Embed Size (px)
Citation preview

The Philosophical Aspects of Data Modelling
Emir MuñozNational University of Ireland Galway
Semantics of Object Representation in Machine Learning
Birkan TunçCenter for Biomedical Image Computing and Analytics,
University of Pennsylvania, Philadelphia, PA, USA

2

3
Machine LearningField of study that gives computers the ability to learn without being explicitly programmed
(Arthur Samuel, 1959)
https://www.informatik.uni-hamburg.de/ML/
Contribution
Philosopher
INTRODUCTION
“”

4
Text recognition Recommender Systems
Face detection Self-driving Cars
http://commons.wikimedia.org/ML APPLICATIONS
5
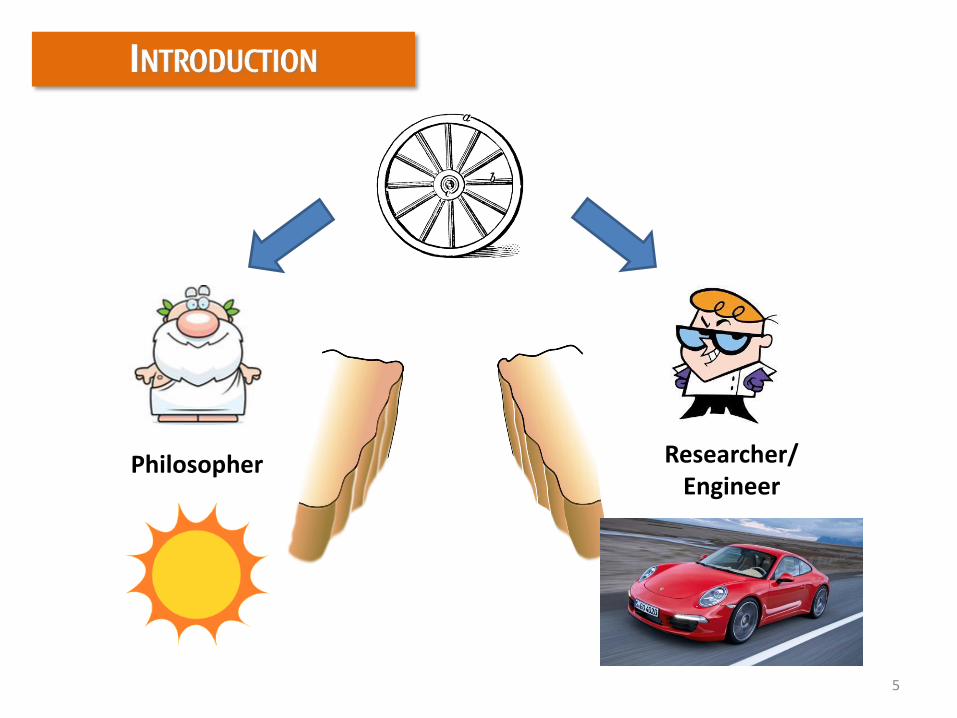
INTRODUCTION
Philosopher Researcher/Engineer
6
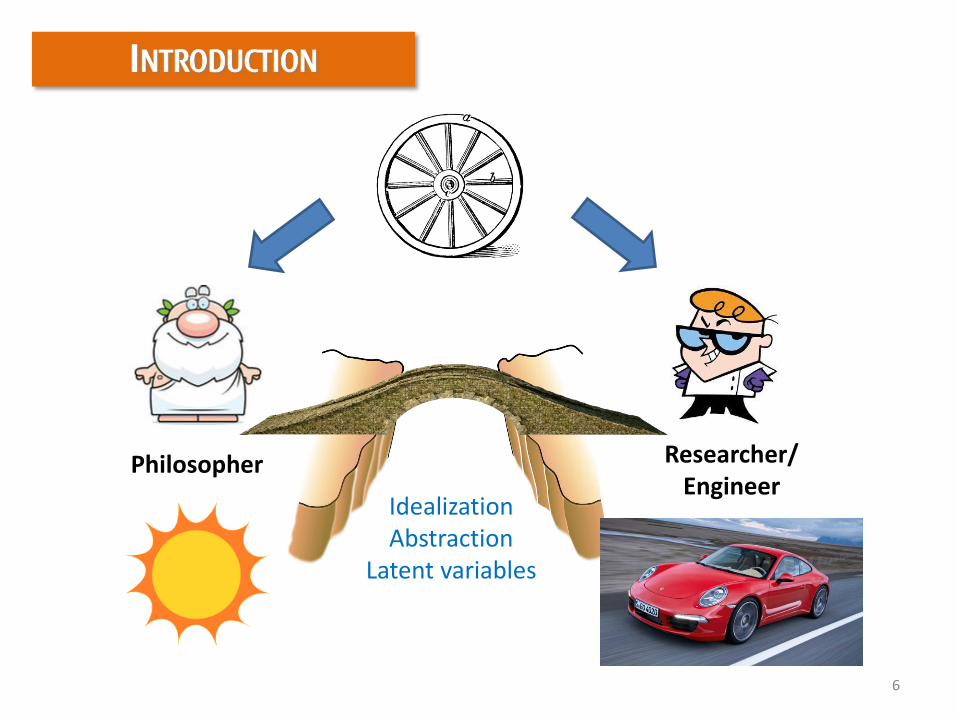
INTRODUCTION
Philosopher Researcher/Engineer
IdealizationAbstraction
Latent variables
7
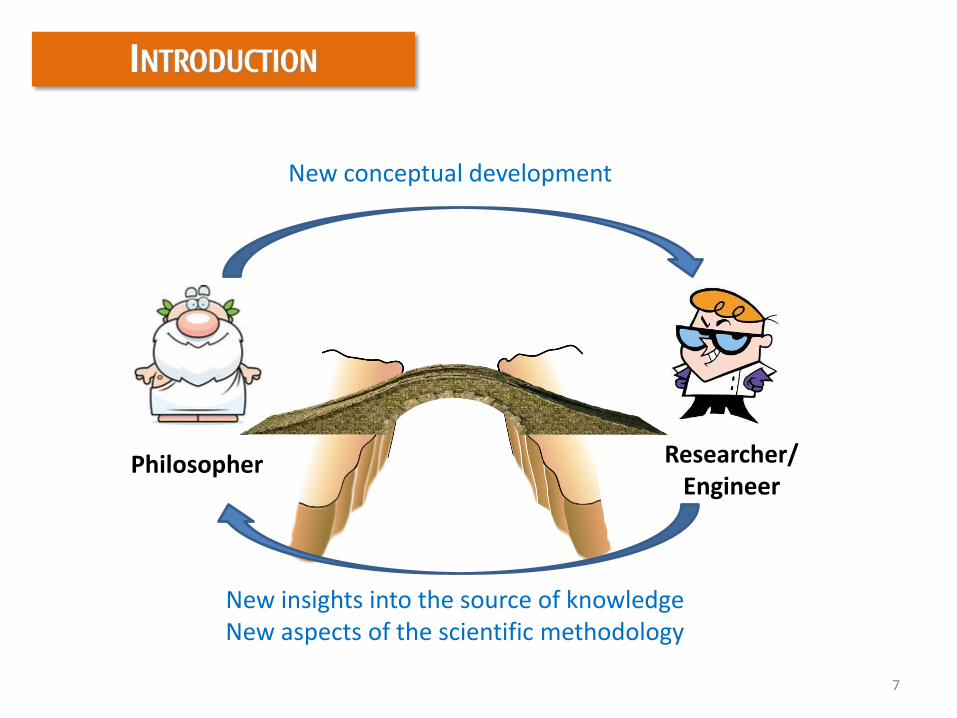
INTRODUCTION
Philosopher Researcher/Engineer
New conceptual development
New insights into the source of knowledgeNew aspects of the scientific methodology

8
Regression Classification Clustering
STATISTICAL LEARNING
Continuous labels Discrete labels Densities

• Author’s proposal:– Machine learning needs to be cultivated with the
vocabulary of philosophy to extend the range of questions that raised when evaluating various aspects of machine learning, pertaining to data representation
9
STATISTICAL LEARNING
Real Entity- Nature- Structure
𝑋 → 𝑓(𝑋)
Mathematical Object- Properties

10
Duck?
Beaver?
Otter?
A Platypus
WHO CARES?

11
• «The foundations of pattern recognition can be traced to Plato, later extended by Aristotle, who distinguished between an “essential property” […] from an “accidental property” […]»
WHO CARES?
Pattern recognition find such essential properties

12
Training Data
Test DataMachine Learning
Algorithm
Hypothesis Performance
Feedback
What is the justificationto use this model and object
representation ?
WHO CARES?
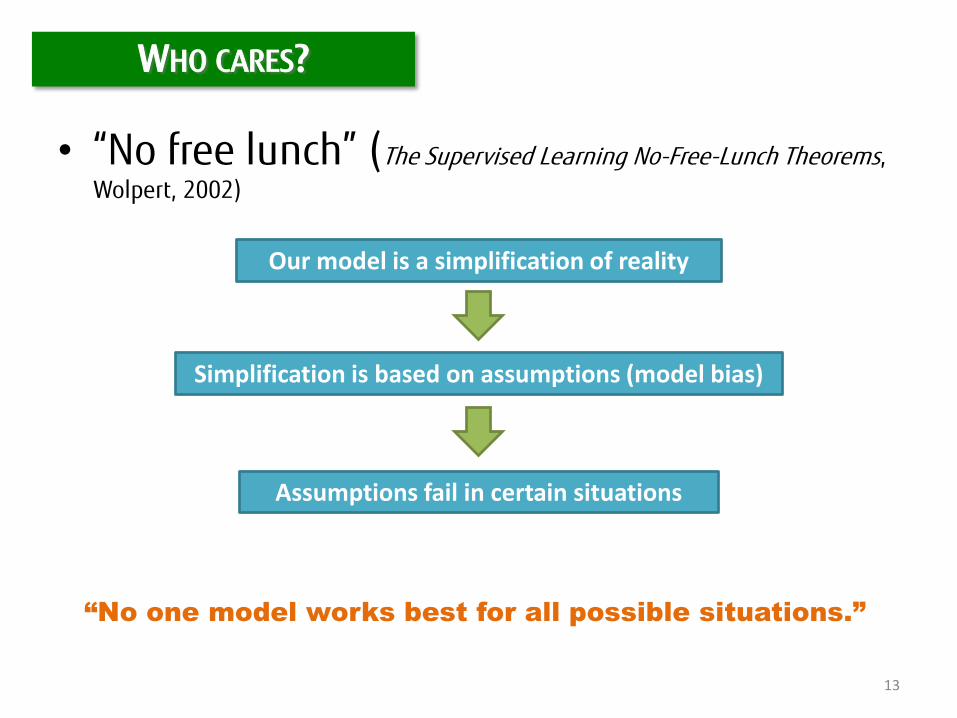
• “No free lunch” (The Supervised Learning No-Free-Lunch Theorems,
Wolpert, 2002)
13
Our model is a simplification of reality
Simplification is based on assumptions (model bias)
Assumptions fail in certain situations
“No one model works best for all possible situations.”
WHO CARES?

14
• What is the justification to use this model and object representation ?
Absolute performance Relative performance
Quantified by probabilistic bounds of the generalization error
Compared to the relative algorithms and other configurations
Examples:• Confusion matrix• Accuracy• Misclassification rate
Examples:• Mahalanobis distance• Kolmogorov-Smirnov distance• ROC curves and AUC• Gini
Need for philosophical attention
WHO CARES?
(Varieties of Justification in Machine Learning, Corfield, 2010)

15
WHO CARES?
Mental disordersVs.
Normality
f(X)

16
WHO CARES?
Which one is better now?
I told you, we need to look beyond
the accuracy, consistency, and
relative performance…

17
WHO CARES?
Kernel Trick
Linear separationWith errors
Non-linear separationNo errors
Non-linear surfacecorresponding to a linear
surface in the feature space
We boost the performance of our
model, regardless of the nonlinearity
of original features

18
WHO CARES?
f(X)
Output prediction is not the main goal.
But a more extensive comprehension of the interactions betweenthe main players of the system.

19
INDUCTIVE INFERENCE
• Deductive reasoning (strong syllogism)
• Inductive inference (weak syllogism)
“if A is true then B is true;
A is true;
therefore B is true”
“if A is true then B is true;
B is true;
therefore A is plausible”

20
INDUCTIVE INFERENCE
• Deductive reasoning (strong syllogism)
• Inductive inference (weak syllogism)
“if A is true then B is true;
A is true;
therefore B is true”
“if A is true then B is true;
B is true;
therefore A is plausible”
TruthPreservation
TruthPreservation

21
INDUCTIVE INFERENCE
• Statistical learning (weaker than weak syllogism)
“if A is true then B is plausible;
B is true;
therefore A is plausible”
Tools to evaluate the degree of plausibility that corresponds to our credence on the truth of conclusions
22
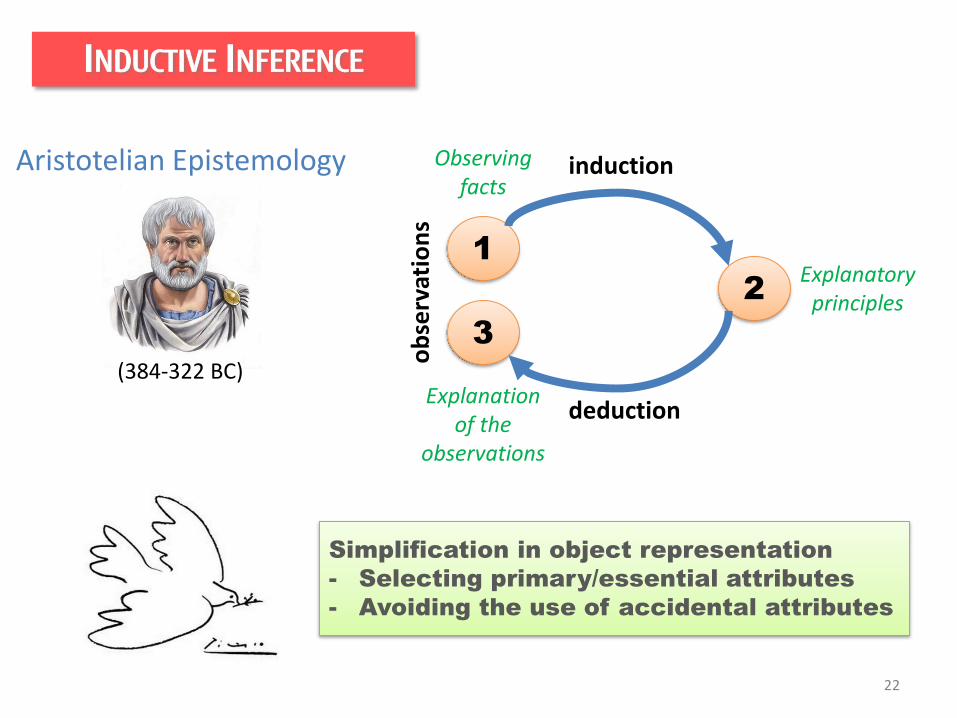
INDUCTIVE INFERENCE
Aristotelian Epistemology
(384-322 BC)
1
2
3
induction
deductiono
bse
rvat
ion
s
Observingfacts
Explanatoryprinciples
Explanationof the
observations
Simplification in object representation
- Selecting primary/essential attributes
- Avoiding the use of accidental attributes

23
INDUCTIVE INFERENCE
Aristotelian Epistemology
(384-322 BC)
Example linear discriminant
𝑔 𝒙 = 𝒘𝑇𝒙
x ∈ ℜ𝒏
w ∈ ℜ𝒏
Observable
Hyperplane
Most objects of class A reside on the side of the
hyperplane where 𝑔 𝒙 > 0.5
Definition of vector 𝒙, which needs feature extraction and selection
“Most objects of class A reside on the side of the hyperplane
where 𝑔(𝒙)>0.5; 𝑔(𝒙’)>0.5 is true for an object 𝒙’; therefore 𝒙’ is plausible of class A”

24
INDUCTIVE INFERENCE
Galilean Epistemology
(1564-1642)
Unlike heavenly bodies, the mundane objects of the earth
were not suitable for mathematical models, as they did
not manifest ideal behaviours.
Abstraction Idealization
representing an object with another object that is easier to
handle
simplifying properties of an object
3D space to deal with the motion
of particles
Frictionless surface
of rocks falling

25
INDUCTIVE INFERENCE
Linear AlgebraVector Space ModelFace Recognition
Example of abstraction
Example of idealization
Galilean idealization is pragmatic and aims to reduce computational limitations.E.g., feature selection to facilitate –otherwise infeasible- training of a classifier.

26
INDUCTIVE INFERENCE
Abstraction (a.k.a. Aristotelian idealization)
Idealization (a.k.a. Galilean idealization)
Given a class of individuals, an idealization is a conceptunder which all of the individuals almost fall (in somepragmatically relevant sense), while at least one individualis excluded by the idealization
Given a class of individuals, an abstraction is a concept under which all of the individuals fall.

27
OBJECT REPRESENTATION IN MACHINE LEARNING
• Two main types of indeterminacy in learning problems:– Unknown nature of data
– Unknown functional form between input and corresponding outputs
• complicate the selection of hypothesis space, but also hinders the identification of essential attributes!!

• More problems: high degree of freedom in the configuration of learning algorithms
28
OBJECT REPRESENTATION IN MACHINE LEARNING
Researchers play with the original feature
space, for example using Principal
Component Analysis (PCA).
PCA is used for both:
- Dimensionality reduction and;
- Space transformation by identifying
directions of maximum variance.

29
OBJECT REPRESENTATION IN MACHINE LEARNING
• Abstraction

30
OBJECT REPRESENTATION IN MACHINE LEARNING
• Abstraction
Kernel Trick
𝑥1 = 𝑓1, 𝑓2, … , 𝑓𝑛
𝑥2 = 𝑓′1, 𝑓′2, … , 𝑓′𝑛
Let 𝑥 ∈ 𝑉, and a mapping 𝜙 𝑥 ∶ 𝑉 → 𝑊
Real objects
𝐾(𝑥1, 𝑥2) ≡ 𝜙 𝑥1 , 𝜙(𝑥2)
The Kernel Trick (Rasmussen & Williams, 2005):
- Enable us to work in very complex vector spaces
without even knowing the mapping itself.
31
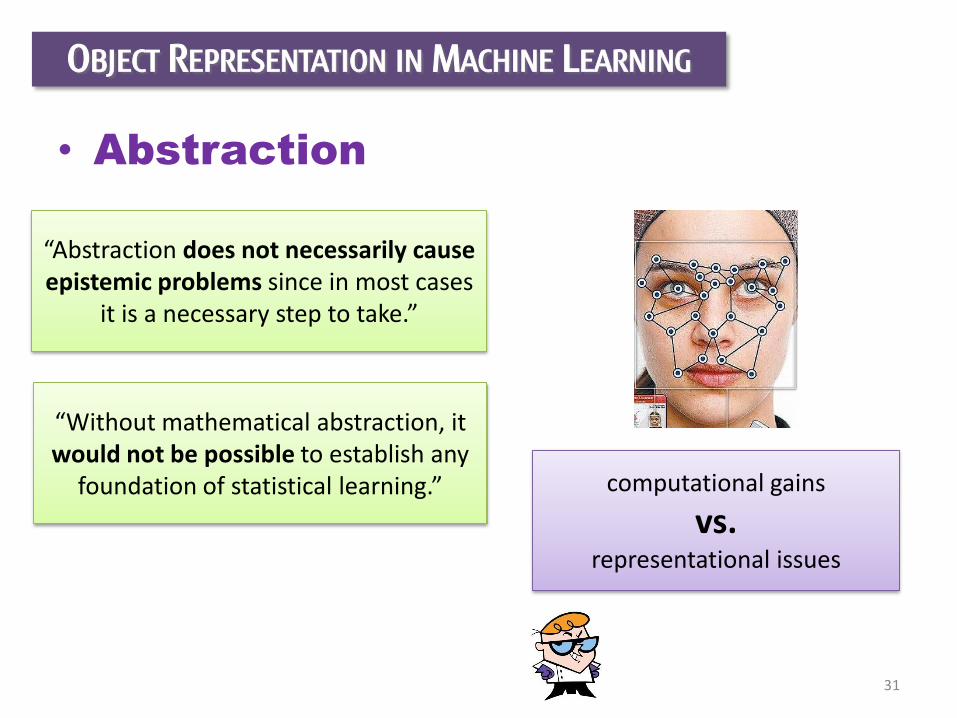
OBJECT REPRESENTATION IN MACHINE LEARNING
• Abstraction
“Abstraction does not necessarily cause epistemic problems since in most cases
it is a necessary step to take.”
“Without mathematical abstraction, it would not be possible to establish any
foundation of statistical learning.” computational gains
vs. representational issues

32
OBJECT REPRESENTATION IN MACHINE LEARNING
• Idealization
It does not only act over the features but is also realized during the model construction.
Remove irrelevant features to sort out the accidental attributes
Remove irrelevant features to alleviate computational issues such as to reduce
the dimensionality

33
OBJECT REPRESENTATION IN MACHINE LEARNING
• Idealization
– (Weisberg, 2007) identifies 3 kinds of idealization used in scientific models
Multi model idealization
• Boosting, voting (ensemble methods)
• Used when no single model can characterize the underlying causal structure
• Small models with different set of features
Galilean idealization
• Performed against technical difficulties
• Deliberate distortions
• Bayesian learning model struggles with computational complexities without idealization
Minimalist (Aristotelian) idealization
• ‘stripping away’ all properties from a concrete object that we believe are not relevant to the problem at hand.
• focus on a limited set of properties in isolation
34
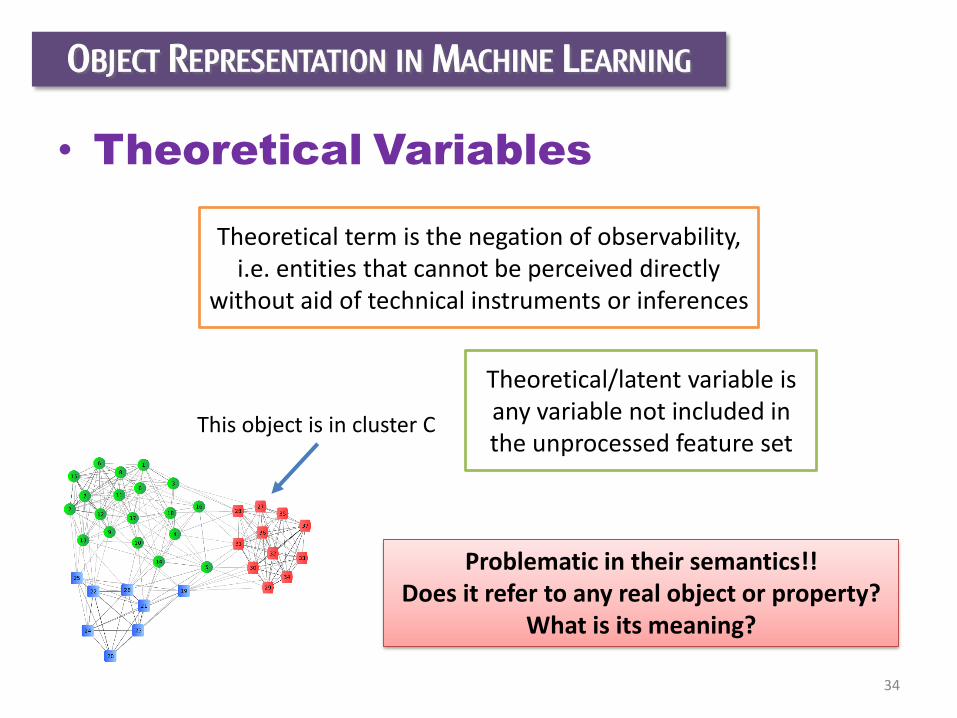
OBJECT REPRESENTATION IN MACHINE LEARNING
• Theoretical Variables
Theoretical term is the negation of observability, i.e. entities that cannot be perceived directly
without aid of technical instruments or inferences
This object is in cluster C
Theoretical/latent variable is any variable not included in the unprocessed feature set
Problematic in their semantics!!Does it refer to any real object or property?
What is its meaning?

35
How old am I?
Latent Variables
Based on teeth.• Count them. Kittens will have 26 deciduous teeth and adult cats will have 30 teeth.• Cats younger than 8 weeks will still be developing their deciduous, or "baby" teeth.
http://www.wikihow.com/Know-Your-Cat%27s-Age
Based on fur.• Like humans, cats will also develop grey hairs with age.
Based on paws, claws, and pads.• As cats age, their nails will harden and become brittle and overgrown.
Based on eyes.• Older cats will develop a cloudiness not present in kittens and younger cats, who have sharp, clear eyes.
Based on behaviour.• Younger cats--like younger people--are generally more energetic and attracted to play.
Hidden variablesNot directly observed but inferred
OBJECT REPRESENTATION IN MACHINE LEARNING
• Multiple successful applications of Machine Learning– Not mainly rooted in our glorious technological
advancements
36
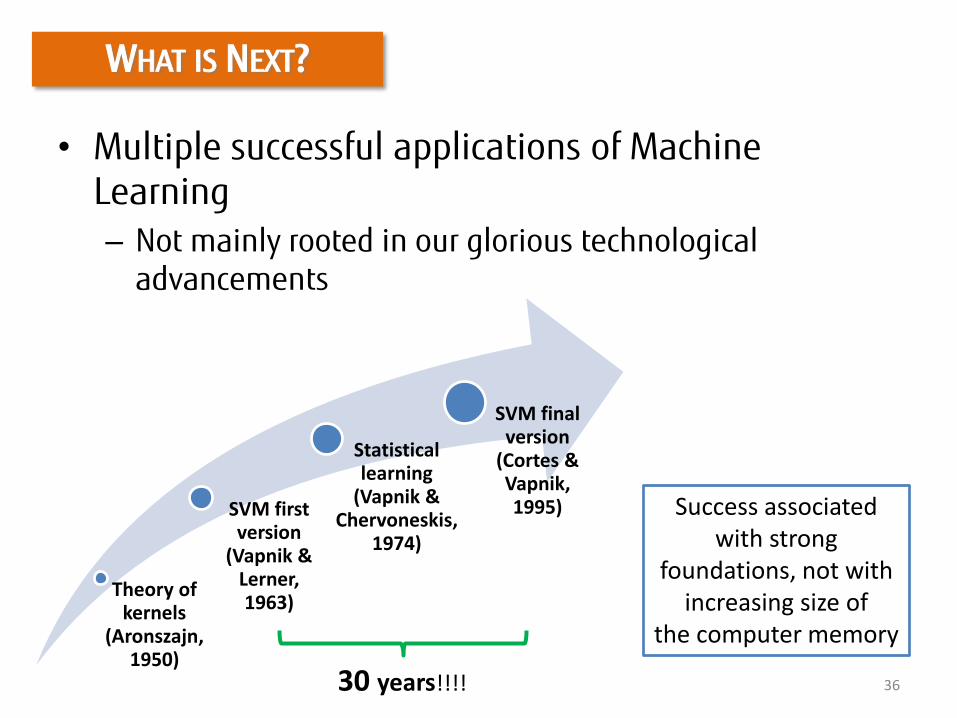
WHAT IS NEXT?
Theory of kernels
(Aronszajn, 1950)
SVM first version
(Vapnik & Lerner, 1963)
Statistical learning
(Vapnik & Chervoneskis,
1974)
SVM final version
(Cortes & Vapnik, 1995)
30 years!!!!
Success associatedwith strong
foundations, not withincreasing size of
the computer memory

37
WHAT IS NEXT?
First steps into therelationship betweenPhilosophy and Machine Learning
Which one is better now?

38
What real entity
corresponds this?
WHAT IS NEXT?

39
WHAT IS NEXT?

40
HOW THIS IS RELATED TO MY PHD
• RDFmethod for conceptual description or modelling of information
• Linked Data method of publishing structured data
• I want to apply ML techniques over Linked Data
• What is the nature or structure of a Linked Data dataset?
Thanks!





























