test 2: parallel version of Floyd’s algorithmFor analyzing the behavior of MPIWS with a real application
we have used a parallel version of Floyd’s algorithm. This programcomputes the single-source shortest path from a vertex v ∈ V toall other vertices in V of a weighted graph. The program uses anN ×N matrix of distances between pairs of vertices, and computesthe shortest path between every pair of vertices.
In order to measure the time needed by the application tocomplete the algorithm using different numbers of nodes we haveused the Floyd MPI version described in [17]. In this version,the rows of the matrix are distributed among all processes. Eachprocess executesN iterations. In order to perform the computation,during each iteration k of the algorithm, row k is made available toevery process using a broadcast operation. Therefore, each processexecutes N iterations, and in each iteration it performs a broadcastoperation at the beginning, and a computational part at the end ofthe iteration. The complexity of the parallel program is Θ(n3/p +
n2 log p), p being the number of processes used.The results for the parallel version of Floyd’s algorithm, for
N = 1024, are shown in Figs. 6 and 8. Fig. 6 shows the timeneeded to compute Floyd’s algorithm with 1, 2, 4, and 8 processesin the two platforms used for the evaluation. Fig. 6 shows theperformance using the cluster platform with 1, 2, 4 and 8 nodes,and we compare the performance obtained in this cluster withthe performance obtained using MPIWS when the application is
Fig. 6. Floyd execution time on a cluster with 1, 2, 4 and 8 nodes in OpenMPI, andon 1, 2, 4, and 8 volunteer computers using MPIWS.
deployed on 8 volunteer computers. In this case, the stub MPIprogram is also executed only in one node of the cluster that isused as the stub cluster.
As we mentioned before, the parallel version of this programthat uses theMPI version uses anMPI stub located only in one nodeof the first cluster, i.e. all processes of the stubMPI programexecutein the same node.
The results are interesting because, even though the OpenMPIresults are better, the difference from the proposed prototype isminimal. By using compression, the results are even better whenthe number of processes is increased, due to the total amount ofdata exchange being lower – the number of messages is the same,but compressionmakes themessages shorter. The results obtaineddemonstrate that the use of our approach is valid and appropriateto execute MPI applications in platforms different from typicalclusters.
5.2.3. Test 3: task throughputIn order to know the task throughput (number of parallel
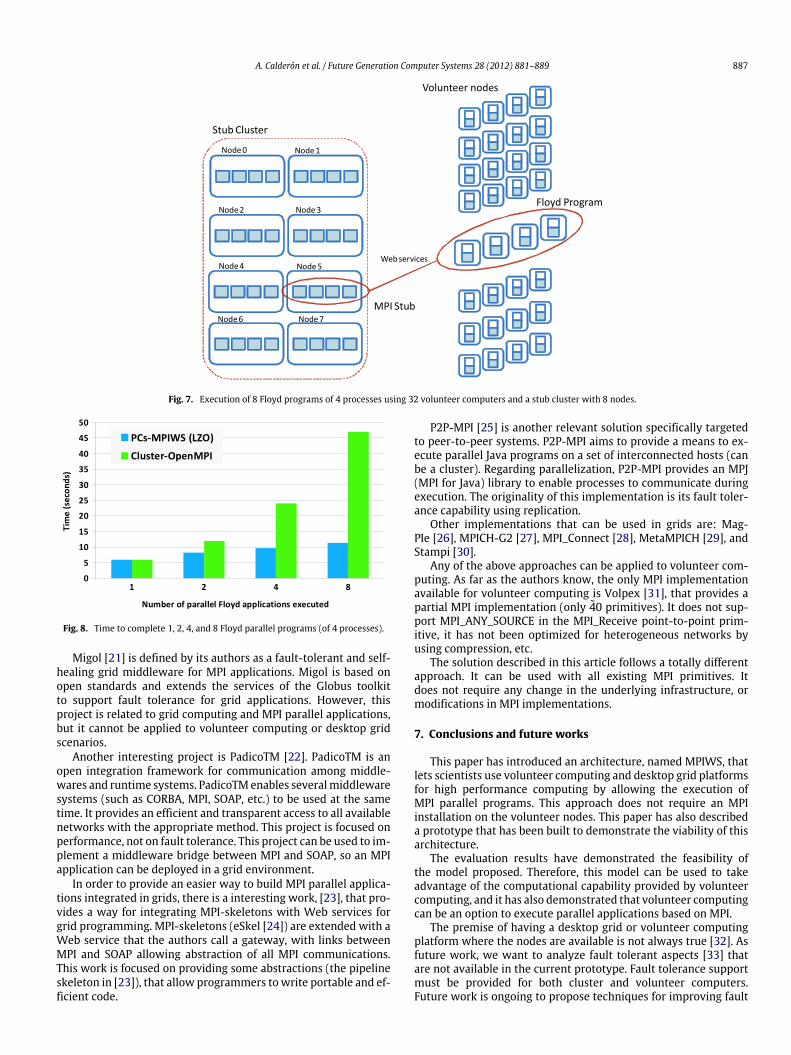
applications done per time unit), we run several FloydMPI parallelprograms with 4 processes each. In the cluster, we launch 1, 2, 4,and 8 parallel Floyd applications with OpenMPI, andwe launch thesame 1, 2, 4, and 8 parallel Floyd applications using 32 volunteercomputers and the cluster as stub cluster.
In the latter case, the computational part of the Floydapplication is done on the volunteer computers, and the associatedstub MPI is executed on the cluster, as Fig. 7 shows. All processesof the MPI stub associated to each Floyd application execute in thesame node of the stub cluster.
The results are shown in Fig. 8. As can be shown, the timeneeded to execute 8 parallel Floyd applications of 4 processes eachis dramatically lower than if this workload is executed only on theavailable cluster. These results demonstrate that the use of theMPIimplementation proposed in this paper allows us to use a set of vol-unteer computers to increase the computational capacity. This factallows us to increase the productivity in MPI parallel applications.
6. Related work
Some initial ideas has beenproposed in order to integrateMPI incomputational grids [18]. The mechanism used in many of them isthe whole implementation of the MPI interface using web services(by using SOAP, for example), as proposed in [19]. The mechanismused in other approaches is the modification of an existing MPIimplementation in order to use SOAP when the nodes involved inthe MPI function are not in the same domain [20]. The differencesamong the proposed solutions (whatever mechanism is used) arethe software architectures around the MPI Web service.
A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889 887
Fig. 7. Execution of 8 Floyd programs of 4 processes using 32 volunteer computers and a stub cluster with 8 nodes.
Fig. 8. Time to complete 1, 2, 4, and 8 Floyd parallel programs (of 4 processes).
Migol [21] is defined by its authors as a fault-tolerant and self-healing grid middleware for MPI applications. Migol is based onopen standards and extends the services of the Globus toolkitto support fault tolerance for grid applications. However, thisproject is related to grid computing and MPI parallel applications,but it cannot be applied to volunteer computing or desktop gridscenarios.
Another interesting project is PadicoTM [22]. PadicoTM is anopen integration framework for communication among middle-wares and runtime systems. PadicoTMenables severalmiddlewaresystems (such as CORBA, MPI, SOAP, etc.) to be used at the sametime. It provides an efficient and transparent access to all availablenetworks with the appropriate method. This project is focused onperformance, not on fault tolerance. This project can be used to im-plement a middleware bridge between MPI and SOAP, so an MPIapplication can be deployed in a grid environment.
In order to provide an easier way to build MPI parallel applica-tions integrated in grids, there is a interesting work, [23], that pro-vides a way for integrating MPI-skeletons with Web services forgrid programming. MPI-skeletons (eSkel [24]) are extended with aWeb service that the authors call a gateway, with links betweenMPI and SOAP allowing abstraction of all MPI communications.This work is focused on providing some abstractions (the pipelineskeleton in [23]), that allow programmers to write portable and ef-ficient code.
P2P-MPI [25] is another relevant solution specifically targetedto peer-to-peer systems. P2P-MPI aims to provide a means to ex-ecute parallel Java programs on a set of interconnected hosts (canbe a cluster). Regarding parallelization, P2P-MPI provides an MPJ(MPI for Java) library to enable processes to communicate duringexecution. The originality of this implementation is its fault toler-ance capability using replication.
Other implementations that can be used in grids are: Mag-PIe [26], MPICH-G2 [27], MPI_Connect [28], MetaMPICH [29], andStampi [30].
Any of the above approaches can be applied to volunteer com-puting. As far as the authors know, the only MPI implementationavailable for volunteer computing is Volpex [31], that provides apartial MPI implementation (only 40 primitives). It does not sup-port MPI_ANY_SOURCE in the MPI_Receive point-to-point prim-itive, it has not been optimized for heterogeneous networks byusing compression, etc.
The solution described in this article follows a totally differentapproach. It can be used with all existing MPI primitives. Itdoes not require any change in the underlying infrastructure, ormodifications in MPI implementations.
7. Conclusions and future works
This paper has introduced an architecture, named MPIWS, thatlets scientists use volunteer computing and desktop grid platformsfor high performance computing by allowing the execution ofMPI parallel programs. This approach does not require an MPIinstallation on the volunteer nodes. This paper has also describeda prototype that has been built to demonstrate the viability of thisarchitecture.
The evaluation results have demonstrated the feasibility ofthe model proposed. Therefore, this model can be used to takeadvantage of the computational capability provided by volunteercomputing, and it has also demonstrated that volunteer computingcan be an option to execute parallel applications based on MPI.
The premise of having a desktop grid or volunteer computingplatform where the nodes are available is not always true [32]. Asfuture work, we want to analyze fault tolerant aspects [33] thatare not available in the current prototype. Fault tolerance supportmust be provided for both cluster and volunteer computers.Future work is ongoing to propose techniques for improving fault

888 A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889
tolerance. In the cluster executing the stub MPI, a high availabilityconfiguration can be used, because the number of cluster nodes islower than the number of volunteer nodes, and they are all in thesame physical place.
For the volunteer computing side there are some possiblesolutions to fault tolerance: remote checkpointing could be useddirectly if the volunteer computer can provide it (for example,saving its state in other volunteer computers). If a volunteercomputer cannot provide checkpointing-like solutions, the stubMPI application can record all messages exchanged among MPIprocesses (from all remote communications) into a log. When avolunteer computer fails, the process (or processes) that this nodewas executing could be restarted on another computational node,and its executionwill be recovered by re-doing all communicationsrecordedpreviously in the log. Another solution is to use redundantcomputing, so that the same MPI process is executed in two ormore volunteer computers at the same time. If any of them fails,the others will keep working.
The implementation developed does not take into account lo-cal communications among processes located in the same com-putational resource; all communications in this paper have beenconsidered as remote. As future work, we plan to extend the im-plementation in order to consider possible local communicationsamong processes located in the same computational resource byusing the MPI implementation available on this resource.
Acknowledgments
This work has been partially funded by project TIN2007-63092of the SpanishMinistry of Education andproject CCG08-UC3M/TIC-4059 of the Madrid State Government.
References
[1] D.P. Anderson, G. Fedak, The computational and storage potential of volunteercomputing, in: CCGRID’06, Proceedings of the Sixth IEEE InternationalSymposium on Cluster Computing and the Grid, IEEE Computer Society, 2006,pp. 73–80.
[2] L.F.G. Sarmenta, S. Hirano, Bayanihan: building and studying web-basedvolunteer computing systems using Java, Future Generation ComputerSystems 15 (1999) 675–686.
[3] BOINCHelpWanted, TheBOINCwebsite, 2010. http://boinc.berkeley.edu/trac/wiki/DevProjects.
[4] Volunteer Computing, BOINC, WWW page, 2008. http://boinc.berkeley.edu/trac/wiki/VolunteerComputing.
[5] David P. Anderson, Boinc: a system for public-resource computing and storage,in: GRID’04: Proceedings of the 5th IEEE/ACM InternationalWorkshop on GridComputing, IEEE Computer Society, Washington, DC, USA, 2004, pp. 4–10.
[6] David P. Anderson, Jeff Cobb, Eric Korpela, Matt Lebofsky, Dan Werthimer,SETI@home: an experiment in public-resource computing, Communicationsof the ACM 45 (11) (2002) 56–61.
[7] The BOINC Project. The BOINCstats website, 2010. http://es.boincstats.com/stats/project_graph.php.
[8] Top 500 Supercomputing list, WWW page, 2010. http://www.top500.org.[9] MPI forum website, 2010. http://www.mpi-forum.org.
[10] S. Acharya, M. Franklin, S. Zdonik, Balancing push and pull for databroadcast, in: SIGMOD’97, Proceedings of the 1997ACMSIGMOD InternationalConference on Management of Data, ACM, 1997, pp. 183–194.
[11] B.M. Segal, P. Buncic, D.G. Quintas, D.L. Gonzalez, A. Harutyunyan, J. Rantala,D. Weir, Building a volunteer cloud, Memorias de la ULA 0 (1) (2009) http://proyectos.saber.ula.ve/ojs/index.php/memoriasula/article/view/114/121.
[12] B. Hendrickson, Computational science: emerging opportunities and chal-lenges, Journal of Physics: Conference Series 180 (1) (2009) 012013.
[13] Markus F.X.J. Oberhumer, LZO data compression library, 1999.http://wildsau.idv.uni-linz.ac.at/mfx/lzo.html.
[14] A. Calderon, F. Garcia, J. Carretero, J. Fernandez, O. Perez, New techniquesfor collective communications in clusters: a case study with MPI, in: ICPP’01,Proceedings of the International Conference on Parallel Processing, IEEEComputer Society, 2001.
[15] F. García, A. Calderón, J. Carretero, MiMPI: a multithred-safe implementationof MPI, in: Proceedings of the 6th European PVM/MPI Users’ Group Meetingon Recent Advances in Parallel VirtualMachine andMessage Passing Interface,Springer-Verlag, 1999, pp. 207–214.
[16] E. Gabriel, G.E. Fagg, G. Bosilca, T. Angskun, J.J. Dongarra, J.M. Squyres, V. Sahay,P. Kambadur, B. Barrett, A. Lumsdaine, R.H. Castain, D.J. Daniel, R.L. Graham,T.S. Woodall, Open MPI: Goals, concept, and design of a next generation MPIimplementation, in: Proceedings of the 11th European PVM/MPI Users’ GroupMeeting on Recent Advances in Parallel Virtual Machine and Message PassingInterface, Springer-Verlag, Budapest, Hungary, 2004, pp. 97–104.
[17] M.J. Quinn, Designing Efficient Algorithms for Parallel Computers, McGraw-Hill, 1987.
[18] Beniamino Di Martino, Dieter Kranzlmüller, Jack Dongarra, Special section:grid computing and the message passing interface, Future GenerationComputer Systems 24 (2) (2008) 119–120.
[19] D. Puppin, N. Tonellotto, D. Laforenza, How to run scientific applications overweb services, in: ICPPW’05, Proceedings of the 2005 International Conferenceon Parallel Processing Workshops, IEEE Computer Society, 2005, pp. 29–33.
[20] C. Coti, A. Rezmerita, T. Hérault, F. Cappello, Grid services for MPI,in: Proceedings of the 14th European PVM/MPI Users’ Group Meeting onRecent Advances in Parallel Virtual Machine and Message Passing Interface,Springer-Verlag, 2007, pp. 393–394.
[21] A. Luckow, B. Schnor, Migol: a fault-tolerant service framework for MPIapplications in the Grid, Future Generation Computer Systems 24 (2) (2008)no.
[22] A. Denis, Meta-communications in component-based communication frame-works for Grids, Cluster Computing 10 (3) (2007) 253–263.
[23] J. Dünnweber, A. Benoit, M. Cole, S. Gorlatch, Integrating MPI-Skeletons withweb services, in: PARCO, 2005, pp. 787–794.
[24] M. Cole, Bringing skeletons out of the closet: a pragmaticmanifesto for skeletalparallel programming, Parallel Computing 30 (3) (2004) 389–406.
[25] S. Genaud, C. Rattanapoka, A peer-to-peer framework for message passingparallel programs, in: Fatos Xhafa (Ed.), Parallel Programming, Models andApplications in Grid and P2P Systems, in: Advances in Parallel Computing,vol. 17, IOS Press, 2009, pp. 118–147. ISSN: 978-1-60750-004-9.
[26] T. Kielmann, H.E. Bal, J. Maassen, R. van Nieuwpoort, L. Eyraud, R.F.H.Hofman, K. Verstoep, Programming environments for high-performancee Gridcomputing: the albatross project, Future Generation Computer Systems 18 (8)(2002) 1113–1125.
[27] N. Karonis, B. Toonen, I. Foster, MPICH-G2: a grid-enabled implementation ofthe message passing interface, Journal of Parallel and Distributed Computing(2003).
[28] G.E. Fagg, K.S. London, J. Dongarra, MPI connect, managing heterogeneousMPI applications ineroperation and process control, in: Proceedings ofthe 5th European PVM/MPI Users’ Group Meeting on Recent Advances inParallel VirtualMachine andMessage Passing Interface, Springer-Verlag, 1998,pp. 93–96.
[29] C. Clauss, M. Poppe, T. Bemmerl, Optimising MPI applications for heteroge-neous coupled clusters with MetaMPICH, in: Proceedings of the IEEE Interna-tional Conference on Parallel Computing in Electrical Engineering, Dresden,Germany, 2004.
[30] T. Imamura, Y. Tsujita, H. Koide, H. Takemiya, An architecture of stampi: MPIlibrary on a cluster of parallel computers, in: Proceedings of the 7th EuropeanPVM/MPI Users’ Group Meeting on Recent Advances in Parallel VirtualMachine and Message Passing Interface, Springer-Verlag, 2000, pp. 200–207.
[31] T. Leblanc, J. Subhlok, E. Gabriel, A high-level interpreted MPI library forparallel computing in volunteer environments, in: 4th Workshop on DesktopGrids and Volunteer Computing Systems, PCGrid 2010, Melbourne, Australia,May 2010.
[32] Luis F.G. Sarmenta, Sabotage-tolerance mechanisms for volunteer computingsystems, Future Generation Computer Systems 18 (4) (2002) 561–572.
[33] Deqing Zou, Weide Zheng, Jinjiu Long, Hai Jin, Xueguang Chen, Constructingtrusted virtual execution environment in P2P grids, Future GenerationComputer Systems 26 (5) (2010) 769–775.
Alejandro Calderón obtained his M.S. in ComputerScience from the Universidad Politecnica de Madrid in2000 and his Ph.D. in 2005 from the Universidad Carlos IIIde Madrid. He is an Associate Professor in the ComputerScience Department at the Carlos III University of Madrid(Spain).
His research interests include high performancecomputing, large distributed computing, and parallel filesystems. Alejandro has participated in the implementationofMiMPI, amultithread implementation ofMPI, and in theExpand parallel file system. He is the coauthor of more
than 40 articles in journals and conferences.
Felix García-Carballeira received his M.S. degree inComputer Science in 1993 at the Universidad Politecnicade Madrid, and his Ph.D. degree in Computer Science in1996 at the same university. From 1996 to 2000 he wasan Associate Professor in the Department of ComputerArchitecture at the Universidad Politecnica de Madrid.
He is currently a Full Professor in the ComputerScience Department at the Universidad Carlos III deMadrid. His research interests include high performancecomputing and parallel and distributed file systems. Heis co-author of 13 books and has published more than 80
articles in journals and conferences.

A. Calderón et al. / Future Generation Computer Systems 28 (2012) 881–889 889
Borja Bergua obtained his Computer Science degree atthe Universidad Carlos III de Madrid. He has been anAssistant Professor since 2004 at the Universidad Carlos IIIde Madrid teaching Computer Architecture and OperatingSystems.
His research interest is focused on parallel anddistributed Systems.
Luis Miguel Sánchez obtained his Computer Sciencedegree at the Universidad Carlos III de Madrid in 2003.He has been an Assistant Professor since 2003 at theUniversidad Carlos III de Madrid teaching ComputerArchitecture and Operating Systems. His research interestis focused on parallel and distributed systems, especiallydata storage systems.
Jesús Carretero is a Full Professor of Computer Ar-chitecture and Tecnology at Universidad Carlos III deMadrid (Spain), where he has been responsible for thatknowledge area since 2000. He is also Director of theMaster in Administration and Management of ComputerSystems, that he founded in 2004. He also serves and hasserved as a TecnologyAdvisor in several companies. His re-search activity is centered on high-performance comput-ing systems, distributed systems and real-time systems.He has participated in and led several national and in-ternational research projects in this area, funded by the
Madrid Regional Government, the Spanish Education Ministry and the EuropeanUnion. As a result of his research activity, he has obtained the following awards andgrants: The 2007 World Congress in Computer Science, Computer Engineering andApplied Computing; WorldComp ‘07 Achievement Award for Organization Contri-butions, Las Vegas, USA, 2007; International Symposium on Computers and Com-munication 2005, Award in Recognition for the Tutorial Session Success, IEEE 2005;NATO Grant for Studies Abroad. Jesús Carretero obtained his M.Sc. in Informaticsfrom Universidad Politecnica de Madrid in 1989, and his Ph.D. in Informatics fromUniversidad Politécnica de Madrid in 1995 with Honors. He is a senior memberof IEEE.





























