
Guide to IBM InformixEnterprise Replication
Version 9.3August 2001Part No. 000-8334

ii Guide to IBM Informix
© Copyright International Business Machines Corporation 2001. All rights reserved.
Trademarks
AIX; DB2; DB2 Universal Database; Distributed Relational Database Architecture; NUMA-Q; OS/2, OS/390, andOS/400; IBM Informix ; C-ISAM ; Foundation.2000TM; IBM Informix 4GL; IBM Informix DataBlade Module;Client SDKTM; CloudscapeTM; CloudsyncTM; IBM Informix Connect; IBM Informix Driver for JDBC; DynamicConnectTM; IBM Informix Dynamic Scalable ArchitectureTM (DSA); IBM Informix Dynamic ServerTM; IBMInformix Enterprise Gateway Manager (Enterprise Gateway Manager); IBM Informix Extended ParallelServerTM; i. Financial ServicesTM; J/FoundationTM; MaxConnectTM; Object TranslatorTM; Red BrickDecision ServerTM; IBM Informix SE; IBM Informix SQL; InformiXMLTM; RedBack ; SystemBuilderTM; U2TM;UniData ; UniVerse ; wintegrate are trademarks or registered trademarks of International BusinessMachines Corporation.
Java and all Java-based trademarks and logos are trademarks or registered trademarks of Sun Microsystems,Inc. in the United States and other countries.
Windows, Windows NT, and Excel are either registered trademarks or trademarks of Microsoft Corporation inthe United States and/or other countries.
UNIX is a registered trademark in the United States and other countries licensed exclusively through X/OpenCompany Limited.
Other company, product, and service names used in this publication may be trademarks or service marks ofothers.
Documentation Team: Diane Kirsten-Martin, Karin Moore, Hanna Nelson
Enterprise Replication

Table of Contents
Table ofContents
IntroductionIn This Introduction . . . . . . . . . . . . . . . . . 3About This Manual . . . . . . . . . . . . . . . . . . 3
Types of Users . . . . . . . . . . . . . . . . . . 3Software Dependencies . . . . . . . . . . . . . . . 4Assumptions About Your Locale. . . . . . . . . . . . 4Demonstration Databases . . . . . . . . . . . . . . 5
New Features in Dynamic Server, Version 9.3 . . . . . . . . . 5Extensibility Enhancements . . . . . . . . . . . . . 6Performance Improvements . . . . . . . . . . . . . 7Functionality Enhancements . . . . . . . . . . . . . 8Command-Line Changes . . . . . . . . . . . . . . 9
Documentation Conventions . . . . . . . . . . . . . . 10Typographical Conventions . . . . . . . . . . . . . 10Icon Conventions . . . . . . . . . . . . . . . . . 11Command-Line Conventions . . . . . . . . . . . . . 12Sample-Code Conventions . . . . . . . . . . . . . . 14
Additional Documentation . . . . . . . . . . . . . . . 15Related Reading . . . . . . . . . . . . . . . . . . . 17Compliance with Industry Standards . . . . . . . . . . . 18Informix Welcomes Your Comments . . . . . . . . . . . . 18

iv Guide
Section I Introducing Enterprise Replication
Chapter 1 About Informix Enterprise ReplicationIn This Chapter . . . . . . . . . . . . . . . . . . . 1-3Informix Enterprise Replication . . . . . . . . . . . . . 1-3
Asynchronous Data Replication. . . . . . . . . . . . 1-4Log-Based Data Capture . . . . . . . . . . . . . . 1-5High Performance . . . . . . . . . . . . . . . . 1-6High Availability . . . . . . . . . . . . . . . . . 1-6Consistent Information Delivery . . . . . . . . . . . 1-6Flexible Architecture . . . . . . . . . . . . . . . 1-7Centralized Administration . . . . . . . . . . . . . 1-8
How Enterprise Replication Replicates Data . . . . . . . . . 1-8Capture Transactions . . . . . . . . . . . . . . . 1-9Evaluate Data for Replication . . . . . . . . . . . . 1-9Distribute Data . . . . . . . . . . . . . . . . . 1-17Apply Replicated Data . . . . . . . . . . . . . . . 1-17
Chapter 2 Overview of Enterprise Replication AdministrationIn This Chapter . . . . . . . . . . . . . . . . . . . 2-3Overview of Enterprise Replication Administration . . . . . . 2-3Enterprise Replication Server Administrator . . . . . . . . . 2-4Enterprise Replication Terminology . . . . . . . . . . . . 2-4
Enterprise Replication Server . . . . . . . . . . . . 2-5Replicate. . . . . . . . . . . . . . . . . . . . 2-5Participant . . . . . . . . . . . . . . . . . . . 2-5Replicate Set . . . . . . . . . . . . . . . . . . 2-6Global Catalog . . . . . . . . . . . . . . . . . 2-6Operational Considerations . . . . . . . . . . . . . 2-8Backup and Restore Considerations . . . . . . . . . . 2-9Database and Table Design Considerations . . . . . . . . 2-9Transaction Processing Considerations . . . . . . . . . 2-14Replication Environment Considerations . . . . . . . . 2-17Enterprise Replication Data Types . . . . . . . . . . . 2-19
to IBM Informix Enterprise Replication

Section II Setting Up and Managing Enterprise Replication
Chapter 3 Selecting the Enterprise Replication System and Network TopologyIn This Chapter . . . . . . . . . . . . . . . . . . 3-3Selecting the Enterprise Replication System . . . . . . . . 3-3
Primary-Target Replication System . . . . . . . . . . 3-3Update-Anywhere Replication System . . . . . . . . . 3-10Conflict Resolution . . . . . . . . . . . . . . . 3-11
Choosing a Replication Network Topology . . . . . . . . . 3-19Fully Connected Topology . . . . . . . . . . . . . 3-20Hierarchical Replication Topologies . . . . . . . . . . 3-21
Chapter 4 Preparing the Replication EnvironmentIn This Chapter . . . . . . . . . . . . . . . . . . 4-3Preparing the Network Environment . . . . . . . . . . . 4-3
Setting Up the Hosts File . . . . . . . . . . . . . 4-4Setting Up the Services File. . . . . . . . . . . . . 4-4Setting Up the Trusted Environment . . . . . . . . . 4-5Verifying SQLHOSTS. . . . . . . . . . . . . . . 4-5Testing the Network Environment . . . . . . . . . . 4-8
Preparing the Disk . . . . . . . . . . . . . . . . . 4-9Planning for Disk Space Requirements . . . . . . . . . 4-9Setting Up Send and Receive Queue Spool Areas . . . . . 4-11Creating ATS and RIS Directories . . . . . . . . . . 4-15
Preparing the Database Server Environment . . . . . . . . 4-16Preparing Data for Replication . . . . . . . . . . . . . 4-18
Preparing Consistent Data . . . . . . . . . . . . . 4-18Blocking Replication . . . . . . . . . . . . . . . 4-18Preparing to Replicate Opaque User-Defined Types . . . . 4-21Preparing Tables for Conflict Resolution . . . . . . . . 4-21Preparing Logging Databases . . . . . . . . . . . . 4-22
Loading and Unloading Data . . . . . . . . . . . . . 4-22Data Preparation Example . . . . . . . . . . . . . . 4-24
Table of Contents v

vi Guide
Chapter 5 Defining and Modifying Replication Servers, Replicates, andParticipantsIn This Chapter . . . . . . . . . . . . . . . . . . . 5-3Initializing Database Servers . . . . . . . . . . . . . . 5-4Defining Replication Servers . . . . . . . . . . . . . . 5-5
Customizing the Replication Server Definition . . . . . . 5-6Defining Replicates . . . . . . . . . . . . . . . . . 5-7
Defining Participants . . . . . . . . . . . . . . . 5-8Specifying Conflict Resolution Rules and Scope . . . . . . 5-10Specifying Replication Frequency . . . . . . . . . . . 5-10Setting Up Error Logging . . . . . . . . . . . . . . 5-11Replicating Only Changed Columns . . . . . . . . . . 5-11Using the IEEE Floating Point or Canonical Format . . . . . 5-13Enabling Triggers . . . . . . . . . . . . . . . . 5-14
Modifying Replication Servers . . . . . . . . . . . . . 5-14Modifying Replicates . . . . . . . . . . . . . . . . . 5-15
Adding or Deleting Participants . . . . . . . . . . . 5-15Changing Replicate Attributes . . . . . . . . . . . . 5-16
Resynchronizing Replication Servers . . . . . . . . . . . 5-17
Chapter 6 Managing Replication Servers and ReplicatesIn This Chapter . . . . . . . . . . . . . . . . . . . 6-3Managing Replication Servers . . . . . . . . . . . . . . 6-3
Viewing Replication Server Attributes . . . . . . . . . 6-3Connecting to Another Replication Server . . . . . . . . 6-4Stopping Replication on a Server . . . . . . . . . . . 6-4Restarting Replication on a Stopped Server . . . . . . . . 6-5Suspending Replication for a Server . . . . . . . . . . 6-5Resuming a Suspended Replication Server . . . . . . . . 6-6Deleting a Replication Server . . . . . . . . . . . . 6-6
Managing Replicates . . . . . . . . . . . . . . . . . 6-7Viewing Replicate Properties. . . . . . . . . . . . . 6-7Starting a Replicate . . . . . . . . . . . . . . . . 6-7Stopping a Replicate . . . . . . . . . . . . . . . 6-8Suspending a Replicate. . . . . . . . . . . . . . . 6-9Resuming a Suspended Replicate . . . . . . . . . . . 6-9Deleting a Replicate . . . . . . . . . . . . . . . . 6-9
to IBM Informix Enterprise Replication

Managing Replication Server Network Connections . . . . . 6-10Viewing Network Connection Status . . . . . . . . . 6-10Dropping the Network Connection . . . . . . . . . . 6-10Reestablishing the Network Connection . . . . . . . . 6-11
Chapter 7 Creating and Managing Replicate SetsIn This Chapter . . . . . . . . . . . . . . . . . . 7-3Creating Replicate Sets . . . . . . . . . . . . . . . . 7-4
Exclusive Replicate Sets . . . . . . . . . . . . . . 7-4Non-Exclusive Replicate Sets . . . . . . . . . . . . 7-5Customizing the Replicate Set Definition . . . . . . . . 7-5
Viewing Replicate Set Properties . . . . . . . . . . . . 7-6Managing Replicate Sets . . . . . . . . . . . . . . . 7-6
Starting a Replicate Set . . . . . . . . . . . . . . 7-7Stopping a Replicate Set . . . . . . . . . . . . . . 7-7Suspending a Replicate Set . . . . . . . . . . . . . 7-7Resuming a Replicate Set . . . . . . . . . . . . . 7-8Deleting a Replicate Set . . . . . . . . . . . . . . 7-8
Modifying Replicate Sets . . . . . . . . . . . . . . . 7-9Adding or Deleting Replicates From a Replicate Set . . . . 7-9Changing Replication Frequency For the Replicate Set . . . 7-10
Chapter 8 Monitoring and Troubleshooting Enterprise ReplicationIn This Chapter . . . . . . . . . . . . . . . . . . 8-3Aborted Transaction Spooling Files . . . . . . . . . . . 8-3
Preparing to Use ATS . . . . . . . . . . . . . . . 8-4About ATS Filenames. . . . . . . . . . . . . . . 8-5About ATS File Information . . . . . . . . . . . . 8-6BYTE and TEXT Information in ATS Files . . . . . . . . 8-7Changed Column Information in ATS Files . . . . . . . 8-8BLOB and CLOB Information in ATS Files . . . . . . . 8-8UDT Information in ATS Files . . . . . . . . . . . . 8-8
Row Information Spooling Files . . . . . . . . . . . . 8-9Preparing to Use RIS . . . . . . . . . . . . . . . 8-9About RIS Filenames . . . . . . . . . . . . . . . 8-10BYTE and TEXT Information in RIS Files . . . . . . . . 8-12Changed Column Information in RIS Files . . . . . . . 8-12BLOB and CLOB Information in RIS Files . . . . . . . . 8-12UDT Information in RIS Files . . . . . . . . . . . . 8-12
Table of Contents vii

viii Guid
Preventing Memory Queues from Overflowing . . . . . . . . 8-13Preventing Blockout Mode . . . . . . . . . . . . . 8-14Monitoring Disk Usage for Send and Receive Queue Spool . . 8-15Increasing the Sizes of Storage Spaces . . . . . . . . . 8-16Recovering when Storage Spaces Fill . . . . . . . . . . 8-16
Solving Common Configuration Problems . . . . . . . . . 8-17Enterprise Replication Event Alarms . . . . . . . . . . . 8-19
Section III Appendixes
Appendix A Command-Line Utility Reference
Appendix B Configuration Parameter Reference
Appendix C onstat Command Reference
Appendix D SMI Table Reference
Appendix E Replication Examples
Appendix F SQLHOSTS Registry Key
Index
e to IBM Informix Enterprise Replication

Introduction
Introduction
In This Introduction . . . . . . . . . . . . . . . . . . 3
About This Manual . . . . . . . . . . . . . . . . . . . 3Types of Users . . . . . . . . . . . . . . . . . . . 3Software Dependencies . . . . . . . . . . . . . . . . 4Assumptions About Your Locale . . . . . . . . . . . . . 4Demonstration Databases . . . . . . . . . . . . . . . 5
New Features in Dynamic Server, Version 9.3 . . . . . . . . . . 5Extensibility Enhancements . . . . . . . . . . . . . . 6Performance Improvements . . . . . . . . . . . . . . 7Functionality Enhancements . . . . . . . . . . . . . . 8Command-Line Changes . . . . . . . . . . . . . . . 9
Documentation Conventions . . . . . . . . . . . . . . . 10Typographical Conventions . . . . . . . . . . . . . . 10Icon Conventions . . . . . . . . . . . . . . . . . . 11
Comment Icons . . . . . . . . . . . . . . . . . 11Feature, Product, and Platform Icons . . . . . . . . . . 11
Command-Line Conventions . . . . . . . . . . . . . . 12How to Read a Command-Line Diagram . . . . . . . . 14
Sample-Code Conventions . . . . . . . . . . . . . . . 14
Additional Documentation . . . . . . . . . . . . . . . . 15
Related Reading . . . . . . . . . . . . . . . . . . . . 17
Compliance with Industry Standards . . . . . . . . . . . . 18
Informix Welcomes Your Comments . . . . . . . . . . . . . 18

2 Guide
to IBM Informix Enterprise Replication
In This IntroductionThis introduction provides an overview of the information in this manualand describes the conventions it uses.
About This ManualThis manual describes Informix Enterprise Replication and the concepts ofdata replication. This manual explains how to design your replicationsystem, as well as administer and manage data replication throughout yourenterprise.
This section discusses the intended audience and the associated softwareproducts that you must have to use Enterprise Replication.
Types of UsersThis manual is for database server administrators and assumes that you havethe following background:
■ A working knowledge of your computer, your operating system,and the utilities that your operating system provides
■ Some experience working with relational databases or exposure todatabase concepts
■ Some experience with database server administration, operating-system administration, and network administration
If you have limited experience with relational databases, SQL, or youroperating system, refer to your Getting Started manual for a list of supple-mentary titles.
Introduction 3

Software Dependencies
Software DependenciesTo use Enterprise Replication, you must use Informix Dynamic Server asyour database server. Check the release notes for specific versioncompatibility.
This manual assumes that you are using Dynamic Server, Version 9.3,as your database server.
Assumptions About Your LocaleInformix products can support many languages, cultures, and code sets. Allthe information related to character set, collation and representation ofnumeric data, currency, date, and time is brought together in a singleenvironment, called a GLS (Global Language Support) locale.
The examples in this manual are written with the assumption that you areusing the default locale, en_us.8859-1. This locale supports U.S. Englishformat conventions for date, time, and currency. In addition, this localesupports the ISO 8859-1 code set, which includes the ASCII code set plusmany 8-bit characters such as é, è, and ñ.
If you plan to use nondefault characters in your data or your SQL identifiers,or if you want to conform to the nondefault collation rules of character data,you need to specify the appropriate nondefault locale.
For instructions on how to specify a nondefault locale, additional syntax, andother considerations related to GLS locales, see the Informix Guide to GLSFunctionality.
4 Guide to IBM Informix Enterprise Replication

Demonstration Databases
Demonstration DatabasesThe DB-Access utility, which is provided with your Informix database serverproducts, includes one or more of the following demonstration databases:
■ The stores_demo database illustrates a relational schema with infor-mation about a fictitious wholesale sporting-goods distributor.Many examples in Informix manuals are based on the stores_demodatabase.
■ The superstores_demo database illustrates an object-relationalschema. The superstores_demo database contains examples ofextended data types, type and table inheritance, and user-definedroutines. ♦
For information about how to create and populate the demonstrationdatabases, see the DB-Access User’s Manual. For descriptions of the databasesand their contents, see the Informix Guide to SQL: Reference.
The scripts that you use to install the demonstration databases reside in the$INFORMIXDIR/bin directory on UNIX platforms and in the%INFORMIXDIR%\bin directory in Windows environments.
New Features in Dynamic Server, Version 9.3This section describes new features relevant to this manual. These featuresfall into the following areas:
■ Extensibility Enhancements
■ Performance Improvements
■ Functionality Enhancements
■ Command-Line Changes
For a description of all new features, see the Getting Started manual.
Introduction 5

Extensibility Enhancements
Extensibility EnhancementsEnterprise Replication in Version 9.3 of Dynamic Server provides support forreplicating the following extensible data types:
■ Data stored as smart large objects (smart blobs) in sbspaces (CLOBand BLOB data types), CLOB and BLOB columns (explicitly specifiedin the table schema), and updates to CLOB and BLOB columns (withsome restrictions)
See “Replicating Simple and Smart Large Objects” on page 2-20.
■ Opaque user-defined types (UDTs)
Version 9.3 does not include support for replication of the followinguser-defined types:
❑ Row types
❑ Collections
❑ Lists
❑ Sets and multisets
For more information on which user-defined types are not sup-ported, see the release notes.
■ Informix Spatial DataBlade module
In addition, this release of Enterprise Replication allows the following (withsome restrictions):
■ UDT column references and UDRs in replicate WHERE clauses
■ UDTs for primary key columns
For more information about restrictions on replicating opaque types, see“Considerations for Replicating Opaque Data Types” on page 2-25.
■ Support Functions
To replicate UDTs, Enterprise Replication requires that the UDTdesigner provide two support functions: streamwrite( ) andstreamread( ). See “UDT Support Functions” on page 2-25. For infor-mation on writing these support functions, see the section onEnterprise Replication stream support functions in the DataBlade APIProgrammer’s Manual.
6 Guide to IBM Informix Enterprise Replication

Performance Improvements
Performance ImprovementsEnterprise Replication for Dynamic Server, Version 9.3 includes thefollowing performance improvements by improving parallel processing:
■ Enterprise Replication now applies all replicates (in replicate setsand individually) in parallel by default.
■ Enterprise Replication threads now apply transactions from thesame source in parallel unless they contain updates to the same row.
■ Enterprise Replication threads normally commit on the target in thesame order as on the source.
■ Enterprise Replication threads can commit out of order on the targetif there are no conflicts.
■ Enterprise Replication now uses buffered logging to applytransactions.
Improved parallel processing is built-in and requires no user configuration orinteraction. However, this feature is automatically disabled if you are usingpage-level locking.
Introduction 7

Functionality Enhancements
Functionality EnhancementsEnterprise Replication for Dynamic Server, Version 9.3 includes thefollowing functionality enhancements:
■ SERIAL Column Primary Keys
The CDR_SERIAL configuration parameter enables control over gen-erating values for SERIAL and SERIAL8 columns in tables defined forreplication. This is useful for generating SERIAL column primarykeys in an Enterprise Replication environment.
For more information, see “CDR_SERIAL” on page B-11.
■ Replicate Sets
You can now manage replicates together in replicate sets, both indi-vidually and as part of the set.
For more information, see Chapter 7, “Creating and Managing Rep-licate Sets.”
Pre-Version 9.3 replicate groups are not supported in Version 9.3 andlater. Before migrating to Version 9.3, you must remove any replicategroups. Follow the important instructions in the Informix MigrationGuide.
■ Replicating Only Changed Columns
This release of Enterprise Replication provides the ability to replicateonly the columns that changed, rather than the entire row. For moreinformation, see “Replicating Only Changed Columns” onpage 5-11.
If only changed columns are replicated, the data for all replicated col-umns might not be available for spooling to the ATS (AbortedTransaction Spooling) and RIS (Row Information Spooling) files.Therefore, the format for these files has changed. For more informa-tion, see “Aborted Transaction Spooling Files” on page 8-3 and “RowInformation Spooling Files” on page 8-9.
8 Guide to IBM Informix Enterprise Replication

Command-Line Changes
■ Spooling Changes
Enterprise Replication now spools row data in the send and receivequeues to an sbspace, specified by the CDR_QDATA_SBSPACE config-uration parameter (see “CDR_QDATA_SBSPACE” on page B-9). Inaddition, you can control logging of these sbspaces. For more infor-mation, see “Setting Up Send and Receive Queue Spool Areas” onpage 4-11.
Enterprise Replication also now spools transaction records from thesend and receive queues to a single dbspace, specified by theCDR_QHDR_DBSPACE configuration parameter (see“CDR_QHDR_DBSPACE” on page B-8).
For more information, see “Defining Replication Servers” onpage 5-5.
■ In-place ALTER Statement
The following ALTER statements are now processed as in-place alters(in most cases) and therefore complete much more quickly:
ALTER TABLE ... ADD CRCOLSALTER TABLE ... DROP CRCOLS
The in-place processing of these ALTER statements is implicit andrequires no user action.
For more information about in-place alters, see the “Altering a TableDefinition” section in the Performance Guide. For more informationabout CRCOLS, see “Preparing Tables for Conflict Resolution” onpage 4-21.
Command-Line ChangesThis release includes updates to the command-line interface to support newfeatures, including a new cdr finderr utility that looks up a specific EnterpriseReplication error number and displays the corresponding error text.
For more information, see Appendix A, “Command-Line Utility Reference.”
Introduction 9

Documentation Conventions
Documentation ConventionsThis section describes the conventions that this manual uses. Theseconventions make it easier to gather information from this and other volumesin the documentation set.
Typographical ConventionsThis manual uses the following conventions to introduce new terms,illustrate screen displays, describe command syntax, and so forth.
Tip: When you are instructed to “enter” characters or to “execute” a command,immediately press RETURN after the entry. When you are instructed to “type” thetext or to “press” other keys, no RETURN is required.
Convention Meaning
KEYWORD All primary elements in a programming language statement(keywords) appear in uppercase letters in a serif font.
italicsitalicsitalics
Within text, new terms and emphasized words appear in italics.Within syntax and code examples, variable values that you areto specify appear in italics.
boldfaceboldface
Names of program entities (such as classes, events, and tables),environment variables, file and pathnames, and interfaceelements (such as icons, menu items, and buttons) appear inboldface.
monospacemonospace
Information that the product displays and information that youenter appear in a monospace typeface.
KEYSTROKE Keys that you are to press appear in uppercase letters in a sansserif font.
♦ This symbol indicates the end of one or more product- orplatform-specific paragraphs.
➞ This symbol indicates a menu item. For example, “ChooseTools➞ Options” means choose the Options item from theTools menu.
10 Guide to IBM Informix Enterprise Replication

Icon Conventions
Icon ConventionsThroughout the documentation, you will find text that is identified by severaldifferent types of icons. This section describes these icons.
Comment Icons
Comment icons identify three types of information, as the following tabledescribes. This information always appears in italics.
Feature, Product, and Platform Icons
Feature, product, and platform icons identify paragraphs that containfeature-specific, product-specific, or platform-specific information.
Icon Label Description
Warning: Identifies paragraphs that contain vital instructions,cautions, or critical information
Important: Identifies paragraphs that contain significantinformation about the feature or operation that isbeing described
Tip: Identifies paragraphs that offer additional details orshortcuts for the functionality that is being described
Icon Description
Identifies information that relates to the Informix GlobalLanguage Support (GLS) feature
Identifies information that is specific to UNIX operatingsystem
Identifies information that is specific to the Windows NTand Windows 2000 environments
GLS
UNIX
WIN NT/2000
Introduction 11

Command-Line Conventions
These icons can apply to an entire section or to one or more paragraphswithin a section. If an icon appears next to a section heading, the informationthat applies ends at the next heading at the same or higher level. A ♦ symbolindicates the end of information that appears in one or more paragraphswithin a section.
Command-Line ConventionsThis section defines and illustrates the format of commands that are availablein Informix products. These commands have their own conventions, whichmight include alternative forms of a command, required and optional partsof the command, and so forth.
Each diagram displays the sequences of required and optional elements thatare valid in a command. A diagram begins at the upper-left corner with acommand. It ends at the upper-right corner with a vertical line. Betweenthese points, you can trace any path that does not stop or back up. Each pathdescribes a valid form of the command. You must supply a value for wordsthat are in italics.
You might encounter one or more of the following elements on a command-line path.
Element Description
command This required element is usually the product name orother short word that invokes the product or calls thecompiler or preprocessor script for a compiled Informixproduct. It might appear alone or precede one or moreoptions. You must spell a command exactly as shownand use lowercase letters.
variable A word in italics represents a value that you mustsupply, such as a database, file, or program name. A tablefollowing the diagram explains the value.
-flag A flag is usually an abbreviation for a function, menu, oroption name, or for a compiler or preprocessorargument. You must enter a flag exactly as shown,including the preceding hyphen.
(1 of 2)
12 Guide to IBM Informix Enterprise Replication

Command-Line Conventions
.ext A filename extension, such as .sql or .cob, might followa variable that represents a filename. Type this extensionexactly as shown, immediately after the name of the file.The extension might be optional in certain products.
( . , ; + * - / ) Punctuation and mathematical notations are literalsymbols that you must enter exactly as shown.
' ' Single quotes are literal symbols that you must enter asshown.
A reference in a box represents a subdiagram. Imaginethat the subdiagram is spliced into the main diagram atthis point. When a page number is not specified, thesubdiagram appears on the same page.
A shaded option is the default action.
Syntax within a pair of arrows indicates a subdiagram.
The vertical line terminates the command.
A branch below the main path indicates an optionalpath. (Any term on the main path is required, unless abranch can circumvent it.)
A loop indicates a path that you can repeat. Punctuationalong the top of the loop indicates the separator symbolfor list items.
A gate ( ) on a path indicates that you can only usethat path the indicated number of times, even if it is partof a larger loop. You can specify size no more than threetimes within this statement segment.
Element Description
(2 of 2)
Privilegesp. 5-17
Privileges
ALL
ON
-f OFF
variable
,
size3
, 3
Introduction 13

Sample-Code Conventions
How to Read a Command-Line Diagram
Figure 1 shows a command-line diagram that uses some of the elements thatare listed in the previous table.
To construct a command correctly, start at the top left with the command.Follow the diagram to the right, including the elements that you want. Theelements in the diagram are case sensitive.
Figure 1 illustrates the following steps:
1. Type setenv.
2. Type INFORMIXC.
3. Supply either a compiler name or a pathname.
After you choose compiler or pathname, you come to the terminator.Your command is complete.
4. Press RETURN to execute the command.
Sample-Code ConventionsExamples of SQL code occur throughout this manual. Except where noted,the code is not specific to any single Informix application development tool.If only SQL statements are listed in the example, they are not delimited bysemicolons. For instance, you might see the code in the following example:
CONNECT TO stores_demo...
DELETE FROM customerWHERE customer_num = 121
...
COMMIT WORKDISCONNECT CURRENT
Figure 1Example of a Command-Line Diagram
pathname
compilersetenv INFORMIXC
14 Guide to IBM Informix Enterprise Replication

Additional Documentation
To use this SQL code for a specific product, you must apply the syntax rulesfor that product. For example, if you are using DB-Access, you must delimitmultiple statements with semicolons. If you are using an SQL API, you mustuse EXEC SQL at the start of each statement and a semicolon (or other appro-priate delimiter) at the end of the statement.
Tip: Ellipsis points in a code example indicate that more code would be added in afull application, but it is not necessary to show it to describe the concept beingdiscussed.
For detailed directions on using SQL statements for a particular applicationdevelopment tool or SQL API, see the manual for your product.
Additional DocumentationInformix Dynamic Server documentation is provided in a variety of formats:
■ Online manuals. The Informix OnLine Documentation Web site athttp://www.informix.com/answers contains manuals thatInformix provides for your use. This Web site enables you to printchapters or entire books.
■ Online help. Informix provides online help with each graphical userinterface (GUI) that displays information about those interfaces andthe functions that they perform. Use the help facilities that each GUIprovides to display the online help.
This facility can provide context-sensitive help, an error message ref-erence, language syntax, and more. To order a printed manual, call1-800-331-1763 or send email to [email protected]. Providethe following information when you place your order:
❑ The documentation that you need
❑ The quantity that you need
❑ Your name, address, and telephone number
■ Documentation notes. Documentation notes, which containadditions and corrections to the manuals, are also located at theOnLine Documentation site at http://www.informix.com/answers.Examine these files before you begin using your database server.
Introduction 15

Additional Documentation
■ Release notes. Release notes contain vital information about appli-cation and performance issues. These files are located athttp://www.informix.com/informix/services/techinfo. This site isa password controlled site. Examine these files before you beginusing your database server.
Documentation notes, release notes, and machine notes are alsolocated in the directory where the product is installed. The followingtable describes these files.
On UNIX platforms, the following online files appear in the$INFORMIXDIR/release/en_us/0333 directory.
Online File Purpose
erep_docnotes_9.30.html The documentation notes file for yourversion of this manual describes topicsthat are not covered in the manual orthat were modified since publication.
release_notes_9.30.html The release notes file describes featuredifferences from earlier versions ofInformix products and how thesedifferences might affect currentproducts. This file also contains infor-mation about any known problemsand their workarounds.
machine_notes_9.30.txt The machine notes file describes anyspecial actions that you must take toconfigure and use Informix productson your computer. Machine notes arenamed for the product described.
♦
UNIX
16 Guide to IBM Informix Enterprise Replication

Related Reading
The following items appear in the Informix folder. To display thisfolder, choose Start➞ Programs➞ Informix Dynamic Server 9.30➞
Documentation Notes or Release Notes from the task bar.
Machine notes do not apply to Windows NT platforms. ♦■ Error message files. Informix software products provide ASCII files
that contain Informix error messages and their corrective actions. Fora detailed description of these error messages, refer to Informix ErrorMessages in Answers OnLine.
To read the error messages on UNIX, use the following command.
♦To read error messages and corrective actions on Windows NT, usethe Informix Find Error utility. To display this utility, chooseStart➞ Programs➞ Informix from the task bar. ♦
Related ReadingFor a list of publications that provide an introduction to database servers andoperating-system platforms, refer to your Getting Started manual.
Program Group Item Description
Documentation Notes This item includes additions or corrections tomanuals with information about features thatmight not be covered in the manuals or thathave been modified since publication.
Release Notes This item describes feature differences fromearlier versions of Informix products and howthese differences might affect currentproducts. This file also contains informationabout any known problems and theirworkarounds.
Command Description
finderr Displays error messages online
Windows
UNIX
WIN NT
Introduction 17

Compliance with Industry Standards
Compliance with Industry StandardsThe American National Standards Institute (ANSI) has established a set ofindustry standards for SQL. Informix SQL-based products are fully compliantwith SQL-92 Entry Level (published as ANSI X3.135-1992), which is identicalto ISO 9075:1992. In addition, many features of Informix database serverscomply with the SQL-92 Intermediate and Full Level and X/Open SQL CAE(common applications environment) standards.
Informix Welcomes Your CommentsWe want to know about any corrections or clarifications that you would finduseful in our manuals that would help us with future versions. Include thefollowing information:
■ The name and version of the manual that you are using
■ Any comments that you have about the manual
■ Your name, address, and phone number
Send electronic mail to us at the following address:
This address is reserved for reporting errors and omissions in our documen-tation. For immediate help with a technical problem, contact InformixCustomer Services.
We appreciate your suggestions.
18 Guide to IBM Informix Enterprise Replication

on I
Introducing EnterpriseReplication
Sect
i
Chapter 1 About Informix Enterprise Replication
Chapter 2 Overview of Enterprise Replication Administration


1Chapter
About Informix EnterpriseReplication
In This Chapter . . . . . . . . . . . . . . . . . . . . 1-3
Informix Enterprise Replication . . . . . . . . . . . . . . 1-3Asynchronous Data Replication . . . . . . . . . . . . . 1-4Log-Based Data Capture . . . . . . . . . . . . . . . 1-5High Performance . . . . . . . . . . . . . . . . . . 1-6High Availability . . . . . . . . . . . . . . . . . . 1-6Consistent Information Delivery . . . . . . . . . . . . . 1-6Flexible Architecture . . . . . . . . . . . . . . . . . 1-7Centralized Administration . . . . . . . . . . . . . . 1-8
How Enterprise Replication Replicates Data . . . . . . . . . . 1-8Capture Transactions . . . . . . . . . . . . . . . . . 1-9Evaluate Data for Replication . . . . . . . . . . . . . . 1-9
Row Images . . . . . . . . . . . . . . . . . . 1-9Evaluating Rows for Updates . . . . . . . . . . . . 1-12Send Data Queues and Receive Data Queues . . . . . . . 1-13Data Evaluation Examples . . . . . . . . . . . . . 1-14
Distribute Data . . . . . . . . . . . . . . . . . . . 1-17Apply Replicated Data . . . . . . . . . . . . . . . . 1-17

1-2 Guid
e to IBM Informix Enterprise Replication
In This ChapterData replication generates and manages multiple copies of data at one ormore sites, which allows an enterprise to share corporate data throughout itsorganization.
This chapter introduces Informix Enterprise Replication and explains howthis product replicates data.
Informix Enterprise ReplicationInformix Enterprise Replication is an asynchronous, log-based tool for repli-cating data between Informix Dynamic Server database servers. EnterpriseReplication on the source server captures transactions to be replicated byreading the logical log, storing the transactions, and reliably transmittingeach transaction as replication data to the target servers.
At each target server, Enterprise Replication receives and applies each trans-action contained in the replication data to the appropriate databases andtables as a normal, logged transaction.
Informix Enterprise Replication provides the following:
■ Asynchronous Data Replication
■ Log-Based Data Capture
■ High Performance
■ High Availability
■ Consistent Information Delivery
■ Flexible Architecture
■ Centralized Administration
About Informix Enterprise Replication 1-3

Asynchronous Data Replication
Asynchronous Data ReplicationEnterprise Replication uses asynchronous data replication to update thedatabases that reside at a replicated site after the primary database hascommitted a change.
With asynchronous replication, the delay to update the replicated-sitedatabases can vary depending on the business application and user require-ments. However, the data eventually synchronizes to the same value at allsites. The major benefit of this type of data replication is that if a particulardatabase server fails, the replication process can continue and all transactionsin the replication system will be committed.
In contrast with synchronous data replication, the replicated data is updatedimmediately when the source data is updated. Synchronous data replicationuses the two-phase commit technology to protect data integrity. In a two-phasecommit, a transaction is applied only if all interconnected distributed sitesagree to accept the transaction. Synchronous data replication is appropriatefor applications that require immediate data synchronization. However,synchronous data replication requires that all hardware components andnetworks in the replication system be available at all times. For more infor-mation about synchronous replication, refer to the discussion of two-phasecommit in your Administrator’s Guide for Informix Dynamic Server.
Asynchronous replication is the more common type of data replication inopen-system environments because it protects against system and networkfailures.
Asynchronous replication allows the following replication models:
■ Primary-target (“Primary-Target Replication System” on page 3-3)
All database changes originate at the primary database and arereplicated to the target databases. Changes at the target databasesare not replicated to the primary.
■ Update-anywhere (“Update-Anywhere Replication System” onpage 3-10)
All databases have read and write capabilities. Updates are appliedat all databases.
1-4 Guide to IBM Informix Enterprise Replication

Log-Based Data Capture
The update-anywhere model provides the greater challenge in asynchronousreplication. For example, if a replication system contains three replicationsites that all have read and write capabilities, conflicts occur when the sitestry to update the same data at the same time. Conflicts must be detected andresolved so that the data elements eventually have the same value at everysite. For more information, see “Conflict Resolution” on page 3-11.
Log-Based Data CaptureEnterprise Replication uses log-based data capture to gather data for repli-cation. Enterprise Replication reads the logical log to obtain the row imagesfor tables that participate in replication and then evaluates the row images.
Log-based data capture takes changes from the logical log and does notcompete with transactions for access to production tables. Log-based data-capture systems operate as part of the normal database-logging process andthus add minimal overhead to the system.
Two additional methods of data capture, which Enterprise Replication doesnot support, include:
■ Trigger-based data capture
A trigger is code in the database that is associated with a piece ofdata. When the data changes, the trigger activates the replicationprocess.
■ Trigger-based transaction capture
A trigger is associated with a table. Data changes are grouped intotransactions and a single transaction might trigger several replica-tions if it modifies several tables. The trigger receives the wholetransaction, but the procedure that captures the data runs as a part ofthe original transaction, thus slowing down the original transaction.
About Informix Enterprise Replication 1-5

High Performance
High PerformanceEnterprise Replication provides high performance by not overly burdeningthe source of the data and by using networks and all other resourcesefficiently.
Because Enterprise Replication captures changes from the logical log insteadof competing with transactions that access production tables, EnterpriseReplication minimizes the effect on transaction performance. Because thecapture mechanism is internal to the database, the database server imple-ments this capture mechanism efficiently. For more information, see “Log-Based Data Capture” on page 1-5.
All Enterprise Replication operations are performed in parallel, whichfurther extends the performance of Enterprise Replication. For more infor-mation, see “Performance Improvements” on page 7 of the Introduction.
High AvailabilityBecause Enterprise Replication implements asynchronous data replication,network and target database server outages are tolerated. In the event of adatabase server or network failure, the local database server continues toservice local users. The local database server stores replicated transactions inpersistent storage until the remote server becomes available.
Consistent Information DeliveryEnterprise Replication protects data integrity. All Enterprise Replicationtransactions are stored in a reliable queue to maintain the consistency oftransactions.
Enterprise Replication uses a data-synchronization process to ensure thattransactions are applied at the target database servers in any order equivalentto the order that they were committed on the source database server. If Enter-prise Replication can preserve the consistency of the database, EnterpriseReplication might commit transactions out-of-order on the target database.
1-6 Guide to IBM Informix Enterprise Replication

Flexible Architecture
If update conflicts occur, Enterprise Replication provides built-in automaticconflict detection and resolution. You can configure the way conflictresolution behaves to meet the needs of your enterprise. For more infor-mation, see “Conflict Resolution” on page 3-11.
Flexible ArchitectureEnterprise Replication allows replications based on specific business andapplication requirements and does not impose model or methodologyrestrictions on the enterprise.
Enterprise Replication supports both primary-target and update-anywherereplication models. For more information, see “Selecting the EnterpriseReplication System” on page 3-3.
Enterprise Replication supports the following network topologies:
■ Fully connected
Continuous connectivity between all participating database servers.
■ Hierarchical tree
A parent-child configuration that supports continuous and intermit-tent connectivity.
■ Forest of trees
Multiple hierarchical trees that connect at the root database servers.
For more information, see “Choosing a Replication Network Topology” onpage 3-19.
Enterprise Replication supports all built-in Informix data types, as well asopaque user-defined data types. For more information, see “New Features inDynamic Server, Version 9.3” on page 5 of the Introduction and “EnterpriseReplication Data Types” on page 2-19.
Enterprise Replication operates in a LAN, WAN, and combined LAN/WANconfiguration across a range of network transport protocols.
Enterprise Replication supports the Global Language Support (GLS) feature,which allows Informix products to handle different languages, regionalconventions, and code sets. For more information, see “Using GLS withEnterprise Replication” on page 2-18.
About Informix Enterprise Replication 1-7

Centralized Administration
Centralized AdministrationEnterprise Replication allows administrators to easily manage all thedistributed components of the replication system from a single point ofcontrol.
You can use the command-line utility (CLU) to administer the replicationsystem from your system command prompt and connect to other serversinvolved in replication, as necessary. For information, see Appendix A,“Command-Line Utility Reference.”
In addition, you can use Informix Server Administrator (ISA) to administeryour replication system from a web browser. For more information, see theDocumentation Notes described in “Additional Documentation” on page 15of the Introduction.
How Enterprise Replication Replicates DataBefore you can replicate data, you must declare a database server for repli-cation and define the replicates (the data to replicate and the database serversthat participate in replication). To declare a database server for replication,see “Defining Replication Servers” on page 5-5. To define replicates, see“Defining Replicates” on page 5-7. Appendix E, “Replication Examples,” hassimple examples of declaring replication servers and defining replicates.
After the servers and replicates are defined, Enterprise Replication uses thefollowing steps to replicate data:
1. Capture Transactions.
2. Evaluate Data for Replication.
3. Distribute Data.
4. Apply Replicated Data.
1-8 Guide to IBM Informix Enterprise Replication

Capture Transactions
Capture TransactionsAs the database server writes rows to the logical log, it marks rows thatshould be replicated. Later, Enterprise Replication reads the logical log toobtain the row images for tables that participate in replication.
Informix database servers manage the logical log in a circular fashion; themost recent logical-log entries write over the oldest entries. Enterprise Repli-cation must read the logical log quickly enough to prevent new logical-logentries from overwriting the logs Enterprise Replication has not yetprocessed. If the database server comes close to overwriting a logical log thatEnterprise Replication has not yet processed, user transactions are blockeduntil Enterprise Replication can advance. (This situation is called blockoutmode and occurs only if the system is severely misconfigured.)
The row images that participate in replication are passed to Enterprise Repli-cation for further evaluation.
Evaluate Data for ReplicationEnterprise Replication evaluates transactions based on a change to a finalimage of a row.
Row Images
Enterprise Replication evaluates the initial and final images of a row and anychanges that occur between the two row images to determine which rows toreplicate. Each row image contains the data in the row as well as the actionperformed on that row.
A row might change more than once in a particular transaction. For example,a transaction might insert and then update a row prior to committing. Enter-prise Replication evaluates the net effect (final state) of a transaction based onthe row buffers in the log. Enterprise Replication then determines whatshould replicate, based on the net effect, the initial state of the row, andwhether the replicate definition (in particular, the WHERE clause) applies tothe initial and final state.
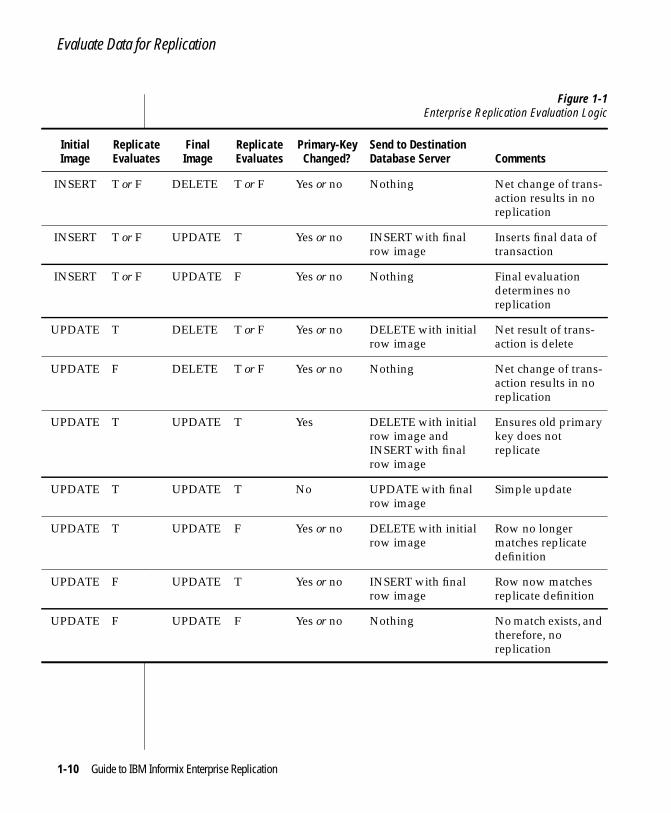
The table in Figure 1-1 shows the logic that determines which rows are candi-dates for replication.
About Informix Enterprise Replication 1-9
Evaluate Data for Replication
Figure 1-1Enterprise Replication Evaluation Logic
InitialImage
ReplicateEvaluates
FinalImage
ReplicateEvaluates
Primary-KeyChanged?
Send to DestinationDatabase Server Comments
INSERT T or F DELETE T or F Yes or no Nothing Net change of trans-action results in noreplication
INSERT T or F UPDATE T Yes or no INSERT with finalrow image
Inserts final data oftransaction
INSERT T or F UPDATE F Yes or no Nothing Final evaluationdetermines noreplication
UPDATE T DELETE T or F Yes or no DELETE with initialrow image
Net result of trans-action is delete
UPDATE F DELETE T or F Yes or no Nothing Net change of trans-action results in noreplication
UPDATE T UPDATE T Yes DELETE with initialrow image andINSERT with finalrow image
Ensures old primarykey does notreplicate
UPDATE T UPDATE T No UPDATE with finalrow image
Simple update
UPDATE T UPDATE F Yes or no DELETE with initialrow image
Row no longermatches replicatedefinition
UPDATE F UPDATE T Yes or no INSERT with finalrow image
Row now matchesreplicate definition
UPDATE F UPDATE F Yes or no Nothing No match exists, andtherefore, noreplication
1-10 Guide to IBM Informix Enterprise Replication

Evaluate Data for Replication
Where:
■ Initial image is the before image of the transaction in the logical log.
■ The replicate evaluates to T (true) or F (false).
■ Final Image is the image of the transaction that is replicated.
The table in Figure 1-1 on page 1-10 illustrates how Enterprise Replicationevaluates the row-image type (INSERT, UPDATE, DELETE), the results ofevaluating the replicate WHERE clause for both the initial and final image,and whether the primary key changes as a result of the transaction.
Tip: The evaluation logic in Figure 1-1 on page 1-10 assumes that the source and thedestination tables are initially synchronized (identical before replication begins). Ifthe tables are not synchronized, anomalous behavior could result.
After Enterprise Replication identifies transactions that qualify for repli-cation, Enterprise Replication transfers the transaction data to a queue.
About Informix Enterprise Replication 1-11

Evaluate Data for Replication
Evaluating Rows for Updates
Enterprise Replication evaluates rows for primary-key updates, for WHEREclause column updates, and for multiple updates to the same row. Thefollowing list describes an occurrence in a transaction and the EnterpriseReplication action:
■ Primary-key updates
Enterprise Replication translates an update of a primary key into adelete of the original row and an insert of the row image with thenew primary key. If triggers are enabled on the target system, inserttriggers are executed.
■ WHERE clause column updates
If a replicate includes a WHERE clause in its data selection, theWHERE clause imposes selection criteria for rows in the replicatedtable.
❑ If an update changes a row so that it no longer passes theselection criteria on the source, it is deleted from the target table.Enterprise Replication translates the update into a delete andsends it to the target.
❑ If an update changes a row so that it passes the selection criteriaon the source, it is inserted into the target table. Enterprise Repli-cation translates the update into an insert and sends it to thetarget.
■ Multiple-row images in a transaction
Enterprise Replication compresses multiple-row images and onlysends the net change to the target. Because of this, triggers might notexecute on the target database. For more information, see “Triggers”on page 2-13.
Enterprise Replication supports the replication of BYTE and TEXT data types(simple large objects) and BLOB and CLOB data types (smart large objects),and opaque user-defined data types, as well as all built-in Informix datatypes. However, Enterprise Replication implements the replication of thesetypes of data somewhat differently from the replication of other data types.For more information, see “Extensibility Enhancements” on page 6 of theIntroduction, “Replicating Simple and Smart Large Objects” on page 2-20,and “Replicating Opaque User-Defined Data Types” on page 2-25.
1-12 Guide to IBM Informix Enterprise Replication

Evaluate Data for Replication
Send Data Queues and Receive Data Queues
Enterprise Replication uses send and receive queues to receive and deliverreplication data to and from database servers that participate in a replicate:
■ Send queue
Enterprise Replication stores replication data in memory to be deliv-ered to target database servers that participate in a replicate. If thesend queue fills, Enterprise Replication spools the send queue trans-action records to a dbspace and the send queue row data to ansbspace.
■ Receive queue
Enterprise Replication stores replication data in memory at the targetdatabase server until the target database server acknowledgesreceipt of the data. If the receive queue fills as a result of a large trans-action (“Large Transactions” on page 2-15), Enterprise Replicationspools the receive queue transaction header to a dbspace and thereceive queue row data to an sbspace.
For more information, see “Setting Up Send and Receive Queue Spool Areas”on page 4-11 and “Preventing Memory Queues from Overflowing” onpage 8-13.
The data contains the filtered log records for a single transaction. EnterpriseReplication stores the replication data in a stable (recoverable) send queue onthe source database server. Target sites acknowledge receipt of data when itis applied to or rejected from the target database.
If a target database server is unreachable, the replication data remains in astable queue at the source database server. Temporary failures are commonand no immediate action is taken by the source database server; it continuesto queue transactions. When the target database server becomes availableagain, queued transactions are transmitted and applied (see “Apply Repli-cated Data” on page 1-17).
About Informix Enterprise Replication 1-13

Evaluate Data for Replication
If the target database server is unavailable for an extended period, the sendqueue on the source database server might consume excessive resources. Inthis situation, you might not want to save all transactions for the targetdatabase server. To prevent unlimited transaction accumulation, you canremove the unavailable target database server from the replicate (see“Managing Replication Servers” on page 6-3). Before the database server thatis removed rejoins any replicate, however, you must synchronize (bringtables to consistency) with the other database servers (see “ResynchronizingReplication Servers” on page 5-17).
Data Evaluation Examples
Figure 1-2, Figure 1-4 on page 1-15, and Figure 1-6 on page 1-16 show threeexamples of how Enterprise Replication uses logic to evaluate transactionsfor potential replication.
Figure 1-2 shows a transaction that takes place at the Dallas office. EnterpriseReplication uses the logic in Figure 1-3 to evaluate whether any informationis sent to the destination database server at the Phoenix office.
Figure 1-2Insert Followed by a
Deletedallas_office
INSERT INTO employeeVALUES (927, “Smith”...
DELETE FROM employeeWHERE emp_id=927
BEGIN WORK;
COMMIT WORK;
phoenix_office
Replicate SQL=SELECT emp_id, salary FROM employee WHERE exempt = “N”;
1-14 Guide to IBM Informix Enterprise Replication

Evaluate Data for Replication
Figure 1-3Insert Followed by a Delete Evaluation Logic
Enterprise Replication determines that the insert followed by a delete resultsin no replication operation; therefore, no replication data is sent.
In Figure 1-4, Enterprise Replication uses the logic in Figure 1-5 to evaluatewhether any information is sent to the destination database server.
Initial ImageReplicateEvaluates Final Image
ReplicateEvaluates
Primary-KeyChanged?
Send to DestinationDatabase Server
INSERT T or F DELETE T or F Yes or no Nothing
Figure 1-4Insert Followed by
an Update
INSERT INTO employeeVALUES (927, "Smith", "N" ...
BEGIN WORK;
COMMIT WORK;
Replicate SQL=SELECT emp_id, salary FROM employee WHERE exempt = “N”;
UPDATE employeeSET lname = "Jones"WHERE emp_id = 927
BEGIN WORK;
INSERT INTO employeeVALUES (927, "Jones" ...
COMMIT WORK;
dallas_office phoenix_office
About Informix Enterprise Replication 1-15

Evaluate Data for Replication
Figure 1-5Insert Followed by An Update Evaluation Logic
The replicate WHERE clause imposes the restriction that only rows with theexempt column equal to “N” are replicated. Enterprise Replication evaluatesthe transaction (an insert followed by an update) and converts it to an insertto propagate the updated (final) image.
In Figure 1-6, Enterprise Replication uses the logic in Figure 1-7 to evaluatewhether any information is sent to the destination database server.
Figure 1-7Update; Not Selected to Selected Evaluation Logic
Initial ImageReplicateEvaluates Final Image
ReplicateEvaluates
Primary-KeyChanged?
Send to Destination DatabaseServer
INSERT T or F UPDATE T Yes or no INSERT with final rowimage
Figure 1-6Update; NotSelected to
Selecteddallas_office
UPDATE employeeSET EXEMPT = "N"WHERE emp_id = 927
BEGIN WORK;
COMMIT WORK;
phoenix_office
Replicate SQL=SELECT emp_id, salary FROM employee WHERE exempt = “N”;
BEGIN WORK;
INSERT INTO employeeVALUES (927, "Jones", ...
COMMIT WORK;
Initial ImageReplicateEvaluates Final Image
ReplicateEvaluates
Primary-KeyChanged?
Send to Destination DatabaseServer
UPDATE F UPDATE T Yes or no INSERT with final row image
1-16 Guide to IBM Informix Enterprise Replication

Distribute Data
The example shows a replicate WHERE clause column update. A row thatdoes not meet the WHERE clause selection criteria is updated to meet thecriteria. Enterprise Replication replicates the updated row image andconverts the update to an insert.
Distribute DataEnterprise Replication ensures that all data reaches the appropriate server,regardless of a network or system failure. In the event of a failure, EnterpriseReplication stores data until the network or system is operational. EnterpriseReplication replicates data efficiently with a minimum of data copying andsending.
Apply Replicated DataEnterprise Replication uses a data-synchronization process to apply the repli-cated data to target database servers. The target database serversacknowledge receipt of data when the data is applied to the target database.The data-synchronization process ensures that transactions are applied at thetarget database servers in any order equivalent to the order that they werecommitted on the source database server. If Enterprise Replication canpreserve the consistency of the database, Enterprise Replication mightcommit transactions out of order on the target database.
When Enterprise Replication applies replication data, it checks to make surethat no collisions exist. A collision occurs when two database servers updatethe same data simultaneously. Enterprise Replication reviews the data onerow at a time to detect a collision.
About Informix Enterprise Replication 1-17

Apply Replicated Data
If Enterprise Replication finds a collision, it must resolve the conflict beforeapplying the replication data to the target database server.
Figure 1-8 shows a situation that yields a conflict. Pakistan updates the rowtwo seconds before Bangkok updates the same row. The Bangkok updatearrives at the India site first, and the Pakistan update follows. The Pakistantime is earlier than the Bangkok time. Because both updates involve the samedata and a time discrepancy exists, Enterprise Replication detects a collision.
For more information, see “Conflict Resolution” on page 3-11.
Enterprise Replication scans to see if the same primary key already exists inthe target table or in the associated delete table, or if a replication order error isdetected. A delete table stores the row images of deleted rows. A replicationorder error is the result of replication data that arrives from differentdatabase servers with one of the following illogical results:
■ A replicated DELETE that finds no row to DELETE on the target
■ An UPDATE that finds no row to UPDATE on the target
■ An INSERT that finds a row that already exists on the target
Figure 1-8Collision Example
Column Column...field value field valuefield valuefield value
...
Products (in inventory)Time= 12:29:25
Time= 12:29:27
India
Bangkok
Pakistan
Bangkok
Pakistan
1-18 Guide to IBM Informix Enterprise Replication

2Chapter
Overview of EnterpriseReplication Administration
In This Chapter . . . . . . . . . . . . . . . . . . . . 2-3
Overview of Enterprise Replication Administration . . . . . . . 2-3
Enterprise Replication Server Administrator . . . . . . . . . . 2-4
Enterprise Replication Terminology . . . . . . . . . . . . . 2-4Enterprise Replication Server . . . . . . . . . . . . . . 2-5Replicate . . . . . . . . . . . . . . . . . . . . . 2-5Participant . . . . . . . . . . . . . . . . . . . . 2-5Replicate Set . . . . . . . . . . . . . . . . . . . . 2-6Global Catalog . . . . . . . . . . . . . . . . . . . 2-6Enterprise Replication Considerations . . . . . . . . . . . 2-8Operational Considerations . . . . . . . . . . . . . . 2-8Backup and Restore Considerations. . . . . . . . . . . . 2-9Database and Table Design Considerations . . . . . . . . . 2-9
Unbuffered Logging. . . . . . . . . . . . . . . . 2-10Table Types . . . . . . . . . . . . . . . . . . . 2-10Out-of-Row Data . . . . . . . . . . . . . . . . . 2-11Shadow Columns. . . . . . . . . . . . . . . . . 2-11Primary Key Constraint . . . . . . . . . . . . . . 2-11SERIAL Data Types and Primary Keys . . . . . . . . . 2-12Cascading Deletes . . . . . . . . . . . . . . . . 2-12Triggers . . . . . . . . . . . . . . . . . . . . 2-13
Transaction Processing Considerations. . . . . . . . . . . 2-14Replication Volume . . . . . . . . . . . . . . . . 2-14Distributed Transactions . . . . . . . . . . . . . . 2-14Large Transactions . . . . . . . . . . . . . . . . 2-15Supported SQL Statements . . . . . . . . . . . . . 2-15

2-2 Guid
Replication Environment Considerations . . . . . . . . . . 2-17Time Synchronization . . . . . . . . . . . . . . . 2-17Using GLS with Enterprise Replication . . . . . . . . . 2-18
Enterprise Replication Data Types . . . . . . . . . . . . 2-19Replicating on Heterogeneous Hardware . . . . . . . . 2-19Replicating Simple and Smart Large Objects . . . . . . . 2-20Replicating Opaque User-Defined Data Types . . . . . . . 2-25
e to IBM Informix Enterprise Replication

In This ChapterThis chapter introduces you to Enterprise Replication administration anddescribes the Enterprise Replication server administrator, terminology, andconsiderations for using Enterprise Replication.
Overview of Enterprise Replication AdministrationTo set up Enterprise Replication
1. Select the Enterprise Replication system and network topology touse for your replication environment.
For information, see Chapter 3, “Selecting the Enterprise ReplicationSystem and Network Topology.”
2. Prepare the replication environment.
For information, see Chapter 4, “Preparing the ReplicationEnvironment.”
3. Initialize the database server.
For information, see Chapter 5, “Defining and Modifying Replica-tion Servers, Replicates, and Participants.”
4. Define database servers for replication.
For information, see Chapter 5.
5. Define replicates and participants.
For information, see Chapter 6, “Managing Replication Servers andReplicates.”
6. Create replicate sets (optional).
For information, see Chapter 7, “Creating and Managing ReplicateSets.”
Overview of Enterprise Replication Administration 2-3

Enterprise Replication Server Administrator
7. Start the replicate.
For information, see Chapter 6.
Once you configure Enterprise Replication, use this information to manageyour replication environment:
■ “Managing Replication Servers” on page 6-3
■ “Managing Replicates” on page 6-7
■ “Managing Replicate Sets” on page 7-6
■ “Monitoring and Troubleshooting Enterprise Replication” onpage 8-1
Enterprise Replication Server AdministratorThe Enterprise Replication server administrator must have Informix admin-istrative privileges to configure and manage Enterprise Replication.
Enterprise Replication TerminologyThe following terms define the data in an Enterprise Replication system andhow it is treated:
■ Enterprise Replication Server
■ Replicate
■ Participant
■ Replicate Set
■ Global Catalog
Operating System Privileges
UNIX user informix
Windows member of the Informix-Admin group
2-4 Guide to IBM Informix Enterprise Replication

Enterprise Replication Server
Enterprise Replication ServerAn Enterprise Replication server, or replication server, is an Informix databaseserver that participates in data replication. The replication server maintainsinformation about the replication environment, which columns should bereplicated, and the conditions under which the data should be replicated.This information is stored in a database, syscdr, that the database servercreates when it is initialized. Multiple database servers can be on the samephysical computer, and each database server can participate in EnterpriseReplication.
Important: For each server participating in replication, you must set up a databaseserver group in the SQLHOSTS file (UNIX) or registry (Windows). For more infor-mation, see “Setting up Database Server Groups” on page 4-5 and Appendix F,“SQLHOSTS Registry Key.”
Tip: This manual uses the convention that the name of a database server group is g_followed by the name of a database server that is in the group; for example, g_italy.
For more information, see “Defining Replication Servers” on page 5-5 and“cdr define server” on page A-20.
ReplicateA replicate defines the replication participants and various attributes of how toreplicate the data, such as frequency and how to handle any conflicts duringreplication.
For more information, see “Defining Replicates” on page 5-7 and “cdr definereplicate” on page A-10.
ParticipantA participant specifies the data (database, table, and columns) to replicate andthe database servers to which the data replicates.
Important: You cannot start and stop replicates that have no participants.
For more information, see “Defining Participants” on page 5-8 and “Partic-ipant” on page A-88.
Overview of Enterprise Replication Administration 2-5

Replicate Set
Replicate SetA replicate set combines several replicates to form a set that can be adminis-tered together as a unit.
If your replication system contains many replicates that you define as part ofa replicate set, you can use a single command to start, stop, suspend, orresume all the replicates in the set.
For more information, see Chapter 7, “Creating and Managing ReplicateSets” and “cdr change replicateset” on page A-6.
Global CatalogEach database server that participates in Enterprise Replication maintainstables in the syscdr database to keep track of Enterprise Replication configu-ration information and state. For all root and nonroot (“Replication TopologyTerms” on page 3-21) replication servers, this catalog is a global catalog thatmaintains a global inventory of Enterprise Replication configuration infor-mation. The global catalog is created when you define the server forreplication.
The global catalog includes the following:
■ Enterprise Replication server definitions and state
■ Routing and connectivity information
■ Replicate definitions and state
■ Participant definitions and state
■ Replicate set definitions and state
■ Conflict detection and resolution rules and any associated SPLroutines
The tables in one global catalog instance are automatically replicated to theglobal catalogs of all other replication servers (except leaf servers), thus youcan manage the entire replication environment from one non-leaf replicationserver. For information about managing replication servers (and their globalcatalogs), refer to “Managing Replication Servers” on page 6-3.
2-6 Guide to IBM Informix Enterprise Replication

Global Catalog
Leaf replication servers (“Replication Topology Terms” on page 3-21) have alimited catalog. Because the parent database server always manages opera-tions that involve a leaf database server, the catalog of the leaf databaseserver contains only enough data to allow it to interact with its parent server.Limiting the catalog of leaf database servers makes the replication systemmore efficient because the global catalogs do not need to be replicated to theleaf servers.
For information on defining root, nonroot, and leaf servers, see “Customizingthe Replication Server Definition” on page 5-6.
Overview of Enterprise Replication Administration 2-7

Enterprise Replication Considerations
Enterprise Replication ConsiderationsThis section discusses items to consider when planning to use EnterpriseReplication:
■ Operational Considerations
■ Backup and Restore Considerations
■ Database and Table Design Considerations
■ Transaction Processing Considerations
■ Replication Environment Considerations
■ Enterprise Replication Data Types
Operational ConsiderationsEnterprise Replication imposes the following operational limitations:
■ Enterprise Replication supports replication on Informix DynamicServer only.
■ High-Availability Data Replication (HDR) cannot run concurrentlywith Enterprise Replication. For more information, see the chapteron High-Availability Data Replication in the Administrator’s Guide forInformix Dynamic Server.
■ Replication is restricted to base tables. That is, you cannot define areplicate on a view or synonym. A view is a synthetic table, asynthesis of data that exists in real tables and other views. A synonymis an alternative name for a table or a view. For more information onviews and synonyms, see the Informix Guide to Database Design andImplementation.
Enterprise Replication asynchronously propagates many control operationsthrough the Enterprise Replication network. When you perform adminis-trative functions using Enterprise Replication, the status returning fromthose operations is indicative only of the success or failure of the operation atthe database server to which you are directly connected. The operation mightstill be propagating through the other Enterprise Replication databaseservers in the network at that time.
2-8 Guide to IBM Informix Enterprise Replication

Backup and Restore Considerations
Due to this asynchronous propagation, avoid performing control operationsin quick succession that might directly conflict with one another withoutverifying that the first operation has successfully propagated through theentire enterprise network. Specifically, avoid deleting Enterprise Replicationobjects such as replicates, replicate sets, and Enterprise Replication servers,and immediately re-creating those objects with the same name. Doing so cancause failures in the Enterprise Replication system at the time of theoperation or later. These failures might manifest themselves in ways that donot directly indicate the source of the problem.
If you must delete and re-create a definition, use a different name for the newobject (for example, delete replicate a.001 and recreate it as a.002) or wait untilthe delete action has successfully propagated through the entire EnterpriseReplication system before you re-create the object. The former strategy isespecially appropriate if you have database servers that are not connected tothe Enterprise Replication network at all times. It might take significant timebefore the operation is propagated to those disconnected servers.
Backup and Restore ConsiderationsWhen backing up and restoring database servers that participate in repli-cation, do not stop Enterprise Replication before performing a backup on anEnterprise Replication system.
Database and Table Design ConsiderationsConsider the following when designing databases and tables for replication:
■ Unbuffered Logging
■ Table Types
■ Shadow Columns
■ SERIAL Data Types and Primary Keys
■ Cascading Deletes
■ Triggers
Overview of Enterprise Replication Administration 2-9

Database and Table Design Considerations
Unbuffered Logging
Databases on all server instances involved in replication must be created withlogging.
Informix recommends that you replicate tables only from databases createdwith unbuffered logging. Enterprise Replication evaluates the logical log fortransactions that modify tables defined for replication. If a table defined forreplication resides in a database that uses buffered logging, the transactionsare not immediately written to the logical log, but are instead buffered andthen written to the logical log in a block of logical records. When this occurs,Enterprise Replication evaluates the buffer of logical-log records all at once,which consumes excess CPU time and memory. When you define a table forreplication in a database created with unbuffered logging, Enterprise Repli-cation can evaluate the transactions as they are produced.
To create a database with unbuffered logging, use:
CREATE DATABASE db_name WITH LOG
For more information, see the section on CREATE DATABASE in the InformixGuide to Database Design and Implementation.
Table Types
The following table types are not supported by Enterprise Replication:
■ RAW tables
Because RAW tables are not logged, they cannot be replicated usingEnterprise Replication.
■ Temporary tables
Because the database server deletes temporary tables when an appli-cation terminates or closes the database, you should not includethese tables in your replication environment.
For more information on table types, see Informix Guide to Database Design andImplementation.
2-10 Guide to IBM Informix Enterprise Replication

Database and Table Design Considerations
Out-of-Row Data
Enterprise Replication collects out-of-row data for transmission after the usertransaction has committed. Due to activity on the replicated row, the datamight not exist at the time Enterprise Replication collects it for replication. Insuch cases, Enterprise Replication normally applies a NULL on the targetsystem. Therefore, you should avoid placing a NOT NULL constraint on anyreplicated column that includes out-of-row data.
Shadow Columns
In an update-anywhere replication environment, you must provide forconflict resolution using a conflict-resolution rule (see “Conflict Resolution”on page 3-11). When you create a table that uses the time stamp or time stampplus SPL conflict-resolution rule, you must define the shadow columns,cdrserver and cdrtime on both the source and target replication servers.
Tip: If you plan to use only the ignore conflict-resolution rule, you do not need todefine the cdrserver and cdrtime shadow columns.
For more information, see “Preparing Tables for Conflict Resolution” onpage 4-21.
Primary Key Constraint
All tables involved in replication must have a PRIMARY KEY constraintdefined on at least one column, which forces the column to be unique. (Formore information about primary keys, see the Informix Guide to DatabaseDesign and Implementation and the Informix Guide to SQL: Syntax.)
Important: Because primary key updates are sent as DELETE/INSERT statementpairs, avoid changing the primary key and updating data in the same transaction.
Overview of Enterprise Replication Administration 2-11

Database and Table Design Considerations
SERIAL Data Types and Primary Keys
If you plan to use SERIAL data types (SERIAL and SERIAL8) as the primary keyfor a table, the same serial value might be generated on two servers at thesame time.
To avoid this problem, use the CDR_SERIAL configuration parameter togenerate non-overlapping (unique) values for SERIAL columns across alldatabase servers in your replication environment. Set CDR_SERIAL in theONCONFIG file for each primary (source) database server. For more infor-mation and examples, see “CDR_SERIAL” on page B-11.
If you do not set CDR_SERIAL, you must specify that the serial column is partof a composite primary key, to avoid generating non-unique SERIAL primarykeys. The non-serial column part of the primary key identifies the server onwhich the row was initially created.
Cascading Deletes
If a table includes a cascading delete, when a parent row is deleted, the childrenare also deleted. If both the parent and child tables participate in replication,the deletes for both the parent and child are replicated to the target servers.
If the same table definition exists on the target database, Enterprise Repli-cation attempts to delete the child rows twice. Enterprise Replication usuallyprocesses deletes on the parent first and then the children. When EnterpriseReplication processes deletes on the children, an error might result, becausethe rows were already deleted when the parent was deleted. The table inFigure 2-1 indicates how Enterprise Replication resolves cascading deleteswith conflict-resolution scopes and rules.
For more information on cascading deletes, see the ON DELETE CASCADEsection in the Informix Guide to SQL: Syntax.
2-12 Guide to IBM Informix Enterprise Replication

Database and Table Design Considerations
Figure 2-1Resolving Cascade Deletes
Triggers
A trigger is a database object that automatically sets off a specified set of SQLstatements when a specified event occurs.
If the --firetrigger option is enabled on a replicate, any triggers defined on atable that participates in replication are invoked when transactions areprocessed on the target server. However, because Enterprise Replication onlyreplicates the final result of a transaction, triggers execute only once on thetarget regardless of how many triggers executed on the source. In caseswhere the final evaluation of the transaction results in no replication (forexample, an INSERT where the final row image is a DELETE, as shown inFigure 1-3 on page 1-15), no triggers execute on the target database.
If the same triggers are defined on both the source and target tables, anyINSERT, UPDATE, or DELETE operation that the triggers generate are also sentto the target database server. For example, the target table might receivereplicate data caused by a trigger that also executes locally. Depending on theconflict-resolution rule and scope, these operations can result in errors. Toavoid this problem, define the replicate to not fire triggers on the target table.
For more information on triggers, see “Enabling Triggers” on page 5-14 andthe CREATE TRIGGER section in Informix Guide to SQL: Syntax.
Conflict-ResolutionRule Conflict-Resolution Scope Actions on Delete Errors Result
Time stamp Row-by-row or transaction Note as replicationexceptions
Process children rows
Ignore Transaction Report as errors Abort entire transaction
Ignore Row-by-row Report as errors Reject row
Overview of Enterprise Replication Administration 2-13

Transaction Processing Considerations
Transaction Processing ConsiderationsMany variables affect the impact that replicating data has on your transactionprocessing. This section discusses some of these variables:
■ Replication Volume
■ Distributed Transactions
■ Large Transactions
■ Supported SQL Statements
Replication Volume
To determine replication volume, you must estimate how many data rowschange per day. For example, an application issues a simple INSERTstatement that inserts 100 rows. If this table is replicated, Enterprise Repli-cation must propagate and analyze these 100 rows before applying them tothe targets.
Distributed Transactions
A distributed transaction is a transaction that commits data in a single trans-action over two or more database servers.
Outside of the replication environment, Dynamic Server uses a two-phasecommit protocol to ensure that the transaction is either committedcompletely across all servers involved or is not committed on any server. Formore information about the two-phase commit protocol, see the Adminis-trator’s Guide for Informix Dynamic Server.
In a replication environment, when a distributed transaction is committedacross the source servers, each part of the transaction that applies to the localserver is written to the local logical logs. When Enterprise Replicationretrieves the transaction from the logical logs and forms its transaction data,it is unable to identify the separate transaction data as the original singletransaction.
2-14 Guide to IBM Informix Enterprise Replication

Transaction Processing Considerations
This situation could result in Enterprise Replication applying one transactionsuccessfully while aborting another. Another result might be a time lapsebetween when Enterprise Replication applies the two transactions(depending on the number of transaction data in each server’s send queueand the state of the server).
Large Transactions
Because Enterprise Replication is optimized to handle small transactionsefficiently, avoid replicating very large transactions or batch jobs on targetsystems.
Instead of using Enterprise Replication to perform a batch job, Informixrecommends that you use the BEGIN WORK WITHOUT REPLICATION to runthe batch job locally on each database server. For more information, see“Blocking Replication” on page 4-18.
Supported SQL Statements
After you define Enterprise Replication on a table by including that table asa participant in a replicate, you cannot execute any operation that changesthe structure of the table. In addition, you cannot exclusively lock a databasethat is involved in replication (or perform operations that require anexclusive lock). However, you can exclusively lock a table in a database.
Forbidden SQL Statements
You cannot use the following SQL statements against a table that is includedin a replicate:
■ DROP TABLE
■ RENAME TABLE
■ ALTER FRAGMENT
Overview of Enterprise Replication Administration 2-15

Transaction Processing Considerations
Limited SQL Statements
The following additional limitations also apply to tables defined forreplication:
■ Do not remove or disable the primary key constraint.
■ Do not rename, add, or drop columns.
■ Do not modify a column type.
■ Do not add or drop rowids.
■ Do not add or drop CRCOLS (shadow columns):
❑ ALTER TABLE ... ADD CRCOLS
❑ ALTER TABLE ... DROP CRCOLS
For more information about CRCOLS, see “Preparing Tables for Con-flict Resolution” on page 4-21.
■ Do not modify the primary key columns.
For example, do not alter the column to add default values or otherconstraints.
Important: Because primary key updates are sent as DELETE/INSERT statementpairs, avoid changing the primary key and updating data in the same transaction.
■ Do not create or alter clustered indexes.
Important: Creating or altering a clustered index on a replicated table is not allowed.
Tip: To use the forbidden and limited SQL statements against a table defined for repli-cation, you must first stop (not suspend) the replicate that contains the table, beforerunning the SQL statement. After modifying the table, restart the replicate. For moreinformation, see “Managing Replicates” on page 6-7.
Permitted SQL Statements
Enterprise Replication permits the following SQL statements with nolimitations:
■ SET object mode (no disabling of primary key constraint)
■ START VIOLATIONS TABLE
■ STOP VIOLATIONS TABLE
2-16 Guide to IBM Informix Enterprise Replication

Replication Environment Considerations
■ CREATE TRIGGER
■ DROP TRIGGER
■ CREATE VIEW
■ DROP VIEW
■ CREATE SYNONYM
■ DROP SYNONYM
■ ADD INDEX
■ DROP INDEX
■ ALTER INDEX (except TO CLUSTER)
■ ALTER TABLE constraints (except for the primary key)
Replication Environment ConsiderationsEach replication system that you create affects your environment. Considerthe following when setting up your replication environment:
■ Time Synchronization
■ Using GLS with Enterprise Replication
Time Synchronization
Whenever you use replication that requires time stamp conflict resolution(see “Conflict Resolution” on page 3-11), the operating system times of thedatabase servers that participate in the replicate must be synchronized. Alltime stamps and internal computations are performed in Greenwich MeanTime (GMT) and have an accuracy of plus or minus one second.
Important: Enterprise Replication does not manage clock synchronization betweendatabase servers that participate in a replicate.
Overview of Enterprise Replication Administration 2-17

Replication Environment Considerations
To synchronize the time on one database server with the time on anotherdatabase server, use one of the following commands.
Important: These commands do not guarantee the times will remain synchronized.Informix recommends that you use a product that supplies a network time protocolto ensure that times remain synchronized. For information on tools for synchro-nizing the times, refer to your operating system documentation.
Using GLS with Enterprise Replication
An Enterprise Replication system can include databases in different locales,with the following restrictions:
■ When you define a database server for Enterprise Replication, thatserver must be running in the English locale.
In other words, the syscdr database on every Enterprise Replicationserver must be in the English locale.
■ You can replicate only between databases that are in the same locale.
■ Replicate names can be in the locale of the database.
Code-set conversion with the GLS library requires only those code-setconversion files found in the $INFORMIXDIR/gls/cv9 directory.
■ For U.S. English, locales are handled automatically by the ClientSDK/Informix Connnect installation and setup.
■ For non-U.S. English locales, you might need to explicitly provide thelocale and conversion files.
For information about how to specify a nondefault locale and other consid-erations related to GLS locales, see the Informix Guide to GLS Functionality.
Operating System Command
UNIX rdate hostname
Windows net time \\servername /set
net time /domain:servername /set
GLS
2-18 Guide to IBM Informix Enterprise Replication

Enterprise Replication Data Types
Enterprise Replication Data TypesEnterprise Replication supports Informix-defined data types, includinglimited support of user-defined data types. This section describes how Enter-prise Replication handles special data types:
■ Replicating on Heterogeneous Hardware
■ Replicating Simple and Smart Large Objects
■ Replicating Opaque User-Defined Data Types
For general information on data types, refer to the Informix Guide to SQL:Reference and Informix Guide to Database Design and Implementation.
Important: Enterprise Replication does not support replication of simple largeobjects stored on optical devices.
Important: Enterprise Replication does not verify the data types of columns in tablesthat participate in replication. The replicated column in a table on the source databaseserver must have the same data type as the corresponding column on the targetserver. The exception to this rule is cross-replication between simple large objects andsmart large objects.
If you use SERIAL or SERIAL8 data types, you must be careful when definingserial columns. For more information, see “SERIAL Data Types and PrimaryKeys” on page 2-12.
Replicating on Heterogeneous Hardware
Enterprise Replication supports all primitive data types across heteroge-neous hardware. If you define a replicate that includes non-primitive datatypes (for example, BYTE and TEXT data), the application must resolve data-representation issues that are architecture dependent.
If you use floating-point data types with heterogeneous hardware, you mightneed to use IEEE floating point or canonical format for the data transfers. Formore information, see “Using the IEEE Floating Point or Canonical Format”on page 5-13.
Overview of Enterprise Replication Administration 2-19

Enterprise Replication Data Types
Replicating Simple and Smart Large Objects
Informix supports replicating:
■ Simple large object data types (blobs)
You can store simple large objects either in the tblspace with the restof the table columns (in a dbspace) or in a blobspace.
■ Smart large object data types (smart blobs)
You must store smart large objects in sbspaces.
For more information about database storage, see the Administrator’s Guidefor Informix Dynamic Server.
Replicating Simple Large Objects from Tblspaces
Simple large object data that is stored in tblspaces (rather than in blobspaces)is placed in the logical log. Enterprise Replication reads the logical log tocapture and evaluate the data for potential replication.
Replicating Large Objects from Blobspaces or Sbspaces
Enterprise Replication does not retrieve simple large object data that is storedin blobspaces and smart large object data that is stored in sbspaces from thelogical log. Instead, Enterprise Replication retrieves the large object datadirectly from the blobspace/sbspace before sending the data to the targetdatabase server.
It is possible that a transaction subsequent to the transaction being replicatedhas modified or deleted a simple or smart large object that Enterprise Repli-cation is trying to retrieve.
If Enterprise Replication encounters a row whose large object (simple orsmart) has been modified or deleted by a subsequent transaction, EnterpriseReplication does not send the data in the large object.
In most cases, the subsequent transaction that modified or deleted the largeobject will also be replicated, so the data again becomes consistent once thattransaction is replicated. The data in the large object is inconsistent only in asmall window of time.
2-20 Guide to IBM Informix Enterprise Replication

Enterprise Replication Data Types
Keep in mind that if you specify sending only the columns that changed, thedata might not get updated during the next update of the row. For moreinformation, see “Replicating Only Changed Columns” on page 5-11.
Tip: Enterprise Replication allows cross-replication between simple large objects andsmart large objects. For example, you can replicate a simple large object on the sourcedatabase server to a smart large object on the target server or vice versa.
Conflict Resolution for Simple and Smart Large Objects
By default, Enterprise Replication performs all conflict detection andresolution at the row level. However, in some cases, simple large object datathat is stored in a tblspace (rather than in a blobspace) is accepted by thetarget server even if the row is rejected. This does not apply to simple largeobject data that is stored in blobspaces or smart large object data that is storedin sbspaces.
Time-Stamp Conflict Resolution for Simple Large Objects
When a replicated BYTE or TEXT column is modified on the source databaseserver, Enterprise Replication records the value of cdrserver and cdrtime forthat column. (For more information on cdrserver and cdrtime, see“Preparing Tables for Conflict Resolution” on page 4-21.) If the column onthe target database server is also stored in a tablespace (rather than in ablobspace), Enterprise Replication evaluates the cdrserver and cdrtimevalues in the source and target columns and uses the following logic todetermine if the data is to be applied:
■ If the column of the replicated data has a time stamp that is greaterthan the time stamp of the column on the local row, the data for thecolumn is accepted for replication.
■ If the server ID and time stamp of the replicated column are equal tothe server ID and time stamp on the column on the local row, the datafor the column is accepted for replication.
Overview of Enterprise Replication Administration 2-21

Enterprise Replication Data Types
SPL Conflict Resolution for Simple Large Objects
If the replicate is defined with an SPL conflict-resolution rule, the SPL routinemust return the desired action for each BYTE or TEXT column. When theroutine is invoked, information about each BYTE or TEXT column is passed tothe routine as five separate fields. The following table describes the fields.
For information on creating stored procedures, see the Informix Guide to SQL:Tutorial.
If the routine returns an action code of A, D, I, or U, the routine parses thereturn values of the replicated columns. Each BYTE or TEXT column canreturn a two-character field. For information about the action codes, refer to“SPL Conflict-Resolution Rule” on page 3-15.
Argument Description
Column size (INTEGER) The size of the column (if data exists for thiscolumn).
NULL if the column is NULL.
BLOB flag [CHAR(1)] For the local row, the field is always NULL.
For the replicated row:
■ D indicates BYTE or TEXT data is sent from thesource database server.
■ U indicates BYTE or TEXT data is unchanged onthe source database server.
Column type [CHAR(1)] ■ P indicates tablespace data.
■ B indicates blobspace data.
ID of last update server[CHAR(18)]
The ID of the database server that last updatedthis column for tablespace data
For blobspace data: NULL
Last update time (DATETIMEYEAR TO SECOND)
For tablespace data: The date and time when thedata was last updated.
For blobspace data: NULL
2-22 Guide to IBM Informix Enterprise Replication

Enterprise Replication Data Types
The first character defines the desired option for the BYTE or TEXT column, asthe following table shows.
The second character defines the desired option for blobspace data if the datais found to be undeliverable, as the following table shows.
SPL Conflict Resolution for Smart Large Objects
Enterprise Replication handles conflict resolution for smart large objectsusing the SPL conflict-resolution rule in the same way as for simple largeobjects. See “Conflict Resolution for Simple and Smart Large Objects” onpage 2-21.
Value Function
C Performs a time-stamp check for this column as used by the time-stamp rule
N Sets the replicate column to NULL
R Accepts the replicated data as it is received
L Retains the local data
Value Function
N Sets the replicated column to NULL
L Retains the local data (default)
O Aborts the row
X Aborts the transaction
Overview of Enterprise Replication Administration 2-23

Enterprise Replication Data Types
Distributing BYTE and TEXT Data
If Enterprise Replication processes a row and discovers undeliverable BYTEor TEXT columns, the following actions can occur:
■ Any undeliverable columns are set to NULL if the replicationoperation is an INSERT and the row does not already exist at thetarget.
■ The old value of the local row is retained if the replication operationis an UPDATE or if the row already exists on the target.
Considerations for Replicating Smart Large Objects
The following conditions apply to replicating smart large objects:
■ Enterprise Replication does not support replication of smart largeobject updates performed outside of a row update.
■ After you update a smart large object that is referenced explicitly inthe table schema, you must update the referencing row before Enter-prise Replication can replicate the updated smart large object. Forexample:
UPDATE table_name SET smart_large_object_column = x
For more information, see the Informix Guide to SQL: Syntax.
■ Enterprise Replication replicates updates to in-place smart largeobjects by sending a new copy of the entire smart large object. Enter-prise Replication does not send only the logged changes to updatesmart large objects.
■ Enterprise Replication does not support sharing out-of-row data(multiple references to a smart large object) during replication. If youtry to replicate multiple references to the same smart large object onthe source database server, Enterprise Replication does not re-createthose references on the target database server. Instead, EnterpriseReplication creates multiple smart large objects on the targetdatabase server.
2-24 Guide to IBM Informix Enterprise Replication

Enterprise Replication Data Types
Replicating Opaque User-Defined Data Types
Enterprise Replication supports built-in Informix data types and opaqueuser-defined types (UDTs). For a list of supported extensible data types, see“Extensibility Enhancements” on page 6 of the Introduction.
UDT Support Functions
If you plan to replicate opaque user-defined types (UDTs), the UDT designermust provide two support functions, streamwrite( ) and streamread( ).
The purpose of these functions is similar to the existing send( ) and receive( )functions provided for client/server transmissions.
For information on writing these support functions, see the section on Enter-prise Replication stream support functions in the DataBlade API Programmer’sManual.
When preparing a row that includes any UDT columns to queue to the targetsystem, Enterprise Replication calls the streamwrite( ) function on each UDTcolumn. The function converts the UDT column data from the in-server repre-sentation to a representation that can be shipped over the network. Thisallows Enterprise Replication to replicate the column without understandingthe internal representation of the UDT.
On the target server, Enterprise Replication calls the streamread( ) functionfor each UDT column that it transmitted using the streamwrite( ) function.
Considerations for Replicating Opaque Data Types
The following conditions apply to replicating opaque data types:
■ The WHERE clause of the SELECT statement of the participantmodifier can reference an opaque UDT as long as the UDT is alwaysstored in row.
■ Any UDRs in a WHERE clause can use only parameters whose valuescan be extracted fully from the logged row images, plus any optionalconstants.
Overview of Enterprise Replication Administration 2-25

Enterprise Replication Data Types
■ All of the columns in the SELECT statement of each participantdefinition must be actual columns in that table. Enterprise Repli-cation does not support virtual columns (results of UDRs on tablecolumns).
See “Participant Modifier” on page A-90 for information on theWHERE clause in participant definitions.
■ You cannot use SPL routines for conflict resolution if the replicateincludes any UDTs in the SELECT statement or if the replicate isdefined to replicate only changed columns.
See “Conflict Resolution” on page 3-11 and “Replicating OnlyChanged Columns” on page 5-11.
■ Enterprise Replication allows you to define replicates on tables thatcontain one or more UDT columns as the primary key.
For more information, see the section on primary key constraints inthe Informix Guide to SQL: Syntax.
Replicating Table Hierarchies
To replicate tables that form a hierarchy, you must define a separate replicatefor each table. If you define a replicate on a super table, Enterprise Repli-cation does not automatically create implicit replicate definitions on thesubordinate tables.
Tip: Enterprise Replication does not require that the table hierarchies be identical onthe source and target servers.
You must use conflict resolution uniformly for all tables in the hierarchy. Inother words, either no conflict resolution for all tables or conflict resolutionfor all tables.
2-26 Guide to IBM Informix Enterprise Replication

n II
Setting Up and ManagingEnterprise Replication
Sect
io
Chapter 3 Selecting the Enterprise Replication System and NetworkTopology
Chapter 4 Preparing the Replication Environment
Chapter 5 Defining and Modifying Replication Servers, Replicates,and Participants
Chapter 6 Managing Replication Servers and Replicates
Chapter 7 Creating and Managing Replicate Sets
Chapter 8 Monitoring and Troubleshooting Enterprise Replication


3Chapter
Selecting the EnterpriseReplication System andNetwork Topology
In This Chapter . . . . . . . . . . . . . . . . . . . . 3-3Selecting the Enterprise Replication System . . . . . . . . . . 3-3Primary-Target Replication System . . . . . . . . . . . . 3-3
Primary-Target Business Models . . . . . . . . . . . 3-4Primary-Target Considerations . . . . . . . . . . . . 3-9
Update-Anywhere Replication System. . . . . . . . . . . 3-10Update-Anywhere Considerations . . . . . . . . . . . 3-11
Conflict Resolution . . . . . . . . . . . . . . . . . 3-11Conflict-Resolution Rule . . . . . . . . . . . . . . 3-12Scope . . . . . . . . . . . . . . . . . . . . . 3-18
Choosing a Replication Network Topology . . . . . . . . . . 3-19Fully Connected Topology . . . . . . . . . . . . . . . 3-20Hierarchical Replication Topologies. . . . . . . . . . . . 3-21
HR Topology Terminology . . . . . . . . . . . . . 3-21Hierarchical Tree . . . . . . . . . . . . . . . . . 3-22Forest of Trees . . . . . . . . . . . . . . . . . . 3-24

3-2 Guid
e to IBM Informix Enterprise Replication
In This ChapterThis chapter describes types of replication systems provided by EnterpriseReplication and discusses the trade-offs associated with performance anddata availability.
Selecting the Enterprise Replication SystemEnterprise Replication supports the following types of replication systems:
■ Primary-Target Replication System
■ Update-Anywhere Replication System
Primary-Target Replication SystemIn the primary-target replication system, the flow of information is in onedirection. That is, the primary always sends data to the target. The target doesnot send data to the primary.
In primary-target replication, all database changes originate at the primarydatabase and are replicated to the target databases. Changes at the targetdatabases are not replicated to the primary.
Selecting the Enterprise Replication System and Network Topology 3-3

Primary-Target Replication System
A primary-target replication system can provide one-to-many or many-to-one replication:
■ One-to-many replication
In the one-to-many (distribution) replication, all changes to a primarydatabase server are replicated to many target database servers. Usethis replication model when information gathered at a central sitemust be disseminated to many scattered sites.
■ Many-to-one replication
In many-to-one (consolidation) replication, many primary serverssend information to a single target server. Use this replication modelwhen many sites are gathering information (for example, local fieldstudies for an environmental study) that needs to be centralized forfinal processing.
Primary-Target Business Models
Primary-target Enterprise Replication systems support the followingbusiness models:
■ Data Dissemination
■ Data Consolidation
■ Workload Partitioning
■ Workflow Replication
3-4 Guide to IBM Informix Enterprise Replication

Primary-Target Replication System
Data Dissemination
Data dissemination supports business needs where data is updated in acentral location and then replicated to read-only sites. This method of distri-bution can be particularly useful for online transaction processing (OLTP)systems where data is required at several sites, but because of the largeamounts of data, read-write capabilities at all sites would cripple the perfor-mance of the application. Figure 3-1 illustrates data dissemination.
Figure 3-1Data Disseminationin a Primary-TargetReplication System
Primary(Read only)
(Read only) (Read only)
(Read only)
(Read-write)
Databaseserver
Databaseserver
Databaseserver
Databaseserver
Databaseserver
Target Target
TargetTarget
Selecting the Enterprise Replication System and Network Topology 3-5

Primary-Target Replication System
Data Consolidation
As businesses reorganize to become more competitive, many choose toconsolidate data into one central database server. Data consolidation allowsthe migration of data from several database servers to one central databaseserver. In Figure 3-2, the remote locations have read-write capabilities whilethe central database server is read only.
Businesses can also use data consolidation to off-load OLTP data for decisionsupport (DSS) analysis. For example, data from several OLTP systems can bereplicated to a DSS system for read-only analysis. Pay close attention to theconfiguration of the tables from which data is replicated to ensure that eachprimary key is unique among the multiple primary database servers.
Figure 3-2Data Consolidationin a Primary-TargetReplication System
(Read-write)
(Read-write)
(Read only)
(Read-write)
(Read-write)
Databaseserver
PrimaryDatabaseserver
Primary
Databaseserver
Primary
Databaseserver
Primary
Databaseserver
Target
3-6 Guide to IBM Informix Enterprise Replication

Primary-Target Replication System
Workload Partitioning
Workload partitioning gives businesses the flexibility of assigning dataownership at the table-partition level, rather than within an application.Figure 3-3 illustrates workload partitioning.
In Figure 3-3, the replication model matches the partition model for theemployee tables. The Asia-Pacific computer owns the partition and cantherefore update, insert, and delete employee records for personnel in itsregion. The changes are then propagated to the U.S. and European regions.Asia-Pacific can query or read the other partitions locally, but cannot updatethose partitions locally. This strategy applies to other regions as well.
Figure 3-3Workload
Partitioning in aPrimary-Target
Replication System
U.S.A. Europe
A-P Partitionemp# empname5783 A. Alder1235 M. Markar
U.S.A. Partitionemp# empname9631 J. Jones4951 H. Height
Europe Partitionemp# empname8002 F. Fire9966 S. Smith
A-P Partitionemp# empname2994 N. Night4402 R. River
U.S.A. Partitionemp# empname6398 D. Davis9456 E. Eldridge
Europe Partitionemp# empname6520 P. Peters3798 G. Gladys
A-P Partitionemp# empname5761 B. Barry6642 Z. Zachary
U.S.A. Partitionemp# empname3622 C. Cowpar7333 K. Kristen
Europe Partitionemp# empname3711 L. Lane5540 T. Thomas
Owner of partition (Read-write) Read-only privileges
Databaseserver
Asia-Pacific
Databaseserver
Databaseserver
Selecting the Enterprise Replication System and Network Topology 3-7

Primary-Target Replication System
Workflow Replication
Unlike the data dissemination model, in a workflow-replication system, thedata moves from site to site. Each site processes or approves the data beforesending it on to the next site.
Figure 3-4 illustrates an order-processing system. Order processing typicallyfollows a well-ordered series of steps: orders are entered, approved byaccounting, inventory is reconciled, and the order is finally shipped.
In a workflow-replication system, application modules can be distributedacross multiple sites and databases. Data can also be replicated to sites thatneed read-only access to the data (for example, if order-entry sites want tomonitor the progress of an order).
A workflow-replication system, like the primary-target replication system,allows only unidirectional updates. Many facts that you need to consider fora primary-target replication system should also be considered for theworkflow-replication system.
However, unlike the primary-target replication system, availability canbecome an issue if a database server goes down. The database servers in theworkflow-replication system rely on the data updated at a previous site.Consider this fact when you select a workflow-replication system.
Figure 3-4A Workflow-
Replication SystemWhere Update
Authority MovesFrom Site to Site
Order entrycustno custname1234 XYZ LTD1235 XSPORTS
Shipcustno custname1234 XYZ LTD1235 XSPORTS
Accountingcustno custname1234 XYZ LTD1235 XSPORTS
Inventorymanagementcustno custname1234 XYZ LTD1235 XSPORTS
Orderprocessing
Orderprocessing
Orderprocessing
Orderprocessing
3-8 Guide to IBM Informix Enterprise Replication

Primary-Target Replication System
Primary-Target Considerations
The following sections describe some of the factors to consider when youselect a primary-target replication system:
■ Administration
Primary-target replication systems are the easiest to administerbecause all updates are unidirectional and therefore, no data updateconflicts occur. Primary-target replication systems use the ignore con-flict-resolution rule. See “Conflict-Resolution Rule” on page 3-12.
■ Capacity Planning
All replication systems require you to plan for capacity changes. Formore information, see “Preparing Data for Replication” onpage 4-18.
■ High Availability Planning
In the primary-target replication system, if a target database serveror network connection goes down, Enterprise Replication continuesto log information for the database server until it becomes availableagain. If a database server is unavailable for some time, you mightwant to remove the database server from the replication system. Ifthe unavailable database server is the read-write database server,you must plan a course of action to change read-write capabilities onanother database server. If you require a fail-safe replication system,you should select an update-anywhere replication system.
Selecting the Enterprise Replication System and Network Topology 3-9

Update-Anywhere Replication System
Update-Anywhere Replication SystemIn update-anywhere replication, changes made on any participatingdatabase server are replicated to all other participating database servers. Thiscapability allows users to function autonomously even when other systemsor networks in the replication system are not available.
Figure 3-5 illustrates an update-anywhere replication system.
Because each service center can update a copy of the data, conflicts can occurwhen the data is replicated to the other sites. To resolve update conflicts,Enterprise Replication uses conflict resolution. For more information, see“Conflict Resolution” on page 3-11.
Figure 3-5Update-Anywhere
Replication SystemUpdate
UpdateUpdate
Washingtonservice center
Los Angelesservice center
New Yorkservice center
Databaseserver
Databaseserver
Databaseserver
3-10 Guide to IBM Informix Enterprise Replication

Conflict Resolution
Update-Anywhere Considerations
Review the following information before you select your update-anywherereplication system:
■ Administration
Update-anywhere replication systems allow peer-to-peer updates,and therefore require conflict-resolution (see “Conflict Resolution” onpage 3-11). Update-anywhere replication systems require moreadministration than primary-target replication systems.
■ Information Consistency
Some risk is associated with delivering consistent information in anupdate-anywhere replication system. You determine the amount ofrisk based on the type of conflict-resolution rules and routines youchoose with which to resolve conflicts. You can configure an update-anywhere replication system where no data is ever lost; however,you might find that other factors (for example, performance) out-weigh your need for a fail-safe mechanism to deliver consistentinformation.
■ Capacity Planning
All replication systems require you to plan for capacity changes. Formore information, see “Preparing Data for Replication” onpage 4-18. In particular, if you choose the time stamp or time stampplus SPL routine conflict-resolution rule, see “Delete Table DiskSpace” and “Shadow Column Disk Space” on page 4-11.
Conflict ResolutionWhen multiple database servers try to update the same row simultaneously(the time stamp for both updates is the same GMT time), a collision exists(“Apply Replicated Data” on page 1-17). Enterprise Replication mustdetermine which new data to replicate. To solve conflict resolution, you mustspecify the following for each replicate:
■ Conflict-Resolution Rule
■ Scope
Selecting the Enterprise Replication System and Network Topology 3-11

Conflict Resolution
Conflict-Resolution Rule
Enterprise Replication supports the following conflict-resolution rules.
For all conflict-resolution rules except ignore, you must create shadowcolumns in the tables on both the source and target servers involved in repli-cation. See “Shadow Columns” on page 2-11.
Enterprise Replication supports up to two conflict-resolution rules for eachreplicate: a primary rule and a secondary rule (if desired). Figure 3-6 showsthe valid combinations of Enterprise Replication conflict-resolution rules.
Figure 3-6Valid Conflict-Resolution Rule Combinations
Conflict Resolution Rule Effect Reference
Ignore Enterprise Replication does notattempt to resolve conflicts.
page 3-13
Time stamp The row or transaction with themost recent time stamp isapplied.
page 3-14
SPL routine Enterprise Replication uses aroutine written in SPL (StoredProcedure Language) that youprovide to determine which datashould be applied.
page 3-15
Time stamp with SPLroutine
If the time stamps are identical,Enterprise Replication invokes anSPL routine that you provide toresolve the conflict.
page 3-14,page 3-15
Primary Rule Secondary Rule
Ignore None
Time stamp None
Time stamp SPL routine
SPL routine None
3-12 Guide to IBM Informix Enterprise Replication

Conflict Resolution
Ignore Conflict-Resolution Rule
The ignore conflict-resolution rule does not attempt to detect or resolveconflicts. A row or transaction either applies successfully or it fails. A rowmight fail to replicate because of standard database reasons, such as adeadlock situation, when an application locks rows.
The ignore conflict-resolution rule can only be used as a primary conflict-resolution rule and can have either a transaction or a row scope (as describedin “Scope” on page 3-18). Figure 3-7 describes the ignore conflict-resolutionrule.
Figure 3-7Ignore Conflict-Resolution Rule
When a replication message fails to apply on a target, you can spool theinformation to one or both of the following directories:
■ Aborted-transaction spooling (ATS)
If selected, all buffers in a failed replication message that compose atransaction are written to this directory.
■ Row-information spooling (RIS)
If selected, the replication message for a row that could not beapplied to a target is written to this directory.
For more information, see Chapter 8, “Monitoring and TroubleshootingEnterprise Replication.”
Row Exists in Target?
Database Operation
Insert Update Delete
No Apply row Discard row Discard row
Yes Discard row Apply row Apply row
Selecting the Enterprise Replication System and Network Topology 3-13

Conflict Resolution
Time-Stamp Conflict-Resolution Rule
The time-stamp rule evaluates the latest time stamp of the replication againstthe target and determines a winner.
Tip: All time stamps and internal computations are performed in Greenwich MeanTime (GMT).
The time-stamp resolution rule behaves differently depending on whichscope is in effect:
■ Row scope
Enterprise Replication evaluates one row at a time. The row with themost recent time stamp wins the conflict and is applied to the targetdatabase servers. If an SPL routine is defined as a secondary conflict-resolution rule, the routine resolves the conflict when the row timesare equal.
■ Transaction scope
Enterprise Replication evaluates the most recent row-update timeamong all the rows in the replicated transaction. This time is com-pared to the time stamp of the appropriate target row. If the timestamp of the replicated row is more recent than the target, the entirereplicated transaction is applied. If a routine is defined as a second-ary conflict-resolution rule, it is used to resolve the conflict when thetime stamps are equal.
For more information, see “Scope” on page 3-18.
Tip: A secondary routine is invoked only if Enterprise Replication evaluates rowsand discovers equal time stamps.
If either type of scope (row or transaction) evaluates rows and discovers equal timestamps, and no routine is defined as a secondary conflict-resolution rule, the repli-cated row or transaction is applied.
Figure 3-8 on page 3-15 shows how a conflict is resolved based on the latesttime stamp with row scope. The time stamp Tlast_update (the time of the lastupdate) represents the row on the target database server with the last (mostrecent) update. The time stamp Trepl (the time when replication occurs) repre-sents the time stamp on the incoming row.
Enterprise Replication first checks to see if a row with the same primary keyexists in either the target table or its corresponding delete table.
3-14 Guide to IBM Informix Enterprise Replication
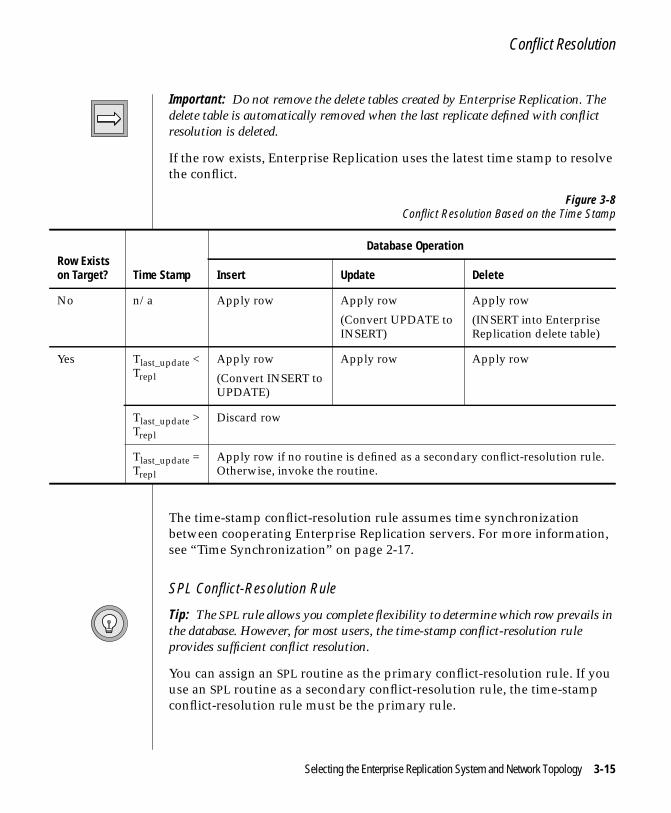
Conflict Resolution
Important: Do not remove the delete tables created by Enterprise Replication. Thedelete table is automatically removed when the last replicate defined with conflictresolution is deleted.
If the row exists, Enterprise Replication uses the latest time stamp to resolvethe conflict.
Figure 3-8Conflict Resolution Based on the Time Stamp
The time-stamp conflict-resolution rule assumes time synchronizationbetween cooperating Enterprise Replication servers. For more information,see “Time Synchronization” on page 2-17.
SPL Conflict-Resolution Rule
Tip: The SPL rule allows you complete flexibility to determine which row prevails inthe database. However, for most users, the time-stamp conflict-resolution ruleprovides sufficient conflict resolution.
You can assign an SPL routine as the primary conflict-resolution rule. If youuse an SPL routine as a secondary conflict-resolution rule, the time-stampconflict-resolution rule must be the primary rule.
Row Existson Target? Time Stamp
Database Operation
Insert Update Delete
No n/a Apply row Apply row
(Convert UPDATE toINSERT)
Apply row
(INSERT into EnterpriseReplication delete table)
Yes Tlast_update <Trepl
Apply row
(Convert INSERT toUPDATE)
Apply row Apply row
Tlast_update >Trepl
Discard row
Tlast_update =Trepl
Apply row if no routine is defined as a secondary conflict-resolution rule.Otherwise, invoke the routine.
Selecting the Enterprise Replication System and Network Topology 3-15

Conflict Resolution
Important: The owner of an SPL routine used for conflict resolution must be thesame as the owner of the table.
Routines for conflict-resolution must be in SPL. Enterprise Replication doesnot allow user-defined routines in C or in Java.
Important: You cannot use SPL routine or time stamp with SPL routine if thereplicate is defined to replicate only changed columns or the replicated table containsany extensible data types. See “Replicating Only Changed Columns” on page 5-11and “Extensibility Enhancements” on page 6 of the Introduction.
Enterprise Replication passes the following information to an SPL routine asarguments.
Argument Description
Server name [CHAR(18)] From the local target row
NULL if local target row does not exist
Time stamp (DATETIME YEAR TO SECOND) From the local target row
NULL if local target row does not exist
Local delete-table indicator [CHAR(1)]
or
Local key delete-row indicator [CHAR(1)]
■ Y indicates the origin of the row is the delete table
■ K indicates the origin of the row is the replicate-keydelete row (for a key update that is sent as a key deleteand a key insert) because the local target row with theold key does not exist
Server name [CHAR(18)] Of the replicate source
Time stamp (DATETIME YEAR TO SECOND) From the replicated row
Replicate action type [CHAR(1)] I- insertD- deleteU- update
Local row data returned in regular SQL format Where the regular SQL format is taken from the SELECTclause of the participant list
Replicate row data after-image returned inregular SQL format
Where the regular SQL format is taken from the SELECTclause of the participant list
3-16 Guide to IBM Informix Enterprise Replication

Conflict Resolution
The routine must set the following arguments before the routine can beapplied to the replication message.
You can use the arguments to develop application-specific routines. Forexample, you can create a routine in which a database server always wins aconflict regardless of the time stamp.
The following list includes some items to consider when you use an SPLroutine for conflict resolution:
■ Any action that a routine takes as a result of replication does notreplicate.
■ You cannot use an SPL routine to start another transaction.
■ Frequent use of routines might affect performance.
Argument Description
An indicator of the desired database operationto be performed [CHAR(1)]
Same as the replicate action codes with the followingadditional codes
■ A - Accept the replicated row and apply the columnvalues returned by the SPL routine.
For example, if Enterprise Replication receives an insertand the row already exists locally, the insert is convertedto an update
■ S - Accept the replicated row and apply the columnvalues as received from the other site.
For example, if Enterprise Replication receives an insertand the row already exists locally, the insert fails at thetime Enterprise Replication tries to apply the transactionto the database, and the transaction aborts with a SQLerror.
■ O - Discard the replicated row.
■ X - Abort the transaction.
A non-zero integer value to request logging ofthe resolution and the integer value in thespooling files (INTEGER)
Logging value takes effect only if logging is configuredfor this replicate.
The columns of the row to be applied to thetarget table replicate action type in regularSQL format
This list of column values is not parsed if the replicateaction type that the routine returns is S, O, or X.
Selecting the Enterprise Replication System and Network Topology 3-17

Conflict Resolution
In addition, you must determine when the SPL routine executes:
■ An optimized SPL routine is called only when a collision is detectedand the row to be replicated fails to meet one of the following twoconditions:
❑ It is from the same database server that last updated the localrow on the target table.
❑ It has a time stamp greater than or equal to that of the local row.
■ A nonoptimized SPL routine executes every time Enterprise Repli-cation detects a collision. By default, SPL routines are nonoptimized.
For information on specifying that the SPL routine is optimized, see “ConflictOptions” on page A-11.
Tip: Do not assign a routine that is not optimized as a primary conflict-resolutionrule for applications that usually insert rows successfully.
Scope
Each conflict-resolution rule behaves differently depending on the scope.Enterprise Replication uses the following scopes:
■ Row scope
When you choose a row scope, Enterprise Replication evaluates onerow at a time. It only applies replicated rows that win the conflict res-olution with the target row. If an entire replicated transactionreceives row-by-row evaluation, some replicated rows are appliedwhile other replicated rows might not be applied.
■ Transaction scope
When you choose a transaction scope, Enterprise Replication appliesthe entire transaction if the replicated transaction wins the conflictresolution. If the target wins the conflict (or other database errors arepresent), the entire replicated transaction is not applied.
A transaction scope for conflict resolution guarantees transactionalintegrity.
3-18 Guide to IBM Informix Enterprise Replication

Choosing a Replication Network Topology
Important: Enterprise Replication defers some constraint checking on the targettables until the transaction commits. If a unique constraint or foreign-key constraintviolation is found on any row of the transaction at commit time, the entire trans-action is rejected (regardless of the scope) and, if you have ATS set up, written to theATS directory. For more information, see “Aborted Transaction Spooling Files” onpage 8-3.
Choosing a Replication Network TopologyEnterprise Replication topology describes connections that replication serversmake to interact with each other. You must define the replication topologywithin the topology of the physical network, but the replication topology isnot synonymous with the physical network topology. The order in which youdefine the database servers for replication and the options that you use whenyou define the database server determine the replication topology.
Enterprise Replication supports two types of network topology:
■ Fully Connected Topology
■ Hierarchical Replication Topologies
The topology that you choose influences the types of replication that you canuse. The next sections describe the topologies that Enterprise Replicationsupports.
Selecting the Enterprise Replication System and Network Topology 3-19

Fully Connected Topology
Fully Connected TopologyFully connected replication topology indicates that all database serversconnect to each other and that Enterprise Replication establishes andmanages the connections. Replication messages are sent directly from onedatabase server to another. No additional routing is necessary to deliverreplication messages. Figure 3-9 shows a fully connected replicationtopology. Each database server connects directly to every other databaseserver in the replication environment.
Figure 3-9Fully Connected
Topology
GermanyItaly
France
Europe
3-20 Guide to IBM Informix Enterprise Replication

Hierarchical Replication Topologies
Hierarchical Replication TopologiesEnterprise Replication provides two types of Hierarchical Routing (HR)topology:
■ Hierarchical Tree
■ Forest of Trees
HR Topology Terminology
Enterprise Replication uses the terms in the Figure 3-10 to describe HRtopology.
Figure 3-10Replication Topology Terms
A root server is fully connected to all other root servers. It has informationabout all other replication servers in its replication environment. Figure 3-9on page 3-20 shows an environment with four root servers.
Term Definition
Root server An Enterprise Replication server that is the uppermostlevel in a hierarchically organized set of information. Theroot is the point from which database servers branch intoa logical sequence. All root database servers within Enter-prise Replication must be fully interconnected.
Nonroot server An Enterprise Replication server that is not a rootdatabase server but that has a complete global catalog andis connected to its parent and to its children.
Tree A data structure that contains database servers that arelinked in a hierarchical manner. The topmost node iscalled the root. The root can have zero or more childdatabase servers; the root is the parent database server toits children.
Parent-child A relationship between database servers in a tree datastructure in which the parent is one step closer to the rootthan the child.
Leaf server A database server that has a limited catalog and nochildren.
Selecting the Enterprise Replication System and Network Topology 3-21

Hierarchical Replication Topologies
A nonroot server is similar to a root server except that it forwards all replicatedmessages for other root servers (and their children) through its parent. Allnonroot servers are known to all root and other nonroot servers. A nonrootserver might or might not have children. All root and nonroot servers areaware of all other servers in the replication environment.
Important: In HR topologies, Enterprise Replication specifies the synchronizationserver as the new server’s parent in the current topology. For more information, see“Customizing the Replication Server Definition” on page 5-6 and “cdr defineserver” on page A-20.
Hierarchical Tree
A hierarchical tree consists of a root database server and one or more databaseservers organized into a tree topology. The tree contains only one root, whichhas no parent. Each database server within the tree references its parent. Adatabase server that is not a parent is a leaf. Figure 3-11 illustrates a repli-cation tree.
Figure 3-11Hierarchical Tree
Topology
China
Guangzhou
Hong Kong
Japan
Beijing
Shanghai
Asia
3-22 Guide to IBM Informix Enterprise Replication

Hierarchical Replication Topologies
In Figure 3-11, the parent-child relationship within the tree is as follows:
■ Asia is the parent of China and Japan.
■ China is the child of Asia and the parent of Beijing, Shanghai, andGuangzhou.
■ Guangzhou is the child of China and the parent of Hong Kong.
Asia is the root database server. Japan, China, and Guangzhou are nonrootdatabase servers. You can define Beijing, Shanghai, and Hong Kong aseither nonroot database servers or leaf database servers, depending on howyou plan to use them. The dashed connection from China to Shanghaiindicates that Shanghai is a leaf server.
Selecting the Enterprise Replication System and Network Topology 3-23
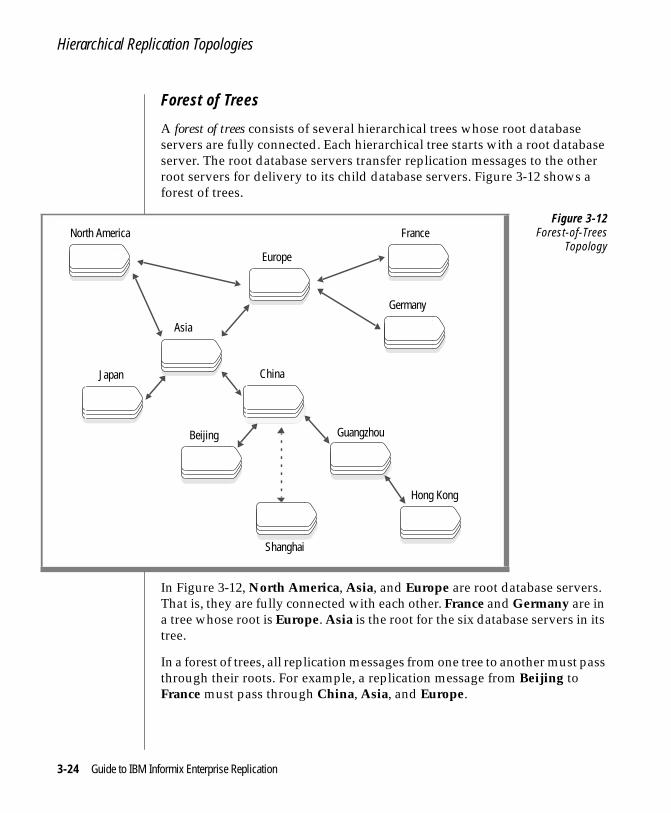
Hierarchical Replication Topologies
Forest of Trees
A forest of trees consists of several hierarchical trees whose root databaseservers are fully connected. Each hierarchical tree starts with a root databaseserver. The root database servers transfer replication messages to the otherroot servers for delivery to its child database servers. Figure 3-12 shows aforest of trees.
In Figure 3-12, North America, Asia, and Europe are root database servers.That is, they are fully connected with each other. France and Germany are ina tree whose root is Europe. Asia is the root for the six database servers in itstree.
In a forest of trees, all replication messages from one tree to another must passthrough their roots. For example, a replication message from Beijing toFrance must pass through China, Asia, and Europe.
Figure 3-12Forest-of-Trees
Topology
China
Guangzhou
Hong Kong
Japan
Beijing
Shanghai
Asia
Germany
France
Europe
North America
3-24 Guide to IBM Informix Enterprise Replication

Hierarchical Replication Topologies
Organizing the database servers in a hierarchical tree or a forest of treesgreatly reduces the number of physical connections that are required to makea replication system. If all the database servers in Figure 3-12 were fullyconnected, instead of being organized in trees, 55 connections would berequired.
Selecting the Enterprise Replication System and Network Topology 3-25


4Chapter
Preparing the ReplicationEnvironment
In This Chapter . . . . . . . . . . . . . . . . . . . . 4-3
Preparing the Network Environment . . . . . . . . . . . . 4-3Setting Up the Hosts File . . . . . . . . . . . . . . . 4-4Setting Up the Services File. . . . . . . . . . . . . . . 4-4Setting Up the Trusted Environment . . . . . . . . . . . 4-5Verifying SQLHOSTS. . . . . . . . . . . . . . . . . 4-5
Setting up Database Server Groups . . . . . . . . . . 4-5Hierarchical Routing Topologies and SQLHOSTS . . . . . 4-8
Testing the Network Environment . . . . . . . . . . . . 4-8
Preparing the Disk . . . . . . . . . . . . . . . . . . . 4-9Planning for Disk Space Requirements. . . . . . . . . . . 4-9
Logical Log Configuration Disk Space . . . . . . . . . 4-9Logical Log Configuration Guidelines . . . . . . . . . 4-10Delete Table Disk Space . . . . . . . . . . . . . . 4-10Shadow Column Disk Space . . . . . . . . . . . . . 4-11
Setting Up Send and Receive Queue Spool Areas . . . . . . . 4-11Transaction Record dbspace . . . . . . . . . . . . . 4-12Row Data sbspace . . . . . . . . . . . . . . . . 4-13
Creating ATS and RIS Directories . . . . . . . . . . . . 4-15
Preparing the Database Server Environment . . . . . . . . . . 4-16
Preparing Data for Replication . . . . . . . . . . . . . . . 4-18Preparing Consistent Data . . . . . . . . . . . . . . . 4-18Blocking Replication . . . . . . . . . . . . . . . . . 4-18
Using DB-Access to Begin Work Without Replication . . . . 4-20Using ESQL/C to Begin Work Without Replication . . . . . 4-20

4-2 Guid
Preparing to Replicate Opaque User-Defined Types . . . . . . 4-21Preparing Tables for Conflict Resolution . . . . . . . . . . 4-21Preparing Logging Databases . . . . . . . . . . . . . . 4-22
Loading and Unloading Data . . . . . . . . . . . . . . . 4-22High-Performance Loader . . . . . . . . . . . . . . 4-23onunload and onload Utilities . . . . . . . . . . . . 4-23dbexport and dbimport Utilities . . . . . . . . . . . . 4-24UNLOAD and LOAD Statements . . . . . . . . . . . 4-24
Data Preparation Example . . . . . . . . . . . . . . . . 4-24
e to IBM Informix Enterprise Replication

In This ChapterThis chapter covers the steps to take to prepare your environment for repli-cating data with Enterprise Replication, which involves preparing thenetwork environment, the disk, the server environment, and the data.
Preparing the Network EnvironmentFor more information on preparing the network environment, see the chapteron client/server connectivity in the Administrator’s Guide for Informix DynamicServer. See Appendix E, “Replication Examples,” for a sample setup.
To prepare your network environment
1. Set up the hosts file.
For information, see “Setting Up the Hosts File” on page 4-4.
2. Set up the services file.
For information, see “Setting Up the Services File” on page 4-4.
3. Set up the trusted environment
For information, see “Setting Up the Trusted Environment” onpage 4-5.
4. Verify the SQLHOSTS information.
For information, see “Verifying SQLHOSTS” on page 4-5.
5. Test the network environment.
For information, see “Testing the Network Environment” onpage 4-8.
Preparing the Replication Environment 4-3

Setting Up the Hosts File
Setting Up the Hosts FileFirst, make sure the hosts file includes the IP addresses and system names forall database servers involved in Enterprise Replication.
Important: If you are using Domain Name Service (DNS) to identify IP addressesand system names, you do not need to configure the hosts file.
The hosts file is in the following location.
Important: Leave a blank line at the end of the hosts file on Windows.
For example, your hosts file might look like the following:
123.456.789.1 sydney123.456.789.2 melbourne
Setting Up the Services FileNext, make sure that the services file includes the port numbers and servicenames for all the database servers involved in Enterprise Replication. Theservices file is in the following location.
Important: Leave a blank line at the end of the services file on Windows.
For example, your services file might look like the following:
sydney 5327/tcpmelbourne 5327/tcp
Operating System File
UNIX /etc/hosts
Windows %WINDIR%\system32\drivers\etc\hosts
Operating System File
UNIX /etc/services
Windows %WINDIR%\system32\drivers\etc\services
4-4 Guide to IBM Informix Enterprise Replication

Setting Up the Trusted Environment
If the database servers reside on the same system, you must provide uniqueport numbers for each.
Setting Up the Trusted EnvironmentTo establish the trust relationship for all users, set up the hosts.equiv file. Thehosts.equiv file is in the following location.
For example, your hosts.equiv file might look like the following:
sydneymelbourne
Tip: Instead of allowing access to all users, you can set up .rhosts files in the homedirectory of specific users. See your operating system documentation for moreinformation.
Verifying SQLHOSTSMake sure that the SQLHOSTS file is set up properly on each server partici-pating in replication.
Setting up Database Server Groups
Enterprise Replication requires that all database servers participating inreplication be members of database server groups. Each server in the enter-prise must have a unique identifier. The database server group uniquelyidentifies the server.
Typically, a server group includes only one database server. However, if thecomputer has multiple network protocols or network interface cards, theserver group includes all aliases for the database server. Enterprise Repli-cation treats the server group as one object, whether it includes one or severaldatabase server names.
Operating System File
UNIX /etc/hosts.equiv
Windows %WINDIR%\system32\drivers\etc\hosts.equiv
Preparing the Replication Environment 4-5

Verifying SQLHOSTS
All Enterprise Replication commands and options (except the --connectoption which can use both) use the name of the database server group insteadof the more familiar database server name (that is, the name specified by theINFORMIXSERVER environment variable) for all references to databaseservers. This manual also refers to a database server group as a server group.
This manual uses the convention that the name of a database server group isg_ followed by the name of a database server that is in the group. This use ofg_ is only a convention; g_ is not required syntax.
Database Server Groups on UNIX
On UNIX, a database server group is defined in the sqlhosts file. Thefollowing example shows a very simple sqlhosts file for four EnterpriseReplication servers, john, paul, george, and ringo and their database servergroups. The first line describes the database server group g_john, whichincludes the database server john, and so on.
The following table describes the fields in the sqlhosts example above.
dbservername nettype hostname servicename options
g_john group - - i=143
john ontlitcp sydney.australia.com 10110 g=g_john
g_paul group - - i=144
paul ontlitcp melbourne.australia.com 2939 g=g_paul
g_george group - - i=145
george ontlitcp perth.australia.com 5329 g=g_george
g_ringo group - - i=146
ringo ontlitcp brisbane.australia.com 10101 g=g_ringo
dbservername Database server group name or database server name
nettype Type of connection (composed of the database serverproduct, interface type, and network protocol)
(1 of 2)
UNIX
4-6 Guide to IBM Informix Enterprise Replication

Verifying SQLHOSTS
Important: The network connection entry should appear immediately after thedatabase server group definition.
Important: If you use both DBSERVERNAME and DBSERVERALIASES, DBSERV-ERNAME should refer to the network connection and not to a shared-memoryconnection. For information about database server aliases, refer to the Adminis-trator’s Guide for Informix Dynamic Server.
For more information about database server groups and setting upSQLHOSTS, see the chapter on client/server communications in the Adminis-trator’s Guide for Informix Dynamic Server.
Database Server Groups on Windows
For information about preparing the SQLHOSTS connectivity information onWindows, see Appendix F, “SQLHOSTS Registry Key.”
Important: Informix strongly recommends that you use Informix Server Adminis-trator (ISA), rather than regedt32, to set up the SQLHOSTS registry key anddatabase server group registry key on your Windows system. In addition, ISA allowsyou to administer your replication system from a web browser. For more information,see the Documentation Notes described in “Additional Documentation” on page 15of the Introduction.
hostname The name of the computer where the database serverresides
servicename The service name or port number entry in the services file
options ■ The g option specifies the name of the group to which thedatabase server belongs.
■ The i option specifies a unique identifier for the databaseserver. Make sure that this identifier is consistent for thedatabase server across all nodes in the enterprise.
(2 of 2)
WIN NT/2000
Preparing the Replication Environment 4-7

Testing the Network Environment
Hierarchical Routing Topologies and SQLHOSTS
For hierarchical routing (HR) topologies:
■ Root and nonroot servers must each have complete SQLHOSTS servergroup information for the entire enterprise.
■ The leaf servers require only the SQLHOSTS connectivity informationfor itself and its parent (hub).
Root and nonroot servers contain the complete global catalog; leaf servers donot. For more information, see “HR Topology Terminology” on page 3-21and “Global Catalog” on page 2-6.
Testing the Network EnvironmentOnce you have verified the network setup information, test the networkenvironment.
To test the network environment
1. Verify the network connection.
Use the ping command to test the connection between two systems.For example, from sydney, test the connection to melbourne:
ping melbourne
2. Test the trusted environment.
a. Run dbaccess.
b. Select the Connection menu option.
c. Select the Connect menu option.
d. Connect to the server group name and the server name of theother hosts.
For example, if you are running dbaccess on sydney, and you aretesting the connection to a database server on melbourne, selectpaul and g_paul.
e. When prompted for the USER NAME, press ENTER.
If you can connect to the host database server, the host server istrusted for user informix.
For more information, see the DB-Access User’s Manual.
4-8 Guide to IBM Informix Enterprise Replication

Preparing the Disk
Preparing the DiskPreparing your disk for Enterprise Replication includes the following:
■ Planning for Disk Space Requirements
■ Setting Up Send and Receive Queue Spool Areas
■ Creating ATS and RIS Directories
Planning for Disk Space RequirementsEnterprise Replication requires additional disk space for storing the logicallogs and, depending on your conflict-resolution configuration, delete tablesand shadow columns.
Logical Log Configuration Disk Space
The database server uses the logical log to store a record of changes to thedata since the last archive. Enterprise Replication requires the logical log tocontain entire row images for updated rows, including deleted rows.
The database server normally logs only columns that have changed. Thisbehavior is called the logical-log record reduction option. EnterpriseReplication deactivates this option for tables that participate in replication.(The logical-log record reduction option remains enabled for tables that donot participate in Enterprise Replication.) Enterprise Replication logs allcolumns, not only the columns that have changed, which increases the sizeof your logical log.
To determine the size of your logical log, examine your data activity fornormal operations and for the replication system you defined. Keep in mindthat defining replication on a table causes Enterprise Replication todeactivate log reduction for that table, and that your transactions might logmore data.
Important: Enterprise Replication performs internal cleanup tasks based on howoften the log files switch. If the log files switch too frequently, Enterprise Replicationmight perform excessive cleanup work.
Preparing the Replication Environment 4-9

Planning for Disk Space Requirements
Logical Log Configuration Guidelines
Use the following guidelines when configuring your logical log files:
■ Make sure that all logical log files are approximately the same size.
■ Make the size of the logical log files large enough so that the databaseserver switches log files no more than once every 15 minutes duringnormal processing.
■ Plan to have sufficient logical-log space to hold at least four times themaximum transaction size.
■ Set LTXEHWM (long-transaction, exclusive-access, high-water mark)30 percent larger than LTXHWM (long-transaction high-water mark).
Important: If you specify that the database server allocate logical log files dynami-cally (DYNAMIC_LOGS), Informix recommends that you set LTXEHWM to no higherthan 70 when using Enterprise Replication.
For more information about logical logs and these configuration parameters,see Informix Administrator’s Reference and Administrator’s Guide for InformixDynamic Server.
Delete Table Disk Space
If you use the time stamp or time stamp and SPL routine conflict-resolutionrules, Enterprise Replication creates delete tables to keep track of modifiedrows for conflict resolution. (Enterprise Replication creates delete tables onlyfor tables that have replicates defined with a conflict-resolution rule otherthan ignore.) Delete tables handle conflicts such as when a DELETE or UPDATEfinds no corresponding row on the target.
For more information, see “Conflict-Resolution Rule” on page 3-12.
Delete tables are created on the database server where the data originates andon all the database servers to which data gets replicated. Delete tables arestored in the same dbspaces, using the same fragmentation strategy, as theirbase tables.
To determine the disk space requirements to accommodate delete tables,estimate how many rows will be deleted or modified. For example, if the basetable has 100 megabytes of data, but only half the rows might be deleted ormodified, then 50 megabytes is a reasonable estimate for the size of the deletetable.
4-10 Guide to IBM Informix Enterprise Replication

Setting Up Send and Receive Queue Spool Areas
Important: Do not remove the delete tables created by Enterprise Replication. Thedelete table is automatically removed when the last replicate defined with conflictresolution is deleted.
Shadow Column Disk Space
When you define a replicate that uses any conflict-resolution rule exceptignore, you must define shadow columns (CRCOLS) with the WITH CRCOLSclause. The shadow columns, cdrserver and cdrtime, store server and timestamp information that Enterprise Replication uses for conflict resolution.The two shadow columns are integers, which adds a total of 8 bytes to eachrow in the table involved in a replicate that uses conflict resolution.
Tip: If you plan to use only the ignore conflict-resolution rule, you do not need todefine the cdrserver and cdrtime shadow columns.
For more information, see “Conflict-Resolution Rule” on page 3-12 and“Preparing Tables for Conflict Resolution” on page 4-21.
Setting Up Send and Receive Queue Spool AreasThe term data queue refers to both the send queue and the receive queue. Enter-prise Replication collects information from the logical logs and places thedata to be transferred in the send queue. Then Enterprise Replicationtransfers the contents of the send queue to the receive queue on the targetserver. Enterprise Replication on the target reads the data from the receivequeue and applies the changes to the tables on the target server.
The send and receive queues reside in memory and are managed by theReliable Queue Manager (RQM). The CDR_QUEUEMEM configurationparameter (“CDR_QUEUEMEM” on page B-7) specifies the amount ofmemory space that is available for the data queues.
When a queue in memory fills (for the receive queue, this only occurs withlarge transactions), the transaction buffers are written (spooled) to disk.Spooled transactions consist of transaction records (headers that containinternal information for Enterprise Replication) and row data (the actual repli-cated data). Spooled transaction records are stored in the transaction tables ina single dbspace. Spooled row data is stored in a single sbspace.
Preparing the Replication Environment 4-11

Setting Up Send and Receive Queue Spool Areas
Important: To prevent the send and receive queues from spooling to disk, see“Preventing Memory Queues from Overflowing” on page 8-13.
Transaction Record dbspace
By default, the transaction records are stored in the root dbspace. BecauseEnterprise Replication and other database servers become unavailable if theroot dbspace fills, Informix recommends that you define a single, separatedbspace for the send and receive queue transaction records before you definethe replication server.
To determine the size of your transaction record dbspace, you mustdetermine the estimated number of transactions in a given period. Youshould allocate 110 bytes per transaction to the dbspace and allocate enoughdisk space to store 24 hours of transaction records. For example, if yournetwork is down for 24 hours, and you estimate that you will log 1000 trans-actions each day, the size of the transaction record dbspace should be at least108 kilobytes (110 bytes * 1000 transactions / 1024).
To create the transaction record dbspace, use onspaces -c. For example, tocreate a 110 kilobyte dbspace called er_dbspace using raw disk space onUNIX with an offset of 0, enter:
onspaces -c -d er_dbspace -p /dev/raw_dev1 -o 0 -s 110
The pathname for the dbspace cannot be longer than 256 bytes.
Set the CDR_QHDR_DBSPACE configuration parameter(“CDR_QHDR_DBSPACE” on page B-8) in the ONCONFIG file to thelocation of the transaction record dbspace (er_dbspace, in this example).
Warning: Do not change the value of CDR_QHDR_DBSPACE after you initializeEnterprise Replication on a server.
For information on creating dbspaces, see the chapter on managing diskspace in the Administrator’s Guide for Informix Dynamic Server and the utilitieschapter in the Informix Administrator’s Reference.
4-12 Guide to IBM Informix Enterprise Replication

Setting Up Send and Receive Queue Spool Areas
Row Data sbspace
Because replicated data might include UDT and CLOB/BLOB data types, thespooled row data is stored as a smart large object in an sbspace.
Important: You must create an sbspace for the spooled row data and set theCDR_QDATA_SBSPACE configuration parameter to the location of this sbspacebefore starting Enterprise Replication.
Informix recommends that you create a separate sbspace for EnterpriseReplication and that the sbspace size be sufficiently large.
Warning: When the send queue sbspace fills, Enterprise Replication hangs until youeither resolve the problem that is causing Enterprise Replication to spool and/orallocate additional disk space to the sbspace. For more information, see “PreventingMemory Queues from Overflowing” on page 8-13.
To determine the size of your spooled row data sbspace, determine your logusage and then consider how much data you can collect if your network goesdown. For example, assume that you usually log 40 megabytes of data eachday, but only 10 percent of that is replicated data. If your network is down for24 hours and you estimate that you will log 4 megabytes of replicated dataeach day, the sbspace you identify for the spooled row data must be at least4 megabytes.
On Windows, increase the resulting size of the sbspace by approximately afactor of two. (The default page size, the way that data maps onto a page, andthe number of pages written to disk are different on Windows.) ♦
To create the row data sbspace, use onspaces -c. For example, to create a4-megabyte sbspace, called er_sbspace, using raw disk space on UNIX withan offset of 0, enter:
onspaces -c -S er_sbspace -p /dev/rdsk/c0t1d0s4 -o 0 -s 4000\ -m /dev/rdsk2/c0t1d0s4 0 \ -Df "AVG_LO_SIZE=2,LOGGING=OFF"
The pathname for the sbspace cannot be longer than 256 bytes.
WIN NT/2000
Preparing the Replication Environment 4-13

Setting Up Send and Receive Queue Spool Areas
The -m option specifies the location and offset of the sbspace mirror. The -Dfoption specifies default behavior of the smart large objects stored in thesbspace:
■ AVG_LO_SIZE (average large object size)
Set this parameter to the expected average transaction size (in kilo-bytes). The database server uses this value to calculate the metadatasize. The minimum value for AVG_LO_SIZE is 2 kilobytes, which isappropriate for Enterprise Replication in most cases. (The defaultvalue of AVG_LO_SIZE is 32 kilobytes.) If you set AVG_LO_SIZE tolarger than the expected transaction size, you might run out of meta-data space. If you set AVG_LO_SIZE too small, you might waste spaceon metadata.
■ LOGGING
Informix recommends that you set this parameter to OFF to turn offlogging for the smart large object, but that you mirror the sbspace.Because Enterprise Replication writes spooled data to disk before thereplay pointer is updated, there is no need to log the row datasbspace. If you set LOGGING to OFF and Enterprise Replicationspools to disk, you experience enhanced performance because Enter-prise Replication writes less data to disk.
After creating the sbspace and sbspace mirror, you can use theCDR_SBFLAGS configuration parameter (“CDR_QDATA_SBFLAGS”on page B-10) in the ONCONFIG file to override the current loggingsetting for the CDR_SBSPACE smart large object.
For information on creating and mirroring sbspaces, see the chapter onmanaging disk space in the Administrator’s Guide for Informix Dynamic Serverand the utilities chapter in the Informix Administrator’s Reference.
Set the CDR_QDATA_SBSPACE configuration parameter(“CDR_QDATA_SBSPACE” on page B-9) in the ONCONFIG file to thelocation of the row data sbspace (er_sbspace, in this example).
Warning: Do not change the value of CDR_QDATA_SBSPACE after you initializeEnterprise Replication.
4-14 Guide to IBM Informix Enterprise Replication

Creating ATS and RIS Directories
Creating ATS and RIS DirectoriesThe Aborted Transactions Spooling (ATS) and Row Information Spooling(RIS) files contain information about failed transactions and aborted rows.
If you set up ATS and RIS, Enterprise Replication writes ATS and RIS files todirectories on the system:
■ ATS files
If you are using primary-target replication, create the ATS directoryon the target system. If you are using update-anywhere replication(“Update-Anywhere Replication System” on page 3-10) and haveconflict resolution (“Conflict Resolution” on page 3-11) enabled, cre-ate the ATS directory on all participating replication systems.
■ RIS files
If you have conflict resolution enabled, create the RIS directory on allparticipating replication systems.
The default location for these directories is /tmp (UNIX) or \tmp (Windows).Informix recommends that you specify a location other than /tmp or \tmp forthe spooling directories.
Create the new location for these directories before you define the server forreplication.The pathnames for the ATS and RIS directories can be no longerthan 256 characters.
For information about ATS and RIS, refer to Chapter 8, “Monitoring andTroubleshooting Enterprise Replication.”
Preparing the Replication Environment 4-15

Preparing the Database Server Environment
Preparing the Database Server EnvironmentTo configure the database server environment, verify that the followingenvironment variables are set correctly:
■ INFORMIXDIR is set to the full path of the Informix directory.
■ INFORMIXSERVER is set to the name of the default database server.
See also “Connect Option” on page A-87.
■ INFORMIXSQLHOSTS is set to the full path to the SQLHOSTS file(UNIX) or the SQLHOSTS registry host machine (Windows).
For more information, see the Informix Administrator’s Reference.
In addition, in the ONCONFIG file for each database server, make sure that thefollowing configuration parameters are set:
■ DBSERVERNAME is set to the correct database server.
Important: If you use both DBSERVERNAME and DBSERVERALIASES, DBSERV-ERNAME should refer to the TCP connection and not to a shared-memory connection.For information about database server aliases, refer to the Administrator’s Guide forInformix Dynamic Server.
■ CDR_QUEUEMEM (“CDR_QUEUEMEM” on page B-7) is set to themaximum amount of memory to be used for the send and receivequeues.
■ CDR_QHDR_DBSPACE (“CDR_QHDR_DBSPACE” on page B-8) is setto the location of the transaction record dbspace.
For more information, see “Transaction Record dbspace” onpage 4-12.
■ CDR_QDATA_SBSPACE (“CDR_QDATA_SBSPACE” on page B-9) isset to the location of the row data sbspace.
Important: If the CDR_QDATA_SBSPACE configuration parameter is not set inONCONFIG or the sbspace name specified by CDR_QDATA_SBSPACE is invalid,Enterprise Replication fails to define the server.
For more information, see “Row Data sbspace” on page 4-13.
4-16 Guide to IBM Informix Enterprise Replication

Preparing the Database Server Environment
■ CDR_SERIAL (“CDR_SERIAL” on page B-11) is set to enable controlover generating values for serial columns in tables defined forreplication.
For more information, see “SERIAL Data Types and Primary Keys”on page 2-12.
Preparing the Replication Environment 4-17

Preparing Data for Replication
Preparing Data for ReplicationThe goal of data replication is to provide identical, or at least consistent, dataon multiple database servers. This section describes how to prepare the infor-mation in your databases for replication.
When you define a new replicate on tables with existing data on differentdatabase servers, the data might not be consistent. Similarly, if you add aparticipant to an existing replicate, you must ensure that all the databases inthe replicate have consistent values.
For more information, see “Data Preparation Example” on page 4-24.
Preparing Consistent DataIn most cases, preparing consistent data simply requires that you decidewhich of your databases has the most accurate data and then copy that dataonto the target database. If the target database already has data, for dataconsistency, you must remove that data before adding the copied data. See“Loading and Unloading Data” on page 4-22 for information on loading thedata.
Blocking ReplicationYou might need to put data into a database that you do not want replicated,perhaps for a new server or because you had to drop and re-create a table.
To block replication while you prepare a table, use the BEGIN WORKWITHOUT REPLICATION statement. This starts a transaction that does notreplicate to other database servers.
The following code fragment shows how you might use this statement:
BEGIN WORK WITHOUT REPLICATIONLOCK TABLE officeDELETE FROM office WHERE description = 'portlandR_D'COMMIT WORK
4-18 Guide to IBM Informix Enterprise Replication

Blocking Replication
The following list indicates actions that occur when a transaction starts withBEGIN WORK WITHOUT REPLICATION:
■ SQL does not generate any values for the shadow columns (cdrserverand cdrtime) for the rows that are inserted or updated within thetransaction. You must supply values for these columns with theexplicit column list. You must supply these values even if you wantthe column values to be NULL.
■ To modify a table with shadow columns that is already defined inEnterprise Replication, you must explicitly list the columns to bemodified. The following two examples show an SQL statement andthe correct changes to the statement to modify columns:
❑ If table_name1 is a table defined for replication, you mustchange the following statement:LOAD FROM filename INSERT INTO table_name1;
to:LOAD FROM filename INSERT INTO table_name1 \
(list of columns);
The list of columns must match the order and the number offields in the load file.
❑ If table_name3 and table_name4 are tables defined for repli-cation with the same schema, you must change the followingstatement:INSERT INTO table_name3 SELECT * FROM table_name4;
to an explicit statement, where col1, col2,..., colN are the columnsof the table:INSERT INTO table_name3 VALUES
(cdrserver, cdrtime, col1, ..., colN) cdrserver, cdrtime *FROM table_name4;
The shadow columns (cdrserver and cdrtime) are not includedin an * list.
For more information about these statements, refer to the Informix Guide toSQL: Syntax.
Preparing the Replication Environment 4-19

Blocking Replication
Using DB-Access to Begin Work Without Replication
The following example shows how to use DB-Access to begin work withoutreplication as well as update the Enterprise Replication shadow columnscdrserver and cdrtime:
DATABASE adatabase;BEGIN WORK WITHOUT REPLICATIONINSERT into mytable (cdrserver, cdrtime, col1, col2, ....)
VALUES (10, 845484154, value1, value2, ....);UPDATE mytable
SET cdrserver = 10, cdrtime = 945484154WHERE col1 > col2;
COMMIT WORK
Using ESQL/C to Begin Work Without Replication
The following example shows how to use ESQL/C to begin work withoutreplication as well as update the Enterprise Replication shadow columnscdrserver and cdrtime:
MAIN (argc, argv)INT argc;CHAR *argv[];
{EXEC SQL CHARstmt[256];EXEC SQL database mydatabase;
sprintf(stmt, “BEGIN WORK WITHOUT REPLICATION”);EXEC SQL execute immediate :stmt;
EXEC SQL insert into mytable (cdrserver, cdrtime,col1, col2, ...)values (10, 845494154, value1, value2, ...);
EXEC SQL update mytableset cdrserver = 10, cdrtime = 845494154where col1 > col2;EXEC SQL commit work;
}
Important: You must use the following syntax when you issue the BEGIN WORKWITHOUT REPLICATION statement from ESQL/C programs. Do not use the ‘$’syntax.
sprintf(stmt, “BEGIN WORK WITHOUT REPLICATION”);EXEC SQL execute immediate :stmt;
4-20 Guide to IBM Informix Enterprise Replication

Preparing to Replicate Opaque User-Defined Types
Preparing to Replicate Opaque User-Defined TypesFor Enterprise Replication to be able to replicate opaque user-defined types(UDTs), the UDT designer must provide two support functions,streamwrite( ) and streamread( ). For more information, see “ReplicatingOpaque User-Defined Data Types” on page 2-25.
Preparing Tables for Conflict ResolutionTo use any conflict-resolution rule other than ignore, you must define theshadow columns, cdrserver and cdrtime.
Tip: If you plan to use only the ignore conflict-resolution rule, you do not need todefine the cdrserver and cdrtime shadow columns.
For more information about update-anywhere and conflict resolution, see“Update-Anywhere Replication System” on page 3-10.
To define the shadow columns in your table, use the following statements:
■ For new tables, use:CREATE TABLE table_name WITH CRCOLS;
■ For existing tables, use:ALTER TABLE table_name ADD CRCOLS;
Important: If a table already participates in Enterprise Replication, you must stopreplication before altering it with the ADD CRCOLS clause. For more information,see “Stopping a Replicate” on page 6-8.
To drop the cdrserver and cdrtime shadow columns, use:
ALTER TABLE table_name DROP CRCOLS;
Tip: The ADD CRCOLS and DROP CRCOLS clauses to the ALTER TABLE statementare now processed as in-place alters in most cases. For more information, see “Perfor-mance Improvements” on page 7 of the Introduction and the section on in-placealters in the Performance Guide. For more information on CREATE TABLE andALTER TABLE, see the sections in the Informix Guide to SQL: Syntax.
Preparing the Replication Environment 4-21

Preparing Logging Databases
Preparing Logging DatabasesDatabases on all server instances involved in replication must be created withlogging. Informix recommends that you use unbuffered logging. For moreinformation, see “Unbuffered Logging” on page 2-10.
Loading and Unloading DataFor loading data, you can use the following tools:
■ High-Performance Loader
■ onunload and onload Utilities
■ dbexport and dbimport Utilities
■ UNLOAD and LOAD Statements
When you unload and load data, you must use the same type of utility forboth the unload and load operations. For example, you cannot unload datawith the onunload utility and then load the data with a LOAD statement.
If the table that you are preparing for replication is in a database that alreadyuses replication, you might need to block replication while you prepare thetable. See “Blocking Replication” on page 4-18 for information on how to dothis.
If a table that you plan to replicate includes the shadow columns, cdrserverand cdrtime, the statements that you use for unloading the data mustexplicitly name the shadow columns. If you use * FROM table_name to the datato unload, the data from the shadow columns will not be unloaded. Toinclude the shadow columns in the unloaded data, use a statement like thefollowing:
SELECT cdrserver, cdrtime, * FROM table_name
For more information, see “Shadow Columns” on page 2-11.
4-22 Guide to IBM Informix Enterprise Replication

Loading and Unloading Data
High-Performance Loader
The High-Performance Loader (HPL) provides a high-speed tool for movingdata between databases.
How you use the HPL depends on how you defined the tables to replicate. Ifthe table definition included the WITH CRCOLS clause, you must take specialsteps when you unload the data.
If the table contains shadow columns, you must:
■ Include the cdrserver and cdrtime columns in your map when youload the data.
■ Use express mode to load data that contains the cdrserver andcdrtime columns. You must perform a level-0 archive aftercompletion.
You can also use deluxe mode without replication to load data. After a deluxemode load, you do not need to perform a level-0 archive. Deluxe mode alsoallows you to load TEXT and BYTE data and opaque user-defined types.
For information about HPL, refer to the Guide to the High-Performance Loader.
onunload and onload Utilities
You can use the onunload and onload utilities only to unload and load anentire table. If you want to unload selected columns of a table, you must useeither unload or the HPL.
Important: You can only use onunload and onload in identical (homogeneous)environments.
For more information about onunload and onload, see the Informix MigrationGuide.
Preparing the Replication Environment 4-23

Data Preparation Example
dbexport and dbimport Utilities
If you need to copy an entire database for replication, you can use thedbexport and dbimport utilities. These utilities unload an entire database,including its schema, and then re-create the database. If you want to moveselected tables or selected columns of a table, you must use some other utility.
For more information about dbexport and dbimport, see the InformixMigration Guide.
UNLOAD and LOAD Statements
The UNLOAD and LOAD statements allow you to move data within thecontext of an SQL program.
If the table contains shadow columns, you must:
■ Include the cdrserver and cdrtime columns explicitly in yourstatement when you unload your data.
■ List the columns that you want to load in the INSERT statement andexplicitly include the cdrserver and cdrtime columns in the list whenyou load your data.
For more information about the UNLOAD and LOAD statements, see theInformix Guide to SQL: Syntax.
Data Preparation ExampleThe following steps provide an example of how to add a new participant(delta) to an existing replicate using the LOAD, UNLOAD, and BEGIN WORKWITHOUT REPLICATION statements. Replicate zebra replicates data fromtable table1 for the following database servers: alpha, beta, and gamma.
The servers alpha, beta, and gamma belong to the server groups g_alpha,g_beta, and g_gamma, respectively. Assume that alpha is the database serverfrom which you want to get the initial copy of the data.
4-24 Guide to IBM Informix Enterprise Replication

Data Preparation Example
To add a new participant to an existing replicate
1. Declare server delta to Enterprise Replication. For example,cdr def ser -c delta -I -S g_alpha g_delta
At the end of this step, all servers in the replication environmentinclude information in the syscdr database about delta, and deltahas information about all other servers.
2. Add delta as a participant to replicate zebra. For example,cdr cha rep -a zebra “dbname@g_delta:owner.table1”
This step updates the replication catalog. The servers alpha, beta,and gamma do not queue any qualifying replication data for deltabecause the replicate on delta, although defined, has not beenstarted.
3. Suspend server to delta on alpha, beta, and gamma.cdr sus ser g_alpha g_beta g_gamma
As a result of this step, replication data is queued for delta, but nodata is delivered.
4. Start replication for replicate zebra on delta.cdr sta rep zebra g_delta
This step causes servers alpha, beta, and gamma to start queueingdata for delta. No data is delivered to delta because delta is sus-pended. Then, delta queues and delivers qualifying data (if any) tothe other servers.
Informix recommends that you do not run any transactions on deltathat affect table table1 until you finish the synchronization process.
5. Unload data from table table1 using the UNLOAD statement or theunload utility on HPL.
6. Copy the unloaded data to delta.
7. Start transactions with BEGIN WORK WITHOUT REPLICATION, loadthe data using the LOAD statement, and commit the transaction.
If you used the HPL to unload the data in step 5, then use the HPLDeluxe load without replication to load the data into table1 on delta.
Preparing the Replication Environment 4-25

Data Preparation Example
8. Resume server delta on alpha, beta, and gamma.
This step starts the flow of data from alpha, beta, and gamma todelta.
At this point you might see some transactions aborted because ofconflict. Transaction can abort because alpha, beta, and gammastarted queueing data from delta in step 4. However, those sametransactions might have been moved in steps 5 and 7.
It might seem strange to declare replication on server delta and then immedi-ately suspend replication. You must do this because, while you are preparingthe replicates and unloading and loading files, the other servers in thereplicate (alpha, beta, and gamma) might be collecting information thatneeds to be replicated. After you finish loading the initial data to delta andresume replication, the information that was generated during the loadingprocess can be replicated.
4-26 Guide to IBM Informix Enterprise Replication

5Chapter
Defining and ModifyingReplication Servers,Replicates, and Participants
In This Chapter . . . . . . . . . . . . . . . . . . . . 5-3Initializing Database Servers . . . . . . . . . . . . . . . 5-4
Defining Replication Servers . . . . . . . . . . . . . . . 5-5Customizing the Replication Server Definition . . . . . . . . 5-6
Defining Replicates . . . . . . . . . . . . . . . . . . . 5-7Defining Participants . . . . . . . . . . . . . . . . . 5-8
Defining Replicates on Table Hierarchies . . . . . . . . 5-9Specifying Conflict Resolution Rules and Scope . . . . . . . 5-10Specifying Replication Frequency . . . . . . . . . . . . 5-10Setting Up Error Logging . . . . . . . . . . . . . . . 5-11Replicating Only Changed Columns . . . . . . . . . . . 5-11Using the IEEE Floating Point or Canonical Format . . . . . . 5-13Enabling Triggers . . . . . . . . . . . . . . . . . . 5-14
Modifying Replication Servers . . . . . . . . . . . . . . . 5-14
Modifying Replicates . . . . . . . . . . . . . . . . . . 5-15Adding or Deleting Participants . . . . . . . . . . . . . 5-15Changing Replicate Attributes . . . . . . . . . . . . . 5-16
Resynchronizing Replication Servers. . . . . . . . . . . . . 5-17

5-2 Guid
e to IBM Informix Enterprise Replication
In This ChapterThis chapter describes the steps for declaring a database server for EnterpriseReplication.
To define a replication server
1. Initialize the database server.
For information, see “Initializing Database Servers” on page 5-4.
2. Declare the database server to Enterprise Replication.
3. For information, see “Defining Replication Servers” on page 5-4.
Once you define the server for replication, the server is known as areplication server.
4. Define replicates.
The replicate definition includes information about the participants,replication options, frequency, and conflict-resolution rules andscope.
For information, see “Defining Replicates” on page 5-7.
5. Define participants.
A participant definition specifies the data (database, table, and col-umns) that should be replicated. Although you can define a replicatewith fewer, a replicate should contain two or more participants to beuseful.
For information, see “Defining Participants” on page 5-8.
Important: You must be the Enterprise Replication server administrator (“Enter-prise Replication Server Administrator” on page 2-4) to define the replication server.
Defining and Modifying Replication Servers, Replicates, and Participants 5-3

Initializing Database Servers
This chapter also covers the following topics:
■ Modifying Replication Servers
■ Modifying Replicates
■ Resynchronizing Replication Servers
For information on managing your replication servers and replicates, see“Managing Replication Servers and Replicates” on page 6-1.
Initializing Database ServersThe database server must be online before you can declare it for replication.
To bring the server from offline to online, issue the following command foryour operating system.
To bring the server from quiescent mode to online on either UNIX orWindows, enter onmode -m.
For more information on initializing the database server, see the chapter ondatabase operating modes in the Administrator’s Guide for Informix DynamicServer.
Operating System Command
UNIX oninit
Windows starts dbservername
5-4 Guide to IBM Informix Enterprise Replication

Defining Replication Servers
Defining Replication ServersOnce you bring the database server online, the next step is to declare theserver to Enterprise Replication.
To define the replication server, use the cdr define server command. Forexample:
cdr define server --init [--connect=server_name] \options server_group_name
The --init option initializes the server. If INFORMIXSERVER is not set to theserver that you are defining, specify the --connect=server_name option(“Connecting to Another Replication Server” on page 6-4).
Tip: All Enterprise Replication commands and options (except the --connect optionwhich can use both) use the name of the database server group (also known as a servergroup) instead of the more familiar database server name for all references to databaseservers. This manual uses the convention that the name of a server group is g_followed by the server group name.
Important: If the CDR_SBSPACE configuration parameter is not set in ONCONFIGor specifies an invalid sbspace, Enterprise Replication fails to define the server.
For more information, see “Row Data sbspace” on page 4-13.
Defining and Modifying Replication Servers, Replicates, and Participants 5-5

Customizing the Replication Server Definition
Customizing the Replication Server DefinitionWhen you define a replication server, you can change the following aspectsof the server in the replication environment:
■ Synchronize the new server’s global catalog (“Global Catalog” onpage 2-6) with another Enterprise Replication server.
For all servers except the first server you define in your EnterpriseReplication system, you must use --sync=sync_server in your serverdefinition to synchronize the global catalog with an existing server.
For Hierarchical Routing (HR) topologies, Enterprise Replicationalso uses the synchronization server as the parent of the new serverin the current topology. For example, if you add a new server kauaiand synchronize its global catalog with hawaii, kauai is connected tohawaii in the Enterprise Replication topology. For more information,see “Choosing a Replication Network Topology” on page 3-19.
■ Set the idle timeout.
To specify the time (in minutes) that you want to allow the connec-tion between two Enterprise Replication servers to remain idlebefore disconnecting, use --idle=timeout.
Depending on the type of Enterprise Replication system (primary-target orupdate-anywhere) and network topology (fully connected or hierarchical)that you chose in Chapter 3, “Selecting the Enterprise Replication System andNetwork Topology,” set the following options:
■ Specify the location of the ATS directory.
To use ATS, specify the directory for the Aborted Transaction Spool-ing (ATS) files for the server using --ats=dir.
For more information, see “Creating ATS and RIS Directories” onpage 4-15 and Chapter 8, “Monitoring and Troubleshooting Enter-prise Replication.”
■ Specify the location of the RIS directory.
To use RIS, specify the directory for the Row Information Spooling(RIS) files for the server using --ris=dir.
For more information, see “Creating ATS and RIS Directories” onpage 4-15 and Chapter 8, “Monitoring and Troubleshooting Enter-prise Replication.”
5-6 Guide to IBM Informix Enterprise Replication

Defining Replicates
■ Specify the type of server (hierarchical replication).
❑ To specify the server as a nonroot server, use --nonroot.
❑ To specify the server as a leaf server, use --leaf.
If neither --leaf nor --nonroot is specified, the server is defined as aroot server.
For more information, see “Hierarchical Replication Topologies” onpage 3-21.
For more information, see “cdr define server” on page A-20.
Defining ReplicatesTo define a replicate, use the cdr define replicate command.
You must provide the following information in the replicate definition:
■ Participants
See “Defining Participants” on page 5-8.
■ Conflict resolution rules and scope
See “Specifying Conflict Resolution Rules and Scope” on page 5-10.
■ Replication frequency
See “Specifying Replication Frequency” on page 5-10.
■ Error logging
See “Setting Up Error Logging” on page 5-11.
■ Replicate full rows or only changed columns
See “Replicating Only Changed Columns” on page 5-11.
■ IEEE or canonical message formats
See “Using the IEEE Floating Point or Canonical Format” onpage 5-13.
■ Database triggers
See “Enabling Triggers” on page 13.
Defining and Modifying Replication Servers, Replicates, and Participants 5-7

Defining Participants
Once you define the replicate and participants, you must manually start thereplicate using the cdr start replicate command. See “Starting a Replicate” onpage 6-7.
Defining ParticipantsYou must define participants for each server involved in the replicate in thereplicate definition using the cdr define replicate command.
Important: You cannot start and stop replicates that have no participants.
Each participant definition includes the following information:
■ Database server group name
■ Database in which the table to be replicated resides
■ Table name
■ Table owner
See “Table Owner” on page A-89.
■ SELECT statement and optional WHERE clause
See “Participant Modifier” on page A-90.
If you use SELECT * from table_name, the tables must be identical onall database servers defined for the replicate.
Important: Do not create more than one participant definition for each row andcolumn to replicate. If the participant is the same, Enterprise Replication attempts toinsert or update duplicate values during replication. For example, if one participantmodifier includes WHERE x < 50 and another includes WHERE x < 100, EnterpriseReplication sends the data twice.
In addition, for a primary-target replication system, you can specify theparticipant type as either primary or target (receive-only). If you do not specifythe participant type, Enterprise Replication defines the participant as update-anywhere by default. For more information, see “Primary-Target ReplicationSystem” on page 3-3 and “Participant Type” on page A-89.
For example, in the following participant definition, the P indicates that inthis replicate, hawaii is a primary server.
“P db1@g_hawaii:informix.mfct” “select * from mfct” \
5-8 Guide to IBM Informix Enterprise Replication

Defining Participants
If any data in the selected columns changes, that changed data is to be sent tothe secondary servers.
In the following example, the R indicates that in this replicate, maui is asecondary server:
“R db2@g_maui:informix.mfct” “select * from mfct”
The specified table and columns receive information sent from the primaryserver. Changes to those columns on maui are not replicated.
Important: The R in the participant definition indicates that the table is receive-onlymode, not that the table is in read-only mode.
If you do not specify the participant type, Enterprise Replication defines theparticipant as update-anywhere by default. For example:
“db1@g_hawaii:informix.mfct” “select * from mfct” \“db2@g_maui:informix.mfct” “select * from mfct”
For more information, see “Participant” on page A-88.
Defining Replicates on Table Hierarchies
When you define replicates on inherited table hierarchies, use the followingguidelines to replicate operations:
■ For both the parent and child tables, define a replicate on each table.
■ For only the parent table (not the child table), define a replicate on theparent table only.
■ For only the child table (not the parent table), define a replicate on thechild table only.
Defining and Modifying Replication Servers, Replicates, and Participants 5-9

Specifying Conflict Resolution Rules and Scope
Specifying Conflict Resolution Rules and ScopeFor update-anywhere replication systems, you must specify the conflict-resolution rules in the replicate definition using the --conflict=rule option.The conflict resolution rules are:
■ ignore
■ timestamp
■ routine_name
If you use an SPL routine for your conflict-resolution rule, you canalso use the --optimize option to specify that the routine isoptimized.
For more information, see the following:
■ “Update-Anywhere Replication System” on page 3-10
■ “Conflict-Resolution Rule” on page 3-12
■ “Conflict Options” on page A-11
You can also specify the scope using the --scope=scope option:
■ transaction (default)
■ row
For more information, see “Scope” on page 3-18, and “Scope Options” onpage A-11.
Specifying Replication FrequencyThe replication frequency options allow you to specify the interval betweenreplications, or the time of day when an action should occur. If you do notspecify the frequency, the default action is that replication always occursimmediately when data arrives.
The frequency options are:
■ --immed
■ --every=interval
■ --at=time
5-10 Guide to IBM Informix Enterprise Replication

Setting Up Error Logging
For more information, see “Frequency Options” on page A-92.
Important: If you use time-based replication and two tables have referentialconstraints, the replicates must belong to the same exclusive replicate set. For moreinformation, see “Exclusive Replicate Sets” on page 7-4.
Setting Up Error LoggingThe Aborted Transaction Spooling (ATS) files and Row Information Spooling(RIS) files contain information about failed transactions and aborted rows.You can use this information to help you diagnose problems that arise duringreplication. Informix recommends that, until you become thoroughlyfamiliar with the behavior of the replication system, you select both options.For more information about these files, refer to Chapter 8, “Monitoring andTroubleshooting Enterprise Replication.”
To configure your replicate to use ATS and RIS
1. First, set up the ATS and RIS directories (“Creating ATS and RISDirectories” on page 4-15).
2. Then, when you define your server (“Defining Replication Servers”on page 5-4), specify the location of the ATS and RIS directories.
3. Now, when you define the replicate, specify that the replicate useATS and RIS by including the --ats and --ris options in the replicatedefinition.
For more information, see “Special Options” on page A-13.
Replicating Only Changed ColumnsBy default, Enterprise Replication replicates the entire row, even if only onecolumn changed. (For more information on how Enterprise Replicationevaluates data for replication, see “Evaluate Data for Replication” onpage 1-9.)
You can change the default behavior to replicate only the columns thatchanged. To replicate only changed columns, include the --fullrow n optionin the replicate definition.
Defining and Modifying Replication Servers, Replicates, and Participants 5-11

Replicating Only Changed Columns
Tip: Enterprise Replication always sends the primary key column, even if youspecify to replicate only changed columns.
Replicating only the columns that changed has the following advantages:
■ Sends less data
This is particularly useful when replicating large objects, such asdata stored as smart large objects and opaque user-defined types(UDTs). For example, when you replicate a row with a large columnthat changes infrequently and a small column that changes fre-quently, Enterprise Replication sends significantly less data eachtime it updates the row if it only replicates the changed columns.
■ Uses fewer Enterprise Replication resources, such as memory
If Enterprise Replication replicates an entire row from the source and thecorresponding row does not exist on the target, Enterprise Replicationapplies the update as an INSERT, also known as an UPSERT, on the target. Byreplicating the entire row, Enterprise Replication self-corrects any errorsduring replication. If any errors occur in an update of the target databaseserver (for example, a large object is deleted before Enterprise Replication cansend the data), the next update from the source database server (a completerow image) corrects the data on the target server.
Important: If you replicate only changed columns:
■ Enterprise Replication does not apply upserts.
If the row to replicate does not exist on the target, Enterprise Replicationdoes not apply it. If you set up error logging (“Setting Up Error Logging”on page 5-11), Enterprise Replication logs this information as a failedoperation.
■ You cannot use the SPL routine or time stamp with SPL routine conflict-resolution rules. For more information, see “Conflict Resolution” onpage 3-11.
■ All database servers in the enterprise must be Version 9.3 or later.
Enterprise Replication does not enforce this restriction. If you attempt toreplicate only changed columns to a pre-Version 9.3 database server, youwill experience corrupt data on that database server.
Enterprise Replication logs bitmap information about the updated columnsin the logical-log file. For more information, see the CDR record type in thelogical-logs chapter in the Informix Administrator’s Reference.
5-12 Guide to IBM Informix Enterprise Replication

Using the IEEE Floating Point or Canonical Format
For more information on the --fullrow option, see “Special Options” onpage A-13.
Using the IEEE Floating Point or Canonical FormatThe FLOAT and SMALLFLOAT data types are handled inconsistently acrossdifferent platforms. You can specify sending this data in either IEEE floatingpoint format or machine-independent decimal representation:
■ Enable IEEE floating point format to send all floating point values ineither 32-bit (for SMALLFLOAT) or 64-bit (for FLOAT) IEEE floatingpoint format.
To use IEE floating point format, include the --floatieee option inyour replicate definition.
Informix recommends that you define all new replicates with the--floatieee option.
■ Enable canonical format to send floating-point values in a machine-independent decimal representation when you replicate databetween dissimilar hardware platforms.
To use canonical format, include the --floatcanon option in your rep-licate definition. The --floatcanon option is provided for backward-compatibility only; Informix recommends that you use the--floatieee option when defining new replicates.
■ If you specify neither IEEE or canonical formats, Enterprise Repli-cation sends FLOAT and SMALLFLOAT data types as a straight copyof machine representation. If you are replicating across differentplatforms, replicated floating-point numbers will be incorrect.
For more information, see “Special Options” on page A-13.
Important: Once set, you cannot modify the replicate to change the --floatieee or--floatcanon options.
Defining and Modifying Replication Servers, Replicates, and Participants 5-13

Enabling Triggers
Enabling TriggersBy default, when a replicate causes an insert, update, or delete on a targettable, triggers associated with the table are not executed. However, you canspecify that triggers are executed when the replicate data is applied byenabling triggers in the replicate definition.
To enable triggers, include the --firetrigger option in your replicatedefinition.
For information, refer to “Triggers” on page 2-13 and “Special Options” onpage A-13.
Modifying Replication ServersTo modify a replication server, use the cdr modify server command. With thiscommand, you can change the following attributes of the server:
■ Idle timeout
■ Location of the directory for the Aborted Transaction Spooling (ATS)files
■ Location of the directory for the Row Information Spooling (RIS) files
For information about each of these attributes, see “Defining ReplicationServers” on page 5-4. For more information, see “cdr modify server” onpage A-56.
5-14 Guide to IBM Informix Enterprise Replication

Modifying Replicates
Modifying ReplicatesYou can modify replicates in two ways:
■ Adding or Deleting Participants
■ Changing Replicate Attributes
Adding or Deleting ParticipantsTo be useful, a replicate must include at least two participants. You can definea replicate (“Defining Replicates” on page 5-7) that has fewer than two partic-ipants, but before you can use that replicate, you must add more participants.
To add a participant to an existing replicate, use cdr change replicate --add.For example, to add two participants to the sales_data replicate, enter:
cdr change replicate --add sales_data \“db1@hawaii:jane.table1” “select * from table1” \“db2@maui:john.table2” “select * from table2”
To delete a participant from the replicate, use cdr change replicate --delete.
For example, to delete these two participants from the replicate, enter:
cdr change replicate --delete sales_data \“db1@hawaii:jane.table1” “db2@maui:john.table2”
For more information, see “cdr change replicate” on page A-4.
Defining and Modifying Replication Servers, Replicates, and Participants 5-15

Changing Replicate Attributes
Changing Replicate AttributesYou can change the following attributes of a replicate using the cdr modifyreplicate command:
■ Conflict-resolution rules and scope
■ Replication frequency
■ Error logging
■ Replicate full rows or only changed columns
■ Database triggers
■ Participant type
Important: You cannot change the conflict resolution from ignore to a non-ignoreoption (time stamp, SPL routine, or time stamp and SPL routine). You cannot changea non-ignore conflict resolution option to ignore.
For information on each of these attributes, see “Defining Replicates” onpage 5-7.
For example, to change the replication frequency for the sales_data replicateto every Sunday at noon, enter:
cdr modify replicate sales_data Sunday.12:00
For more information, see “cdr modify replicate” on page A-49.
5-16 Guide to IBM Informix Enterprise Replication

Resynchronizing Replication Servers
Resynchronizing Replication ServersYou might want to resynchronize servers in your replication environment,for example, if replicated tables between Enterprise Replication servers havebecome out of sync after stopping and restarting replication for a server.
Warning: Make sure that there are no user transactions performing updates on anyreplicated tables while you run this procedure.
To synchronize the replication g_papeete with the g_raratonga
1. Suspend replication to the replication server group g_papeete.
See “Suspending Replication for a Server” on page 6-5.
2. Unload the table from the server group g_raratonga.
See “Loading and Unloading Data” on page 4-22.
3. Load the table on g_papeete and specify BEGIN WORK WITHOUTREPLICATION.
See “Loading and Unloading Data” on page 4-22 and “Blocking Rep-lication” on page 4-18.
4. Resume replication to g_papeete.
See “Resuming a Suspended Replication Server” on page 6-6.
Important: If tables that you are synchronizing include shadow columns, you mustexplicitly unload and load these columns. If these values are not included, EnterpriseReplication inserts NULL values. For more information, see “Shadow Column DiskSpace” on page 4-11 and “Loading and Unloading Data” on page 4-22.
Defining and Modifying Replication Servers, Replicates, and Participants 5-17


6Chapter
Managing Replication Serversand Replicates
In This Chapter . . . . . . . . . . . . . . . . . . . . 6-3
Managing Replication Servers . . . . . . . . . . . . . . . 6-3Viewing Replication Server Attributes . . . . . . . . . . . 6-3Connecting to Another Replication Server . . . . . . . . . 6-4Stopping Replication on a Server. . . . . . . . . . . . . 6-4Restarting Replication on a Stopped Server . . . . . . . . . 6-5Suspending Replication for a Server . . . . . . . . . . . 6-5Resuming a Suspended Replication Server . . . . . . . . . 6-6Deleting a Replication Server . . . . . . . . . . . . . . 6-6
Managing Replicates . . . . . . . . . . . . . . . . . . 6-7Viewing Replicate Properties . . . . . . . . . . . . . . 6-7Starting a Replicate . . . . . . . . . . . . . . . . . 6-7Stopping a Replicate . . . . . . . . . . . . . . . . . 6-8Suspending a Replicate . . . . . . . . . . . . . . . . 6-9Resuming a Suspended Replicate . . . . . . . . . . . . 6-9Deleting a Replicate . . . . . . . . . . . . . . . . . 6-9
Managing Replication Server Network Connections . . . . . . . 6-10Viewing Network Connection Status . . . . . . . . . . . 6-10Dropping the Network Connection . . . . . . . . . . . . 6-10Reestablishing the Network Connection . . . . . . . . . . 6-11

6-2 Guid
e to IBM Informix Enterprise Replication
In This ChapterThis chapter covers how to manage your Enterprise Replication system,including managing replication servers, replicates and participants in Enter-prise Replication, and replication server network connections.
Managing Replication ServersThe state of the server refers to the relationship between the source server andthe target server. To determine the current state of the server, use cdr listserver server_name. For more information about the possible server states, see“The STATE Column” on page A-46.
Viewing Replication Server AttributesOnce you define a server for replication (“Defining Replication Servers” onpage 5-5), you can view information about the server using the cdr list servercommand. If you do not specify the name of a defined server on thecommand line, Enterprise Replication lists all the servers that are visible tothe current server. If you specify a server name, Enterprise Replicationdisplays information about the current server, including server ID, serverstate, and attributes.
For more information, see “cdr list server” on page A-45.
Managing Replication Servers and Replicates 6-3

Connecting to Another Replication Server
Connecting to Another Replication ServerBy default, when you view information about a server, Enterprise Repli-cation connects to the global catalog of the database server specified by$INFORMIXSERVER. You can connect to the global catalog of anotherdatabase server using the --connect option.
For example, to connect to the global catalog of the database server idaho,enter:
cdr list server --connect idaho
For more information, see “Global Catalog” on page 2-6 and “ConnectOption” on page A-87.
Stopping Replication on a ServerEnterprise Replication starts automatically when you use cdr define serverto declare the server for replication. The replication threads continue runninguntil you shut the database server down or you remove the server with cdrdelete server. If you shut down the database server while Enterprise Repli-cation is running, replication begins again when you restart the databaseserver. For more information about managing the database server, see thechapter on database operating modes in the Administrator’s Guide for InformixDynamic Server.
Generally, to stop Enterprise Replication on a server, you should bring downthe server. However, you might want to temporarily stop the EnterpriseReplication threads without stopping the server. To stop replication, use thecdr stop command.
When you use cdr stop, Enterprise Replication stops capturing data to bereplicated. To ensure consistency, verify that no database update activityoccurs while Enterprise Replication is stopped. Replication threads remainstopped (even if the database server is stopped and restarted) until you issuea cdr start command.
Warning: When you stop replication on a server, you must ensure that the sendqueues on the other Enterprise Replication servers participating in replication do notfill.
For more information, see “cdr stop” on page A-71.
6-4 Guide to IBM Informix Enterprise Replication

Restarting Replication on a Stopped Server
Restarting Replication on a Stopped ServerTo restart replication for a stopped server, use the cdr start command. Whenyou restart the server, the Enterprise Replication threads start and continue.
Enterprise Replication resumes evaluating the logical logs at the replayposition (where Enterprise Replication stopped evaluating the logical logwhen the server was stopped).
Warning: If the logical log corresponding to the replay position no longer exists, thenthe restart partially fails and no database updates performed on the local databaseserver are replicated.
For more information, see “cdr start” on page A-65.
Suspending Replication for a ServerIf you do not want to completely shut down the Enterprise Replicationthreads, you can suspend replication of data to the server using the cdrsuspend server command. When replication is suspended to the server, thesource server queues replicated data, but suspends delivery of replicateddata to the target server. Note that this command does not affect the networkconnection to the suspended server. The source server continues to sendother messages, such as acknowledgement and control messages.
For example, to suspend replication of data to the server group g_papeetefrom the server group g_raratonga, enter:
cdr suspend server g_papeete g_raratonga
To suspend replication to g_papeete from all servers in the enterprise, enter:
cdr suspend server g_papeete
Warning: When you suspend replication on a server, you must ensure that the sendqueues on the other Enterprise Replication servers participating in replication do notfill.
For more information, see “cdr suspend server” on page A-81.
Managing Replication Servers and Replicates 6-5

Resuming a Suspended Replication Server
Resuming a Suspended Replication ServerTo resume replication to a suspended server, use the cdr resume servercommand. When you resume the server, the queued data is delivered.
For example, to resume replication to the g_papeete server group, enter:
cdr resume server g_papeete
If you do not specify the server group (g_papeete in the example), cdrresume server resumes replication from all servers participating inreplication.
For more information, see “cdr resume server” on page A-63.
Deleting a Replication Server
To delete a replication server, use the cdr delete server command. You mustrun the cdr delete server command twice.
For example, to remove the server group g_papeete from Enterprise Repli-cation, set $INFORMIXSERVER to papeete and run the following commands:
cdr delete server g_papeetecdr delete server --connect raratonga g_papeete
The first command deletes the local server group (g_papeete) from Enter-prise Replication and the second connects to another server in the replicationenvironment (raratonga) and deletes g_papeete from that server. The changethen replicates to the other servers in the replication environment.
Warning: Avoid deleting an Enterprise Replication server and immediately recre-ating it with the same name. If you re-create the objects immediately (before theoperation finishes propagating to the other Enterprise Replication database servers inthe network), you might experience failures in the Enterprise Replication system atthe time of the operation or later. For more information, see “Operational Consider-ations” on page 2-8.
For more information, see “cdr delete server” on page A-29.
6-6 Guide to IBM Informix Enterprise Replication

Managing Replicates
Managing ReplicatesFor more information about the possible replicate states, see “DisplayingInformation About Replicates” on page A-40.
Important: If a replicate belongs to an exclusive replicate set (“Exclusive ReplicateSets” on page 7-4), you cannot manage the replicates individually. With theexception of deleting the replicate, you must manage the replicate as part of theexclusive replicate set. For more information, see “Managing Replicate Sets” onpage 7-6.
If the replicate belongs to a non-exclusive replicate set (“Non-Exclusive ReplicateSets” on page 7-5), you can manage the replicates both individually and as part of theset.
Viewing Replicate PropertiesOnce you define a replicate (“Defining Replicates” on page 5-7), you canview the properties of the replicate using the cdr list replicate command. Ifyou do not specify the name of a defined replicate on the command line,Enterprise Replication lists all the replicates defined on the current server. Ifyou specify a replicate name, Enterprise Replication displays detailed infor-mation, including participant information, about the replicate.
For information about this command, see “cdr list replicate” on page A-39.
Starting a ReplicateWhen you define a replicate, the replicate does not begin until you explicitlychange its state to active. When a replicate is active, Enterprise Replicationcaptures data from the logical log and transmits it to the participants.
Important: You cannot start replicates that have no participants.
To change the replicate state to active, use the cdr start replicate command.For example, to start the replicate sales_data on the servers server1 andserver23, enter:
cdr start replicate sales_data server1 server23
Managing Replication Servers and Replicates 6-7

Stopping a Replicate
This command causes server1 and server23 to start sending data for thesales_data replicate.
If you omit the server names, this command starts the replicate on all serversthat are included in that replicate.
Warning: Run the cdr start replicate command on an idle system (no transactionsare occurring) or use the BEGIN WORK WITHOUT REPLICATION statement untilafter you successfully start the replicate.
Important: If a replicate belongs to an exclusive replicate set (“Exclusive ReplicateSets” on page 7-4), you must start the replicate set to which the replicate belongs. Formore information, see “Starting a Replicate Set” on page 7-7.
For more information, see “cdr start replicate” on page A-67.
Stopping a ReplicateTo stop the replicate, use the cdr stop replicate command. This commandchanges the replicate state to inactive and deletes any data in the send queuefor that replicate. When a replicate is inactive, Enterprise Replication does notcapture, transmit, or process any database changes.
Important: You cannot stop replicates that have no participants.
For example, to stop the sales_data replicate on the servers server1 andserver23, enter:
cdr stop replicate sales_data server1 server23
This command causes server1 and server23 to purge any data in the sendqueue for the sales_data replicate and stops sending data for that replicate.Any servers not listed on the command line continue to capture and senddata for the sales_data replicate (even to server1 and server23).
If you omit the server names, this command stops the replicate on all serversthat are included in that replicate.
Important: If a replicate belongs to an exclusive replicate set (“Exclusive ReplicateSets” on page 7-4), you must stop the replicate set to which the replicate belongs. Formore information, see “Stopping a Replicate Set” on page 7-7.
For more information, see “cdr stop replicate” on page A-73.
6-8 Guide to IBM Informix Enterprise Replication

Suspending a Replicate
Suspending a ReplicateIf you do not want to completely halt all processing for a replicate, you cansuspend a replicate using the cdr suspend replicate command. When areplicate is suspended, the replicate captures and accumulates changes to thesource database, but does not transmit the captured data to the targetdatabase.
For example, to suspend the sales_data replicate, enter:
cdr suspend replicate sales_data
Important: If a replicate belongs to an exclusive replicate set (“Exclusive ReplicateSets” on page 7-4), you must suspend the replicate set to which the replicate belongs.For more information, see “Suspending a Replicate Set” on page 7-7.
For more information, see “cdr suspend replicate” on page A-77.
Resuming a Suspended ReplicateTo return the state of a suspended replicate to active, use the cdr resumereplicate command. For example:
cdr resume replicate sales_data
Important: If a replicate belongs to an exclusive replicate set (“Exclusive ReplicateSets” on page 7-4), you must resume the replicate set to which the replicate belongs.For more information, see “Resuming a Replicate Set” on page 7-8.
For more information, see “cdr resume replicate” on page A-59.
Deleting a ReplicateTo delete the replicate from the global catalog, use the cdr delete replicatecommand. When you delete a replicate, Enterprise Replication purges allreplication data for the replicate from the send queue at all participatingdatabase servers.
For example, to delete sales_data from the global catalog, enter:
cdr delete replicate sales_data
Managing Replication Servers and Replicates 6-9

Managing Replication Server Network Connections
Warning: Avoid deleting a replicate and immediately re-creating it with the samename. If you re-create the objects immediately (before the operation finishes propa-gating to the other Enterprise Replication database servers in the network), youmight experience failures in the Enterprise Replication system at the time of theoperation or later. For more information, see “Operational Considerations” onpage 2-8.
For more information, see “cdr delete replicate” on page A-25.
Managing Replication Server Network ConnectionsManaging replication network connections consists of viewing the networkconnection status, dropping the network connection, and reestablish adropped network connection.
Viewing Network Connection StatusTo determine the current status of the network connection to each of theservers participating in replication, use cdr list server. For more informationabout network connection status, see “The STATUS Column” on page A-46.
For more information, see “cdr list server” on page A-45.
Dropping the Network ConnectionTo drop the Enterprise Replication network connection for a server, use thecdr disconnect server command. When you drop the connection, EnterpriseReplication continues to function and queue transactions. For example, todisconnect the network connection between the current replication serverand the server g_papeete, enter:
cdr disconnect server g_papeete
Warning: When you disconnect a server from Enterprise Replication, you mustensure that the send queues on all other Enterprise Replication servers participatingin replication do not fill.
For more information, see “cdr disconnect server” on page A-33.
6-10 Guide to IBM Informix Enterprise Replication

Reestablishing the Network Connection
Reestablishing the Network ConnectionTo reestablish a dropped network connection, use the cdr connect servercommand.
For example, to reestablish the network connection between the current repli-cation server and the server g_papeete, enter:
cdr connect server g_papeete
For more information, see “cdr connect server” on page A-9.
Managing Replication Servers and Replicates 6-11


7Chapter
Creating and ManagingReplicate Sets
In This Chapter . . . . . . . . . . . . . . . . . . . . 7-3
Creating Replicate Sets . . . . . . . . . . . . . . . . . 7-4Exclusive Replicate Sets . . . . . . . . . . . . . . . . 7-4Non-Exclusive Replicate Sets . . . . . . . . . . . . . . 7-5Customizing the Replicate Set Definition . . . . . . . . . . 7-5
Viewing Replicate Set Properties . . . . . . . . . . . . . . 7-6
Managing Replicate Sets . . . . . . . . . . . . . . . . . 7-6Starting a Replicate Set . . . . . . . . . . . . . . . . 7-7Stopping a Replicate Set . . . . . . . . . . . . . . . . 7-7Suspending a Replicate Set . . . . . . . . . . . . . . . 7-7Resuming a Replicate Set . . . . . . . . . . . . . . . 7-8Deleting a Replicate Set . . . . . . . . . . . . . . . . 7-8
Modifying Replicate Sets . . . . . . . . . . . . . . . . . 7-9Adding or Deleting Replicates From a Replicate Set . . . . . . 7-9Changing Replication Frequency For the Replicate Set . . . . . 7-10

7-2 Guid
e to IBM Informix Enterprise Replication
In This ChapterThis chapter covers creating replicate sets, viewing replicate set properties,and managing and modifying replicate sets.
A replicate set is a collection of several replicates that you can manage togetheras a unit. By default, you can manage replicates that belong to a replicate setboth individually and as part of the set, or as a set only.
Important: Enterprise Replication supports replicate sets for Informix DynamicServer Version 9.3 and later only. You cannot define or modify replicate sets toinclude replicates with participants that are Version 9.2 and earlier. In addition,replicate sets are different from and incompatible with replicate groups (inVersion 9.2 and earlier).
To create, manage, or modify a replicate set on a database server other thanthe server specified by $INFORMIXSERVER, use the --connect option(“Connecting to Another Replication Server” on page 6-4) to connect to thatserver.
Creating and Managing Replicate Sets 7-3

Creating Replicate Sets
Creating Replicate SetsTo create a replicate set, use the cdr define replicateset command.
Enterprise Replication supports two types of replicate sets: exclusive and non-exclusive.
Exclusive Replicate SetsTo maintain referential integrity between replicates that include tables thathave referential constraints placed on columns, you must create an exclusivereplicate set and add the replicate to it.
An exclusive replicate set has the following characteristics:
■ All replicates in an exclusive replicate set have the same state andfrequency (“Displaying Information About Replicates” onpage A-40) settings.
■ When you create the replicate set, Enterprise Replication sets theinitial state of the replicate set to active.
■ You can manage the replicates in an exclusive replicate set only aspart of the set. Enterprise Replication does not support the followingactions for the individual replicates in an exclusive replicate set:
❑ Starting a Replicate
❑ Stopping a Replicate
❑ Suspending a Replicate
❑ Resuming a Suspended Replicate
■ Replicates that belong to an exclusive replicate set cannot belong toany other replicate sets.
To create an exclusive replicate set, use the --exclusive (-X) option with cdrdefine replicateset.
Important: Once you create an exclusive replicate set, you cannot change it to non-exclusive and vice versa.
7-4 Guide to IBM Informix Enterprise Replication

Non-Exclusive Replicate Sets
Non-Exclusive Replicate SetsBy default, cdr define replicateset creates non-exclusive replicate sets.
A non-exclusive replicate set has the following characteristics:
■ You can manage replicates that belong to a non-exclusive replicateset both individually and as part of the set.
■ Because individual replicates in a non-exclusive replicate set canhave different states, the non-exclusive replicate set itself has nostate.
■ You should not use non-exclusive replicate sets for replicates thatinclude tables that have referential constraints placed on columns.
■ A replicate can belong to more than one non-exclusive replicate set.
Important: Once you create a non-exclusive replicate set, you cannot change it toexclusive.
Use non-exclusive replicate sets if you want to add a replicate to more thanone replicate set. For example, you might want to create replicate sets tomanage replicates on the target server, table, or entire database. To do this,create three non-exclusive replicate sets:
■ A set that contains the replicates that replicate to the target server
■ A set that contains the replicates on a particular table
■ A set that contains all the replicates
In this scenario, each replicate belongs to three non-exclusive replicate sets.
Customizing the Replicate Set DefinitionYou can specify the replication frequency (“Specifying ReplicationFrequency” on page 5-10) for all the replicates when you define the replicateset. For example, to define the non-exclusive replicate set sales_set with thereplicates sales_fiji and sales_tahiti and specify that the members ofsales_set replicate at 4:00 A.M. every day, enter:
cdr define replicateset --at 4:00 sales_set sales_fiji \sales_tahiti
Creating and Managing Replicate Sets 7-5

Viewing Replicate Set Properties
To define the exclusive replicate set dev_set with the replicates dev_pdx anddev_lenexa and specify that the members of dev_set replicate at 5:00 P.M.every day, enter:
cdr define replicateset -X --at 17:00 dev_set dev_pdx\dev_lenexa
Important: For replicates that belong to an exclusive replicate set, you cannot specifythe frequency for the individual replicates in the set.
For more information, see “cdr define replicateset” on page A-17.
Viewing Replicate Set PropertiesTo view the properties of the replicate set, use the cdr list replicatesetcommand. The cdr list replicateset command displays the replicate set nameand a list of the replicates that are members of the set. To find out more abouteach replicate in the replicate set, see “Viewing Replicate Properties” onpage 6-7.
For more information, see “cdr list replicateset” on page A-43.
Managing Replicate SetsWhen you create a replicate set, you can manage the replicates that belong tothat set together or individually. If the replicate set is exclusive, you can onlymanage the individual replicates as part of the set.
Important: All operations on a replicate set (except cdr delete replicateset) areequivalent to performing the operation on each replicate in the replicate setindividually.
For more information, see “Managing Replicates” on page 6-7.
7-6 Guide to IBM Informix Enterprise Replication

Starting a Replicate Set
Starting a Replicate SetTo change the state of all the replicates in the replicate set to active, use thecdr start replicateset command. For example, to start the replicate setsales_set, enter:
cdr start replicateset sales_set
Warning: Run the cdr start replicateset command on an idle system (when notransactions are occurring) or use the BEGIN WORK WITHOUT REPLICATIONstatement until after you successfully start the replicate.
For more information, see “cdr start replicateset” on page A-69 and “cdr startreplicate” on page A-67.
Stopping a Replicate SetTo stop the replicates in the replicate set, use the cdr stop replicatesetcommand. This command changes the state of all the replicates in the set toinactive.
For example, to stop the sales_set replicate set, enter:
cdr stop replicateset sales_set
For more information, see “cdr stop replicateset” on page A-75 and “cdr stopreplicate” on page A-73.
Suspending a Replicate SetIf you do not want to completely halt all processing for the replicates in areplicate set, you can suspend the replicates in the set using the cdr suspendreplicateset command.
For example, to suspend the sales_set replicate set, enter:
cdr suspend replicateset sales_set
For more information, see “cdr suspend replicateset” on page A-79 and “cdrsuspend replicate” on page A-77.
Creating and Managing Replicate Sets 7-7

Resuming a Replicate Set
Resuming a Replicate SetTo return the suspended replicates in the replicate set to active, use the cdrresume replicateset command. For example:
cdr resume replicateset sales_set
For more information, see “cdr resume replicateset” on page A-61 and “cdrresume replicate” on page A-59.
Deleting a Replicate SetTo delete the replicate set, use the cdr delete replicateset command.
Tip: When you delete a replicate set, Enterprise Replication does not delete the repli-cates that are members of the replicate set. The replicates remain in the state they werein when the set was deleted.
For example, to delete sales_set, enter:
cdr delete replicateset sales_set
Warning: Avoid deleting a replicate set and immediately re-creating it with the samename. If you re-create the objects immediately (before the operation finishes propa-gating to the other Enterprise Replication database servers in the network), youmight experience failures in the Enterprise Replication system at the time of theoperation or later. For more information, see “Operational Considerations” onpage 2-8.
For more information, see “cdr delete replicateset” on page A-27.
7-8 Guide to IBM Informix Enterprise Replication

Modifying Replicate Sets
Modifying Replicate SetsYou can modify replicate sets in two ways:
■ Adding or Deleting Replicates From a Replicate Set
■ Changing Replication Frequency For the Replicate Set
Adding or Deleting Replicates From a Replicate SetTo add a replicate to an existing replicate set, use the command cdr changereplicateset --add. For example, to add two replicates to sales_set, enter:
cdr change replicateset --add sales_set sales_kauai \sales_moorea
When you add a replicate to:
■ A non-exclusive replicate set, the state of the new replicate remainsas it was when you added it to the set. To bring all the replicates inthe non-exclusive set to the same state, use one of the commandsdescribed in “Managing Replicate Sets” on page 7-6.
■ An exclusive replicate set, Enterprise Replication changes theexisting state and replication frequency settings of the replicate to thecurrent properties of the exclusive replicate set.
To delete a replicate from the replicate set, use cdr change replicate --delete.
For example, to delete the two replicates, sales_kauai and sales_moorea,from the replicate set, enter:
cdr change replicateset --delete sales_set sales_kauai\sales_moorea
When you add or remove a replicate from an exclusive replicate set that issuspended (“Suspending a Replicate Set” on page 7-7) or that is defined witha frequency interval (“Frequency Options” on page A-92), Enterprise Repli-cation transmits all the data in the queue for the replicates in the replicate setup to the point when you added or removed the replicate.
For more information, see “cdr change replicateset” on page A-6.
Creating and Managing Replicate Sets 7-9

Changing Replication Frequency For the Replicate Set
Changing Replication Frequency For the Replicate SetYou can change the replication frequency (“Specifying ReplicationFrequency” on page 5-10) for the replicates in an exclusive or non-exclusivereplicate set using the cdr modify replicateset command.
For example, to change the replication frequency for each of the replicates inthe sales_set to every Monday at midnight, enter:
cdr modify replicateset sales_set Monday.24:00
For more information, see “cdr change replicateset” on page A-6.
7-10 Guide to IBM Informix Enterprise Replication

8Chapter
Monitoring andTroubleshooting EnterpriseReplication
In This Chapter . . . . . . . . . . . . . . . . . . . . 8-3Aborted Transaction Spooling Files . . . . . . . . . . . . . 8-3Preparing to Use ATS. . . . . . . . . . . . . . . . . 8-4About ATS Filenames . . . . . . . . . . . . . . . . 8-5About ATS File Information . . . . . . . . . . . . . . 8-6BYTE and TEXT Information in ATS Files. . . . . . . . . . 8-7
Example 1 . . . . . . . . . . . . . . . . . . . 8-7Example 2 . . . . . . . . . . . . . . . . . . . 8-7Example 3 . . . . . . . . . . . . . . . . . . . 8-7
Changed Column Information in ATS Files . . . . . . . . . 8-8BLOB and CLOB Information in ATS Files . . . . . . . . . 8-8UDT Information in ATS Files. . . . . . . . . . . . . . 8-8
Row Information Spooling Files . . . . . . . . . . . . . . 8-9Preparing to Use RIS . . . . . . . . . . . . . . . . . 8-9About RIS Filenames . . . . . . . . . . . . . . . . . 8-10BYTE and TEXT Information in RIS Files . . . . . . . . . . 8-12
Example 1 . . . . . . . . . . . . . . . . . . . 8-12Example 2 . . . . . . . . . . . . . . . . . . . 8-12
Changed Column Information in RIS Files . . . . . . . . . 8-12BLOB and CLOB Information in RIS Files. . . . . . . . . . 8-12UDT Information in RIS Files . . . . . . . . . . . . . . 8-12
Preventing Memory Queues from Overflowing . . . . . . . . . 8-13Preventing Blockout Mode . . . . . . . . . . . . . . . 8-14Monitoring Disk Usage for Send and Receive Queue Spool . . . 8-15Increasing the Sizes of Storage Spaces . . . . . . . . . . . 8-16Recovering when Storage Spaces Fill . . . . . . . . . . . 8-16

8-2 Guid
Solving Common Configuration Problems . . . . . . . . . . . 8-17
Enterprise Replication Event Alarms . . . . . . . . . . . . . 8-19
e to IBM Informix Enterprise Replication

In This ChapterEnterprise Replication provides tools to help diagnose problems that ariseduring replications. The Aborted Transaction Spooling (ATS) and Row Infor-mation Spooling (RIS) files contain information about failed transactions.
In addition, you can use tools provided with the server, such as the onstatcommand, to display statistics that you can use to diagnose problems. Formore information on the onstat commands that are relevant to EnterpriseReplication, see Appendix C, “onstat Command Reference.”
This chapter covers the following topics:
■ Aborted Transaction Spooling Files
■ Row Information Spooling Files
■ Preventing Memory Queues from Overflowing
■ Solving Common Configuration Problems
■ Enterprise Replication Event Alarms
Aborted Transaction Spooling FilesWhen ATS is active, all failed replication transactions are recorded in ATSfiles. Each ATS file contains all the information pertinent to a single failedtransaction. If a replicated transaction fails for any reason (constraintviolation, duplication, and so on), all the buffers in the replication messagethat compose the transaction are written to a local operating-system file. Youcan use the ATS files to identify problems or as input to custom utilities thatextract or reapply the aborted rows.
Monitoring and Troubleshooting Enterprise Replication 8-3

Preparing to Use ATS
Aborted-transaction spooling only occurs if the entire transaction is aborted.Transactions defined with row scope that have aborted rows but are success-fully committed on the target tables are not logged.
All rows that fail conflict resolution for a transaction that has row scopedefined are also written to the RIS file (“Row Information Spooling Files” onpage 8-9), if defined.
In some cases, such as with long transactions, the database server itself abortstransactions. In these cases, Enterprise Replication does not generate an ATSfile.
Preparing to Use ATSFailed transactions are not automatically recorded in ATS files.
To collect ATS information
1. Create a directory for Enterprise Replication to store ATS files.
■ If you are using primary-target replication, create the directoryon the target system.
■ If you are using update-anywhere replication and have conflictresolution enabled, create the directory on all participating repli-cation systems.
For more information, see “Creating ATS and RIS Directories” onpage 4-15.
2. When you define a server for Enterprise Replication, specify thelocation of the ATS directory you created in step 1.
To do this, include the --ats option with the cdr define servercommand.
If you do not specify an ATS directory:
■ Enterprise Replication stores the ATS files in the /tmpdirectory. ♦
■ Enterprise Replication stores the ATS files in the \tmp directoryof the drive that contains %INFORMIXDIR% ♦
For more information, see “Creating ATS and RIS Directories” onpage 4-15.
UNIX
WIN NT/2000
8-4 Guide to IBM Informix Enterprise Replication

About ATS Filenames
3. When you define a replicate, specify that ATS is active.
To do this, include the --ats option with the cdr define replicatecommand.
For more information, see “Setting Up Error Logging” on page 5-11.
About ATS FilenamesWhen ATS is active, each aborted transaction is written to a file in thespecified directory.
The following table provides the naming convention for ATS files:
ats.target.source.threadId.timestamp.sequence
The naming convention ensures that all filenames that ATS generates areunique, and therefore name collision is unlikely. However, when ATS opensa file for writing, any previous file contents will be overwritten. (ATS does notappend to a spool file; if a name collision does occur with an existing file, theoriginal contents of the file will be lost.)
The following is an example ATS filename for a transaction sent by serverg_amsterdam to server g_beijing:
ats.g_beijing.g_amsterdam.D_2.000529_23:27:16.6
Name Description
target The name of the database server receiving this replicate transaction
source The name of the database server that originated the transaction
threadId The identifier of the thread that processed this transaction
timestamp The value of the internal time stamp at the time that this ATSinstance was started
sequence A unique integer, incremented by ATS each time a transaction isspooled
Monitoring and Troubleshooting Enterprise Replication 8-5

About ATS File Information
About ATS File InformationThe first three characters in each line of the ATS spool file describe the type ofinformation for the line, as the following table defines.
Label Name Description
TXH Transactionheading
This line contains information from the transactionheader, including the sending server ID and the committime, the receiving server ID and the received time, andany Enterprise Replication, SQL, or ISAM error infor-mation for the transaction.
RRH Replicatedrow heading
This line contains header information from the replicatedrows, including the row number within the transaction,the group ID, the replicate ID (same as replicate group IDif replicate is not part of any replicate group), the database,owner, table name, and the database operation.
RRS Replicatedrow shadowcolumns
This line contains shadow column information from repli-cated rows, including the source server ID and the timewhen the row is updated on the source server. This line isprinted only if the replicate is defined with a conflict-resolution rule.
RRD Replicatedrow data
This line contains the list of replicated columns in the sameorder as in the SELECT statement in the define replicatecommand. Each column is separated by a ‘|’ anddisplayed in ASCII format.
When the spooling program encounters severe errors (forexample, cannot retrieve replicate id for the replicatedrow, unable to determine the replicated column’s type,size, or length), it displays this row data in hexadecimalformat. The spooling program also displays the row datain hexidecimal format if a row includes replicated UDTcolumns.
8-6 Guide to IBM Informix Enterprise Replication

BYTE and TEXT Information in ATS Files
BYTE and TEXT Information in ATS FilesWhen the information recorded in the ATS file includes BYTE or TEXT data,the replicated row data (RRD) information is reported, as the followingexamples show.
Example 1<1200, TEXT, PB 877(necromsv) 840338515(00/08/17 20:21:55)>
In this example:
■ 1200 is the size of the data.
■ TEXT is the data type (it is either BYTE or TEXT).
■ PB is the storage type (PB when the BYTE or TEXT is stored in thetablespace, BB for blobspace storage).
■ The next two fields are the server identifier and the time stamp forthe column if the conflict-resolution rule is defined for this replicateand the column is stored in a tablespace.
Example 2<500 (NoChange), TEXT, PB 877(necromsv) 840338478(00/08/17 20:21:18)>
In this example, (NoChange) after the 500 indicates that the TEXT data has asize of 500, but the data has not been changed on the source server. Thereforethe data is not sent from the source server.
Example 3<(Keep local blob),75400, BYTE, PB 877(necromsv) 840338515(00/08/1720:21:55)>”)
In this example, (Keep local blob) indicates that the replicated data for thiscolumn was not applied on the target table, but instead the local BYTE datawas kept. This usually happens when time-stamp conflict resolution isdefined and the local column has a time stamp greater than the replicatedcolumn.
Monitoring and Troubleshooting Enterprise Replication 8-7

Changed Column Information in ATS Files
Changed Column Information in ATS FilesIf you define a replicate to only replicate columns that changed, the RRDentry in the ATS and RIS files show a ? for the value of any columns that arenot available. For example:
RRD 427|amsterdam|?|?|?|?|?|?|?|?|?|?|?
For more information, see “Replicating Only Changed Columns” onpage 5-11).
BLOB and CLOB Information in ATS FilesIf a replicate includes one or more BLOB or CLOB columns, the RRD entry inthe ATS file displays the smart blob metadata (the in-row descriptor of thedata), not the smart blob itself, in hexadecimal format in the ATS file. See“UDT Information in ATS Files” for an example.
UDT Information in ATS FilesIf a replicate includes one or more UDT columns, the RRD entry in the ATS filedisplays the row data in hexadecimal format in the ATS file. This represen-tation includes a column number in the form Cnnn where nnn is the columnnumber. For example:
RRS C001 0000000a ^@RRS C002 394925cb ^@9I%ËRRD C003 00000016 ^@RRD C004 074b4d70 5d6f784a 00000000 00000000 ^@.KMp]oxJ
8-8 Guide to IBM Informix Enterprise Replication

Row Information Spooling Files
Row Information Spooling FilesRow Information Spooling logs the following types of information in RISfiles:
■ Individual aborted row errors
■ Replication exceptions (such as when a row is converted by Enter-prise Replication from insert to update, or from update to insert, andso on)
■ Special SPL routine return codes, as defined by the application (if anSPL routine is called to resolve a conflict)
Preparing to Use RISFailed transactions are not automatically recorded in RIS files.
To collect RIS information
1. Create a directory for Enterprise Replication to store RIS files.
If you have conflict resolution enabled, create the directory on allparticipating replication systems.
For more information, see “Creating ATS and RIS Directories” onpage 4-15.
2. When you define a server for Enterprise Replication, specify thelocation of the RIS directory you created in step 1.
To do this, include the --ris option with the cdr define servercommand.
If you do not specify an RIS directory:
■ Enterprise Replication stores the RIS files in the /tmp directory. ♦■ Enterprise Replication stores the RIS files in the \tmp directory
of the drive that contains %INFORMIXDIR%. ♦If the default directory does not exist, Enterprise Replication returnsan error.
For more information, see “Creating ATS and RIS Directories” onpage 4-15.
UNIX
WIN NT/2000
Monitoring and Troubleshooting Enterprise Replication 8-9

About RIS Filenames
3. When you define a replicate, specify that RIS is active.
To do this, include the --ris option with the cdr define replicatecommand.
For more information, see “Setting Up Error Logging” on page 5-11.
About RIS FilenamesThe RIS row information is written at the time that the data-synchronizationcomponent finishes processing the replicated row and can therefore alsoprovide the local row information. The RIS filename algorithm is analogousto the one that ATS uses, with the ats prefix replaced by ris. The RIS file thatcorresponds to the ATS file described in the previous section is, for example:
ris.g_beijing.g_amsterdam.D_2.000529_23:27:16.5
For more information, see “About ATS Filenames” on page 8-5.
8-10 Guide to IBM Informix Enterprise Replication

About RIS Filenames
In addition to the four types of records printed in ATS, the RIS file alsoincludes the following information.
Label Name Description
LRH Local-row header Indicates if the local row is found in the delete tableand not in the target table.
LRS Local-row shadowcolumns
Contains the server id and the time when the row isupdated on the target server. This line is printed onlyif the replicate is defined with a conflict-resolutionrule.
LRD Local-row data Contains the list of replicated columns extractedfrom the local row and displayed in the same orderas the replicated row data. Similar to the replicatedrow data, each column is separated by a ‘|’ andwritten in ASCII format.
When the spooling program encounters severeerrors (for example, cannot retrieve replicate id forthe replicated row, unable to determine the repli-cated column’s type, size, or length) or the tableincludes UDT columns (whether defined for repli-cation or not), it displays the replicated row data inhexadecimal format. In this case, the local row data isnot spooled.
Monitoring and Troubleshooting Enterprise Replication 8-11

BYTE and TEXT Information in RIS Files
BYTE and TEXT Information in RIS FilesWhen the information recorded in the RIS file includes BYTE or TEXT data, theRRD information is reported as the following examples show.
Example 1“<1200, TEXT, PB 877(necromsv) 840338515(00/08/17 20:21:55)>
In this example:
■ 1200 is the size of the TEXT data.
■ TEXT is the data type (it is either BYTE or TEXT).
■ PB is the storage type (PB for storage in the tablespace, BB forblobspace storage).
■ The next two fields are the server identifier and the time stamp forthe column if the conflict-resolution rule is defined for this replicateand the column is stored in a blobspace.
Example 2“<500 (NoChange), TEXT, PB 877(necromsv) 840338478(0000/08/17 20:21:18)>
In this example, (NoChange) after 500 indicates the TEXT data has size of 500but the data has not been changed on the source server. Therefore the data isnot sent from the source server.
Changed Column Information in RIS FilesSee “Changed Column Information in ATS Files” on page 8-8.
BLOB and CLOB Information in RIS FilesSee “BLOB and CLOB Information in ATS Files” on page 8-8.
UDT Information in RIS FilesSee “UDT Information in ATS Files” on page 8-8.
8-12 Guide to IBM Informix Enterprise Replication

Preventing Memory Queues from Overflowing
Preventing Memory Queues from OverflowingIn a well-tuned Enterprise Replication system, the send queue and receivequeue should not regularly overflow from memory to disk. However, if thequeues in memory fill, the transaction buffers are written (spooled) to disk.Spooled transactions consist of transaction records and row data. Spooled trans-action records are stored in the transaction tables in a single dbspace. Spooledrow data is stored in a single sbspace.
For more information, see “Setting Up Send and Receive Queue Spool Areas”on page 4-11.
The following situations can cause Enterprise Replication to spool to disk:
■ Receiving server is down or suspended.
■ Network connection is down.
If the receiving server or network connection is down or suspended,Enterprise Replication might spool transaction buffers to disk.
To check for a down server or network connection, run cdr list serveron a root server. This command shows all servers and their connec-tion status and state.
For more information, see “Viewing Replication Server Attributes”on page 6-3 and “cdr list server” on page A-45.
■ Replicate is suspended.
If a replicate is suspended, Enterprise Replication might spool trans-action buffers to disk.
To check for a suspended replicate, run cdr list replicate. This com-mand shows all replicates and their state.
For more information, see “Viewing Replicate Properties” onpage 6-7 and “cdr list replicate” on page A-39.
■ Enterprise Replication is replicating large transactions.
Enterprise Replication is optimized to handle small transactions effi-ciently. Very large transactions or batch jobs may force EnterpriseReplication into an exceptional processing path that results in spool-ing. Avoid replicating these types of transactions.
For more information, see “Large Transactions” on page 2-15.
Monitoring and Troubleshooting Enterprise Replication 8-13

Preventing Blockout Mode
■ Logical log files are too small or too few.
If the logical log files are too small or the number of logical log filesis too few, Enterprise Replication is more likely to spool transactionbuffers to disk.
To increase the size of the logical logs, see the chapter on logical logsin the Administrator’s Guide for Informix Dynamic Server. For moreinformation on configuring your logical log files for use with Enter-prise Replication, see “Logical Log Configuration Guidelines” onpage 4-10.
■ Server is overloaded.
If a server is low on resources, Enterprise Replication might not beable to hold all transactions replicating from a source server in mem-ory during processing, and the transactions spool to disk.
If this happens, check the system resources; in particular, check diskspeed, RAM, and CPU resources.
Preventing Blockout ModeIf the database server comes close to overwriting a logical log that EnterpriseReplication has not yet processed (log wrap), Enterprise Replication entersblockout mode. In blockout mode, user transactions are blocked and you seethe following error in the message log:
DDR Log Snooping - Catchup phase started, userthreads blocked
Blockout mode can occur if your Enterprise Replication system is regularlyspooling to disk. To prevent blockout mode, prevent Enterprise Replicationfrom spooling to disk. For information, see “Preventing Memory Queuesfrom Overflowing” on page 8-13.
If Enterprise Replication enters blockout mode, you can immediatelyincrease the size or number of the logical logs (see the chapter on logical logsin the Administrator’s Guide for Informix Dynamic Server) while you determinewhat situation is causing excessive spooling. You should also check to see ifthe Enterprise Replication dbspace or sbspace (for send and receive queuespooling) is running out of disk space (see “Monitoring Disk Usage for Sendand Receive Queue Spool” on page 8-15 and “Increasing the Sizes of StorageSpaces” on page 8-15).
8-14 Guide to IBM Informix Enterprise Replication

Monitoring Disk Usage for Send and Receive Queue Spool
Use onstat -g ddr to monitor the status of the Enterprise Replication databaselog reader. For more information, see “onstat -g ddr” on page C-4.
If the situation that is causing blockout mode is not resolved, you see thefollowing error in the message log:
WARNING: The replay position was overrun, data may not be replicated.
Once this occurs, you must manually resynchronize the source and targetdatabases. For more information, see “Resynchronizing Replication Servers”on page 5-17.
Monitoring Disk Usage for Send and Receive Queue SpoolYou should periodically monitor disk usage for the dbspace (specified byCDR_QHDR_DBSPACE configuration parameter) and the sbspace(CDR_QDATA_SBSPACE) that Enterprise Replication uses to spool thequeues to disk.
To check disk usage for:
■ dbspaces
Use onstat -d.
For more information, see the section on monitoring disk usage inthe Administrator’s Guide for Informix Dynamic Server and the utilitieschapter of the Informix Administrator’s Reference.
■ sbspaces
Use onstat -d or oncheck -cs,-cS, -ce, -pe, -ps, and -pS.
For more information, see the section on monitoring sbspaces in thePerformance Guide for Informix Dynamic Server and the utilities chapterof the Informix Administrator’s Reference.
Tip: When you use onstat -d to monitor disk usage, the S flag in the Flags columnindicates an sbspace. For each sbspace chunk, the first row displays information aboutthe whole sbspace and user-data area. The second row displays information about themetadata area.
Monitoring and Troubleshooting Enterprise Replication 8-15

Increasing the Sizes of Storage Spaces
Increasing the Sizes of Storage SpacesIf you notice that the Enterprise Replication dbspace or sbspace is runningout of disk space, you can increase the size of the space by adding chunks tothe space.
To add a chunk to a dbspace, use onspaces -a. For example, to add a 110kilobyte chunk with an offset of 0 to the er_dbspace dbspace, enter:
onspaces -a er_dbspace -p /dev/raw_dev2 -o 0 -s 110
To add a chunk to an sbspace, use the same onspaces command above,however you can specify more information about the chunk that you areadding. After you add a chunk to the sbspace, you must perform a level-0backup of the root dbspace and the sbspace.
For more information, see the sections on adding chunks to dbspaces andsbspaces in the Administrator’s Guide for Informix Extended Parallel Server andthe utilities chapter of the Informix Administrator’s Reference.
Recovering when Storage Spaces FillWhen the Enterprise Replication dbspace runs out of disk space, EnterpriseReplication raises an alarm and writes a message to the log. When thesbspace runs out of disk space, Enterprise Replication hangs. In either case,you must resolve the problem that is causing Enterprise Replication to spool(“Preventing Memory Queues from Overflowing” on page 8-13) or you mustallocate additional disk space (“Increasing the Sizes of Storage Spaces” onpage 8-15) before you can continue replication.
8-16 Guide to IBM Informix Enterprise Replication

Solving Common Configuration Problems
Solving Common Configuration ProblemsIf you experience problems setting up Enterprise Replication, check thefollowing:
■ Make sure that you created an sbspace for the row data and set theCDR_QDATA_SBSPACE in the ONCONFIG file.
For more information, see “Setting Up Send and Receive QueueSpool Areas” on page 4-11 and “CDR_QDATA_SBSPACE” onpage B-9.
■ Verify that the trusted environment is set up correctly.
For more information, see “Setting Up the Trusted Environment” onpage 4-5.
■ Verify that your SQLHOSTS file is set up properly on each serverparticipating in replication. You must set up database server groupsin the SQLHOSTS file.
For more information, see “Verifying SQLHOSTS” on page 4-5.
■ Verify the format of the SQLHOSTS file.
The network connection (not the shared memory connection) entryshould appear immediately after the database server group defini-tion. If the network connection does not appear immediately afterthe database server group definition, you might see the followingerror when you run cdr define server:
command failed -- unable to connect to server specified(5)
You might also see a message like the following in the message logfor the target server:
Reason: ASF connect error (-25592)
■ Make sure that the unique identifier for each database server (i= inthe options field of the SQLHOSTS information) is consistent acrossall nodes in the enterprise.
For more information, see “Database Server Groups on UNIX” onpage 4-6 and Appendix F, “SQLHOSTS Registry Key.”
■ Verify that the operating system times of the database servers thatparticipate in the replicate are synchronized.
For more information, see “Time Synchronization” on page 2-17.
Monitoring and Troubleshooting Enterprise Replication 8-17

Solving Common Configuration Problems
■ Make sure that the database server has adequate logical log diskspace. If the database server does not have enough logical log spaceat initialization, you will see the following error:
command failed -- fatal server error (100)
■ Check the $INFORMIXDIR/etc/buildsmi.xxx files to see if a problemoccurred when the databases server built the SMI tables.
■ Make sure that the databases on all database server instancesinvolved in replication are set to logging (unbuffered logging isrecommended).
For more information, see “Unbuffered Logging” on page 2-10.
■ For replicates that use any conflict-resolution rule except ignore,make sure that you define shadow columns (CRCOLS) for each tableinvolved in replication.
For more information, see “Preparing Tables for Conflict Resolution”on page 4-21.
■ If you defined a participant using SELECT * from table_name, makesure that the tables are identical on all database servers defined forthe replicate.
For more information, see “Defining Participants” on page 5-8 and“Participant Type” on page A-89.
■ Verify that each replicated column in a table on the source databaseserver has the same data type as the corresponding column on thetarget server.
Enterprise Replication does not support replicating a column withone data type to a column on another database server with a differentdata type.
The exception to this rule is cross-replication between simple largeobjects and smart large objects.
For more information, see “Enterprise Replication Data Types” onpage 2-19.
■ Verify that all tables defined in a replicate have one PRIMARY KEYconstraint.
For more information, see “Primary Key Constraint” on page 2-11,the Informix Guide to Database Design and Implementation and InformixGuide to SQL: Syntax.
8-18 Guide to IBM Informix Enterprise Replication

Enterprise Replication Event Alarms
Enterprise Replication Event AlarmsThe following table describes the alarms that are raised by Enterprise Repli-cation and the events that trigger the alarms. For more information onhandling event alarms, see the appendix on event alarms in the InformixAdministrator’s Reference.
Situation Level Message
Snoopy receives a bad buffer during a logread
ALRM_EMERGENCY s_cdr_err_logcurrupt
Snoopy sets DDR blockout (“PreventingBlockout Mode” on page 8-14)
ALRM_ATTENTION s_ddrblock
Snoopy unsets DDR blockout(“Preventing Blockout Mode” onpage 8-14)
ALRM_ATTENTION s_ddrunblock
Snoopy detects that the replay positionhas been overwritten (page 8-14)
ALRM_EMERGENCY s_cdr_replay_trounced
An RQM queue runs out of room to spool(“Recovering when Storage Spaces Fill”on page 8-16)
ALRM_EMERGENCY s_cdr_que_fullsendq
RQM cannot find the replicate in theglobal catalog for which it has atransaction
ALRM_ATTENTION s_cdr_badrepid
Unable to allocate memory whenanalyzing opaque UDTs incollections/rows
ALRM_INFO s_cdr_nomem
Datasync received transaction that wasaborted in first buffer, so there is nothingto spool to ATS/RIS
ALRM_INFO not yet assigned s_ message
Grouper was unable to apply an undo(rollback to savepoint) to a transaction
ALRM_ATTENTION s_cdr_undo_error_tx_skipped
(1 of 2)
Monitoring and Troubleshooting Enterprise Replication 8-19

Enterprise Replication Event Alarms
Grouper evaluator is aborting ALRM_EMERGENCY s_cdr_grp_abort
Grouper fanout is aborting ALRM_EMERGENCY s_cdr_grp_abort
Datasync is aborting ALRM_ATTENTION s_cdr_ds_abort
Situation Level Message
(2 of 2)
8-20 Guide to IBM Informix Enterprise Replication

III
AppendixesSect
ion
Appendix A Command-Line Utility Reference
Appendix B Configuration Parameter Reference
Appendix C onstat Command Reference
Appendix D SMI Table Reference
Appendix E Replication Examples
Appendix F SQLHOSTS Registry Key


AAppendix
Command-Line UtilityReference
The command-line utility (CLU) lets you configure and controlEnterprise Replication from the command line on your UNIX orWindows operating system.
This appendix covers the following topics:
■ Command Summary
■ Command Syntax
■ Interpreting the Command-Line Utility Syntax
Command SummaryThe following table shows the commands and the page wherethe command is documented.
Command Page
cdr change replicate A-4
cdr change replicateset A-6
cdr connect server A-9
cdr define replicate A-10
cdr define replicateset A-17
cdr define server A-20
(1 of 2)

Command Summary
cdr delete replicate A-25
cdr delete replicateset A-27
cdr delete server A-29
cdr disconnect server A-33
cdr error A-35
cdr finderr A-38
cdr list replicate A-39
cdr list replicateset A-43
cdr list server A-45
cdr modify replicate A-49
cdr modify replicateset A-54
cdr modify server A-56
cdr resume replicate A-59
cdr resume replicateset A-61
cdr resume server A-63
cdr start A-65
cdr start replicate A-67
cdr start replicateset A-69
cdr stop A-71
cdr stop replicate A-73
cdr stop replicateset A-75
cdr suspend replicate A-77
cdr suspend replicateset A-79
cdr suspend server A-81
Command Page
(2 of 2)
A-2 Guide to IBM Informix Enterprise Replication

Command Syntax
Command SyntaxThe next sections show the syntax for all the variations of the cdr commands.
Command-Line Utility Reference A-3

cdr change replicate
cdr change replicateThe cdr change replicate command allows you to modify an existingreplicate by adding or deleting one or more participants.
Syntax
The following table describes the options to cdr change replicate.
Element Purpose Restrictions Syntaxmodifier Specifies the rows and columns
to replicateSee “Considerations for theSELECT Statement” onpage A-90.
“ParticipantModifier” onpage A-90
participant Specifies the database server andtable for replication
The participant must exist. “Participant” onpage A-87
replicate Name of the replicate to change The replicate must exist. “Long Identifiers”on page A-86
cdr change replicate
replicate
Connect Optionp. A-87
--add
--delete participant
participant modifierreplicate
Options
Long Form Short Form Meaning
--add -a Add participants to a replicate.
--delete -d Remove participants from a replicate.
A-4 Guide to IBM Informix Enterprise Replication

cdr change replicate
UsageUse this command to add or delete a participant from a replicate. You candefine a replicate that has zero or one participants, but to be useful, a replicatemust have at least two participants.
Important: You cannot start and stop replicates that have no participants.
Important: Enterprise Replication adds the participant to the replicate in an inactivestate, regardless of the state of the replicate. To activate the new participant, run cdrstart replicate with the name of the server group. See “cdr start replicate” onpage A-67.
ExamplesThe following example adds two participants to the replicate named repl_1:db1@server1:antonio.table with the modifier select * from table1, anddb2@server2:carlo.table2 with the modifier select * from table2:
cdr change repl -a repl_1 \“db1@server1:antonio.table1” “select * from table1” \“db2@server2:carlo.table2” “select * from table2”
The following example removes the same two participants from replicaterepl_1:
cdr change repl -d repl_1 \“db1@server1:antonio.table1” \“db2@server2:carlo.table2”
See Also■ “cdr define replicate” on page A-10
■ “cdr delete replicate” on page A-25
■ “cdr list replicate” on page A-39
■ “cdr modify replicate” on page A-49
■ “cdr resume replicate” on page A-59
■ “cdr start replicate” on page A-67
■ “cdr stop replicate” on page A-73
■ “cdr suspend replicate” on page A-77
Command-Line Utility Reference A-5

cdr change replicateset
cdr change replicatesetThe cdr change replicateset (or cdr change replset) command changes areplicate set by adding or deleting replicates.
Syntax
The following table describes the options to cdr change replicateset
Element Purpose Restrictions Syntaxrepl_set Name of the replicate set to
changeThe replicate set must exist. “Long Identifiers”
on page A-86replicate Name of the replicates to add to
or delete from the setThe replicates must exist. “Long Identifiers”
on page A-86
cdr change replicateset replicaterepl_set
Connect Optionp. A-87
--add
--delete
Options
Long Form Short Form Meaning
--add -a Add replicates to a replicate set.
--delete -d Remove replicates from a replicate set.
A-6 Guide to IBM Informix Enterprise Replication

cdr change replicateset
UsageUse this command to add replicates to a replicate set or to remove replicatesfrom an exclusive or non-exclusive replicate set:
■ If you add a replicate to an exclusive replicate set, Enterprise Repli-cation changes the existing state and replication frequency settings ofthe replicate to the current properties of the exclusive replicate set.
If you remove a replicate from an exclusive replicate set, the replicateretains the properties of the replicate set at the time of removal (notthe state the replicate was in when it joined the exclusive replicateset).
When you add or remove a replicate from an exclusive replicate setthat is suspended (“Suspending a Replicate Set” on page 7-7) or thatis defined with a frequency interval (“Frequency Options” onpage A-91), Enterprise Replication transmits all the data in the queuefor the replicates in the replicate set up to the point when you addedor removed the replicate.
■ If you add or remove a replicate to a non-exclusive replicate set, thereplicate retains its individual state and replication frequencysettings.
ExamplesThe following example adds the replicates house and barn to replicate setbuilding_set:
cdr change replicateset -add building_set house barn
The following example removes the replicates teepee and wigwam fromreplicate set favorite_set:
cdr cha replset -del favorite_set teepee wigwam
See Also■ “cdr define replicate” on page A-10
■ “cdr delete replicateset” on page A-27
■ “cdr list replicateset” on page A-43
■ “cdr modify replicateset” on page A-54
Command-Line Utility Reference A-7

cdr change replicateset
■ “cdr resume replicateset” on page A-61
■ “cdr start replicateset” on page A-69
■ “cdr stop replicateset” on page A-75
■ “cdr suspend replicateset” on page A-79
A-8 Guide to IBM Informix Enterprise Replication

cdr connect server
cdr connect serverThe cdr connect server command reestablishes a connection to a databaseserver that has been disconnected with a cdr disconnect server command.
Syntax
UsageThe cdr connect server command reestablishes a connection to the serverserver_group.
See Also■ “cdr define server” on page A-20
■ “cdr delete server” on page A-29
■ “cdr disconnect server” on page A-33
■ “cdr list server” on page A-45
■ “cdr modify server” on page A-56
■ “cdr resume server” on page A-63
■ “cdr suspend server” on page A-81
cdr connect server
Connect Optionp. A-87
server_group
Element Purpose Restrictions Syntaxserver_group Name of database server group
to resumeThe database server group mustbe defined for replication and bedisconnected.
Command-Line Utility Reference A-9

cdr define replicate
cdr define replicateThe cdr define replicate command defines a replicate in the global catalog.
Syntax
UsageTo be useful, a replicate must include at least two participants. You can definea replicate that has only one participant, but before you can use that replicate,you must use cdr change replicate to add more participants.
Important: You cannot start and stop replicates that have no participants.
When you define a replicate, the replicate does not begin until you explicitlychange its state to active. For more information, see “cdr start replicate” onpage A-67.
Element Purpose Restrictions Syntaxmodifier Specifies the rows and columns
to replicateSee “Considerations for theSELECT Statement” onpage A-90.
“ParticipantModifier” onpage A-90
participant Name of a participant in thereplication
The participant must exist. “Participant” onpage A-87
replicate Name of the new replicate The replicate name must beunique.
“Long Identifiers”on page A-86
Connect Optionp. A-87
cdr define replicate participant modifierreplicateConflict Optionsp. A-11
Frequency Optionsp. A-91
Special Optionsp. A-13
Scope Optionsp. A-11
A-10 Guide to IBM Informix Enterprise Replication

cdr define replicate
Important: Do not create more than one replicate definition for each row and columnset of data to replicate. If the participant is the same, Enterprise Replication attemptsto insert duplicate values during replication.
Conflict OptionsThe conflict options specify how Enterprise Replication should resolveconflicts with data arriving at the database server.
Scope OptionsThe scope options specify how Enterprise Replication should handleproblems with data arriving at the database server.
Element Purpose Restrictions SyntaxSPL_routine SPL routine for conflict
resolutionThe SPL routine must exist. “Long Identifiers”
on page A-86
timestamp
--conflict=
Conflict Options Back to cdr define replicate p. A-10Back to cdr modify replicate p. A-49
,
ignore
SPL_routine
--optimize
SPL_routine
--optimize
Scope Options Back to cdr define replicate p. A-10Back to cdr modify replicate p. A-49
transaction
row--scope=
Command-Line Utility Reference A-11

cdr define replicate
For more information, see “Conflict Resolution” on page 3-11.
The following table describes the conflict and scope options.
Options
Long Form Short Form Meaning
--conflict= -C Specifies the rule that will be used for conflictresolution. The action that Enterprise Replicationtakes depends upon the scope.
--optimize -O Specifies that the SPL routine is optimized.
An optimized SPL routine is called only when acollision is detected and the row to be replicatedmeets the following two conditions:
■ It is from the same database server that lastupdated the local row on the target table.
■ It has a time stamp greater than or equal to that ofthe local row.
When this option is not present, Enterprise Repli-cation always calls the SPL routine defined for thereplicate when a conflict is detected.
--scope= -S= Specifies the scope that will be invoked when Enter-prise Replication encounters a problem with data ora conflict occurs.
For more information, see “Scope” on page 3-18.
If scope is not specified, the default scope istransaction.
When specifying the scope, you can abbreviate trans-action to tra.
A-12 Guide to IBM Informix Enterprise Replication

cdr define replicate
Special Options
The following table describes the special options to cdr define replicate.
Options
Long Form Short Form Meaning
--ats -A Activates aborted transaction spooling forreplicate transactions that fail to be applied tothe target database. For more information, see“Setting Up Error Logging” on page 5-11 andChapter 8, “Monitoring and TroubleshootingEnterprise Replication.”
--ris -R Activates row-information spooling forreplicate row data that fails conflict resolutionor encounters replication order problems. Formore information, see “Setting Up ErrorLogging” on page 5-11 and Chapter 8,“Monitoring and Troubleshooting EnterpriseReplication.”
(1 of 2)
Special Options Back to cdr define replicatep. A-10
--ats
-- ris
--floatieee
--floatcanon
--fullrow y
n
1
1
1
1
1
--firetrigger1
Command-Line Utility Reference A-13

cdr define replicate
--fullrow y | n -f y | n Specifies to (y) replicate the full row and enableupserts or (n) replicate only changed columnsand disable upserts. By default, EnterpriseReplication always replicates the entire rowand enables upserts. For more information, see“Replicating Only Changed Columns” onpage 5-11.
--floatieee -I Transfers replicated floating-point numbers inin either 32-bit (for SMALLFLOAT) or 64-bit(for FLOAT) IEEE floating-point format.Informix recommends that you use this optionfor all new replicate definitions. For more infor-mation, see “Using the IEEE Floating Point orCanonical Format” on page 5-13.
--floatcanon -F Transfers replicated floating-point numbers inmachine-independent decimal representation.This format is portable, but can lose accuracy.This format is provided for backward-compatibility only; Informix recommends thatyou use --floatieee for all new replicate defini-tions. For more information, see “Using theIEEE Floating Point or Canonical Format” onpage 5-13.
--firetrigger -T Specifies that the rows that this replicate insertsfire triggers at the destination. For more infor-mation, see “Enabling Triggers” on page 5-14.
Options
Long Form Short Form Meaning
(2 of 2)
A-14 Guide to IBM Informix Enterprise Replication

cdr define replicate
ExamplesThe following example illustrates the use of cdr define replicate:
1 cdr define repl --conflict=timestamp,sp1 \2 --scope=tran --ats --fullrow n --floatieee newrepl \3 “db1@iowa:antonio.table1” “select * from table1” \4 “db2@utah:carlo.table2” “select * from table2”
Line 1 of the example specifies a primary conflict-resolution rule of timestamp.If the primary rule fails, the SPL routine sp1 will be invoked to resolve theconflict. Because no database server is specified here (or on any later line), thecommand connects to the database server named in the INFORMIXSERVERenvironment variable.
Line 2 specifies that the replicate has a transaction scope for conflict-resolution scope and enables aborted transaction spooling. Enterprise Repli-cation will only replicate the rows that changed and uses the IEEE floatingpoint format to send floating-point numbers across dissimilar platforms. Thefinal item specifies the name of the replicate, newrepl.
Line 3 defines the first participant, “db1@iowa:antonio.table1”, with theselect statement “select * from table1”.
Line 4 defines a second participant, “db2@utah:carlo.table2”, with theselect statement “select * from table2”.
The next example is the same as the preceding example with the followingexceptions:
Line 1 instructs Enterprise Replication to use the global catalog on databaseserver ohio. Line 2 also specifies that the data should be replicated every fivehours.
1 cdr def repl -c ohio -C timestamp,sp1 \2 -S tran -A -e 5:00 -I newrepl \3 “db1@iowa:antonio.table1” “select * from table1” \4 “db2@utah:carlo.table2” “select * from table2”
See Also■ “cdr change replicate” on page A-4
■ “cdr delete replicate” on page A-25
■ “cdr list replicate” on page A-39
Command-Line Utility Reference A-15

cdr define replicate
■ “cdr modify replicate” on page A-49
■ “cdr resume replicate” on page A-59
■ “cdr start replicate” on page A-67
■ “cdr stop replicate” on page A-73
■ “cdr suspend replicate” on page A-77
A-16 Guide to IBM Informix Enterprise Replication

cdr define replicateset
cdr define replicatesetThe cdr define replicateset (or cdr define replset) command defines areplicate set. A replicate set is a collection of several replicates to be managedtogether.
Important: Enterprise Replication supports replicate sets for Informix DynamicServer Version 9.3 and later only. You cannot define or modify replicate sets toinclude replicates with participants that are Version 9.2 and earlier. In addition,replicate sets are different from and are incompatible with replicate groups (inVersion 9.2 and earlier).
Syntax
Element Purpose Restrictions Syntaxrepl_set Name of replicate set to create The name must be unique and
cannot be the same as a replicatename.
“Long Identifiers”on page A-86
replicate Name of a replicate to beincluded in the replicate set
The replicate must exist. “Long Identifiers”on page A-86
cdr define replicateset replicaterepl_set
1
1
Connect Optionp. A-87
Frequency Optionsp. A-91
--exclusive
Command-Line Utility Reference A-17

cdr define replicateset
The following table describes the option to cdr define replicateset.
UsageUse the cdr define replicateset command to define a replicate set.
Any valid replicate can be defined as part of a replicate set. A replicate canbelong to more than one non-exclusive replicate set, but to only one exclusivereplicate set. For details on the differences between exclusive and non-exclusive replicate sets, see “Creating Replicate Sets” on page 7-4.
When you create an exclusive replicate set, the state is initially set to active(see “Displaying Information About Replicates” on page A-40).
To create an exclusive replicate set and set the state to inactive
1. Create an empty replicate set.
2. Stop the replicate set.
3. Add replicates to the replicate set.
4. Set the state of the replicate set to active by running cdr startreplicateset.
Because individual replicates in a non-exclusive replicate set can havedifferent states, the non-exclusive replicate set itself has no state.
Important: Once you create an exclusive replicate set, you cannot change it to non-exclusive, and vice versa.
Options
Long Form Short Form Meaning
--exclusive -X Creates an exclusive replicate set. Formore information, see “ExclusiveReplicate Sets” on page 7-4.
A-18 Guide to IBM Informix Enterprise Replication

cdr define replicateset
ExampleThe following example connects to the default server and defines the non-exclusive replicate set accounts_set with replicate participants repl1, repl2,and repl3:
cdr def replset accounts_set repl1 repl2 repl3
The following example connects to the server olive and defines the exclusivereplicate set market_set with replicate participants basil and thyme:
cdr def replset --connect=olive --exclusive market_set basil thyme
See Also■ “cdr change replicateset” on page A-6
■ “cdr delete replicateset” on page A-27
■ “cdr list replicateset” on page A-43
■ “cdr modify replicateset” on page A-54
■ “cdr resume replicateset” on page A-61
■ “cdr start replicateset” on page A-69
■ “cdr stop replicateset” on page A-75
■ “cdr suspend replicateset” on page A-79
Command-Line Utility Reference A-19

cdr define server
cdr define serverThe cdr define server command defines a database server group and all itsmembers (that is, all database servers that are members of the database servergroup) for Enterprise Replication.
Syntax
Element Purpose Restrictions Syntaxserver_group Name of a database server group
to declare for EnterpriseReplication
Must be the name of an existingdatabase server group inSQLHOSTS. See “Setting upDatabase Server Groups” onpage 4-5.
sync_server Name of server to use forsynchronization for all subse-quent server definitions to anexisting replication system
Must be a server that is registeredwith Enterprise Replication. Theserver must be online.
“Long Identifiers”on page A-86
cdr define server
--nonroot
--connect server_group
Optionsp. A-22
server_group-- init
-- leaf
--sync=sync_server
A-20 Guide to IBM Informix Enterprise Replication
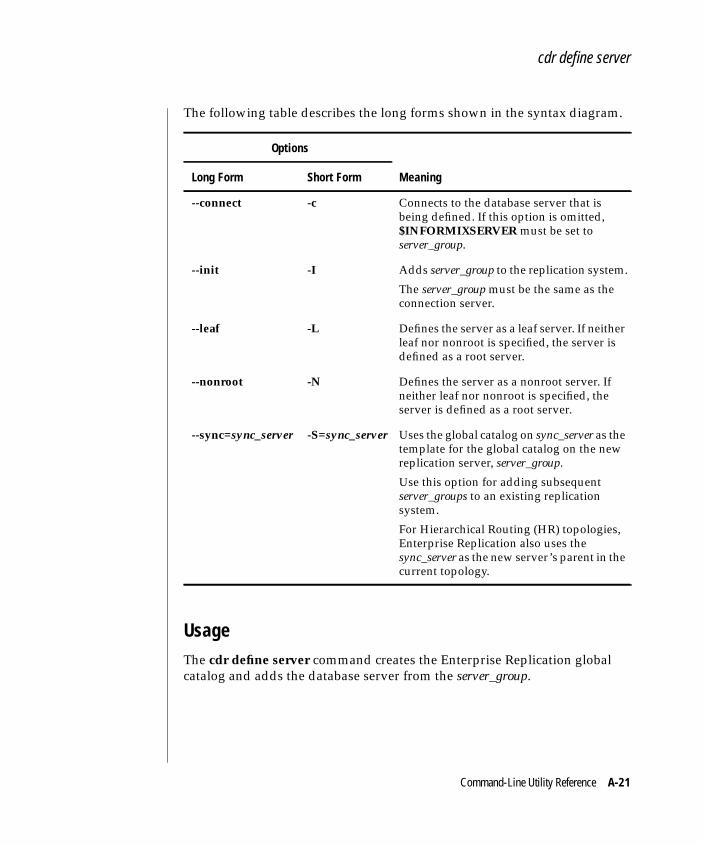
cdr define server
The following table describes the long forms shown in the syntax diagram.
UsageThe cdr define server command creates the Enterprise Replication globalcatalog and adds the database server from the server_group.
Options
Long Form Short Form Meaning
--connect -c Connects to the database server that isbeing defined. If this option is omitted,$INFORMIXSERVER must be set toserver_group.
--init -I Adds server_group to the replication system.
The server_group must be the same as theconnection server.
--leaf -L Defines the server as a leaf server. If neitherleaf nor nonroot is specified, the server isdefined as a root server.
--nonroot -N Defines the server as a nonroot server. Ifneither leaf nor nonroot is specified, theserver is defined as a root server.
--sync=sync_server -S=sync_server Uses the global catalog on sync_server as thetemplate for the global catalog on the newreplication server, server_group.
Use this option for adding subsequentserver_groups to an existing replicationsystem.
For Hierarchical Routing (HR) topologies,Enterprise Replication also uses thesync_server as the new server’s parent in thecurrent topology.
Command-Line Utility Reference A-21

cdr define server
OptionsThe options allow you to modify the default behavior of cdr define server.
Options Back to cdr define serverp. A-20
--ats=ats_dir
-- ris= ris_dir
-- idle= timeout
Element Purpose Restrictions Syntaxats_dir Name of the directory for
Aborted Transaction SpoolingMust be a full pathname. Thepath for the directory can be nolonger than 256 bytes.
Follows namingconventions on youroperating system
ris_dir Name of the directory for RowInformation Spooling
Must be a full pathname. Thepath for the directory can be nolonger than 256 characters.
Follows namingconventions on youroperating system
timeout Idle timeout for this replicationserver
Must be an integer number ofminutes. 0 indicates no timeout.The maximum value is 32,767.
Integer
A-22 Guide to IBM Informix Enterprise Replication

cdr define server
The following table describes the options to cdr define server.
ExamplesThe first example defines the first database server in a replicationenvironment. The command connects to the database server stan, initializesEnterprise Replication, and sets the idle time-out to 500 minutes. Theexample also specifies that any files that ATS generates will go into the/cdr/ats directory.
cdr define server --connect=stan --idle=500 --ats /cdr/ats \--init g_stan
Options
Long Form Short Form Meaning
--ats=ats_dir -A=ats_dir Activates aborted transaction spoolingfor replicate transactions that fail to beapplied to the target database. For moreinformation, see Chapter 8, “Monitoringand Troubleshooting EnterpriseReplication.”
--ris=ris_dir -R=ris_dir Activates row information spooling forreplicate row data that fails conflictresolution or encounters replication-order problems. For more information,see Chapter 8, “Monitoring and Trouble-shooting Enterprise Replication.”
--idle=timeout -i=timeout Causes an inactive connection to beterminated after timeout minutes. If time-out is 0, the connection does not time out.The default value is 0.
Command-Line Utility Reference A-23

cdr define server
The following example adds a database server to the replication environmentin the first example. The command connects to the database server oliver,initializes Enterprise Replication, synchronizes its catalogs with the catalogson the existing database server stan, and defines the database server oliverwith an idle time-out of 600 minutes. This command also specifies that anyfiles that ATS generates will go into the /cdr/ats directory.
cdr define server -c oliver -i 600 -A /cdr/ats -I -S \g_stan g_oliver
See Also■ “cdr connect server” on page A-9
■ “cdr delete server” on page A-29
■ “cdr disconnect server” on page A-33
■ “cdr list server” on page A-45
■ “cdr modify server” on page A-56
■ “cdr resume server” on page A-63
■ “cdr suspend server” on page A-81
A-24 Guide to IBM Informix Enterprise Replication

cdr delete replicate
cdr delete replicateThe cdr delete replicate command deletes a replicate from the global catalog.
Syntax
UsageThe cdr delete replicate command deletes the replicate repl_name from theglobal catalog. All replication data for the replicate is purged from the sendqueue at all participating database servers.
Warning: Avoid deleting a replicate and immediately re-creating it with the samename. If you re-create the objects immediately (before the operation finishes propa-gating to the other Enterprise Replication database servers in the network), youmight experience failures in the Enterprise Replication system at the time of theoperation or later. For more information, see “Operational Considerations” onpage 2-8.
ExampleThe following command connects to the default database server specified by$INFORMIXSERVER and deletes the replicate smile:
cdr del rep smile
cdr delete replicate
Connect Optionp. A-87
repl_name
Element Purpose Restrictions Syntaxrepl_name Name of the replicate to delete The replicate must exist. “Long Identifiers”
on page A-86
Command-Line Utility Reference A-25

cdr delete replicate
See Also■ “cdr change replicate” on page A-4
■ “cdr define replicate” on page A-10
■ “cdr list replicate” on page A-39
■ “cdr modify replicate” on page A-49
■ “cdr resume replicate” on page A-59
■ “cdr start replicate” on page A-67
■ “cdr stop replicate” on page A-73
■ “cdr suspend replicate” on page A-77
A-26 Guide to IBM Informix Enterprise Replication

cdr delete replicateset
cdr delete replicatesetThe cdr delete replicateset (or cdr delete replset) command deletes areplicate set.
Syntax
UsageThe cdr delete replicateset command deletes the exclusive or non-exclusivereplicate set repl_set from the global catalog.
The cdr delete replicateset command does not affect the replicates orassociated data. When a replicate set is deleted, the individual replicateswithin the replicate set are unchanged.
Warning: Do not delete time-based exclusive replicate sets. Doing so might result ininconsistent data.
Warning: Avoid deleting a replicate set and immediately re-creating it with the samename. If you re-create the objects immediately (before the operation finishes propa-gating to the other Enterprise Replication database servers in the network), youmight experience failures in the Enterprise Replication system at the time of theoperation or later. For more information, see “Operational Considerations” onpage 2-8.
cdr delete replicateset
Connect Optionp. A-87
repl_set
Element Purpose Restrictions Syntaxrepl_set Name of replicate set to delete The replicate set must exist. “Long Identifiers”
on page A-86
Command-Line Utility Reference A-27

cdr delete replicateset
ExampleThe following example connects to the default database server and deletesthe replicate set accounts_set:
cdr del replset accounts_set
See Also■ “cdr change replicateset” on page A-6
■ “cdr define replicate” on page A-10
■ “cdr list replicateset” on page A-43
■ “cdr modify replicateset” on page A-54
■ “cdr resume replicateset” on page A-61
■ “cdr start replicateset” on page A-69
■ “cdr stop replicateset” on page A-75
■ “cdr suspend replicateset” on page A-79
A-28 Guide to IBM Informix Enterprise Replication

cdr delete server
cdr delete serverThe cdr delete server command deletes a database server from the globalcatalog.
Syntax
UsageThe cdr delete server command deletes the database server in server_groupfrom the global catalog, removes the database server from all participatingreplicates, and purges all replication data from the send queues for thespecified database server. The command shuts down Enterprise Replicationon the database server and removes the global catalog from the databaseserver.
When you delete an Enterprise Replication server, you must issue the cdrdelete server command twice: once on the server being deleted and once onanother server in the enterprise. The first cdr delete server removes theEnterprise Replication server from the local global catalog and removes theEnterprise Replication connection to other hosts. The second cdr deleteserver removes the Enterprise Replication server from the other replicationservers in the system. For more information, see the “Examples” onpage A-30.
cdr delete server
Connect Optionp. A-87
server_group
Element Purpose Restrictions Syntaxserver_group Name of database server group
to remove from the global catalogThe database server group mustbe currently defined in Enter-prise Replication.
Command-Line Utility Reference A-29

cdr delete server
You can issue the cdr delete server command from any replication server.The only limitation is that you cannot delete a server with children. You mustdelete the children of a server before deleting the parent server.
You cannot delete a server from the enterprise if it is stopped. To delete aserver with cdr delete server, you must issue a cdr start command first.
Warning: Avoid deleting a replication server and immediately re-creating it with thesame name. If you re-create the objects immediately (before the operation finishespropagating to the other Enterprise Replication database servers in the network), youmight experience failures in the Enterprise Replication system at the time of theoperation or later. For more information, see “Operational Considerations” onpage 2-8.
ExamplesThis example removes the server g_italy from the replication environment.(assume that you issue the commands from the replication server g_usa):
cdr delete server g_italycdr delete server -c italy g_italy
The first command performs the following actions:
■ Removes g_italy from the usa global catalog
■ Drops the connection from g_usa to g_italy
■ Removes g_italy from all participating replicates
■ Purges the replication data destined for g_italy from send queues
■ Broadcasts this delete server command to all other servers (otherthan g_italy) so that they can perform the same actions
The second command connects to server italy, and removes Enterprise Repli-cation from italy. That is, it removes the syscdr database and removes orstops other components of Enterprise Replication.
A-30 Guide to IBM Informix Enterprise Replication

cdr delete server
Figure A-1 shows a replication environment with three replication servers,g_usa, g_italy, and g_japan.
To remove Enterprise Replication from this environment, issue the followingcommands from the computer where the usa replication server resides.
To remove Enterprise Replication from this environment
1. Run:cdr delete server g_italy
This command removes connections between the italy replicationserver and all other servers in the replication system (usa and japan)and removes any queued data.
2. Run:cdr delete server -c italy g_italy
This command removes all replication information (including thesyscdr database) from the italy database server.
3. Run:cdr delete server g_japancdr delete server -c g_japan
These commands remove the japan replication server.
4. Run:cdr delete server g_usa
This command removes the replication information from the usareplication server itself.
Figure A-1Three Replication Servers
g_italy
g_japan
g_usa
Command-Line Utility Reference A-31

cdr delete server
See Also■ “cdr connect server” on page A-9
■ “cdr define server” on page A-20
■ “cdr disconnect server” on page A-33
■ “cdr list server” on page A-45
■ “cdr modify server” on page A-56
■ “cdr resume server” on page A-63
■ “cdr suspend server” on page A-81
A-32 Guide to IBM Informix Enterprise Replication

cdr disconnect server
cdr disconnect serverThe cdr disconnect server command stops a server connection.
Syntax
UsageThe cdr disconnect server command drops the connection (for example, fora dialup line) between server_group and the server specified in the --connectoption. If the --connect option is omitted, the command drops the connectionbetween server_group and the default database server ($INFORMIXSERVER).
ExampleThe following example drops the connection between the default databaseserver ($INFORMIXSERVER) and the server group g_store1:
cdr disconnect server g_store1
See Also■ “cdr connect server” on page A-9
■ “cdr define server” on page A-20
■ “cdr delete server” on page A-29
■ “cdr list server” on page A-45
cdr disconnect server
Connect Optionp. A-87
server_group
Element Purpose Restrictions Syntaxserver_group Name of the database server
group to disconnectThe database server group mustbe currently active in EnterpriseReplication.
Command-Line Utility Reference A-33

cdr disconnect server
■ “cdr modify server” on page A-56
■ “cdr resume server” on page A-63
■ “cdr suspend server” on page A-81
A-34 Guide to IBM Informix Enterprise Replication

cdr error
cdr errorThe cdr error command manages the error table and provides convenientdisplays of errors.
Syntax
Element Purpose Restrictions Syntaxerr_server Name of database server group
that holds the error tableThe server must be registered forEnterprise Replication.
“Long Identifiers” onpage A-86
first Start date for a range You must provide a valid dateand time.
“Time of Day” onpage A-92
last Ending date for range You must provide a later dateand time than first.
“Time of Day” onpage A-92
seqno Sequence number of a specificerror
You must provide the number ofan error in the error table.
Integer
cdr error
--nomark
Connect Optionp. A-87
--all
-- follow
--all=
--zap
,first
--prune "" last
--seq=err_server:seqno
Command-Line Utility Reference A-35

cdr error
The following table describes the options to cdr error:
UsageThe cdr error command allows you to examine replication errors on anyreplication server. Sometimes a command succeeds on the server on which itis executed, but fails on one of the remote servers. For example, if you executecdr define replicate on server1 but the table name is misspelled on server2,the command succeeds on server1 and appears to have completed success-fully. You can use cdr error -c server2 to see why replication is failing.
The cdr error command also allows you to administer the cdr error tableremotely. The reviewed flag lets you watch for new errors while keeping theold errors in the table. For example, you could run cdr error periodically andappend the output to a file.
Options
Long Form Short Form Meaning
(no optionsspecified)
Print the current list of errors. After the errors havebeen printed, mark them as reviewed. EnterpriseReplication does not display errors marked asreviewed.
--all -a When used with the -move option, move the errortable to dbspace on all defined servers. Otherwise,print all errors, including those already reviewed.
--follow -f Continuously monitor the error table.
--nomark -n Do not mark errors as reviewed.
--prune -p Prune the error table to those times in the range fromfirst to last. If first is omitted, then all errors earlierthan last are removed.
--seq -s Remove the (single) error specified by server:seqnofrom the error table.
--zap -z Remove all errors from the error table.
A-36 Guide to IBM Informix Enterprise Replication

cdr error
ExamplesThe following command displays the current list of errors on database serverhill:
cdr error --connect=hill
After the errors are displayed, Enterprise Replication marks the errors asreviewed.
The following command connects to the database server lake and removesfrom the error table all errors that occurred before the time when thecommand was issued:
cdr error -c lake --zap
The following command deletes all errors from the error table that occurredat or before 2:56 in the afternoon on May 1, 2000:
cdr error -p “2000-05-01 14:56:00”
The following command deletes all errors from the error table that occurredat or after noon on May 1, 2000 and before or at 2:56 in the afternoon onMay 1, 2000:
cdr error -p “2000-05-01 14:56:00,2000-05-01 12:00:00”
Command-Line Utility Reference A-37

cdr finderr
cdr finderrThe cdr finderr command looks up a specific Enterprise Replication errornumber and displays the corresponding error text.
Syntax
You can also view the Enterprise Replication error messages in the file$INFORMIXDIR/incl/esql/cdrerr.h.
cdr finderr ER_error_number
Element Purpose Restrictions Syntaxerror_number Enterprise Replication error
number to look up.Must be a positive integer.
A-38 Guide to IBM Informix Enterprise Replication

cdr list replicate
cdr list replicateThe cdr list replicate command displays information about the replicates onthe current server.
Syntax
UsageThe cdr list replicate command displays information about replicates. If noreplicates are named, the command lists all replicates on the current server.If one or more replicates are named, the command displays detailed infor-mation about those replicates.
You do not need to be user informix to use this command.
ExampleThe following example displays a list of the replicates on the current server:
cdr list replicate
cdr list replicate
Connect Optionp. A-87
replicate
Element Purpose Restrictions Syntaxreplicate Name of the replicates The replicates must exist. “Long Identifiers”
on page A-86
Command-Line Utility Reference A-39

cdr list replicate
The output from the previous command might be the following:
CURRENTLY DEFINED REPLICATES---------------------------------------------REPLICATE: Repl1STATE: InactiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: bank:joe.tellerOPTIONS: row,ris,ats
REPLICATE: Repl2STATE: InactiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: bank:joe.accountOPTIONS: row,ris,ats
Displaying Information About Replicates
The STATE field can include the following values.
Value Description
Active Specifies that Enterprise Replication captures data from the logicallog and transmits it to participants
DefinitionFailed
Indicates that the replication definition failed on a peer server
Inactive Specifies that no database changes are captured, transmitted, orprocessed
Pending Indicates that a cdr delete replicate command has been issued andthe replicate is waiting for acknowledgement from the participants
Quiescent Specifies that no database changes are captured for the replicate orparticipant
Suspended Specifies that the replicate captures and accumulates databasechanges but does not transmit any of the captured data
A-40 Guide to IBM Informix Enterprise Replication

cdr list replicate
The CONFLICT field can include the following values.
The FREQUENCY field can include the following values.
The following example specifies the names of replicate:
cdr list repl Repl1
The following output might result from the previous command:
Value Description
Ignore Specifies that the replicate uses the ignore conflict-resolutionrule
Timestamp Specifies that the replicate uses the time stamp conflict-resolution rule
Procedure Specifies that the replicate uses an SPL routine as theconflict-resolution rule
Value Description
immediate Specifies that replication occurs immediately
every hh:mm Specifies that replications occur at intervals (for example,13:20 specifies every thirteen hours and 20 minutes)
at day.hh:mm Specifies that replications occur at a particular time on aparticular day (for example, 15.18:30 specifies on the 15thday of the month at 6:30 P.M.)
REPLICATE TABLE SELECT
------------------------------------------------------------
Repl1 bank@g_newyork:joe.teller select * from joe.teller
Repl1 bank@g_sanfrancisco:joe.teller select * from joe.teller
Repl1 bank@g_portland:joe.teller select * from joe.teller
Command-Line Utility Reference A-41

cdr list replicate
See Also■ “cdr change replicate” on page A-4
■ “cdr define replicate” on page A-10
■ “cdr delete replicate” on page A-25
■ “cdr modify replicate” on page A-49
■ “cdr resume replicate” on page A-59
■ “cdr start replicate” on page A-67
■ “cdr stop replicate” on page A-73
■ “cdr suspend replicate” on page A-77
A-42 Guide to IBM Informix Enterprise Replication

cdr list replicateset
cdr list replicatesetThe cdr list replicateset (or cdr list replset) command displays informationabout the replication sets defined on the current server.
Syntax
UsageThe cdr list replicateset command displays a list of the replicate sets that arecurrently defined. To list the information about each of the replicates withinthe replicate set, use cdr list replicateset repl_set. For more information, see“Displaying Information About Replicates” on page A-40.
You do not need to be user informix to use this command.
ExamplesThe following example displays a list of the replicate sets on the currentserver:
cdr list replicateset
The following output might result from the previous command:
REPLSET PARTICIPANTS
--------------------------------------------------
g1 [Exclusive] Repl1, Repl4
g2 Repl2
g3 Repl3
cdr list replicateset
Connect Optionp. A-87
repl_set
Command-Line Utility Reference A-43

cdr list replicateset
This example displays information for all the replicates in the replicate setsales_set:
cdr list replset g1
The following output might result from the previous command:
REPLICATE SET:g1 [Exclusive]CURRENTLY DEFINED REPLICATES----------------------------------------------------------------------REPLICATE: Repl1STATE: InactiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: bank:arthur.accountOPTIONS: row,ris,ats
REPLICATE: Repl4STATE: InactiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: bank:arthur.tellerOPTIONS: row,ris,ats
See Also■ “cdr change replicateset” on page A-6
■ “cdr define replicate” on page A-10
■ “cdr delete replicateset” on page A-27
■ “cdr modify replicateset” on page A-54
■ “cdr resume replicateset” on page A-61
■ “cdr start replicateset” on page A-69
■ “cdr stop replicateset” on page A-75
■ “cdr suspend replicateset” on page A-79
A-44 Guide to IBM Informix Enterprise Replication

cdr list server
cdr list serverThe cdr list server command displays a list of the Enterprise Replicationservers that are visible to the current server.
Syntax
UsageThe cdr list server command displays information about servers. You do notneed to be user informix to use this command.
Listing All Enterprise Replication Servers
When no server-group name is given, the cdr list server command lists alldatabase server groups that are visible to the current replication server.
For example, cdr list server might give the following output:
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED--------------------------------------------------------------g_newyork 1 Active Local 0g_portland 2 Active Connected 0 Mar 19 13:48:44g_sanfrancisco 3 Active Connected 0 Mar 19 13:48:40
The SERVER and ID Columns
The SERVER and ID columns display the name and unique identifier of theEnterprise Replication server group.
cdr list server
Connect Optionp. A-87
server_group
Command-Line Utility Reference A-45

cdr list server
The STATE Column
The STATE column can have the following values:
The STATUS Column
The STATUS column can have the following values:
The QUEUE Column
The QUEUE column displays the size of the queue for the server group.
Active Indicates that the server is active and replicating data
Deleted Indicates that the server has been deleted and that it is notcapturing or delivering data and the queues are being drained
Quiescent Indicates that the server is in the process of being defined
Suspended Indicates that delivery of replication data to the server is suspended
Connected Indicates that the server connection is up
Connecting Indicates that the server is attempting to connect
Disconnect Indicates that the server connection is down in response to anexplicit disconnect
Dropped Indicates that the server connection is down due to a network errorbecause the server is unavailable
Error Indicates that an error has occurred (check the log and contactcustomer support, if necessary)
Local Identifies that this server is the local server as opposed to a remoteserver
Timeout Indicates that the connection is down due to an idle timeout
A-46 Guide to IBM Informix Enterprise Replication

cdr list server
The CONNECTION CHANGED Column
The CONNECTION CHANGED column displays the most recent time that thestatus of the server connection was changed.
Displaying Details about a Single Replication Server
When the cdr list server command includes the name of a database servergroup, the command displays the attributes of that database server. Forexample, cdr list server g_usa might give the following output:
NAME ID ATTRIBUTES-----------------------------------------------------g_usa 3 timeout=15,atsdir=/w/ats risdir=/w/ris
ExamplesIn Figure A-2 and in the following examples, usa and italy are root servers,denver and boston are nonroot servers, and miami is a leaf server. The usaserver is the parent of denver and boston, and boston is the parent of miami.
Figure A-2cdr list server
example
bostondenver
miami
usa italy
Command-Line Utility Reference A-47

cdr list server
The example is created by running the following commands:
cdr list server g_usag_usa 1 timeout=15 hub
cdr list server -c denver g_denverg_denver 27 root=g_usa
cdr list server -c italy g_denverg_denver 27 root=g_usa forward=g_usa
cdr list server g_miamig_miami 4 root=g_boston leaf
See Also■ “cdr connect server” on page A-9
■ “cdr define server” on page A-20
■ “cdr delete server” on page A-29
■ “cdr disconnect server” on page A-33
■ “cdr modify server” on page A-56
■ “cdr resume server” on page A-63
■ “cdr start” on page A-65
■ “cdr suspend server” on page A-81
A-48 Guide to IBM Informix Enterprise Replication

cdr modify replicate
cdr modify replicateThe cdr modify replicate command modifies replicate attributes.
Syntax
UsageThe cdr modify replicate command modifies the attributes of a replicate orof one or more participants in the replicate. You can also change the mode ofa participant. If the command does not specify participants, the changesapply to all participants in the replicate.
For attribute information, see “cdr define replicate” on page A-10.
To add or delete a participant, see “cdr change replicate” on page A-4.
Element Purpose Restrictions Syntaxparticipant Name of a participant in the
replicationThe participant must be amember of the replicate.
“Participant” onpage A-87
replicate Name of the replicate to modify The replicate name must exist. “Long Identifiers”on page A-86
cdr modify replicate
Connect Optionp. A-87
participant
replicate
FrequencyOptions p. A-91
Special Optionsp. A-51
Conflict Optionsp. A-11
Scope Optionsp. A-11
1
1
1
Command-Line Utility Reference A-49

cdr modify replicate
Important: If you change the conflict-resolution rule with cdr modify replicate,you must also explicitly state SCOPE parameter, even if the SCOPE value does notchange.
Restrictions
The attributes for cdr modify replicate are the same as the attributes for cdrdefine replicate, with the following exceptions:
■ You cannot change the machine-independent decimal representation(--floatcanon) or IEEE floating point (--floatieee) formats.
■ You cannot change the conflict resolution from ignore to a non-ignoreoption (time stamp, SPL routine, or time stamp and SPL routine).You cannot change a non-ignore conflict resolution option to ignore.
However, you can change from time stamp resolution to SPL routineresolution or from SPL routine resolution to time stamp.
■ The --ats, --ris, --firetrigger, and --fullrow options require a yes (y) orno (n) argument.
A-50 Guide to IBM Informix Enterprise Replication

cdr modify replicate
Special Options
The following table describes the special options to cdr modify replicate. Formore information on these options, see “Special Options” on page A-13.
Options
Long Form Short Form Meaning
--ats y | n -A y | n Activate (y) or deactivate (n) aborted-trans-action spooling for replicate transactions thatfail to be applied to the target database.
--ris y | n -R y | n Activate (y) or deactivate (n) row-informationspooling for replicate row data that fails conflictresolution or encounters replication-orderproblems.
(1 of 2)
y--firetrigger
Special Options Back to cdr modify replicatep. A-49
n
y
n
y
n
-- ris
--ats
y
n
-- fullrow
Command-Line Utility Reference A-51

cdr modify replicate
ExamplesThe following example modifies the frequency attributes of replicate smile toreplicate every five hours:
cdr modify repl -every=300 smile
The following example modifies the frequency attributes of replicate smile toreplicate daily at 1:00 A.M.:
cdr modify repl -a 01:00 smile
The following example modifies the frequency attributes of replicate smile toreplicate on the last day of every month at 5:00 A.M., to generate ATS files, andnot to fire triggers:
cdr modify repl -a L.5:00 -A y -T n smile
The following example changes the mode of the first participant listed toreceive-only and the mode of the second to primary.
cdr mod repl smile “R db1@server1:antonio.table1” \ “P db2@server2:carlo.table2”
See Also■ “cdr change replicate” on page A-4
■ “cdr define replicate” on page A-10
■ “cdr delete replicate” on page A-25
■ “cdr list replicate” on page A-39
■ “cdr resume replicate” on page A-59
--firetrigger y | n -T y | n Cause the rows inserted by this replicate to fire(y) or not fire (n) triggers at the destination.
--fullrow y | n -f y | n Specifies to (y) replicate the full row and enableupserts (default) or (n) replicate only changedcolumns and disable upserts.
Options
Long Form Short Form Meaning
(2 of 2)
A-52 Guide to IBM Informix Enterprise Replication

cdr modify replicate
■ “cdr start replicate” on page A-67
■ “cdr stop replicate” on page A-73
■ “cdr suspend replicate” on page A-77
Command-Line Utility Reference A-53

cdr modify replicateset
cdr modify replicatesetThe cdr modify replicateset (or cdr modify replset) command modifies allthe replicates in a replicate set.
Syntax
UsageThe cdr modify replicateset command modifies the attributes of all the repli-cates in the replicate set repl_set. To add or delete replicates from a replicateset, use the cdr change replicateset command (“cdr change replicateset” onpage A-6).
Important: Once you create a replicateset, you cannot change it from exclusive tonon-exclusive or vice versa.
ExampleThe following example connects to the default server ($INFORMIXSERVER)and modifies the replicate set sales_set to process replication data everyhour:
cdr mod replset --every 60 sales_set
Element Purpose Restrictions Syntaxrepl_set Name of replicate set to modify The replicate set must exist. “Long Identifiers”
on page A-86
cdr modify replicateset repl_set
Connect Optionp. A-87
Frequency Optionsp. A-91
A-54 Guide to IBM Informix Enterprise Replication

cdr modify replicateset
See Also■ “cdr change replicateset” on page A-6
■ “cdr define replicate” on page A-10
■ “cdr delete replicateset” on page A-27
■ “cdr list replicateset” on page A-43
■ “cdr resume replicateset” on page A-61
■ “cdr start replicateset” on page A-69
■ “cdr stop replicateset” on page A-75
■ “cdr suspend replicateset” on page A-79
Command-Line Utility Reference A-55

cdr modify server
cdr modify serverThe cdr modify server command modifies the Enterprise Replicationattributes of a database server.
Syntax
Element Purpose Restrictions Syntaxserver_group Name of a database server group
to modifyThe database server group mustbe defined in EnterpriseReplication.
interval Idle time-out for this server The value must be an integer>=0.0 = no timeout.
Integer number ofminutes.
ats_dir Name of Aborted TransactionSpooling directory
The directory must be a fullpathname.
Directory name onyour operatingsystem.
ris_dir Name of the Row InformationSpooling directory
The directory must be a fullpathname.
Directory name onyour operatingsystem.
Connect Optionp. A-87
-- idle= interval
cdr modify server server_group
receive-only
primary--mode
-- ris=ris_dir
--ats=ats_dir
A-56 Guide to IBM Informix Enterprise Replication

cdr modify server
UsageThe cdr modify server command modifies the replication serverserver_group.
The following table describes the options to cdr modify server.
ExamplesThe following example connects to the database server paris and modifiesthe idle time-out of server group g_rome to 10 minutes. ATS files go into thedirectory /cdr/atsdir.
cdr modify server -c paris -i 10 -A /cdr/atsdir g_rome
The following example connects to the default database server and sets themodes of all participants on g_geometrix to primary:
cdr mod ser -m primary g_geometrix
Options
Long Form Short Form Meaning
--idle -i Causes an inactive connection to be terminated afteridle time
--mode -m Changes the mode of all replicates using this serverto primary (p) or to receive-only (r)
--ats -A Activates aborted-transaction spooling for replicatetransactions that fail to be applied to the targetdatabase
For more information, see Chapter 8, “Monitoringand Troubleshooting Enterprise Replication.”
--ris -R Activates row-information spooling for replicate-row data that fails conflict resolution or encountersreplication-order problems
For more information, see Chapter 8, “Monitoringand Troubleshooting Enterprise Replication.”
Command-Line Utility Reference A-57

cdr modify server
See Also■ “cdr connect server” on page A-9
■ “cdr define server” on page A-20
■ “cdr delete server” on page A-29
■ “cdr disconnect server” on page A-33
■ “cdr list server” on page A-45
■ “cdr resume server” on page A-63
■ “cdr suspend server” on page A-81
A-58 Guide to IBM Informix Enterprise Replication

cdr resume replicate
cdr resume replicateThe cdr resume replicate command resumes delivery of replication data.
Syntax
UsageThe cdr resume replicate command causes all participants in the replicaterepl_name to enter the active state.
For more information on replicate states, refer to “The STATE Column” onpage A-46.
Important: If a replicate belongs to an exclusive replicate set (“Exclusive ReplicateSets” on page 7-4), you cannot run cdr resume replicate to resume that individualreplicate. You must use cdr resume replicateset to resume all replicates in theexclusive replicate set.
If a replicate belongs to a non-exclusive replicate set, you can resume the individualreplicates in the set.
ExampleThe following example connects to the default database server($INFORMIXSERVER) and resumes the replicate smile:
cdr res repl smile
cdr resume replicate
Connect Optionp. A-87
repl_name
Element Purpose Restrictions Syntaxrepl_name Name of the replicate to change
to active state.The replicate must be suspended. “Long Identifiers”
on page A-86
Command-Line Utility Reference A-59

cdr resume replicate
See Also■ “cdr change replicate” on page A-4
■ “cdr define replicate” on page A-10
■ “cdr delete replicate” on page A-25
■ “cdr list replicate” on page A-39
■ “cdr modify replicate” on page A-49
■ “cdr start replicate” on page A-67
■ “cdr stop replicate” on page A-73
■ “cdr suspend replicate” on page A-77
A-60 Guide to IBM Informix Enterprise Replication

cdr resume replicateset
cdr resume replicatesetThe cdr resume replicateset (or cdr resume replset) command resumesdelivery of replication data for all the replicates in a replicate set.
Syntax
UsageThe cdr resume replicateset command causes all replicates contained in thereplicate set repl_set to enter the active state for all participants.
Important: If not all the replicates in a non-exclusive replicate set are suspended, thecdr resume replicateset command displays a warning and only resumes the repli-cates that are currently suspended.
For more information on replicate states, refer to “The STATE Column” onpage A-46.
ExampleThe following example connects to the default database server($INFORMIXSERVER) and resumes the replicate set accounts_set:
cdr res replset accounts_set
cdr resume replicateset
Connect Optionp. A-87
repl_set
Element Purpose Restrictions Syntaxrepl_set Name of replicate set to resume None “Long Identifiers”
on page A-86
Command-Line Utility Reference A-61

cdr resume replicateset
See Also■ “cdr change replicateset” on page A-6
■ “cdr define replicate” on page A-10
■ “cdr delete replicateset” on page A-27
■ “cdr list replicateset” on page A-43
■ “cdr modify replicateset” on page A-54
■ “cdr start replicateset” on page A-69
■ “cdr stop replicateset” on page A-75
■ “cdr suspend replicateset” on page A-79
A-62 Guide to IBM Informix Enterprise Replication

cdr resume server
cdr resume serverThe cdr resume server command resumes delivery of replication data to asuspended database server.
Syntax
UsageThe cdr resume server command resumes delivery of replication data to theto_server_group database server from the database servers included in thefrom_server_group list. If the from_server_group list is omitted, the commandresumes replication of data from all database servers participating in theEnterprise Replication system to the to_server_group. Replication data musthave previously been suspended to the server with the cdr suspend servercommand (“cdr suspend server” on page A-81).
Element Purpose Restrictions Syntaxto_server_group Name of database server
group to which to resumedelivery of replication data
The database server group mustbe currently active in EnterpriseReplication.
from_server_group Name of the database servergroup from which to resumesending data toto_server_group
The database server group mustbe currently active in EnterpriseReplication.
Connect Optionp. A-87
cdr resume server to_server_group
from_server_group
Command-Line Utility Reference A-63

cdr resume server
ExampleThe following example connects to the default server ($INFORMIXSERVER)and resumes replication of data to the server g_iowa from the servers g_ohioand g_utah:
cdr sus serv g_iowa g_ohio g_utah
See Also■ “cdr connect server” on page A-9
■ “cdr define server” on page A-20
■ “cdr delete server” on page A-29
■ “cdr disconnect server” on page A-33
■ “cdr list server” on page A-45
■ “cdr modify server” on page A-56
■ “cdr suspend server” on page A-81
A-64 Guide to IBM Informix Enterprise Replication

cdr start
cdr startThe cdr start command starts Enterprise Replication processing.
Syntax
UsageUse cdr start to restart Enterprise Replication after you stop it with cdr stop.When you issue cdr start, Enterprise Replication brings up all connections toother adjacent replication servers. Replication servers, replicates, and groupsthat were suspended before the cdr stop command was issued remainsuspended; no data is sent for the suspended servers, replicates, or groups.
Enterprise Replication resumes evaluation of the logical log (if required forthe instance of Enterprise Replication) at the replay position. The replayposition is the position where Enterprise Replication stops evaluating thelogical log when cdr stop is executed. If the evaluation process is runningand the logical log ID for the replay position no longer exists when EnterpriseReplication is started, then the restart partially fails (the database server logcontains an error message stating that the replay position is invalid). If therestart partially fails, no database updates performed on the local databaseserver are replicated.
Warning: Informix recommends that you issue cdr start and cdr stop with extremecaution.
ExampleThe following example restarts Enterprise Replication processing ondatabase server utah:
cdr sta -c utah
cdr start
Connect Optionp. A-87
Command-Line Utility Reference A-65

cdr start
See Also■ “cdr stop” on page A-71
A-66 Guide to IBM Informix Enterprise Replication

cdr start replicate
cdr start replicateThe cdr start replicate command starts the capture and transmittal of repli-cation transactions.
Syntax
UsageThe cdr start replicate command causes the replicate repl_name to enter theactive state (capture-send) on the database servers in server_group. If noserver is specified, the repl_name starts on all servers that are included in thereplicate. A replicate can have both active and inactive participants. When atleast one participant is active, the replicate is active.
Important: You cannot start replicates that have no participants.
Important: If a replicate belongs to an exclusive replicate set, you cannot run cdrstart replicate to start that individual replicate. You must use cdr start replica-teset to start all replicates in the exclusive replicate set.
Element Purpose Restrictions Syntaxrepl_name Name of the replicate to start The replicate must exist. “Long Identifiers”
on page A-86server_group Name of database server groups
on which to start the replicateThe database server groups mustbe defined for EnterpriseReplication.
Connect Optionp. A-87
cdr start replicate
server_group
repl_name
Command-Line Utility Reference A-67

cdr start replicate
Because Enterprise Replication does not process log records that wereproduced before the cdr start replicate command took place, transactionsthat occur during this period might be partially replicated. To avoidproblems, either issue the cdr start replicate command on an idle system (notransactions are occurring) or use the BEGIN WORK WITHOUT REPLICATIONstatement until after you successfully start the replicate.
ExampleThe following command starts the replicate accounts on the server groupsg_svr1 and g_svr2:
cdr sta rep accounts g_svr1 g_svr2
See Also■ “cdr change replicate” on page A-4
■ “cdr define replicate” on page A-10
■ “cdr delete replicate” on page A-25
■ “cdr list replicate” on page A-39
■ “cdr modify replicate” on page A-49
■ “cdr resume replicate” on page A-59
■ “cdr stop replicate” on page A-73
■ “cdr suspend replicate” on page A-77
A-68 Guide to IBM Informix Enterprise Replication

cdr start replicateset
cdr start replicatesetThe cdr start replicateset (or cdr start replset) command starts the captureand transmittal of replication transactions for all the replicates in a replicateset.
Syntax
UsageThe replicates defined in the replicate set repl_set enter the active state(capture-send) on the database servers in server_group.
If the server_group list is omitted, the replicate set repl_set enters the activestate for all database servers participating in the replicate set.
Because Enterprise Replication does not process log records that wereproduced before the cdr start replicateset command took place, transactionsthat occur during this period might be partially replicated. To avoidproblems, either issue the cdr start replicateset command on an idle system(no transactions are occurring) or use the BEGIN WORK WITHOUT REPLI-CATION statement until after you successfully start the replicates in thereplicate set.
Element Purpose Restrictions Syntaxrepl_set Name of replicate set to start The replicate set must exist. “Long Identifiers”
on page A-86server_group Names of database server groups
on which to start the replicate setThe database server groups mustbe defined for EnterpriseReplication.
Connect Optionp. A-87
cdr start replicateset
server_group
repl_set
Command-Line Utility Reference A-69

cdr start replicateset
Important: If not all the replicates in a non-exclusive replicate state are inactive, thecdr start replicateset command displays a warning and only starts the replicatesthat are currently inactive.
ExampleThe following example connects to the default database server specified by$INFORMIXSERVER and starts the replicate set accounts_set on the servergroups g_hill and g_lake:
cdr sta replset accounts_set g_hill g_lake
See Also■ “cdr change replicateset” on page A-6
■ “cdr define replicate” on page A-10
■ “cdr delete replicateset” on page A-27
■ “cdr list replicateset” on page A-43
■ “cdr modify replicateset” on page A-54
■ “cdr resume replicateset” on page A-61
■ “cdr stop replicateset” on page A-75
■ “cdr suspend replicateset” on page A-79
A-70 Guide to IBM Informix Enterprise Replication

cdr stop
cdr stopThe cdr stop command stops Enterprise Replication processing.
Syntax
UsageIn most situations, Enterprise Replication starts when cdr define server isfirst executed. The replication threads remain running until the databaseserver is shut down or until the local database server is deleted with thecdr delete server command. If you shut down the database server whileEnterprise Replication is running, replication begins again when you restartthe database server.
Under rare conditions, you might want to temporarily stop the EnterpriseReplication processing without stopping the database server. The cdr stopcommand shuts down all Enterprise Replication threads in an orderlymanner; however no data to be replicated is captured. When the shutdownof Enterprise Replication is complete, the message CDR shutdown complete
appears in the database server log file.
After issuing the cdr stop command, replication threads remain stopped(even if the database server is stopped and restarted) until you issue a cdrstart command.
You cannot delete a server from the enterprise if it is stopped. To delete aserver with cdr delete server, you must issue a cdr start command first.
Warning: If you issue cdr stop and database activity continues, the database serverfrom which the command is issued and the other database servers participating inreplicates will become inconsistent. To ensure consistency, verify that no databaseupdate activity occurs while Enterprise Replication is stopped.
cdr stop
Connect Optionp. A-87
Command-Line Utility Reference A-71

cdr stop
ExampleThe following example stops Enterprise Replication processing on databaseserver paris. Processing does not resume until a cdr start command restartsit:
cdr stop -c paris
See Also■ “cdr start” on page A-65
A-72 Guide to IBM Informix Enterprise Replication

cdr stop replicate
cdr stop replicateThe cdr stop replicate command stops the capture and transmittal of trans-actions for replication.
Syntax
UsageThe cdr stop replicate command changes the state of the replicate repl_nameto inactive (no capture, no send) on the replicate servers in the specifiedat_server_group list. In addition, this command deletes any data in the sendqueue for the stopped replicate.
Important: You cannot stop replicates that have no participants.
Warning: If there was any data in the send queue when you issued the cdr stopreplicate command, or if any database activity occurs while the replicate is stopped,the replicate servers will get out of synch. For information on resynchronizing repli-cation servers, see “Resynchronizing Replication Servers” on page 5-17.
If you omit the at_server_group list, the replicate enters the inactive state on alldatabase servers participating in the replicate and all send queues for thereplicate are deleted.
Element Purpose Restrictions Syntaxrepl_name Name of the new replicate The replicate must be active and
not in a replicate group.“Long Identifiers”on page A-86
at_server_group
List of database server groups onwhich to stop the replicate
The database server groups mustbe defined for EnterpriseReplication.
Connect Optionp. A-87
cdr stop replicate
at_server_grou
repl_name
Command-Line Utility Reference A-73

cdr stop replicate
Important: If a replicate belongs to an exclusive replicate set, you cannot run cdrstop replicate to stop that individual replicate. You must use cdr stop replicatesetto stop all replicates in the exclusive replicate set.
ExampleThe following command connects to the database server lake and stops thereplicate aRepl on server groups g_server1 and g_server2:
cdr sto rep -c lake aRepl g_server1 g_server2
See Also■ “cdr change replicate” on page A-4
■ “cdr define replicate” on page A-10
■ “cdr delete replicate” on page A-25
■ “cdr list replicate” on page A-39
■ “cdr modify replicate” on page A-49
■ “cdr resume replicate” on page A-59
■ “cdr start replicate” on page A-67
■ “cdr suspend replicate” on page A-77
A-74 Guide to IBM Informix Enterprise Replication

cdr stop replicateset
cdr stop replicatesetThe cdr stop replicateset (or cdr stop replset) command stops capture andtransmittal transactions for all the replicates in a replicate set.
Syntax
UsageThe cdr stop replicateset command causes all replicates in the replicate setrepl_set to enter the inactive state (no capture, no send) on the database serversin the server_group list.
If the server_group list is omitted, the replicate set repl_set enters the inactivestate for all database servers participating in the replicate set.
Important: If not all the replicates in the non-exclusive replicate set are active, thecdr stop replicateset command displays a warning and only stops the replicatesthat are currently active.
Element Purpose Restrictions Syntaxrepl_set Name of replicate set to stop “Long Identifiers”
on page A-86server_group Name of database server group
on which to stop the replicategroup
The database server groups mustbe defined for EnterpriseReplication.
Connect Optionp. A-87
cdr stop replicateset
server_group
repl_set
Command-Line Utility Reference A-75

cdr stop replicateset
ExampleThe following example connects to the database server paris and stops thereplicate set accounts_set on server groups g_utah and g_iowa:
cdr sto replset --connect=paris accounts_set g_utah g_iowa
See Also■ “cdr change replicateset” on page A-6
■ “cdr define replicate” on page A-10
■ “cdr delete replicateset” on page A-27
■ “cdr list replicateset” on page A-43
■ “cdr modify replicateset” on page A-54
■ “cdr resume replicateset” on page A-61
■ “cdr start replicateset” on page A-69
■ “cdr suspend replicateset” on page A-79
A-76 Guide to IBM Informix Enterprise Replication

cdr suspend replicate
cdr suspend replicateThe cdr suspend replicate command suspends delivery of replication data.
Syntax
UsageThe cdr suspend replicate command causes the replicate repl_name to enterthe suspend state (capture, no send) for all participants.
Warning: When a replicate is suspended, Enterprise Replication holds the replicationdata in the send queue until the replicate is resumed. If a large amount of data isgenerated for the replicate while it is suspended, the send queue space can fill, causingdata to be lost.
Warning: Enterprise Replication does not synchronize transactions if a replicate issuspended. For example, a transaction that updates tables X and Y will be split ifreplication for table X is suspended.
Important: If a replicate belongs to an exclusive replicate set, you cannot run cdrsuspend replicate to stop that individual replicate. You must use cdr suspendreplicateset to suspend all replicates in the exclusive replicate set.
cdr suspend replicate
Connect Optionp. A-87
repl_name
Element Purpose Restrictions Syntaxrepl_name Name of the replicate The replicate must be active. “Long Identifiers”
on page A-86
Command-Line Utility Reference A-77

cdr suspend replicate
ExampleThe following example connects to the database server stan and suspends thereplicate house:
cdr sus repl --connect stan house
See Also■ “cdr change replicate” on page A-4
■ “cdr define replicate” on page A-10
■ “cdr delete replicate” on page A-25
■ “cdr list replicate” on page A-39
■ “cdr modify replicate” on page A-49
■ “cdr resume replicate” on page A-59
■ “cdr start replicate” on page A-67
■ “cdr stop replicate” on page A-73
A-78 Guide to IBM Informix Enterprise Replication

cdr suspend replicateset
cdr suspend replicatesetThe cdr suspend replicateset (or cdr suspend replset) command suspendsdelivery of replication data for all the replicates in a replicate set.
Syntax
UsageThe cdr suspend replicateset command causes all the replicates in thereplicate set repl_set to enter the suspend state. Information is captured, butno data is sent for any replicate in the set. The data is queued to be sent whenthe set is resumed.
Warning: When a replicate set is suspended, Enterprise Replication holds the repli-cation data in the send queue until the set is resumed. If a large amount of data isgenerated for the replicates in the set while it is suspended, the send queue space canfill, causing data to be lost.
Warning: Enterprise Replication does not synchronize transactions if a replicate ina replicate set is suspended. For example, a transaction that updates tables X and Ywill be split if replication for table X is suspended.
Important: If not all the replicates in the non-exclusive replicate set are active, thecdr suspend replicateset command displays a warning and only suspends the repli-cates that are currently active.
cdr suspend replicateset
Connect Optionp. A-87
repl_set
Element Purpose Restrictions Syntaxrepl_set Name of replicate set to suspend “Long Identifiers”
on page A-86
Command-Line Utility Reference A-79

cdr suspend replicateset
ExampleThe following example connects to the default database server specified by$INFORMIXSERVER and suspends the replicate set accounts_set:
cdr sus replset account_set
See Also■ “cdr change replicateset” on page A-6
■ “cdr define replicate” on page A-10
■ “cdr delete replicateset” on page A-27
■ “cdr list replicateset” on page A-43
■ “cdr modify replicateset” on page A-54
■ “cdr resume replicateset” on page A-61
■ “cdr start replicateset” on page A-69
■ “cdr stop replicateset” on page A-75
A-80 Guide to IBM Informix Enterprise Replication

cdr suspend server
cdr suspend serverThe cdr suspend server command suspends the delivery of replication datato a database server from either a specified list of database servers or from alldatabase servers in the enterprise.
Syntax
UsageThe cdr suspend server command suspends delivery of replication data tothe to_server_group database server from the database servers included in thefrom_server_group list. If the from_server_group list is omitted, the commandsuspends replication of data from all database servers participating in theEnterprise Replication system to the to_server_group.
The connection to the suspended server is unaffected, and control andacknowledge messages continue to be sent to that server. Enterprise Repli-cation continues to replicate data between all database servers unaffected bythe cdr suspend server command.
Element Purpose Restrictions Syntaxto_server_group Name of database server
group to which to suspenddelivery of replication data
The database server group mustbe currently active in EnterpriseReplication.
from_server_group Name of the database servergroup from which to stopsending data toto_server_group
The database server group mustbe currently active in EnterpriseReplication.
Connect Optionp. A-87
cdr suspend server to_server_group
from_server_group
Command-Line Utility Reference A-81

cdr suspend server
ExampleThe following example connects to the default server ($INFORMIXSERVER)and suspends replication of data to the server g_iowa from the serversg_ohio and g_utah:
cdr sus serv g_iowa g_ohio g_utah
See Also■ “cdr connect server” on page A-9
■ “cdr define server” on page A-20
■ “cdr delete server” on page A-29
■ “cdr disconnect server” on page A-33
■ “cdr list server” on page A-45
■ “cdr modify server” on page A-56
■ “cdr resume server” on page A-63
A-82 Guide to IBM Informix Enterprise Replication

Interpreting the Command-Line Utility Syntax
Interpreting the Command-Line Utility SyntaxThis section defines the terminology and conventions used in the descrip-tions of the command-line utility (CLU).
Each command follows the same approximate format, with the followingcomponents:
■ Command and its variation
The command specifies the action that should be taken.
■ Options
The options modify the action of the command. Each option startswith a minus (-) or a double-minus (--).
■ Target
The target specifies the Enterprise Replication object that should beacted upon.
■ Other objects
Other objects specify objects that are affected by the change to thetarget.
If you enter an incorrect cdr command at the command-line prompt, thedatabase server returns a usage message that summarizes the cdr commands.For a more detailed usage message, enter cdr variation -h. For example, cdrlist server -h.
Important: You must be the Enterprise Replication server administrator (“Enter-prise Replication Server Administrator” on page 2-4) to execute any of the CLUcommands except the cdr list options.
This section covers the following topics:
■ Command Abbreviations
■ Option Abbreviations
■ Option Order
■ Long Command-Line Examples
■ Long Identifiers
■ Connect Option
Command-Line Utility Reference A-83

Command Abbreviations
■ Participant
■ Return Codes
■ Frequency Options
Command AbbreviationsFor most commands, each of the words that make up a cdr commandvariation can be abbreviated to three or more characters. For example, thefollowing commands are all equivalent:
cdr define replicatecdr define replcdr def rep
The exceptions to this rule are the replicateset commands, which can beabbreviated to replset. For example, the following commands are equivalent:
cdr define replicatesetcdr def replset
Option AbbreviationsEach option for a command has a long form and a short form. You can useeither form, and you can mix long and short forms within a single command.For example, using long forms on UNIX you can write:
cdr define server --connect=ohio --idle=500 \--ats=/cdr/ats --initial utah
♦
On Windows, this command line might look like:
cdr define server --connect=ohio --idle=500 \--ats=D:\cdr\ats --initial utah
♦
UNIX
WIN NT/2000
A-84 Guide to IBM Informix Enterprise Replication

Option Order
Using short forms, you can write the previous examples as follows:
cdr def ser -c ohio -i 500 -A /cdr/ats -I utah
♦
cdr def ser -c ohio -i 500 -A D:\cdr\ats -I utah
♦
The long form is always preceded by a double minus (--). Most (but not all)long forms require an equal sign (=) between the option and its argument.The short form is preceded by a single minus (-) and is the first letter of thelong form. The short form never requires an equal sign. However, sometimesthe short form is capitalized and sometimes not. To find the correct syntax forthe short form, check the table that accompanies each command variation.
Tip: Informix recommends that you use the long forms of options to increasereadability.
With the exception of the keyword transaction, all keywords (or letter combi-nations) that modify the command options must be written as shown in thesyntax diagrams. For example, in the “Conflict Options” on page A-11, theoption (conflict) can be abbreviated, but the keyword ignore cannot be abbre-viated. Both of the following forms are correct:
--conflict=ignore-C ignore
Option OrderYou can specify the options of the CLU commands in any order. Some of thesyntax diagrams in this chapter show the options in a specific order becauseit makes the diagram easier to read.
Do not repeat any options. The following fragment is incorrect because -cappears twice. In most cases, the CLU will catch this inconsistency and flag itas an error. However, if no error is given, the database server uses the lastinstance of the option. In the following example, the database server uses thevalue -c=utah:
-c=ohio -i=500 -c=utah
Tip: Informix suggests that, for ease of maintenance, you always use the same orderfor your options.
UNIX
WIN NT/2000
Command-Line Utility Reference A-85

Long Command-Line Examples
Long Command-Line ExamplesThe examples in this guide use the convention of a backslash (\) to indicatethat a long command line continues on the next line. The following twocommands are equivalent. The first command is too long to fit on a singleline, so it is continued on the next line. The second example, which uses shortforms for the options, fits on one line.
cdr define server --connect=katmandu --idle=500 \--ats=/cdrfiles/ats
cdr def ser -c=katmandu -i=500 -A=/cdrfiles/ats
♦
On Windows, these command lines might look like:
cdr define server --connect=honolulu --idle=500 \--ats=D:\cdrfiles\ats
cdr def ser -c=honolulu -i=500 -A=D:\cdr\ats
♦
For information on how to manage long lines at your command prompt,check your operating system documentation.
Long IdentifiersIdentifiers are the names of objects that Dynamic Server and Enterprise Repli-cation use, such as database servers, databases, columns, replicates, replicatesets, and so on.
An identifier is a character string that must start with a letter or an under-score. The remaining characters can be letters, numbers, or underscores. OnInformix Dynamic Server, all identifiers, including replicates and replicatesets, can be 128 bytes long. However, if you have any database servers in yourreplication environment that are an earlier version, you must follow thelength restrictions for that version.
For more information about identifiers, see the Informix Guide to SQL: Syntax.
The location of files, such as the location of the ATS files, can be 256 bytes.
UNIX
WIN NT/2000
A-86 Guide to IBM Informix Enterprise Replication

Connect Option
User login IDs can be a maximum of 32 bytes. The owner of a table is derivedfrom a user ID and is thus limited to 32 bytes.
Connect OptionThe --connect option causes the command to use the global catalog that is onthe specified server. If you do not specify this option, the connection defaultsto the database server specified by the INFORMIXSERVER environmentvariable.
You must use the --connect option when you add a database server to yourreplication environment with the cdr define server command.
You might use the --connect option if the database server to which you wouldnormally attach is unavailable.
For more information about the global catalog, refer to “Global Catalog” onpage 2-6.
--connect=server_group
-c server
-c server_group
--connect=server
Element Purpose Restrictions Syntaxserver Name of the database server to
connect toThe name must be the name of adatabase server.
“Long Identifiers”on page A-86
server_group Name of the database servergroup that includes the databaseserver to connect to
The name must be the name of anexisting database server group.
“Long Identifiers”on page A-86
Command-Line Utility Reference A-87

Participant
ParticipantA participant defines the data (database, table, and columns) on a databaseserver to be replicated. A replicate contains two or more participants. Theparticipant definition includes the following information:
■ Database server group (“Setting up Database Server Groups” onpage 4-5)
■ Database in which the table resides
■ Table name
■ Table owner (“Table Owner” on page A-89)
■ Participant type (“Participant Type” on page A-89)
■ SELECT statement (“Participant Modifier” on page A-90)
Important: You cannot start and stop replicates that have no participants.
You must include the server group, database, table owner, and table namewhen defining a participant, and enclose the entire participant definition inquote marks.
Element Purpose Restrictions Syntaxdatabase Name of the database that
includes the table to be replicatedThe database server must beregistered with EnterpriseReplication.
“Long Identifiers”on page A-86
owner User ID of the owner of the tableto be replicated
“Long Identifiers”on page A-86
server_group Name of the database servergroup that includes the server toconnect to
The database server group namemust be the name of an existingEnterprise Replication servergroup in SQLHOSTS.
“Long Identifiers”on page A-86
table Name of the table to be replicated The table must be an actual table.It cannot be a synonym or a view.
“Long Identifiers”on page A-86
" "database@server_group:owner. table
R
P
I
O
A-88 Guide to IBM Informix Enterprise Replication

Participant
Important: Do not create more than one replicate definition for each row and columnset of data to replicate. If the participant overlaps, Enterprise Replication attempts toinsert duplicate values during replication.
You can define participants with the following commands:
■ cdr define replicate
■ cdr modify replicate
■ cdr change replicate
Table Owner
The O (owner) option causes permission checks for owner to be applied to theoperation (such as insert or update) that is to be replicated and to all actionsfired by any triggers. When the O option is omitted, all operations areperformed with the privileges of user informix.
If a trigger requires any system-level commands (as specified using thesystem( ) command in an SPL statement), the system-level commands areexecuted as the table owner, if the participant includes the O option. ♦
If a trigger requires any system-level commands, the system-level commandsare executed as a less privileged user because, on Windows, you cannotimpersonate another user without having the password, whether or not theparticipant includes the O option. ♦
Use the I option to disable the table-owner option.
Participant Type
In a primary-target replicate, specify the participant type using the P(primary) and R (receive-only or target) options in the participant definition.
■ A primary participant both sends and receives replicate data.
■ A target participant only receives data from primary participants.
The replicate can contain multiple primary participants.
In an update-anywhere replicate, do not specify either P or R for theparticipant. Enterprise Replication defines the participant as primary in anupdate-anywhere replication system.
UNIX
WIN NT/2000
Command-Line Utility Reference A-89

Participant
For example, in the following definition, replicate Rone is update-anywhere:
cdr define repl-c serv1 -C timestamp -S tran Rone \"db@serv1:owner.table" "select * from table" \"db@serv2:owner.table" "select * from table"
In replicate Rtwo, serv2 is the primary and serv1 is receive-only.
cdr define repl-c serv1 -C ignore -S tran Rtwo \"R db@serv1:owner.table" "select * from table" \"P db@serv2:owner.table" "select * from table"
For more information, see “Primary-Target Replication System” on page 3-3.
Participant Modifier
The participant modifier is a restricted SELECT statement. The participantmodifier specifies the rows and columns that will be replicated. Theparticipant modifier must be enclosed in quote marks.
Element Purpose Restrictions Syntaxcolumn Name of a column in the table
specified by the participantThe column must exist. “Long Identifiers”
on page A-86table The table specified by the
participantThis must be the table name only.
You cannot specify an owner or adatabase server. You cannotspecify a synonym or a view.
“Long Identifiers”on page A-86
WHEREClause
Clause that specifies a subset oftable rows to be replicated
WHERE clausesyntax; refer toInformix Guide toSQL: Syntax
" "SELECT WHERE Clausecolumn
,
*
FROM table
A-90 Guide to IBM Informix Enterprise Replication

Return Codes
Considerations for the SELECT Statement
The following guidelines apply to a SELECT statement that is used as a partic-ipant modifier:
■ The statement cannot include a join or a subquery.
■ The FROM clause of the SELECT statement can reference only a singletable.
■ The table in the FROM clause must be the table specified by theparticipant.
■ The columns selected must include the primary key.
■ The columns selected can include any columns in the table,including those that contain smart large objects and TEXT and BYTEdata.
■ The statement cannot perform operations on the selected columns.
■ The statement can include an optional WHERE clause.
The WHERE clause of the SELECT statement of the participant modi-fier can reference an opaque UDT, as long as the UDT is always storedin row. For more information, see “Considerations for ReplicatingOpaque Data Types” on page 2-25.
For detailed information about the SELECT statement and WHERE clause,refer to the Informix Guide to SQL: Syntax.
Informix recommends that, except for replicating between SERIAL and INTAND between BYTE/TEXT and BLOB/CLOB, you only replicate between likedata types. For example, do not replicate between the following:
■ CHAR(40) to CHAR(20)
■ INT to FLOAT
Return CodesIf the command encounters an error, the database server returns an errormessage and a return-code value. The message briefly describes the error. Forinformation on interpreting the return code, use the cdr finderr command.
Command-Line Utility Reference A-91

Frequency Options
Frequency OptionsThe following commands allow you to specify the interval between replica-tions or the time of day when an action should occur. If you do not specify atime, the action occurs immediately:
■ cdr define replicate
■ cdr define replicate
■ cdr modify replicate
■ cdr modify replicateset
The following table describes the frequency options.
-- immed
Frequency Options
--every= interval
--at= time
Element Purpose Restrictions Syntaxinterval Time interval for replication The smallest interval in minutes. “Intervals” on
page A-94time Specific time for replication Time is given with respect to a 24-
hour clock.“Time of Day” onpage A-92
Time OptionsLong Form Short Form Meaning
--immed -i Action occurs immediately.
--every -e Action occurs immediately and repeats at thefrequency specified by interval.
--at -a Action occurs at the specified day and time.
A-92 Guide to IBM Informix Enterprise Replication

Frequency Options
Time of Day
Enterprise Replication always gives the time of day in 24-hour time. Forexample, 19:30 is 7:30 P.M. Enterprise Replication always gives times withrespect to the local time, unless the $TZ environment variable is set. However,Enterprise Replication stores times in the global catalog in Greenwich MeanTime (GMT).
The -a time option lets you specify the day on which an action should occur.The string time can have the following formats:
■ Day of week
To specify a specific day of the week, give either the long or shortform of the day, followed by a period and then the time. For example,--atime Sunday.18:40 or -a Sun.18:40, specifies that the actionshould occur every Sunday at 6:40 P.M.
The day of the week is given in the locale of the client. For example,with a French locale, you might have --atime Lundi.3:30 or-a Lun.3:30. The time and day are in the time zone of the server.
■ Day of month
To specify a specific date in the month, give the date, followed by aperiod, and then the time. For example, 1.3:00 specifies that theaction should occur at 3:00 A.M. on the first day of every month.
The special character L represents the last day of the month. Forexample, L.17:00 is 5:00 P.M. on the last day of the month.
■ Daily
To specify that replication should occur each day, give only the time.For example, 4:40 specifies that the action should occur every day at4:40 AM.
Command-Line Utility Reference A-93

Intervals
The -e length option lets you specify the interval between actions. The lengthof time between replications can be either of the following formats:
■ The number of minutes
To specify the number of minutes, specify an integer value. Forexample, -e 60 indicates 60 minutes between replications.
Important: If you specify the length of time between replications in minutes, thelongest interval allowed is 1966020.
■ The number of hours and minutes
To specify hours and minutes, give the number of hours, followed bya colon, and then the number of minutes. For example, -e 5:45 indi-cates 5 hours and 45 minutes between replications.
Important: If you specify the length of time in hours and minutes, the longestinterval allowed is 32767:59.

BAppendix
Configuration ParameterReference
The database server configuration file ($ONCONFIG) includesthe following configuration parameters that affect the behaviorof Enterprise Replication:
■ CDR_DSLOCKWAIT
■ CDR_EVALTHREADS
■ CDR_NIFCOMPRESS
■ CDR_QUEUEMEM
■ CDR_QHDR_DBSPACE
■ CDR_QDATA_SBSPACE
■ CDR_QDATA_SBFLAGS
■ CDR_SERIAL
Important: If you use both DBSERVERNAME andDBSERVERALIASES, DBSERVERNAME should refer to the networkconnection and not to a shared-memory connection. For informationabout database server aliases, refer to the Administrator’s Guide forInformix Dynamic Server.

CDR_DSLOCKWAIT
CDR_DSLOCKWAIT
The CDR_DSLOCKWAIT configuration parameter specifies the number ofseconds the Datasync (data synchronization) component waits for databaselocks to be released. The CDR_DSLOCKWAIT parameter behaves similarly tothe SET LOCK MODE statement: while the SET LOCK MODE is set by the enduser application, CDR_DSLOCKWAIT is used by Enterprise Replication whileapplying data at the target database. This parameter is useful in conditionswhere different sources require locks on the replicated table. These sourcescould be a replicated transaction from another server or a local applicationoperating on that table.
Transactions that receive updates and deletes from another server in thereplicate can abort because of locking problems. If you experience transactionaborts in the Datasync due to lock timeouts like this, you might want toincrease the value of this parameter.
default value 5
units seconds
takes effect when shared memory is initialized
B-2 Guide to IBM Informix Enterprise Replication
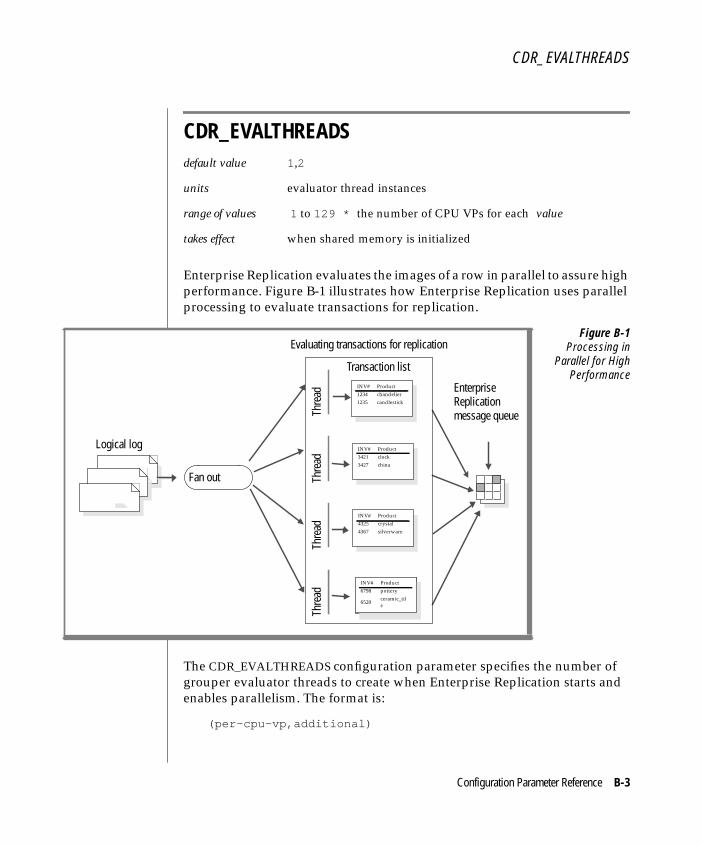
CDR_EVALTHREADS
CDR_EVALTHREADS
Enterprise Replication evaluates the images of a row in parallel to assure highperformance. Figure B-1 illustrates how Enterprise Replication uses parallelprocessing to evaluate transactions for replication.
The CDR_EVALTHREADS configuration parameter specifies the number ofgrouper evaluator threads to create when Enterprise Replication starts andenables parallelism. The format is:
(per-cpu-vp,additional)
default value 1,2
units evaluator thread instances
range of values 1 to 129 * the number of CPU VPs for each value
takes effect when shared memory is initialized
Figure B-1Processing in
Parallel for HighPerformance
Logical log
Thre
ad
custno custname1234 XYZ LTD1235 XSPORTS
Fan out
EnterpriseReplicationmessage queue
Thre
adTh
read
Thre
ad
Evaluating transactions for replication
Transaction list
INV# Product6798 pottery
6520ceramic_tile
INV# Product4325 crystal4367 silverware
INV# Product3421 clock3427 china
INV# Product1234 chandelier1235 candlestick
Configuration Parameter Reference B-3

CDR_EVALTHREADS
The following table provides four examples of CDR_EVALTHREADS.
Warning: Informix recommends that you not configure the total number of evaluatorthreads to be smaller than the number of CPU VPs in the system.
Number of Threads Explanation Example
1,2 1 evaluator thread per CPU VP, plus 2 For a 3 CPU VP server: (3 * 1) + 2 = 5
2 2 evaluator threads per CPU VP For a 3 CPU VP server: (3 * 2) = 6
2,0 2 evaluator threads per CPU VP For a 3 CPU VP server: (3* 2)+0 = 6
0,4 4 evaluator threads for any databaseserver
For a 3 CPU VP server: (3 * 0) +4 = 4
B-4 Guide to IBM Informix Enterprise Replication

CDR_NIFCOMPRESS
CDR_NIFCOMPRESS
The CDR_NIFCOMPRESS (network interface compression) configurationparameter specifies the level of compression that the database server usesbefore sending data from the source database server to the target databaseserver. Network compression saves network bandwidth over slow links butuses more CPU to compress and decompress the data.
The values have the following meanings.
When Enterprise Replication is defined between two database servers, theCDR_NIFCOMPRESS values of the two servers are compared and changed tothe higher compression values.
default value 0
range of values ■ -1 specifies no compression
■ 0 specifies to compress only if the target server expectscompression
■ 1 - 9 specifies increasing levels of compression
takes effect when Enterprise Replication is initialized
Value Meaning
-1 The source database server never compresses the data, regardless ofwhether or not the target site uses compression.
0 The source database server compresses the data only if the targetdatabase server expects compressed data.
1 The database server performs a minimum amount of compression.
9 The database server performs the maximum possible compression.
Configuration Parameter Reference B-5

CDR_NIFCOMPRESS
The compression values determine how much memory can be used to storeinformation while compressing, as follows:
0 = no additional memory1 = 128k + 1k = 129k2 = 128k + 2k = 130k
...6 = 128k + 32k = 160k
...8 = 128k + 128k = 256k9 = 128k + 256k = 384k
Higher levels of CDR_NIFCOMPRESS cause greater compression.
Different sites can have different levels. For example, Figure B-2 shows a setof three root servers connected with LAN and a nonroot server connectedover a modem. The CDR_NIFCOMPRESS configuration parameter is set sothat connections between A, B, and C use no compression. The connectionfrom C to D uses level 6.
Important: Informix recommends that you disable NIF compression if the networklink performs compression in hardware.
Figure B-2Database Servers
with DifferentCompression
Levels
B
D
C
A
B-6 Guide to IBM Informix Enterprise Replication

CDR_QUEUEMEM
CDR_QUEUEMEM
The CDR_QUEUEMEM configuration parameter specifies the maximumamount of memory that is used for the send and receive queues. If yourlogical logs are large, the Enterprise Replication reads a large amount of datainto queues in memory. You can use CDR_QUEUEMEM to limit the amount ofmemory devoted to the queues.
The maximum memory used for queued elements on a replication server isthe total number of database servers involved in replication, multiplied bythe value of CDR_QUEUEMEM.
When you increase the value of CDR_QUEUEMEM, you reduce the number ofelements that must be written to disk, which can eliminate I/O overhead.Therefore, if elements are frequently stored on disk, increase the value ofCDR_QUEUEMEM. Conversely, if you set the value of CDR_QUEUEMEM toohigh, you might adversely impact the performance of your system. Highvalues for CDR_QUEUEMEM also increase the time necessary for recovery.Tune the value of CDR_QUEUEMEM for the amount of memory available onyour computer.
default value 4096
units kilobytes
range of values > = 500
takes effect when shared memory is initialized
Configuration Parameter Reference B-7

CDR_QHDR_DBSPACE
CDR_QHDR_DBSPACE
The CDR_QHDR_DBSPACE configuration parameter specifies the location ofthe dbspace that Enterprise Replication uses to store the transaction recordheaders spooled from the send and receive queues. By default, EnterpriseReplication stores the transaction record headers in the root dbspace. Formore information, see “Transaction Record dbspace” on page 4-12.
Warning: Do not change the value of CDR_QHDR_DBSPACE after you initializeEnterprise Replication.
default value the name of the dbspace specified by the ROOTNAME configu-ration parameter
For more information, see the Informix Administrator’s Reference.
takes effect when Enterprise Replication is initialized
B-8 Guide to IBM Informix Enterprise Replication

CDR_QDATA_SBSPACE
CDR_QDATA_SBSPACE
The CDR_QDATA_SBSPACE configuration parameter specifies the name of thesbspace that Enterprise Replication uses to store spooled transaction rowdata. Enterprise Replication creates one smart large object per transaction.
Important: You must set the CDR_QDATA_SBSPACE configuration parameter andcreate the sbspace specified by CDR_QDATA_SBSPACE before defining a server forreplication. If the configuration parameter is not set in ONCONFIG or the sbspacename specified by CDR_QDATA_SBSPACE is invalid, Enterprise Replication fails todefine the server.
For more information, see “Row Data sbspace” on page 4-13 and “Defining Repli-cation Servers” on page 5-5.
Warning: Do not change the value of CDR_QDATA_SBSPACE after you initializeEnterprise Replication.
takes effect when Enterprise Replication is initialized
Configuration Parameter Reference B-9

CDR_QDATA_SBFLAGS
CDR_QDATA_SBFLAGS
The CDR_QDATA_SBFLAGS configuration parameter specifies the loggingflag to use for the smart large object that contains spooled row data (specifiedby CDR_QDATA_SBSPACE). By default, CDR_QDATA_SBFLAGS is set for nologging; the smart large object specified by CDR_QDATA_SBSPACE is notlogged. Informix recommends that you set this parameter to OFF to turn offlogging for the smart large object, but that you mirror the sbspace.
For more information, see “LOGGING” on page 4-14.
Tip: Use CDR_QDATA_SBFLAGS at any time to turn logging on or off for thespooled row data smart large object. You must restart Enterprise Replication for thechange to take effect.
default value 0,0
range of values 0 turn on logging
2 turn off logging
takes effect each time Enterprise Replication is started
B-10 Guide to IBM Informix Enterprise Replication

CDR_SERIAL
CDR_SERIAL
The CDR_SERIAL configuration parameter enables control over generatingvalues for SERIAL and SERIAL8 columns in tables defined for replication. Thisis useful for generating unique SERIAL column primary keys in an EnterpriseReplication environment.
The format is:
CDR_SERIAL delta,offset
where:
You should set the delta to greater than the expected number of serverswithin your enterprise and make sure the offset is unique on each server.
When you set CDR_SERIAL, only tables that are marked as the source of areplicate use this method of serial column generation. By default,CDR_SERIAL is set to 0 to disable control over generating SERIAL and SERIAL8values.
For more information, see “SERIAL Data Types and Primary Keys” onpage 2-12.
default value 0,0
units delta,offset
range of values 0,0 disable control of SERIAL column value generation
>0,>0 enable control of SERIAL column value generation
takes effect when Enterprise Replication is initialized
delta determines the incremental size of the serial column values
offset determines the specific number within the delta that will begenerated.
Example CDR_SERIAL Value Resulting Value for the SERIAL Column
CDR_SERIAL 100,1 1, 101, 201, 301, and so on
CDR_SERIAL 200,2 2, 202, 402, 602, and so on
Configuration Parameter Reference B-11


CAppendix
onstat CommandReference
This appendix describes forms of the onstat command that arerelevant to Enterprise Replication. The onstat utility readsshared-memory structures and provides statistics about thedatabase server that are accurate at the instant that the commandexecutes. The system-monitoring interface (SMI) also providesinformation about the database server. For general informationabout onstat and SMI, refer to the Administrator’s Reference. Forinformation specific to Enterprise Replication, see Appendix D,“SMI Table Reference.”

onstat -g ath
onstat -g Command Summary
The onstat -g commands are provided for support and debugging only. Youcan include only one of these options with each onstat -g command. Thisappendix describes the following onstat -g commands:
onstat -g athThe onstat -g ath command prints information about all threads.
Command Page
onstat -g ath C-2
onstat -g cat C-4
onstat -g ddr C-4
onstat -g dss C-5
onstat -g dtc C-5
onstat -g grp C-6
onstat -g nif C-7
onstat -g que C-8
onstat -g rcv C-8
onstat -g rep C-9
onstat -g rqm C-9
C-2 Guide to IBM Informix Enterprise Replication

onstat -g ath
The following table summarizes the threads that Enterprise Replication uses.You can use this information about threads when you evaluate memory use.For more information, see the utilities chapter of the Informix Administrator’sReference.
Number ofThreads Thread Name Thread Description
1 ddr_snoopy Performs physical I/O from logical log, verifies potential replication, andsends applicable log-record entries to Enterprise Replication
1 CDRGfan Receives log entries and passes entries to evaluator thread
n CDRGevaln Evaluates log entry to determine if it should be replicated (n is thenumber of evaluator threads specified by CDR_EVALTHREADS)
This thread also performs transaction compression on the receipt ofCOMMIT WORK and queues completed replication messages.
1 CDRCparse Parses all SQL statements for replicate definitions
1 perconnection
CDRNsTn
CDRNsAn
Sending thread for site
1 perconnection
CDRNrn Receiving thread for site
2...n CDRACK_n Accepts acknowledgments from site
At least 2, up to a maximum of the number of active connections
# CPUs... CDRD_n Replays transaction on the target system (DataSync thread)
At least one thread is created for each CPU virtual processor (VP). Themaximum number of threads is 4*(number of CPU VPs).
1 CDRSchedMgr Schedules internal Enterprise Replication events
0 or 1 CDRM_Monitor Monitors and adjusts DataSync performance for optimum performance(on the target)
0 or 1 CDRDTCleaner Deletes (cleans) rows from the deleted rows shadow table when they areno longer needed
onstat Command Reference C-3

onstat -g cat
onstat -g catThe onstat -g cat command prints information from the Enterprise Repli-cation global catalog. The global catalog contains a summary of informationabout the defined servers, replicates, and replicate sets on each of the serverswithin the enterprise. For example, use this command to determine thecurrent bitmap mask for a given server, which table matches a givenreplicate, or whether a server is a root or leaf server.
The onstat -g cat command has the following formats:
onstat -g catonstat -g cat scopeonstat -g cat replname
The following table describes replans and scope.
onstat -g ddrThe onstat -g ddr command prints the status of the Enterprise Replicationdatabase log reader. The ddr, or ddr_snoopy, is an internal component ofEnterprise Replication that reads the log buffers and passes information tothe grouper. If log reading is blocked, data might not be replicated until theproblem is resolved. If the block is not resolved, the database server mightoverwrite the read (snoopy) position of Enterprise Replication, which meansthat data will not be replicated. Once this occurs, you must manually resyn-chronize the source and target databases.
Modifier Description
replans The name of a replicate
scope One of the following values:
■ servers
■ repls
■ full
Print information on servers only
Print information on replicates only
Print expanded information for both replicateservers and replicates
C-4 Guide to IBM Informix Enterprise Replication

onstat -g dss
onstat -g dssThe onstat -g dss command prints detailed statistical information about theactivity of individual data sync threads. The data sync thread applies thetransaction on the target server. Statistics include the number of appliedtransactions and failures and when the last transaction from a source wasapplied.
The onstat -g dss command has the following formats:
onstat -g dssonstat -g dss modifier
The following table describes the values for modifier.
onstat -g dtcThe onstat -g dtc command prints statistics about the delete table cleaner. Thedelete table cleaner removes rows from the delete table when they are nolonger needed.
The -g dtc option is used primarily as a debugging tool and by InformixTechnical Support.
Modifier Action
UDR Prints summary information about any UDR invocations by the datasync threads.
UDRx Prints expanded information (including a summary of error infor-mation) about any UDR invocations by the data sync threads. TheProcid column lists the UDR procedure ID.
onstat Command Reference C-5

onstat -g grp
onstat -g grpThe onstat -g grp command prints statistics about the grouper. The grouperevaluates the log records, rebuilds the individual log records into the originaltransaction, packages the transaction, and queues the transaction fortransmission.
The -g grp option is used primarily as a debugging tool and by InformixTechnical Support.
The onstat -g grp command has the following formats:
onstat -g grponstat -g grp modifier
The following table describes the values for modifier.
Modifier Action
A Prints all the information printed by the G, T, P, E, R, and S modifiers
E Prints grouper evaluator statistics
Ex Prints grouper evaluator statistics, expands user-defined routine (UDR)environments
G Prints grouper general statistics
L Prints grouper global list
Lx Prints grouper global list, expands open transactions
M Prints grouper compression statistics
Mz Clears grouper compression statistics
P Prints grouper table partition statistics
R Prints grouper replicate statistics
S Prints grouper serial list head
Sl Prints grouper serial list
Sx Prints grouper serial list, expands open transactions
(1 of 2)
C-6 Guide to IBM Informix Enterprise Replication

onstat -g nif
onstat -g nifThe onstat -g nif command prints statistics about the network interface,including a summary of the number of buffers sent and received for each site.Because this command reports the status of the various network connectionsand traffic between the various servers, it can be useful to determine whydata is not replicating.
The -g nif option is used primarily as a debugging tool and by InformixTechnical Support.
The onstat -g nif command has the following formats:
onstat -g nifonstat -g nif modifier
The following table describes the values for modifier.
T Prints grouper transaction statistics
UDR Prints summary information about any UDR invocations by thegrouper threads
UDRx Prints expanded information (including a summary of error infor-mation) about any UDR invocations by the grouper threads
The Procid column lists the UDR procedure ID.
Modifier Action
all Prints the sum and the sites
sites Prints the NIF site context blocks
serverid Prints information about the replication server whose groupID isserverID
sum Prints the sum of the number of buffers sent and received for eachsite
(2 of 2)
onstat Command Reference C-7

onstat -g que
onstat -g queThe onstat -g que command prints statistics for the high-level queueinterface. The queuer manages the logical aspects of the queue. The RQM(reliable queue manager) manages the physical queue.
The -g que option is used primarily as a debugging tool and by InformixTechnical Support.
onstat -g rcvThe onstat -g rcv command prints statistics about the receive manager. Thereceive manager is a set of service routines between the receive queues anddata sync.
The onstat -g rcv command has the following formats:
onstat -g rcvonstat -g rcv serveridonstat -g rcv full
The serverID modifier causes the command to print only those outputmessages received from the replication server whose groupID is serverid. Thefull modifier causes the command to print all statistics.
The onstat -g rcv command includes the Receive Parallelism Statisticssection, a summary of the data sync threads by source server.
Field Description
Server Source server ID
Tot.Txn. Total number of transactions applied from this source server
Pending Number of current transactions in the pending list for this sourceserver
Active Number of current transactions currently being applied from thissource server
MaxPnd Maximum number of transactions in the pending list queue
MaxAct Maximum number of transaction in the active list queue
(1 of 2)
C-8 Guide to IBM Informix Enterprise Replication

onstat -g rep
The -g rcv option is used primarily as a debugging tool and by InformixTechnical Support.
onstat -g repThe onstat -g rep command prints events that are in the queue for theschedule manager. The -g rep option is used primarily as a debugging tooland by Informix Technical Support.
The onstat -g rep command has the following formats:
onstat -g reponstat -g rep replname
The repl_name modifier limits the output to those events originated by thereplicate named repl_name.
onstat -g rqmThe onstat -g rqm command prints statistics and contents of the low-levelqueues (send queue, receive queue, ack send queue, sync send queue, andcontrol send queue) managed by the Reliable Queue Manager (RQM). TheRQM manages the insertion and removal of items to and from the variousqueues. The RQM also manages spooling of the in-memory portions of thequeue to and from disk. The -g rqm option displays the contents of the queue,size of the transactions in the queue, how much of the queue is in memoryand on disk, the location of various handles to the queue, and the contents ofthe various progress tables.
If a queue is empty, no information is printed for that queue.
The onstat -g rqm command has the following formats:
onstat -g rqmonstat -g rqm modifier
AvgPnd Average depth of the pending list queue
AvgAct Average depth of the active list queue
CommitRt Commit rate of transaction from this source server based on trans-actions per second
(2 of 2)
onstat Command Reference C-9

onstat -g rqm
The following table describes the values for modifier.
When you specify a modifier to select a specific queue, the command printsall the statistics for that queue and information about the first and last in-memory transactions for that queue.
The other modifiers of the onstat -g rqm command are used primarily as adebugging tool and by Informix Technical Support.
Modifier Action
ACKQ Prints the ack send queue
CNTRLQ Prints the control send queue
RECVQ Prints the receive queue
SENDQ Prints the send queue
SYNCQ Prints the sync send queue
FULL Prints full information about every in-memory transaction for everyqueue
BRIEF Prints a brief summary of the number of transactions in eachof the queues and the replication servers for which the data isqueued
Use this modifier to quickly identify sites where a problem exists. Iflarge amounts of data are queued for a single server, then that serveris probably down or off the network.
VERBOSE Prints all the buffer headers in memory
C-10 Guide to IBM Informix Enterprise Replication
DAppendix
SMI Table Reference
The system-monitoring interface (SMI) tables in the sysmasterdatabase provide information about the state of the databaseserver. Enterprise Replication uses the SMI tables listed in “SMITable Summary” to access information about database serversdeclared to Enterprise Replication.
SMI Table Summary
Table Description Reference
syscdrack_buf Buffers for the acknowledge queue page D-3
syscdrack_txn Transactions in the acknowledgequeue
page D-3
syscdrctrl_buf Buffers for the control queue page D-3
syscdrctrl_txn Transactions in the control queue page D-4
syscdrerror Enterprise Replication errorinformation
page D-4
syscdrpart Participant information page D-5
syscdrprog Contents of the Enterprise Repli-cation progress tables
page D-5
syscdrq Queued data information (brief) page D-6
syscdrqueued Queued data information (detailed) page D-7
(1 of 2)

SMI Table Summary
syscdrrecv_buf Buffers in the receive queue page D-7
syscdrrecv_txn Transactions in the receive queue page D-7
syscdrrepl Replicate information page D-8
syscdrreplset Replicate set information page D-9
syscdrs Server information page D-10
syscdrsend_buf Buffers in the send queue page D-11
syscdrsend_txn Transactions in the send queue page D-11
syscdrserver Database server information page D-12
syscdrsync_buf Buffers in the synchronizationqueue
page D-13
syscdrsync_txn Transactions in the synchronizationqueue
page D-13
syscdrtx Transaction information page D-13
Table Description Reference
(2 of 2)
D-2 Guide to IBM Informix Enterprise Replication

syscdrack_buf
SMI Tables for Enterprise ReplicationThe following sections describe the individual tables of the sysmasterdatabase that refer to Enterprise Replication.
syscdrack_bufThe syscdrack_buf table contains information about the buffers that form theacknowledgment queue. When the target database server applies transac-tions, it sends an acknowledgment to the source database server. When thesource database server receives the acknowledgment, it can then delete thosetransactions from its send queue.
For information on the columns of the syscdrack_buf table, refer to“Columns of the Buffer Tables” on page D-17.
syscdrack_txnThe syscdrack_txn table contains information about the acknowledgmentqueue. When the target database server applies transactions, it sends anacknowledgment to the source database server. When the source databaseserver receives the acknowledgment, it can then delete those transactionsfrom its send queue.
The acknowledgment queue is an in-memory only queue. That is, it is avolatile queue that is lost if the database server is stopped.
For information on the columns of the syscdrack_txn table, refer to“Columns of the Transaction Tables” on page D-16.
syscdrctrl_bufThe syscdrctrl_buf table contains buffers that provide information about thecontrol queue. The control queue is a stable queue that contains controlmessages for the replication system.
For information on the columns of the syscdrctrl_buf table, refer to“Columns of the Buffer Tables” on page D-17.
SMI Table Reference D-3

syscdrctrl_txn
syscdrctrl_txnThe syscdrctrl_txn table contains information about the control queue. Thecontrol queue is a stable queue that contains control messages for the repli-cation system.
For information on the columns of the syscdrctrl_txn table, refer to “Columnsof the Transaction Tables” on page D-16.
syscdrerrorThe syscdrerror table contains information about errors that EnterpriseReplication has encountered.
Column Type Description
errornum integer Error number
errorserv char(128) Database server name where error occurred
errorseqnum integer Sequence number that can be used to prune single-error table
errortime datetimeyear tosecond
Time error occurred
sendserv char(128) Database server name, if applicable, that initiatederror behavior
reviewed char(1) Y if reviewed and set by DBAN if not reviewed
errorstmnt text Error description
D-4 Guide to IBM Informix Enterprise Replication

syscdrpart
syscdrpartThe syscdrspart table contains participant information.
syscdrprogThe syscdrprog table lists the contents of the Enterprise Replication progresstables. The progress tables keep track of what data has been sent to whichservers and which servers have acknowledged receipt of what data. Enter-prise Replication uses the transaction keys and stamps to keep track of thisinformation.
The progress table is two dimensional. For each server to which EnterpriseReplication sends data, the progress tables keep progress information on aper-replicate basis.
Column Type Description
replname lvarchar Replicate name
servername char(128) Database server name
partstate char(50) Participant state: ACTIVE, INACTIVE
partmode char(1) P = primary database server (read-write)R = target database server (receive only)
dbsname lvarchar Database name
owner lvarchar Owner name
tabname lvarchar Table name
Column Type Description
dest_id integer Server ID of the destination server
repl_id integer The ID that Enterprise Replication uses to identifythe replicate for which this information is valid
source_id integer Server ID of the server from which the dataoriginated
(1 of 2)
SMI Table Reference D-5
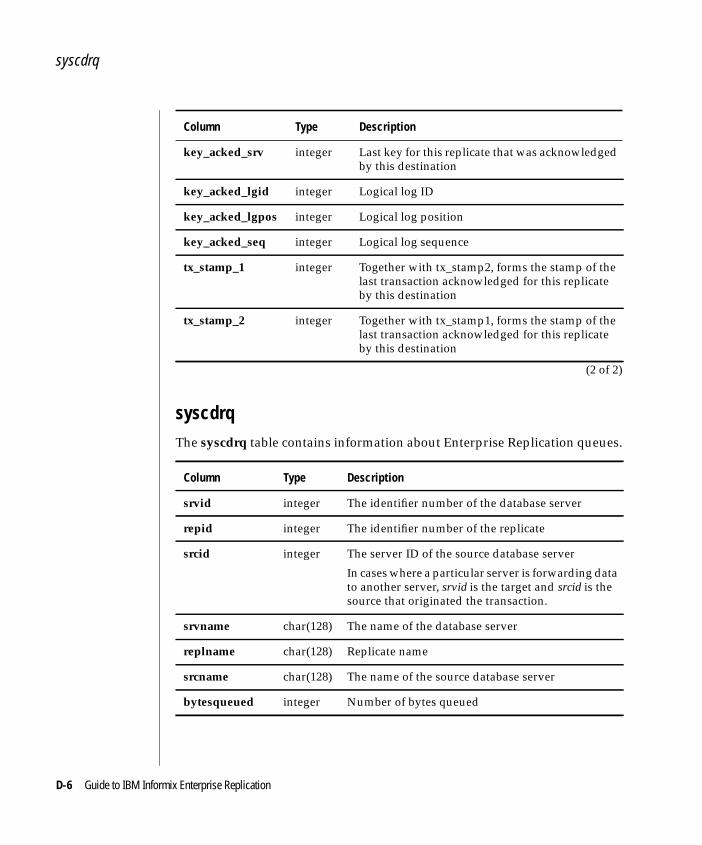
syscdrq
syscdrqThe syscdrq table contains information about Enterprise Replication queues.
key_acked_srv integer Last key for this replicate that was acknowledgedby this destination
key_acked_lgid integer Logical log ID
key_acked_lgpos integer Logical log position
key_acked_seq integer Logical log sequence
tx_stamp_1 integer Together with tx_stamp2, forms the stamp of thelast transaction acknowledged for this replicateby this destination
tx_stamp_2 integer Together with tx_stamp1, forms the stamp of thelast transaction acknowledged for this replicateby this destination
Column Type Description
(2 of 2)
Column Type Description
srvid integer The identifier number of the database server
repid integer The identifier number of the replicate
srcid integer The server ID of the source database server
In cases where a particular server is forwarding datato another server, srvid is the target and srcid is thesource that originated the transaction.
srvname char(128) The name of the database server
replname char(128) Replicate name
srcname char(128) The name of the source database server
bytesqueued integer Number of bytes queued
D-6 Guide to IBM Informix Enterprise Replication

syscdrqueued
syscdrqueuedThe syscdrqueued table contains data-queued information.
syscdrrecv_bufThe syscdrrecv_buf table contains buffers that provide information about thedata-receive queue. When a replication server receives replicated data froma source database server, it puts this data on the receive queue for processing.On the target side, Enterprise Replication picks up transactions from thisqueue and applies them on the target.
For information on the columns of the syscdrrecv_buf table, refer to“Columns of the Buffer Tables” on page D-17.
syscdrrecv_txnThe syscdrrecv_txn table contains information about the data receive queue.The receive queue is an in-memory queue.
When a replication server receives replicated data from a source databaseserver, it puts this data on the receive queue, picks up transactions from thisqueue, and applies them on the target.
For information on the columns of the syscdrrecv_txn table, refer to“Columns of the Transaction Tables” on page D-16.
Column Type Description
servername char(128) Sending to database server name
name char(128) Replicate name
bytesqueued decimal(32,0) Number of bytes queued for the serverservername
SMI Table Reference D-7

syscdrrepl
syscdrreplThe syscdrrepl table contains replicate information.
Column Type Description
replname lvarchar Replicate name
replstate char(50) Replicate state
For possible values, refer to “The STATE Column”on page A-46.
freqtype char(1) Type of replication frequency:C = continuousI = intervalT = time basedM = day of monthW = day of week
freqmin smallint Minute (after the hour) refresh should occur
Null if continuous
freqhour smallint Hour refresh should occur
Null if continuous
freqday smallint Day of week or month refresh should occur
scope char(1) Replication scope:T = transactionR = row-by-row
invokerow-spool
char(1) Y = row spooling is invokedN = no row spooling is invoked
invoketranspool
char(1) Y = transaction spooling is invokedN = no transaction spooling is invoked
primresolution char(1) Type of primary conflict resolution:I = ignoreT = time stampS = SPL routine
secresolution char(1) Type of secondary conflict resolution:S = SPL routineNull = not configured
(1 of 2)
D-8 Guide to IBM Informix Enterprise Replication

syscdrreplset
syscdrreplsetThe syscdrreplset table contains replicate set information.
storedprocname lvarchar Name of SPL routine for secondary conflictresolutionNull if not defined.
floattype char(1) C = converts floating point numbers to canonicalformatI= converts floating point numbers to IEEE formatN= does not convert floating point numbers (sendsin native format)
istriggerfire char(1) Y = triggers are invokedN = triggers are not invoked
isfullrow char(1) Y = sends the full row and enables upsertsN = sends only changed columns and disablesupserts.
Column Type Description
replname lvarchar Replicate name
replsetname lvarchar Replicate set name
Column Type Description
(2 of 2)
SMI Table Reference D-9

syscdrs
syscdrsThe syscdrs table contains information about database servers that have beendeclared to Enterprise Replication.
Column Type Description
servid integer Server identifier
servname char(128) Database server name
cnnstate char(1) Status of connection to this database server:C = ConnectedD = Connection disconnected (will be retried)T = Idle time-out caused connection to terminateX = Connection closed by user command
Connection unavailable until reset by user
cnnstatechg integer Time that connection state was last changed
servstate char(1) Status of database server:A = ActiveS = SuspendedQ = Quiescent (initial sync state only)
ishub char(1) Y = Server is a hubN = Server is not a hub
A hub is any replication server that forwards infor-mation to another replication server.
isleaf char(1) Y = Server is a leaf serverN = Server is not a leaf server
rootserverid integer The identifier of the root server
forwardnodeid integer The identifier of the parent server
timeout integer Idle timeout
D-10 Guide to IBM Informix Enterprise Replication

syscdrsend_buf
Although not directly connected, a nonroot server is similar to a root serverexcept it forwards all replicated messages through its parent (root) server. Allnonroot servers are known to all root servers and other nonroot servers. Anonroot server can be a terminal point in a tree or it can be the parent foranother nonroot server or a leaf server. Nonroot and root servers are awareof all replication servers in the replication environment, including all the leafservers.
A leaf server is a nonroot server that has a partial catalog. A leaf server hasknowledge only of itself and its parent server. It does not contain informationabout replicates of which it is not a participant. The leaf server must be aterminal point in a replication hierarchy.
syscdrsend_bufThe syscdrsend_buf table contains buffers that give information about thesend queue. When a user performs transactions on the source databaseserver, Enterprise Replication queues the data on the send queue for deliveryto the target servers.
For information on the columns of the syscdrsend_buf table, refer to“Columns of the Buffer Tables” on page D-17.
syscdrsend_txnThe syscdrsend_txn table contains information about the send queue. Whena user performs transactions on the source database server, Enterprise Repli-cation queues the data on the send queue for delivery to the target servers.
For information on the columns of the syscdrsync_txn table, refer to“Columns of the Transaction Tables” on page D-16.
SMI Table Reference D-11

syscdrserver
syscdrserverThe syscdrserver table contains information about database servers declaredto Enterprise Replication.
Column Type Description
servid integer Replication server ID
servername char(128) Database server group name
connstate char(1) Status of connection to this database server:C = ConnectedD = Connection disconnected (will be retried)T = Idle time-out caused connection to terminateX = Connection closed by user command
Connection unavailable until reset by user
connstate-change
integer Time that connection state was last changed
servstate char(50) Status of this database server:A = ActiveS = SuspendedQ = Quiescent (initial sync state only)
ishub char(1) Y = Server is a hubN = Server is not a hub
isleaf char(1) Y = Server is a leaf serverN = Server connection is not a leaf server
rootserverid integer The identifier of the root server
forwardnodeid integer The identifier of the parent server
idletimeout integer Idle time-out
atsdir lvarchar ATS directory spooling name
risdir lvarchar RIS directory spooling name
D-12 Guide to IBM Informix Enterprise Replication

syscdrsync_buf
syscdrsync_bufThe syscdrsync_buf table contains buffers that give information about thesynchronization queue. Enterprise Replication uses this queue only whendefining a replication server and synchronizing its global catalog withanother replication server.
For information on the columns of the syscdrsync_buf table, refer to“Columns of the Buffer Tables” on page D-17.
syscdrsync_txnThe syscdrsync_txn table contains information about the synchronizationqueue. This queue is currently used only when defining a replication serverand synchronizing its global catalog with another replication server. Thesynchronization queue is an in-memory-only queue.
For information on the columns of the syscdrsync_txn table, refer to“Columns of the Transaction Tables” on page D-16.
syscdrtxThe syscdrtx table contains information about Enterprise Replicationtransactions.
Column Type Description
srvid integer Server ID
srvname char(128) Name of database server from which data isreceived
txprocssd integer Transaction processed from database server srvname
txcmmtd integer Transaction committed from database serversrvname
txabrtd integer Transaction aborted from database server srvname
(1 of 2)
SMI Table Reference D-13

syscdrtx
rowscmmtd integer Rows committed from database server srvname
rowsabrtd integer Rows aborted from database server srvname
txbadcnt integer Number of transactions with source commit time(on database server srvname) greater than targetcommit time
Column Type Description
(2 of 2)
D-14 Guide to IBM Informix Enterprise Replication

syscdrtx
Enterprise Replication QueuesOne group of sysmaster tables shows information about Enterprise Repli-cation queues. The sysmaster database reports the status of these queues inthe tables that have the suffixes _buf and _txn.
The name of each table that describes an Enterprise Replication queue iscomposed of the following three pieces:
■ syscdr, which indicates that the table describes EnterpriseReplication
■ An abbreviation that indicates which queue the table describes
■ A suffix, either _buf or _txn, which specifies whether the tableincludes buffers or transactions
Selecting from these tables provides information about the contents of eachqueue. For example, the following SELECT statement returns a list of all trans-actions queued on the send queue:
SELECT * FROM syscdrsend_txn
The following example returns a list of all transactions queued on the in-memory send queue and returns the number of buffers and the size of eachbuffer for each transaction on the send queue:
SELECT cbkeyserverid,cbkeyid,cbkeypos,count(*),sum(cbsize)from syscdrsend_bufgroup by cbkeyserverid, cbkeyid, cbkeyposorder by cbkeyserverid, cbkeyid, cbkeypos
All queues are present on all the replication servers, regardless of whether thereplication server is a source or a target for a particular transaction. Some ofthe queues are always empty. For instance, the send queue on a target-onlyserver is always empty.
Each queue is two-dimensional. Every queue has a list of transaction headers.Each transaction header in turn has a list of buffers that belong to thattransaction.
SMI Table Reference D-15
Columns of the Transaction Tables
Columns of the Transaction TablesAll the tables whose names end with _txn have the same columns and thesame column definitions. The information in the tables represents only trans-actions in memory and not those spooled to disk.
The ctstamp1 and ctstamp2 columns combine to form the primary key forthese tables.
Column Type Description
ctkeyserverid integer Server ID of the database server where this dataoriginated
This server ID is the group ID from the sqlhosts fileor the SQLHOSTS registry key.
ctkeyid integer Logical log ID
ctkeypos integer Position in the logical log on the source server forthe transaction represented by the buffer
ctkeysequence integer Sequence number for the buffer within thetransaction
ctstamp1 integer Together with ctstamp2, forms an insertion stampthat specifies the order of the transaction in thequeue
ctstamp2 integer Together with ctstamp1, forms an insertion stampthat specifies the order of the transaction in thequeue
ctcommittime integer Time when the transaction represented by thisbuffer was committed
ctuserid integer Login ID of the user who committed this transaction
ctfromid integer Server ID of the server that sent this transaction
Used only in hierarchical replication
D-16 Guide to IBM Informix Enterprise Replication

Columns of the Buffer Tables
Columns of the Buffer TablesThe tables whose names end with _buf give information about the buffersthat form the transactions listed in the _txn table. All the _buf tables have thesame columns and the same column definitions.
The following columns combine to form the primary key for this table:cbkeyserverid, cbkeyid, cbkeypos, cbkeysequence.
The columns cbkeyserverid, cbkeyid, and cbkeypos form a foreign key thatpoints to the transaction in the _txn table that the buffer represents.
Column Type Description
cbflags integer Internal flags for this buffer
cbsize integer Size of this buffer in bytes
cbkeyserverid integer Server ID of the database server where this dataoriginated
This server ID is group ID from the sqlhosts file orthe SQLHOSTS registry key.
cbkeyid integer Login ID of the user who originated the transactionrepresented by this buffer
cbkeypos integer Log position on the source server for the transactionrepresented by this buffer
cbkeysequence integer Sequence number for this buffer within thetransaction
cbreplid integer Replicate identifier for the data in this buffer
cbcommittime integer Time when the transaction represented by thisbuffer was committed
SMI Table Reference D-17


EAppendix
Replication Examples
This appendix contains simple examples of replication using thecommand-line utility (CLU). Appendix A, “Command-Line UtilityReference” documents the CLU.
Replication Example EnvironmentTo run the replication examples in this chapter, you need threeInformix database servers. Each database server must be in adatabase server group.
This example uses the following environment:
■ Three computers (s1, s2, and s3) are hosts for thedatabase servers usa, italy, and japan, respectively. Eachcomputer has active network connections to the othertwo computers.
■ The database servers usa, italy, and japan are membersof the database server groups g_usa, g_italy, andg_japan, respectively.
For information about database server groups, see “Set-ting up Database Server Groups” on page 4-5.

Replication Example Environment
■ The UNIX sqlhosts file for each database server contains thefollowing connectivity information.
♦See Appendix F, “SQLHOSTS Registry Key” for information on howto prepare the SQLHOSTS connectivity information using the infor-mation in the UNIX sqlhosts file. ♦
■ The ONCONFIG file contains the following CDR_QDATA_SBSPACEentry:
CDR_QDATA_SBSPACE sbspace #CDR queue smart blob space
You must create an sbspace for the row data and set theCDR_QDATA_SBSPACE parameter to the location of that sbspace. Formore information, see “Setting Up Send and Receive Queue SpoolAreas” on page 4-11 and “CDR_QDATA_SBSPACE” on page B-9.
■ All commands in this example, except for creation of the sampledatabases on italy and japan, are issued from the computer s1.
■ The databases for the examples in this chapter are identicalstores_demo databases with logging, as follows:
❑ Create a database named stores on the usa database server:s1> dbaccessdemo -log stores
❑ Create a database named stores on the italy database server:s1> rlogin s2s2> dbaccessdemo -log stores
❑ Create a database named stores on the japan database server:s1> rlogin s3s2> dbaccessdemo -log stores
For information on preparing data for replication, see “Data Prepa-ration Example” on page 4-24.
g_usa group - - i=1
usa ontlitcp s1 techpubs1 g=g_usa
g_italy group - - i=8
italy ontlitcp s2 techpubs2 g=g_italy
g_japan group - - i=6
japan ontlitcp s3 techpub6 g=g_usa
UNIX
WIN NT/2000
E-2 Guide to IBM Informix Enterprise Replication

Primary-Target Example
Primary-Target ExampleThis section contains a simple example of primary-target replication. Inprimary-target replication, only changes to the primary table are replicatedto the other tables in the replicate. Changes to the secondary tables are notreplicated.
Preparing for a Primary-Target ReplicationIn this example, define the g_usa and g_italy database server groups asEnterprise Replication servers and create a replicate, repl1.
To define the database server groups and create the replicate
1. Create and populate the database that defines the usa databaseserver as a replication server:
cdr define server --init g_usa
Before replicating data, you must define the database servers as rep-lication servers. A replication server is a database server that has anextra database that holds replication information.
The --init option specifies that this server is a new replication server.When you define a replication server, you must use the name of thedatabase server group (g_usa) rather than the database server name.
2. Display the replication server that you defined to verify that thedefinition succeeded:
cdr list server
The command returns the following information:SERVER ID STATE STATUS QUEUE CONNECTION CHANGED----------------------------------------------------------g_usa 1 Active Local 0
Replication Examples E-3

Preparing for a Primary-Target Replication
3. Define the second database server, italy, as a replication server:cdr define server --connect=italy --init \--sync=g_usa g_italy
The --connect option allows you to define italy (on the s2 computer)while working at the s1 (usa) computer. The --sync option instructsthe command to use the already-defined replication server (g_usa) asa pattern for the new definition. The --sync option also links the tworeplication servers into a replication environment.
Tip: In all options except the --connect option, Enterprise Replication uses thename of the database server group to which a database server belongs, instead of thename of the database server itself.
4. Verify that the second definition succeeded:cdr list server
The command returns the following information:
5. Define the replicate repl1:cdr define replicate --conflict=ignore repl1 \"P stores@g_usa:informix.manufact" \"select * from manufact" \"R stores@g_italy:informix.manufact" \"select * from manufact"
These lines are all one command. The backslashes (\) at the end ofthe lines indicate that the command continues on the next line.
This step specifies that conflicts should be ignored and describes twoparticipants, usa and italy, in the replicate:
■ The P indicates that in this replicate usa is a primary server. Thatis, if any data in the selected columns changes, that changed datashould be sent to the secondary servers.
■ The R indicates that in this replicate italy is a secondary server(receive-only). The specified table and columns receive infor-mation that is sent from the primary server. Changes to thosecolumns on italy are not replicated.
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED
----------------------------------------------------------------------
g_italy 8 Active Connected 0 JUN 14 14:38:44 2000
g_usa 1 Active Local 0
E-4 Guide to IBM Informix Enterprise Replication

Preparing for a Primary-Target Replication
6. Display the replicate that you defined, so that you can verify that thedefinition succeeded:
cdr list replicate
The command returns the following information:CURRENTLY DEFINED REPLICATES------------------------------------------------REPLICATE: repl1STATE: InactiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: g_usa:informix.manufact
g_italy:informix.manufact
Step 5 defines a replicate but does not make the replicate active. Theoutput of step 6 shows that the STATE of the replicate is INACTIVE.
7. Make the replicate active:cdr start replicate repl1
8. Display the replicate so that you can verify that the STATE haschanged to ACTIVE:
cdr list replicate
The command returns the following information:CURRENTLY DEFINED REPLICATES------------------------------------------------REPLICATE: repl1STATE: ActiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: g_usa:informix.manufact
g_italy:informix.manufact
If any changes are made to the manufact table, the changes will bereplicated to the other participants in the replicate.
Replication Examples E-5

Cause a Replication
Cause a ReplicationNow you can modify the manufact table on the usa database server and seethe change reflected in the manufact table on the italy database server.
To cause a replication
1. Use DB-Access to insert a value into the manufact table on usa:INSERT INTO stores@usa:manufact \VALUES ('AWN','Allwyn','8');
2. Observe the changes on usa and on italy:SELECT * from stores@usa:manufactSELECT * from stores@italy:manufact
Do Not Cause a ReplicationIn repl1, usa is the primary database server and italy is the target. Changesmade to the manufact table on italy do not replicate to usa.
To not cause a replication
1. Use DB-Access to insert a value into the manufact table on italy:INSERT INTO stores@italy:manufact \VALUES ('ZZZ','Zip','9');
2. Verify that the change occurred on italy but did not replicate to themanufact table on usa:
SELECT * from stores@usa:manufactSELECT * from stores@italy:manufact
Update-Anywhere ExampleThis example builds on the previous example and creates a simple update-anywhere replication. In update-anywhere replication, changes to any table inthe replicate are replicated to all other tables in the replicate. In this example,any change to the stock table of the stores database on any database serverin the replicate will be replicated to the stock table on the other databaseservers.
E-6 Guide to IBM Informix Enterprise Replication

Preparing for an Update-Anywhere Replication
Preparing for an Update-Anywhere ReplicationIn this example, define the repl2 replicate.
To prepare for update-anywhere replication
1. Define the replicate, repl2:cdr define replicate --conflict=ignore repl2 \"stores@g_usa:informix.stock" "select * from stock" \"stores@g_italy:informix.stock" "select * from stock"
These lines are all one command. The backslashes (\) at the end ofthe lines indicate that the command continues on the next line.
This step specifies that conflicts should be ignored and describes twoparticipants, usa and italy (including the table and the columns toreplicate) in the replicate.
Because neither P (primary) nor R (receive-only) is specified, the rep-licate is defined as update-anywhere. If any data in the selectedcolumns changes, on either participant, that changed data should besent to the other participants in the replicate.
2. Display all the replicates so that you can verify that your definitionof repl2 succeeded:
cdr list replicate
The command returns the following information:CURRENTLY DEFINED REPLICATES---------------------------------------------------------REPLICATE: repl1STATE: ActiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: g_usa:informix.manufact
g_italy:informix.manufact
REPLICATE: repl2STATE: InactiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: g_usa:informix.stock
g_italy:informix.manufact
Although this output shows that repl2 exists, it does not show theparticipant modifiers (the SELECT statements) for repl2.
Replication Examples E-7

Preparing for an Update-Anywhere Replication
3. Display the participant modifiers for repl2:cdr list replicate repl2
This command returns the following information:
4. Add the japan database server to the replication system alreadydefined in the previous example:
cdr define server --connect=japan --init \--sync=g_usa g_japan
You can use either g_usa or g_italy in the --sync option.
Enterprise Replication maintains identical information on all serversthat participate in the replication system. Therefore, when you addthe japan database server, information about that server is propa-gated to all previously-defined replication servers (usa and italy).
5. Display the replication servers so that you can verify that thedefinition succeeded:
cdr list server
The command returns the following information:
6. Add the participant and participant modifier to repl2:cdr change replicate --add repl2 \"stores@g_japan:informix.stock" "select * from stock"
REPLICATE TABLE SELECT
------------------------------------------------------------
repl2 stores@g_usa:informix.stock select * from stock
repl2 stores@g_italy:informix.stock select * from stock
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED
----------------------------------------------------------------------
g_italy 8 Active Connected 0 JUN 14 14:38:44 2000
g_japan 6 Active Connected 0 JUN 14 14:38:44 2000
g_usa 1 Active Local
E-8 Guide to IBM Informix Enterprise Replication

Preparing for an Update-Anywhere Replication
7. Display detailed information about repl2 after adding the partic-ipant in step 6:
cdr list replicate repl2
The command returns the following information:
8. Make the replicate active:cdr start replicate repl2
Changes made to the stock table on usa are reflected in the stocktables on both italy and japan.
9. Display a list of replicates so that you can verify that the STATE ofrepl2 has changed to ACTIVE
cdr list replicate
The command returns the following information:
CURRENTLY DEFINED REPLICATES------------------------------------------------------REPLICATE: repl1STATE: ActiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: g_usa:informix.manufact
g_italy:informix.manufact
REPLICATE: repl2STATE: ActiveCONFLICT: IgnoreFREQUENCY: immediateQUEUE SIZE: 0PARTICIPANT: g_usa:informix.stock
g_italy:informix.manufactg_japan:informix.manufact
REPLICATE TABLE SELECT
------------------------------------------------------------
repl2 stores@g_usa:informix.stock select * from stock
repl2 stores@g_italy:informix.stock select * from stock
repl2 stores@g_japan:informix.stock select * from stock
Replication Examples E-9

Cause a Replication
Cause a ReplicationNow you can modify the stock table on one database server and see thechange reflected on the other database servers.
To cause a replication
1. Use DB-Access to insert a line into the stock table on usa:INSERT INTO stores@usa:stock VALUES (401, “PRC”, “ski boots”,200.00, “pair”, “pair”);
2. Observe the change on the italy and japan database servers:SELECT * from stores@italy:stock;SELECT * from stores@japan:stock;
To update the stock table on the japan database server
1. Use DB-Access to change a value in the stock table on japan:UPDATE stores@japan:stock SET unit_price = 190.00WHERE stock_num = 401;
2. Verify that the change has replicated to the stock table on usa and onitaly:
SELECT * from stores@usa:stock WHERE stock_num = 401;SELECT * from stores@italy:stock WHERE stock_num = 401;
E-10 Guide to IBM Informix Enterprise Replication

Hierarchy Example
Hierarchy ExampleThe example in this section adds a replication tree to the fully-connectedenvironment of the usa, italy, and japan replication servers. The nonrootservers boston and denver are children of usa. (The leaf server miami is achild of boston.) Figure E-1 shows the replication hierarchy.
Preparing for a Hierarchy ExampleTo try this example, you need to prepare three additional database servers:boston, denver, and miami. To prepare the database servers, use thetechniques described in “Replication Example Environment” on page E-1.
Figure E-1Hierarchical Tree
Example
root
usa
boston
leaf
miaminonroot
denver
root
japan
root
italy
nonroot
Replication Examples E-11

Defining a Hierarchy
Defining a HierarchyThe following example defines a replication hierarchy that includes denver,boston, and miami and whose root is usa.
To define a hierarchy
1. Add boston to the replication hierarchy as a nonroot server attachedto the root server usa:
cdr define server --connect boston --nonroot --init \--sync g_usa g_boston
The backslash (\) indicates that the command continues on the nextline.
2. Add denver to the replication hierarchy as a nonroot server attachedto the root server usa:
cdr define server -c denver -I -N --ats=/ix/myats \-S g_usa g_denver
This command uses short forms for the connect, init, and syncoptions. (For information about the short forms, refer to “OptionAbbreviations” on page A-84.) The command also specifies a direc-tory for collecting information about failed replication transactions,/ix/myats.
3. List the replication servers as seen by the usa replication server:cdr list server
The root server usa is fully connected to all the other root servers.Therefore usa knows the connection status of all other root serversand of its two child servers, denver and boston. The commandreturns the following information:
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED
----------------------------------------------------------------------
g_boston 3 Active Connected 0 Aug 19 14:20:03 2000
g_denver 27 Active Connected 0 Aug 19 14:20:03 2000
g_italy 8 Active Connected 0 Aug 19 14:20:03 2000
g_japan 6 Active Connected 0 Aug 19 14:20:03 2000
g_usa 1 Active Local 0
E-12 Guide to IBM Informix Enterprise Replication

Defining a Hierarchy
4. List the replication servers as seen by the denver replication server:cdr list server --connect denver
The nonroot server denver has a complete global catalog of replica-tion information, so it knows all the other servers in its replicationsystem. However, denver knows the connection status only of itselfand its parent, usa.
The command returns the following information:
5. Define miami as a leaf server whose parent is boston:cdr define server -c miami -I --leaf -S g_boston g_miami
6. List the replication servers as seen by miami:cdr list server -c miami
As a leaf replication server, miami has a limited catalog of replicationinformation. It knows only about itself and its parent.
The command returns the following information:
7. List details about the usa replication server:cdr list server g_usa
The server is a hub; that is, it forwards replication information to andfrom other servers. It uses the default values for idle timeout, sendqueue, receive queue, and ATS directory.
The command returns the following information:
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED
----------------------------------------------------------------------
g_boston 3 Active 0
g_denver 27 Active Local 0
g_italy 8 Active 0
g_japan 6 Active 0
g_usa 1 Active Connected 0 Aug 19 14:20:03 2000
SERVER ID STATE STATUS QUEUE CONNECTION CHANGED
----------------------------------------------------------------------
g_boston 3 Active Connected 0 Aug19 14:35:17 2000
g_miami 4 Active Local 0
NAME ID ATTRIBUTES
----------------------------------------------------------------------
g_usa 1 timeout=15 hub sendq=rootdbs recvq=rootdbs atsdir=/tmp
Replication Examples E-13


FAppendix
SQLHOSTS Registry KeyWIN NT/2000
When you install the database server, the setup program createsthe following key in the Windows registry:
HKEY_LOCAL_MACHINE\SOFTWARE\INFORMIX\SQLHOSTS
This branch of the HKEY_LOCAL_MACHINE subtree stores thesqlhosts information. Each key on the SQLHOSTS branch is thename of a database server. When you click the database servername, the registry displays the values of the HOST, OPTIONS,PROTOCOL, and SERVICE fields for that particular databaseserver.
Each computer that hosts a database server or a client mustinclude the connectivity information either in the SQLHOSTSregistry key or in a central registry. When the client applicationruns on the same computer as the database server, they share asingle SQLHOSTS registry key.
The Location of the SQLHOSTS Registry KeyWhen you install the database server on Windows, the instal-lation program asks where you want to store the SQLHOSTSregistry key. You can specify one of the following two options:
■ The local computer where you are installing thedatabase server
■ Another computer in the network that serves as acentral, shared repository of sqlhosts information formultiple database servers in the network

Local SQLHOSTS Registry Key
Local SQLHOSTS Registry KeyIf you use the SQLHOSTS registry key on the local computer, for all databaseservers, the correct SQLHOSTS registry key must exist on all computersinvolved in replication. In addition, the hosts and services files on eachcomputer must include information about all database servers.
For example, to set up replication between the server instance srv1 on thecomputer host1 and the server instance srv2 on host2, you must ensure thefollowing:
■ Both host1 and host2 include SQLHOSTS registry key entries for srv1and srv2.
■ The services file on both computers include the details of the servicesused by both database server instances.
Shared SQLHOSTS Registry KeyIf you use a shared SQLHOSTS registry key you do not need to maintain thesame sqlhosts information on multiple computers. However, the hosts andservices files on each computer must contain information about all computersthat have database servers.
If you specify a shared SQLHOSTS registry key, you must set the environmentvariable INFORMIXSQLHOSTS on your local computer to the name of theWindows computer that stores the registry. The database server first looks forthe SQLHOSTS registry key on the INFORMIXSQLHOSTS computer. If thedatabase server does not find an SQLHOSTS registry key on the INFORMIX-SQLHOSTS computer, or if $INFORMIXSQLHOSTS is not set, the databaseserver looks for an SQLHOSTS registry key on the local computer.
You must comply with Windows network-access conventions and filepermissions to ensure that the local computer has access to the sharedSQLHOSTS registry key. For information about network-access conventionsand file permissions, see your Windows documentation.
F-2 Guide to IBM Informix Enterprise Replication

Preparing the SQLHOSTS Connectivity Information
Preparing the SQLHOSTS Connectivity InformationPreparing the SQLHOSTS connectivity information consists of setting upregistry keys on each computer that hosts a database server that participatesin a replicate.
To prepare the SQLHOSTS connectivity information
1. Set up the SQLHOSTS registry key on the local computer.
2. Set up the database server group registry key on the local computer.
See “Setting Up the Database Server Group Registry Key” onpage F-6.
3. Set up the SQLHOSTS and group registry keys on all computers thatare participants in the replicate.
See “Setting up the Registry Keys on All Computers” on page F-8.
4. Ensure that the services files on each computer include entries for alldatabase servers that are participants in the replicate.
See “Verifying the services Files on All Computers” on page F-8.
Setting up the SQLHOSTS Registry with ISAImportant: Informix strongly recommends that you use Informix Server Adminis-trator (ISA), rather than regedt32, to set up the SQLHOSTS registry key anddatabase server group registry key on your Windows system. *In addition, ISAallows you to administer your replication system from a web browser. For more infor-mation, see the Documentation Notes described in “Additional Documentation” onpage 15 of the Introduction.
See the online help for ISA for details on setting up the SQLHOSTS registrykey and database server group registry key.
SQLHOSTS Registry Key F-3

Setting up the SQLHOSTS Registry Key with regedt32
Setting up the SQLHOSTS Registry Key with regedt32Informix recommends that you use ISA to set up the SQLHOSTS registry key.
Important: Use extreme caution with regedt32. If you make mistakes when editingthe registry, you can destroy the configuration, not only of your Informix products,but of your other applications.
To set up SQLHOSTS with regedt32
1. Run the Windows program, regedt32.
2. In the Registry Editor window, select the window for theHKEY_LOCAL_MACHINE subtree.
3. Click the folder icons to select the \SOFTWARE\INFORMIX\SQLHOSTS branch.
4. With the SQLHOSTS key selected, choose Edit➞ Add Key.
5. In the Add Key dialog box, type the name of the database server inthe Key Name dialog box.
Leave the Class dialog box blank. Click OK.
6. Select the new key that you just made (the key with the databaseserver name).
7. Choose Edit➞ Add Value.
8. In the Add Value dialog box, type one of the fields of the sqlhostsinformation (HOST, OPTIONS, PROTOCOL, SERVICE) in the ValueName dialog box.
Do not change the Data Type box. Click OK.
9. In the String Editor dialog box, type the value for the field that youselected and click OK.
10. Repeat steps 8 and 9 for each field of the sqlhosts information.
Figure F-1 illustrates the location and contents of the SQLHOSTS registry key.
F-4 Guide to IBM Informix Enterprise Replication

Setting up the SQLHOSTS Registry Key with regedt32
Figure F-1sqlhosts Information in the Windows Registry
SQLHOSTS Registry Key F-5

Setting Up the Database Server Group Registry Key
Setting Up the Database Server Group Registry KeyAfter you create the registry key for the database server, you must make aregistry key for the database server group that includes the database server.For more information, refer to “Verifying SQLHOSTS” on page 4-5.
To set up the database server group registry key
1. With the SQLHOSTS key selected, choose Edit➞ Add Key.
2. In the Add Key dialog box, type the name of the database servergroup in the Key Name dialog box.
This value must correspond to the OPTIONS value in the databaseserver name key.
Tip: In this manual (and in Figure F-1 on page F-5), each of the names of thedatabase server groups are the database server names prefixed by g_. The g_ prefix isnot a requirement; it is just the convention that this manual uses.
Leave the Class dialog box blank. Click OK.
3. Select the new key that you just made (the key with the databaseserver group name).
4. Choose Edit➞ Add Value.
5. In the Add Value dialog box, type one of the fields of the sqlhostsinformation (HOST, OPTIONS, PROTOCOL, SERVICE) in the ValueName dialog box.
Do not change the Data Type dialog box. Click OK.
6. In the String Editor dialog box, type the value for the field that youselected and click OK.
For a database server group, enter the following values:HOST -OPTIONS i=unique-integer-valuePROTOCOL groupSERVICE -
Each database server group must have an associated identifier value(i=) that is unique among all database servers in your environment.Enter a minus (-) for HOST and SERVICE to indicate that you are notassigning specific values to those fields.
F-6 Guide to IBM Informix Enterprise Replication
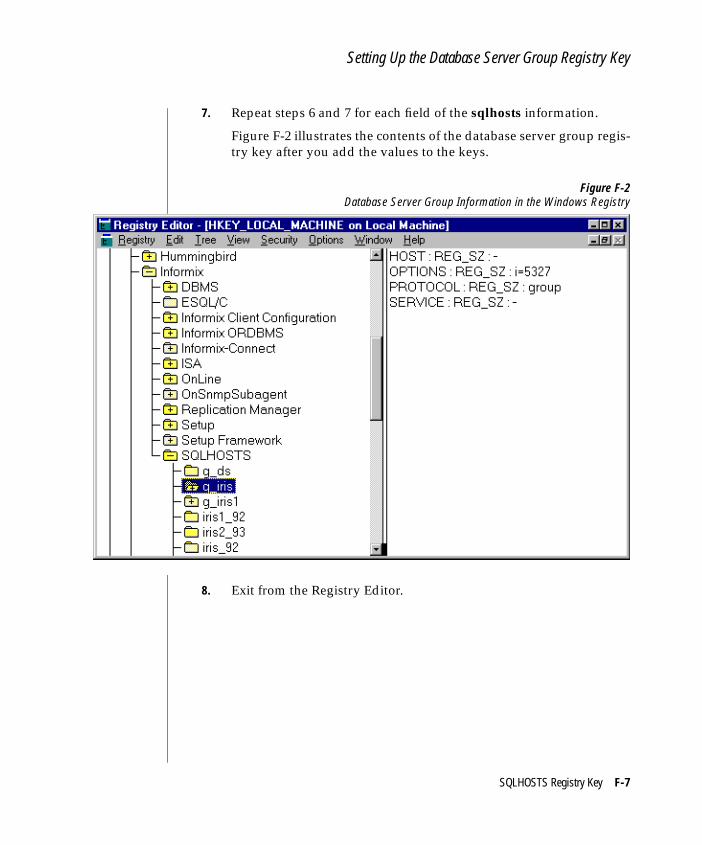
Setting Up the Database Server Group Registry Key
7. Repeat steps 6 and 7 for each field of the sqlhosts information.
Figure F-2 illustrates the contents of the database server group regis-try key after you add the values to the keys.
8. Exit from the Registry Editor.
Figure F-2Database Server Group Information in the Windows Registry
SQLHOSTS Registry Key F-7

Setting up the Registry Keys on All Computers
Setting up the Registry Keys on All ComputersNow, update the registry keys on all computers that participate inreplication.
To update the registry keys on all computers
1. Set up the SQLHOSTS registry key on all computers that participatein replication.
See “Setting up the SQLHOSTS Registry Key with regedt32” onpage F-4.
2. Set up the database server group registry key on all computers thatparticipate in replication.
See “Setting Up the Database Server Group Registry Key” onpage F-6.
Verifying the services Files on All ComputersFinally, on each computer that participates in replication, make sure that theservices file (located in the C:\WINNT/system32/drivers/etc/ directory)contains entries for all the database servers.
To verify the services files on all computers
1. Check the services file on the first host (for example, host1).
The file might look like thistechpubs27 4599/tcp # service for online instance denvertechpubs28 4600/tcp # service for online instance boston
2. Check the services file on the second host (for example, host2).
The file might should look the same as the file on host1:techpubs27 4599/tcp # service for online instance denvertechpubs28 4600/tcp # service for online instance boston
F-8 Guide to IBM Informix Enterprise Replication

@
Index
O QCA B D E F G H I J K L M N P R S T U V W X Y Z
Index
AAbbreviations
cdr define replicate set A-84commands A-84options A-84
Aborted rows, and ATS files 8-4Aborted Transaction Spooling. See
ATS.Activating
ATS A-13, A-23RIS A-13, A-23triggers A-14
Active statedefinition of 6-7replicates A-40server A-46
ADD CRCOLSdefining shadow columns 4-21
--add optioncdr change replicate 5-15, A-4cdr change replicateset 7-9, A-6
Addingchunks to storage spaces 8-16columns to a table 2-16participants to replicates 5-15,
A-4replicates to replicate sets 7-9,
A-6rowids 2-16
Administering EnterpriseReplication
CLU 1-8ISA 1-8overview 2-3
Administrationprimary-target replication
systems 3-9update-anywhere replication
systems 3-11Advantages, replicating
only changed columns 5-12Alarms, event 8-19--all option, cdr error A-36ALTER FRAGMENT
statement 2-15ALTER statements,
processing Intro-9ALTER TABLE statement
ADD and DROP CRCOLS 4-21See also Informix Guide to SQL:
Syntax.Alters, in-place Intro-9, 4-21ANSI compliance
level Intro-18Application-specific routines 3-17Applying data, process 1-17Arguments, in SPL routine 3-16,
3-17Asynchronous
data replication 1-4propagation, considerations 2-9
--at option 5-10, A-92time formats A-93
ATSactivating A-13, A-23capacity planning 4-15filenames, description of 8-5modifying directory 5-14specifying directory 5-6, A-22,
A-56

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
ATS filesBLOB and CLOB information 8-8BYTE and TEXT data 8-7changed column information 8-8configuring 5-11description of 8-3naming conventions 8-5preparing to use 8-4smart large objects 8-8UDT information 8-8UDTs 8-8
--ats option 5-6, 5-11, 8-4, A-13cdr define server A-23cdr modify replicate A-51cdr modify server A-57
Attributesreplicate, changing 5-16viewing 6-3
Average large object size. SeeAVG_LO_SIZE parameter.
AVG_LO_SIZE parameter 4-14
BBacking up databases,
considerations 2-9Batch jobs 2-15BEGIN WORK WITHOUT
REPLICATION 2-15, 4-18behavior 4-19DB-Access 4-20ESQL/C 4-20
Bitmap information, in logical logfiles 5-12
BLOB and CLOB informationin ATS files 8-8in RIS files 8-12
BLOB data type Intro-6spooled row data 4-13
Blobspacesinconsistent replicated data 2-20replicating from 2-20storing simple large objects 2-20
Blobs. See Simple large objects. 2-20Blocking replication 4-18Blockout mode, preventing 8-14Boldface type Intro-10Buffer tables, columns D-17
Buffers, transaction, spooling todisk 4-11, 8-13
Built-in Informix data types,support for 2-25
Business models, primary-targetsystems 3-4
BYTE dataATS files 8-7distributing 2-24loading with deluxe mode 4-23RIS files 8-12SPL conflict resolution 2-22storing in tblspaces 2-21
CCanonical format 5-13, A-14Capacity planning
for delete tables 4-10primary-target 3-9spooling directories 4-15update-anywhere 3-11
Capture mechanismslog-based data capture 1-5trigger-based data capture 1-5trigger-based transaction
capture 1-5Cascading deletes,
considerations 2-12cdr change replicate 5-15, A-4
examples A-5cdr change replicateset 7-9, A-6
examples A-7cdr change replset. See cdr change
replicateset.cdr connect server 6-11, A-9cdr define replicate 5-7, A-10
defining participants 5-8examples A-15options A-13
cdr define replicateset 7-4, A-17abbreviation A-84examples A-19
cdr define replset. See cdr definereplicateset.
cdr define server 5-5, A-20examples A-23options A-22 to A-23
cdr delete replicate 6-9, A-25examples A-25
cdr delete replicateset 7-8, A-27examples A-28
cdr delete replset. See cdr deletereplicateset.
cdr delete server 6-6, A-29examples A-30 to A-31
cdr disconnect server 6-10, A-33examples A-33
cdr error A-35examples A-37options A-36
cdr finderr A-38, A-91cdr list replicate 6-7, A-39
examples A-39, A-41cdr list replicateset 7-6, A-43
examples A-43cdr list replset. See cdr list
replicateset.cdr list server 6-3, A-45
CONNECTION CHANGEDcolumn A-47
description of output A-45examples A-45, A-47QUEUE column A-46STATE column A-46STATUS column A-46viewing network connection
status 6-10cdr modify replicate 5-16, A-49
examples A-52options A-51restrictions A-50
cdr modify replicateset 7-10, A-54examples A-54
cdr modify replset. See cdr modifyreplicateset.
cdr modify server 5-14, A-56examples A-57options A-57
CDR record type 5-12See also Informix Administrator’s
Reference.cdr resume replicate 6-9, A-59
examples A-59cdr resume replicateset 7-8, A-61cdr resume replset. See cdr resume
replicateset.
2 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
cdr resume server 6-6, A-63cdr start 6-5, A-65
examples A-65cdr start replicate 6-7, A-67
examples A-68cdr start replicateset 7-7, A-69
examples A-70cdr start replset. See cdr start
replicateset.cdr stop 6-4, A-71
examples A-72cdr stop replicate 6-8, A-73
examples A-74cdr stop replicateset 7-7, A-75
examples A-76cdr stop replset. See cdr stop
replicateset.cdr suspend replicate 6-9, A-77
examples A-78cdr suspend replicateset 7-7, A-79
examples A-80cdr suspend replset. See cdr
suspend replicateset.cdr suspend server 6-5, A-81
examples A-64, A-82cdrerr.h file A-38cdrserver shadow column 2-11,
2-21behavior with BEGIN WORK
WITHOUTREPLICATION 4-19
definition of 4-11See also Shadow columns.
cdrtime shadow column 2-11, 2-21behavior with BEGIN WORK
WITHOUTREPLICATION 4-19
definition of 4-11See also Shadow columns.
CDR_DSLOCKWAITparameter B-2
CDR_EVALTHREADSparameter B-3 to B-4
CDR_NIFCOMPRESSparameter B-5 to B-6
CDR_QDATA_SBFLAGSparameter B-10
CDR_QDATA_SBSPACEparameter Intro-9, 4-13, 4-14,4-16, B-9
CDR_QHDR_DBSPACEparameter Intro-9, 4-12, 4-16,B-8
CDR_QUEUEMEMparameter 4-11, 4-16, B-7
CDR_SBFLAGS parameter 4-14CDR_SBSPACE parameter 5-5CDR_SERIAL parameter Intro-8,
4-17, B-11Central registry, SQLHOSTS F-1Changed column information
in ATS files 8-8in RIS files 8-12
Changed column information, inATS files 8-8
Changed columns, replicating 5-11Changing
database triggers 5-16participant mode A-49replicate attributes 5-16replicate set state A-61
Child database server 3-21Choosing a replication network
topology 3-19Chunks, adding to storage
spaces 8-16CLOB data type Intro-6
spooled row data 4-13Clock synchronization 2-17, 8-17Clustered indexes, creating or
altering 2-16CLU. See
Command-line utility.Commands.
Code samples, conventionsfor Intro-14
Codeset conversion files 2-18Collision
definition of 1-17example 1-17
Columns D-16adding 2-16dropping 2-16modifying type 2-16primary key 5-12renaming 2-16
replicating changed only Intro-8,5-11
shadow. See Shadow columns.virtual 2-26
columns D-17Command-line conventions
elements of Intro-12example diagram Intro-14how to read Intro-14
Command-line utilityadministering Enterprise
Replication--connect option 4-6, 5-5description of A-1syntax, interpreting A-83terminology A-83See also Commands.
Commandsabbreviations A-84cdr change replicate 5-15, A-4cdr change replicateset 7-9, A-6cdr change replset. See
Commandscdr change replicateset
cdr connect server 6-11, A-9cdr define replicate 5-8, A-10cdr define replicateset 7-4, A-17cdr define replset. See cdr define
replicateset.cdr define server 5-5, A-20cdr delete replicate 6-9, A-25cdr delete replicateset 7-8, A-27cdr delete replset. See cdr delete
replicateset.cdr delete server 6-6, A-29cdr disconnect server 6-10, A-33cdr error A-35cdr finderr A-38, A-91cdr list replicate 6-7, A-39cdr list replicateset 7-6, A-43cdr list replset. See cdr list
replicateset.cdr list server 6-3, 6-10, A-45cdr modify replicate 5-16, A-49cdr modify replicateset 7-10, A-54cdr modify replset. See cdr modify
replicateset.cdr modify server 5-14, A-56cdr resume replicate 6-9, A-59
Index 3

@O QCA B D E F G H I J K L M N P R S T U V W X Y Z
cdr resume replicateset 7-8, A-61cdr resume replset. See cdr resume
replicateset.cdr resume server 6-6, A-63cdr start 6-5, A-65cdr start replicate 6-7, A-67cdr start replicateset 7-7, A-69cdr start replset. See cdr start
replicateset.cdr stop 6-4, A-71cdr stop replicate 6-8, A-73cdr stop replicateset 7-7, A-75cdr stop replset. See cdr stop
replicateset.cdr suspend replicate 6-9, A-77cdr suspend replicateset 7-7, A-79cdr suspend replset. See cdr
suspend replicateset.cdr suspend server 6-5, A-81dbaccess 4-8error return codes A-91net time 2-18oninit 5-4onmode 5-4onspaces 4-12, 4-13, 8-16onstat 8-3, 8-15, C-1 to C-10onstat -g ath C-2onstat -g cat C-4onstat -g ddr C-4onstat -g dss C-5onstat -g dtc C-5onstat -g grp C-6onstat -g nif C-7onstat -g que C-8onstat -g rcv C-8onstat -g rep C-9onstat -g rqm C-9ping 4-8rdate 2-18starts 5-4summary of A-1synchronizing clocks 2-18
Comment icons Intro-11Compliance
with industry standards Intro-18Configuration parameters. See
Parameters.Configuration problems,
solving 8-17 to 8-18
ConfiguringATS and RIS files 5-11logical logs files, for Enterprise
Replication 4-10trusted environment 4-5
CONFLICT fieldcdr list replicate output A-41
--conflict option 5-10, A-12Conflict resolution
and table hierarchies 2-26BYTE data 2-22cdrserver 2-21cdrtime 2-21considerations for SPL
routine 3-17CRCOLS, adding and
dropping 2-16delete tables 3-14, 4-10description of 3-11options A-11preparing tables for 4-21rules 3-12
behavior 3-18changing 5-16ignore 3-13, 5-10replicating only changed
columns 5-12shadow columns 3-12specifying 5-10SPL routine 3-15, 5-10time synchronization 3-15timestamp 3-14, 5-10valid combinations 3-12
scopechanging 5-16options A-11row 3-18, 5-10specifying 5-10transaction 3-18, 5-10
shadow columns 2-21simple large objects 2-21specifying options A-11SPL 2-22support for UDRs 3-16TEXT data 2-22timestamp 2-17, 2-21transactional integrity 3-18triggers 2-13update-anywhere 3-10
Conflicts, and asynchronouspropagation 2-9
--connect optionand database server name 5-5and replicate sets 7-3connecting to another replication
server 6-4description of A-21
Connected status, replicationservers A-46
Connecting status, replicationservers A-46
Connecting to a databaseserver A-9
CONNECTION CHANGEDcolumn, cdr list serveroutput A-47
Connections, testing network 4-8Considerations
distributed transactions 2-14large transactions 2-15memory use C-3planning to use Enterprise
Replication 2-8primary-target replication
systems 3-9replicating
changed columns only 5-12extensible data types 2-25
replicationenvironment 2-17volume 2-14
SELECT statement A-91SPL routines for conflict
resolution 3-17transaction processing 2-14update-anywhere replication
systems 3-11Consistency, ensuring 4-18Consolidation replication. See
Many-to-one replication.Constraints
checking 3-19primary key 2-11referential 5-11
Contact information Intro-18Conventions
ATS files 8-5code samples Intro-14
4 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
command-line utility A-83database server groups 4-6documentation Intro-10
CRCOLS. See Shadow columns.CREATE TABLE statement 4-21
See also Informix Guide to SQL:Syntax.
Creatingclustered indexes 2-16databases with unbuffered
logging 2-10demonstration databases Intro-5replicate sets 7-4row data sbspace 4-13
Cross-replication, between simplelarge objects and smart largeobjects 2-21
Customizingreplicate sets 7-5replicates 5-7replication server definition 5-6
DData
applying 1-17capture types 1-5distributing 1-17inconsistent 2-20loading 4-22maintaining consistency 1-6preparing 4-18unloading 4-22
Data deliveryresuming A-59, A-61, A-63suspending
for replicate sets A-79for replicates A-77for replication servers A-81
Data dissemination model,description of 3-5
Data propagation, considerationsfor asynchronous 2-9
Data replicationasynchronous, definition of 1-4capture mechanisms
log-based data capture 1-5trigger-based data capture 1-5
trigger-based transactioncapture 1-5
definition of 1-3synchronous, definition of 1-4
Data typesBLOB Intro-6built-in 1-7, 2-25CLOB Intro-6extensible 2-25FLOAT 5-13floating point 2-19SERIAL 2-12SERIAL and SERIAL8 2-19SERIAL8 2-12SMALLFLOAT 5-13supported Intro-6, 2-19user-defined 1-7
See also UDTs.Database server groups
conventions 4-6registry key F-6SQLHOSTS file 2-5, 4-5UNIX 4-6usage 4-6, 5-5Windows 4-7See also Administrator’s Guide for
Informix Dynamic Server.Database servers
aliases 4-5, 4-7connecting to A-9declaring for Enterprise
Replication 5-3disconnecting from A-33initializing 5-4listing A-45preparing environment 4-16removing from Enterprise
Replication A-29resuming data delivery A-63specifying type 5-7suspending data delivery A-81See also Administrator’s Guide for
Informix Dynamic Server.Database triggers, changing 5-16Databases
considerationsbacking up 2-9restoring 2-9
creatingdemonstration Intro-5with unbuffered logging 2-10
designing, considerations 2-9locking 2-15logging 4-22unbuffered logging 2-10
Data-consolidation model,description of 3-6
dbaccess commandtesting network environment 4-8See also
DB-Access utility.DB-Access User’s Manual.
DB-Access utilityBEGIN WORK WITHOUT
REPLICATION 4-20included databases Intro-5
dbexport utility 4-24See also Informix Migration Guide.
dbimport utility 4-24See also Informix Migration Guide.
DBSERVERALIASESparameter 4-7, 4-16, B-1
DBSERVERNAME parameter 4-7,4-16, B-1
dbservername, description of 4-6Dbspaces
creating 4-12delete table storage 4-10increasing size 8-16monitoring disk usage 8-15pathname limitations 4-12root 4-12size of transaction record 4-12spooled transaction records 4-11transaction record 4-12See also
Administrator’s Guide for InformixDynamic Server.
Informix Administrator’sReference.
Deadlock situation, definitionof 3-13
Decision support systems. See DSS.Declaring database server for
Enterprise Replication 5-3
Index 5

@O QCA B D E F G H I J K L M N P R S T U V W X Y Z
Defaultbehavior of Enterprise
Replication 5-11dbspace for transaction
records 4-12locale Intro-4spooling directories 4-15
Definingparticipants 5-8replicate sets A-17replicates 5-7 to 5-14, A-10replication servers 5-3, 5-5, A-20shadow columns 4-21
Definition Failed state A-40--delete option 5-15, 7-9
cdr change replicate A-4cdr change replicateset A-6
Delete tablescapacity planning 4-10definition of 1-18, 4-10disk space 4-10in conflict resolution 3-14, 3-16storage 4-10timestamp conflict resolution
rule 4-10Deleted state, server A-46Deletes, cascading. See Cascading
deletes.Deleting
Enterprise Replication objects 2-9participants from replicates 5-15,
A-4replicate sets 7-8, A-27replicates from global catalog 6-9,
A-25replicates from replicate sets 7-9,
A-6replication servers 6-6, A-29
Deluxe mode withoutreplication 4-23
Demonstration databases Intro-5Dependencies, software Intro-4Designing databases and tables 2-9Determining size
logical log files 4-9spooled row data sbspace 4-13transaction record dbspace 4-12
DirectoriesINFORMIXDIR/bin Intro-5INFORMIXDIR/gls/cv9 2-18specifying
ATS location 5-6RIS location 5-6
spooling, planning forcapacity 4-15
Disconnect status, replicationservers A-46
Disconnecting serverconnection A-33
Disk space requirementsdelete table 4-10message queue spooling 4-11planning 4-9shadow columns 4-11
Disk usage, monitoring 8-15Disk, preparing for Enterprise
Replication 4-9Displaying information about
replicates A-40Distributed transactions
definition of 2-14two-phase commit 2-14
DistributingBYTE and TEXT data 2-24data, process for 1-17
Distribution replication. See One-to-many replication.
DNS 4-4Documentation notes Intro-16Documentation notes, program
item Intro-17Documentation, types of Intro-15
documentation notes Intro-16machine notes Intro-16release notes Intro-16
Domain Name Service. See DNS.DROP CRCOLS statement 4-21DROP TABLE statement 2-15Dropped network connections,
reestablishing 6-11Dropped status, replication
servers A-46Dropping
columns from a table 2-16network connection 6-10rowids 2-16
shadow columns 4-21DSS, and data consolidation
business model 3-6
EEnabling triggers 5-14English locale 2-18Enterprise Replication
administering 1-8administration overview 2-3and cascading deletes 2-12and High availability data
replication 2-8and triggers 2-13batch jobs 2-15consistency 1-6data types 2-19default behavior 5-11definition of 1-3deleting and recreating
objects 2-9evaluation logic 1-9event alarms 8-19flexible architecture 1-7high availability 1-6managing 2-4performance 1-6process for replicating data 1-8queues D-15role of logical log files 2-10selecting replication systems 3-3server
administrator 2-4definition of 2-5definitions in global catalog 2-6
starting A-65stopping A-71supported database servers 2-8synonyms 2-8terminology 2-4threads
list of C-3restarting 6-5stopping 6-4
using Global LanguageSupport 2-18
views 2-8
6 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
Environmentdatabase server, preparing 4-16network
preparing 4-3testing 4-8
trusted, configuring 4-5Environment variables Intro-10
INFORMIXDIR 4-16INFORMIXSERVER 4-6, 4-16,
5-5, 6-4INFORMIXSQLHOSTS 4-16, F-2setting 4-16TZ A-93See also Informix Administrator’s
Reference.en_us.8859-1 locale Intro-4Error
interpreting error numbers A-38logging
changing 5-16setting up 5-11
message filescdrerr.h A-38
replication server status A-46return codes A-91table
managing A-35ESQL/C, BEGIN WORK
WITHOUTREPLICATION 4-20
\etc\hosts file 4-4\etc\hosts.equiv file 4-5\etc\services file 4-4/etc/hosts file 4-4/etc/hosts.equiv file 4-5/etc/services file 4-4Evaluating
datafor replication 1-9
data, examples of 1-14rows 1-9, 1-12
Evaluation logic 1-9Event alarms 8-19--every option 5-10, A-92Examples
adding replicates to replicatesets 7-9
ATS filenames 8-5
BEGIN WORK WITHOUTREPLICATION 4-20
BYTE and TEXT datain ATS files 8-7in RIS files 8-12
cdr change replicate A-5cdr change replicateset A-7cdr define replicate A-15cdr define replicateset A-19cdr define server A-23cdr delete replicate A-25cdr delete replicateset A-28cdr delete server A-30 to A-31cdr disconnect server A-33cdr error A-37cdr list replicate A-39, A-41cdr list replicateset A-43cdr list server A-45, A-47cdr modify replicate A-52cdr modify replicateset A-54cdr modify server A-57cdr resume replicate A-59cdr resume replicateset A-61cdr start A-65cdr start replicate A-68cdr start replicateset A-70cdr stop A-72cdr stop replicate A-74cdr stop replicateset A-76cdr suspend replicate A-78cdr suspend replicateset A-80cdr suspend server A-64, A-82changing frequency for replicate
sets 7-10collision 1-17connecting to global catalog 6-4DB-Access 4-20defining replicate sets 7-5deleting
replicate sets 7-8replicates 6-9replicates from replicate sets 7-9replication servers 6-6
evaluating data 1-14hierarchy E-11hosts.equiv 4-5non-exclusive replicate sets 7-5participant definition 5-8
preparing data forreplication 4-24 to 4-26
primary-target E-3replicate sets A-76, A-80replication E-1 to E-13replication environment E-1resuming
replicate sets 7-8replicates 6-9replication servers 6-6
RIS filenames 8-10services file 4-4SQLHOSTS file 4-6starting
replicate sets 7-7replicates 6-7
stoppingreplicate sets 7-7replicates 6-8
suspendingreplicate sets 7-7replicates 6-9replication 6-5
unloading shadow columns 4-22update-anywhere E-6updating shadow columns 4-20using ESQL/C 4-20
Exclusive locks 2-15--exclusive option 7-4, A-18Exclusive replicate sets
adding replicates to 7-9characteristics of 7-4definition of 7-4--exclusive option 7-4, A-18managing replicates 6-7referential constraints 5-11resuming replicates 6-9starting replicates 6-8stopping replicates 6-8suspending replicates 6-9
Extensible data typesreplicating 2-25support for Intro-6
Index 7

@O QCA B D E F G H I J K L M N P R S T U V W X Y Z
FFailed transactions
and RIS files 5-11, 8-9recorded in ATS files 5-11, 8-3
Fail-safe replication system 3-9Feature icons Intro-11Features
extensible data types Intro-6new Intro-5 to Intro-9performance Intro-7
Filescdrerr.h A-38hosts 4-4hosts.equiv 4-5logical log 4-10ONCONFIG 2-12, 4-16services 4-4SQLHOSTS 4-5, 4-6, 4-16.rhosts 4-5/etc/hosts 4-4/etc/hosts.equiv 4-5/etc/services 4-4\etc\hosts 4-4\etc\hosts.equiv 4-5\etc\services 4-4
finderr utility Intro-17--firetrigger option 5-14, A-14
modifying replicates A-52FLOAT data type 5-13--floatcanon option 5-13, A-14Floating-point
data types 2-19numbers
canonical format A-14IEEE format A-14
numbers, canonical format A-14values, and canonical message
format 5-13--follow option, cdr error A-36Forbidden SQL statements 2-15Forest of trees
definition of 3-24illustrated 3-24network topology 1-7
Frequencyattributes
description of 5-10examples A-52
description of A-92replication, specifying 5-10
FREQUENCY field, cdr listreplicate output A-41
Full row replication, changing 5-16--fullrow option 5-11, A-14
modifying replicates A-52Fully connected topology
definition of 3-20support for 1-7
Functions, writing for UDTreplication 2-25
GGlobal catalog
contents of 2-6description of 2-6leaf servers 2-7, 4-8root and nonroot servers 4-8synchronizing 5-6
Global Language Supportdescription of Intro-4locale of date A-93support of 1-7using with Enterprise
Replication 2-18GLS. See Global Language Support.Groups. See Database server
groups.Guidelines for configuring logical
log files 4-10
HHardware platforms
dissimilar 5-13heterogeneous 2-19
HDR. See High availability.Help Intro-15Heterogeneous hardware,
replicating on 2-19Hierarchical routing topologies
SQLHOSTS 4-8supported types 3-21synchronization server 3-22, 5-6terminology 3-21
Hierarchical treedefinition of 3-22network topology 1-7
Hierarchiesreplicating table hierarchies 2-26replication examples E-11
High availabilitydata replication, and Enterprise
Replication 2-8planning
primary-target 3-9using Enterprise Replication
for 1-6High-Performance Loader 4-23
See also Guide to the High-Performance Loader.
HKEY_LOCAL_MACHINE F-1hostname, in sqlhosts 4-7Hosts file, preparing 4-4hosts.equiv file 4-5HPL. See High-Performance
Loader.HR. See Hierarchical routing
topologies.
IIcons
feature Intro-11Important Intro-11platform Intro-11product Intro-11Tip Intro-11Warning Intro-11
ID column, cdr list serveroutput A-45
Identifiers A-86See also Informix Guide to SQL:
Syntax.--idle option
cdr define server 5-6, A-23cdr modify server A-57
Idle timeoutmodifying 5-14setting 5-6specifying A-22
IEEE floating point format 5-13,A-14
8 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
Ignore conflict-resolution rule 3-12,3-13, 5-10, A-41
database action 3-13--immed option 5-10, A-92Immediate frequency A-41Important paragraphs, icon
for Intro-11Inactive state
definition of 6-8description of A-40
Inconsistent data with blobspacesor sbspaces 2-20
Increasing storage space size 8-16Indexes, creating or altering
clustered 2-16Industry standards, compliance
with Intro-18Information consistency, update-
anywhere 3-11Informix data types 2-25Informix Server Administrator
(ISA) 1-8setting up SQLHOSTS
registry 4-7, F-3informix user 2-4Informix-Admin group,
Windows 2-4INFORMIXDIR environment
variable 4-16$INFORMIXDIR/bin
directory Intro-5$INFORMIXDIR/gls/cv9
directory 2-18$INFORMIXDIR/incl/esql/
cdrerr.h file A-38INFORMIXSERVER environment
variable 4-6, 4-16, 5-5, 6-4INFORMIXSQLHOSTS
environment variable 4-16, F-2--init option 5-5, A-21Initializing
database servers 5-4See also Administrator’s Guide for
Informix Dynamic Server.In-place alters, ADD and DROP
CRCOLS Intro-9, 4-21Interval formats A-94Invalid sbspace 5-5
IP addresses, specifying in hostsfile 4-4
ISA. See Informix ServerAdministrator.
ISO 8859-1 code set Intro-4
KKeys, primary
and constraints 2-11and SERIAL data types 2-12and UDT columns 2-26removing constraints 2-16
LLarge objects, replicating only
changed columns 5-12Large transactions, considerations
for Enterprise Replication 2-15--leaf option 5-7, A-21Leaf servers
definition of 3-21global catalog 2-6, 4-8limited catalog 2-7specifying 5-7SQLHOSTS information 4-8
Limitations, SPL conflictresolution 3-16
Limited SQL statements 2-16Listing
Enterprise Replicationservers A-45
replicate sets A-43replicates A-39
LOAD statement 4-22, 4-24See also Informix Guide to SQL:
Syntax.Loading data 4-22Local status, replication
servers A-46Locales
different 2-18Enterprise Replication 2-18specifying nondefault 2-18
Locking databases 2-15Locks, exclusive. See Exclusive
locks.
Log-based data capture 1-5Logging
aborted transactions 8-4databases, preparing 4-22errors 5-11unbuffered 2-10, 4-22
LOGGING parameter 4-14Logical log files 4-10
and maximum transactionsize 4-10
bitmap information aboutupdated columns 5-12
capacity planning 4-9configuration guidelines 4-10determining size 4-9disk space
error 8-18requirements 4-9
increasing size 8-14overwriting 8-14reading of 1-9role in Enterprise
Replication 2-10size 4-10switching 4-9See also
Administrator’s Guide for InformixDynamic Server.
Informix Administrator’sReference.
Logical Log Record reductionoption, and EnterpriseReplication 4-9
Long identifiers A-86LRD label, RIS files 8-11LRH label, RIS files 8-11LRS label, RIS files 8-11LTXEHWM parameter 4-10LTXHWM parameter 4-10
MMachine notes Intro-16Machine-independent format 5-13,
A-14Maintaining consistency 1-6
Index 9

@O QCA B D E F G H I J K L M N P R S T U V W X Y Z
Managingdatabase servers. See
Administrator’s Guide forInformix Dynamic Server.
Enterprise Replication,overview 2-4
replicate sets 7-6 to 7-8replicates 6-7 to 6-10
in exclusive replicate sets 6-7replication server network
connections 6-10 to 6-11replication servers 6-3 to 6-6
Many-to-one replication, definitionof 3-4
Maximum transaction size, andlogical log files 4-10
Memory queuespreventing overflows 8-13receive Intro-9send Intro-9
Memory use considerations C-3Message file for error
messages Intro-17Message formats
canonical 5-13IEEE 5-13
Message queuesCDR_QUEUEMEM
parameter 4-11definition of 4-11planning disk space 4-11
--mode option, cdr modifyserver A-57
Modes, changing participant A-49Modifying
column types 2-16primary-key constraint 2-16replicate attributes A-49replicate sets 7-9 to 7-10, A-54replicates 5-15replication servers 5-14 to 5-16,
A-56Monitoring
dbspaces, onstat command 8-15disk usage 8-15sbspaces 8-15
oncheck command 8-15onstat command 8-15
See alsoAdministrator’s Guide for Informix
Dynamic Server.Informix Administrator’s
Reference.Performance Guide for Informix
Dynamic Server.Multiple
references to a smart largeobject 2-24
updates to the same row 1-12
Nnet time command, synchronizing
clocks 2-18nettype, description of 4-6Network connections
dropping 6-10managing 6-10 to 6-11reestablishing 6-11troubleshooting 8-13viewing status 6-10
Network environmentpreparing 4-3testing 4-8See also Administrator’s Guide for
Informix Dynamic Server.Network topologies
choosing 3-19forest of trees 1-7fully connected 1-7hierarchical tree 1-7supported types 3-19
New features Intro-5 to Intro-9--nomark option, cdr error A-36Non-exclusive replicate sets
adding replicates to 7-9characteristics of 7-5definition of 7-5example of 7-5
Nonoptimized SPL routine 3-18--nonroot option 5-7, A-21Nonroot servers
definition of 3-21global catalog 2-6, 4-8specifying type 5-7SQLHOSTS information 4-8
OOLTP, and data dissemination
business model 3-5oncheck command, monitoring
sbspaces 8-15ONCONFIG file
configurationparameters B-1 to B-10
settingDBSERVERALIASES 4-7DBSERVERNAME 4-7parameters 2-12, 4-16
ONCONFIG parameters. SeeParameters.
One-to-many replication, definitionof 3-4
oninit command. initializingdatabase servers 5-4
Online help Intro-15Online manuals Intro-15Online transaction processing. See
OLTP.onload utility 4-23
See also Informix Migration Guide.onmode command 5-4onspaces command
adding chunks 8-16creating
row data sbspace 4-13transaction record dbspace 4-12
onstat command 8-3, C-1 to C-10monitoring
dbspaces 8-15sbspaces 8-15
onstat -g ath command C-2onstat -g cat command C-4onstat -g ddr command C-4onstat -g dss command C-5onstat -g dtc command C-5onstat -g grp command C-6onstat -g nif command C-7onstat -g que command C-8onstat -g rcv command C-8onstat -g rep command C-9onstat -g rqm command C-9onunload utility 4-22, 4-23
See also Informix Migration Guide.
10 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
Operating system times,synchronizing 2-17, 8-17
Optical devices, not supported 2-19--optimize option 5-10, A-12Optimized SPL routine, definition
of 3-18Options
abbreviations A-84--add 5-15, 7-9, A-4, A-6--all A-36--at 5-10, A-92--ats 5-6, 5-11, 8-4, A-13, A-23,
A-51, A-57cdr define replicate A-13cdr define server A-22 to A-23cdr error A-36cdr modify replicate A-51cdr modify server A-57--conflict 5-10, A-12conflict resolution A-11--connect 4-6, 5-5, 6-4, 7-3, A-21--connect option A-87--delete 5-15, 7-9, A-4, A-6--every 5-10, A-92--exclusive 7-4, A-18--firetrigger 5-14, A-14, A-52--floatcanon 5-13, A-14--follow A-36frequency A-92--fullrow 5-11, A-14, A-52--idle 5-6, A-23, A-57--immed 5-10, A-92in SQLHOSTS, description of 4-7--init 5-5, A-21--leaf 5-7, A-21--mode A-57--nomark A-36--nonroot 5-7, A-21--optimize 5-10, A-12order of A-85participant owner A-89primary A-89--prune A-36read-only A-89--ris 5-6, 5-11, 8-9, A-13, A-23,
A-51, A-57scope A-11--scope 5-10, A-12--seq A-36
--sync 5-6, A-21--zap A-36
Out-of-row data, sharing duringreplication 2-24
Overflowing memory queues,preventing 8-13
Overview of Enterprise Replicationadministration 2-3
Overwriting logical log files 8-14
PParallel processing
improvements Intro-7Parameters
AVG_LO_SIZE 4-14CDR_DSLOCKWAIT B-2CDR_EVALTHREADS B-3 to B-4CDR_NIFCOMPRESS B-5 to B-6CDR_QDATA_SBFLAGS B-10CDR_QDATA_SBSPACE Intro-9
, 4-13, 4-14, 4-16, B-9CDR_QHDR_DBSPACE Intro-9,
4-12, 4-16, B-8CDR_QUEUEMEM 4-11, 4-16,
B-7CDR_SBFLAGS 4-14CDR_SBSPACE 5-5CDR_SERIAL Intro-8, 4-17, B-11configuration B-1 to B-10DBSERVERALIASES 4-16, B-1DBSERVERNAME 4-16, B-1LOGGING 4-14LTXEHWM 4-10LTXHWM 4-10setting in ONCONFIG file 2-12,
4-16Parent database server. definition
of 3-21Parent-child
definition of 3-21Participant definition
contents 5-8example 5-8
Participant modifiersdescription of A-88restrictions 2-25, A-91
Participant typechanging 5-16default 5-8Primary 5-8Target 5-8
Participantsadding to replicates 5-15changing mode A-49defining 5-8, A-88definition of 2-5, 5-3, A-88deleting from replicates 5-15modifier A-90owner option A-89primary option A-89read-only option A-89specifying type A-89update-anywhere 5-9
PathnamesATS and RIS directories 4-15dbspaces 4-12sbspaces 4-13
Pending state, description of A-40Performance
Enterprise Replication 1-6LOGGING parameter 4-14new improvements Intro-7
Permitted SQL statements 2-16ping command, testing network
connection 4-8Planning
considerations 2-8for disk space requirements 4-9
Platform icons Intro-11Port numbers, services file 4-5Preparing
consistent data 4-18data for replication
description of 4-18example of 4-24 to 4-26
database serverenvironment 4-16
disk, for EnterpriseReplication 4-9
for UDT replication 4-21hosts file 4-4logging databases 4-22network environment 4-3services file 4-4
Index 11

@O QCA B D E F G H I J K L M N P R S T U V W X Y Z
SQLHOSTS connectivityinformation F-3
tables for conflict resolution 4-21to use ATS 8-4to use RIS 8-9
Preventing blockout mode 8-14Preventing memory queues from
overflowing 8-13Primary
option A-89participant type 5-8
Primary conflict-resolutionrule 3-12, 3-13
PRIMARY KEY constraint 2-11See also
Informix Guide to DatabaseDesign and Implementation
Informix Guide to SQL: Syntax.Informix Guide to SQL: Syntax.
Primary keysand SERIAL data types 2-12constraints 2-11modifying column 2-16removing constraint 2-16replicating changed columns 5-12UDT columns Intro-6, 2-26updates 1-12
Primary-targetexample E-3replication systems
business models 3-4considerations 3-9definition of 3-3
Problems, solvingconfiguration 8-17 to 8-18
Procedure conflict-resolutionrule A-41
Processing ALTERstatements Intro-9
Product icons Intro-11Program group
Documentation notes Intro-17Release notes Intro-17
Properties, replicate sets 7-6--prune option, cdr error A-36
QQUEUE column, cdr list server
output A-46Queues. See Memory queues.Quiescent state
description of A-40server A-46
RRAW tables, unsupported 2-10rdate command, synchronizing
clocks 2-18Read-only
option A-89participant type. See Target
participant type.Receive queues Intro-9
definition of 1-13, 4-11See also Memory queues.
Recording failed transactions, inATS files 8-4
RecreatingEnterprise Replication objects 2-9replicate sets 7-8replicates 6-10replication servers 6-6
Reestablishing networkconnections 6-11
Referential constraints 7-4and time-based replication 5-11
Referential integrity, and replicatesets 7-4
regedt32 program and sqlhostsregistry F-4
Release notes Intro-16Release notes, program
item Intro-17Reliable Queue Manager, definition
of 4-11Removing primary key
constraint 2-16RENAME TABLE statement 2-15Renaming columns 2-16Replicate sets Intro-8
adding and deletingreplicates 7-9
changing replicationfrequency 7-10
changing state A-61--connect option 7-3creating 7-4customizing 7-5defining A-17definition of 2-6, 7-3deleting 7-8, A-27examples A-61, A-70, A-76, A-80exclusive 7-4frequency 7-5listing A-43managing 7-6 to 7-8modifying 7-9 to 7-10, A-54non-exclusive 7-5recreating 7-8referential constraints 5-11resuming 7-8, A-61starting 7-7, A-69stopping 7-7, A-75supported versions 7-3, A-17suspending 7-7, A-79viewing properties 7-6
Replicatesactivating
ATS A-13RIS A-13
active state 6-7adding
participants A-4to replicate sets 7-9
CONFLICT field A-41conflict options A-11customizing 5-7defining 5-7 to 5-14, A-10definition of 2-5, 5-3deleting
from global catalog 6-9, A-25from replicate sets 7-9participants A-4
displaying informationabout A-40
FREQUENCY field A-41inactive state 6-8listing A-39managing 6-7 to 6-10modifying 5-15, A-49recreating 6-10
12 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
resuming 6-9, A-59exclusive replicate sets 6-9
starting 6-7, A-67exclusive replicate sets 6-8
STATE field A-40stopping 6-8, A-73
exclusive replicate sets 6-8suspending 6-9, A-77
exclusive replicate sets 6-9viewing properties 6-7
Replicatingchanged columns only 5-11, 5-12columns Intro-8extensible data types
considerations 2-25floating-point values 5-13large objects 5-12multiple references to a smart
large object 2-24simple large objects 2-20 to 2-24smart large objects 2-20 to 2-24table hierarchies 2-26UDTs 2-25
Replicating datacapturing transactions 1-9evaluating
data 1-9row images 1-9
process 1-8Replication
blocking 4-18choosing network topology 3-19environment
considerations 2-17managing 2-4
examples E-1 to E-13frequency
changing 5-16, 7-10replicate sets 7-5specifying 5-10
modelsprimary-target 1-4update-anywhere 1-4
order error, definition of 1-18restarting 6-5stopping 6-4suspending 6-5tree, illustrated 3-22volume 2-14
Replication servers 2-5connecting to 6-4customizing 5-6defining 5-3, 5-5, A-20definition of 2-5, 5-3deleting 6-6, A-29listing A-45managing 6-3 to 6-6modifying 5-14 to 5-16, A-56recreating 6-6resuming 6-6resynchronizing 5-17state, definition of 6-3suspending A-81synchronizing 5-6troubleshooting 8-13viewing attributes 6-3
Replication systemsprimary-target 3-3, 3-9supported by Enterprise
Replication 3-3update-anywhere 3-10
Replication topologiesforest of trees 3-24fully-connected 3-20hierarchical 3-21hierarchical tree 3-22terminology 3-21
Requirements, disk spacedelete tables 4-10logical log files 4-9message queue spooling 4-11planning for 4-9shadow columns 4-11
Restarting replication 6-5Restoring databases,
considerations 2-9Restrictions
cdr modify replicate A-50participant modifiers A-91
Resumingdata delivery
for replicate sets A-61for replicates A-59for replication servers A-63
replicate sets 7-8suspended
replicates 6-9replication servers 6-6
Resynchronizing replicationservers 5-17
Return codes, description of A-91.rhosts file 4-5RIS
activating A-13, A-23capacity planning 4-15filenames, description of 8-10modifying directory 5-14specifying directory 5-6, A-22,
A-56RIS files
BLOB and CLOBinformation 8-12
BYTE and TEXT data 8-12changed column
information 8-12configuring 5-11description of 8-9preparing to use 8-9UDT information 8-12
--ris option 5-6, 5-11, 8-9, A-13cdr define server A-23cdr modify replicate A-51cdr modify server A-57
root dbspace, transactionrecords 4-12
Root serversdefinition of 3-21global catalog 2-6, 4-8SQLHOSTS information 4-8
Routines, application-specific 3-17Row conflict resolution scope 3-14,
3-18, 5-10, 8-4Row data
creating sbspace for 4-13storage 4-11
Row Information Spooling. See RIS.Rowids, adding and dropping 2-16Rows, replicating entire 5-12RQM. See Reliable Queue Manager.RRD label, ATS files 8-6RRH label, ATS files 8-6RRS label, ATS files 8-6Rules
conflict resolution 3-12for extensible data types 2-26for simple large objects 2-22smart large objects 2-23
Index 13

@O QCA B D E F G H I J K L M N P R S T U V W X Y Z
time-stamp 3-15See also Conflict resolution.
SSample-code conventions Intro-14Sbspaces 2-20
inconsistent replicated data 2-20increasing sizes 8-16invalid 5-5monitoring disk usage 8-15pathname limitations 4-13row data 4-13spooled row data Intro-9, 4-11,
4-13See also
Administrator’s Guide for InformixDynamic Server.
Informix Administrator’sReference.
Scopedefinition of 3-18row 3-14, 3-18transaction 3-14See also Conflict resolution.
--scope option 5-10, A-12Scope options A-11Secondary conflict-resolution
rule 3-12SELECT statement
considerations A-91limitations A-91participant modifier A-90with shadow columns 4-22
Send queues Intro-9definition of 1-13, 4-11See also Memory queues.
--seq option, cdr error A-36SERIAL data types 2-12, 2-19SERIAL8 data types 2-12, 2-19Server administrator, Enterprise
Replication 2-4SERVER column, cdr list server
output A-45Server connections, stopping A-33Server definitions, global
catalog 2-6
Server groups. See Database servergroups.
Server state, global catalog 2-6Server. See Database servers.servicename, description of 4-7services file
example 4-4preparing 4-4
Sets. See Replicate sets.Setting
AVG_LO_SIZE 4-14CDR_QDATA_SBSPACE 4-14environment variables 4-16idle timeout 5-6LOGGING parameter 4-14
Setting uperror logging 5-11SQLHOSTS file 4-5SQLHOSTS registry key F-4
setup program, for SQLHOSTSregistry F-1
Shadow columnsADD CRCOLS 4-21adding 2-16behavior with BEGIN WORK
WITHOUTREPLICATION 4-19
cdrserver 2-11, 2-21cdrtime 2-11, 2-21conflict resolution rules 3-12creating 2-11, 4-11, 8-18defining 4-21disk space requirements 4-9, 4-11dropping 2-16, 4-21High-Performance Loader 4-23in ATS files 8-6loading and unloading data 4-22UNLOAD statement 4-24updating with DB-Access 4-20WITH CRCOLS statement 4-21
Simple large objectsconflict resolution 2-21cross-replication 2-21replicating 2-20 to 2-24
from blobspaces 2-20from tblspaces 2-20
SPL conflict resolution 2-22storing
in blobspaces 2-20
in tblspaces 2-20timestamp conflict
resolution 2-21Size
storage spaces 8-16transaction record dbspace 4-12
SMALLFLOAT data type 5-13Smart blobs. See Smart large objects.Smart large objects
cross replication 2-21in ATS files 8-8multiple references to 2-24replicating 2-20 to 2-24replicating only changed
columns 5-12specifying default behavior 4-14SPL conflict resolution 2-23spooled row data 4-13storing in sbspaces 2-20
SMI tables D-1 to D-17summary D-1syscdrack_buf D-3syscdrack_txn D-3syscdrctrl_buf D-3syscdrctrl_txn D-4syscdrerror D-4, D-13syscdrpart D-5syscdrprog D-5syscdrq D-6syscdrqueued D-7syscdrrecv_buf D-7syscdrrecv_txn D-7syscdrrepl D-8syscdrreplset D-9syscdrs D-10syscdrsend_buf D-11syscdrsend_txn D-11syscdrserver D-12syscdrtx D-13
Software dependencies Intro-4Solving configuration
problems 8-17 to 8-18Specifying
ATS directory A-22, A-56conflict resolution
options A-11rules 5-10scope 5-10
database server type 5-7
14 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
default behavior for smart largeobjects 4-14
idle timeout A-22location
ATS directory 5-6RIS directory 5-6
replication frequency 5-10RIS directory A-22, A-56
SPL conflict resolutionlimitations 3-16rule 3-12, 3-15, 5-10simple large objects 2-22smart large objects 2-23
SPL routinesarguments 3-16considerations 3-17delete table 3-16information passed by Enterprise
Replication 3-16limitations for conflict
resolution 2-26nonoptimized 3-18optimized 3-18
Spooled row data sbspace,determining size 4-13
Spooled transactions 8-13definition of 4-11storage 4-11troubleshooting 8-13
Spoolingdirectories
ATS and RIS 3-13capacity planning 4-15default 4-15
planning for disk space 4-11row data to sbspaces Intro-9transaction records to
dbspaces Intro-9SQL code Intro-14SQL statements
forbidden 2-15limited 2-16permitted 2-16supported 2-15See also Informix Guide to SQL:
Syntax.SQLHOSTS
hierarchical routinetopologies 4-8
INFORMIXSQLHOSTSenvironment variable F-2
leaf servers 4-8nonroot servers 4-8on UNIX E-2on Windows F-1preparing connectivity
information F-3registry key F-1, F-8
local F-2setting up F-4shared F-2
root servers 4-8setting up with ISA 4-7, F-3specifying registry host
machine 4-16SQLHOSTS file
example 4-6format 8-17server group 2-5setting up 4-5specifying location 4-16UNIX 4-6
Startingdata delivery
for replicate sets A-69for replicates A-67
Enterprise Replication A-65replicate sets 7-7replicates 6-7
starts command 5-4STATE column, cdr list server
output A-46STATE field, cdr list replicate
output A-40Statements
ALTER TABLE 4-21BEGIN WORK WITHOUT
REPLICATION 4-18CREATE TABLE 4-21DROP CRCOLS 4-21LOAD 4-22, 4-24SELECT 4-22SQL, supported 2-15UNLOAD 4-24WITH CRCOLS 4-21
Statesactive 6-7inactive 6-8
STATUS column, cdr list serveroutput A-46
Stoppingdata capture
for replicate sets A-75for replicates A-73
Enterprise Replication A-71replicate sets 7-7replicates 6-8replication 6-4server connection A-33
Storagedelete tables 4-10increasing size of spaces 8-16spooled transactions 4-11
Stored procedure language. See SPLroutines.
stores_demo database Intro-5Storing data in tblspaces 2-21streamread support functions 2-25,
4-21streamwrite support
functions 2-25, 4-21Summary
commands A-1SMI tables D-1
superstores_demo database Intro-5Support functions
for replicating UDTs 2-25, 4-21streamread 2-25, 4-21streamwrite 2-25, 4-21writing 2-25, 4-21See also DataBlade API
Programmer’s Manual.Supported
data types 2-19database servers 2-8SQL statements 2-15table types 2-10
Suspended statedescription of A-40server A-46
Suspendingdata delivery
for replicate sets A-79for replicates A-77
database servers A-81replicate sets 7-7replicates 6-9
Index 15

@O QCA B D E F G H I J K L M N P R S T U V W X Y Z
replication 6-5Switching logical log files 4-9--sync option 5-6, A-21Synchronization
servers 3-22, 5-6times 3-15
Synchronizingclocks
net time command 2-18rdate command 2-18
dataonload and onunload
utilities 4-23using DB-Access 4-20using ESQL/C 4-20
global catalog 5-6operating system times 2-17, 8-17
Synchronous data replicationdefinition of 1-4two-phase commit
technology 1-4Synonyms, and Enterprise
Replication 2-8Syntax
command-line utility A-83participant definition A-88
syscdr database 2-6syscdrack_buf table D-3syscdrack_txn table D-3syscdrctrl_buf table D-3syscdrctrl_txn table D-4syscdrerror table D-4, D-13syscdrpart table D-5syscdrprog table D-5syscdrq table D-6syscdrqueued table D-7syscdrrecv_buf table D-7syscdrrecv_txn table D-7syscdrrepl table D-8syscdrreplset table D-9syscdrs table D-10syscdrsend_buf table D-11syscdrsend_txn table D-11syscdrserver table D-12syscdrtx table D-13sysmaster database, SMI tables D-1System Monitoring Interface. See
SMI tables.System names, in hosts file 4-4
System requirementsdatabase Intro-4software Intro-4
TTable hierarchies, replicating 2-26Table types, unsupported 2-10Tables
buffer D-17designing, considerations 2-9locking 2-15preparing for conflict
resolution 4-21RAW 2-10SMI D-1 to D-17temporary 2-10transaction D-16unsupported 2-10
Target participant type 5-8Tblspaces 2-20
storing BYTE and TEXTdata 2-20, 2-21
Temporary tables 2-10Terminology
command-line utility A-83Enterprise Replication 2-4Enterprise Replication servers 2-5global catalog 2-6hierarchical topology 3-21participant 2-5replicate 2-5replicate set 2-6replication servers 2-5
Testingnetwork environment 4-8trusted environment 4-8
TEXT dataATS files 8-7distributing 2-24RIS files 8-12SPL conflict resolution 2-22storing in tblspaces 2-21types, loading 4-23
Threads used by EnterpriseReplication C-3
Time formats A-93
Time synchronization 2-17, 3-15,8-17
Timeoutidle, setting 5-6status, replication servers A-46
Timestamp conflict resolutionrule 3-12, 3-14, 5-10, A-41
database action 3-15definition of 3-14delete table 4-10simple large objects 2-21
Tip icons Intro-11Tools for loading and unloading
data 4-22Topology, choosing network 3-19Transaction
buffers, spooling to disk 4-11,8-13
constraint checking 3-19evaluation examples 1-14 to 1-17evaluation logic 1-10processing 2-14tables D-16
Transaction conflict resolutionscope 3-14, 3-18, 5-10
Transaction recordsdefault dbspace 4-12spooling Intro-9storage 4-11
Transactional integrity 3-18Transactions
distributed 2-14failed, ATS and RIS files 5-11, 8-3large 2-15
Tree topology, illustrated 3-22Tree, definition of 3-21Trigger-based data capture 1-5Trigger-based transaction
capture 1-5Triggers
activating A-14changing 5-16definition of 1-5enabling 5-14errors with Enterprise
Replication 2-13firing A-52in primary key updates 1-12permissions A-89
16 Guide to IBM Informix Enterprise Replication

O QCA B D E F G H I J K L M N P R S T U V W X Y Z @
Troubleshootingconfiguration
problems 8-17 to 8-18spooled transactions 8-13
Trusted environmentconfiguring 4-5testing 4-8
Two-phase commitdefinition of 1-4distributed transactions 2-14
TXH label, ATS files 8-6TZ environment variable A-93
UUDRs, SPL conflict resolution 3-16UDT information
in ATS files 8-8in RIS files 8-12
UDTscolumn reference Intro-6columns, primary key 2-26in ATS files 8-8loading with deluxe mode 4-23preparing to replicate 4-21primary key column Intro-6replicating
only changed columns 5-12preparation 2-25support for Intro-6
spooled row data 4-13support functions 2-25WHERE clause Intro-6
Unbuffered logging 2-10, 4-22UNIX
database server groups 4-6oninit command 5-4onmode command 5-4SQLHOSTS file 4-6, 4-16
UNLOAD statement 4-24See also Informix Guide to SQL:
Syntax.unload utility 4-23Unloading data 4-22Unsupported table types 2-10Update-anywhere
examples E-6participants 5-9
replication systems, descriptionof 3-10
Updatesmultiple-row images 1-12primary key 1-12WHERE clause column 1-12
Updating shadow columns 4-20UPSERTs
definition of 5-12replicating only changed
columns 5-12User-defined data types. See UDTs.User-defined routines. See UDRs.User-defined types. See UDTs.Users, informix 2-4Using
canonical format 5-13IEEE floating point format 5-13
Utilitiesdbexport 4-24dbimport 4-24onload 4-23onunload 4-22, 4-23unload 4-23
VValues, sending floating-point 5-13Variables. See Environment
variables.Viewing
network connection status 6-10replicate attributes 6-7replicate set attributes 7-6replication server attributes 6-3
Views, and EnterpriseReplication 2-8
Virtual columns, support for 2-26
WWarning icons Intro-11WHERE clause
column updates 1-12UDT column reference Intro-6
Windowsdatabase server groups 4-7Informix-Admin group 2-4
onmode command 5-4SQLHOSTS registry host 4-16starts command 5-4
WITH CRCOLS statementdefining shadow columns 4-21
Workflow replication businessmodel 3-8
Workload partitioning businessmodel 3-7
Writingsupport functions 2-25transaction buffers to disk 8-13
XX/Open compliance level Intro-18
Z--zap option, cdr error A-36
Index 17

Recommended

















