Embed Size (px)
Citation preview

| HAO WANATHA MARIA DEL CON MI MINUT US009836646B2
( 12 ) United States Patent Collet et al .
( 10 ) Patent No . : US 9 , 836 , 646 B2 ( 45 ) Date of Patent : Dec . 5 , 2017
( 54 ) METHOD FOR IDENTIFYING A CHARACTER IN A DIGITAL IMAGE
FOREIGN PATENT DOCUMENTS WO 0237933 A2 5 / 2002
( 71 ) Applicant : I . R . I . S . , Mont - Saint - Guibert ( BE ) OTHER PUBLICATIONS ( 72 ) Inventors : Frederic Collet , Etterbeek ( BE ) ; Jordi
Hautot , Neupre ( BE ) ; Michel Dauw , Machelen ( BE ) ; Pierre De Muelenaere , Court - Saint - Etienne ( BE )
( 73 ) Assignee : I . R . I . S . , Mont - Saint - Guibert ( BE )
Fukushima T et al : “ On - line writing - box - free recognition of hand written japanese text considering character size variations ” , Pro ceedings / 15th International Conference on Pattern Recognition : Barcelona , Spain , Sep . 3 - 7 , 2000 ; [ Proceedings of the International Conference on Pattern Recognition . ( ICPR ) ] . IEEE Computer Soci ety , Los Alamitos , CA , vol . 2 , ( Sep . 3 , 2000 ) , pp . 359 - 363 , XPO10533829 , DOI : 10 . 1109 / ICPR . 2000 . 906087 . ISBN : 978 - 0 7695 - 0750 - 7 — the whole document .
( Continued )
( * ) Notice : Subject to any disclaimer , the term of this patent is extended or adjusted under 35 U . S . C . 154 ( b ) by 126 days .
( 21 ) Appl . No . : 14 / 884 , 361 ( 22 ) Filed : Oct . 15 , 2015 Primary Examiner — Yosef Kassa
( 74 ) Attorney , Agent , or Firm — Jerold I . Schneider ; Schneider Rothman Intellectual Property Law Group , PLLC
( 65 ) Prior Publication Data US 2017 / 0109573 A1 Apr . 20 , 2017
( 51 ) Int . CI . G06K 9 / 46 ( 2006 . 01 ) G06K 9 / 00 ( 2006 . 01 )
( Continued ) ( 52 ) U . S . Cl .
CPC . . . . . . . . . GO6K 9 / 00422 ( 2013 . 01 ) ; GO6K 9 / 344 ( 2013 . 01 ) ; G06K 9 / 348 ( 2013 . 01 ) ;
( Continued ) ( 58 ) Field of Classification Search
CPC . . . . . . . . . . . GO6K 2209 / 01 ; G06K 9 / 00463 ; G06K 9 / 00483 ; GO6K 9 / 46
( Continued )
( 57 ) ABSTRACT
The invention relates to a method for combining a first Optical Character Recognition ( OCR ) and a second OCR . The first OCR is run first on an image of string of characters . Its output ( first identified characters , positions of the char acters and likelihood parameters of the characters ) is used to generate a first graph . Segmentation points related to the positions of the first identified characters are used as input by the second OCR performing a combined segmentation and classification on the image of string of characters . The output ( second identified characters , positions of the char acters and likelihood parameters of the characters ) of the second OCR is used to update the first graph to generate a second graph that combines the output of the first OCR with the output of the second OCR . Decision models are then used to modify the weights of paths in the second graph to generate a third graph . A best path is determined on the third graph to obtain the identification of the characters present in the image of string of characters .
( 56 ) References Cited U . S . PATENT DOCUMENTS
551 , 978 A 6 , 348 , 214 B1 *
12 / 1895 Lyons 2 / 2002 Onyuksel . . . . . . . . . . . . . A61K 9 / 1271
264 / 4 . 1 ( Continued ) 24 Claims , 5 Drawing Sheets
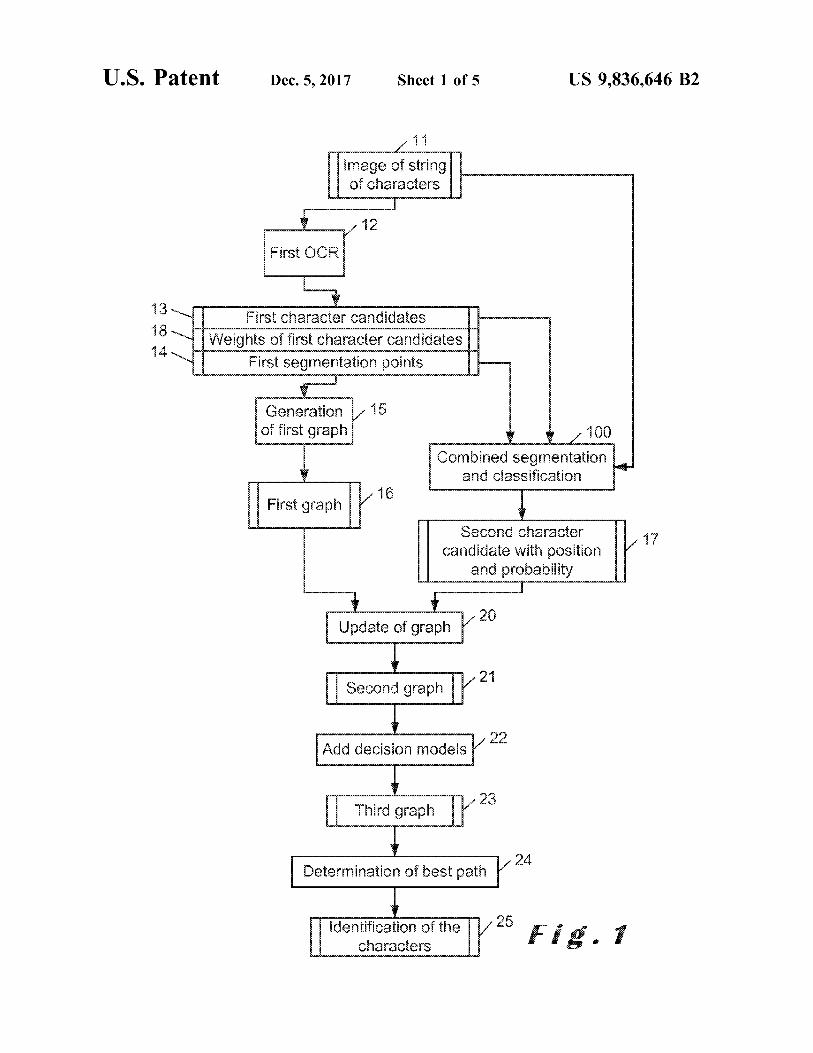
11 age of string
of characters
- 12
First OCR pa bon 13 VT 14 -
First character candidates Weights of first character candidates
First segmentation points 1
Generation of first graph
- 15 100
Combined segmentation and classlication
16 First graph Second character
candidate with position and probability LE in ord? -
seven proves | 20 Update of graph
21 Second graph
Add decision models dolay 22
Third graph 1 23
Determination of best path 724
Identification of the characters homienione tra 1 *

US 9 , 836 , 646 B2 Page 2
6 , 504 , 540 B1 * 1 / 2003 Nakatsuka . . . . . . . . . GOOK 9 / 00442 345 / 619
7 , 222 , 306 B2 * 5 / 2007 Kaasila . . . . . . . . . . . . . . . . G06F 3 / 0481 715 / 760
8 , 315 , 462 B2 * 11 / 2012 Nakamura . . . . . . . . . . GO6K 9 / 3233 382 / 177
8 , 620 , 858 B2 * 12 / 2013 Backholm . . . . . . . . . G06F 17 / 30575 707 / 609
2010 / 0310172 A1 12 / 2010 Natarajan et al . 2015 / 0063700 Al 3 / 2015 Soundararajan et al . 2015 / 0302598 A1 10 / 2015 Collet
( 51 ) Int . CI . G06K 9 / 62 ( 2006 . 01 ) G06K 9 / 68 ( 2006 . 01 ) G06K 9 / 34 ( 2006 . 01 )
( 52 ) U . S . CI . CPC . . . . . . . . . . . G06K 986277 ( 2013 . 01 ) ; G06K 9 / 685
( 2013 . 01 ) ; G06K 9 / 6857 ( 2013 . 01 ) ; G06K 2009 / 6864 ( 2013 . 01 ) ; G06K 2209 / 01
( 2013 . 01 ) ( 58 ) Field of Classification Search
USPC . . . . . . . 382 / 170 , 171 , 190 , 200 , 209 , 224 , 229 , 382 / 278 , 282 ; 358 / 1 . 11 , 537 , 538
See application file for complete search history .
( 56 ) References Cited U . S . PATENT DOCUMENTS
6 , 473 , 517 B1 * 10 / 2002 Tyan . . . . . . . . . . . . G06K 9 / 344 382 / 105
OTHER PUBLICATIONS R . G . Casey et al : “ A survey of methods and strategies in character segmentation ” , IEEE Transactions on Pattern Analysis and Machine Intelligence . vol . 18 , No . 7 , Jul . 1 , 1996 , pp . 690 - 706 , XPO55087686 , ISSN : 0162 - 8828 , DOI : 10 . 1109 / 34 . 50672 the whole document .
* cited by examiner
U . S . Patent Dec . 5 , 2017 Sheet 1 of 5 US 9 , 836 , 646 B2
Image of string of characters MY ,
Y amawawand
First OCR
43 - with me First character candidates
Weights of first character candidates First segmentation points Wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww 14 m wwwwwwwwwwwwwwwwwwwwwwwwwwwwwww Generation of first graph 100
Combined segmentation and classification w
16 First graph
muito 7 WARKAKKU Second character candidate with position
and probability •••••• Update of graph
1 Second graph 21
Add decision models
T1 / 23 | Third graph | | 23 Third graph
Determination of best path Determination of best path24 bath24 INILUUUUUUUUUU
mon wwwwwww Identification of the characters characters ris Fig . 1
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww
U . S . Patent Dec . 5 , 2017 Sheet 2 of 5 US 9 , 836 , 646 B2
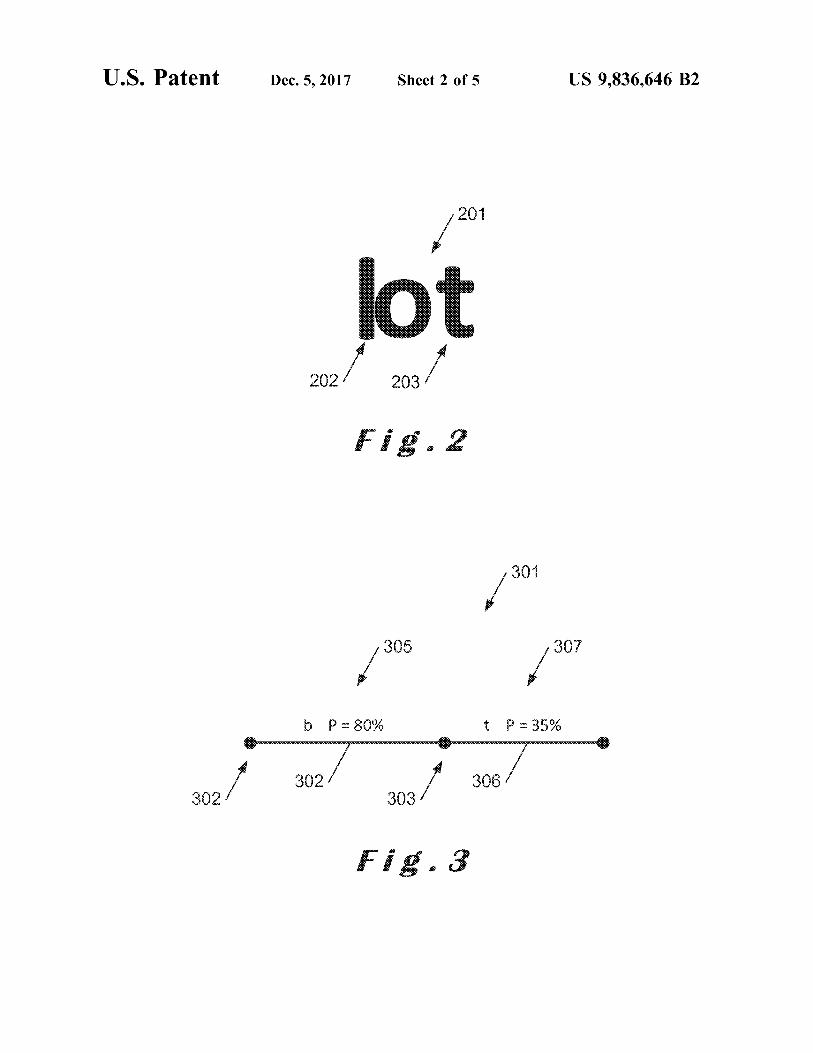
202 203
Fig . 2
307 , 305 307
b = 80 % t P - 35 %
302 302 306 / 302
Fig . 3
U . S . Patent Dec . 5 , 2017 Sheet 3 of 5 US 9 , 836 , 646 B2
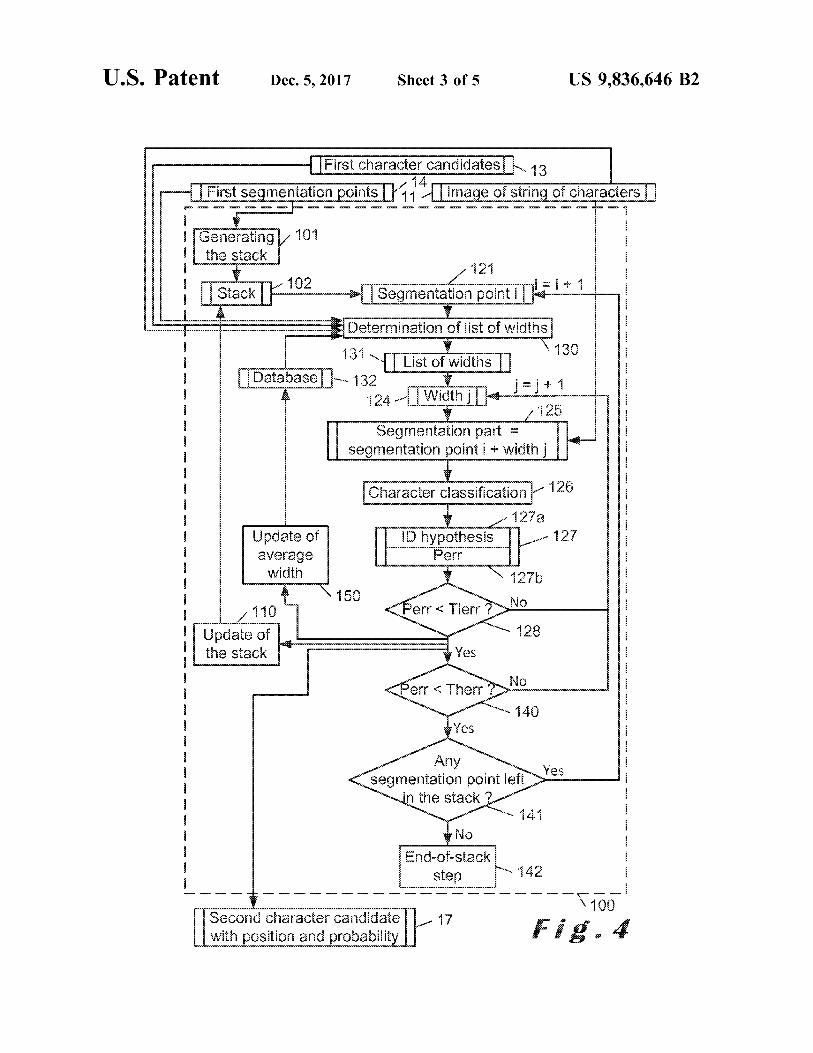
???????????????????????? .
.
.
.
.
.
. First character candidates .
.
.
.
.
.
. .
YYYYYYY
First segmentation points Image of string of characters KKK KK DOOD
XXXXXXXXXXXXEEEEEEE11111
wwwwwwwwwwwwwwwww X DOUD 0000 S - - - - - O w x www * * * * * * * W X X X *
* wwwwwwwwwwwwwwww AAAAAAAAAAAAKKKKKKKKKKKKKKKKKKVwwwwwwwwwwww 101 ww *
mm mm mm mm Generating
{ } sk *
121 *
i = 1 oli 1 * Stack wwwwwww 1 Segmentation point il ANNOUNOUN
*
w ww ! ???
VERKET KUL WU
A KLXXXXXXXXXXXXXXXXXXX * * * * * * * * * * * * * * EKKKKKKKKKKKK X XXXXXXXXXX * * * * * * * * * * * EEEEEEEEEEEEE Determination of list of widths ???????????????? ? ???? ? ???? ????
* w 1000EEEEEEE11111
w 130 1111111111111111 *
w 131 YT List of widths TI - 132
* *
Database w
* * = 1 + 1 1 Width 124 - * *
H
a
w
wwwww MOMO a Segmentation part = segmentation point i + width
w
w
WWWWWWWWWWWWWWWWWWWWW 2 444 2U 4424
w
W 433 633
Character classification 127a
D hypothesis 1 Perr
633 Wu Wu Wu Wu Wu 127 *
?????????????
Update of average width XXXXXXXXXXXXXXXXXXLLLLLLL LLLLLLLLLLL wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww *
* * 1276 w
* * *
150 w
*
cancer 110 Perr < Tierr ? No w
*
128 w * Update of
the stack 90000000000000000UUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUUU
WWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWWwwwwwwwwww WEEEEEEEEEEEEEEEEEEEEEEwwwwwwwwwwwwwww Yes a
w
* * *
w
* * * Perr < Therr w
No 140
* *
w * * * *
Yes w
2
w
o
C zu
Wu 444 mm wwwwwwwwwwwwwwwwwwwwwwwuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuuu 442 4444
Wu W
Any Yes segmentation point left
in the stack operatorrent werden 141
No End - of - stack
Step
Wu 333
Wu *
Wu
Wu *
wwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwwww www www www
00L Second character candidate with position and probability Fig . 4
LLLLLLLLLLLLLLLLLLLLLLLLLLLLLLLL
U . S . Patent Dec . 5 , 2017 Sheet 4 of 5 US 9 , 836 , 646 B2
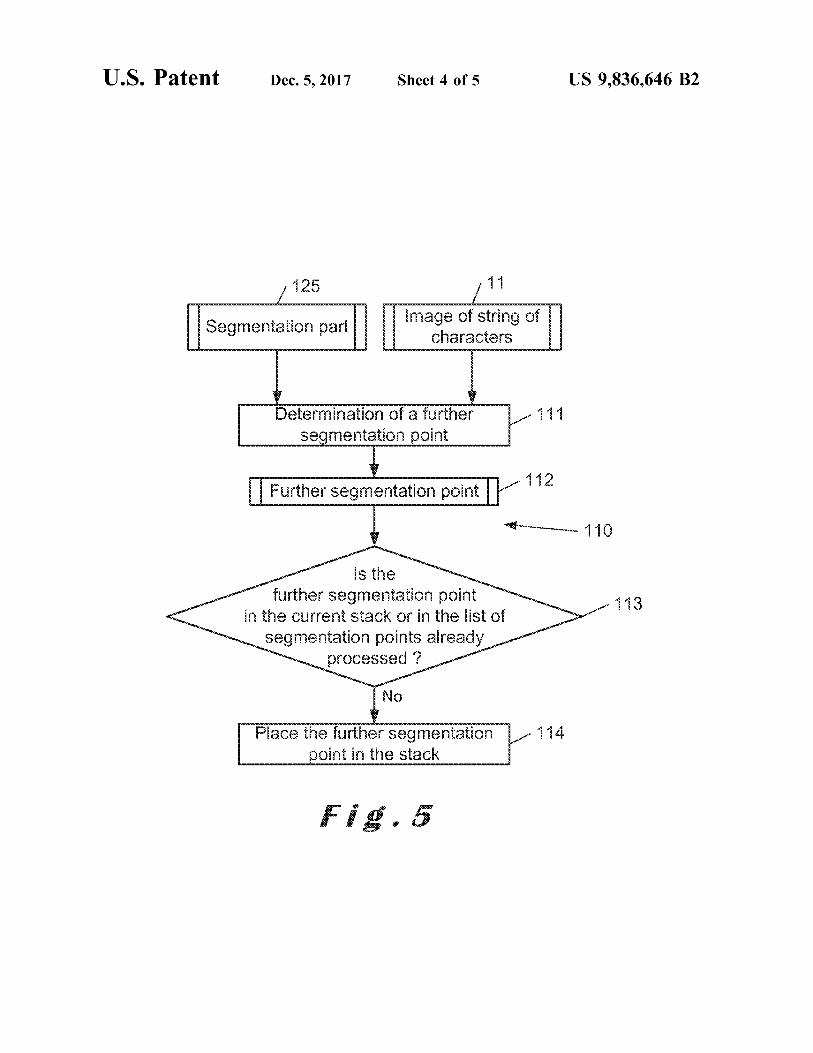
125 wwwwwww
w
Image of string of characters
? Segmentation part
111 Determination of a further segmentation point WY
| Further segmentation point con
the recentemen 110
1 1
Is the further segmentation point
in the current stack or in the list of segmentation points already
processed ?
No wwwwwwwwWWWWWWWWWWWWWWWWWWWWW
114 Place the further segmentation 1 point in the stack
Fig . 5
U . S . Patent Dec . 5 , 2017 Sheet 5 of 5 US 9 , 836 , 646 B2
11
lot lot 601 / 1602 1
Fig . 6a Fig . 6b mama ' 1 1
lot lot 6017 U 1605 602 / 604
Fig . 60 Fig . 6d 11
lot Fig . be 605 607
1 , 701 , 712 1 2 / 702 , 713 b p = 80 % 1 P - 95 %
wwwwwwwww w wwww
voorn out P . 99 , 5 % b = 70 % 704 procent 705
\ 703
706 P - 85 % P - 85 %
and 14 Fig . 7

US 9 , 836 , 646 B2
METHOD FOR IDENTIFYING A In the method according to the invention , the segmenta CHARACTER IN A DIGITAL IMAGE tion points determined from the first character identification
process ( first OCR ) are used as input for a combined TECHNICAL FIELD segmentation and classification process ( which includes
5 steps b , c , d and e ) , which is a second OCR . Therefore , the The present invention relates to methods and programs for second OCR is able to perform a better segmentation than if
identifying characters in a digital image . it was running alone , without the input of the first OCR . This allows the second OCR to use segmentation points that it
BACKGROUND ART would not have determined alone , and thus to recognize 10 some characters , for example Asian characters , which it
Optical Character Recognition ( OCR ) methods which would not have recognized alone . Moreover , the second convert text present in an image into machine - readable code OCR works faster with this input from the first OCR , since are known . its initial estimation of the width of the following character
U . S . Pat . No . 5 , 519 , 786 describes a method for imple is better than without this input . menting a weighted voting scheme for reading and accu - 15 In embodiments of the invention , the method further rately recognizing characters in a scanned image . A plurality comprises a step f ) of updating the list of segmentation of optical character recognition processors scan the image points with a further segmentation point determined based and read the same image characters . Each OCR processor on the portion of the digital image corresponding to the outputs a reported character corresponding to each character selected second character candidate . This further segmenta read . For a particular character read , the characters reported 20 tion point is expected to be useful for the character following by each OCR processor are grouped into a set of character the character that has just been identified candidates . For each character candidate , a weight is gen - In an embodiment of the invention , step f ) comprises erated in accordance with a confusion matrix which stores checking whether the further segmentation point is probabilities of a particular OCR to identify characters already in the list of segmentation points , and accurately . The weights are then compared to determine 25 adding the further segmentation point in the list of seg which character candidate to output . mentation points if the further segmentation point is not
Such a method has several limitations . First , since OCR already present in the list of segmentation point . processors are run in parallel , a character that would not be In an embodiment of the invention , at step b ) the list of recognized by any of the OCR processors taken indepen - character widths is generated based on at least the list of dently cannot be recognized by the method as a whole . 30 segmentation points of the first character candidates . The list
Second , a preprocessor has to quantify the strengths and of character widths can therefore be generated quickly and weaknesses of the OCR processors to generate the cells of reliably since its determination is based on data coming from the confusion matrix that contain probabilities that the the first OCR . character read by an OCR processor is the character reported In an advantageous way , steps b , c , d and e are performed by the OCR processor . This step can take time . Moreover , if 35 for each segmentation point of the list of segmentation this step is not well performed , for example because the points . T training set used for it is not suitable for a given type of In an embodiment of the invention , steps c , d and e are character , a probability can be low for a character that is repeated for another character width of the list of character actually well recognized and the OCR method may provide widths if the likelihood parameter does not fulfil the first worse results than the OCR processors taken independently . 40 predetermined criterion . If the likelihood parameter does not
fulfil the first predetermined criterion , it indicates that the ID DISCLOSURE OF THE INVENTION hypothesis may not be correct . It is therefore worthwhile
considering another portion of the digital image starting at It is an aim of the present invention to provide an the same segmentation point and which therefore covers at
improved method for applying multiple character identifi - 45 least partially the same connected components . cation processes on a digital image to achieve better and / or In an embodiment of the invention , steps c , d and e are faster identification results . This aim is achieved according repeated for another character width of the list of character to the invention with a method for selecting character widths if the likelihood parameter fulfils the first predeter candidates in a method for identifying characters in a digital mined criterion and does not fulfil a second predetermined image , the method comprising the steps of 50 criterion .
a ) applying a first character identification process to In an embodiment of the invention , the method further determine first character candidates and a list of seg - comprises the steps of : mentation points of the first character candidates , generating a data structure from the first character candi
b ) generating a list of character widths corresponding to dates and their segmentation points , and a segmentation point from the list of segmentation 55 updating the data structure with the selected second points , character candidate and a following segmentation point
c ) determining a portion of the digital image correspond - calculated from the character width of the selected second ing to the segmentation point and a character width character candidate and the segmentation point used for from the list of character widths , determining the portion of the digital image corresponding
d ) applying a character classification method on the 60 to the selected second character candidate . portion of the digital image to obtain an ID hypothesis first purpose of the data structure is to combine the of a character possibly present in the portion of the results of the character classification method with the results digital image and a likelihood parameter that relates to of first character identification process . a likelihood that the ID hypothesis is correct , and In an embodiment of the invention , step a ) comprises
e ) selecting the ID hypothesis as a second character 65 determining first likelihood parameters of the first character candidate in the digital image if the likelihood param - candidates providing an indication of the chance that the eter fulfils a first predetermined criterion . candidate character is correct , the data structure includes the

US 9 , 836 , 646 B2
first likelihood parameters of the first character candidates , d ) updating the graph by adding the at least one second and the method further comprises the steps of : character candidate to the first graph , and
changing the scale of the first likelihood parameters of the e ) selecting in the updated graph character candidates as the first character candidates and / or the likelihood parameters of characters of the digital image . the second character candidates to make them comparable to 5 In this method , the graph , when generated , includes as each other , and vertices the segmentation points from the first OCR and as
updating the data structure with the likelihood parameters edges the IDs from the first OCR . The graph is then updated of the second character candidates . with new vertices and new edges coming from the second
The likelihood parameters increase the accuracy of the OCR . During the selection of character candidates ( step e ) ) , 10 method . all edges are considered and none of them is a priori Preferably , the data structure is a graph wherein segmen - discarded . There is no need to benchmark the OCRs against
tation points are represented by vertices and character can - each other to determine their weaknesses since all IDs , didates are represented by edges between vertices . coming from all OCRs , are considered , even if a decision
Advantageously , the method includes the step of applying 15 rule favoring some edges according to some conditions a decision model method on the updated data structure . might be introduced in the graph . There is no need of a Decision models improves the accuracy of the method . structure like the confusion matrix either .
In an embodiment of the invention , the method further Preferably , the second character identification method comprises the steps of generates at least one second segmentation point and the at
determining a best path in the updated data structure , and 20 least one second segmentation point is added to the graph at selecting the character candidates corresponding to the step d ) .
edges in the best path as the characters in the digital image . In an embodiment of the invention , the first character Like that , the first OCR , the second OCR and the decision identification method provides first likelihood parameters
models are all taken into account at once to determine the providing a likelihood that the first character candidates are identification of the characters . 25 correct , the second character identification method provides
Preferably , the step of applying a decision model method second likelihood parameters providing a likelihood that the comprises favouring character candidates which have the at least one second character candidate is correct , and the first likelihood parameters of first character candidates and method further comprises the steps of : the second likelihood parameters of second character can changing the scale of the first likelihood parameters didates fulfilling a third predetermined criterion . and / or the second likelihood parameters to make them In an embodiment of the invention , the first character comparable to each other , identification method provides first character candidates for adding the first likelihood parameters in the first graph , characters of a first type , wherein the character classification method provides second character candidates for characters and of a second type , and the decision model method comprises 35 25 adding the second likelihood parameters in the updated favouring character candidates of the first type if the char acter candidates are provided by the first character identific Advantageously , the method comprises the step of apply cation process and favouring character candidates of the ing a decision model method on the updated graph . second type if the character candidates are provided by the In an embodiment of the invention , the decision model classification method . 40 method comprises a rule which favours character candidates
In an embodiment of the invention , the first character which have the first likelihood parameter and the second identification process comprises a decision model method . likelihood parameters fulfilling a third predetermined crite
In an embodiment of the invention , the first character rion . identification process provides positions of first character In embodiments of the invention , some of the first and candidates and further comprises a step of determining the 45 second character candidates are characters of a first or list of segmentation points of the first character candidates second type , and the decision model method comprises a from the positions of first character candidates . If the seg - rule which favours character candidates corresponding to the mentation points are not provided by the first character first type of characters if these character candidates have identification process , they can be determined from the been determined by the first character identification method positions of first character candidates by the combined 50 and favours character candidates corresponding to the sec segmentation and classification or by an independent step ond type of characters if these character candidates have performed preferably between steps a ) and b ) and possibly been determined by the second character identification between steps b ) and c ) . method .
It is another aim of the present invention to provide a Preferably , the second character identification method method for identifying characters in a digital image . 55 uses as input , at step c ) , the first segmentation points from
This aim is achieved according to the invention with a the first character identification method . With this method , method comprising : the second character identification method is able to perform a ) applying a first character identification method to deter - a better segmentation than if it was run alone . mine first character candidates and first segmentation It is another aim of the present invention to provide a points corresponding to the first character candidates , 60 computer program which applies better multiple character
b ) generating a first graph based on the first character identification processes on a digital image to achieve better candidates and the first segmentation points , wherein the and / or faster identification results . first segmentation points are represented by vertices and This aim is achieved according to the invention with a the first character candidates by edges , non - transitory computer readable medium storing a program
c ) applying a second character identification method on at 65 causing a computer to execute a method for identifying least part of the digital image to generate at least one characters in a digital image , the method comprising the second character candidate , steps of :
graph .

US 9 , 836 , 646 B2
and
a ) applying a first character identification process to described herein can operate in other orientations than determine first character candidates and a list of seg - described or illustrated herein . mentation points of the first character candidates , Furthermore , the various embodiments , although referred
b ) generating a list of character widths corresponding to to as “ preferred ” are to be construed as exemplary manners a segmentation point from the list of segmentation 5 in which the invention may be implemented rather than as points , limiting the scope of the invention .
c ) determining a portion of the digital image correspond The term " comprising ” , used in the claims , should not be ing to the segmentation point provided by the position interpreted as being restricted to the elements or steps listed
thereafter ; it does not exclude other elements or steps . It of an initial first character candidate and a character width from the list of character widths , 10 needs to be interpreted as specifying the presence of the
stated features , integers , steps or components as referred to , d ) applying a character classification method on the but does not preclude the presence or addition of one or portion of the digital image to obtain an ID hypothesis more other features , integers , steps or components , or of a character possibly present in the portion of the groups thereof . Thus , the scope of the expression “ a device digital image and a likelihood parameter that relates to 15 15 comprising A and B ” should not be limited to devices a likelihood that the ID hypothesis is correct , and consisting only of components A and B , rather with respect
e ) selecting the ID hypothesis as a character in the digital to the present invention , the only enumerated components of image if the likelihood parameter fulfils a first prede the device are A and B , and further the claim should be termined criterion . interpreted as including equivalents of those components .
The method according to the invention is preferably 20 The term “ character ” , as used herein , refers to a symbol designed to be run on a computer . or sign used in writing like a grapheme , a logogram , an
alphabetic letter , a typographical ligature , a numerical digit BRIEF DESCRIPTION OF THE DRAWINGS or a punctuation sign .
The terms “ identification , identifier and ID ” , as used The invention will be further elucidated by means of the 25 herein , refer to a one or several characters recognized in
following description and the appended figures . machine - readable code to obtain a searchable string of FIG . 1 illustrates a flowchart of an OCR method accord characters .
ing to the invention ; The term " position " , as used herein with respect to a FIG . 2 illustrates an example of an image of a string of character position , refers to data which makes it possible to
characters with segmentation points ; 30 locate the character . For example , the position may be FIG . 3 illustrates an example of a graph corresponding to provided by the coordinates of the pixels of a bounding box
the image and the segmentation points of FIG . 2 ; that surrounds the character . FIG . 4 illustrates a flowchart of combined segmentation The expression “ segmentation point ” as used herein refers
and classification according to an embodiment of the inven - to the point at a boundary between characters . A segmenta tion ; 35 tion point of a character may for example be provided by the
FIG . 5 illustrates an update of a list of segmentation points leftmost black pixel of a bounding box of the character or by according to an embodiment of the invention ; the leftmost black pixel of the character .
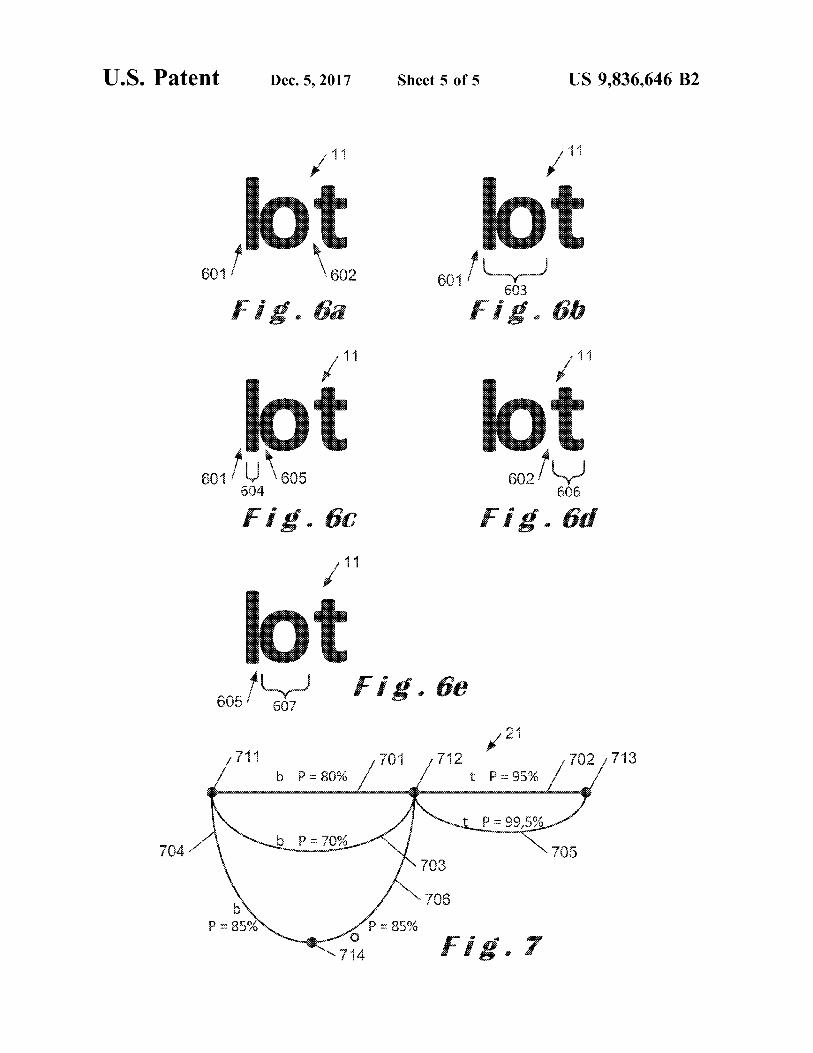
FIG . 6 , comprising FIGS . 6a - 6e illustrate a very simple The expression “ segmentation part ” , as used herein , refers example of the combined segmentation and classification to a part of an image of a string of characters that undergoes according to the invention ; and 40 processes to determine if it represents a character , a group of
FIG . 7 illustrates a graph at the end of the combined characters , a pattern , . . . The leftmost point of a segmen segmentation and classification illustrated at FIG . 6 . tation part is preferably a segmentation point .
The term “ classification ” , as used herein , refers to the MODES FOR CARRYING OUT THE generation of at least one hypothesis on the identification of
INVENTION 45 one or several characters . Each identification hypothesis , or ID hypothesis , is associated with a likelihood parameter .
The present invention will be described with respect to The term “ Optical Character Recognition ( OCR ) ” , as particular embodiments and with reference to certain draw used herein , refers to any conversion to a text present in an ings but the invention is not limited thereto but only by the image into machine - readable code . An OCR can be very claims . The drawings described are only schematic and are 50 complex and includes , for example , decision models , as well non - limiting . In the drawings , the size of some of the as it can be a pretty simple single - character classification . elements may be exaggerated and not drawn on scale for The terms " candidates , hypotheses , ID hypotheses or illustrative purposes . The dimensions and the relative identification hypotheses ” , as used herein , refer to alterna dimensions do not necessarily correspond to actual reduc - tive possible solutions for the identification of a character or tions to practice of the invention . 55 group of characters . They are often related to a likelihood
Furthermore , the terms first , second , third and the like in parameter . the description and in the claims , are used for distinguishing The term “ likelihood parameter ” as used herein refer to a between similar elements and not necessarily for describing parameter which has a value that provides an indication of a sequential or chronological order . The terms are inter - probability that the identification hypothesis , ID hypotheses , changeable under appropriate circumstances and the 60 character candidate , etc . is correct , i . e . , that the image or embodiments of the invention can operate in other segmentation part that undergoes the classification indeed sequences than described or illustrated herein . represents the character or group of characters of the iden Moreover , the terms top , bottom , over , under and the like tification hypothesis . A likelihood parameter can be for
in the description and the claims are used for descriptive example a probability or a weight . Likelihood parameters purposes and not necessarily for describing relative posi - 65 coming from various OCRs can be on different scales , in tions . The terms so used are interchangeable under appro - which case , a conversion may be used to get them on the priate circumstances and the embodiments of the invention same scale and make them comparable .

US 9 , 836 , 646 B2
The term " data structure ” , as used herein , refers to an sponds to segmentation point 202 . Edge 304 corresponds to entity comprising data . letter b , and the associated parameter of 80 % 305 is also
The term “ graph ” , as used herein , refers to a data structure included in the first graph 301 . Vertex 303 corresponds to comprising vertices and edges . segmentation point 203 . Edge 306 corresponds to letter t ,
As used herein , the expression “ connected component ” in 5 and the associated parameter of 95 % 307 is also included in a black - and - white image is intended to refer to a group of the first graph 301 . black pixels that are connected to each other by black pixels . Referring now to FIG . 1 , the first segmentation point 14
FIG . 1 shows a flowchart of an OCR method 10 according and the image of string of characters 11 are used as input for to the invention . a combined segmentation and classification 100 . In an An image 11 of a string of characters is taken as input by 10 embodiment of the invention wherein the positions are
a first OCR 12 . The image 11 of a string of characters is outputted by the first OCR 12 instead of the first segmen preferably a black - and - white digital image . The first OCR tation points 14 , the first segmentation points 14 are deter 12 processes the information contained in the image and mined at another step of the method 10 , for example during provides , as outputs , first character candidates 13 with the combined segmentation and classification 100 . For segmentation points 14 of the characters in the image and 15 example , if the first OCR 12 outputs the bounding boxes of preferably weights 18 of the characters , the weights being the first characters , the segmentation points can be deter likelihood parameters . The first character candidates 13 with mined as the points of the leftmost black pixel in each the segmentation points 14 of the characters in the image bounding box . may be a sequence of character candidates with the seg . The combined segmentation and classification 100 is a mentation points 14 provided by the positions of the char - 20 second OCR and will be described later referring to FIG . 4 . acters , possibly with related weights , or it may be a plurality The combined segmentation and classification 100 gener of possible sequences of character candidates with the ates , preferably at least once for each character in the image positions of the characters , possibly with related weights . of the string of character 11 , at least one second character The segmentation points 14 of the first character candidates candidate with its position and preferably a probability of 13 may be referred as first segmentation points 14 . The 25 the second character candidate 17 . The segmentation point plurality of segmentation points 14 may be considered as a 121 that has provided the ID hypothesis 127a that was list of segmentation points 14 . selected as second character candidate 17 may be used
The first OCR may or may not use decision models . instead of , or on top of , the position of the second character The first character candidates 13 , with their segmentation candidate 17 . This segmentation point 121 may be called
points 14 and weights 18 , are used as input in a generation 30 second segmentation point . The probability of the second 15 of a first graph , which outputs a first graph 16 . If character candidate is a second likelihood parameter . necessary , the generation 15 of the first graph determines In an embodiment of the invention , there can be one or first segmentation points from the character candidate seg several second character candidates each having its corre mentation points 14 . If necessary , the generation 15 of the sponding position and preferably each having its probability first graph converts the weights 18 into first likelihood 35 determined by the combined segmentation and classification parameters to make them corresponds to another scale of 100 for each character in the image of the string of charac likelihood parameters . In the first graph 16 , the first seg - ters 11 . mentation points are represented as vertices , the first char - The second character candidate , its position and its prob acter candidates are represented as edges and the first ability 17 are , every time they are generated , used as input likelihood parameters of the first character candidates are 40 for an update 20 of the graph that updates the first graph 16 . represented as edge values of corresponding edges . At the end of the combined segmentation and classification
A graph typically starts with a first vertex , which corre - 100 , the global output of the updates 20 of the graph is a sponds to an initial segmentation point , which is the seg second graph 21 which combines the output of the first OCR mentation point the most on the left on the image of the 12 and the output of the combined segmentation and clas string of characters 11 . The first vertex is linked to another 45 sification 100 . If necessary , the update 20 of the graph vertex , which corresponds to another segmentation point , by converts the probabilities into second likelihood parameters an edge corresponding to the character identified between having the same scale as the first likelihood parameters to the initial and the other segmentation points . The graph make them comparable . The update 20 of the graph adds a continues with a vertex for each segmentation point and an new edge for each second ID . The update 20 of the graph edge for each character between the segmentation points . 50 adds a new vertex at the end of each new edge that does not The likelihood parameters of the characters are represented end on a vertex already present in the graph . by edge values at the corresponding edges . The graph ends The second graph 21 includes an edge for each of the first with a vertex corresponding to a point at the right of the last IDs and for each of the second IDs , associated with their character in the image of the string of characters 11 . This respective likelihood parameter , and a vertex for each of the point at the right of the last character in the image of the 55 first segmentation points and for each of the second seg string of characters 11 is preferably not a segmentation mentation points . An example of second graph is illustrated point . at FIG . 7 and will be described later . Edges and / or vertices
Other types of data structures than a graph may be used in the second graph 21 may have a label that indicates if they to order the outputs of the OCR without departing from the have been generated from the first OCR or from the com scope of the invention . 60 bined segmentation and classification 100 .
FIG . 2 illustrates of an image of a string of characters 11 . The second graph 21 is then used as input in an optional In this example 201 , the first OCR 12 has identified a b step of adding decision models 22 , which generates a third starting at a segmentation point 202 with a likelihood decision graph 23 . Step 22 may add the decision models to parameter of 80 % and a t starting at a segmentation point the graph by use of a weighted finite state transducer 203 with a likelihood parameter of 95 % . 65 ( WFST ) based algorithm . This step 22 is actually an appli
FIG . 3 illustrates the first graph 301 generated at step 15 cation of a decision model method . The addition of decision from the output 13 of the first OCR 12 . Vertex 302 corre - models 22 modifies the likelihood parameters of edges , i . e .

US 9 , 836 , 646 B2 10
characters , or group of edges , i . e . groups of characters , in characters present in the image 11 of the string of characters . order to favour those that are a priori the most probable , for The determination of best path 24 determines , amongst the example in view of the context . Decision models modify the possible paths defined by the edges joined by vertices in the weights of paths . Decision models are preferably related to third graph 23 , and taking into account the likelihood contextual decision . Decision models strongly improve 5 parameters associated with the edges , the path , i . e . the identification accuracy . sequence of IDs , with the highest probability to correspond
The decision models may involve bigrams , typographical to the image 11 of the string of characters . The determination metrics , lists of words like dictionaries , character n - grams , of best path 24 may use a weighted finite state transducer punctuation rules and spacing rules . ( WFST ) based decision algorithm that optimizes a path
A first kind of decision model is a linguistic model . If the 10 weight to find the best solution . word “ ornate ” is present in the image of string of character FIG . 4 illustrates a flow chart for the combined segmen to be identified , the first or the second OCR can for example tation and classification 100 according to an embodiment of find the word “ ornate ” and the word “ ornate ” as IDs with the invention . similar likelihood parameters because the letters rn taken This flow chart includes a stack 102 , which is a list of together look like the letter m . A linguistic model using a 15 segmentation points or a data structure comprising segmen dictionary is able to detect that the word “ ornate ” does not tation points . The first segmentation points 14 are used as exist , while the word “ ornate ” does . input by a step 101 of creating the stack . During this step
In an embodiment of the present invention , the linguistic 101 , the initial data of the stack are determined . The first model uses an n - gram model . If the word “ TRESMEUR ” is character candidates 13 might also be used by step 101 . present in the image of string of character 11 , the first or the 20 Preferably , before this step 101 , the stack 102 does not exist second OCR can for example find the word “ TRE5MEUR ” or is empty . In an embodiment of the invention , during this and the word “ TRESMEUR ” as IDs with similar likelihood step 101 , the first segmentation points 14 are placed into the parameters because the letters “ S ’ may look like the letter “ 5 stack 102 . in a printed text . A linguistic model using a bigram ( n - gram The combined segmentation and classification 100 starts with n = 2 ) model would prefer " TRESMEUR ” if " ES " and 25 iterating on the segmentation points of the stack with a “ SM ” have better probabilities of occurrence than “ E5 ” and segmentation point index i set equal to a first value , for “ SM ” . example 1 . A corresponding segmentation point 121 , com
Another kind of model used in an embodiment of the ing from the stack 102 , is considered . The first time that a present invention is a typographical model . If the word segmentation point 121 is considered in the combined “ Loguivy ” is present in the image of string of character 11 , 30 segmentation and classification 100 , the segmentation point the first or the second OCR can for example find the word 121 is preferably one of the first segmentation points 14 that “ Loguivy " and the word " Loguiw ” as IDs with similar was determined by the first OCR . The segmentation point likelihood parameters because the letters ‘ y ’ may look like 121 is preferably removed from the stack 102 , in such a way the letter ' v ' in a printed text . A typographic model using that the stack 102 contains only segmentation points that still font metrics would prefer " Loguivy ” because the position of 35 have to be considered . The segmentation point 121 is the bottom of the final character corresponds more likely to preferably placed in a list of segmentation points already the bottom position of a ' y ' ( in his model ) than a ' v ' . processed .
In an embodiment of the present invention , the typo - Then , the combined segmentation and classification 100 graphical model considers the position of the character in the determines , at step 130 , a list of widths 131 . Preferably , this image to check if sizes and positions are expected or not . 40 determination 130 does not use as input a list of widths
In a decision model involving punctuation and spacing determined for another segmentation point . In an embodi rules , some combinations of punctuation and / or spaces are ment of the invention , the list 131 of widths is generated at disfavoured . step 130 as described in U . S . patent application Ser . No .
In an embodiment of the invention , a decision model is 14 / 254 , 096 which is incorporated in the current application added at step 22 that favours IDs that have the first likeli - 45 by reference , wherein the first segmentation points 14 are hood parameter and the second likelihood parameter fulfill - used as input . The image of string of character 11 and / or the ing a predetermined criterion . Indeed , it is expected that , if first character candidates may also be used as inputs . In an a same ID is found by the first OCR 12 and the combined embodiment of the invention , the determination 130 uses a segmentation and classification 100 , the ID is more trust - database 132 storing reference character widths , storing an able . Therefore , if for an ID , both the first likelihood 50 average width and possibly storing other character statistics . parameter and the second likelihood parameter are above a The determination 130 is preferably based on this average threshold of , for example , 90 % , the ID can be favoured . width provided by the database 132 and size ( s ) of connected
In an embodiment of the invention , a decision model is component ( s ) around the segmentation point i , the size ( s ) added at step 22 that is equivalent to an OCR voting because being provided by the image 11 of string of characters . The it favours the first OCR in some cases and the second OCR 55 determination 130 is more preferably based on this average in other cases . For example , if the first OCR is known to be width provided by the database 132 and the size ( s ) of extremely accurate for a first type of characters , like kata connected component ( s ) following the segmentation point i , kana characters , while the combined segmentation and clas - the size ( s ) being provided by the image 11 of string of sification 100 is known to be extremely accurate for a second characters . type of characters , like kanji , a decision model may be added 60 In an embodiment of the invention , the determination 130 that favours IDs corresponding to the first type of characters estimates , from the first segmentation points 14 , from size ( s ) ( katakana ) if these IDs have been determined by the first of connected component ( s ) around the segmentation point OCR and favours IDs corresponding to the second type of 121 , and from the database 132 , the width for the character characters ( kanji ) if these IDs have been determined by the following the segmentation point 121 . combined segmentation and classification 100 . 65 The list 131 of widths is preferably ordered from most
A step of determination of best path 24 is then performed likely to less likely character width , as described in the U . S . on the third graph 23 to determine the IDs 25 of the patent application Ser . No . 14 / 254 , 096 .

US 9 , 836 , 646 B2 11 12
Then , the combined segmentation and classification 100 t ified , i . e . , by the segmentation point i and the width j that starts iterating on the widths of the list of widths 131 , with were considered . The probability of the second character a width index j set equal to a first value , for example 1 . A candidate is equal to 1 - Perr , with the value of Perr of 127b . width 124 , coming from the list of widths 131 , is considered . The update of the graph 20 ( FIG . 1 ) is preferably per The combination of the segmentation point i and the width 5 formed immediately after the selection of the ID hypothesis j provides a segmentation part 125 , which is a portion of the 127 as the second character candidate by step 128 . In other image of string of characters 11 . A character classification words , the update of the graph 20 is preferably performed 126 is performed on the segmentation part 125 . The char for each segmentation part 125 that provides and ID hypoth acter classification 126 is preferably a single - character clas - esis 127a that has a likelihood parameter 127b that satisfies sification . The character classification 126 can include a 10 the first predetermined criterion 128 . character classification designed for a first type of character , The character classification 126 may provide a plurality of for example Asian characters , and a character classification ID hypotheses 127a , each with their respective likelihood of designed for a second type of character , for example Latin error P 127b , all corresponding to the same segmentation characters . Such a character classification is described in the part 125 . In such a case , checks 128 and 140 are performed U . S . patent application Ser . No . 14 / 299 , 205 which is incor - 15 on the ID hypothesis with the lowest Per , i . e . , the ID porated here by reference . hypothesis that is the most expected to be right . The second
The character classification 126 provides an ID hypoth character candidate with position and probability ” 17 of the esis 127a with likelihood of error Perr 127b . The ID hypoth - figures includes then the plurality of ID hypotheses , with esis 127a is an hypothesis about the character possibly each their respective position and probability . They are all present on the segmentation part 125 . The likelihood of error 20 included 20 in the graph at once , before moving to a next Po . 127b is a likelihood parameter . The likelihood of error segmentation part 125 . Per 127b is a percentage that decreases with the probability In the combined segmentation and classification 100 , any that the classification 126 has correctly identified the content segmentation part 125 is considered only once . of the segmentation part 125 . The probability that the The first predetermined criterion provides a tunable classification 126 has correctly identified the content of the 25 parameter to determine the threshold of probability from segmentation part 125 is equal to 1 - Perr . Perr and the which the ID hypothesis 127a are added into the graph . A probability equal to 1 - Perr may both be called “ second very high The provides a very large second graph 21 , which likelihood parameter ” since they both provide an indication gives a high accuracy but might slow down the OCR method of probability that the identification hypothesis 127a is 10 . A lower Th provides a smaller second graph 21 , which correct for the character classification 126 . 30 might give a lower accuracy but speeds up the OCR method
The combined segmentation - classification 100 checks 10 . then , at step 128 , if the likelihood of error Po , , , fulfills a first In an embodiment of the invention , different criteria might predetermined criterion , which is that Pay is smaller than a be used to determine whether the second character candi threshold to have a high likelihood of error Thor Thor is date , its position and its probability 17 are used in an update preferably chosen close to 100 % , for example equal to 35 20 of the graph , whether the update 110 of the stack is 99 . 9 % . Like that , the first predetermined criterion discards performed , whether the update 150 of the list of widths is hypotheses that are really unlikely . If the first predetermined performed and / or whether another width ( j = i + 1 ) is consid criterion is not fulfilled , the index j is incremented and a next ered . width , coming from the list of widths 131 , is considered . If the first predetermined criterion is fulfilled , the com
If the first predetermined criterion is fulfilled , it indicates 40 bined segmentation - classification 100 checks , at step 140 , if that the ID hypothesis might have a chance to be right . If the the likelihood of error Po fulfills a second predetermined first predetermined criterion is fulfilled , an update 110 of the criterion , which is that Perr is smaller than a threshold to stack is performed . This update 110 of the stack is described have a low likelihood of error T1 . Tie is preferably below , referring to FIG . 5 . chosen between 5 % and 50 % , for example equal to 20 % .
If the first predetermined criterion is fulfilled , an update 45 Like that , the second predetermined criterion is fulfilled only 150 of the average list is performed and the updated average in cases where the ID hypothesis is really likely . If the width replaces the average width in the database 132 . In an second predetermined criterion is not fulfilled , the index j is embodiment of the invention , the update 150 of the average incremented and a next width , coming from the list of widths width is performed as described in U . S . patent application 131 , is considered . If the second predetermined criterion is Ser . No . 14 / 254 , 096 which is incorporated here by reference . 50 fulfilled , the combined segmentation - classification 100
In an embodiment of the invention , the update 150 of the checks , at step 141 , if the stack 102 still contains at least one average width is followed by the determination 130 of the segmentation point . list of widths , which generates the list of widths 131 to be If the stack 102 still contains at least one segmentation used for the same segmentation point i in the next iteration point , the index i of segmentation points is incremented and about the widths , by the combined segmentation and clas - 55 a next segmentation point 121 is considered . sification 100 . If the stack 102 contains no more segmentation point , the
If the first predetermined criterion is fulfilled , the second combined segmentation - classification 100 preferably per character candidate , its position and its probability 17 are forms an end - of - stack step 142 . The end - of - stack step 142 added in the graph during the corresponding update 20 of the comprises a verification that the end of the image of the graph ( FIG . 1 ) . The second character candidate , its position 60 string of characters 11 has been reached , for example by and its probability 17 may not be outputted as such by the checking that the ID of the character located the rightmost combined segmentation and classification 100 , but just in the second graph 21 includes the rightmost black pixel of added in the graph . The second character candidate is equal the image of the string of characters 11 . to the ID hypothesis 127a . In other words , the ID hypothesis If the end of the image of the string of characters 11 has is selected as the second character candidate . The position of 65 not been reached , an empty character with a probability the second character candidate is provided by the segmen - equal to 0 is inserted in the graph starting at the vertex tation part where the second character candidate was iden - corresponding to the rightmost segmentation point that has

an
US 9 , 836 , 646 B2 13 14
been considered , a segmentation point corresponding to the ( step 111 ) . It is found at step 112 that this further segmen end of this empty character is placed in the stack 102 and the tation point which corresponds to the point 602 is already in combined segmentation and classification 100 resumes with the stack 102 . Therefore , this further segmentation point is this segmentation point . not added in the stack 102 . The update 150 of the average
If the end of the image of the string of characters 11 has 5 width is performed , which updates the database 132 . The been reached , an empty character with probability equal to determination 130 of the list of widths is also performed to O may be added in the second graph 21 between each vertex take into account the update in the database . Since Per that is not connected to a next vertex ( each segmentation ( 30 % ) is not lower than Tler ( 20 % ) , another width 604 from point for which no second character candidate 17 has been the list 131 is tried . selected ) and the next vertex . 10 FIG . 6c shows the width 604 , which is considered FIG . 5 shows the update 110 of the stack according to an together with the segmentation point 601 in the classification embodiment of the invention . When performed , the update 126 . The classification 126 finds that the segmentation part 110 of the stack takes as inputs the segmentation part 125 considered at that moment in the combined segmentation provided by the segmentation point 601 and the width 604
acters 15 represents a l with a probability of 85 % . Since Perr ( 15 % ) is 11 . The update 110 of the stack includes a determination 111 lower than Therr ( 99 . 9 % ) , a corresponding edge 704 is added of a further segmentation point . This further segmentation in the graph 21 during an update 20 of the graph and a vertex point 112 is expected to correspond to the beginning of a 714 , which corresponds to a segmentation point 605 at the character at the right of the character that has just been end of the 1 , is added in the graph 21 . identified in the segmentation part 125 by the character 20 A further segmentation point 605 is then determined at classification 126 . The further segmentation point 112 is step 111 of the update 110 of the stack . Since the point 605 preferably determined as the leftmost black pixel at the right is not in the stack ( step 113 ) , it is added to the stack . The of the segmentation part 125 . The inter - character space can update 150 of the average width and the determination 130 have a predetermined value or be calculated during the of the list of widths are also performed . combined segmentation and classification 100 . 25 Since Per ( 15 % ) is lower than T1 , ( 20 % ) , there is a
Alternatively , the further segmentation point 112 may be check ( step 141 ) to verify if there is any segmentation point calculated , for example during the character classification left in the stack 102 . The segmentation points 602 and 605 126 , and provided to the update 110 of the stack . being still in the stack 102 , the next segmentation point , 602 ,
In an embodiment of the invention , the determination 111 is considered . of a further segmentation point uses information coming 30 FIG . 6d shows the segmentation point 602 considered from the database 132 . together with a width 606 in the classification 126 . The
The update 110 of the stack then checks , at step 113 , if the classification 126 finds that the segmentation part provided further segmentation point 112 is currently present in the by the segmentation point 602 and the width 606 represents stack 102 or in the list of segmentation points already a t with a probability of 99 . 5 % . Since Perr ( 0 . 5 % ) is lower processed . If not , the further segmentation point 112 is 35 than Therr ( 99 . 9 % ) , a corresponding edge 705 is added in the placed in the stack 102 . graph 21 during an update 20 of the graph . The update 110
Since a character is expected to start a bit after the of the stack is not performed because the end of the string previous character , this update 110 of the stack generates of characters has been reached . The update 150 of the segmentation points that are probable starting points for a average width and the determination 130 of the list of widths next character . The check at step 113 avoids that a segmen - 40 are performed . tation point appears twice in the stack 102 . Since Per ( 0 . 5 % ) is lower than Tler ( 20 % ) , there is a
FIG . 6 illustrates a very simple example of the combined check ( step 141 ) to verify if there is any segmentation point segmentation and classification 100 according to the inven - left in the stack 102 . The segmentation 605 being still in the tion . FIG . 7 illustrates the second graph 21 at the end of the stack 102 , this segmentation point , 605 , is considered . combined segmentation and classification 100 illustrated at 45 FIG . 6e shows the segmentation point 605 considered FIG . 6 . together with a width 607 in the classification 126 . The
FIG . 6a shows an image of string of characters 11 with the classification 126 finds that the segmentation part provided word lot and wherein the letters 1 and o are so close that it by the segmentation point 605 and the width 607 represents is difficult to determine if there are 1 and o , or b . The first ao with a probability of 85 % . Since P ( 15 % ) is lower than OCR 12 has provided the IDs b and t with their position and 50 Thor ( 99 . 9 % ) , a corresponding edge 706 is added in the their probability ( P = 80 % for b and P = 95 % for t ) . From their graph 21 during an update 20 of the graph . The update 110 position , segmentation points 601 and 602 can be deter - of the stack determines the further segmentation point ( step mined ( FIG . 6a ) . The graph , which is the first graph at that 111 ) . It is found at step 112 that this further segmentation stage , comprises the vertices 711 , 712 and 713 and the edges point which corresponds to the point 602 is in the list of 701 and 702 ( FIG . 7 ) . 55 segmentation points that have already been processed .
The stack contains the segmentation points 601 and 602 . Therefore , this further segmentation point is not added in the For the segmentation point 601 , the determination 130 of the stack 102 . The update 150 of the average width and the list of widths determines possible widths including a width determination 130 of the list of widths are also performed . 603 . The width 603 is placed in the list 131 of widths . Since Perr ( 15 % ) is lower than Tler ( 20 % ) , there is a
FIG . 6b shows the width 603 that is considered first 60 check ( step 141 ) to verify if there is any segmentation point together with the segmentation point 601 in the classification left in the stack 102 . Since the stack 102 is empty , the 126 . The classification 126 finds that the segmentation part combined segmentation and classification 100 moves to the provided by the segmentation point 601 and the width 603 end - of - stack steps 142 . represents a b with a probability of 70 % . Since Perr ( 30 % ) is The end - of - stack steps verifies that the rightmost pixel of lower than Therr ( 99 . 9 % ) , a corresponding edge 703 is added 65 the image of the string of characters 11 is indeed part of the in the graph 21 during an update 20 of the graph . The update t . All vertices in the graph 21 are connected to a next vertex 110 of the stack determines the further segmentation point and therefore no empty character is added in the graph 21 .

US 9 , 836 , 646 B2 16
Decision models can then be added to the second graph The invention claimed is : shown at FIG . 7 . The decision models may modify the 1 . A method for selecting character candidates in a method probabilities indicated in the graph . A contextual decision for identifying characters in a digital image , the method model based on an English dictionary can for example strongly favors the string of characters “ lot ” with respect to 5 a ) applying a first character identification process to the string of characters “ bt ” . determine first character candidates and a list of seg The present invention includes a combination of a first mentation points of the first character candidates , OCR 12 and a second OCR , which is the combined seg b ) generating a list of character widths corresponding to mentation and classification 100 , at several stages : at the a segmentation point from the list of segmentation input of the first segmentation points 14 in the stack 102 of 10 points , the second OCR 100 , at the update 20 of the graph generated c ) determining a portion of the digital image correspond from the first OCR 12 that generates the second graph 21 , ing to the segmentation point and a character width and in the decision models 22 .
The invention does not require to have insight about the from the list of character widths , way the first OCR 12 is performed . It only requires to obtain 15 d ) applying a character classification method on the from the first OCR 12 the sequence of character IDs , their portion of the digital image to obtain an ID hypothesis position in the image of the string of characters , and if of a character possibly present in the portion of the possible their likelihood parameters , which are the usual digital image and a likelihood parameter that relates to outputs of any OCR . Therefore , the invention is able to a likelihood that the ID hypothesis is correct , and combine almost any commercial OCR with the second 20 e ) selecting the ID hypothesis as a second character OCR . candidate in the digital image if the likelihood param
Moreover , the invention takes the best of both OCRs in eter fulfils a first predetermined criterion . such a way that the output of the OCR method 10 according 2 . A method according to claim 1 , the method further to the invention is better than the output of the first OCR 12 comprising step f ) of updating the list of segmentation points and better than the output of the second OCR 100 . 25 with a further segmentation point determined based on the
If , furthermore , the first OCR 12 is very fast , the com - portion of the digital image corresponding to the selected putation time taken by the OCR method 10 according to the second character candidate . invention is hardly higher than the computation time taken 3 . A method according to claim 2 , wherein step f ) com by the second OCR 100 followed by decision models . prises
Altogether , in the OCR method according to the inven - 30 checking whether the further segmentation point is tion , two segmentations are performed . A first segmentation already in the list of segmentation points , and is performed during the first OCR 12 . A second segmenta adding the further segmentation point in the list of seg tion , based on segmentation points and widths and which is mentation points if the further segmentation point is not combined with the classification as described with reference already present in the list of segmentation point . to FIG . 4 , is performed during the second OCR 100 . The 35 4 . A method according to claim 1 , wherein at step b ) the second segmentation uses the segmentation points found by list of character widths is generated based on at least the list the first segmentation as input . of segmentation points of the first character candidates .
According to an embodiment of the invention , at least one 5 . A method according to claim 1 , wherein steps b , c , d additional OCR is performed after the second OCR . The at and e are performed for each segmentation point of the list least one additional OCR uses the segmentation points 40 of segmentation points . provided by one or more OCRs previously performed and 6 . A method according to claim 1 , wherein steps c , d and outputs IDs of character with their positions and likelihood e are repeated for another character width of the list of parameters that are used to update the graph before the character widths if the likelihood parameter does not fulfil addition of decision models 22 . the first predetermined criterion .
According to an embodiment of the invention , at least part 45 7 . A method according to claim 1 , wherein steps c , d and of the method according to the invention may be executed by e are repeated for another character width of the list of a computer . character widths if the likelihood parameter fulfils the first
In other words , the invention relates to a method and a predetermined criterion and does not fulfil a second prede program for combining a first Optical Character Recognition termined criterion . ( OCR ) 12 and a second OCR 100 . The first OCR 12 is run 50 8 . A method according to claim 1 , wherein the method first on an image of a string of characters 11 . Its output 13 further comprises the steps of : ( first identified characters , positions of the characters and f ) generating a data structure from the first character likelihood parameters of the characters ) is used to generate candidates and the list of segmentation points , and a first graph 16 . Segmentation points related to the positions g ) updating the data structure with the selected second of the first identified characters 14 are used as input by the 55 character candidate and a further segmentation point second OCR 100 performing a combined segmentation and calculated from the character width of the selected classification on the image of string of characters 11 . The second character candidate and the segmentation point output 17 ( second identified characters , positions of the used for determining the portion of the digital image characters and likelihood parameters of the characters ) of corresponding to the selected second character candi the second OCR 100 is used to update 20 the first graph 16 , 60 date . to generate a second graph 21 that combines the output 13 9 . A method according to claim 8 , wherein step a ) of the first OCR 12 with the output 17 of the second OCR comprises determining first likelihood parameters of the first 100 . Decision models are then used to modify 22 the weights character candidates providing an indication of the chance of paths in the second graph 21 to generate a third graph 23 . that the candidate character is correct , wherein the data A best path is determined 24 on the third graph 23 to obtain 65 structure includes the first likelihood parameters of the first the identification 25 of the characters present in the image of character candidates , and wherein the method further com string of characters 11 . prises the steps of :
gy

US 9 , 836 , 646 B2 17 18
graph .
changing the scale of the first likelihood parameters of the 19 . Method according to claim 18 , wherein the first first character candidates and / or the likelihood param character identification method provides first likelihood eters of the second character candidates to make them parameters providing a likelihood that the first character comparable to each other , and candidates are correct , wherein the second character iden
updating the data structure with the likelihood parameters 5 tification method provides second likelihood parameters of the second character candidates . providing a likelihood that the at least one second character 10 . A method according to claim 9 , wherein the data candidate is correct , and wherein the method further com structure is a graph in which segmentation points are rep prises the steps of : resented by vertices and character candidates are represented changing the scale of the first likelihood parameters by edges between vertices . and / or the second likelihood parameters to make them 11 . A method according to claim 10 , further comprising comparable to each other , the step of applying a decision model method on the updated
data structure . adding the first likelihood parameters in the first graph , 12 . A method according to claim 11 , further comprising and
the steps of adding the second likelihood parameters in the updated determining a best path in the updated data structure , and graph . selecting the first and second character candidates corre 20 . Method according to claim 19 , further comprising the
sponding to the edges in the best path as the characters step of applying a decision model method on the updated in the digital image .
13 . A method according to claim 12 , wherein the step of 20 21 . A method according to claim 20 , wherein the decision model method comprises a rule which favours character applying a decision model method comprises favouring
character candidates which have the first likelihood param candidates which have the first likelihood parameter and the eters of first character candidates and the second likelihood second likelihood parameters fulfilling a third predeter parameters of second character candidates fulfilling a third mined criterion . predetermined criterion . 25 22 . A method according to claim 21 , wherein the first 22 .
14 . A method according to claim 13 , wherein some of the character identification method provides character candi first and second character candidates are characters of a first dates for characters of a first type , wherein the second or second type , and wherein the decision model method character identification method provides character candi comprises favouring character candidates of the first type if dates for characters of a second type , and wherein the
the character candidates are provided by the first character 30 decision model method comprises a rule which favours identification process and favouring character candidates of character candidates corresponding to the first type of char the second type if the character candidates are provided by acters if these character candidates have been determined by the classification method . the first character identification method and favours charac
15 . A method according to claim 1 , wherein the first ter candidates corresponding to the second type of characters character identification process comprises a decision model 35 if these character candidates have been determined by the method . second character identification method .
16 . A method according to claim 1 , wherein the first 23 . A method according to claim 17 , wherein the second character identification process provides positions of first character identification method uses as input , at step c ) , the character candidates and further comprising a step of deter first segmentation points from the first character identifica mining the list of segmentation points of the first character 40 tion method . candidates from the positions of the first character candi 24 . A non - transitory computer readable medium storing a dates . program causing a computer to execute a method for iden
17 . A method for identifying characters in a digital image , tifying characters in a digital image , the method comprising the method comprising the steps of : the steps of :
a ) applying a first character identification method to 45 a ) applying a first character identification process to determine first character candidates and first segmen determine first character candidates and a list of seg tation points corresponding to the first character can mentation points of the first character candidates , didates , b ) generating a list of character widths corresponding to
b ) generating a first graph based on the first character a segmentation point from the list of segmentation candidates and the first segmentation points , wherein 50 points , the first segmentation points are represented by vertices c ) determining a portion of the digital image correspond and the first character candidates by edges , ing to the segmentation point from the list of segmen
c ) applying a second character identification method on at tation points and a character width from the list of least part of the digital image to generate at least one character widths , second character candidate , d ) applying a character classification method on the
d ) updating the graph by adding the at least one second portion of the digital image to obtain an ID hypothesis character candidate to the first graph , and of a character possibly present in the portion of the
e ) selecting in the updated graph character candidates as digital image and a likelihood parameter that relates to the characters of the digital image . a likelihood that the ID hypothesis is correct , and
18 . Method according to claim 17 . wherein the second 60 e ) selecting the ID hypothesis as a second character character identification method generates at least one second candidate in the digital image if the likelihood param segmentation point and wherein the at least one second eter fulfils a first predetermined criterion . segmentation point is added to the graph at step d ) . * * * *
55





























