Embed Size (px)
Citation preview

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Implementation and Comparison of SoftcoreMultiplier Architectures for FPGAs
Shahid Abbas
Projektarbeit (Master of Science)Fachgebiet Digitaltechnik
Universtat Kassel
August 22, 2014
1 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Outline
1 Introduction and BackgroundMotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
2 Multiplier ArchitecturesTarget Specific ImplementationLUT-Based Multipliers
3 ResultsSimulationSynthesis Results
4 Conclusion
2 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Outline
1 Introduction and BackgroundMotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
2 Multiplier ArchitecturesTarget Specific ImplementationLUT-Based Multipliers
3 ResultsSimulationSynthesis Results
4 Conclusion
2 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Outline
1 Introduction and BackgroundMotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
2 Multiplier ArchitecturesTarget Specific ImplementationLUT-Based Multipliers
3 ResultsSimulationSynthesis Results
4 Conclusion
2 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Outline
1 Introduction and BackgroundMotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
2 Multiplier ArchitecturesTarget Specific ImplementationLUT-Based Multipliers
3 ResultsSimulationSynthesis Results
4 Conclusion
2 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Motivations
Fast Multiplication for Signal Processing
Limited number of DSP Blocks in FPGA [1]
Fixed word size
Use big multiplier for small word size
Fixed allocation
Place and routing issues
Use of FPGA logic blocks for multiplier of any word size
Softcore multiplier that work in conjunction with DSP multipliers
3 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Fundamentals of Binary Multiplication
1 Partial Products Calculation
2 Addition of Partial Products by proper shifting
A=A3
B=B3
20·B0·A
x
+
Step 1
Step 2
A0…
… B0
21·B1·A
22·B2·A
23·B3·A
+
+
=
Figure: Binary 4×4-bit Multiplication
4 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Fundamentals of Binary Multiplication
1 Partial Products Calculation
2 Addition of Partial Products by proper shifting
A=A3
B=B3
20·B0·A
x
+
Step 1
Step 2
A0…
… B0
21·B1·A
22·B2·A
23·B3·A
+
+
=
Figure: Binary 4×4-bit Multiplication
4 / 25
Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
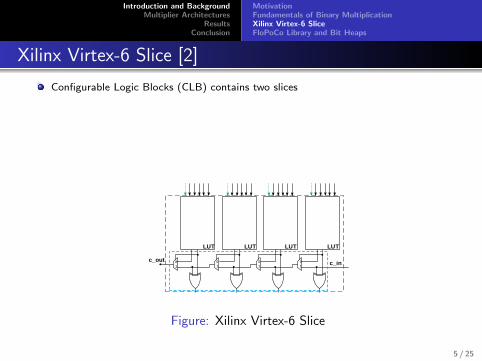
Xilinx Virtex-6 Slice [2]
Configurable Logic Blocks (CLB) contains two slices
Each slice contains four Look-Up Tables (LUT), eight Flip-Flops, multiplexers and acarry-propagation logic.
Single or two outputs per LUT
0
1
0
1
0
10
1c_in
c_out
LUTLUTLUTLUT
Figure: Xilinx Virtex-6 Slice
5 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
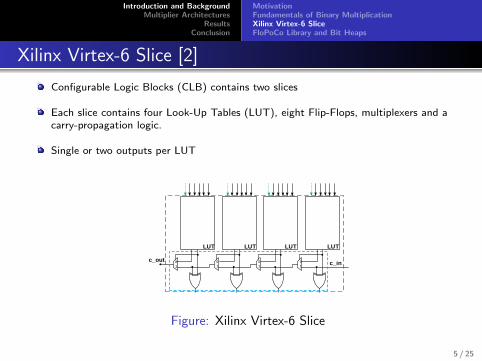
Xilinx Virtex-6 Slice [2]
Configurable Logic Blocks (CLB) contains two slices
Each slice contains four Look-Up Tables (LUT), eight Flip-Flops, multiplexers and acarry-propagation logic.
Single or two outputs per LUT
0
1
0
1
0
10
1c_in
c_out
LUTLUTLUTLUT
Figure: Xilinx Virtex-6 Slice
5 / 25
Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
Xilinx Virtex-6 Slice [2]
Configurable Logic Blocks (CLB) contains two slices
Each slice contains four Look-Up Tables (LUT), eight Flip-Flops, multiplexers and acarry-propagation logic.
Single or two outputs per LUT
0
1
0
1
0
10
1c_in
c_out
LUTLUTLUTLUT
Figure: Xilinx Virtex-6 Slice
5 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
FloPoCo Library and Bit Heaps
Floating-Point Cores (FloPoCo), C++ framework for synthesizable VHDL code [3] [4].
Bit heap is a data-structure holds unevaluated sum of any number of bits weighted bypower of two [5].
Equally weighted bits aligned in column as order is irrelevant for sum
before first compression
1 0.530 ns
1 1.061 ns
before 3-bit height additions
before final addition
Figure: Bit-Heap Structure for 16×16-Bit Multiplier
6 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
FloPoCo Library and Bit Heaps
Floating-Point Cores (FloPoCo), C++ framework for synthesizable VHDL code [3] [4].
Bit heap is a data-structure holds unevaluated sum of any number of bits weighted bypower of two [5].
Equally weighted bits aligned in column as order is irrelevant for sum
before first compression
1 0.530 ns
1 1.061 ns
before 3-bit height additions
before final addition
Figure: Bit-Heap Structure for 16×16-Bit Multiplier
6 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
MotivationFundamentals of Binary MultiplicationXilinx Virtex-6 SliceFloPoCo Library and Bit Heaps
FloPoCo Library and Bit Heaps
Floating-Point Cores (FloPoCo), C++ framework for synthesizable VHDL code [3] [4].
Bit heap is a data-structure holds unevaluated sum of any number of bits weighted bypower of two [5].
Equally weighted bits aligned in column as order is irrelevant for sum
before first compression
1 0.530 ns
1 1.061 ns
before 3-bit height additions
before final addition
Figure: Bit-Heap Structure for 16×16-Bit Multiplier
6 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation [6]
Best Fit design in Logic Blocks = Better Performance
a b
c_out c_in
sum
0
1
Figure: Full Adder Implementation with Multiplexer and XOR-Gates
7 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation [6]
0
1
0
1
0
10
1c_in
c_out
S0S1S2S3
LUTLUTLUTLUT
a0b0a1b1a2b2a3b3a4b4a5b5a6b6a7b7
Figure: Slice configuration of 4-LUTs for Partial Product and Addition
8 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation (Automated)
vector < vector < pair < int, int >>>
0
00
0
0
c_in=0
c_out (to bit-heap)
Partial-Product Calculation
Re-arrangement
3-LUT Slice
4-LUT Slice
n 8-bit
m 8-bit
Before MultiplicationA
B
20·B0·A
21·B1·A
22·B2·A
23·B3·A
24·B4·A
25·B5·A
26·B6·A
27·B7·A
Figure: 8×8-bit Multiplier Implementation in FloPoCo9 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation (For 8×8-bit Multiplier)
Automated Implementation
vector < vector < pair < int, int >>>
Manual interconnection of Slices
Addition using Bit Heaps
Addition using Arithmetic Expressions
10 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation (For 8×8-bit Multiplier)
Automated Implementation
vector < vector < pair < int, int >>>
Manual interconnection of Slices
Addition using Bit Heaps
Addition using Arithmetic Expressions
10 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation (For 8×8-bit Multiplier)
Automated Implementation
vector < vector < pair < int, int >>>
Manual interconnection of Slices
Addition using Bit Heaps
Addition using Arithmetic Expressions
10 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation (For 8×8-bit Multiplier)
Automated Implementation
vector < vector < pair < int, int >>>
Manual interconnection of Slices
Addition using Bit Heaps
Addition using Arithmetic Expressions
10 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation (For 8×8-bit Multiplier)
Automated Implementation
vector < vector < pair < int, int >>>
Manual interconnection of Slices
Addition using Bit Heaps
Addition using Arithmetic Expressions
10 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
Target Specific Implementation (Manual)
Re-arrangement
To b
it h
eap
To b
it h
eap
To b
it h
eap
To b
it h
eap
To b
it h
eap
AND-gate
Figure: 8×8-bit Multiplier with Manual Interconnection of Slices
11 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers [7] [5]
Multiplication of two numbers can be obtained by the bit shifted additions ofsmall multiplier result
A = 2nA1 + A0 (1)
B = 2nB1 + B0 (2)
A× B = 22nA1B1 + 2n(A1B0 + A0B1) + A0B0 (3)
A basic n ×m-bit multiplier can be instantiated multiple times
Add results of each instance through proper shifting
12 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers [7] [5]
Multiplication of two numbers can be obtained by the bit shifted additions ofsmall multiplier result
A = 2nA1 + A0 (1)
B = 2nB1 + B0 (2)
A× B = 22nA1B1 + 2n(A1B0 + A0B1) + A0B0 (3)
A basic n ×m-bit multiplier can be instantiated multiple times
Add results of each instance through proper shifting
12 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers [7] [5]
Multiplication of two numbers can be obtained by the bit shifted additions ofsmall multiplier result
A = 2nA1 + A0 (1)
B = 2nB1 + B0 (2)
A× B = 22nA1B1 + 2n(A1B0 + A0B1) + A0B0 (3)
A basic n ×m-bit multiplier can be instantiated multiple times
Add results of each instance through proper shifting
12 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers [7] [5]
3×3-LUT based Multipliers (Needs 6-LUTs for 6 output Bits)
3×2-LUT based Multipliers (Needs 3-LUTs for 5 output Bits)
1×4-LUT based Multipliers
33
6
A B
Y
Figure: 3×3-LUT Multiplier
3
5
A B
Y
2
Figure: 3×2-LUT Multiplier
13 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers [7] [5]
3×3-LUT based Multipliers (Needs 6-LUTs for 6 output Bits)
3×2-LUT based Multipliers (Needs 3-LUTs for 5 output Bits)
1×4-LUT based Multipliers
33
6
A B
Y
Figure: 3×3-LUT Multiplier
3
5
A B
Y
2
Figure: 3×2-LUT Multiplier
13 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers [7] [5]
3×3-LUT based Multipliers (Needs 6-LUTs for 6 output Bits)
3×2-LUT based Multipliers (Needs 3-LUTs for 5 output Bits)
1×4-LUT based Multipliers
33
6
A B
Y
Figure: 3×3-LUT Multiplier
3
5
A B
Y
2
Figure: 3×2-LUT Multiplier
13 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers (3×3-LUT based 8×7 Multiplier)
3x3 3x3
3x33x3
0 1 2 3 4 5
0
1
23
4
5
2x3
2x3
3x1 3x16 2x1
6 7
A
B
i ii
iii iv
v
vi
vii viii ix
Figure: 8×7-bit LUT-Multiplier Implementation in FloPoCo
AB = A0..2B0..2 + 23(A3..5B0..2 + A0..2B3..5) + 26(A6..7B0..2 + A3..5B3..5 + A0..2B6)
+ 29(A6..7B3..5 + A3..5B6) + 212A6..7B6
(4)
14 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Target Specific ImplementationLUT-Based Multipliers
LUT-Based Multipliers (3×3-LUT based 8×7 Multiplier)
3x3 3x3
3x33x3
0 1 2 3 4 5
0
1
23
4
5
2x3
2x3
3x1 3x16 2x1
6 7
A
B
i ii
iii iv
v
vi
vii viii ix
Figure: 8×7-bit LUT-Multiplier Implementation in FloPoCo
AB = A0..2B0..2 + 23(A3..5B0..2 + A0..2B3..5) + 26(A6..7B0..2 + A3..5B3..5 + A0..2B6)
+ 29(A6..7B3..5 + A3..5B6) + 212A6..7B6
(4)
14 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Simulation
1 Word sizes are even and equal
2 Word sizes are even and unequal.
3 Width of large word is even and other is odd
4 Width of large word is odd and other is even
5 Word sizes are odd and unequal
6 Word sizes are odd and equal
Eight Designs for every of above specifications
48-Designs for each architecture
Self-Checking testbenches were generated using FloPoCo function emulate(TestCase*tc)
TestBench 10000 option was used to generated 10000 random testcases during core-generation.
Simulation on ModelSim
15 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Synthesis Results
0 500 1000 1500 2000 2500 3000 3500 4000 45000
100
200
300
400
500
600
700
800
900
1000
Speed Vs Complexity (N X M)
Complexity (N X M)
Fre
quency (
MH
z)
fmax
= 906.62 MHz in Target Specific Multiplier
Target Specfic Multiplier
3x3 LUT Multiplier
1x4 LUT Multiplier
3x2 LUT Multiplier
Figure: Comparison of Architectures on the basis of Speed (for N×M-bit)
16 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Synthesis Results
0 10 20 30 40 50 60 700
100
200
300
400
500
600
700Speed Vs Complexity (N X N)
Complexity (N)
Fre
quency (
MH
z)
Target Specfic Multiplier
3x3 LUT Multiplier
1x4 LUT Multiplier
3x2 LUT Multiplier
Figure: Comparison of Architectures on the basis of Speed (for N×N-bit)
17 / 25
Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
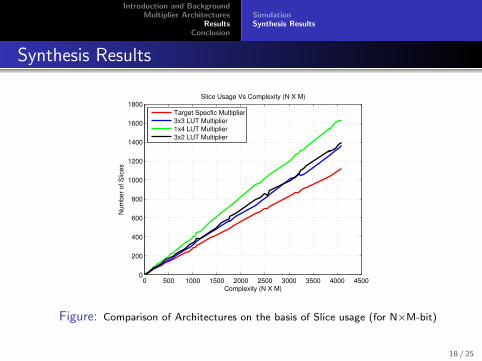
Synthesis Results
0 500 1000 1500 2000 2500 3000 3500 4000 45000
200
400
600
800
1000
1200
1400
1600
1800Slice Usage Vs Complexity (N X M)
Complexity (N X M)
Num
ber
of S
lices
Target Specfic Multiplier
3x3 LUT Multiplier
1x4 LUT Multiplier
3x2 LUT Multiplier
Figure: Comparison of Architectures on the basis of Slice usage (for N×M-bit)
18 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Synthesis Results
0 10 20 30 40 50 60 700
200
400
600
800
1000
1200
1400
1600
1800Slice Usage Vs Complexity (N X N)
Complexity (N)
Num
ber
of S
lices
Target Specfic Multiplier
3x3 LUT Multiplier
1x4 LUT Multiplier
3x2 LUT Multiplier
Figure: Comparison of Architectures on the basis of Speed (for N×N-bit)
19 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Synthesis Results
Average Performance
Table: Average values of parameters for different architectures
Architecture No. of Flip-Flops No. of LUTs No. of Slices Frequency (MHz)
Target Specific 1144 1615 419 346.36
3×3-LUT 1422 1893 491 301.03
3×2-LUT 1730 1962 513 264.95
1×4-LUT 2019 2340 610 259.98
20 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Synthesis Results
Automatic Vs Manual Interconnection of Slices (8×8-bit)
Table: Automatic Vs Manual routing between Slices
No. of FFs No. of LUTs No. of Slices Frequency (MHz)
Automatic 56 74 21 686.81
Manual(Bit Heap) 22 74 20 256.61
Manual (Without Bit Heap) 40 59 16 414.08
21 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
SimulationSynthesis Results
Synthesis Results
Automatic Vs Manual Interconnection of Slices (8×8-bit)
before first compression
before 3-bit height additions
before final addition
Figure: Bit Heap Structure for AutomaticInterconnection of Slices
before first compression
1 0.530 ns
before 3-bit height additions
before final addition
Figure: Bit Heap Structure for ManualInterconnection of Slices
22 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Conclusion
Fast multipliers with minimum resources can be implementedby choosing appropriate architecture.
Target Specific Implementation showed best results due toaverage fast speed and less consumption of resources.
Automated generation of this approach can modified withintroduction of AND-gate for corner elements.
Slice usage can be improved by their manual interconnection,with compromise over speed.
23 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Conclusion
Fast multipliers with minimum resources can be implementedby choosing appropriate architecture.
Target Specific Implementation showed best results due toaverage fast speed and less consumption of resources.
Automated generation of this approach can modified withintroduction of AND-gate for corner elements.
Slice usage can be improved by their manual interconnection,with compromise over speed.
23 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Conclusion
Fast multipliers with minimum resources can be implementedby choosing appropriate architecture.
Target Specific Implementation showed best results due toaverage fast speed and less consumption of resources.
Automated generation of this approach can modified withintroduction of AND-gate for corner elements.
Slice usage can be improved by their manual interconnection,with compromise over speed.
23 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Conclusion
Fast multipliers with minimum resources can be implementedby choosing appropriate architecture.
Target Specific Implementation showed best results due toaverage fast speed and less consumption of resources.
Automated generation of this approach can modified withintroduction of AND-gate for corner elements.
Slice usage can be improved by their manual interconnection,with compromise over speed.
23 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
References
[1] Ian Kuon and J. Rose.Measuring the Gap Between FPGAs and ASICs.Computer-Aided Design of Integrated Circuits and Systems, 26:203–215, February 2007.
[2] Xilinx.Virtex-6 FPGA, Configurable Logic Block User Guide, UG364 (v1.2).http://www.xilinx.com/support/documentation/user_guides/ug364.pdf, 2012.
[3] F. de Dinechin and B. Pasca.Designing Custom Arithmetic Data Paths with FloPoCo.Design and Test of Computers, 28:18–27, 2011.
[4] Florent de Dinechin.Tutorial held at HiPEAC’2013 “Building Custom Arithmetic Operators with the FloPoCo Generator”.http://perso.citi-lab.fr/fdedinec/recherche/2013-HiPEAC-Tutorial-FloPoCo/flopoco-tutorial.pdf,2013.
[5] Brunie N., de Dinechin F., Istoan M., Sergent G., Illyes K., and Popa B.Arithmetic core generation using bit heaps.In Proc. IEEE FPL ’2013, pages 1–8, Porto, Portugal, 2–4, 2013.
[6] H. ParandehAfshar and P. Ienne.Measuring and Reducing the Performance Gap between Embedded and Soft Multipliers on FPGAs.In Proc. IEEE FPL ’2011, pages 225–231, Chania, Greece, 5–7, 2011.
[7] F. de Dinechin and B. Pasca.Large multipliers with fewer DSP blocks.In Proc. IEEE FPL ’2009, pages 225–231, Chania, Greece, Aug 31-Sept 2 2011.
24 / 25

Introduction and BackgroundMultiplier Architectures
ResultsConclusion
Thanks for your attention !
25 / 25





























