
2007.02.08 - SLIDE 1IS 240 – Spring 2007
Lecture 8: Clustering
University of California, BerkeleySchool of Information
IS 245: Organization of Information In Collections
Automatic Classification
Some slides in this lecture were originally created by Prof. Marti Hearst

2007.02.08 - SLIDE 2IS 240 – Spring 2007
Overview
• Introduction to Automatic Classification and Clustering
• Classification of Classification Methods
• Classification Clusters and Information Retrieval in Cheshire II
• The 4W project revisited…

2007.02.08 - SLIDE 3IS 240 – Spring 2007
Classification
• The grouping together of items (including documents or their representations) which are then treated as a unit. The groupings may be predefined or generated algorithmically. The process itself may be manual or automated.
• In document classification the items are grouped together because they are likely to be wanted together– For example, items about the same topic.

2007.02.08 - SLIDE 4IS 240 – Spring 2007
Automatic Indexing and Classification
• Automatic indexing is typically the simple deriving of keywords from a document and providing access to all of those words.
• More complex Automatic Indexing Systems attempt to select controlled vocabulary terms based on terms in the document.
• Automatic classification attempts to automatically group similar documents using either:– A fully automatic clustering method.– An established classification scheme and set of
documents already indexed by that scheme.

2007.02.08 - SLIDE 5IS 240 – Spring 2007
Background and Origins
• Early suggestion by Fairthorne – “The Mathematics of Classification”
• Early experiments by Maron (1961) and Borko and Bernick(1963)
• Work in Numerical Taxonomy and its application to Information retrieval Jardine, Sibson, van Rijsbergen, Salton (1970’s).
• Early IR clustering work more concerned with efficiency issues than semantic issues.

2007.02.08 - SLIDE 6IS 240 – Spring 2007
Cluster Hypothesis
• The basic notion behind the use of classification and clustering methods:
• “Closely associated documents tend to be relevant to the same requests.”– C.J. van Rijsbergen

2007.02.08 - SLIDE 7IS 240 – Spring 2007
Classification of Classification Methods
• Class Structure– Intellectually Formulated
• Manual assignment (e.g. Library classification)• Automatic assignment (e.g. Cheshire Classification
Mapping)
– Automatically derived from collection of items• Hierarchic Clustering Methods (e.g. Single Link)• Agglomerative Clustering Methods (e.g. Dattola)• Hybrid Methods (e.g. Query Clustering)

2007.02.08 - SLIDE 8IS 240 – Spring 2007
Classification of Classification Methods
• Relationship between properties and classes– monothetic– polythetic
• Relation between objects and classes– exclusive– overlapping
• Relation between classes and classes– ordered– unordered
Adapted from Sparck Jones

2007.02.08 - SLIDE 9IS 240 – Spring 2007
Properties and Classes
• Monothetic– Class defined by a set of properties that are both
necessary and sufficient for membership in the class
• Polythetic– Class defined by a set of properties such that to be a
member of the class some individual must have some number (usually large) of those properties, and that a large number of individuals in the class possess some of those properties, and no individual possesses all of the properties.

2007.02.08 - SLIDE 10IS 240 – Spring 2007
A B C D E F G H 1 + + +2 + + +3 + + +4 + + +5 + + +6 + + +7 + + +8 + + +
Monothetic vs. Polythetic
Polythetic
Monothetic
Adapted from van Rijsbergen, ‘79

2007.02.08 - SLIDE 11IS 240 – Spring 2007
Exclusive Vs. Overlapping
• Item can either belong exclusively to a single class
• Items can belong to many classes, sometimes with a “membership weight”

2007.02.08 - SLIDE 12IS 240 – Spring 2007
Ordered Vs. Unordered
• Ordered classes have some sort of structure imposed on them– Hierarchies are typical of ordered classes
• Unordered classes have no imposed precedence or structure and each class is considered on the same “level”– Typical in agglomerative methods

2007.02.08 - SLIDE 13IS 240 – Spring 2007
Clustering Methods
• Hierarchical
• Agglomerative
• Hybrid
• Automatic Class Assignment

2007.02.08 - SLIDE 14IS 240 – Spring 2007
Coefficients of Association
• Simple
• Dice’s coefficient
• Jaccard’s coefficient
• Cosine coefficient
• Overlap coefficient
|||,min(|||
||||
||
||||
||||
||2
||
BABA
BA
BA
BABA
BA
BA
BA

2007.02.08 - SLIDE 15IS 240 – Spring 2007
Hierarchical Methods
2 .43 .4 .24 .3 .3 .35 .1 .4 .4 .1 1 2 3 4
Single Link Dissimilarity Matrix
Hierarchical methods: Polythetic, Usually Exclusive, OrderedClusters are order-independent
||||
||1
BA
BAitydissimilar

2007.02.08 - SLIDE 16IS 240 – Spring 2007
Threshold = .1
Single Link Dissimilarity Matrix
2 .43 .4 .24 .3 .3 .35 .1 .4 .4 .1 1 2 3 4
2 03 0 04 0 0 05 1 0 0 1 1 2 3 4
2
1
35
4

2007.02.08 - SLIDE 17IS 240 – Spring 2007
Threshold = .2
2 .43 .4 .24 .3 .3 .35 .1 .4 .4 .1 1 2 3 4
2 03 0 14 0 0 05 1 0 0 1 1 2 3 4
2
1
35
4

2007.02.08 - SLIDE 18IS 240 – Spring 2007
Threshold = .3
2 .43 .4 .24 .3 .3 .35 .1 .4 .4 .1 1 2 3 4
2 03 0 14 1 1 15 1 0 0 1 1 2 3 4
2
1
35
4

2007.02.08 - SLIDE 19IS 240 – Spring 2007
Clustering
Agglomerative methods: Polythetic, Exclusive or Overlapping, Unorderedclusters are order-dependent.
DocDoc
DocDoc
DocDoc
DocDoc
1. Select initial centers (I.e. seed the space)2. Assign docs to highest matching centers and compute centroids3. Reassign all documents to centroid(s)
Rocchio’s method (similar to current K-means methods

2007.02.08 - SLIDE 20IS 240 – Spring 2007
Automatic Class Assignment
DocDoc
DocDoc
DocDoc
Doc
SearchEngine
1. Create pseudo-documents representing intellectually derived classes.2. Search using document contents3. Obtain ranked list4. Assign document to N categories ranked over threshold. OR assign to top-ranked category
Automatic Class Assignment: Polythetic, Exclusive or Overlapping, usually orderedclusters are order-independent, usually based on an intellectually derived scheme

2007.02.08 - SLIDE 21IS 240 – Spring 2007
Automatic Categorization in Cheshire II
• The Cheshire II system is intended to provide a bridge between the purely bibliographic realm of previous generations of online catalogs and the rapidly expanding realm of full-text and multimedia information resources. It is currently used in the UC Berkeley Digital Library Project and for a number of other sites and projects.

2007.02.08 - SLIDE 22IS 240 – Spring 2007
Overview of Cheshire II
• It supports SGML as the primary database type.• It is a client/server application.• Uses the Z39.50 Information Retrieval Protocol.• Supports Boolean searching of all servers.• Supports probabilistic ranked retrieval in the
Cheshire search engine.• Supports ``nearest neighbor'' searches,
relevance feedback and Two-Stage Search.• GUI interface on X window displays (Tcl/Tk).• HTTP/CGI interface for the Web (Tcl scripting).

2007.02.08 - SLIDE 23IS 240 – Spring 2007
Cheshire II - Cluster Generation• Define basis for clustering records.
– Select field to form the basis of the cluster.– Evidence Fields to use as contents of the pseudo-
documents.
• During indexing cluster keys are generated with basis and evidence from each record.
• Cluster keys are sorted and merged on basis and pseudo-documents created for each unique basis element containing all evidence fields.
• Pseudo-Documents (Class clusters) are indexed on combined evidence fields.

2007.02.08 - SLIDE 24IS 240 – Spring 2007
Cheshire II - Two-Stage Retrieval• Using the LC Classification System
– Pseudo-Document created for each LC class containing terms derived from “content-rich” portions of documents in that class (subject headings, titles, etc.)
– Permits searching by any term in the class– Ranked Probabilistic retrieval techniques attempt to
present the “Best Matches” to a query first.– User selects classes to feed back for the “second
stage” search of documents.
• Can be used with any classified/Indexed collection.

2007.02.08 - SLIDE 25IS 240 – Spring 2007
Probabilistic Retrieval: Logistic Regression
• Estimates for relevance based on log-linear model with various statistical measures of document content as independent variables.
nnkji vcvcvcctdR|qO ...),,(log 22110
)),|(log(1
1),|(
ji dqROjie
dqRP
m
kkjiji ROtdqROdqRO
1, )](log),|([log),|(log
Log odds of relevance is a linear function of attributes:
Term contributions summed:
Probability of Relevance is inverse of log odds:

2007.02.08 - SLIDE 26IS 240 – Spring 2007
Probabilistic Retrieval: Logistic Regression
6
10),|(
iii XccDQRP
In Cheshire II probability of relevance is based onLogistic regression from a sample set of TREC documents to determine values of the coefficients.At retrieval the probability estimate is obtained by:
For 6 attributes or “clues” about term usage in the documents and the query

2007.02.08 - SLIDE 27IS 240 – Spring 2007
Probabilistic Retrieval: Logistic Regression attributes
MX
n
nNIDF
IDFM
X
DLX
DAFM
X
QLX
QAFM
X
j
j
j
j
j
t
t
M
t
M
t
M
t
log
log1
log1
log1
6
15
4
13
2
11
Average Absolute Query Frequency
Query Length
Average Absolute Document Frequency
Document Length
Average Inverse Document Frequency
Inverse Document Frequency
Number of Terms in common between query and document (M) -- logged

2007.02.08 - SLIDE 28IS 240 – Spring 2007
Cheshire II Demo
• Examples from the:– SciMentor(BioSearch) project
• Journal of Biological Chemistry and MEDLINE data
– CHESTER (EconLit)• Journal of Economic Literature subjects
– Unfamiliar Metadata & TIDES Projects• Basis for clusters is a normalized Library of Congress Class
Number• Evidence is provided by terms from record titles (and subject
headings for the “all languages”• Five different training sets (Russian, German, French,
Spanish, and All Languages• Testing cross-language retrieval and classification
– 4W Project Search

2007.02.08 - SLIDE 29IS 240 – Spring 2007
References
• Christian Plaunt & Barbara Norgard, “An Association Based Method for Automatic Indexing with a Controlled Vocabulary”. JASIS 49(10), 1998.– Preprint available available on class web site
• Ray R. Larson, Jerome McDonough, Lucy Kuntz, Paul O’Leary & Ralph Moon, “Cheshire II: Designing a Next-Generation Online Catalog”. JASIS, 47(7) 555-567, 1996.

2007.02.08 - SLIDE 30IS 240 – Spring 2007
Developing a Metadata Infrastructure for Information
Access:What, Where, When and
Who?Prof. Ray R. Larson
University of California, BerkeleySchool of Information

2007.02.08 - SLIDE 31IS 240 – Spring 2007
Overview
• Metadata as Infrastructure– What, Where, When and Who?
• What are Entry Vocabulary Indexes?– Notion of an EVI– How are EVIs Built
• Time Period Directories– Mining Metadata for new metadata

2007.02.08 - SLIDE 32IS 240 – Spring 2007
Metadata as Infrastructure
• The difference between memorization and understanding lies in knowing the context and relationships of whatever is of interest. When setting out to learn about a new topic, a well-tested practice is to follow the traditional “5Ws and the H”: Who?, What?, When?, Where?, Why?, and How?

2007.02.08 - SLIDE 33IS 240 – Spring 2007
Metadata as Infrastructure
• The reference collections of paper-based libraries provide a structured environment for resources, with encyclopedias and subject catalogs, gazetteers, chronologies, and biographical dictionaries, offering direct support for at least What, Where, When, and Who.
• The digital environment does not yet provide an effective, and easily exploited, infrastructure comparable to the traditional reference library.

2007.02.08 - SLIDE 34IS 240 – Spring 2007
What?
Searching texts by topic, e.g. Dewey, LCSH, any subject index, or category scheme applied to documents.
• Two kinds of mapping in every search:– Documents are assigned to topic categories, e.g.
Dewey– Queries have to map to topic categories, e.g. Dewey’s
Relativ Index from ordinary words/phrases to Decimal Classification numbers.
• Also mapping between topic systems, e.g. US Patent classification and International Patent Classification.

2007.02.08 - SLIDE 35IS 240 – Spring 2007
Texts
‘What’ searches involve mapping to controlled vocabularies
Thesaurus/Ontology

2007.02.08 - SLIDE 36IS 240 – Spring 2007
Start with a collection of documents.

2007.02.08 - SLIDE 37IS 240 – Spring 2007
Classify and index with controlled
vocabulary
Or use a pre-indexed
collection.
Index

2007.02.08 - SLIDE 38IS 240 – Spring 2007
Problem:Controlled
Vocabularies can be
difficult for people to
use.“pass mtr veh spark ign eng”
Index
Use: “Economic Policy”
In Library of Congress subj
For: “Wirtschaftspolitik”

2007.02.08 - SLIDE 39IS 240 – Spring 2007
Solution:Entry Level Vocabulary
Indexes.Index
EVIpass mtr veh
spark ign eng”
= “Automobile”

2007.02.08 - SLIDE 40IS 240 – Spring 2007
“What” and Entry Vocabulary Indexes
• EVIs are a means of mapping from user’s vocabulary to the controlled vocabulary of a collection of documents…

2007.02.08 - SLIDE 41IS 240 – Spring 2007
Has an Entry Vocabulary
Module been built?
User selects a subject domain of
interest.
Download a set of training data.
Build associations between extracted terms & controlled
vocabularies.
Map user’s query to ranked list of
controlled vocabulary terms
Part of speech tagging
Use an existing EVI.
Extract terms (words and noun phrases) from
titles and abstracts.
User selects search terms from the ranked
list of terms returned by the EVI.
YES
Building an Entry Vocabulary Module (EVI)
Searching
For noun phrases
Internet DB indexed with a controlled
vocabulary.
Domains to select from: Engineering, Medicine, Biology, Social science, etc.
User has question but is unfamiliar with the domain
he wants to search.
NO
Building and Searching EVIs

2007.02.08 - SLIDE 42IS 240 – Spring 2007
Technical Details
Download a set of
training data.
Build associations between extracted terms & controlled
vocabularies.
Part of speech tagging
Extract terms (words and noun
phrases) from titles and abstracts.
Building an Entry Vocabulary Module (EVI)
For noun phrases
Internet DB indexed with a
controlled vocabulary.

2007.02.08 - SLIDE 43IS 240 – Spring 2007
Association Measure
C ¬Ct a b¬t c d
Where t is the occurrence of a term and C is the occurrence of a class in the training set

2007.02.08 - SLIDE 44IS 240 – Spring 2007
Association Measure
• Maximum Likelihood ratio
W(C,t) = 2[logL(p1,a,a+b) + logL(p2,c,c+d) - logL(p,a,a+b) – logL(p,c,c+d)] where logL(p,n,k) = klog(p) + (n – k)log(1- p)
and p1= p2= p=
a a+b
c c+d
a+c a+b+c+d
Vis. Dunning

2007.02.08 - SLIDE 45IS 240 – Spring 2007
Alternatively
• Because the “evidence” terms in EVIs can be considered a document, you can also use IR techniques and use the top-ranked classes for classification or query expansion

2007.02.08 - SLIDE 46IS 240 – Spring 2007
FindPlutonium
In Arabic Chinese Greek Japanese Korean Russian Tamil
...),,2[logL(p t)W(c, 1 baaStatistical association
Digital library resources

2007.02.08 - SLIDE 47IS 240 – Spring 2007
EVI example
EVI 1
Index term:“pass mtr veh spark ign eng”User
Query “Automobile
” EVI 2Index term:“automobiles”OR
“internal combustible engines”

2007.02.08 - SLIDE 48IS 240 – Spring 2007
But why stop there?
Index
EVI

2007.02.08 - SLIDE 49IS 240 – Spring 2007
“Which EVI do I use?”
Index
EVI
Index
Index EVI
IndexEVI

2007.02.08 - SLIDE 50IS 240 – Spring 2007
EVI to EVIs
Index
EVI
Index
Index EVI
IndexEVI
EVI2

2007.02.08 - SLIDE 51IS 240 – Spring 2007
FindPlutonium
In Arabic Chinese Greek Japanese Korean Russian Tamil
Why not treat language the same way?

2007.02.08 - SLIDE 52IS 240 – Spring 2007
Texts
Numericdatasets
It is also difficult to move between different media forms
Thesaurus/Ontology
EVI

2007.02.08 - SLIDE 53IS 240 – Spring 2007
Searching across data types
• Different media can be linked indirectly via metadata, but often (e.g. for socio-economic numeric data series) you also need to specify WHERE to get correct results

2007.02.08 - SLIDE 54IS 240 – Spring 2007
Texts
Numericdatasets
But texts associated with numeric data can be mapped as well…
Thesaurus/Ontology
captions
EVI
EVI
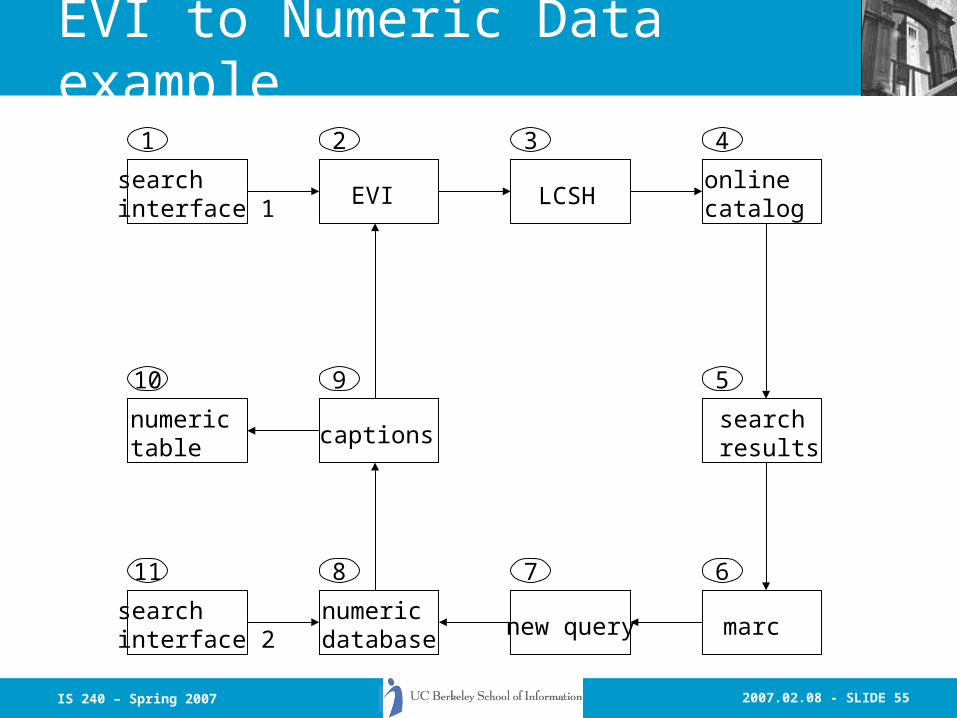
2007.02.08 - SLIDE 55IS 240 – Spring 2007
EVI to Numeric Data example
EVI LCSH
marcnew query
search resultscaptions
numeric table
numeric database
online catalog
search interface 1
search interface 2
1
8 7 6
5
432
11
10 9

2007.02.08 - SLIDE 56IS 240 – Spring 2007
Texts
Numericdatasets
But there are also geographic dependencies…
Thesaurus/Ontology
captionsMaps/Geo Data
EVI
EVI

2007.02.08 - SLIDE 57IS 240 – Spring 2007
WHERE: Place names are problematic…
• Variant forms: St. Petersburg, Санкт Петербург, Saint-Pétersbourg, . . .
• Multiple names: Cluj, in Romania / Roumania / Rumania, is also called Klausenburg and Kolozsvar.
• Names changes: Bombay Mumbai.• Homographs:Vienna, VA, and Vienna, Austria;
– 50 Springfields.• Anachronisms: No Germany before 1870• Vague, e.g. Midwest, Silicon Valley• Unstable boundaries: 19th century Poland;
Balkans; USSR• Use a gazetteer!

2007.02.08 - SLIDE 58IS 240 – Spring 2007
WHERE. Geo-temporal search interface. Place names found in documents. Gazetteer provided lat. & long. Places displayed on map.
Timebar

2007.02.08 - SLIDE 59IS 240 – Spring 2007
Zoom on map. Click on place for a list of records. Click on record to display text.

2007.02.08 - SLIDE 60IS 240 – Spring 2007
Catalogs and gazetteers should talk to each other!
Geographic sort / display of catalog search result.
Catalog search
Gazetteer search

2007.02.08 - SLIDE 61IS 240 – Spring 2007
Texts
Numericdatasets
So geographic search becomes part of the infrastructure
Thesaurus/Ontology
Gazetteers captionsMaps/Geo Data
EVI

2007.02.08 - SLIDE 62IS 240 – Spring 2007
WHEN: Search by time is also weakly supported…
• Calendars are the standard for time• But people use the names of events to refer to
time periods• Named time periods resemble place names in
being:– Unstable: European War, Great War, First World War– Multiple: Second World War, Great Patriotic War– Ambiguous: “Civil war” in different centuries in
England, USA, Spain, etc.
• Places have temporal aspects & periods have geographical aspects: When the Stone Age was, varies by region

2007.02.08 - SLIDE 63IS 240 – Spring 2007
• Suggests a similar solution: A gazetteer-like Time Period Directory.
• Gazetteer:– Place name – Type – Spatial markers (Lat & long) -- When
• Time Period Directory: – Period name – Type – Time markers (Calendar) – Where
• Note the symmetry in the connections between Where and When.
Similarity between place names and period names

2007.02.08 - SLIDE 64IS 240 – Spring 2007
Solution - Time Period Directories
• Initial development involved mining the Library of Congress Subject Authority file for named time periods…

2007.02.08 - SLIDE 65IS 240 – Spring 2007
LC MARC Authorities Records
<USMARC><Fld001>sh 00000613 </Fld001><Fld151><a>Magdeburg
(Germany)</a><x>History</x><y>Siege, 1550-1551</y></Fld151>
<Fld550><w>g</w><a>Sieges</a><z>Germany</z></Fld550><Fld670><a>Work cat.: 45053442: Besselmeier, S. Warhafftige
history vnd beschreibung des Magdeburgischen Kriegs, 1552.</a></Fld670>
<Fld670><a>Cath. encyc.</a><b>(Magdeburg: besieged (1550-51) by the Margrave Maurice of Saxony)</b></Fld670>
<Fld670><a>Ox. encyc. reformation</a><b>(Magdeburg: ... during the 1550-1551 siege of Magdeburg ...)</b></Fld670>
</USMARC>

2007.02.08 - SLIDE 66IS 240 – Spring 2007
timePeriodEntry Time Period Directory InstanceContains components described below
- periodID Unique identifier
- periodName Period name, can be repeated for alternative namesInformation about language, script, transliteration schemeSource information and notes (where was the period name mentioned)
- descriptiveNotes Description of time period
- dates Calendar and date formatBegin & end date (exact, earliest, latest, most-likely, advocated-by-source, ongoing)Notes, sources
- periodClassification Period type, e.g. Period of Conflict, Art movementCan plug in different classification schemesCan be repeated for several classifications
- location Associated places with time periodContains both place name and entry to a gazetteer providing more specific place information like latitude / longitude coordinatesCan plug in different location indicators (e.g. ADL gazetteer, Getty Thesaurus of Geographic names)Recently added coordinates for direct use
- relatedPeriod Related time periodsperiodID of related periodsInformation about relationship type (part-of, successor etc.)Can plug in different relationship type schemes
- entryMetadata Notes about creator / creation of instanceEntry dateModification date

2007.02.08 - SLIDE 67IS 240 – Spring 2007

2007.02.08 - SLIDE 68IS 240 – Spring 2007
Time periods by named location

2007.02.08 - SLIDE 69IS 240 – Spring 2007
Catalog Search Result

2007.02.08 - SLIDE 70IS 240 – Spring 2007
Web Interface - Access by map
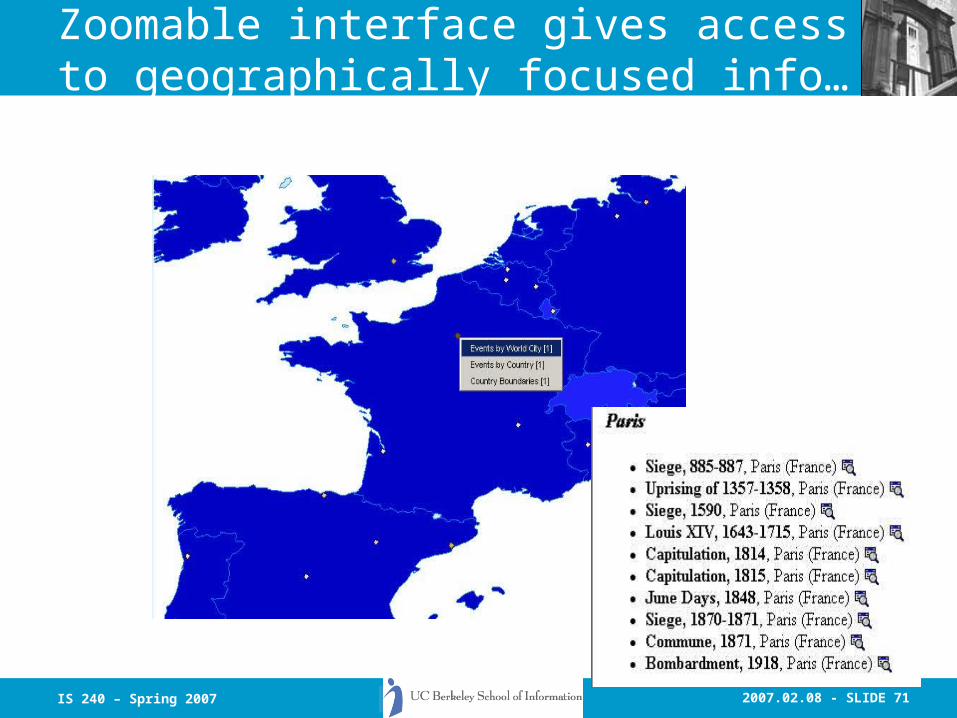
2007.02.08 - SLIDE 71IS 240 – Spring 2007
Zoomable interface gives access to geographically focused info…

2007.02.08 - SLIDE 72IS 240 – Spring 2007
Link initiates search of theLibrary of Congress catalogfor all records relating to thistime period.
Web Interface - Access by timeline

2007.02.08 - SLIDE 73IS 240 – Spring 2007
WHEN and WHAT
• These named time periods are derived from Library of Congress catalog subject headings and so can be used for catalog searching which finds books on topics important for that time period

2007.02.08 - SLIDE 74IS 240 – Spring 2007
Time period directories link via the place (or time)
Texts
Numericdatasets
Thesaurus/Ontology
Gazetteers captionsMaps/Geo Data
EVI
Time Period Directory Time lines, Chronologies

2007.02.08 - SLIDE 75IS 240 – Spring 2007
WHEN, WHERE and WHO
• Catalog records found from a time period search commonly include names of persons important at that time. Their names can be forwarded to, e.g., biographies in the Wikipedia encyclopedia.

2007.02.08 - SLIDE 76IS 240 – Spring 2007
Place and time are broadly important across numerous tools and genres including, e.g. Language atlases, Library catalogs,Biographical dictionaries, Bibliographies, Archival finding aids, Museum records, etc., etc.
Biographical dictionaries are heavy on place and time: Emanuel Goldberg, Born Moscow 1881. PhD under Wilhelm Ostwald, Univ. of Leipzig, 1906. Director, Zeiss Ikon, Dresden, 1926-33. Moved to Palestine 1937. Died Tel Aviv, 1970.
Life as a series of episodes involving Activity (WHAT), WHERE, WHEN, and WHO else.

2007.02.08 - SLIDE 77IS 240 – Spring 2007
A new form of biographical dictionary would link to all
Texts
Numericdatasets
Thesaurus/Ontology
Gazetteers captionsMaps/Geo Data
EVI
Time Period Directory Time lines, Chronologies
Biographical Dictionary

2007.02.08 - SLIDE 78IS 240 – Spring 2007
A Metadata Infrastructure
CATALOGS
AchivesHistorical Societies
LibrariesMuseums
Public TelevisionPublishersBooksellers
AudioImages
Numeric DataObjectsTexts
Virtual RealityWebpages
RESOURCES
INTERMEDIA INFRASTRUCTURE
Text and ImagesBiographical DictionaryWHO
TimelinesTime Period DirectoryWHEN
MapsGazetteerWHERE
Syndetic StructureThesaurusWHAT
Special Display ToolsAuthority ControlFacet
Learners
Dossiers

2007.02.08 - SLIDE 79IS 240 – Spring 2007
Acknowledgements
• Electronic Cultural Atlas Initiative project• This work was partially supported by the
Institute of Museum and Library Services through a National Leadership Grant for Libraries, award number LG-02-04-0041-04, Oct 2004 - Sept 2006 entitled “Supporting the Learner: What, Where, When and Who” – See: http://ecai.org/imls2004
• Michael Buckland, Fred Gey, Vivien Petras, Matt Meiske, Kim Carl, Anya Kartavenko, Minakshi Mukherjee
• Contact: [email protected]
Recommended

















