Embed Size (px)
Citation preview

UNIVERSITATEA TEHNICĂ “GH.ASACHI” IAŞI FACULTATEA DE AUTOMATICĂ ŞI CALCULATOARE
Ing. Cristian-Győző Haba
CONTRIBUŢII LA SINTEZA STRUCTURILOR NUMERICE DE
COMANDĂ
REZUMATUL TEZEI DE DOCTORAT
CONDUCĂTOR ŞTIINŢIFIC PROF.DR.ING. CORNELIU HUŢANU
1999

_

UNIVERSITATEA TEHNICĂ "GH.ASACHI" IAŞI RECTORATUL
Către ____________________________________________
Vă facem cunoscut că în ziua de ……………………la ora…………în Aula Universităţii Tehnice "Gh.Asachi" Iaşi, va avea loc susţinerea publică a tezei de doctorat intitulată
"CONTRIBUŢII LA SINTEZA STRUCTURILOR NUMERICE DE COMANDĂ" elaborată de către domnul inginer Cristian-Győző Haba, în vederea conferirii titlului ştiinţific de doctor inginer.
Comisia de doctorat este formată din:
Prof.univ.dr.ing. Mihail VOICU preşedinte Decan al Facultăţii de Automatică şi Calculatoare Universitatea Tehnică "Gh.Asachi" Iaşi
Prof.univ.dr.ing. Corneliu HUŢANU conducător ştiinţific Facultatea de Automatică şi Calculatoare Universitatea Tehnică "Gh.Asachi" Iaşi
Prof.univ.dr.ing. Mircea PETRESCU membru Facultatea de Automatică şi Calculatoare Universitatea "Politehnica" Bucureşti Prof.univ.dr.ing. Mircea IVĂNESCU membru Facultatea de Automatică, Calculatoarelor şi Electronică Universitatea Craiova Prof.univ.dr.ing. Eugen BALABAN membru Facultatea de Automatică şi Calculatoare Universitatea Tehnică "Gh.Asachi" Iaşi Vă transmitem rezumatul tezei de doctorat cu rugămintea de a ne comunica, în scris, aprecierile şi observaţiile dumneavoastră. Cu această ocazie, vă invităm să participaţi la susţinerea publică a tezei de doctorat.

_

CUPRINS
1 INTRODUCERE .............................................................................................................................1/1.1
1.1 SCOPUL LUCRĂRII..........................................................................................................................1.1 1.2 ACTUALITATEA ÎN DOMENIU ......................................................................................................1/1.2
1.2.1 Proiectarea structurilor numerice .....................................................................................1/1.2 1.2.2 Sinteza sistemelor numerice..................................................................................................1.5 1.2.3 Limbajele de descriere a hardware-ului...............................................................................1.6 1.2.4 Diagramele de decizie binare ............................................................................................2/1.6 1.2.5 Structuri numerice secvenţiale.........................................................................................3/1.11
1.3 STRUCTURA LUCRĂRII .................................................................................................................1.16
2 NOŢIUNI TEORETICE ŞI DEFINIŢII...........................................................................................2.1
2.1. MULŢIMI ŞI RELAŢII.......................................................................................................................2.1 2.2. ALGEBRĂ BOOLEANĂ ....................................................................................................................2.3 2.3. FUNCŢII BOOLEENE........................................................................................................................2.5 2.4. CODIFICAREA IMPLICANŢILOR.......................................................................................................2.9 2.5. GRAFURI......................................................................................................................................2.11 2.6. REPREZENTAREA OBDD.............................................................................................................2.11 2.7. TEORIA AUTOMATELOR ...............................................................................................................2.14
3 REPREZENTAREA FUNCŢIILOR BOOLEENE CU AJUTORUL DIAGRAMELOR DE
DECIZIE BINARĂ..................................................................................................................................4/3.1
3.1 INTRODUCERE ...............................................................................................................................3.1 3.1.1 Ordinea variabilelor .............................................................................................................3.2 3.1.2 Manipularea funcţiilor booleene folosind ROBDD ..............................................................3.3
3.2 TEHNICI DE PROGRAMARE UTILIZATE PENTRU CREŞTEREA EFICIENŢEI MANIPULĂRII FUNCŢIILOR BOOLEENE FOLOSIND ROBDD .................................................................................................................3.5
3.2.1 Tabela de dispersie ...............................................................................................................3.5 3.2.2 Memorator pentru funcţii......................................................................................................3.6 3.2.3 Tabelă de dispersie de tip cache...........................................................................................3.6 3.2.4 Tabela unicatelor..................................................................................................................3.7 3.2.5 Recuperarea memoriei nefolosite .........................................................................................3.7 3.2.6 Algoritmul ITE......................................................................................................................3.8 3.2.7 Utilizarea arcelor negate......................................................................................................3.8 3.2.8 Triplete reprezentative..........................................................................................................3.9
3.3 ALTE REPREZENTĂRI FOLOSIND OPERATORUL ITE......................................................................3.11 3.4 CONTRIBUŢII LA REPREZENTAREA FUNCŢIILOR BOOLEENE UTILIZÂND ROBDD......................4/3.12
3.4.1 Reducerea Fuziune ..........................................................................................................4/3.12 3.4.2 Reducerea Stâng=Drept ..................................................................................................4/3.13 3.4.3 Reducerea Stâng=0 .........................................................................................................4/3.13 3.4.4 Reducerea Stâng=1 .........................................................................................................5/3.13 3.4.5 Reducerea Drept=0 .........................................................................................................6/3.14 3.4.6 Reducerea Drept=1 .........................................................................................................6/3.15 3.4.7 Reducerea Stâng<>Drept................................................................................................6/3.16 3.4.8 Diagrame de decizie binară cu suprimarea lui 0.............................................................6/3.17 3.4.9 Manipularea funcţiilor booleene date în forma normal disjunctivă ................................6/3.20
3.5 REZULTATE EXPERIMENTALE .................................................................................................10/3.29 3.6 CONCLUZII ŞI OBIECTIVE DE VIITOR........................................................................................12/3.36
4 CONTRIBUŢII LA UTILIZAREA TEHNICILOR IMPLICITE DE CALCUL ÎN SINTEZA STRUCTURILOR NUMERICE..........................................................................................................12/4.1
4.1 INTRODUCERE ..........................................................................................................................12/4.1 4.2 REPREZENTAREA CUBICĂ POZIŢIONALĂ A OBIECTELOR ŞI MULŢIMILOR DE OBIECTE.....................4.1 4.3 OPERAŢII CU MULŢIMI DE OBIECTE...........................................................................................13/4.3 4.4 REPREZENTĂRI IMPLICITE ALE AUTOMATELOR FINITE..............................................................14/4.8 4.5 IMPLEMENTAREA OPERATORILOR IMPLICIŢI ...........................................................................16/4.13 4.6 TABELA DE CALCUL FUNCŢIONALĂ ........................................................................................17/4.14
4.6.1 Introducere ....................................................................................................................17/4.14 4.6.2 Generalităţi....................................................................................................................17/4.15 4.6.3 Implementarea tabelei de calcul funcţionale .................................................................18/4.18

4.6.4 Implementarea operatorilor de manipulare implicită a funcţiilor booleene utilizând tabela de calcul funcţională.....................................................................................................................19/4.20 4.6.5 Rezultate experimentale.................................................................................................20/4.22
4.7 CONCLUZII ŞI OBIECTIVE DE VIITOR........................................................................................22/4.27
5 COMPUNEREA ŞI DESCOMPUNEREA AUTOMATELOR FINITE ..................................23/5.1
5.1 INTRODUCERE ..........................................................................................................................23/5.1 5.2 OPERAŢII CU AUTOMATE ...............................................................................................................5.1 5.3 CONTRIBUŢII PRIVIND REALIZAREA OPERAŢIILOR CU AUTOMATE UTILIZÂND TEHNICI IMPLICITE23/5.4
5.3.1 Obţinerea grupării în paralel a două automate folosind tehnici implicite ......................23/5.4 5.3.2 Obţinerea grupării în serie a două automate folosind tehnici implicite ..........................24/5.8
5.4 DESCOMPUNEREA ÎN SERIE ŞI ÎN PARALEL A AUTOMATELOR FINITE .......................................24/5.10 5.5 CONTRIBUŢII PRIVIND DESCOMPUNEREA AUTOMATELOR FINITE PRIN FACTORIZARE .............25/5.12 5.6 CONTRIBUŢII LA DESCOMPUNEREA ÎN SERIE ŞI ÎN PARALEL FOLOSIND TEHNICI IMPLICITE......29/5.23
5.6.1 Determinarea partiţiilor având proprietatea de substituţie...........................................29/5.23 5.6.2 Operatori pentru descompunerea în serie şi în paralel folosind tehnicile implicite......30/5.25
5.7 DESCOMPUNEREA PRIN FACTORIZARE FOLOSIND TEHNICI IMPLICITE .....................................31/5.26 5.7.1 Determinarea perechilor de stări o-echivalente ............................................................31/5.26 5.7.2 Determinarea perechilor de stări i-echivalente.............................................................32/5.27 5.7.3 Determinarea perechilor de stări io-echivalente...........................................................32/5.28 5.7.4 Determinarea şi validarea candidaţilor ........................................................................32/5.29 5.7.5 Determinarea automatelor master şi slave folosind metode implicite...........................33/5.29
5.8 IMPLEMENTAREA OPERATORILOR PENTRU COMPUNEREA ŞI DESCOMPUNEREA AUTOMATELOR FINITE ...............................................................................................................................................33/5.30 5.9 REZULTATE EXPERIMENTALE .................................................................................................34/5.31 5.10 CONCLUZII ŞI OBIECTIVE DE VIITOR........................................................................................35/5.34
6 RFSM: PACHET DE PROGRAME PENTRU SINTEZA ASISTATĂ DE CALCULATOR A STRUCTURILOR NUMERICE SECVENŢIALE ............................................................................35/6.1
6.1 INTRODUCERE ..........................................................................................................................35/6.1 6.2 PROGRAMUL RFSM...................................................................................................................35/6.2 6.3 DESCRIEREA PROGRAMULUI RFSMVIEW ..................................................................................36/6.5
6.3.1 Fereastra principală ........................................................................................................37/6.6 6.4 MENIURILE PROGRAMULUI.......................................................................................................37/6.9
6.4.1 Meniul File.......................................................................................................................37/6.9 6.4.2 Meniul Edit ....................................................................................................................37/6.10 6.4.3 Meniul Search................................................................................................................37/6.12 6.4.4 Meniul View...................................................................................................................37/6.15 6.4.5 Meniul Drawing.............................................................................................................38/6.15 6.4.6 Meniul Options ..............................................................................................................38/6.16 6.4.7 Meniul Tools ..................................................................................................................38/6.20 6.4.8 Meniul Help ...................................................................................................................39/6.21
6.5 LEGĂTURA PROGRAMULUI RFSMVIEW CU ALTE SISTEME DE PROIECTARE ASISTATĂ DE CALCULATOR ÎN DOMENIUL VLSI ......................................................................................................39/6.22
6.5.1 Pachetul de programe Alliance ..........................................................................................6.22 6.5.2 Exemplu de proiectare ........................................................................................................6.24
6.6 CONCLUZII ŞI OBIECTIVE DE VIITOR........................................................................................45/6.27
7 CONCLUZII FINALE. CONTRIBUŢII ORIGINALE. OBIECTIVE DE VIITOR ..............40/7.1
7.1 CONCLUZII FINALE ........................................................................................................................7.1 7.2 CONTRIBUŢII ORIGINALE ..........................................................................................................40/7.3 7.3 OBIECTIVE DE VIITOR ...............................................................................................................42/7.6
A FORMATE DE FIŞIERE .................................................................................................................A.1
A.1 FORMATUL KISS..........................................................................................................................A.1 A.2 FORMATUL KISS EXTINS..............................................................................................................A.1 A.3 FORMATUL FSM ..........................................................................................................................A.4 A.4 FORMATUL CODES .....................................................................................................................A.6 A.5 FORMATUL COD..........................................................................................................................A.7 A.6 FORMATUL EQN ..........................................................................................................................A.8
B FUNCŢIILE PACHETULUI RFSM. REZUMATE. ..................................................................... B.1
B.1 FUNCŢII EXTERNE ALE PACHETULUI RFSM.................................................................................... B.1

B.2 FUNCŢII EXTERNE ALE PACHETULUI RFSM.................................................................................... B.5
C DESCRIEREA FUNCŢIILOPR PACHETULUI RFSM.............................................................. C.1
C.1 FUNCŢII EXTERNE ALE PACHETULUI RFSM....................................................................................C.1 C.2 FUNCŢII EXTERNE ALE PACHETULUI RFSM..................................................................................C.27
D CONSTANTE, TIPURI ŞI STRUCTURI UTILIZATE ÎN PACHETUL RFSM....................... D.1
BIBLIOGRAFIE ..................................................................................................................................43/E.1
Rezumat/Teză

1
1 INTRODUCERE
1.2 Actualitatea în domeniu 1.2.1 Proiectarea structurilor numerice
Structurile numerice integrate încep să fie tot mai mult utilizate în nenumărate domenii ale activităţii umane. Acestea înglobează un număr tot mai mare de funcţii, în dispozitive având dimensiuni din ce în ce mai mici şi consumând din ce în ce mai puţină energie. Toate acestea au la bază, atât evoluţia tehnologiilor VLSI (Very Large Scale Integration) care a permis ca numărul de tranzistori care pot fi integraţi pe un chip să se dubleze aproape în fiecare an, cât şi metodele şi sistemele de proiectare, mereu îmbunătăţite pentru ca acestea dispozitive să fie utilizate la maximum.
Realizarea unui sistem numeric presupune parcurgerea mai multor etape: proiectarea conceptuală, fabricarea, testarea şi realizarea circuitului integrat. La rândul ei, etapa de proiectare cuprinde şi ea mai multe etape: descrierea sistemului, sinteza, optimizarea şi validarea sistemului.
Un rol important în evoluţia sistemelor numerice de comandă au avut-o şi o au mediile de proiectare asistate de calculator. Acestea au permis reducerea timpului de proiectare şi îmbunătăţirea calităţii sistemelor concepute. Pe măsură ce complexitatea sistemelor proiectate creşte, este tot mai dificilă ducerea la bun sfârşit a proiectului într-un timp scurt şi fără ca acesta să aibă erori. În plus, posibilităţile de optimizare ale sistemului proiectat cresc odată cu creşterea dimensiunilor acestuia şi ca urmare, este greu ca această sarcină să fie rezolvată doar de proiectanţi.
Evoluţia mediilor de proiectare a trebuit să urmeze evoluţia sistemelor numerice. Pe măsură ce complexitatea acestor sisteme a crescut, mediile de proiectare au trebuit să-şi depăşească limitele prin înglobarea de metode noi de proiectare, să adopte standarde cu largă răspândire şi să permită legătura cu alte medii de proiectare din domeniu.
Descrierea unui sistem numeric poate fi făcută la diverse niveluri, fie sub formă textuală fie sub formă picturală [Arm93]. Descrierile textuale sunt făcute utilizând diverse limbaje mai mult sau mai puţin apropiate de limbajul natural. Dintre cele mai utilizate familii de limbaje amintim: descrierile în limbajul natural, descrierile folosind ecuaţiile booleene, descrierile folosind limbajele de programare (C,ADA), descrierile folosind limbajele de descriere a hardware-ului (Verilog [Arn99], VHDL[Sjo96]).
Descrierile picturale cuprind o multitudine de forme care fac uz de reprezentări de tip tabelar, de tip diagrame sau grafice. Dintre cele mai utilizate descrieri de tip pictural amintim: diagramele temporale, diagramele logice, grafurile de tranziţie şi tabelele de tranziţii. Deşi în decursul ultimilor ani limbajele de descriere a hardware-lui s-au impus tot mai mult, unele din ele devenind şi standarde în domeniu, aceste limbaje nu au reuşit să elimine reprezentările picturale. Multe din companiile care dezvoltă medii de proiectare asistată a sistemelor numerice, furnizează în cadrul acestor pachete atât posibilitatea de specificare a proiectelor folosind limbajele HDL standard (VHDL, Verilog) cât şi unelte de descriere picturale (editoare grafice pentru schema electrică, editoare pentru graful de tranziţie, editoare grafice pentru macrouri sau pentru descrierea picturală a ciclului de proiectare, etc.).
1.2.2 Sinteza sistemelor numerice
Proiectarea unui sistem numeric presupune pornirea de la o descriere a sistemului numeric şi transformarea succesivă a acesteia până când se obţine o reprezentare care poate fi implementată în mod direct utilizând tehnologia existentă. Această operaţie mai poartă numele şi de sinteză.
În funcţie de nivelul de abstracţie de la care plecăm şi de cel la care dorim să ajungem, proiectarea sistemului numeric va conţine mai multe etape de sinteză. O astfel de etapă se poate

desfăşura la acelaşi nivel sau între niveluri diferite. O sinteză la acelaşi nivel de abstracţie va realiza o transformare a reprezentării comportamentale într-o reprezentare structurală care să implementeze comportamentul dorit. Sinteza între nivele are rolul de a transforma o reprezentare corespunzătoare unui anumit nivel de abstractizare, într-o reprezentare la un nivel de abstractizare inferior. Trecerea de la un nivel de reprezentare superior la unul inferior, va duce la creşterea nivelului de detalii pe care le va conţine reprezentarea.
1.2.4 Diagramele de decizie binare
Diagramele de decizie binare (BDD) [Ake78,Bra86] au căpătat în ultimii ani o largă utilizare în mai toate domeniile proiectării structurilor numerice şi în multe alte domenii conexe. Principala caracteristică ce le face atât de utilizate este capacitatea acestora de a reprezenta în mod foarte eficient funcţiile booleene Având în vedere că problemele dintr-o gamă largă ce priveşte proiectarea structurilor numerice pot fi exprimate şi rezolvate utilizând funcţiile booleene, folosirea diagramelor de decizie binare apare ca fiind foarte utilă.
Principala problemă care trebuie rezolvată la utilizarea diagramelor de decizie binară este limitarea dimensiunilor acestora. Se caută să se obţină diagrame care să aibă un număr redus de noduri astfel încât memoria ocupată şi viteza algoritmilor de manipulare (în general proporţională cu numărul de noduri ale diagramei) să fie cât mai mică. Există diverse abordări pentru rezolvarea acestei probleme dintre care cele mai importante vizează: ordinea variabilelor, extinderea acestor tipuri de reprezentări şi utilizarea diverselor metode de memorare a acestor structuri în memoria calculatorului. Diverse studii au arătat că dimensiunile diagramelor de decizie binare depind de ordinea variabilelor de intrare.
O a doua problemă importantă privind utilizarea diagramelor de decizie binară este legată de viteza de manipulare a acestora. Rezolvarea acestei probleme presupune găsirea unor algoritmi având viteze mari care să permită prelucrarea într-un timp scurt, a unui număr mare de diagrame sau a unor diagrame cu dimensiuni mari.
Datorită caracteristicilor pe care le posedă diagramele de decizie binare, acestea sunt utilizate în cele mai diverse domenii: alocarea resurselor (mapping) [Jac93], analiza temporală [McG89], compararea funcţiilor booleene, demonstrarea automată a teoremelor [Gou96], descompunerea funcţiilor booleene [Lai93], implementarea tehnicilor implicite de manipulare a funcţiilor booleene [Tou90,Kam95b,Vil95a], înmulţirea întregilor [Bry91], inteligenţa artificială [Oli91], manipularea automatelor finite [Tou90,Kam95b,Vil95a,Hab98c], manipularea polinoamelor [Min95], optimizarea logică a circuitelor combinaţionale [Bab92, Swa92, Wu93, Min92, Cou92a], programarea 0-1 [Jeo92a], simulare simbolică, sinteza multinivel [Roa93], [Wur94], sinteza şi alocarea resurselor pentru circuitele de tip FPGA [Bes92,Sch93], testarea circuitelor numerice şi generarea vectorilor de test [Bec94], testarea echivalenţei automatelor finite [Cou89b],[Moo93], testarea echivalenţei funcţiilor booleene [CheD93], [Moh93], verificare circuitelor structurilor numerice combinaţionale [Fuj88].
1.2.4.1 Pachete de programe ce implementează BDD
Datorită amploarei pe care a luat-o utilizarea BDD, o serie de colective de cercetare au pus la punct pachete de programe care implementează aceste structuri şi algoritmii de manipulare corespunzători. Dintre cele mai cunoscute pachete amintim: BDD[Sen92a] dezvoltat la Universitatea Berkeley California, CMU-BDD[Rud93] ABCD[BYan98] dezvoltat de Armin Biere, CAL[Ran97a] autori Rajeev Ranjan şi Jagesh Sanghavi, CUDD[Som97] autor Fabio Somenzi, EHV[BYan98] autor Geert Janssen, PBF[BYan98] autori Bwolen Yang şi Ying-An Chen, TiGeR[Cou93d] autori Olivier Coudert, Jean C. Madre şi Herve Touati, BuDDy[Lind98] autor Jørn Lind-Nielsen.
Datorită avantajelor pe care le prezintă utilizarea diagramelor de decizie binară în manipularea funcţiilor booleene, aceste reprezentări au fost implementate în diverse medii de proiectare asistată de calculator fiind utilizate în diverse etape ale proiectării. Dintre aceste medii de proiectare amintim: pachetele de programe SIS [Sen92a], HSIS[Azi94] şi VIS[Bra95] de la Universitatea Berkeley din California, pachetul de programe Alliance [Gre93] dezvoltat în cadrul

laboratorului MASI al Universităţii Piere et Marie Curie din Paris, pachetul ASYL [Ino93] dezvoltat în cadrul laboratorului CSI al INP Grenoble. 1.2.5 Structuri numerice secvenţiale
Structurile numerice secvenţiale sunt cele la care evoluţia ieşirilor depinde nu numai de valorile curente ale intrărilor dar şi de valorile anterioare ale intrărilor. În funcţie de modul în care lucrează, structurile numerice secvenţiale pot fi clasificate în structuri numerice secvenţiale sincrone şi structuri numerice secvenţiale asincrone. Structurile numerice sincrone sunt structurile la care circulaţia şi prelucrarea informaţiei se efectuează sincronizat cu unul sau mai multe semnale globale numite semnale de ceas sau de tact. La sistemele numerice asincrone nu avem un astfel de semnal. În această teză sunt studiate sistemele numerice de tip sincron deoarece ele reprezintă marea majoritate a sistemelor numerice existente.
Descrierea structurilor numerice secvenţiale se face în mod formal prin intermediul automatelor finite la care o noţiune importantă este cea de stare.
1.2.5.1 Reprezentare automatelor finite
Automatele finite sunt reprezentate cel mai adesea prin intermediul tabelei de tranziţii sau prin intermediul grafului de tranziţii. Grafurile de tranziţii sunt constituite dintr-un număr de stări şi o mulţime de tranziţii între aceste stări. O altă reprezentare este cea folosind diagramele temporale. Ele reprezintă legătura care există între intrări şi ieşiri prin figurarea acestora de-a lungul axei timpului.
Reprezentările în memoria calculatorului trebuie să fie mai puţin sugestive din punct de vedere al utilizatorului în schimb trebuie să fie compacte şi uşor de manipulat de către diverşii algoritmi. În acest scop sistemele numerice secvenţiale sunt reprezentate în mod explicit sau implicit. În mod explicit, pentru automatul finit, se reprezintă în memoria calculatorului tabelul sau graful de tranziţii. În mod implicit, sistemele numerice secvenţiale pot reprezentate prin intermediul funcţiilor caracteristice corespunzătoare funcţiilor de tranziţie şi de ieşire sau prin intermediul funcţiei caracteristice a relaţiei de tranziţie-ieşire. Acestea au avantajul că pot fi reprezentate şi manipulate în mod eficient utilizând diagramele de decizie binare.
1.2.5.2 Descompunerea automatelor
Descompunerea automatelor finite este în general utilizată pentru a obţine o partiţionare a unui automat conform unei anumite topologii. Partiţionarea automatelor poate duce la îmbunătăţirea performanţelor, la uşurarea testării şi implementării fizice în cazul folosirii anumitor tehnologii de implementare.
Descompunerea automatelor finite pornind de la graful de tranziţie permite analiza unei părţi mai mari din spaţiul soluţiilor faţă de cazul în care descompunerea ar încerca să se facă la nivel logic. Aceste metode au însă dezavantajul că nu permit o evaluare precisă a efectelor asupra costului final al implementării ce urmează descompunerii. Fiind dat un automat finit prin intermediul tabelei sau a grafului de tranziţie, problema descompunerii acestuia presupune găsirea a două sau mai multe automate finite care, conectate în modul determinat, vor avea acelaşi comportament ca şi automatul iniţial. Automatele individuale care realizează întregul ansamblu sunt numite automate componente.
Principalele tipuri de descompuneri sunt cele în serie şi în paralel. Descompunerea automatelor finite a fost pentru prima dată tratată în mod formal de către Hartmanis în [Har60] folosindu-se noţiunea de partiţii închise numite şi partiţii având proprietatea de substituţie. Studiul a fost mai apoi extins în [Yoe61, Har66] şi pentru acoperiri închise sau acoperiri având proprietatea de substituţie. Metode pentru determinarea partiţiilor sau acoperirilor închise pentru un automat finit pot fi găsite în [Har66, Cre73, Fri75, Koh78].
O serie de studii [Dev89b, Dev89c, Ash92a, Ash92b] au arătat că grafurile de tranziţii ale unor automate finite pot avea subgrafuri izomorfe. Instanţele unor astfel de grafuri pot fi implementate ca fiind graful de tranziţie al unui automat separat, diferit de automatul din care au fost extrase. Această operaţie, care poartă numele de factorizare, poate duce la reducerea ariei

ocupate la implementarea automatului şi poate de asemeni îmbunătăţi performanţele ansamblului. În cazul acestui tip de descompunere, ambele componente primesc informaţii despre starea în care se află cealaltă componentă de aceea, ea se încadrează în categoria descompunerii generale ale unui automat. S-a arătat de asemeni că această metodă de descompunere poate fi folosită şi ca ajutor pentru ghidarea etapei de codificare a stărilor unui automat. Pentru realizarea descompunerii prin factorizare se încearcă găsirea unor subgrafuri izomorfe de preferinţă având dimensiunile cât mai mari. Rezultatele experimentale au arătat [Dev89b] că în cazul în care există factori exacţi de mari dimensiuni, ansamblul obţinut în urma descompunerii va avea o complexitate redusă.
3 REPREZENTAREA FUNCŢIILOR BOOLEENE CU AJUTORUL DIAGRAMELOR DE DECIZIE BINARĂ
3.4 Contribuţii la reprezentarea funcţiilor booleene utilizând ROBDD Pornind de la regulile de reducere pentru diagramele de decizie binare ordonate (OBDD)
[Bry86] autorul a efectuat un studiu prin care s-a analizat posibilitatea aplicării altor reguli de reducere a OBDD şi modul în care influenţează aceste reguli dimensiunile reprezentărilor şi algoritmii de manipulare. S-a căutat să se vadă dacă utilizarea altor reguli de reducere nu duce la obţinerea unei reprezentări mai compacte sau care să fie manipulate cu ajutorul unor algoritmi mai simpli şi mai rapizi. În continuarea acestui capitol, prezentăm o serie de noi reprezentări ale funcţiilor booleene obţinute prin aplicarea la reprezentarea OBDD iniţială a unor noi reguli de reducere [Hab94,Hab96]. 3.4.1 Reducerea Fuziune
Această primă regulă de reducere este aceeaşi cu a doua regulă de reducere de la reprezentarea diagramelor de decizie binară reduse (ROBDD) propusă de Bryant [Bry86]. În urma aplicării acestei reguli, OBDD nu conţine noduri distincte v1 şi v2 astfel încât subgrafurile ale căror rădăcini sunt v1 respectiv v2 să fie izomorfe (fig.3.4.1.1). Prin aceasta cele două noduri utilizează în comun reprezentarea subgrafurilor identice. Această regulă poate fi aplicată împreună cu alte reguli după cum vom vedea în reducerile studiate în continuare.
Fig. 3.4.1.1 Aplicarea reducerii Fuziune.
3.4.2 Reducerea Stâng=Drept Această reducere este dată de cele două reguli de reducere propuse de Bryant [Bry86] pentru
obţinerea unei reprezentări de tip ROBDD.
3.4.3 Reducerea Stâng=0 Aceasta reducere este dată de două reguli de reducere care se aplică în mod repetat până când
numai sunt aplicabile. Cele două reguli sunt: 1) Elimină orice nod v al cărui nod fiu Stâng este un nod terminal cu valoarea 0
( valoare(v.stâng)=0 ), după care arcul care ducea la nodul eliminat se leagă la fiul drept al nodului

eliminat ca în figura 3.4.3.1. 2) Aplică regula Fuziune.
Observaţie: Se poate vedea că, spre deosebire de cazul clasic Stâng=Drept, în acest caz nu se elimină nodurile ale căror arce conduc la acelaşi nod. Din acest motiv această regulă de reducere este asimetrică pentru cele două arce deoarece nu se elimină nodurile al căror arc marcat cu 0 conduce la noduri terminale.
Fig. 3.4.3.1 Aplicarea reducerii Stâng=0.
Fig. 3.4.3.2 Aplicarea reducerii Stâng=1.
Fig. 3.4.3.3 Aplicarea reducerii Drept=0.
Fig. 3.4.3.4 Aplicarea regulii Drept=1.
Fig. 3.4.3.5 Aplicarea reducerii Stâng<>Drept cu
regulile 1(a)-1(b).
Fig. 3.4.3.6 Aplicarea reducerii Stâng<>Drept cu
regulile 1'(a)-1'(b).
3.4.4 Reducerea Stâng=1 La fel ca şi în cazul precedent, această reducere este dată de regulile de mai jos: 1) Elimină orice nod v al cărui nod fiu stâng este un nod terminal cu valoarea 1
(valoare(v.stâng)=1) după care arcul care ducea la nodul eliminat se leagă la fiul drept al nodului eliminat ca în figura 3.4.3.2.
2) Aplică regula Fuziune. Următoarele două reduceri sunt asemănătoare cu cele doua de mai sus deosebirea fiind ca ele se aplică arcelor marcate cu 1.
3.4.5 Reducerea Drept=0 Această reducere este dată de regulile de mai jos: 1) Elimină orice nod v al cărui nod fiu drept este un nod terminal cu valoarea 0
(valoare(v.drept)=0 ) după care arcul care ducea la nodul eliminat se leagă la fiul drept al nodului

eliminat ca în figura 3.4.3.3. 2) Aplică regula Fuziune.
3.4.6 Reducerea Drept=1 În cazul acestei reduceri regulile folosite sunt cele date mai jos: 1) Elimină orice nod v al căror nod fiu drept este un nod terminal cu valoarea 1
(valoare(v.drept)=1) după care arcul care ducea la nodul eliminat se leagă la fiul drept al nodului eliminat ca în figura 3.4.3.4. 2) Aplică regula Fuziune.
3.4.7 Reducerea Stâng<>Drept Această reducere este într-un fel opusa reducerii Stâng=Drept. Pentru această reducere există
două situaţii distincte în urma cărora rezultă două reprezentări diferite. Regulile după care se face această reducere sunt:
1) Elimină toate nodurile v ale căror arce conduc la noduri terminale diferite. Arcul care ducea la nodul v care se elimină se leagă la un nod terminal t după următoarele reguli:
1.a) daca valoare(v.stâng)=0 şi valoare(v.drept)=1 atunci valoare(t)=0; 1.b) dacă valoare(v.stâng)=1 şi valoare(v.drept)=0 atunci valoare(t)=1. 2) Aplică regula Fuziune. Observaţie: Daca se consideră combinaţia (valoare(v.stâng),valoare(v.drept)), regulile 1.a) şi
1.b) realizează o corespondenţă (0,1)→0 şi (1,0)→1. Se pot alege însă şi regulile complementare caz în care, obţinem cea de a doua variantă de reprezentare pentru care avem codificarea (0,1)→1 şi (1,0)→0. Aceste reguli sunt:
1'.a) daca valoare(v.stâng)=0 şi valoare(v.drept)=1 atunci valoare(t)=1; 1'.b) daca valoare(v.stâng)=1 şi valoare(v.drept)=0 atunci valoare(t)=0. Observaţie: După cum se poate intui, reducerea Stâng<>Drept este mai slabă decât reducerea
Stâng=Drept. Aceasta rezultă din faptul că prima regulă de reducere, conform definirii ei, se aplică numai nodurilor v care au ambii fii noduri terminale în timp ce reducerea Stâng=Drept poate fi aplicată oricărui nod, fie el şi intermediar, pentru care nodurile fii sunt egale.
Exemplificarea aplicării acestei reguli în cele două variante se poate vedea în figurile 3.4.3.5 şi 3.4.3.6. În figura 3.4.3.5 este dată aplicarea regulii pentru cazul în care se aplică regulile 1(a)-1(b), în timp ce în figura 3.4.3.6 este dată aplicarea regulii pentru cazul în care se aplică regulile 1'(a)-1'(b).
3.4.8 Manipularea funcţiilor booleene date în forma normal disjunctivă
O mulţime importantă de algoritmi utilizaţi în proiectarea structurilor numerice care au la bază utilizarea funcţiilor booleene folosesc reprezentarea acestor funcţii sub forme normal disjunctive (sume de termeni produs). O problemă care se pune este reprezentarea eficientă a acestor termeni produs atât din punct de vedere al memoriei necesare cât şi a algoritmilor necesari manipulării lor. Reprezentarea termenilor produs se realizează prin codificarea acestora utilizând variabile booleene.
În acest paragraf se caută să se pună în evidenţă influenţa pe care o are alegerea unei anumite codificări şi alegerea unei anumite reprezentări ROBDD asupra reprezentării funcţiei date în formă normal disjunctivă [Hab99b].
În literatură au fost propuse mai multe codificări ale termenilor produs. Oricare dintre aceste codificări trebuie să ţină cont de cele 3 situaţii existente: prezenţa literalului x în termenul produs; prezenţa literalului x în termenul produs; prezenţa ambilor literali x şi x în termenul produs. În ultimul caz, literalul x este omis şi nu mai apare în termenul produs. Ca urmare, se poate vedea că pentru fiecare literal din termenul produs avem nevoie de cel puţin 2 variabile booleene prin care să codificăm cele 3 situaţii. Utilizând codificarea cu 2 variabile, din cele 4 combinaţii posibile vor fi utilizate numai 3, acestea fiind puse în corespondenţă cu cele 3 situaţii existente. Rezultă că pentru
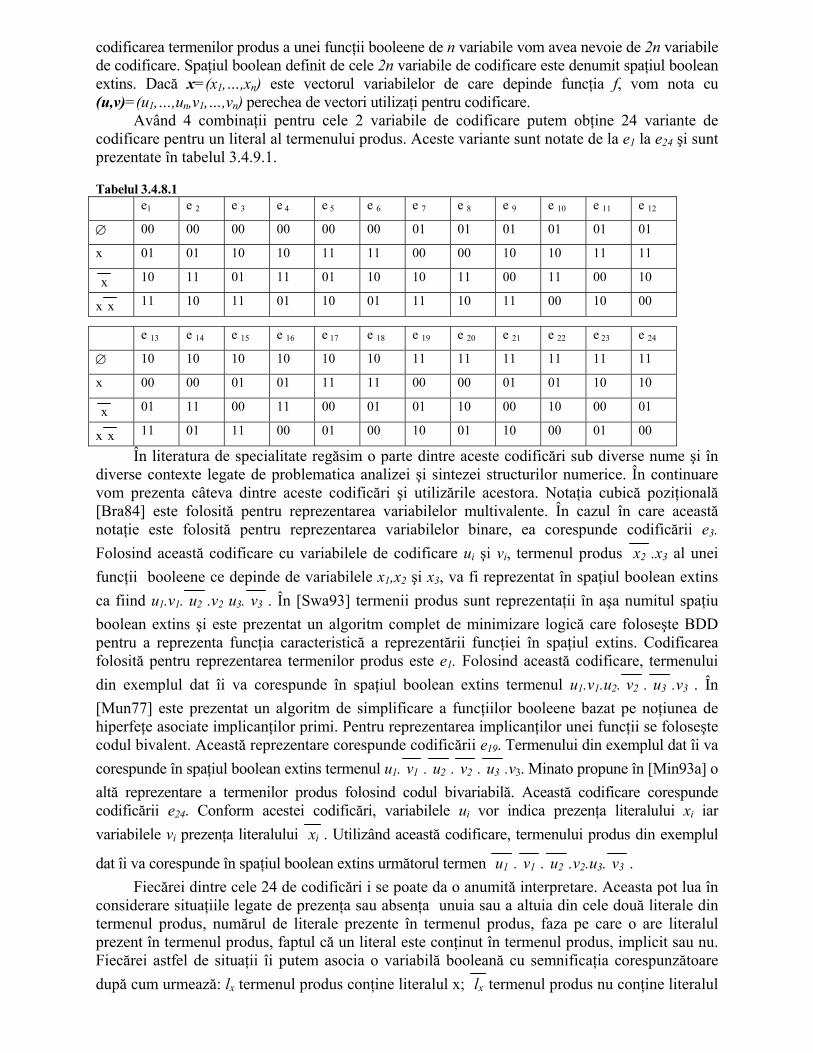
codificarea termenilor produs a unei funcţii booleene de n variabile vom avea nevoie de 2n variabile de codificare. Spaţiul boolean definit de cele 2n variabile de codificare este denumit spaţiul boolean extins. Dacă x=(x1,…,xn) este vectorul variabilelor de care depinde funcţia f, vom nota cu (u,v)=(u1,…,un,v1,…,vn) perechea de vectori utilizaţi pentru codificare.
Având 4 combinaţii pentru cele 2 variabile de codificare putem obţine 24 variante de codificare pentru un literal al termenului produs. Aceste variante sunt notate de la e1 la e24 şi sunt prezentate în tabelul 3.4.9.1. Tabelul 3.4.8.1 e1 e 2 e 3 e 4 e 5 e 6 e 7 e 8 e 9 e 10 e 11 e 12
∅ 00 00 00 00 00 00 01 01 01 01 01 01
x 01 01 10 10 11 11 00 00 10 10 11 11
x 10 11 01 11 01 10 10 11 00 11 00 10
x x 11 10 11 01 10 01 11 10 11 00 10 00
e 13 e 14 e 15 e 16 e 17 e 18 e 19 e 20 e 21 e 22 e 23 e 24
∅ 10 10 10 10 10 10 11 11 11 11 11 11
x 00 00 01 01 11 11 00 00 01 01 10 10
x 01 11 00 11 00 01 01 10 00 10 00 01
x x 11 01 11 00 01 00 10 01 10 00 01 00
În literatura de specialitate regăsim o parte dintre aceste codificări sub diverse nume şi în diverse contexte legate de problematica analizei şi sintezei structurilor numerice. În continuare vom prezenta câteva dintre aceste codificări şi utilizările acestora. Notaţia cubică poziţională [Bra84] este folosită pentru reprezentarea variabilelor multivalente. În cazul în care această notaţie este folosită pentru reprezentarea variabilelor binare, ea corespunde codificării e3. Folosind această codificare cu variabilele de codificare ui şi vi, termenul produs x2 .x3 al unei funcţii booleene ce depinde de variabilele x1,x2 şi x3, va fi reprezentat în spaţiul boolean extins ca fiind u1.v1. u2 .v2 u3. v3 . În [Swa93] termenii produs sunt reprezentaţii în aşa numitul spaţiu boolean extins şi este prezentat un algoritm complet de minimizare logică care foloseşte BDD pentru a reprezenta funcţia caracteristică a reprezentării funcţiei în spaţiul extins. Codificarea folosită pentru reprezentarea termenilor produs este e1. Folosind această codificare, termenului din exemplul dat îi va corespunde în spaţiul boolean extins termenul u1.v1.u2. v2 . u3 .v3 . În [Mun77] este prezentat un algoritm de simplificare a funcţiilor booleene bazat pe noţiunea de hiperfeţe asociate implicanţilor primi. Pentru reprezentarea implicanţilor unei funcţii se foloseşte codul bivalent. Această reprezentare corespunde codificării e19. Termenului din exemplul dat îi va corespunde în spaţiul boolean extins termenul u1. v1 . u2 . v2 . u3 .v3. Minato propune în [Min93a] o altă reprezentare a termenilor produs folosind codul bivariabilă. Această codificare corespunde codificării e24. Conform acestei codificări, variabilele ui vor indica prezenţa literalului xi iar variabilele vi prezenţa literalului xi . Utilizând această codificare, termenului produs din exemplul
dat îi va corespunde în spaţiul boolean extins următorul termen u1 . v1 . u2 .v2.u3. v3 . Fiecărei dintre cele 24 de codificări i se poate da o anumită interpretare. Aceasta pot lua în
considerare situaţiile legate de prezenţa sau absenţa unuia sau a altuia din cele două literale din termenul produs, numărul de literale prezente în termenul produs, faza pe care o are literalul prezent în termenul produs, faptul că un literal este conţinut în termenul produs, implicit sau nu. Fiecărei astfel de situaţii îi putem asocia o variabilă booleană cu semnificaţia corespunzătoare după cum urmează: lx termenul produs conţine literalul x; lx termenul produs nu conţine literalul

x; xl termenul produs conţine literalul x ; xl termenul produs nu conţine literalul x ; variabila φ
indică faza literalului prezent în termenul produs (x prezent, φ=1; x prezent, φ=0); variabila φ indică faza literalului prezent în termenul produs semnificaţia fiind opusă cazului precedent (x prezent, φ=0; x prezent, φ=1); 1x în termenul produs este prezent doar un singur literal fie x,
fie x ; 1x în termenul produs sunt prezente fie ambele literale fie niciunul. Folosind aceste variabile, putem reprezenta care sunt semnificaţiile fiecărei din cele 24 de
codificări posibile. Tabelul 3.4.8.2 e1 e 2 e 3 e 4 e 5 e 6 e 7 e 8 e 9 e 10 e 11 e 12
xl xl xl x1 xl xl x1 xl xl x1 x1 xl xl x1 xl
xl
xl x1 x1 φ xl xl x1
e 13 e 14 e 15 e 16 e 17 e 18 e 19 e 20 e 21 e 22 e 23 e 24
x1 xl xl xl
x1 xl φ x1 xl
xl xl x1 xl φ φ xl x1 xl x
l xl xl x1 xlxl
Conform tabelului 3.4.9.2, ţinând cont că pentru codificare vom folosi variabilele u şi v, de exemplu, semnificaţiile pentru codificările e1 şi e19 vor fi:
e1 : variabila u arată că literalul x este conţinut în termenul produs, variabila v arată că literalul x este conţinut în termenul produs.
e19 : variabila u arată că termenul produs nu conţine literalul x sau x , variabila v arată faza variabilei x.
În [Min93a] se arată că folosind ROBDD obţinute prin reducerea Drept=0 putem reprezenta în mod unic şi eficient mulţimi de termenii produs cu număr redus de elemente şi care sunt codificate folosind codificarea e22. Eficienţa este dată pe de o parte de faptul că numărul de căi care duc spre terminalul 1 este egal cu numărul de termeni produs. Restul vor duce spre terminalul 0, ceea ce va face ca un număr mare de noduri ale căror arc Drept duce la nodul terminal 0 să fie reduse şi deci eliminate din reprezentare. În al doilea rând, într-un termen produs literalii x şi x nu apar niciodată în acelaşi timp. Aceasta înseamnă că cel puţin una din variabile este 0 şi zerourile sunt eliminate în mod convenabil din reprezentarea ROBDD folosind reducerea Drept=0. Aceleaşi consideraţii sunt valabile şi pentru codificarea e24.
În cazul codificărilor e1 şi e3 este de asemeni adevărat că în termenul produs literalii x şi x nu apar în acelaşi timp. De această dată însă, spre deosebire de codificările e22 şi e24 unde
lipsa literalului este codificat cu 00, lipsa literalului este codificată cu 11. Aceasta înseamnă că cel puţin una din variabilele de codificare va fi 1. În această situaţie reducerea Drept=0 nu mai are aceeaşi eficienţă ca în cazul precedent în schimb, putem folosi reducerea Stâng=0 care va elimina în mod convenabil 1. Ca şi în cazul precedent, un număr mic de termeni produs face ca un număr mare de noduri ale căror arc Stâng duce la nodul terminal 0 să fie reduse şi deci eliminate din reprezentare.
Aceste reprezentări devin mai puţin eficiente pentru cazul în care numărul de termeni produs ai funcţiei este mare. În această situaţie, numărul de căi care duc la nodul terminal 1 este mare, ceea ce face ca posibilitatea de aplicare a reducerilor Drept=0 sau Stâng=0 să scadă. Ca urmare, eficienţa acestor reduceri va fi scăzută, în schimb devin eficiente reducerile Drept=1 sau Stâng=1 care pot duce la micşorarea numărului de noduri ale diagramei de decizie binare reduse. Exemplu 3.4.8.1. Pentru exemplificare am ales reprezentarea funcţiei f dată sub forma normal disjunctivă următoare: f=a.b+ c [Min93a]. Folosind codificarea e22 obţinem următorii termeni:
A a b b c c Termen

1 0 1 0 0 0 a.b 0 0 0 0 0 1 c
Reprezentarea funcţiei folosind BDD este dată în figura 3.4.9.1. În această reprezentare, fiecărui termen produs al funcţiei îi corespunde o cale care duce la nodul terminal 1. Reprezentarea ROBDD obţinută cu regula Drept=0 este dată în figura 3.4.9.2. Dacă folosim codificarea e3 , obţinem următoarea reprezentare în spaţiul boolean extins:
u1 v1 u2 v2 u3 v3 Termen 0 1 0 1 1 1 a.b 1 1 1 1 1 0 c
Folosind pentru această funcţie codificarea e3 se obţine reprezentarea BDD din figura 3.4.9.3. Pentru reprezentarea ROBDD obţinută cu reducerea Drept=0 (fig. 3.4.9.4(a)), vedem că numărul de noduri obţinut este mult mai mare decât în cazul anterior. Aceasta arată că acest tip de reprezentare nu mai are aceeaşi eficienţă şi în cazul acestei codificării ca şi în cazul codificării e22. O reprezentare la fel de eficientă ca şi prima, deci având acelaşi număr de noduri se obţine dacă se utilizează ROBDD obţinută folosind reducerea Stâng=0 (fig. 3.4.9.4(b)). Exemplu 3.4.8.2. Considerăm funcţia g(a,b,c)= a+ a +b+ b +c+a.c+a. b +.a. c +b.c+b. c
+ a .b+ a .c+ a . b + a . c + b .c+ b . c + a. b. c +a. b . c +a.b. c +a. b .c+ a .b. c
+ a. b .c+ a .b.c. Dacă folosim pentru această funcţie codificare e24 se obţine reprezentarea BDD din figura 3.4.9.5. Pentru reducerea Drept=0 se obţine reprezentarea din figura 3.4.9.6(a) iar dacă se foloseşte reducerea Stâng=1 se obţine reprezentarea din figura 3.4.9.6(b). Se observă că în primul caz numărul de noduri este mult mai mare decât în cel de al doilea caz. Aceasta deoarece numărul de căi care duc la nodul terminal 1 (62) este mult mai mare decât numărul de căi care duc la nodul terminal 0 (2) (vezi figura 3.4.9.5). Ca urmare, reducerea Drept=0 nu mai poate fi aplicată decât pentru una din căi rezultând reducerea unui singur nod. În schimb, dat fiind numărul mare de căi care duc spre nodul terminal 1, reducerea Stâng=1 se poate aplica unui număr mare de căi, numărul de noduri eliminate fiind semnificativ. a
a
b
b
c
c
0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 Fig. 3.4.8.1 Reprezentarea BDD a funcţiei f=a.b+ c folosind codificarea e22 .
Fig. 3.4.8.2 Reprezentarea funcţiei f=a.b+ c folosind codificarea e22 şi reducerea Drept=0.

u1
v1
u2
v2
u3
v3
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 Fig. 3.4.8.3 Reprezentarea BDD a funcţiei f=a.b+ c folosind codificarea e3 .
a) b) Fig. 3.4.8.4 Reprezentarea funcţiei f=a.b+ c folosind codificarea e3 şi reducerile a) Drept=0, b) Stâng=0.
u1
v1
u2
v2
u3
v3
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 0 1 Fig. 3.4.8.5 Reprezentarea BDD a funcţiei g(a,b,c) folosind
codificarea e24.
a) b) Fig. 3.4.8.6 Reprezentarea funcţiei g(a,b,c) folosind codificarea e24 şi folosind reducerile a) Drept=0, b) Stâng=1.
Ţinând cont de cele spuse mai sus, rezultă că în cazul în care se foloseşte o anumită codificare a termenilor produs, pentru a se obţine o reprezentare cu număr cât mai mic de noduri, trebuie folosite reprezentările ROBDD obţinute cu regulile de reducere corespunzătoare, de exemplu e22 cu Drept=0, e3 cu Stâng=0, etc. În plus, trebuie ţinut cont şi de numărul de termeni care sunt reprezentaţi de-a lungul întregii durate de aplicare a algoritmilor.
3.5 Rezultate experimentale Autorul a realizat un program prin care se poate genera reprezentarea OBDD corespunzătoare
unei funcţii booleene de n variabile. Metodele de reducere prezentate anterior au fost implementate fiecare în câte o procedura care primeşte la intrare o reprezentare OBDD şi furnizează la ieşire reprezentarea OBDD redusă conform regulii corespunzătoare. Implementarea pachetului a fost inspirată de [Brc90] unde nucleul procedurilor îl constituie operatorul ITE. În implementarea făcută de noi am folosit structuri similare ca cele descrise în [Brc90] cum ar fi: tabela unicatelor, memoratorul, tabela de dispersie, arce complementate, etc. Algoritmul care implementează operatorul ITE este prezentat în figura 3.5.1. unde aplică_regula_de_reducere este funcţia prin care se testează dacă este posibilă şi, aplică una din regulile Stâng=Drept, Stâng=0, Stâng=1, Drept=0, Drept=1, Stâng<>Drept.
În continuare s-au generat reprezentările OBDD pentru toate funcţiile booleene cu n=2,3 şi 4 variabile şi pentru fiecare reprezentare s-au aplicat regulile de reducere Stâng=Drept, Stâng=0, Stâng=1, Drept=0, Drept=1, Stâng<>Drept. S-au redat pentru exemplificare doar datele obţinute pentru cazul n=2 în tabelul 3.5.1. Prima linie a tabelului cuprinde toate funcţiile booleene cu 2 variabile iar în liniile următoare este dat, pentru fiecare din cele 16 funcţii, numărul de noduri ale reprezentării după aplicarea reducerii respective.
Din datele obţinute rezultă următoarele concluzii: (1) pentru majoritatea funcţiilor booleene
reprezentările corespunzătoare diferitelor reduceri au dimensiuni diferite; (2) diferenţa dintre dimensiunile a doua reprezentări cu reduceri diferite poate sa fie foarte mare; (3) există funcţii la care o anumită reducere nu poate fi aplicată. ite(F,G,H) { if (caz terminal) {return rezultat_caz_terminal; }
else if (memorator conţine {F,G,H}) {return valoarea memorată în memorator } else
{ fie v variabila cu indexul cel mai mic din {F,G,H}; T=ite(Fv,Gv,Hv);
E=ite(Fv̄,Gv̄,Hv̄); aplică_regula_de_reducere(T,E); R=caută_sau_găseşte_în_tabela_unică(v,T,E); inserează_în_memorator({F,G,H},R); return R; }
} Fig. 3.5.1 Algoritmul ite.
Tabelul 3.5.1 f 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 Stâng=Drept 0 2 2 1 2 1 3 2 2 3 1 2 1 2 2 0 Stâng=0 0 2 1 2 1 2 2 3 0 2 1 2 1 3 2 2 Stâng=1 2 2 3 1 2 1 2 0 3 2 2 1 2 1 2 0 Drept=0 0 0 1 1 1 1 2 2 2 2 2 3 2 2 3 2 Drept=1 2 3 2 2 3 2 2 2 2 2 1 1 1 1 0 0 Stâng<>Drept 2 2 2 3 3 2 2 3 3 2 2 3 3 2 2 2 Fuziune 2 3 3 3 3 2 3 3 3 3 2 3 3 3 3 2
Pentru fiecare din cele trei clase de funcţii studiate cu 2, 3 respectiv 4 variabile, am determinat numărul de funcţii pentru care reprezentarea ROBDD pentru o anumită reducere are aceeaşi dimensiune. S-a constatat că pentru reducerile Stâng=Drept, Stâng=0, Stâng=1, Drept=0 şi Drept=1 numărul de funcţii având aceiaşi dimensiune este acelaşi. În tabelul 3.5.2 se dau rezultatele obţinute pentru n=2 pentru toate reducerile iar în tabelul 3.5.3 se dau valorile şi pentru n=3 şi n=4 numai pentru reducerile Stâng=Drept şi Stâng<>Drept care sunt diferite. Din datele obţinute se poate spune că pe ansamblul clasei funcţiilor booleene de n variabile reducerile Stâng=Drept, Stâng=0, Stâng=1, Drept=0 şi Drept=1 au aceeaşi eficacitate în timp ce reprezentarea Stâng<>Drept este mai puţin eficientă decât celelalte. Tabelul 3.5.2 Nr. 0 1 2 3 Suma Stâng=Drept 2 4 8 2 26 Stâng=1 2 4 8 2 26 Stâng=0 2 4 8 2 26 Drept=0 2 4 8 2 26 Drept=1 2 4 8 2 26 Stâng<>Drept 2 2 10 2 28 Fuziune 0 0 4 12 44
Pentru extinderea studiului utilizării acestor reprezentări s-a scris un program care să citească descrierea unui circuit combinaţional în format EQN şi cu care am construit reprezentările ROBDD pentru mai multe seturi de circuite numerice care fac parte dintr-un set standard (MCNC) de circuite de test. Pentru fiecare circuit a fost construită reprezentarea pentru fiecare tip de ROBDD. Analizând rezultatele s-a observat că pentru un număr mare de circuite, reprezentarea clasică Stâng=Drept nu constituie reprezentarea cea mai economică în raport cu dimensiunea structurii (numărul de noduri), complexitatea algoritmilor fiind aceeaşi pentru toate reprezentările studiate. Dintre reprezentările noi introduse, pe ansamblul circuitelor analizate, cele obţinute cu regula Stâng=1 dau cele mai bune rezultate (vezi tabelul 3.5.4). Tabelul 3.5.3
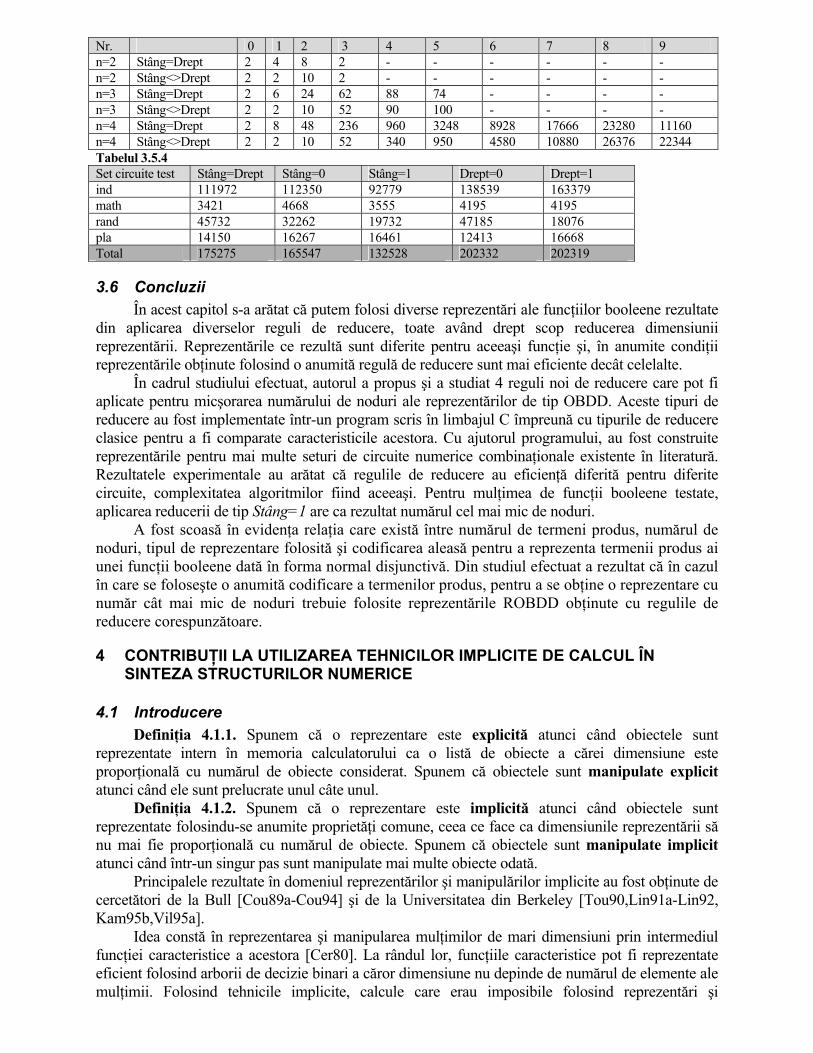
Nr. 0 1 2 3 4 5 6 7 8 9 n=2 Stâng=Drept 2 4 8 2 - - - - - - n=2 Stâng<>Drept 2 2 10 2 - - - - - - n=3 Stâng=Drept 2 6 24 62 88 74 - - - - n=3 Stâng<>Drept 2 2 10 52 90 100 - - - - n=4 Stâng=Drept 2 8 48 236 960 3248 8928 17666 23280 11160 n=4 Stâng<>Drept 2 2 10 52 340 950 4580 10880 26376 22344 Tabelul 3.5.4 Set circuite test Stâng=Drept Stâng=0 Stâng=1 Drept=0 Drept=1 ind 111972 112350 92779 138539 163379 math 3421 4668 3555 4195 4195 rand 45732 32262 19732 47185 18076 pla 14150 16267 16461 12413 16668 Total 175275 165547 132528 202332 202319
3.6 Concluzii În acest capitol s-a arătat că putem folosi diverse reprezentări ale funcţiilor booleene rezultate
din aplicarea diverselor reguli de reducere, toate având drept scop reducerea dimensiunii reprezentării. Reprezentările ce rezultă sunt diferite pentru aceeaşi funcţie şi, în anumite condiţii reprezentările obţinute folosind o anumită regulă de reducere sunt mai eficiente decât celelalte.
În cadrul studiului efectuat, autorul a propus şi a studiat 4 reguli noi de reducere care pot fi aplicate pentru micşorarea numărului de noduri ale reprezentărilor de tip OBDD. Aceste tipuri de reducere au fost implementate într-un program scris în limbajul C împreună cu tipurile de reducere clasice pentru a fi comparate caracteristicile acestora. Cu ajutorul programului, au fost construite reprezentările pentru mai multe seturi de circuite numerice combinaţionale existente în literatură. Rezultatele experimentale au arătat că regulile de reducere au eficienţă diferită pentru diferite circuite, complexitatea algoritmilor fiind aceeaşi. Pentru mulţimea de funcţii booleene testate, aplicarea reducerii de tip Stâng=1 are ca rezultat numărul cel mai mic de noduri.
A fost scoasă în evidenţa relaţia care există între numărul de termeni produs, numărul de noduri, tipul de reprezentare folosită şi codificarea aleasă pentru a reprezenta termenii produs ai unei funcţii booleene dată în forma normal disjunctivă. Din studiul efectuat a rezultat că în cazul în care se foloseşte o anumită codificare a termenilor produs, pentru a se obţine o reprezentare cu număr cât mai mic de noduri trebuie folosite reprezentările ROBDD obţinute cu regulile de reducere corespunzătoare.
4 CONTRIBUŢII LA UTILIZAREA TEHNICILOR IMPLICITE DE CALCUL ÎN SINTEZA STRUCTURILOR NUMERICE
4.1 Introducere Definiţia 4.1.1. Spunem că o reprezentare este explicită atunci când obiectele sunt
reprezentate intern în memoria calculatorului ca o listă de obiecte a cărei dimensiune este proporţională cu numărul de obiecte considerat. Spunem că obiectele sunt manipulate explicit atunci când ele sunt prelucrate unul câte unul.
Definiţia 4.1.2. Spunem că o reprezentare este implicită atunci când obiectele sunt reprezentate folosindu-se anumite proprietăţi comune, ceea ce face ca dimensiunile reprezentării să nu mai fie proporţională cu numărul de obiecte. Spunem că obiectele sunt manipulate implicit atunci când într-un singur pas sunt manipulate mai multe obiecte odată.
Principalele rezultate în domeniul reprezentărilor şi manipulărilor implicite au fost obţinute de cercetători de la Bull [Cou89a-Cou94] şi de la Universitatea din Berkeley [Tou90,Lin91a-Lin92, Kam95b,Vil95a].
Idea constă în reprezentarea şi manipularea mulţimilor de mari dimensiuni prin intermediul funcţiei caracteristice a acestora [Cer80]. La rândul lor, funcţiile caracteristice pot fi reprezentate eficient folosind arborii de decizie binari a căror dimensiune nu depinde de numărul de elemente ale mulţimii. Folosind tehnicile implicite, calcule care erau imposibile folosind reprezentări şi

manipulări explicite pot fi duse la bun sfârşit şi pot necesita un timp rezonabil.
4.3 Operaţii cu mulţimi de obiecte Folosind reprezentarea cubică poziţională, operaţiilor cu mulţimi de obiecte le va corespunde
operaţii booleene asupra funcţiilor caracteristice ale acestora. În [Kam95b] sunt definiţi o serie de operatori utilizaţi pentru manipularea mulţimilor date în
notaţie cubică poziţională. Dintre aceştia îi prezentăm pe cei mai importanţi împreună cu o serie de operatori noi, utilizaţi pentru manipularea mulţimilor de stări în cadrul unor algoritmi propuşi de autor.
Propoziţia 4.3.1.. Relaţiile egalitate, oglindire, incluziune şi incluziune strictă între două mulţimi x şi y reprezentate în notaţie cubică poziţională se pot calcula astfel:
(x=y) ≡Equal(x,y) ≡ ∏ = ⇔nk kk yx1 )( ;
(x= y ) ≡ Compl(x,y) ≡ ∏ = ⇔nk kk yx1 )( ;
(x ⊇y) ≡ ∏ = ⇒nk kk xy1 )( ;
(x⊃y) ≡ (x ⊇y).(x≠y)≡ (x ⊇y). (x=y) .
(4.3.1)
Propoziţia 4.3.2. Relaţia egalitate-reuniune este adevărată dacă mulţimea de obiecte reprezentată prin x este reuniunea mulţimilor de obiecte reprezentate prin y şi z şi poate fi calculată cu:
∏=
+⇔=∪=n
kkkk zyx
1)()zyx(
(4.3.2)
Propoziţia 4.3.3. Relaţia egalitate-intersecţie este adevărată dacă mulţimea de obiecte reprezentată prin x este intersecţia mulţimilor de obiecte reprezentate prin y şi z şi poate fi calculată astfel:
∏=
⋅⇔=∩=n
kkkk zyx
1)()zyx(
(4.3.3)
Propoziţia 4.3.4. Relaţia egalitate-conţine este adevărată dacă mulţimea de obiecte reprezentată prin x este egală cu relaţia de incluziune dintre mulţimilor de obiecte reprezentate prin y şi z şi poate fi calculată astfel:
∏=
⊆⇔=⊆=n
kkkk zyx
1)()zyx(
(4.3.4)
Propoziţia 4.3.5. Mulţimea Maximal a unei mulţimi F de mulţimi este mulţimea care conţine mulţimile din F care nu sunt incluse strict de altă mulţime din F. Această mulţime poate fi calculată astfel:
Maximalx(fcF)=fc
F(x).¬(∃y[fcF(y).(y⊃x)]). (4.3.5)
Propoziţia 4.3.6. Relaţia ordpair este adevărată dacă cele două mulţimi de obiecte reprezentate prin notaţia cubică poziţională sunt în relaţia x<y unde < este relaţie de ordine totală, şi poate fi calculată astfel:
kn
kk yx∏
=<=<
1)yx(
(4.3.6)
Propoziţia 4.3.7. Reuniunea unei mulţimi S de mulţimi de obiecte, union, se poate calcula cu relaţia:
unionx(fcS)=Maximalx(υ(x)) (4.3.7)
unde υ(x) este punctul fix al următoarei ecuaţii:
)]zyx).(z().y([zy)x(
)x()x(1
0
∪=υυ∃∃=υ
=υ
+ kkk
cSf
(4.3.8)

Iteraţia se termină atunci când : υk+1(x)=υk(x)=υ(x) (4.3.9)
Propoziţia 4.3.8. Operatorul Tuplen,k(x) va conţine toate mulţimile poziţionale care au exact k elemente adică |x|=k. Câteva cazuri particulare ale operatorului Tuplen,k(x) prezintă o semnificaţie aparte: Tuplen,1(x) conţine mulţimea de elemente din M; Tuplen,2(x) conţine mulţimea de perechi formate cu elemente din M; Tuplen,n(x) conţine mulţimea tuturor submulţimilor din M.
Propoziţia 4.3.9. Închiderea tranzitivă a unei relaţii σ poate fi calculată cu operatorul transitive dat de următoarea relaţie:
transitive(σ (x,y))=σ(x,y)+τσ(x,y) (4.3.10) unde τσ(x,y) este punctul fix al următoarei ecuaţii:
τσ0(x,y)=σ(x,y) τσn+1 (x,y)=∃u(τσn(y,u).τσn(u,z))
(4.3.11)
Iteraţia se opreşte atunci când τσn+1(x,y)=τσn(x,y). Demonstraţie. Operatorul transitive definit de relaţiile de mai sus calculează închiderea
tranzitivă a relaţiei σ pe baza relaţiei σ*=σ0 ∪ …∪σn şi ţinând seama de faptul că pentru scăderea numărului de iteraţii se utilizează dezvoltarea de forma σ*=σp cu p=2r.
Propoziţia 4.3.10. Închiderea simetrică a unei relaţii σ poate fi calculată cu operatorul symetry dat de următoarea relaţie:
symetry(σ (x,y))=σ(y,z)+σ(z,y) (4.3.12) Demonstraţie. σ(y,z) reprezintă implicit relaţia σ şi deci va conţine perechile (y,x). σ(z,y) se
obţine schimbând între ele variabilele y şi z. Astfel, dacă σ(y,z) conţine perechea (y1,z1) atunci σ(z,y) va conţine perechea (z1,y1) oricare ar fi perechea (y1,z1)∈σ(y,z). Reunind perechile celor două relaţii se obţine rezultatul căutat.
Propoziţia 4.3.11. Relaţia identitate poate fi calculată cu operatorul identitate dat de următoarea relaţie:
identity(x,y)=Tuplen,1(x).Tuplen,1(y).(x=y) (4.3.13) Demonstraţie. Tuplen,1(x) (Tuplen,1(y)) reprezintă mulţimea de elemente singulare având
suportul x (y). Produsul Tuplen,1(x).Tuplen,1(y) va conţine toate perechile de elemente (x,y) care se pot construi cu suporturile x şi y. Prin înmulţirea cu operatorul (x=y) dintre aceste perechi se aleg numai cele pentru care xk=yk obţinându-se astfel rezultatul dorit.
4.4 Reprezentări implicite ale automatelor finite Se ştie că automatele finite pot fi reprezentate printr-o formă binivel unde tranziţiile sunt
precizate explicit una câte una. În cazul automatelor finite de mari dimensiuni numărul acestor tranziţii şi dimensiunile termenilor produs care reprezintă aceste tranziţii pot fi foarte mari. De asemeni, în cadrul algoritmilor de sinteză a automatelor finite obiectele folosite (mulţimi de stări, mulţimi de mulţimi de stări, relaţii de echivalenţă, relaţii de compatibilitate, etc.) pot deveni foarte mari şi imposibil de ţinut în memoria calculatorului şi de manipulat în timp optim dacă acestea sunt reprezentate explicit. Pentru a se depăşi aceste inconveniente, se caută ca aceste mulţimi să se reprezinte implicit şi manipularea să se facă folosind tehnici care să utilizeze cât mai eficient proprietăţile acestor reprezentări.
Reprezentarea implicită a unui automat finit se poate obţine pornind de la următoarele definiţii:
Definiţia 4.4.1. Se numeşte automat finit o cvintuplă A=(I,O,S,τ,ω) unde I este mulţimea semnalelor de intrare, O este mulţimea semnalelor de ieşire iar S este mulţimea stărilor.τ este relaţia de tranziţie definită ca funcţia caracteristică τ:I×S×S →B unde τ(i,p,n)=1 dacă şi numai dacă n=δ(p,i) iar ω este relaţia de ieşire definită ca funcţia caracteristică ω:I×S×O →B unde ω(i,p,o)=1 dacă şi numai dacă o= λ(p,i).
Cele două relaţii pot fi adunate într-o singură relaţie numită relaţia de tranziţie-ieşire conform definiţiei:
Definiţia 4.4.2. Se numeşte automat finit o cvatruplă A=(I,O,S,π) unde I este mulţimea

semnalelor de intrare, O este mulţimea semnalelor de ieşire iar S este mulţimea stărilor. Relaţia π este relaţia de tranziţie-ieşire definită ca funcţia caracteristică π:I×S×S×O→B unde: π(i,p,n,o)=1 dacă şi numai dacă n este starea următoare definită pentru starea prezentă p şi intrarea i iar o este ieşirea definită pentru starea prezentă p şi intrarea i (deci dacă şi numai dacă n=δ(p,i) şi o= λ(p,i)).
Exemplul 4.4.1: Considerăm automatul A definit prin tabelul 4.4.1. Tabelul 4.4.1
i s
0 1
st1 st2/1 st1/0 st2 st2/1 st1/0
Reprezentarea în notaţia cubică poziţională a stărilor va necesita două variabile s1, s2 pentru starea prezentă şi două variabile S1, S2 pentru starea următoare. Variabilele de intrare şi de ieşire sunt binare de aceea ele nu vor fi codificate. Pentru relaţiile π, τ şi ω vor rezulta următoarele expresii:
π(i,s1,s2,S1,S2,o)= i .s1. s2 . S1 .S2.o+i.s1. s2 .S1. S2 . o + i . s1 .s2. S1 .S2.o+
+ i. s1 .s2.S1. S2 .o
τ(i,s1,s2,S1,S2)= i .s1. s2 . S1 .S2 + i.s1. s2 .S1. S2 + i . s1 .s2. S1 .S2 +
+ i. s1 .s2.S1. S2
ω(i,s1,s2,S1,S2,o)= i .s1. s2 .o + i.s1. s2 . o + i . s1 .s2.o + i. s1 .s2.o
(4.4.1)
Există situaţii în care şi intrările şi ieşirile sunt reprezentate folosind notaţia cubică poziţională.
Fig. 4.4.1 Reprezentare implicită a automatului A.
Fig. 4.4.2 Reprezentare implicită a automatului A utilizând reprezentarea multivalentă pentru variabilele de intrare şi de ieşire.
Dacă se utilizează şi pentru variabilele de intrare şi pentru cele de ieşire reprezentarea prin notaţia cubică poziţională, va rezulta următoarea reprezentare (fig.4.4.1) a celor trei relaţii:
π(i,s1,s2,S1,S2,o)= i .s1. s2 . S1 .S2.o+i.s1. s2 .S1. S2 . o + i . s1 .s2. S1 .S2.o+
+ i. s1 .s2.S1. S2 .o
τ(i,s1,s2,S1,S2)= i .s1. s2 . S1 .S2 + i.s1. s2 .S1. S2 + i . s1 .s2. S1 .S2 +
+ i. s1 .s2.S1. S2
ω(i,s1,s2,S1,S2,o)= i .s1. s2 .o + i.s1. s2 . o + i . s1 .s2.o + i. s1 .s2.o
(4.4.2)
Există situaţii în care şi intrările şi ieşirile sunt reprezentate folosind notaţia cubică poziţională. Dacă se utilizează şi pentru variabilele de intrare şi pentru cele de ieşire reprezentarea prin notaţia cubică poziţională, va rezulta următoarea reprezentare (fig.4.4.2) a celor trei relaţii:
π(i1,i2,s1,s2,S1,S2,o1,o2)= i1 .i2.s1. s2 . S1 .S2. o1 .o2+ i1 .i2.s1. s2 .S1. S2 . o1 .o2+

+ i1 .i2. s1 .s2. S1 .S2. o1 .o2 + i1 .i2. s1 .s2.S1. S2 . o1 .o2
τ(i1,i2,s1,s2,S1,S2)= i1 .i2.s1. s2 . S1 .S2 + i1 .i2.s1. s2 .S1. S2 + i1 .i2. s1 .s2. S1 .S2 +
+ i1 .i2. s1 .s2.S1. S2
ω(i1,i2,s1,s2,S1,S2,o1,o2)= i1 .i2.s1. s2 . o1 .o2+ i1 .i2.s1. s2 . o1 .o2 + i1 .i2. s1 .s2. o1 .o2 +
+ i1 .i2. s1 .s2. o1 .o2
(4.4.3)
4.5 Implementarea operatorilor impliciţi Operatorii impliciţi prezentaţi în subcapitolele precedente au fost implementaţi utilizând
limbajul C şi pachetul CUDD [Som97]. O descriere sumară a acestor operatori este dată în anexa B iar o descriere mai detaliată a fiecărui operator este dată în anexa C.
a)
Fig. 4.5.1 Operatorul (x=y) pentru două ordini ale variabilelor a) naturală, b) intercalată. Operatorii au fost concepuţi pentru a fi utilizaţi la implementarea unor algoritmi de
manipulare a stărilor sau mulţimilor de stări ale automatelor finite. În cadrul acestor algoritmi, mulţimile de stări sunt reprezentate prin intermediul mai multor variabile multidimensionale. În plus, în cadrul acestor algoritmi, apare de multe ori necesitatea utilizării unor variabile auxiliare care să conţină rezultatul unor calcule intermediare. Cu cât numărul de astfel de variabile este mai mare, cu atât creşte probabilitatea ca o operaţie ce manipulează diagrame de decizie binare ce depind de aceste variabile să aibă ca rezultat o BDD care să sufere o explozie exponenţială a numărului de noduri. Pentru a micşora această probabilitate, s-a căutat implementarea operatorilor astfel încât ei să folosească un număr fix de variabile. Din acest punct de vedere, operatorii implementaţi pot fi împărţiţi în două categorii: (1) independenţi de setul de variabile fixat; (2) dependente de setul de variabile fixat.
Aşa cum s-a arătat în capitolul 3, un element important de care trebuie ţinut seama pentru evitarea exploziei exponenţiale a numărului de noduri ale diagramelor de decizie binare rezultate în urma anumitor operaţii, este ordinea variabilelor. Pentru reducerea dimensiunii operatorilor, s-a ales ca variabilele să fie intercalate. În fig. 4.5.1 se poate observa diferenţa dintre dimensiunile reprezentărilor operatorului (x=y), pentru cazul în care variabilele sunt în ordinea naturală (fig.4.5.1(a)) şi cazul când variabilele sunt intercalate (fig.4.5.1(b)).
4.6 Tabela de calcul funcţională 4.6.1 Introducere
Pentru manipularea eficientă a diagramelor de decizie binară se utilizează tabele, numite tabele cache, în care sunt memorate rezultate intermediare.

S-a observat de multe ori că în cazul unor algoritmi, prin introducerea unor structuri de date suplimentare, s-a reuşit ca să se mărească viteza de execuţie a lor. Pentru a reduce timpul de calcul al unor algoritmi care folosesc tehnicile implicite de manipulare a funcţiilor booleene, în acest capitol propunem o nouă structură de date numită tabelă de calcul funcţională [Hab98b]. Ca şi în cazul tabelei cache normale, aceasta structură este o tabelă utilizată pentru a memora rezultate parţiale ce sunt susceptibile să apară din nou în etape ulterioare ale calculelor. Diferenţa faţă de tabela de calcul normală constă în faptul că valorile calculate sunt memorate în tabela de calcul funcţională ca o structură care include implicit mai mult de un rezultat al aceluiaşi operator. În funcţie de operanzii cu care este apelat operatorul, dimensiunea rezultatului memorat se poate modifica. 4.6.2 Generalităţi
Noua structură de date, tabela de calcul funcţională, este concepută astfel încât să poată reduce timpii de calcul. Modul în care ea poate accelera unele calcule este prezentat mai jos: (1) Operatorul f este apelat prima dată cu operanzii xn,yn,zn. Este construit arborele binar corespunzător Fn(x,y,z) şi memorat în tabela de calcul funcţională. (2) Este apelat operatorul f cu operanzii xn,yn,zn. Arborele binar Fn(x,y,z) este deja construit şi memorat in tabela de calcul funcţională de aceea se va returna rezultatul memorat în tabela de calcul funcţională; (3) Este apelata operatorul f cu operanzii xi,yi,zi, cu i<n. Arborele de decizie binar pentru Fi(x,y,z) poate fi obţinut din Fn(x,y,z) care este deja construit şi se află in tabela de calcul funcţională deoarece Fi(x,y,z) este un sub-arbore a lui Fn(x,y,z). (4) Apelăm operatorul f cu operanzii xj,yj,zj, unde j>n. Arborele de decizie binar Fj(x,y,z) poate fi obţinut din Fn(x,y,z) care este deja construit şi se află in tabela de calcul funcţională prin expandarea acestuia. (5) Apelăm operatorul f cu operanzii uk,vk,wk. În acest caz avem următoarele situaţii:
a. k=n, atunci Fk(u,v,w)=Fn(u → x, v → y, w → z); b. k=i<n, atunci Fk(u,v,w)=Fi(u → x, v → y, w → z), cu Fi obţinut ca şi în cazul
(3); c. k=j>n, atunci Fk(u,v,w)=Fj(u → x, v → y, w → z) cu Fj obţinut ca şi în cazul (4);
Prin F(u → x) am notat faptul că x este substituit cu u în operatorul F.
Definiţia 4.6.2.1 Fie Opn={op| op:A1 ×…×An →B } o mulţime de operatori n-ari şi N(Opn) mulţimea identificatorilor acestor operatori sau a numelor acestora. O tabelă de calcul funcţională este definită formal după cum urmează:
FC={e| e=(numop,d,opd1,…,opn,r) } (4.6.2.1) unde numop ∈N(On), d ∈N, opdi ∈Ai, ∀ i=1,…,n şi r ∈B astfel încât
op(opd1,…,opdn)=r |opd1|=…=|opdn|=d
(4.6.2.2)
Pentru a construi un tip de date abstracte pornind de la noţiunea matematică de tabelă de calcul funcţională definim ansamblul reprezentativ de operaţii ce se pot efectua asupra obiectelor de tip tabelă de calcul funcţională. Acestea sunt: Init(fc) - iniţializarea structurii; Free(fc) - eliberarea memoriei alocate Insert(fc,numop,d,opd1,opd2,…,opdn,r) - crează o nouă intrare în tabela de calcul funcţională LookUp(fc,numop,d,opd1,opd2,…,opdn) - se caută rezultatul în tabela funcţională.
Tabela de calcul funcţională poate fi folosită pentru operatorii cu următoarele restricţii: operatorii trebuie să satisfacă următoarele proprietăţi - fiind date xi=x1,...,xm, xj=xm,...,xn, xk=x1,...,xm+n, yi=y1,...,ym, yj=ym,...,yn, yk=y1,...,ym+n , operatorul f şi F reprezentarea acestuia prin arbore de decizie binar atunci F(xk,yk)= F(xi,yi) F(xj,yj).
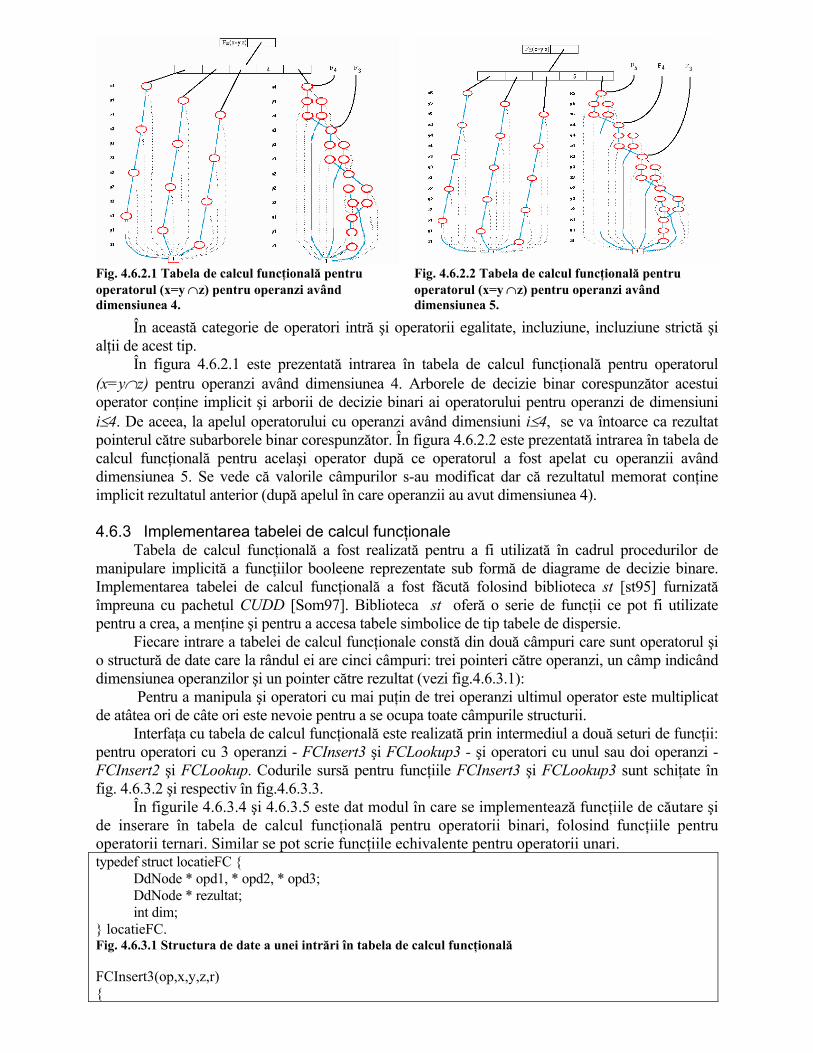
Fig. 4.6.2.1 Tabela de calcul funcţională pentru operatorul (x=y ∩z) pentru operanzi având dimensiunea 4.
Fig. 4.6.2.2 Tabela de calcul funcţională pentru operatorul (x=y ∩z) pentru operanzi având dimensiunea 5.
În această categorie de operatori intră şi operatorii egalitate, incluziune, incluziune strictă şi alţii de acest tip.
În figura 4.6.2.1 este prezentată intrarea în tabela de calcul funcţională pentru operatorul (x=y∩z) pentru operanzi având dimensiunea 4. Arborele de decizie binar corespunzător acestui operator conţine implicit şi arborii de decizie binari ai operatorului pentru operanzi de dimensiuni i≤4. De aceea, la apelul operatorului cu operanzi având dimensiuni i≤4, se va întoarce ca rezultat pointerul către subarborele binar corespunzător. În figura 4.6.2.2 este prezentată intrarea în tabela de calcul funcţională pentru acelaşi operator după ce operatorul a fost apelat cu operanzii având dimensiunea 5. Se vede că valorile câmpurilor s-au modificat dar că rezultatul memorat conţine implicit rezultatul anterior (după apelul în care operanzii au avut dimensiunea 4). 4.6.3 Implementarea tabelei de calcul funcţionale
Tabela de calcul funcţională a fost realizată pentru a fi utilizată în cadrul procedurilor de manipulare implicită a funcţiilor booleene reprezentate sub formă de diagrame de decizie binare. Implementarea tabelei de calcul funcţională a fost făcută folosind biblioteca st [st95] furnizată împreuna cu pachetul CUDD [Som97]. Biblioteca st oferă o serie de funcţii ce pot fi utilizate pentru a crea, a menţine şi pentru a accesa tabele simbolice de tip tabele de dispersie.
Fiecare intrare a tabelei de calcul funcţionale constă din două câmpuri care sunt operatorul şi o structură de date care la rândul ei are cinci câmpuri: trei pointeri către operanzi, un câmp indicând dimensiunea operanzilor şi un pointer către rezultat (vezi fig.4.6.3.1):
Pentru a manipula şi operatori cu mai puţin de trei operanzi ultimul operator este multiplicat de atâtea ori de câte ori este nevoie pentru a se ocupa toate câmpurile structurii.
Interfaţa cu tabela de calcul funcţională este realizată prin intermediul a două seturi de funcţii: pentru operatori cu 3 operanzi - FCInsert3 şi FCLookup3 - şi operatori cu unul sau doi operanzi - FCInsert2 şi FCLookup. Codurile sursă pentru funcţiile FCInsert3 şi FCLookup3 sunt schiţate în fig. 4.6.3.2 şi respectiv în fig.4.6.3.3.
În figurile 4.6.3.4 şi 4.6.3.5 este dat modul în care se implementează funcţiile de căutare şi de inserare în tabela de calcul funcţională pentru operatorii binari, folosind funcţiile pentru operatorii ternari. Similar se pot scrie funcţiile echivalente pentru operatorii unari. typedef struct locatieFC {
DdNode * opd1, * opd2, * opd3; DdNode * rezultat; int dim;
} locatieFC. Fig. 4.6.3.1 Structura de date a unei intrări în tabela de calcul funcţională FCInsert3(op,x,y,z,r) {

dn->opd1=x; dn->opd2=y; dn->opd3=z dn->dim=|x|; dn->rezultat=r; st_insert(op,dn); } Fig. 4.6.3.2 Funcţia de inserare în tabela de calcul funcţională pentru operatori ternari. FCLookup3(op,x,y,z) { dd->opd1=x;dd-opd2=y; dd->opd3=z, dd->dim=|x|; if (st_lookup(op,dc)
{ if (dc->dim=dd->dim){ if (aceaşi operanzi în dd şi dc) return dc->rezultat; else {if dd->opdj ≠dc->opdj then return result=rc(dd->opdj → dc->opdj )} } if (dc->dim>dd->dim){ restricţioneză dc->opdj la dimensiunea dd->dim (fie dc'->opdj); restricţionează dc'->rezultat la variabilele dc'->opdj (fie dc'->rezultat); return result= dc'->rezultat (dd->opdj → dc'->opdj); } if (dc->dim < dd->dim){ împarte dd->opdj,în dd1->opdj, dd2->opdj cu dd1->dim=dc->dim; result=FCcacheLookup2(op, dd1->opd1, dd1->opd2, dd1->opd3). FCcacheLookup2(op, dd2->opd1, dd2->opd2, dd2->opd3); dn->opdj =dd-opdj, dn->dim=dd->dim; FCcacheInsert3(op, dn->dim,dn->opd1,dn->opd2,dn->opd3,dn->rezultat ); return result; } } else return NULL; } Fig. 4.6.3.3 Funcţia de căutare în tabela de calcul funcţională pentru operatori ternari. FCInsert2(op,x,y,r); { FCInsert3(op,x,y,y,r); } Fig. 4.6.3.4 Funcţia de inserare în tabela de calcul funcţională pentru operatori binari folosind funcţia de inserare definită pentru operatori ternari. FCLookup2(op,x,y) { FCLookup3(op,x,y,y); } Fig. 4.6.3.5 Funcţia de căutare în tabela de calcul funcţională pentru operatori binari folosind funcţia de căutare definită pentru operatori ternari. 4.6.4 Implementarea operatorilor de manipulare implicită a funcţiilor booleene utilizând
tabela de calcul funcţională În cazul în care un operator îndeplineşte condiţiile precizate în paragraful 4.6.2 el poate fi
implementat folosind tabela de calcul funcţională. În acest fel, viteza lui poate fi mărită considerabil pentru anumite cazuri. Tabela de calcul funcţională poate fi implementată astfel încât ea să preia şi funcţiile tabelei cache sau poate fi implementată independent de aceasta. În cazul de faţă s-a ales cea de a doua soluţie astfel încât toţi operatorii să utilizeze în acelaşi mod tabela cache iar cei care îndeplinesc condiţiile să beneficieze şi de aportul noii structuri. Codul sursa pentru implementarea operatorilor astfel încât să utilizeze tabela de calcul funcţională este dat în figura 4.6.5.1.

4.6.5 Rezultate experimentale Subrutinele necesare implementării şi manipulării tabelei de calcul funcţionale au fost scrise
în limbajul C folosind pachetul CUDD [Som97] şi biblioteca st [st95]. S-au făcut o serie de teste pentru punerea în evidenţă a faptului că folosirea tabelei de calcul
funcţionale duce la micşorarea timpului de necesar construirii arborelui de decizie binar pentru un operator atunci când un pentru acest operator a mai fost construit în prealabil arborele de decizie binar. Pentru aceasta s-a construit arborele de decizie binar pentru un operator (binar) având a şi b ca operanzi. Apoi s-a construit arborele de decizie binar pentru acelaşi operator având b şi c ca operanzi. Construcţia s-a făcut mai întâi fără a folosi tabela de calcul funcţională şi apoi cu ajutorul acesteia. Tabelul 4.6.5.1 prezintă rezultatele obţinute pentru diverşi operatori binari iar tabelul 4.6.5.2 pentru diverşi operatori ternari definiţi în capitolul 4.
Tabelul 4.6.5.3 ne prezintă comparativ timpii necesari construirii arborelui de decizie binar folosind sau nu tabela de calcul funcţională pentru operatorul (x ⊆y ∪z), având operanzi cu dimensiunea n=300, în cinci cazuri diferite: (1) nu este folosită tabela de calcul funcţională; (2) operanzii cu care este apelat operatorul sunt diferiţi de cei din tabela de calcul funcţională; (3) unul din cei trei operanzi este identic cu unul din tabela de calcul funcţională; (4) doi dintre cei trei operanzi sunt identici cu doi dintre operanzii din tabela de calcul funcţională; (5) cei trei operanzi sunt identici cu cei trei operanzi din tabela de calcul funcţională (în această situaţie rezultatul se obţine din tabela cache).
În tabelele prezentate, NFC corespunde construcţiei fără utilizarea tabelei de calcul funcţionale iar FC înseamnă că tabela de calcul funcţională a fost utilizată la construcţia reprezentării operatorului.
S-a testat tabela de calcul funcţională într-o rutină de determinare a partiţiilor pe mulţime stărilor automatului, partiţii având proprietatea de substituţie. Procedura este descrisă în capitolul 5 privind descompunerea automatelor şi conţine apeluri la câţiva din operatorii impliciţi amintiţi mai sus. Ea a fost aplicată unui set de automate care fac parte din setul MCNC de automate de test cu şi fără a folosi tabela de calcul funcţională. Timpii necesari rulării acestei proceduri sunt daţi în tabelul 4.6.5.3 în secunde. Numărul de variabile utilizate pentru manipularea reprezentării implicite a automatului (coloana 2) se calculează cu relaţia:
m=ni+no+7.ns (4.6.5.3) unde nI = numărul de intrări, no = numărul de ieşiri, ns = numărul de stări ale automatului.
OpFC(x,y,fc) { /* Cauta în tabela cache */ p = cuddCacheLookup2(OpFC,x,y); if (result != NULL) return(result); /* Nu este în tabela cache. Cauta în tabela de calcul funcţională */ result=FCLookup2(fc,OpFC,x,y); if (result != NULL) return(result); /* Nu este în tabela de calcul funcţională. Calculează rezultatul folosind operatorul normal. */ result=Op(x,y); /* Memorează rezultatul în tabela cache şi în tabela de calcul funcţională */ cuddCacheInsert2(OpFC,x,y,result); FCInsert2(fc,OpFC,x,y,result); /* Întoarce rezultatul */ return (result); }
Fig. 4.6.5.1 Codul sursă pentru construirea reprezentării ROBDD pentru un operator binar folosind tabela de calcul funcţională.
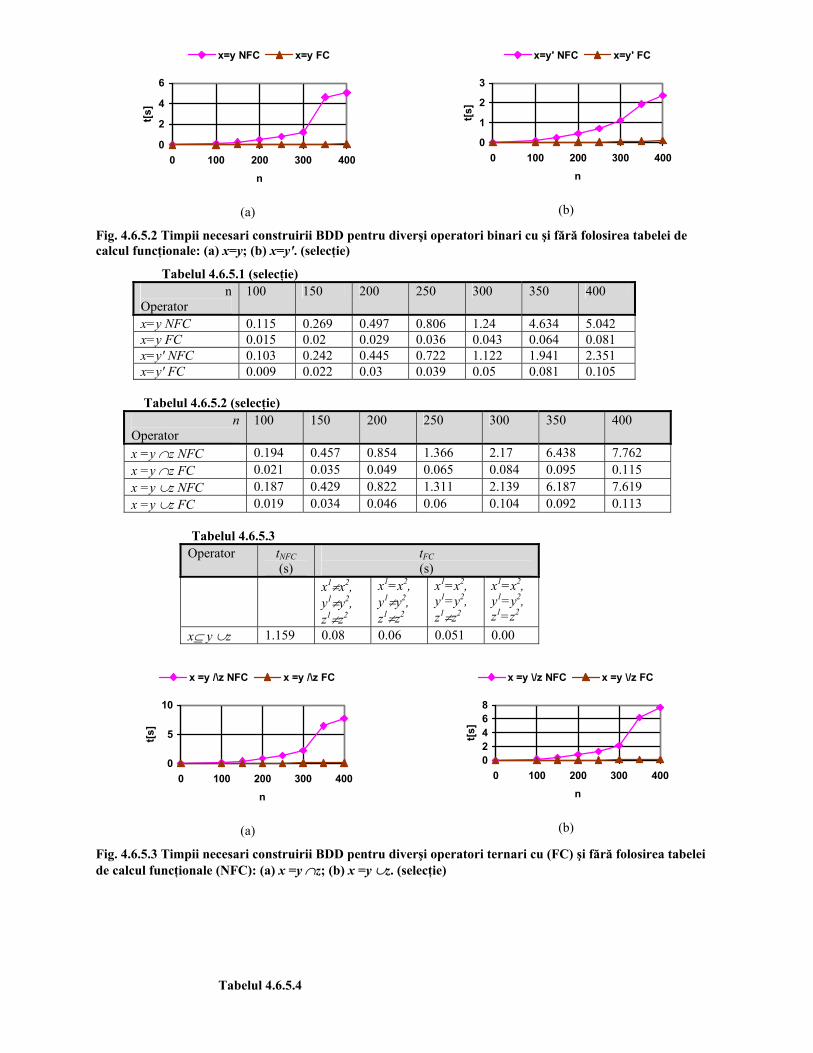
0
2
4
6
0 100 200 300 400n
t[s]
x=y NFC x=y FC
(a)
0
1
2
3
0 100 200 300 400n
t[s]
x=y' NFC x=y' FC
(b)
Fig. 4.6.5.2 Timpii necesari construirii BDD pentru diverşi operatori binari cu şi fără folosirea tabelei de calcul funcţionale: (a) x=y; (b) x=y'. (selecţie)
Tabelul 4.6.5.1 (selecţie) n
Operator 100 150 200 250 300 350 400
x=y NFC 0.115 0.269 0.497 0.806 1.24 4.634 5.042 x=y FC 0.015 0.02 0.029 0.036 0.043 0.064 0.081 x=y' NFC 0.103 0.242 0.445 0.722 1.122 1.941 2.351 x=y' FC 0.009 0.022 0.03 0.039 0.05 0.081 0.105 Tabelul 4.6.5.2 (selecţie)
n Operator
100 150 200 250 300 350 400
x =y ∩z NFC 0.194 0.457 0.854 1.366 2.17 6.438 7.762 x =y ∩z FC 0.021 0.035 0.049 0.065 0.084 0.095 0.115 x =y ∪z NFC 0.187 0.429 0.822 1.311 2.139 6.187 7.619 x =y ∪z FC 0.019 0.034 0.046 0.06 0.104 0.092 0.113
Tabelul 4.6.5.3
Operator tNFC (s)
tFC (s)
x1≠x2, y1≠y2, z1≠z2
x1=x2, y1≠y2, z1≠z2
x1=x2, y1=y2, z1≠z2
x1=x2, y1=y2, z1=z2
x⊆ y ∪z 1.159 0.08 0.06 0.051 0.00
0
5
10
0 100 200 300 400n
t[s]
x =y /\z NFC x =y /\z FC
(a)
02468
0 100 200 300 400n
t[s]
x =y \/z NFC x =y \/z FC
(b)
Fig. 4.6.5.3 Timpii necesari construirii BDD pentru diverşi operatori ternari cu (FC) şi fără folosirea tabelei de calcul funcţionale (NFC): (a) x =y ∩z; (b) x =y ∪z. (selecţie)
Tabelul 4.6.5.4
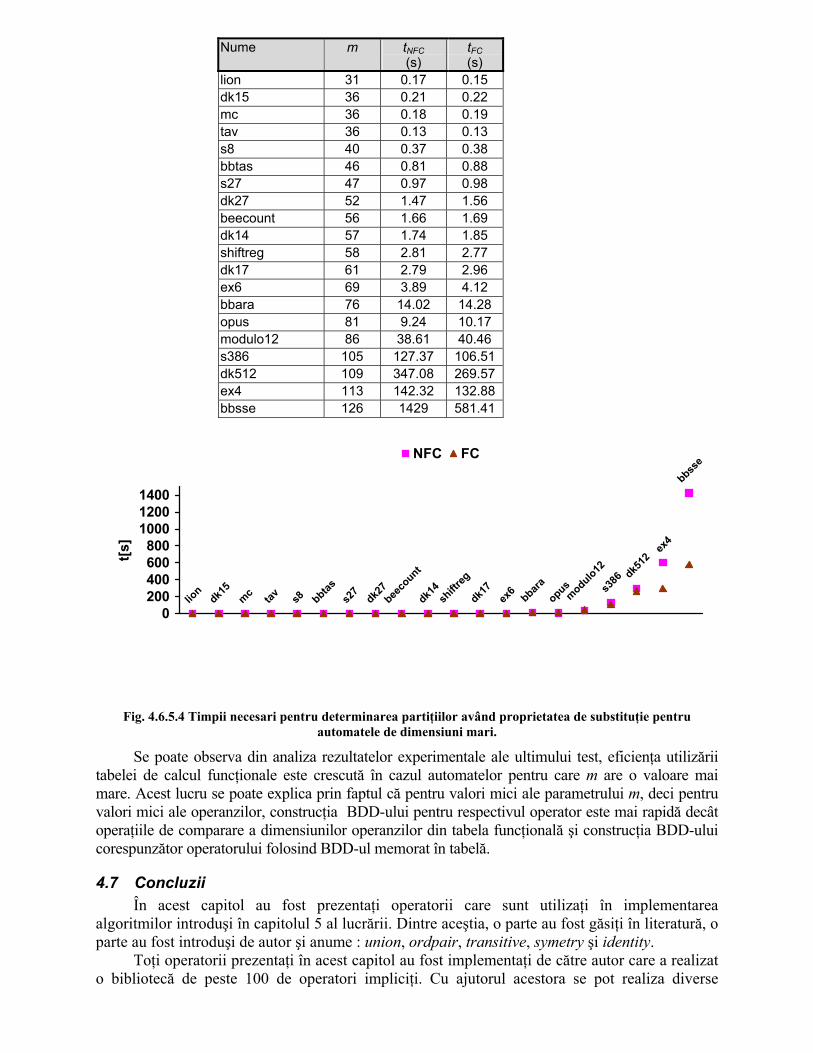
Nume m tNFC (s)
tFC (s)
lion 31 0.17 0.15 dk15 36 0.21 0.22 mc 36 0.18 0.19 tav 36 0.13 0.13 s8 40 0.37 0.38 bbtas 46 0.81 0.88 s27 47 0.97 0.98 dk27 52 1.47 1.56 beecount 56 1.66 1.69 dk14 57 1.74 1.85 shiftreg 58 2.81 2.77 dk17 61 2.79 2.96 ex6 69 3.89 4.12 bbara 76 14.02 14.28 opus 81 9.24 10.17 modulo12 86 38.61 40.46 s386 105 127.37 106.51 dk512 109 347.08 269.57 ex4 113 142.32 132.88 bbsse 126 1429 581.41
lion
dk15
mc tav s8 bbtass2
7dk2
7bee
count
dk14
shiftr
eg
dk17
ex6
bbaraopus
modulo12
s386 dk5
12ex
4
bbsse
0200400600800
100012001400
lion
dk15 mc tav s8
bbtas s2
7dk
27
beec
ount
dk14
shiftr
egdk
17 ex6
bbara op
us
modulo
12s3
86dk
512
ex4
bbss
e
t[s]
NFC FC
Fig. 4.6.5.4 Timpii necesari pentru determinarea partiţiilor având proprietatea de substituţie pentru automatele de dimensiuni mari.
Se poate observa din analiza rezultatelor experimentale ale ultimului test, eficienţa utilizării tabelei de calcul funcţionale este crescută în cazul automatelor pentru care m are o valoare mai mare. Acest lucru se poate explica prin faptul că pentru valori mici ale parametrului m, deci pentru valori mici ale operanzilor, construcţia BDD-ului pentru respectivul operator este mai rapidă decât operaţiile de comparare a dimensiunilor operanzilor din tabela funcţională şi construcţia BDD-ului corespunzător operatorului folosind BDD-ul memorat în tabelă.
4.7 Concluzii În acest capitol au fost prezentaţi operatorii care sunt utilizaţi în implementarea
algoritmilor introduşi în capitolul 5 al lucrării. Dintre aceştia, o parte au fost găsiţi în literatură, o parte au fost introduşi de autor şi anume : union, ordpair, transitive, symetry şi identity.
Toţi operatorii prezentaţi în acest capitol au fost implementaţi de către autor care a realizat o bibliotecă de peste 100 de operatori impliciţi. Cu ajutorul acestora se pot realiza diverse

proceduri de manipulare ale reprezentărilor implicite în general, şi a celor corespunzătoare automatelor finite în particular.
Introducerea unor structuri de date suplimentare poate duce la creşterea vitezei unor operatori. O astfel de structură numită tabela de calcul funcţională a fost introdusă de autor. Aceasta extinde avantajele pe care le au tabelele cache prin aceea că ele pot memora nu numai un singur rezultat, ci un set de rezultate ale aceluiaşi operator. În acest fel, se reduce numărul de calcule în cazul în care acelaşi operator este folosit de mai multe ori. Structura de tabelă de calcul funcţională împreună cu operaţiile de manipulare au fost implementate de autor folosind limbajul C şi pachetul CUDD şi testată pentru o serie de proceduri care conţin operatorii susceptibili de a fi acceleraţi prin folosirea acestei structuri. Rezultatele au confirmat faptul ca prin utilizarea tabelei de calcul funcţionale, poate fi crescută viteza de execuţie a anumitor operatori impliciţi şi ca urmare, a procedurilor în care aceştia sunt utilizaţi.
5 COMPUNEREA ŞI DESCOMPUNEREA AUTOMATELOR FINITE
5.1 Introducere Automatele de complexitate ridicată se pot obţine prin gruparea mai multor automate de
complexitate redusă. În prima parte a acestui capitol ne vom ocupa de gruparea în cascadă a automatelor şi ca nişte cazuri particulare ale acesteia, de gruparea în serie şi în paralel. Acestea pot fi văzute şi ca operaţiile inverse descompunerii în serie şi în paralel a automatelor studiate în partea a doua a capitolului.
Uneori un automat finit, poate fi implementat mai uşor prin descompunerea lui într-o reţea de componente mai mici (subautomate) având o complexitate redusă şi care sunt ulterior sintetizate separat. Descompunerea automatelor este de asemeni utilă în cazul când sunt folosite tehnologiile de implementare ce utilizează FPGA-uri şi dispozitive logice programabile (PLD). În alte cazuri se urmăreşte ca pentru minimizarea problemelor legate de transmiterea semnalele de tact sau pentru simplificarea layout-ului, logica de control pentru o cale de date să fie distribuită de o asemenea manieră încât partea de căi de date şi partea de control cu care interacţionează să fie plasate cât mai aproape una lângă alta.
Scopul acestui capitol este de a deduce operatorii impliciţi cu ajutorul cărora putem realiza operaţiile descrise mai sus şi de a-i implementa în cadrul unor proceduri utilizate pentru sinteza automatelor finite.
5.3 Contribuţii privind realizarea operaţiilor cu automate utilizând tehnici implicite Pornind de la definiţia operaţiilor de grupare în cascadă precum şi a operaţiilor particulare de
grupare în serie şi în paralel, prezentate în [Cre73] s-au dedus operatorii impliciţi care realizează aceste operaţii. 5.3.1 Obţinerea grupării în paralel a două automate folosind tehnici implicite
Presupunem că cele două automate sunt date prin relaţiile tranziţie-ieşire după cum urmează: T1(i,s1,S1,o1)=1, T2(i,s2,S2,o2)=1 (5.3.1.1)
Fiind date stările iniţiale ale celor două automate, r1 şi r2, atunci relaţia de tranziţie a automatului ce reprezintă gruparea în paralel a celor două automate T|| poate fi obţinută folosind relaţiile:
T||0=∅;
π0=(r1,r2) T||
k+1(is1s2 S1S2 o1o2)= T||k(is1s2 S1S2 o1o2)+T1(is1S1o1).T2(is2S2o2).πk(s1s2)
πk+1(S1S2)=∃ is1s2 o1o2T||k(is1s2 S1S2 o1o2)
(5.3.1.2)
Iteraţia se opreşte atunci când T||k+1= T||
k T||
k(is||S||o||)=∃ s1s2 S1S2[T||k(is1s2 S1S2 o1o2).assign(s1s2,s||).assign(S1S2,S||)] (5.3.1.3)
Unde assign(s1s2,s||) este relaţia prin care fiecărei perechi distincte de stări (s1,s2) i se asignează în mod unic o stare unică s|| în automatul A|| iar o||=o1o2.

5.3.2 Obţinerea grupării în serie a două automate folosind tehnici implicite Presupunem că cele două automate sunt date prin relaţiile tranziţie-ieşire după cum urmează:
T1(i1,s1,S1,o1)=1, T2(i2,s2,S2,o2)=1 (5.3.2.1) şi care satisfac condiţia I2=O1.
Din acestea se pot obţine relaţiile de tranziţie şi cele de ieşire după cum urmează: δ1(i1,s1,S1)=∃o1 T1(i1,s1,S1,o1), λ1(i1,s1,o1)=∃S1 T1(i1,s1,S1,o1) δ2(i2,s2,S2) =∃o2 T2(i2,s2,S2,o2), λ2(i2,s2,o2)=∃S2 T2(i2,s2,S2,o2)
(5.3.2.2)
Fiind date stările iniţiale ale celor două automate, r1 şi r2, atunci relaţia de tranziţie a automatului ce reprezintă gruparea în serie a celor două automate poate fi obţinută folosind relaţiile:
T→ 0=∅;
π0=(r1,r2) ω( i1s1s2o2)= ∃o1 [λ2(o1,s2,o2). λ1(i1,s1,o1)] σ(i1s1s2 S1S2)=∃o1 [δ2(o1,s2,S2). λ1(i1,s1,o1)]
T→k+1(i1s1s2 S1S2o2)= T→
k(i1s1s2 S1S2o2)+ σ(i1s1s2 S1S2).ω( i1s1s2o2).πk(s1s2)
πk+1(S1S2)=∃ i1s1s2 o2T→k(i1s1s2 S1S2o2)
(5.3.2.3)
Iteraţia se opreşte atunci când T→k+1= T→
k T→
k(i1s→S→o2)=∃ s1s2 S1S2[T→k(i1s1s2 S1S2o2).assign(s1s2,s→).assign(S1S2,S→)] (5.3.2.4)
Unde assign(s1s2,s→) este relaţia prin care fiecărei perechi distincte de stări (s1,s2) i se asignează în mod unic o stare unică s→ în automatul A→.
5.4 Descompunerea în serie şi în paralel a automatelor finite Definiţia 5.4.1. O relaţie de congruenţă pe mulţimea stărilor unui automat este o relaţie de
echivalenţă σ ∈Eq(S) având proprietatea: ∀ (s1,s2) ∈ σ → (f(s1,i),f(s2,i)) ∈ σ, ∀ i ∈ I. (5.4.1)
Partiţia indusă de relaţie de congruenţă pe mulţimea stărilor unui automat este denumită partiţie închisă sau partiţie având proprietatea de substituţie.
Teorema 5.4.1. Produsul π1.π2 şi suma π1+π2 a două partiţii având proprietatea de substituţie pe mulţimea stărilor unui automat este tot o partiţie având proprietatea de substituţie.
O demonstraţie a acestei teoreme poate fi găsită în [Koh78]. Din această teoremă rezultă că pentru fiecare pereche de partiţii închise există cel mai mare minorant comun, π1.π2 şi cel mai mic majorant comun π1+π2 şi că mulţimea partiţiilor închise pe mulţimea stărilor unui automat este închisă faţă de operaţiile "+" şi "." şi deci are o structură de latice.
Teorema care urmează ne indică o metodă prin care pentru un automat finit se pot determina toate partiţiile având proprietatea de substituţie. Teorema 5.4.2. Fie θs1,s2 cea mai mică congruenţă pe A având proprietatea (s1,s2) ∈θs1,s2 şi θ o congruenţă. Atunci
θ=∨{ θs's''|(s',s'') ∈ θ} (5.4.2) Demonstraţia este dată în [Cre73]. Pe baza acestei relaţii, în [Cre73] se dă un procedeu de
determinare a partiţiilor având proprietatea de substituţie care constă în determinarea congruenţelor θs's" pentru toate perechile (s',s")∈S×S. O altă metodă pentru determinarea partiţiilor având proprietatea de substituţie este indicată in [Koh78]. Prin această metodă se determină mai întâi cele mai mici partiţii care conţin stările s' şi s" pentru toate perechile de stări (s',s") numite şi partiţii de bază. Restul de partiţii se determină efectuând cu partiţiile de bază toate sumele posibile.
Teorema 5.4.3. Pentru un automat A=(I,S,O,δ,λ) putem obţine o descompunere în cascadă formată din două automate Ai=(Ii,Si,Oi,δi,λi), |Sj|<|S| dacă şi numai dacă există o congruenţă nebanală pentru A.
O demonstraţie a teoremei poate fi găsită în [Cre73]. Cele două automate componente sunt M1=(I,S/σ,S/σ × I,δ1,λ1), numit şi automatul predecesor
şi M2=( S/σ × I, S/τ, O ,δ2,λ2), numit şi automatul succesor unde: δ1([s]σ,i)=[f(s,i)]σ, λ1([s]σ,i)=( [s]σ,i)
δ2([s1]τ,([s]σ,i))=[s2]τ s2=δ([s1]τ,∩[s]σ,i) λ2([s1]τ,([s]σ,i))=λ([s1]τ,∩[s]σ,i)
(5.4.3)

unde τ este o partiţie astfel încât σ×τ=ιS. Partiţia τ nu trebuie să aibă proprietatea de substituţie. Teorema 5.4.4. Pentru un automat A=(I,S,O,δ,λ) putem obţine o descompunere în paralel
formată din două automate Ai=(Ii,Si,Oi,δi,λi), |Sj|<|S| dacă şi numai dacă există două congruenţe netriviale σ1 şi σ2 pe mulţimea de stări ale automatului A astfel încât produsul lor să fie egal cu ιS.
O demonstraţie a teoremei poate fi găsită în [Cre73]. Cele două automate Mj=(I,S/σj,S/σj × I,δj,λj) j=1,2 sunt definite de relaţiile:
δj([s]σj,i)=[f(s,i)]σj λj([s]σj,i)=( [s]σj,i) (5.4.4)
5.5 Contribuţii privind descompunerea automatelor finite prin factorizare O serie de studii [Dev89b, Dev89c, Ash92a, Ash92b] au arătat că grafurile de tranziţii ale
unor automate finite pot avea subgrafuri izomorfe. Instanţele unor astfel de grafuri pot fi implementate ca fiind graful de tranziţie a unui automat separat, diferit de automatul din care au fost extrase. Această operaţie poartă numele de factorizare şi ea poate duce la reducerea ariei ocupate la implementarea automatului şi la îmbunătăţirea performanţelor ansamblului. S-a arătat de asemeni că această metodă de descompunere poate fi folosită şi ca ajutor pentru ghidarea etapei de codificare a stărilor unui automat. Pentru realizarea descompunerii prin factorizare se caută găsirea unor subgrafuri izomorfe de preferinţă având dimensiunile cât mai mari.
În prezentarea noastră vom folosi o parte din definiţiile introduse în [Dev89c]. Acestea se referă însă numai la anumite tipuri de factori. Vor fi prezentate o serie de definiţii noi care se referă la cazul mai general al descompunerii prin factorizare o parte din acestea fiind utilizate şi pentru a introduce un nou algoritm de descompunere bazat pe operaţia de factorizare.
Definiţia 5.5.1. Fie un automat finit A=(I,S,O,δ,λ). Fie S1,S2 două submulţimi ale mulţimii S. Mulţimile S1 şi S2 sunt n-echivalente, (S1,S2) ∈ρn dacă:
λ(S1,p)=λ(S2,p) ∀p ∈I*, 0<l(p) ≤n (5.5.1) Stările s1,s2 ∈S sunt n-echivalente dacă ({s1},{s2})∈ρn. Fie un automat finit A=(I,S,O,δ,λ). Stările s1,s2 sunt echivalente în ieşiri dacă şi numai dacă
ele sunt 1-echivalente. Cu alte cuvinte, pentru orice combinaţie a variabilelor de intrare aplicate automatului la ieşire se vor obţine aceleaşi combinaţii ale variabilelor de ieşire indiferent de stările în care trece automatul. Formal putem scrie:
s1≡os2 s1,s2 ∈ S ⇔ ∀i ∈ I, λ(s1,i)=λ(s2,i) (5.5.2) Stările echivalente în ieşiri le vom numi stări o-echivalente. Definiţia 5.5.2. Fie un automat finit A=(I,S,O,δ,λ). Stările s1,s2 sunt echivalente în intrări
dacă şi numai dacă pentru orice combinaţie a variabilelor de intrare aplicate automatului la ieşire există două stări t1 şi t2 astfel încât automatul fiind în aceste stări şi aplicând combinaţia de intrare, automatul trece în starea s1 respectiv s2 şi se obţin aceleaşi valori pentru variabilele de ieşire. Formal acest lucru se exprimă:
s1≡is2 s1,s2 ∈S ⇔ ∀i ∈I, ∃ t1,t2 ∈ S a.î. δ(t1,i)=s1, δ(t2,i)=s2 şi λ(t1,i)=λ(t2,i) (5.5.3) Stările echivalente în intrări le vom numi stări i-echivalente. Definiţia 5.5.3. Fie un automat finit A=(I,S,O,δ,λ). Stările s1,s2 sunt echivalente în intrări şi
ieşiri dacă şi numai dacă ele sunt echivalente atât în ieşiri cât şi în intrări. s1≡ios2 s1,s2 ∈ S ⇔ s1≡is2 şi s1≡os2. (5.5.4)
Stările echivalente în intrări şi ieşiri le vom numi stări io-echivalente. Se poate verifica cu uşurinţă că relaţiile definite mai sus sunt relaţii de echivalenţă veritabile
adică, sunt reflexive, simetrice şi tranzitive. Definiţia 5.5.4. Un factor [Dev89c] F este o mulţime de nF mulţimi de stări din mulţimea de
stări ale automatului şi toate arcele care ies din aceste stări în automatul dat. Fiecare mulţime din aceste mulţimi se numeşte o instanţă a factorului F şi se notează cu Ii
F. Numărul de stări în fiecare factor este ns
F (nsF≥2).
În această lucrare vom folosi o definiţie alternativă pentru factor după cum urmează: Definiţia 5.5.5. Un factor F este o mulţime de nF mulţimi de tranziţii şi stările între care au loc
aceste tranziţii şi cu condiţia ca graful neorientat ataşat să fie conex. Fiecare mulţime din aceste

mulţimi se numeşte o instanţă a factorului F şi se notează cu IiF. Numărul de stări în fiecare factor
este nsF (ns
F≥2). Definiţia 5.5.6. [Dev89c] O tranziţie aparţinând unei instanţe a factorului F este numită
tranziţie internă dacă ea se face din şi într-o stare care aparţine instanţei respective. Definiţia 5.5.7. [Dev89c] Într-o instanţă a factorului F, se numeşte stare de intrare starea s
pentru care există cel puţin o tranziţie dintr-o stare care nu aparţine lui IiF.
Definiţia 5.5.8. [Dev89c] Într-o instanţă a factorului F, se numeşte stare de ieşire starea s pentru care există cel puţin o tranziţie într-o stare care nu aparţine lui Ii
F. Definiţia 5.5.9. [Dev89c] Într-o instanţă a factorului F, starea s se numeşte stare internă dacă
toate tranziţiile care au loc din s sunt tranziţii interne. Definiţia 5.5.10. [Dev89c] Un factor F se numeşte e-accesibil dacă pentru fiecare instanţă a
lui există cel puţin o stare si0 din care să fie accesibile toate celelalte stări ale instanţei. O astfel de
stare se numeşte stare iniţială a lui IiF. Un factor e-accesibil poate avea mai multe stări iniţiale şi nu
mai mult de nsF-1 stări de ieşire.
Definiţia 5.5.11. Fiind date j instanţe ale factorului F, I1F,…,Ij
F, se numeşte o j-tuplă de stări corespondente j-tupla (s1,...,sj) cu si ∈Ii
F. În cazul în care j=2 vorbim despre perechi de stări corespondente.
Definiţia 5.5.12. [Dev89c] Un factor F este exact dacă: 1) există o corespondenţă între stările celor nF instanţe Ii
F astfel încât să nu existe nici o stare care să apară în mai mult de o nF-tuplă de stări corespondente.
2) pentru fiecare tranziţie internă ti=(ii,pi,ni,oi) din instanţa IiF , dacă ∅≠
≠=I
ijnj
jF
i,1
pentru
orice tranziţii tj=(ij,pj,nj,oj) aparţinând instanţelor IjF, pi şi pj respectiv ni şi nj fac parte din aceleaşi
tuple de stări corespondente. Definiţia 5.5.13. Un factor F este un h-factor dacă: 1) există o corespondenţă între stările celor nF instanţe Ii
F astfel încât să nu existe nici o stare care să apară în mai mult de o nF-tuplă de stări corespondente,
2) corespondenţa stărilor interne ale instanţelor IiF este realizată pe baza relaţiei de echivalenţă
în intrări şi ieşiri. Într-un astfel de factor întâlnim mai multe tipuri de stări. Fiind dată o instanţa Ii
F a factorului F, notăm cu ISiF mulţimea stărilor din Ii
F şi cu ITiF
mulţimea tranziţiilor din IiF. Astfel Ii
F=ISiF ∪ ITi
F Definiţia 5.5.14. Fiind dat factorul F şi instanţele acestuia Ii
F avem: a) Starea s este o stare externă dacă toate tranziţiile în această stare se fac din stări sj
aparţinând mulţimii S\∑iFiIS . Notăm cu Ext(Ii
F) mulţimea stărilor externe instanţei IiF.
s ∈Ext(IiF) ⇔∀t=(i,p,s,o), p ∈ S\∑i
FiIS (5.5.5)
b) Starea s este o stare internă a instanţei IiF dacă toate tranziţiile din şi în această stare se fac
din stări t aparţinând mulţimii IiF. Notăm cu Int(Ii
F) mulţimea tuturor stărilor interne ale instanţei IiF.
s ∈Int(IiF) ⇔ ∀t1=(i,s,n,o) ∀t2=(i,p,s,o), p,n ∈Ii
F . (5.5.6) c) Starea s este o stare de frontieră a instanţei Ii
F dacă există tranziţii care se fac dinspre sau spre mulţimea S\∑i
FiIS . Notăm cu Front(Ii
F) mulţimea tuturor stărilor de frontieră ale instanţei IiF.
s ∈Front(IiF) ⇔ ∃t1=(i,s,n,o) sau ∃t2=(i,p,s,o), p ∈ S\∑i
FiIS sau n ∈ S\∑i
FiIS . (5.5.7)
d) Starea s este o stare de intrare pentru instanţa IiF dacă există cel puţin o tranziţie de la s
spre o stare internă. Notăm cu In(IiF) mulţimea tuturor stărilor de intrare ale instanţei Ii
F. s ∈ In(Ii
F) ⇔ ∃t=(i,s,n,o) n ∈ Int(IiF). (5.5.8)
e) Starea s este o stare strict de intrare pentru instanţa IiF dacă toate tranziţiile care se fac în
starea s se fac din stări externe. Notăm cu SInt(IiF) mulţimea tuturor stărilor strict de intrare ale
instanţei IiF .
s ∈ SInt(IiF) ⇔ ∀t=(i,p,s,o), p ∈Ext(Ii
F). (5.5.9)

f) Starea s este o stare de ieşire pentru instanţa IiF dacă există cel puţin o tranziţie care se face
din s spre o stare externă. Notăm cu Out(IiF) mulţimea tuturor stărilor de ieşire ale instanţei Ii
F. s ∈ Out(Ii
F) ⇔ ∃t=(i,s,n,o), n ∈Ext(IiF). (5.5.10)
g) Starea s este o stare strict de ieşire pentru instanţa IiF dacă toate tranziţiile care se fac din s
se fac către stări externe. Notăm cu SOut(IiF) mulţimea tuturor stărilor de ieşire ale instanţei Ii
F. s∈ SOut(Ii
F) ⇔ ∀t=(i,s,n,o), n ∈Ext(IiF) . (5.5.11)
h) Starea s este o stare mixtă dacă ea este atât stare de intrare cât şi stare de ieşire. Definiţia 5.5.15. Fiind dat un automat finit A=(I,S,O,δ,λ), M o mulţime de stări M ⊂ S cu
proprietatea că stările sunt echivalente în intrări şi ieşiri şi s un element al mulţimii M, se numeşte candidat instanţă mulţimea K ⊂ S obţinută conform relaţiei:
K={s} ∪ {n| ∃i ∈I, n=δ(s,i)} ∪ {p| ∃i ∈I, s=δ(p,i)}. (5.5.12) Cu alte cuvinte, mulţimea K este mulţimea care conţine starea s la care se adaugă stările în
care se poate ajunge din s printr-o singură tranziţie şi stările din care se poate ajunge în starea s printr-o singură tranziţie.
Definiţia 5.5.16. Fiind dat un automat finit A=(I,S,O,δ,λ), M o mulţime de stări M ⊂ S cu proprietatea că stările sunt echivalente în intrări şi ieşiri, vom numi candidaţi fraţi, candidaţii corespunzători stărilor s ∈M.
Pentru un automat având ni intrări, no ieşiri şi ns stări pentru care există un factor F cu nF instanţe fiecare instanţă având F
sn stări, avem următoarele relaţii: pentru automatul master:
Ssi
Mi nnn +≤ , o
Mo nn = , FF
nF
sMs nnnnn +−= ).( (5.5.13)
şi pentru automatul slave:
Msi
Si nnn +≤ , o
So nn = , 1+= F
sSs nn (5.5.14)
unde Min =numărul de intrări ale automatului master, S
in =numărul de intrări ale automatului slave, M
on = numărul de ieşiri ale automatului master, Soin =numărul de ieşiri ale automatului slave,
Msin =numărul de stări ale automatului master, S
sn =numărul de stări ale automatului slave, Se poate defini câştigul în numărul de stări obţinut prin factorizare prin diferenţa dintre
numărul de stări ale automatului iniţial şi numărul de stări ale ansamblului format din automatul master şi automatele slave rezultate în urma factorizării. Pentru un automat având ns stări pentru care există un factor F cu nF instanţe fiecare instanţă având F
sn stări, câştigul în numărul de stări obţinut în urma factorizării este dat de relaţia:
Ss
Msss nnnC −−= (5.5.15)
şi ţinând cont de relaţiile 5.4.13 şi 5.4.14
1.)1().( −−−=+−+−−= Fs
FFs
FFs
FFs
Fsss nnnnnnnnnnC (5.5.16)
În tabelul 4.4.1 sunt date valorile câştigului în numărul de stări pentru diverse valori ale numărului de factori şi a numărului de stări pe care instanţele acestor factori le au. Tabelul 5.5.1
Fsn
nF
2 3 4 5 6
2 -1 0 1 2 3 3 0 2 4 6 8 4 1 4 7 10 13 5 2 6 10 14 18 6 3 8 13 18 24
Este evident că putem vorbi despre existenţa unui factor dacă el are cel puţin două instanţe şi acestea au cel puţin două stări. Analizând valorile din tabelul 5.5.1 se pot face următoarele observaţii: (1) câştigul în numărul de stări poate fi negativ, zero sau pozitiv, ceea ce înseamnă că ansamblul automat master + automat slave va avea un număr mai mare, egal sau mai mic decât
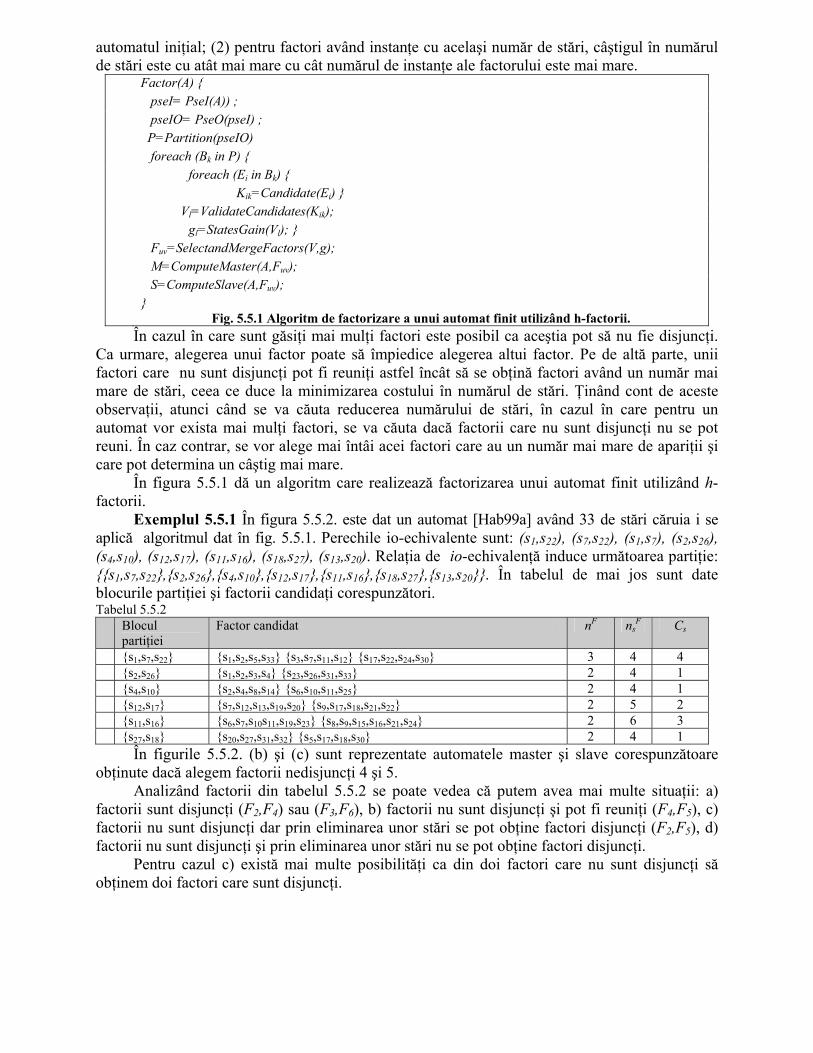
automatul iniţial; (2) pentru factori având instanţe cu acelaşi număr de stări, câştigul în numărul de stări este cu atât mai mare cu cât numărul de instanţe ale factorului este mai mare.
Factor(A) { pseI= PseI(A)) ; pseIO= PseO(pseI) ; P=Partition(pseIO) foreach (Bk in P) { foreach (Ei in Bk) { Kik=Candidate(Ei) } Vl=ValidateCandidates(Kik); gl=StatesGain(Vl); } Fuv=SelectandMergeFactors(V,g); M=ComputeMaster(A,Fuv); S=ComputeSlave(A,Fuv); }
Fig. 5.5.1 Algoritm de factorizare a unui automat finit utilizând h-factorii. În cazul în care sunt găsiţi mai mulţi factori este posibil ca aceştia pot să nu fie disjuncţi.
Ca urmare, alegerea unui factor poate să împiedice alegerea altui factor. Pe de altă parte, unii factori care nu sunt disjuncţi pot fi reuniţi astfel încât să se obţină factori având un număr mai mare de stări, ceea ce duce la minimizarea costului în numărul de stări. Ţinând cont de aceste observaţii, atunci când se va căuta reducerea numărului de stări, în cazul în care pentru un automat vor exista mai mulţi factori, se va căuta dacă factorii care nu sunt disjuncţi nu se pot reuni. În caz contrar, se vor alege mai întâi acei factori care au un număr mai mare de apariţii şi care pot determina un câştig mai mare.
În figura 5.5.1 dă un algoritm care realizează factorizarea unui automat finit utilizând h-factorii.
Exemplul 5.5.1 În figura 5.5.2. este dat un automat [Hab99a] având 33 de stări căruia i se aplică algoritmul dat în fig. 5.5.1. Perechile io-echivalente sunt: (s1,s22), (s7,s22), (s1,s7), (s2,s26), (s4,s10), (s12,s17), (s11,s16), (s18,s27), (s13,s20). Relaţia de io-echivalenţă induce următoarea partiţie: {{s1,s7,s22},{s2,s26},{s4,s10},{s12,s17},{s11,s16},{s18,s27},{s13,s20}}. În tabelul de mai jos sunt date blocurile partiţiei şi factorii candidaţi corespunzători. Tabelul 5.5.2
Blocul partiţiei
Factor candidat nF nsF Cs
{s1,s7,s22} {s1,s2,s5,s33} {s3,s7,s11,s12} {s17,s22,s24,s30} 3 4 4 {s2,s26} {s1,s2,s3,s4} {s23,s26,s31,s33} 2 4 1 {s4,s10} {s2,s4,s8,s14} {s6,s10,s11,s25} 2 4 1 {s12,s17} {s7,s12,s13,s19,s20} {s9,s17,s18,s21,s22} 2 5 2 {s11,s16} {s6,s7,s10s11,s19,s23} {s8,s9,s15,s16,s21,s24} 2 6 3 {s27,s18} {s20,s27,s31,s32} {s5,s17,s18,s30} 2 4 1
În figurile 5.5.2. (b) şi (c) sunt reprezentate automatele master şi slave corespunzătoare obţinute dacă alegem factorii nedisjuncţi 4 şi 5.
Analizând factorii din tabelul 5.5.2 se poate vedea că putem avea mai multe situaţii: a) factorii sunt disjuncţi (F2,F4) sau (F3,F6), b) factorii nu sunt disjuncţi şi pot fi reuniţi (F4,F5), c) factorii nu sunt disjuncţi dar prin eliminarea unor stări se pot obţine factori disjuncţi (F2,F5), d) factorii nu sunt disjuncţi şi prin eliminarea unor stări nu se pot obţine factori disjuncţi.
Pentru cazul c) există mai multe posibilităţi ca din doi factori care nu sunt disjuncţi să obţinem doi factori care sunt disjuncţi.

(a)
(b)
(c) Fig. 5.5.2. Factorizarea automatului pentru factorul obţinut prin reunirea factorilor F4 şi F5: a) instanţele
celor doi factori a căror reuniune este {s6,s7,s10,s11,s12,s13,s19,s20,s23} şi {s8,s9,s15,s16,s17,s18,s21,s22,s24}, (b) automatul master, (c) automatul slave.
5.6 Contribuţii la descompunerea în serie şi în paralel folosind tehnici implicite Folosind teoremele 5.4.2, 5.4.3 şi 5.4.4 pot fi deduşi operatorii impliciţi cu ajutorul cărora pot
fi obţinute descompunerile în cascadă şi în paralel ale unui automat finit [Hab98c]. 5.6.1 Determinarea partiţiilor având proprietatea de substituţie
Existenţa unor descompuneri în serie (paralel) este condiţionată de existenţa unei partiţii (două partiţii) având proprietatea de substituţie. În continuare vor fi prezentaţi operatorii impliciţi care calculează relaţiile de congruenţă pe mulţimea automatului finit şi operatorii care calculează partiţiile având proprietatea de substituţie pe baza relaţiilor de congruenţă obţinute.
Propoziţia 5.6.1 . Fiind dată o pereche de stări (s1,s2), relaţia de congruenţă pe mulţimea de stări a automatului A este dată de cel mai mic punct fix al ecuaţiei:
)](θ[)(θ)(θ ssssss vu,).zv,i,().yu,i,(vuizy,zy, 212121 δδ∃∃∃+= (5.6.1)
şi poate fi calculat folosind următoarea iteraţie:
)](θ[)(θ)(θ
},s{sθ
kss
kss
kss
ssss
vu,).zv,i,().yu,i,(vuizy,zy,212121
2121
1
0
δδ∃∃∃+=
=
+
(5.6.2)
Iteraţia se va termina când )(θ)(θ kss
kss zy,zy,
2121
1 =+ şi relaţia de congruenţă va fi )(θθ kssss zy,
2121= .
Demonstraţie. Calcularea punctului fix porneşte cu mulţimea formată de perechea de stări {s1,s2}. După cea de a k+1 iteraţie )1
21zy,(θ k
ss+ conţine toate perechile de stări (y,z) care au apărut ca
perechi în relaţia de congruenţă în k+1 sau mai puţine tranziţii. Mulţimea este obţinută prin

adăugarea perechilor de stări (y,z) la mulţimea )121
zy,(θ kss+ dacă există o intrare i care să ducă perechea
de stări (y,z) într-o pereche de stări (u,v) deja existentă în relaţia de congruenţă. Pornind de la relaţia de congruenţă
21ssθ corespunzătoare stărilor s1 şi s2 se calculează 21
/ ssS θ care constă din blocurile partiţiei corespunzătoarea acestei relaţii. Mulţimea
21/ ssS θ este formată din
blocurile B1,...,Bα,Bα+1 unde Bα+1 este calculat cu:
Uα
=+α =
11 \
jjBSB
(5.6.3)
iar modul de calcul al blocurilor B1,...,Bα a fost dat în paragraful 5.3. Definiţia 5.6.1. Relaţia redusă a unei relaţii de echivalenţă σ este relaţia obţinută din σ
după efectuarea următoarelor operaţii: r0=transitive(σ)
r1= r0- ιS r=r1 ∩ ordpairS
(5.6.4)
Propoziţia 5.6.2. Fiind dată o relaţie de echivalenţă σ, relaţia redusă a acesteia poate fi calculată implicit cu relaţia:
)zy.()zy,()).zy,((),( <σ=σ EqualtransitivezyRed (5.6.5)
Definiţia 5.6.2. Fiind dată o mulţime M şi o relaţie redusă r a unei relaţii de echivalenţă pe M, un bloc pereche este o submulţime pb ∈ P(M), |pb|=2 definită după cum urmează:
m1,m2 ∈M, (m1,m2) ∈r ⇒pb={m1,m2}⊆ M. (5.6.6) Propoziţia 5.6.3. Fiind dată relaţia redusă a unei relaţii de echivalenţă, mulţimea de blocuri
pereche poate fi determinată cu relaţia: PB(x)=∃y∃z(Redσ (y,z).(x=y ∪z)) (5.6.7)
Mulţimea de blocuri B1,...,Bα induse de relaţia de congruenţă σ poate fi calculată urmărind paşii de mai jos: 1. calculează relaţia redusă r corespunzătoare lui σ. 2. calculează mulţimea de blocuri pereche PB. 3. calculează blocurile B1,...,Bα prin reunirea blocurilor care au intersecţia nevidă. Acest lucru se poate realiza calculând punctul fix maxim al relaţiei nb(x).
nb0(x)=PB(x) IPBk(y,z)= ∃x ( (nbk(y).nbk(z).(x=y ∩ z)]-Tuple0(x))
nbk+1(x)= ∃y ∃z {[IPBk(y,z)].(x=y∪z)}
(5.6.8)
Iteraţia se opreşte atunci când nbk+1(x)= nbk(x)=nb(x) . NB(x)=maximalx(nb(x))
4. calculează mulţimea de blocuri B1,...,Bα, Bα+1 cu Partition(x)= NB(x)+[Tuplen(x)-unionx(NB(x)] (5.6.9)
Odată calculate partiţiile închise ale automatului se poate construi laticea partiţiilor închise ale automatului. Aceasta se poate face fie folosind relaţia de ordine pe mulţimea partiţiilor închise fie folosind operaţiile "+" şi "." definite pe mulţimea partiţiilor. 5.6.2 Operatori pentru descompunerea în serie şi în paralel folosind tehnicile implicite
Fiind dată partiţia netrivială σ(x), putem obţine implicit descompunerea în cascadă şi relaţiile de tranziţie pentru automatele componente. Pentru automatul predecesor avem:
T'(i,y,z)=∃s∃t [(δ(i,s,t).σ(y).σ(z)(y⊇s)(z⊇t))] Thead(i,s,t)=∃y∃z[T'(i,y,z).] assignbls,y(σ(y)).assignblt,z(σ(z))
(5.6.10)
unde assignbl este un operator care atribuie fiecărui bloc a partiţiei o nouă variabilă care reprezintă o stare în primul automat.
Pentru automatul succesor trebuie mai întâi să determinăm o echivalenţă nebanală τ cu proprietatea ca σ ∩ τ = ιS. În [Cre73] este prezentată o cale prin care se poate obţine o astfel de partiţie pornind de la congruenţa nebanală σ. Vom denumi partiţia τ partiţia asociată partiţiei σ.

Această partiţie poate fi obţinută conform următoarei metode. Notăm cu S/σ={Bj|j ∈J} şi jB
Jj
k max∈
= . Congruenţa σ fiind o congruenţă nebanală, k<|S| şi |S/σ|<|S|. Numerotăm elementele
din fiecare bloc Bj cu 1,2,…,nj cu nj≤k. O pereche de elemente vor aparţine relaţiei τ dacă ele sunt numerotate identic.
Relaţia de tranziţie-ieşire pentru automatul predecesor poate fi calculată implicit folosind următoarele relaţii:
A(i,x,y,z)=inputs(i).σ(y).(ap(σ)(z))(x=y ∩z) B(i,t,y,z,o)= ∃s [T(i,s,t,o).A(i,s,y,z)]
C(i,s,y,z,o)= ∃t [B(i,s,t,y,z,o).AP(s)(s⊂t)] Ttail(i,u,s,t,o)=C(i,s,y,z,o).assignbls,u(σ(s)).assignbly,s(ap(σ)(y)).assignblz,t(ap(σ)(z))
(5.6.11)
unde prin ap(σ) am notat operatorul care calculează partiţia asociată a partiţiei σ. Conform teoremei 5.3.4, dacă pentru un automat avem două congruenţe nebanale σ1 şi σ2
care îndeplinesc condiţia σ1 ∩σ2=ιS atunci el poate fi descompus în două automate care sunt legate în paralel.
Relaţiile de tranziţie-ieşire pentru cele două automate pot fi determinate implicit folosind următoarele relaţii:
T1'(i,y,z)=∃s∃t [(δ(i,s,t).σ1(y).σ1(z)(y⊇s)(z⊇t))] T1(i,s,t)=∃y∃z[T1'(i,y,z).] assignbls,y(σ1(y)).assignblt,z(σ1(z))
T2'(i,y,z)=∃s∃t [(δ(i,s,t).σ2(y).σ2(z)(y⊇s)(z⊇t))] T2(i,s,t)=∃y∃z[T2'(i,y,z).] assignbls,y(σ2(y)).assignblt,z(σ2(z))
(5.6.12)
5.7 Descompunerea prin factorizare folosind tehnici implicite 5.7.1 Determinarea perechilor de stări o-echivalente
Presupunem că automatul este dat prin relaţia de tranziţie-ieşire T(i,p,n,o). Mulţimea perechilor de stări o-echivalente se obţine conform următorului algoritm: PairStatesEqualO(T) { pairStatesEqualO(p)=∅ P1(i,p,n,o,i',p',n',o')=T(i,p,n,o).T(i',p',n',o') P2(i,p,o,i',p',o')=∃n ∃n' P1(i,p,n,o,i',p',n',o'). P3(i,p,o,i',p',o')=P2(i,p,o,i',p',o'). Equal(p,p') P4(i,p,o,i',p',o')=P3(i,p,o,i',p',o').Equal(i,i'). Equal(o,o') P5(p,p')=∃i ∃i' ∃o ∃o' P4(i,p,o,i',p',o') P6(p,p')=P5(p,p').Ordpair(p,p') pentru fiecare (q(p),q'(p)) ∈P6 { P7(i,p,n,o)=q(p). T(i,p,n,o) P8(i,p,n,o)=q'(p). T(i,p,n,o) P9(i,o)=∃p ∃n P7(i,p,n,o) P10(i,o)=∃p ∃n P8(i,p,n,o) dacă ( (|P7|==|P8|) şi (P9==P10) ) { pairStatesEqualO(p)= pairStatesEqualO(p)+ (q(p),q'(p)) } } return(pairStatesEqualO(p)) }
Acest algoritm poate fi generalizat şi pentru cazul n>2 astfel încât să se calculeze n-uplele de stări o-echivalente. Din punct de vedere al calcului folosind tehnicile implicite apar următoarele probleme.
- Relaţia P1 va deveni P1=∏
iT )o,n,p,i( iiii cu i=1..n. (5.7.1.1)
Acest lucru înseamnă în primul rând că vom avea nevoie de un număr crescut de variabile ceea ce implică şi creşterea dimensiunilor ROBDD necesare pentru reprezentarea mulţimilor

folosite în cadrul algoritmului. În al doilea rând, operatorii binari vor trebui să fie înlocuiţi cu operatori n-ari a căror complexitate este mult mai mare.
O altă metodă este să ne folosim de faptul că această relaţie este o relaţie de echivalenţă. Astfel, determinarea mulţimilor de stări echivalente la ieşiri este echivalentă cu determinarea claselor de echivalenţă în raport cu relaţia de echivalenţă în ieşiri. În acest scop poate fi folosit operatorul Partition(r) descris anterior care, dacă i se furnizează ca argument la intrare relaţia de echivalenţă r, dată ca mulţime a perechilor echivalente, furnizează ca rezultat mulţimea claselor de echivalenţă corespunzătoare acestei relaţii.
StatesEqualI(p)=Partition(PairStatesEqualO(p)) (5.7.1.2)
5.7.2 Determinarea perechilor de stări i-echivalente Algoritmul de determinare a perechilor de stări i-echivalente la intrări este prezentat mai jos:
PairStatesEqualI(T) { pairStatesEqualI(n)=∅ P1(i,p,n,o,i',p',n',o')=T(i,p,n,o).T(i',p',n',o') P2(i,n,o,i',n',o')=∃p ∃p' P1(i,p,n,o,i',p',n',o'). P3(i,n,o,i',n',o')=P2. Equal(n,n') P4(i,n,o,i',n',o')=P3(i,p,o,i',p',o').Equal(io,i'o') P5(n,n')=∃i ∃i' ∃o ∃o' P4(i,n,o,i',n',o') P6(n,n')=P5(n,n').ordpair(n,n') pentru fiecare (q(n),q'(n)) ∈P6 {
P7(i,p,n,o)=q(n). T(i,p,n,o) P8(i,p,n,o)=q'(n). T(i,p,n,o) P9(i,o)=∃p ∃n P7(i,p,n,o) P10(i,o)=∃p ∃n P8(i,p,n,o) dacă ( (|P7|==|P8|) şi (P9==P10) ) { pairStatesEqualI(n)= pairStatesEqualI(n)+ (q(n),q'(n)) }
} }
La fel ca şi în precedentul caz, se poate generaliza algoritmul pentru cazul n>2 fiind valabile aceleaşi observaţii. Şi în acest caz va fi de preferat determinarea claselor de echivalenţă pornind de la mulţimea perechilor de stări i-echivalente. Astfel:
StatesEqualI(n)=Partition(PairStatesEqualI(n)). (5.7.2.1) 5.7.3 Determinarea perechilor de stări io-echivalente
Conform definiţiei, stările sunt io-echivalente dacă ele sunt atât i-echivalente cât şi o-echivalente. Făcând intersecţia celor două mulţimi de perechi de stări obţinem mulţimea de perechi de stări io-echivalente.
PairStatesEqualIO(p)=PairStatesEqualI(p).PairStatesEqualO(p). (5.7.3.1) Pentru cazul general avem două posibilităţi. Fie folosim mulţimile date de relaţiile (13) şi
(14) şi facem intersecţia celor două mulţimi, StatesEqualIO(p)=StatesEqualI(p).StatesEqualO(p). (5.7.3.2)
fie pornind de la relaţia (15) determinăm clasele de echivalenţă ale relaţiei de echivalenţă la intrări şi ieşiri conform relaţiei:
StatesEqualIO(n)=Partition(PairStatesEqualIO(n)). (5.7.3.3) În implementarea făcută am ales cea de a doua posibilitate datorită faptului că numărul de
calcule este mai redus. 5.7.4 Determinarea şi validarea candidaţilor
Conform definiţiei 5.5.15 candidatul instanţă corespunzător stării unei stări s se obţine adăugând la starea s stările în care se poate ajunge din s printr-o singură tranziţie şi stările din care se poate ajunge în starea s printr-o singură tranziţie.
Propoziţia 5.7.4.1 Mulţimea stărilor în care se poate ajunge din starea x printr-o singură tranziţie poate fi obţinută cu ajutorul operatorului dat de relaţia:

Nextx(S)=∃i ∃s ∃o (T(i,s,S,o).x(s)) (5.7.4.1) Propoziţia 5.7.4.2 Mulţimea stărilor din care se poate ajunge în starea x printr-o singură
tranziţie poate fi obţinută cu ajutorul operatorului dat de relaţia: Previousx(s)=∃i ∃S ∃o (T(i,s,S,o).x(S)) (5.7.4.2)
Folosind relaţiile 5.7.4.1 şi 5.7.4.2 se obţine operatorul care calculează candidatul instanţă corespunzător stării x şi care este dat de relaţia:
Candidatex(s)=x(s)+Nextx(s)+Previousx(s) (5.7.4.3)
5.7.5 Determinarea automatelor master şi slave folosind metode implicite Odată găsiţi factorii, urmează construcţia automatelor master şi slave. Pentru aceasta se
porneşte de la relaţia de tranziţie-ieşire a automatului original şi de la relaţia care reprezintă mulţimea instanţelor factorului considerat. Relaţia de tranziţie-ieşire a automatului master este dat de relaţia:
MFT (i,u,s,S,o)=∃v ∃V [T(i,v,V,o).KA(v,s) .KA(V,S) .KF(u,v)] (5.7.5.1)
unde relaţia KA(v,s) asociază stărilor v ale automatului iniţial o variabilă s care identifică faptul că aceste stări aparţin instanţei i a factorului F sau nu aparţine nici unei instanţe. Astfel stărilor care aparţin instanţei i li se vor asocia aceeaşi variabilă, diferită faţă de cea asociată oricărei alte instanţei j≠i. Fiecărei stări care nu aparţine factorului F i se va asocia o variabilă diferită de a celorlalte stări aparţinând factorului sau nu. Relaţia KF(u,v) asociază stărilor factorului o variabilă u astfel încât stărilor corespondente să le fie asociată aceeaşi variabilă.
Relaţia de tranziţie-ieşire a automatului slave este dat de relaţia: S
FT (i,u,s,S,o)=∃v ∃V [T(i,v,V,o).KF(v,s) .KF(V,S) .KA(u,v)] (5.7.5.2) unde KA şi KF au aceeaşi semnificaţie ca şi în cazul de mai sus. Algoritmul complet pentru factorizarea unui automat finit folosind h-factorii este schiţat
mai jos: Factor(T) { Prod(i,s,S,o,i',s',S',o')=T(i,s,S,o).T(i',s',S',o') if (ni≥no) pseIO(s)= pseI(pseO(Prod(i,s,S,o,i',s',S',o'))) ; else pseIO(s)= pseO(pseI(Prod(i,s,S,o,i',s',S',o'))) ; P(s)=Partition(pseIO(s)) foreach (Bk(s) in P(s)) { foreach (Ei(s) in Bk(s)) { Kik(s)=Candidate(Ei(s)) } Vk=ValidateCandidates(Kik(s)); gk=StatesGain(Vl(s)); } Fuv(s)=SelectandMergeFactors(V(s),g); TM(im,sm,Sm,om)=ComputeMaster(T(i,s,S,o),Fuv); TS(is,ss,Ss,os)=ComputeSlave(T(i,s,S,o),Fuv); return (TM,TS)}
5.8 Implementarea operatorilor pentru compunerea şi descompunerea automatelor finite
Operatorii impliciţi prezentaţi în acest capitol au fost implementaţi utilizând limbajul C, pachetul CUDD [Som97] precum şi operatorii impliciţi realizaţi de autor şi prezentaţi în capitolele precedente. O descriere sumară a acestor operatori este dată în anexa B iar o descriere mai detaliată a fiecărui operator este dată în anexa C.
Pentru realizarea descompunerilor în serie şi în paralel se determină laticea partiţiilor închise ale automatului. Pe baza relaţiilor care există între aceste partiţii, utilizatorul are posibilitatea de a realiza descompunerea în serie sau în paralel. Operatorii implementează descompunerea în serie (în paralel) pentru cazul N=2 unde N este numărul de componente în care este descompus automatul iniţial. Prin aplicarea în continuare la componentele obţinute a operatorilor de descompunere, se poate obţine descompunerea automatului iniţial în mai multe componente şi chiar realizarea unor descompuneri serie-paralel sau paralel-serie.
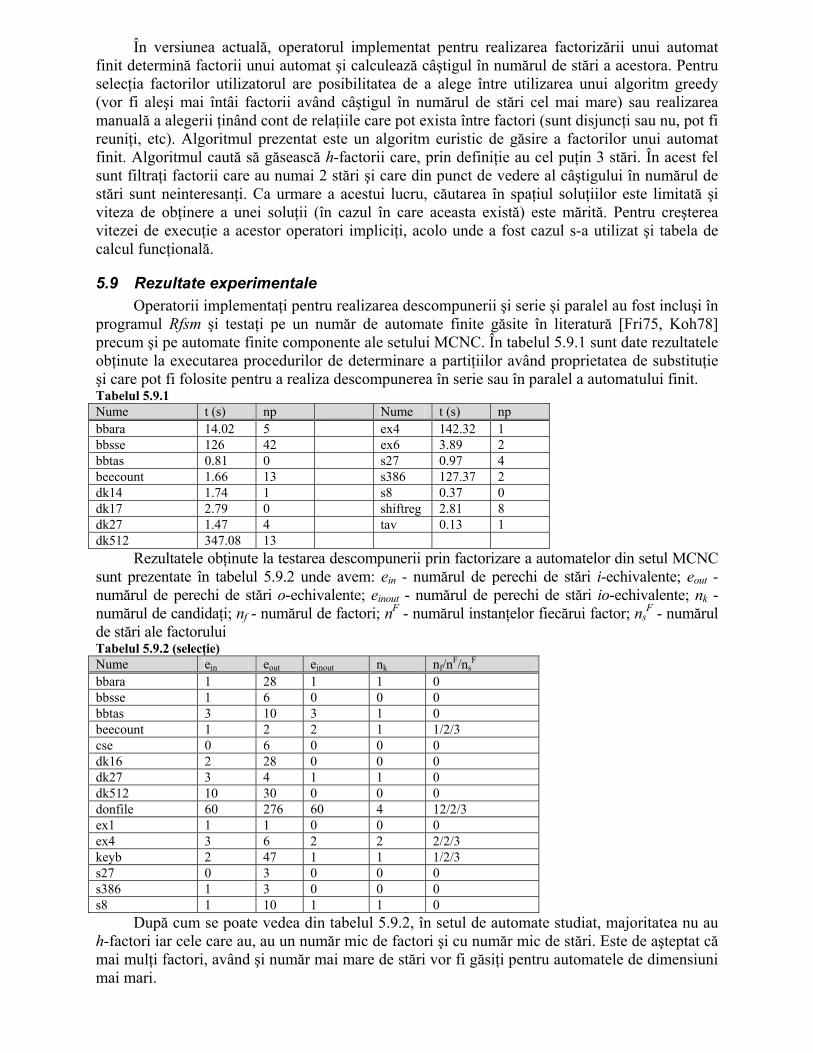
În versiunea actuală, operatorul implementat pentru realizarea factorizării unui automat finit determină factorii unui automat şi calculează câştigul în numărul de stări a acestora. Pentru selecţia factorilor utilizatorul are posibilitatea de a alege între utilizarea unui algoritm greedy (vor fi aleşi mai întâi factorii având câştigul în numărul de stări cel mai mare) sau realizarea manuală a alegerii ţinând cont de relaţiile care pot exista între factori (sunt disjuncţi sau nu, pot fi reuniţi, etc). Algoritmul prezentat este un algoritm euristic de găsire a factorilor unui automat finit. Algoritmul caută să găsească h-factorii care, prin definiţie au cel puţin 3 stări. În acest fel sunt filtraţi factorii care au numai 2 stări şi care din punct de vedere al câştigului în numărul de stări sunt neinteresanţi. Ca urmare a acestui lucru, căutarea în spaţiul soluţiilor este limitată şi viteza de obţinere a unei soluţii (în cazul în care aceasta există) este mărită. Pentru creşterea vitezei de execuţie a acestor operatori impliciţi, acolo unde a fost cazul s-a utilizat şi tabela de calcul funcţională.
5.9 Rezultate experimentale Operatorii implementaţi pentru realizarea descompunerii şi serie şi paralel au fost incluşi în
programul Rfsm şi testaţi pe un număr de automate finite găsite în literatură [Fri75, Koh78] precum şi pe automate finite componente ale setului MCNC. În tabelul 5.9.1 sunt date rezultatele obţinute la executarea procedurilor de determinare a partiţiilor având proprietatea de substituţie şi care pot fi folosite pentru a realiza descompunerea în serie sau în paralel a automatului finit. Tabelul 5.9.1 Nume t (s) np Nume t (s) np bbara 14.02 5 ex4 142.32 1 bbsse 126 42 ex6 3.89 2 bbtas 0.81 0 s27 0.97 4 beecount 1.66 13 s386 127.37 2 dk14 1.74 1 s8 0.37 0 dk17 2.79 0 shiftreg 2.81 8 dk27 1.47 4 tav 0.13 1 dk512 347.08 13
Rezultatele obţinute la testarea descompunerii prin factorizare a automatelor din setul MCNC sunt prezentate în tabelul 5.9.2 unde avem: ein - numărul de perechi de stări i-echivalente; eout - numărul de perechi de stări o-echivalente; einout - numărul de perechi de stări io-echivalente; nk - numărul de candidaţi; nf - numărul de factori; nF - numărul instanţelor fiecărui factor; ns
F - numărul de stări ale factorului Tabelul 5.9.2 (selecţie) Nume ein eout einout nk nf/nF/ns
F bbara 1 28 1 1 0 bbsse 1 6 0 0 0 bbtas 3 10 3 1 0 beecount 1 2 2 1 1/2/3 cse 0 6 0 0 0 dk16 2 28 0 0 0 dk27 3 4 1 1 0 dk512 10 30 0 0 0 donfile 60 276 60 4 12/2/3 ex1 1 1 0 0 0 ex4 3 6 2 2 2/2/3 keyb 2 47 1 1 1/2/3 s27 0 3 0 0 0 s386 1 3 0 0 0 s8 1 10 1 1 0
După cum se poate vedea din tabelul 5.9.2, în setul de automate studiat, majoritatea nu au h-factori iar cele care au, au un număr mic de factori şi cu număr mic de stări. Este de aşteptat că mai mulţi factori, având şi număr mai mare de stări vor fi găsiţi pentru automatele de dimensiuni mai mari.

5.10 Concluzii În acest capitol s-au prezentat două operaţii de compunere a automatelor finite şi trei tipuri
de descompunere a acestora. Pentru fiecare operaţie s-au propus operatorii impliciţi cu ajutorul cărora să poată fi efectuate aceste operaţii.
Pentru realizarea descompunerii în serie şi în paralel s-a utilizat teoria partiţiilor având proprietatea de substituţie şi s-au prezentat operatorii cu ajutorul cărora se poate obţine laticea acestor partiţii. Cunoaşterea structurii acesteia este utilă atât pentru a realiza descompunerilor serie şi paralel dar şi a celor care constituie o combinaţie a acestor două: descompuneri serie-paralel şi paralel-serie.
Tot în acest capitol s-au introdus o serie de definiţii noi privitore la descompunerea prin factorizare a unui automat finit menite să extindă definiţiile introduse în [Dev89c]. S-a prezentat un algoritm nou prin care se pot determina factorii unui automat finit. Acest algoritm se bazează pe proprietăţile de echivalenţă la intrări şi la ieşiri definită pe mulţimea stărilor unui automat. Prin intermediul acestui algoritm se determină factorii candidaţi care trebuie apoi validaţi.
Toţi operatorii descrişi în acest capitol au fost implementaţi folosind limbajul C şi pachetul CUDD şi au fost înglobaţi în programul Rfsm realizat de autor.
6 RFSM: PACHET DE PROGRAME PENTRU SINTEZA ASISTATĂ DE CALCULATOR A STRUCTURILOR NUMERICE SECVENŢIALE
6.1 Introducere Capitolul de faţă prezintă încercarea autorului de a integra mai multe programe într-un mediu
de proiectare care să rezolve problemele ce apar la proiectarea structurilor numerice în general şi a automatelor finite în particular. O serie de programe sunt disponibile în reţeaua universitară, la acestea se adaugă programul Rfsm (Reduced Finite State Machines) realizat de autor. Este prezentat de asemeni şi modul în care aceste programe pot fi folosite împreună pentru proiectarea asistată a automatelor finite cu ajutorul interfeţei grafice RfsmView realizată de asemeni de autor.
Programul Rfsm conţine funcţiile şi procedurile realizate de autor prezentate în capitolele anterioare şi care permit realizarea diverselor operaţii asupra automatelor finite.
Descrierea folosind limbajul VHDL nu este întotdeauna metoda cea mai familiară proiectantului, acesta fiind cel mai adesea obişnuit să descrie automatul finit folosind tabelul de tranziţii sau mai intuitiv, graful de tranziţie. Pentru a veni în ajutorul proiectantului, autorul a realizat un editor grafic RfsmView care permite trasarea grafului de tranziţii pentru automat, editarea lui şi salvarea acest graf într-un fişier în format kiss. Programul RfsmView a fost realizat şi ca o interfaţă care permite utilizarea programelor prezentate mai sus astfel încât să se poată realiza următoarele operaţii: desenarea şi editarea grafului de tranziţie a unui automat, salvarea lui în format kiss, minimizarea stărilor folosind programul Stamina [Rho91], codificarea stărilor automatului folosind programul Nova [Vil90], compunerea automatelor în serie şi în paralel, descompunerea automatului în componente mai mici folosind programul Rfsm, vizualizarea descrierilor implicite cu ajutorul ROBDD folosind programul dot [Kou96], conversia automată a descrierii unui automat finit din formatul kiss în formatul VHDL [All92] recunoscut de componenta Syf [All93] a pachetului Alliance.
6.2 Programul Rfsm Programul Rfsm permite realizarea unor operaţii asupra automatelor finite folosind algoritmii
prezentaţi de autor în capitolele precedente. Algoritmii se bazează pe utilizarea tehnicilor implicite de manipulare a reprezentărilor automatului dat sub forma de ROBDD. În acest scop au fost utilizaţi operatorii impliciţi descrişi în anexele B şi C. Programul a fost scris în limbajul C şi s-au folosit bibliotecile de funcţii ale pachetelor CUDD şi st. Versiunea actuală a fost realizată pentru a funcţiona şi a fost testată sub sistemul de operare Linux.
Utilizarea programului Rfsm se face în mod linie de comandă. Linia de comandă este de forma
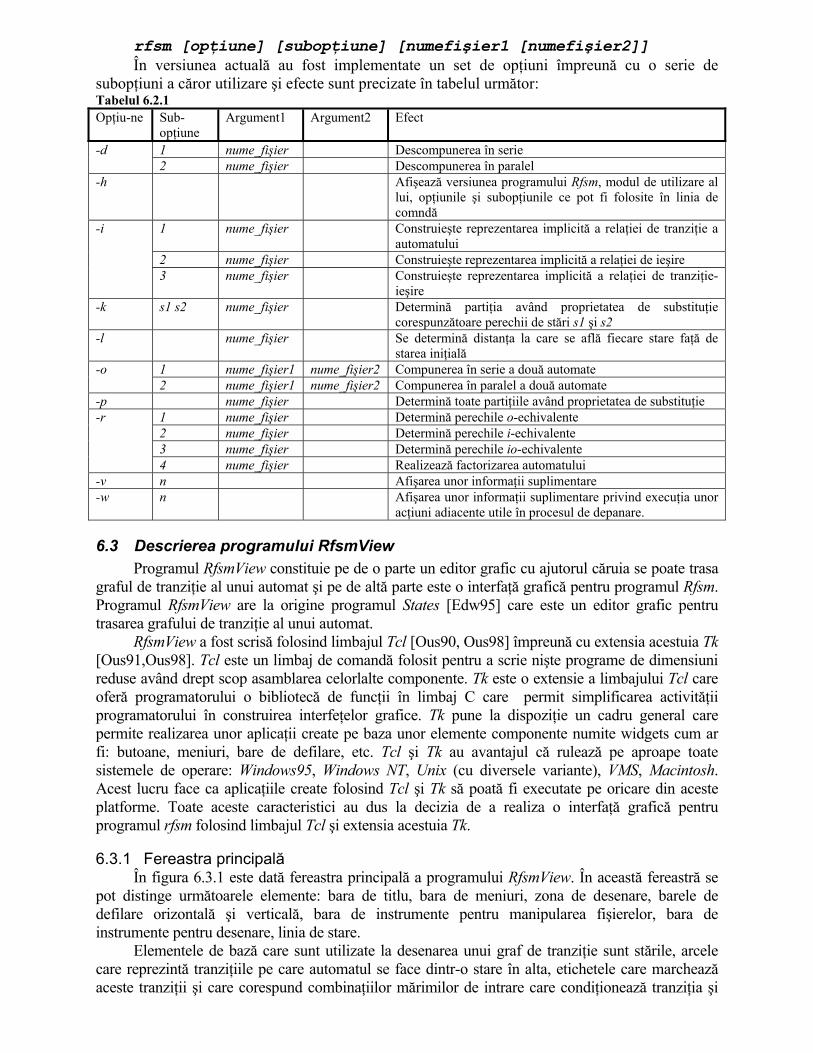
rfsm [opţiune] [subopţiune] [numefişier1 [numefişier2]] În versiunea actuală au fost implementate un set de opţiuni împreună cu o serie de
subopţiuni a căror utilizare şi efecte sunt precizate în tabelul următor: Tabelul 6.2.1 Opţiu-ne Sub-
opţiune Argument1 Argument2 Efect
-d 1 nume_fişier Descompunerea în serie 2 nume_fişier Descompunerea în paralel -h Afişează versiunea programului Rfsm, modul de utilizare al
lui, opţiunile şi subopţiunile ce pot fi folosite în linia de comndă
-i 1 nume_fişier Construieşte reprezentarea implicită a relaţiei de tranziţie a automatului
2 nume_fişier Construieşte reprezentarea implicită a relaţiei de ieşire 3 nume_fişier Construieşte reprezentarea implicită a relaţiei de tranziţie-
ieşire -k s1 s2 nume_fişier Determină partiţia având proprietatea de substituţie
corespunzătoare perechii de stări s1 şi s2 -l nume_fişier Se determină distanţa la care se află fiecare stare faţă de
starea iniţială -o 1 nume_fişier1 nume_fişier2 Compunerea în serie a două automate 2 nume_fişier1 nume_fişier2 Compunerea în paralel a două automate -p nume_fişier Determină toate partiţiile având proprietatea de substituţie -r 1 nume_fişier Determină perechile o-echivalente 2 nume_fişier Determină perechile i-echivalente 3 nume_fişier Determină perechile io-echivalente 4 nume_fişier Realizează factorizarea automatului -v n Afişarea unor informaţii suplimentare -w n Afişarea unor informaţii suplimentare privind execuţia unor
acţiuni adiacente utile în procesul de depanare.
6.3 Descrierea programului RfsmView Programul RfsmView constituie pe de o parte un editor grafic cu ajutorul căruia se poate trasa
graful de tranziţie al unui automat şi pe de altă parte este o interfaţă grafică pentru programul Rfsm. Programul RfsmView are la origine programul States [Edw95] care este un editor grafic pentru trasarea grafului de tranziţie al unui automat.
RfsmView a fost scrisă folosind limbajul Tcl [Ous90, Ous98] împreună cu extensia acestuia Tk [Ous91,Ous98]. Tcl este un limbaj de comandă folosit pentru a scrie nişte programe de dimensiuni reduse având drept scop asamblarea celorlalte componente. Tk este o extensie a limbajului Tcl care oferă programatorului o bibliotecă de funcţii în limbaj C care permit simplificarea activităţii programatorului în construirea interfeţelor grafice. Tk pune la dispoziţie un cadru general care permite realizarea unor aplicaţii create pe baza unor elemente componente numite widgets cum ar fi: butoane, meniuri, bare de defilare, etc. Tcl şi Tk au avantajul că rulează pe aproape toate sistemele de operare: Windows95, Windows NT, Unix (cu diversele variante), VMS, Macintosh. Acest lucru face ca aplicaţiile create folosind Tcl şi Tk să poată fi executate pe oricare din aceste platforme. Toate aceste caracteristici au dus la decizia de a realiza o interfaţă grafică pentru programul rfsm folosind limbajul Tcl şi extensia acestuia Tk. 6.3.1 Fereastra principală
În figura 6.3.1 este dată fereastra principală a programului RfsmView. În această fereastră se pot distinge următoarele elemente: bara de titlu, bara de meniuri, zona de desenare, barele de defilare orizontală şi verticală, bara de instrumente pentru manipularea fişierelor, bara de instrumente pentru desenare, linia de stare.
Elementele de bază care sunt utilizate la desenarea unui graf de tranziţie sunt stările, arcele care reprezintă tranziţiile pe care automatul se face dintr-o stare în alta, etichetele care marchează aceste tranziţii şi care corespund combinaţiilor mărimilor de intrare care condiţionează tranziţia şi

combinaţiilor de ieşire sunt elaborate în cadrul tranziţiei respective. În caz de nevoie, graful de tranziţie mai poate fi adnotat cu text pentru a facilita mai buna înţelegere a structurii şi funcţionării acestuia. Toate aceste elemente pot fi trasate fie utilizând comenzile din meniul de comenzi, fie folosind bara cu butoane de desenare.
Fig. 6.3.1 Fereastra principală a programului RfsmView
6.4 Meniurile programului 6.4.1 Meniul File
Sunt implementate principalele comenzi referitoare la fişierele în care sunt salvate grafurile de tranziţii. Aceste comenzi sunt: New, Load Kiss, Save, Save As, Create Postscript, File History, Quit 6.4.2 Meniul Edit
Sunt implementate principalele comenzi prin care poate fi editat graful de tranziţie al unui automat. Aceste comenzi sunt: Delete, Select All, Select Unselected, Memorize Selected, Remind Selected, Straighten, Set, Reset State, Resize State Bubbles 6.4.3 Meniul Search
Sunt implementate o serie de comenzi care permit găsirea uşoară într-un graf de tranziţii a stărilor, tranziţiilor, textului de comentariu. Aceste comenzi sunt: Find State, Find Transition, Find Floating Text 6.4.4 Meniul View
Sunt implementate comenzile prin care sunt afişate sau ascunse barele de unelte şi sunt afişate valorile unor variabile din program. Aceste comenzi sunt: View File Toolbar, View Drawing Toolbar, View Variables 6.4.5 Meniul Drawing
Sunt implementate comenzile utilizate pentru desenare grafului de tranziţie şi adnotarea acestuia. Aceste comenzi sunt: Select Object, Insert State, Insert Transition, Edit text 6.4.6 Meniul Options
Sunt implementate comenzile prin care pot fi stabilite valorile pentru diferite opţiuni de configurare a interfeţei grafice. Aceste comenzi sunt: Arrange machine - Circle -Horizontal

Flow -Vertical Flow, Grid,Save graphic data, Use FC, Set File History Size, Preferences
Fig. 6.4.6.1 Meniul Edit
Fig. 6.4.6.2 Fereastra de dialog Preferences
6.4.7 Meniul Tools
Sunt implementate comenzile prin care se comandă aplicarea diverselor etape de sinteză automatului a cărui graf de tranziţie este editat. Aceste comenzi sunt: View/Edit kiss file, Implicit Description-Transition Relation, Output Relation, Transition-Output Relation, State Assignment, State Minimization, Convert to FSM, Write to dot file, Decomposition-Serial Decomposition - Parallel Decomposition - Factorization, Operations, Evaluation - Selected Previous Set - Selected Next Set, Arrange Selected States.
Fig. 6.4.7.1 Meniul Tools 6.4.8 Meniul Help
Sunt implementate comenzile prin care se pot obţine informaţii privind modul de utilizare al programului şi formatele de fişiere utilizate. Aceste comenzi sunt: About, On Editing, File Formats
6.5 Legătura programului RfsmView cu alte sisteme de proiectare asistată de calculator în domeniul VLSI

Pachetul de programe Alliance este alcătuit dintr-un set complet de programe care pot fi utilizate pentru proiectarea şi învăţarea proiectării asistate de calculator a circuitelor VLSI. Fiecare
program poate fi folosit separat sau pot fi utilizate împreună conform metodei de proiectare propusă de autorii pachetului de programe [Gre93].
Pentru specificarea unui automat finit pachetul de programe Alliance foloseşte un subset al limbajului VHDL numit şi VHDL FSM.. Un automat descris folosind acest subset poate fi sintetizat folosind componenta syf a pachetului de programe Alliance. Această componentă realizează generarea descrierii tip data-flow în subsetul VHDL recunoscut de celelalte componente ale pachetului. Subsetul VHDL FSM permite descrierea a trei tipuri de automate şi anume Mealy, Moore şi automat cu stivă. În această lucrare ne vom referi doar la primele două tipuri. Componenta syf citeşte o descriere a unui automat finit dat în subsetul VHDL FSM, verifică această descriere, face asignarea stărilor automatului şi generează apoi descrierea data-flow care apoi poate fi
sintetizată mai departe folosind metodologia de proiectare propusă în [Gre93]. O problemă importantă în proiectare ţine de modul în care se face descrierea sistemului ce se
doreşte a fi implementat. De-a lungul timpului s-au evidenţiat două tipuri de reprezentări şi anume reprezentările textuale şi reprezentările grafice. Păstrarea unui echilibru între cele două tipuri de descrieri este un lucru de dorit pentru orice pachet de programe pentru a permite fiecărui proiectant să folosească un mediu cât mai apropiat de metodele lui de proiectare. În acest scop ne-am propus să completăm pachetul Alliance, care este preponderent textual cu o serie de programe care, în cazul automatelor finite, să permită specificarea acestora folosind şi descrierea grafică. Extensia realizată de autor este dată în figura 1 şi ea indică programele folosite şi legăturile dintre acestea. Se poate observa că proiectantul are mai multe puncte de intrare şi poate urma diverse căi pentru a realiza obiectivul dorit.
Programul RfsmView s-a utilizat ca interfaţă grafică pentru descrierea automatului finit prin graf de tranziţie şi obţinere descrierii acestuia în formatul KISS. Această descriere poate fi transmisă unui program de minimizare a numărului de stări a automatului (MS) sau/şi unui program de asignare a stărilor (AS) pentru a obţine vectorii de codificare a stărilor utilizate apoi pentru codificarea şi implementarea automatului [Hab98a].
Reprezentarea din formatul KISS este transformată într-o descriere în format VHDL FSM cu ajutorul programului Kiss2fsm şi aceasta este transmisă mai departe programului Syf împreună eventual cu codurile asignate stărilor furnizate de proiectant sau obţinute de la programul MS. (programul Codes2cod face conversia între formatul .codes în care sunt descrise codurile generate de programul Nova[Vil90] în formatul .cod acceptat de Syf). Metodologia de proiectare urmează apoi pe cea propusă în [Gre93].
6.6 Concluzii Autorul a realizat un mediu de proiectare asistată de calculator care oferă posibilitatea
utilizării programului Rfsm realizat de autor împreună cu alte programe care permit sinteza structurilor de comandă secvenţiale. Integrarea acestor programe diferite se realizează prin intermediul interfeţei grafice RfsmView realizată de autor şi de programele de conversie dintre
RfsmView
Syf
Asimut
Kiss2fsmSA
Codes2cod
MSp.kiss2
p.fsm
p.vbe
p.codes
p.cod
TextEditor
Alliance
Fig. 6.5.1 Legătura între programul RfsmView şi
celelalte programe utilizate.

diferitele formate de fişiere pe care acestea le utilizează. Folosind acest mediu de programare, descrierea structurile numerice secvenţiale poate fi făcută grafic cu ajutorul grafului de tranziţii sau folosind unul din formatele textuale prezentate în anexa A.
Programul Rfsm a fost conceput pentru a putea fi utilizat atât în mod linie de comandă (în acest caz necesarul de memorie este mai mic) cât şi în mod integrat prin intermediul interfeţei RfsmView. Programul Rfsm permite obţinerea reprezentărilor implicite, realizarea operaţiilor de compunere în serie şi în paralel, determinarea laticii partiţiilor închise, descompunerea în serie, în paralel şi prin factorizare pentru automatelor finite. Algoritmii se bazează pe utilizarea tehnicilor implicite de manipulare a reprezentărilor automatului dat sub forma de diagrame de decizie binare. Programul a fost scris în limbajul C versiunea actuală fiind realizată şi testată pentru a funcţiona sub sistemul de operare Linux.
Principalele facilităţi pe care le are interfaţa grafică RfsmView sunt: comenzile sunt disponibile prin intermediul meniurilor de comenzi şi a barelor de butoane, posibilitatea de modificare a opţiunilor de afişare a grafului de tranziţie, un set important de comenzi de editare şi căutare în graful de tranziţii, apelarea simplă a programelor componente ale mediului şi configurare uşoară a opţiunilor prin intermediul ferestrelor de dialog prevăzute cu butoane de tip radio şi de tip de selectare, afişarea în bara de stare a informaţiilor despre automat şi despre elementele acestuia (intrări, ieşiri, stări), portabilitatea pe diverse sisteme de operare şi tipuri de calculatoare datorită folosirii limbajului Tcl/Tk (a fost testată sub sistemele de operare Linux şi DOS/Windows).
7 CONCLUZII FINALE. CONTRIBUŢII ORIGINALE. OBIECTIVE DE VIITOR
7.2 Contribuţii originale Lucrarea elaborată reprezintă rezultatul unor cercetări în domeniul teoriei şi proiectării
automatelor finite în scopul realizării unui sistem care să permită sinteza structurilor numerice de comandă şi care să înglobeze metode noi de proiectare. Rezultatele acestei activităţi şi care constituie contribuţiile proprii sunt următoarele: • introducerea unor tipuri noi de reprezentări utilizând diagramele de decizie binare pe baza
folosirii de noi reguli de reducere; • stabilirea legăturii care există între reprezentările funcţiilor booleene reprezentate sub formă
de sume de produse folosind noile tipuri de reprezentări şi modul de codificare a termenilor produs
• introducerea unor operatori impliciţi pentru manipularea mulţimilor de obiecte • introducerea unei structuri originale de date, numită tabelă de calcul funcţională, utilizată
pentru îmbunătăţirea unei anumite clase de operatori impliciţi, în vederea creşterii vitezei de execuţie a acestora,
• introducerea unei metode euristice de descompunere a automatelor finite prin factorizare utilizând relaţia de echivalenţă la intrări şi la ieşiri definită pe mulţimea de stări a automatului
• realizarea unei biblioteci de peste 100 operatori impliciţi care pot fi folosiţi pentru manipularea funcţiilor booleene şi a automatelor finite reprezentate implicit prin intermediul diagramelor de decizie binară,
• realizarea unui program numit Rfsm care, folosind tehnicile implicite şi diagramele de decizie binare, permite obţinerea reprezentărilor implicite a relaţiilor de tranziţie-ieşire ale unui automat finit, realizarea operaţiilor de compunere în serie şi în paralel a două automate finite, descompunerea în serie şi în paralel a automatelor finite, descompunerea automatelor finite prin factorizare. Programul a fost scris în limbaj C şi a fost testat sub sistemul de operare Linux.
• realizarea unei interfeţe grafice numită RfsmView prin care sunt reunite mai multe programe ce pot fi utilizate în diverse etape ale proiectării automatelor finite şi care are şi rolul de editor grafic permiţând trasarea şi editarea grafului de tranziţie al unui automat. Această interfaţă a fost testată atât sub sistemul de operare Linux cât şi sub sistemul de operare DOS/Windows.

În structura lucrării capitolele 3, 4, 5 şi 6 conţin contribuţiile proprii. Rezultatele obţinute au fost prezentate sub formă de lucrări la diverse conferinţe naţionale şi internaţionale sau au fost publicate în reviste.
În capitolul 3 s-a arătat că putem folosi diverse reprezentări ale funcţiilor booleene rezultate din aplicarea diverselor reguli de reducere având drept scop reducerea dimensiunii reprezentării. Aceste reprezentări sunt diferite pentru aceeaşi funcţie şi, în anumite condiţii anumite reprezentări sunt mai eficiente decât celelalte.
În cadrul studiului efectuat, autorul a propus şi a studiat 4 reguli noi de reducere (Drept=1, Stâng=0, Stâng=1, Drept≠Stâng) care pot fi aplicate pentru micşorarea numărului de noduri ale reprezentărilor de tip OBDD. Aceste tipuri de reducere au fost implementate într-un program scris în limbajul C împreună cu tipurile de reducere întâlnite în literatură (Fuziune, Drept=Stâng, Drept=0). Cu ajutorul programului realizat, au fost construite reprezentările pentru mai multe seturi de circuite numerice combinaţionale a căror funcţionalitate este descrisă cu ajutorul funcţiilor booleene. Rezultatele experimentale au arătat că regulile de reducere au eficienţă diferită pentru circuite diferite şi pentru mulţimea de funcţii booleene testate, aplicarea reducerii de tip Stâng=1 are ca rezultat numărul cel mai mic de noduri.
A fost scoasă în evidenţa relaţia care există între numărul de noduri, tipul de reprezentare folosită şi codificarea aleasă pentru a reprezenta termenii produs ai unei funcţii booleene dată în forma normal disjunctivă. S-a arătat că există un număr de 24 moduri de codificare a literalilor unui termen produs şi s-a dat o interpretare pentru fiecare din aceste codificări. Din studiul efectuat a rezultat că în cazul în care se foloseşte o anumită codificare a termenilor produs, pentru a se obţine o reprezentare cu număr cât mai mic de noduri trebuie folosite reprezentările ROBDD obţinute cu regulile de reducere corespunzătoare. În plus, s-a arătat că trebuie ţinut cont şi de numărul de termeni care sunt reprezentaţi de-a lungul întregii durate de aplicare a algoritmilor.
În capitolul 4 au fost prezentaţi operatorii care au fost utilizaţi în implementarea algoritmilor introduşi în capitolul 5 al lucrării. Dintre aceştia, o parte au fost găsiţi în literatură, o parte au fost introduşi de autor. În ultima categorie intră operatorii union, ordpair, transitive, symetry şi identity. Toţi operatorii prezentaţi în acest capitol au fost implementaţi de către autor pe calculator. Prin aceasta s-a realizat o bibliotecă de peste 100 de operatori impliciţi cu ajutorul cărora se pot realiza diverse proceduri de manipulare ale reprezentărilor implicite în general, şi a celor corespunzătoare automatelor finite în particular.
Introducerea unor structuri de date suplimentare poate duce la creşterea vitezei unor operatori. O astfel de structură numită tabela de calcul funcţională a fost introdusă de autor. Aceasta extinde avantajele pe care le au tabelele cache prin aceea că ele pot memora, nu numai un singur rezultat, ci un set de rezultate ale aceluiaşi operator. În acest fel, se reduce numărul de calcule în cazul în care acelaşi operator este folosit de mai multe ori, prin apelare cu aceeaşi operanzi sau cu operanzi diferiţi. Structura de tabelă de calcul funcţională împreună cu operaţiile de manipulare au fost implementate de către autor folosind limbajul C şi pachetul CUDD şi testată pentru o serie de proceduri care conţin operatorii susceptibili de a fi acceleraţi prin folosirea acestei structuri. Rezultatele experimentale au confirmat faptul că prin utilizarea tabelei de calcul funcţionale poate fi crescută viteza de execuţie a anumitor operatori impliciţi şi ca urmare, a procedurilor în care aceştia sunt utilizaţi.
În capitolul 5 s-au prezentat două operaţii de compunere a automatelor finite şi trei tipuri de descompunere a acestora. Contribuţia autorului a constat în propunerea pentru fiecare operaţie şi pentru fiecare din descompunerile clasice (în serie şi în paralel) a unor operatori impliciţi cu ajutorul cărora să poată fi efectuate aceste operaţii utilizând reprezentările implicite ale automatelor finite.
Tot în acest capitol autorul a introdus o serie de definiţii noi privitore la descompunerea prin factorizare a unui automat finit, definiţii menite să extindă definiţiile introduse în [Dev89c]. S-a prezentat un algoritm nou prin care se pot determina o parte din factorii unui automat finit. Acest algoritm se bazează pe proprietăţile de echivalenţă la intrări şi la ieşiri definită pe

mulţimea stărilor unui automat. Toţi operatorii descrişi în acest capitol au fost implementaţi de către autor folosind limbajul
C, pachetul CUDD şi operatorii impliciţi descrişi în capitolul 4, ei fiind înglobaţi în programul Rfsm.
În capitolul 6 autorul a prezentat realizarea un mediu de proiectare asistată de calculator care oferă posibilitatea utilizării programului Rfsm conceput de autor, împreună cu alte programe şi care permit sinteza structurilor de comandă secvenţiale. Integrarea acestor programe diferite se realizează prin intermediul interfeţei grafice RfsmView şi cu ajutorul programele de conversie dintre diferitele formate de fişiere pe care acestea le utilizează, toate realizate de autor. Folosind acest mediu de programare, descrierea structurile numerice secvenţiale poate fi făcută grafic cu ajutorul grafului de tranziţii sau folosind unul din formatele textuale prezentate în anexa A.
Programul Rfsm a fost conceput pentru a putea fi utilizat atât în mod linie de comandă (în acest caz necesarul de memorie este mai mic) cât şi în mod integrat prin intermediul interfeţei RfsmView. Programul Rfsm permite realizarea unor operaţii asupra automatelor finite folosind algoritmii prezentaţi de autor în capitolele precedente. Dintre acestea amintim: obţinerea reprezentărilor implicite, realizarea operaţiilor de compunere în serie şi în paralel, determinarea laticii partiţiilor închise, descompunerea în serie, în paralel şi prin factorizare pentru automatele finite. Algoritmii se bazează pe utilizarea tehnicilor implicite de manipulare a reprezentărilor automatului dat sub forma de ROBDD.
Interfaţa RfsmView conţine un număr mare de comenzi ce pot fi accesate prin intermediul meniurilor de comenzi sau a barelor de butoane. Ea este uşor de utilizat contribuind astfel la creşterea vitezei procesului de proiectare asistată. Utilizarea limbajului Tcl/Tk face ca ea să poată fi rulată pe cele mai cunoscute sisteme de operare cu modificări minore.
7.3 Obiective de viitor Lucrarea de faţa constituie în opinia autorului începutul unei activităţi care va viza domeniul
sintezei structurilor numerice de comandă. O serie de probleme au rămas deschise şi ele vor fi abordate în viitorul apropiat.
Din cele arătate în capitolul 3 se presupune faptul că, folosind noile tipuri de reduceri s-ar putea obţine o reprezentare eterogenă a funcţiilor booleene care să fie mai avantajoasă. Aceasta ar presupune ca funcţia booleană să fie reprezentată prin acea OBDD care are numărul minim de noduri (deci cea obţinută cu reducerea cea mai avantajoasa). Astfel, în reprezentarea internă ea va fi memorată printr-o OBDD la care se adaugă un indice care să precizeze regula de reducere care a fost folosită. Un interes deosebit îl va prezenta realizarea unui compromis între cantitatea de memorie economisită şi viteza procedurilor de manipulare ale unor astfel de reprezentări prin alegerea a numai două din cele cinci reprezentări. În acest caz va fi de ajuns un singur bit pentru deosebirea celor două tipuri de reprezentări, asemănător metodei de diferenţiere între arcele normale şi cele negate utilizată pentru reprezentările ROBDD ce utilizează arce negate.
Pe viitor se urmăreşte realizarea unei biblioteci de operatori impliciţi care să aibă un grad de generalitate mai mare, în acest fel ei vor putea fi folosiţi şi la alte domenii ale sintezei şi analizei sistemelor numerice de comandă. Se va căuta ca prin introducerea unor mecanisme noi să fie crescută eficienţa acestor operatori, fie din punct de vedere al vitezei de execuţie, fie din punct de vedere al memoriei utilizate.
Rezultatele experimentale obţinute pentru tabela de calcul funcţională ne dau speranţa că ea va putea fi utilizată şi în cazul altor proceduri din domeniul proiectării asistate a structurilor numerice. Studiile vor trebui să aibă în vedere pe de o parte, posibilitatea extinderii utilizării acestei structuri şi la alte clase de operatori iar pe de altă parte, realizarea unei implementări a structurilor astfel încât acestea să fie optime din punct de vedere a memoriei utilizate şi a gradului de accelerare a operatorilor.
În viitor se are în vedere extinderea studiului privind descompunerea automatelor finite şi la alte metode de descompunere de tip general. În ceea ce priveşte descompunerea prin factorizare, se va căuta implementarea mai multor mecanisme de selecţie a factorilor şi se vor

studia efectul asupra descompunerii rezultate în funcţie de alegerea diverselor funcţii de cost. Ca un alt obiectiv de viitor este prevăzută îmbunătăţirea programului RfsmView din două
puncte de vedere. Primul punct are în vedere îmbunătăţirea editorului grafului de tranziţie astfel încât acesta să ofere următoarele facilităţi: utilizarea meniurilor de context accesibile folosind butonul din stânga al mouse-ului; posibilitatea de a desena mai multe grafuri de tranziţii în fereastra de desenare; adăugarea de noi comenzi care să mărească viteza şi să uşureze desenarea grafului de tranziţie; adăugarea comenzii de tipărire directă la imprimantă. A doua direcţie are în vedere integrarea în această interfaţă a viitoarelor comenzi de manipulare, analiză, prelucrare a automatelor finite aparţinând fie programului Rfsm, fie altor programe similare. De asemeni, se va căuta portarea programului Rfsm astfel încât el să poată fi utilizat şi pe platformele rulând sistemul de operare DOS/Windows.
BIBLIOGRAFIE SELECTIVĂ [Ake78] Akers,S.B. - Binary Decision Diagrams - IEEE Trans. on Comp. Vol. C-27, No.6, June 1978 [All92] Alliance package. FSM - VHDL Finite State Machine subset, Release 2.1, man page, November
1992. [All93] Alliance package. SYF - Finite State Machine Synthesis, Release 2.2. man page, May 1993. [Arm93] J.R.Armstrong and F.G.Gray. Structured Logic Design with VHDL. Prentice-Hall, Englewood
Cliffs, New Jersey 07632, 1993. [Arn99] M.Arnold - Verilog Digital Computer Design. Prentice-Hall, Englewood Cliffs, New Jersery,
1999. [Ash90a] P. Ashar, S. Devadas, and A. R. Newton. A unified approach to the decomposition and re-
decomposition of sequential machines. The Proceedings of the Design Automation Conference, pp 601-606, June 1990.
[Ash91] P. Ashar, S. Devadas, and A. R. Newton. Optimum and heuristic algorithms for an approach to finite state machine decomposition. IEEE Transactions on Computer-Aided Design, pp 296-310, March 1991.
[Ash92a] P. Ashar. Synthesis of sequential circuits for VLSI design. PhD thesis, University of California, Berkeley, 1992.
[Ash92b] P.Ashar, S.Devadas, A.R.Newton - Sequential logic synthesis, Kluwer Academic Publishers, Norwell, MA, USA, 1992
[Azi94] A. Aziz, F. Balarin, S. Cheng, R. Hojati, T. Kam, S. Krishnan, R. Ranjan, T. Shiple, V. Singhal, S. Tasiran, H. Wang, R. Brayton, and A. Sangiovanni-Vincentelli. HSIS: A BDD-based environment for formal verification. Proceedings of the Design Automation Conference, pp 454-459, June 1994.
[Bec94] B.Becker, R.Drechsler - Testability of Circuits Derived from Functional Decision Diagrams, Proceedings of The European Design and Test Conference, pg.667, Paris, France, 1994.
[Bes92] T.Besson. - Synthesis on Multiplexer-Based FPGA Using Binary Decision Diagrams - ICCD 92. [Bie98] A.Biere. ABCD: an experimental BDD library, 1998. [Bra84] R. Brayton, G. Hachtel, C. McMullen, and A. Sangiovanni-Vincentelli. Logic Minimization
Algorithms for VLSI Synthesis. Kluwer Academic Publishers, 1984. [Bra95] R. K. Brayton et al. VIS: A system for verification and synthesis. Technical Report UCB/ERL
M95/104, Electronics Research Lab, Univ. of California, December 1995. [Brc90] K. Brace, R. Rudell, and R. Bryant. Efficient implementation of a BDD package. Proceedings
of the Design Automation Conference, pp 40-45, June 1990. [Bre99a] L.Breniuc, E. Cretu, C.G.Haba: A Study on the Efficiency of Non-linear Conversion Used in
the Fourier Transformate Computation, Buletinul Institutului Politehnic Iasi, Tomul XLV(IL), Fasc.5,1999, Electrotehnică, Energetică, Electronică, pag.18-23.
[Bre99b] L.Breniuc, C.G.Haba, E. Cretu: The Possibility of Implementing a Succesive Approximation A/D Converter Using FPGAs, Buletinul Institutului Politehnic Iasi, Tomul XLV(IL), Fasc.5,1999, Electrotehnică, Energetică, Electronică, pag.210-215.
[Bry86] R. Bryant. Graph based algorithm for Boolean function manipulation. IEEE Transactions on Computers, pp C-35(8):667-691, August 1986.
[Bry91] R. E. Bryant. On the complexity of VLSI implementations and graph representations of Boolean functions with applications to integer multiplication. IEEE Transactions on Computers, C-40:205-213,February 1991.

[BYan98a] B.Yang et al - A Performance Study of BDD-Based Model Checking, FMCAD 1998. [Cer80] E. Cerny. Characteristic functions in multivalued logic systems. Digital Processes, vol. 6:167-
174, June 1980. [CheD93] D.I.Cheng, M.Marek-Sadowska - Verifying Equivalence of Functions with Unknown Input
Correspondence - EDAC/EuroASIC, Paris, France, 1993. [Cou89a] O. Coudert, C. Berthet, and J. C. Madre. Verification of synchronous sequential machines
based on symbolic execution. Proceedings of the Workshop on Automatic Verification Methods for Finite State Systems, June 1989.
[Cou89b] O. Coudert, C. Berthet, and J. C. Madre. Verification of sequential machines using functional Boolean vectors. IFIP Conference, November 1989.
[Cou92a] O. Coudert and J.C. Madre. A new method to compute prime and essential prime implicants of boolean functions. Advanced Research in VLSI and Parallel Systems, pp 113-128. The MIT Press, T. Knight and J. Savage Editors, March 1992.
[Cou93d] Coudert, O., Madre, J. C., and Touati, H. TiGeR Version 1.0 User Guide.Digital Paris Research Lab, December 1993.
[Cre73] I.Creangă, C.Reischer, D.Simovici. - Introducere algebrică în informatică. Ed. Junimea Iaşi, 1973. [Dev89b] S. Devadas. General decomposition of sequential machines: Relationships to state assignment.
The Proceedings of the Design Automation Conference, pp 314-320, June 1989. [Dev89c] S. Devadas and A. R. Newton. Decomposition and factorization of sequential finite state
machines. IEEE Transactions on CAD, pp 1206-1217, November 1989. [Dom98] C.Domnişoru, C.G.Haba Lucrări practice de programare, Rotaprint Universitatea Tehnică
G.Asachi Iaşi.1988 [Edw95] S.Edwards. States Graphical Manipulation Tool for FSM, Program help. March 1995. [Fri75] A.D.Friedman, P.R.Menon - Theory and Design of Switching Circuits, Computer Press,
Woodland Hills, California, 1975. [Fos88] M.Foster. Cascade decomposition of finite state machines. AT&T Bell Laboratories Internal
Memorandum, August 1988. [Fuj88] M. Fujita, H. Fujisawa, and N. Kawato. Evaluation and improvements of Boolean comparison
method based on binary decision diagrams. Digest of Technical Papers of the IEEE International Conference on Computer-Aided Design, pp 2-5, November 1988.
[Gou96] J.Goubault-Larrecq. Implementing Tableaux by Decision Diagrams, 29 August 1996. [Gre93] A.Grenier, F.Pêcheux - ALLIANCE: A complete Set of CAD Tools for Teaching VLSI Design.
3rd Eurochip Workshop on VLSI Design Training, pp.230-237, Grenoble, France, 1993. [Hab93] C.G.Haba, Stadiul actual în sinteza structurilor numerice. Referat 1. Iaşi, 1993. [Haba94] C.G.Haba, Contribuţii la sinteza structurilor numerice prin metode simbolice, Referat 2., Iaşi,
1994. [Hab96] C.G.Haba, C.Huţanu New Boolean Function Representations Using ROBDDs. Proceedings of
the Automatic Control and Test Conference, Cluj, Romania, 23-24 May 1996, pp. 201-207. [Hab98a] C.G.Haba, Using VLSI design tools for Finite State Machine Implementation. Proceedings of
the A&Q 98 International Conference on Automation and Quality Control, Cluj-Napoca, Romania, May 28-29, 1998.
[Hab98b] C.G.Haba, Using Functional Cache to Speed Computation in FSM Design, Proceedings of the A&Q 98 International Conference on Automation and Quality Control, Cluj-Napoca, Romania, May 28-29, 1998.
[Hab98c] C.G.Haba, Finite State Machine Decomposition using Implicit Techniques, Proceedings of Sintes 9 International Symposium on Systems Theory, Robotics and Process Informatics, Craiova, Romania, June 4-6 1998.
[Hab99a] C.G.Haba, A Method For Fsm Decomposition Using Factorization, Bul.Inst.Polit.Iasi, t. XLV(IL), s.III, Fasc.5,1999.
[Hab99b] C.G.Haba, Cube Set Manipulation Using BDDs, Bul.Inst.Polit.Iasi, t. XLV(IL), s.III Fasc.5,1999.
[Har60] J.Hartmanis - Symbolic analysis of a decomposition of information processing. Inform. Contr. pp.154-178, June 1960.
[Har66] J. Hartmanis and R. E. Stearns. Algebraic Structure Theory of Sequential Machines. Prentice Hall, Englewood Cliffs, N. J., 1966.
[Ino93] Inovative Synthesis Technologies. Asyl-Plus. User Manual Release 2.5.0. Grenoble, France. October 1993.

[Jac93] R.Jacobi,A.M.Trullemans - Boolean Mapping with Binary Decision Diagrams. IFIP Workshop on Logic and Architecture Synthesis, pp.19-38 INPG Grenoble, France, December, 1993.
[Jan__] G.Janssen, The Eindhoven BDD Package. University of Eindhoven. Anonymous FTP address: ftp://ftp.ics.ele.tue.nl/pub/users/geert/bdd.tar.gz.
[Jeo92a] S.-W. Jeong and F. Somenzi. A new algorithm for 0-1 programming based on binary decision diagrams. Proceedings of ISKIT-92, Inter. symp. on logic synthesis and microproc. arch., Iizuka, Japan, pp 177-184, July 1992.
[Kam90] T. Kam and R.K. Brayton. Multi-valued decision diagrams. Tech. Report No. UCB/ERL M90/125, December 1990.
[Kam95b] T. Kam. State minimization of finite state machines using implicit techniques. Ph.D. Thesis, University of California, Berkeley, 1995.
[Koh78] Z. Kohavi. Switching and Finite Automata Theory. McGraw-Hill Book Company, New York, New York, second edition, 1978.
[Kou96] E.Koutsofios, S.C.North - Drawing graph with dot (dot User Manual) - AT&T Laboratories, Murray Hill, NJ, USA, November 1996.
[Kuk91] J.Kukula, S.Devadas - Finite state machine decomposition by transition pairing. Proceedings of the International Conference on Computer-Aided Design, pp.560-563, November, 1991.
[Lai93] Y.T.Lai, M.Pedram, S.B.K.Vrudhula - BDD Based Decomposition of Logic Functions with Application to FPGA Synthesis - 30th ACM/IEEE Design Automation Conference, 1993.
[Lin91a] B. Lin and A.R. Newton. Implicit manipulation of equivalence classes using binary decision diagrams. The Proceedings of the International Conference on Computer Design, pp 81-85, September 1991.
[Lin91b] B. Lin. Synthesis of VLSI designs with symbolic techniques. Tech. Report No. UCB/ERL M91/105, November 1991.
[Lin91c] B. Lin. Synthesis of VLSI designs with symbolic techniques. PhD thesis, University of California, Berkeley, November 1991.
[Lin92] B. Lin, O. Coudert, and J. C. Madre. Symbolic prime generation for multiple-valued functions. Proceedings of the Design Automation Conference, pp 40-44, June 1992.
[Lind98] J.Lind-Nielsen Verification of Large State/Event systems Using Compositionality and Dependency Analysis, Tools and Algorithms for the Construction and Analysis of Systems '98 (TACAS'98). LICS 1384, Springer-Verlag.
[Min92] S.Minato - Fast Generation of Irredundant Sum-of-Product Forms from Binary Decision Diagrams, Sasimi '92, pp.64-73, Japon, 1992
[Min93a] S.-I. Minato. Zero-suppressed BDDs for set manipulation in combinatorial problems. Proceedings of the 30th Design Automation Conference, pp 272-277, Dallas, TX, June 1993.
[Moo93] J.Moondanos, J.A.Wehbeh, J.A.Abraham, D.G.Saab - VERTEX: VERification of Transistor-level circuits based on model EXtraction. Proceedings of EDAC/EuroASIC, pp.111-115, Paris, France, 1993.
[Mun77] I.Muntean. - Sinteza automatelor finite. - Ed. Tehnică,Bucureşti, 1977. [Ous90] J.K. Ousterhout. Tcl: An Embeddable Command Language. Proceedings of the Winter
USENIX Conference, 1990. [Ous91] J.K. Ousterhout. An X11 Toolkit Based on the Tcl Language. Proceedings of the Winter
USENIX Conference, 1991. [Ous98] J.K. Ousterhout. Scripting: Higher Level Programming for the 21st Century, IEEE Computer
magazine, March 1998. [Ran97a] R.K.Ranjan, W.Gosti, R.K.Brayton, A.Sangiovanni-Vincentelli - Dynamic Reordering in a
Breadth-First Manipulation Based BDD Package: Challenges and Solutions Proceedings of IEEE/ACM International Conference on Computer Design, , Austin, Texas, USA, October, 1997.
[Rho91] J.-K. Rho and F. Somenzi. Stamina. Computer Program, 1991. [Roa93] R. Roane, F. Poirot - Multilevel Synthesis using BDD - IFIP Workshop on Logic and Architecture
Synthesis, pp.61-72,Grenoble, France, 1993. [Rud93] R. Rudell. Dynamic variable ordering for ordered binary decision diagrams. Digest of
Technical Papers of the IEEE International Conference on Computer-Aided Design, pp 42-47, November 1993.
[Sen92a] E.Sentovich et al. SIS: A System for Sequential Circuit Synthesis, Memorandum No.UCB/ERL M92/41, University of Berkeley, California, May 1992.

[Sjo96] S.Sjoholm, L.Lindh - VHDL for Designers. Prentice-Hall, Englewood Clifss, New Jersey, 1996. [Som97] F.Somenzi. CUDD: CU Decision Diagram Package Release 2.1.2, Department of Electrical
and Computer Engineering, University of Colorado at Boulder, April, 1997. [st95] st.doc, September 1995. [Swa92] G.Swamy, R.Brayton, and P.McGeer. A fully implicit Quine-McCluskey procedure using
BDD's. Tech. Report No. UCB/ERL M92/127, 1992. [Swa93] G.Swamy. An Exact Logic Minimizer Using Implicit Binary Decision Diagram Based
Methods. Master Thesis, University of California, Berkeley, USA, 1993. [Tou90] H. Touati et al, Implicit state enumeration of finite state machines using BDD's. The
Proceedings of the International Conference on Computer-Aided Design, pp. 130-133, November 1990.
[Vil90] T. Villa and A. Sangiovanni-Vincentelli. NOVA: State assignment for optimal two-level logic implementations. IEEE Transactions on Computer-Aided Design, pp. 905-924, September 1990.
[Vil95a] T. Villa. Encoding Problems in Logic Synthesis. PhD thesis, University of California, Berkeley, May 1995.
[Yoe61] M.Yoeli. - The cascade decomposition of sequential machines. IRE Trans. Electron.Computers, vol.EC-10, pp.-587-592, April 1961.





























