Embed Size (px)
Citation preview

Gray& Reuter FT
3: 1
Lampson Sturgis Fault ModelLampson Sturgis Fault ModelJim Gray Jim Gray
Microsoft, Gray @ Microsoft.comMicrosoft, Gray @ Microsoft.com
Andreas ReuterAndreas ReuterInternational University, [email protected] University, [email protected]
9:00
11:00
1:30
3:30
7:00
Overview
Faults
Tolerance
T Models
Party
TP mons
Lock Theory
Lock Techniq
Queues
Workflow
Log
ResMgr
CICS & Inet
Adv TM
Cyberbrick
Files &Buffers
COM+
Corba
Replication
Party
B-tree
Access Paths
Groupware
Benchmark
Mon Tue Wed Thur Fri

Gray& Reuter FT
3: 2
RationaleRationale Fault Tolerance Needs a Fault Model Fault Tolerance Needs a Fault Model
What do you tolerate?What do you tolerate?
Fault tolerance needs a fault model.Model needs to be simple enough to understand.With a model,
can design hardware/software to tolerate the faults.can make statements about the system behavior.

Gray& Reuter FT
3: 3
Byzantine Fault ModelSome modules are fault free (during the period of interest).
Other modules may fail (in the worst way). Make statements about of the fault-free module behavior
SynchronousAll operations happen within a time limit.
Asynchronous: No time limit on anything, No lost messages.
Timed: (used here)Notion of timeout and retry
Key result: N modules can tolerate N/3 faults.

Gray& Reuter FT
3: 4
Lampson Sturgis ModelLampson Sturgis ModelProcesses:
Correct: Execute a program at a finite rate.Fault: Reset to null state and "stop" for a finite time.
Message:Correct: Eventually arrives and is correct.Fault: Lost, duplicated, or corrupted.
Storage:Correct: Read(x) returns the most recent value of x.
Write(x, v) sets the value of x to v.Fault: All pages reset to null.
A page resets to null.Read or Write operate on the wrong page.
Other faults (called disasters) not dealt with.
Assumption: Disasters are rare.

Gray& Reuter FT
3: 5
Byzantine vs. Lampson-Sturgis Fault Models
Connections unclear.
Byzantine focuses on bounded-time bounded-faults (real-time systems)asynchronous (mostly) or synchronous (real time)
Lampson/Sturgis focuses on long-term behavior no time or fault limits time and timeout heavily used to detect faults

Gray& Reuter FT
3: 6
Roadmap of What's Coming• Lampson-Sturgis Fault Model• Building highly available
processes, messages, storage
from faulty components. • Process pairs give quick repair• Kinds of process pairs:
–Checkpoint / Restart based on storage –Checkpoint / Restart based on
messages–Restart based on transactions (easy to
program).

Gray& Reuter FT
3: 7
Model of Storage and its FaultsModel of Storage and its FaultsSystem has several stores (discs). System has several stores (discs). Each has a set of pages.Each has a set of pages.Stores fail independently.Stores fail independently.
probability write has no effect: 1 in a million probability write has no effect: 1 in a million mean time to a page fail, a few daysmean time to a page fail, a few daysmean time to disc fail is a few yearsmean time to disc fail is a few yearswild read/write modeled as a page fail.wild read/write modeled as a page fail.
a page status value
a store status
store_write(store, address, value)
store_read (store, address, value)

Gray& Reuter FT
3: 8
PageDecay
StoreFailure
Storage Decay (the demon)/* There is one store_decay process for each store in the system */#define mttvf 7E5 /* mean time (sec) to a page fail, a few days */#define mttsf 1E8 /* mean time(sec) to disc fail is a few years */void store_decay(astore store) /* */
{ Ulong addr; /* the random places that will decay */Ulong page_fail = time() + mttvf*randf();/* timeto next page decay */Ulong store_fail = time() + mttsf*randf(); /* timeto next store decay */while (TRUE) /* repeat this loop forever */{ wait(min(page_fail,store_fail) - time());/* wait for next event*/if (time() >= page_fail) /* if the event is a page decay */{ addr = randf()*MAXSTORE; /* pick a random address */store.page[addr].status = FALSE; /* set it invalid */page_fail = time() - log(randf())*mttvf; /* pick next fault time*/}; /* negative exp distributed, mean mttvf */if (time() >= store_fail) /* if the event is a storage fault */{ store.status = FALSE; /* mark the store as broken */for (addr = 0; addr < MAXSTORE; addr++) /*invalidate all pages */store.page[addr].status = FALSE; /* */store_fail = time() + log(randf())*mttsf; /* pick next fault time*/}; /* negative exp distributed, mean mttsf */}; /* end of endless while loop */}; /* */
Simulates (specifies) system behavior.

Gray& Reuter FT
3: 9
Reliable Write: Write all members of a N-plex set. #define nplex 2 /* code works for n>2, but do duplex */Boolean reliable_write(Ulong group, address addr, avalue value) /* */{ Ulong i; /* index on elements of store group */
Boolean status = FALSE; /* true if any write worked *//* each group uses Nplex stores */for (i = 0; i < nplex; i++ ) /*write each store in the group */ { status = status || /* status indicates if any write worked */store_write(stores[group*nplex+i],addr,value); /* */
} /* loop to write all stores of group */return status; /* return indicates if ANY write worked*/}; /* */
Reliable Write

Gray& Reuter FT
3: 10
Reliable Read: read all members of N-plex setProblems: All fail: Disaster
Ambiguity: (N-different answers)Take majorityTake "newest"
Reliable read
on bad readrewrite with best value
Ulong version(avalue); /* returns version of a value *//* read an n-plex group to find the most recent version of a page */Boolean reliable_read(Ulong group, address addr, avalue value) /* */
{ Ulong I = 0; /* index on store group */Boolean gotone = FALSE; /* flag says had a good read */Boolean bad = FALSE; /* bad says group needs repair */avalue next; /* next value that is read */Boolean status; /* read ok */for (i = 0; i < nplex; i++ ) /* for each page in the nplex set */
{ status = store_read(stores[group*nplex+i],addr,next); /*read value */ if (! status ) bad = TRUE; /* if status bad, ignore value */ else /* have a good read */ if (! gotone) /* if it is first good value */ {copy(value,next,VSIZE); gotone = TRUE;}/* make it best value */ else if ( version(next) != version(value)) /*if new val,compare */ { bad = TRUE; /* if different, repair needed */
if (version(next) > version(value)) /* if new is best version */ copy(value, next, VSIZE); /* copy it to best value */
}; }; /* end of read all copies */if (! gotone) return FALSE; /* disaster, no good pages */if (bad) reliable_write(group,addr,value); /* repair any bad pages */return TRUE; /* success */

Gray& Reuter FT
3: 11
Background Store Repair Process /* repair the broken pages in an n-plex group. *//* Group is in 0,...,(MAXSTORE/nplex)-1 */void store_repair(Ulong group) /* */{ int i; /* next address to be repaired */
avalue value; /* buffer holds value to be read */while (TRUE) /* do forever */
{for (i = 0; i <MAXSTORE; i++) /* for each page in the store */{ wait(1); /* wait a second */reliable_read(group,i,value); /* a reliable read repairs page*/
}; };}; /* if they do not match */
Needed to minimize chances of N-failures.Needed to minimize chances of N-failures.Repair is important.Repair is important.
Reliable readData
Scrubberon bad read
rewrite with best value

Gray& Reuter FT
3: 12
Optimistic ReadsMost implementations do optimistic reads:
read only one value.
Boolean optimistic_read(Ulong group,address addr,avalue value) /* */{if (group >= MAXSTORES/nplex) return FALSE; /* return false if bad addr*/if (store_read(stores[nplex*group],addr,value)) /* read one value */return TRUE; /* and if that is ok return it as the true value */else /* if reading one value returned bad then */return (reliable_read(group,addr,value)); /* n-plex read & repair. */}; /* */
This is dangerous (especially without repair).

Gray& Reuter FT
3: 13
Storage Fault Summary
• Simple fault model.• Allows discussion/specification of fault tolerance.• Uncovers some problems in many implementations:• Ambiguous reads• Repair process.• Optimistic reads.

Gray& Reuter FT
3: 14
Process Fault Model• Process executes a program and has state.• Program causes state change plus: send/get message.• Process fails by stopping (for a while) and then
resetting its data and message state.
status valuenext
Queue of Input Messages to the process Receiver Process
Program Data
Sender Process
Program Data
a new message

Gray& Reuter FT
3: 15
Process Fault Model: The Break/Fix loop#define MAXPROCESS MANY /* the system will have many processes */
typedef Ulong processid; /* process id is an integer index into array */typedef struct {char program[MANY/2];char data[MANY/2]} state;/* program + data */struct { state initial; /* process initial state */
state current; /* value of the process state */amessagep messages; /* queue of messages waiting for process */} process [MAXPROCESS]; /* */
/* Process Decay : execute a process and occasionally inject faults into it */ #define mttpf 1E7 /* mean time to process failure Å4 months */#define mttpr 1E4 /* mean time to repair is 3 hours */void process_execution(processid pid) /* */
{ Ulong proc_fail;/* time of next process fault */Ulong proc_repair; /* time to repair process */amessagep msg, next; /* pointers to process messages */while (TRUE) /* global execution loop */{ proc_fail = time() - log(randf())*mttpf; /* the time of next fail */proc_repair = -log(randf())*mttpr; /* delay in next process repair */while (time() < proc_fail) /* */ { execute(process[pid].current);}; /* execute for about 4 months (work) */(void) wait(proc_repair); /* wait about 3 hrs for repair (break) */copy(process[pid].current,process[pid].initial,MANY); /* reset (fix) */while (message_get(msg,status) {}; /* read and discard all msgs in queue */}; }; /* bottom of work, break, fix loop */
Execute4 Months
Fail!!!
Repair 3 hrs

Gray& Reuter FT
3: 16
Checkpoint/Restart Process (Storage based)/* A checkpoint-restart process server generating unique sequence numbers */checkpoint_restart_process() /* */
{ Ulong disc = 0; /* a reliable storage group with state */Ulong address[2] = {0,1}; /* page address of two states on disc */Ulong old; /* index of the disc with the old state */struct { Ulong ticketno; /* process reads its state from disc. */ char filler[VSIZE]; /* newest state has max ticket number */} value [2]; /* current state kept in value[0] */struct msg{ /* buffer to hold input message */processid him; /* contains requesting process id */char filler[VSIZE]; /* reply (ticket num) sent to process */} msg; /* *//* Restart logic: recover ticket number from persistent storage */for (old = 0; old<=1, old++) /* read the two states from disc */{ if (!reliable_read(disc,address[old],value[old] )) /*if read fails */panic(); }; /* then failfast */if (value[1].ticketno < value[0].ticketno) old = 1; /* pick max seq no */else { old = 0; copy(value[0], value[1],VSIZE);};/*which is old val *//* Processing logic: generate next number, checkpoint, and reply */while (TRUE) /* do forever */{ while (! get_msg(&msg)) {}; /* get next request for a ticket number */value[0].ticketno = value[0].ticketno + 1; /* increment ticket num */if ( ! reliable_write(disc,address[old],value[0])) panic(); /* checkpoint */old = (old + 1) % 2; /* use other disc for state next time */message_send(msg.him, value[0]); /* send the ticket number to client */}; }; /* endless loop to get messages. */
At ReseartGet Ticket Number
From Disk
Get requestbump ticket #Save to disk
Send to client
Gray& Reuter FT
3: 17
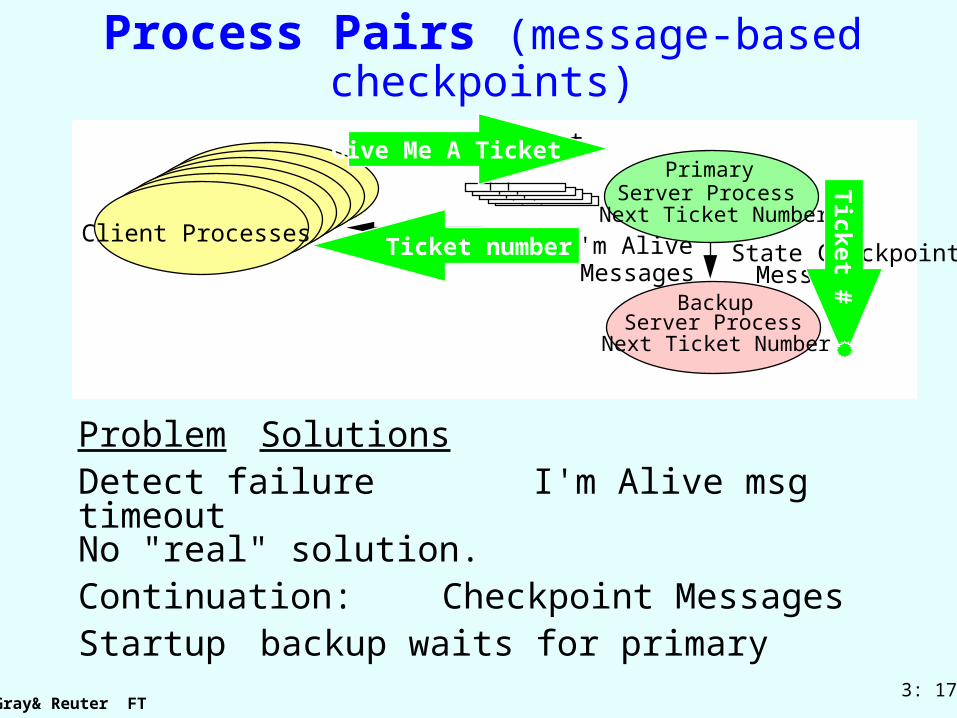
Process Pairs (message-based checkpoints)
Client Processes
Give me a ticket
Ticket Numbers
Server ProcessNext Ticket Number
Primary
Server ProcessNext Ticket Number
Backup
State Checkpoint Messages
I'm Alive Messages
Give Me A TicketTicket #
Ticket number
Problem SolutionsDetect failure I'm Alive msg
timeoutNo "real" solution.
Continuation: Checkpoint MessagesStartup backup waits for primary

Gray& Reuter FT
3: 18
Process Pairs (message-based checkpoints)
• Primary in tight loop sending "I'm alive" or state change Primary in tight loop sending "I'm alive" or state change messages to backupmessages to backup
• Backup thinks primary dead if no messages in previous second. Backup thinks primary dead if no messages in previous second.
Read it
reply
Compute new state.Send new state to backup. Send state to backup.
+-
Read it
Wait a second
Set my state to new state
any input?
newer state?
new state in last second?
- -+
-+
+
Restart
Broadcast: "Im Primary"Reply to last request
+
am I default primary?-Wait a second
Im alivereplies
requests
any input?
Primary Loop
Backup Loop

Gray& Reuter FT
3: 19
What We Have Done So FarWhat We Have Done So FarConverted "faulty" processes to reliable ones.Tolerate hardware and some software faultsCan repair in seconds or milli-seconds.Unlike checkpoint restart: No process creation/setup time
No client reconnect time.Operating systems are beginning to provide process pairs.Stateless process pairs can use transactional servers to
Store their stateCleanup the mess at takeover.Like storage-based checkpoint/restart except process setup/connection is instant.

Gray& Reuter FT
3: 20
Persistent process pairs
persistent_process() /* prototypical persistent process */{ wait_to_be_primary(); /* wait to be told you are primary */while (TRUE) /* when primary, do forever */{ begin_work(); /* start transaction or subtransaction */read request(); /* read a request */doit(); /* perform the desired function */reply();/* reply */commit_work(); /* finish transaction or subtransaction*/}; /* did a step, now get next request */}; /* */

Gray& Reuter FT
3: 21
Persistent Process Pairs The ticket server redone as a transactional server.
/* A transactional persistent server process generating unique tickets */perstistent_ticket_server() /* current state kept in sql database */
{ int ticketno; /* next ticket # ( from DB) */struct msg{ /* buffer to hold input message */
processid him; /* contains requesting process id */ char filler[VSIZE]; /* reply (ticket num) sent to that addr */
} msg; /* *//* Restart logic: recover ticket number from persistent storage */wait_to_be_primary(); /* wait to be told you are primary *//* Processing logic: generate next number, checkpoint, and reply */while (TRUE) /* do forever */
{ begin_work(); /* begin a transaction */while (! get_msg(&msg)); /* get next request for a ticket */exec sql update ticket /* increment the next ticket number */
set ticketno = ticketno + 1; /* */exec sql select max(ticketno) /* fetch current ticket number */
into :ticketno /* into program local variable */from ticket; /* from SQL database */
commit_work(); /* commit transaction */message_send(msg.him, value); /* send the ticket number to client */
}; }; /* endless loop to get messages. */
Wait to be Primary
Begin Trans &Get request
bump ticket #in DatabaseCommit and
Send to client

Gray& Reuter FT
3: 22
Messages: Fault Model
Each process has a queue of incoming messages.Messages can be
corrupted: checksum detects itduplicated: sequence number detects it. delayed arbitrarily long (ack + retransmit).can be lost (ack + retransmit+seq number).
Techniques here give messages fail-fast semantics.

Gray& Reuter FT
3: 23
Message Verbs: SEND
/*send a message to a process: returns true if the process exists */
Boolean message_send(processid him, avalue value) /* */{ amessagep it; /* pointer to message created by this
call*/amessagep queue; /* pointer to process message queue */if (him > MAXPROCESS) return FALSE; /* test for valid process */
loop: it = malloc(sizeof(amessage)); /* allocate space to hold message */it->status = TRUE; it->next = NULL; /* and fill in the fields */copy(it->value,value,VSIZE); /* copy msg data to message body */queue = process[him].messages; /* look at process message queue */if (queue == NULL) process[him].messages = it; /* if the empty then */else /* place this message at queue head */ {while (queue->next != NULL) queue = queue->next; /* else place */ queue->next = it;} /* the message at queue end . */if (randf() < pmf) it->status = FALSE; /* sometimes message corrupted */if (randf() < pmd) goto loop; /* sometimes the message duplicated */return TRUE; /* */}; /* */
Build&Queue
Msg
CorruptMsgDuplicateMsg

Gray& Reuter FT
3: 24
Message Verbs: GET /* get the next input message of this process: returns true if a message */
Boolean message_get(avalue * valuep, Boolean * msg_status)/**/{ processid me = MyPID(); /* caller’s process number */amessagep it; /* pointer to input message */it = process[me].messages; /* find caller’s message input queue */if (it == NULL) return FALSE; /* return false if queue is empty */process[me].messages = it->next;/* take first message off the queue */*msg_status = it->status; /* record its status */copy(valuep,it->value,VSIZE); /* value = it->value */free(it); /* deallocate its space */return TRUE; /* return status to caller */}; /* */

Gray& Reuter FT
3: 25
Sessions Make Messages FailFast
• CRC makes corrupt look like lost message• Sequence numbers detect duplicates => lost message• So, only failure is lost message• Timeout/retransmit masks lost messages. => Only failure is delay.
3 377
Process
•••ack 7••••inout in
out63acknowledged acknowledged
3 377in
out inout
73acknowledged acknowledged
SessionProcess
3 376
Process 7 ••••••••••in
out inout
63acknowledged acknowledged7
Ack 7

Gray& Reuter FT
3: 26
Sessions Plus Process Pairs Give Highly Available Messages
Checkpoint messages and sequence numbers to backupBackup resumes session if primary fails.Backup broadcasts new identity at takeover (see book for code)
3
7in
out3acknowledged
37
inout
6 acked7 •••••••••••••••
•••ack 7•••••••
3
7in
out3acknowledged
37
inout
7 acked•••ack 7•••••••
Process Session
3 3
76send
7 •••••••••••••••in
out in
out63acknowledged acked
3
7
in
out6 acked
37
inout
37
inout
6 acknowledged6 ackcheckpointProcess Pair
7ack 7
7
ack 7

Gray& Reuter FT
3: 27
Highly Available Message Verbs
Hide under reliable get/send msg– Sequence number, – ack retransmit logic– checkpoint – process pair takeover– resend of most recent reply.
Uses a Listener process (thread) to do all this async work
Input Message SessionAcknowledged Input Messages
The Listener Process
Application Programs
reliable_get_msg()
reliable_send_msg()
Output Message Session

Gray& Reuter FT
3: 28
SummarySummary
Went from faulty storage, processes, messages to fault tolerant versions of each.
Simple fault model explains many techniques used (and mis-used) in FT systems.












![forum.konkurdl.konkur.in/PHD/97/249-E-PHD97-[].pdf · wrench fault transform fault (r model Of Wadati— model of double Wadati- unbending model of double wadati Sagging model of](https://img.dokumen.tips/doc/110x75/5fae40088c2601506155979f/forumkonkurdl-pdf-wrench-fault-transform-fault-r-model-of-wadatia-model.jpg)
















