Embed Size (px)
Citation preview

Hunk: analýza surových dat do 60 minut
1
Hunk: analýza surových dat do 60 minut
Kamil Brzak, SCSR
Project Manager at Trask solutions a.s.

Hunk: analýza surových dat do 60 minut
2
Obsah 0. – 20. minuta: Nastavení prostředí .............................................................................................................................. 3
20. – 40. minuta: Konfigurace Hunk s využitím UI ......................................................................................................... 3
20. – 40. minuta: Konfigurace Hunk pomocí konfiguračních souborů ......................................................................... 9
Krok 1 ........................................................................................................................................................................... 9
Krok 2 ......................................................................................................................................................................... 10
Krok 3 ......................................................................................................................................................................... 11
49. – 50. minuta: Analyzujte data z Hadoopu .............................................................................................................. 11
59. – in infinitum: Hunkujte .......................................................................................................................................... 12
Originál článku: „Hunk: Raw data to analytics in < 60 minutes“, Ledion Bitincka 8.11.2013

Hunk: analýza surových dat do 60 minut
3
0. – 20. minuta: Nastavení prostředí Příprava prostředí vyžaduje instalaci následujících komponent:
1. Instalační balíček Hunk – je ke stažení jako 60-denní zkušební verze na tomto místě,
2. Java – alespoň ve verzi 1.6 a vyšší (případně verze odpovídající potřebám klientských knihoven Hadoop),
3. Klientské knihovny Hadoop – lze je získat od dodavatele Hadoopu, v případě distribuce Apache jsou ke
stažení právě zde.
Instalace Hunku probíhá velmi jednoduše:
#1. untar the package
> tar -xvf splunk-6.0-<BUILD#>-Linux-x86_64.tgz
#2. start Splunk
> ./splunk/bin/splunk start
Je potřeba dodržet postup dle instalačních průvodců pro Javu a klientských knihoven Hadoop. Ujistěte se jen, že
jsou vytvořené JAVA_HOME a HADOOP_HOME, jelikož s nimi budeme dále pracovat.
20. – 40. minuta: Konfigurace Hunk s využitím UI Hunk je možno konfigurovat buď prostřednictvím grafického rozhraní (UI) v sekci Settings > Virtual Indexes, anebo
editací konfiguračních souborů, indexes.conf. Protože jde o popis dvou metod, vyskytují se kapitoly, popisující 20.
– 40. minutu v textu dvakrát, jednou pro každou metodu.
1. Přihlašte se do Hunku (výchozí username: admin, password: changeme)
Hunk: analýza surových dat do 60 minut
4
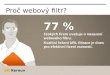
2. Přejděte do Settings > Virtual Indexes
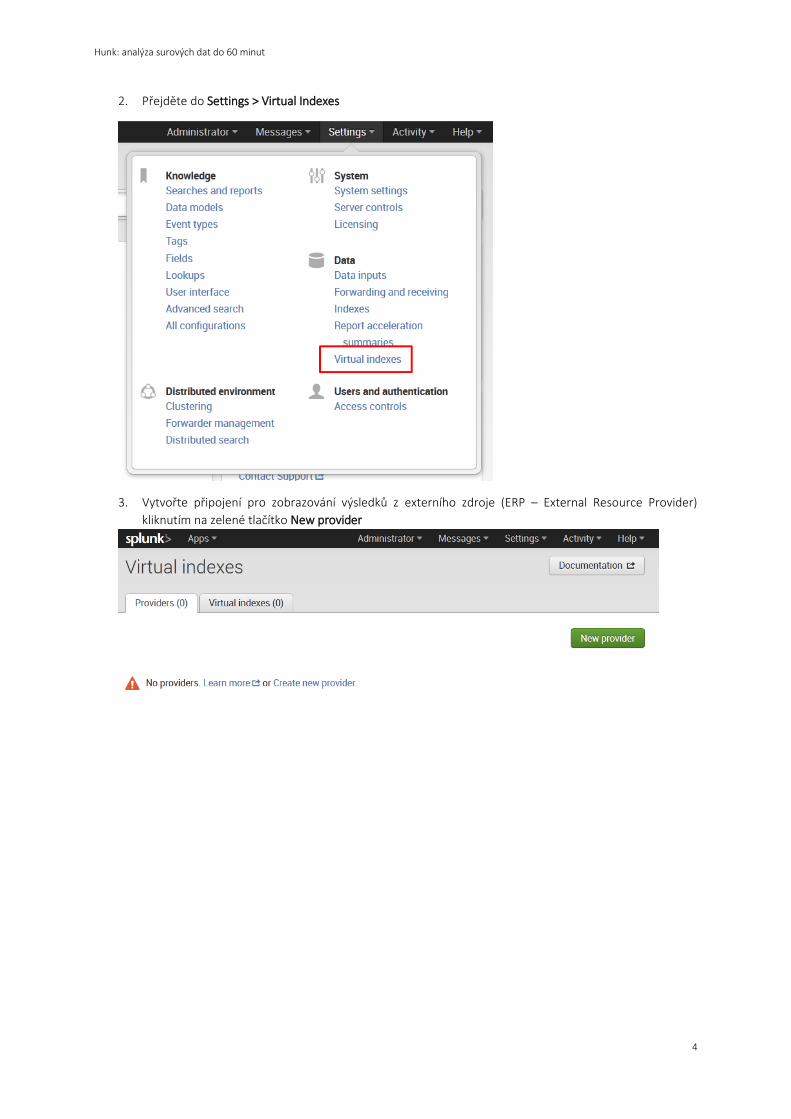
3. Vytvořte připojení pro zobrazování výsledků z externího zdroje (ERP – External Resource Provider)
kliknutím na zelené tlačítko New provider
Hunk: analýza surových dat do 60 minut
5
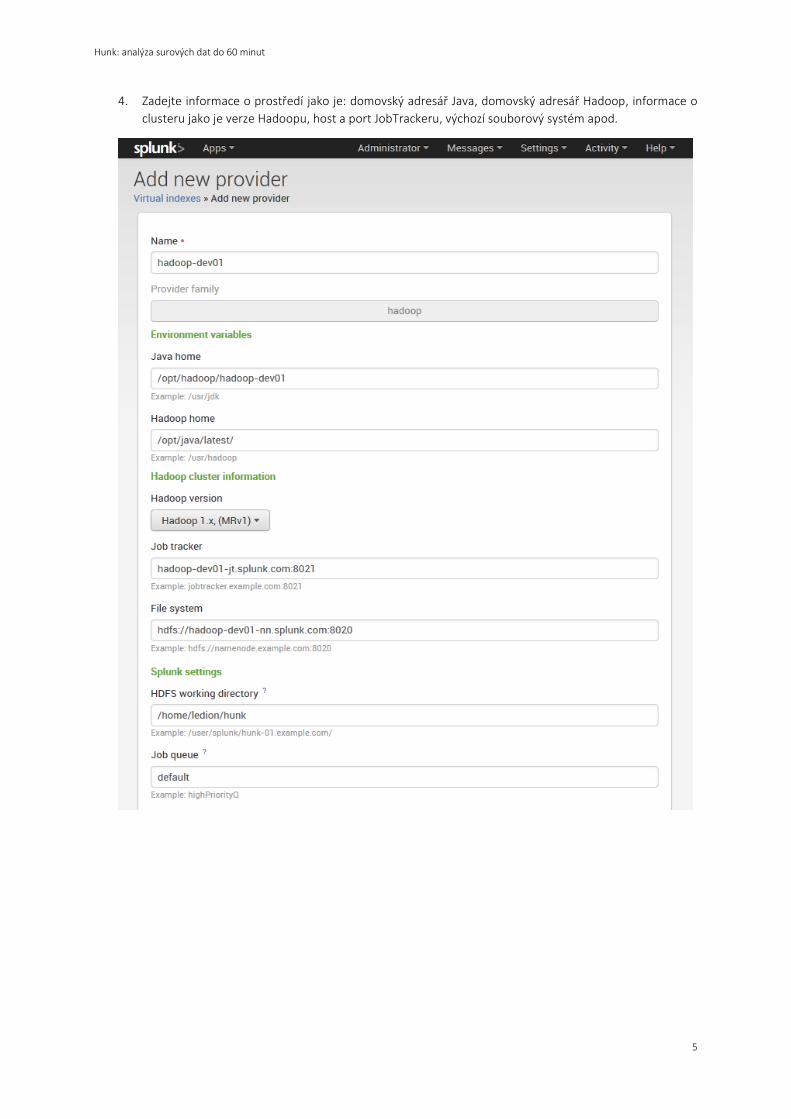
4. Zadejte informace o prostředí jako je: domovský adresář Java, domovský adresář Hadoop, informace o
clusteru jako je verze Hadoopu, host a port JobTrackeru, výchozí souborový systém apod.
Hunk: analýza surových dat do 60 minut
6
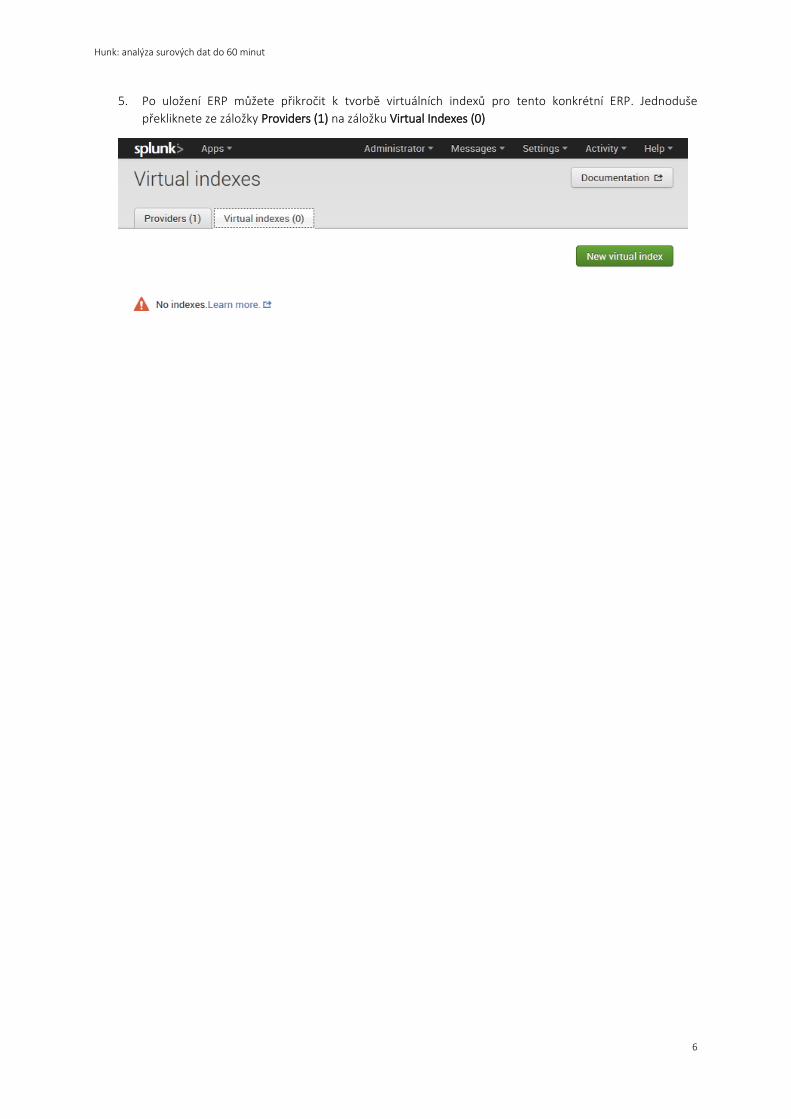
5. Po uložení ERP můžete přikročit k tvorbě virtuálních indexů pro tento konkrétní ERP. Jednoduše
překliknete ze záložky Providers (1) na záložku Virtual Indexes (0)
Hunk: analýza surových dat do 60 minut
7
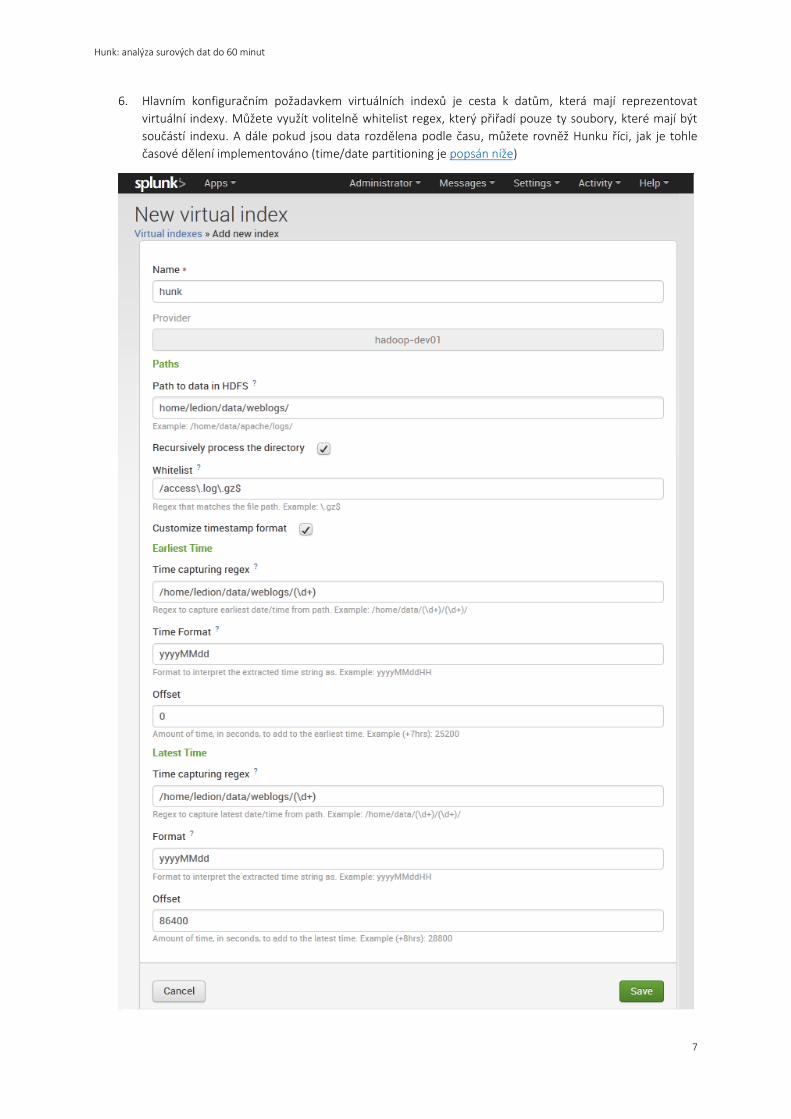
6. Hlavním konfiguračním požadavkem virtuálních indexů je cesta k datům, která mají reprezentovat
virtuální indexy. Můžete využít volitelně whitelist regex, který přiřadí pouze ty soubory, které mají být
součástí indexu. A dále pokud jsou data rozdělena podle času, můžete rovněž Hunku říci, jak je tohle
časové dělení implementováno (time/date partitioning je popsán níže)
Hunk: analýza surových dat do 60 minut
8
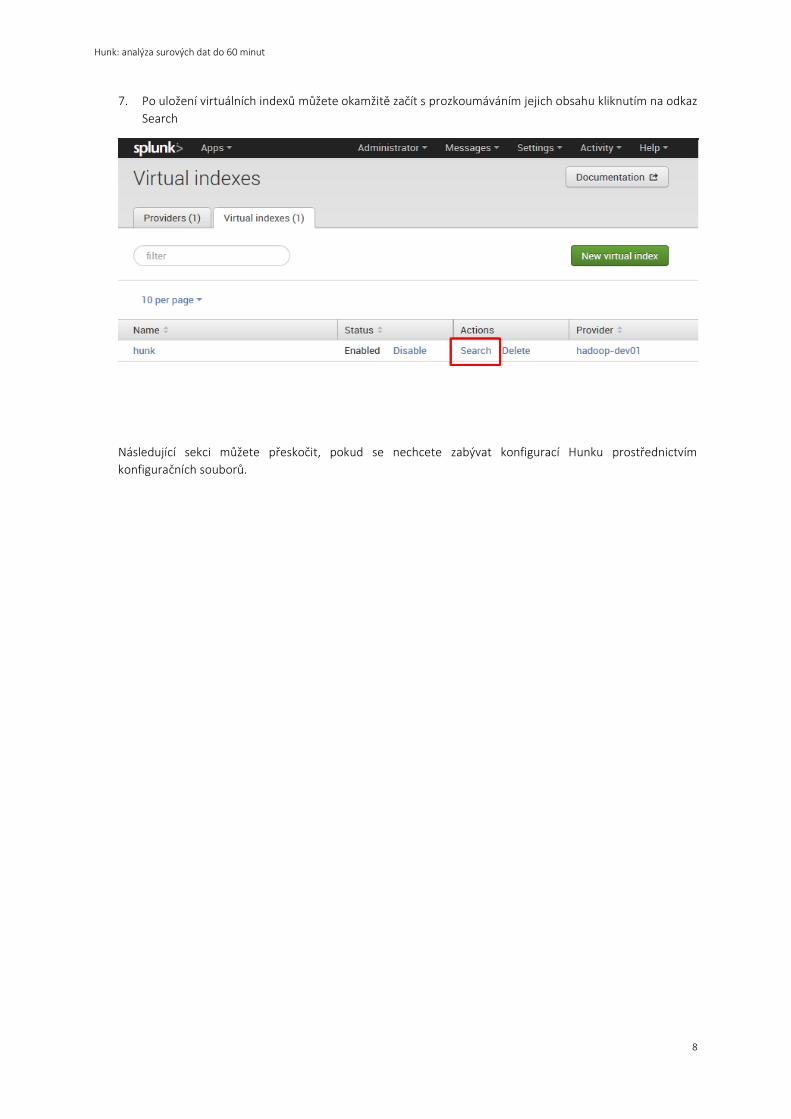
7. Po uložení virtuálních indexů můžete okamžitě začít s prozkoumáváním jejich obsahu kliknutím na odkaz
Search
Následující sekci můžete přeskočit, pokud se nechcete zabývat konfigurací Hunku prostřednictvím
konfiguračních souborů.

Hunk: analýza surových dat do 60 minut
9
20. – 40. minuta: Konfigurace Hunk pomocí konfiguračních souborů V této sekci je popsán postup konfigurace Hunku editací konfiguračních souborů. Soubor, který bude editován je
následující:
$SPLUNK_HOME/etc/system/local/indexes.conf
Krok 1 Nejprve musíme říci Hunku o Hadoop clusteru, kde leží data a jak s nimi komunikovat – v terminologii Hunku jde
o ERP (External Resource Provider). Následující stanza ukazuje příklad takové definice ERP v Hunku.
[provider:hadoop-dev01]
# this exact setting is required
vix.family = hadoop
# location of the Hadoop client libraries and Java
vix.env.HADOOP_HOME = /opt/hadoop/hadoop-dev01
vix.env.JAVA_HOME = /opt/java/latest/
# job tracker and default file system
vix.fs.default.name = hdfs://hadoop-dev01-
nn.splunk.com:8020
vix.mapred.job.tracker = hadoop-dev01-jt.splunk.com:8021
# uncomment this line if you're running Hadoop 2.0 with
MRv1
#vix.command.arg.3 = $SPLUNK_HOME/bin/jars/SplunkMR-
s6.0-h2.0.jar
vix.splunk.home.hdfs = /home/ledion/hunk
vix.splunk.setup.package = /opt/splunkbeta-6.0-171187-
Linux-x86_64.tgz
Většina z výše uvedených konfigurací je jednoduše vysvětlitelná, přesto se zastavme u některých řádků:
[stanza name]
Musí začínat „provider:“, aby Hunk poznal, že se jedná o ERP. Zbytek řetězce je pojmenování poskytovatele.
vix.splunk.home.hdfs
Cesta v HDFS (nebo v čemkoliv co je výchozím souborovým systémem), kterou využívá Hunk jako umístění
pracovního adresáře (scratch space).
vix.splunk.setup.package
Cesta v Hunk serveru, kde může Hunk nalézt balíček Linux x64_64, který bude vyexpedován a používán na
TaskTrackerech/Datových uzlech.

Hunk: analýza surových dat do 60 minut
10
Krok 2 Nyní je potřeba vydefinovat virtuální index, který obsahuje data, jež chceme analyzovat. V tomto případě je využito
dat z Apache access logu. Ta jsou rozdělená podle času, uložená v HDFS v adresářové struktuře, která může vypada
např. takto:
/home/ledion/data/weblogs/20130628/access.log.gz
/home/ledion/data/weblogs/20130627/access.log.gz
/home/ledion/data/weblogs/20130626/access.log.gz
...
A teď lze nakonfigurovat virtuální index (opět v souboru indexes.conf), který bude obsahovat následující data:
[hunk]
# name of the provider stanza we defined above
# without the "provider:" prefix
vix.provider = hadoop-dev01
# path to data that this virtual index encapsulates
vix.input.1.path = /home/ledion/data/weblogs/...
vix.input.1.accept = /access\.log\.gz$
vix.input.1.ignore = ^$
# (optional) time range extraction from paths
vix.input.1.et.regex = /home/ledion/data/weblogs/(\d+)
vix.input.1.et.format = yyyyMMdd
vix.input.1.et.offset = 0
vix.input.1.lt.regex = /home/ledion/data/weblogs/(\d+)
vix.input.1.lt.format = yyyyMMdd
vix.input.1.lt.offset = 86400
V souboru se nachází mnoho míst, která je dobré blíže vysvětlit:
vix.input1.path
Odkazuje na adresář ve výchozím souborovém systému (např. HDFS) poskytovatele. Tam se nalézají data
virtuálního indexu. POZN.: „...“ na konci cesty znamená, že Hunk rekurzivně přidá i obsah všech podadresářů.
vix.input.1.accept a vix.input.1.ignore
Umožňují specifikovat regulární výraz, který filtruje vstupní a výstupní soubory (na základě plné cesty), jež mají
nebo nemají být vnímané jako součást tohoto virtuálního indexu. Je potřeba podotknout že ignore má vyšší
prioritu, než accept. Obecným příkladem, kdy využít ignore, je např. u dočasných souborů nebo u souborů, do
kterých je právě zapisováno.
.et a .lt prvky
Je to koncept první třídy ze Splunku (Hunk je vlastně přizpůsobená aplikace Splunku nad Hadoopem). Data jsou
organizovaná v adresářové struktuře a využívá se rozdělování na základě data. .et a .lt říkají Hunku v rámci jaké
časové rozteče se vyhledávání v adresáři očekává. Vychází se z následující logiky: porovnává se regex vůči cestě,
spojí se všechny zachycené skupiny, interpretují v daném formátu a nakonec se přidá nebo odebere počet sekund
(offset) k výslednému času. Offset přijde vhod, pokud chcete rozšířit vyextrahovaný časový rámec – např. pokud

Hunk: analýza surových dat do 60 minut
11
několik minut daného dne končí v adresářích z předešlého nebo následujícího dne nebo dochází k rozdílům daným
časovými pásmy umístěného Hadoop serveru oproti Hunk serveru. Celá rutina časové extrakce se provádí dvakrát
za sebou, právě aby došlo k vymezení nejdřívějšího a nejpozdějšího času. Jakmile je časová extrakce
nakonfigurovaná, Hunk může přeskočit nebo ignorovat adresáře a soubory, které nespadají do odpovídajícího
časového rámce. V terminologii Hunku jde o průřez dělením na základě času (time based partition pruning).
Krok 3 Dále je potřeba Hunku sdělit, jak schematizovat data na základě časového vyhledávání. V tomto okamžiku
vkládáme změny do klasické konfigurace Splunku. Kromě toho budeme editovat další soubor, ze kterého na sebe
Hunk naváže schema.
$SPLUNK_HOME/etc/system/local/props.conf
[source::/home/ledion/data/weblogs/...]
priority = 100
sourcetype = access_combined
Tato stanza řekne Hunku, aby napojil sourcetype access_combined na všechna data v našem virtuálním indexu
(např. všechna data v adresáři /home/crm_team/data/weblogs/). Sourcetype access_combined je vydefinován v
$SPLUNK_HOME/etc/system/default/props.conf a říká, jak budou data z access logu zpracovávána (např. že každá
událost je na samostatném řádku, kde najde časové razítko a jak vyextrahuje ta správná pole ze surové události).
49. – 50. minuta: Analyzujte data z Hadoopu Nyní jsme připraveni začít s průzkumem a analýzou dat. Jednoduše provádíme vyhledávání nad virtuálním
indexem, jakoby to byl nativní index Splunku. Jako na následujícím příkladu.
1. Prozkoumejte surová data

Hunk: analýza surových dat do 60 minut
12
2. Zobrazte graf s pořadím stavových kódů v průběhu 30 dní s granularitou (bucketem) jednoho dne:
59. – in infinitum: Hunkujte