Embed Size (px)
Citation preview

Research ArticleResearch on Dynamic Path Planning of Mobile Robot Based onImproved DDPG Algorithm
Peng Li1 Xiangcheng Ding 1 Hongfang Sun2 Shiquan Zhao1 and Ricardo Cajo34
1College of Intelligent Science and Engineering Harbin Engineering University Harbin Heilongjiang China2Qingdao Ship Science and Technology Co Ltd Harbin Engineering University Harbin Shandong China3Department of Electromechanical Systems and Metal Engineering Ghent University Ghent Belgium4Facultad de Ingenierıa en Electricidad y Computacion Escuela Superior Politecnica del Litoral (ESPOL) Guayaquil Ecuador
Correspondence should be addressed to Xiangcheng Ding dingxiangchenghrbeueducn
Received 20 August 2021 Revised 10 October 2021 Accepted 27 October 2021 Published 12 November 2021
Academic Editor Xingsi Xue
Copyright copy 2021 Peng Li et alis is an open access article distributed under the Creative Commons Attribution License whichpermits unrestricted use distribution and reproduction in any medium provided the original work is properly cited
Aiming at the problems of low success rate and slow learning speed of the DDPG algorithm in path planning of a mobile robot in adynamic environment an improved DDPG algorithm is designed In this article the RAdam algorithm is used to replace theneural network optimizer in DDPG combined with the curiosity algorithm to improve the success rate and convergence speedBased on the improved algorithm priority experience replay is added and transfer learning is introduced to improve the trainingeffect rough the ROS robot operating system and Gazebo simulation software a dynamic simulation environment isestablished and the improved DDPG algorithm and DDPG algorithm are compared For the dynamic path planning task of themobile robot the simulation results show that the convergence speed of the improved DDPG algorithm is increased by 21 andthe success rate is increased to 90 compared with the original DDPG algorithm It has a good effect on dynamic path planning formobile robots with continuous action space
1 Introduction
Path planning is a very important part of the autonomousnavigation of robots e robot path planning problem canbe described as finding an optimal path from the currentpoint to the specified target point in the robot workingenvironment according to one or more optimization ob-jectives under the condition that the robotrsquos position isknown [1 2] At present the commonly used algorithmsinclude the artificial potential field method [3] genetic al-gorithm [4] fuzzy logic method [5] and reinforcementlearning method [6] In recent years many scholars haveproposed path planning methods in a dynamic environ-ment In 2018 Qian [7] proposed an improved artificialpotential field method based on connectivity analysis for thepath planning problem of dynamic targets in the LBSSystem In 2019 in order to solve the long-distance pathplanning problem of outdoor robots Huang [8] proposed animproved Dlowast algorithm which is combined with Gaode
mapping based on a vector model In 2020 Nair and Supriya[9] applied neural network algorithm LSTM to path plan-ning in a dynamic environment e reinforcement learning(RL) algorithm is a learning algorithm that does not requireagents to know the environment in advance e mobilerobot takes corresponding actions while perceiving thecurrent environment According to the current state and theactions taken the mobile robot migrates from the currentstate to the next state e Q-learning algorithm [10] is aclassical reinforcement learning algorithm that is simple andconvergent and has been widely used However when theenvironment is complex with the increase of the dimensionof state space the reinforcement learning algorithm is proneto fall into ldquodimension explosionrdquo Deep learning (DL) has agood ability to deal with high-dimensional informationDeep reinforcement learning (DRL) which combines DLwith reinforcement learning [11 12] can not only deal withhigh-dimensional environmental information but also carryout corresponding planning tasks by learning an end-to-end
HindawiMobile Information SystemsVolume 2021 Article ID 5169460 10 pageshttpsdoiorg10115520215169460
modelerefore the DQN algorithm [13] comes into being Itusually solves the problem of discrete and low-dimensionalaction spacee Deep Deterministic Policy Gradient (DDPG)algorithm proposed by DeepMind team in 2016 uses the actor-critical algorithm framework and draws lessons from the ideaof the DQN algorithm to solve the problem of continuousaction space [14] However when the DDPG algorithm isapplied to path planning in a dynamic environment it hassome shortcomings such as low success rate and slow con-vergence speed and most of the related research stays at thetheoretical level lacking solutions to practical problems
In this article a new DDPG algorithm is proposed inwhich the RAdam algorithm is used to replace the neuralnetwork algorithm in the original algorithm combined withthe curiosity algorithm to improve the success rate andconvergence speed and introduce priority experience replayand transfer learning e original data is obtained throughthe lidar carried by the mobile robot the dynamic obstacleinformation is obtained and the improved algorithm is ap-plied to the path planning of the mobile robot in the dynamicenvironment so that it canmove safely from the starting pointto the end point in a short time get the shortest path andverify the effectiveness of the improved algorithm
e organizational structure of this article is as followsthe first section is an introduction the second section in-troduces the DDPG algorithm principle and network pa-rameter setting the third section is path planning design ofimproved DDPG algorithm the fourth section shows thesimulation experiment and analyzed results and the sum-maries are given in the last section
11 DDPG Algorithm Principle and Network ParameterSetting
111 Principle of DDPG Algorithm DDPG used in thisarticle is a strategy learning method that outputs continuousactions Based on the DPG algorithm and using the ad-vantages of Actor-Criticrsquos strategy gradient single-step up-date and DQNrsquos experience replay and target networktechnology for reference the convergence of Actor-Critic isimproved e DDPG algorithm consists of policy networkand Q network DDPG uses deterministic policy to selectaction at μ(st|θ
μ) so the output is not the probability ofbehavior but the specific behavior where θμ is the parameterof policy network at is the action and st is the state eDDPG algorithm framework is shown in Figure 1
Actor uses policy gradient to learn strategies and selectrobot actions in the current given environment In contrastCritic uses policy evaluation to evaluate the value functionand generate signals to evaluate Actorrsquos actions During pathplanning the environmental data obtained by the robotsensor is input into the Actor network and the actions thatthe robot needs to make are output e Critic networkinputs the environmental state of the robot and the pathplanning actions and outputs the corresponding Q value forevaluation In the DDPG algorithm both Actor and Criticare represented by DNN (Deep Neural Network) Actornetwork and Critic network approximate θμ μ and Q
functions respectively When the algorithm performs iter-ative updating firstly the sample data of the experience poolis accumulated until the number specified by the minimumbatch is reached then the Critic network is updated by usingthe sample data parameter θQ of the Q network is updatedby the loss function and the gradient of the objectivefunction relative to the action θμ is obtained [15] enupdate θμ with Adam Optimizer
2 DDPG Network Parameter Setting
21 For State Space Settings e robot in this article obtainsthe distance between itself and the surrounding obstaclesthrough lidar e detection distance range of lidar is (01235) (unit m) and the angle range of lidar [16] detection is(minus90 90) that is 0deg in front of the robot 90deg to the left and90deg to the right e lidar data are 20 dimensions and theangle between radar data in each dimension is 9deg e basisfor judging whether the robot hits an obstacle in the processof moving if the distance from the obstacle is less than 02mit is judged as hitting the obstacle In an actual simulation20-dimensional lidar distance information is obtained
According to the distance between the robot and theobstacle the state between the robot and the obstacle isdivided into navigation state N and obstacle collision state C
as follows
S N di(t)gt 02m
C di(t)le 02m1113896 (1)
where di(t) is the i-th dimension lidar distance data of therobot at time t When the distance between the robot andthe obstacle is di(t)le 02m the robot is in state C of hittingthe obstacle When the distance between the robot and theobstacle di(t)gt 02m the robot is in the normal navigationstate N [17 18]
22 Action Space Setting e final output of DDPGrsquos de-cision network is a continuous angular velocity value in acertain interval e output is the continuous angular ve-locity which is more in line with the kinematic character-istics of the robot so the trajectory of the robot in the processof moving will be smoother and the output action will bemore continuous In the simulation it is necessary to limitthe angular velocity not to be too large so the maximumangular velocity is set to 05 rads Hence the final outputangular velocity interval of DDPG is (minus05 05) (unit rads)the linear velocity value is 025ms the forward speed (linearvelocity (v) angular velocity (ω)) is (025 0) the left turnspeed is (025 minus05) and the right turn speed is (025 05)
23 Reward Function Settings
Reward
minus200 diminus0(t)le 02
100 diminust(t)le 02
300 middot diminust(t minus 1) minus diminust(t)( 1113857
⎧⎪⎪⎨
⎪⎪⎩
(2)
2 Mobile Information Systems
In the above formula reward is the return value diminus0(t) isthe distance between the robot and the obstacle In the ex-perimental simulation when diminus0(t) is less than 02 thereturn value of collision with the obstacle is minus200 diminust(t) isthe distance value between the robot and the target point and100 is rewarded when reaching the target point In other casesthe difference between the distance from the target point atthe previousmoment and the distance from the target point atthe current moment that is 300 middot (diminust(t minus 1) minus diminust(t)) istaken as the return value e design is to make the robotmove to the target point continuously so that every actiontaken by the robot can get feedback in time ensuring thecontinuity of the reward function and speeding up theconvergence speed of the algorithm
24 Path Planning Design of Improved DDPG Algorithm
241 RAdam Optimization Algorithm Design In deeplearning most neural networks adopt the adaptive learningrate optimization method which has the problem of ex-cessive variance Reducing this difference problem canimprove training efficiency and recognition accuracy
In some neural network optimizer algorithms SGD con-verges well but it takes a lot of time In contrast Adamconverges quickly but it is easy to fall into local solutionsRAdam uses the warm-up method to solve the problem thatAdam can easily converge to the local optimal solution andselects the relatively stable SGD+momentum for training inthe early stage to reduce the variance stablyerefore RAdamis superior to other neural network optimizers In addition theRAdam algorithm [19] is an algorithm proposed in recentyears which has the characteristics of fast convergence and
high precision and the RAdam algorithm can effectively solvethe differences in adaptive learning methods erefore theRAdam algorithm is introduced into the DDPG algorithm tosolve the problems of low success rate and slow convergencespeed of mobile robot path planning in the dynamic envi-ronment caused by neural network variance problem [20]eRAdam algorithm formula can be expressed as follows
θt+1 θt minus αtrt
1113954mt
1113954vt
1113954vt
vt
1 minus βt2
1113971
rt
ρt minus 4( 1113857 ρt minus 2( 1113857ρinfinρinfin minus 4( 1113857 ρinfin minus 2( 1113857ρt
1113971
ρt ρinfin minus2tβt
2
1 minus βt2
1113954mt mt
1 minus βt1
vt β2vtminus1 + 1 minus β2( 1113857g2t
mt β1mtminus1 + 1 minus β1( 1113857gt
gt nablaθJ(θ)
⎧⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎩
(3)
Policy Gradient
softupdate
at
atst
Online Actor Netmicro (s|θmicro)
Target Actor Netμprime (s|θt)
Actor Network
Loss FunctionL = E[(rt + rQprime(st+1 at+1) ndash Q(stat))]
update update
softupdate
Online Critic NetQ (s a|θQ)
Target Critic NetQprime (s a|θQ)
Critic Network
Replay buffer D(st at rt st+1)
st+1 st+1
at+1
Q (st at) Qprime (s a|θQ)
Figure 1 Flowchart of DDPG algorithm
Mobile Information Systems 3
where θt is the parameters to be trained t is the trainingtime αt is the step size rt is the rectification term 1113954vt is themoving second-order moment after bias correction 1113954mt isthe moving average after bias correction attenuation rate β1 β2 β
t1 β
t2 is the attenuation rate at time t mt is the
first-order moment (momentum) vt is the second-ordermoment (adaptive learning rate) gt is the gradient ρinfin is themaximum length of the simple moving average ρt is themaximum value of the simple moving average J(θ) is thetarget parameter and nablaθ is the gradient coefficient
25 Prioritized Experience Replay In the path planning ofmobile robot in a dynamic environment because of theuncertainty of the environment there are a lot of invalidexperiences due to collision in the early stage of trainingeoriginal DDPG algorithm uses these invalid experiences fortraining which leads to a low success rate of path planningafter training and wastes a lot of time In order to solve theproblem that the success rate of mobile robot path planningin a dynamic environment is not high due to ineffectiveexperience this article designs and adds prioritized expe-rience replay When prioritized experience replay extractsexperiences priority is given to extracting the most valuableexperiences but not only the most valuable experiencesotherwise overfitting will be caused e higher the valuethe greater the probability of extraction When the value islowest there is also a certain probability of extraction
Prioritized experience replay uses the size of TD(Temporal Difference) error to measure which experienceshave greater contributions to the learning process In theDDPG algorithm its core update formula is
Qw st at( 1113857 Qw st at( 1113857 + rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 11138571113858 1113859
(4)
where TD-error is
δt rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 1113857 (5)
where maxaQw(st+1 at+1) is the action at+1 selected from theaction space when the mobile robot is in the state st+1 so thatQw(st+1 at+1) is the maximum value of Q values corre-sponding to all actions and t is the training time As adiscount factor c make it take the value between (0 1) sothat the mobile robot does not pay too much attention to thereward value brought by each action in the future nor does itbecome short-sighted but only pays attention to the im-mediate action return rt+1 is the return value obtained by themobile robot executing the action at and transitioning fromstates st to st+1 e goal of priority experience replay is tomake TD-error as small as possible If TD-error is relativelylarge it means that our current Q function is still far fromthe target Q function and should be updated moreerefore the TD-error is used to measure the value ofexperience Finally the binary tree method is used to extractthe experiences with their respective priorities efficiently
26CuriosityAlgorithm e core of interaction between thedeep reinforcement learning algorithm and environment is
the setting of the reward mechanism A reasonable rewardmechanism can speed up the learning process of the agentand achieve good results However in the path planning ofmobile robots in a dynamic environment as the workingenvironment of mobile robots becomes more and morecomplex external reward training alone cannot get goodresults quickly erefore the curiosity algorithm [21] isintroduced in this document to provide internal rewards byreducing the form of actions and self-errors in the learningprocess of agents through internal curiosity module (ICM)so that mobile robots can train under the combined action ofinternal and external rewards and achieve good pathplanning effect e final reward value combined with theDDPG algorithm is max rt ri
t + rεt where rt is the totalreward value ri
t is the internal reward of curiosity moduleand rεt is the external reward of the DDPG algorithm
In a complete training process the original and next statevalues and actions should be calculated through the internalcuriosity module as shown in Figure 2 Specifically thecuriosity algorithm uses two submodules the first sub-module encodes st into φ(st) and the second submoduleuses two consecutive states φ(st) and φ(st+1) encoded bythe previous module to predict action at at is the actionof the agent will pass through the forward model1113954at g(st st+1 θI) where 1113954at is the predicted estimation valueof the action st and st+1 represent the original state and thenext state of the agent θI is the neural network parameterand the function g is the inverse dynamic model Errorcalculation is carried out between the state prediction of theforward model and the coding of the next state and thecalculation result obtains an internal reward e codingprinciple is as follows
1113954φ st+1( 1113857 f φ st( 1113857 at θF( 1113857 (6)
where 1113954φ(st+1) represents a state prediction value φ(st)
represents a feature vector encoded by the original state st at
is the action θF is a neural network parameter and thelearning function f is called a forward dynamics model
e neural network parameter θF is optimized byminimizing the loss function LF
LF φ st( 1113857φ st+1( 1113857( 1113857 12
1113954φ st+1( 1113857φ st+1( 1113857
22 (7)
e intrinsic reward value is
rit
η2
1113954φ st+1( 1113857φ st+1( 1113857
22 (8)
where η is the scale factor satisfyingηgt 0 e coding resultsof the original state and the next state will be predicted by theinverse dynamic model
e overall optimization objectives of the curiosity al-gorithm are summarized as follows
minθPθIθF
minusλEπ StθP( ) 1113944 rt1113960 1113961 +(1 minus β)LI + βLF1113876 1113877 (9)
In the formula β and λ are scalars θI and θP is the neuralnetwork parameter the losses of the inverse model and theforward model are weighted to β satisfy 0le βle 1 the
4 Mobile Information Systems
importance of gradient loss to the reward signal in learningis measured λ λgt 0 is satisfied LI is the loss function tomeasure the difference between the prediction and the actualaction rt is the internal reward value at time t and π(st θP)
represents a parameterized policy In the simulation ex-periment β is 02 and λ is 01
27 Simulation Experiment and Result Analysis
271 Establishment of Simulation Experiment EnvironmentHardware configuration of simulation experiment Intel i5-3320M CPU and 4G memory e operating system isUbuntu 1804 e ROS Melodic robot operating system isinstalled and the simulation environment is establishedusing Gazebo 9 under ROS e generated experimentalenvironment is shown in Figure 3
In that simulation environment of Figure 3(a) a squareenvironment with a length and width of 8meters is estab-lished no obstacles are added the position of the mobilerobot at the starting point is set to (minus2 25) and the colorcircle at the target point is set to (2 minus2) which is mainly usedto train the mobile robotrsquos ability to complete the target in alimited space for transfer learning In that simulation en-vironment of Figure 3(b) eight dynamic obstacles are addedon the basis of the above environment among which themiddle four (03times 03times 03)m3 obstacles rotate counter-clockwise at a speed of 05ms the upper and lower two(1times 1times 1) m3 obstacles move horizontally at a speed of03ms and the middle two (1times 1times 1) m3 obstacles movevertically at a speed of 03ms e starting point and targetpoint of the mobile robot are the same as those of the firstsimulation environment and the second simulation envi-ronment is used to train the robot to plan its path in adynamic environment
28 Simulation Experiment and Result Analysis In order toverify the algorithm the original DDPG and the improvedDDPGmobile robot path planning algorithm are trained for1500 rounds in the simulation environment with the samedynamic obstacles and the total return value of the mobilerobot in each round of simulation training is recorded A
graph with the number of training rounds as the abscissa andthe return value of each training round as the ordinate isdrawn as follows
e results of Figure 4 show that when the DDPG al-gorithm is trained in a dynamic obstacle simulation envi-ronment the total return value curve has a gradual upwardand downward trend with the increase of the number oftraining rounds indicating that the mobile robot training ina dynamic obstacle environment does not converge at laste total return value fluctuates greatly from 0 to 200rounds and the return value is mostly negative is showsthat the robot is ldquolearningrdquo to reach the target point Ob-serving the training process it can be seen that the mobilerobot collides with dynamic obstacles when graduallyapproaching the target point and the total return value canreach 2400 or so in 200 to 400 rounds Observing thetraining process it can be seen that the robot can reach thetarget point in a few cases After 400 rounds the return valueis high and low and most of them are stable at about 500Observing the training process we can see that most of themend up colliding with dynamic obstacles
Figure 5 shows the return curve of DDPG algorithmtraining in a dynamic environment with transfer learning Itcan be seen from Figure 5 that the robot will move towardsthe target point at the beginning because of the addition oftransfer learning so the learning negative value of the returncurve is much less than that in Figure 4 but the overall curveis uneven and does not converge
Figure 6 shows the return curve of the DDPG algorithmtrained in a dynamic environment with only priority ex-perience replay Because the priority experience replayeliminates a large number of invalid data in the early stage oftraining it can be seen from Figure 6 that the return curvegradually increases from negative value and tends to bestable but the convergence speed is slow and the success rateis low
Figure 7 is a return graph of DDPG algorithm training ina dynamic environment with priority experience replay andtransfer learning It can be seen from Figure 7 that the returnvalue curve is improved compared with Figure 4 but theconvergence effect has not yet been achieved
Figure 8 shows that when the DDPG algorithm withRAdam is introduced and priority experience replay andtransfer learning are added to train in the dynamic obstaclesimulation environment the return value curve graduallyincreases and tends to be stable with the increase of thenumber of training rounds e results show that the DDPGalgorithm with RAdam is approximately convergent in thedynamic obstacle environment Because through the com-bination of internal and external rewards compared withFigure 7 the convergence speed and success rate are ob-viously improved which shows that adding the RAdamalgorithm optimizer has a better effect on the path planningof mobile robots in a dynamic environment
Figure 9 shows that when the improved DDPG algo-rithm (ie curiosity module is introduced on the basis of theRAdam algorithm optimizer) and priority experience replayand transfer learning are added to train in a dynamic ob-stacle simulation environment the return value curve
ForwardModel
features
st
rit
at
at
st+1
ϕ (st+1)ϕ (st)
features
ICM
InverseModelϕ (st + 1)
Figure 2 Curiosity module flowchart
Mobile Information Systems 5
gradually increases and tends to stabilize with the increase ofthe number of training rounds Compared with Figure 8 theconvergence speed and success rate are significantly im-proved and the return value is also significantly improved
compared with the previous one due to the internal rewardprovided by the curiosity module
Figures 10(a)ndash10(d) show the simulation process of theimproved DDPG algorithm for path planning to reach the
(a) (b)
Figure 3 Experimental simulation environment
2500
2000
1500
1000
500
0
ndash500
ndash10000 200 400 600 800 1000
Episode1200 1400
Episo
de R
ewar
d
Figure 4 Experimental results of the original DDPG algorithm
0 200 400 600 800 1000Episode
1200 1400
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
Figure 5 Experimental results of adding transfer learning
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 6 Add priority experience to replay the experimentalresults
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 7 Experimental results with transfer learning and preferredexperience replay added
6 Mobile Information Systems
target point in a dynamic environment As shown in Fig-ure 10 the mobile robot avoids all dynamic obstacles fromthe starting point to reach the end point
29 Comparative Analysis of Experimental Results In orderto verify the success rate of path planning of the trainedmodels in the dynamic environment the four trainingmodels were tested 50 times in the training dynamic en-vironment and the same test was carried out three times toget the average value e experiment is done three times toensure the validity of the data e test results and the timetaken to train the model are recorded in Table 1
Experimental results show that in Table 1 the successrate of the original DDPG algorithm can reach 50 and thetraining time of the model is 14 hours After only addingtransfer learning although the training time is reduced thesuccess rate is reduced Only adding priority experiencereplay the success rate increased to 70 but the trainingtime did not decrease By adding priority experience replayand introducing transfer learning the success rate increasesto 74 and themodel training time is shortened to 13 hoursAfter adding the RAdam algorithm the success rate in-creases to 86 and the model training time is shortened to12 hours Finally the success rate of the curiosity module isincreased to 90 and the model training time is shortened
to 11 hours Compared with the original DDPG algorithmthe convergence speed is increased by 21 and the successrate is increased to 90
During the experiment Rviz subscribes to the self-odometer message Odom released by the mobile robotvisualizes the pose information of the mobile robot at eachmoment in the form of coordinate axes and gives the pathplanning to reach the target point before and after im-provement as shown in Figures 11ndash 13
e time and path results of the mobile robot reachingthe target point in the dynamic environment after the im-provement of the DDPG algorithm are shown in Table 2 Inorder to ensure the validity of the results the test results areaveraged 10 times
According to the data in Table 2 it takes 86 seconds and280 steps for the original DDPG algorithm to reach thetarget point in the path planning of the mobile robot in adynamic environment of this article Adding the RAdamneural network optimizer algorithm the time is shortened to76 s and the step size is reduced to 250e curiosity moduleis introduced on the basis of the previous one the timereaches 60 s and the step size is shortened to 210 roughexperimental comparison it is proven that the time and stepsize of the improved DDPG algorithm in mobile robot pathplanning in a dynamic environment are improved whichverifies the algorithmrsquos effectiveness
2000
1500
1000
500
Episo
de R
ewar
d0 200 400 600 800 1000
Episode1200 1400
Figure 8 Experimental result of introducing the RAdam algorithm
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 9 Experimental results of the improved DDPG algorithm
Mobile Information Systems 7
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems

modelerefore the DQN algorithm [13] comes into being Itusually solves the problem of discrete and low-dimensionalaction spacee Deep Deterministic Policy Gradient (DDPG)algorithm proposed by DeepMind team in 2016 uses the actor-critical algorithm framework and draws lessons from the ideaof the DQN algorithm to solve the problem of continuousaction space [14] However when the DDPG algorithm isapplied to path planning in a dynamic environment it hassome shortcomings such as low success rate and slow con-vergence speed and most of the related research stays at thetheoretical level lacking solutions to practical problems
In this article a new DDPG algorithm is proposed inwhich the RAdam algorithm is used to replace the neuralnetwork algorithm in the original algorithm combined withthe curiosity algorithm to improve the success rate andconvergence speed and introduce priority experience replayand transfer learning e original data is obtained throughthe lidar carried by the mobile robot the dynamic obstacleinformation is obtained and the improved algorithm is ap-plied to the path planning of the mobile robot in the dynamicenvironment so that it canmove safely from the starting pointto the end point in a short time get the shortest path andverify the effectiveness of the improved algorithm
e organizational structure of this article is as followsthe first section is an introduction the second section in-troduces the DDPG algorithm principle and network pa-rameter setting the third section is path planning design ofimproved DDPG algorithm the fourth section shows thesimulation experiment and analyzed results and the sum-maries are given in the last section
11 DDPG Algorithm Principle and Network ParameterSetting
111 Principle of DDPG Algorithm DDPG used in thisarticle is a strategy learning method that outputs continuousactions Based on the DPG algorithm and using the ad-vantages of Actor-Criticrsquos strategy gradient single-step up-date and DQNrsquos experience replay and target networktechnology for reference the convergence of Actor-Critic isimproved e DDPG algorithm consists of policy networkand Q network DDPG uses deterministic policy to selectaction at μ(st|θ
μ) so the output is not the probability ofbehavior but the specific behavior where θμ is the parameterof policy network at is the action and st is the state eDDPG algorithm framework is shown in Figure 1
Actor uses policy gradient to learn strategies and selectrobot actions in the current given environment In contrastCritic uses policy evaluation to evaluate the value functionand generate signals to evaluate Actorrsquos actions During pathplanning the environmental data obtained by the robotsensor is input into the Actor network and the actions thatthe robot needs to make are output e Critic networkinputs the environmental state of the robot and the pathplanning actions and outputs the corresponding Q value forevaluation In the DDPG algorithm both Actor and Criticare represented by DNN (Deep Neural Network) Actornetwork and Critic network approximate θμ μ and Q
functions respectively When the algorithm performs iter-ative updating firstly the sample data of the experience poolis accumulated until the number specified by the minimumbatch is reached then the Critic network is updated by usingthe sample data parameter θQ of the Q network is updatedby the loss function and the gradient of the objectivefunction relative to the action θμ is obtained [15] enupdate θμ with Adam Optimizer
2 DDPG Network Parameter Setting
21 For State Space Settings e robot in this article obtainsthe distance between itself and the surrounding obstaclesthrough lidar e detection distance range of lidar is (01235) (unit m) and the angle range of lidar [16] detection is(minus90 90) that is 0deg in front of the robot 90deg to the left and90deg to the right e lidar data are 20 dimensions and theangle between radar data in each dimension is 9deg e basisfor judging whether the robot hits an obstacle in the processof moving if the distance from the obstacle is less than 02mit is judged as hitting the obstacle In an actual simulation20-dimensional lidar distance information is obtained
According to the distance between the robot and theobstacle the state between the robot and the obstacle isdivided into navigation state N and obstacle collision state C
as follows
S N di(t)gt 02m
C di(t)le 02m1113896 (1)
where di(t) is the i-th dimension lidar distance data of therobot at time t When the distance between the robot andthe obstacle is di(t)le 02m the robot is in state C of hittingthe obstacle When the distance between the robot and theobstacle di(t)gt 02m the robot is in the normal navigationstate N [17 18]
22 Action Space Setting e final output of DDPGrsquos de-cision network is a continuous angular velocity value in acertain interval e output is the continuous angular ve-locity which is more in line with the kinematic character-istics of the robot so the trajectory of the robot in the processof moving will be smoother and the output action will bemore continuous In the simulation it is necessary to limitthe angular velocity not to be too large so the maximumangular velocity is set to 05 rads Hence the final outputangular velocity interval of DDPG is (minus05 05) (unit rads)the linear velocity value is 025ms the forward speed (linearvelocity (v) angular velocity (ω)) is (025 0) the left turnspeed is (025 minus05) and the right turn speed is (025 05)
23 Reward Function Settings
Reward
minus200 diminus0(t)le 02
100 diminust(t)le 02
300 middot diminust(t minus 1) minus diminust(t)( 1113857
⎧⎪⎪⎨
⎪⎪⎩
(2)
2 Mobile Information Systems
In the above formula reward is the return value diminus0(t) isthe distance between the robot and the obstacle In the ex-perimental simulation when diminus0(t) is less than 02 thereturn value of collision with the obstacle is minus200 diminust(t) isthe distance value between the robot and the target point and100 is rewarded when reaching the target point In other casesthe difference between the distance from the target point atthe previousmoment and the distance from the target point atthe current moment that is 300 middot (diminust(t minus 1) minus diminust(t)) istaken as the return value e design is to make the robotmove to the target point continuously so that every actiontaken by the robot can get feedback in time ensuring thecontinuity of the reward function and speeding up theconvergence speed of the algorithm
24 Path Planning Design of Improved DDPG Algorithm
241 RAdam Optimization Algorithm Design In deeplearning most neural networks adopt the adaptive learningrate optimization method which has the problem of ex-cessive variance Reducing this difference problem canimprove training efficiency and recognition accuracy
In some neural network optimizer algorithms SGD con-verges well but it takes a lot of time In contrast Adamconverges quickly but it is easy to fall into local solutionsRAdam uses the warm-up method to solve the problem thatAdam can easily converge to the local optimal solution andselects the relatively stable SGD+momentum for training inthe early stage to reduce the variance stablyerefore RAdamis superior to other neural network optimizers In addition theRAdam algorithm [19] is an algorithm proposed in recentyears which has the characteristics of fast convergence and
high precision and the RAdam algorithm can effectively solvethe differences in adaptive learning methods erefore theRAdam algorithm is introduced into the DDPG algorithm tosolve the problems of low success rate and slow convergencespeed of mobile robot path planning in the dynamic envi-ronment caused by neural network variance problem [20]eRAdam algorithm formula can be expressed as follows
θt+1 θt minus αtrt
1113954mt
1113954vt
1113954vt
vt
1 minus βt2
1113971
rt
ρt minus 4( 1113857 ρt minus 2( 1113857ρinfinρinfin minus 4( 1113857 ρinfin minus 2( 1113857ρt
1113971
ρt ρinfin minus2tβt
2
1 minus βt2
1113954mt mt
1 minus βt1
vt β2vtminus1 + 1 minus β2( 1113857g2t
mt β1mtminus1 + 1 minus β1( 1113857gt
gt nablaθJ(θ)
⎧⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎩
(3)
Policy Gradient
softupdate
at
atst
Online Actor Netmicro (s|θmicro)
Target Actor Netμprime (s|θt)
Actor Network
Loss FunctionL = E[(rt + rQprime(st+1 at+1) ndash Q(stat))]
update update
softupdate
Online Critic NetQ (s a|θQ)
Target Critic NetQprime (s a|θQ)
Critic Network
Replay buffer D(st at rt st+1)
st+1 st+1
at+1
Q (st at) Qprime (s a|θQ)
Figure 1 Flowchart of DDPG algorithm
Mobile Information Systems 3
where θt is the parameters to be trained t is the trainingtime αt is the step size rt is the rectification term 1113954vt is themoving second-order moment after bias correction 1113954mt isthe moving average after bias correction attenuation rate β1 β2 β
t1 β
t2 is the attenuation rate at time t mt is the
first-order moment (momentum) vt is the second-ordermoment (adaptive learning rate) gt is the gradient ρinfin is themaximum length of the simple moving average ρt is themaximum value of the simple moving average J(θ) is thetarget parameter and nablaθ is the gradient coefficient
25 Prioritized Experience Replay In the path planning ofmobile robot in a dynamic environment because of theuncertainty of the environment there are a lot of invalidexperiences due to collision in the early stage of trainingeoriginal DDPG algorithm uses these invalid experiences fortraining which leads to a low success rate of path planningafter training and wastes a lot of time In order to solve theproblem that the success rate of mobile robot path planningin a dynamic environment is not high due to ineffectiveexperience this article designs and adds prioritized expe-rience replay When prioritized experience replay extractsexperiences priority is given to extracting the most valuableexperiences but not only the most valuable experiencesotherwise overfitting will be caused e higher the valuethe greater the probability of extraction When the value islowest there is also a certain probability of extraction
Prioritized experience replay uses the size of TD(Temporal Difference) error to measure which experienceshave greater contributions to the learning process In theDDPG algorithm its core update formula is
Qw st at( 1113857 Qw st at( 1113857 + rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 11138571113858 1113859
(4)
where TD-error is
δt rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 1113857 (5)
where maxaQw(st+1 at+1) is the action at+1 selected from theaction space when the mobile robot is in the state st+1 so thatQw(st+1 at+1) is the maximum value of Q values corre-sponding to all actions and t is the training time As adiscount factor c make it take the value between (0 1) sothat the mobile robot does not pay too much attention to thereward value brought by each action in the future nor does itbecome short-sighted but only pays attention to the im-mediate action return rt+1 is the return value obtained by themobile robot executing the action at and transitioning fromstates st to st+1 e goal of priority experience replay is tomake TD-error as small as possible If TD-error is relativelylarge it means that our current Q function is still far fromthe target Q function and should be updated moreerefore the TD-error is used to measure the value ofexperience Finally the binary tree method is used to extractthe experiences with their respective priorities efficiently
26CuriosityAlgorithm e core of interaction between thedeep reinforcement learning algorithm and environment is
the setting of the reward mechanism A reasonable rewardmechanism can speed up the learning process of the agentand achieve good results However in the path planning ofmobile robots in a dynamic environment as the workingenvironment of mobile robots becomes more and morecomplex external reward training alone cannot get goodresults quickly erefore the curiosity algorithm [21] isintroduced in this document to provide internal rewards byreducing the form of actions and self-errors in the learningprocess of agents through internal curiosity module (ICM)so that mobile robots can train under the combined action ofinternal and external rewards and achieve good pathplanning effect e final reward value combined with theDDPG algorithm is max rt ri
t + rεt where rt is the totalreward value ri
t is the internal reward of curiosity moduleand rεt is the external reward of the DDPG algorithm
In a complete training process the original and next statevalues and actions should be calculated through the internalcuriosity module as shown in Figure 2 Specifically thecuriosity algorithm uses two submodules the first sub-module encodes st into φ(st) and the second submoduleuses two consecutive states φ(st) and φ(st+1) encoded bythe previous module to predict action at at is the actionof the agent will pass through the forward model1113954at g(st st+1 θI) where 1113954at is the predicted estimation valueof the action st and st+1 represent the original state and thenext state of the agent θI is the neural network parameterand the function g is the inverse dynamic model Errorcalculation is carried out between the state prediction of theforward model and the coding of the next state and thecalculation result obtains an internal reward e codingprinciple is as follows
1113954φ st+1( 1113857 f φ st( 1113857 at θF( 1113857 (6)
where 1113954φ(st+1) represents a state prediction value φ(st)
represents a feature vector encoded by the original state st at
is the action θF is a neural network parameter and thelearning function f is called a forward dynamics model
e neural network parameter θF is optimized byminimizing the loss function LF
LF φ st( 1113857φ st+1( 1113857( 1113857 12
1113954φ st+1( 1113857φ st+1( 1113857
22 (7)
e intrinsic reward value is
rit
η2
1113954φ st+1( 1113857φ st+1( 1113857
22 (8)
where η is the scale factor satisfyingηgt 0 e coding resultsof the original state and the next state will be predicted by theinverse dynamic model
e overall optimization objectives of the curiosity al-gorithm are summarized as follows
minθPθIθF
minusλEπ StθP( ) 1113944 rt1113960 1113961 +(1 minus β)LI + βLF1113876 1113877 (9)
In the formula β and λ are scalars θI and θP is the neuralnetwork parameter the losses of the inverse model and theforward model are weighted to β satisfy 0le βle 1 the
4 Mobile Information Systems
importance of gradient loss to the reward signal in learningis measured λ λgt 0 is satisfied LI is the loss function tomeasure the difference between the prediction and the actualaction rt is the internal reward value at time t and π(st θP)
represents a parameterized policy In the simulation ex-periment β is 02 and λ is 01
27 Simulation Experiment and Result Analysis
271 Establishment of Simulation Experiment EnvironmentHardware configuration of simulation experiment Intel i5-3320M CPU and 4G memory e operating system isUbuntu 1804 e ROS Melodic robot operating system isinstalled and the simulation environment is establishedusing Gazebo 9 under ROS e generated experimentalenvironment is shown in Figure 3
In that simulation environment of Figure 3(a) a squareenvironment with a length and width of 8meters is estab-lished no obstacles are added the position of the mobilerobot at the starting point is set to (minus2 25) and the colorcircle at the target point is set to (2 minus2) which is mainly usedto train the mobile robotrsquos ability to complete the target in alimited space for transfer learning In that simulation en-vironment of Figure 3(b) eight dynamic obstacles are addedon the basis of the above environment among which themiddle four (03times 03times 03)m3 obstacles rotate counter-clockwise at a speed of 05ms the upper and lower two(1times 1times 1) m3 obstacles move horizontally at a speed of03ms and the middle two (1times 1times 1) m3 obstacles movevertically at a speed of 03ms e starting point and targetpoint of the mobile robot are the same as those of the firstsimulation environment and the second simulation envi-ronment is used to train the robot to plan its path in adynamic environment
28 Simulation Experiment and Result Analysis In order toverify the algorithm the original DDPG and the improvedDDPGmobile robot path planning algorithm are trained for1500 rounds in the simulation environment with the samedynamic obstacles and the total return value of the mobilerobot in each round of simulation training is recorded A
graph with the number of training rounds as the abscissa andthe return value of each training round as the ordinate isdrawn as follows
e results of Figure 4 show that when the DDPG al-gorithm is trained in a dynamic obstacle simulation envi-ronment the total return value curve has a gradual upwardand downward trend with the increase of the number oftraining rounds indicating that the mobile robot training ina dynamic obstacle environment does not converge at laste total return value fluctuates greatly from 0 to 200rounds and the return value is mostly negative is showsthat the robot is ldquolearningrdquo to reach the target point Ob-serving the training process it can be seen that the mobilerobot collides with dynamic obstacles when graduallyapproaching the target point and the total return value canreach 2400 or so in 200 to 400 rounds Observing thetraining process it can be seen that the robot can reach thetarget point in a few cases After 400 rounds the return valueis high and low and most of them are stable at about 500Observing the training process we can see that most of themend up colliding with dynamic obstacles
Figure 5 shows the return curve of DDPG algorithmtraining in a dynamic environment with transfer learning Itcan be seen from Figure 5 that the robot will move towardsthe target point at the beginning because of the addition oftransfer learning so the learning negative value of the returncurve is much less than that in Figure 4 but the overall curveis uneven and does not converge
Figure 6 shows the return curve of the DDPG algorithmtrained in a dynamic environment with only priority ex-perience replay Because the priority experience replayeliminates a large number of invalid data in the early stage oftraining it can be seen from Figure 6 that the return curvegradually increases from negative value and tends to bestable but the convergence speed is slow and the success rateis low
Figure 7 is a return graph of DDPG algorithm training ina dynamic environment with priority experience replay andtransfer learning It can be seen from Figure 7 that the returnvalue curve is improved compared with Figure 4 but theconvergence effect has not yet been achieved
Figure 8 shows that when the DDPG algorithm withRAdam is introduced and priority experience replay andtransfer learning are added to train in the dynamic obstaclesimulation environment the return value curve graduallyincreases and tends to be stable with the increase of thenumber of training rounds e results show that the DDPGalgorithm with RAdam is approximately convergent in thedynamic obstacle environment Because through the com-bination of internal and external rewards compared withFigure 7 the convergence speed and success rate are ob-viously improved which shows that adding the RAdamalgorithm optimizer has a better effect on the path planningof mobile robots in a dynamic environment
Figure 9 shows that when the improved DDPG algo-rithm (ie curiosity module is introduced on the basis of theRAdam algorithm optimizer) and priority experience replayand transfer learning are added to train in a dynamic ob-stacle simulation environment the return value curve
ForwardModel
features
st
rit
at
at
st+1
ϕ (st+1)ϕ (st)
features
ICM
InverseModelϕ (st + 1)
Figure 2 Curiosity module flowchart
Mobile Information Systems 5
gradually increases and tends to stabilize with the increase ofthe number of training rounds Compared with Figure 8 theconvergence speed and success rate are significantly im-proved and the return value is also significantly improved
compared with the previous one due to the internal rewardprovided by the curiosity module
Figures 10(a)ndash10(d) show the simulation process of theimproved DDPG algorithm for path planning to reach the
(a) (b)
Figure 3 Experimental simulation environment
2500
2000
1500
1000
500
0
ndash500
ndash10000 200 400 600 800 1000
Episode1200 1400
Episo
de R
ewar
d
Figure 4 Experimental results of the original DDPG algorithm
0 200 400 600 800 1000Episode
1200 1400
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
Figure 5 Experimental results of adding transfer learning
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 6 Add priority experience to replay the experimentalresults
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 7 Experimental results with transfer learning and preferredexperience replay added
6 Mobile Information Systems
target point in a dynamic environment As shown in Fig-ure 10 the mobile robot avoids all dynamic obstacles fromthe starting point to reach the end point
29 Comparative Analysis of Experimental Results In orderto verify the success rate of path planning of the trainedmodels in the dynamic environment the four trainingmodels were tested 50 times in the training dynamic en-vironment and the same test was carried out three times toget the average value e experiment is done three times toensure the validity of the data e test results and the timetaken to train the model are recorded in Table 1
Experimental results show that in Table 1 the successrate of the original DDPG algorithm can reach 50 and thetraining time of the model is 14 hours After only addingtransfer learning although the training time is reduced thesuccess rate is reduced Only adding priority experiencereplay the success rate increased to 70 but the trainingtime did not decrease By adding priority experience replayand introducing transfer learning the success rate increasesto 74 and themodel training time is shortened to 13 hoursAfter adding the RAdam algorithm the success rate in-creases to 86 and the model training time is shortened to12 hours Finally the success rate of the curiosity module isincreased to 90 and the model training time is shortened
to 11 hours Compared with the original DDPG algorithmthe convergence speed is increased by 21 and the successrate is increased to 90
During the experiment Rviz subscribes to the self-odometer message Odom released by the mobile robotvisualizes the pose information of the mobile robot at eachmoment in the form of coordinate axes and gives the pathplanning to reach the target point before and after im-provement as shown in Figures 11ndash 13
e time and path results of the mobile robot reachingthe target point in the dynamic environment after the im-provement of the DDPG algorithm are shown in Table 2 Inorder to ensure the validity of the results the test results areaveraged 10 times
According to the data in Table 2 it takes 86 seconds and280 steps for the original DDPG algorithm to reach thetarget point in the path planning of the mobile robot in adynamic environment of this article Adding the RAdamneural network optimizer algorithm the time is shortened to76 s and the step size is reduced to 250e curiosity moduleis introduced on the basis of the previous one the timereaches 60 s and the step size is shortened to 210 roughexperimental comparison it is proven that the time and stepsize of the improved DDPG algorithm in mobile robot pathplanning in a dynamic environment are improved whichverifies the algorithmrsquos effectiveness
2000
1500
1000
500
Episo
de R
ewar
d0 200 400 600 800 1000
Episode1200 1400
Figure 8 Experimental result of introducing the RAdam algorithm
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 9 Experimental results of the improved DDPG algorithm
Mobile Information Systems 7
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems

In the above formula reward is the return value diminus0(t) isthe distance between the robot and the obstacle In the ex-perimental simulation when diminus0(t) is less than 02 thereturn value of collision with the obstacle is minus200 diminust(t) isthe distance value between the robot and the target point and100 is rewarded when reaching the target point In other casesthe difference between the distance from the target point atthe previousmoment and the distance from the target point atthe current moment that is 300 middot (diminust(t minus 1) minus diminust(t)) istaken as the return value e design is to make the robotmove to the target point continuously so that every actiontaken by the robot can get feedback in time ensuring thecontinuity of the reward function and speeding up theconvergence speed of the algorithm
24 Path Planning Design of Improved DDPG Algorithm
241 RAdam Optimization Algorithm Design In deeplearning most neural networks adopt the adaptive learningrate optimization method which has the problem of ex-cessive variance Reducing this difference problem canimprove training efficiency and recognition accuracy
In some neural network optimizer algorithms SGD con-verges well but it takes a lot of time In contrast Adamconverges quickly but it is easy to fall into local solutionsRAdam uses the warm-up method to solve the problem thatAdam can easily converge to the local optimal solution andselects the relatively stable SGD+momentum for training inthe early stage to reduce the variance stablyerefore RAdamis superior to other neural network optimizers In addition theRAdam algorithm [19] is an algorithm proposed in recentyears which has the characteristics of fast convergence and
high precision and the RAdam algorithm can effectively solvethe differences in adaptive learning methods erefore theRAdam algorithm is introduced into the DDPG algorithm tosolve the problems of low success rate and slow convergencespeed of mobile robot path planning in the dynamic envi-ronment caused by neural network variance problem [20]eRAdam algorithm formula can be expressed as follows
θt+1 θt minus αtrt
1113954mt
1113954vt
1113954vt
vt
1 minus βt2
1113971
rt
ρt minus 4( 1113857 ρt minus 2( 1113857ρinfinρinfin minus 4( 1113857 ρinfin minus 2( 1113857ρt
1113971
ρt ρinfin minus2tβt
2
1 minus βt2
1113954mt mt
1 minus βt1
vt β2vtminus1 + 1 minus β2( 1113857g2t
mt β1mtminus1 + 1 minus β1( 1113857gt
gt nablaθJ(θ)
⎧⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎨
⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎩
(3)
Policy Gradient
softupdate
at
atst
Online Actor Netmicro (s|θmicro)
Target Actor Netμprime (s|θt)
Actor Network
Loss FunctionL = E[(rt + rQprime(st+1 at+1) ndash Q(stat))]
update update
softupdate
Online Critic NetQ (s a|θQ)
Target Critic NetQprime (s a|θQ)
Critic Network
Replay buffer D(st at rt st+1)
st+1 st+1
at+1
Q (st at) Qprime (s a|θQ)
Figure 1 Flowchart of DDPG algorithm
Mobile Information Systems 3
where θt is the parameters to be trained t is the trainingtime αt is the step size rt is the rectification term 1113954vt is themoving second-order moment after bias correction 1113954mt isthe moving average after bias correction attenuation rate β1 β2 β
t1 β
t2 is the attenuation rate at time t mt is the
first-order moment (momentum) vt is the second-ordermoment (adaptive learning rate) gt is the gradient ρinfin is themaximum length of the simple moving average ρt is themaximum value of the simple moving average J(θ) is thetarget parameter and nablaθ is the gradient coefficient
25 Prioritized Experience Replay In the path planning ofmobile robot in a dynamic environment because of theuncertainty of the environment there are a lot of invalidexperiences due to collision in the early stage of trainingeoriginal DDPG algorithm uses these invalid experiences fortraining which leads to a low success rate of path planningafter training and wastes a lot of time In order to solve theproblem that the success rate of mobile robot path planningin a dynamic environment is not high due to ineffectiveexperience this article designs and adds prioritized expe-rience replay When prioritized experience replay extractsexperiences priority is given to extracting the most valuableexperiences but not only the most valuable experiencesotherwise overfitting will be caused e higher the valuethe greater the probability of extraction When the value islowest there is also a certain probability of extraction
Prioritized experience replay uses the size of TD(Temporal Difference) error to measure which experienceshave greater contributions to the learning process In theDDPG algorithm its core update formula is
Qw st at( 1113857 Qw st at( 1113857 + rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 11138571113858 1113859
(4)
where TD-error is
δt rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 1113857 (5)
where maxaQw(st+1 at+1) is the action at+1 selected from theaction space when the mobile robot is in the state st+1 so thatQw(st+1 at+1) is the maximum value of Q values corre-sponding to all actions and t is the training time As adiscount factor c make it take the value between (0 1) sothat the mobile robot does not pay too much attention to thereward value brought by each action in the future nor does itbecome short-sighted but only pays attention to the im-mediate action return rt+1 is the return value obtained by themobile robot executing the action at and transitioning fromstates st to st+1 e goal of priority experience replay is tomake TD-error as small as possible If TD-error is relativelylarge it means that our current Q function is still far fromthe target Q function and should be updated moreerefore the TD-error is used to measure the value ofexperience Finally the binary tree method is used to extractthe experiences with their respective priorities efficiently
26CuriosityAlgorithm e core of interaction between thedeep reinforcement learning algorithm and environment is
the setting of the reward mechanism A reasonable rewardmechanism can speed up the learning process of the agentand achieve good results However in the path planning ofmobile robots in a dynamic environment as the workingenvironment of mobile robots becomes more and morecomplex external reward training alone cannot get goodresults quickly erefore the curiosity algorithm [21] isintroduced in this document to provide internal rewards byreducing the form of actions and self-errors in the learningprocess of agents through internal curiosity module (ICM)so that mobile robots can train under the combined action ofinternal and external rewards and achieve good pathplanning effect e final reward value combined with theDDPG algorithm is max rt ri
t + rεt where rt is the totalreward value ri
t is the internal reward of curiosity moduleand rεt is the external reward of the DDPG algorithm
In a complete training process the original and next statevalues and actions should be calculated through the internalcuriosity module as shown in Figure 2 Specifically thecuriosity algorithm uses two submodules the first sub-module encodes st into φ(st) and the second submoduleuses two consecutive states φ(st) and φ(st+1) encoded bythe previous module to predict action at at is the actionof the agent will pass through the forward model1113954at g(st st+1 θI) where 1113954at is the predicted estimation valueof the action st and st+1 represent the original state and thenext state of the agent θI is the neural network parameterand the function g is the inverse dynamic model Errorcalculation is carried out between the state prediction of theforward model and the coding of the next state and thecalculation result obtains an internal reward e codingprinciple is as follows
1113954φ st+1( 1113857 f φ st( 1113857 at θF( 1113857 (6)
where 1113954φ(st+1) represents a state prediction value φ(st)
represents a feature vector encoded by the original state st at
is the action θF is a neural network parameter and thelearning function f is called a forward dynamics model
e neural network parameter θF is optimized byminimizing the loss function LF
LF φ st( 1113857φ st+1( 1113857( 1113857 12
1113954φ st+1( 1113857φ st+1( 1113857
22 (7)
e intrinsic reward value is
rit
η2
1113954φ st+1( 1113857φ st+1( 1113857
22 (8)
where η is the scale factor satisfyingηgt 0 e coding resultsof the original state and the next state will be predicted by theinverse dynamic model
e overall optimization objectives of the curiosity al-gorithm are summarized as follows
minθPθIθF
minusλEπ StθP( ) 1113944 rt1113960 1113961 +(1 minus β)LI + βLF1113876 1113877 (9)
In the formula β and λ are scalars θI and θP is the neuralnetwork parameter the losses of the inverse model and theforward model are weighted to β satisfy 0le βle 1 the
4 Mobile Information Systems
importance of gradient loss to the reward signal in learningis measured λ λgt 0 is satisfied LI is the loss function tomeasure the difference between the prediction and the actualaction rt is the internal reward value at time t and π(st θP)
represents a parameterized policy In the simulation ex-periment β is 02 and λ is 01
27 Simulation Experiment and Result Analysis
271 Establishment of Simulation Experiment EnvironmentHardware configuration of simulation experiment Intel i5-3320M CPU and 4G memory e operating system isUbuntu 1804 e ROS Melodic robot operating system isinstalled and the simulation environment is establishedusing Gazebo 9 under ROS e generated experimentalenvironment is shown in Figure 3
In that simulation environment of Figure 3(a) a squareenvironment with a length and width of 8meters is estab-lished no obstacles are added the position of the mobilerobot at the starting point is set to (minus2 25) and the colorcircle at the target point is set to (2 minus2) which is mainly usedto train the mobile robotrsquos ability to complete the target in alimited space for transfer learning In that simulation en-vironment of Figure 3(b) eight dynamic obstacles are addedon the basis of the above environment among which themiddle four (03times 03times 03)m3 obstacles rotate counter-clockwise at a speed of 05ms the upper and lower two(1times 1times 1) m3 obstacles move horizontally at a speed of03ms and the middle two (1times 1times 1) m3 obstacles movevertically at a speed of 03ms e starting point and targetpoint of the mobile robot are the same as those of the firstsimulation environment and the second simulation envi-ronment is used to train the robot to plan its path in adynamic environment
28 Simulation Experiment and Result Analysis In order toverify the algorithm the original DDPG and the improvedDDPGmobile robot path planning algorithm are trained for1500 rounds in the simulation environment with the samedynamic obstacles and the total return value of the mobilerobot in each round of simulation training is recorded A
graph with the number of training rounds as the abscissa andthe return value of each training round as the ordinate isdrawn as follows
e results of Figure 4 show that when the DDPG al-gorithm is trained in a dynamic obstacle simulation envi-ronment the total return value curve has a gradual upwardand downward trend with the increase of the number oftraining rounds indicating that the mobile robot training ina dynamic obstacle environment does not converge at laste total return value fluctuates greatly from 0 to 200rounds and the return value is mostly negative is showsthat the robot is ldquolearningrdquo to reach the target point Ob-serving the training process it can be seen that the mobilerobot collides with dynamic obstacles when graduallyapproaching the target point and the total return value canreach 2400 or so in 200 to 400 rounds Observing thetraining process it can be seen that the robot can reach thetarget point in a few cases After 400 rounds the return valueis high and low and most of them are stable at about 500Observing the training process we can see that most of themend up colliding with dynamic obstacles
Figure 5 shows the return curve of DDPG algorithmtraining in a dynamic environment with transfer learning Itcan be seen from Figure 5 that the robot will move towardsthe target point at the beginning because of the addition oftransfer learning so the learning negative value of the returncurve is much less than that in Figure 4 but the overall curveis uneven and does not converge
Figure 6 shows the return curve of the DDPG algorithmtrained in a dynamic environment with only priority ex-perience replay Because the priority experience replayeliminates a large number of invalid data in the early stage oftraining it can be seen from Figure 6 that the return curvegradually increases from negative value and tends to bestable but the convergence speed is slow and the success rateis low
Figure 7 is a return graph of DDPG algorithm training ina dynamic environment with priority experience replay andtransfer learning It can be seen from Figure 7 that the returnvalue curve is improved compared with Figure 4 but theconvergence effect has not yet been achieved
Figure 8 shows that when the DDPG algorithm withRAdam is introduced and priority experience replay andtransfer learning are added to train in the dynamic obstaclesimulation environment the return value curve graduallyincreases and tends to be stable with the increase of thenumber of training rounds e results show that the DDPGalgorithm with RAdam is approximately convergent in thedynamic obstacle environment Because through the com-bination of internal and external rewards compared withFigure 7 the convergence speed and success rate are ob-viously improved which shows that adding the RAdamalgorithm optimizer has a better effect on the path planningof mobile robots in a dynamic environment
Figure 9 shows that when the improved DDPG algo-rithm (ie curiosity module is introduced on the basis of theRAdam algorithm optimizer) and priority experience replayand transfer learning are added to train in a dynamic ob-stacle simulation environment the return value curve
ForwardModel
features
st
rit
at
at
st+1
ϕ (st+1)ϕ (st)
features
ICM
InverseModelϕ (st + 1)
Figure 2 Curiosity module flowchart
Mobile Information Systems 5
gradually increases and tends to stabilize with the increase ofthe number of training rounds Compared with Figure 8 theconvergence speed and success rate are significantly im-proved and the return value is also significantly improved
compared with the previous one due to the internal rewardprovided by the curiosity module
Figures 10(a)ndash10(d) show the simulation process of theimproved DDPG algorithm for path planning to reach the
(a) (b)
Figure 3 Experimental simulation environment
2500
2000
1500
1000
500
0
ndash500
ndash10000 200 400 600 800 1000
Episode1200 1400
Episo
de R
ewar
d
Figure 4 Experimental results of the original DDPG algorithm
0 200 400 600 800 1000Episode
1200 1400
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
Figure 5 Experimental results of adding transfer learning
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 6 Add priority experience to replay the experimentalresults
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 7 Experimental results with transfer learning and preferredexperience replay added
6 Mobile Information Systems
target point in a dynamic environment As shown in Fig-ure 10 the mobile robot avoids all dynamic obstacles fromthe starting point to reach the end point
29 Comparative Analysis of Experimental Results In orderto verify the success rate of path planning of the trainedmodels in the dynamic environment the four trainingmodels were tested 50 times in the training dynamic en-vironment and the same test was carried out three times toget the average value e experiment is done three times toensure the validity of the data e test results and the timetaken to train the model are recorded in Table 1
Experimental results show that in Table 1 the successrate of the original DDPG algorithm can reach 50 and thetraining time of the model is 14 hours After only addingtransfer learning although the training time is reduced thesuccess rate is reduced Only adding priority experiencereplay the success rate increased to 70 but the trainingtime did not decrease By adding priority experience replayand introducing transfer learning the success rate increasesto 74 and themodel training time is shortened to 13 hoursAfter adding the RAdam algorithm the success rate in-creases to 86 and the model training time is shortened to12 hours Finally the success rate of the curiosity module isincreased to 90 and the model training time is shortened
to 11 hours Compared with the original DDPG algorithmthe convergence speed is increased by 21 and the successrate is increased to 90
During the experiment Rviz subscribes to the self-odometer message Odom released by the mobile robotvisualizes the pose information of the mobile robot at eachmoment in the form of coordinate axes and gives the pathplanning to reach the target point before and after im-provement as shown in Figures 11ndash 13
e time and path results of the mobile robot reachingthe target point in the dynamic environment after the im-provement of the DDPG algorithm are shown in Table 2 Inorder to ensure the validity of the results the test results areaveraged 10 times
According to the data in Table 2 it takes 86 seconds and280 steps for the original DDPG algorithm to reach thetarget point in the path planning of the mobile robot in adynamic environment of this article Adding the RAdamneural network optimizer algorithm the time is shortened to76 s and the step size is reduced to 250e curiosity moduleis introduced on the basis of the previous one the timereaches 60 s and the step size is shortened to 210 roughexperimental comparison it is proven that the time and stepsize of the improved DDPG algorithm in mobile robot pathplanning in a dynamic environment are improved whichverifies the algorithmrsquos effectiveness
2000
1500
1000
500
Episo
de R
ewar
d0 200 400 600 800 1000
Episode1200 1400
Figure 8 Experimental result of introducing the RAdam algorithm
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 9 Experimental results of the improved DDPG algorithm
Mobile Information Systems 7
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems

where θt is the parameters to be trained t is the trainingtime αt is the step size rt is the rectification term 1113954vt is themoving second-order moment after bias correction 1113954mt isthe moving average after bias correction attenuation rate β1 β2 β
t1 β
t2 is the attenuation rate at time t mt is the
first-order moment (momentum) vt is the second-ordermoment (adaptive learning rate) gt is the gradient ρinfin is themaximum length of the simple moving average ρt is themaximum value of the simple moving average J(θ) is thetarget parameter and nablaθ is the gradient coefficient
25 Prioritized Experience Replay In the path planning ofmobile robot in a dynamic environment because of theuncertainty of the environment there are a lot of invalidexperiences due to collision in the early stage of trainingeoriginal DDPG algorithm uses these invalid experiences fortraining which leads to a low success rate of path planningafter training and wastes a lot of time In order to solve theproblem that the success rate of mobile robot path planningin a dynamic environment is not high due to ineffectiveexperience this article designs and adds prioritized expe-rience replay When prioritized experience replay extractsexperiences priority is given to extracting the most valuableexperiences but not only the most valuable experiencesotherwise overfitting will be caused e higher the valuethe greater the probability of extraction When the value islowest there is also a certain probability of extraction
Prioritized experience replay uses the size of TD(Temporal Difference) error to measure which experienceshave greater contributions to the learning process In theDDPG algorithm its core update formula is
Qw st at( 1113857 Qw st at( 1113857 + rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 11138571113858 1113859
(4)
where TD-error is
δt rt+1 + cmaxaQw st+1 at+1( 1113857 minus Qw st at( 1113857 (5)
where maxaQw(st+1 at+1) is the action at+1 selected from theaction space when the mobile robot is in the state st+1 so thatQw(st+1 at+1) is the maximum value of Q values corre-sponding to all actions and t is the training time As adiscount factor c make it take the value between (0 1) sothat the mobile robot does not pay too much attention to thereward value brought by each action in the future nor does itbecome short-sighted but only pays attention to the im-mediate action return rt+1 is the return value obtained by themobile robot executing the action at and transitioning fromstates st to st+1 e goal of priority experience replay is tomake TD-error as small as possible If TD-error is relativelylarge it means that our current Q function is still far fromthe target Q function and should be updated moreerefore the TD-error is used to measure the value ofexperience Finally the binary tree method is used to extractthe experiences with their respective priorities efficiently
26CuriosityAlgorithm e core of interaction between thedeep reinforcement learning algorithm and environment is
the setting of the reward mechanism A reasonable rewardmechanism can speed up the learning process of the agentand achieve good results However in the path planning ofmobile robots in a dynamic environment as the workingenvironment of mobile robots becomes more and morecomplex external reward training alone cannot get goodresults quickly erefore the curiosity algorithm [21] isintroduced in this document to provide internal rewards byreducing the form of actions and self-errors in the learningprocess of agents through internal curiosity module (ICM)so that mobile robots can train under the combined action ofinternal and external rewards and achieve good pathplanning effect e final reward value combined with theDDPG algorithm is max rt ri
t + rεt where rt is the totalreward value ri
t is the internal reward of curiosity moduleand rεt is the external reward of the DDPG algorithm
In a complete training process the original and next statevalues and actions should be calculated through the internalcuriosity module as shown in Figure 2 Specifically thecuriosity algorithm uses two submodules the first sub-module encodes st into φ(st) and the second submoduleuses two consecutive states φ(st) and φ(st+1) encoded bythe previous module to predict action at at is the actionof the agent will pass through the forward model1113954at g(st st+1 θI) where 1113954at is the predicted estimation valueof the action st and st+1 represent the original state and thenext state of the agent θI is the neural network parameterand the function g is the inverse dynamic model Errorcalculation is carried out between the state prediction of theforward model and the coding of the next state and thecalculation result obtains an internal reward e codingprinciple is as follows
1113954φ st+1( 1113857 f φ st( 1113857 at θF( 1113857 (6)
where 1113954φ(st+1) represents a state prediction value φ(st)
represents a feature vector encoded by the original state st at
is the action θF is a neural network parameter and thelearning function f is called a forward dynamics model
e neural network parameter θF is optimized byminimizing the loss function LF
LF φ st( 1113857φ st+1( 1113857( 1113857 12
1113954φ st+1( 1113857φ st+1( 1113857
22 (7)
e intrinsic reward value is
rit
η2
1113954φ st+1( 1113857φ st+1( 1113857
22 (8)
where η is the scale factor satisfyingηgt 0 e coding resultsof the original state and the next state will be predicted by theinverse dynamic model
e overall optimization objectives of the curiosity al-gorithm are summarized as follows
minθPθIθF
minusλEπ StθP( ) 1113944 rt1113960 1113961 +(1 minus β)LI + βLF1113876 1113877 (9)
In the formula β and λ are scalars θI and θP is the neuralnetwork parameter the losses of the inverse model and theforward model are weighted to β satisfy 0le βle 1 the
4 Mobile Information Systems
importance of gradient loss to the reward signal in learningis measured λ λgt 0 is satisfied LI is the loss function tomeasure the difference between the prediction and the actualaction rt is the internal reward value at time t and π(st θP)
represents a parameterized policy In the simulation ex-periment β is 02 and λ is 01
27 Simulation Experiment and Result Analysis
271 Establishment of Simulation Experiment EnvironmentHardware configuration of simulation experiment Intel i5-3320M CPU and 4G memory e operating system isUbuntu 1804 e ROS Melodic robot operating system isinstalled and the simulation environment is establishedusing Gazebo 9 under ROS e generated experimentalenvironment is shown in Figure 3
In that simulation environment of Figure 3(a) a squareenvironment with a length and width of 8meters is estab-lished no obstacles are added the position of the mobilerobot at the starting point is set to (minus2 25) and the colorcircle at the target point is set to (2 minus2) which is mainly usedto train the mobile robotrsquos ability to complete the target in alimited space for transfer learning In that simulation en-vironment of Figure 3(b) eight dynamic obstacles are addedon the basis of the above environment among which themiddle four (03times 03times 03)m3 obstacles rotate counter-clockwise at a speed of 05ms the upper and lower two(1times 1times 1) m3 obstacles move horizontally at a speed of03ms and the middle two (1times 1times 1) m3 obstacles movevertically at a speed of 03ms e starting point and targetpoint of the mobile robot are the same as those of the firstsimulation environment and the second simulation envi-ronment is used to train the robot to plan its path in adynamic environment
28 Simulation Experiment and Result Analysis In order toverify the algorithm the original DDPG and the improvedDDPGmobile robot path planning algorithm are trained for1500 rounds in the simulation environment with the samedynamic obstacles and the total return value of the mobilerobot in each round of simulation training is recorded A
graph with the number of training rounds as the abscissa andthe return value of each training round as the ordinate isdrawn as follows
e results of Figure 4 show that when the DDPG al-gorithm is trained in a dynamic obstacle simulation envi-ronment the total return value curve has a gradual upwardand downward trend with the increase of the number oftraining rounds indicating that the mobile robot training ina dynamic obstacle environment does not converge at laste total return value fluctuates greatly from 0 to 200rounds and the return value is mostly negative is showsthat the robot is ldquolearningrdquo to reach the target point Ob-serving the training process it can be seen that the mobilerobot collides with dynamic obstacles when graduallyapproaching the target point and the total return value canreach 2400 or so in 200 to 400 rounds Observing thetraining process it can be seen that the robot can reach thetarget point in a few cases After 400 rounds the return valueis high and low and most of them are stable at about 500Observing the training process we can see that most of themend up colliding with dynamic obstacles
Figure 5 shows the return curve of DDPG algorithmtraining in a dynamic environment with transfer learning Itcan be seen from Figure 5 that the robot will move towardsthe target point at the beginning because of the addition oftransfer learning so the learning negative value of the returncurve is much less than that in Figure 4 but the overall curveis uneven and does not converge
Figure 6 shows the return curve of the DDPG algorithmtrained in a dynamic environment with only priority ex-perience replay Because the priority experience replayeliminates a large number of invalid data in the early stage oftraining it can be seen from Figure 6 that the return curvegradually increases from negative value and tends to bestable but the convergence speed is slow and the success rateis low
Figure 7 is a return graph of DDPG algorithm training ina dynamic environment with priority experience replay andtransfer learning It can be seen from Figure 7 that the returnvalue curve is improved compared with Figure 4 but theconvergence effect has not yet been achieved
Figure 8 shows that when the DDPG algorithm withRAdam is introduced and priority experience replay andtransfer learning are added to train in the dynamic obstaclesimulation environment the return value curve graduallyincreases and tends to be stable with the increase of thenumber of training rounds e results show that the DDPGalgorithm with RAdam is approximately convergent in thedynamic obstacle environment Because through the com-bination of internal and external rewards compared withFigure 7 the convergence speed and success rate are ob-viously improved which shows that adding the RAdamalgorithm optimizer has a better effect on the path planningof mobile robots in a dynamic environment
Figure 9 shows that when the improved DDPG algo-rithm (ie curiosity module is introduced on the basis of theRAdam algorithm optimizer) and priority experience replayand transfer learning are added to train in a dynamic ob-stacle simulation environment the return value curve
ForwardModel
features
st
rit
at
at
st+1
ϕ (st+1)ϕ (st)
features
ICM
InverseModelϕ (st + 1)
Figure 2 Curiosity module flowchart
Mobile Information Systems 5
gradually increases and tends to stabilize with the increase ofthe number of training rounds Compared with Figure 8 theconvergence speed and success rate are significantly im-proved and the return value is also significantly improved
compared with the previous one due to the internal rewardprovided by the curiosity module
Figures 10(a)ndash10(d) show the simulation process of theimproved DDPG algorithm for path planning to reach the
(a) (b)
Figure 3 Experimental simulation environment
2500
2000
1500
1000
500
0
ndash500
ndash10000 200 400 600 800 1000
Episode1200 1400
Episo
de R
ewar
d
Figure 4 Experimental results of the original DDPG algorithm
0 200 400 600 800 1000Episode
1200 1400
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
Figure 5 Experimental results of adding transfer learning
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 6 Add priority experience to replay the experimentalresults
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 7 Experimental results with transfer learning and preferredexperience replay added
6 Mobile Information Systems
target point in a dynamic environment As shown in Fig-ure 10 the mobile robot avoids all dynamic obstacles fromthe starting point to reach the end point
29 Comparative Analysis of Experimental Results In orderto verify the success rate of path planning of the trainedmodels in the dynamic environment the four trainingmodels were tested 50 times in the training dynamic en-vironment and the same test was carried out three times toget the average value e experiment is done three times toensure the validity of the data e test results and the timetaken to train the model are recorded in Table 1
Experimental results show that in Table 1 the successrate of the original DDPG algorithm can reach 50 and thetraining time of the model is 14 hours After only addingtransfer learning although the training time is reduced thesuccess rate is reduced Only adding priority experiencereplay the success rate increased to 70 but the trainingtime did not decrease By adding priority experience replayand introducing transfer learning the success rate increasesto 74 and themodel training time is shortened to 13 hoursAfter adding the RAdam algorithm the success rate in-creases to 86 and the model training time is shortened to12 hours Finally the success rate of the curiosity module isincreased to 90 and the model training time is shortened
to 11 hours Compared with the original DDPG algorithmthe convergence speed is increased by 21 and the successrate is increased to 90
During the experiment Rviz subscribes to the self-odometer message Odom released by the mobile robotvisualizes the pose information of the mobile robot at eachmoment in the form of coordinate axes and gives the pathplanning to reach the target point before and after im-provement as shown in Figures 11ndash 13
e time and path results of the mobile robot reachingthe target point in the dynamic environment after the im-provement of the DDPG algorithm are shown in Table 2 Inorder to ensure the validity of the results the test results areaveraged 10 times
According to the data in Table 2 it takes 86 seconds and280 steps for the original DDPG algorithm to reach thetarget point in the path planning of the mobile robot in adynamic environment of this article Adding the RAdamneural network optimizer algorithm the time is shortened to76 s and the step size is reduced to 250e curiosity moduleis introduced on the basis of the previous one the timereaches 60 s and the step size is shortened to 210 roughexperimental comparison it is proven that the time and stepsize of the improved DDPG algorithm in mobile robot pathplanning in a dynamic environment are improved whichverifies the algorithmrsquos effectiveness
2000
1500
1000
500
Episo
de R
ewar
d0 200 400 600 800 1000
Episode1200 1400
Figure 8 Experimental result of introducing the RAdam algorithm
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 9 Experimental results of the improved DDPG algorithm
Mobile Information Systems 7
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems

importance of gradient loss to the reward signal in learningis measured λ λgt 0 is satisfied LI is the loss function tomeasure the difference between the prediction and the actualaction rt is the internal reward value at time t and π(st θP)
represents a parameterized policy In the simulation ex-periment β is 02 and λ is 01
27 Simulation Experiment and Result Analysis
271 Establishment of Simulation Experiment EnvironmentHardware configuration of simulation experiment Intel i5-3320M CPU and 4G memory e operating system isUbuntu 1804 e ROS Melodic robot operating system isinstalled and the simulation environment is establishedusing Gazebo 9 under ROS e generated experimentalenvironment is shown in Figure 3
In that simulation environment of Figure 3(a) a squareenvironment with a length and width of 8meters is estab-lished no obstacles are added the position of the mobilerobot at the starting point is set to (minus2 25) and the colorcircle at the target point is set to (2 minus2) which is mainly usedto train the mobile robotrsquos ability to complete the target in alimited space for transfer learning In that simulation en-vironment of Figure 3(b) eight dynamic obstacles are addedon the basis of the above environment among which themiddle four (03times 03times 03)m3 obstacles rotate counter-clockwise at a speed of 05ms the upper and lower two(1times 1times 1) m3 obstacles move horizontally at a speed of03ms and the middle two (1times 1times 1) m3 obstacles movevertically at a speed of 03ms e starting point and targetpoint of the mobile robot are the same as those of the firstsimulation environment and the second simulation envi-ronment is used to train the robot to plan its path in adynamic environment
28 Simulation Experiment and Result Analysis In order toverify the algorithm the original DDPG and the improvedDDPGmobile robot path planning algorithm are trained for1500 rounds in the simulation environment with the samedynamic obstacles and the total return value of the mobilerobot in each round of simulation training is recorded A
graph with the number of training rounds as the abscissa andthe return value of each training round as the ordinate isdrawn as follows
e results of Figure 4 show that when the DDPG al-gorithm is trained in a dynamic obstacle simulation envi-ronment the total return value curve has a gradual upwardand downward trend with the increase of the number oftraining rounds indicating that the mobile robot training ina dynamic obstacle environment does not converge at laste total return value fluctuates greatly from 0 to 200rounds and the return value is mostly negative is showsthat the robot is ldquolearningrdquo to reach the target point Ob-serving the training process it can be seen that the mobilerobot collides with dynamic obstacles when graduallyapproaching the target point and the total return value canreach 2400 or so in 200 to 400 rounds Observing thetraining process it can be seen that the robot can reach thetarget point in a few cases After 400 rounds the return valueis high and low and most of them are stable at about 500Observing the training process we can see that most of themend up colliding with dynamic obstacles
Figure 5 shows the return curve of DDPG algorithmtraining in a dynamic environment with transfer learning Itcan be seen from Figure 5 that the robot will move towardsthe target point at the beginning because of the addition oftransfer learning so the learning negative value of the returncurve is much less than that in Figure 4 but the overall curveis uneven and does not converge
Figure 6 shows the return curve of the DDPG algorithmtrained in a dynamic environment with only priority ex-perience replay Because the priority experience replayeliminates a large number of invalid data in the early stage oftraining it can be seen from Figure 6 that the return curvegradually increases from negative value and tends to bestable but the convergence speed is slow and the success rateis low
Figure 7 is a return graph of DDPG algorithm training ina dynamic environment with priority experience replay andtransfer learning It can be seen from Figure 7 that the returnvalue curve is improved compared with Figure 4 but theconvergence effect has not yet been achieved
Figure 8 shows that when the DDPG algorithm withRAdam is introduced and priority experience replay andtransfer learning are added to train in the dynamic obstaclesimulation environment the return value curve graduallyincreases and tends to be stable with the increase of thenumber of training rounds e results show that the DDPGalgorithm with RAdam is approximately convergent in thedynamic obstacle environment Because through the com-bination of internal and external rewards compared withFigure 7 the convergence speed and success rate are ob-viously improved which shows that adding the RAdamalgorithm optimizer has a better effect on the path planningof mobile robots in a dynamic environment
Figure 9 shows that when the improved DDPG algo-rithm (ie curiosity module is introduced on the basis of theRAdam algorithm optimizer) and priority experience replayand transfer learning are added to train in a dynamic ob-stacle simulation environment the return value curve
ForwardModel
features
st
rit
at
at
st+1
ϕ (st+1)ϕ (st)
features
ICM
InverseModelϕ (st + 1)
Figure 2 Curiosity module flowchart
Mobile Information Systems 5
gradually increases and tends to stabilize with the increase ofthe number of training rounds Compared with Figure 8 theconvergence speed and success rate are significantly im-proved and the return value is also significantly improved
compared with the previous one due to the internal rewardprovided by the curiosity module
Figures 10(a)ndash10(d) show the simulation process of theimproved DDPG algorithm for path planning to reach the
(a) (b)
Figure 3 Experimental simulation environment
2500
2000
1500
1000
500
0
ndash500
ndash10000 200 400 600 800 1000
Episode1200 1400
Episo
de R
ewar
d
Figure 4 Experimental results of the original DDPG algorithm
0 200 400 600 800 1000Episode
1200 1400
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
Figure 5 Experimental results of adding transfer learning
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 6 Add priority experience to replay the experimentalresults
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 7 Experimental results with transfer learning and preferredexperience replay added
6 Mobile Information Systems
target point in a dynamic environment As shown in Fig-ure 10 the mobile robot avoids all dynamic obstacles fromthe starting point to reach the end point
29 Comparative Analysis of Experimental Results In orderto verify the success rate of path planning of the trainedmodels in the dynamic environment the four trainingmodels were tested 50 times in the training dynamic en-vironment and the same test was carried out three times toget the average value e experiment is done three times toensure the validity of the data e test results and the timetaken to train the model are recorded in Table 1
Experimental results show that in Table 1 the successrate of the original DDPG algorithm can reach 50 and thetraining time of the model is 14 hours After only addingtransfer learning although the training time is reduced thesuccess rate is reduced Only adding priority experiencereplay the success rate increased to 70 but the trainingtime did not decrease By adding priority experience replayand introducing transfer learning the success rate increasesto 74 and themodel training time is shortened to 13 hoursAfter adding the RAdam algorithm the success rate in-creases to 86 and the model training time is shortened to12 hours Finally the success rate of the curiosity module isincreased to 90 and the model training time is shortened
to 11 hours Compared with the original DDPG algorithmthe convergence speed is increased by 21 and the successrate is increased to 90
During the experiment Rviz subscribes to the self-odometer message Odom released by the mobile robotvisualizes the pose information of the mobile robot at eachmoment in the form of coordinate axes and gives the pathplanning to reach the target point before and after im-provement as shown in Figures 11ndash 13
e time and path results of the mobile robot reachingthe target point in the dynamic environment after the im-provement of the DDPG algorithm are shown in Table 2 Inorder to ensure the validity of the results the test results areaveraged 10 times
According to the data in Table 2 it takes 86 seconds and280 steps for the original DDPG algorithm to reach thetarget point in the path planning of the mobile robot in adynamic environment of this article Adding the RAdamneural network optimizer algorithm the time is shortened to76 s and the step size is reduced to 250e curiosity moduleis introduced on the basis of the previous one the timereaches 60 s and the step size is shortened to 210 roughexperimental comparison it is proven that the time and stepsize of the improved DDPG algorithm in mobile robot pathplanning in a dynamic environment are improved whichverifies the algorithmrsquos effectiveness
2000
1500
1000
500
Episo
de R
ewar
d0 200 400 600 800 1000
Episode1200 1400
Figure 8 Experimental result of introducing the RAdam algorithm
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 9 Experimental results of the improved DDPG algorithm
Mobile Information Systems 7
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems
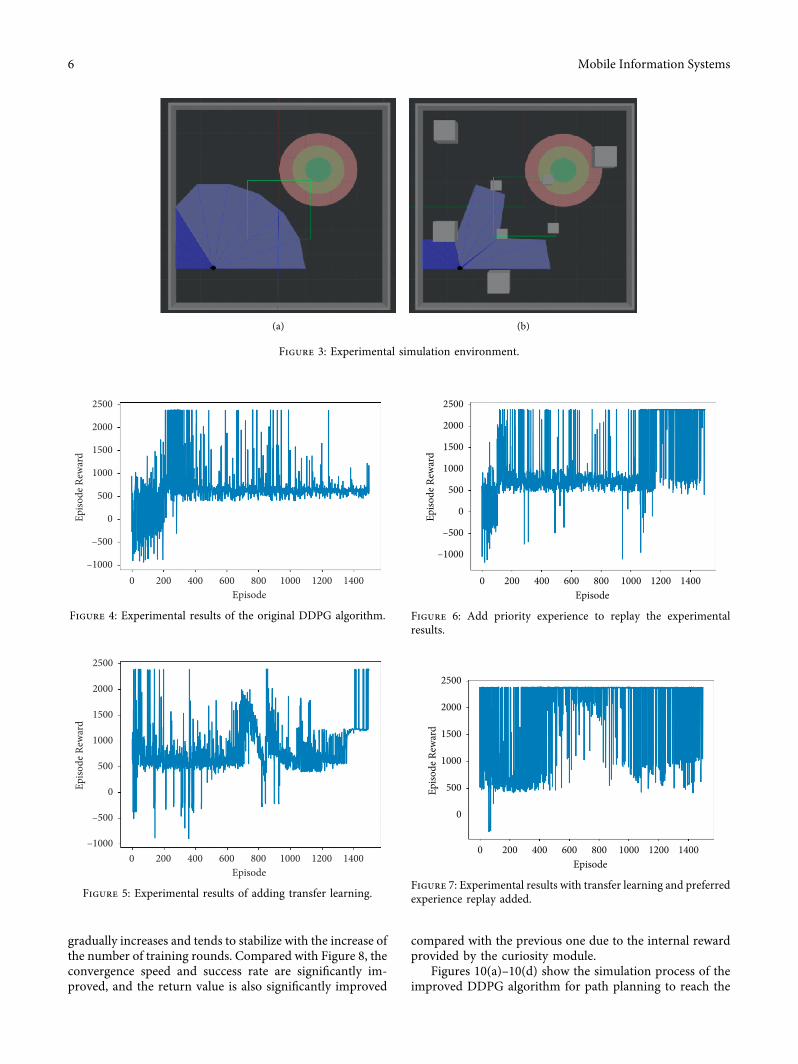
gradually increases and tends to stabilize with the increase ofthe number of training rounds Compared with Figure 8 theconvergence speed and success rate are significantly im-proved and the return value is also significantly improved
compared with the previous one due to the internal rewardprovided by the curiosity module
Figures 10(a)ndash10(d) show the simulation process of theimproved DDPG algorithm for path planning to reach the
(a) (b)
Figure 3 Experimental simulation environment
2500
2000
1500
1000
500
0
ndash500
ndash10000 200 400 600 800 1000
Episode1200 1400
Episo
de R
ewar
d
Figure 4 Experimental results of the original DDPG algorithm
0 200 400 600 800 1000Episode
1200 1400
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
Figure 5 Experimental results of adding transfer learning
2500
2000
1500
1000
500
0
ndash500
ndash1000
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 6 Add priority experience to replay the experimentalresults
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 7 Experimental results with transfer learning and preferredexperience replay added
6 Mobile Information Systems
target point in a dynamic environment As shown in Fig-ure 10 the mobile robot avoids all dynamic obstacles fromthe starting point to reach the end point
29 Comparative Analysis of Experimental Results In orderto verify the success rate of path planning of the trainedmodels in the dynamic environment the four trainingmodels were tested 50 times in the training dynamic en-vironment and the same test was carried out three times toget the average value e experiment is done three times toensure the validity of the data e test results and the timetaken to train the model are recorded in Table 1
Experimental results show that in Table 1 the successrate of the original DDPG algorithm can reach 50 and thetraining time of the model is 14 hours After only addingtransfer learning although the training time is reduced thesuccess rate is reduced Only adding priority experiencereplay the success rate increased to 70 but the trainingtime did not decrease By adding priority experience replayand introducing transfer learning the success rate increasesto 74 and themodel training time is shortened to 13 hoursAfter adding the RAdam algorithm the success rate in-creases to 86 and the model training time is shortened to12 hours Finally the success rate of the curiosity module isincreased to 90 and the model training time is shortened
to 11 hours Compared with the original DDPG algorithmthe convergence speed is increased by 21 and the successrate is increased to 90
During the experiment Rviz subscribes to the self-odometer message Odom released by the mobile robotvisualizes the pose information of the mobile robot at eachmoment in the form of coordinate axes and gives the pathplanning to reach the target point before and after im-provement as shown in Figures 11ndash 13
e time and path results of the mobile robot reachingthe target point in the dynamic environment after the im-provement of the DDPG algorithm are shown in Table 2 Inorder to ensure the validity of the results the test results areaveraged 10 times
According to the data in Table 2 it takes 86 seconds and280 steps for the original DDPG algorithm to reach thetarget point in the path planning of the mobile robot in adynamic environment of this article Adding the RAdamneural network optimizer algorithm the time is shortened to76 s and the step size is reduced to 250e curiosity moduleis introduced on the basis of the previous one the timereaches 60 s and the step size is shortened to 210 roughexperimental comparison it is proven that the time and stepsize of the improved DDPG algorithm in mobile robot pathplanning in a dynamic environment are improved whichverifies the algorithmrsquos effectiveness
2000
1500
1000
500
Episo
de R
ewar
d0 200 400 600 800 1000
Episode1200 1400
Figure 8 Experimental result of introducing the RAdam algorithm
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 9 Experimental results of the improved DDPG algorithm
Mobile Information Systems 7
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems
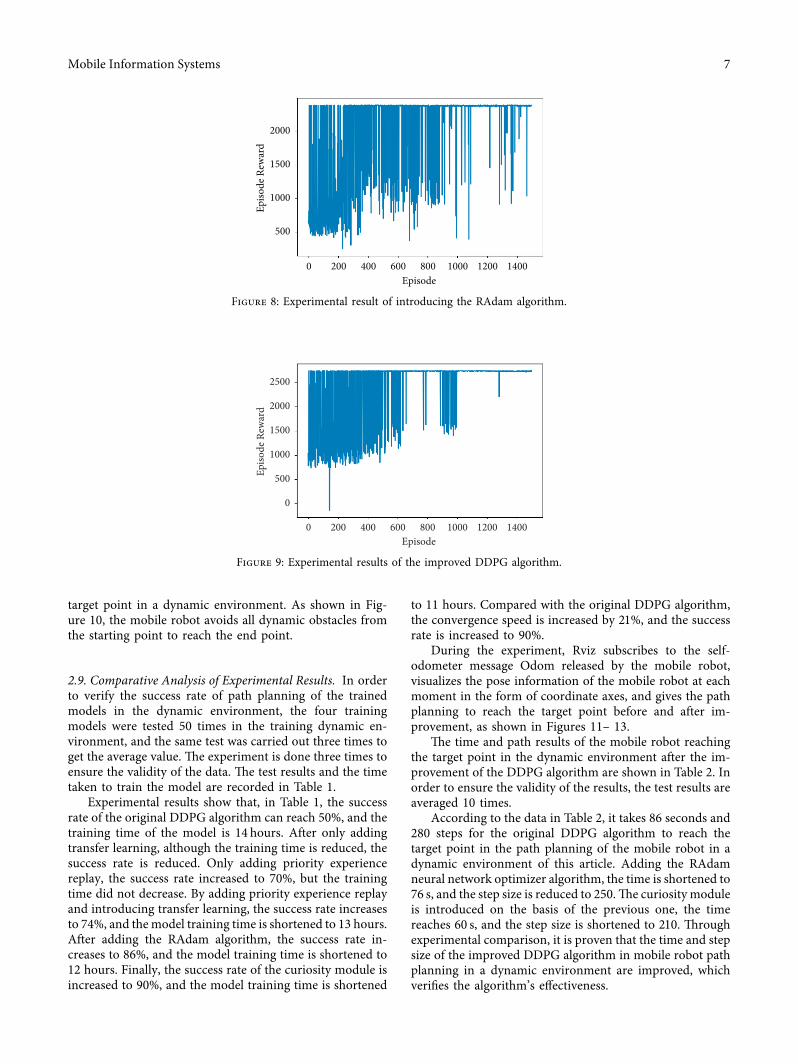
target point in a dynamic environment As shown in Fig-ure 10 the mobile robot avoids all dynamic obstacles fromthe starting point to reach the end point
29 Comparative Analysis of Experimental Results In orderto verify the success rate of path planning of the trainedmodels in the dynamic environment the four trainingmodels were tested 50 times in the training dynamic en-vironment and the same test was carried out three times toget the average value e experiment is done three times toensure the validity of the data e test results and the timetaken to train the model are recorded in Table 1
Experimental results show that in Table 1 the successrate of the original DDPG algorithm can reach 50 and thetraining time of the model is 14 hours After only addingtransfer learning although the training time is reduced thesuccess rate is reduced Only adding priority experiencereplay the success rate increased to 70 but the trainingtime did not decrease By adding priority experience replayand introducing transfer learning the success rate increasesto 74 and themodel training time is shortened to 13 hoursAfter adding the RAdam algorithm the success rate in-creases to 86 and the model training time is shortened to12 hours Finally the success rate of the curiosity module isincreased to 90 and the model training time is shortened
to 11 hours Compared with the original DDPG algorithmthe convergence speed is increased by 21 and the successrate is increased to 90
During the experiment Rviz subscribes to the self-odometer message Odom released by the mobile robotvisualizes the pose information of the mobile robot at eachmoment in the form of coordinate axes and gives the pathplanning to reach the target point before and after im-provement as shown in Figures 11ndash 13
e time and path results of the mobile robot reachingthe target point in the dynamic environment after the im-provement of the DDPG algorithm are shown in Table 2 Inorder to ensure the validity of the results the test results areaveraged 10 times
According to the data in Table 2 it takes 86 seconds and280 steps for the original DDPG algorithm to reach thetarget point in the path planning of the mobile robot in adynamic environment of this article Adding the RAdamneural network optimizer algorithm the time is shortened to76 s and the step size is reduced to 250e curiosity moduleis introduced on the basis of the previous one the timereaches 60 s and the step size is shortened to 210 roughexperimental comparison it is proven that the time and stepsize of the improved DDPG algorithm in mobile robot pathplanning in a dynamic environment are improved whichverifies the algorithmrsquos effectiveness
2000
1500
1000
500
Episo
de R
ewar
d0 200 400 600 800 1000
Episode1200 1400
Figure 8 Experimental result of introducing the RAdam algorithm
2500
2000
1500
1000
500
0
Episo
de R
ewar
d
0 200 400 600 800 1000Episode
1200 1400
Figure 9 Experimental results of the improved DDPG algorithm
Mobile Information Systems 7
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems
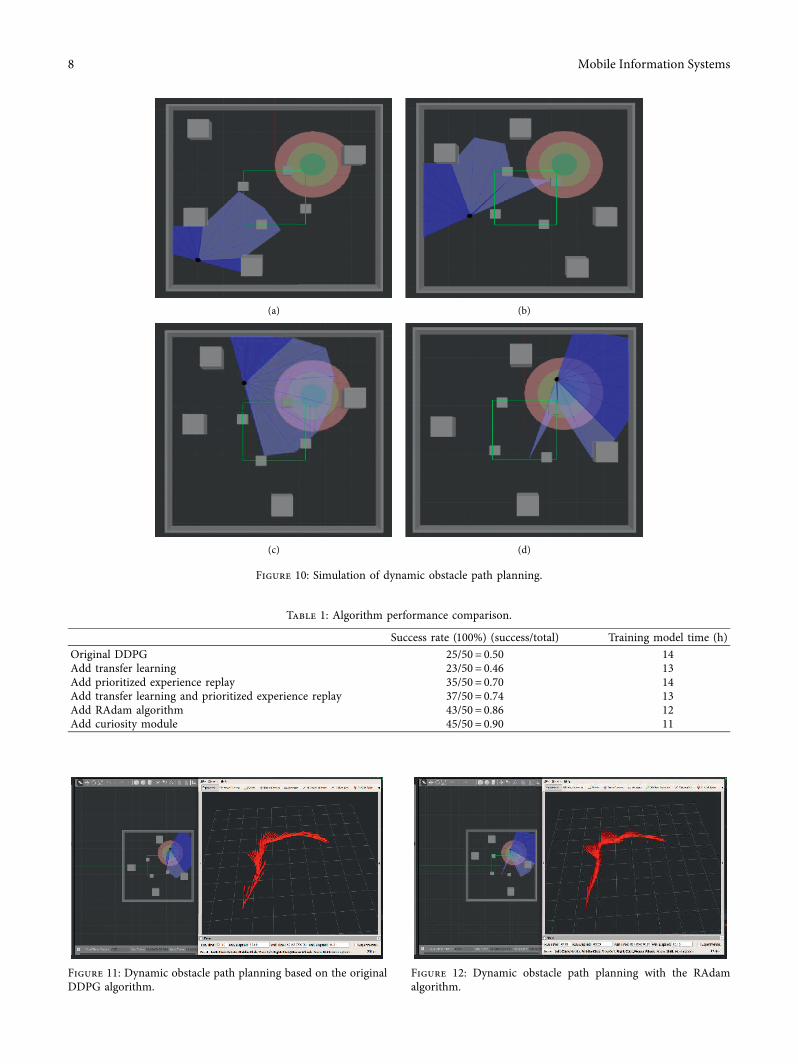
(a) (b)
(c) (d)
Figure 10 Simulation of dynamic obstacle path planning
Table 1 Algorithm performance comparison
Success rate (100) (successtotal) Training model time (h)Original DDPG 2550 050 14Add transfer learning 2350 046 13Add prioritized experience replay 3550 070 14Add transfer learning and prioritized experience replay 3750 074 13Add RAdam algorithm 4350 086 12Add curiosity module 4550 090 11
Figure 12 Dynamic obstacle path planning with the RAdamalgorithm
Figure 11 Dynamic obstacle path planning based on the originalDDPG algorithm
8 Mobile Information Systems
3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems

3 Conclusion
In this article an improved DDPG algorithm is designed tosolve the problems of slow convergence speed and lowsuccess rate in mobile robot path planning in a dynamicenvironment e improved algorithm uses the RAdamalgorithm as the neural network optimizer of the originalalgorithm introduces curiosity module and adds priorityexperience replay and transfer learning e DDPG algo-rithm and the improved DDPG algorithm are used tosimulate the path planning of mobile robots in a dynamicenvironment e comparison results show that the im-proved algorithm has a faster convergence speed and highersuccess rate and has strong adaptability to the path planningof mobile robots in a dynamic environment
Data Availability
e data used to support the findings of this study areavailable from the corresponding author upon request
Conflicts of Interest
e authors declare that there are no conflicts of interestregarding the publication of this article
Acknowledgments
is work was supported by the Fundamental ResearchFunds for the Central Universities (no 3072021CFJ0408)
References
[1] L Jiang H Huang and Z Ding ldquoPath planning for intelligentrobots based on deep Q-learning with experience replay andheuristic knowledgerdquo IEEECAA Journal of AutomaticaSinica vol 7 no 4 pp 1179ndash1189 July 2020
[2] M Manuel Silva ldquoIntroduction to the special issue on mobileservice robotics and associated technologiesrdquo Journal of Ar-tificial Intelligence and Technology vol 1 no 3 p 145 2021
[3] C Zhang ldquoPath planning for robot based on chaotic artificialpotential field methodrdquo Technology amp Engineering vol 317no 1 pp 12ndash56 2018
[4] R De Santis R Montanari G Vignali and E Bottani ldquoAnadapted ant colony optimization algorithm for the minimi-zation of the travel distance of pickers in manual warehousesrdquoEuropean Journal of Operational Research vol 267 no 1pp 120ndash137 2018
[5] P Sun and Z Yu ldquoTracking control for a cushion robot basedon fuzzy path planning with safe angular velocityrdquo IEEECAAJournal of Automatica Sinica vol 4 no 4 pp 610ndash619 2017
[6] J Xin H Zhao D Liu and M Li ldquoApplication of deepreinforcement learning in mobile robot path planningrdquo inProceedings of the 2017 Chinese Automation Congress (CAC)pp 7112ndash7116 Jinan China October 2017
[7] C Qian Z Qisong and H Li ldquoImproved artificial potentialfield method for dynamic target path planning in LBSrdquo inProceedings of the 2018 Chinese Control and Decision Con-ference (CCDC) pp 2710ndash2714 Shenyang China June 2018
[8] H Huang P Huang S Zhong et al ldquoDynamic path planningbased on improved Dlowast algorithms of gaode maprdquo in Pro-ceedings of the 2019 IEEE 3rd Information Technology Net-working Electronic and Automation Control Conference(ITNEC) pp 1121ndash1124 Chengdu China March 2019
[9] R S Nair and P Supriya ldquoRobotic path planning using re-current neural networksrdquo in Proceedings of the 2020 11thInternational Conference on Computing Communication andNetworking Technologies (ICCCNT) pp 1ndash5 KharagpurIndia July 2020
[10] F Li M Zhou and Y Ding ldquoAn adaptive online co-searchmethod with distributed samples for dynamic target track-ingrdquo IEEE Transactions on Control Systems Technologyvol 26 no 2 pp 439ndash451 2017
[11] Y Gao T Hu Y Wang and Y Zhang ldquoResearch on the PathPlanning Algorithm of Mobile Robotrdquo in Proceedings of the2021 13th International Conference on Measuring Technologyand Mechatronics Automation (ICMTMA) pp 447ndash450Beihai Chnia January 2021
[12] H Kretzschmar M Spies C Sprunk and W BurgardldquoSocially compliant mobile robot navigation via inverse re-inforcement learningrdquo Oe International Journal of RoboticsResearch vol 35 no 11 pp 1289ndash1307 2016
[13] Y Yang L Juntao and P Lingling ldquoMulti-robot pathplanning based on a deep reinforcement learning DQN al-gorithmrdquo CAAI Transactions on Intelligence Technologyvol 5 no 3 pp 177ndash183 2020
[14] S Yang J Wu S Zhang and W Han ldquoAutonomous drivingin the uncertain trafficmdasha deep reinforcement learning ap-proachrdquo Oe Journal of China Universities of Posts andTelecommunications vol 25 no 6 pp 21ndash30 2018
[15] A K Budati and S S H Ling ldquoGuest editorial machinelearning in wireless networksrdquo CAAI Transactions on Intel-ligence Technology vol 6 no 2 pp 133-134 2021
[16] Y Dong and X Zou ldquoMobile Robot Path Planning Based onImproved DDPG Reinforcement Learning Algorithmrdquo inProceedings of the 2020 IEEE 11th International Conference onSoftware Engineering and Service Science (ICSESS) pp 52ndash56Beijing China October 2020
[17] X Xue and J Zhang ldquoMatching large-scale biomedical on-tologies with central concept based partitioning algorithm and
Table 2 Path effect comparison
Time (s) Step size (step)Original DDPG algorithm 86 280Adding RAdam algorithm 76 250Add curiosity module 60 210
Figure 13 Improved algorithm for dynamic obstacle pathplanning
Mobile Information Systems 9
adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems

adaptive compact evolutionary algorithmrdquo Applied SoftComputing vol 106 pp 1ndash11 2021
[18] X Xue C Yang C Jiang P-W Tsai G Mao and H ZhuldquoOptimizing ontology alignment through linkage learning onentity correspondencesrdquo complexity vol 2021 p 12 ArticleID 5574732 2021
[19] K Cui Z Zhan and C Pan ldquoApplying Radam method toimprove treatment of convolutional neural network onbanknote identificationrdquo in Proceedings of the 2020 Inter-national Conference on Computer Engineering and Application(ICCEA) pp 468ndash476 Guangzhou China March 2020
[20] X Xue X Wu C Jiang G Mao and H Zhu ldquoIntegratingsensor ontologies with global and local alignment extrac-tionsrdquo Wireless Communications amp Mobile Computingvol 2021 p 10 Article ID 6625184 2021
[21] P Reizinger and M Szemenyei ldquoAttention-based curiosity-driven exploration in deep reinforcement learningrdquo in Pro-ceedings of the ICASSP 2020 - 2020 IEEE InternationalConference on Acoustics Speech and Signal Processing(ICASSP) pp 3542ndash3546 Barcelona Spain May 2020
10 Mobile Information Systems





























