Embed Size (px)
Citation preview

Machine Learning for Language Technology 2015http://stp.lingfil.uu.se/~santinim/ml/2015/ml4lt_2015.htm
Basic Concepts of Machine LearningInduction & Evaluation
Marina [email protected]
Department of Linguistics and PhilologyUppsala University, Uppsala, Sweden
Autumn 2015

Acknowledgments
• Daume’ (2015), Alpaydin (2010), NLTK website, other web sites.
Lecture 3: Basic Concepts of ML 2

Outline
• Induction– Induction pipeline
• Training set, test set and development set• Parameters• Hyperparameters• Accuracy, precision, recall, f-measure• Confusion matrix• Crossvalidation• Leave one out• Stratification
Lecture 3: Basic Concepts of ML 3
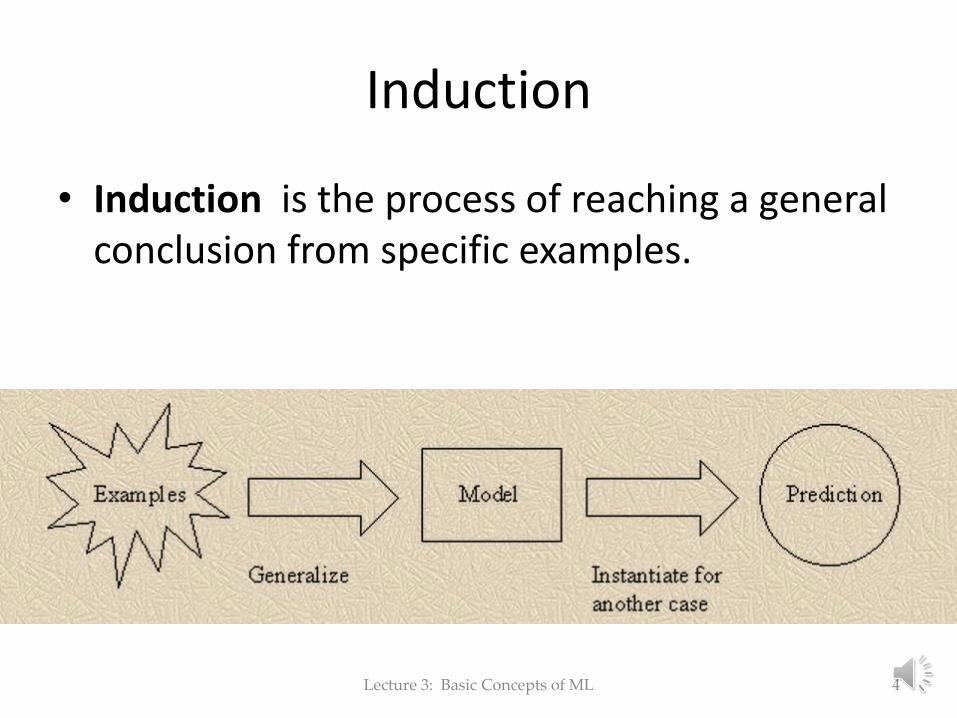
Induction
• Induction is the process of reaching a general conclusion from specific examples.
Lecture 3: Basic Concepts of ML 4

Inductive Machine Learning
• The goal of inductive machine learning is to take some training data and use it to induce a function (model, classifier, learning algorithm).
• This function will be evaluated on the test data.
• The machine learning algorithm has succeeded if its performance on the test data is high.
Lecture 3: Basic Concepts of ML 5

Pipeline
• Induction pipeline
Lecture 3: Basic Concepts of ML 6

Task• Predict the class for this ”unseen” example:Sepal length – Sepal width – Petal length – Petal width - Type
5.2 3.7 1.7 0.3 ???
Lecture 1: What is Machine Learning? 7
Require us to
generalize from
the training data

Splitting data to measure performance
• Training data& Test Data
– Common splits: 80/20; 90/10
• NEVER TOUCH THE TEST DATA!
• TEST DATA MUST BELONG TO THE SAME STATISTICAL DISTRIBUTION AS THE TRAINING DATA
Lecture 3: Basic Concepts of ML 8

Modelling
• ML uses formal models that might perform well on our data.
• The choice of using one model rather than another is our choice.
• A model tells us what sort of things we can learn.
• A model tells us what our inductive bias is.
Lecture 3: Basic Concepts of ML 9

Parameters
• Models can have many parameters and finding the best combination of parameters is not trivial.
Lecture 3: Basic Concepts of ML 10

Hyperparameters
• A hyperparameter is a parameter that controls other parameters of the model.
Lecture 3: Basic Concepts of ML 11

Development Set• Split your data into 70% training data, 10% development
data and 20% test data.
• For each possible setting of the hyperparameters:– Train a model using that setting on the training data
– Compute the model error rate on the development data
– From the above collection of medels, choos the one that achieve the lowest error rate on development data.
– Evaluate that model on the test data to estimate future test performance.
Lecture 3: Basic Concepts of ML 12

Accuracy
• Accuracy measures the percentage of correct results that a classifier has achieved.
Lecture 3: Basic Concepts of ML 13

True and False Positives and Negatives
• True positives are relevant items that we correctly identified as relevant.• True negatives are irrelevant items that we correctly identified as
irrelevant.• False positives (or Type I errors) are irrelevant items that we incorrectly
identified as relevant.• False negatives (or Type II errors) are relevant items that we incorrectly
identified as irrelevant.
Lecture 3: Basic Concepts of ML 14

Precision, Recall, F-Measure
• Given these four numbers, we can define the following metrics:
– Precision, which indicates how many of the items that we identified were relevant, is TP/(TP+FP).
– Recall, which indicates how many of the relevant items that we identified, is TP/(TP+FN).
– The F-Measure (or F-Score), which combines the precision and recall to give a single score, is defined to be the harmonic mean of the precision and recall: (2 × Precision × Recall) / (Precision + Recall).
Lecture 3: Basic Concepts of ML 15

Accuracy, Precision, Recall, F-measure
• Accuracy = (TP + TN)/(TP + TN + FP + FN)
• Precision = TP / TP + FP
• Recall = TP / TP + FN
• F-measure = 2*((precision*recall)/(precision+recall))
Lecture 3: Basic Concepts of ML 16

Confusion Matrix
• This is a useful table that presents both the class distribution in the data and the classifiers predicted class distribution with a breakdown of error types.
• Usually, the rows are the observed/actual class labels and the columns the predicted class labels.
• Each cell contains the number of predictions made by the classifier that fall into that cell.
Lecture 3: Basic Concepts of ML 17
actual
predicted

Multi-Class Confusion Matrix
• If a classification system has been trained to distinguish between cats, dogs and rabbits, a confusion matrix will summarize the results:
Lecture 3: Basic Concepts of ML 18

Cross validation
• In 10-fold cross-validation you break you training data up into 10 equally-sized partitions.
• You train a learning algorithm on 9 of them and tst it on the remaining 1.
• You do this 10 times, each holding out a different partition as the test data.
• Typical choices for n-fold are 2, 5, 10.
• 10-fold cross validation is the most common.
Lecture 3: Basic Concepts of ML 19

Leave One Out
• Leave One Out (or LOO) is a simple cross-validation. Each learning set is created by taking all the samples except one, the test set being the sample left out.
Lecture 3: Basic Concepts of ML 20

Stratification
• Proportion of each class in the traning set and test sets is the same as the proportion in the original sample.
Lecture 3: Basic Concepts of ML 21

Weka Cross validation
• 10-fold cross validation
Lecture 3: Basic Concepts of ML 22

Weka: Output
• Classifier output
Lecture 3: Basic Concepts of ML 23

Remember: Underfitting & Overfitting
Underfitting: the model has not learned enough from the data and is unable to generalize
Overfitting: the model has learned too many idiosyncrasies (noise) and is unable to generalize
Lecture 3: Basic Concepts of ML 24

Summary: Performance of a learning model: Requirements
• Our goal when we choose a machine learning model is that it does well on future, unseen data.
• The way in which we measure performance should depend on the problem we are trying to solve.
• There should be a strong relationship between the data that our algorithm sees at training time and the data it sees at test time.
Lecture 3: Basic Concepts of ML 25

Not everything is learnable
– Noise at feature level
– Noise at class label level
– Features are insufficient
– Labels are controversial
– Inductive bias not appropriate for the kind of problem we try to learn
Lecture 3: Decision Trees (1) 26

Quiz 1: Stratification
• What does it mean ”stratified” cross validation?
1. The examples of a class are all in the training set, and the rest of the classes are in the test set.
2. The proportion of each class in the sets ae the same as the proportion in the original sample
3. None of the above.
Lecture 3: Basic Concepts of ML 27

Quiz 2: Accuracy
• Why is accuracy alone an unreliable measure?
1. Because it can be biassed towards the most frequent class.
2. Because it always guesses wrong.
3. None of the above
Lecture 3: Basic Concepts of ML 28

Quiz 3: Data Splits
• Which are recommended splits between training and test data?
1. 80/20
2. 50/50
3. 10/90
Lecture 3: Basic Concepts of ML 29

Quiz 4: Overfitting
• What does it mean overfitting?
1. the model has not learned enough from the data and is unable to generalize
2. The proportion of each class in the sets is the same as the proportion in the original sample
3. None of the above.
Lecture 3: Basic Concepts of ML 30

The End
Lecture 3: Basic Concepts of ML 31





























