Embed Size (px)
Citation preview

1
William Markito@william_markito
Fred Melo@fredmelo_br
Build your first Internet of Things app today with open source

Trilateration and its limitations
2

Particle Filters - Calculating the optimum solution
3

The solution
4
1. Capture signal strength 2. Calculate distance from
antenna 3. Trilaterate different
sensors to predict location in real-time
4. Show on a map with live updates

Architecture Overview
5
Ingest
SpringXD
Groovy
JSON HTTP
+ Distance
Transform Sink
Calculate Device DistancePredict
Location
Spring Boot
Application Platform
GUI

6
Introduction to Geode

A distributed, memory-based data management platform for data oriented apps that need: • high performance, scalability, resiliency and continuous
availability • fast access to critical data set • location aware distributed data processing • event driven data architecture
7
Introduction

• Cache
• In-memory storage and management for your data
• Configurable through XML, Spring, Java API or CLI
• Collection of Region
8
Concepts
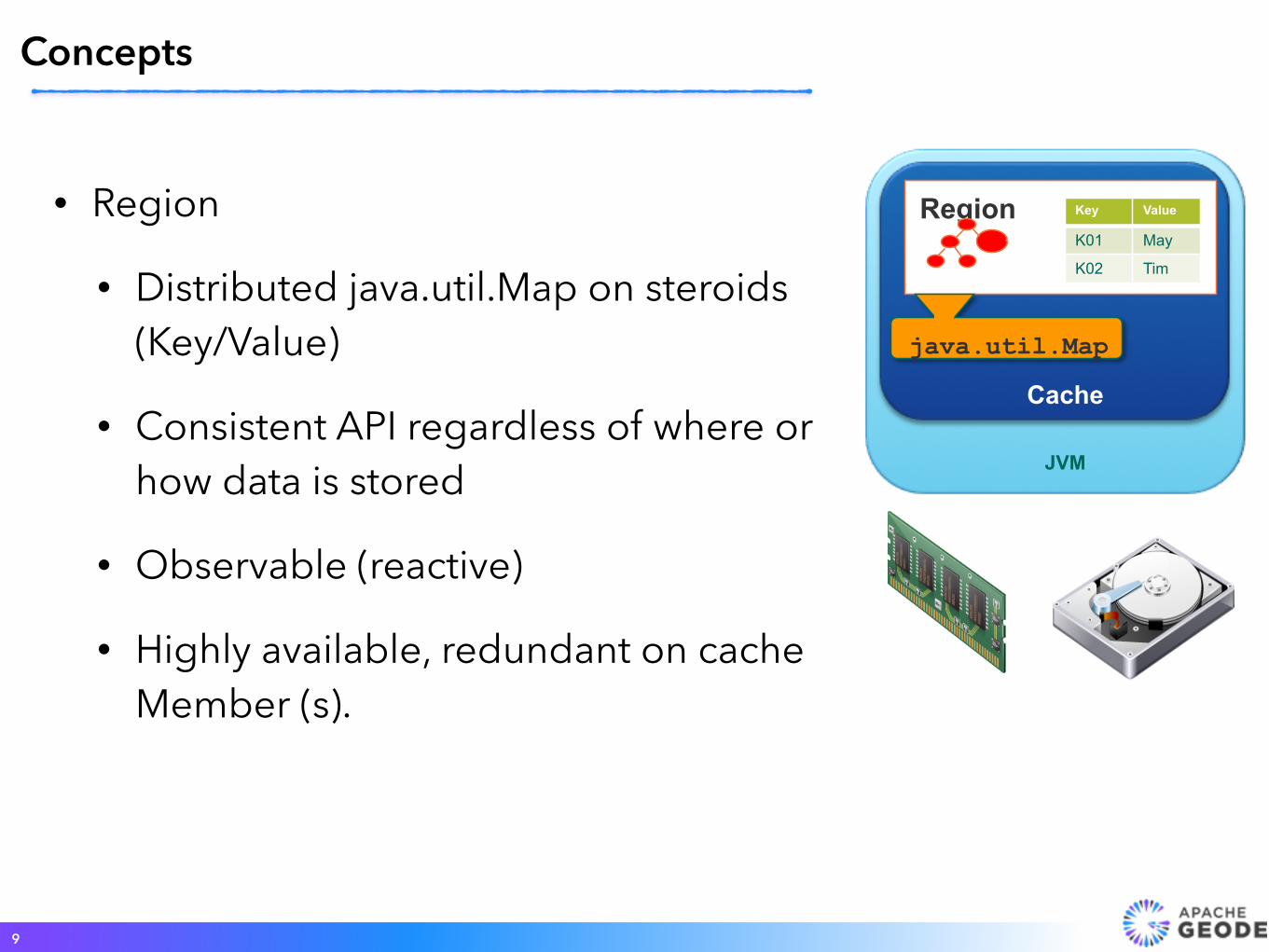
Region
Region
Region
Cache
JVM
• Region
• Distributed java.util.Map on steroids (Key/Value)
• Consistent API regardless of where or how data is stored
• Observable (reactive)
• Highly available, redundant on cache Member (s).
9
Concepts
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim

• Region
• Local, Replicated or Partitioned
• In-memory or persistent
• Redundant
• LRU
• Overflow
10
Concepts
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
LOCAL LOCAL_HEAP_LRU LOCAL_OVERFLOW LOCAL_PERSISTENT LOCAL_PERSISTENT_OVERFLOW PARTITION PARTITION_HEAP_LRU PARTITION_OVERFLOW PARTITION_PERSISTENT PARTITION_PERSISTENT_OVERFLOW PARTITION_PROXY PARTITION_PROXY_REDUNDANT PARTITION_REDUNDANT PARTITION_REDUNDANT_HEAP_LRU PARTITION_REDUNDANT_OVERFLOW PARTITION_REDUNDANT_PERSISTENT PARTITION_REDUNDANT_PERSISTENT_OVERFLOW REPLICATE REPLICATE_HEAP_LRU REPLICATE_OVERFLOW REPLICATE_PERSISTENT REPLICATE_PERSISTENT_OVERFLOW REPLICATE_PROXY

• Persistent Regions
• Durability
• WAL for efficient writing
• Consistent recovery
• Compaction
11
Concepts
Modify k1->v5
Create k6->v6
Create k2->v2
Create k4->v4 Oplog2.crf
Member 1
Modify k4->v7 Oplog3.crf
Put k4->v7
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
Region
Cache
java.util.Map
JVM
Key Value
K01 May
K02 Tim
Server 1 Server N

• Member
• A process that has a connection to the system
• A process that has created a cache
• Embeddable within your application
12
Concepts
Client
Locator
Server

• Client cache
• A process connected to the Geode server(s)
• Can have a local copy of the data
• Can be notified about events on the servers
13
Concepts
Application
GemFire Server
Region
Region
Region Client Cache

• Functions
• Used for distributed concurrent processing (Map/Reduce, stored procedure)
• Highly available
• Data oriented
• Member oriented
14
Concepts
Submit (f1)
f1 , f2 , … fn
Execute Functions

15
Concepts
Server
Server
FunctionService.onRegion.withFilter.execute ResultCollector.getResult
Server Distributed System
execute
Server
Server
6
1
result
execute
execute
result result
2
5
3
4 3 4
Server
Partitioned Region Data Store - X
Partitioned Region Data Store - Y
Partitioned Region Data Store - Z
Partitioned Region Data Accessor
Partitioned Region Data Accessor
filter = Keys X, Y Client Region
• Functions

• Listeners
• CacheWriter / CacheListener
• AsyncEventListener (queue / batch)
• Parallel or Serial
• Conflation
16
Concepts

LAB

Introduction to SpringXD
18
Runs as a distributed application or as a single node
Spring XD
19
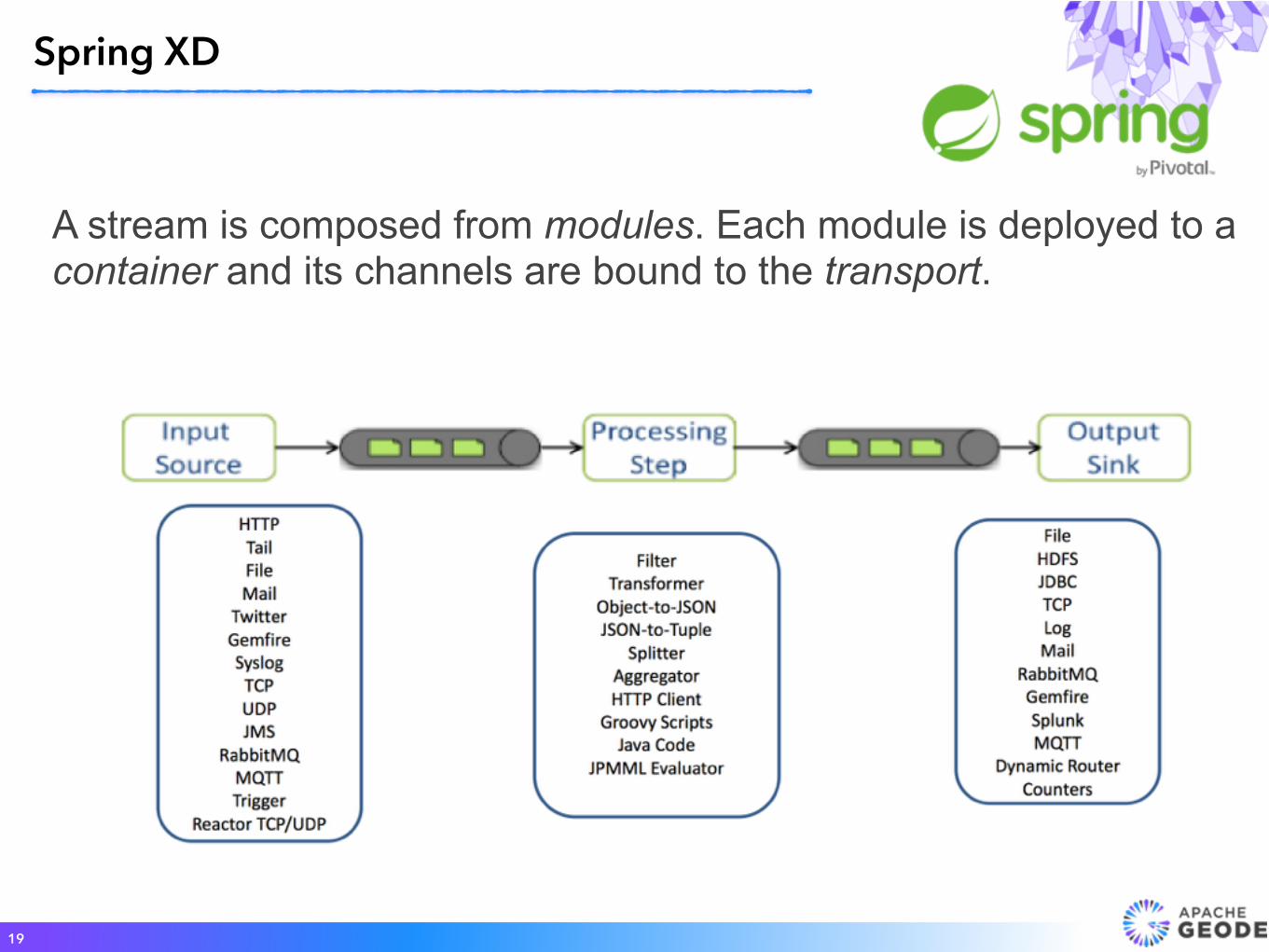
A stream is composed from modules. Each module is deployed to a container and its channels are bound to the transport.

LAB

• HDFS Persistence • Off-heap memory storage • Lucene Search • Spark Integration • Cloud Foundry service
21
Apache Geode Roadmap

22
Spark Connector
"An RDD in Spark is simply an immutable distributed collection of objects. Each RDD is split into multiple partitions, which may be computed on different nodes of the cluster. RDDs can contain any type of Python, Java, or Scala objects, including user-defined classes."
Learning Spark By Holden Karau, Andy Konwinski, Patrick Wendell, Matei Zaharia
Publisher: O'Reilly Media
• Geode Spark Connector allows:
• Regions exposed as RDD
• RDDs persisted in Geode
• Execute queries on Geode using OQL

23
Spark Connector
• Web based REPL • Multiple Interpreters
• Apache Spark • Markdown • Flink • Python…
• Iterative & Exploratory
• Data store • In-memory & Persistent • Highly Consistent • Transaction processing • Thousands of concurrent
clients
• Data Processing • Columnar queries • RDDs • Machine Learning • Analytics • Streaming

LAB

25
https://github.com/Pivotal-Open-Source-Hub/WifiAnalyticsIoTSource code and detailed instructions available at:





























