Embed Size (px)
Citation preview

이어서시작하면서
•알파고해부하기 1부에서이어지는게시물입니다• 예상독자층은알파고의원리를정확히알고싶어하는분들
• 프로그래밍, 딥러닝, 머신러닝연구자분들포함입니다
• “프로그래머를위한알파고”로생각해주세요..
•내용이어렵다면 “쉬운” 알파고게시물도있어요1. 모두의알파고
2. 바둑인들을위한알파고
3/16/2016 알파고해부하기 2부 © 이동헌 2

당부말씀
•정확성을최우선가치로씁니다• 정확하지않은내용을찾으시면꼭! 피드백부탁드립니다
• 내용의한부분만뚝잘라서인용하시면위험합니다• 정확한내용들이보통그렇듯이, 부분을잘라내면뜻이달라질수있어요
3/16/2016 알파고해부하기 2부 © 이동헌 3

1부까지의진행상황
•알파고의구조
•알파고소프트웨어의구성• 알파고 S/W 구성: Deep Learning 유관부분
• 바둑판인식프로그램
•알파고 S/W의대국시동작법
•알파고 S/W의대국전트레이닝법
•알파고 S/W의혁신점
•알파고의혁신점
3/16/2016 알파고해부하기 2부 © 이동헌 4

목차
•알파고의구조
•알파고소프트웨어의구성• 알파고 S/W 구성: Deep Learning 유관부분
• 알파고 S/W 구성: Reinforcement Learning 유관부분
• 알파고 S/W 구성: Monte-Carlo Tree Search 유관부분
•알파고 S/W의대국시동작법
•알파고 S/W의대국전트레이닝법
•알파고 S/W의혁신점
•알파고의혁신점
3/16/2016 알파고해부하기 2부 © 이동헌 5

알파고 S/W 구성: Deep Learning
•먼저가능한모든바둑판공간을정의합니다• 바둑판을 19x19 행렬로봅시다
• 자연스러운생각이라면, 행렬에넣을수있는원소는 {흑, 백, 빈칸}중하나
• 하지만컴퓨터는 0/1로보는게제일좋습니다
• 그래서위의상황을• “흑돌” 바둑판 19x19 행렬 (0이면흑돌이없고, 1이면놓인)
• “백돌” 바둑판 19x19 행렬 (0이면백돌이없고, 1이면놓인)
• “빈칸” 바둑판 19x19 행렬 (0이면뭔가돌이있고, 1이면빈칸인)
• 이렇게 3개층을쌓은 19x19x3 텐서로만듭니다• (텐서는개념상 2차원이상의행렬로생각하면됩니다)
3/16/2016 알파고해부하기 2부 © 이동헌 6

알파고 S/W 구성: Deep Learning
•여기에추가로 feature를집어넣습니다• 기존흑/백/빈칸에추가로
• 19x19 행렬원소별로, 주어진칸에
3/16/2016 알파고해부하기 2부 © 이동헌 7

알파고 S/W 구성: Deep Learning
•여기에추가로 feature를집어넣습니다• 기존흑/백/빈칸에추가로
• 19x19 행렬원소별로, 주어진칸에• 그냥상수 1 (“그칸고유의특성”을모델링)
• 돌이있다면, 몇수전에놓였는지 (최소 1, 최대 8) (길이8의 binary array)
• 연결된말의현재활로가몇개인지 (최소 1, 최대 8)
• 상대가돌을놓는다면내가잃을돌의수 (최소 1, 최대 8)
• 내가돌을놓는다면그돌에연결된말의활로가몇개가될지 (최소 1, 최대 8)
• 내가돌을놓는다면, 내가축을만드는데성공할지
• 내가돌을놓는다면, 내가축을탈출하는데성공할지
• 돌을놓는것이바둑의규칙에어긋나는지
• 내가흑돌인지백돌인지 (이건 Value Network (판세분석) 에만쓰입니다)(알파고논문에나온 Extended Data Table 2 참조)
3/16/2016 알파고해부하기 2부 © 이동헌 8

알파고 S/W 구성: Deep Learning
•여기에추가로 feature를집어넣습니다• 기존흑/백/빈칸에추가로
• 19x19 행렬원소별로, 주어진칸에• 이것저것, 도합 48개의 binary input
• 바둑판각칸별로길이 48의 binary array로구성된 feature가됩니다• (Policy Network는 48, Value Network는 49)
• 바둑판이 19x19 행렬이니,
• 이렇게만들어진 Deep Learning input은 19x19x48 텐서.• Value Network는 19x19x49
3/16/2016 알파고해부하기 2부 © 이동헌 9

알파고 S/W 구성: Deep Learning
• Input 텐서• Policy Network (다음수예측) 용도와 Value Network (판세예측) 용도에따라 feature가조금다릅니다
3/16/2016 알파고해부하기 2부 © 이동헌 10

알파고 S/W 구성: Deep Learning
• Input 텐서• Policy Network (다음수예측) 용도와 Value Network (판세예측) 용도에따라 feature가조금다릅니다
• Output• 당연히 Policy Network와 Value Network가다릅니다
• Policy Network의경우, 𝑃(𝑎|𝑠)• “바둑판 s가주어질때, 다음착수가 a일확률값”
• Value Network의경우, 𝐸 𝑧𝑡 𝑠𝑡 = 𝑠, 𝑎𝑡…𝑇~𝑝]• “바둑판 s가주어질때, 바둑기사양쪽모두착수전략 p를따라대국종료까지두었을때, 게임기대값 (z가 -1(패)이나 1(승)이므로, 0이면 50:50 비등비등상황임”
3/16/2016 알파고해부하기 2부 © 이동헌 11

알파고 S/W 구성: Deep Learning
•각모듈별내부구조를설명하기전에…
•지금까지설명한부분을요약한다면• Policy Network (다음수예측)과 Value Network (판세예측) 양쪽에공통인
• “바둑판상황인식” 프로그램
• 에해당하는 Deep Learning 부분입니다. Input 부분을중점으로다뤘지요.
3/16/2016 알파고해부하기 2부 © 이동헌 12

알파고 S/W 구성: Deep Learning
•각모듈별내부구조를설명하기전에…
•지금까지설명한부분을요약한다면• Policy Network (다음수예측)과 Value Network (판세예측) 양쪽에공통인
• “바둑판상황인식” 프로그램
• 에해당하는 Deep Learning 부분입니다. Input 부분을중점으로다뤘지요.
•이제부터• Policy Network
• Value Network
양쪽에사용된 CNN (Convolutional Neural Network) 구조를설명합니다
3/16/2016 알파고해부하기 2부 © 이동헌 13

알파고소프트웨어의구성
• Policy Network
• Deep Learning과
• Reinforcement Learning의
• 적절한만남!
알파고바둑프로그램
바둑판미래예측시도
여러번미래예측후가장많이둔수로선택RL
MCTS RL
MCTS
RL
바둑판현상황인식프로그램DL
3/16/2016 알파고해부하기 2부 © 이동헌 14
바둑경기상황
유/불리분석
프로그램
DL RL
상대바둑기사다음수
예측프로그램
알파고의다음수
결정프로그램
DL DLRL RL

알파고 S/W 구성: “Policy Network”
• Policy Network: 19x19행렬의 48층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution
• 하기위해서, 상하좌우언저리로 0으로채워진 2행 2열씩추가
• 23x23 행렬로만들어서 2D convolution
• ReLU 유닛사용
3/16/2016 알파고해부하기 2부 © 이동헌 15

알파고 S/W 구성: “Policy Network”
• Policy Network: 19x19행렬의 48층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution
• 하기위해서, 상하좌우언저리로 0으로채워진 2행 2열씩추가
• 23x23 행렬로만들어서 2D convolution
• ReLU 유닛사용
• 제 2~12층은 3x3 filter 192종으로, stride 1로 convolution• 하기위해서, 상하좌우언저리로 0으로채워진 1행 1열씩추가
• 21x21 행렬로만들어서 2D convolution
• ReLU 유닛사용
3/16/2016 알파고해부하기 2부 © 이동헌 16

알파고 S/W 구성: “Policy Network”
• Policy Network: 19x19행렬의 48층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution
• 하기위해서, 상하좌우언저리로 0으로채워진 2행 2열씩추가
• 23x23 행렬로만들어서 2D convolution
• ReLU 유닛사용
• 제 2~12층은 3x3 filter 192종으로, stride 1로 convolution• 하기위해서, 상하좌우언저리로 0으로채워진 1행 1열씩추가
• 21x21 행렬로만들어서 2D convolution
• ReLU 유닛사용
• 제 13층은특별한필터없이 1:1 대응으로• 각위치별 bias를다르게해서
• Softmax 유닛사용
3/16/2016 알파고해부하기 2부 © 이동헌 17

알파고 S/W 구성: “Policy Network”
• Policy Network: 19x19행렬의 48층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~12층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 13층은특별한필터없이 1:1대응 softmax
•위구조를선택한 (이론적) 이유를헤아려보려면?• 기본적으로 Convolutional Neural Network (CNN) 공부필요
• CNN 설명자료는인터넷에많습니다
3/16/2016 알파고해부하기 2부 © 이동헌 18

알파고 S/W 구성: “Policy Network”
• Policy Network: 19x19행렬의 48층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~12층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 13층은특별한필터없이 1:1대응 softmax
• ReLU를사용하는이유?• 이론적: Vanishing gradient 문제가없음
• 종전 neural net에자주쓰이던 sigmoid 계열함수의경우이문제가있지요
• 실험적: Deep network에서실험적효과좋음 (효율성측면)• 실제로잘된다고보고된바가많다니선택의근거로인정합니다..
3/16/2016 알파고해부하기 2부 © 이동헌 19

• Policy Network: 19x19행렬의 48층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~12층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 13층은특별한필터없이 1:1대응 softmax
•근데왜뜬금없는 softmax 함수
• State의가치값Q으로 a를결정하는방법중하나: softmax함수사용• 참고문헌: Humprey 1999. 박사논문 [바로가기] 25페이지
• Policy Network output이 𝑃(𝑎|𝑠)이므로이것에맞춘형태• “바둑판 s가주어질때, 다음착수가 a일확률값”
• Reinforcement Learning의영향
알파고 S/W 구성: “Policy Network”
3/16/2016 알파고해부하기 2부 © 이동헌 20

알파고소프트웨어의구성
• Value Network
• Deep Learning과
• Reinforcement Learning을
• 살짝다르게접합
알파고바둑프로그램
상대바둑기사다음수
예측프로그램
알파고의다음수
결정프로그램
바둑판미래예측시도
여러번미래예측후가장많이둔수로선택
DL DLRL RL
RL
MCTS RL
MCTS
RL
바둑판현상황인식프로그램DL
3/16/2016 알파고해부하기 2부 © 이동헌 21
바둑경기상황
유/불리분석
프로그램
DL RL

알파고 S/W 구성: “Value Network”
• Value Network: 19x19행렬의 49층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~11층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
3/16/2016 알파고해부하기 2부 © 이동헌 22
이부분은 Policy Network와동일구조사용

알파고 S/W 구성: “Value Network”
• Value Network: 19x19행렬의 49층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~11층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 12층은 “additional convolution layer” (추가정보없음..)
• 제 13층은특별한필터없이 1:1대응 (사용된 function정보없음)
3/16/2016 알파고해부하기 2부 © 이동헌 23
논문이제대로설명해주지않는부분..

알파고 S/W 구성: “Value Network”
• Value Network: 19x19행렬의 49층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~11층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 12층은 “additional convolution layer” (추가정보없음..)
• 제 13층은특별한필터없이 1:1대응 (사용된 function정보없음)
• 제 14층은 256개의 ReLU유닛, fully connected linear
• Output은 1개의 tanh유닛, fully connected linear
3/16/2016 알파고해부하기 2부 © 이동헌 24
Value Network에Deep Learning 적용하기위해
특화한구조부분

알파고 S/W 구성: “Value Network”
• Value Network: 19x19행렬의 49층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~11층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 12층은 “additional convolution layer” (추가정보없음..)
• 제 13층은특별한필터없이 1:1대응 (사용된 function정보없음)
• 제 14층은 256개의 ReLU유닛, fully connected linear
• Output은 1개의 tanh유닛, fully connected linear
3/16/2016 알파고해부하기 2부 © 이동헌 25

알파고 S/W 구성: “Value Network”
• Value Network: 19x19행렬의 49층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~11층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 12층은 “additional convolution layer” (추가정보없음..)
• 제 13층은특별한필터없이 1:1대응 (사용된 function정보없음)
• 제 14층은 256개의 ReLU유닛, fully connected linear
• Output은 1개의 tanh유닛, fully connected linear
• 엄청난최적화공밀레의현장을발굴하고있습니다!!• 여담이지만.. 엔지니어분들의노고는최종산출물만으로계산하면안될일입니다
• 딥러닝사용자및연구자분들(회사/대학원불문)의몸/마음고생좀덜어주세요…
3/16/2016 알파고해부하기 2부 © 이동헌 26

• Value Network: 19x19행렬의 49층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~11층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 12층은 “additional convolution layer” (추가정보없음..)
• 제 13층은특별한필터없이 1:1대응 (사용된 function정보없음)
• 제 14층은 256개의 ReLU유닛, fully connected linear
• Output은 1개의 tanh유닛, fully connected linear
알파고 S/W 구성: “Value Network”
3/16/2016 알파고해부하기 2부 © 이동헌 27

• Value Network: 19x19행렬의 49층짜리 input을…• 제 1층은 5x5 filter 192종으로, stride 1로 convolution후 ReLU
• 제 2~11층은 3x3 filter 192종으로, stride 1로 convolution후 ReLU
• 제 12층은 “additional convolution layer” (추가정보없음..)
• 제 13층은특별한필터없이 1:1대응 (사용된 function정보없음)
• 제 14층은 256개의 ReLU유닛, fully connected linear
• Output은 1개의 tanh유닛, fully connected linear
• Value Network에맞춰주기위한선택: 1개의 tanh 유닛
• Value Network의경우, 𝐸 𝑧𝑡 𝑠𝑡 = 𝑠, 𝑎𝑡…𝑇~𝑝]• “바둑판 s가주어질때, 바둑기사양쪽모두착수전략 p를따라대국종료까지두었을때, 게임기대값 (z가 -1(패)이나 1(승)이므로, 0이면 50:50 비등비등상황임”
알파고 S/W 구성: “Value Network”
3/16/2016 알파고해부하기 2부 © 이동헌 28

알파고 S/W 구성: DL, Policy Net, Value Net
•요약합니다
• Deep Learning (DL) 적용부• 핵심적용부분
• 바둑판상황인식모듈
• 양쪽에모듈로사용• Policy Network
• 알파고다음수결정
• 바둑기사다음수결정
• Value Network
• 바둑판세파악
알파고바둑프로그램
바둑판미래예측시도
여러번미래예측후가장많이둔수로선택RL
MCTS RL
MCTS
RL
3/16/2016 알파고해부하기 2부 © 이동헌 29
상대바둑기사다음수
예측프로그램
알파고의다음수
결정프로그램
DL DLRL RL
바둑경기상황
유/불리분석
프로그램
DL RL
바둑판현상황인식프로그램DL

목차
•알파고의구조
•알파고소프트웨어의구성• 알파고 S/W 구성: Deep Learning 유관부분
• 알파고 S/W 구성: Reinforcement Learning 유관부분
• 알파고 S/W 구성: Monte-Carlo Tree Search 유관부분
•알파고 S/W의대국시동작법
•알파고 S/W의대국전트레이닝법
•알파고 S/W의혁신점
•알파고의혁신점
3/16/2016 알파고해부하기 2부 © 이동헌 30

알파고 S/W 구성: Reinforcement Learning
• Reinforcement Learning (RL)?• 전반적으로고루적용되어적용부하나하나나누기가힘듭니다
•지금까지나온 RL 적용부• DL을전체틀에접합하는이론적근거/토대• (나름) 합리적인접합법제시
• RL 적용부는계속됩니다• 나올때마다설명예정
알파고바둑프로그램
바둑판미래예측시도
여러번미래예측후가장많이둔수로선택RL
MCTS RL
MCTS
RL
3/16/2016 알파고해부하기 2부 © 이동헌 31
상대바둑기사다음수
예측프로그램
알파고의다음수
결정프로그램
DL DLRL RL
바둑경기상황
유/불리분석
프로그램
DL RL
바둑판현상황인식프로그램DL

알파고소프트웨어의구성
•다음차례: MCTS 적용부• 핵심: 바둑판미래예측
• 여기에도 RL 포함
알파고바둑프로그램
RL
3/16/2016 알파고해부하기 2부 © 이동헌 32
상대바둑기사다음수
예측프로그램
알파고의다음수
결정프로그램
DL DLRL RL
바둑경기상황
유/불리분석
프로그램
DL RL
바둑판현상황인식프로그램DL
바둑판미래예측시도
MCTS RL
여러번미래예측후가장많이둔수로선택RLMCTS

목차
•알파고의구조
•알파고소프트웨어의구성• 알파고 S/W 구성: Deep Learning 유관부분
• 알파고 S/W 구성: Reinforcement Learning 유관부분
• 알파고 S/W 구성: Monte-Carlo Tree Search 유관부분
•알파고 S/W의대국시동작법
•알파고 S/W의대국전트레이닝법
•알파고 S/W의혁신점
•알파고의혁신점
3/16/2016 알파고해부하기 2부 © 이동헌 33
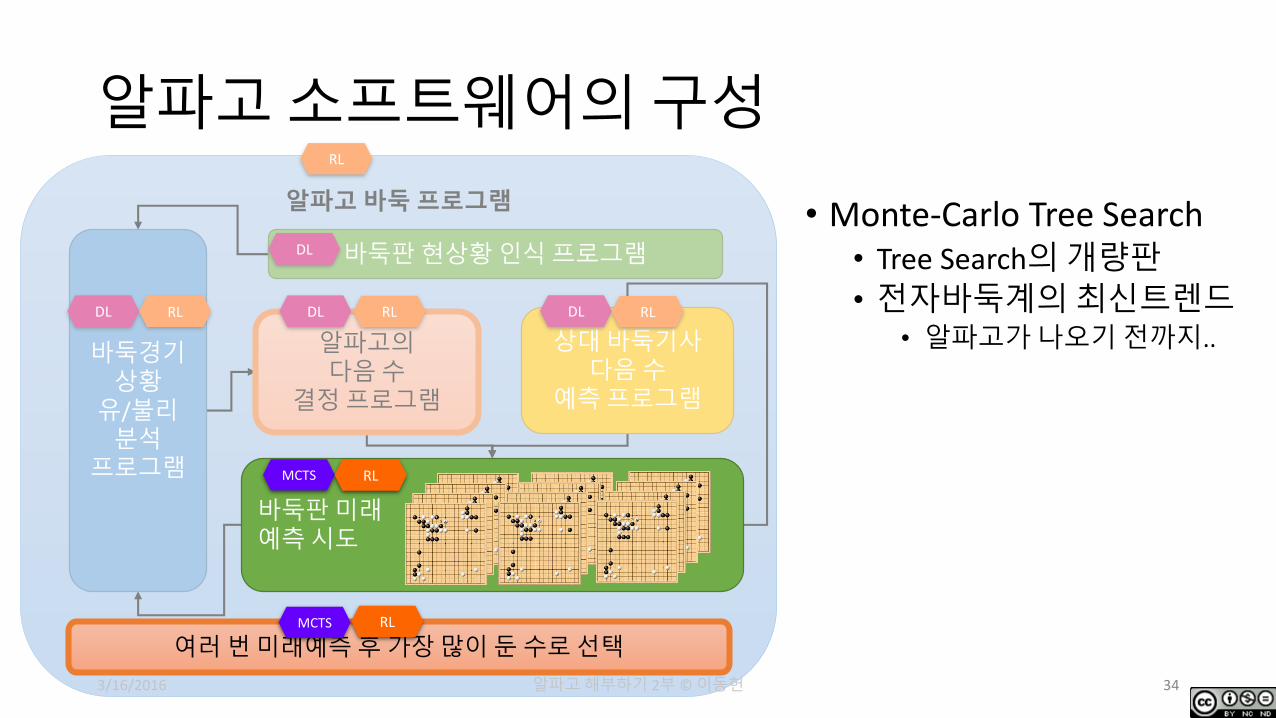
알파고소프트웨어의구성
• Monte-Carlo Tree Search• Tree Search의개량판
• 전자바둑계의최신트렌드• 알파고가나오기전까지..
알파고바둑프로그램
RL
3/16/2016 알파고해부하기 2부 © 이동헌 34
상대바둑기사다음수
예측프로그램
알파고의다음수
결정프로그램
DL DLRL RL
바둑경기상황
유/불리분석
프로그램
DL RL
바둑판현상황인식프로그램DL
바둑판미래예측시도
MCTS RL
여러번미래예측후가장많이둔수로선택RLMCTS

알파고 S/W 구성: MCTS
•게임전략에서의 Tree Search를말하자면• 그냥가능한것다해보고제일좋은걸골라보자는겁니다
• 말이쉽지..너무너무가짓수가많아서컴퓨터로도도저히불가능한게있습니다• 이것의대표적인예가바둑입니다
• 한수한수놓을수있는게너무갯수가많은데, 게임끝까지모든가능한기보숫자는…
• “경우의수가우주의원자수보다많다” 이런말이여기서나옵니다
3/16/2016 알파고해부하기 2부 © 이동헌 35

알파고 S/W 구성: MCTS
•게임전략에서의 Tree Search를말하자면• 그냥가능한것다해보고제일좋은걸골라보자는겁니다
• 말이쉽지..너무너무가짓수가많아서컴퓨터로도도저히불가능한게있습니다• 이것의대표적인예가바둑입니다
• 한수한수놓을수있는게너무갯수가많은데, 게임끝까지모든가능한기보숫자는…
• “경우의수가우주의원자수보다많다” 이런말이여기서나옵니다
•그러면, 다해보기보단, “쓸만한것부터” 해보자• “쓸만한것 …” + “… 부터해보자”: 이두부분이MCTS의핵심입니다
• Monte-Carlo Tree Search에대한구체적설명은이미많이되어있습니다• MCTS 이론설명은다른분들이수고하신자료에맡기고
• 바로알파고해부를하면서, 이론은그때그때필요한만큼만설명하겠습니다
3/16/2016 알파고해부하기 2부 © 이동헌 36

알파고 S/W 구성: MCTS
•쓸만한것 “부터해보자”
•모든걸닥치고다해보는게하는게불가능하니• 조금만해서많이알수없을까?
• 무엇부터해보는게좋을까?• 흔히들알고있는 Alpha-beta pruning은 “해도안될건하지말자” 개량입니다
3/16/2016 알파고해부하기 2부 © 이동헌 37

알파고 S/W 구성: MCTS
•쓸만한것 “부터해보자”
•모든걸닥치고다해보는게하는게불가능하니• 조금만해서많이알수없을까?
• 무엇부터해보는게좋을까?• 흔히들알고있는 Alpha-beta pruning은 “해도안될건하지말자” 개량입니다
• 이렇게하다보면, 언젠가는정답이나올까?• 이런이론적근거가있으면더해볼만하겠죠?
• 하지만이이야기는조금뒤로미뤄두고
• 일단 Tree Search에서당장뭘해볼지고르는부분부터봅시다.
3/16/2016 알파고해부하기 2부 © 이동헌 38

알파고 S/W 구성: MCTS
•알파고의바둑게임 Search Tree 구성• 바둑판의구성 s, 다음둘수 a 를동시에고려해서
• 첫차례라면, • 바둑판구성 s는앞에서설명했듯이 19x19x48 텐서 (binary). 모두빈칸셋팅.
• 다음수는어디든둘수있으니 19x19 가지의 a 중하나
3/16/2016 알파고해부하기 2부 © 이동헌 39

알파고 S/W 구성: MCTS
•알파고의바둑게임 Search Tree 구성• 바둑판의구성 s, 다음둘수 a 를동시에고려해서
• 첫차례라면, • 바둑판구성 s는앞에서설명했듯이 19x19x48 텐서 (binary). 모두빈칸셋팅.
• 다음수는어디든둘수있으니 19x19 가지의 a 중하나
• (s,a)를정합니다• 첫차례라면 s는정해져있고, 19x19가지의 a가있으니, 19x19가지의 (s,a)입니다
3/16/2016 알파고해부하기 2부 © 이동헌 40

알파고 S/W 구성: MCTS
•알파고의바둑게임 Search Tree 구성• 바둑판의구성 s, 다음둘수 a 를동시에고려해서
• 첫차례라면, • 바둑판구성 s는앞에서설명했듯이 19x19x48 텐서 (binary). 모두빈칸셋팅.
• 다음수는어디든둘수있으니 19x19 가지의 a 중하나
• (s,a)를정합니다• 첫차례라면 s는정해져있고, 19x19가지의 a가있으니, 19x19가지의 (s,a)입니다
• 각각의 (s,a)에대해서다음값들이저장되어있습니다• 𝑃 𝑠, 𝑎
• 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎
• 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎
• 𝑄 𝑠, 𝑎
3/16/2016 알파고해부하기 2부 © 이동헌 41

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된값설명• 𝑃 𝑠, 𝑎
• 착수 a를해보지않고도, 미리선험적으로알고있는값. (당연히튜닝값입니다)
• 저아래에있는 𝑄 𝑠, 𝑎 와단위가같습니다• (물리문제풀때의그 m/s 맞추는개념의그단위)
• 저 𝑄 𝑠, 𝑎 값과균형을맞추는역할을나중에담당합니다
• 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎
• 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎
• 𝑄 𝑠, 𝑎
3/16/2016 알파고해부하기 2부 © 이동헌 42

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된값설명• 𝑃 𝑠, 𝑎
• 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎• 착수 a를한다고결정한Monte-Carlo 시뮬레이션횟수
• v가달린것은판세분석경로가된횟수, r이달린것은미래예측경로가된횟수
• 이부분의자세한내용은추후알파고의대국시작동원리부분에서다루어집니다
• 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎
• 𝑄 𝑠, 𝑎
3/16/2016 알파고해부하기 2부 © 이동헌 43

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된값설명• 𝑃 𝑠, 𝑎
• 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎
• 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎• 착수 a를한다고하고, Monte-Carlo 시뮬레이션한결과나온승리/패배횟수의합
• v가달린것은판세분석경로에서나온누적합, r이달린것은미래예측경로쪽누적합.
• 이부분의자세한내용은추후알파고의대국시작동원리부분에서다루어집니다
• 𝑄 𝑠, 𝑎
3/16/2016 알파고해부하기 2부 © 이동헌 44

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된값설명• 𝑃 𝑠, 𝑎
• 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎
• 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎
• 𝑄 𝑠, 𝑎• 이값의의미를어렵게적으면 (알파고논문에이렇게적어놨죠) 다음과같습니다
𝑄 𝑠, 𝑎 = 1 − 𝜆𝑊𝑣(𝑠, 𝑎)
𝑁𝑣(𝑠, 𝑎)+ 𝜆
𝑊𝑟(𝑠, 𝑎)
𝑁𝑟(𝑠, 𝑎)
• 알파고논문에서 “𝜆 = 0.5를쓰니제일성능이좋아서이걸로쓰겠다”고합니다
3/16/2016 알파고해부하기 2부 © 이동헌 45

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된값설명• 𝑃 𝑠, 𝑎
• 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎
• 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎
• 𝑄 𝑠, 𝑎• 이값의의미를어렵게적으면 (알파고논문에이렇게적어놨죠) 다음과같습니다
𝑄 𝑠, 𝑎 = 1 − 𝜆𝑊𝑣(𝑠, 𝑎)
𝑁𝑣(𝑠, 𝑎)+ 𝜆
𝑊𝑟(𝑠, 𝑎)
𝑁𝑟(𝑠, 𝑎)
• 알파고논문에서 “𝜆 = 0.5를쓰니제일성능이좋아서이걸로쓰겠다”고합니다
• 쉽게말해, 판세분석과미래예측두모듈의승/패시뮬레이션확률의 1:1 선형합
3/16/2016 알파고해부하기 2부 © 이동헌 46

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된값설명• 𝑃 𝑠, 𝑎
• 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎
• 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎
• 𝑄 𝑠, 𝑎• 이값의의미를어렵게적으면 (알파고논문에이렇게적어놨죠) 다음과같습니다
𝑄 𝑠, 𝑎 = 1 − 𝜆𝑊𝑣(𝑠, 𝑎)
𝑁𝑣(𝑠, 𝑎)+ 𝜆
𝑊𝑟(𝑠, 𝑎)
𝑁𝑟(𝑠, 𝑎)
• 알파고논문에서 “𝜆 = 0.5를쓰니제일성능이좋아서이걸로쓰겠다”고합니다
• 쉽게말해, 판세분석과미래예측두모듈의승/패시뮬레이션확률의 1:1 선형합• 더쉽게말해, 착수 a의승/패예측치두종류의평균값
3/16/2016 알파고해부하기 2부 © 이동헌 47

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된아래값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
•쓸만한것 “부터해보자”
3/16/2016 알파고해부하기 2부 © 이동헌 48

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된아래값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
•쓸만한것 “부터해보자”• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a “부터해보자”
3/16/2016 알파고해부하기 2부 © 이동헌 49

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된아래값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
•쓸만한것 “부터해보자”• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a “부터해보자”• 여기서새로튀어나온 u라는것을논하기전에..
• 지금까지설명한걸요약해봅시다.
3/16/2016 알파고해부하기 2부 © 이동헌 50

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된아래값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
•쓸만한것 “부터해보자”• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a “부터해보자”• 여기서새로튀어나온 u라는것을논하기전에..
• 지금까지설명한걸요약해봅시다.
• Tree search를할때, “무엇부터해볼까” 부분을설명했습니다• 이게알파고가다음수읽기를할때머리를굴리는방법입니다
3/16/2016 알파고해부하기 2부 © 이동헌 51

알파고 S/W 구성: MCTS
•각각의 (s,a)에대해저장된아래값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
•쓸만한것 “부터해보자”• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a “부터해보자”• 여기서새로튀어나온 u라는것을논하기전에..
• 지금까지설명한걸요약해봅시다.
• Tree search를할때, “무엇부터해볼까” 부분을설명했습니다• 이게알파고가다음수읽기를할때머리를굴리는방법입니다
• 이제 u를논하러갑니다3/16/2016 알파고해부하기 2부 © 이동헌 52

알파고 S/W 구성: MCTS
• “쓸만한것” 부터해보자• 쓸만한것만하면되나요?
• 이론적으로안됩니다
• 쓸만하다고생각해보지않은것에정답이있을수도있지요
3/16/2016 알파고해부하기 2부 © 이동헌 53

알파고 S/W 구성: MCTS
• “쓸만한것” 부터해보자• 쓸만한것만하면되나요?
• 이론적으로안됩니다
• 쓸만하다고생각해보지않은것에정답이있을수도있지요
•쓸만한것부터해보되, 다른것들도해봐야합니다• 이렇게하다보면언젠가는정답(평균적으로제일좋은답)이나옵니다
• Monte-Carlo Simulation의이론적정당성에서따라나옵니다• 더들어가면, 통계학의 “큰수의법칙”에서나옵니다
• 어차피 approximation만하면되므로, (약한) 큰수의법칙만으로충분합니다
3/16/2016 알파고해부하기 2부 © 이동헌 54

알파고 S/W 구성: MCTS
• “쓸만한것” 부터해보자• 쓸만한것만하면되나요?
• 이론적으로안됩니다
• 쓸만하다고생각해보지않은것에정답이있을수도있지요
•그럼쓸만한거말고다른걸섞어야되는데.. 어떻게하나요?• 이문제를다루는부분이바로
𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)
• 저부분입니다
3/16/2016 알파고해부하기 2부 © 이동헌 55

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자• 갑자기새로튀어나온저것은
𝑢 𝑠𝑡 , 𝑎 = 𝑐𝑝𝑢𝑐𝑡𝑃(𝑠, 𝑎)σ𝑏𝑁𝑟(𝑠, 𝑏)
1 + 𝑁𝑟(𝑠, 𝑎)• 선험적으로알고있는바둑판 s에서착수a에대한선호도 𝑃(𝑠, 𝑎)와,
3/16/2016 알파고해부하기 2부 © 이동헌 56

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자• 갑자기새로튀어나온저것은
𝑢 𝑠𝑡 , 𝑎 = 𝑐𝑝𝑢𝑐𝑡𝑃(𝑠, 𝑎)σ𝑏𝑁𝑟(𝑠, 𝑏)
1 + 𝑁𝑟(𝑠, 𝑎)• 선험적으로알고있는바둑판 s에서착수a에대한선호도 𝑃(𝑠, 𝑎)와,
• 미래예측으로덜놓아본착수에대해서더커지고, 많이놓아본착수에대해서는더작아져서, 무한히많이미래예측한다면결국모두 0으로수렴하는복잡한수식과,
3/16/2016 알파고해부하기 2부 © 이동헌 57

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자• 갑자기새로튀어나온저것은
𝑢 𝑠𝑡 , 𝑎 = 𝑐𝑝𝑢𝑐𝑡𝑃(𝑠, 𝑎)σ𝑏𝑁𝑟(𝑠, 𝑏)
1 + 𝑁𝑟(𝑠, 𝑎)• 선험적으로알고있는바둑판 s에서착수a에대한선호도 𝑃(𝑠, 𝑎)와,
• 미래예측으로덜놓아본착수에대해서더커지고, 많이놓아본착수에대해서는더작아져서, 무한히많이미래예측한다면결국모두 0으로수렴하는복잡한수식과,
3/16/2016 알파고해부하기 2부 © 이동헌 58

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자• 갑자기새로튀어나온저것은
𝑢 𝑠𝑡 , 𝑎 = 𝑐𝑝𝑢𝑐𝑡𝑃(𝑠, 𝑎)σ𝑏𝑁𝑟(𝑠, 𝑏)
1 + 𝑁𝑟(𝑠, 𝑎)• 선험적으로알고있는바둑판 s에서착수a에대한선호도 𝑃(𝑠, 𝑎)와,
• 미래예측으로덜놓아본착수에대해서더커지고, 많이놓아본착수에대해서는더작아져서, 무한히많이미래예측한다면결국모두 0으로수렴하는복잡한수식과,
3/16/2016 알파고해부하기 2부 © 이동헌 59

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자• 갑자기새로튀어나온저것은
𝑢 𝑠𝑡 , 𝑎 = 𝑐𝑝𝑢𝑐𝑡𝑃(𝑠, 𝑎)σ𝑏𝑁𝑟(𝑠, 𝑏)
1 + 𝑁𝑟(𝑠, 𝑎)• 선험적으로알고있는바둑판 s에서착수a에대한선호도 𝑃(𝑠, 𝑎)와,
• 미래예측으로덜놓아본착수에대해서더커지고, 많이놓아본착수에대해서는더작아져서, 무한히많이미래예측한다면결국모두 0으로수렴하는복잡한수식과,
• 튜닝으로결정되는상수계수값의곱입니다.
3/16/2016 알파고해부하기 2부 © 이동헌 60

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자
•즉, 수읽기를반복하면서태도가바뀌는알파고입니다• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
3/16/2016 알파고해부하기 2부 © 이동헌 61

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자
•즉, 수읽기를반복하면서태도가바뀌는알파고입니다• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
3/16/2016 알파고해부하기 2부 © 이동헌 62

알파고 S/W 구성: MCTS
•각각의 (s,a)에대한값들이있다고합시다• 𝑃 𝑠, 𝑎 , 𝑁𝑣 𝑠, 𝑎 , 𝑁𝑟 𝑠, 𝑎 , 𝑊𝑣 𝑠, 𝑎 , 𝑊𝑟 𝑠, 𝑎 , 𝑄 𝑠, 𝑎
• “쓸만한것” 부터해보자• 지금현재바둑판을 𝑠𝑡라할때
• 𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a 부터해보자
•즉, 수읽기를반복하면서태도가바뀌는알파고입니다• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
• 무한히오래하면결국에는쓸만해보이는지만을놓고정하겠다
3/16/2016 알파고해부하기 2부 © 이동헌 63

알파고 S/W 구성: MCTS
•수읽기를반복하면서태도가바뀌는알파고• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
• 무한히오래하면결국에는쓸만해보이는지만을놓고정하겠다
•무한히반복하면정답이나오나요?
3/16/2016 알파고해부하기 2부 © 이동헌 64

알파고 S/W 구성: MCTS
•수읽기를반복하면서태도가바뀌는알파고• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
• 무한히오래하면결국에는쓸만해보이는지만을놓고정하겠다
•무한히반복하면정답이나오나요?• 나옵니다
• 주어진바둑판에서, 모든가능한착수에대해서승리기대치의평균이나옵니다
• 이중에제일평균이높은착수를고르는것은금방입니다
3/16/2016 알파고해부하기 2부 © 이동헌 65

알파고 S/W 구성: MCTS
•수읽기를반복하면서태도가바뀌는알파고• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
• 무한히오래하면결국에는쓸만해보이는지만을놓고정하겠다
•무한히반복하면정답이나오나요?• 나옵니다
• 주어진바둑판에서, 모든가능한착수에대해서승리기대치의평균이나옵니다
• 이중에제일평균이높은착수를고르는것은금방입니다
• 다만알파고에서는,• 가장많이골랐던착수 == 가장평균이높은착수를확인하고
• 다음착수를고르게됩니다 (자세한내용은 “알파고대국시동작법”에서)3/16/2016 알파고해부하기 2부 © 이동헌 66

알파고 S/W 구성: MCTS
•수읽기를반복하면서태도가바뀌는알파고• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
• 무한히오래하면결국에는쓸만해보이는지만을놓고정하겠다
•현실은무한히못한다는게단점• 어느정도하다가끊어줘야됩니다
3/16/2016 알파고해부하기 2부 © 이동헌 67

알파고 S/W 구성: MCTS
•수읽기를반복하면서태도가바뀌는알파고• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
• 무한히오래하면결국에는쓸만해보이는지만을놓고정하겠다
•현실은무한히못한다는게단점• 어느정도하다가끊어줘야됩니다
• 이걸더많이할수록정확해집니다• 알파고의착수시간제한을줄이면실력이떨어집니다
• 판후이 2단경기때, 비공식에서는알파고가몇번졌지요 (비공식때제한시간이더짧음)
3/16/2016 알파고해부하기 2부 © 이동헌 68

알파고 S/W 구성: MCTS
•수읽기를반복하면서태도가바뀌는알파고• 시뮬레이션반복초기에는덜쓸만해보이는것도해보지만
• 계속하다보면는쓸만해보이는지에대한추정치를점점더중시하고
• 무한히오래하면결국에는쓸만해보이는지만을놓고정하겠다
•현실은무한히못한다는게단점• 어느정도하다가끊어줘야됩니다
• 이걸더많이할수록정확해집니다• 알파고의착수시간제한을줄이면실력이떨어집니다
• 판후이 2단경기때, 비공식에서는알파고가몇번졌지요 (비공식때제한시간이더짧음)
• 알파고가더많은컴퓨터를동시에사용가능하면실력이올라갑니다• 판후이 2단때 1202 CPU이세돌 9단때 1920 CPU. 같은시간에더많은시뮬레이션가능.
3/16/2016 알파고해부하기 2부 © 이동헌 69

알파고 S/W 구성: MCTS
•그런데 Reinforcement Learning은어디있나요?• 순수한버젼의 MCTS와비교해보면정확히답이나옵니다
• MCTS사용한바둑프로그램 Crazy Stone 논문 [바로가기]
3/16/2016 알파고해부하기 2부 © 이동헌 70

알파고 S/W 구성: MCTS
•그런데 Reinforcement Learning은어디있나요?• 순수한버젼의 MCTS와비교해보면정확히답이나옵니다
• MCTS사용한바둑프로그램 Crazy Stone 논문 [바로가기]
• 여기에 Upper Confidence Bound (UCB) 성분을추가합니다
𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a를하자
3/16/2016 알파고해부하기 2부 © 이동헌 71

알파고 S/W 구성: MCTS
•그런데 Reinforcement Learning은어디있나요?• 순수한버젼의 MCTS와비교해보면정확히답이나옵니다
• MCTS사용한바둑프로그램 Crazy Stone 논문 [바로가기]
• 여기에 Upper Confidence Bound (UCB) 성분을추가합니다
𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a를하자
• 여기에 Q-learning의큰틀에서바둑프로그램제작 (“Q”값이에요)
𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을기반해서Monte-Carlo적으로접근하는것으로바둑을공략해보자!
3/16/2016 알파고해부하기 2부 © 이동헌 72

알파고 S/W 구성: MCTS
•그런데 Reinforcement Learning은어디있나요?• 순수한버젼의 MCTS와비교해보면정확히답이나옵니다
• MCTS사용한바둑프로그램 Crazy Stone 논문 [바로가기]
• 여기에 Upper Confidence Bound (UCB) 성분을추가합니다
𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을가장크게만드는착수 a를하자
• 여기에 Q-learning의큰틀에서바둑프로그램제작 (“Q”값이에요)
𝑄 𝑠𝑡 , 𝑎 + 𝑢(𝑠𝑡 , 𝑎)값을기반해서Monte-Carlo적으로접근하는것으로바둑을공략해보자!
• 더진지하게연구하실분들을위해참고문헌을드리겠습니다
3/16/2016 알파고해부하기 2부 © 이동헌 73

알파고 S/W 구성: MCTS
•그런데 Reinforcement Learning은어디있나요?• 알파고미래예측 = MCTS + PUCT (UCB) 변형 + Q-learning 변형
• PUCT를살짝변형하면서MCTS에넣어알파고에쓰인바둑미래예측부분구조설계
• Upper Confidence Bound (UCB) 계열참고문헌• 2002: Multiarmed bandit문제에 UCB적용한 UCB1 알고리즘등장 [논문바로가기]
• 2006: MCST에 UCB1을합쳐버린 UCT알고리즘등장 [논문바로가기]
• 2009: 여기에 “Predictor” 요소를더해서 PUCT 등장 [논문바로가기]
• Q-learning 계열참고문헌• 1989: 오리지널 Q-learnin은 CJCJ Watkins 박사논문 [축약판논문바로가기]
• 1993: Q-learnin의수학적으로엄밀한수렴증명 [논문바로가기]
• 2013: 알파고에사용된 Q-learning 변형법과비슷한내용 [논문바로가기]
3/16/2016 알파고해부하기 2부 © 이동헌 74

알파고 S/W 구성: MCTS
•그런데 Reinforcement Learning은어디있나요?• 알파고미래예측 = MCTS + PUCT (UCB) 변형 + Q-learning 변형
• PUCT를살짝변형하면서MCTS에넣어알파고에쓰인바둑미래예측부분구조설계
• Upper Confidence Bound (UCB) 계열참고문헌• 2002: Multiarmed bandit문제에 UCB적용한 UCB1 알고리즘등장 [논문바로가기]
• 2006: MCST에 UCB1을합쳐버린 UCT알고리즘등장 [논문바로가기]
• 2009: 여기에 “Predictor” 요소를더해서 PUCT 등장 [논문바로가기]
• Q-learning 계열참고문헌• 1989: 오리지널 Q-learnin은 CJCJ Watkins 박사논문 [축약판논문바로가기]
• 1993: Q-learnin의수학적으로엄밀한수렴증명 [논문바로가기]
• 2013: 알파고에사용된 Q-learning 변형법과비슷한내용 [논문바로가기]
3/16/2016 알파고해부하기 2부 © 이동헌 75
솔직히, 참고문헌논문들읽기힘듭니다.
저도인공지능알고리즘박사과정에들지않았으면
아마도읽을일없었겠지요…
여러분들이참고문헌을끝까지읽어보시지않으시더라도다만한가지알아주셨으면하는것두가지가있어요.
알파고의기반에놓인이론들은알파고탄생한참전에이미나왔다는점*
그리고알파고의이론도알파고의실체도결국사람이만들었다는점입니다.
* Jaehyun Park (스탠포드)님의건의감사합니다!!

알파고소프트웨어의구성
•요약합니다
• MCTS 적용부분• 미래예측부분입니다
• Monte-Carlo Tree Search
• Reinforcement Learning
• 다양한내용이버무려져있습니다
알파고바둑프로그램
RL
3/16/2016 알파고해부하기 2부 © 이동헌 76
상대바둑기사다음수
예측프로그램
알파고의다음수
결정프로그램
DL DLRL RL
바둑경기상황
유/불리분석
프로그램
DL RL
바둑판현상황인식프로그램DL
바둑판미래예측시도
MCTS RL
여러번미래예측후가장많이둔수로선택RLMCTS

목차
•알파고의구조
•알파고소프트웨어의구성• 알파고 S/W 구성: Deep Learning 유관부분
• 알파고 S/W 구성: Reinforcement Learning 유관부분
• 알파고 S/W 구성: Monte-Carlo Tree Search 유관부분
•알파고 S/W의대국시동작법
•알파고 S/W의대국전트레이닝법
•알파고 S/W의혁신점
•알파고의혁신점
3/16/2016 알파고해부하기 2부 © 이동헌 77

Time Over
•이번감기오래가네요.. 그래도• 연차내고집에서쉬느라시간이좀많이생겼어요
• 덕분에생각보다일찍 2부를내놓습니다
•벌써거의 80슬라이드!• 3부에서이어서뵙겠습니다…
•이세돌 9단수고하셨습니다!!!
3/16/2016 알파고해부하기 2부 © 이동헌 78

다음이야기
•다음링크를따라가시면됩니다• 알파고해부하기 3부
•피드백/오류제보이메일이필요하시면여기로보내주세요• [email protected]
3/16/2016 알파고해부하기 2부 © 이동헌 79



















![[액션스크립트] 2부 액션 스크립트 2.0](https://img.dokumen.tips/doc/110x75/557bd8dfd8b42aac4c8b49e7/-2-20.jpg)










