Embed Size (px)
Citation preview

Copyright©2016 NTT corp. All Rights Reserved.
強化学習の基礎NTT 研究所 山田真徳

Copyright©2016 NTT corp. All Rights Reserved. 2
教師あり学習 教師なし学習 強化学習
機械学習は大きくわけて3つ
ラベルがついていないものの性質を調べる( 基本はクラスタリング )ラベル ( 教師データ ) があるもの使い教師データと同じ写像を見つける
( 基本は回帰か分類 )
f:x→yy=f(x)
本質は教師データ {x,y} から f を決める問題 距離などを参考に色 ( ラベル ) がわからない状態でクラスタイリング
良さの方向だけを与えておいて、環境を探索して良い方向に行くように教師を自ら生成して学習する
行動の最適化問題
参考画像 https://qiita-image-store.s3.amazonaws.com/0/72529/dc77a4fe-85a1-a69e-e0e3-571e2e04a33f.png

Copyright©2016 NTT corp. All Rights Reserved. 3
目的
強化学習 (Q 学習 ) の基礎となる方策改善定理を理解する
Copyright©2016 NTT corp. All Rights Reserved. 4
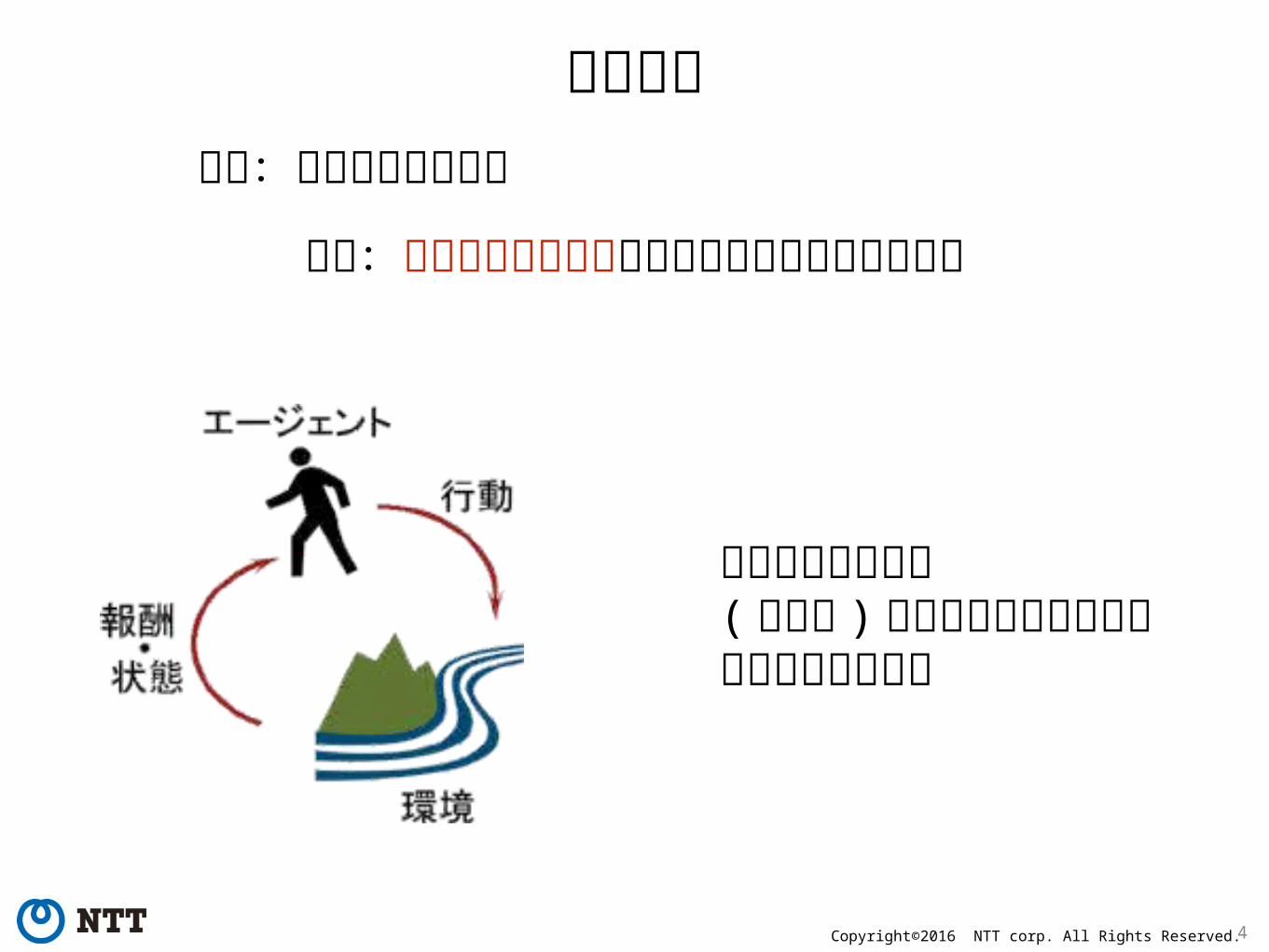
方針:未来の報酬期待値が最大になるように学習する
強化学習目的:行動選択の最適化
教師あり学習とも( 普通の ) 教師なし学習とも違う環境探索型の学習
Copyright©2016 NTT corp. All Rights Reserved. 5
DQN(Deep Q NeuralNetwork) 学習:戦略を学ぶ例
Copyright©2016 NTT corp. All Rights Reserved. 6
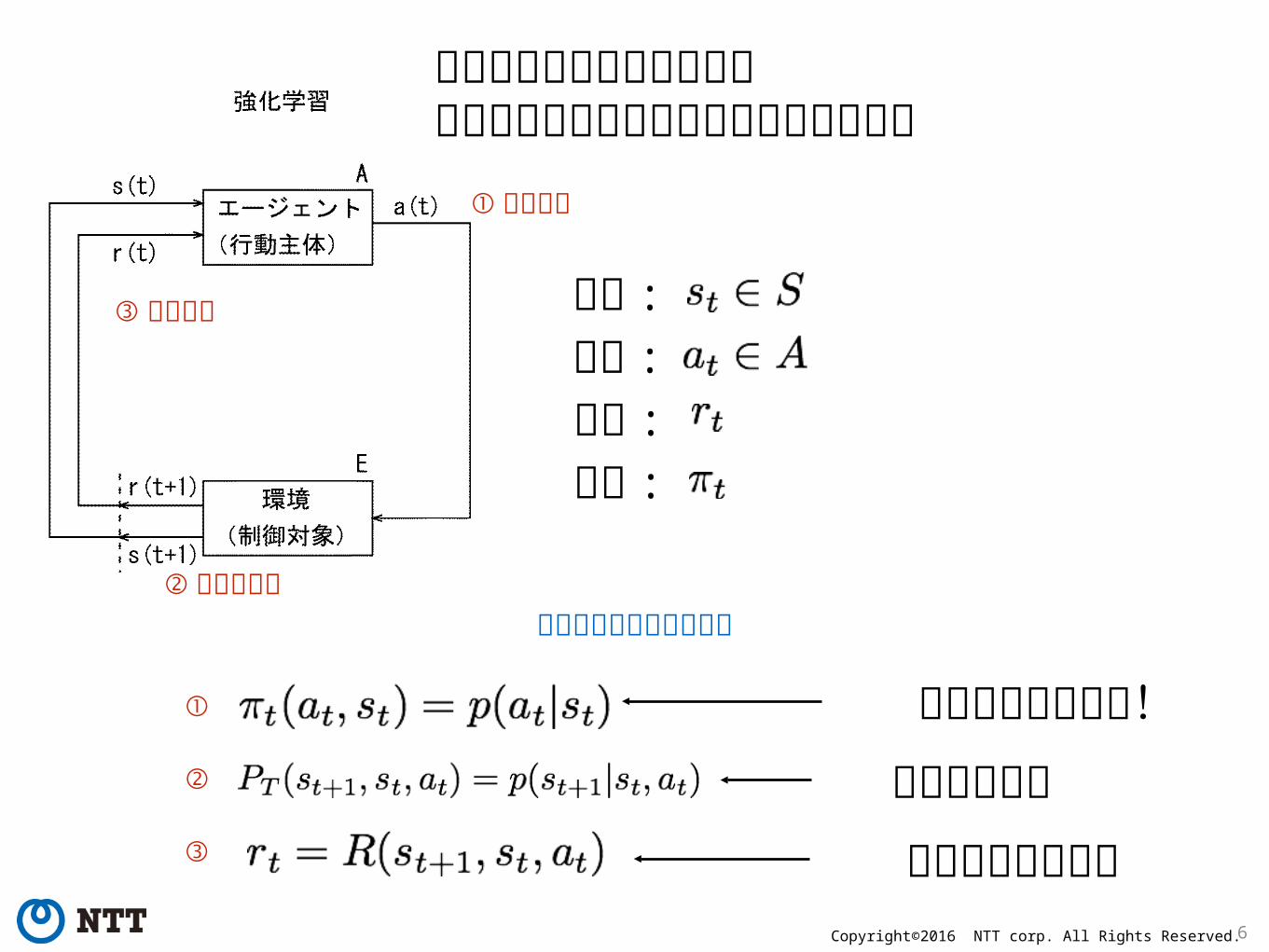
環境と相互作用がある学習良いという方向を決めて教師を自ら生成① 行動選択
①
② 環境の更新
②
③
③ 報酬決定 状態 :行動 :報酬 :方策 :
これを学習したい!環境で決まるユーザーが与える
状態のマルコフ性を仮定

Copyright©2016 NTT corp. All Rights Reserved. 7
マルコフ決定過程 (MDP) :アクションつきマルコフ過程のこと
マルコフ過程: 1 つ前の状態にしかよらないという近似
近似
マルコフ決定過程

Copyright©2016 NTT corp. All Rights Reserved. 8
R の期待値
Q 関数: R をその場の状態と行動で決める
定義より V と Q の関係を明確に
V 関数: R をその場の状態だけで決める
π は固定
Copyright©2016 NTT corp. All Rights Reserved. 9
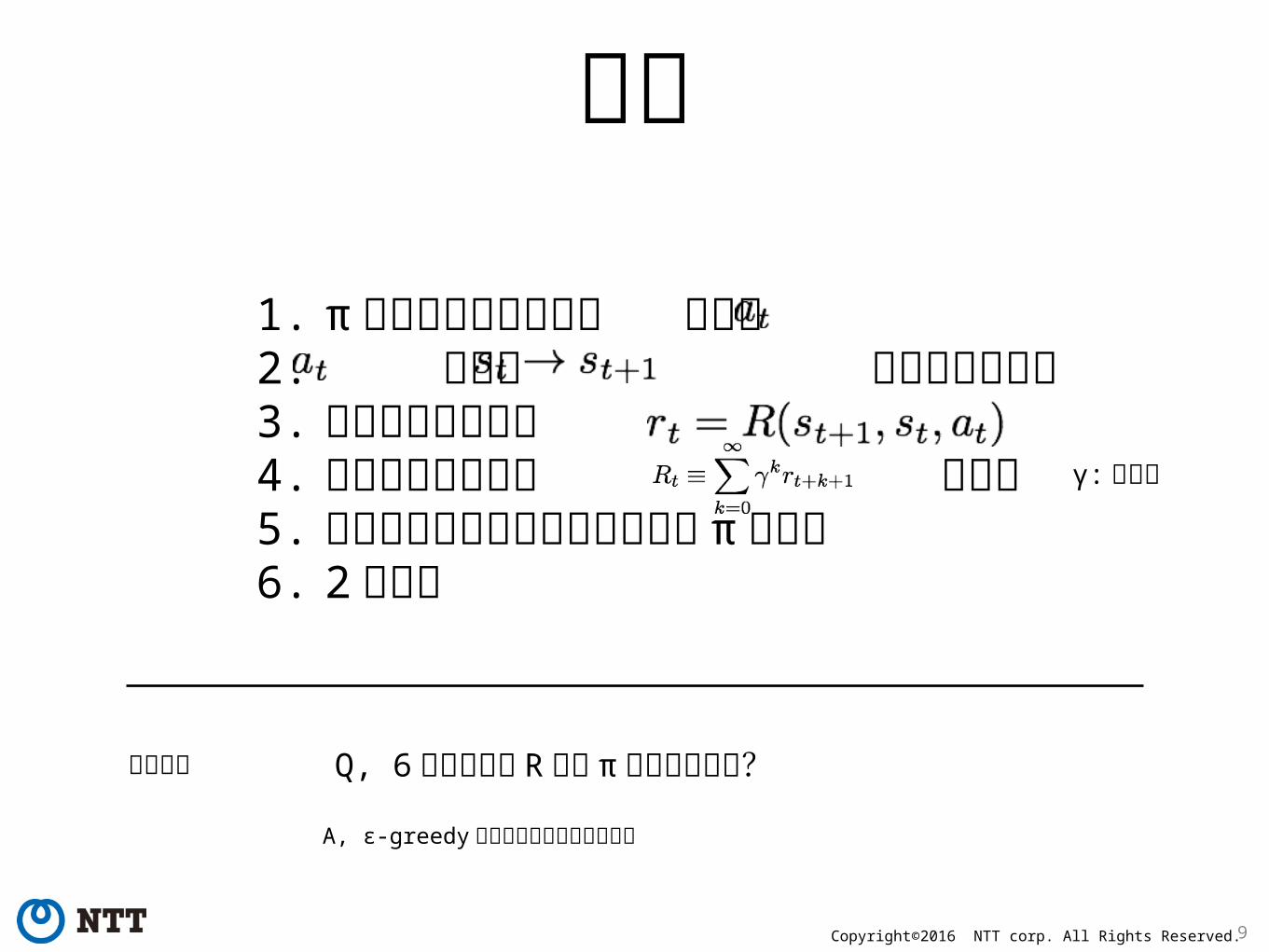
手順1. π に従い確率的に行動 を決定2. により が確率的に決定3. 現在の報酬が決定4. 将来の報酬の合計 を計算5. 将来の報酬が最大になるように π を修正6. 2 に戻る
ポイント Q, 6 どうやって R から π を修正するか?
γ: 割引率
A, ε-greedy 法というものを使えばいい

ε-greedy 法
基本的には常に Q を最大にする a を選びなさいただし ε の確率で他のも試しなさい
利用探索

Copyright©2016 NTT corp. All Rights Reserved. 11
以下を示したい
Q を計算して ε-greedy で π を修正すること⇔R の最大とする方策 π* を求めること

良い方策 π を V から定義する
最適状態関数 V* を定義
π の大小関係を定義すると定義の時のみ
全ての において
最適方策 π* は最大の π と定義
最適行動価値関数 Q* を定義

Copyright©2016 NTT corp. All Rights Reserved. 13
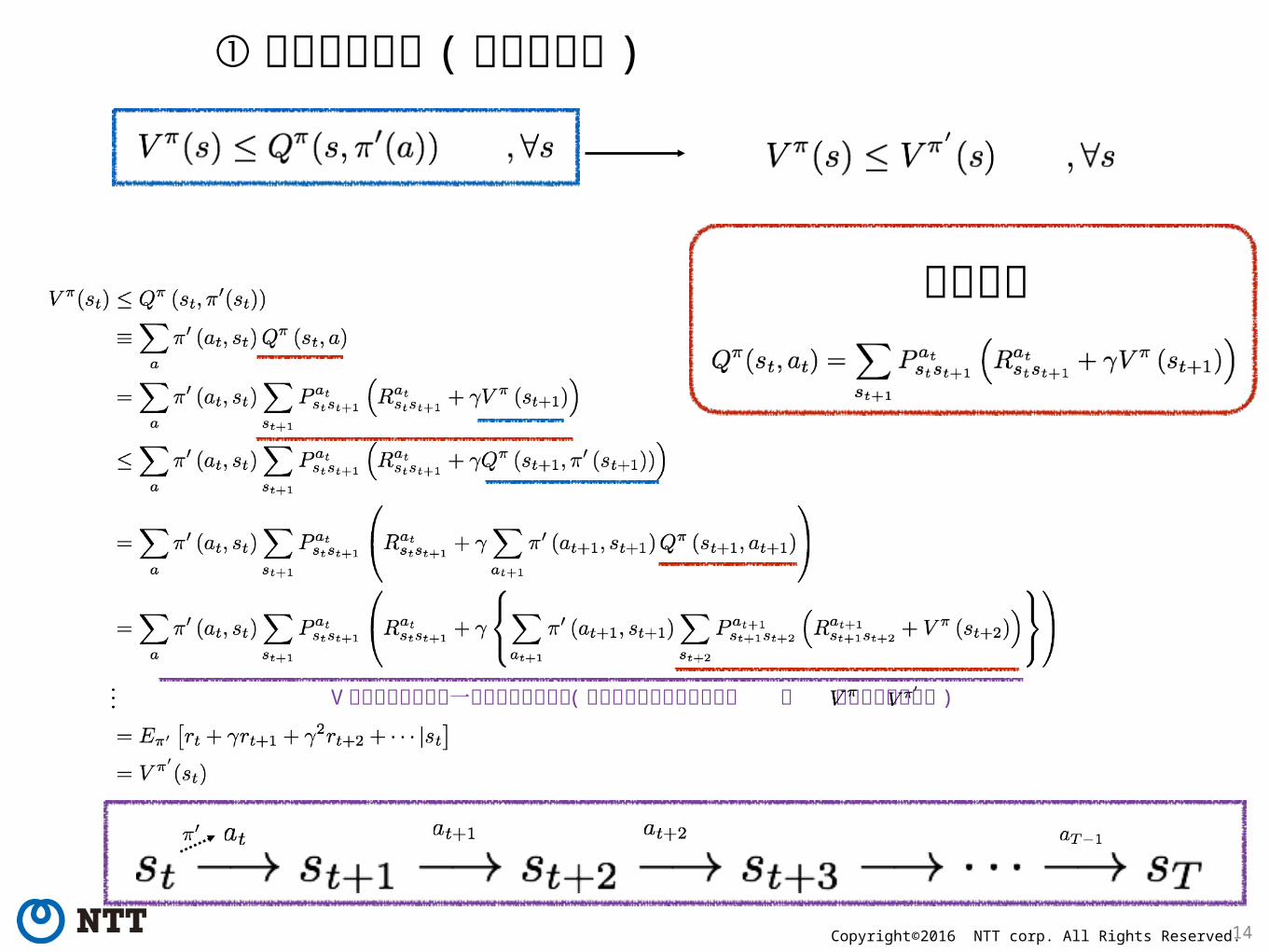
① 方策改善定理 ( 改善の保証 )次のターンのみ a を π’ で取る
②ε-greedy が方策改善になっている
以下の2つを示せばよい
Copyright©2016 NTT corp. All Rights Reserved. 14
① 方策改善定理 ( 改善の保証 )
後で示す
V の漸化式方程式の一般式になっている ( 報酬の収束を仮定し最後は と の違いは効かない )

Copyright©2016 NTT corp. All Rights Reserved. 15
証明
MDP
便利な表現

Copyright©2016 NTT corp. All Rights Reserved. 16
②ε-greedy も方策改善になっている
平均化された最大値≧合計1になる非負の重み付き平均
´

Copyright©2016 NTT corp. All Rights Reserved. 17
Atari games(57 個 )半分以上のゲームで人間を超えた
DQN(NIPS 2013)←Q を関数近似で汎化V. Mnih et al., "Playing atari with deep reinforcement learning”
DQN (Nature 2015) ←NIPS DQN の θ の更新を改良V. Mnih et al., "Human-level control through deep reinforcement learning”
Double DQN (arXiv:1509.06461 [cs])← 本質的な改良Hado van Hasselt et al., “Deep Reinforcement Learning with Double Q-learning”
Double Q-learning(NIPS 2010)← 理解に役立つHado van Hasselt et al., “Double Q-learning”
Dueling Network(2016)← ネットワークを工夫ZiyuWang et al., “Dueling Network Architectures for Deep Reinforcement Learning”
FRMQN(2016)← いい感じで記憶を持たせるJunhyuk Oh et al., “Control of Memory, Active Perception, and Action in Minecraft”
Intrinsic Motivation (2016)← 探索に重みをつけるっぽいMarc G. Bellemare et al., “Unifying Count-Based Exploration and Intrinsic Motivation”
時間が余れば最近の DQN






![テストプロセス改善技術 入門ガイド [ver1.0.0]aster.or.jp/business/testprocess_sg/pdf/ASTER_TPIGuide_v...テストプロセス改善技術 入門ガイド [ver1.0.0]](https://img.dokumen.tips/doc/110x75/60ff1b3c7b9557609f2c94ca/ffffe-ef-ver100asterorjpbusinesstestprocesssgpdfastertpiguidev.jpg)






















