Embed Size (px)
Citation preview

E-service Searching on the Web
Celia Ghedini Ralha1 , Jose Carlos Loureiro Ralha1 , Charles Antonio Nascimento Costa1
1Departamento de Ciencia da ComputacaoInstituto de Ciencias Exatas
Universidade de BrasıliaCampus Universitario Darcy RibeiroCaixa Postal 4466 - CEP 70.919-970
Brasılia DF
{ghedini,ralha }@cic.unb.br
Abstract. There are many limitations at the state of the art of electronic service thatrequires original research results and practical development experiences among re-searchers and application developers from different e-service intelligent related areas.Concerning e-service searching, the only based on attribute match is not sufficientenough to deal with partial matches and semantic conflicts on the Web. This paperproposes the use of a framework to automatic connect information on the Web, that in-volves qualitative spatial reasoning as a spatial metaphor to help the service discoveryissue in terms of relatedness and capability analysis. A system called HyperMap wasdeveloped aiming to make experiments on e-service searching on the Web.
Resumo.Ha muitas limitacoes no estado da arte daarea de servico eletronico, o qualrequer resultados de pesquisa original e desenvolvimento pratico de experiencias en-tre os pesquisadores e desenvolvedores de diversasareas relacionadas ao e-serviceinteligente. Relacionado ao e-service de busca, a abordagem baseada apenas no ca-samento de atributos nao e suficiente para lidar com o casamento parcial e os con-flitos semanticos na Web. Este artigo propoe o uso de um framework para coneccaoautomatica de informacao na Web, o qual involve raciocınio qualitativo como umametafora espacial para auxiliar no servico de descoberta, em termos de relacionamentosemantico e capacidade de analise. Um sistema chamado HyperMap foi desenvolvidovisando a experimentacao de e-service de busca na Web.
1. Introduction
Electronic services (e-services) offer great opportunities and challenges for many areas such asbusiness, finance, commerce, marketing and education. Thus, it involves various on-line ser-vice delivery systems and applications including e-government, e-business, e-commerce, and e-learning. Together with intelligent on-line services it has identified a new direction and next stagewith much higher quality and integrated information services. Web site classification through au-tomatic structuring of information done by intelligent e-services is a challenging task that requiresefforts from different research areas to provide adaptive, personalized, proactive and accessibilityfrom a broader variety of devices.
This paper proposes the use of a framework for Web site classification in the contextof e-service intelligent. This framework was theoretically presented in [Ralha, 1996a], aimingto automatic link information on the Web that can help in the features of dynamic and servicediscovery through the use of relatedness and advanced capability analysis. The authors believethat this approach can be useful to the business process since business process dynamics are onlypartially covered by current service descriptions in terms of operations or capabilities: businessdynamics with matching and partial matching algorithms are lacking. Considering the state of
V ENIA 474

the art service representation languages are not able to sufficiently capture the semantics of thebusiness domain and the structure of the service, e. g. the sub-service, the parts of the services,the overlapping, the identical or not relevant.
The rest of the paper is organized as follows. In section 2 we briefly discuss the basis ofthe proposed framework to e-service searching. In section 3 we present the system architecture.Section 4 includes a running example and in section 5 we discuss the system evaluation. Section6 we present some conclusions and related work.
2. Proposed Framework
Automatic e-service searching for Web sites involves dealing with large amount of informationto dynamically discover the relatedness and capability analysis. Our approach to this problem isa twofold one. First, we build a method of dynamic linking; secondly, if nodes can be viewedas spatial regions on the Web then these dynamic links can be used as a way of topologicallystructuring the space. As a space metaphor we propose to model the topology of the Web withqualitative spatial relations based on the primitive concept ofconnectionbetween spatial regions.We may say that the framework includes two ways of reasoning: quantitative relations, wherewe apply the dynamic linking method, and the qualitative relations through the use of spatialreasoning.
2.1. Dynamic Linking
In this work we use a method for the automatic computation ofrelatednessbetween nodes onthe Web, where conceptual connectivity or semantic proximity is considered. This method isimportant in our approach as it deals with large Web material where the activation of a node willautomatically indicate to the user the most relevant nodes without the need for the link betweenthe two nodes ever to have been explicitly coded.
In our approach, the use of dynamic linking to build the Web map is based on a mod-ified version of the computer model of human memory proposed at the cognitive researcharea [Hintzman, 1986]. For a more complete theoretical comprehension of the model see[Ralha and Ralha, 2003a]. We will briefly define the main elements of our framework:
• Attribute: an ordered list of features related to an object which represents a memory traceor a record of an experience.
• Probe: an active representation of an experience or the focus of our interest during asearching section. Each memory trace or record of an experience is assumed to be acti-vated according to its similarity to the probe (quantitative relation).
• Frame: a schematic representation of information associated to each Web site. A framehas the corresponding URL address, and a collection of attributes.
In our framework we focused the problem of measuring the degree of activation of a trace.[Kohonen, 1987] states that associative recall ought to have some form of the concept of similarity.We consider this very appropriate since the usefulness of a model of information depends on itsability for selective recall of the desired items. Different similarity measures (for a good overviewsee [Lee, 1999] and their evaluation [Dagan et al., 1999]) are available from the statistical naturallanguage processing (NLP) community. In our framework we have been using the Jaccard orTanimoto coefficientX∩Y
X∪Y for the experiments (see [Manning and Schuetze, 1999]), but we intendto use the cosine similarity measure, a normalized correlation coefficient, between two vectors of
attributes from a probe and activated frames (~x and~y) given bycos(~x, ~y) =Pn
i=1 xi.yi√Pni=1 x2.
√Pni=1 y2
The cosine similarity is a technique used in information retrieval (see[Baeza-Yates and Ribeiro-Neto, 1999]) which determines the similarity between documentsby measuring the cosine of the angles between vectors of terms, or attributes. Documents andqueries can be represented by vectors of terms, such that a system selects documents in responseto a query, or probe, by identifying documents whose vector representations are most similar tothat of the query vector.
V ENIA 475

x
C1 C2 C3
x y y x y
Figure 1: The three C relations (limit cases); a solid line indicates closure.
The cosine measure proved to be one of the most important measure in the area of statis-tical NLP; though it is not a metric in the strong sense it has been quite successfully applied. Notethat this function is independent of the length of the attribute vectors and that the degree of simi-larity grows directly with the value ofcos(~x, ~y) (e.g.cos(~x, ~y) = 0.5 represents higher correlationthancos(~x, ~y) = 0). We have defined an algorithm to dynamic link related material on the Web,where we used a threshold limit to activate the frames. We might notice that the whole activationprocess is highly context-specific and how a frame emerges will vary according to which objecthave been linked by the probe.
2.2. Qualitative Reasoning
We now focus the problem of intelligent mapping of the domain material already created by dy-namic linking which is done through the application of a theory of qualitative spatial reasoning.This intelligent Web site classification aid is intended to give a bird’s-eye view of the content of alarge multi-dimensional information space. This is intended to help users during business activi-ties through the abilities of connectedness and capability analysis related to the service discoveryissue.
The basic part of the theory assumes a primitive dyadic relationC(x, y) read asx con-nects withy which is defined on regions. However, the concept of connection is far from simple.As shown in [Cohn and Varzi, 2003], there are many different ways to understand the primitiveC(x, y), as for example
C1(x, y) ⇔ x ∩ y 6= ∅C2(x, y) ⇔ x ∩ c(y) 6= ∅ or c(x) ∩ y 6= ∅C3(x, y) ⇔ c(x) ∩ c(y) 6= ∅
where eachCn, 1 ≤ n ≤ 3, can be understood as the connection predicate in the object languageof a theory and the double arrow as conveying the intended semantic meaning. ForC1, setsx andy share a common entity; forC2, one of the sets shares an entity with the closure of the other;for C3, the closures ofx andy share a common entity.1 Figure 1, from [Cohn and Varzi, 2003],provides a pictorial explanation forC1, C2, andC3. For the Web hyperspace metaphor, ifx is aprobe vector andy a Web page, thenC1 meansx andy share some terms;C2 means one vectorshare some terms with thesemantic closure2 of the other; andC3 means both vector share someelements on the semantic closure of them.C3 is surely the most interesting kind of connection touse; indeed, it is the one used in the present paper due to stemmer usage.
When computing the correlation coefficient between two vectors of attributes (list of ob-ject features) of a frame and the probe, operations are carried out which can be used to inducea topological structure on the information space. A set of spatial relations are used based onthe theory of space and time developed in a series of papers. The revised theory can be foundin [Randell et al., 1992] and a survey in [Cohn, 1999]. The theory has evaluated, extended andimplemented a theory of space and time based on ([Clarke, 1981], [Clarke, 1985]) calculus ofindividuals based on connection and is expressed in the many sorted logic LLAMA [Cohn, 1987].
With respect to connection relationC, two axioms are used to specify thatC is reflexiveand symmetric. In terms of points incident in regions,C(x, y) holds when the topological closure
1Topologically speaking, a closure operator on a setA is a functionc associating with each subsetx of A a subsetc(x) satisfying: (i)∅ = c(∅); (ii)x ⊆ c(x); (iii) c(c(x)) ⊆ c(x); (iv) c(x) ∪ c(y) = c(x ∪ y).
2Understand semantic closure of a term as a correspondent term or a connected term as exemplified by the use ofstemmer, such as [Paice, 1990], and ontologies.
V ENIA 476

of the regionsx andy share a common point. With the relationC(x, y), eight jointly exhaustiveand pairwise disjoint dyadic relations are defined. These relations describe different degrees ofconnection between regions from being externally connected, to sharing mutual parts and beingidentical.
In our framework (similarly to [Lehmann and Cohn, 1994]) we currently use five basicspatial relations formed by disjoining certain pairs of the eight mentioned above. Given the vectorof attributes from activated frames(x) and from a probe(y), we may say that the two eithercoincideEQ(x, y), overlapPO(x, y), have proper containmentPP (x, y) (as PP is asymmetricsupports an inverse), inverse of proper containmentPP−1(x, y), or are disjointDR(x, y) (whatmeans their closures have empty intersection and therefore, the attribute and probe vectors areorthogonal).
The five predicates presented can be formally defined as below, whereP andO are auxil-iary predicates used to define the others:
DR(x, y) ≡def ¬C(x, y)P (x, y) ≡def ∀z[C(z, x) → C(z, y)]PP (x, y) ≡def P (x, y) ∧ ¬P (y, x)EQ(x, y) ≡def P (x, y) ∧ P (y, x)O(x, y) ≡def ∃z[P (z, x) ∧ P (z, y)]PO(x, y) ≡def O(x, y) ∧ ¬P (x, y) ∧ ¬P (y, x)PP−1(x, y) ≡def PP (y, x)
The qualitative closeness between the set of attributes from activated frames(x) andthe set of attributes from the probe(y) corresponds to the left-to-right order in Fig. 2 from[Lehmann and Cohn, 1994]. Although, all relation may provide information to the user we maysay that to have an empty intersectionDR(x, y) is worst, to overlapPO(x, y) is better, to haveproper containmentPP (x, y) is still better, and to coincidex = y is perfection. Proper contain-mentPP and its inversePP−1 are incomparable3.
EQ(A,B)
PP−1
(A,B)
DR(A,B)
PO(A,B)
PP(A,B)
Figure 2: This figure depicts the possible transition between the five binary spatial rela-tions, assuming a notion of continuity.
We have briefly discussed the basis of the framework used in terms of quantitative andqualitative reasoning over related material on the Web. For service representation, discovery andcomposition for e-marketplaces the framework presented allow comprehensive service semanticsmaking possible to define matching algorithms to determine relations of identity (EQ), part-of(PP , PP−1), overlapping (PO) and not relevant or disconnection (DR). The definition of suchalgorithms improve capability analysis related to service discovery issues allowing to capture thesemantics of the business domain and the structure of the service.
3. System Architecture
A system to implement the framework for Web site classification was developed during 2004. Thesystem is called HyperMap, coded in Java 1.4.1. The system consists of six main components asshow in Fig. 3.
1. A User Interface: it enables the user to interact with the system
3See Figure 4 of [Lehmann and Cohn, 1994] for examples.
V ENIA 477

Similarity Computation Spatial Relations Computation
Reasoning Component
Linguistic Component
HTML filtering Text steamization Frame generation
Web browsing Component(google or yahoo)
The Web
1
4
5
6
HyperMap´ s User Interface
Input Parameters & Validation Component2
3
Map Generation Component
qualitative reasoningquantitative reasoning
DBMS
Figure 3: HyperMap’s architecture.
2. The Input and Validation Component: it validates the user inputs such as probe keywords,similarity threshold limit (default 0, but user can set in the range of0 ≤ S ≤ 1), maximumresults to be displayed, the Web search engine to be used in the search (Google or Yahoo).System validates the entered parameters and stores them in the DBMS.
3. The Web Browsing Component: it crawls the Web to find static or dynamic pages andrecords the outgoing links. The Web site topology of related material is collected throughGoogle or Yahoo’s API.
4. The Linguistic Component: At this phase, system filters the irrelevant words from the ma-terial collected through the use of stoplists. Words such as articles, prepositions, pronounsand special characters are eliminated leaving only content words/tokens to be computedaccording to their frequency. Morphological variations of the content words/attributes aretreated by stemmer processing. The most representative content words (in terms of fre-quency) will be included as attributes in the corresponding frames. Frames are generatedand stored at the DBMS.
5. The Reasoning Component: it performs two kinds of reasoning, the quantitative phasethrough the dynamic linking approach and the qualitative phase with the spatial relations.Using the dynamic linking approach, in this phase the system will build the frames foreach URL given by Google or Yahoo’s results. First, the similarity measure (S(x, y))will be computed between each framex and the probey stored at the DBMS, taking intoaccount the similarity threshold. Then, the spatial relations will be computed betweenthe framesx and probey to map the Web:EQ(x, y), PO(x, y), PP (x, y), PP−1 andDR(x, y). The similarity measure and spacial relations hold among the related framesand the probe are saved in the DBMS.
6. The Map Generation Component: The resulting set of spatial relations and similarityindex, hold among probe and frames, already stored at the DBMS, has to be presented touser through the Web map. This component is still under development stage.
4. A Running Example
In this section we use a running example to show how HyperMap works. In this example, wewant to sell a car and we are looking for car dealers through an e-service searcher. For thatreason we done a search on the Web at the 10th of March 2005, giving as keywords:sell car .HyperMap’s interface is shown in Fig. 4.
The left part of the screen shows the user’s input parameters. The right part of the screenshows the search results with the frame ID, the similarity measure, the spatial relations and thelist of attributes for each frame. Note that HyperMap has given 20 sites that the user might be
V ENIA 478

Figure 4: HyperMap interface screen with sell car as a probe.
interested in, according to the max results parameter on the left panel. If we look at the similaritymeasure column, we note that frame number seven is the most similar site on quantitative figures.In addition, if we look at the spatial relations column, we note that the most significant site inqualitative terms is also number seven, which holds an equal relation to the probe. Note that thereare many other spatial relations among the presented sites, e.g. fivePP , twoPP−1, sevenPO andfive DR which follow a degree of importance as the left-to-right order in Fig. 2. Finally, framesone, six, eleven and sixteen hold a disjoint relation to the probe because they have no attributes intheir frames, since we are not treating non textual contents. Frame five holds a disjoint relation asit does not share any attribute to the probe.
Figure 5: HyperMap interface screen with carestoration.com as a probe.
Suppose one is interested in BMW around northern California and has given Hyper-Map the following probesell BMW Northern California . Among the twenty re-
V ENIA 479

turned sites, one is interested in checking the similarity and spatial relations using the sitewww.carestoration.com/sell.htm as a probe. Figure 5 shows this case. Note that thebiggest similarity measure are sites nineteen, thirteen, eighteen and fifth, which hold a (PO) rela-tion to the probe; what means they are all very close related to the probe site. More specificallytalking carestoration.com is a good BMW dealer in San Diego county and so are sitesnineteen and eighteen located in Monterey. Note also that although site thirteen is hosted in Bel-gium it has a link tohttp://bmw.niello.com/ in northern California. In summary, siteswith higher similarity measures, holding a (PO) relation to the probe are all good BMW deal-ers and work around northern California area. Thus, for service discovery and composition overe-marketplaces, HyperMap allows comprehensive service making possible to determine differentrelations from the worst (DR) to the best (PO). Therefore one could find interesting relationsamong sites on the Web improving capability analysis related to service discovery issues.
5. EvaluationSince the proposed technique deals with subjective interestingness of information, it is difficult tohave an objective measure of its performance. Although, there are many intelligent approachesto find interesting and useful information on the Web, there is no existing system that is able toperform our task in terms of relatedness and advanced capability analysis. Thus, we could notperform a comparison. On the other hand, we have carried out a number of experiments involvingsix regular search engine users to check whether HyperMap is useful in practice. In this sectionwe discuss our application experiences and then report experiments results on the time efficiencyof the system.
5.1. Application Experiences
The six users are from a public educational institution in Brazil, with different backgrounds andeducational levels, and all are daily users of Web searchers such as Google and Yahoo. Accordingto their opinion, HyperMap helped them find a lot of connections of information that they didnot find previously. The main reason is that Google and Yahoo resulting searching always have alarge number of pages and related links without giving any clue to specific relations among them.For example, the competitor’s site of a car dealer company can have many content relations to beexplored when checked against many other competitors. HyperMap can help users to find manypreviously undiscovered relations among interesting pages returned through a Web search engine(at the moment, Google and Yahoo are being used).
HyperMap can also classify in terms of importance the relation given assuming a notionof continuity from identity,EQ(x, y), to disconnection,DR(x, y), according to the proposedframework already presented in subsection 2.2. HyperMap helped users to find some previouslyunknown links since it gives a bird’s-eye view of the large amount of returned links. In termsof business application HyperMap as an e-service tool can offer great opportunities to improvecompanies Web site in relation to the competitor’s one, as many pieces of interesting informationwere discovered, e. g. unexpected services and alliances, outgoing links, which were all of im-mediate use to our user companies. With HyperMap any company site can be set the probe ofa search and then five spatial relations are going to be computed with the similarity index beingcalculated which allows the user company discover interesting kinds of connections to use to im-prove its own site, varying from coincident(EQ), overlapping(PO), proper-part,(PP, PP−1)and disconnection(DR) of site contents.
The users agreed that HyperMap helped them perform better analysis due to:
• quick focus on those potentially interesting pages or links,• with the difficulty of manual analysis users said that they often gave up after browsing
some top-level pages. HyperMap was able to help users perform a more complete analysisof a large amount of related sites,
• if a page is long, users often do not read it carefully and consequently may miss usefulinformation. HyperMap summarizes each page with keywords, which makes easier toinspect even manually,
V ENIA 480
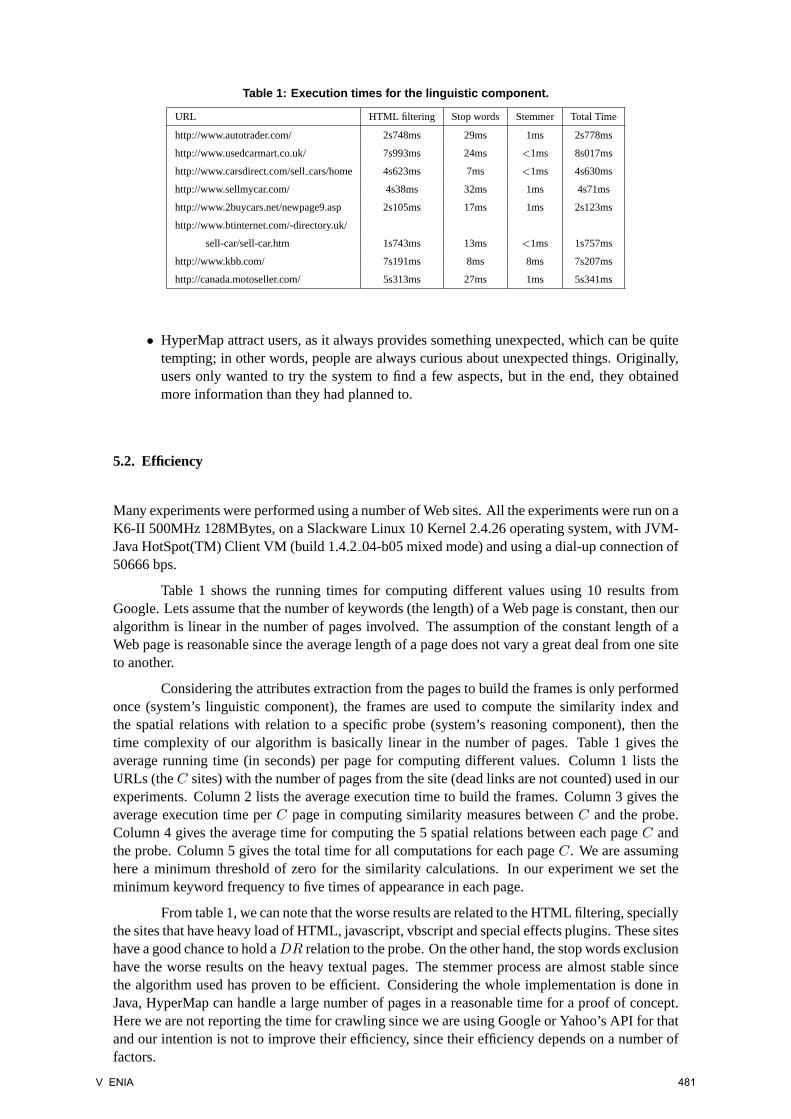
Table 1: Execution times for the linguistic component.
URL HTML filtering Stop words Stemmer Total Time
http://www.autotrader.com/ 2s748ms 29ms 1ms 2s778ms
http://www.usedcarmart.co.uk/ 7s993ms 24ms <1ms 8s017ms
http://www.carsdirect.com/sellcars/home 4s623ms 7ms <1ms 4s630ms
http://www.sellmycar.com/ 4s38ms 32ms 1ms 4s71ms
http://www.2buycars.net/newpage9.asp 2s105ms 17ms 1ms 2s123ms
http://www.btinternet.com/˜directory.uk/
sell-car/sell-car.htm 1s743ms 13ms <1ms 1s757ms
http://www.kbb.com/ 7s191ms 8ms 8ms 7s207ms
http://canada.motoseller.com/ 5s313ms 27ms 1ms 5s341ms
• HyperMap attract users, as it always provides something unexpected, which can be quitetempting; in other words, people are always curious about unexpected things. Originally,users only wanted to try the system to find a few aspects, but in the end, they obtainedmore information than they had planned to.
5.2. Efficiency
Many experiments were performed using a number of Web sites. All the experiments were run on aK6-II 500MHz 128MBytes, on a Slackware Linux 10 Kernel 2.4.26 operating system, with JVM-Java HotSpot(TM) Client VM (build 1.4.204-b05 mixed mode) and using a dial-up connection of50666 bps.
Table 1 shows the running times for computing different values using 10 results fromGoogle. Lets assume that the number of keywords (the length) of a Web page is constant, then ouralgorithm is linear in the number of pages involved. The assumption of the constant length of aWeb page is reasonable since the average length of a page does not vary a great deal from one siteto another.
Considering the attributes extraction from the pages to build the frames is only performedonce (system’s linguistic component), the frames are used to compute the similarity index andthe spatial relations with relation to a specific probe (system’s reasoning component), then thetime complexity of our algorithm is basically linear in the number of pages. Table 1 gives theaverage running time (in seconds) per page for computing different values. Column 1 lists theURLs (theC sites) with the number of pages from the site (dead links are not counted) used in ourexperiments. Column 2 lists the average execution time to build the frames. Column 3 gives theaverage execution time perC page in computing similarity measures betweenC and the probe.Column 4 gives the average time for computing the 5 spatial relations between each pageC andthe probe. Column 5 gives the total time for all computations for each pageC. We are assuminghere a minimum threshold of zero for the similarity calculations. In our experiment we set theminimum keyword frequency to five times of appearance in each page.
From table 1, we can note that the worse results are related to the HTML filtering, speciallythe sites that have heavy load of HTML, javascript, vbscript and special effects plugins. These siteshave a good chance to hold aDR relation to the probe. On the other hand, the stop words exclusionhave the worse results on the heavy textual pages. The stemmer process are almost stable sincethe algorithm used has proven to be efficient. Considering the whole implementation is done inJava, HyperMap can handle a large number of pages in a reasonable time for a proof of concept.Here we are not reporting the time for crawling since we are using Google or Yahoo’s API for thatand our intention is not to improve their efficiency, since their efficiency depends on a number offactors.
V ENIA 481

6. Conclusions
This paper proposes the use of a framework to automaticallyconnectinformation on the Webthat involves dynamic linking and qualitative spatial reasoning as a spatial metaphor to help theservice discover issue in terms of semantic relatedness. As a proof-of-concept, a system calledHyperMap was developed at University of Brasilia under a multidisciplinary research leading todifferent applications. HyperMap may help the knowledge engineer’s initial understanding ofthe domain during the conceptualization process of knowledge acquisition (KA). In this case, thestructuring of informal knowledge can be understood as a pre-processing to the KA process as in[Ralha, 1996b]. Still considering the Web map, users can benefit either to extract or to discoveruseful information on the Web [Ralha and Ralha, 2003b].
To the best of our knowledge, related work on semantic relatedness on the Webis done through infrastructure resources, methodology and tools focusing ontology develop-ment such as [Maedche et al., 2003], [Bozsak et al., 2002], [Pinheiro and de C. Moura, 2004] and[Agarwal and Lamparter, 2005]. These approaches encompass extensional logics like descriptionlogic. Unlikely the main trend on semantic relatedness on the Web, the approach presented inhere brings originality in the sense that encompass a kind of intensional reasoning through thesemantics mapped onto the spatial metaphor.
The presented system needs further development in order to permit the whole evaluationof the used framework. In addition, this multidisciplinary approach maintains different subjects ofresearch projects, such as refining the automatic extraction of attributes and concepts from textualand non-textual information since the Web is getting more and more image oriented. Also thevisualization issue to present the search results may benefit from using new technologies such asvirtual reality to present large amount of related information, which would improve interactionand adaptability. Finally, this paper reports on research under evaluation. However, we believethat the framework and the system presented, encompass an useful approach to the challengingtask of e-service searching on the Web.
References
Agarwal, S. and Lamparter, S. (2005). sMart - a semantic matchmaking portal for electronicmarkets. InProceedings of the 7th International IEEE Conference on E-Commerce Technology2005, Munich, Germany. IEEE Computer Society.
Baeza-Yates, R. and Ribeiro-Neto, B. (1999).Modern Information Retrieval. Addison-Wesley.
Bozsak, E., Ehrig, M., Handschuh, S., Hotho, A., Maedche, A., Motik, B., Oberle, D., Schmitz,C., Staab, S., Stojanovic, L., Stojanovic, N., Studer, R., Stumme, G., Sure, Y., Tane, J., Volz,R., and Zacharias, V. (2002). Kaon - towards a large scale semantic web. In Bauknecht, K.,Tjoa, A. M., and Quirchmayr, G., editors,E-Commerce and Web Technologies, Third Interna-tional Conference, EC-Web 2002, Aix-en-Provence, France, September 2-6, 2002, Proceedings,volume 2455 ofLecture Notes in Computer Science, pages 304–313. Springer.
Clarke, B. L. (1981). A calculus of individuals based on ‘Connection’.Notre Dame Journal ofFormal Logic, 23(3):204–218.
Clarke, B. L. (1985). Individuals and points.Notre Dame Journal of Formal Logic, 26(1):61–75.
Cohn, A. G. (1987). A more expressive formulation of many sorted logic.Journal of AutomatedReasoning, 3:113–200.
Cohn, A. G. (1999). Qualitative spatial representations. InProc. IJCAI-99 Workshop on AdaptativeSpatial Representations of Dynamic Environments.
Cohn, A. G. and Varzi, A. (2003). Mereotopological connection.Journal of Philosophical Logic,32:357–390.
Dagan, I., Lee, L., and Pereira, F. (1999). Similarity-based models of cooccurrence probabilities.Machine Learning, 34(1-3):43–69.
V ENIA 482

Hintzman, D. L. (1986). ‘Schema abstraction’ in a multiple-trace memory model.PsychologicalReview, 93(4):411–428.
Kohonen, T. (1987).Content-Addressable Memories. Springer-Verlag, New York.
Lee, L. (1999). Measures of distributional similarity. InProc. of the ACL99, pages 25–32.
Lehmann, F. and Cohn, A. G. (1994). The EGG/YOLK Reliability Hierarchy: Data translation andmodel integration using ordered sorts with prototypes. InProc. 3rd Int. Conf. on KnowledgeManagement (CIKM94), Gaithersburg, Maryland. ACM Press.
Maedche, A., Staab, S., Stojanovic, N., Studer, R., and Sure, Y. (2003). SEmantic portAL - theSEAL approach. In Fensel, D., Hendler, J., Lieberman, H., and (eds.), W. W., editors,Spinningthe Semantic Web, pages 317–359. MIT Press, Cambridge, MA.
Manning, C. D. and Schuetze, H., editors (1999).Foundations of Statistical Natural LanguageProcessing. MIT Press.
Paice, C. D. (1990). Another stemmer.SIGIR Forum, 24(3):56–61.
Pinheiro, W. A. and de C. Moura, A. M. (2004). An ontology based-approach for semantic searchin portals. InProc. of the 15th Int. Workshop on Database and Expert Systems Applications(DEXA’04). IEEE Computer Society.
Ralha, C. G. (1996a).A Framework for Dynamic Structuring of Information. PhD thesis, Schoolof Computing, University of Leeds.
Ralha, C. G. (1996b). Structuring information in a distributed hypermedia system. In Shadbolt, N.,O’Hara, K., and Schreiber, G., editors,Advances in Knowledge Acquisition - Proc. 9th EKAW,pages 163–178. Springer-Verlag.
Ralha, C. G. and Ralha, J. C. L. (2003a). A framework for dynamic structuring of information. Inde O. Anido, R. and Masiero, P. C., editors,Anais do IV ENIA/XXIII Congresso da SBC, pages173–182. SBC. Volume VII.
Ralha, C. G. and Ralha, J. C. L. (2003b). Intelligent mapping of hyperspace. In Liu, J., Liu, C.,Klush, M., Zhong, N., and Cercone, N., editors,Proc. IEEE/WIC International Conference onWeb Intelligence, pages 558–561. The IEEE, Inc.
Randell, D. A., Cui, Z., and Cohn, A. G. (1992). A spatial logic based on regions and connec-tion. In Proc. 3rd Int. Conf. on Knowledge Representation and Reasoning, pages 165–176, SanMateo. Morgan Kaufmann.
V ENIA 483





























