Embed Size (px)
Citation preview

Designing High Availability Networks, Systems, and Software
for the University Environment
Deke Kassabian and Shumon HuqueThe University of Pennsylvania
January 14, 2004

About Penn
The University of Pennsylvania was founded by Ben Franklin in 1751
Penn is part of the Ivy League Located in western Philadelphia Community of more than 30,000 people

General Goals Networked services available as expected
by our users Minimized time to repair (TTR) for when
outages do occur Ability to perform maintenance and
upgrades (planned downtime) non-disruptively
Cost effectiveness in meeting these goals

Definitions
Availability High Availability (HA) Rapid Recovery (RR) Disaster Recovery (DR) Basic Systems

Definitions
Disaster Recovery (DR) -The process of restoring a service to full operation after an interruption in service

Definitions
Basic System - a Basic System is a {Network, System, Service} with only the most basic of protections against outages
Examples: A network recoverable using spare parts A single computer system with RAID disk A service recoverable from tape backups

Definitions
Availability - the percentage of total time that a {Network, System, Service} is available for use
Related points: Advertised periods of availability Availability as advertised Absolute availability

Definitions
High Availability (HA) - a {Network, System, Service} with specific design elements intended to keep availability above a high threshold (eg, 99.99%)

Definitions
Rapid Recovery (RR) - a {Network, System, Service} with specific design elements intended to recover from downtime very quickly (eg, 15 minutes)

Metrics Economics of high availability (the
costs of non-available) Calculating availability How availability measurements are
performed

Economics of high availability What is the cost of an outage in your
Student Courseware systems and student record systems
Financial systems Primary campus web site and Email servers DNS, DHCP and AuthN systems Internet connection(s) Development / Gifts systems
How much should you be willing to spend to minimize downtime of any or all of these?

Calculating availability
Availability can be measured directly through periodic polling (eg, SNMP, Mon, Nagios)
A formula for predicting availability of a single component
MTBF(MTBF+TTR) 1 TTR
(MTBF+TTR)or

Design Principals Towards HA
Minimize points of catastrophic failure Maximize redundancy Minimize fault zones Minimize complexity and cost
Applying the above principles to Networks Systems Services

Specific examples at Penn High Availability Services Rapid Recovery Services

High Availability Design Strategies employed to achieve HA:
Server redundancy Hardware component redundancy Storage redundancy (RAID) Network redundancy Redundant power, A/C, cooling etc Application protocols that can transparently
failover to alternate servers Secondary offsite hosting (of some services like
DNS)

Rapid Recovery Design Strategies employed to achieve RR:
Standby servers and storage Some HA design elements:
Hardware redundancy, storage redundancy, network redundancy, power, A/C redundancy etc
Note: services deployed in the RR model typically don’t have an easy way to transparently failover to alternate servers (eg. E-mail, Web etc)

Network Aggregation Point Abbreviation: NAP Machine rooms in separate campus locations
that house critical network electronics and servers.
Good environmentals and extensive connectivity to campus fiber-optic cable plant
Both HA and RR services utilize multiple NAPs

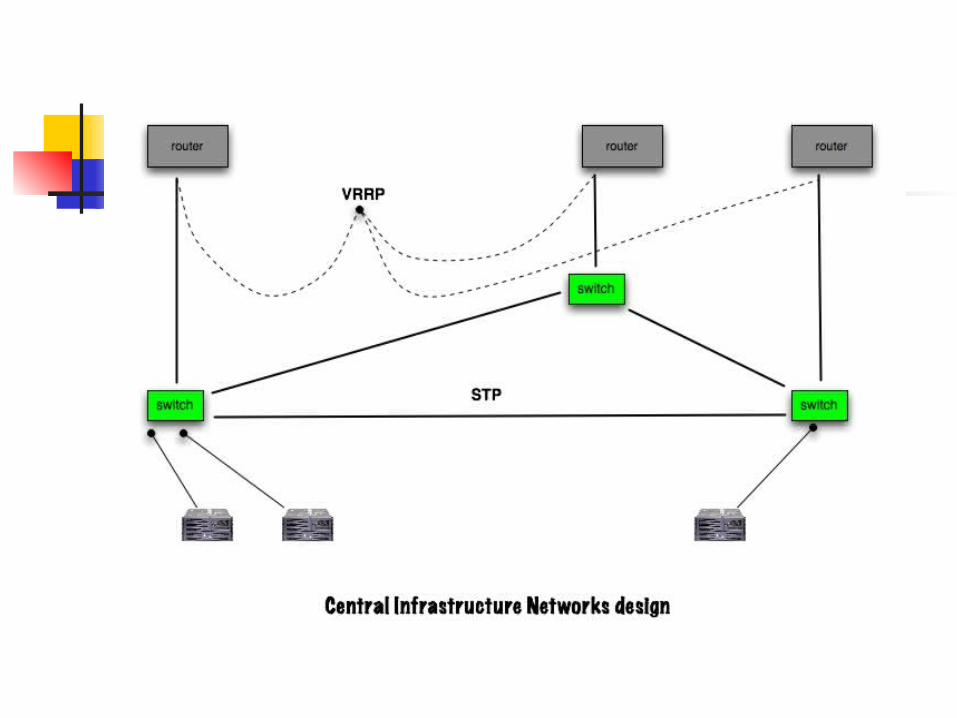
Central Infra. Networks AKA “NOC Networks” (historical name) 3 highly redundant IP networks that house systems
providing critical infrastructure services Each network is triply connected to campus routing
core via distinct NAP locations Network wiring traverses physically diverse fiber
conduit pathways Use of router redundancy protocols (VRRP) & Layer-
2 path redundancy (802.1D) for high availability

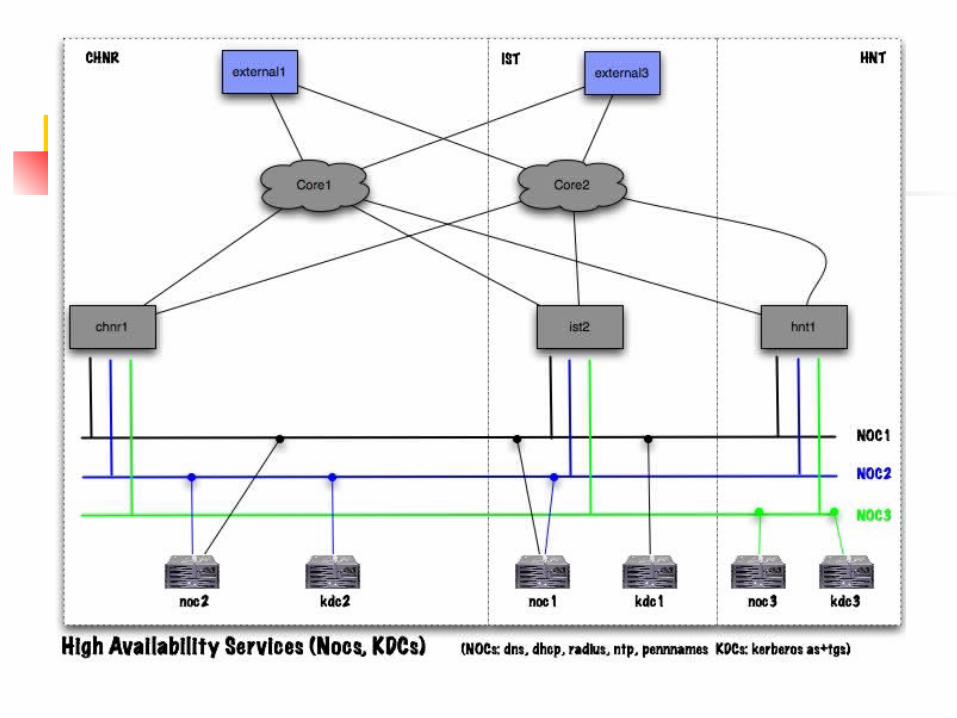
HA Server Platforms Two sets of three replicated servers
3 KDC servers: central authentication 3 NOC servers: everything else
Kerberos runs on separate systems mainly for security reasons.

High Availability: KDCs KDCs (3):
3 distinct machines (kdc1, kdc2, kdc3) Run only Kerberos AS and TGS Each located in a different campus machine room Each connected to a distinct IP network
Via a distinct IP core router Additionally each network is triply connected to the
campus routing core via 3 NAPs

High Availability: NOCs 3 “NOC” systems (a historical name)
Provide: DNS, DHCP, NTP, RADIUS plus a few homegrown services
Same physical and network connectivity as the KDCs
In addition: some servers have a secondary interface on a different NOC network (for reasons to be explained later)



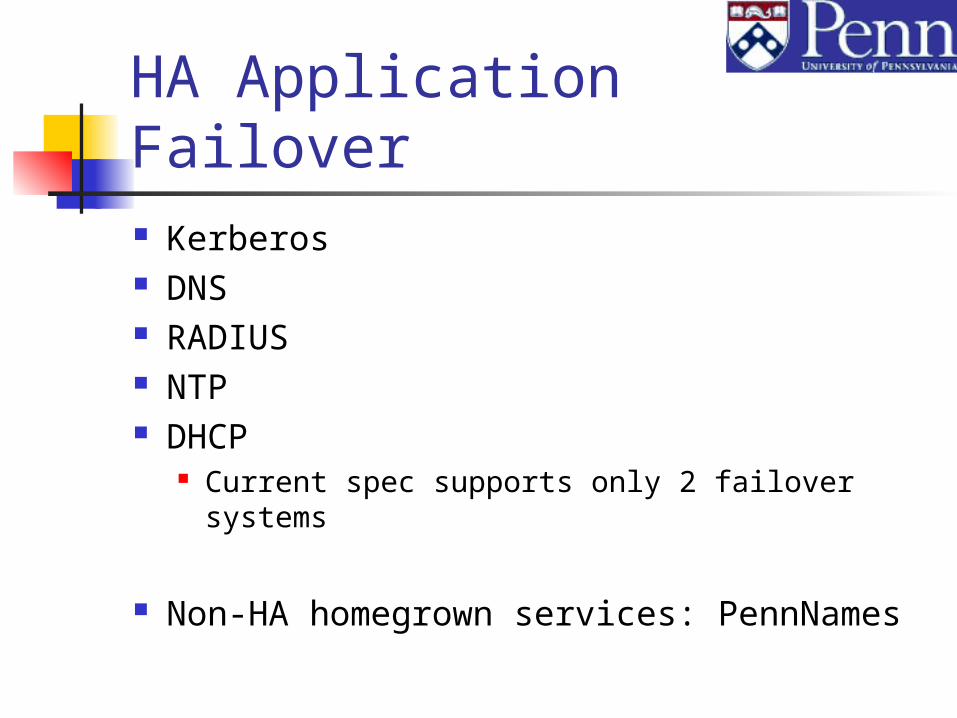
HA Application Failover Kerberos DNS RADIUS NTP DHCP
Current spec supports only 2 failover systems
Non-HA homegrown services: PennNames

Rapid Recovery service Example: E-mail and Web service A set of servers and storage is replicated at two sites: primary
and standby Primary site: active servers and storage Secondary site: standby servers and replicated storage Data from 1st site is synchronously replicated to 2nd Two separate fibrechannel networks interconnect systems and
storage at both sites Catastrophic failure event: system can be manually reconfigured
to use the standby servers and/or secondary storage ( ~ 30 minutes)
Servers are located on the HA primary infrastructure network


Experiences at Penn Where these approaches have been helpful
Higher availability, non-disruptive maintenance Where they have not
Complexity can be hard to manage! Where cost has been high
Replicated systems and networks, high-end storage solutions
Real availability experience DNS, a critical service, went from 99.0% to
99.999% availability!

Future Enhancements Making RR services highly available:
“clustering”, IETF rserpool etc Metropolitan area DR (or better) Rolling disaster protection Others:
IP Multipathing Trunking links to servers
802.3ad, SMLT, DMLT or similar Rapid Spanning Tree (IEEE 802.1w) Multi-master KADM service
Improved management and monitoring infrastructure

Feedback
Questions, comments Your designs, experiences, successes
Contact Info:[email protected]@isc.upenn.edu





























