Embed Size (px)
Citation preview

Driving in TORCS withDeep Deterministic Policy Gradient
Final Report
Naoto Yoshida

About Me
● Ph.D. student from Tohoku University● My Hobby:
○ Reading Books○ TBA
● NEWS:○ My conference paper on the reward function was
accepted!■ SCIS&ISIS2016 @ Hokkaido

Outline● TORCS and Deep Reinforcement Learning● DDPG: An Overview● In Toy Domains● In TORCS Domain● Conclusion / Impressions

TORCS and Deep Reinforcement Learning

TORCS: The Open source Racing Car Simulator● Open source● Realistic (?) dynamics simulation of the car environment

Deep Reinforcement Learning● Reinforcement Learning + Deep Learning
○ From Pixel to Action■ General game play in ATARI domain■ Car Driver■ (Go Expert)
● Deep Reinforcement Learning in Continuous Action Domain: DDPG○ Lillicrap, Timothy P., et al.
"Continuous control with deep reinforcement learning." , ICLR 2016
Vision-based Car agent in TORCSSteering + Accel/Blake = 2 dim continuous actions

DDPG: An overview

GOAL: Maximization of in expectation
Reinforcement Learning
Agent
Environment
Action : a
State : sReward : r

GOAL: Maximization of in expectation
Reinforcement Learning
Agent
Environment
Action : a
State : sReward : r
Interface
Raw output: u
Raw input: x

Deterministic Policy Gradient● Formal Objective Function: Maximization of True Action Value
● Policy Evaluation: Approximation of the objective function
● Policy Improvement: Improvement of the objective function
where
Bellman equationwrt Deterministic Policy
Loss for Critic
Update direction of Actor
Silver, David, et al. "Deterministic policy gradient algorithms." ICML. 2014.

Deep Deterministic Policy Gradient
Initialization
Update of Critic+ minibatch
Update of Actor+ minibatch
Update of Target
Sampling / Interaction
RL agent(DDPG)
s, ra
TORCS
Lillicrap, Timothy P., et al. "Continuous control with deep reinforcement learning.", ICLR 2016
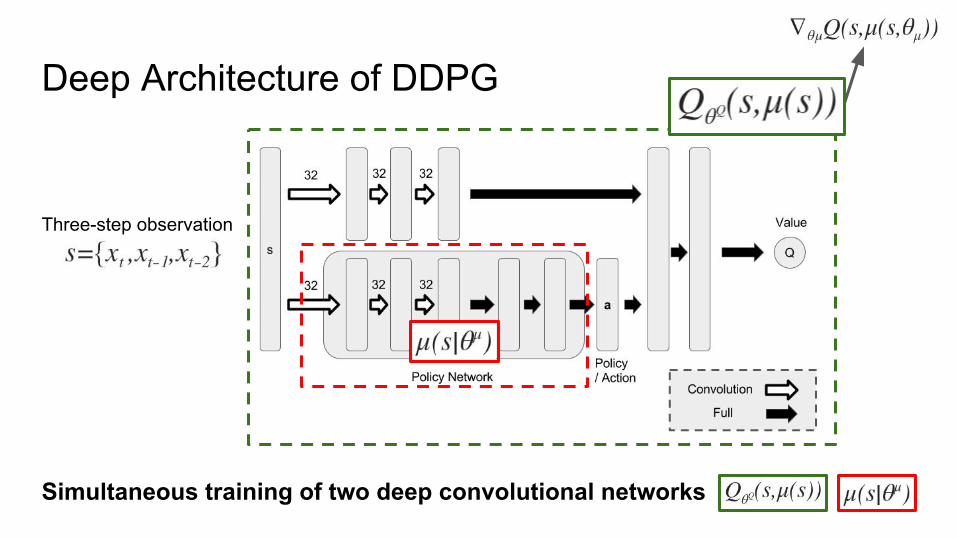
Deep Architecture of DDPG
Three-step observation
Simultaneous training of two deep convolutional networks

Exploration: Ornstein–Uhlenbeck process● Gaussian noise with moments
○ θ,σ:parameters○ dt:time difference○ μ:mean (= 0.)
● Stochastic Differential Equation:
● Exact Solution for the discrete time step:
SDE
Wiener Process
Gaussian

OU process: Example
GaussianOU Process
θ = 0.15, σ = 0.2,μ = 0

DDPG in Toy Domains
https://gym.openai.com/

Toy Problem: Pendulum Swingup● Classical RL benchmark task
○ Nonlinear control:○ Action: Torque○ State:
○ Reward:
From “Reinforcement Learning In Continuous Time and Space”, Kenji Doya, 2000

Results
# of Episode

Results: SVG(0)
# of Episode

Toy Problem 2: Cart-pole Balancing● Another classical benchmark task
○ Action: Horizontal Force○ State:
○ Reward: (other definition is possible)■ +1 (angle is in the area)■ 0 (Episode Terminal)
Angle Area
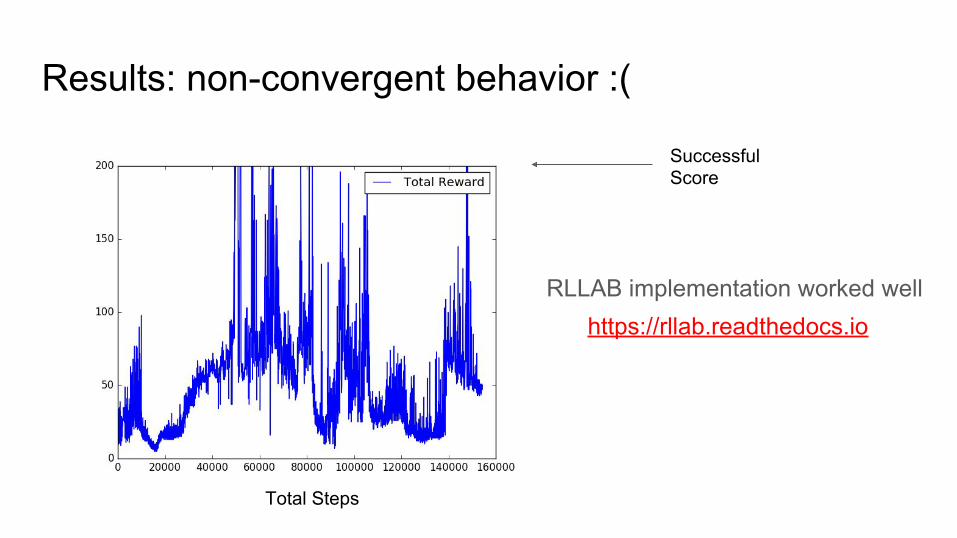
Results: non-convergent behavior :(
RLLAB implementation worked well
SuccessfulScore
Total Steps
https://rllab.readthedocs.io

DDPG in TORCS Domain
Note: Red line : Parameters with Author Confirmation / DDPG paper Blue line : Estimated/Hand-tuned Parameters

Track: Michigan Speedway● Used in DDPG paper● This track actually exists!
www.mispeedway.com

TORCS: Low-dimensional observation● TORCS supports low-dimensional sensor outputs for AI agent
○ “Track” sensor○ “Opponent” sensor○ Speed sensor○ Fuel, damage, wheel spin speed etc.
● Track + speed sensor as observation● Network: Shallow network● Action: Steering (1 dim) ● Reward:
○ If car clashed/course out , car gets penalty -1○ otherwise
“Track” Laser Sensor
Track Axis
Car Axis
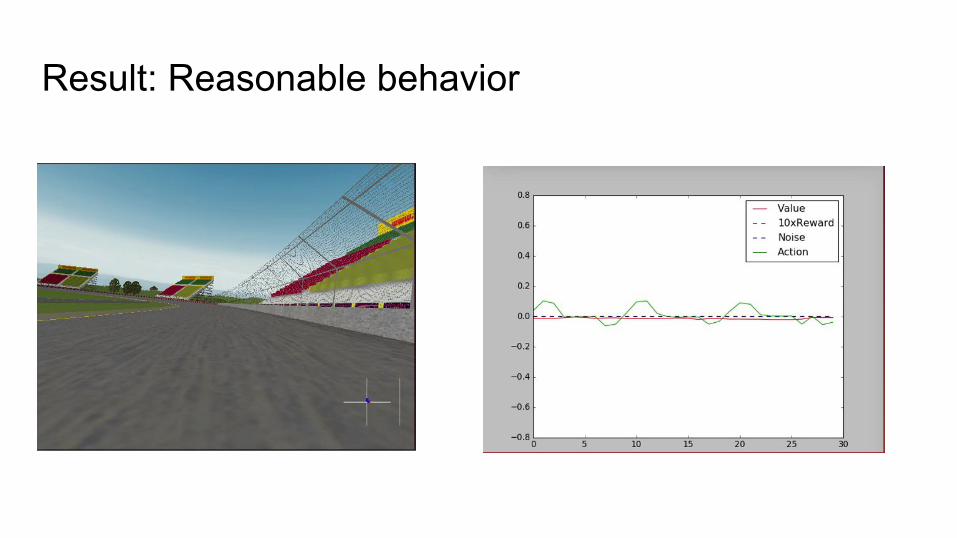
Result: Reasonable behavior

TORCS: Vision inputs● Two deep convolutional neural networks
○ Convolution:■ 1st layer: 32 filters, 5x5 kernel, stride 2, paddling 2■ 2nd, 3rd layer: 32 filters, 3x3 kernel, stride 2, paddling 1■ Full-connection: 200 hidden nodes

VTORCS-RL-color
● Visual TORCS○ TORCS for Vision-based AI agent
■ Original TORCS does not have vision API!■ vtorcs:
● Koutník et al., "Evolving deep unsupervised convolutional networks for vision-based reinforcement learning, ACM, 2014.
○ Monochrome image from TORCS server■ Modification for the color vision → vtorcs-RL-color
○ Restart bug■ Solved with help of mentors’ substantial suggestions!

Result: Still not a good result...

What was the cause of the failure?● DDPG implementation?
○ Worked correctly, at least in toy domains.■ The approximation of value functions → ok
● However, policy improvement failed in the end.■ Default exploration strategy is problematic in TORCS environment
● This setting may be for general tasks● Higher order exploration in POMDP is required
● TROCS environment?○ Still several unknown environment parameters
■ Reward → ok (DDPG author check)■ Episode terminal condition → still various possibilities
(from DDPG paper)

gym-torcs・TORCS environment with openAI-Gym like interface

Impressions● On DDPG
○ Learning of the continuous control is a tough problem :(■ Difficulty of policy update in DDPG■ “Twice” recommendation of Async method by DDPG author (^ ^;)
● Throughout this PFN internship:○ Weakness: Coding
■ Thank you! Fujita-san, Kusumoto-san■ I knew many weakness of my coding style
○ Advantage: Reinforcement Learning Theory■ and its branched algorithms, topics and relationships between RL and Inference■ For DEEP RL, Fujita-san is an auth. in Japan :)

Update after the PFI seminar
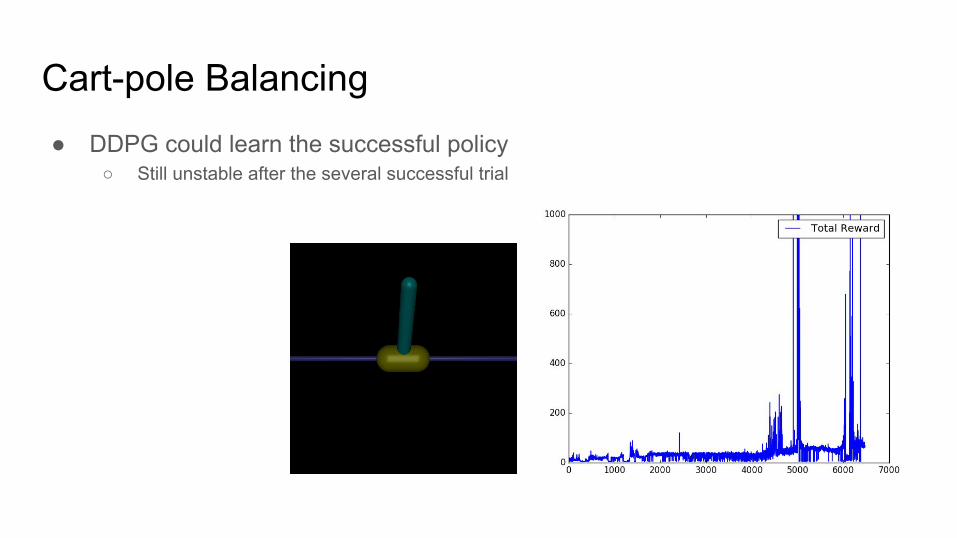
Cart-pole Balancing● DDPG could learn the successful policy
○ Still unstable after the several successful trial

Success in Half-Cheetah Experiment● We could run successful experiment with identical hyper parameters in cart-
pole.
300-step total reward
Episode

Keys in DDPG / deep RL● Normalization of the environment
○ Preprocess is known to be very important for deep learning. ■ This is also true in deep RL.■ Scaling of inputs (possibly, and actions, rewards) will help the agent to learn.
● Possible normalization:○ Simple normalization helps: x_norm = (x - mean_x)/std_x ○ Mean and Standard deviation are obtained during the initial exploration.○ Other normalization like ZCA/PCA whitening may also help.
● Epsilon parameter in Adam/RMS prop can be large value○ 0.1, 0.01, 0.001… We still need a hand-tuning / grid search...





























