Embed Size (px)
Citation preview

Faktorenanalyse und Strukturgleichungsmodelle I
VL Forschungsmethoden

EinführungGrundlagen
Zwischenfazit
Outline
EinführungGrundlagenZwischenfazit
Karl G. Joreskog
VL Forschungsmethoden SEM I (1/14)

EinführungGrundlagen
Zwischenfazit
Was ist ein „Faktor“?
I „Faktor“ oder „latente Variable“I Common factor(s) = Gemeinsamkeit(en) zwischen
verschiedenen VariablenI D.h. nicht direkt beobachtbare GrößeI Die beobachtbare Variablen („Indikatoren“) beeinflußt
I Typische Beispiele: Einstellungen, PersönlichkeitsmerkmaleI Grundidee: Muster in beobachteten Korrelationsmatrizen
erklärenI Psychologische Intelligenzforschung
VL Forschungsmethoden SEM I (2/14)

EinführungGrundlagen
Zwischenfazit
Beispiel: Politisches Vertrauen
I ESS 4, DeutschlandI Nationales Parlament, Gerichte, Polizei, Politiker, Parteien,
Europaparlament
. corr trstprl-trstep(obs=2492)
trstprl trstlgl trstplc trstplt trstprt trstep
trstprl 1.0000trstlgl 0.5366 1.0000trstplc 0.3796 0.6029 1.0000trstplt 0.6693 0.4508 0.3446 1.0000trstprt 0.5912 0.4160 0.3025 0.8061 1.0000trstep 0.5563 0.4146 0.3122 0.5577 0.5898 1.0000
VL Forschungsmethoden SEM I (3/14)

EinführungGrundlagen
Zwischenfazit
Grundidee der (explorativen) Faktorenanalyse
I Konstruiere eine oder mehrere (wenige) „künstliche“ Variablendie Ausgangsmatrix „erklären“ können
I Jede gemessene Variable sollte hoch mit einem Faktorkorrelieren
I Korrelation mit Faktor: „erklärte“ VarianzI Rest: „Störvarianz“
I Regression der Ausgangsvariablen auf FaktorenI Varianten:
I Wie werden Faktoren konstruiert?I Wieviele Faktoren werden extrahiert?I Können Faktoren untereinander korrelieren?
I Explorativ ≈ atheoretisch
VL Forschungsmethoden SEM I (4/14)

EinführungGrundlagen
Zwischenfazit
Beispiel Vertrauen: 1-Faktor-Lösung. factor trstprl-trstep,factor(1)(obs=2492)Factor analysis/correlation Number of obs = 2492
Method: principal factors Retained factors = 1Rotation: (unrotated) Number of params = 6
Factor Eigenvalue Difference Proportion Cumulative
Factor1 3.10719 2.62503 0.9665 0.9665Factor2 0.48216 0.47331 0.1500 1.1165Factor3 0.00885 0.04933 0.0028 1.1193Factor4 -0.04048 0.10374 -0.0126 1.1067Factor5 -0.14422 0.05452 -0.0449 1.0618Factor6 -0.19874 . -0.0618 1.0000
LR test: independent vs. saturated: chi2(15) = 7563.17 Prob>chi2 = 0.0000Factor loadings (pattern matrix) and unique variances
Variable Factor1 Uniqueness
trstprl 0.7674 0.4111trstlgl 0.6564 0.5692trstplc 0.5234 0.7261trstplt 0.8411 0.2926trstprt 0.8075 0.3480trstep 0.6739 0.5459
VL Forschungsmethoden SEM I (5/14)

EinführungGrundlagen
Zwischenfazit
Warum kann explorative Faktorenanalyse problematischsein?
„factor analysis: it’s what the data get into when theory goes onholiday“
I Bezieht sich auf explorative (= böse?) FaktorenanalyseI Standardprozedur („little jiffy“); Extraktion von
Hauptkomponenten, Kaiserkriterium, VARIMAXI Findet oft vorhandene Strukturen nicht („Tom Swift’s Electric
Factor Analysis Machine“)I Findet Strukturen, die gar nicht vorhanden sind?I Konfirmatorische Faktorenanalyse: Prüfung, ob theoretisch
sinnvolle Strukturen mit den Daten vereinbar sindI Meßmodelle, Erweiterung möglich („LISREL“-Modell)
VL Forschungsmethoden SEM I (6/14)

EinführungGrundlagen
Zwischenfazit
Wie werden die Beziehungen graphisch dargestellt?
I Kreise oder Ovale für latente Variablen/Meßfehler (ξ, δ)I Rechtecke oder Quadrate für beobachtete Variablen (x)I Gerichtete Pfeile für (kausale) WirkungenI Doppelpfeile für KovarianzenI Kausalität?
VL Forschungsmethoden SEM I (7/14)

EinführungGrundlagen
Zwischenfazit
Was gehört zur Spezfikation?
1. Zahl der gemeinsamen Faktoren2. Zahl der beobachteten Variablen3. Varianzen/Kovarianzen der gemeinsamen Faktoren4. Beziehungen zwischen gemeinsamen Faktoren und
beobachteten Variablen5. Beziehungen zwischen beobachteten Variablen und
spezifischen Faktoren6. Varianzen/Kovarianzen der spezifischen Faktoren (Meßfehler)
I Spezfikation ursprünglich durch eine Reihe von MatrizenI Heute
I Einfache Gleichungen oder graphische EingabeI (Normalerweise) vernünftige Voreinstellungen
VL Forschungsmethoden SEM I (8/14)

EinführungGrundlagen
Zwischenfazit
Was gehört zur Spezfikation?
1. Zahl der gemeinsamen Faktoren2. Zahl der beobachteten Variablen3. Varianzen/Kovarianzen der gemeinsamen Faktoren4. Beziehungen zwischen gemeinsamen Faktoren und
beobachteten Variablen5. Beziehungen zwischen beobachteten Variablen und
spezifischen Faktoren6. Varianzen/Kovarianzen der spezifischen Faktoren (Meßfehler)
I Spezfikation ursprünglich durch eine Reihe von Matrizen
I HeuteI Einfache Gleichungen oder graphische EingabeI (Normalerweise) vernünftige Voreinstellungen
VL Forschungsmethoden SEM I (8/14)

EinführungGrundlagen
Zwischenfazit
Was gehört zur Spezfikation?
1. Zahl der gemeinsamen Faktoren2. Zahl der beobachteten Variablen3. Varianzen/Kovarianzen der gemeinsamen Faktoren4. Beziehungen zwischen gemeinsamen Faktoren und
beobachteten Variablen5. Beziehungen zwischen beobachteten Variablen und
spezifischen Faktoren6. Varianzen/Kovarianzen der spezifischen Faktoren (Meßfehler)
I Spezfikation ursprünglich durch eine Reihe von MatrizenI Heute
I Einfache Gleichungen oder graphische EingabeI (Normalerweise) vernünftige Voreinstellungen
VL Forschungsmethoden SEM I (8/14)

EinführungGrundlagen
Zwischenfazit
Wie sieht die Terminologie aus?
I Primär interessant: Beziehungen zwischen gemeinsamenFaktoren und beobachteten Variablen
I Werden mit λ bezeichnetI Z. B. x2 = λ21ξ1 + δ2
I λ21 gibt an, wie sich x2 verändert, wenn Faktor um einszunimmt
I Analog zu y = β0 + β1x1 + ε
I Alle (latente und manifeste) Variablen sind zentriert →Mittelwert von null, kein Achsenabschnitt notwendig
VL Forschungsmethoden SEM I (9/14)

EinführungGrundlagen
Zwischenfazit
Wie sieht die Terminologie aus?
I Primär interessant: Beziehungen zwischen gemeinsamenFaktoren und beobachteten Variablen
I Werden mit λ bezeichnetI Z. B. x2 = λ21ξ1 + δ2
I λ21 gibt an, wie sich x2 verändert, wenn Faktor um einszunimmt
I Analog zu y = β0 + β1x1 + ε
I Alle (latente und manifeste) Variablen sind zentriert →Mittelwert von null, kein Achsenabschnitt notwendig
VL Forschungsmethoden SEM I (9/14)

EinführungGrundlagen
Zwischenfazit
Wie sieht die Terminologie aus?
I Kovarianzen zwischen gemeinsamen Faktoren möglich, z. B.φ12
I Kovarianzen zwischen spezifischen Fehlervarianzen möglichz. B. θ24
I Unterschied zu explorativer Analyse?
VL Forschungsmethoden SEM I (10/14)

EinführungGrundlagen
Zwischenfazit
Noch mehr Terminologie?Matrix Dimension Mittelwert Kovarianz Dimension Bedeutung
ξ (s × 1) 0 Φ = E(ξξ′) (s × s) GemeinsameFaktoren
x (q × 1) 0 Σ = E(xx ′) (q × q) beobachteteVariablen
Λ (q × s) Faktorladungenδ (q × 1) 0 Θ = E(δδ′) (q × q) Meßfehler
I Faktor-Gleichung: x = Λξ+ δ
I Kovarianz-Gleichung: Σ = ΛΦΛ′ +Θ
I Annahmen:
I Variablen sind zentriert: E(ξ) = E(x) = E(δ) = 0I q: Zahl der beobachteten Variablen; s: Zahl der gemeinsamen
Faktoren; q > sI Keine Korrelation zwischen Faktoren/Fehlervarianzen:
E(ξδ′) = 0
VL Forschungsmethoden SEM I (11/14)

EinführungGrundlagen
Zwischenfazit
Noch mehr Terminologie?Matrix Dimension Mittelwert Kovarianz Dimension Bedeutung
ξ (s × 1) 0 Φ = E(ξξ′) (s × s) GemeinsameFaktoren
x (q × 1) 0 Σ = E(xx ′) (q × q) beobachteteVariablen
Λ (q × s) Faktorladungenδ (q × 1) 0 Θ = E(δδ′) (q × q) Meßfehler
I Faktor-Gleichung: x = Λξ+ δ
I Kovarianz-Gleichung: Σ = ΛΦΛ′ +Θ
I Annahmen:
I Variablen sind zentriert: E(ξ) = E(x) = E(δ) = 0I q: Zahl der beobachteten Variablen; s: Zahl der gemeinsamen
Faktoren; q > sI Keine Korrelation zwischen Faktoren/Fehlervarianzen:
E(ξδ′) = 0
VL Forschungsmethoden SEM I (11/14)

EinführungGrundlagen
Zwischenfazit
Noch mehr Terminologie?Matrix Dimension Mittelwert Kovarianz Dimension Bedeutung
ξ (s × 1) 0 Φ = E(ξξ′) (s × s) GemeinsameFaktoren
x (q × 1) 0 Σ = E(xx ′) (q × q) beobachteteVariablen
Λ (q × s) Faktorladungenδ (q × 1) 0 Θ = E(δδ′) (q × q) Meßfehler
I Faktor-Gleichung: x = Λξ+ δ
I Kovarianz-Gleichung: Σ = ΛΦΛ′ +Θ
I Annahmen:
I Variablen sind zentriert: E(ξ) = E(x) = E(δ) = 0I q: Zahl der beobachteten Variablen; s: Zahl der gemeinsamen
Faktoren; q > sI Keine Korrelation zwischen Faktoren/Fehlervarianzen:
E(ξδ′) = 0
VL Forschungsmethoden SEM I (11/14)

EinführungGrundlagen
Zwischenfazit
Noch mehr Terminologie?Matrix Dimension Mittelwert Kovarianz Dimension Bedeutung
ξ (s × 1) 0 Φ = E(ξξ′) (s × s) GemeinsameFaktoren
x (q × 1) 0 Σ = E(xx ′) (q × q) beobachteteVariablen
Λ (q × s) Faktorladungenδ (q × 1) 0 Θ = E(δδ′) (q × q) Meßfehler
I Faktor-Gleichung: x = Λξ+ δ
I Kovarianz-Gleichung: Σ = ΛΦΛ′ +Θ
I Annahmen:I Variablen sind zentriert: E(ξ) = E(x) = E(δ) = 0
I q: Zahl der beobachteten Variablen; s: Zahl der gemeinsamenFaktoren; q > s
I Keine Korrelation zwischen Faktoren/Fehlervarianzen:E(ξδ′) = 0
VL Forschungsmethoden SEM I (11/14)

EinführungGrundlagen
Zwischenfazit
Noch mehr Terminologie?Matrix Dimension Mittelwert Kovarianz Dimension Bedeutung
ξ (s × 1) 0 Φ = E(ξξ′) (s × s) GemeinsameFaktoren
x (q × 1) 0 Σ = E(xx ′) (q × q) beobachteteVariablen
Λ (q × s) Faktorladungenδ (q × 1) 0 Θ = E(δδ′) (q × q) Meßfehler
I Faktor-Gleichung: x = Λξ+ δ
I Kovarianz-Gleichung: Σ = ΛΦΛ′ +Θ
I Annahmen:I Variablen sind zentriert: E(ξ) = E(x) = E(δ) = 0I q: Zahl der beobachteten Variablen; s: Zahl der gemeinsamen
Faktoren; q > s
I Keine Korrelation zwischen Faktoren/Fehlervarianzen:E(ξδ′) = 0
VL Forschungsmethoden SEM I (11/14)

EinführungGrundlagen
Zwischenfazit
Noch mehr Terminologie?Matrix Dimension Mittelwert Kovarianz Dimension Bedeutung
ξ (s × 1) 0 Φ = E(ξξ′) (s × s) GemeinsameFaktoren
x (q × 1) 0 Σ = E(xx ′) (q × q) beobachteteVariablen
Λ (q × s) Faktorladungenδ (q × 1) 0 Θ = E(δδ′) (q × q) Meßfehler
I Faktor-Gleichung: x = Λξ+ δ
I Kovarianz-Gleichung: Σ = ΛΦΛ′ +Θ
I Annahmen:I Variablen sind zentriert: E(ξ) = E(x) = E(δ) = 0I q: Zahl der beobachteten Variablen; s: Zahl der gemeinsamen
Faktoren; q > sI Keine Korrelation zwischen Faktoren/Fehlervarianzen:
E(ξδ′) = 0VL Forschungsmethoden SEM I (11/14)

EinführungGrundlagen
Zwischenfazit
Was macht man nun damit?
I Mit diesen sieben Matrizen/Vektoren kann das ganze Modellvollständig beschrieben werden
I Pfeile in graphischer Darstellung entsprechen Bedingungen(constraints) in Matrizen
I Für Items, die nicht auf einen Faktor laden, wird entsprechendeZelle in Λ auf null gesetzt
I Keine Kovarianz zwischen gemeinsamen Faktoren:(Redundante) Elemente in Φ auf null
I Keine korrelierten Meßfehler: Alle Elemente außerhalbDiagonale in Θ auf null
VL Forschungsmethoden SEM I (12/14)

EinführungGrundlagen
Zwischenfazit
Wie kommt man zu den Schätzungen?
I Konfirmatorische Faktorenanalyse geht immer vonVarianz-Kovarianz-Matrix aus
I Originaldaten werden nicht benötigtI Schlüssel ist die Kovarianz-Gleichung, die sich auf die
Grundgesamtheit beziehtI Gestattet Zerlegung der Kovarianzen in Werte für Pfade
(Λ,Φ,Θ)I Beobachtete Kovarianzen S als Schätzung für ΣI Schätzung setzt Identifikation vorausI Identifikation notwendige, aber nicht hinreichende Bedingung
für gültige Schätzung
VL Forschungsmethoden SEM I (13/14)

EinführungGrundlagen
Zwischenfazit
Zusammenfassung für heute
I Faktorenanalyse mächtiges Verfahren, Vielzahl vonMöglichkeiten
I Besonders adäquat für sozialwissenschaftliche DatenI Explorative Analyse explorativ (und unzuverlässig)I Konfirmatorische Analyse besonders adäquat für
sozialwissenschaftliche TheorienI MeßfehlerI Latente VariablenI Modellierung (kleiner) Systeme
VL Forschungsmethoden SEM I (14/14)

Faktorenanalyse und Strukturgleichungsmodelle II
VL Forschungsmethoden

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Outline
Fortsetzung EinführungAnwendungen
(Likert)-SkalierungKomplexe ModelleSoftware
Beispiel: Einstellungen zu MigrantenFazit
Karl G. Joreskog
VL Forschungsmethoden SEM II (1/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Was ist Identifikation?
I Identifikation ist Eigenschaft des ModellsI Modell identifiziert: Es gibt genau eine Lösung für
GleichungssystemI Modell nicht identifiziert: Es existieren mehrere (oft unendlich
viele) gleichwertige LösungenI (Notwendig, nicht hinreichend): Zahl der zu schätzenden
Parameter kleiner als Zahl der unabhängigen Informationen
I Voraussetzungen/constraints1. Nicht alle Items können auf alle Faktoren laden → theoretische
Überlegungen2. Die Metrik der gemeinsamen Faktoren muß festgelegt werden
I Woher weiß ich, daß Modell identifiziert ist?
VL Forschungsmethoden SEM II (2/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Was ist Identifikation?
I Identifikation ist Eigenschaft des ModellsI Modell identifiziert: Es gibt genau eine Lösung für
GleichungssystemI Modell nicht identifiziert: Es existieren mehrere (oft unendlich
viele) gleichwertige LösungenI (Notwendig, nicht hinreichend): Zahl der zu schätzenden
Parameter kleiner als Zahl der unabhängigen InformationenI Voraussetzungen/constraints
1. Nicht alle Items können auf alle Faktoren laden → theoretischeÜberlegungen
2. Die Metrik der gemeinsamen Faktoren muß festgelegt werden
I Woher weiß ich, daß Modell identifiziert ist?
VL Forschungsmethoden SEM II (2/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Warum ist die Skalierung der Faktoren wichtig?
I Große Varianz des Faktors/niedrige Faktorladung und kleineVarianz/hohe Faktorladung im Muster der Kovarianzen nichtzu unterscheiden
I Varianz des Faktors empirisch nicht zu bestimmen (latenteVariable)
I Willkürliche Festlegung (das ist kein Problem)
VL Forschungsmethoden SEM II (3/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Warum ist die Skalierung der Faktoren wichtig?
I Große Varianz des Faktors/niedrige Faktorladung und kleineVarianz/hohe Faktorladung im Muster der Kovarianzen nichtzu unterscheiden
I Varianz des Faktors empirisch nicht zu bestimmen (latenteVariable)
I Willkürliche Festlegung (das ist kein Problem)
VL Forschungsmethoden SEM II (3/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Warum ist die Skalierung der Faktoren wichtig?
I Große Varianz des Faktors/niedrige Faktorladung und kleineVarianz/hohe Faktorladung im Muster der Kovarianzen nichtzu unterscheiden
I Varianz des Faktors empirisch nicht zu bestimmen (latenteVariable)
I Willkürliche Festlegung (das ist kein Problem)
VL Forschungsmethoden SEM II (3/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Wie kann die Metrik eines Faktors festgelegt werden?
1. Die Ladung eines Items auf den Faktor wird auf eins gesetztI Faktor hat gleiche Metrik wie betreffendes ItemI Varianz des Faktors wird geschätzt
2. Die Varianz des Faktors wird auf eins gesetztI Alle Faktorladungen werden geschätztI Faktor ist dimensionslose vollstandardisierte VariableI Kovarianzen zwischen solchen Faktoren sind Korrelationen
VL Forschungsmethoden SEM II (4/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Wie kann die Metrik eines Faktors festgelegt werden?
1. Die Ladung eines Items auf den Faktor wird auf eins gesetztI Faktor hat gleiche Metrik wie betreffendes ItemI Varianz des Faktors wird geschätzt
2. Die Varianz des Faktors wird auf eins gesetztI Alle Faktorladungen werden geschätztI Faktor ist dimensionslose vollstandardisierte VariableI Kovarianzen zwischen solchen Faktoren sind Korrelationen
VL Forschungsmethoden SEM II (4/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Wie werden die Parameter nun geschätzt?
I Iterative Verfahren (u. a. GLS, ML, WLS)I Für Λ,Φ,Θ Startwerte annehmen → implizieren eine
Varianz-Kovarianz-Matrix Σ∗
I „Differenz“ (fitting function) zwischen Σ∗ und S minimierenI Verschiedene fitting functions für verschiedene (asymptotisch
äquivalente) VerfahrenI Multivariate Normalverteilung der x-Variablen wird
vorausgesetzt → Verletzungen, Asymptotik?I Tests für Koeffizienten/Pfade: Wald oder LR,
Lagrange-MultiplierI Heywood Cases
VL Forschungsmethoden SEM II (5/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
ModelfitI Wie gut passen Modellschätzungen zu den Daten?I Traditionell: Test auf Basis eines χ2-Wertes
I Wie wahrscheinlich sind Abweichungen zwischen wahrer (Σ)und vom Modell implizierter Kovarianzmatrix (Σ(Θ)) . . .
I . . . wenn Modell in GG so zutrifft?I (Da Σ nicht bekannt, S als Schätzung)
I Probleme?
I Annahme Σ = S unrealistischI Annahme perfekte Reproduktion (Nullhypothese) unrealistischI Signifikanztests und Fallzahlen
I Vielzahl von Anpassungsindizes („shot gun approach“)I Momentan populär: RMSEA
I Weniger abhängig von StichprobenumfangI Relativiert Abweichungen an der Zahl der Freiheitsgrade →
Strafe für overfittingI Geht nicht von perfekter Anpassung aus; Konfidenzintervall
VL Forschungsmethoden SEM II (6/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
ModelfitI Wie gut passen Modellschätzungen zu den Daten?I Traditionell: Test auf Basis eines χ2-Wertes
I Wie wahrscheinlich sind Abweichungen zwischen wahrer (Σ)und vom Modell implizierter Kovarianzmatrix (Σ(Θ)) . . .
I . . . wenn Modell in GG so zutrifft?I (Da Σ nicht bekannt, S als Schätzung)
I Probleme?I Annahme Σ = S unrealistischI Annahme perfekte Reproduktion (Nullhypothese) unrealistischI Signifikanztests und Fallzahlen
I Vielzahl von Anpassungsindizes („shot gun approach“)I Momentan populär: RMSEA
I Weniger abhängig von StichprobenumfangI Relativiert Abweichungen an der Zahl der Freiheitsgrade →
Strafe für overfittingI Geht nicht von perfekter Anpassung aus; Konfidenzintervall
VL Forschungsmethoden SEM II (6/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
ModelfitI Wie gut passen Modellschätzungen zu den Daten?I Traditionell: Test auf Basis eines χ2-Wertes
I Wie wahrscheinlich sind Abweichungen zwischen wahrer (Σ)und vom Modell implizierter Kovarianzmatrix (Σ(Θ)) . . .
I . . . wenn Modell in GG so zutrifft?I (Da Σ nicht bekannt, S als Schätzung)
I Probleme?I Annahme Σ = S unrealistischI Annahme perfekte Reproduktion (Nullhypothese) unrealistischI Signifikanztests und Fallzahlen
I Vielzahl von Anpassungsindizes („shot gun approach“)
I Momentan populär: RMSEAI Weniger abhängig von StichprobenumfangI Relativiert Abweichungen an der Zahl der Freiheitsgrade →
Strafe für overfittingI Geht nicht von perfekter Anpassung aus; Konfidenzintervall
VL Forschungsmethoden SEM II (6/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
ModelfitI Wie gut passen Modellschätzungen zu den Daten?I Traditionell: Test auf Basis eines χ2-Wertes
I Wie wahrscheinlich sind Abweichungen zwischen wahrer (Σ)und vom Modell implizierter Kovarianzmatrix (Σ(Θ)) . . .
I . . . wenn Modell in GG so zutrifft?I (Da Σ nicht bekannt, S als Schätzung)
I Probleme?I Annahme Σ = S unrealistischI Annahme perfekte Reproduktion (Nullhypothese) unrealistischI Signifikanztests und Fallzahlen
I Vielzahl von Anpassungsindizes („shot gun approach“)I Momentan populär: RMSEA
I Weniger abhängig von StichprobenumfangI Relativiert Abweichungen an der Zahl der Freiheitsgrade →
Strafe für overfittingI Geht nicht von perfekter Anpassung aus; Konfidenzintervall
VL Forschungsmethoden SEM II (6/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
Reliabilität und Dimensionalität
Reliabilität: Zuverlässigkeit, Konsistenz einer MessungSkala: Instrument mit mehreren äquivalenten
EinzelindikatorenInterne Konsistenz: Korrelation der Indikatoren untereinander
I Einfache SEM (konfirmatorische Faktorenanalyse) � vieleProbleme der Skalierung
I Konsistenz und schwache ItemsI Eine oder mehrere DimensionenI Meßfehlerbereinigte Korrelation zwischen KonstruktenI Stabilität von (wahren) Meßwerten über die Zeit
VL Forschungsmethoden SEM II (7/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
Gruppenvergleiche und interkulturelle EinstellungsforschungI SEM ermöglicht systematischen Vergleich von Gruppen (z. B.
Test von Gleichheitsrestriktionen)I Funktionieren Instrumente in verschiedenen Ländern in gleicher
Weise (z. B. ESS, ISSP); bspw. verschiedeneIndikatoren/Aspekte von Nationalismus/Patriotismus (Davidov2009)
I Definitionen von Äquivalenz1. Configural Invariance: Indikatoren laden überall auf selbe
Faktoren (gleiche Grafik)2. Metric Invariance: Faktorladungen in allen Ländern gleich
(mittleres Niveau kann sich trotzdem unterscheiden)3. Scalar Invariance: Zusätzlich Achsenabschnitte der Indikatoren
über Länder identisch → Absolute Werte vonIndikatoren/Faktoren vergleichbar, Fehlervarianzen können sichunterscheiden
VL Forschungsmethoden SEM II (8/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
Komplexes Beispiel: Arzheimer/Carter 2009
I Komplexe SEM bilden Systeme von Hypothesen abI Z. B. Arzheimer/Carter 2009: Negative Einstellungen zu
Migranten, Religiosität, Parteiidentifikation und RechtswahlI In verschiedenen europäischen Ländern (mehrere Gruppen)
VL Forschungsmethoden SEM II (9/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
Mega-Monster-Modell (vereinfacht)
rra1 rra2 rra3 rra...
RadicalRightAttitudes
Socio−Demographics(I) RadicalRightVote(IV)
CD−PID
Religiosity(II)
rel1 rel2 rel3 rel4
(III)
VL Forschungsmethoden SEM II (10/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
LISREL
I Für viele Synonym für StrukturgleichungsmodelleI Lange Zeit unzugänglich wg SyntaxI Seit 90er Jahre graphische Oberfläche und vereinfachte Syntax
(SIMPLIS)I Zahlreiche neue ErweiterungenI Test- und Studierendenversionen hier:
http://www.ssicentral.com/lisrel/
VL Forschungsmethoden SEM II (11/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
EQS
I Peter BentlerI Kleine Unterschiede im Modell, äquivalent zu LISRELI In Deutschland wenig verbreitetI Entwicklung seit Jahren stockendI http://www.mvsoft.com/eqs60.htm
VL Forschungsmethoden SEM II (12/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
AMOS
I James ArbuckleI Technische Besonderheiten und graphische Oberfläche (ca.
1988)I Später Modul für SPSSI Inzwischen Übernahme durch IBMI http://www.amosdevelopment.com/ und
http://www-01.ibm.com/software/analytics/spss/products/statistics/amos/
VL Forschungsmethoden SEM II (13/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
MPlus
I Bengt MuthénI Strukturgleichungsmodelle als Spezialfall eines generelleren
ModellsI Transparente Behandlung von kategorialen Variablen
(Indikatoren und Faktoren)I Relativ altmodische Oberfläche, aber sehr schnell und
leistungsfähigI http://www.statmodel.com/demo.shtml
VL Forschungsmethoden SEM II (14/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
(Likert)-SkalierungKomplexe ModelleSoftware
Weitere
I Mehrere Implementationen in R (unter anderem lavaan,http://lavaan.ugent.be/ und OpenMx,http://openmx.psyc.virginia.edu/)
I SmartPLS, http://www.smartpls.de/forum/I Ox (nur für hardcore user, http://www.doornik.com/ox/)I Sehr gute Implementation ab Stata 12
VL Forschungsmethoden SEM II (15/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Dimensionalität
I Theorie: Unterscheidung zwischen kulturellen undökonomischen Bedrohungsgefühlen
I Aber: Findet sich das so in der Realität? → ForschungsfrageI Kann zum Beispiel mit ESS 1 untersucht werden
VL Forschungsmethoden SEM II (16/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Indikatoren
1. „Was würden Sie sagen, nehmen Zuwanderer, die hierher kommen, imAllgemeinen Arbeitnehmern in Deutschland die Arbeitsplätze weg oder helfen sieim Allgemeinen, neue Arbeitsplätze zu schaffen?“ (nehmen Arbeitsplätze weg(10) – schaffen neue Arbeitsplätze (0), imtcjob)
2. „Die meisten Zuwanderer, die hierher kommen, arbeiten und zahlen Steuern. Sienehmen außerdem das Gesundheitssystem und Sozialleistungen in Anspruch.Wenn Sie abwägen, denken Sie, dass Zuwanderer mehr bekommen als sie geben,oder mehr geben, als sie bekommen?“ (bekommen mehr (10) – geben mehr (0)imbleco)
3. „Würden Sie sagen, dass das kulturelle Leben in Deutschland im Allgemeinendurch Zuwanderer untergraben oder bereichert wird?“ (untergraben (10) –bereichert (0) imueclt)
4. „Wird Deutschland durch Zuwanderer zu einem schlechteren oder besseren Ortzum Leben?“ (schlechterer Ort (10) – besserer Ort (0) imwbcnt)
VL Forschungsmethoden SEM II (17/23)
Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
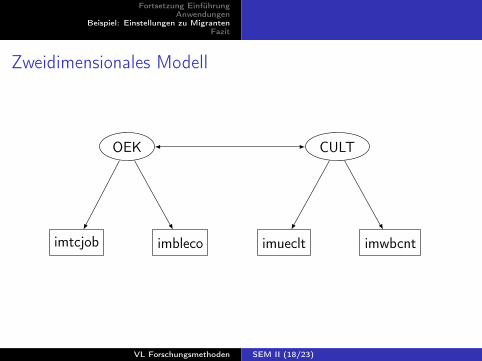
Zweidimensionales Modell
imwbcntimbleco
OEK CULT
imtcjob imueclt
VL Forschungsmethoden SEM II (18/23)
Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
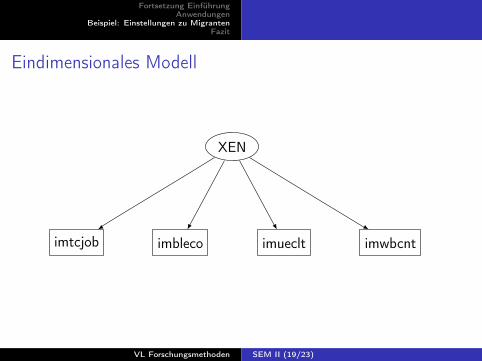
Eindimensionales Modell
imblecoimtcjob
XEN
imueclt imwbcnt
VL Forschungsmethoden SEM II (19/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
In Stata
1 * Zweidimensionales Modell , ML-Schaetzung ,standardisierte Faktoren
2 sem (imtcjob <-OEK) (imbleco <-OEK) (imueclt <-CULT) ///3 (imwbcnt <-CULT) , means(OEK@0 CULT@0) var(OEK@1
CULT@1)4 * Schaetzungen speichern5 est store zweiml6 estat eqgof7 estat gof , stats(ic rmsea)8 * Eindimensionales Modell , ML-Schaetzung ,
standardisierte Faktoren9 sem (imtcjob <-XEN) (imbleco <-XEN) (imueclt <-XEN) ///
10 (imwbcnt <-XEN) , means(XEN@0) var(XEN@1)11 est store einml12 estat eqgof13 estat gof , stats(ic rmsea)
VL Forschungsmethoden SEM II (20/23)
Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
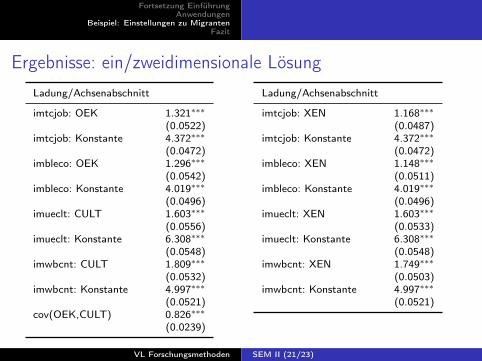
Ergebnisse: ein/zweidimensionale LösungLadung/Achsenabschnitt
imtcjob: OEK 1.321∗∗∗
(0.0522)imtcjob: Konstante 4.372∗∗∗
(0.0472)imbleco: OEK 1.296∗∗∗
(0.0542)imbleco: Konstante 4.019∗∗∗
(0.0496)imueclt: CULT 1.603∗∗∗
(0.0556)imueclt: Konstante 6.308∗∗∗
(0.0548)imwbcnt: CULT 1.809∗∗∗
(0.0532)imwbcnt: Konstante 4.997∗∗∗
(0.0521)cov(OEK,CULT) 0.826∗∗∗
(0.0239)
Ladung/Achsenabschnitt
imtcjob: XEN 1.168∗∗∗
(0.0487)imtcjob: Konstante 4.372∗∗∗
(0.0472)imbleco: XEN 1.148∗∗∗
(0.0511)imbleco: Konstante 4.019∗∗∗
(0.0496)imueclt: XEN 1.603∗∗∗
(0.0533)imueclt: Konstante 6.308∗∗∗
(0.0548)imwbcnt: XEN 1.749∗∗∗
(0.0503)imwbcnt: Konstante 4.997∗∗∗
(0.0521)
VL Forschungsmethoden SEM II (21/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Modellvergleich
Anpassungsmaße ein Faktor zwei Faktoren
Parameter 12 13dfM 2 1χ2M 63.9 12.8RMSEA .137 .0843TLI .897 .961BIC 26842 26799LL -13377 -13351N 1659 1659
VL Forschungsmethoden SEM II (22/23)

Fortsetzung EinführungAnwendungen
Beispiel: Einstellungen zu MigrantenFazit
Zusammenfassung
I SEM: Extrem mächtiges Verfahren (mit diversen Fallstricken)I Kein WundermittelI Aber ausgezeichnetes Werkzeug zur Bearbeitung vieler
sozialwissenschaftlicher Fragen
VL Forschungsmethoden SEM II (23/23)











![Vorlesung: Pädiatrie Infektiologie Teil I · (Microsoft PowerPoint - 1. Vorlesung Infekt.NETZ.ppt [Schreibgesch tzt] [Kompatibilit tsmodus]) Vorlesung Infekt.NETZ.ppt [Schreibgesch](https://img.dokumen.tips/doc/110x75/5d4b913888c99388658b7be4/vorlesung-paediatrie-infektiologie-teil-i-microsoft-powerpoint-1-vorlesung.jpg)

















