Embed Size (px)
Citation preview

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
RAPPORT DE STAGE
Table des matières
1. Présentation Entreprise 2
1.1. Présentation Equipe 3
2. Gestions d’incidents 4-5
2.1. Catégorisation des incidents 5-62.2. Liste d’incidents et résolution 6-82.3. Clôture 92.4. Bilan 10
3. Supervision Nagios 10-12
3.1. Infrastructure 123.2. Interface Nagstamon 133.3. Gestion d’alertes 133.4. Types d’alertes et procédures de résolutions 14-193.5. Bilan 19
4. Formations 19-20
5. Conclusion globale 21
Page 1

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
1. Présentation Entreprise
Cegid est le premier éditeur français de logiciels de gestion avec un chiffre d’affaires de 258.1 M€ en 2012, le groupe Cegid compte plus de 2 000 collaborateurs et près de 400 000 utilisateurs tant en France qu’à l’étranger. Étant implanté un peu partout dans le Monde, Cegid s’appuie aussi sur des accords de distribution partout dans le monde, afin d’accompagner ses clients dans leur développement international. Éditeur de solutions dédiées à la performance des entreprises et à leur développement, le groupe Cegid a fondé son savoir-faire sur des expertises « métier » et « fonctionnelles ». L’offre Cegid, également disponible en mode « on demand » (SaaS), est adaptée aux entreprises et établissements publics de toutes tailles. Avec des technologies qui s’intègrent naturellement et qui répondent aux enjeux métier des utilisateurs, Cegid donne une nouvelle dimension à l’informatique : la création de valeur pour l’entreprise et ceux qui contribuent à son développement.
Pour plus d’informations sur le Cloud Privé mis en place :
Lien vidéo : http://www.youtube.com/watch?v=dELnaDsCcjQ
Ce stage consistera à l’intégration de l’équipe de support de Niveau 1 et 2 au niveau Hébergement, ainsi qu’au traitement des incidents éventuels. C’est à dire, gestion d’incidents, liés à l’Hébergement. Problème d’accès, de connexion, de mot passe, de compte utilisateurs, de Token (Authentification forte), création d’utilisateurs, remontée de sauvegarde… De plus, la vérification de certains scripts (PowerShell, SQL) sera nécessaire pour les créations des utilisateurs, car ceux-ci, automatisés provoquent quelques problèmes. Puis la gestion de la Supervision Nagios via l’outil Nagstamon sur Windows 7, le réglage d’alertes suite aux remontées. Comme des erreurs de disques pleins, des problèmes de services, de serveurs "Down", surcharge de CPU, problème d’accès à des sites internet… L’équipe que j’intègre est une équipe Hébergement, c’est à dire que nous gérons toute la partie hébergé par Cegid. (Serveurs des clients hébergés, serveurs internes pour les connexions et gestion des comptes utilisateurs des entreprises).
Page 2

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
1.1. Présentation Equipe
L’équipe de support SaaS de niveau 1 est composé de deux personnes.
L’équipe de support SaaS de niveau 2 est composé de trois personnes.
Ces personnes travaillent en équipe pour répondre aux incidents déposés sur la plateforme. Le travail d’équipe est important, car certains incidents sont transmis au niveau 2 en passant par un diagnostic du niveau 1. C’est pourquoi, la communication est importante afin de pouvoir traiter les incidents le plus rapidement possible !
Les horaires sont variables. Pour ma part, je travaillais sur des horaires de 8h à 12h05. Puis de 13h35 à 17h, selon le travail à fournir ou demandé.
Certains des employés ont des horaires de matins, tandis que d’autres sont de journées.
Le travail de l’équipe consiste à répondre aux incidents liés à l’hébergement. Si ces incidents ne sont pas liés à l’hébergement, nous devions les déplacer dans le secteur approprié.
Page 3

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
2. Gestions d’incidents
Interface ITSM (Remedy) :
Contexte :
J’ai travaillé dans une grande Entreprise, Cegid. Composé de plus de 800 salariés. J’ai intégré l’équipe de support SaaS – Hébergement, de niveau 1 et de niveau 2. Mon travail était via l’interface de Gestion d’Incidents fournies, de gérer les différents incidents des clients afin de répondre à une attente de support comprise dans le contrat. Le support étant basé seulement sur la plateforme Hébergement composé de plus de 1600 serveurs. L’entreprise subit une augmentation de 40% de clients par an, c’est pourquoi ce service doit être fonctionnel. La plupart des incidents étant déposés au SaaS Niveau 1, si ceux-ci prennent plus de 30 minutes de résolution, ou une difficulté trop élevée, ceux-ci sont envoyés au SaaS Niveau 2. Des procédures sont à suivre selon l’incident. Selon la difficulté de l'incident et des informations fournies, l'appel téléphonique pouvait être requis.
Page 4

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Besoins :
Le contrat des clients consiste à obtenir un support efficace et opérationnel selon leurs demandes. Chaque entreprises étant hébergées par Cegid, à des nécessités quant aux blocages de leurs sessions, aux problèmes de mot de passe, à la création ou la suppression d’utilisateurs pouvant accéder à l’application, à la réinitialisation de profils, aux problèmes de sessions plantées ou bloquées, aux problèmes liés aux comptes LDAP, au restauration de dossiers ou aux Token RSA. Les tokens RSA étant un système d’authentification forte afin de protéger les utilisateurs grâce à un code temporaire se renouvelant à des délais constants. Le dépannage par appel téléphonique pouvait être important pour obtenir la confirmation de fonctionnement chez le client.
Réalisation :
Pour répondre aux incidents, il a fallu que je m’approprie la structure réseau de l’entreprise ainsi que les différents serveurs. Chaque incident étant différent, il a fallu apprendre à suivre différentes procédures pour pouvoir répondre directement et correctement à la demande. Il m’a fallu installer différents outils sur mon poste. (Active Directory avec les différents domaines, Remote Desktop Manager afin de pouvoir accéder aux différents serveurs, Consoles Citrix pour la gestion de comptes utilisateurs…). Ainsi que contacter directement les clients afin d'obtenir leur confirmation sur le fonctionnement de leur outil, ou de leur connexion.
2.1. Catégorisation d’incidents
La catégorisation d’incident se faisait directement via l’interface ITSM. (Outil Remedy).
Lors de l’ouverture d’un incident, il nous fallait les catégoriser afin de savoir précisément sur quel outil le problème a été traité.
Page 5

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Catégorisation :
2.2. Liste d’incidents
- Suppression d’utilisateurs
La procédure étant de trouver l’utilisateur ainsi que son Login dans l’Active Directory. Par la suite, avec les informations se trouvant dans l’AD, nous pouvions accéder au serveur de profil concerné. Dans le disque D, il fallait accéder au "tseprofils" et au "tseusers" afin de supprimé le profil concerné. Une fois tout cela réalisé, il fallait supprimer l’utilisateur dans l’Active Directory.
Catégorisation : Sourcing – Citrix – Gestion Utilisateurs
- Création de compte utilisateurs
La procédure étant de trouver l’entreprise dans l’Active Directory. Par la suite, une fois l’entreprise et le chemin d’accès trouvé, il fallait accéder à un serveur sur lequel se trouvait un script de création
Page 6

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
d’utilisateur. Ce script permettait de créer l’utilisateur en renseignant le nom de l’entreprise ainsi que son "Code" afin que la création se fasse au bon endroit.
Catégorisation : Sourcing – Citrix – Gestion Utilisateurs
- Problème de token RSA (temporaire)
La procédure étant de trouver le numéro de Token concerné, via une interface WEB, généralement communiqué par le client lors de l’ouverture de son incident. Par la suite, il fallait modifier le Token et accéder aux configurations afin de mettre un code temporaire pour pouvoir accéder au compte Token relié au compte AD où retirer ce code car l’obtention du nouveau Token a été faite.
Catégorisation : Sourcing – Gestions des Tokens – Initialisation
- Problème de token RSA bloqué
La procédure étant toujours sous l’interface WEB, dans les configurations du Token via une recherche avec le numéro ou le compte utilisateur. Il fallait retirer le statut "Locked" et puis réinitialisé le nombre de tentatives d’authentification, car celles-ci bloquent à partir de la cinquième tentative.
Catégorisation : Sourcing – Gestions des Tokens – Déblocage
- Réinitialisation de profil d’utilisateurs
La procédure étant de trouver l’utilisateur dans l’Active Directory ainsi que son Login, puis d’accéder au serveur de profil concerné. Par la suite, il fallait vérifier si l’utilisateur était connecté car la réinitialisation de son profil ne peut avoir lieu si une connexion est établie. Si l’utilisateur est connecté, nous devions l’appeler afin de lui demander sa déconnexion pour quelques minutes. Ensuite, sur le serveur, via un script développé en Interne, en renseignant juste le login de l’utilisateur, pour le supprimer et le recréer.
Catégorisation : Sourcing – Citrix – Gestion Utilisateurs
- Problème de token RSA expiré
Page 7

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
La procédure étant toujours sur l’interface WEB, et si le client à renouveler son contrat Token, il fallait dans la configuration du Token, lui affecter un mot de passe temporaire afin qu’il puisse accéder à son compte en attendant l’arrivée de son nouveau Token RSA.
Catégorisation : Sourcing – Gestions des Tokens – Initialisation
- Problème de session bloquée
La procédure étant de trouver l’utilisateur dans l’AD, sauf si celui-ci renseigne directement son Login. Il fallait alors, ouvrir la console Citrix et faire une recherche sur les serveurs avec le login concerné. Si une session apparaît, Inactive ou Active, il suffit alors de faire un clic droit et de "fermer la session en cours".
Catégorisation : Sourcing – Citrix – Session Citrix Bloquée
- Problème de clé registre
Pour certains utilisateurs, des clés registres pouvaient bloqués quelques fonctionnalité des applications. C’est pourquoi, il fallait quelques fois, accéder au serveur de profil de l’utilisateur concerné afin de supprimé certaines clés registres sous son profil. (Ouvrir le regedit ainsi que le NTUSER.DAT afin de charger la ruche de clés du profil).
Catégorisation : Sourcing – Citrix – Gestion Utilisateurs
- Problème de mot de passe
La procédure étant de trouver encore une fois, l’utilisateur dans l’Active Directory, puis une fois l’utilisateur repérer, selon l’incident, de réinitialisé le mot de passe et de permettre le client de le modifier par la suite, ou alors, de saisir le mot de passe en "DUR", si celui-ci renseigne un mot de passe précis.
Catégorisation : Sourcing – Citrix – Gestion Mot de Passe
- Problème de compte LDAP (verrouillage ou mot de passe)
Page 8

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Une interface WEB étant mise en ligne en interne à Cegid, permettait de répertorier les différents comptes LDAP de la plateforme, sous différentes entreprises. Un bouton "réinitialiser" était situé directement à côté du compte une fois celui-ci trouvé. Un mot de passe aléatoire se génère et celui-ci est communiqué par mail, qu’il faut ensuite communiqué au client.
Catégorisation : Sourcing – Cwas – Gestion Mot de Passe
Mais le support SaaS au sein de l'équipe Hébergement, ne correspond pas seulement à la résolution d'incidents arrivant sur la plateforme. Ces incidents, sont résolus de différentes façons. Par exemple, beaucoup d'incidents, mal renseigné, nécessitent des appels afin d'obtenir les informations correctes pour notre intervention. Tandis que d'autres appels, sont plutôt pour vérifier la correction du problème rencontré. C'est pourquoi, il m'a fallu apprendre et développé certaines compétences sociales afin de pouvoir correctement intervertir avec les clients. (Message de présentation, message de réponses...). Sachant que beaucoup d'incidents sont traités par appel car la saisie par le client de son incident manque généralement d'informations sur l'action à effectuer.
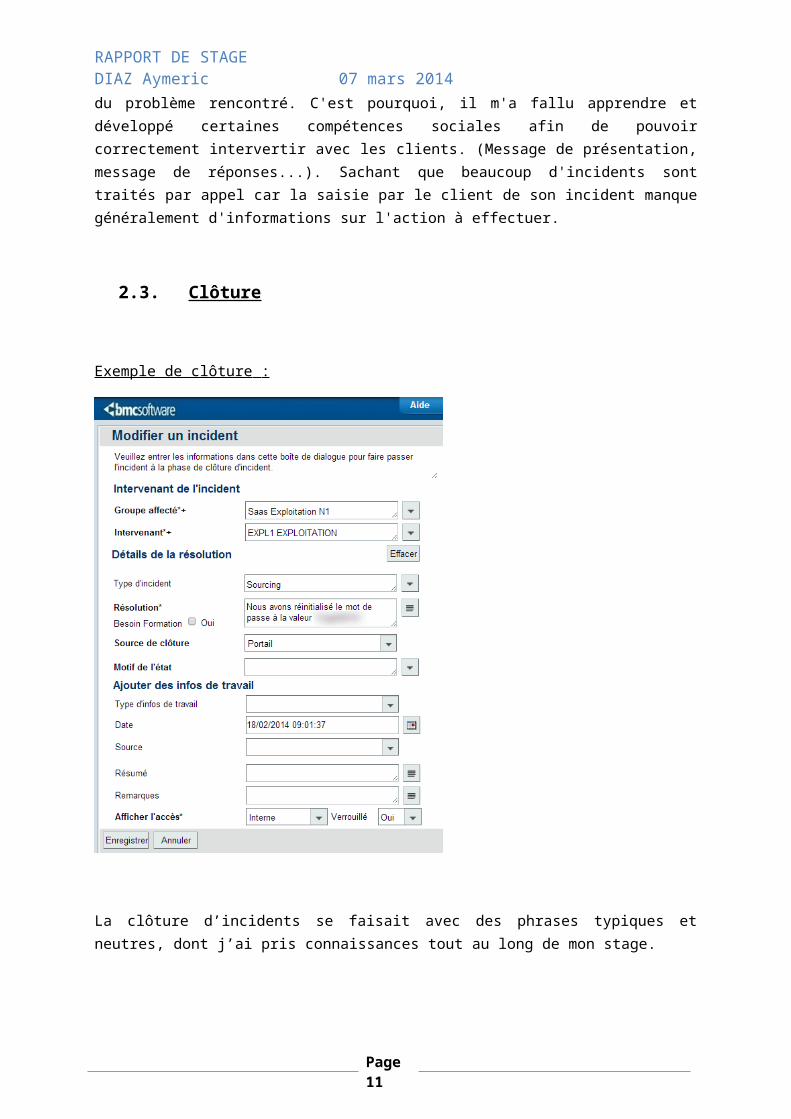
2.3. Clôture
Exemple de clôture :
Page 9

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
La clôture d’incidents se faisait avec des phrases typiques et neutres, dont j’ai pris connaissances tout au long de mon stage.
2.4. Bilan
J’ai appris à travailler en équipe pour certaine résolutions d’incidents, à utiliser des procédures
définies dans l’entreprise.
J’ai appris à prendre en main les logiciels et les interfaces WEB, en autonomie.
3. Supervision Nagios
Page 10
RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Interface Nagstamon :
Contexte :
J’ai travaillé dans une grande Entreprise, Cegid. Composé de plus de 800 salariés. J’ai intégré l’équipe
de support SaaS – Hébergement, de niveau 1 et de niveau 2. Par la suite, j’ai été intégré dans une
équipe de gestion des alertes Nagios car seulement une équipe de mon étage gérait les alertes
Nagios seulement le matin. Mon travail était, via l’interface et l’outil Nagstamon, de surveiller les
remontés d’alertes possibles sur les différents serveurs sur le réseau. Ces serveurs étant directement
liés à la plateforme hébergement et pouvant expliquer certains incidents lors des
dysfonctionnements internes. Chaque alerte remontée par les serveurs Nagios étaient suivies d’une
Page 11

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
documentation à suivre pour répondre correctement et rapidement au problème détecté. Les
documentations seront disponibles lors de mes explications sur les procédures à suivre.
Besoins :
Ces serveurs ont été mis en place afin de garantir un accès continu aux serveurs de la plateforme. La
continuité de service est de rigueur, car les clients ne peuvent pas se permettre une interruption sur
certains logiciels, surtout si celle-ci dure dans le temps. Pour maintenir les serveurs opérationnels,
sachant que ceux-ci sont tous, ou pratiquement, virtualisés et hébergés dans un Datacenter d’IBM.
Tandis qu’avant, ceux-ci étaient hébergés par Cegid. Mais cette gestion était trop importante, c’est
pourquoi la migration chez IBM a été initialisé. Les principales alertes que j’ai pu traiter sont les
problèmes d’espaces disques, les problèmes de services non démarrés, problème de serveur "Down"
ou inaccessible, problème de processeur serveur, problème de site HTTP. Ce sont deux serveurs
Nagios qui remontent les alertes, et ceux-ci se surveillent eux-mêmes.
Réalisation :
Pour répondre à ces alertes s’affichant via l’outil Nagstamon sur Windows 7, il a fallu d’abord
configurer l’application sur mon poste afin d’obtenir les informations envoyées par les serveurs
Nagios. Chaque alertes étaient suivies d’une documentation afin de corriger cette dernière,
Page 12

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
cependant, les alertes ne sont pas toutes résolues pas la même manipulation même si ces alertes
sont identiques. Le seul outil que je devais utiliser était Remote Desktop Manager afin d’accéder à
distance aux serveurs concernés.
3.1. Infrastructure
L’infrastructure pour la remontée d’alertes, se fait avec deux serveurs Nagios qui sont paramétrés et
qui se surveillent entre eux.
Schéma de l'architecture des serveurs Nagios :
3.2. Interface Nagstamon
Page 13

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Nagstamon est un outil compatible Windows 7 et paramétrable avec les adresses des serveurs Nagios. Afin d’obtenir une remontée d’alertes simplifiés et catégorisés.
3.3. Gestions d’alertes
Catégorisation des alertes :
- Noir : Alertes de type "Down" - Très importante.
- Rouge : Alertes de type "Critical" - Importante.
- Orange : Alertes de type "Unknow" - Erreur inconnu.
- Jaune : Alertes de type "Warning" - A surveillé.
La gestion d’alertes me semble plutôt simple à comprendre une fois la catégorisation connue. Les alertes les plus importantes étant les alertes de couleur noir, sont les alertes à traiter immédiatement. Les alertes rouges, moins importantes, sont à traitées rapidement aussi, car celle si peuvent amener à une alerte plus dangereuse. Les alertes oranges, sont des alertes inconnues, leurs traitements est plutôt « en attente ». Les alertes jaunes sont les moins importantes, mais peuvent rapidement devenir une alertes rouges. C’est pourquoi, il faut les surveiller et les traiter avant qu’elles deviennent plus importantes.
3.4. Types d’alertes
Page 14

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
- Problème d'espace disque
Les problèmes d'espace disque étaient remontés et régler selon une taille stricte. L'alerte était répertoriée en "Warning" si la capacité restante du disque était inférieure à 3000 MB, puis celle-ci passait en "Critical" si la capacité restante du disque était inférieure à 2000 MB. Pour régler cette alerte, il fallait se connecter au serveur et lancer l'outil "WinDirStat" afin d'avoir une vue globale sur le disque ainsi qu'aux éléments prenant de la place dessus.
Documentation :
- Problème de Services (redémarrage nécessaire)
Les problèmes de services sont remontés dès que le service est en état "Non démarré". La simplicité de cette alerte étant de se connecter au serveur, d'accéder aux services de celui-ci et soit de démarrer le service concerné, soit de le redémarrer.
- Problème de serveur inaccessible ou "Down"
Page 15

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Les alertes de ce type sont importantes, surtout pour l'équipe de SaaS Support. Toutes ces alertes peuvent être causes de certains incidents arrivant sur la plateforme ITSM (Remedy). Le seul problème étant, que si le serveur "Down" est un serveur de connexion Citrix, il fallait absolument faire une capture d'écran des utilisateurs connectés sur le serveur lors de son redémarrage, car si les incidents reviennent au Support, ceux-ci peuvent y répondre plus facilement.
Documentation :
- Problème de CPU
Page 16

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Les alertes de CPU sont remontées sous deux catégories, celles "Warning" quand le processeur du serveur tourne au-dessus de 80 %. Ces alertes passent en "Critical" si le processeur du serveur tourne au-dessus de 95 %. Ces alertes pouvant rendre les serveurs lents ou inaccessible devaient être traités rapidement. En vérifiant simplement quel processus s'emballait. Cependant, seul certains processus pouvaient prendre de la mémoire et être redémarré. Car l'activité importante des clients sur un serveur, pouvait faire monter une alerte CPU sans nécessité de la traiter.
Documentation :
- Problème de site HTTP (non-disponible, non-joignable)
Les alertes concernant la disponibilité des sites des entreprises, sont importantes. Sur le serveur WEB concerné il fallait tester l'accès à l'URL en local et faire un "ping" de l'alias DNS du site.
Documentation :
Page 17

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
- Problème "CHECK_NRPE"
Les alertes de type "CHECK_NRPE" n'étaient pas forcément importantes. Ce sont des alertes dues à un dysfonctionnement d'un service qu'il faut simplement redémarrer peut être plusieurs fois, afin que l'alerte se désactive. ("Service SNMP")
Documentation :
Page 18

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
- Problème de type "CWAS"
Page 19

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Les problèmes de type "CWAS" étaient les plus complexes à mon avis. Il fallait accéder aux "Logs" sur les serveurs répertoriant les divers services "CWAS". Afin de pouvoir analyser le log et de pouvoir savoir où l'erreur se situe correctement.
3.5. Bilan :
Le plus important était le travail en équipe afin d'avertir l'équipe des alertes que l'on traite.
Le travail en autonomie l'était tout autant, car la suivie des documentations pour la résolution d'alertes, ne se faisait qu'en autonomie.
4. Formations
Contexte :
Dans le cadre de mon stage, j’ai suivi quelques formations pour connaître les nouveaux outils mis en place pour mon équipe. Ces formations ne concernaient pas que mon unique personne, car les fonctionnalités présentées en formation, sont de nouvelles fonctionnalités sur la plateforme. Il faut donc que l’équipe soit au courant et connaisse quelque peu le nouvel outil. Les formations qui ont été suivis pour ma part, sont des formations sur Citrix, PRTG et Nagios.
Besoins :
Page 20

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Le besoin était simple, les employés utilisant les fonctionnalités suivies en formation, avaient besoin de plus d’informations ou même d’explications sur l’interface, ou sur la façon d’utiliser correctement les fonctionnalités. Même pour savoir, si certaines fonctionnalités requises par les techniciens pouvaient être fournies ou non. Des réponses étaient données, cependant, des modifications pourraient être apportées par l’équipe prenant en charge la fonctionnalité afin d’essayer d’apporter la fonctionnalité requise par les techniciens.
Réalisation :
Les formations étaient suivies dans une salle de mon étage, que seul celui-ci dispose. Car normalement, ces salles ne sont pas autorisées ailleurs dans le bâtiment. Les locaux où j’étais situé sont des locaux sécurisés et étant donné que les formations pouvaient divulguer des informations clients, celles-ci devaient être organisées dans un lieu sécurisé. C’est pourquoi toutes les réunions et formations se passaient à mon étage.
Bilan :
Le suivi de ces formations m'a permis de connaître un peu mieux certaines fonctionnalités et interfaces. Cependant, la plupart des informations avaient déjà été vu lors de l'utilisation des fonctionnalités.
L'autonomie et les notes étaient importantes pour pouvoir travailler correctement.
5. Conclusion Globale
Page 21

RAPPORT DE STAGEDIAZ Aymeric 07 mars 2014
Ce stage m’a permis de comprendre un peu mieux le travail professionnel. Les points forts de ce que j’ai pu apprendre de mon stage sont importants. Dans un premier temps, j’ai appris l’intégration dans une équipe. Et l’importance de l’observation afin de pouvoir travailler rapidement et efficacement. Dans l’informatique, le travail en équipe est important quand les actions sont exercées sur un réseau important.
Le travail en équipe consistait à la résolution d’incident. Le traitement, et la résolution de ceux-ci était important, hébergeant les connexions pour plusieurs entreprises, les problèmes de « mot de passe oublié » sont importantes. C’est pourquoi le respect d’utilisation des procédures définies dans l’entreprise est de rigueur. Car lors de résolution de ceux-ci, il faut être clair et précis. Afin que le client comprenne le problème.
L’autonomie est aussi importante. Chaque entreprise dispose d’interface personnalisée si ceux-ci possède des programmeurs. C’est pourquoi j’ai dû apprendre à prendre en main les logiciels et les interfaces WEB.
Le traitement d’alerte prenait la plupart du temps dans mes journées au début. Par la suite, j’ai été amené à traiter la surveillance par serveurs Nagios de la plateforme sur laquelle les incidents étaient source. La liaison entre les deux m’a permis de communiquer correctement avec mon équipe. Pour permettre à une équipe de comprendre certains des incidents qui peuvent arrivés.
Par la suite, avec la surveillance des alertes remontées par les serveurs Nagios, j’ai dû travailler en autonomie dans la résolution de celle-ci, grâce à des documentations fournies et actualisé par l’entreprise. Pour ce passage, afin de pouvoir être efficace, il m’a fallu comprendre et apprendre les documentations. Afin de ne pas avoir à les utiliser tout le temps.
J’ai aussi eu la chance de participé à quelques formations sur les outils dont je me servais. Le suivi de ces formations m'a permis de connaître un peu mieux certaines fonctionnalités et interfaces. Cependant, la plupart des informations avaient déjà été vu lors de l'utilisation des fonctionnalités.
Ce stage m’a permis de connaître l’importance de la continuité de services pour les grandes entreprises. Ainsi que l’importance des documentations afin de ne pas être le seul à pouvoir utiliser une alerte, un logiciel, ou tout autre fonctionnalités dans l’entreprise.
Page 22





























