Embed Size (px)
Citation preview

WLCG@GridPP31 1
WLCG Outlook
Ian Bird, CERN
GridPP Meeting24th September 2013
Accelerating Science and Innovation24-Sep-2013

2WLCG@GridPP3124-Sep-2013
A success s
tory!

WLCG@GridPP31 3
From the 2013 update to the European Strategy for Particle Physics
g. Theory is a strong driver of particle physics and provides essential input to experiments, witness the major role played by theory in the recent discovery of the Higgs boson, from the foundations of the Standard Model to detailed calculations guiding the experimental searches. Europe should support a diverse, vibrant theoretical physics programme, ranging from abstract to applied topics, in close collaboration with experiments and extending to neighbouring fields such as astroparticle physics and cosmology. Such support should extend also to high- performance computing and software development.
24-Sep-2013
i. The success of particle physics experiments, such as those required for the high-luminosity LHC, relies on innovative instrumentation, state-of-the- art infrastructures and large-scale data-intensive computing. Detector R&D programmes should be supported strongly at CERN, national institutes, laboratories and universities. Infrastructure and engineering capabilities for the R&D programme and construction of large detectors, as well as infrastructures for data analysis, data preservation and distributed data-intensive computing should be maintained and further developed.
High Performance Computing
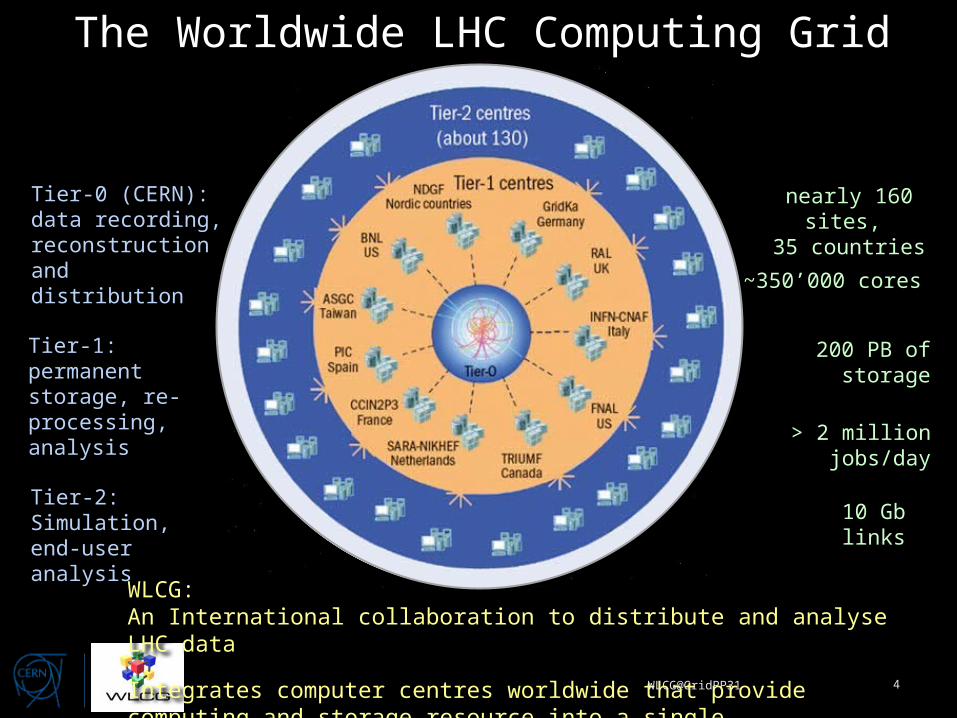
The Worldwide LHC Computing Grid
Tier-1: permanent storage, re-processing, analysis
Tier-0 (CERN): data recording, reconstruction and distribution
Tier-2: Simulation,end-user analysis
> 2 million jobs/day
~350’000 cores
200 PB of storage
nearly 160 sites, 35 countries
10 Gb links
WLCG:An International collaboration to distribute and analyse LHC data
Integrates computer centres worldwide that provide computing and storage resource into a single infrastructure accessible by all LHC physicistsWLCG@GridPP31 4
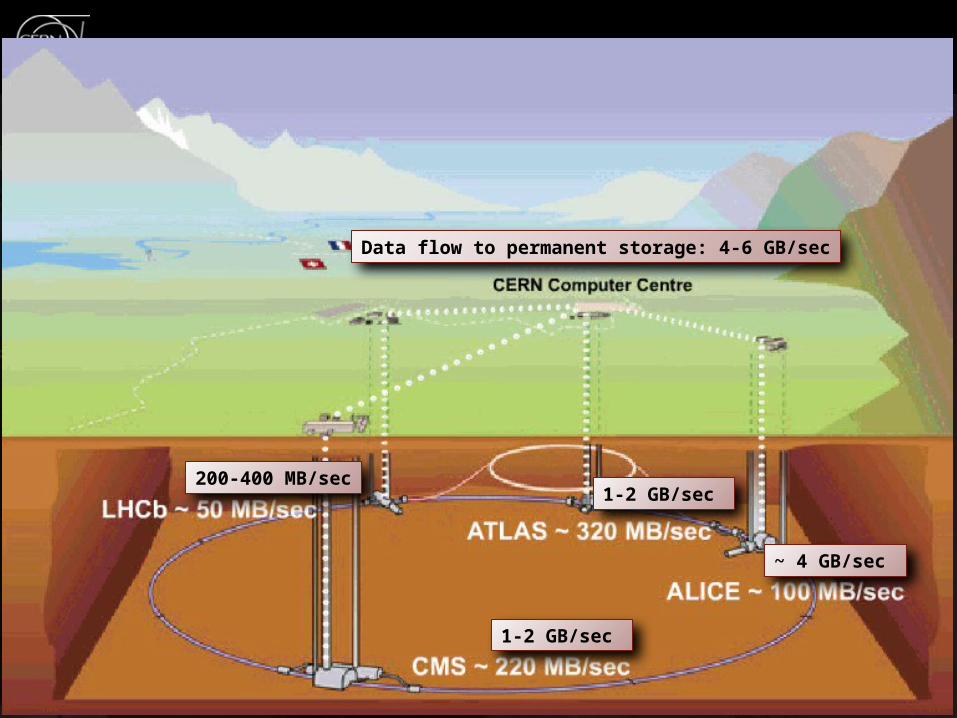
5
200-400 MB/sec
Data flow to permanent storage: 4-6 GB/sec
~ 4 GB/sec
1-2 GB/sec
1-2 GB/sec

• Relies on – OPN, GEANT, US-LHCNet– NRENs & other national &
international providersWLCG@GridPP31 6
LHC Networking

WLCG@GridPP31 7
A lot more to come …
24-Sep-2013
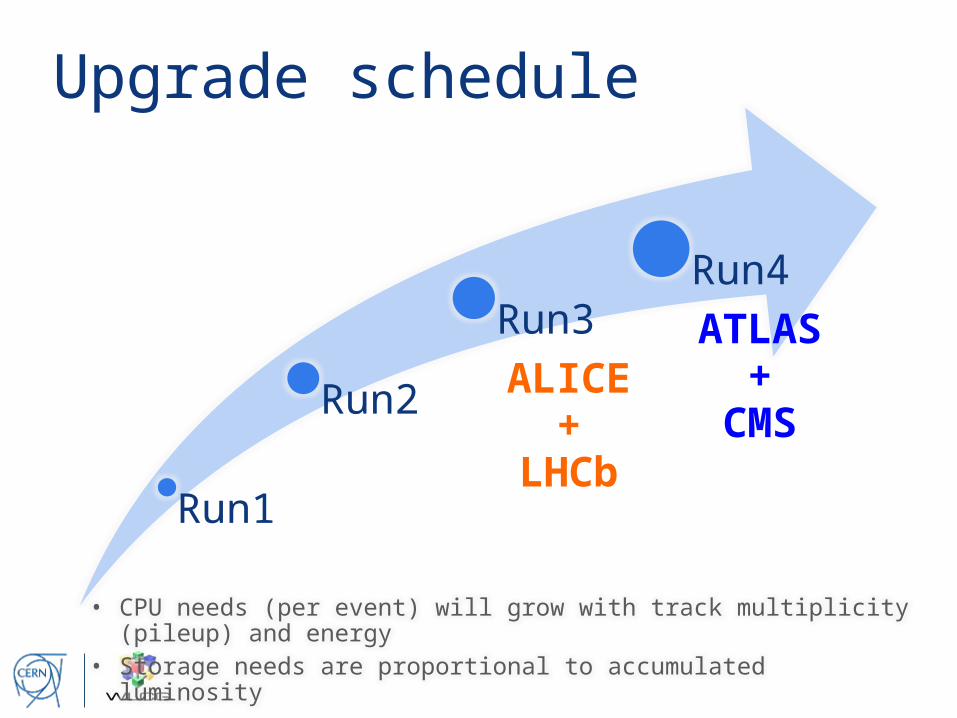
Upgrade schedule
Run1
Run2
Run3
ALICE+
LHCb
Run4
ATLAS+
CMS
• CPU needs (per event) will grow with track multiplicity (pileup) and energy• Storage needs are proportional to accumulated luminosity

WLCG@GridPP31 9
Evolution of requirements
24-Sep-2013
Estimated evolution of requirements 2015-2017 (NB. Not yet reviewed by LHCC or RRB)
2008-2013: Actual deployed capacity
Line: extrapolation of 2008-2012 actual resources
Curves: expected potential growth of technology with a constant budget (see next) CPU: 20% yearly growth Disk: 15% yearly growth

WLCG@GridPP31 10
Technology outlook
• Effective yearly growth: CPU 20%, Disk 15%, Tape 15%• Assumes:
- 75% budget additional capacity, 25% replacement- Other factors: infrastructure, network & increasing power costs
24-Sep-2013
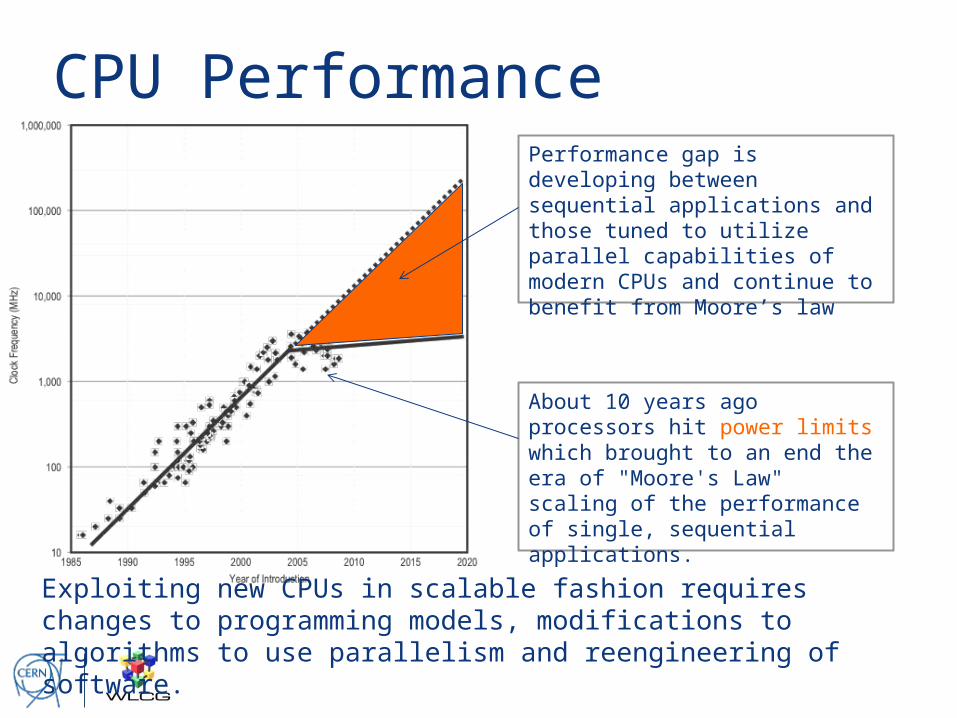
CPU Performance
Exploiting new CPUs in scalable fashion requires changes to programming models, modifications to algorithms to use parallelism and reengineering of software.
About 10 years ago processors hit power limits which brought to an end the era of "Moore's Law" scaling of the performance of single, sequential applications.
Performance gap is developing between sequential applications and those tuned to utilize parallel capabilities of modern CPUs and continue to benefit from Moore’s law

• Clock frequency • Vectors • Instruction Pipelining • Instruction Level Parallelism (ILP) • Hardware threading • Multi-core • Multi-socket • Multi-node
Running differentjobs as we do now is still the best solution for High Throughput Computing (Grid/Cloud)
} Gain in memory footprint and time-to-finishbut not in throughput
Very little gain to be expected and no action to be taken
Micro-parallelism: gain in throughput and in time-to-finish
8 “dimensions of performance”
SOFTWARE
>>

HEP Software Challenge• Must make more efficient use of modern cores, accelerators,
etc- And better use of the memory
• Implies:- Multi-threading, parallelism at all levels, optimisation of libraries,
redesign of data structures, etc
• All this requires significant re-engineering of frameworks, data structures, algorithms, …
• HEP must develop expertise in concurrent programming• Requires investment of effort• Initiative started: concurrency forum• Strengthen this to a more formal HEP-software collaboration
- Enable recognition for contributions- Clear plan – areas where people can contribute, etc

WLCG@GridPP31 14
Grids: what did we achieve? And fail to achieve?
• Solved our problem of making effective use of distributed resources
• Made it work at huge scale
• Effective to ensure all collaborators have access to the data
• Networks are a significant resource
• Federation of trust and policies – important for future
• Cluster computing/grids not suitable/needed for many sciences
• Operational cost is high
• Very complex middleware was not (all) necessary
• Many tools were too HEP-specific
24-Sep-2013

WLCG@GridPP31 15
Some lessons for HEP• Predicting the future is difficult …
- Did not really foresee what the networks would do for us
• Initial computing models too rigid – and too hierarchical• Service deployment was too complex, driven by:
- Fears of unreliable networks,- Unrealistic expectations (“requirements”)- Lack of understanding of distributed environment where
everything can and will fail- E.g. distributed databases; evolved to caches, and simple
central instances
• Original data placement model was far too wasteful• Data management was/is the main problem
24-Sep-2013

WLCG@GridPP31 16
And the world has moved on• Today we all use distributed computing
services all the time- Dropbox, google drive, …- Streaming video, catch-up TV, …- Streaming music- Amazon, Google, Microsoft, etc web/cloud
services – compute and storage- …
24-Sep-2013

WLCG@GridPP31 17
Networks a problem?• Global traffic within
data centres is around 2000 EB/year- Global HEP traffic is
~2 EB/year;
• Global traffic between data centres is some 200 EB/year, - Global HEP traffic ~0.3
EB/year
24-Sep-2013
• By 2015-16: global IP traffic will be ~1000 EB/year (75% video)- And we are 0.3…
BUT, many areas where connectivity is a real problem

WLCG@GridPP31 18
Industry involvement
Clouds?
24-Sep-2013
Today’s grids – evolving technology
Private clouds
(federated?)
Public clouds for science
Public-Private
partnerships
Commercial clouds

Cloud characteristics• 10 times more CPU cores @ 10 times fewer sites
• Reduces complexity• Reduces management and maintenance cost
• Does not pretend to be a unified resource• User has to select a particular zone to connect and stay in the same
zone• Data access across the zones is possible
• But not for free• Data storage offers high availability
• At the expense of lower performance• Provides means to communicate and move data
asynchronously
• Does not prevent users to setup their own arbitrary infrastructure on top of the basic Cloud services

WLCG@GridPP31 20
Evolution of today’s grids• Grid sites are already deploying cloud
software and using virtualisation- Many already offer cloud services
• Cloud software could replace parts of grid middleware- Even some encouragement to do this
• Huge support community compared to grid middleware - More sustainable support opportunities
24-Sep-2013

What would be needed?• Open Source Cloud middleware
OpenStack, CloudStack, OpenNebula… • VM building tools and infrastructure
CernVM+CernVM/FS, boxgrinder..• Common API
• EC2 is de facto standard but proprietary • Common Authentication/Authorization
• Lots of experience with Grids• High performance global data federation
• This is where we have a lot of experience• HEP wide Content Delivery Network
• To support software distribution, conditions data• Cloud Federation
• To unify access and provide cross Cloud scheduling

Evolution of the Grid• Reduce operational effort so that WLCG Tiers can be self
supporting (no need for external funds for operations) • The experiments should be able to use pledged and
opportunistic resources with ~zero configuration• (Grid) clusters, clouds, HPC, …
• Implications:• Must simplify the grid model (middleware) to as thin
a layer as possible• Make service management lightweight• Centralize key services at a few large centers• Make it look like a Cloud

WLCG@GridPP31 23
Commercial clouds• USA and Europe (and rest of world) are very
different markets – and costs• Outside of HEP, data often has intrinsic
value (IP and/or commercial value)- E.g. genomics, satellite imagery, …- Concerns over data location, privacy, data
access for many sciences- Several policy issues related to this
• European market is fragmented- No large (European) cloud providers
24-Sep-2013

WLCG@GridPP31 24
Pricing…• Costs are often higher than incremental
costs of in-house clusters- some exceptions:• Spot markets
- Eg used by BNL to submit to Amazon
• “Backfill”- Use idle capacity for non-critical workloads –
e.g. MC
• Also eventually may see other “value”:- Hosting data sets – get free CPU (because the
data attracts other users)
24-Sep-2013

Scaling CERN Data Centre(s) to anticipated Physics needs
WLCG@GridPP31 25
CERN Data Centre dates back to the 70’s• Upgraded in 2005 to support LHC (2.9 MW)• Still optimizing the current facility (cooling automation,
temperatures, infrastructure)
Exploitation of 100 KW of remote facility down town• Understanding costs, remote dynamic management, improve
business continuity
Exploitation of a remote Data centre in Hungary• Max. 2.7 MW (N+1 redundancy)
- Improve business continuity• 100 Gbps connections
Renovation of the “barn” for accommodating 450 KW of “critical” IT loads (increasing DC total to 3.5 MW)
A second networking hub at CERN scheduled for 2014
24-Sep-2013

WLCG@GridPP31 26
Connectivity (100 Gbps)
24-Sep-2013

WLCG@GridPP31 27
CERN CC – new infrastructure• Replace (almost) entire toolchain• Deploy as a private cloud• Rationale
- Support operations at scale• Same staffing levels with new data centre capacity
- HEP is not a special case for data centres- Improve IT efficiency, e.g.
• Use hardware before final allocation• Small virtual machines onto large physical hardware• Flexible migration between operating systems• Run existing applications on top of the cloud
- Enable cloud interfaces for physics• Support new APIs, CLIs and workflows
24-Sep-2013

24-Sep-2013
Bamboo
Koji, Mock
AIMS/PXEForeman
Yum repoPulp
Puppet-DB
mcollective, yum
JIRA
Lemon /Hadoop /
LogStash /Kibana
git
OpenStack Nova
Hardware database
Puppet
Active Directory /LDAP
WLCG@GridPP31 28

WLCG@GridPP31 29
CERN Private Cloud• Computing Resources on Demand
- Ask for a server through a web page- Get the server in 2 to 15 minutes
• Flexible- Windows, Linux or roll-your-own- Various #cores, disk space options
• Amazon-like Infrastructure as a Service- Programmable through APIs
24-Sep-2013

WLCG@GridPP31 30
Private Cloud Software
24-Sep-2013
• We use OpenStack, an open source cloud project http://openstack.org• The same project is used for
• ATLAS and CMS High Level Trigger clouds• HEP Clouds at BNL, IN2P3, NECTaR, FutureGrid, …• Clouds at HP, IBM, Rackspace, eBay, PayPal, Yahoo!, Comcast,
Bloomberg, Fidelity, NSA, CloudWatt, Numergy, Intel, Cisco …

Status• Toolchain implemented in 18 months with
enhancements and bug fixes submitted back to the community
• CERN IT cloud• Hypervisors: 1300 + 100/week• Cores: 24 000 + 1200/week
• Now in production in 3 OpenStack clouds (over 50,000 cores in total) in Geneva and Budapest managed by Puppet
24-Sep-2013 WLCG@GridPP31 31

WLCG@GridPP31 32
Initial Service Level• Basic – like Amazon
- Estimate 99.9% available (8 hours/year)- Each user has a 10 VM quota (Personal Project)- Experiments can request new projects and
quotas from their pledges- You can upload your own images- Availability zones for load balancing services
24-Sep-2013

WLCG@GridPP31 33
Production using Basic SLA• Applications need to be ‘cloud enabled’ for
production use (if need >99.9%)• Use IT reliable backing stores such as
- AFS, DataBase on Demand (MySQL), Oracle
• Use an automated configuration system- Puppet/Foreman- Contextualisation- CERNVMFS
• Backup if needed by the client (e.g. TSM)
24-Sep-2013

WLCG@GridPP31 34
Coming …• Deployment to new data centre in Budapest
- Additional capacity and disaster recovery
• More flexibility and availability- Kerberos and X.509 support- E-groups for project members- Larger disk capacity VMs (like Amazon EBS)- Higher Availability VMs (CVI-like)- Other OpenStack functions as released
• Aim is 90% CERN IT capacity in the private cloud by 2015- Around 15,000 hypervisors, 150,000 – 300,000 virtual
machines
24-Sep-2013

WLCG@GridPP31 35
A Future e-Infrastructure for Science?
24-Sep-2013

WLCG@GridPP31 36
What is needed• Clear sustainable model (i.e. funding) essential to get buy-in
of large research infrastructures currently in construction- FAIR, XFEL, ELIXIR, EPOS, ESS, SKA, ITER and upgrades to
ILL and ESRF etc.
• Must support the needs of the whole research community, including the “long tail of science”
• Cannot be a one-size-fits-all solution• Focus on solid set of reliable core services of general utility
- But provide a way to share experience and knowledge (and higher level solutions
• The user community should have a strong voice in the governance of the e-Infrastructure
• Essential that European industry engage with the scientific community in building and providing such services
24-Sep-2013

WLCG@GridPP31 37
What do we have already?• Experience, lessons, or products from:
• Existing European e-infrastructure long-term projects- GEANT, EGI, PRACE
• Many “pathfinder” initiatives have prototyped aspects of what will be needed in the future- Includes much of the work in the existing e-Infrastructure
projects but also projects such as EUDAT, Helix Nebula, OpenAIRE+, etc
- Thematic projects such as WLCG, BioMedBridges/ CRISP/ DASISH/ ENVRI, as well as Transplant, VERCE, Genesi-DEC and many others
24-Sep-2013

WLCG@GridPP31 38
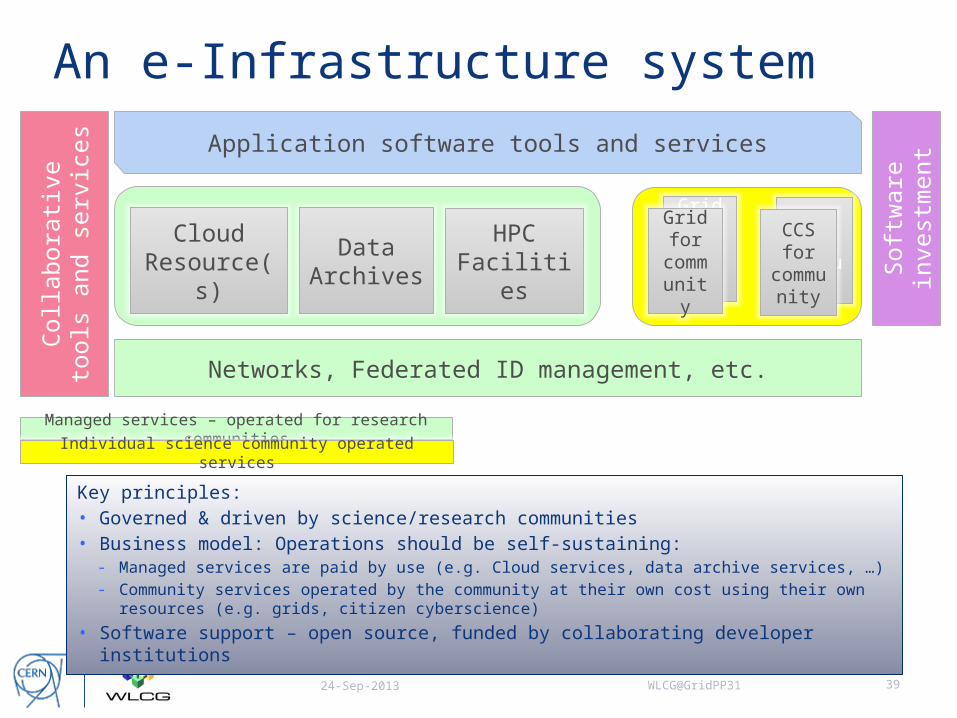
What does an e-Infrastructure look like?
• Common platform with 3 integrated areas- International network, authorization & authentication,
persistent digital identifiers- Small number of facilities to provide cloud and data
services of general and widespread usage- Software services and tools to provide value-added
abilities to the research communities, in a managed repository
• Address fragmentation of users (big science vs. long tail)- Make services attractive and relevant to individuals and
communities
• Evolution must respond directly to user feedback and need
24-Sep-2013
WLCG@GridPP31 39
An e-Infrastructure system
24-Sep-2013
Networks, Federated ID management, etc.
Grid for
community
Grid for
community
CCS for
community
CCS for
community
Application software tools and services
Cloud Resource(s)
Data Archives
HPC Facilities
Col
labo
rativ
e to
ols
and
serv
ices
Sof
twar
e in
vest
men
t
Managed services – operated for research communities
Individual science community operated services
Key principles:• Governed & driven by science/research communities• Business model: Operations should be self-sustaining:
- Managed services are paid by use (e.g. Cloud services, data archive services, …)- Community services operated by the community at their own cost using their own
resources (e.g. grids, citizen cyberscience)
• Software support – open source, funded by collaborating developer institutions

WLCG@GridPP31 40
Prototype public cloud for science“Centre of Excellence”
• CERN proposes a prototype to focus on data-centric services on which more sophisticated services can later be developed
• Use the resources installed by CERN at the Wigner Research Centre for Physics in Budapest, Hungary
• Accessible via federated identity (EDUGAIN):- Multi-tenant compute environment to provision/manage networks of VMs
on-demand- ‘dropbox’ style service for secure file sharing over the internet- Point-to-point reliable, automated file transfer service for bulk data
transfers- Open access repository for publications and supporting data allowing
users to create and control their own digital libraries (see www.zenodo.org)
- Long-term archiving service- Integrated Digital Conferencing tools allowing users to manage their
conferences, workshops and meetings- Oline training material for the services24-Sep-2013

WLCG@GridPP31 41
Prototype:• Based on open source software: Openstack, owncloud, CERN
storage services, FTS3, zenodo, Indico• Services not offered commercially but run on a cost recovery basis• All services will be free at the point of use
- i.e. the end user does not have to pay to access the service
• All stakeholders participate in the funding model which will evolve over time
• CERN will:- Operate the services at the Wigner data centre- Not exert any ownership or IP rights over deposited material- Cover the operating costs during the first year- Make formal agreements with partners that wish to jointly develop/use
the services- Negotiate/Procure services from commercial suppliers on-behalf of all
partners
24-Sep-2013

WLCG@GridPP31 42
Beyond the initial prototype• Learn from the prototype to build similar structures
around Europe- Not identical: each has its own portfolio of services and funding
model- All interconnected: to offer a continuum of services- All integrated with public e-infrastructures:
• GEANT network (commercial networks are not excluded!)• PRACE capability HPC centres• EGI ?
• Determine whether this is:- Useful- Sustainable
• Understand the costs and determine what could be commercially provided
24-Sep-2013

WLCG@GridPP31 43
Conclusions• WLCG has successfully supported the first LHC
run, at unprecedented scale- Will evolve to make the best use of technology and
lessons learned
• HEP must make a major investment in software• Proposal for a series of workshops to rethink the
outdated HEP computing models – - 10-year outlook will not possible to continue to do
things in the “old” way
• For the future we see a need for basic e-infrastructures for science, that support community-specific needs- Propose a prototype of a few basic services to
understand the utility of such a model24-Sep-2013







![Accelerating Innovation Training [SolutionPeople v2.0]](https://img.dokumen.tips/doc/110x75/577cd2e51a28ab9e78964000/accelerating-innovation-training-solutionpeople-v20.jpg)





















