Embed Size (px)
Citation preview

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Vlad Vlasceanu, Ganesh Subramaniam & Brandon Cuff
November 29, 2016
DAT309
How Fulfillment by Amazon (FBA) and Scopely
Improved Results and Reduced Costs
with a Serverless Architecture

What to Expect from the Session
• Overview of serverless architectures
• Serverless patterns in high performance data use cases
• Fulfillment by Amazon: Serverless stream processing
• Scopely: Serverless logging & hot key detection

What is a Serverless Architecture?
Build applications and services

What is a Serverless Architecture?
Build applications and services
… without managing infrastructure

What is a Serverless Architecture?
Build applications and services
… without managing infrastructure
• Function as a unit of scale
• Decrease complexity, abstracted
language runtime
• Run code when it’s needed
• Enable increased agility

Components of Serverless Architectures
AWS LambdaTrigger-based Lambda functions

Components of Serverless Architectures
AWS LambdaTrigger-based Lambda functions
Streaming DataAmazon Kinesis
Amazon DynamoDB Streams
APIsAmazon API Gateway
Event SourcesAmazon CloudWatch
Amazon S3
AWS Config
Amazon SNS
Data PersistenceAmazon DynamoDB
AWS Elasticsearch Service
Amazon S3
Integration PointsAmazon VPC resources
AWS service APIs
3rd party services

Data Enablement
• Data is always part of the architecture

Data Enablement
• Data is always part of the architecture
• Data as a trigger for serverless processing
• Data as the object of serverless processing
• Data as the result of serverless processing

Data Processing Abstraction
• Lambda functions as event handlers:
one function per event type
• Lambda functions as serverless back ends:
one function per API / path
• Lambda functions for stream/data processing
one function per record or data type
Helps maintainability - hard to end up with monolithic/spaghetti code

Active Role
• Processing data at scale
• Event-based invocation
• ETL orchestration
• On-demand processing
Advantages:
• Reduce operational complexities
• Operational cost optimization
Serverless High Performance Data Patterns
Support Role
• Optimization of pre-existing
workloads and database utilization
• Management, monitoring
• Improved anomaly detection and
reaction
Advantages:
• Improved resilience
• Operational cost optimization

Serverless High Performance Data Patterns
FBA Seller Inventory Authority
PlatformServerless Logging &
Hot Key Detection

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
FBA Seller
Inventory Authority PlatformAn Inventory Data Platform Using Serverless Architecture
Ganesh Subramaniam, Sr. Software Engineer, Amazon

How Does FBA Work?
1 Send
Inventory
2 Receive & Store
4 Pick, Pack & Ship
5 Customer Service
6 Customer Returns
Customer
Orders Product3


Data Platform Goals
• Single source of truth for seller’s inventory
• Reconciled view of inventory
• Surface and track discrepancies

Design Requirements
• Should handle high volume of input messages (> 10000 tps)
• Should handle hot keys in input messages
• E.g., Received inventory message for a very large shipment
• Should handle duplicate and out of order input messages
• Must maintain an audit trail for every inventory quantity
change

Seller Inventory Authority Platform
Inventory Transaction Service
Kinesis
AWS Lambda
Pre-receive
processor
Adjustment
processorTransaction
processor
Shipments Adjustment Inventory
transactions
Invento
ry Q
uery
Serv
ice
Warehouse
Management
Systems
Warehouse
Management
Systems
DDB Streams A/C balance
Processor
DDB Streams
Archivers Kinesis Firehose
S3
Account
Balances
Redshift
Analytics
Inbound
RecordsPublisher Amazon
Elasticsearch
Archivers
Kinesis Firehose
SNS Topics
Clients
ClientsInventory Events/
Notifications

Launch Results
• 22 dev weeks savings in operational costs across 11
fleets
• Design to launch < 4 months
• Improved the accuracy of inbound quantities between
5% to 10%
• Reduced cost of business operations (for example,
seller contacts)
• Developers in the team enjoyed using AWS managed
services

Best Practices that helped
• Container reuse
• Instrument, measure and monitor
• Abstract Launch scaffolding from entity processing
• Canary and Dashboards

Best Practices that helped
• Container reuse
• Instrument, measure and monitor
• Abstract Launch scaffolding from entity processing
• Canary and Dashboards

Metrics and Instrumentation
if (adjustmentManager.doesAdjustmentAlreadyExist(metrics, adjustment)) {// this adjustment already exists in our store. Nothing further needs to be done.metrics.addCount(METRIC_IDEMPOTENT_CHECK_FAILED, 1, Unit.ONE);log.debug("Adjustment already exists in DB. " + adjustment);return null;
}metrics.addCount(adjustment.getType().name(), 1, Unit.ONE);metrics.addCount(String.join("#", adjustment.getSource().name(),
adjustment.getType().name()), 1, Unit.ONE);
To mitigate the lack of debug/tracing capabilities with Lambda, we
placed significant emphasis in instrumenting our code to help
understand how the code was performing during runtime.

Best Practices that helped
• Container reuse
• Instrument, measure and monitor
• Abstract Launch scaffolding from entity processing
• Canary and Dashboards

LambdaLaunchHelper
Invokes the appropriate event handler with the metrics instance and the
input
Event Handler is responsible for the deserialization of the items in the
request payload and invokes the Entity processor with the metrics instance
and the deserialized entity.
Common error/fault handling – writing to S3 and skipping the individual
entity at fault or fail the entire batch.
Common metrics• Batch Size
• Total Time to process the batch
• Time to process an individual entity
• Entity Count in the batch
• Fault Count

Best Practices that helped
• Container reuse
• Instrument, measure and monitor
• Abstract Launch scaffolding from entity processing
• Canary and Dashboards

Canary and Availability of Pipeline
• Regular submission of synthetic transactions and events
to the pipeline to monitor the health of the pipeline.
• Use different keys to ensure that we monitor the various
shards at random
• Also helps us monitor to ensure we are within SLA for end to
end processing time
• Use Kinesis shard-level metrics to identify any potential
backlog or issues in the stream processing pipeline.

Dashboard and Monitoring
Average Transaction Processing Time Oldest Transaction Age Canary Processing Time

© 2016, Amazon Web Services, Inc. or its Affiliates. All rights reserved.
Brandon Cuff, Sr. Software Engineer, Scopely
Serverless Logging &
Hot Key Detection

Scopely’s Mobile Games
6+ million daily active users
1 million requests per minute
100+ API servers (c3.2xlarge)

Scopely’s Game Server Architecture

Amazon DynamoDB Partitioning

Our Hot Key Problem
What are hot keys?
• Heavily requested keys/objects
localized on a single
partition/shard/node
• Subject to capacity of that single
partition/shard/node
Amazon DynamoDB table
symptoms:
• Total consumed capacity is less
than provisioned capacity
• And experiencing throttle events

Our Hot Key Detection Process
Application uses Count Min Sketch to track top 10 keys then logs them
periodically (once per minute)
Count Min Sketch
• Probabilistic algorithm
• Fixed size of memory to track unlimited operations
• Small chance of a error
memcached-get-count topkey[1]: key=3.user.41401542 count=354 totalCount=68912 frequency=.00514

Architecture Overview

Hot Key Event
Lambda will take our log message and convert it into an Elasticsearch
document
memcached-get-count topkey[1]: key=3.user.41401542 count=354 totalCount=68912 frequency=.00514
{
...
"topkey_category": "memcached-get-count",
"topkey_key": "3.user.41401542",
"topkey_count": 354,
"topkey_totalCount": 68912,
"topkey_frequency": .00514
}
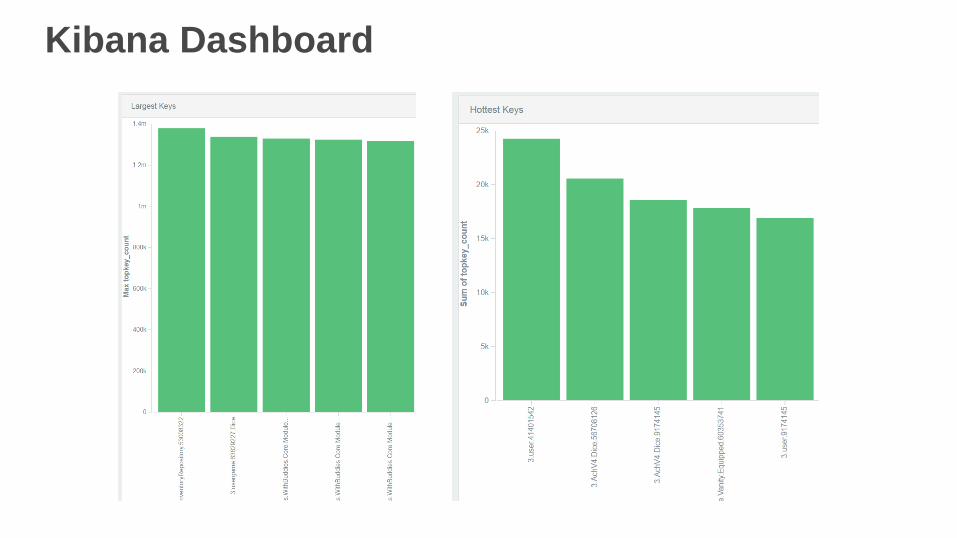
Kibana Dashboard

Results & Lessons Learned

We Had More Bugs Than We Thought We Did!
Special case user ids
Key: “user.-1”
Configuration objects with a single
key retrieved on every request
Key: “dice-game-settings”
Didn’t notice because it wasn’t
causing problems (yet...).
ElastiCache Memcached Nodes
One node is sending out much more
data than the rest

Large Keys Are Also a Problem
We can look for unusually large keys if we increment by the size of objects
rather than 1
You can get the total bandwidth consumed by a specific key by summing the
events over a time period.
memcached-get-count topkey[1]: key=3.Dice.inv.21645428 size=20354 totalCount=1008912 frequency=.0203

We Caught Some Bots and Spammers
Initially shut bad users down
by deleting accounts.
Later implemented per-user
request rate limiting via
Memcached counters

Discovered Poor Client Behavior
• Hot keys were discovered on
several users
• Filtering by client platform revealed
that they were all from Android
• Android client made a request for
every game in the game list which
was huge for some small number
of users (making their user ids hot
keys)

Thank you!

Remember to complete
your evaluations!

Related Sessions
ARC402 - Serverless Architectural Patterns and Best Practices- Drew Dennis & Maitreya Ranganath, AWS Solutions Architects; Ajoy Kumar, Architect,
BMC Software
DAT304 - Deep Dive on Amazon DynamoDB- Rick Houlihan, AWS Principal TPM, DBS NoSQL
DAT306 – ElastiCache Deep Dive: Best Practices and Usage Patterns
- Michael Labib, AWS In-Memory NoSQL Solutions Architect; Brian Kaiser, CTO, Hudl






























