Embed Size (px)
Citation preview

A Probabilistic Relational Approach for Web
Document Clustering
E. Fersini a,∗ E. Messina a F. Archetti a,b
aDipartimento di Informatica Sistemistica e Comunicazione, Universita degli Studidi Milano-Bicocca, Italy
bConsorzio Milano Ricerche, Italy
Abstract
The exponential growth of information available on the World Wide Web, andretrievable by search engines, has implied the necessity to develop efficient and ef-fective methods for organizing relevant contents. In this field document clusteringplays an important role and remains an interesting and challenging problem in thefield of web computing. In this paper we present a document clustering method,which takes into account both contents information and hyperlink structure of webpage collection, where a document is viewed as a set of semantic units. We ex-ploit this representation to determine the strength of a relation between two linkedpages and to define a relational clustering algorithm based on a probabilistic graphrepresentation. The experimental results show that the proposed approach, calledRED-clustering, outperforms two of the most well known clustering algorithm ask-Means and Expectation Maximization.
Key words: Relational Document Clustering, Relational web structure estimation
Please cite: E. Fersini, E. Messina, F. Archetti. A Probabilistic Relational Approachfor Web Document Clustering. Information Processing and Management, 46(2), pp.117 - 130, 2010. doi:10.1016/j.ipm.2009.08.003∗ Tel.: +39 0264487918; fax: +39 0264487880
Email address: [email protected] (E. Fersini).
Preprint submitted to Elsevier Science 20 January 2015

1 Introduction
Due to the increasing volume of information available on the World WideWeb, several attempts to handle the large number of documents returned bysearch engines have been made. Traditional Data Mining and Information Re-trieval approaches aim at finding common patterns in a document collectionby considering all instances as independent. In order to organize search engineresults, different clustering methods have been explored based on this inde-pendence assumption. These algorithms can be categorized into partitional,hierarchical and model-based.Partitional clustering decomposes the dataset into disjoint clusters throughthe minimization/maximization of a local (or global) criterion based on somemeasure of dissimilarity/similarity. The most widely-used algorithm in parti-tional document clustering is known as K-Means (MacQueen, J.B. (1967)).Several variations stemmed from it are among Constrained k-Means (Wagsta,K. et al. (2001)), Spherical k-Means (Zhong, S. (2005) and Peng, J. & Zhu,J. (2006)), and Bisecting k-Means (Steinbach, M et al. (2000) and Archetti,F. et al. (2006)).The hierarchical clustering approach aims at obtaining a hierarchy of clus-ters through an iterative process that merges small clusters into larger ones(agglomerative algorithms) or splits large clusters into smaller ones (divisivealgorithms). Interesting approaches belonging to this class are presented inDittenbach, M. et al. (2001), Fung, B.C.M. et al. (2003) and Joo, K.H,Lee, S. (2005). There are some hybrid document clustering approaches thatcombine hierarchical and partitional algorithms. Two interesting instances be-longing to this class are Buckshot (Cutting, D. et al. (1992)), which is a basick-Means but uses a hierarchical approach to set cluster centroids, and CSM(Lin, C. & Chen, M. (2005)), which partitions the input dataset into severalsmall sub-clusters in the first phase and then continuously merges the sub-clusters based on cohesion in a hierarchical manner in the second phase.Finally, model-based clustering attempt to learn generative models from doc-uments. These methods are based on the assumption that the documentsreferring to a given topic are characterized by Gaussian distributions. The en-tire document collection can therefore be modeled as a mixture of Gaussians,where each of these components represents a document class. The clusteringproblem consists in making the best possible estimation of the componentdensities and assign a cluster label to each document based on the most likelycomponent to have generated it. Zhong, S. & Ghosh, J. (2003) describes aunified framework based on a bipartite graph view of data, where each docu-ment is connected to a generative model and the connection between them isgiven by a log-likelihood function.
All of these approaches are consistent with the classical statistical inferenceproblem formulation, in which the instances are independent and identically
2

distributed (i.i.d.). In the real world instances belonging to a document collec-tion do not exist in isolation because they could be interrelated through a setof relationships. Two web pages can be related because they share the sameauthor, topic, web domain, or because they are connected by a more explicitrelationship represented by hyperlinks.Figure 1 shows different web representation models. A web page collection canbe viewed as a set of unrelated document, where each web page di is indepen-dent and described by its terms wj, see figure 1(a). This is the most populardocument representation, known as the ”bag-of-words” model. An alternativerepresentation, that tries to include some information about linked documents,proposed by Chakrabarti, S. et al. (1998), is showed in figure 1(b). Here eachdocument di is described by its ”bag-of-words” and by a set of ”linked words”belonging to the linked documents.A more extensive representation, that holds relational reasoning, is depicted infigure 1(c), where a web page collection is characterized by using not only doc-ument ”bag-of-words”, but also considering the relations instantiated throughthe hyperlinks.
(a) (b)
(c)
Fig. 1. Web Representations
A propositional representation of the WWW, in which a document collection
3

can be represented by using a single ”flat” table of ”bag-of-words”, leads us toa substantial loss of information related to the relational features, highlightingthe necessity to undertake the relational reasoning direction.
Even if unsupervised relational learning is still in a early stage, in the lastyears a variety of extensions of traditional clustering methods has been pro-posed to deal with more general data structures, which accounts for relations.The first contribution in this direction was given by Taskar, B. et al. (2001),who developed a relational clustering approach based on Probabilistic Rela-tional Models (PRM), introduced by Friedman, N. et al. (2001). PRM canbe viewed as a bayesian networks extended to the relational domain throughthe first-order logic, which accounts for relations.Other interesting approaches, based on mutual reinforcement clustering, arethe frameworks proposed in Zeng, H.J. et al. (2002) and Wang, J. et al.(2003). In this case the document collection is represented by a two-layeredgraph of pointing and pointed pages, and the clustering algorithm iterativelygroup one layer in order to mutually reinforce grouping of the other layer.Two other interesting approaches, based on graph partitioning, are presentedin Neville, J. et al. (2003) and Takahashi, K. et al. (2005). In Neville, J. et al.(2003), the authors investigate different hybrid techniques, adapting similaritymetrics and traditional algorithms for graphs, in order to include informationabout link structure and contents. In Takahashi, K. et al. (2005) the resultsof two clustering techniques are combined in order to produce a clustering so-lution: the first one considers a distance between web pages based on in-linksand out-links, while the second one uses a the distance based on their vectorspace model representation (Salton, G. et al. (1975)). Their respective resultsare combined through the conjunction of the two clustering output.
These approaches assume a binary relational representation of data, wherea connection between two objects assumes either 0 or 1 value. In the realworld, links between web pages can represent relation of different ”degrees”of importance, i.e. some linked pages may help the inference of the linkingpage topic while some others may only add noise. For example the link froma page speaking about football to a page for the pdf reader download assumesless importance than a link between two football web pages. In this direction,in which a relation between two objects can be represented by a probabilis-tic connection, we propose RED-clustering (RElational Document clustering).The main idea of the proposed approach is to retain and weight the relationalstructure in order to enhance the knowledge related to a set of documents.In this way a relational reasoning combines the instances contents with thelinked web page contents and the structural information among them.RED-clustering considers the WWW as a graph in which nodes are docu-ments and the link among them are weighted according to the strength oftheir relationships. In order to weight the relational structure underlying aweb collection, we perform a structural analysis based on document visual
4

layout perception. Semantic blocks containing hyperlinks are identified andevaluated w.r.t the origin and the destination page in order to associate toeach link a value representing the ”strength” of the relationship (in section2.1 we will define this value as jumping probability).
RED-clustering performs each instance cluster assignment, following the as-sumption that the category of web page is conditionally independent of itsancestors given its parents, considering both ”bag-of-words” contents rep-resentation and the underlying weighted relational structure. The proposedapproach has been validated with respect to two of the most well known al-gorithm: k-Means (MacQueen, J.B. (1967)) and Expectation Maximization(Dempster, A. et al. (1977)).
The outline of this paper is the following. In section 2 we present our method-ology with respect to the web document clustering domain. In Section 3 wedescribe the dataset and the performance measure used for validating our ap-proach. In Section 4 experimental results are presented and discussed. Finally,in Section 6 conclusions are derived.
2 RED-clustering
A link from a web page A to a web page B can be viewed as a reference interms of recommendation, in which A ”ensures” the web page B validity onthe same or related topic. In this sense links include highly semantic clues,but we have to take into account some exceptions : (1) some web pages aresimply lists of hyperlinks and contain no direct information themselves; (2)links contain semantic information which will be lost when they are treatedas simple text; (3) links are noisy, some links lead to related documents, butothers don’t; (4) two web pages could be linked because they share a partof the same macro-topic, but do not describe the same argument; (5) a linkbetween two web pages could be meaningful for a sub-part of the involvedpages.A simple example can be viewed in figure 2: (1) the origin page is composedby a set of hyperlinks, with no descriptive text (orange frame); (2) the link inthe pink frame, if considered as a simple text, doesn’t give any useful infor-mation; (3) among the listed links, two are noisy (yellow frames); (4) the twolinked pages are related because they share the same macro-topic art, but theydon’t describe the same argument: the origin page is about dance, while thedestination page is about music; (5) only a sub part of the origin document(red frame) is referred to the argument of the linked page.
The proposed relational clustering approach, which takes into account theabove considerations, works as follows: if a web page A is referenced by a set
5

Fig. 2. Exceptions in highly semantic clues of links
of ancestors of several categories, then its probability to belong to one of thiscategory can be determined not only by its contents, but also analyzing thecontents of its ancestors and the strength of relations with them.
Therefore, in order to apply the proposed relational clustering algorithm weneed to estimate the strength of relations.
2.1 Jumping Probability Estimation
Most of the well known clustering algorithms consider a ”flat” data represen-tation of contents, or in the best case, binary relationships among web pages(linked/not linked). To overcome these limitations and take into account se-mantic relation triggered by links, we consider a relation between two pagesas a probabilistic link.
Intuitively we can think about a probabilistic link, in a web document cluster-ing domain, as the HTML element that a web surfer chooses to follow duringits browsing: a user that observes a web page di of interest (belonging to agiven category), will be motivated in jumping forward to dm if the link (i,m)leads to a page whose semantic is representative of the same interest. Oth-erwise user will go back to di and will not follow that link. In the documentclustering domain, the jumping behavior described above, combined with thereference validity given by the author of an hyperlink, suggest to consider thelink as an indication that two pages belong to the same cluster with a givenprobability.
In this way, modeling the web as a directed web graph G = (V,E), where Vrepresents the set of web pages and E the edges among them, a probabilisticlink (i,m) ∈ E between di, dm ∈ V describes the probability JP (i,m) to jumpfrom di to dm estimated as the degree of textual coherence that origin page di
6

and destination page dm share through the link (i,m).
In order to estimate JP (i,m), we need to evaluate the degree of textual co-herence that the origin and destination page share through the link (i,m).In particular, we need (1) to identify which semantic portion of a web pagecontains a probabilistic link and (2) to evaluate its coherence w.r.t. the originand the destination pages.
The first activity is aimed at partitioning a html document, following the ideathat it can be viewed not as an atomic unit but also as a granular composi-tion of sub-entities. A multi-entity document representation, that reflects howpeople perceive a web page, help us to identify the semantic area of web pagesin which a hyperlink is embedded (wrapped). For this purpose we can see aweb page di belonging to a document collection Q as:
di = (Θi,Φi) where
Θi = {di1, di2, ..., dik, ...din} , Φi = {φi1, φi2, ..., φim}(1)
Θi represents the finite set of visual blocks and Φi is the set of horizontal andvertical separators. A visual block dik ∈ Θi denotes a semantic part of the webpage, does not overlap any other blocks and can be recursively considered asa web page.
Given a multi-entity web page representation, in order to estimate the jumpingprobability JP (i,m) related to a probabilistic link (i,m), we need to computethe coherence of the semantic area where a link is located w.r.t. the origin page(Internal Coherence) and w.r.t. the destination page (External Coherence).This lead us to define an enriched relational web representation as depictedin figure 3, where each document di is described by its ”bag-of-words” wj andthe relationships that hold among linked web pages are weighted through theJP (i,m) values associated to the link from page i to page m.The semantic areas containing links are identified by visual blocks and detectedby using spatial and visual cues described by the layout information embeddedinto the HTML language as reported in Cai, D. et al. (2003b). Before definingInternal and External Coherence we introduce the concept of link-block.
Definition 1 (Link Block) Given a document di = (Θi,Φi), a visual blockdik ∈ Θi is called link block, and denoted by d∗ik, if there exists a link (i,m)from d∗ik to a destination page dm.
Given a link block d∗ik we compute its coherence with respect to the origin andthe destination page through Internal and External coherence respectively.
Definition 2 (Internal Coherence) Given a web page of origin di = (Θi,Φi),
7

Fig. 3. The proposed weighted relational web Representations
let Θ∗i ⊆ Θi be the set of link blocks belonging to di, and let W be the set ofterms contained into d∗ik, i.e. W = {tj ∈ d∗ik}. The Internal Coherence (IC) ofa link block d∗ik w.r.t origin document di is defined as:
IC(d∗ik, di) =
1
|W ||W |∑j=1
γi(tj)− σik(tj)σik(tj)× γi(tj)
if |Θi| > 1
1 otherwise
(2)
where σik(tj) represents the number of occurrences of term tj into d∗ik, γi(tj)is the number of occurrences of term tj in di.
The IC index takes value into the interval [0, 1]. The extreme values are takenrespectively when no terms are shared between d∗ik and the rest of the doc-ument di and when di consists of a single visual block, i.e. |Θi| = |Θ∗i |=1.In this last case we set IC(d∗ik, di) = 1, stating that d∗ik is coherent to itselfand consequently to di. In all other cases, the Internal Coherence, assumesvalues between 0 and 1. In particular, if a subset of terms belongs to a visualblock d∗ik ∈ Θ∗i and these terms are frequent throughout the remaining partof the document di, then the IC index tends to 1 stating that d∗ik is likely tobe coherent to the document di. If these terms are not frequent in the rest ofthe document we may suppose that either d∗ik is not related for the documenttopic or we have a multi-topic document, determining IC values that tend to0. See Fersini, E. et al. (2008) for more details.
Definition 3 (External Coherence) Given a web page of origin di = (Θi,Φi)and a destination web page dm, let Θ∗i ⊆ Θi be the set of link blocks belonging
8

to di, and let W be the set of terms contained into d∗ik, i.e. W = {tj ∈ d∗ik}.The External Coherence (EC) of d∗ik w.r.t. the destination page dm is definedas:
EC(d∗ik, dm) =1
|W |ρm
|W |∑j=1
δmk(tj) (3)
where δmk(tj) represents the number of occurrences of term tj in dm such thattj appears into the visual block d∗ik, ρm is the number of occurrences of themost frequent term in dm out of all the terms in dm.
This metric estimates the External Coherence as the relative frequency ofterms tj that occur into the destination page dm (and at the same time ap-pears into the link block d∗ik), w.r.t the number of occurrences of the most“important” term in dm. If a subset of terms belongs to a visual blocks d∗ikand these terms are important into the destination document dm, then d∗ik islikely to be coherent to dm.
Definition 4 (Jumping Probability) Given an origin web page di and adestination web page dm belonging to a document collection Q, let d∗ik ∈ Θ∗i bethe visual block containing an outgoing hyperlink from di to dm. We define theJumping Probability (JP) from page di to page dm as the arithmetic mean ofInternal and External Coherence presented respectively in (2) and (3):
JP (i,m) =IC(d∗ik, di) + EC(d∗ik, dm)
2(4)
When the number of link blocks from an origin page di to a destination pagedm is greater than 1, an aggregation funtion can be used. In our investigationthe mean aggregation function has been used. Although the mean aggrega-tion function shown interesting results into the experimental investigation, itimplies some biases when several links to the same destination page exist. Inparticular, if an origin page has many outlink to the same destination pageand only one of these links has a high jumping probability, the mean aggre-gation tends to decrease the final index due to the low jumping probabilitiesof the remaining link block. Future investigation will be aimed at consideringfurther aggregation functions as the maximum one.
Considering the visual layout analysis of an origin page, we can easy identifysemantic hyperlink areas and compute their coherence w.r.t. the pointing andpointed pages, allowing the subsequent measurement of probability to jumpfrom a web page of interest to another one. The jumping probability, that
9

measures the degree of relationship of two linked pages in terms of probabil-ity to belong to the same cluster, can be used during the clustering processfor smoothing a cluster assignment of an instance by taking into account itsparents relations. The computational complexity for estimating the jumpingprobability is given in appendix A.1.
2.2 The clustering process
The clustering process starts by setting the parameter K as the number ofclusters to obtain. From a clustering point of view, since the author of webpage di of topic Ct gives a reference validity to the pointed page dm, we canassume that a jumping probability (JP) can measure the joint probability thatboth a linking and a linked pages belong to the same cluster (category), i.e.:
P (dm ∈ Ct ∧ di ∈ Ct|Pa(dm) = di) ≈ JP (i,m) (5)
where Pa(dm) = di means that di is the parent of dm, i.e. there exists ahyperlink from di to dm. If there exist a loop between di and dm and weare dealing the element di, we consider Pa(di) = dm as evidence and we useJP (k, i) during the inference process.
Unfortunately, during a clustering process, we don’t have certain evidenceabout a document category: we can only estimate the most probable topic onthe base of web page contents. In fact, the document class labels is hidden andwe can only estimate the probabilistic evidence that a document dm is similarto a representative element ct of the cluster Ct.Following the vector representation presented in Salton, G. et al. (1975) andthe terms weighting approach introduced in Salton, G. & Buckley, C. (1998),we can compute the probability of dm to belong to the cluster Ct as the angle
between−→dm and −→ct :
P (dm ∈ Ct) ≈ sim(dm, ct) =<−→dm,−→ct >
|−→dm||−→ct |
(6)
where−→d denote the vector representation of d as (wi1, wi2, ..., wi|Z|), where
wij is the weight of the jth term in the ith document. More details are givenin section 4.
Starting from this probabilistic evidence, we can smooth its probability assign-ment to a given topic by considering the probabilistic evidence of its parentsand the link among them.In this way, given a destination page dm and a set Sk of its directly linking
10

parents di, we can tune the probability assignment of dm to a given cluster byusing the Bayes’ rule as follows:
P (dm|Sk) = P (dm)|Sk|∏i=1
P (dm|Pa(dm) = di) = P (dm)|Sk|∏i=1
P (dm ∧ di|Pa(dm) = di)
P (di)(7)
In equation (7) P (dm) represents the prior probability for dm to belong to agiven cluster Ct, computed through (6), while the joint probability P (dm ∈Ct ∧ di ∈ Ct) is computed by (5).
In order to choose the maximum probability cluster assignment for the webpages, we need to evaluate each dm w.r.t. each cluster Ct and to considerthe probabilistic evidences about parents di ∈ Sk. This cluster assignment isperformed iteratively, leading us to deal two possible cases:
(1) Agreement probabilistic evidences between dm and its parents:if element dm is evaluated w.r.t a given cluster Ct and its parents di havebeen previously assigned to the same cluster, then dm will be more at-tracted to Ct.
Given a document dm assigned by its contents similarity to the clus-
ter Ct and its set of parents SAk =|Sk|⋃i=1{di ∈ Ct}, with SAk ⊆ Sk, we can
compute the probability assignment of dm to the cluster Ct as follows:
P (dm ∈ Ct|SAk ) = P (dm ∈ Ct)|SA
k |∏i=1
P (dm ∈ Ct ∧ di ∈ Ct|Pa(dm) = di)
P (di ∈ Ct)≈
≈ sim(dm, Ct)
|SAk |∏
i=1
JP (i,m)
sim(di, Ct)
(8)
Since P (dm ∈ Ct|SAk ) is computed through an approximation, in orderto have probability values between 0 and 1, we need to compute theprobability assignment of dm to the complementary cluster Ct as follows:
P (dm ∈ Ct|SAk ) = P (dm ∈ Ct)
|SAk |∏
i=1
P (dm ∈ Ct ∧ di ∈ Ct)|Pa(dm) = di)
P (di ∈ Ct)≈
≈ (1− sim(dm, Ct))
|SAk |∏
i=1
(1− JP (i,m))
sim(di, Ct)
(9)
11

Combining equation (8) with (9), the probability of dm to belong tothe same cluster of its parents SAk is normalized:
PN(dm ∈ Ct|SAk ) = α < P (dm ∈ Ct|SAk ), P (dm ∈ Ct|SAk ) > (10)
where α is a normalizing constant.
(2) Disagreement probabilistic evidences between dm and its par-ents: if element dm is evaluated w.r.t a given cluster Ct and its parentsdi have been previously assigned to a different cluster Cz, then the prob-ability to assign dm to Ct parents will be penalized.
Given a document dm assigned by its contents similarity to the clus-
ter Ct and its set of parents SDk =|Sk|⋃i=1{di ∈ Cz, ∀z 6= t}, with SDk ⊆ Sk,
we can compute the probability assignment of dm to the cluster Ct asfollows:
P (dm ∈ Ct|SDk ) = P (dm ∈ Ct)|SD
k |∏i=1
P (dm ∈ Ct ∧ di ∈ Cz)|Pa(dm) = di)
P (di ∈ Cz)≈
≈ sim(dm, Ct)
|SDk |∏
i=1
(1− JP (i,m))
sim(di, Cz)
(11)
Since P (dm ∈ Ct|SDk ) is computed through an approximation, in orderto have probability values between 0 and 1, we need to compute theprobability assignment of dm to the complementary cluster Ct as follows:
P (dm ∈ Ct|SDk ) = P (dm ∈ Ct)
|SDk |∏
i=1
P (dm ∈ Ct ∧ di ∈ Cz)|Pa(dm) = di)
P (di ∈ Cz)≈
≈ (1− sim(dm, Ct))
|SDk |∏
i=1
JP (i,m)
sim(di, Cz)
(12)
Combining equation (11) with (12), the probability of dm to belong tothe cluster Ctw.r.t. its parents SDk is normalized as follows:
PN(dm ∈ Ct|SDk ) = α < P (dm ∈ Ct|SDk ), P (dm ∈ Ct|SDk > (13)
where α is a normalizing constant.
12
RED-clustering combines the probability models given in equation (10) and(13) with a decision rule that picks the most probable hypothesis Ct, belongingto the hypothesis space H, as follows:
H∗ = arg maxCt∈H
{PN(dm ∈ Ct|SAk ) · PN(dm ∈ Ct|SDk )} (14)
Details about RED-clustering iterative implementation and its computationalcomplexity are given in appendix A.2.
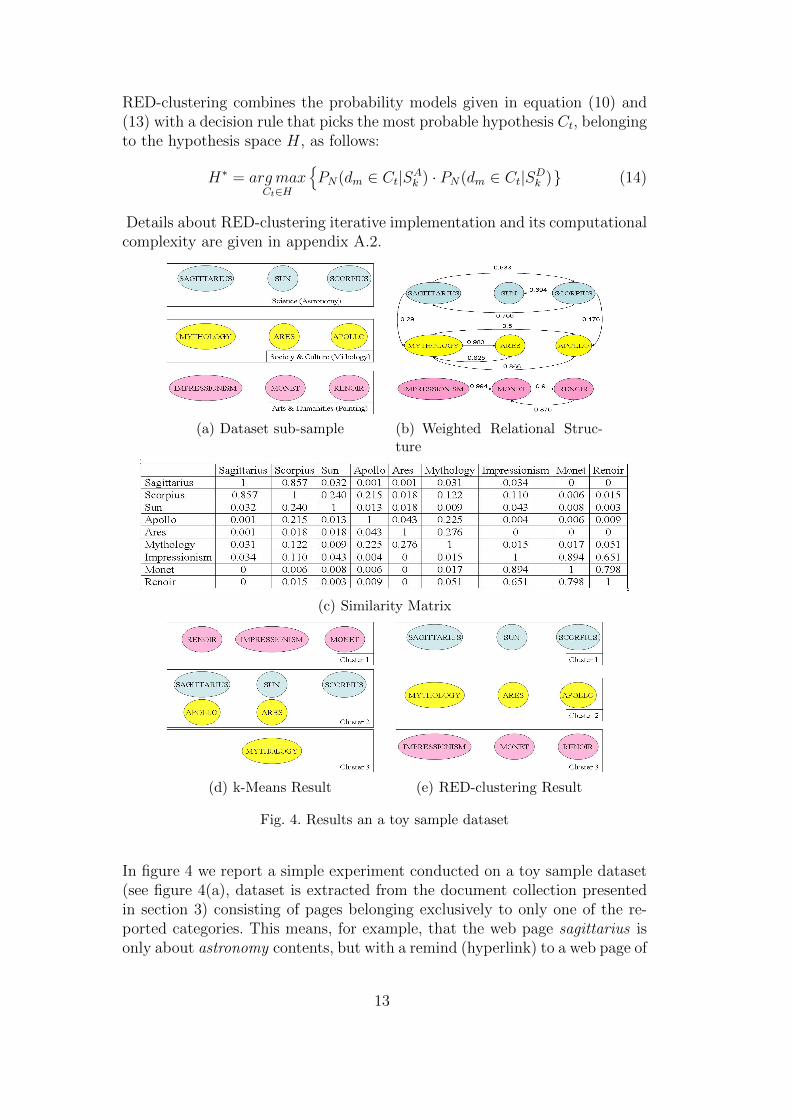
(a) Dataset sub-sample (b) Weighted Relational Struc-ture
(c) Similarity Matrix
(d) k-Means Result (e) RED-clustering Result
Fig. 4. Results an a toy sample dataset
In figure 4 we report a simple experiment conducted on a toy sample dataset(see figure 4(a), dataset is extracted from the document collection presentedin section 3) consisting of pages belonging exclusively to only one of the re-ported categories. This means, for example, that the web page sagittarius isonly about astronomy contents, but with a remind (hyperlink) to a web page of
13

mythology for related aspects. In figure 4(b) the weighted relational structureestimated by our approach is reported. In order to show the contribution ofthe proposed JP estimation, we report the similarity matrix among elementsin figure 4(c).
It is interesting to note that even if two documents belongs to the same cat-egory, their similarity assume often low values while the links among themeidentify ”strong relation”. For example the document scorpius belonging tothe category astronomy has a more or less the same similarity with the doc-ument sun and the document apollo, even if the first one belongs to the samecategory (astronomy) and the second one belongs to the category mythology.The jumping probability estimation, however, highlights on one hand an at-tractive relation between scorpius and sun and on the other hand a repulsiverelation between scorpius and apollo.
The clustering results are compared by using the best solution (over 100 runs)produced by the k-means algorithm (figure 4(d)) and our approach (figure4(e)): embedded patterns among documents are better identified by RED-clustering then k-Means approach.
3 Dataset and Evaluation Measure
In order to evaluate the effectiveness of the proposed clustering solution, wecompare the performance obtained by our RED-clustering to that obtainedby the well known k-Means and Expectation Maximization algorithms.Our experimental investigation starts from a dataset construction step, inwhich about 10000 web pages from popular sites listed in 5 categories of Yahoo!Directories (http://dir.yahoo.com/) are downloaded. See table 1.
Category # of document
Art & Humanities 3280
Science 2810
Health 1740
Recreation & Sports 1250
Society & Culture 960
Table 1Dataset Features
In order to evaluate and monitor the performance of different clustering meth-ods, we apply a feature selection procedure based on the Term FrequencyVariance index presented in Nicholas, C. et al. (2003) and given by:
14

q(tj) =n1∑i=1
f 2ij −
1
n1
[n1∑i=1
fij
]2
(15)
where n1 is the number of documents in Q containing tj at least once andfij is the frequency of term tj in the document di. During the experimentalphase we restrict the vocabulary dimension selecting a set T of terms with thehighest Term Frequency Variance index.
The clustering performance in terms of effectiveness is measured by threeexternal evaluation metrics, F-Measure, Entropy and Corrected Rand Coef-ficient, comparing class labels with cluster assignments. In our experimentalinvestigation we set K = 5, i.e. the number of clusters obtained by all testedalgorithms is equal to the number of dataset categories (see Table 1). TheF-Measure metric, presented in van Rijsbergen, C. J. (1979), represents acombination of the Precision and Recall measure typical of Information Re-trieval. Given a set of class label L, related to the Category reported in table1, we compute the Precision and Recall for each class label l ∈ L with respectto the cluster j as:
Precision(l, j) =nljnl
(16)
Recall(l, j) =nljnj
(17)
where
• nlj is the number of elements belonging to the class label l and located inthe cluster j• nj represents the cardinality of cluster j, and• nl is the number of web document with class label l.
The F-Measure for each class label l ∈ L is computed as the harmonic meanof Precision and Recall:
F (l, j) =2×Recall(l, j)× Precision(l, j)
Recall(l, j) + Precision(l, j)(18)
The overall quality, that represents the effectiveness of the obtained clusteringsolution, is given by a scalar F ∗ computed as the weighted sum of the F-Measure values taken over all the class labels l ∈ L:
F ∗ =|L|∑l
nl|Q|
maxj∈J{F (l, j)} (19)
In order to quantify the purity of a clustering solution, i.e. how the documentclasses are distributed in each cluster, we compute the Entropy of the obtainedclusters as presented in Strehl, A. et al. (2000). We first calculate the classdistribution of the objects in each cluster, i.e. for each cluster j we compute
15

plj, the probability that a member of cluster j belongs to class label l. Giventhis class distribution, the Entropy of cluster j is calculated using the standardEntropy:
Ej = −|L|∑l
plj log(plj) (20)
The total Entropy is denoted by a scalar E∗ and computed as the weightedsum of the Entropies of each cluster j over all the obtained cluster J :
E∗ =|J |∑j=1
nj|Q|
Ej (21)
In order to compare the performance obtained by our approach w.r.t. thatobtained by the benchmark clustering algorithms we also used the well-knownCorrected Rand Coefficient (Hulbert, L., Arabie, P. , 1985), which measuresthe agreement between two partitions. It can take values from -1 to 1, with1 indicating a perfect agreement between the obtained clusters and the orig-inal categories, and the negatives or near 0 values corresponding to clusteragreements found by chance. Given the confusion matrix established by theclustering algorithms, where the entry nlj represents the number of data itemsbelonging to cluster j and class l, the Corrected Rand Coefficient is computedas follows:
CRC =
|J |∑j=1
|L|∑l=1
(nlj
2
)−[1/(|Q|2
)] |J |∑j=1
(nj
2
) |L|∑l=1
(nl
2
)(1/2)
(|J |∑j=1
(nj
2
)+|L|∑l=1
(nl
2
))−[1/(|Q|2
)] |J |∑j=1
(nj
2
) |L|∑l=1
(nl
2
) (22)
4 Experimental Results
The proposed algorithm has been evaluated comparing its F-Measure, En-tropy and Corrected Rand Coefficient, to that one obtained by the k-Meansand Expectation Maximization algorithms. These two benchmark algorithmsare obtained by using the Weka environment.The document collection Q given in table 1 is submitted to the three algo-rithms. A pre-processing activity on Q is performed in order to make pagecases insensitive, remove stop words, acronyms, non-alphanumeric characters,html tags and apply stemming rules, using Porter’s suffix stripping algorithm.Then, Q is mapped into a matrix M = [mij], where each row of M representsa document d, following the Vector Space Model presented in Salton, G. et al.(1975):
16

−→di = (wi1, wi2, ..., wi|Z|) (23)
where |Z| is the number of distinct terms contained in the document set Q andwij is the weight of the jth term in the ith document. This weight is computedusing the TFxIDF scoring technique, presented in Salton, G. & Buckley, C.(1998), as follows:
wij = TF (tj, di)× IDF (tj) j = 1, ..., |Z|, i = 1, ..., |Q| (24)
where TF (tj, di) is the Term Frequency, i.e. the number of occurrences ofterm tj in di, and IDF (tj) is the Inverse Document Frequency. IDF (tj) isa factor which enhances the terms which appear in fewer documents, whiledowngrading the terms occurring in many documents and is defined as
IDF (tj) = log
(|Q|
DF (tj)
)j = 1, ..., |Z| (25)
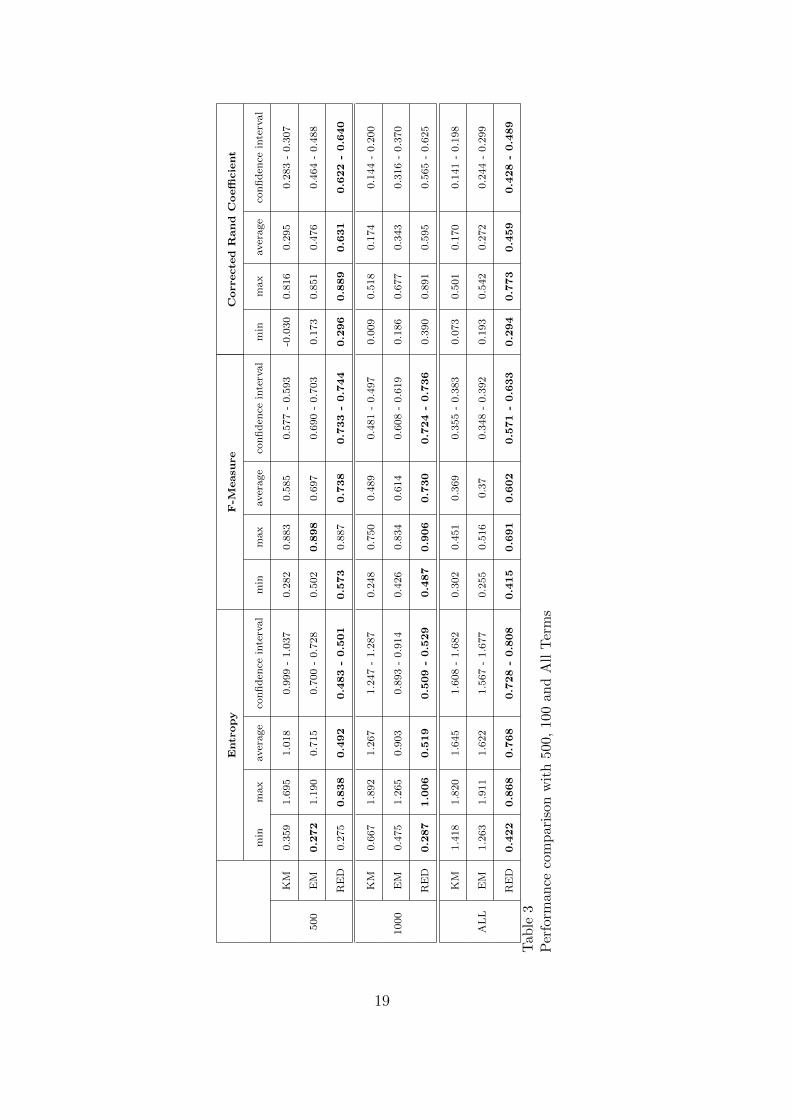
where DF (tj) is the number of documents containing the jth term.Moreover, since all the compared approaches depend on the initial choice ofthe representative element of each cluster (centroids) during the initializa-tion phase, we report the obtained performance over 500 runs. In particularwe show, both for Entropy, F-Measure and Corrected Rand Coefficient, theirrespective minimum, maximum, average value and confidence interval (confi-dence level at 95%).In tables 2 and 3 we report the cluster quality measures obtained for increasingnumber of features, i.e. terms considered descriptive of the document collec-tion Q. This means that the performance have been evaluated on a vocabularydimensioned as T = 20, 50, 100, 500, 1000, |Z| following the Term Variance fea-ture evaluation showed in equation (15).
17

Entr
opy
F-M
easu
re
Correcte
dR
an
dC
oeffi
cie
nt
min
max
aver
age
con
fid
ence
inte
rval
min
max
aver
age
con
fid
ence
inte
rval
min
max
aver
age
con
fid
ence
inte
rval
KM
0.6
41
1.2
83
0.8
64
0.8
54
-0.8
73
0.4
48
0.7
40
0.6
30.6
25
-0.6
35
0.1
54
0.6
60
0.3
71
0.3
63
-0.3
78
20
EM
0.7
61
1.4
31
1.0
45
1.0
34
-1.0
56
0.3
87
0.7
12
0.5
55
0.5
50
-0.5
60
0.0
91
0.5
63
0.3
16
0.3
09
-0.3
22
RE
D0.4
66
1.0
72
0.6
62
0.6
54
-0.6
71
0.4
54
0.8
01
0.6
62
0.6
58
-0.6
67
0.2
70
0.6
73
0.4
79
0.4
72
-0.4
86
KM
0.4
05
1.3
41
0.7
65
0.7
52
-0.7
78
0.4
48
0.8
58
0.6
72
0.6
66
-0.6
78
0.0
97
0.6
78
0.4
15
0.4
06
-0.4
23
50
EM
0.5
88
1.2
31
0.8
77
0.8
67
-0.8
87
0.4
57
0.7
91
0.6
33
0.6
28
-0.6
38
0.2
29
0.6
63
0.4
18
0.4
11
-0.4
25
RE
D0.3
45
0.8
67
0.5
09
0.5
01
-0.5
17
0.5
78
0.8
77
0.7
51
0.7
47
-0.7
55
0.4
33
0.8
44
0.6
35
0.6
28
-0.6
42
KM
0.2
13
1.1
82
0.6
75
0.6
61
-0.6
89
0.4
37
0.9
37
0.6
88
0.6
81
-0.6
95
0.1
35
0.9
10
0.4
77
0.4
66
-0.4
89
100
EM
0.4
56
1.0
81
0.7
39
0.7
30
-0.7
49
0.5
15
0.8
21
0.6
89
0.6
84
-0.6
94
0.2
55
0.7
02
0.4
90
0.4
83
-0.4
96
RE
D0.2
90
0.7
41
0.4
51
0.4
43
-0.4
58
0.5
89
0.9
02
0.7
60
0.7
55
-0.7
66
0.4
41
0.9
35
0.6
89
0.6
81
-0.6
97
Tab
le2
Per
form
ance
com
par
ison
wit
h20
,50
and
100
Ter
ms
18
Entr
opy
F-M
easu
re
Correcte
dR
an
dC
oeffi
cie
nt
min
max
aver
age
con
fid
ence
inte
rval
min
max
aver
age
con
fid
ence
inte
rval
min
max
aver
age
con
fid
ence
inte
rval
KM
0.3
59
1.6
95
1.0
18
0.9
99
-1.0
37
0.2
82
0.8
83
0.5
85
0.5
77
-0.5
93
-0.0
30
0.8
16
0.2
95
0.2
83
-0.3
07
500
EM
0.2
72
1.1
90
0.7
15
0.7
00
-0.7
28
0.5
02
0.8
98
0.6
97
0.6
90
-0.7
03
0.1
73
0.8
51
0.4
76
0.4
64
-0.4
88
RE
D0.2
75
0.8
38
0.4
92
0.4
83
-0.5
01
0.5
73
0.8
87
0.7
38
0.7
33
-0.7
44
0.2
96
0.8
89
0.6
31
0.6
22
-0.6
40
KM
0.6
67
1.8
92
1.2
67
1.2
47
-1.2
87
0.2
48
0.7
50
0.4
89
0.4
81
-0.4
97
0.0
09
0.5
18
0.1
74
0.1
44
-0.2
00
1000
EM
0.4
75
1.2
65
0.9
03
0.8
93
-0.9
14
0.4
26
0.8
34
0.6
14
0.6
08
-0.6
19
0.1
86
0.6
77
0.3
43
0.3
16
-0.3
70
RE
D0.2
87
1.0
06
0.5
19
0.5
09
-0.5
29
0.4
87
0.9
06
0.7
30
0.7
24
-0.7
36
0.3
90
0.8
91
0.5
95
0.5
65
-0.6
25
KM
1.4
18
1.8
20
1.6
45
1.6
08
-1.6
82
0.3
02
0.4
51
0.3
69
0.3
55
-0.3
83
0.0
73
0.5
01
0.1
70
0.1
41
-0.1
98
AL
LE
M1.2
63
1.9
11
1.6
22
1.5
67
-1.6
77
0.2
55
0.5
16
0.3
70.3
48
-0.3
92
0.1
93
0.5
42
0.2
72
0.2
44
-0.2
99
RE
D0.4
22
0.8
68
0.7
68
0.7
28
-0.8
08
0.4
15
0.6
91
0.6
02
0.5
71
-0.6
33
0.2
94
0.7
73
0.4
59
0.4
28
-0.4
89
Tab
le3
Per
form
ance
com
par
ison
wit
h50
0,10
0an
dA
llT
erm
s
19
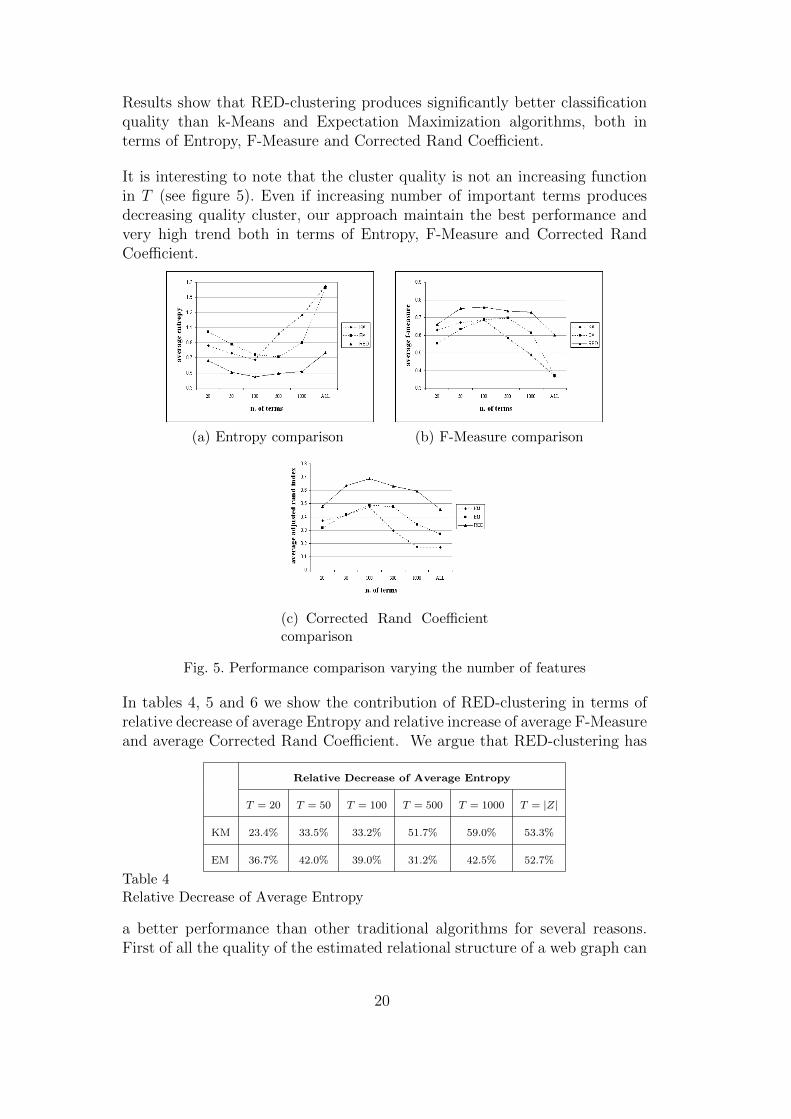
Results show that RED-clustering produces significantly better classificationquality than k-Means and Expectation Maximization algorithms, both interms of Entropy, F-Measure and Corrected Rand Coefficient.
It is interesting to note that the cluster quality is not an increasing functionin T (see figure 5). Even if increasing number of important terms producesdecreasing quality cluster, our approach maintain the best performance andvery high trend both in terms of Entropy, F-Measure and Corrected RandCoefficient.
(a) Entropy comparison (b) F-Measure comparison
(c) Corrected Rand Coefficientcomparison
Fig. 5. Performance comparison varying the number of features
In tables 4, 5 and 6 we show the contribution of RED-clustering in terms ofrelative decrease of average Entropy and relative increase of average F-Measureand average Corrected Rand Coefficient. We argue that RED-clustering has
Relative Decrease of Average Entropy
T = 20 T = 50 T = 100 T = 500 T = 1000 T = |Z|
KM 23.4% 33.5% 33.2% 51.7% 59.0% 53.3%
EM 36.7% 42.0% 39.0% 31.2% 42.5% 52.7%
Table 4Relative Decrease of Average Entropy
a better performance than other traditional algorithms for several reasons.First of all the quality of the estimated relational structure of a web graph can
20
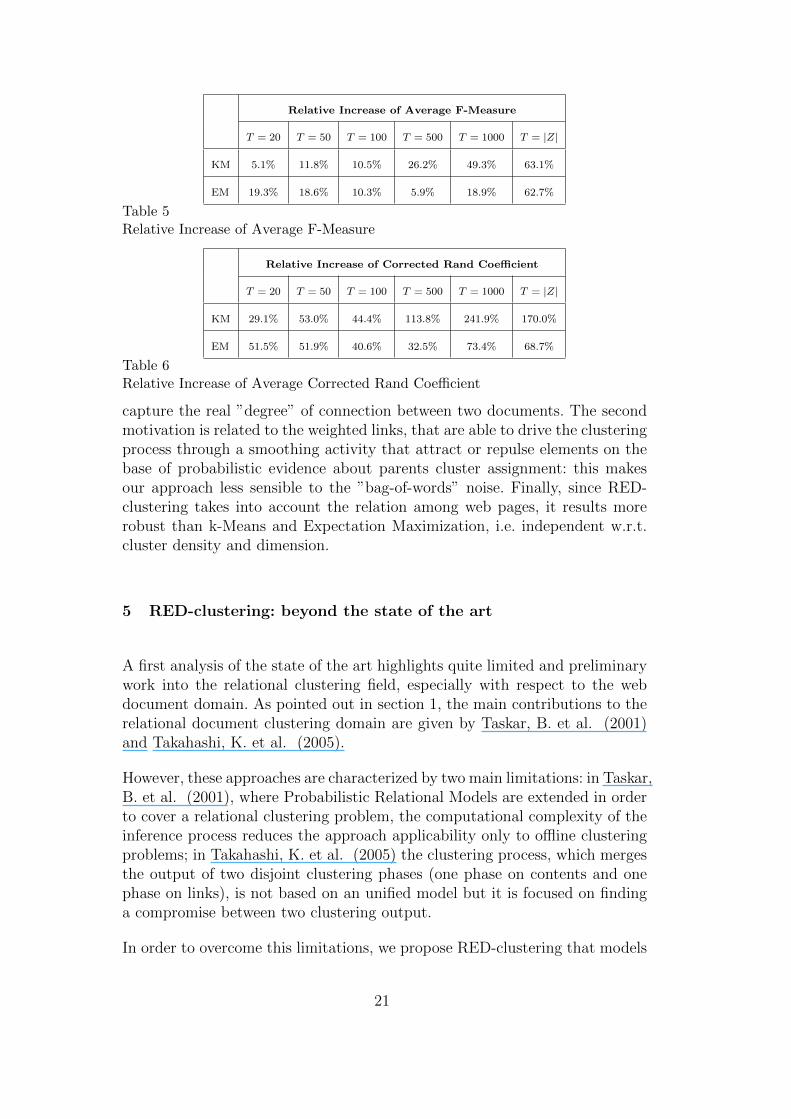
Relative Increase of Average F-Measure
T = 20 T = 50 T = 100 T = 500 T = 1000 T = |Z|
KM 5.1% 11.8% 10.5% 26.2% 49.3% 63.1%
EM 19.3% 18.6% 10.3% 5.9% 18.9% 62.7%
Table 5Relative Increase of Average F-Measure
Relative Increase of Corrected Rand Coefficient
T = 20 T = 50 T = 100 T = 500 T = 1000 T = |Z|
KM 29.1% 53.0% 44.4% 113.8% 241.9% 170.0%
EM 51.5% 51.9% 40.6% 32.5% 73.4% 68.7%
Table 6Relative Increase of Average Corrected Rand Coefficient
capture the real ”degree” of connection between two documents. The secondmotivation is related to the weighted links, that are able to drive the clusteringprocess through a smoothing activity that attract or repulse elements on thebase of probabilistic evidence about parents cluster assignment: this makesour approach less sensible to the ”bag-of-words” noise. Finally, since RED-clustering takes into account the relation among web pages, it results morerobust than k-Means and Expectation Maximization, i.e. independent w.r.t.cluster density and dimension.
5 RED-clustering: beyond the state of the art
A first analysis of the state of the art highlights quite limited and preliminarywork into the relational clustering field, especially with respect to the webdocument domain. As pointed out in section 1, the main contributions to therelational document clustering domain are given by Taskar, B. et al. (2001)and Takahashi, K. et al. (2005).
However, these approaches are characterized by two main limitations: in Taskar,B. et al. (2001), where Probabilistic Relational Models are extended in orderto cover a relational clustering problem, the computational complexity of theinference process reduces the approach applicability only to offline clusteringproblems; in Takahashi, K. et al. (2005) the clustering process, which mergesthe output of two disjoint clustering phases (one phase on contents and onephase on links), is not based on an unified model but it is focused on findinga compromise between two clustering output.
In order to overcome this limitations, we propose RED-clustering that models
21

both document contents and document relationships in an unified mannerfollowing a low computational complexity procedure. The originality of ourunified model is due to two main contributions: (1) the estimation of theJumping Probability as a measure of joint probability of two linked documentsto belong to the same cluster; (2) the introduction of probabilistic relationsinto the partitioning process to smooth the cluster assignment of each elementgiven the degree of relationship with its parent documents.
The combination of these two contributions makes RED-clustering suitable forevery kind of web page collection, not only for its unsupervised computationof Jumping Probability, but also for the low complexity of the smoothingprocedure included into the clustering process.
6 Conclusions
In this paper we presented a novel approach, called RED-clustering, for webdocument partitioning. The main idea of our approach is to retain and weightthe relational structure underlying a document collection in order to enhancethe knowledge related to them. The proposed RED-clustering considers theWWW as graph in which nodes are documents and the link among themare weighted according to the strength of their relationships. RED-clustering,which is aimed at identifying embedded patterns of web document collection,converges to a solution that include different kind of information: semantic vi-sual coherence, contents features and several relations with different ”degrees”of importance between documents. The experimental results show that RED-clustering outperforms two of the most well known algorithm as k-Means andExpectation Maximization, both in terms of effectiveness, purity and agree-ment between classes and partitions.
References
Archetti, F., Campanelli, P., Fersini, E., Messina, E. (2006). A Hierarchi-cal Document Clustering Environment Based on the Induced Bisecting k-Means. In Larsen, H.L., Pasi, G., Arroyo, D.O., Andreasen, T. and Chris-tiansen H. (Eds.), Proceeding of 7the International Conference on FlexibleQuery Answering Systems, (pp.257-269). Heidelberg: Springer Berlin.
Cai, D., Yu, S., Wen, J. R. & Ma, W. Y. (2003). Extracting content struc-ture for web pages based on visual representation. In Zhou, X., Zhang, Y.,Orlowska, M. E. (Eds.), Proceedings of the Pacific Web Conference, (pp.406-417).
Chakrabarti, S., Dom, B., & Indyk, P. (1998). Enhanced hypertext catego-
22

rization using hyperlinks. In Haas, L.M., Tiwary, A. (Eds.), Proceedingsof ACM SIGMOD International Conference on Management of Data, (pp.307-318). New York: ACM Press.
Cutting, D., Karger, D., Pedersen, J. & Tukey, J. (1992). Scatter/Gather:A Cluster-based Approach to Browsing Large Document Collections. InBelkin, N. J., Ingwersen, P., Pejtersen, A.M. (Eds.), Proceedings of the15th Annual International ACM SIGIR Conference on Research and Devel-opment in Information Retrieval, (pp. 318-329). New York: ACM Press.
Dempster, A., Laird, N., Rubin D. (1977). Maximum likelihood from incom-plete data via the EM algorithm. Journal of the Royal Statistical Society,39(1):1-38.
Dittenbach, M. ,Merkl, D. & Rauber, A. (2001). Hierarchical Clustering ofDocument Archives with the Growing Hierarchical Self-Organizing Map. InDorffner, G., Bischof, H., Hornik, K. (Eds.), Proceedings of the InternationalConference on Artificial Neural Networks (ICANN01). Springer-Verlag
Fersini, E., Messina, E., Archetti, F. (2008). Enhancing web page classifica-tion through image-block importance analysis. Information Processing andManagement, Vol. 44, No. 4, pp.1431–1447.
Friedman, N., Getoor, L., Koller, D., Pfeffer, A. (2001). Learning probabilis-tic relational models . In Dean, T. (Eds.), Proceedings of the SixteenthInternational Joint Conference on Artificial Intelligence (IJCAI 99), (pp.1300-1309). San Francisco: Morgan Kauffman.
Fung, B.C.M., Wang K. & Ester, M. (2003). Hierarchical Document ClusteringUsing Frequent Itemsets. In Barbara, D., Kamath, C. (Eds.), Proceedingsof the Third SIAM International Conference on Data Mining. Philadelphia:Society for Industrial and Applied Mathematics.
Hubert, L., & Arabie, P. (1985). Comparing partitions. Journal of Classifica-tion, 2(1), 193218.
Joo, K.H, Lee, S. (2005). An Incremental Document Clustering AlgorithmBased on a Hierarchical Agglomerative Approach. In Chakraborty, G.(Eds.), Proceedings of Distributed Computing and Internet Technology, Sec-ond International Conference, (pp. 321-332). Heidelberg: Springer Berlin.
Lin, C. & Chen, M. (2005). Combining Partitional and Hierarchical Algorithmsfor Robust and Efficient Data Clustering with Cohesion Self-Merging. IEEETransactions on Knowledge and Data Engineering, 17(2):145-158.
Long, B., Zhang, Z.M., Yu, P.S. (2007). A Probabilistic Framework for Rela-tional Clustering. In Berkhin P., Caruana, R. and Wu, X. (Eds.), Proceed-ings of the 13th ACM International Conference on Knowledge Discoveryand Data Mining, (pp.470-479).New York: ACM Press.
MacQueen, J.B. (1967). Some Methods for classification and Analysis of Mul-tivariate Observations. In LeCam, L.M., Neyman, N. (Eds.), Proceedings ofthe fifth Berkeley Symposium on Mathematical Statistics and Probability,(pp.281-297). Berkeley: University of California Press.
Neville, J., Adler, M. & Jensen, D. (2003). Clustering Relational Data UsingAttribute and Link Information. In Gottlob, G., Walsh, T. (Eds.), Proceed-
23

ings of the Text Mining and Link Analysis Workshop, 18th InternationalJoint Conference on Artificial Intelligence.
Nicholas, C., Dhillon, I. & Kogan, J. (2003). Feature selection and documentclustering. In Berry, M. W. (Ed.), A Comprehensive Survey of Text Mining.Springer-Verlag.
Peng, J., Zhu, J. (2006). Refining Spherical K-Means for Clustering Docu-ments. In Proceeding of the IEEE International Joint Conference on NeuralNetworks (IJCNN 2006), 4146-4150.
Salton, G., Wong, A. & Yang, C., S. (1975). A vector space model for auto-matic indexing. Communications of the ACM, 18(11): 613-620.
Salton, G. & Buckley, C. (1998). Term-weighting approaches in automatic textretrieval. Information Processing and Management, 24(5):513-523.
Steinbach, M., Karypis, G., & Kumar, V. (2000). A comparison of documentclustering techniques. In Simoff, S.J.,Zaane O.R. (Eds.), Proceedings of theSixth ACM SIGKDD International Conference on Knowledge Discovery andData Mining. New York: ACM Press.
Strehl, A., Ghosh, J. & Mooney, R. (2000). Impact of Similarity Measureson Web-page Clustering. In Proceedings of the 17th National Conferenceon Artificial Intelligence: Workshop of Artificial Intelligence for Web Search(AAAI 2000), (pp.58-64). AAAI Press.
Takahashi, K., Miura, T. & Shioya, I. (2005). Clustering web document basedon correlation of hyperlinks. In Proceedings of the 21st International Con-ference on Data Engineering (ICDE 2005), (pp. 1225-1225).
Taskar, B., Segal, E., Koller, D. (2001). Probabilistic classification and cluster-ing in relational data. In Nebel, B. (Eds.), Proceedings of the SeventeenthInternational Joint Conference on Artificial Intelligence (IJCAI), (pp. 870-878). San Francisco: Morgan Kauffman.
van Rijsbergen, C. J. (1979). Information Retrieval. London: Butterworths.Second Edition.
Wagsta, K., Cardie, C., Rogers, S., Schroedl, S. (2001). Constrained K-meansClustering with Background Knowledge. In Brodley, C.E., Danyluk, A.(Eds.), Proceedings of 18th International Conference on Machine Learning,(pp.577-584). San Francisco: Morgan Kauffman.
Wang, J., Zeng, H.J., Chen, Z., Lu, H., Tao, L., Ma W.Y. (2003). Recom: rein-forcement clustering of multi-type interrelated data objects. In Proceedingsof the 26th Annual International ACM SIGIR Conference on Research andDevelopment in Information Retrieval, (pp.274-281). New York: ACM Press.
Zhao, Y. & Karypis, G. (2004). Criterion functions for document clustering:Experiments and analysis. Machine Learning, 55(3):311331.
Zeng, H.J., Chen, Z., Ma W.Y. (2002). A unified framework for clustering het-erogeneous web objects. In Ling, T.W, Dayal, U., Bertino, E., Ng, W.K.,Goh, A., Proceedings of the 3rd International Conference on Web Informa-tion Systems Engineering (WISE 2002), (pp. 161-172). Washington: IEEEComputer Society.
Zhong, S. (2005). Efficient online spherical k-means clustering. In Prokhorov,
24

D. (Eds.), Proceeding of the IEEE International Joint Conference on NeuralNetworks (IJCNN 2005), 3180-3185.
Zhong, S., Ghosh, J. (2003). A unified framework for model-based clustering.Journal of Machine Learning Research, 4:1001-1037.
A Computational complexity
A.1 Jumping Probability Estimation
The proposed jumping probability estimation is able to determine the strengthof a relation between two linked pages and is necessary for defining a proba-bilistic graph representation for the subsequent clustering process. Moreover,this estimation requires a visual layout segmentation in order to find those se-mantic visual blocks containing hyperlinks. The page segmentation algorithmneeds the exploration of web pages DOM tree and therefor has O(|N | · |Q|)time complexity, where |N | is the number of nodes in the DOM tree, and |Q|is the number of web pages in the repository. Nevertheless, this is the com-plexity in the worst case, when a partitioning procedure has to consider pathsto all possible nodes. In the best case, when the DOM root is not dividable atfirst time, this search reduces to O(Q) since for each web page its complexityis o(1).
Algorithm 1 JP Estimation (Document Collection Q)
1: for each di ∈ Q do2: for each n ∈ N do3: vipsAnalysis (di);
4: for each d∗ik ∈ Θ∗i do5: for each ti ∈ d∗ik do
6: IC(d∗ik, di) = IC(d∗ik, di) +γij−σijk
σijk×γij
7: EC(d∗ik, dm) = EC(d∗ik, dm) +σijk
ρk
8: JP (i,m) = 12
IC(d∗ik,di)+EC(d∗ik,dm)
|d∗ik|
The computational complexity covered by the entire jumping probability es-timation can therefore be summarized by a simple procedure of four nestediterative cycles as reported in Algorithm 1. The first cycle is over all doc-uments dj, the second one is over the nodes of the DOM tree of each page,the third one is over the visual block set containing outgoing hyperlinks fromdi to dm, and the last one includes the computation of Internal and ExternalCoherence considering all the terms in a given block.The jumping probability estimation, computed off-line during the indexing
25

phase of documents, is characterized by a O(|Q| · |Θ∗i |+ |N | · |d∗i |) time com-plexity, where |Q| represents the document collection, |N | is the number ofnodes in the DOM tree, Θ∗i is the visual block set containing outgoing hyper-links from di to dl and |d∗ik| is the number of terms belonging to a hyperlinksemantic area d∗ik.
A.2 RED-clustering
The proposed RED-clustering, in order to assign each document to a givencluster, follows the iterative refinement heuristic known as Lloyd’s algorithm.The algorithm starts by partitioning the input points into m initial clusters.Each document is assigned to the most probable cluster considering its simi-larity with the a set of representative elements of the clusters (centroids) andits parents assignment: the probability that a document belongs to a clusteris smoothed considering those parents already assigned to a cluster during thesame iteration. In this way, those parents already assigned to a cluster tendsto ”attract” or ”repulse” the linking documents by considering the ”strength”of relation between them. Then the centroids are recalculated for the new clus-ters as the means of document belonging to that cluster, and the algorithmrepeated by alternate application of these two steps until convergence.The convergence is obtained when any document switches clusters.The pseudocode reported in Algorithm 2 show the assignment process de-scribed above. The procedure should compute for each document its proba-bility to belong to a cluster, for all the clusters, in order to choose the bestcluster hypothesis. This operation is iterated until convergence. Consideringa document collection Q, the number of desired cluster m and a fixed num-ber of iteration i needed to reach the convergence, the time required by theRED-clustering algorithm is O(|Q| ·m · i).
26

Algorithm 2 RED-clustering (JP Matrix R, Document Collection Q, Cen-troid Set C, Number of Cluster K)
1: Set h = 0, converged = false, Ch = C;2: while (converged == false) do3: converged = true;4: for each dm ∈ Q do5: P (H∗,hk ) = −1;6: H∗,hk = ∅;7: for each cht ∈ Ch do8: P (dm ∈ Ch
t ) = 1;
9: P (dm ∈ Cht ) = 1;
10: sim(dm, cht ) =
<−→dm,−→cht >
|−→dm||−→cht |
11: if (Sk 6= ∅) then12: for each di ∈ Sk do13: if (R[i][k] > 0 and di ∈ Ch
x ) then
14: sim(di, chx) = <
−→di ,−→chx>
|−→di ||−→chx|
15: if (Cht == Ch
x ) then
16: P (dm∈Cht |di∈Ch
t )=P (dm∈Cht )
sim(dm,cht )R[i][k]
sim(di,chx)
;
17: if (Cht 6= Ch
x ) then
18: P (dm∈Cht |di∈Ch
x )=P (dm∈Cht )
sim(dm,cht )(1−R[i][k])
sim(di,chx)
19: P (dm ∈ Cht |Sk) = P (dm ∈ Ch
t |di ∈ Cht )P (dm ∈ Ch
t |di ∈ Chx )
20: if (P (dm∈Cht |Sk)>P (H∗,h
k) and ∃di∈Sk|di∈Ch
x ,0≤x≤K) then21: P (H∗,h+1
k ) = P (dm ∈ Cht |Sk)
22: H∗,h+1k = Ch
t
23: if ((Sk==∅) or (@di∈Sk|di∈Chx ,0≤x≤K)) then
24: P (H∗,h+1k ) = sim(dm, c
ht )
25: H∗,h+1k = Ch
t
26: if (H∗,h+1k 6= H∗,hk ) then
27: converged = false
28: h = h+ 1;29: updateCentroids(Ch);
27





























