Embed Size (px)
Citation preview

SSD: Single Shot Multibox Detector
NamHyuk Ahn

Object Detection
- mean Average Precision (mAP)
• Popular eval metric
• Compute average precisionfor single class, and average them over all classes
• Detections is True-positive if box is overlap with ground-truth more than some threshold (usually use 0.5)

Object Detection
- R-CNN Family• Most popular detection method in deep learning
• Use region proposal method <- make model slow
• Good accuracy (Faster: 73.2% mAP), but very slow
• R-CNN: 50 sec/img, Fast: 2 sec/img, Faster: 0.2 sec/img (7 FPS)
- YOLO (You Only Look Once)• Real-time (45 FPS), but low accuracy (63.4% mAP)

YOLO:You Only Look Once- Single shot detector model
• Not separate classification and bbox regression
- Divide image into S x S grid (7x7 in paper)• Within each grid cell, (4+1)*B + C vector,
• B: # of boxes in each grid (2 in paper)C: # of classes (20 in paper)(4+1): 4 box coord + 1 box confidence
- Direct prediction using CNN with regression loss
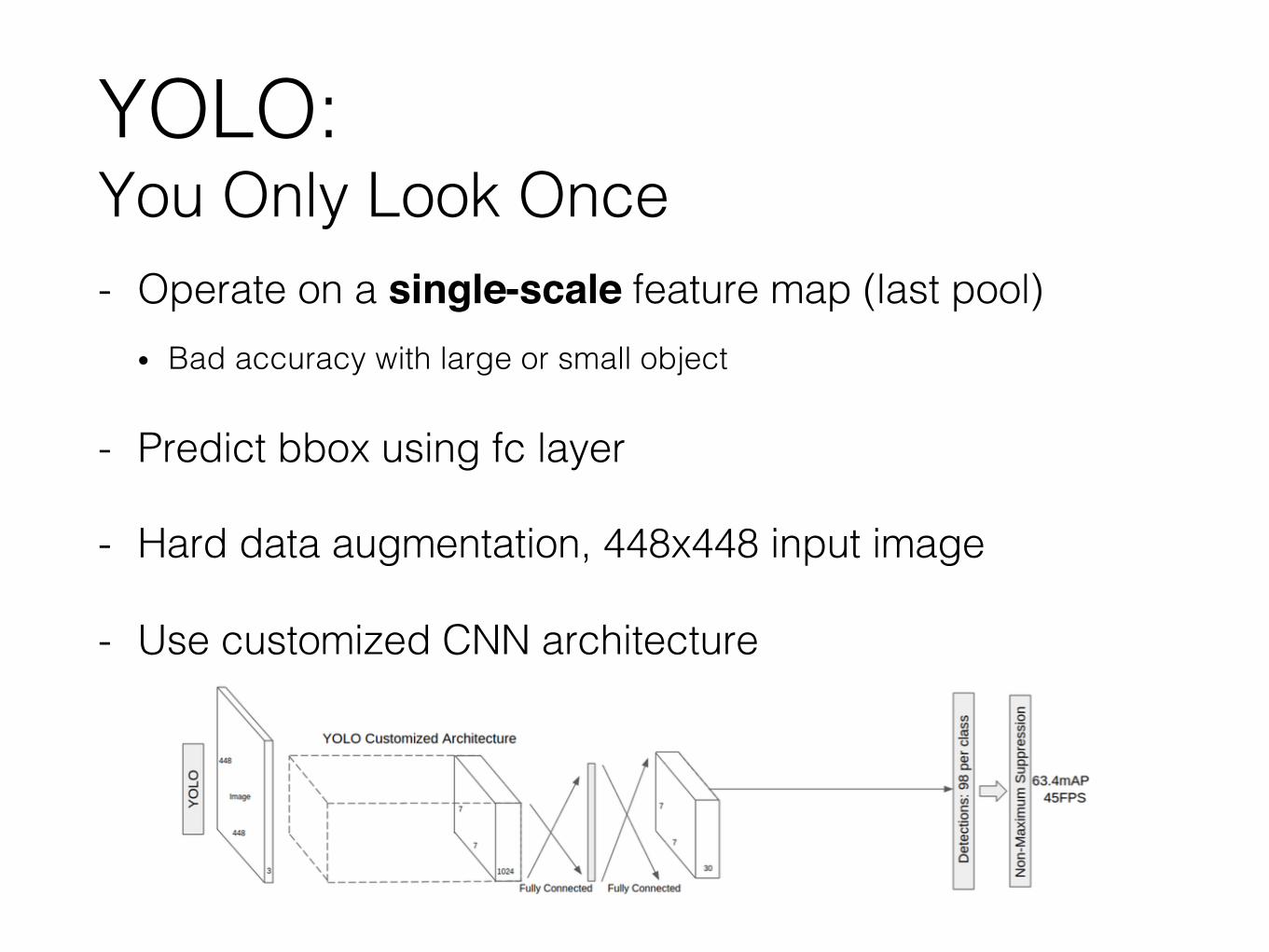
YOLO:You Only Look Once- Operate on a single-scale feature map (last pool)
• Bad accuracy with large or small object
- Predict bbox using fc layer
- Hard data augmentation, 448x448 input image
- Use customized CNN architecture

SSD:Single Shot Multibox Detector
- Multi-scale feature maps for detection • Add conv layer at the end of base network, decrease size progressively
• Concat output of multi-scale feature map at the last layer
- Convolutional predictors for detection• YOLO use fc layer, but SSD use 3x3 conv kernel

SSD:Single Shot Multibox Detector- Default boxes and aspect ratios
• Set default boxes at each location, and predict offset relative to corresponding default box
• output dims: (C+4)K*M*N, K=# of default box, C=# of classes, MN=feature dims

SSD:Single Shot Multibox Detector
- Default boxes and aspect ratios• Use 6 default boxes at each feature cell
• { 1, 2, 3, 1/2, 1/3 } aspect ratio boxes + 1 box with 1 aspect ratio
• Set 3 boxes in conv4_3 to reduce computation

SSD:Single Shot Multibox Detector- Output feature (final layer)
• With given output boxes from multi-scale features, sort them using class confidence
• Pick top-200 boxes and make each box 7-dim vector
• [ batch_idx, class_confidence, label, box offset…]
• Output feature dim is 7x200
•

Model analysis- Data argumentation is very important
- More feature map is better• Lower feature map can capture fine-grained details of object
- More default box shape is better• If you only 4 boxes, performance drop by 0.9%
• Using variety shape of default box makes predicting box easier
- Astrous VGG is better and faster
Result
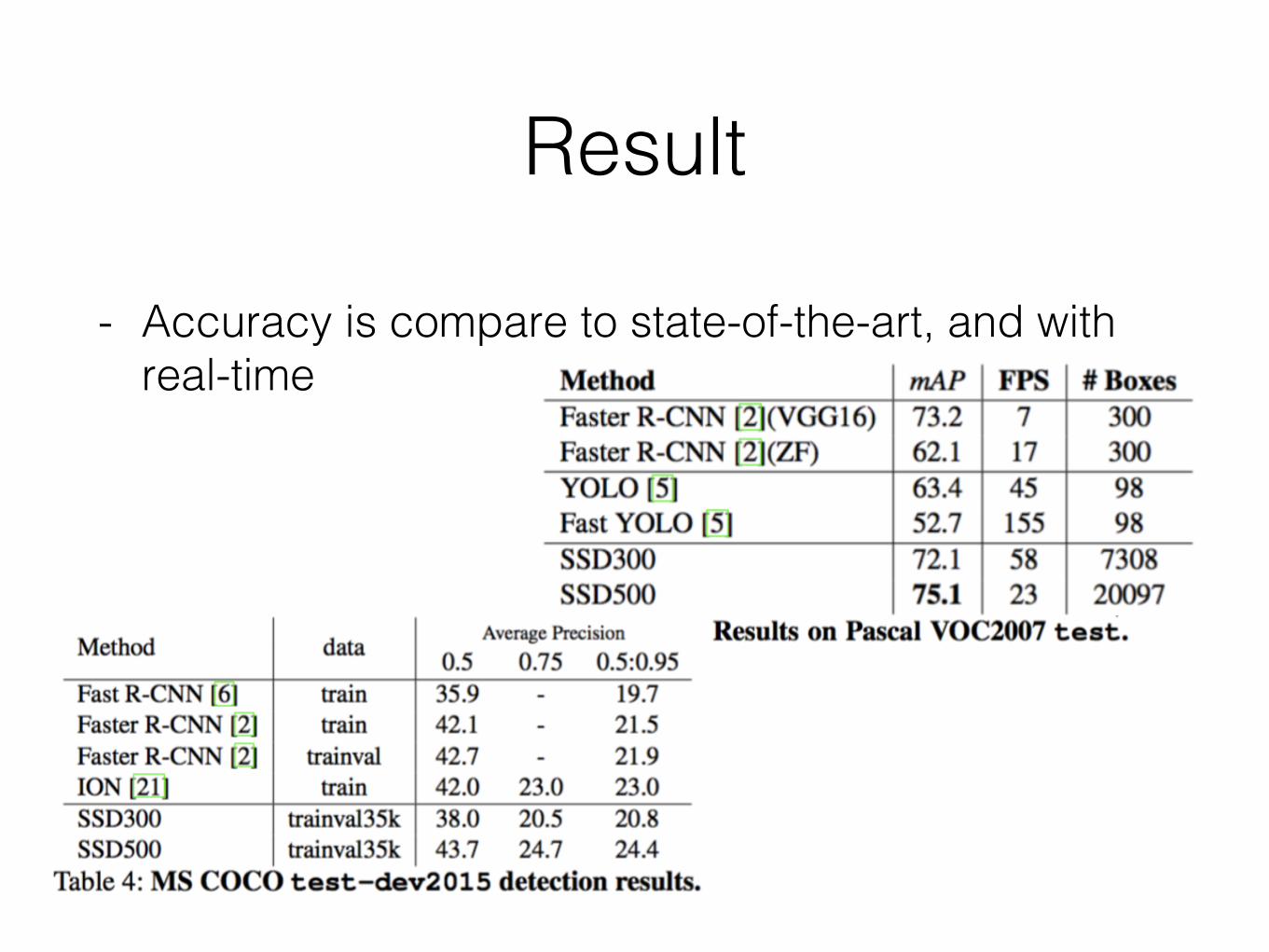
- Accuracy is compare to state-of-the-art, and with real-time

Reference
- Liu, Wei, et al. "SSD: Single Shot MultiBox Detector." arXiv preprint arXiv:1512.02325 (2015).
![Single Shot Text Detector with Regional Attention · Single Shot Text Detector with Regional Attention ... Single shot multibox detector, ECCV, 2016. [5] C. Szegedy, W. Liu, Y. Jia,](https://img.dokumen.tips/doc/110x75/5ece2fa46bbfcd2591178dd5/single-shot-text-detector-with-regional-attention-single-shot-text-detector-with.jpg)











![An algorithm for highway vehicle detection based on ... · Faster R-CNN and Single Shot MultiBox Detector (SSD) using aspect ratios are [0.5, 1, 2], but the aspect ratio range of](https://img.dokumen.tips/doc/110x75/5ece30266bbfcd2591178efa/an-algorithm-for-highway-vehicle-detection-based-on-faster-r-cnn-and-single.jpg)



![Detect-SLAM: Making Object Detection and SLAM Mutually ... · Single Shot Multibox Object Detector (SSD) [14] is the first DNN-based real-time object detector that achieves above](https://img.dokumen.tips/doc/110x75/5ece30266bbfcd2591178ef9/detect-slam-making-object-detection-and-slam-mutually-single-shot-multibox.jpg)

![arXiv:1512.02325v2 [cs.CV] 30 Mar 2016 · PDF fileSSD: Single Shot MultiBox Detector Wei Liu1, Dragomir Anguelov2, Dumitru Erhan3, Christian Szegedy3, Scott Reed4, Cheng-Yang Fu 1,](https://img.dokumen.tips/doc/110x75/5a7c29977f8b9a2e358c7b16/arxiv151202325v2-cscv-30-mar-2016-single-shot-multibox-detector-wei-liu1-dragomir.jpg)










