Embed Size (px)
Citation preview

ASK, 2000, nr 9, strony 115- 134 Copyright by ASK, ISSN 1234-9224
WSTĘP
Jarosław Górniak Uniwersytet Jagielloński
ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH SPOŁECZNYCH
I MARKETINGOWYCH
Analiza korespondencji jest zaliczana, podobnie jak analiza czynnikowa czy skalowanie wielowymiarowe, do tzw. niepełnych metod taksonomicznych (Bacher 1996). Jest technikq eksploracyjnej analizy danych, której celem jest odkrywanie struktur i wzorów w danych gromadzonych w toku badań. Z punktu widzenia taksonomii jest to metoda niepełna, gdyż identyfikacja skupień i zaliczanie analizowanych obiektów do skupień następuje w toku interpretacji przez analityka przestrzennej konfiguracji wyników. Poza interpretacją taksonomiczną metoda ta daje możliwość interpretacji czynnikowej: wyjaśniania tendencji do występowania określonej konfiguracji obiektów przez odwołanie się do oddziaływania ukrytych cech, reprezentowanych przez uzyskane w wyniku analizy czynniki/wymiary.
Sposób podejścia charakterystyczny dla analizy korespondencji występował już wcześniej pod innymi nazwami w literaturze statystycznej, jednak rozkwit tej metody zawdzięczamy francuskiej szkole eksploracyjnej analizy danych, której mistrzem był J.P. Benzecri. Sposób podejścia do analizy danych wynikał z jego naukowego „światopoglądu". Sądził on, że nauki humanistyczne zagrożone są idealizmem, polegającym na zastępowaniu przez badaczy wyników badań empirycznych przez założenia i rozstrzygnięcia przyjmowane a priori (The BMS 1994). ,,To nowe narzędzie, którym jest komputer elektroniczny, może pozwolić nam zastąpić zdroworozsądkowe sądy jakościowe statystycznie zdefiniowanymi wielkościami w taki sposób, że ostateczne konstrukcje, oparte na wystarczającej podstawie empirycznej, będą niezależne od arbitralnych konstrukcji wynikających z idei a priori" - pisał w 1973 roku (Benzecri 1973). Z takiej postawy wyrasta analiza korespondencji jako technika poszukująca struktury rzeczywistości leżącej u podłoża obserwowanych danych. Wiąże się to z filozoficznym i religijnym przeświadcze-
* Uwagi do Autora lub prośby o nadbitki prosimy kierować: Jarosław Górniak, Instytut Socjologii UJ. ul. Grodzka 52, 30-044 Kraków; e-mail: [email protected].

116 JA ROSŁA W GÓRNIAK
niem, że rzeczywistość ma takq strukturę, ład, który jest dziełem Boga, a badacz strukturę tę powinien i może odkrywać. Konsekwencjq takiej pozycji jest także podejście do interpretacji wyników analizy korespondencji: Benzecri uważa, że ważne sq nie tyle obserwowane dane i ich reprodukcja w wyniku analizy, ile czynniki, których dane sq niedoskonałq reprezentacjq. Podejście szkoły Benzecriego było zasadniczo opisowe. ,,Model musi podqżać za danymi, a nie na odwrót", jak zwykł mawiać mistrz, podkreślajqc odrębność swego ujęcia w stosunku do „doktryny anglosaskiej", która miała hołdować zasadzie: ,,najpierw sformułuj model, a następnie spróbuj dopasować go do danych". Ostatnio rozwój analizy korespondencji idzie w kierunku komplementarności i kompromisu z owym „anglosaskim" ujęciem, niemniej technika ta pozostaje w swej istocie technikq opisowq i eksploracyjnq.
Pozycję analizy korespondencji w badaniach społecznych ugruntowała
słynna, przetłumaczona na wiele języków ksiqżka P. Bourdieu z 1979 roku: La distinction, poświęcona zagadnieniom zwiqzku stylów życia z pozycjq zajmowanq w strukturze społecznej. Do anglosaskiego świata statystyki wprowadziły analizę korespondencji przede wszystkim dwie prace, które ukazały się w 1984 roku: Theory and Applications of Correspondence Analysis, M. Greenacre'a oraz Multivariate Descriptive Statistical Analysis: Correspondence Analysis and Related Techniques for Large Matrices autorstwa Lebarta, Morineau i Warwicka. Ważnq rolę odegrały prace holenderskich uczonych z Uniwersytetu w Leiden, zwłaszcza skupionych wokół zespołu publikujqcego pod nazwiskiem Gifi. Wśród autorów zwiqzanych z ośrodkiem w Leiden znani sq m.in.: de Leeuw, Meulman, Heiser, a także van de Geer. Podejście „szkoły holenderskiej", w szczegółach odmienne od „szkoły francuskiej", stanowi podstawę popularnego modułu SPSS Categories, którego algorytmy zostały przygotowane pod kierownictwem J. Meulman i W. Heisera.
Analiza korespondencji szybko zyskała popularność wśród badaczy rynku po publikacjach, które od 1986 roku ukazywały się w „Journal of Marketing Research" (autorstwa Hoffman i Frankego, Carrolla, Greena i Schaffer oraz Greenacre'a). Analiza korespondencji okazała się zwłaszcza atrakcyjnym narzędziem do tworzenia map percepcyjnych stosowanych w segmentacji rynku i pozycjonowaniu produktów.
Jednq z istotnych zalet analizy korespondencji jest to, że służy ona do analizy danych jakościowych i nie stawia specjalnych wymogów dotyczqcych rozkła
dów, którym powinny podlegać analizowane zmienne. Dane jakościowe dominujq w badaniach społecznych i tych badaniach marketingowych, które sq oparte na sondażach za pomocq ankiety lub wywiadu kwestionariuszowego. Ponadto w badaniach społecznych na ogół mamy do czynienia z sytuacjami, w których trudno jest spełnić wszystkie rygorystyczne warunki zwiqzane z testowaniem hipotez, natomiast zrozumienie struktury wielowymiarowego zbioru danych staje się
wiodqcym celem badań. Nic więc dziwnego, że możemy mówić o triumfalnym pochodzie analizy korespondencji w świecie badań społecznych, zwłaszcza stosowanych badań społecznych. Także w Polsce, co może wywołać pewne zaskoczenie akademickiego audytorium, technika ta jest jednym z najpopularniejszych narzędzi wśród komercyjnych badaczy rynku Ueśli pominiemy proste techniki, jak np. tabele krzyżowe).

ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 117
Analiza korespondencji występuje w dwóch wariantach: jako prosta analiza korespondencji (CA - Correspondence Analysis) i jako wieloraka lub wielozmiennowa 1 analiza korespondencji (MCA - Multiple Correspondence Analysis).
Prosta analiza korespondencji (CA) jest technikq slużqcq do wizualizacji zależności w tabeli dwudzielczej. Może też służyć do wizualizacji zależności w dowolnych tabelach danych, nie będqcych tabelami kontyngencji, pod warunkiem, że wszystkie wartości w komórkach sq nieujemne i mogq być traktowane jako miary powiqzania pomiędzy wierszami a kolumnami.
Wielowymiarowa analiza korespondencji (MCA) jest traktowana przez szkolę francuskq jako rozszerzenie dwuzmiennowej CA dla potrzeb analizy więcej niż dwóch cech nominalnych. Zespól Gifi traktuje MCA, a właściwie analizę homogeniczności (HOMALS, PRINCALS, OVERALS) jako ogólniejsze podejście do analizy danych, natomiast CA (ANACOR) jako szczególny wariant przeznaczony do analizy zwiqzku między dwiema cechami. Te różnice podejść majq swoje konsekwencje praktyczne w analizie danych, ale ich omówienie musimy odłożyć do odrębnej publikacji poświęconej MCA i pokrewnym technikom.
ISTOTA ANALIZY KORESPONDENCJI DWÓCH ZMIENNYCH
Prosta analiza korespondencji, w swym podstawowym zastosowaniu, pomaga nam w rozpoznaniu struktury zależności między dwiema zmiennymi jakościowymi. W przypadku zmiennych, które majq nieznacznq liczbę kategorii, wystarczajqcym narzędziem analizy jest tradycyjna tabela krzyżowa. W przypadku zmiennych o dużej liczbie kategorii, tabela na ogół przestaje być czytelna i wówczas analiza korespondencji może się okazać bardzo pomocna.
Spójrzmy na przykład tabeli typowej dla badań marketingowych. Tabela l zawiera wyniki odpowiedzi na pytanie o najczęściej kupowanq markę pewnego produktu Y skrzyżowane z aktualnym statusem zawodowym respondentów. Oczywiście, przy pewnej dozie wysiłku i koncentracji, a także obliczajqc dodatkowo procenty w kolumnach, można spróbować odpowiedzieć na następujqce pytania:
l. Które kategorie zawodowe sq podobne do siebie pod względem preferencji wobec marki?
2. Które marki produktu Y charakteryzujq się zbliżonym profilem zawodowym konsumentów?
3. Z którymi segmentami zwiqzane sq szczególnie silnie poszczególne marki?
1 Unikam określenia „wielowymiarowa", gdyż zarówno CA, jak i MCA są technikami wielowymiarowymi.

118 JAROSŁAW GÓRNIAK
Tabela l.
Tabela krzyżowa marka a status zawodowy (w%)
Marka E Cl)
N ("') I,(") to :o
Status zawodowy ~ -s:t" o, ro ro ro ro ro ro o
-"" -"" -"" -"' -"" -"" Cl) ro ro ro ro ro ro c ~ ~ ~ ~ ~ ~ E
Przedsiębiorca 14 5 16 5 28 8 25 100
Dyrektor/Specjalista 12 16 28 2 20 2 20 100
Kierownik 12 4 29 6 29 4 17 100
Specjalista średniego 11 5 16 1 36 7 23 100 szczebla I Urzędnik
Robotnik wykwalifikowany 10 8 9 2 25 14 31 100
Robotnik niewykwalifikowany 9 2 12 2 16 10 50 100
Rolnik 14 16 3 2 16 6 44 100
Emeryt, zawody umysłowe 19 7 19 1 17 1 35 100
Emeryt, zawody fizyczne 18 5 15 1 11 12 37 100
Uczeń 4 13 19 10 35 4 16 100
Gospodyni domowa 12 7 19 5 24 5 29 100
Bezrobotny 7 7 8 1 23 19 44 100
Ogółem 12 7 14 2 24 9 32 100 -
Na tak postawione pytania łatwiej można odpowiedzieć za pomocą analizy korespondencji. Podstawowym wynikiem tej analizy jest wykres rozrzutu - mapa percepcyjna oraz zestaw miar służących ocenie jakości reprezentacji wielowymiarowej przestrzeni rozpiętej na przyjętej, mniejszej liczbie wymiarów, zwykle na płaszczyźnie. Algebraiczną podstawą CA jest dekompozycja macierzy reprezentującej związki między wierszami i kolumnami na wektory osobliwe i wartości osobliwe (singular value decomposition). Elementami tej macierzy są reszty standaryzowane tabeli kontyngencji:
au =(Pu -r,cJ! ~
gdzie: au - reszta standaryzowana w komórce, P;J - częstość względna w komórce, riJ' cii - częstość względna (masa) wiersza, kolumny.
W wyniku dekompozycji uzyskujemy dwie macierze wektorów osobliwych, macierz lewq U i prawą V, oraz macierz diagonalnq D, zawierajqcq dodatnie, uporzqdkowane malejqco wartości osobliwe.

ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 119
S=UDVT
Maksymalna liczba wartości osobliwych i wektorów osobliwych w lewej i prawej macierzy, a zatem maksymalna liczba wymiarów w analizie korespondencji wynosi K=min(/-1, J-1), gdzie I to liczba wierszy, a J to liczba kolumn tabeli.
Następnie obliczane są współrzędne standardowe (standard coordinates) wierszy i kolumn poprzez wymnożenie surowych wartości wektorów osobliwych, odpowiednio lewych i prawych, przez odwrotność pierwiastka proporcji brzegowej odpowiedniego wiersza lub kolumny. W zapisie skalarnym każdą wartość standardowej współrzędnej wiersza możemy obliczyć jako:
fu = u,k I .J;.; natomiast każdą wartość standardowej współrzędnej kolumny jako:
g Jk = u Jk I je; gdzie rj i ej to odpowiednio masa wiersza i lub kolumny j, czyli brzegowa częstość względna kategorii w wierszach lub kolumnach tabeli. Mnożąc współrzędne standardowe przez związaną z danym wymiarem (wektorem osobliwym) wartość osobliwą uzyskujemy współrzędne główne (principal coordinates) wierszy/kolumn dla danego wymiaru. Dodatkową możliwość, wykorzystywaną niekiedy w analizie korespondencji, daje wymnożenie współrzędnych standardowych przez pierwiastek kwadratowy wartości osobliwej związanej z danym wymiarem. Współrzędne obliczone w taki sposób nazywamy kwantyfikacjami kategorii analizowanych zmiennych nominalnych. Są to wartości liczbowe nadane kategoriom w taki sposób, by uzyskać skalę optymalną ze względu na przyjęte kryterium; w przypadku CA kryterium tym jest maksymalizacja współczynników korelacji pomiędzy kwantyfikacjami wierszy i kolumn na kolejnych wymiarach, które są ortogonalne względem siebie (maksymalizacja współczynników korelacji kanonicznej pomiędzy dwoma zestawami zmiennych wskaźnikowych). Korzystając z kombinacji możliwych normalizacji współrzędnych możemy uzyskiwać mapy percepcyjne o różnych właściwościach.
Rodzaj normalizacji Skalowanie zmiennej Skalowanie zmiennej
wierszowej kolumnowej
Wierszowa Współrzędne główne Współrzędne standardowe
Kolumnowa Współrzędne standardowe Współrzędne główne
Główna (Wierszowo-kolumnowa, Współrzędne główne Współrzędne główne Symetryczna)2
Symetryczna (Kanoniczna) Standardowe • .[ci; Standardowe • .[ci;
2 W programie SPSS nazywa się ją normalizacją główną (Principal normalization), podczas gdy nazwy "symetryczna" używa się od wersji 8.0 tego programu w stosunku do normalizacji kanonicznej. Szkoła francuska używa nazwy „symetryczna" dla normalizacji opartej na współrzędnych głównych dla obu zmiennych.

120 JAROSłA W GÓRNIAK
Gdy kategorie zmiennej moją kwantyfikacje wyskoiowone według normalizacji głównej, odległość euklidesowa między tok skwantyfikowanymi kategoriami danej zmiennej równo jest odległości chi-kwadrat między profilami tych kategorii wyznaczonymi przez kategorie drugiej zmiennej. Normalizacjo wierszowa i kolumnowo to tzw. normalizacje asymetryczne. W normalizacji wierszowej odległości pomiędzy kategoriami zmiennej wierszowej są zdefiniowane jako odległości chi-kwadrat, natomiast odległość punktu reprezentującego wiersz od punktu reprezentującego kolumnę (o współrzędnych standardowych) wyraża stopień dominacji danego wierszo w profilu danej kolumny. W przypadku, gdy obie zmienne moją współrzędne o normalizacji głównej, zdefiniowano jest odległość pomiędzy kategoriami każdej z tych zmiennych z osobno, nie można natomiast wprost odnosić do siebie kategorii należących do dwóch różnych
zmiennych (dlatego SPSS nie dopuszcza do automatycznego utworzenia wykresu łącznego, no którym reprezentowane są jednocześnie wiersze i kolumny tabeli. tzw. bip/otu). W przypadku normalizacji kanonicznej (symetrycznej w terminologii SPSS w wersji 8.0 i wyższych), uwago nasza skupiono jest no odległości pomiędzy punktami wierszowymi o punktami kolumnowymi, która reprezentuje tendencję do współwystępowania tych cech, natomiast tracimy możliwość interpretacji odległości pomiędzy kategoriami tej samej zmiennej w kategoriach odległości chi-kwadrat. Dodatkowe możliwości niesie ze sobą przeprowadzenie dla dwóch zmiennych analizy homogenicznośći (HOMALS), czyli w istocie rzeczy MCA. Można w tym przypadku interpretować odległości pomiędzy wszystkimi kategoriami obu zmiennych zgodnie z zasadą, którą przedstawiam dolej, przy okazji MCA.
Sumo kwadratów wartości osobliwych równo jest tzw. bezwładności (inertia), czyli obliczonemu dla danej tabeli chi-kwadrat dzielonemu przez liczebność próby (n). Dano wartość osobliwa podniesiono do kwadratu pozwala ocenić, jak duży jest poziom bezwładności wyjaśnionej przez dony wymiar. Jakość reprezentacji zależności w tabeli no mniejszej liczbie wymiarów pomaga ocenić wielkość zwano udziałem bezwładności danego wymiaru w całkowitej bezwładności tabeli. Ale wróćmy do naszej tabeli. Analizo korespondencji wykonano zostało za pomocą modułu Categories pakietu SPSS.
Analizę korespondencji rozpoczyna tabelo Podsumowanie. Zawiera ono przede wszystkim zakres całkowitej zależności w tabeli (bezwładności = CH12/n) wyjaśniony przez kolejne wymiary (główne składowe) - analogio do proporcji wariancji objaśnionej przez k wymiarów w analizie głównych składowych. Jak widać, dwa pierwsze wymiary wyjaśniają 69% całkowitej bezwładności tabeli. Dodonie trzeciego wymiaru do analizy jest dyskusyjne, choć należy je sprawdzić; dalsze wymiary zdoją się nie mieć znaczenia. Test chi-kwadrat pozwala nom stwierdzić, czy zaobserwowane zależności w tabeli sq statystycznie istotne.

ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 121 - ·----------··-·---~------------····----
Podsumowanie
i---l -i-~--:~-l1- - i-- ;o~o~e~w::~l1 ~art~~nćo;;~:=---1 I ... ~ g ~ . -o I
Wymiar [ , :~ ~ ~ -~ : Sk I Odchylenie -@ ] :f c: Wyjaśniona I umu o- standar- Korelacja
---~ -~ -~-~ . ~---G --~ ~ -~----J wana dowe
11 ł~.~~~-.ro~~o_ --------~ --- ~~~-+--0,4~- 0,027 -0,0~ i 2 O 179 0,032 0,198 0,690 0,028 --~- --'- [ ,----~------~--------~-
3 I 0,15~3_ __ ~_Q,~_ o,833 __ ~~--- ___ _
4 0,114 I 0,013 0,080 0,913 ------- ---- ----
5 0,099 0,01 O 0,061 0,973
6
Ogółem w podsumowaniu
O, --
066 0,004
_lo~T00228
a - 66 stopni swobody
-
0,027 1,000
O,OOOa 1,000 1,000
·--~-- ·-
Następne tabele to przeglqd punktów wierszowych i kolumnowych. Tutaj w kolumnach umieściliśmy zawody, a w wierszach marki (tabela też pierwotnie tak była skonstruowana, jednak została przestawiona dla potrzeb prezentacji).
Wartości współrzędnych wierszy (a także kolumn) sq zależne od przyjętej normalizacji. Normalizacja nie ma jednak wpływu na jakość reprezentacji punktów na mapie percepcyjnej i orientację wymiarów, ani też na calkowitq bezwładność tabeli i udział w niej poszczególnych wymiarów. Udział kategorii zmiennej wierszowej w bezwładności wymiaru pokazuje, w jakim stopniu geometryczna orientacja osi jest zdeterminowana przez poszczególne kategorie tej zmiennej; używane przy interpretacji sensu danego wymiaru. Trzeba uważać na punkty o bardzo malej masie (profilu brzegowym) i bardzo dużym wkładzie do inercji wymiaru - to przypadki znieksztalcajqce (outliers); uwaga zwłaszcza na kategorie o masie mniejszej niż 0,05 i nieproporcjonalnie dużym udziale w bezwładności wymiaru.
Z kolei udział wymiaru w bezwładności każdego wiersza służy do określania jakości reprezentacji danej kategorii na określonym wymiarze i na k pierwszych wymiarach w CA (przez sumowanie wartości dla k pierwszych wymiarów - kolumna Ogółem).
Pierwszy wymiar jest pod silnym wpływem kategorii „Inne", natomiast drugi jest zdominowany przez marki: trzeciq, pierwszą i drugq. Na płaszczyźnie bardzo słabo reprezentowana jest Marka 2. Jej położenie względem innych marek oraz kategorii zawodowych jest zagadkq, której wyjaśnienie wymaga dodania trzeciego wymiaru do analizy (tutaj tę dalszq eksplorację pomijam).

122 JAROSłA W GÓRNIAK
Przegląd punktów wierszowych 0
--Udział
-·--·--
Wartość •(_) •V, punktu w wymiarze o c:::
w bezwładności wymiaru w bezwładności Marka "O ro
ro ~ wymiaru en N ro (!) ~ (])
Ogółem 1 2 1 2 1 2 w przegądzie
Marka 1 O, 116 -0,133 0,280 0,015 0,026 0,284 0,136 0,602 0,738
Marka 2 0,072 O, 133 -0,018 0,019 0,016 0,001 0,067 0,001 0,069
Marka 3 0,144 0,301 0,265 0,026 0,164 0,316 0,504 0,390 0,894
Marka 4 0,024 0,761 -0,083 0,024 0,176 0,005 0,594 0,007 0,601
Marka 5 0,237 0,257 -0,194 0,029 0,197 0,280 0,547 0,312 0,860
Marka 6 0,087 -0,304 -0,204 0,019 O, 101 0,113 0,417 0,187 0,604
Inne 0,320 -0,282 -0,011 O,Q30 0,320 0,001 0,842 0,001 0,843
Aktywne ogółem 1,000 0,162 1,000 1,000
• - normalizacja wierszowa
Analogiczną tabelę mamy dla punktów kolumnowych. Widać, że silny wpływ na orientację pierwszego wymiaru ma grupa uczniów i studentów. Wśród nich cieszy się szczególną popularnością Marka 4, która ma marginalny udział w rynku (0,024), lecz jednocześnie potrafi/a także dość silnie wpłynąć na położenie pierwszego wymiaru. W dalszej analizie należałoby odebrać kategorii uczniów oraz Morce 4 możliwość wpływania no położenie wymiarów i wyświetlić je jako tzw. punkty pasywne (dodatkowe) - ten aspekt analizy również pomijam w tym miejscu. Słabo reprezentowano jest no płaszczyźnie kategorio rolników. Jej położenie może być mylące przy ustalaniu preferencji poszczególnych segmentów wobec marek lub też podobieństwa marek ze względu no wybór ich przez segmenty zawodowe.
ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 123
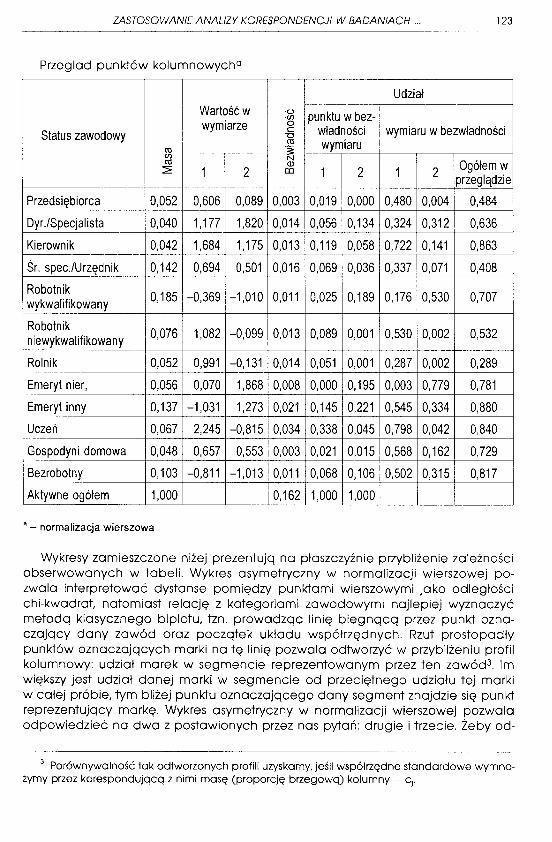
Przeglad punktów kolumnowych 0
Udział ---
Wartość w ,(._)
punktu w bez-,en wymiarze o
Status zawodowy c władności wymiaru w bezwładności "O ro wymiaru ro '"§=
en N ro G) Ogółem w ~ 1 2 en 1 2 1 2 przeglądzie
Przedsiębiorca 0,052 0,606 0,089 0,003 0,019 0,000 0,480 0,004 0,484
Dyr./Specjalista 0,040 1, 177 1,820 0,014 0,056 0,134 0,324 0,312 0,636
Kierownik 0,042 1,684 1, 175 0,013 O, 119 0,058 0,722 O, 141 0,863
Śr. spec./Urzędnik 0,142 0,694 0,501 0,016 0,069 0,036 0,337 0,071 0,408 I
I Robotnik i
wykwalifikowany 0,185 -0,369 -1,010 0,011 0,025 0,189 O, 176 I 0,530 0,707 --
Robotnik 0,076 1,082 -0,099 0,013 0,089 0,001 0,530 0,002 0,532 niewykwalifikowany
Rolnik 0,052 0,991 -0, 131 0,014 0,051 0,001 0,287 0,002 0,289
Emeryt nier, 0,056 0,070 1,868 0,008 0,000 0,195 0,003 0,779 0,781
Emeryt inny 0,137 -1,031 1,273 0,021 0,145 0,221 0,545 0,334 0,880
Uczeń 0,067 2,245 -0,815 0,034 0,338 0,045 0,798 0,042 0,840
Gospodyni domowa 0,048 0,657 0,553 0,003 0,021 0,015 0,568 0,162 0,729
Bezrobotny 0,103 -0,811 -1,013 0,011 0,068 0,106 0,502 0,315 0,817
Aktywne ogółem 1,000 0,162 1,000 1,000
• - normalizacja wierszowa
Wykresy zamieszczone niżej prezentują na płaszczyźnie przybliżenie zależności obserwowanych w tabeli. Wykres asymetryczny w normalizacji wierszowej pozwala interpretować dystanse pomiędzy punktami wierszowymi jako odległości chi-kwadrat, natomiast relację z kategoriami zawodowymi najlepiej wyznaczyć metodą klasycznego biplotu, tzn. prowadząc linię biegnącą przez punkt oznaczający dany zawód oraz początek układu współrzędnych. Rzut prostopadły punktów oznaczających marki na tę linię pozwala odtworzyć w przybliżeniu profil kolumnowy: udział marek w segmencie reprezentowanym przez ten zawód3. Im większy jest udział danej marki w segmencie od przeciętnego udziału tej marki w całej próbie, tym bliżej punktu oznaczającego dany segment znajdzie się punkt reprezentujący markę. Wykres asymetryczny w normalizacji wierszowej pozwala odpowiedzieć na dwa z postawionych przez nas pytań: drugie i trzecie. Żeby od-
3 Porównywalność tak odtworzonych profili uzyskamy. jeśli współrzędne standardowe wymnożymy przez korespondującą z nimi masę (proporcję brzegową) kolumny - Cr

124 JAROSŁAW GÓRNIAK
powiedzieć na pytanie pierwsze, o podobieństwo (bliskość) segmentów zawodowych z punktu widzenia profilu konsumpcji produktu Y, należy sporządzić mapę percepcyjną w normalizacji kolumnowej: wtedy odległości euklidesowe między punktami kolumnowymi są przybliżeniem na płaszczyźnie odległości chi-kwadrat między profilami kategorii zawodowych. Wstępną orientację można już uzyskać bez dodatkowej analizy - spoglądając na wzajemne położenie punktów kolumnowych, które na naszym wykresie są przedstawione na współrzędnych standardowych. Jest to możliwe w związku z tym, że współrzędne główne uzyskujemy przez proste przeskalowanie współrzędnych standardowych, jak to zostało wyżej zaprezentowane.
Normalizacja: wierszowa
2,5
2,0 Eme n er Dyr/Spec
1,5 Emer inny
K1erown1k
1,0
Gosp dom
,5 M arka Marka 3
0,0 n~h ~·
O aprz:eds1ęt:i Inne r, arka2 M arka4
MarKa6 ,.,,,;,, ka5 a
N a a
c:: -,5 • . 2
śr spec./Urz:ęd
U) Uczeń c::
Status zawodowy (i)
-~ -1,0 , Bezrob Rob wyk
o -1,5 O Marka
-1,5 0,0 ,5 1,0 (5 2~0 2,5
Dimension 1
Mapa asymetryczna nie jest efektownym narzędziem prezentacji, choć ma istotne właściwości geometryczne: zdefiniowane są na niej zarówno odległości w obrębie kategorii jednej zmiennej (tej wykreślonej w normalizacji głównej), jak również odległości pomiędzy kategoriami dwóch różnych zmiennych. Jednak punkty o współrzędnych głównych majq tendencję do koncentracji w centrum rozkładu (im bardziej są rozrzucone, tym silniejsza zależność między zmiennymi, mierzona przez chi-kwadrat/n). Dlatego można użyć innych typów map.
Szkoła francuska używa map percepcyjnych, na których zarówno wiersze, jak i kolumny zaprezentowane są w normalizacji głównej. Na takiej mapie można interpretować, w kategoriach odległości chi-kwadrat, dystanse pomiędzy punktami reprezentującymi kategorie jednej zmiennej, natomiast nie są zdefiniowane odległości między kategoriami dwóch różnych zmiennych. W istocie rzeczy, w takim przypadku mamy do czynienia z dwiema mapami (przestrzeniami) nałożonymi na siebie: jednej w normalizacji wierszowej, a drugiej w normalizacji kolumnowej (przy opuszczeniu każdorazowo punktów o współrzędnych standardowych). Wokół takiej prezentacji istnieją kontrowersje, gdyż niedoświadczony użytkownik
ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 125
ma zwykle skłonność do interpretacji wszystkich odległości na mapie percepcyjnej, także tych pomiędzy kategoriami dwóch różnych zmiennych4 .
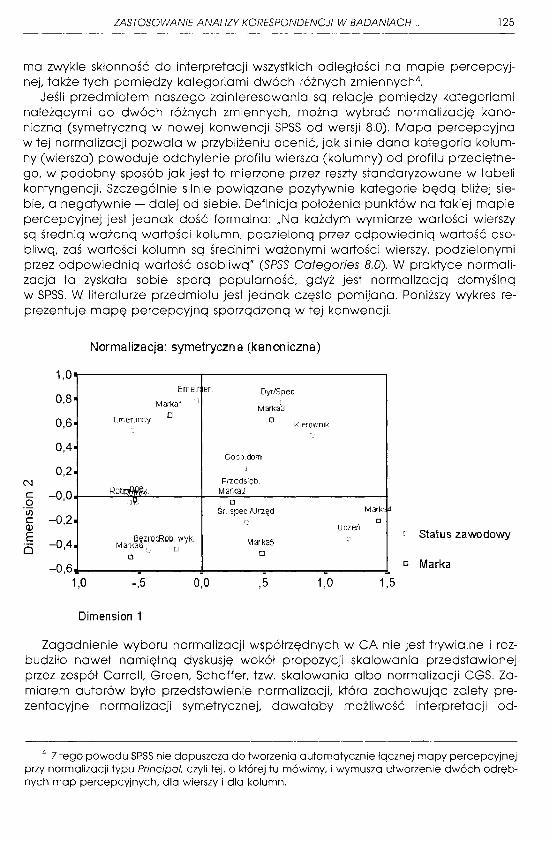
Jeśli przedmiotem naszego zainteresowania są relacje pomiędzy kategoriami należącymi do dwóch różnych zmiennych, można wybrać normalizację kanoniczną (symetryczną w nowej konwencji SPSS od wersji 8.0). Mapa percepcyjna w tej normalizacji pozwala w przybliżeniu ocenić, jak silnie dana kategoria kolumny (wiersza) powoduje odchylenie profilu wiersza (kolumny) od profilu przeciętnego, w podobny sposób jak jest to mierzone przez reszty standaryzowane w tabeli kontyngencji. Szczególnie silnie powiązane pozytywnie kategorie będą bliżej siebie, a negatywnie - dalej od siebie. Definicja położenia punktów na takiej mapie percepcyjnej jest jednak dość formalna: ,,Na każdym wymiarze wartości wierszy są średnią ważoną wartości kolumn, podzieloną przez odpowiednią wartość osobliwą, zaś wartości kolumn są średnimi ważonymi wartości wierszy, podzielonymi przez odpowiednią wartość osobliwą" (SPSS Categories 8.0). W praktyce normalizacja ta zyskała sobie sporą popularność, gdyż jest normalizacją domyślną
w SPSS. W literaturze przedmiotu jest jednak często pomijana. Poniższy wykres reprezentuje mapę percepcyjną sporządzoną w tej konwencji.
N c o (/) c Q)
E o
Normalizacja: symetryczna (kanoniczna)
1,0
0,8 . 0,6 . 0,4 . 0,2 .
-0,0
-0,2 . -0,4 . -0,6
1,0
Eme.r er
Marka1
Em er.inny D
Potpft .','
BezrotRoo. wyk. Marka6
o
- --,5 0,0
Dimension 1
Dyr/Spec
Marka3 o
Kierownik
Gosp.dom
Przedsięb
Marka2 o
śr. spec/Urzęd
Marka5 D
- -,5 1,0
Mark,4 a
Uczeń Status zawodowy
o Marka -1,5
Zagadnienie wyboru normalizacji współrzędnych w CA nie jest trywialne i rozbudziło nawet namiętną dyskusję wokół propozycji skalowania przedstawionej przez zespół Carroll, Green, Schaffer, tzw. skalowania albo normalizacji CGS. Zamiarem autorów było przedstawienie normalizacji, która zachowując zalety prezentacyjne normalizacji symetrycznej, dawałaby możliwość interpretacji od-
4 Z tego powodu SPSS nie dopuszcza do tworzenia automatycznie łącznej mapy percepcyjnej przy normalizacji typu Principal, czyli tej, o której tu mówimy, i wymusza utworzenie dwóch odrębnych map percepcyjnych, dla wierszy i dla kolumn.

126 JAROSŁAW GÓRNIAK
leg/ości zarówno pomiędzy kategoriami jednej zmiennej, jak i kategoriami dwóch różnych zmiennych (w swej istocie polegał on na wykonaniu MCA dla dwóch zmiennych). Zamiar ten jednak nie został powszechnie uznany jako zakończony powodzeniem (por. Carroll, Green i Schaffer 1986, 1989; Greenacre 1989; Hoffman, de Leeuw i Arjunji 1994). Interesująca jest natomiast propozycja użycia analizy HOMALS, która też jest wariantem MCA i w której przyjęty sposób skalowania ma tę właściwość, że punkty reprezentujące kategorii są środkami ciężkości
obiektów, które do nich należą (możliwe jest także łatwe przekształcenie do postaci, w której punkty reprezentujące obiekty są środkami ciężkości kategorii zmiennych, do których należą.
ZASTOSOWANIE WIELOWYMIAROWEJ ANALIZY KORESPONDENCJI W SKALOWANIU DANYCH JAKOŚCIOWYCH NA PRZYKŁADZIE SKALI STATUSU SPOŁECZNO-EKONOMICZNEG05
Wielowymiarowa analiza korespondencji jest techniką analizy danych, która cieszy się dużą popularnością w badaniach marketingowych, zwłaszcza w analizie danych sondażowych. Popularność tę zawdzięcza, jak sądzę, czterem cechom:
przeznaczeniu do analizy dariych jakościowych, a w badaniach sondażowych gromadzone są zwykle dane z pomiarów na skalach nominalnych lub porządkowych; pokrewieństwu ze znanymi i popularnymi technikami analizy danych ilościowych: z analizą czynnikową i analizą głównych składowych; orientacji na wizualizację zależności między cechami badanych obiektów poddaną stosunkowo intuicyjnym (co jednak niekiedy bywa zwodnicze) zasadom interpretacji wykresów analitycznych; możliwość prezentacji wyników w postaci biplotu, tzn. wykresu łącznego, na którym rysowane są zarówno punkty reprezentujące obiekty, jak i punkty reprezentujące ich cechy i istnieją reguły pozwalające na analizę ich wzajemnego położenia.
Nie sposób w tym krótkim artykule przedstawiać rozmaitych aspektów wielowymiarowej analizy korespondencji. Tutaj skoncentruję się na przedstawieniu przykładu zastosowania tej analizy do rozwiązania jednego z typowych problemów w analizie danych w badaniach społecznych i marketingowych: tworzenia skal syntetycznych, mierzących ukryte konstrukty przy wykorzystaniu zestawów obserwowalnych wskaźników mierzonych na poziomie nominalnym lub na skalach o różnym poziomie pomiaru. Popularnym podejściem w analizie korespondencji jest podejście taksonomiczne; przy takim podejściu koncentrujemy się na analizie bliskości punktów reprezentujących obiekty ijlub ich cechy. W mojej analizie zasadniczy akcent został położony jednak no czynnikową interpretację wyników wielowymiarowej analizy korespondencji. W tym podejściu koncentrujemy się
5 Ten fragment artykułu oparty jest na materiale z książki autora (Górniak 2000).

ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 127
na interpretacji wymiarów i traktowanych jako wartości na skali współrzędnych obiektów/cech na tych wymiarach.
Celem naszej analizy jest zbudowanie skali reprezentujqcej ukrytq zmiennq: status społeczno-ekonomiczny, skali opartej na informacji zawartej w analizowanych wyżej wskaźnikach. Zaprezentowane tutaj podejście nie jest jedynym możliwym, jednak ze względu na swe właściwości wydaje się szczególnie atrakcyjne i efektywne: w celu zbudowania skali wykorzystamy szczególne właściwości metody znanej jako analiza homogeniczności (HOMALS6) lub wieloraka analiza korespondencji (MCA). W podejściu tym zmienne sq traktowane wstępnie (tzn. przed kwantyfikacjq) jako w pełni nominalne, a sama analiza może być traktowana jako swego rodzaju analiza głównych składowych dla zmiennych nominalnych.
Rysunek l. Wyniki analizy HOMALS zmiennych definiujqcych SSE
-2
2
1,5
Rob wyk •
0,5
Zasadn -1
Bezrob • • Rolnik
Eme.rerll·5
• 0-399 •
Rob.nwyk „ Podst -1
·1.5
-2
1strz/tech • Prac urn
• 1200-1599 .
red • • : Pom~~\i,5pec Wldo 2
800-1199 • 1600-1999
1
Wl3+ • Dyr.nacz
• Dyr kier
Wyzsze • •
2000+ • Wyż spec
•
Rysunek 2 prezentuje wynik analizy (HOMALS) zwiqzków zachodzqcych pomiędzy kategoriami trzech zmiennych wskaźnikowych dla SSE: wykształcenia ujętego w pięć kategorii opisanych wyżej, dochodu gospodarstwa domowego (z brakami danych uzupełnionymi za pomocq imputacji) i statusu zawodowego, tutaj ujętego w możliwie pełnej formie 7. Pierwszy wymiar ma wartość własnq 0,6668 (2,00
6 Homogeneity analysis via Alternating Least Squares. 7 Jedynie podoficerowie zostali włączeni do kategorii mistrzów i techników, co sugeruje nie tyl
ko związek merytoryczny, ale i analiza wykonana z użyciem wszystkich kategorii. Zasadniczo, w analizie korespondencji (także w HOMALS) należy unikać kategorii zbyt ma/o licznych. W tym przypadku uzyskane rezultaty były bardzo wyraźne i stabilne, dlatego można było eksperymentować z użyciem mało licznych kategorii - nie zmieniało to położenia innych kategorii. W wielu przypadkach takie małe kategorie mogą jednak zniekształcać uzyskane wyniki: są klasycznymi obserwacjami nietypowymi. Lepiej je wówczas traktować jako tzw. obserwacje pasywne (por. Van de Geer, 1993).

128 JAROSŁAW GÓRNIAK
przy zachowaniu analogii do analizy głównych składowych), co daje 8,3% wyjaśnionej inercji8, zaś drugi 0,5272 (1,58), co daje 6,6% wyjaśnianej inercji. Ten nieco pesymistycŻny obraz wynika z faktu, że do podstawy obliczenia procentu wyjaśnianej inercji wchodzi również inercja tabeli sporządzonej dla każdej zmiennej z samą sobą, która z natury rzeczy jest maksymalna i wynosi k-1, gdzie k jest liczbą kategorii danej zmiennej. W literaturze poświęconej analizie korespondencji można znaleźć propozycje poprawek pozwalających lepiej ocenić jakość modelu opartego na określonej liczbie wymiarów; najbardziej znane są propozycje Benzecriego i Greenacre'a. Zgodnie z poprawką Benzecriego9, uznawaną za nieco zbyt optymistyczną, dwa pierwsze wymiary w naszej analizie wyjaśniają łącznie prawie 82% inercji (sam pierwszy wymiar- 61%). Ciekawy sposób poprawnego obliczania części chi-kwadrat wyjaśnianej przez określoną liczbę wymiarów zaproponował także J.Bacher (1996). W tym celu zbudował indeks GFIR*lD: narzędzie do diagnozy jakości modelu opartego na określonej liczbie wymiarów w stosunku do jakości modeli alternatywnych w sytuacji, gdy zamierzamy interpretować uzyskany model w kategoriach analizy czynnikowej, czyli koncentrując się na znaczeniu wymiarów leżących u podstaw zaobserwowanych relacji między kategoriami zmiennych nominalnych. Może on być używany jako formalne kryterium pomagające w określeniu tego, jaką liczbę wymiarów należy zaakceptować i interpretować. Podobnie jak w analizie czynnikowej w przypadku stosowania kryterium Keisera lub Cattella przy określaniu liczby czynników i tu należy się dodatkowo kierować kryterium interpretowalności wymiarów. Indeks GFIR* obliczony został za pomocą napisanej przez J. Bachera procedury MCA, zawartej w pakiecie statystycznym ALMO (Holm 1996). Prezentuję wyniki dla czterech pierwszych wymiarów (czynników):
Wartości indeksu GFIR* w analizie korespondencji wskaźników SSE
Wymiary GFIR
o o.ooo 1 0,488
2 0,568
3 0,656
4 0,544
------·----·-·-·-~-~-··--------~------- ·-·--~ ------- ------------ ---8 Chi-kwadrat/n obliczone dla tzw. tabeli Burta, która ma w boczku i w główce wszystkie
zmienne biorące udział w analizie, zestawione w tej samej kolejności. 9 Skorygowane wartości własne (t,k) obliczane sq dla Q zmiennych i Ak > 1/Q według wzoru
(Rovan 1994):
r 12
Q 1 Ą - Ą --
k~ Q-l K QJ 10 Indeks dobroci dopasowania dla reszt: Goodness of Fit Index for Residua/s (na temat sposo
bu obliczania por. Bacher 1996, s. 65-66).

ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 129
Pierwszy wymiar wyjaśnia 49% całkowitego chi-kwadrat, natomiast dwa pierwsze wymiary - prawie 57%, o więc mniej więcej pośrodku, pomiędzy dwoma poprzednimi szacunkami. Jest to doino granica przedziału określonego przez Bochero (1996: 73) jako zodowolojqce dopasowanie modelu. Za niewystarczojqco dopasowany uwożony jest przez niego model wyjośniojqcy mniej niż 36% całkowitego chi-kwodrot11. Czysto matematyczne względy sugerujq analizę oportq o trzy wymiary: tu GFIR* osiqgo maksimum. Jednak przyrost wyjaśnionego zakresu chi-kwadrat przy dwóch i trzech wymiarach jest niewielki; ponadto za przyjęciem rozwiqzonio jednowymiarowego przemawiojq dodatkowe argumenty.
No wykresie możemy zaobserwować charakterystyczny kształt podkowy. Jest to zjawisko dobrze znane wszystkim badaczom korzystojqcym z analizy korespondencji. Występuje w sytuacji, gdy strukturo zjawisko ma charakter zasadniczo jednowymiarowy. Drugi wymiar jest w takiej sytuacji artefaktem matematycznym (składnik kwadratowy wielomianu) i nie wnosi nic do interpretacji merytorycznej pozo wprowadzeniem dodatkowego kontrastu pomiędzy kategoriami najzamożniejszymi i najuboższymi, gdy odległość pomiędzy punktami mierzymy idqc kolejno od kategorii do kategorii zgodnie z ich uporzqdkowoniem no pierwszym wymiarze (por. no temat „efektu podkowy": Von de Geer 1993b; Weller i Romney 1990). Uzyskane uporzqdkowonie kategorii no pierwszym, poziomym wymiarze jest owocem struktury danych, o nie nałożonych no nie ograniczeń określojqcych uporzqdkowonie; w szczególności, żadnego wpływu nie ma sposób wstępnego przypisania wartości uczniom. Bliskość no wykresie pewnych kategorii różnych zmiennych wskazuje no silniejszą tendencję do przynależności analizowanych obiektów jednocześnie do tych kategorii; większa odległość oznacza sytuację przeciwnq. Bliskość kategorii tej samej zmiennej oznacza większe podobieństwo tych kategorii ze względu no ich profil w kategoriach pozostałych zmiennych użytych w analizie.
W wyniku naszej analizy uzyskaliśmy zatem zasadniczo jednowymiarowq strukturę zależności pomiędzy kategoriami trzech zmiennych wybranych jako wskaźniki statusu społeczno-ekonomicznego 12. Widać wyraźnie, jak uporzqdkowone zostały kategorie poszczególnych zmiennych no pierwszym wymiarze (od prowE;j do lewej strony):
Zawód: wyżsi specjaliści (no wykresie: Wyż.spec); dyrektorzy przedsiębiorstw, organizacji itp. (Dyr.noez); dyrektorzy lub kierownicy jednostek organizacyjnych (Dyr.kier); właściciele przedsiębiorstw zatrudniojqcych powyżej dwóch pracowników (Wl.3+); specjaliści średniego szczebla (Śr.spec); pracownicy umysłowi (Proc.urn); właściciele przedsiębiorstw zotrudniojqcych do dwóch pracowników (Wł.do2); mistrzowie i technicy (wraz z dołączonymi do nich
11 Nie ma klarownej, matematycznej definicji progów, powyżej których indeks dopasowania może być określony jako dobry. Sacher (1996: 73) odwołuje się do praktyki analizy czynnikowej, w której bierze się pod uwagę w interpretacji ładunki o wartości bezwzględnej większej od 0,6. W związku z tym, że indeks dobroci dopasowania GFIR* (a także indeks GFID*, z którego skorzystamy w dalszej części rozdziału) jest wielkością kwadratową (wyjaśniona wariancja), dolny próg został podniesiony do kwadratu, co daje 0,36.
12 W przypadku kolejnych wymiarów spada radykalnie wartość współczynnika dyskryminacji dla dochodu, co wskazuje, że jeśli mają one jakiś sens merytoryczny, to nie jest nim zróżnicowanie SSE w jego integralnej postaci.

130 JAROSŁAW GÓRNIAK
podoficerami) (Mis.tech); inni procujący (lnnyProc); uczniowie i studenci (Uczeń); inni nieprocujący, głównie osoby no długotrwałych urlopach i gospodynie domowe (lnnyNieproc); robotnicy wykwalifikowani (Rob.wyk); emeryci i renciści (Eme.rent); rolnicy (Rolnik); bezrobotni (Bezrob); robotnicy niewykwalifikowani (Rob.nwyk) 13.
Wykształcenie: układ odpowiada naturalnemu uporządkowaniu kategorii, od wykształcenia wyższego do podstawowego; zaznaczmy raz jeszcze, że jest to wynik konfiguracji kategorii traktowanych jako nominalne w relacji do kategorii pozostałych dwóch zmiennych, o nie wartości liczbowej kodów. Dochód: również odtworzone zostało naturalne uporządkowanie kategorii, od najwyższej do najniższej.
Warto zwrócić uwagę również no dużą odległość grupy o najwyższym statusie od pozostałych, co wskazuje no szczególnie wyraźne wyodrębnianie się klasy osób o wyższych dochodach, wykształceniu i pozycji zawodowej. W obrębie tej grupy występuje stosunkowo najsilniej zbieżność - najwyższych wartości - wskaź
ników statusu. Eksploracyjna analizo statystyczno wskaźników SSE z użyciem wielorakiej anali
zy korespondencji (MCA) przyniosło zatem wyniki ogólnie zgodne z oczekiwaniami. Nie oczekiwaliśmy zresztą specjalnych niespodzianek w tym względzie. Potwierdziło się m.in. przypuszczenie, że drobni biznesmeni, właściciele własnych miejsc procy, jak: taksówkarze, sklepikarze, drobni rzemieślnicy powinni być traktowani inaczej niż właściciele większych przedsiębiorstw. Zwykle w kwestionariuszach umieszcza się kategorię: właściciel przedsiębiorstwa. Do niedawno to wystarczało. Teraz i to kategorio podlega procesowi ekonomicznego i społecznego różnicowania. Jak wszędzie w krojach o rozwiniętej gospodarce rynkowej, tok i w Polsce, drobni właściciele przedsiębiorstw, mający często dochody czy wykształcenie porównywalne raczej z pracownikami najemnymi średniego szczebla niż z menedżerami i właścicielami dużych przedsiębiorstw - powinni być kwalifikowani do klasy niższej niż ci ostatni.
Cechą charakterystyczną wielorakiej analizy korespondencji (HOMALS) jest to, że kwantyfikacji podlegają nie tylko kategorie zmiennych, lecz także obserwacje. Pomiędzy obiema kwantyfikacjami zachodzi odpowiedniość. Współrzędne punktu reprezentującego kategorię zmiennej (skwantyfikowane wartości kategorii) są wyliczone no każdym z wymiarów w ten sposób, by punkt, który reprezentuje tę kategorię, był środkiem ciężkości wszystkich skwantyfikowanych obserwacji, które
13 W badaniu nie pytaliśmy o ostatnio wykonywany zawód przez emerytów i rencistów. Ta duża kategoria respondentów jest wewnętrznie niejednorodna. Dominują w niej osoby o niższej pozycji, ale też spotyka się osoby o pozycji wyższej, niż ta, którą uzyskała ta kategoria w naszej analizie. Pewnym remedium na tę sytuację jest właśnie zastosowanie skali optymalnej, opartej jednocześnie na trzech zmiennych. Wyższe wykształcenie i dochód korygują niższą pozycję części emerytów i rencistów wynikającą z przypisanego im statusu zawodowego. Nawet dysponując informacją o ostatnio wykonywanym zawodzie powinniśmy jednak kodować kategorie zawodowe emerytów odrębnie od kategorii zawodowych osób pracujących. Jeśli SSE ma określać uogólnione szanse rynkowe, to pozycja emeryta jest mimo wszystko inna od takiej pozycji związanej z takim samym zawodem, lecz aktywnie wykonywanym. Praktyka GUS, który w badaniach gospodarstw domowych wyróżnia kategorię gospodarstw emeryckich, idzie właśnie tym tropem.

ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 131
do tej kategorii należą. Wartości (współrzędne) każdej obserwacji są wyliczone na wszystkich wymiarach tak, by punkt reprezentujący tę obserwację by/ środkiem ciężkości dla skwantyfikowanych kategorii, do których należy ta obserwacja (Van de Geer 19930; SPSS Categories 1995; Bacher 1996). Poszczególne wymiary, obliczone w wielorakiej analizie korespondencji, możemy traktować jako „latentne (nieznane) zmienne ilościowe h (o średniej O i odchyleniu standardowym l), na których każda osoba g ma określoną wartość skalową y
9h" (Bacher 1996: 55) 14.
Korzystając z takiego podejścia możemy zatem interpretować pierwszy wymiar uzyskany w naszej analizie jako zbudowaną na podstawie relacji pomiędzy obserwowanymi wskaźnikami skalę, mierzącą nieobserwowaną bezpośrednio cechę: status społeczno-ekonomiczny. Wartości (współrzędne) obserwacji na tej skali (pierwszym wymiarze) tworzą nową zmienną, której będziemy odtąd używać w analizie wpływu SSE na inne cechy respondentów uchwycone za pomocą naszego kwestionariusza.
Przedtem warto jeszcze poświęcić chwilę czasu ocenie, jak silnie nasza nowa zmienna reprezentująca status społeczno-ekonomiczny jest skorelowana z wyjściowymi wskaźnikami SSE. Oczywiście, korelacja pomiędzy zmiennymi, które zostały użyte do skonstruowania syntetycznej skali. a samą skalą powinna być i jest wysoka. Zauważmy, że po podniesieniu do kwadratu dają one dokładnie wartość miernika dyskryminacji (discrimination measure), który jest obliczany przez programy SPSS i ALMO. Współczynnik dyskryminacji jest zresztą definiowany jako kwadrat ładunku czynnikowego (ściślej: ładunku głównej składowej) w wielowymiarowej analizie zmiennych jakościowych, zaś ładunek ten jest równy wartości współczynnika korelacji eta (stosunku korelacyjnego) między zmienną (traktowaną jako nominalna) a wymiarem (składową, czynnikiem), który jest zmienną ilościową (Van de Geer 1993b)15. Najniższa wartość współczynnika korelacji eta występuje w przypadku związku pomiędzy skalą SSE a miesięcznym dochodem gospodarstwa domowego.
Tabela l.
Korelacja między skalą SSE a zawodem, wykształceniem i dochodem
Zmienna Miernik Wartość współczynnika dyskryminacji korelacji eta
Status zawodowy 0,750 0,866
Wykształcenie 0,694 0,833
Miesięczny dochód brutto gospodarstwa domowego 0,556 0,746
14 Bacher (1996) zwraca również uwagę na możliwość interpretacji wielorakiej analizy korespondencji jako niepełnej analizy skupień oraz jako latentnej analizy wariancji.
15 Wartości współczynników korelacji eta pomiędzy skalą statusu (pierwszy wymiar MCA) a naszymi trzema wskaźnikami, które zawiera Tabela l, nie zawsze są określane jako ładunki czynnikowe. Na przykład w programie ALMO dokładny odpowiednik ładunków czynnikowych znanych z analizy czynnikowej i głównych składowych jest obliczany dla poszczególnych kategorii zmiennych użytych w analizie (por. też Bacher 1996).

132 JAROSŁAW GÓRNIAK
Wyniki analizy korespondencji możemy interpretować także w kategoriach analizy taksonomicznej (Lebart 1994). W tym celu analizowane kategorie możemy poddać grupowaniu na podstawie wyliczonych wartości współrzędnych. Po obliczeniu współrzędnych dla kategorii powstaje przestrzeń klasyfikacji, w której może zostać obliczony kwadrat odległości euklidesowej. Jest to miara odległości właściwa dla MCA i stanowi ona podstawę dla interpretacji taksonomicznej (Bacher 1996; Carroll, Green i Schaffer 1989). Zwykle dla potrzeb interpretacji taksonomicznej musimy wykorzystać większq liczbę wymiarów MCA niż w przypadku interpretacji czynnikowej. W określeniu liczby wymiarów potrzebnych do dobrego odtworzenia odległości pomiędzy analizowanymi kategoriami pomaga indeks GFID* 16
(Bacher 1996). W przypadku naszych danych jego wartość przekracza 0,5 dopiero przy siedmiu wymiarach, a akceptowalną granicę 0,36 (Bacher 1996) - przy sześciu wymiarach. Wtedy dystanse empiryczne między kategoriami sq w stopniu akceptowalnym odtwarzane przez dystanse wyliczone na bazie współrzędnych MCA. Z drugiej strony, stosujqc tak dużą liczbę wymiarów w analizie taksonomicznej, uzyskałem mało czytelną strukturę skupień kategorii; tylko skupienie złożone z menedżerów i specjalistów wyodrębnia się wyraźnie od pozostałych kategorii. Świadczy to o tym, że dalsze wymiary wprowadzajq tylko tzw. ,,biały szum" do analizowanej struktury.
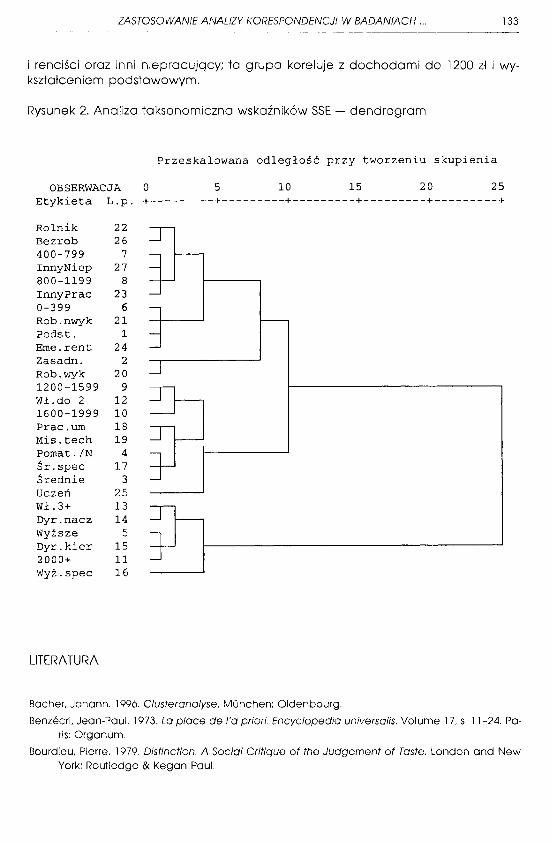
Przy trzech wymiarach, użytych jako podstawa w analizie taksonomicznej, uzyskany obraz jest zdecydowanie wyraźniejszy. Ponieważ jak zawsze w analizie eksploracyjnej kryterium interpretowalności wyników jest wiodqce, ostateczna analiza taksonomiczna, której graficzną reprezentacją jest Rysunek 2, wykonana została wiośnie przy wykorzystaniu trzech wymiarów. Jako miara odległości użyty w niej został, zgodnie z metryką przestrzeni opartej na wymiarach MCA kwadrat odległości euklidesowej; jako algorytm aglomeracji wykorzystana została metoda średnich polqczeń między grupami11.
Na wykresie wyraźnie można rozróżnić cztery skupienia (biorqc pod uwagę dystans przy polqczeniu większy od 2):
l . Kategorie zawodowe: menedżerów, właścicieli większych przedsiębiorstw i samodzielnych specjalistów czy profesjonalistów; ta grupa skojarzona jest z wykształceniem wyższym i najwyższq grupą dochodową.
2. Drobni właściciele firm, specjaliści średniego szczebla, technicy, mistrzowie, urzędnicy i pracownicy umysłowi (a także uczniowie i studenci, choć ta grupa ma pozycję wtórną wobec pozycji rodziców, na których utrzymaniu pozostaje i ma nieokreślonq sytuację zawodową oraz otwartą sytuację pod względem wykształcenia); ta grupa koreluje z dochodami gospodarstwa domowego od 1200 do 1999 zł i wykształceniem średnim lub pomaturalnym i niepełnym wyższym.
3. Robotnicy wykwalifikowani skojarzeni z wykształceniem zasadniczym zawodowym.
4. Rolnicy, robotnicy niewykwalifikowani, inni pracujący, bezrobotni, emeryci
16 Indeks dobroci dopasowania dla dystansów. 17 W nazewnictwie metod aglomeracji panuje spory chaos w literaturze i programach
statystycznych. Tak np. użyta tutaj metoda występuje w literaturze pod sześcioma różnymi nazwami (por. Bacher 1996: 274); w programie SPSS nazywa się ona: Between-Group Linkage, a w programie Statistica: Unweighted pair-group average.
ZASTOSOWANIE ANALIZY KORESPONDENCJI W BADANIACH ... 133
i renciści oraz inni niepracujqcy; ta grupa koreluje z dochodami do 1200 zł i wykształceniem podstawowym.
Rysunek 2. Analiza taksonomiczna wskaźników SSE - dendrogram
Przeskalowana odległość przy tworzeniu skupienia
OBSERWACJA o 5 10 15 20 25 Etykieta L.p. +---------+---------+---------+---------+---------+
Rolnik 22 Bezrob 26 400-799 7 InnyNiep 27 800-1199 8 InnyPrac 23 0-399 6 Rob.nwyk 21 Podst. 1 Eme.rent 24 Zasadn. 2 Rob.wyk 20 1200-1599 9 Wł.do 2 12 1600-1999 10 Prac.urn 18 Mis.tech 19 Pomat. /N 4 Śr.spec 17 Średnie 3 Uczeń 25 Wł.3+ 13 Dyr.nacz 14 Wyższe 5 Dyr.kier 15 2000+ 11 Wyż.spec 16
LITERATURA
Sacher, Johann. 1996. Clusteranalyse. Munchen: Oldenbourg.
Benzecri, Jean-Paul. 1973. La place de /'a priori. Encyclopedia universalis. Volume 17, s. 11-24. Paris: Organum.
Bourdieu, Pierre. 1979. Distinction. A Social Critique of the Judgement of Taste. London and New York: Routledge & Kegan Paul.

134 JAROSŁAW GÓRNIAK
Carroll, J. Douglas, Paul. E. Green i Cathrine M. Schaffer. 1986. lnterpoint Distance Comparisons in Correspondence Analysis. ,,Journal of Marketing Research", 23: 271-280.
Carroll J. Douglas„ Paul[:. Green i Catherine M. Schaffer. 1987. Comparing lnterpoint Distances in Correspondence Analysis: A Clarification. ,,Journal of Marketing Research", 24: 445-450.
Gifi, Albert. 1990. Nonlinear Multivariate Analysis. Chichester: Wiley.
Greenacre, Michael J. 1984. Theory and Applications of Correspondence Analysis. London: Academic Press.
Greenacre, Michael J. 1989. The Carroll-Green-Schaffer Scaling in Correspondence Analysis: A theoretical and Empirical Appraisal. ,,Journal of Marketing Research", 26: 358-368.
Greenacre, Michael J. 1993. Correspondence Analysis in Practice. London: Academic Press.
Greenacre, Michael J. i Jórg Blasius (red.). 1994. Correspondence Analysis in the Social Sciences. London: Academic Press.
Hoffman, Donna L., i George R. Franke. 1986. Correspondence Ana/ysis: Graphical Representation of Categorical Data in Marketing Research. ,,Journal of Marketing Research", 23: 213-227.
Holm, K. 1996. ALMO-Statistiksystem. Linz.
Lebart, Ludovic. 1994. Complementary Use of Correspondence Analysis and Cluster Analysis. W: Greenacre M. i J. Blasius. (red.) Correspondence Analysis in the Social Sciences. London: Academic Press.
Lebart, Ludovic, Alain Morineau i Kenneth M. Warwick. 1984. Multivariate Oescriptive Statistical Analysis: Correspondence Analysis and Realated Techniques for Large Matrices, New York: Wiley.
Rovan, Joze. 1994. Visualizing Solutions in mare than Two Dimensions. W: Greenacre Michael i Blasius Jórg (red.) Correspondence Analysis in the Social Sciences. London: Academic Press.
SPSS. 1998. Categories 8.0. Chicago: SPSS Inc.
The BMS (Karl M. van Meter, Marie-Anje Schlitz, Philippe Cibois i Lise Mounier). 1994. Correspondence Analysis: A History and French Sociological Perspective. W: Greenacre Michael, Blasius Jórg (red.) Correspondence Analysis in the Social Sciences. London: Academic Press.
Van de Geer, Jan P. 19930. Multivariate Analysis of Categorical Data: Theory. Newbury Park, London, New Dehli: Sage Publications.
Van de Geer, Jan P. l 993b. Multivariate Analysis of Categorical Data: Applications. Newbury Park, London, New Dehli: Sage Publications.





























