Embed Size (px)
Citation preview

Universidade Federal de Pernambuco – UFPE Centro de Informática – CIN
Pós-Graduação em Ciência da Computação
PRESLEY: UMA FERRAMENTA DE RECOMENDAÇÃO DE ESPECIALISTAS PARA APOIO À COLABORAÇÃO EM DESENVOLVIMENTO DISTRIBUÍDO DE SOFTWARE
CLEYTON CARVALHO DA TRINDADE
RECIFE Agosto, 2009

Universidade Federal de Pernambuco Centro de Informática Pós-Graduação em Ciência da Computação
CLEYTON CARVALHO DA TRINDADE
PRESLEY: UMA FERRAMENTA DE RECOMENDAÇÃO DE ESPECIALISTAS PARA APOIO À COLABORAÇÃO EM DESENVOLVIMENTO DISTRIBUÍDO DE SOFTWARE
Dissertação apresentada ao Programa de Pós-Graduação em Ciência da Computação do Centro de Informática da Universidade Federal de Pernambuco, como requisito parcial para obtenção do grau de Mestre em Ciência da Computação.
Orientador: Prof. Silvio Romero de Lemos Meira
RECIFE Agosto, 2009

Trindade, Cleyton Carvalho da Presley: uma ferramenta de recomendação de especialistas para apoio à colaboração em desenvolvimento distribuído de software / Cleyton Carvalho da Trindade. - Recife: O Autor, 2009. xii, 88 folhas : il., fig., tab. Dissertação (mestrado) – Universidade Federal de Pernambuco. CIn. Ciência da Computação, 2009.
Inclui bibliografia, glossário e apêndice. 1. Engenharia de software. I. Título. 005.1 CDD (22. ed.) MEI2009 - 148


III
Agradecimentos
Agradeço primeiramente a Deus pela oportunidade concebida e por todas as bênçãos que
recebi durante o mestrado.
Muito obrigado as mulheres da minha vida (minha mãe, minha irmã e minha noiva
Bete) pelo amor, carinho e pela paciência dedicados durante essa jornada de sucesso. A meu
pai, que Deus o tenha, que me ensinou o valor dos estudos.
Obrigado Silvio Meira por ter acreditado neste trabalho e a Alan Kelon por todo
empenho e orientações que foram além do âmbito da pesquisa, valeu amigo.
Aos meus companheiros da FIR (Luciano Cabral, Carlos Brasil e Dalton Nicodemos)
pelas conversas animadas sobre as nossas dificuldades, mostrando que eram possível
superá-las. Também às professoras Cristine Gusmão e Sandra Siebra pelo incentivo a me
escrever no mestrado ao termino da minha graduação.
Ao departamento de informática no DER-PE por ter me liberado na reta final deste
trabalho e pelos momentos de descontração que me faziam esquecer os problemas, como
no dia que fui comentarista de uma partida de xadrez.
Muito obrigado a todos, essa conquista também é de vocês.

IV
Resumo
Atualmente é comum encontrar empresas de software com equipes de desenvolvimento
distribuídas em diferentes localizações; em vários casos esta divisão ocorre em escala global.
O crescimento desta nova modalidade de organização e disposição dos times está ligado aos
interesses das empresas em conseguir os profissionais mais capacitados, reduzir o custo de
desenvolvimento, ter presença globalizada e alcançar maior proximidade com os seus
clientes.
Contudo, o Desenvolvimento Distribuído de Software (DDS) tem criado diversos
desafios na comunicação entre seus colaboradores. Entre os aspectos mais prejudicados
pela comunicação deficiente está a identificação dos especialistas no projeto. Por conta
disso, o inicio do processo de comunicação torna-se lento, afetando o desempenho das
atividades no projeto e gerando atrasos na execução do projeto. Como as equipes podem
ter um tempo de sobreposição de horário de trabalho muito curto, a identificação da pessoa
mais provável a responder mensagens de dúvidas aponta ser uma grande oportunidade para
reduzir os atrasos gerados na comunicação, principalmente assíncrona, entre equipes
distribuídas.
O presente trabalho propõe a ferramenta Presley para identificar e recomendar os
especialistas existentes em um projeto àquelas pessoas que buscam por ajuda durante a
atividade de codificação, reduzindo o tempo de espera e evitando desperdício de esforço na
localização dos especialistas. Isto é realizado através da análise das informações contidas nos
registros de comunicação dos desenvolvedores e no histórico de alterações dos códigos-
fonte. O experimento realizado demonstrou que a ferramenta pode ajudar na colaboração
entre equipes distribuídas e que a comunicação registrada pode fornecer informações
valiosas na identificação dos especialistas.
Palavras-chave: Desenvolvimento Distribuído de Software, Sistemas de
Recomendação de Especialistas

V
Abstract
Nowadays, it is common to find software companies with distributed development teams in
different locations; in many cases, this division occurs in a global extent. The increase of this
new mode of organization and arrangement of teams is connected to the companies’
interest in getting the most capable professionals, reducing the cost of developing, having a
globalized presence and reaching a larger proximity with its clients.
However, the Distributed Software Development has created several challenges in
the communication among its collaborators. Amongst the aspects that were most damaged
by deficient communication, there is the identification of experts in the project. Because of
this, the beginning of the process of communication becomes slow, affecting the
performance of the activities in the project and creating delays in the project’s
accomplishment. As the teams may have a very short overlap of working hours, the
identification of the most probable person to answer doubt messages seems tom be a great
opportunity to reduce the delays created in the communication, mainly asynchronous,
among distributed teams.
The present work proposes the tool Presley to identify and recommend the experts
existing in a project to those people who search for help during the encoding activity,
reducing the waiting time and avoiding waste of effort in the localization of the expert. This
is carried out through the analysis of the information enclosed in the records of
communication of the developers and in the historical of alterations of the source codes. The
experiment carried out demonstrated that the tool can be helpful in the collaboration
between distributed teams and that the communication recorded can provide valuable
information in the identification of the specialists.
Key words: Distributed Software Development, Expert Recommendation Systems.

VI
Sumário
1. Introdução .......................................................................................................................... 1
1.1. Definição do problema ................................................................................................ 2
1.2. Visão geral da solução proposta .................................................................................. 2
1.2.1. Características ...................................................................................................... 2
1.3. Fora do escopo ............................................................................................................. 3
1.4. Contribuições realizadas .............................................................................................. 3
1.5. Organização da dissertação ......................................................................................... 4
2. Comunicação em Desenvolvimento Distribuído de Software ........................................... 5
2.1. Comunicação em Equipes Distribuídas ........................................................................ 7
2.1.1. Percepção ............................................................................................................. 8
2.2. Resultados da Revisão Sistemática ............................................................................ 10
2.2.1. Conceitos e Dificuldades Encontradas na Comunicação .................................... 10
2.2.2. Frequência dos Conceitos nos Artigos Analisados ............................................. 12
2.2.3. Processos e práticas coletadas ........................................................................... 12
2.2.4. Ferramentas de Comunicação ............................................................................ 15
2.3. Conclusão ................................................................................................................... 19
3. Sistemas de Recomendação de Especialistas ................................................................... 20
3.1. Definição e Características dos SRE ........................................................................... 20
3.2. SRE Existentes ............................................................................................................ 22
3.3. Conclusão ................................................................................................................... 26
4. Presley .............................................................................................................................. 27
4.1. Requisitos ................................................................................................................... 27
4.2. Arquitetura e Implementação ................................................................................... 30

VII
4.2.1. Framework Conceitual........................................................................................ 31
4.2.2. Arquitetura ......................................................................................................... 32
4.2.3. Cliente ................................................................................................................. 33
4.2.4. Componente Usuário.......................................................................................... 34
4.2.5. Componente Conhecimento .............................................................................. 35
4.2.6. Componente Mensagem .................................................................................... 36
4.2.7. Componente Inferência ...................................................................................... 37
4.2.8. Detalhes da Implementação ............................................................................... 41
4.3. Uso do Presley ........................................................................................................... 41
4.4. Atendimento aos requisitos pelo Presley .................................................................. 44
4.5. Conclusão ................................................................................................................... 45
5. Experimento e Análise dos Resultados ............................................................................ 46
5.1. Avaliação do Presley .................................................................................................. 46
5.1.1. Definição ............................................................................................................. 46
5.1.2. Planejamento ...................................................................................................... 48
5.1.3. Projeto Utilizado no Experimento ...................................................................... 50
5.1.4. Instrumentação .................................................................................................. 51
5.1.5. Execução ............................................................................................................. 52
5.1.6. Análise e Interpretação ...................................................................................... 53
5.2. Conclusão ................................................................................................................... 65
6. Conclusão.......................................................................................................................... 67
6.1. Contribuições da pesquisa ......................................................................................... 68
6.2. Trabalhos futuros ....................................................................................................... 69
6.3. Contribuições acadêmicas ......................................................................................... 70
6.4. Conclusões finais ........................................................................................................ 70
7. Referências Bibliográficas ................................................................................................. 72

VIII
Apêndice A – Protocolo de Revisão Sistemática ...................................................................... 76
Apêndice B – Formulário de condução da revisão sistemática ................................................ 83

IX
Lista de Figuras
Figura 4-1: Rede de atores de um projeto de software, extraído de (Ye et al., 2007) ............ 32
Figura 4-2: Framework Arquitetural da Ferramenta ................................................................ 33
Figura 4-3: Tabelas Utilizadas pelo Componente Usuário ....................................................... 35
Figura 4-4: Tabelas Utilizadas pelo Componente Conhecimento ............................................ 36
Figura 4-5: Tabelas Utilizadas pelo Componente Mensagem .................................................. 37
Figura 4-6: Sub-Componentes da Inferência ............................................................................ 38
Figura 4-7: Fórmula do cálculo do grau de igualdade (Galho and Moraes, 2004) ................... 39
Figura 4-8: Fórmula da média por operadores "fuzzy" (Galho and Moraes, 2004) ................. 40
Figura 4-9: Cálculo de Participação dos Desenvolvedores nas Interações .............................. 40
Figura 4-10: Cálculo de Participação dos Desenvolvedores no Código-Fonte ......................... 41
Figura 4-11: Presley em destaque na IDE Eclipse ..................................................................... 42
Figura 4-12: Aba Tópicos de Domínio....................................................................................... 42
Figura 4-13: Aba Mensagem de Problema ............................................................................... 43
Figura 5-1: Comparativo da Precisão Geral (a) e de Sucesso (b) apenas com a Comunicação 54
Figura 5-2: Comparativo da Cobertura Geral (a) e de Sucesso (b) apenas com a Comunicação
.................................................................................................................................................. 55
Figura 5-3: Comparativo da acurácia apenas com a Comunicação .......................................... 55
Figura 5-4: Comparativo da precisão geral (a) e de sucesso (b) apenas com o histórico do
código-fonte ............................................................................................................................. 56
Figura 5-5: Comparativo da Cobertura Geral (a) e de Sucesso (b) apenas com o histórico do
código-fonte ............................................................................................................................. 57
Figura 5-6: Comparativo da acurácia apenas com o histórico do código-fonte ...................... 57
Figura 5-7: Precisão Geral (a) e de Sucesso (b) das Recomendações de cada Fonte de Dados
do Presley ................................................................................................................................. 59
Figura 5-8: Cobertura Geral (a) e de Sucesso (b) das Recomendações de cada Fonte de Dados
do Presley ................................................................................................................................. 59
Figura 5-9: Acurácia das Recomendações de cada Fonte de Dados do Presley ...................... 60

X
Figura 5-10: Precisão (a) e a Cobertura (b) gerais das Recomendações por Quantidade de
Respostas dos E-mails ............................................................................................................... 64
Figura 5-11: Precisão (a) e a Cobertura (b) nos casos de sucesso das Recomendações por
Quantidade de Respostas dos E-mails ..................................................................................... 64
Figura 5-12: Acurácia das Recomendações por Quantidade de Respostas dos E-mails .......... 64

XI
Lista de Tabelas
Tabela 2-1: Adaptações as Práticas Propostas pelas Metodologias Ágeis ............................... 13
Tabela 5-1: Quantidade de e-mails por quantidade de respostas enviadas ............................ 52
Tabela 5-2: Quantidade de e-mails por Mês ............................................................................ 53
Tabela 5-3: Informações das versões do código fonte utilizado .............................................. 53
Tabela 5-4: Média comparativa das métricas coletas nas recomendações apenas com a
comunicação ............................................................................................................................. 56
Tabela 5-5: Média comparativa das métricas coletas nas recomendações apenas com o
histórico do código fonte.......................................................................................................... 57
Tabela 5-6: Média comparativa das métricas coletas nas recomendações com e sem
comunicação ............................................................................................................................. 60
Tabela 5-7: Métricas coletadas dos artigos com modelos de descoberta de especialistas em
código-fonte ............................................................................................................................. 61

1
1. Introdução
A globalização da economia gerou várias oportunidades de negócios, o que conduziu
diversas organizações a distribuírem seus recursos com o objetivo de reduzir custos, obter
uma equipe mais especializada e atender a novas demandas de mercado.
Conseqüentemente, torna-se mais comum encontrar empresas de software com equipes de
desenvolvimento distribuídas em diferentes localizações. Em vários casos esta divisão ocorre
em escala global, com os times dispersos entre os continentes (Carmel, 1999).
Porém, se o desenvolvimento de software já é uma atividade complexa quando
realizada da forma tradicional (Curtis et al., 1988; Brooks, 1978; The Standish Group, 2001;
Espinosa e Carmel, 2004), com equipes distribuídas, essa complexidade é ainda maior e
elevada a níveis de complexidade mais difíceis de serem tratados (Ågerfalk et al., 2005).
No desenvolvimento distribuído de software, as distâncias geográfica e temporal
geram deficiências na comunicação e nos diversos níveis de percepção - proximidade,
atividade, presença, processo e perspectiva - da equipe. A deficiência na percepção dificulta
o reconhecimento rápido das pessoas capacitadas a ajudar outros desenvolvedores com
problemas no momento da codificação.
Este problema é evidente quando um membro do grupo necessita de ajuda de outro
integrante, porque o acesso às pessoas de times remotos e as opções de comunicação
síncrona são restritas. As limitações tornam lento o inicio do processo de colaboração entre
os integrantes da equipe. Como conseqüência, projetos distribuídos têm custos adicionais de
atrasos e retrabalhos (Espinosa e Pickering, 2006).
Uma grande oportunidade para reduzir os atrasos gerados na comunicação entre
equipes distribuídas está na identificação das pessoas mais capazes de ajudar os demais
membros do time quando surgem dúvidas na fase de construção do software, ou seja,
identificar os especialistas. Como as equipes podem ter poucas oportunidades de
comunicação síncrona, a rápida identificação da pessoa mais provável a responder
mensagens de dúvidas pode acelerar o processo de colaboração das equipes.

2
Os Sistemas de Recomendação de Especialistas permitem uma melhor colaboração
entre os seus usuários através da identificação de especialistas que possam ajudá-los na
realização das suas tarefas. Contudo, muitos desses sistemas não analisam o conteúdo da
comunicação entre os desenvolvedores como forma de descobrir seus interesses e também
não utilizam os relacionamentos existentes no código-fonte em dúvida durante a seleção
dos especialistas.
1.1. Definição do problema
Motivado pelos problemas citados, o objetivo do trabalho descrito nesta dissertação pode
ser apresentado como:
Este trabalho tem como objetivo recomendar os especialistas na codificação de
projetos fisicamente distribuídos àquelas pessoas que buscam por ajuda durante suas
atividades de codificação do projeto, através dos registros de e-mails trocados entre os
desenvolvedores e do histórico do código-fonte.
1.2. Visão geral da solução proposta
O objetivo deste trabalho foi atingido com o desenvolvimento do Presley, um Sistema de
Recomendação de Especialistas que utiliza elementos geralmente encontrados no
Desenvolvimento Distribuído de Software, como o histórico do código-fonte e os e-mails
enviados pelos desenvolvedores, para diminuir os problemas causados pela comunicação
assíncrona. Esta seção descreve as características da ferramenta proposta.
1.2.1. Características
O Presley utiliza o framework teórico descrito por Ye e colegas (2007). O framework constrói
redes de relacionamentos entre os elementos envolvidos na realização do projeto,
utilizando-as como entradas de uma heurística para selecionar os especialistas aptos a
responderem os problemas enfrentados pelos desenvolvedores na fase de implementação.
Os nós da rede, representando código-fonte, documento e desenvolvedor, mostram o
relacionamento entre as pessoas e as informações geradas durante o projeto.

3
Desta forma, o Presley igualmente recebe como parâmetros o código-fonte, os
artefatos e registros de comunicação entre os pares no projeto. A ferramenta fornece um
canal próprio e específico de comunicação que também será considerado na análise de
identificação de especialistas.
1.3. Fora do escopo
Como a ferramenta proposta foca um contexto específico, vários aspectos relacionados à
comunicação no Desenvolvimento Distribuído de Software foram deixados fora do escopo
deste trabalho. Desta forma, as seguintes questões não foram abordadas neste trabalho:
Especialistas em requisitos. Identificar especialistas nos requisitos que deram origem
aos códigos implementados no projeto não está do escopo do trabalho por envolver pessoas
fora do ambiente de desenvolvimento do projeto, como clientes e usuários do software a ser
entregue.
Padronização dos e-mails. Solicitar aos desenvolvedores que padronizem o conteúdo
de suas mensagens facilitaria a identificação do conhecimento e dos códigos-fontes em
questão, porém este procedimento influencia a rotina natural dos desenvolvedores na
comunicação assíncrona, por isto foi excluso do escopo no trabalho.
Processo de desenvolvimento. A ferramenta proposta utiliza informações
geralmente existentes em projetos de software fisicamente distribuídos, independente do
processo de desenvolvimento a ser seguido. Por isto, o trabalho não envolveu um estudo de
identificação do processo mais indicado para o uso da ferramenta.
1.4. Contribuições realizadas
As seguintes contribuições podem ser listadas como resultado do trabalho apresentado:
• A identificação, através da execução de uma Revisão Sistemática da Literatura, da
baixa percepção entre os participantes de equipes distribuídas como a principal
dificuldade enfrentada na comunicação assíncrona e da oportunidade em selecionar

4
as pessoas mais qualificadas a participar do processo de colaboração como uma
forma de reduzir os problemas gerados.
• A definição dos requisitos, arquitetura e implementação de um Sistema de
Recomendação de Especialistas, assim como a descrição do tratamento realizado nas
fontes de informação utilizadas;
• A descrição das fases de definição, planejamento, execução, análise, interpretação e
apresentação de um experimento que avalia a qualidade das recomendações feitas
pela ferramenta proposta.
1.5. Organização da dissertação
Além do capítulo de Introdução, o presente trabalho envolve outros cinco capítulos,
organizados da seguinte forma:
Capítulo 2. Apresenta os problemas existentes na comunicação entre equipes
distribuídas e os resultados da execução de uma Revisão Sistemática da Literatura.
Capítulo 3. Apresenta os conceitos e as características envolvidas nos Sistemas de
Recomendação de Especialistas, como também a adoção de técnicas originalmente
desenvolvidas pelos tradicionais Sistemas de Recomendação.
Capítulo 4. Descreve a ferramenta Presley, seus requisitos, arquitetura,
implementação e uso da ferramenta.
Capítulo 5. Apresenta as fases realizadas durante a avaliação das recomendações
feitas pelo Presley a partir da execução de um experimento.
Capítulo 6. Resume as contribuições deste trabalho, apresenta os trabalhos
relacionados e direções para trabalhos futuros.

5
2. Comunicação em Desenvolvimento
Distribuído de Software
Impulsionada pelo crescente avanço tecnológico, a comunicação conseguiu
ultrapassar diversas fronteiras e gerou novas oportunidades de cooperação entre as
pessoas. Barreiras como a comunicação assíncrona, o envio de artefatos de trabalho (em
formato digital) pelos indivíduos e a colaboração áudio-visual entre equipes separadas
geograficamente foram vencidas a partir do advento da Internet e de seus vários meios de
comunicação resultantes.
Hoje, já é possível encontrar salas de aula virtuais, com alunos e professores
separados por vários quilômetros de distância (Almeida, 2003), além de mudanças
decorrentes da nova modalidade de trabalho chamado teletrabalho (Sakuda e Vasconcelos,
2005).
Devido à vantagem do baixo custo de transporte dos seus produtos digitais, a
indústria de software é considerada uma das pioneiras em projetos fisicamente distribuídos
(Espinosa e Carmel, 2004). Com a crescente complexidade dos projetos de software atuais,
muitas vezes, torna-se necessário formar equipes com as mais diferentes especialidades. O
Desenvolvimento Distribuído de Software (DDS) traz a possibilidade da criação de grupos de
trabalho virtuais, pois seria difícil e custoso para uma empresa localizar tais pessoas apenas
em sua região.
Muitas empresas de software investem no DDS em busca de novas oportunidades de
negócio e pelo desejo de menores custos no desenvolvimento de seus projetos. Entre os
benefícios dessa modalidade de desenvolvimento estão (Carmel, 1999):
• acesso à mão-de-obra especializada: as empresas querem, em seus projetos, as
pessoas o mais qualificadas possível, independentemente de sua localização
geográfica;

6
• redução do custo de desenvolvimento: contrata-se mão-de-obra mais barata em
países emergentes para tarefas consideradas menos interessantes nos países
industrializados; por exemplo, manutenção, teste e suporte ao usuário;
• presença globalizada: de forma estratégica, muitas empresas buscam o rótulo de
empresas globais como forma de demonstrar aos seus clientes sua grandeza e sua
capacidade de atendimento às filiais espalhadas em vários pontos do planeta;
• redução do tempo para alcançar o mercado: a diferença de horários pode acelerar o
processo de desenvolvimento de um projeto através do chamado follow the Sun
(seguindo o sol). Para isso, uma empresa deve ter centros de desenvolvimento
espalhados em vários países com diferentes fusos horários. Sendo assim, uma
atividade é executada por um centro e, ao término do seu dia de trabalho, essa é
transferida para outra equipe, que inicia suas atividades (Parvathanathan et al.,
2007).
No trabalho distribuído, as equipes devem superar as dificuldades impostas pelas
divisões geográfica, temporal e cultural (Parvathanathan et al., 2007). Na divisão geográfica,
as equipes não interagem de forma presencial; entretanto, podem trocar informações em
tempo real. Já na divisão temporal, existe pouca disponibilidade de horários de trabalho
para interações síncronas; consequentemente, a comunicação não garante o tempo de
resposta da outra parte; enquanto que, na divisão cultural, as equipes são afetadas pelas
diferenças entre as línguas faladas, os costumes, os treinamentos, as políticas locais e outras
questões regionais.
Atualmente, as equipes não mais sentem a distância geográfica como o maior desafio
a ser superado por duas razões (Gumm, 2006): (1) muitos dos membros estão próximos o
suficiente para viajar e realizar regulares reuniões e (2) a atual tecnologia proporciona uma
boa qualidade de comunicação nessa condição. Porém, a separação temporal restringe as
opções de comunicação síncrona, aumenta o custo da realização de trabalhos colaborativos
e dificulta a troca de informações (Espinosa e Pickering, 2006). Como as atividades realizadas
durante um projeto de software são interdependentes, e a maioria dos meios de

7
comunicação adotados são fortemente baseados em comunicação síncrona, os membros
das equipes sentem dificuldades durante suas interações (Steinfield et al., 2002).
2.1. Comunicação em Equipes Distribuídas
Muitas das dificuldades ainda enfrentadas por equipes colocalizadas (nas quais os
participantes estão todos no mesmo local) também são encontradas no Desenvolvimento
Distribuído de Software (DDS), como por exemplo, o grande esforço para realizar mudanças.
Contudo, ao se observar além desses sintomas e buscar as causas, graves falhas na
comunicação são encontradas entre os usuários e os desenvolvedores e entre os próprios
desenvolvedores (Ågerfalk e Fitzgerald, 2006). Em projetos nesse contexto, a comunicação é
realizada em menor quantidade e com menor eficiência (Herbsleb, 2007).
Equipes colocalizadas gastam boa parte do seu tempo em comunicação: em média,
consomem 75 minutos do seu dia em interações não programadas. Contudo, as distâncias
geográfica e temporal diminuem a frequência de comunicação entre as equipes, interferindo
na forma de interagir das pessoas (Herbsleb e Mockus, 2003). Esse problema já pode ser
sentido em ambientes separados por mais de trinta metros (Allen, 1977).
Diante dessas dificuldades, as atividades relacionadas aos requisitos de software
(definição de requisitos, negociação) são diretamente afetadas pela fraca comunicação, pois
obter os requisitos de forma correta e compartilhar seu entendimento torna-se um sério
problema para as equipes.
Os desenvolvedores com incertezas nos requisitos necessitam de comunicação
adicional para esclarecimento de dúvidas, podendo resultar em atrasos no cronograma do
projeto caso a interação não ocorra em momentos de sobreposição de horários dos times
(Espinosa e Carmel, 2004). Define-se aqui incerteza como a diferença entre a quantidade de
informação necessária e a quantidade possuída sobre uma situação, enquanto que equívoco
é a existência de múltiplas e conflitantes interpretações sobre uma situação (Damian et al.,
2008).
Muitas vezes os equívocos gerados pelos requisitos têm fortes impactos no
cumprimento de prazos e aumento da quantidade de retrabalho, levando, em geral, um dia

8
a mais para ser notificado e corrigido quando existe grande separação temporal (Espinosa e
Pickering, 2006).
Para dificultar ainda mais o esclarecimento de equívocos, os desenvolvedores, ao
perguntar, demonstram esquecimento sobre algum conhecimento. Agem de maneiras
diferentes quando fazem uma pergunta em público (para estranhos) ou em privado (para
um amigo), tornando-os, consequentemente, ignorantes no assunto e enfraquecendo seu
relacionamento com a comunidade (Ye et al., 2007). Mesmo quando há resposta às
perguntas, a interpretação não é simples devido às diferenças culturais, organizacionais, de
treinamento etc.
A falta de comunicação também afeta a confiança entre os integrantes das equipes
distribuídas, pois os times precisam de constante confirmação da interação e dos trabalhos
executados para manter um alto nível de confiança (Moe e Smite, 2007). A previsibilidade da
comunicação evita a experiência da sensação de ansiedade e a diminuição da confiança
decorrida da negativa impressão de silêncio ou dos atrasos associados à separação temporal.
Somado a isso, o pobre compartilhamento de informações no DDS transfere aos
participantes do projeto pouco conhecimento sobre as pessoas envolvidas, dificultando a
difusão das tarefas realizadas, sua disponibilidade para comunicação e respectivas
especializações. Do mesmo modo, os times sofrem com a falta de comunicação informal
resultante dos baixos níveis de confiança, de percepção e de progresso dos locais remotos
(Layman et al., 2006).
A percepção e a compreensão do que está acontecendo no ambiente distribuído é
um importante fator na sintonia das atividades. Sentimentos, como a frustração, podem
ocorrer em equipes onde as informações sobre os eventos nas atividades não são
compartilhadas (Steinfield et al. 2002).
2.1.1. Percepção
A percepção abrange o conhecimento sobre os objetivos, as atividades realizadas pelo grupo
e os acontecimentos durante sua execução, assim como, onde estão os participantes e o que
fazem. Contudo, neste trabalho, são enumerados os tipos específicos de percepção
deficientes em equipes de DDS:

9
• Percepção de Atividade (O que eles estão fazendo?): é a importância de conhecer
quem fez o que e quando, porque sem essa propriedade é difícil discernir quem tem
conhecimento sobre determinados assuntos para esclarecer dúvidas, discutir
melhores soluções e repassar conhecimento (Parvathanathan et al., 2007; Espinosa
et al., 2007; Herbsleb e Mockus, 2003). Em DDS, é menos aparente quem são e o que
fazem as pessoas em times remotos;
• Percepção de Proximidade (Com quem minhas atividades se relacionam?): é a
necessidade que os indivíduos possuem de saber quem são as pessoas mais próximas
em termos de estrutura organizacional e de dependência nos artefatos das tarefas
executadas, pois várias pessoas podem ser afetadas caso um determinado
componente seja alterado (Espinosa et al., 2007). As distâncias física e temporal
reduzem a percepção de proximidade;
• Percepção de Presença (Quando posso contatá-lo?): é a possibilidade de saber qual o
melhor momento de iniciar um contato com pessoas de outro time sem que
interrompam suas atividades em momentos inapropriados (Espinosa et al., 2007;
Herbsleb e Mockus, 2003). A percepção de presença é enfraquecida devido à
predominância da comunicação assíncrona;
• Percepção de Processo (Onde estamos no projeto?): é a capacidade de entender
completamente quais foram os principais marcos de entrega, os requisitos das
tarefas dos participantes remotos e como eles impactam na sua própria tarefa (Jang
et al., 2002). Devido às peculiaridades das equipes envolvidas, os participantes têm
dificuldades em compreender como outros times estão se desenvolvendo;
• Percepção de Perspectiva (O que eles estão pensando e por quê?): é a compreensão
e o entendimento de como as outras partes vêem o mesmo projeto; a cognição
coletiva (Jang et al., 2002). Nos projetos distribuídos, está relacionada aos
questionamentos pelos membros das equipes do porquê de seus colegas remotos
falharem ao seguir uma sugestão ou o que eles pensarão sobre alguma contribuição
(colaboração).

10
Tendo em vista todas as dificuldades descritas na interação entre equipes
distribuídas, uma Revisão Sistemática da Literatura (RSL) foi realizada com o objetivo de
identificar os conceitos envolvidos na comunicação dos desenvolvedores, assim como as
experiências nessa área relativas às técnicas, dificuldades encontradas, processos e
ferramentas utilizadas. A partir dos resultados alcançados, foi identificado um importante
fator para diminuir os custos provocados pelas falhas de comunicação decorrentes do DDS
(Trindade et al., 2008). O apêndice A apresenta o protocolo elaborado para conduzir a
revisão e o Apêndice B contém os artigos coletados durante sua execução.
2.2. Resultados da Revisão Sistemática
Os resultados apresentados, que tiveram o propósito de mostrar as descobertas relevantes
da RSL conduzida, foram produzidos a partir das informações extraídas dos artigos coletados
e contidas na matriz de conceitos produzida (Webster e Watson, 2002). As descobertas
foram baseadas na discussão de aspectos significantes pertencentes aos conhecimentos na
área de comunicação em equipes distribuídas.
2.2.1. Conceitos e Dificuldades Encontradas na Comunicação
Com a execução da RSL, vários tópicos e problemas envolvidos na comunicação em equipes
distribuídas foram encontrados nos artigos selecionados. Entre esses estão: a fraca
percepção no ambiente compartilhado, a dificuldade em coordenar as tarefas realizadas, a
baixa frequência de comunicação, a dificuldade em estabelecer redes de contato, o baixo
nível de confiança dos envolvidos e a diferença cultural entre as equipes.
A percepção está relacionada à dificuldade de determinar quais dos integrantes da
equipe têm experiência ou conhecimento sobre as diferentes partes do projeto, à
incapacidade de realizar comunicação através das diferenças de fuso horário e à falta de
conhecimento sobre o andamento das atividades executadas por outras pessoas e equipes
remotas.
A coordenação é conhecida como a gerência das dependências entre as tarefas para
se alcançar um objetivo. Geralmente, na coordenação de trabalhos rotineiros, são utilizados
mecanismos de programação de atividades, como cronogramas; contudo, a comunicação

11
exerce um importante papel na coordenação de trabalhos com aspectos incertos (Espinosa e
Carmel, 2004).
Dificuldades de iniciar um contato, saber quem contatar sobre algum determinado
assunto e comunicar-se eficientemente através das separações física e temporal levam a
sérios problemas de coordenação, a saber:
• sobreposição de horários: muitas empresas costumam mudar ou expandir as horas
de trabalho das equipes no intuito de aumentar a sobreposição de horas de trabalho
com as localizadas remotamente; entretanto, essa prática prejudica os limites entre a
vida profissional e pessoal dos empregados (Espinosa e Carmel, 2003);
• duração do trabalho: o trabalho distribuído introduz atrasos na resolução de
problemas em seu desenvolvimento 2.5 vezes maiores quando comparado aos
colocalizados, o que está diretamente relacionado ao número de pessoas envolvidas
no projeto (Herbsleb et al., 2001) e com a dificuldade de encontrar as pessoas mais
qualificadas na equipe para iniciar uma colaboração. A causa pode estar no gasto de
muito tempo, por parte dos indivíduos, em responder as questões de seus
companheiros, que não é levada em consideração quando as tarefas são atribuídas;
• configuração do trabalho: a comunicação e a separação exercem forte influência na
escolha da configuração dos times no DDS. Por exemplo, é mais indicado distribuir as
tarefas com baixa granularidade quando se adota o trabalho sem sobreposição de
tempo, como nos call center. Porém, quando as tarefas são extensas, recomenda-se
selecionar equipes em regiões onde a junção de seus horários de trabalho tenham
sobreposição (Espinosa e Carmel, 2003).
Outro tópico encontrado, a Frequência de Comunicação, está relacionado com a
quantidade de interações ocorridas entre os membros das equipes. É importante manter
comunicação frequente em ambientes distribuídos para evitar que ocorram mal entendidos,
e para melhorar a compreensão cultural e a confiança da equipe (Ali Babar et al., 2001).
As Redes de Contato descrevem com quem os indivíduos se relacionam dentro de
uma comunidade. Tais indivíduos podem ser desde um membro principal (o líder do grupo)

12
até um periférico (que pouco se comunica). Conhecendo o relacionamento existente entre
as pessoas é possível saber o quanto cada uma contribui na equipe e sua reputação social
para os demais (Ye et al., 2007).
A Confiança é a percepção compartilhada, pela maioria dos membros do time, de
que suas ações serão importantes para todos, como também significa reconhecer e projetar
os interesses corretos dos indivíduos engajados no esforço coletivo (Moe e Smite, 2007). O
baixo nível de confiança das equipes distribuídas está relacionado com a baixa frequência de
comunicação, que impede uma constante confirmação da qualidade do trabalho realizado e
da presença dos integrantes no trabalho, somado à fraca percepção do trabalho e do
progresso dos locais remotos.
As Diferenças Culturais afetam as suposições das pessoas ocorridas durante as
interações, tornando dúbio o entendimento de suas condutas, de suas expectativas sobre as
práticas de liderança e de suas habilidades de trabalho, bem como o entendimento das
ações realizadas pelos participantes e das necessidades para o desempenho de uma tarefa
(Moe e Smite, 2007).
2.2.2. Frequência dos Conceitos nos Artigos Analisados
Dentre os artigos coletados, a percepção foi o tópico mais abordado, presente em 70% dos
artigos analisados, e quase sempre apontada como fonte de problemas na comunicação. Em
segundo lugar, a coordenação esteve entre 50% dos artigos.
Também com forte influência sobre os artigos coletados, as redes de contatos e a
frequência na comunicação tiveram 41% de presença.
Os dois últimos tópicos encontrados, confiança, com 29%, e diferença cultural, com
33%, são barreiras encontradas na comunicação entre equipes distribuídas que também
afetam a percepção.
2.2.3. Processos e práticas coletadas
Vários problemas afetam o desempenho da execução do processo de desenvolvimento em
ambientes distribuídos, como a falta de percepção entre os membros envolvidos, o baixo
nível de confiança, o longo tempo de resposta às solicitações feitas e a baixa frequência na

13
comunicação, principalmente quando as atividades exigem criatividade, inovação e
consenso, ou quando os objetivos são incertos e necessitam de numerosas e complexas
interações entre os participantes (Sakthivel, 2005).
Atividades no DDS podem ser ainda mais sacrificadas porque os problemas das
equipes remotas são facilmente esquecidos (Paasivaara e Lassenius, 2003). As solicitações
recebidas podem não ser consideradas tão importantes ou urgentes para responder quanto
as dos colegas locais ou pode existir um diferente entendimento da abordagem de
colaboração entre os times (Smite, 2006; Canfora et al., 2006).
Diante da problemática na execução das atividades, as práticas indicadas pelas
metodologias ágeis estavam presentes em boa parte dos artigos com processos analisados.
As práticas abaixo tiveram um efeito positivo no DDS:
• entregas frequentes: impedem períodos de desenvolvimento longos e de forma
independente, o que poderia gerar módulos difíceis ou impossíveis de integrar
(Paasivaara e Lassenius, 2003);
• pequenas releases e iterações: reduzem a complexidade e o tempo de validação pelo
cliente nos requisitos entregues, garantem que os desenvolvedores sempre tenham
trabalho suficiente para desenvolver e reduzem o impacto do DDS com comunicação
periódica;
• story cards: transferem os requisitos em pequenos pedaços de maneira menos
formal (Xiaohu et al., 2004).
Porém, houve forte necessidade de adaptações às práticas propostas pelas
metodologias ágeis devido a várias dificuldades inerentes aos projetos de DDS. As
adaptações encontradas nos artigos estão listadas na Tabela 2-1.
Tabela 2-1: Adaptações as Práticas Propostas pelas Metodologias Ágeis
Autores Adaptações
(Ramesh et al., 2006) 1. Ajuste contínuo do processo (planejar as iterações para finalizar os requisitos críticos e desenvolver a arquitetura; documentar os requisitos em diferentes níveis de formalidade);
2. facilidades para compartilhar conhecimento (manter um repositório de processo/produto; foco em funcionalidades bem entendidas em

14
vez de novas funcionalidades críticas; pequenos ciclos, mas não com prazo de desenvolvimento fechado);
3. melhorar a qualidade de comunicação (horas de trabalho sincronizadas; comunicação informal, mas através de canais formais; coordenação balanceada; comunicação constante);
4. construir confiança (frequentes visitas entre os times envolvidos; visitas dos patrocinadores; construir um time de cultura coesa);
5. confiar, mas verificar (equipe de qualidade distribuída; suplementar a comunicação informal com documentação).
(Layman et al., 2006) 1. Definir uma pessoa para o papel de cliente; 2. definir uma pessoa que faça a "ponte" de comunicação entre os
diferentes locais; 3. uso de ferramentas de gestão de projetos para armazenar e monitorar
o andamento do projeto. (Ågerfalk e Fitzgerald, 2006) 1. Consciência de tempo e esforço ao desenvolver a documentação, pois
os documentos muitas vezes não precisam ser detalhados (apenas duas páginas pode ser o suficiente).
(Canfora et al., 2006) Relacionada à programação em par.
1. Treinamentos para os indivíduos conhecerem os seus papéis e responsabilidades;
2. mix de mídias de comunicação (comunicação por voz e um blackboard);
3. monitorar as modificações feitas pelos desenvolvedores para fornecer informações de percepção.
Além das práticas sugeridas pelas metodologias ágeis, outras abordagens foram
encontradas nos trabalhos analisados. Uma dessas foi a prática de definir-se bem os papéis
e divulgar seus representantes entre os grupos. Dois exemplos são os trabalhos realizados
por Paasivaara e Lassenius (2003) e por Layman e colegas (2006). No primeiro, criaram-se
papéis que foram atribuídos aos membros da equipe e indicou-se com quem eles deveriam
se comunicar. Sua experiência mostrou uma estrutura de projeto mais clara e ajudou na
busca da pessoa correta para contatar. No segundo trabalho, um membro chave da equipe
foi responsável pelo papel do cliente. Esse indivíduo tomava decisões sobre as
funcionalidades e sobre o escopo do projeto, sendo essencial na condução da comunicação
entre os times e o cliente. Porém, deve-se ter cuidado ao direcionar a comunicação a um
membro da equipe, pois isso pode sobrecarregá-lo e restringir o fluxo de informação em
casos em que as atividades necessitam de contato direto com outra pessoa.
Uma prática também bastante realizada foram as visitas entre os membros das
equipes. Em alguns casos, integrantes de uma localização eram treinados em outra e, ao
voltarem, traziam consigo conhecimentos que faziam pontes de contato entre os times
(Espinosa e Carmel, 2003). Essa prática contribui bastante na construção de relacionamentos
e no estabelecimento da confiança entre os times, pois as pessoas se sentem mais à vontade

15
para comunicar-se com quem já se encontraram ao menos uma vez (Paasivaara e Lassenius,
2003).
2.2.4. Ferramentas de Comunicação
Apesar da crescente melhora da qualidade e do menor custo para o projeto (comparado ao
telefone), o simples uso de videoconferência dificulta a condução de ideias quando não se
utilizam ferramentas adicionais (Espinosa e Carmel, 2003). Porém, a videoconferência torna-
se mais eficaz na busca de um acordo mútuo em momentos de negociação de requisitos
quando ocorrem discussões prévias nas ferramentas textuais, que podem até servir de pauta
para reuniões síncronas.
As ferramentas assíncronas possibilitam processar a informação e examinar as
questões fora das reuniões em tempo real, como também pesquisar e coletar informações
antes de respondê-las (Damian et al., 2008). A contribuição feita pela combinação de meios
de comunicação (síncrono e assíncrono) pode ser visto pela soma das seguintes
características:
• assíncrona: mais apropriada para comunicação em tarefas com mais incertezas;
• síncrona: mais apropriada para comunicação em tarefas que contêm requisitos com
equívocos.
Os usuários de ferramentas de comunicação assíncrona precisam ter a preocupação
de fornecer respostas o mais rapidamente possível aos seus remetentes para impactar
positivamente na confiança e no compromisso de trabalho (Layman et al., 2006). Outra
preocupação está na formulação das perguntas, pois essas devem ser cuidadosamente
explicadas; caso contrário, os leitores podem não as entender e enviar vários e-mails com
novas perguntas antes de responder a questão inicial (Paasivaara e Lassenius, 2003).
Um meio bastante utilizado na comunicação assíncrona são os repositórios centrais
de informação, que armazenam documentos, banco de dados, códigos fonte e outros
artefatos com informações de produto ou processo. Esses ajudam a melhorar a eficiência no
planejamento e no controle do desenvolvimento de software (Layman et al., 2006). Ao
prover ao time contínuo acesso à informação da situação atual do projeto com possibilidade

16
de monitorar o histórico dos artefatos do projeto e das tarefas executadas, esse meio
fornece percepção aos usuários sobre vários aspectos da execução do projeto, por exemplo:
quem são os responsáveis pelas tarefas, quem já trabalhou com algum artefato e quais são
as necessidades para o desempenho de uma tarefa. Contudo, ferramentas como
repositórios de log contêm uma numerosa quantidade de registros de informações,
consumindo tempo e esforço para consultas, além da questão da leitura ser tediosa (Gutwin
et al., 2005).
Outras ferramentas de comunicação assíncrona, como as listas de discussão, também
possuem a desvantagem do grande volume de registros. Em compensação, esse mecanismo
é o mais utilizado em projetos de código aberto na manutenção da percepção e na
identificação dos especialistas. Participantes, mesmo aqueles passivos na interação,
descobrem pelas discussões quem está falando sobre o que, quem está trabalhando (ou
interessado) em alguma determinada área do projeto e quem são as referências nas áreas
abordadas pelo projeto (Gutwin et al., 2005).
Entre as aplicações de conversação em tempo real, o chat prejudica as pessoas ao
forçá-las continuamente a colocarem atenção em sua janela, assim obrigando-as a tirar os
olhos do código em implementação (Canfora et al., 2006). Em compensação, a comunicação
resultante do chat é mais informal quando comparado a outras vias de comunicação, o que
pode contribuir no aumento da frequência de comunicação e na quebra da barreira cultural
(Gutwin et al., 2004).
Com o passar do tempo, a comunicação através de ferramentas eletrônicas pode ser
suficiente para estabelecer e manter o senso de comunidade. Thissen e colegas (2007)
observaram ao longo da execução de projetos distribuídos o declínio da necessidade e
desejo de reuniões presenciais.
Além dos meios de comunicações popularmente já conhecidos, tais como chat, e-
mail, telefone e videoconferência, foram encontradas as seguintes abordagens nos artigos
descritos:

17
(Mangan et al., 2004) – Destaca um middleware para aplicações colaborativas que aumenta
as informações sobre a percepção de grupo e de ambiente de trabalho disponíveis para os
desenvolvedores.
A arquitetura do middleware é composta por elementos para extração de dados
sobre o uso de ferramentas CASE. O primeiro elemento, a ferramenta CASE, fornece um
conjunto de operações e lida com a coleta e exibição das informações ao usuário. A partir
deste elemento é possível obter um rico contexto das atividades, usado como uma fonte de
informações de percepção. O segundo elemento, o coletor, monitora os eventos
operacionais na ferramenta CASE. O coletor é responsável por extrair dados sobre o estado
atual da aplicação e enviá-los para o sistema de notificação de eventos, que armazena e
distribui as informações fornecidas.
(Gutwin et al., 2005) – Apresenta o ProjectWacher, uma ferramenta que provê para as
pessoas informações de percepção sobre os outros membros da equipe e tem a função de
diminuir os problemas gerados com a falta de percepção encontrado em ambientes de
desenvolvimento distribuído.
Através da observação dos registros de alterações do código-fonte, o sistema prover
visualizações de quem estar ativo no projeto, quais artefatos os desenvolvedores tem
trabalhado e em que parte do projeto estão trabalhando.
Estas informações são extraídas do histórico de alterações do código-fonte utilizado
no projeto e de um segundo repositório com registros fornecidos pela ferramenta. O
repositório criado recebe informações sempre que os desenvolvedores fazem alterações no
código-fonte, por exemplo, ao salvar uma alteração do arquivo. A partir das informações
contidas nos repositórios, a ferramenta identifica as entidades (pacotes, classes e métodos)
e os relacionamentos do código-fonte, assim como as alterações feitas pelos
desenvolvedores em cada método implementado no projeto.
(Gilbert e Karahalios, 2007) – Apresenta o CodeSaw, uma ferramenta que proporciona uma
visualização social do DDS através de informações contidas no repositório de código-fonte e
na comunicação decorrente do desenvolvimento do projeto.

18
A visualização social apresentada pelo sistema é composta por uma linha de tempo.
No topo da linha, um gráfico demonstra a participação do desenvolvedor na implementação
do código-fonte do projeto, enquanto na parte inferior um gráfico demonstra a participação
do desenvolvedor na lista de discussão.
Os gráficos são calculados a partir do número de linhas de código-fonte adicionados a
cada revisão inserida no repositório do projeto e pelo número de palavras escritas nos e-
mails enviados para a lista de discussão.
(Ye et al., 2007) – Descreve uma ferramenta de comunicação que libera os desenvolvedores
da sobrecarga de comunicação não interessante a eles, dessa forma reduzindo o custo total
de comunicação e coordenação no desenvolvimento de software.
A ferramenta foi baseada no framework com o objetivo de identificar os
relacionamentos existentes entre os desenvolvedores, o código-fonte e os documentos
produzidos durante um projeto. Esse relacionamento indica as ligações sociais entre as
entidades envolvidas e possibilita identificar quem ajudou quem no projeto e as
dependências sociais derivadas dos vínculos técnicos do código-fonte e dos documentos.
O framework utilizado possibilita a busca por especialistas quando algum
desenvolvedor necessita de informações durante a implementação do software. Primeiro, é
realizado o processo de identificação dos especialistas através da análise do relacionamento
entre os desenvolvedores e o artefato que gerou a dúvida (documento ou código-fonte).
Após a identificação, é feita a seleção dos especialistas que mais se comunicou com o
desenvolvedor solicitante. Ao termino da seleção é criada uma lista de discussão temporária
entre os especialistas e o desenvolvedor com dúvidas para solucionar o problema
encontrado.
A análise das abordagens encontradas revelou uma forte preocupação em fornecer
informações de percepção aos usuários através do processamento das fontes utilizadas,
como e-mails trocados por listas e arquivos de código fonte. Porém, com exceção ao
mecanismo descrito por Ye e colegas (2007), as ferramentas coletadas não informam quais
os peritos em determinadas áreas do projeto e não utilizam a documentação gerada no
projeto como fonte de informação.

19
2.3. Conclusão
O Desenvolvimento Distribuído de Software vem ganhando destaque em projetos de grande
porte. Porém, a dispersão das equipes - principalmente a assíncrona temporal - dificulta a
colaboração entre seus membros, ocasionando demora na resolução de problemas, pois
nem sempre é claro quem é o especialista naquela porção do software, principalmente
quando essa pessoa está localizada remotamente.
Com a Revisão Sistemática, foi possível identificar várias dificuldades enfrentadas por
equipes distribuídas, principalmente quando estão temporalmente separadas. Dentre os
pontos destacados, a falta de percepção, nesse contexto, mostrou-se um fator de suma
preocupação no DDS, já que esse tópico esteve presente em diversos aspectos na
comunicação entre times.
Um dos aspectos mais prejudicados com a fraca percepção entre os participantes das
equipes está relacionado com a comunicação e, consequentemente, a identificação dos
peritos no projeto. Por conta disso, a comunicação ineficiente afeta o desempenho das
atividades no projeto e gera atrasos na execução do projeto. Como as equipes podem ter um
tempo de sobreposição de horário de trabalho muito curto, a identificação da pessoa mais
provável a responder estas mensagens de dúvidas aponta ser uma grande oportunidade
para reduzir os atrasos gerados na comunicação, principalmente, assíncrona entre equipes
distribuídas.
No próximo capítulo, serão apresentados os principais conceitos que envolvem os
Sistemas de Recomendação de Especialistas e como esses são utilizados na descoberta dos
especialistas existentes em projetos de software.

20
3. Sistemas de Recomendação de
Especialistas
Como discutido anteriormente, as equipes distribuídas são duas vezes e meia mais lentas na
resolução de problemas quando comparadas às co-localizadas. Parte desse problema está
relacionada com a dificuldade de seus membros identificarem as pessoas mais qualificadas
para iniciar uma colaboração. Outro fator está na dificuldade de formação de
relacionamentos, pois a separação temporal cria a sensação de ansiedade e a diminuição da
confiança decorrida da negativa impressão de silêncio ou dos atrasos associados à
comunicação assíncrona.
Os Sistemas de Recomendação de Especialistas (SRE), ao identificarem de forma
automática os mais indicados para ajudar as solicitações fornecidas, aceleram a fase inicial
de comunicação e incentivam a troca de informações entre os membros das equipes,
fortalecendo os relacionamentos. Através das recomendações recebidas, os usuários
identificam os detentores de conhecimento no projeto, que podem sentir-se mais motivados
a colaborar ao serem indicados como especialistas pela ferramenta.
Este capítulo apresenta os conceitos e as características envolvidas nos SRE, como
também a adoção de técnicas originalmente desenvolvidas pelos tradicionais Sistemas de
Recomendação. Por fim, são apresentados alguns exemplos de SRE.
3.1. Definição e Características dos SRE
Assim como na indústria de software, outros setores também se expandiram
geograficamente. A dispersão tornou a colaboração entre as equipes mais virtual do que
física e gerou dificuldades em saber quem são os detentores de conhecimento dentro das
organizações. Isso contribuiu no desenvolvimento de sistemas responsáveis por adquirir e
analisar o conhecimento dos indivíduos para selecionar aqueles mais indicados na solução
de problemas específicos.

21
Os Sistemas de Recomendação de Especialistas (SRE) são sistemas aplicados na
colaboração entre pessoas. Suas recomendações indicam e ajudam na atividade de localizar
pessoas dentro de uma organização. Esses sistemas agem de forma similar a um membro
chave na empresa, como um gerente de projetos ou um arquiteto de software, ao sugerir os
mais qualificados para determinados assuntos (McDonald e Ackerman, 2000).
Além do beneficio de localizar os especialistas, os SRE contribuem no aumento da
percepção da atividade nas empresas e na união de pessoas que talvez nunca tivessem
oportunidade de se conhecer pessoalmente (Petry, 2007).
Nas empresas, os SRE ajudam a representar os conhecimentos adquiridos pelos
funcionários durante a execução de suas atividades, contribuindo numa melhor percepção
dos envolvidos sobre "quem sabe o que" dentro da equipe. Outra vantagem está na
formação de capital social através de melhores relacionamentos entre pessoas que já se
conhecem ou não, contribuindo num melhor comprometimento e cooperação entre os
funcionários (Petry, 2007).
Um método de obter conhecimento sobre os membros de uma organização está no
monitoramento dos resultados de suas atividades. Como as pessoas acumulam
conhecimento através da execução de atividades durante um projeto, os documentos
gerados (e-mails, relatórios, memorandos, etc.) indicam os conhecimentos associados a um
indivíduo (Sim e Crowder, 2004).
Através das funcionalidades descritas por Sim e Crowder (2004), é possível
exemplificar as fases executadas por um SRE até identificar as pessoas a serem
recomendadas:
• extrair conhecimento - identifica potenciais fontes de informação com evidências de
conhecimento ou experiência. Essas fontes podem ser sistemas de armazenamento
de arquivos, de arquivos de e-mail, de repositórios de código fonte, etc.;
• modelar conhecimento - detalha o relacionamento entre uma fonte de
conhecimento e um especialista, por exemplo: o sistema atribui uma maior
importância aos termos encontrados no título de um documento do que no corpo;

22
• seleção dos especialistas - disponibiliza estratégias ou filtros para a seleção dos
especialistas. Dados pessoais e outros tipos de informações (como departamento
onde trabalha) podem ser utilizados como critério de seleção. Os especialistas que
não se enquadram nos critérios e filtros escolhidos são retirados da lista a ser
entregue ao usuário;
• interface com o usuário - lista os especialistas e as evidências utilizadas para a
modelagem do conhecimento, sendo essa lista submetida ao usuário.
Os tradicionais sistemas de recomendação conseguem modelar os gostos, os
interesses e as habilidades de seus usuários. Com perfil formado, o sistema identifica os
artefatos (como documentos, livros, CDs etc.) que melhor atendem as necessidades dos
usuários. Todo o processo e conceitos envolvidos, descritos na próxima seção, ajudam a
entender como os conhecimentos podem ser extraídos e modelados pelos SRE.
3.2. SRE Existentes
De acordo com a proposta de utilizar elementos gerados durante a fase de implementação
como fonte de entrada para localizar os especialistas envolvidos no DDS, foram extraídas da
literatura abordagens que utilizassem ao menos uma fonte de informação derivada da
codificação de software. A seguir são apresentados os trabalhos que descrevem as
abordagens analisadas.
(McDonald e Ackerman, 2000) – Apresenta o Expertise Recommender (ER) e segue a idéia
que os relacionamentos guiam as pessoas ao selecionarem os especialistas dentro das
organizações. Inicialmente, o sistema utiliza os registros de experiências entre as pessoas e o
histórico dos artefatos para identificar os candidatos no projeto.
O ER disponibiliza duas heurísticas para a identificação dos especialistas. A primeira
busca selecionar todos os desenvolvedores que modificaram um arquivo e classifica-os de
acordo com a data da modificação. Nos casos de vários arquivos serem selecionados, a lista
de especialistas é formada pela interseção entre as classificações de cada arquivo. A segunda
heurística consiste em anexar aos erros encontrados, o cliente relacionado, os módulos do

23
sistema envolvido e a pessoa que solucionou. Em seguida, é verificada a similaridade entre o
novo problema identificado e as informações anexadas.
Após a identificação, a recomendação é feita após filtragem dos candidatos por
critérios organizacionais ou sociais. Para isto, a lista é filtrada de forma a selecionar os mais
próximos do usuário na rede social ou no grupo de trabalho, ou seja, separados por no
máximo x pessoas no modelo de relacionamentos sociais.
O pronto forte do ER está na avaliação do contexto social do usuário e na
flexibilidade das suas fontes de dados. O ponto negativo do sistema é o filtro realizado, pois
a pessoa mais especializada nem sempre é retornada caso esteja muito distante da rede
social do usuário.
(Minto e Murphy, 2007) – Descreve o Emergent Expertise Locator (EEL), que baseado no
histórico de alterações dos arquivos e das pessoas que participaram dessas alterações,
encontra os especialistas para um dado conjunto de arquivos de interesse.
O EEL utiliza duas matrizes com informações do histórico de alterações, a matriz de
dependência dos arquivos e a matriz de autoria, para gerar a matriz de especialistas.
A matriz de dependência representa a quantidade de vezes que um par de arquivos
foi alterado no mesmo momento e a matriz de autoria representa a quantidade de
alterações que os desenvolvedores fizeram em cada arquivo. A matriz resultante do cálculo
das duas matrizes anteriores representa o nível de conhecimento dos desenvolvedores
sobre os arquivos em dúvida.
Esse sistema oferece um tratamento diferenciado aos dados armazenados nos
repositórios de código-fonte, porém não é analisado se os arquivos têm dependências ou
forte relacionamento com outros, o que poderia enriquecer a construção das matrizes.
(Sindhgatta, 2008) – A abordagem proposta nesse trabalho busca extrair os conceitos
presentes no código-fonte e associá-los aos desenvolvedores através dos registros de
alterações do código.
A identificação dos conceitos inicia-se pelo processamento dos arquivos de código-
fonte, que gera uma representação com apenas os termos chaves presentes no arquivo.

24
Após isso, os documentos são agrupados de forma homogenia, conforme a ocorrência dos
termos. Os termos chaves resultante do agrupamento são identificados como os conceitos
de domínio e estando presentes nas representações de código-fonte formam os domínios de
especialização dos desenvolvedores.
A vantagem desta abordagem está na análise do conteúdo do código-fonte
desenvolvido, possibilitando identificar quais são os termos mais utilizados na
implementação do software. Contudo, para potencializar os resultados a mesma técnica
adotada no processamento do conteúdo de arquivos de código-fonte poderia ser utilizada
no conteúdo de meios de comunicação, como o e-mail, no intuito de identificar os conceitos
tratados entre os desenvolvedores.
(Vivacqua e Lieberman, 2000; Vivacqua, 1999) – Esse trabalho descreve o Expert Finder (EF)
classifica o conhecimento dos usuários no domínio de programação Java a partir da análise
dos códigos-fonte criados ao longo do projeto. Para montar o perfil dos desenvolvedores, o
sistema analisa periodicamente os arquivos de código-fonte escritos pelos desenvolvedores.
Isso permite identificar o quanto esse tem conhecimento sobre os conceitos e as classes
Java.
Para localizar os especialistas, o sistema analisa a similaridade entre as palavras-
chave fornecidas na busca e as descrições das classes. Após o cálculo, as classes encontradas
são confrontadas com aquelas já utilizadas pelos desenvolvedores e presentes no seu perfil.
Aqueles com o nível de conhecimento um pouco maior sobre a necessidade do solicitante
serão escolhidos para iniciar uma interação.
O EF seleciona os especialistas desta forma por acreditar que a melhor pessoa a
ajudar na solução de um problema nem sempre é aquele com maior grau de conhecimento,
mas aqueles com um pouco mais de conhecimento comparado ao solicitante.
A vantagem do EF encontra-se no fato daquele com maior conhecimento está muitas
vezes indisponível ou desinteressado em solucionar os problemas de desenvolvedores
novatos. A desvantagem do sistema é por apenas analisar o uso das classes pertencentes ao
domínio de programação Java, sendo assim, o sistema não identifica o quanto os
desenvolvedores conhecem sobre as classes desenvolvidas durante o projeto.

25
(Ye et al., 2007) – Baseado no framework apresentado na seção 2.2.4, esse trabalho propõe
o STeP_IN, um sistema que possibilita obter uma lista de especialistas através do código-
fonte e da comunicação realizada durante o desenvolvimento do projeto. Esse sistema tem
como objetivo ajudar os desenvolvedores Java a encontrar as APIs utilizadas no projeto e
aprender com exemplos e como os especialistas as usam. Caso o desenvolvedor ainda tenha
dúvidas sobre uma determinada API, o sistema recomenda um conjunto de especialistas
para ajudá-lo.
A partir do código-fonte e da comunicação, o sistema automaticamente direciona as
perguntas a um grupo de especialistas escolhidos por dois critérios: se eles têm um alto grau
de conhecimento na API desejada e se têm um bom relacionamento com o desenvolvedor
que solicitou ajuda.
A principal vantagem no STeP_IN está na identificação dos relacionamentos
existentes entre os desenvolvedores e as informações geradas no decorrer do projeto,
porém ao selecionar os especialistas o conteúdo na comunicação entre os desenvolvedores
não é analisado, isso impossibilita identificar os assuntos tratados pelas pessoas.
(Kagdi et al., 2008) – Apresenta o xFinder e também tem como objetivo encontrar os
especialistas no código-fonte implementado no projeto. Para isso, a recomendação toma
como base a relação entre cada arquivo de código-fonte e os desenvolvedores. Por meio
dessas informações, os especialistas mais adequados para cada arquivo são selecionados em
função do que lhes é mais útil no momento.
A partir dos dados contidos no histórico de alterações do código-fonte, o XFinder cria
dois vetores, o primeiro com a quantidade de alterações, de dias trabalhados e o último dia
de trabalho de cada desenvolvedor no arquivo em dúvida e o segundo com o número total
de dias de trabalho dos desenvolvedores nos arquivos envolvidos e seu último dia de
trabalho nesses. Depois de formar os vetores, é calculada a distância Euclidiana entre os
vetores para formar a lista de desenvolvedores indicados.
Ao preencher os vetores com dados temporais, esse sistema possibilita encontrar os
desenvolvedores com melhor lembrança sobre como o código-fonte foi implementado,

26
porém assim como no EEL seria possível obter melhores resultados se também fossem
analisados as relações existentes entre os arquivos.
(Anvik et al., 2006) – Essa abordagem busca descobrir os desenvolvedores mais indicados a
resolver os problemas reportados no repositório de bugs de um projeto.
A técnica utilizada envolve um algoritmo de aprendizagem de máquina que analisa o
repositório de bugs e agrupa-os de acordo com as categorias indicadas pelos usuários. O
sistema também aprende os tipos de problemas resolvidos por cada desenvolvedor e gera
um classificador para identificar a categoria dos novos problemas inseridos e sugerir um
pequeno conjunto de desenvolvedores capazes de resolver o problema.
A fonte de dados utilizada na abordagem possibilita extrair os tipos de atividades
desempenhadas pelos desenvolvedores, porém a mesma não contém informações que
possibilite obter um nível de especialização mais profundo (o especialista em determinada
classe desenvolvida) como o histórico de alterações do código-fonte.
3.3. Conclusão
Esse capítulo apresentou as principais características dos Sistemas de Recomendação, as
técnicas para construir os perfis dos especialistas e dos itens (documentos) acessados. Os
SRE são destacados como uma variação desses sistemas, na busca das pessoas mais
preparadas para solucionar as necessidades dos usuários.
Avaliando os SRE existentes, nota-se a necessidade de utilizar os artefatos gerados
durante o desenvolvimento do Software como fontes de informação para encontrar os
especialistas. Com exceção do STeP_IN, os demais sistemas não consideram a comunicação
realizada no decorrer do projeto.
A ferramenta proposta no próximo capítulo preocupa-se com o nível mais próximo
do desenvolvedor, o código-fonte, olhando para seu histórico e evolução, disponível na
ferramenta de controle de versões, e ponderando os esforços prévios de comunicação no
time de desenvolvimento.

27
4. Presley
Vários fatores, descritos no capítulo 2, afetam a comunicação nas equipes distribuídas e
geram riscos de atrasos na execução do projeto por causa da dificuldade das pessoas se
situarem durante sua execução e conseguirem localizar facilmente quem possam ajudá-los
em caso de alguma dificuldade.
No espaço de duração do desenvolvimento do projeto, seus participantes
compartilham conhecimentos sobre vários assuntos necessários e relacionados à condução
das suas atividades e à interação com outros desenvolvedores (Espinosa et al., 2007;
Parvathanathan et al., 2007; Hogan, 2006).
Contudo, as dificuldades encontradas no ambiente distribuído não ajudam a
compartilhar esse tipo de conhecimento. A falta de conhecimento profundo e seguro da
aplicação em si, isto é, do código-fonte que está sendo escrito, tem o potencial de afetar
negativamente a produtividade das equipes, principalmente em DDS. A proposta do Presley
é identificar e recomendar os especialistas em determinadas áreas do código-fonte do
projeto e assim melhorar a colaboração entre os desenvolvedores. A recomendação de
especialistas no código-fonte do projeto supre uma importante parte da percepção e do
compartilhamento de conhecimento necessários numa comunicação eficiente.
Esse capítulo apresenta os requisitos, a arquitetura, a implementação e o uso do
Presley.
4.1. Requisitos
O Presley visa promover uma melhor colaboração entre os desenvolvedores ao ser capaz de
identificar os especialistas em determinadas áreas do código-fonte do projeto, pois não
basta apenas ter conhecimento do domínio do problema. A falta de conhecimento profundo
e seguro da aplicação em si, isto é, do código-fonte que está sendo escrito, afeta
negativamente a produtividade das equipes, principalmente em DDS, provocando

28
necessidade de comunicação extra entre os membros das equipes distribuídas (de Souza et
al, 2004).
Para alcançar os objetivos, o Presley foi desenvolvido com base nas deficiências e nos
requisitos importantes encontrados na literatura. A seguir são listados os requisitos
funcionais (RF) e os não funcionais (RNF) identificados e a próxima seção descreve como
esses foram desenvolvidos.
(RF1) Analisar as contribuições no projeto: os atores envolvidos, direta ou
indiretamente, em dada atividade dão indícios dos detentores dos conhecimentos
necessários para sua realização (Ganesan et al., 2006). A relação entre a execução das
atividades do projeto com seus respectivos artefatos fornecem parte do suporte necessário
para inferir quem é o especialista em cada parte (pacote, classe, método) do software.
Em DDS, a interação entre os desenvolvedores pode ser evidenciada através de e-
mails, na comunicação assíncrona, ou logs de conversas em outros meios de comunicação,
inclusive síncronos. Já a participação na implementação dos códigos-fonte do projeto pode
ser extraída pelos registros contidos na ferramenta de controle de versão.
Se estas informações forem bem manuseadas, há grandes chances de suprir uma
importante parte da percepção e do compartilhamento de conhecimento necessários em
uma comunicação eficiente em DDS através da recomendação de membros dos times mais
capazes.
(RF2) Diminuir o custo da atenção coletiva: as pessoas, ao receberem uma solicitação
de ajuda por e-mail, gastam tempo considerável em sua leitura e na postagem de uma
resposta. Neste custo, também deve ser adicionada à atenção perdida na decisão de
responder ou não a solicitação e a interrupção na atividade realizada pelos participantes. O
custo de interrupções envolve perda do contexto e de fluxo de trabalho (Ye, 2007).
Em projetos que utilizam listas de e-mails, o custo de atenção coletiva é multiplicado
pelo número de participantes envolvidos. Para evitar esse problema é importante as pessoas
apenas receberem solicitações de ajuda referentes a sua área de conhecimento no projeto.

29
(RF3) Evitar exposição dos usuários com problemas: como exposto no capítulo 2, os
participantes das equipes distribuídas não se sente confortáveis quando estão em contato
com pessoas desconhecidas, pois suas dúvidas demonstram desconhecimento no assunto
discutido. Por isto, os participantes apenas devem ser revelados quando existir uma troca de
informações, ou seja, o usuário com problema somente ter conhecimento das pessoas que
respondem a sua solicitação e estes só conhecem aqueles ao responderem as dúvidas
recebidas.
(RF4) Cadastrar os conhecimentos envolvidos no projeto: os repositórios centrais de
informação, apresentados no capítulo 2, mantém dados que podem ser utilizados por todos
os membros das equipes (Moe e Smite, 2007).
Os documentos criados durante a execução do projeto e mantidos nos repositórios
contêm informações sobre os vários conhecimentos envolvidos na implementação do
software e necessário para identificar os assuntos tratados na comunicação que ocorre
durante as atividades. Isto traz a necessidade de registrar os conhecimentos envolvidos nos
projetos e suas fontes de informação (a documentação).
(RF5) Gerenciar a troca de mensagens: por ser uma ferramenta de comunicação
assíncrona, o Presley deve permitir a troca de mensagens entre seus usuários. No contexto
abordado pelo sistema, estas mensagens são tratadas como problemas, relacionadas às
dúvidas enviadas, e soluções, respostas as solicitações.
(RF6) Gerenciar o perfil dos usuários: é importante para os SRE conhecerem as
preferências e os gostos dos seus usuários. A partir da comunicação realizada é possível
obter os assuntos ou os conhecimentos de interesse de cada participante. Outra informação
significante para a construção dos perfis, o histórico de modificações dos artefatos (códigos-
fonte) manipulados pelos usuários fornece conhecimento sobre as atividades executadas
pelos desenvolvedores.
(RF7) Identificar os especialistas nos conhecimentos envolvidos no projeto: durante a
fase de construção surgem, em alguns momentos, dúvidas não relacionadas diretamente ao
código-fonte desenvolvido e sim a outros conhecimentos atrelados à implementação, como
os requisitos ou as decisões dobre os códigos a serem implementados.

30
Dúvidas com essas características também devem ser consideradas pelo sistema e
atreladas aos especialistas do conhecimento tratado, pois são parte importante da
comunicação realizada pelas equipes.
(RF8) Identificar os especialistas no código-fonte: um dos aspectos mais prejudicados
no DDS com o enfraquecimento das várias percepções - evidente nos problemas das
percepções de atividade, proximidade e presença - está na identificação de especialistas no
código-fonte tornando vagarosa e não muito eficiente a escolhas das pessoas mais
qualificadas (Herbsleb, 2007).
O objetivo deste requisito é selecionar as pessoas (especialistas) capazes de ajudar os
demais membros do time quando surgem dúvidas na fase de construção de software.
(RF9) Reduzir o tempo gasto na localização dos especialistas: como as equipes
distribuídas podem ter um tempo de sobreposição de horário de trabalho muito curto, a
identificação da pessoa mais provável a responder as mensagens de dúvidas dobre o projeto
aponta ser uma grande oportunidade para reduzir os atrasos gerados na comunicação,
principalmente assíncrona.
(RNF1) Usabilidade: a ferramenta deve ser de fácil compreensão e utilização por
parte dos usuários.
(RNF2) Integração e transparência ao trabalho do usuário: muitas ferramentas, como
os chats, retiram o foco dos seus usuários das atividades em execução, por isso é importante
obter informações de forma transparente e sem retirar sua atenção sobre o código-fonte a
ser implementado.
Os requisitos descritos abrangem todas as funcionalidades desenvolvidas no Presley
e influenciaram na sua arquitetura, implementação e interface apresentados nas próximas
seções.
4.2. Arquitetura e Implementação
O projeto de arquitetura tem o papel de aprofundar os resultados obtidos com a análise dos
requisitos, o foco desse processo está nos requisitos mais influentes na estrutura do sistema

31
(Larman, 2004). O objetivo dessa etapa no projeto de software é estabelecer a estrutura
básica do sistema, isso envolve a identificação dos principais componentes e a forma como
eles se comunicam (Sommerville, 2003).
Para atender os requisitos anteriormente descritos, a arquitetura do Presley foi
definida em componentes e camadas. A seção seguinte apresenta uma descrição geral da
arquitetura e os detalhes dos principais componentes.
4.2.1. Framework Conceitual
A arquitetura do Presley é baseada no framework descrito por Ye e colegas (2007), que
realiza união entre elementos de conhecimento (os desenvolvedores, os documentos e os
códigos-fonte) envolvidos na realização do projeto, para obter o ecossistema entre estes e
selecionar os especialistas que possam responder aos problemas enfrentados pelos
desenvolvedores na fase de implementação. Os nós da rede (representados por código-
fonte, documento e desenvolvedor) mostram o relacionamento entre as pessoas e as
informações geradas durante o projeto, como apresentado na Figura 4-1.
Além do código-fonte e dos documentos, o Presley também faz uso da comunicação
ocorrida no projeto entre os desenvolvedores através de listas de discussão e mensagens na
própria ferramenta. Desta forma, o Presley recebe como parâmetros o código-fonte, os
artefatos e registros de comunicação. A partir destas entradas são criados os seguintes
relacionamentos:
• Desenvolvedor - Código-fonte: Formados pelos registros encontrados na ferramenta
de controle de versão;
• Código-Fonte - Código-fonte: Formados pelas dependências entre códigos-fonte;
• Desenvolvedor - Desenvolvedor: Formados através da comunicação realizada em
listas de discussões e na ferramenta.

32
Figura 4-1: Rede de atores de um projeto de software, extraído de (Ye et al., 2007)
Os parâmetros escolhidos trazem indícios dos detentores de conhecimento
envolvidos com esses elementos desde sua concepção. A relação entre a execução das
atividades do projeto e seus respectivos artefatos fornecem ao Presley as informações
necessárias para inferir quem é o especialista em cada parte (pacote, classe, método) do
software. Além disso, a interação ocorrida entre os indivíduos permite o sistema identificar
quais são seus interesses dentro do projeto, contribuindo na inferência realizada.
4.2.2. Arquitetura
Como mostrada na Figura 4-2, a arquitetura geral do Presley foi desenvolvida com base na
arquitetura cliente-servidor.

33
Figura 4-2: Framework Arquitetural da Ferramenta
O cliente é responsável por coletar e enviar as informações fornecidas pelo usuário
para o servidor. Já no lado servidor, existe uma divisão de papeis entre os seguintes
componentes: Usuários, Mensagem, Conhecimento, Inferência e Persistência.
O componente Usuário é responsável por administrar as atividades pessoais
envolvidas no projeto e o seu cadastro no sistema. O componente Mensagem permite a
troca de mensagens entre os desenvolvedores e tem a responsabilidade de anexar do seu
conteúdo os comentários dos arquivos fornecidos pelo cliente. O componente
Conhecimento é responsável por gerenciar os conhecimentos envolvidos no projeto e os
documentos que os descrevem. Por fim, o componente Inferência faz a análise dos
conteúdos das mensagens e dos documentos fornecidos, identifica o assunto abordado nas
mensagens e identifica as pessoas mais qualificadas a respondê-las.
4.2.3. Cliente
Este componente é responsável pela interface gráfica com o usuário e por enviar as
informações fornecidas pelos usuários para o servidor, que iniciará o processo de
identificação dos especialistas.
O Cliente foi desenvolvido como um plug-in para a IDE Eclipse (www.eclipse.org),
como uma perspectiva deste ambiente de desenvolvimento. Através dessa camada, o

34
desenvolvedor informa os seus dados pessoais e informações sobre o projeto em
desenvolvimento, os conhecimentos envolvidos, as dúvidas geradas e as respostas
fornecidas. Maiores detalhes sobre a interface gráfica do Presley serão descritos na seção
4.4.
O usuário ao escrever uma mensagem sobre seu problema pode informar o código-
fonte relacionado e o Cliente encarrega-se de buscar os arquivos que fazem referência ao
código indicado, antes de enviá-los ao servidor.
O motivo desse procedimento está nas dependências técnicas dos componentes de
software também criarem dependências sociais entre os desenvolvedores (Souza et al.,
2007) e porque a estrutura de relacionamentos pode indicar elementos importantes que
contribuíram no desenvolvimento do código-fonte (Robillard, 2008). Como exemplo, um
usuário pode ter dúvidas sobre a classe Pessoa classe herdada por Professor, o
desenvolvedor de Professor pode ser tão qualificado quanto o desenvolvedor de Pessoa
para ajudar na dúvida.
O componente JayFx foi incorporado e adaptado ao Cliente como responsável o por
analisar as classes presentes nas mensagens escritas pelos desenvolvedores e retornar as
demais classes.
Os demais componentes descritos são referentes a camada Servidor.
4.2.4. Componente Usuário
O componente Usuário gerência os dados cadastrais dos desenvolvedores envolvidos no
projeto. Outra função do componente está em coletar a participação dos desenvolvedores
na implementação dos códigos-fonte do projeto. A extração dessas informações é feita
através dos registros contidos na ferramenta de controle de versão, como o Subversion.
A Figura 4-3 apresenta as tabelas do banco de dados, no servidor, responsáveis por
manter as informações descritas.

35
Figura 4-3: Tabelas Utilizadas pelo Componente Usuário
4.2.5. Componente Conhecimento
O componente Conhecimento é responsável por administrar o conteúdo dos
documentos que descrevem os tópicos implementados no código-fonte.
A construção de software envolve competência em três domínios: Engenharia de
Software, Problema e Aplicação. O Domínio da Engenharia de Software compreende o
conhecimento de técnicas, métodos, processos e ferramentas para a construção de software
economicamente viável, confiável e eficiente. Este domínio diz como devemos construir o
software. O Domínio do Problema diz respeito ao entendimento de requisitos, regras de
negócio, necessidades e desejos do usuário. Ele informa o que deve ser construído. Por fim,
o Domínio da Aplicação consiste de todo conhecimento necessário para compreender como
o Domínio do Problema está sendo transformado em software, isto é, transcrito e codificado
nos artefatos e código-fonte do projeto. O último domínio reflete as características e
propriedades do software em construção.
Como o Presley busca pelos especialistas no Domínio da Aplicação, o usuário deve
fornecer os tópicos que formam esse conhecimento e os documentos relacionados.
O componente conhecimento ao receber um documento associado a algum tópico
faz uso do sub-componente Classificador, descrito posteriormente na seção Inferência, para
retirar as stopwords do texto (palavras que carregam pouco significado) e obter a freqüência
de cada termo.

36
Estas informações são armazenadas nas tabelas do banco de dados, presentes na
Figura 4-4.
Figura 4-4: Tabelas Utilizadas pelo Componente Conhecimento
4.2.6. Componente Mensagem
O componente Mensagem é responsável por receber os problemas e as soluções propostas
pelos desenvolvedores da camada Cliente. Ele retornará ao Cliente os especialistas indicados
pelo componente Inferência aos problemas cadastrados.
A comunicação realizada através do componente Mensagem é tratada da seguinte
forma: as dúvidas ou perguntas dos desenvolvedores são os problemas ocorridos durante a
implementação do software e as respostas as solicitações de ajuda são as possíveis soluções
indicadas pelos especialistas.
A Figura 4-5 apresenta a tabela problema, com os dados sobre as dúvidas fornecidas
pelos usuários, mensagem, com as pessoas indicadas pelo Presley a respondê-las, e solução,
com as respostas dos especialistas indicados. As demais tabelas são relacionadas com os
arquivos de código-fonte anexados a mensagem.

37
Figura 4-5: Tabelas Utilizadas pelo Componente Mensagem
Em anexo ao conteúdo do problema, o Cliente também envia os arquivos de código-
fonte relacionado ao texto. O componente Mensagem extrai os comentários presentes
nesses códigos e soma-os ao conteúdo do problema que será enviado para o componente
Inferência determinar o conhecimento abordado e recomendar os especialistas mais
indicados na resolução do problema.
4.2.7. Componente Inferência
O componente Inferência dividi-se em três sub-componentes (Classificador, Identificador e
Recomendador) para atingir o objetivo de encontrar os especialistas. A Figura 4-6 ilustra o
fluxo de informação pelos componentes.

38
Figura 4-6: Sub-Componentes da Inferência
Todo conteúdo da mensagem e dos documentos são processados pelo Classificador.
Esse componente calcula a quantidade de palavras utilizadas e retira do texto as stopwords e
os caracteres inválidos. Para extração dessas palavras, foi criada uma lista, chamada de
stoplist, com todas as stopwords a serem excluídas do texto. A stoplist utilizada no Eurekha
(Wives, 1999) foi adotada pelo Presley, sendo composta por artigos, advérbios, conjunções,
preposições, pronomes e interjeições.
Após a identificação das palavras-chave, o componente Classificador calcula a
freqüência das palavras no texto. Ao fim, as mensagens processadas são enviadas ao
componente Identificador para classificá-las em alguns dos conhecimentos existentes.
No Identificador é feito uma análise de todo o conteúdo da mensagem e dos
arquivos textuais registrados pela ferramenta, com o objetivo de identificar as suas
semelhanças.
Existem vários métodos para determinar a similaridade entre dois documentos. No
componente Identificador foi adotada a técnica de similaridade difusa. Este método permite
modelar documentos textuais cuja linguagem e os processos de recuperação são imprecisos
(Wives, 2002). Outro fator positivo foram os resultados obtidos por Wives (1999) em
experimentos para agrupamento de documentos textuais, por Loh (2001), na descoberta de
conhecimento em textos baseados em conceitos e também por Galho (2003) para a
categorização automática de documentos em textos. Os bons resultados desses trabalhos
motivaram a utilização dessa técnica na modelagem no componente.
Para classificar as mensagens recebidas, a técnica de similaridade difusa determina o
grau de semelhança da lista de termos da mensagem com a lista de termos de cada

39
conhecimento. Para cada termo comum entre as listas, calcula-se o grau de igualdade de
seus escores de relevância através da função apresentada na Figura 4-7. As varáveis a e b
representam os escores de relevância do termo.
Figura 4-7: Fórmula do cálculo do grau de igualdade (Galho e Moraes, 2004)
Supondo que o termo comum em análise seja "extração", sendo encontrado 2 vezes
na mensagem e 5 no documento analisado. Aplicando a fórmula apresentada com a = 2 e b =
5, conforme os cálculos abaixo se têm a → b = 2,5 e b → a= 0,4. Os valores calculados
devem pertencer entre 0 e 1, caso não aconteça deve-se normalizá-los, assumindo o valor 1
quando o resultado for maior que 1 e 0, quando for menor que 0. Deste modo, a → b será 1.
Ao efetuar os demais cálculos, tem-se:
25,0
1
41
11
=→=→
−=−=
−=−=
ab
ba
bb
aa
Após obter esses resultados, calcula-se o grau de igualdade do termo:
( ) ( )[ ] ( ) [ ] 625.02/25.012/25.0,4.0min1,1min5,2 =+=+=gi
Desta forma, o termo "extração" da mensagem obteve um grau de igualdade de
0,625 com o mesmo termo do documento arquivado. O resultado obtido indica a
importância do termo e varia entre zero e um, o quanto mais próximo de um mais relevante
é o termo.
Ao término dos cálculos de igualdade entre os termos, calcula-se o grau de
similaridade entre o texto e os arquivos através da soma dos resultados obtidos
anteriormente, conforme a fórmula na Figura 4-8.

40
Figura 4-8: Fórmula da média por operadores "fuzzy" (Galho e Moraes, 2004)
Esse cálculo é repetido em cada documento existente no banco de dados. Aquele que
obtiver o maior grau de similaridade estará relacionado com o conhecimento definido para a
mensagem.
Após a identificação do conhecimento da mensagem, o componente Recomendador
analisa as participações dos usuários para determinar os especialistas. Este processo inicia-se
com a busca dos usuários que mais tiveram problemas ou deram soluções referentes ao
mesmo conhecimento encontrado no passo anterior. O cálculo apresentado na Figura 4-9
demonstra o passo necessário para descobrir a quantidade de participações do usuário u
(em análise) sobre o conhecimento c.
Figura 4-9: Cálculo de Participação dos Desenvolvedores nas Interações
O cálculo acima é repetido com todos os usuários u que enviaram alguma mensagem,
dentro do período de um ano antes do envio da solicitação de ajuda, formando uma lista
com a quantidade de participação na comunicação de todos os participantes sobre o
conhecimento determinado.

41
Em seguida é obtido o nível de participação dos desenvolvedores nos arquivos
anexos à mensagem, através do histórico da ferramenta de controle de versões. A Figura
4-10 apresenta o cálculo realizado.
Figura 4-10: Cálculo de Participação dos Desenvolvedores no Código-Fonte
O cálculo acima é repetido com todos os usuários u que contribuíram no
desenvolvimento dos arquivos A dentro do período de um mês antes do envio da solicitação
de ajuda, formando uma lista de todos os contribuintes destes códigos-fonte.
Após coletar as participações, o componente soma a participação de cada lista e os
cinco melhores classificados serão recomendados para responder a mensagem enviada pelo
usuário.
4.2.8. Detalhes da Implementação
O Presley é uma ferramenta desenvolvida em Java com arquitetura cliente-servidor. A
camada cliente foi implementada como um Plug-in do Eclipse que envia as informações
fornecidas pelos usuários para a camada Servidor. A camada de persistência utiliza o padrão
SQL ANSI para manipular os dados e o banco de dados utilizado no desenvolvimento do
projeto foi o MySQL. A implementação do Presley contém 12.213 linhas de código (Java, SQL
e XML).
4.3. Uso do Presley
A Figura 4-11 exibe o plug-in Presley em destaque na IDE Eclipse.

42
Figura 4-11: Presley em destaque na IDE Eclipse
Para inserir os tópicos de conhecimento do Domínio da Aplicação o usuário deve ir a
aba Domínio mostrada na Figura 4-12.
Figura 4-12: Aba Tópicos de Domínio

43
Nessa aba o analista deverá cadastrar os conhecimentos envolvidos no projeto em
desenvolvimento. Na região (1), os itens de domínio serão informados seguindo uma
estrutura de árvore de conhecimentos, onde os conhecimentos filhos fazem parte do
conhecimento pai. Para incluir documentos base dos itens, o usuário deve selecioná-lo e
seguir para (2), que abrirá uma tela onde poderá selecionar o arquivo desejado.
Após informar os conhecimentos envolvidos no projeto já é possível utilizar a aba
para o envio de mensagens. Essa aba pode ser dividida em três partes como mostra a Figura
4-13.
Figura 4-13: Aba Mensagem de Problema
Os três primeiros botões da região (1) são responsáveis pelo logon, inclusão e
exclusão de usuários do sistema. Com identificação do usuário feita, a ferramenta permite o
uso dos botões de controle de mensagem: inserir (que solicita o título e o texto da
mensagem para o envio), excluir, validar resposta do usuário (para casos da mensagem
enviada receber alguma solução válida) e encerrar (para informar ao sistema que o
problema já foi resolvido).
Na região (2) as mensagens encaminhadas para o desenvolvedor identificado são
mostradas e assim como em (1) as mensagens são acompanhadas pelos sinais (mensagem

44
de problema), (solução enviada) e (resposta a solução). Para o desenvolvedor enviar
uma solução para algum problema recebido, ele deve clicá-lo duas vezes para aparecer uma
tela solicitando o texto a ser enviado.
Por fim, todas as vezes que uma mensagem ou resposta for selecionada essas
poderão ser lidas na região (3).
4.4. Atendimento aos requisitos pelo Presley
A arquitetura e as interfaces gráficas do Presley foram concebidas com o objetivo de
satisfazer os requisitos descritos anteriormente no capítulo.
A camada cliente foi desenvolvida através de um plug-in acoplado a IDE Eclipse,
geralmente utilizado pelos desenvolvedores durante a implementação do software. Outra
qualidade do cliente está na facilidade de uso de envio das mensagens e no cadastrado dos
conhecimentos. Essas capacidades atendem aos requisitos não funcionais facilidade de uso
(RNF1) e integração e transparência ao trabalho do usuário (RNF2).
A interação entre os desenvolvedores no Presley ocorre da seguinte forma: primeiro
o usuário com dúvida envia pelo Cliente sua mensagem; em seguida são identificados os
especialistas; após encontrá-los, o sistema os notifica sobre a nova solicitação, porém sem
exibir o emissor da mensagem; por fim, o especialista envia a solução para o problema
recebido e pode conhecer quem fez a solicitação. Esse procedimento é realizado para
atender o requisito expor os usuários apenas quando receberem respostas a sua solução
(RF3).
Os problemas enfrentados pelos usuários são recebidos pelo componente
Mensagem, que as encaminha aos especialistas indicados pelo componente Inferência. O
componente Mensagem também gerência as soluções propostas pelos especialistas,
satisfazendo o requisito gerenciar a troca de mensagens (RF5).
O componente Usuário gerência os dados cadastrais e as contribuições realizadas
pelos participantes do projeto em junção com as informações administradas pelo
componente Mensagem formam-se o perfil de cada participante do projeto. As informações

45
relatadas são o histórico das contribuições na implementação do software e dos problemas
enfrentados e solicitações fornecidas. A união desses componentes suporta o requisito
gerenciar os perfis do usuário (RF6).
O componente Conhecimento registra os tópicos envolvidos no Domínio da Aplicação
e o conteúdo dos documentos que os descrevem. Este componente executa a
funcionalidade de cadastrar os conhecimentos envolvidos no projeto (RF4).
O componente Inferência ao indicar os especialistas a responder as solicitação do
usuário, utiliza as contribuições dos demais usuários registrados na ferramenta de controle
de versão, atendendo o requisito analisar as contribuições no projeto (RF1). As mensagens
sobre os problemas escritas pelos usuários podem conter ou não trechos de código-fonte, o
que exige do componente analisar o conhecimento utilizado no conteúdo da mensagem e
busca os especialistas tanto no código-fonte indicado, como no conhecimento abordado.
Essa atividade atende aos requisitos identificar os especialistas no código-fonte (RF8) e nos
conhecimentos envolvidos no seu desenvolvimento (RF7).
Ao enviar as mensagens apenas aos especialistas recomendados, o Presley atende ao
requisito reduzir o custo da atenção coletiva (RF2) e o tempo gasto na localização dos
especialistas (RF9).
4.5. Conclusão
Este capítulo apresentou os principais aspectos da ferramenta proposta. Os requisitos e a
arquitetura definidos foram apresentados em detalhes, assim como, foi descrito como os
requisitos foram atendidos pela arquitetura. Por fim, o capítulo demonstrou um cenário de
uso da ferramenta.
O próximo capítulo apresenta um experimento realizado na ferramenta no contexto
do DDS e os resultados obtidos sobre a qualidade das recomendações geradas.

46
5. Experimento e Análise dos
Resultados
Esta dissertação apresentou até aqui o Presley, uma ferramenta que busca identificar os
especialistas existentes no projeto através da comunicação realizada por e-mails e dos
registros de alterações no código-fonte. Contudo, é importante avaliar a eficiência das
recomendações feitas pelo sistema e se as informações utilizadas de fato possibilitam a
escolha de pessoas mais indicadas na resolução dos problemas oriundos da implementação
do software.
Para avaliação do Presley, foi necessário executar um experimento. Essa técnica
possibilitou controlar o uso da ferramenta, manipular determinadas variáveis envolvidas e
analisar o impacto nas recomendações.
Este capítulo apresenta o experimento realizado com o Presley e os resultados
obtidos.
5.1. Avaliação do Presley
O planejamento do experimento seguiu o modelo proposto por Wohlin e colegas (2000) e
também seguido por Brito (2007), sendo dividido em cinco atividades. Na Definição, são
especificados os aspectos mais importantes no experimento e o motivo pelo qual o
experimento é conduzido. No Planejamento, é estabelecido como será realizado o
experimento, enquanto que na Execução, os dados são coletados para avaliação na fase de
Análise e Interpretação. Por fim, os resultados são apresentados na fase de Apresentação.
5.1.1. Definição
O paradigma Goal Question Metric (GQM) (Basili et al., 1994) foi adotado, na definição do
experimento, para formular o objetivo do estudo, as perguntas a serem respondidas e as
métricas necessárias para formar as respostas.

47
Objetivo:
Analisar o Presley com a finalidade de avaliá-lo com respeito à eficiência das
recomendações feitas pela ferramenta do ponto de vista das pessoas que solicitam ajuda no
contexto do Desenvolvimento Distribuído de Software.
Perguntas:
As perguntas a serem respondidas são as seguintes:
P1. A qualidade das recomendações da ferramenta dependente das duas
entradas (histórico do código fonte e rede de contatos)?
P2. A ferramenta realiza recomendações de qualidade?
Métricas:
M1. Precisão (precision): indica se os especialistas recomendados realmente
responderam a uma solicitação de ajuda, ou seja, a proporção de especialistas indicados que
realmente colaboraram em resolver o problema. O cálculo é realizado dividindo-se a
quantidade de recomendações corretas pela quantidade de recomendações feitas (Wives,
199; Minto, 2007). Através da precisão pode-se ter a probabilidade do sistema recomendar
um especialista corretamente.
M2. Cobertura (recall): indica a proporção de especialistas recomendados
corretamente em relação à quantidade de pessoas que de fato responderam as solicitações
fornecidas. O cálculo é realizado dividindo-se a quantidade de recomendações corretas pela
quantidade de pessoas que realmente responderam a solicitação (Wives, 199; Minto, 2007).
O resultado fornece uma importante medida da proporção de especialistas selecionados que
atenderiam as necessidades ou interesses dos desenvolvedores com dúvidas.
M3. Acurácia (accuracy): indica a proporção de mensagens com ao menos um
especialista recomendado corretamente. O cálculo é realizado dividindo-se a quantidade de
mensagens com ao menos uma recomendação correta pela quantidade de mensagens
recebidas (Kagdi et al., 2008). Essa medida é importante, pois um sistema com baixa acurácia

48
não conseguiria recomendar nenhum desenvolvedor capaz de responder a maioria das
dúvidas envidas.
5.1.2. Planejamento
O projeto escolhido para o experimento teve que fornecer os e-mails enviados pelos
desenvolvedores durante a implementação do software, assim como o histórico de
alterações no código fonte armazenado pela ferramenta de controle de versão e a
documentação que melhor descreve o código fonte implementado. Outro fator importante
está na necessidade do software ser desenvolvido na linguagem Java.
Contexto. O objetivo do experimento é avaliar a viabilidade do uso do Presley em
equipes distribuídas, principalmente com existência de distância temporal, no qual o uso de
ferramentas assíncronas é mais evidente. O projeto Apache Lucene-Java foi escolhido por
ser escrito em Java, desenvolvido como um projeto de código aberto e com seus
desenvolvedores espalhados globalmente.
Participantes. Os participantes do estudo são os desenvolvedores que enviaram
algum e-mail para a lista de discussão do projeto Lucene ([email protected]).
Hipóteses nulas. São hipóteses a serem rejeitadas pelo pesquisador da forma mais
significativa possível, pois consiste negar a teoria em prova. Para o experimento, as
hipóteses nulas determinam que o Presley não consegue obter um bom nível de acertos nas
suas recomendações e as entradas não contribuem na identificação dos especialistas. Desta
forma, as seguintes hipóteses foram geradas:
Hn1: precisão do Presley < precisão apenas da comunicação realizada no projeto
Hn2: cobertura do Presley < cobertura apenas da comunicação realizada no projeto
Hn3: acurácia do Presley < acurácia apenas da comunicação realizada no projeto
Hn4: precisão do Presley < precisão apenas do histórico do código fonte
Hn5: cobertura do Presley < cobertura apenas do histórico do código fonte
Hn6: acurácia do Presley < acurácia apenas do histórico do código fonte

49
Hn7: precisão do Presley < precisão da melhor ferramenta disponível na literatura
Hn8: cobertura do Presley < cobertura da melhor ferramenta disponível na literatura
Hn9: acurácia do Presley < acurácia da melhor ferramenta disponível na literatura
Hipóteses Alternativas. São hipóteses com o objetivo de rejeitar a hipótese nula. As
hipóteses alternativas do experimento foram as seguintes:
Ha1: precisão do Presley >= precisão apenas da comunicação realizada no projeto
Ha2: cobertura do Presley >= cobertura apenas da comunicação realizada no projeto
Ha3: acurácia do Presley >= acurácia apenas da comunicação realizada no projeto
Ha4: precisão do Presley >= precisão apenas do histórico do código fonte
Ha5: cobertura do Presley >= cobertura apenas do histórico do código fonte
Ha6: acurácia do Presley >= acurácia apenas do histórico do código fonte
Ha7: precisão do Presley >= precisão da melhor ferramenta disponível na literatura
Ha8: cobertura do Presley >= cobertura da melhor ferramenta disponível na literatura
Ha9: acurácia do Presley >= acurácia da melhor ferramenta disponível na literatura
Variáveis independentes. Todas as variáveis controladas e manipuladas durante o
experimento são chamadas de independentes. As variáveis independentes são as
recomendações feitas pelo Presley, os e-mails extraídos da lista de discussão e os registros
de modificações no código fonte.
Variáveis dependentes. As variáveis dependentes são os objetos de estudo do
experimento; seus valores variam com as mudanças feitas nas variáveis independentes. As
variáveis dependentes do experimento são a precisão, a cobertura e a acurácia das
recomendações feitas pelo Presley.
Validade interna. Verifica se os resultados obtidos são causados pelo tratamento
realizado no experimento, ou seja, se a manipulação das variáveis independentes de fato
refletiu nas variáveis dependentes. Como alguns e-mails presentes na lista de discussão não

50
estão relacionados ao desenvolvimento do projeto ou não tem conteúdo suficiente para
uma correta identificação do conhecimento abordado, o Presley pode recomendar
desenvolvedores que não são especialistas no assunto abordado no e-mail. Porém, como os
e-mails adotados para a coleta das métricas abrangeu um período extenso (6 meses), a
quantidade obtida garante uma boa validade interna.
Validade externa. Verifica se o experimento pode ser generalizado, ou seja, se o
mesmo estudo pode ser repetido em outros projetos. Provavelmente, os resultados são
afetados pelo projeto escolhido, pois no desenvolvimento em código aberto, os
participantes têm a liberdade de contribuírem apenas quando estão interessados, diferente
dos contratos existentes entre empresas e desenvolvedores que estipulam horários de
trabalho (Moraes, 2007). No entanto, como a repetição do experimento apenas depende
das fontes de entrada necessárias para a execução do Presley e o desenvolvimento em
código aberto reflete os problemas existentes na comunicação em equipes fisicamente
distribuídas a validade externa do estudo é considerada suficiente para avaliar as
recomendações realizadas.
Validade de conclusão. Verifica a capacidade do experimento gerar conclusões
corretas sobre as relações entre o tratamento das variáveis e os resultados obtidos. As
conclusões serão projetadas através da análise comparativa das métricas de precisão,
cobertura e acurácia das recomendações feitas pelo Presley com cada fonte de dados
utilizada e com métricas extraídas dos SRE discutidos no capítulo 3. As recomendações serão
realizadas a partir dos e-mails enviados pelos desenvolvedores a lista de discussão do
projeto escolhido.
5.1.3. Projeto Utilizado no Experimento
O projeto escolhido para o experimento foi o Apache Lucene-Java, uma API de indexação e
busca de documentos escrita em Java. Através deste, o experimento pode reportar um
problema real no desenvolvimento distribuído de software, a dificuldade em conhecer os
especialistas para solucionar os problemas gerados durante a implementação do código-
fonte.

51
Com o Lucene, foi possível simular as recomendações de especialistas feitas pelo
Presley na situação em que os desenvolvedores estão distribuídos assincronamente.
5.1.4. Instrumentação
A simulação foi produzida tendo como entrada os registros da lista de discussão, o código-
fonte, seu respectivo histórico na ferramenta de controle de versão e a documentação do
projeto, disponíveis em http://lucene.apache.org.
A primeira informação inserida no Presley foi a documentação do projeto, pois sem o
seu conteúdo não seria possível identificar o assunto abordado nas mensagens enviadas. O
Javadoc (disponível em http://lucene.apache.org/java/2_4_1/index.html) foi utilizado para a
extração das palavras-chaves que descrevem os conhecimentos envolvidos no projeto
Lucene. Cada descrição de classe ou subpacote no Javadoc teve seu conteúdo transferido
para arquivos com extensão txt e representava o conhecimento incluso no desenvolvimento
do pacote principal na qual a classe ou subpacote estava contido.
O passo seguinte foi a inclusão das mensagens, para representar o nível de interesse
dos desenvolvedores sobre os conhecimentos anteriormente definidos. Como os e-mails da
lista de discussão do projeto Lucene estavam agrupados por mês e ano de envio em arquivos
no formato MBox foi necessário desenvolver um sistema aparte para coletar os seguintes
dados:
• Quem enviou o primeiro e-mail de uma discussão;
• Qual foi o assunto, o conteúdo e a data de envio do e-mail anterior;
• E quem foram os demais participantes da discussão realizada.
Após a identificação do conhecimento abordado, os dados coletados das discussões
realizadas no ano de 2008 foram inseridos no banco de dados do Presley. Ao todo foram
utilizados 6.327 e-mails registrados em 2008 e enviados por 292 participantes da lista de
discussão. Entre os participantes, 17 deles também tinham registros de alterações no
histórico do código-fonte.

52
Os registros de discussões realizadas no ano de 2009 foram armazenados em dois
arquivos para a execução do experimento. O primeiro arquivo continha dados sobre o e-mail
que iniciou a discussão entre os desenvolvedores e serviu como a mensagem de solicitação
de recomendação de especialistas, enquanto o segundo arquivo continha a identificação das
pessoas que responderam o e-mail e serviu para confrontar com os especialistas
recomendados pelo Presley.
Através da ferramenta de controle de versão utilizada no projeto Lucene foram
coletadas as versões do código-fonte necessárias para a execução do experimento e o
histórico de alterações dos arquivos. O histórico na ferramenta de controle de versão
conteve 10.764 registros de alterações de código fonte, distribuído entre setembro de 2001
a julho de 2009.
5.1.5. Execução
Para a execução do experimento, foram selecionados todos os e-mails enviados de janeiro a
junho do ano de 2009 que haviam recebido ao menos uma resposta. Os e-mails coletados
(375) foram agrupados pelos meses de envio, totalizando 1187. A Tabela 5-1 apresenta a
quantidade de e-mails por quantidade de respostas enviadas e a Tabela 5-2 por mês de
envio.
Tabela 5-1: Quantidade de e-mails por quantidade de respostas enviadas
Quantidade de respostas enviadas Quantidade de e-mails 1 185 2 89 3 41 4 31 5 8 6 8 7 6 8 3 9 1
10 1 14 1 15 1
Com o objetivo de também simular a evolução da implementação do software junto com a
comunicação realizada, seis versões dos arquivos de código fonte do Lucene, representando

53
cada mês de envio de e-mail, foram extraídos da ferramenta de controle de versão do
projeto. A Tabela 5-3 contém as informações sobre cada versão utilizada.
Tabela 5-2: Quantidade de e-mails por Mês
Mês Quantidade de e-mails Janeiro 51 Fevereiro 37 Março 54 Abril 86 Maio 59 Junho 88
Tabela 5-3: Informações das versões do código fonte utilizado
Data da modificação Mês de referência Quantidade de linhas de código-fonte 30/12/2008 Janeiro 59.064 30/01/2009 Fevereiro 61.326 28/02/2009 Março 61.604 31/03/2009 Abril 62.214 30/04/2009 Maio 63.917 31/05/2009 Junho 65.093
Durante a execução do experimento, os arquivos extraídos do Javadoc eram
adicionados ao Presley e relacionados ao conhecimento equivalente. Para isso, os nomes
dos pacotes principais do Lucene foram cadastrados como os títulos dos conhecimentos
existentes e as palavras-chaves que formam o conhecimento eram extraídas dos arquivos txt
que descreviam as classes pertencentes aos pacotes descritos.
Para obter as recomendações, os e-mails com as questões dos desenvolvedores e os
arquivos de código-fonte eram sempre utilizados com o mesmo mês de referência, ou seja,
quando os e-mails do experimento eram de janeiro, os arquivos deviam ser do mesmo mês.
5.1.6. Análise e Interpretação
Ao fim da execução do projeto, as recomendações realizadas pelo Presley foram
coletadas para o cálculo das três perspectivas: precisão, cobertura e acurácia. A análise foi
realizada utilizando gráficos, com recomendações de até sete especialistas, feitos por cada
entrada utilizada pelo Presley.

54
Como descrito anteriormente, o Presley utiliza como parâmetros de entrada a
comunicação realizada pelos desenvolvedores e os registros de alterações no código fonte
do software em desenvolvimento. Para melhor entendimento dos gráficos apresentados, a
comunicação, contida na lista de e-mails do projeto Lucene, será rotulada como C e o
histórico de alterações no código fonte como H.
Avaliando a importância do histórico do código-fonte: esta análise foi realizada no
objetivo de verificar se o uso do histórico de alterações no código-fonte melhora a qualidade
das recomendações realizadas pelo Presley.
A Figura 5-1 apresenta a precisão geral (com todos os e-mails extraídos da lista de
discussão do Lucene) e a precisão nos casos de sucesso (no qual ao menos um especialista
foi recomendado corretamente) das recomendações realizadas pelo Presley, apenas com a
comunicação dos desenvolvedores (+C -H) e com as duas entradas (+C +H); enquanto que a
Figura 5-2 apresenta a cobertura, e a Figura 5-3, a acurácia das recomendações realizadas
pelo Presley nas mesmas condições.
Figura 5-1: Comparativo da Precisão Geral (a) e de Sucesso (b) apenas com a Comunicação

55
Figura 5-2: Comparativo da Cobertura Geral (a) e de Sucesso (b) apenas com a Comunicação
Figura 5-3: Comparativo da acurácia apenas com a Comunicação
Apenas pelo gráfico, não é possível identificar a melhor precisão, cobertura e
acurácia entre as recomendações realizadas com e sem o histórico do código fonte. Porém,
ao calcular a média dos valores encontrados, presente na Tabela 5-4, a precisão geral
(28,91%), a cobertura geral (49,90%) e acurácia (71,23%) das recomendações feitas pelo
histórico de modificações de código fonte mais a comunicação realizada pelos
desenvolvedores melhoram as recomendações do Presley comparado ao simples uso da
comunicação dos desenvolvedores (28,73%, 49,54% e 70,97%).
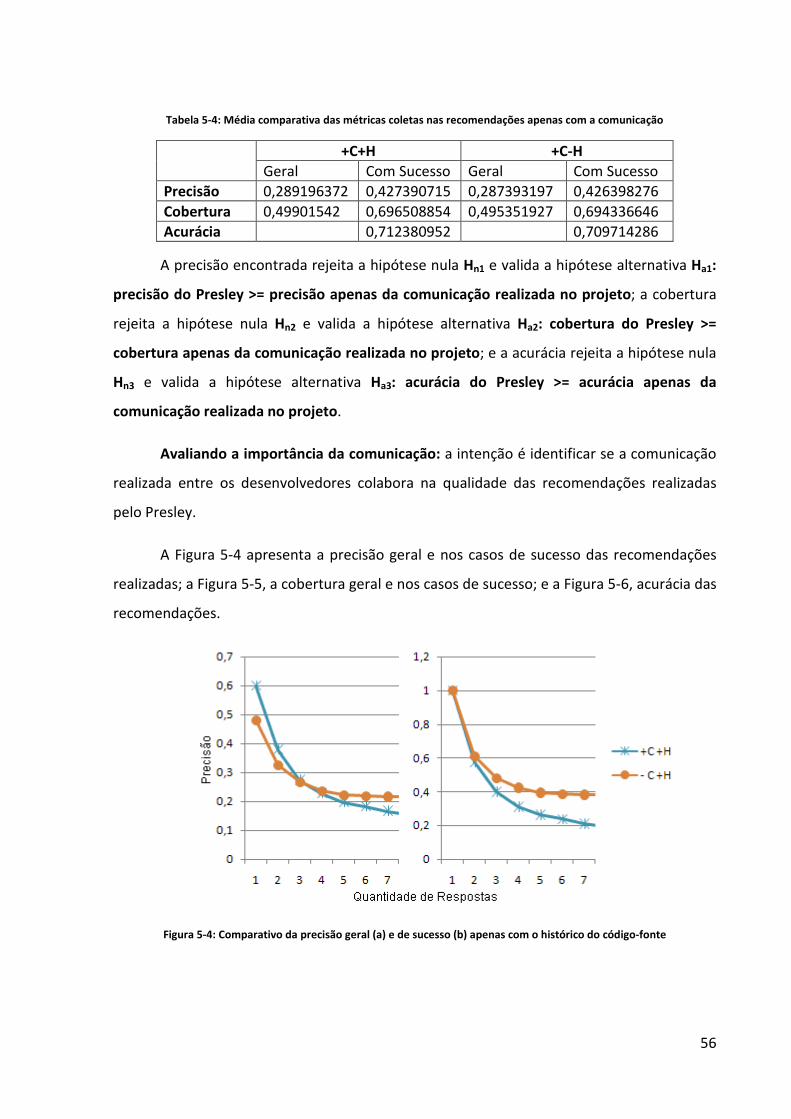
56
Tabela 5-4: Média comparativa das métricas coletas nas recomendações apenas com a comunicação
+C+H +C-H Geral Com Sucesso Geral Com Sucesso
Precisão 0,289196372 0,427390715 0,287393197 0,426398276 Cobertura 0,49901542 0,696508854 0,495351927 0,694336646 Acurácia 0,712380952 0,709714286
A precisão encontrada rejeita a hipótese nula Hn1 e valida a hipótese alternativa Ha1:
precisão do Presley >= precisão apenas da comunicação realizada no projeto; a cobertura
rejeita a hipótese nula Hn2 e valida a hipótese alternativa Ha2: cobertura do Presley >=
cobertura apenas da comunicação realizada no projeto; e a acurácia rejeita a hipótese nula
Hn3 e valida a hipótese alternativa Ha3: acurácia do Presley >= acurácia apenas da
comunicação realizada no projeto.
Avaliando a importância da comunicação: a intenção é identificar se a comunicação
realizada entre os desenvolvedores colabora na qualidade das recomendações realizadas
pelo Presley.
A Figura 5-4 apresenta a precisão geral e nos casos de sucesso das recomendações
realizadas; a Figura 5-5, a cobertura geral e nos casos de sucesso; e a Figura 5-6, acurácia das
recomendações.
Figura 5-4: Comparativo da precisão geral (a) e de sucesso (b) apenas com o histórico do código-fonte

57
Figura 5-5: Comparativo da Cobertura Geral (a) e de Sucesso (b) apenas com o histórico do código-fonte
Figura 5-6: Comparativo da acurácia apenas com o histórico do código-fonte
A média da precisão geral e com sucesso da Tabela 5-5 (28,11% e 52,58%) demonstra
que a precisão das recomendações feitas pelo Presley apenas pelo histórico das alterações
de código fonte é superior ao uso das duas entradas disponíveis (28,92% e 42,73%),
impossibilitando rejeitar a hipótese nula Hn4 e validar a hipótese alternativa Ha4: precisão do
Presley >= precisão apenas do histórico do código-fonte.
Tabela 5-5: Média comparativa das métricas coletas nas recomendações apenas com o histórico do código fonte
+C+H -C+H Geral Com Sucesso Geral Com Sucesso
Precisão 0,289196372 0,427390715 0,281165533 0,525765646 Cobertura 0,49901542 0,696508854 0,37247619 0,67976225 Acurácia 0,712380952 0,546285714

58
Apesar de não obter a precisão desejada, o principal objetivo do Presley é encontrar
ao menos uma pessoa que realmente possa ajudar um desenvolvedor com dificuldades na
implementação do código fonte. Por isso, os valores de cobertura e de acurácia são
considerados mais importantes na definição da qualidade das recomendações feitas pelo
Presley.
As médias de cobertura (49,90% e 69,65%) e acurácia (71,24%), presente na Tabela
5-5, evidenciam que o histórico de modificações de código fonte mais a comunicação
realizada pelos desenvolvedores melhoram as recomendações do Presley comparado ao
simples uso da comunicação no projeto, com cobertura geral de 37,24% e de sucesso
67,98% e acurácia de 54,63%.
Através dos resultados de cobertura e acurácia encontrados, é possível rejeitar a
hipótese nula Hn5 e validar a hipótese alternativa Ha5: cobertura do Presley >= cobertura
apenas do histórico do código-fonte, assim como rejeitar a hipótese nula Hn6 e validar a
hipótese alternativa Ha6: acurácia do Presley >= acurácia apenas do histórico do código-
fonte.
Apesar da hipótese alternativa Ha4 não ter sido válida, as demais hipóteses aprovadas
demonstram que as recomendações realizadas pelo Presley são melhores quando existe a
combinação do histórico de alterações no código fonte e da comunicação realizada no
projeto.
Os resultados encontrados indicam que a comunicação ocorrida no projeto é uma
fonte de informação importante na descoberta dos especialistas no código-fonte, pois, ao
analisar os conhecimentos envolvidos nas mensagens trocadas entre os desenvolvedores, é
possível saber suas preferências e capacidade em responder as solicitações de ajuda, esta
última não é possível apenas com análise do histórico de alterações no código-fonte. Outro
fator positivo na comunicação está na possibilidade do desenvolvedor ter a liberdade de
demonstrar interesses em determinadas partes do projeto, mas que ainda não teve
possibilidade de atuar. Estes fatores podem contribuir numa melhor identificação dos
especialistas no projeto quando se utiliza os registros de comunicação entre os
desenvolvedores.
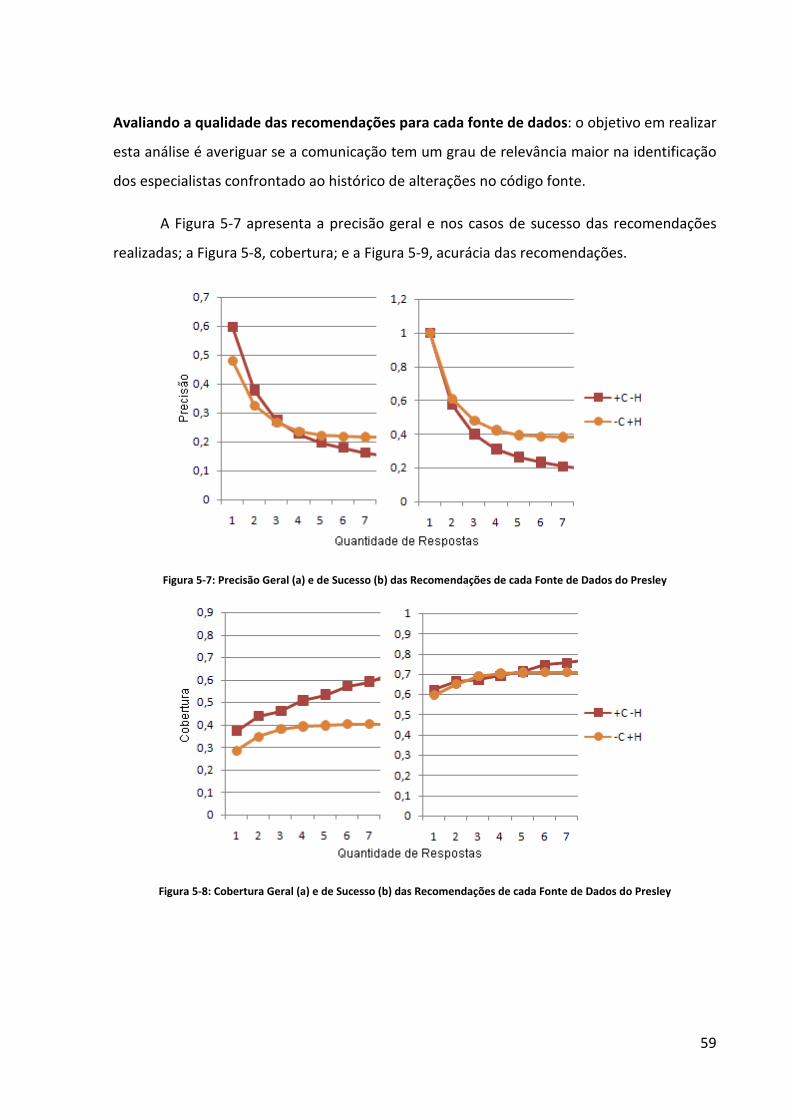
59
Avaliando a qualidade das recomendações para cada fonte de dados: o objetivo em realizar
esta análise é averiguar se a comunicação tem um grau de relevância maior na identificação
dos especialistas confrontado ao histórico de alterações no código fonte.
A Figura 5-7 apresenta a precisão geral e nos casos de sucesso das recomendações
realizadas; a Figura 5-8, cobertura; e a Figura 5-9, acurácia das recomendações.
Figura 5-7: Precisão Geral (a) e de Sucesso (b) das Recomendações de cada Fonte de Dados do Presley
Figura 5-8: Cobertura Geral (a) e de Sucesso (b) das Recomendações de cada Fonte de Dados do Presley

60
Figura 5-9: Acurácia das Recomendações de cada Fonte de Dados do Presley
Através da Tabela 5-6, com a média dos valores obtidos nas figuras apresentadas
anteriormente, é possível determinar a melhor fonte de informação para o Presley. Apesar
de não obter uma boa precisão nos casos de sucesso (42,64% apenas com a comunicação e
52,58% com histórico do código), a comunicação superou o histórico de código fonte nas
demais métricas. As coberturas geral e com sucesso obtidas pelas recomendações feitas com
o histórico de código fonte foram de 37,25% e 67,98% contra 49,54% e 69,43% conquistados
pela comunicação. Na acurácia, o mesmo cenário é repetido: a comunicação, com 70,97%, é
melhor que o histórico de código fonte, com 54,63%.
Os valores indicam que a comunicação realizada entre os desenvolvedores no projeto
tem um grau de importância maior comparado ao histórico de alterações no código fonte.
Tabela 5-6: Média comparativa das métricas coletas nas recomendações com e sem comunicação
+C-H -C+H Geral Com Sucesso Geral Com Sucesso
Precisão 0,287393197 0,426398276 0,281165533 0,525765646 Cobertura 0,495351927 0,694336646 0,37247619 0,67976225 Acurácia 0,709714286 0,546285714
Avaliando a qualidade das recomendações comparada a outras ferramentas: para verificar
se o Presley realiza recomendações de qualidade seria necessário encontrar a melhor
ferramenta disponível na literatura e executar o mesmo experimento realizado com o
Presley. Como não foi possível realizar essa atividade durante o experimento as hipóteses
nulas Hn7, Hn8 e Hn9 não puderam ser testadas; porém, através das métricas de precisão,

61
cobertura e acurácia das abordagens discutidas no capítulo 3 e disponíveis em (McDonald,
2001; Minto e Murphy, 2007; Sindhgatta, 2008; Ye et al., 2007; Anvik et al., 2006; Kagdi et
al., 2008; Vivacqua e Lieberman, 2000), foi possível avaliar as recomendações feitas pelo
Presley.
A Tabela 5-7 apresenta informações sobre a precisão, cobertura e acurácia das
abordagens utilizadas por cada autor identificado na literatura e pelo Presley. Da mesma
forma como foram feitas as avaliações anteriores, os valores adotados para avaliar as
recomendações do Presley foram divididos entre geral e casos de sucesso. Nesta tabela se
encontram o resultado das recomendações do Presley realizadas com o uso das duas fontes
de informação.
Tabela 5-7: Métricas coletadas dos artigos com modelos de descoberta de especialistas em código-fonte
Autores Projeto de Experimento Precisão Cobertura Acurácia (McDonald, 2001) Empresa identificada
como MSC 72%
(Minto e Murphy, 2007) Eclipse, Bugzilla, Firefox
37% 28% 16%
49% 38% 21%
(Sindhgatta, 2008) Projeto identificado apenas como de ferramenta de modelagem UML
68% 93%
(Ye et al., 2007) Lucene 75% (Anvik et al., 2006) Firefox,
Eclipse, Gcc
59% 57% 06%
2% 7%
0,3%
(Kagdi et al., 2008) kdelibs, kdenetwork, kdebase, kdemulimedia, Kdesdk, Apache - Httpd, gcc, koffice
Varia de 43% a 82% entre os
projetos utilizados
(Vivacqua e Lieberman, 2000)
Experts-Exchange fórum 85%
Presley (Geral) Lucene 29% 50% Presley (Com Sucesso) Lucene 43% 70% 71%
Apesar dos valores de precisão (29%) e cobertura (50%) obtidos pelo Presley na
situação geral não serem ruins, o filtro das mensagens selecionadas para o experimento
influenciou no resultado final do experimento ao não avaliar se o conteúdo do e-mail era
suficiente para identificar o conhecimento envolvido. Porém, nos casos de sucesso, é

62
possível representar os e-mails no qual o Presley conseguiu identificar o conhecimento
abordado ou algum código-fonte presente no Lucene, por isto os valores dos casos de
sucesso serão adotados como critério de avaliação com outras ferramentas.
A abordagem desenvolvida pelo Sindhgatta (2008) obteve a melhor precisão (68%) e
cobertura (93%) comparada às demais abordagens. No experimento realizado, um membro
chave do projeto foi escolhido para especificar dez atividades e os conceitos chaves que as
envolvem. Baseado dos conceitos chaves informados, a abordagem desenvolvida
recomendou um conjunto de desenvolvedores para as atividades, que foram comparadas a
lista oito de desenvolvedores indicados pelo membro chave.
Diferente da abordagem de Sindhgatta (2008), o Presley busca identificar
automaticamente os conceitos (tratados como conhecimentos) nas mensagens de dúvidas
dos desenvolvedores para em seguida recomendar os especialistas e o volume de
solicitações de especialistas utilizados no experimento (375 e-mails) foi muito superior ao
volume adotado por Sindhgatta (2008) (10 atividades). Por conta destas diferenças, a
abordagem analisada obteve vantagens que dificultam a comparação entre as métricas de
precisão e cobertura coletadas no Presley.
Com a exclusão do trabalho do Sindhgatta (2008), a melhor precisão obtida está no
trabalho desenvolvido por Anvik e colegas (2006) (com 59% no melhor caso). No
experimento realizado, os dados de entrada foram coletados do repositório de bugs do
projeto selecionado, entre setembro de 2004 a maio de 2005, que permitiu obter um
conjunto de 9.752 relatórios de bugs para treinar a maquina de aprendizagem (machine
learning) desenvolvida. Após realizar a filtragem dos relatórios de bugs registrados em maio
de 2005, apenas 22 relatos foram selecionados para encontrar os especialistas. Da mesma
forma, abordagem escolhida pelos autores também dificulta a comparação direta. Assim
como no Presley, esta abordagem classifica o conteúdo textual da sua fonte de informação
de forma automática. Apesar de não conseguir uma precisão melhor (43%) é possível que
em outros projetos o Presley obtenha melhores percentuais, da mesma forma como
aconteceu no próprio trabalho realizado por Anvik e colegas (2006).
Observando agora a melhor cobertura, principal métrica observada no experimento
realizado, a abordagem desenvolvida por Minto e Murphy (2007) conseguiu a melhor

63
porcentagem entre os trabalhos coletados (49%), porém foi superada pela porcentagem
conquistada pelo Presley (70%). No experimento realizado por esta abordagem, os dados de
entrada foram coletados do repositório de bugs do projeto selecionado no período de dois
anos e permitiu obter um conjunto de 182 bugs como solicitações de especialistas. A
abordagem de Minto e Murphy (2007) tem o mesmo objetivo do Presley, conseguir de
proporcionar um meio de comunicação entre desenvolvedores que precisam de ajuda para
resolver algum determinado problema no código-fonte.
Na última métrica utilizada, Vivacqua e Lieberman (2000) desenvolveu uma
abordagem no qual conseguiu 85% de acurácia. O objetivo deste trabalho é classificar o
conhecimento dos usuários no domínio de programação Java através da análise dos códigos-
fonte criados ao longo do projeto. Para avaliá-lo, foi desenvolvido um protótipo com o perfil
de dez usuários e executado vinte solicitações de especialistas. Após isto, foi verificado se os
especialistas sugeridos seriam capazes de responder as perguntas do questionário extraídas
do fórum Experts-Exchange. Apesar do Presley ter uma menor acurácia (71%), o valor obtido
pode ser considerado importante na avaliação da qualidade das recomendações, indicando
uma boa porcentagem de acerto perante todas as abordagens encontradas (com variação de
43% a 85%).
Avaliando a distribuição das métricas por quantidade de especialistas: por fim, é
necessário distribuir os e-mails selecionados no experimento por quantidade de respostas
recebidas e por quantidade de recomendações para avaliar a situação no qual o Presley
melhor recomenda. A Figura 5-10 e Figura 5-11 apresentam a precisão (a) e a cobertura (b)
nos casos gerais e de sucesso, respectivamente, com os e-mails divididos por quantidade de
respostas recebidas. Já a Figura 5-12 apresenta a acurácia nesta mesma divisão.

64
Figura 5-10: Precisão (a) e a Cobertura (b) gerais das Recomendações por Quantidade de Respostas dos E-mails
Figura 5-11: Precisão (a) e a Cobertura (b) nos casos de sucesso das Recomendações por Quantidade de Respostas dos E-mails
Figura 5-12: Acurácia das Recomendações por Quantidade de Respostas dos E-mails
Como 84% das mensagens utilizadas no experimento contêm três ou menos
respostas, convém analisar o comportamento do Presley apenas para estas mensagens
recomendando três pessoas. Para o caso geral, a ferramenta obteve precisão 24% e

65
cobertura 50%. Porém, como argumentado anteriormente, os casos de sucesso representam
melhor a qualidade das recomendações geradas. Desta forma, a precisão e cobertura são
elevadas para 36% e 77% respectivamente, com a acurácia seria 65%.
Já na situação de mensagens com quatro ou menos respostas, que corresponde a
92% do total, com a ferramenta recomendando quatro pessoas, Presley obteve precisão
20% e cobertura 52% no geral; precisão 29%, cobertura 74% e acurácia 71% apenas nos
casos de sucesso.
Este resultado indica que, na maioria das ocasiões, o Presley conseguiria recomendar
corretamente duas pessoas, aumentando a possibilidade de sucesso na resolução do
problema enfrentado. Por fim, ao observar a acurácia obtida pelo Presley em e-mails com
sete ou menos respostas e para sete recomendações, 79% dos e-mails teriam ao menos uma
recomendação correta e permitiria ao remetente resolver o problema postado.
5.2. Conclusão
Este capítulo apresentou as fases de definição, planejamento, execução, análise,
interpretação e apresentação da avaliação da qualidade das recomendações de especialistas
do Presley. O estudo analisou a possibilidade dos desenvolvedores, em se usando a
ferramenta, terem um menor esforço em localizar os especialistas para os problemas
enfrentados durante a implementação do código fonte.
Mesmo com apenas um projeto, a análise mostrou que o Presley pode ajudar na
colaboração entre equipes distribuídas de desenvolvimento de software e diminuir o tempo
necessário para iniciar a comunicação.
Adicionalmente, o experimento identificou o indício da comunicação registrada nos
e-mails fornecer informações valiosas na identificação dos especialistas ao ponto de superar
a identificação feita através do histórico de alterações no código-fonte. Esta evidência
possibilita a geração de novas hipóteses sobre o valor do conteúdo existente em fontes de
informação textuais. Informações existentes em e-mails, relatórios de bugs ou até nas
descrições das atividades desempenhadas pelos desenvolvedores registradas em

66
ferramentas de apoio a coordenação do projeto (como os cronogramas) podem fornecer
dados importantes na formação dos perfis dos especialistas.
Espera-se com indício encontrado, iniciar de uma investigação mais profunda sobre
como a classificação dos conhecimentos, contidos nos registros de comunicação entre os
desenvolvedores, e poder ajudar na identificação dos especialistas existentes de projetos de
software.
No próximo capítulo, serão apresentadas as conclusões deste trabalho, as principais
contribuições e as direções para trabalhos futuros.

67
6. Conclusão
O Desenvolvimento Distribuído de Software tem sido adotado por várias empresas que
buscam novos mercados, menores custos no desenvolvimento de software e melhor
qualidade nos seus produtos. Como discutido no capítulo 2, existem diversos problemas de
comunicação em equipes distribuídas, entre estes, a dificuldade de saber a quem contatar
quando se tem alguma problema durante a implementação do software pode gerar atrasos
que refletem negativamente no cronograma do projeto, principalmente quando as equipes
estão separadas temporalmente.
Os capítulos 3 e 5 apresentaram sete Sistemas de Recomendação de Especialistas em
código-fonte com objetivos próximos a este trabalho. No entanto, existem diferenças chaves
entre o sistema proposto e os demais. Inicialmente, a análise feita nos relacionamentos
existentes no código-fonte em questão para contribuir na identificação dos especialistas não
é realizado por nenhum outro sistema. Além disso, excluindo o trabalho feito pelo Ye e
colegas (2008), as outras ferramentas não utilizam a comunicação entre os desenvolvedores
como fonte de informação para as suas recomendações. Finalmente, este trabalho buscou
identificar os conhecimentos no qual os desenvolvedores demonstraram interesse ao buscar
por ajuda ou ao contribuir na solução de algum problema.
Neste contexto, este trabalho apresentou e avaliou um Sistema de Recomendação de
Especialistas chamado Presley, com o objetivo de auxiliar a comunicação entre equipes
distribuídas e diminuir o tempo necessário para iniciar a colaboração entre os integrantes da
equipe. O Presley utiliza o conteúdo de arquivos textuais com descrição sobre o código-fonte
implementado, o histórico de alterações deste código e os registros de comunicação
ocorrida entre os desenvolvedores durante o desenvolvimento do software para identificar
as pessoas mais adequadas a solucionar problemas específicos que surgem na fase de
implementação do projeto.

68
6.1. Contribuições da pesquisa
As principais contribuições deste trabalho podem ser divididas nos seguintes
aspectos: (I) a execução de uma Revisão Sistemática da Literatura sobre a comunicação no
Desenvolvimento Distribuído de Software; (II) a formulação e definição dos requisitos,
arquitetura e implementação de um Sistema de Recomendação de Especialistas; e (III) um
experimento que avaliou a qualidade das recomendações feitas pelo sistema proposto.
A Revisão Sistemática da Literatura. O objetivo inicial do trabalho foi entender os
conceitos e os problemas envolvidos na comunicação em equipes de desenvolvimento de
software quando estão distribuídas, assim como as experiências com técnicas, processos e
ferramentas utilizadas nesta área. O resultado da revisão mostrou que a baixa percepção
entre os participantes de equipes distribuídas é a principal dificuldade enfrentada na
comunicação assíncrona (Trindade et al., 2008).
O Presley. Após o estudo sobre as técnicas adotadas pelos Sistemas de
Recomendação tradicionais, o Presley foi definido para identificar as pessoas mais
qualificadas em solucionar problemas relativos ao desenvolvimento do código-fonte. Os
requisitos foram baseados nos resultados obtidos com Revisão Sistemática da Literatura
feita e nos conceitos aprendidos com as técnicas estudadas (Trindade et al., 2009a; Trindade
et al., 2009b).
O Experimento. De forma a avaliar as recomendações feitas pelo Presley, um
experimento foi executado no contexto do Desenvolvimento Distribuído de Software. O
estudo analisou a qualidade das recomendações geradas e identificou que, além da
ferramenta conseguir uma boa taxa de acertos, que reduziria o esforço necessário para
iniciar a comunicação entre os desenvolvedores, a comunicação registrada em ferramentas
de comunicação assíncrona, como e-mail, pode fornecer valiosas informações na
identificação dos especialistas.

69
6.2. Trabalhos futuros
Devido à restrição de tempo imposto pelo Mestrado, este trabalho pode ser considerado o
primeiro passo na direção de uma ferramenta eficiente de comunicação assíncrona no DDS.
Para isto, as seguintes questões devem ser investigadas como trabalhos futuros.
Novos experimentos. Esta dissertação apresentou todo o processo de execução de
um experimento. Porém, novos estudos devem ser realizados tanto em outros projetos de
código aberto, quanto em empresas com seus funcionários distribuídos em várias unidades
de desenvolvimento para certificar que os resultados são generalizáveis.
Comunicação como fonte de identificação de especialistas. O experimento proveu
indícios que, ao analisar o conteúdo dos registros de comunicação, é possível ter uma
melhor identificação dos especialistas comparada a análise feita no histórico do código-
fonte. A hipótese da análise da comunicação ocorrida no projeto ser melhor que a análise
feita no histórico de alterações do código-fonte merece uma investigação mais profunda na
literatura sobre como extrair da comunicação elementos suficientes para comprovar esta
hipótese.
Melhoria no sistema de pontuação para determinar os especialistas. Através do
experimento notou-se que a quantidade de participações na comunicação supera as
participações existentes no histórico de alterações no código-fonte. Como o Presley trata as
duas fontes de informação com o mesmo grau de importância, somando os seus valores, a
participação na comunicação gerou boa parte dos resultados. Por isto, será necessário
formular um novo cálculo que pondere as entradas e defina aquela com maior importância
na identificação dos especialistas.
Inserir o contexto dos desenvolvedores. Conforme o trabalho de Petry (2007), é
importante considerar o contexto da equipe e dos participantes ao iniciar uma colaboração.
As informações contextuais abrangem dados sobre o ambiente virtual de trabalho, a
organização do trabalho, as características e os papéis dos indivíduos, os objetivos, os
prazos, entre outros. Assim como no ICARE (Petry, 2007), seria importante o Presley

70
considerar determinadas informações de contexto como: disponibilidade, acessibilidade,
nível organizacional e rede social.
6.3. Contribuições acadêmicas
O conhecimento adquirido durante o desenvolvimento deste trabalho resultou nas seguintes
publicações:
• Trindade, C. C.; Moraes, A. K. O.; Meira, S. R. L. (2008). Comunicação em equipes
distribuídas de desenvolvimento de software: Revisão sistemática. In ESELAW '08:
Proceedings of the 5th Experimental Software Engineering Latin American Workshop.
• Trindade, C. C.; Moraes, A. K. O.; Barbosa, Y. A. M.; Albuquerque, J. O.; Meira, S. R. L.
(2009). Presley: uma Ferramenta de Recomendação de Especialistas no Contexto de
Código-Fonte para Apoio à Colaboração em Desenvolvimento Distribuído de
Software. XXIII Simpósio Brasileiro de Engenharia de Software, Seção de
ferramentas, Fortaleza, Ceará, Brasil.
• Trindade, C. C.; Moraes, A. K. O.; Barbosa, Y. A. M.; Albuquerque, J. O.; Meira, S. R. L.
(2009). Um Sistema de Recomendação de Especialistas em Desenvolvimento
Distribuído de Software: Requisitos, Projeto e Resultados Preliminares. VI Simpósio
Brasileiro de Sistemas Colaborativos, Fortaleza, Ceará, Brasil.
6.4. Conclusões finais
Atualmente várias empresas recorrem ao Desenvolvimento Distribuído de Software para se
tornarem mais competitivas e obterem os desenvolvedores mais qualificados como parte
dos seus recursos. Porém a baixa percepção de "quem sabe o que" no projeto dificulta o
início do processo de comunicação entre os membros das equipes distribuídas e reflete no
cronograma do projeto.
Neste contexto foi apresentado o Presley para identificar os especialistas em
questões relacionadas à implementação do código-fonte. A ferramenta foi baseada nos
resultados obtidos na Revisão Sistemática da Literatura realizada sobre a comunicação em

71
equipes distribuídas e em conceitos existentes nos Sistemas de Recomendação. A avaliação
da ferramenta foi feita através de um projeto de código aberto e mostrou que as
recomendações de especialistas realizadas conseguiriam reduzir o esforço necessário de
encontrar as pessoas mais qualificadas para resolver questões relacionadas ao código-fonte.

72
7. Referências Bibliográficas
Ågerfalk, P. J. and Fitzgerald, B. (2006) "Flexible and distributed software processes: Old petunias in new bowls?". Communications of the ACM, 49, 27 - 34
Ali Babar, M.; Verner, J. M. and Nguyen, P. T. (2007) "Establishing and maintaining trust in software outsourcing relationships: An empirical investigation". Journal of Systems and Software, 80, 1438 - 1449
Allen, T.J. (1977) Managing the Flow of Technology, MIT Press.
Almeida, M. E. B. (2003) "Educação a distância na internet: abordagens e contribuições dos ambientes digitais de aprendizagem". Educ. Pesqui. [online]. vol.29, n.2, pp. 327-340. ISSN 1517-9702.
Anvik, J.; Hiew, L. and Murphy, G. C. (2006) "Who should fix this bug?" ICSE '06: Proceeding of the 28th international conference on Software engineering, ACM Press, 361-370
Basili, V. R., Caldiera, G. and Rombach, H. D. (1994). "The Goal Question Metric Approach". Encyclopedia of Software Engineering, p. 528-532.
Biolchini, J.; Mian, P. G.; Natali, A. C. C. and Travassos, G. H. (2005) "Systematic Review in Software Engineering". PESC - COPPE/UFRJ
Brereton, P.; Kitchenham, B. A.; Budgen, D.; Turner, M. and Khalil, M. (2007) "Lessons from applying the systematic literature review process within the software engineering domain" J. Syst. Softw., Elsevier Science Inc., 80, 571-583
Brito, K. S. (2007) "LIFT: A Legacy InFormation retrieval Tool". Universidade Federal de Pernambuco
Canfora, G.; Cimitile, A.; Di Lucca, G. A. and Visaggios, C. A. (2006) "How distribution affects the success of pair programming". International Journal of Software Engineering and Knowledge Engineering, 16, 293 - 313
Cardoso, O. N. P. (2000) "Recuperação de Informação". Infocomp Revista de Computação da Ufla, Lavras - MG, v. 1, p. 33-38
Carmel, E. (1999). Global Software Teams: Collaborating Across Borders and Time Zones. Prentice Hall.
Damian, D.; Lanubile, F. and Mallardo, T. (2008) "On the need for mixed media in distributed requirements negotiations" IEEE Transactions on Software Engineering, 34, 116 - 132
de Souza, C. R., Redmiles, D., Cheng, L., Millen, D., and Patterson, J. (2004) "Sometimes you need to see through walls: a field study of application programming interfaces" CSCW '04: Proceedings of the 2004 ACM Conference on Computer Supported Cooperative Work. ACM, New York, NY, 63-71.
de Souza, C. R.; Quirk, S.; Trainer, E. and Redmiles, D. F. (2007) "Supporting collaborative software development through the visualization of socio-technical dependencies" GROUP '07: Proceedings of the 2007 international ACM conference on Supporting group work, ACM, 147-156
Espinosa, A. J. and Carmel, E. (2004) "The Effect of Time Separation on Coordination Costs in Global Software Teams: A Dyad Model", In Proceedings of the Proceedings of the 37th Annual Hawaii International Conference on System Sciences, IEEE Computer Society, Washington, DC, USA
Espinosa, A. J. and Pickering, C. (2006) "The Effect of Time Separation on Coordination Processes and Outcomes: A Case Study", In Proceedings of the 39th Annual Hawaii International Conference on System Sciences, IEEE Computer Society, Washington, DC, USA

73
Espinosa, A. J. et al (2007) "Team Knowledge and Coordination in Geographically Distributed Software Development", Journal of Management Information Systems, Vol. 24, No. 1, pp. 135 - 169
Espinosa, J. A. and Carmel, E. (2003) "The impact of time separation on coordination in global software teams: A conceptual foundation". Software Process Improvement and Practice, 8, 249 - 266
Galho, T. S. (2003) "Categorização automática de Documentos de Texto utilizando Lógica Difusa" Universidade Luterana do Brasil
Galho, T. S. and Moraes, S. M. W. (2003) "Categorização Automática de Documentos de Texto Utilizando Lógica Difusa" XV Salão e XIII Feira de Iniciação_científica da UFRGS, 93-94
Ganesan, D.; Muthig, D.; Knodel, J. and Yoshimura, K. (2006) "Discovering Organizational Aspects from the Source Code History Log during the Product Line Planning Phase-A Case Study" WCRE '06: Proceedings of the 13th Working Conference on Reverse Engineering, IEEE Computer Society, 211-220
Gilbert, E. and Karahalios, K. (2007) "CodeSaw: A social visualization of distributed software development" Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 4663 NCS, 303 - 316
Gumm, D. C. (2006,) "Distribution Dimensions in Software Development Projects: A Taxonomy", IEEE Software, 23, 45-51
Gutwin, C.; Schneider, K.; Paquette, D. and Penner, R. (2005) "Supporting group awareness in distributed software development". Lecture Notes in Computer Science, 3425, 383 - 397
Herbsleb, J. and Mockus, A. (2003) "An empirical study of speed and communication in globally distributed software development", IEEE Transactions on Software Engineering, Publisher IEEE Computer Society Press, volume 29, number 6, pages 481-494
Herbsleb, J. D. (2007) "Global Software Engineering: The Future of Socio-technical Coordination", FOSE '07: 2007 Future of Software Engineering, IEEE Computer Society, 188-198
Herbsleb, J.; Mockus, A.; Finholt, T. and Grinter, R. (2001) "An empirical study of global software development: Distance and speed". Proceedings - International Conference on Software Engineering, 81 - 90
Herlocker, J. L. (2000) "Understanding and Improving Automated Collaborative Filtering Systems" University of Minnesota
Hogan, B. (2006) "Lessons Learned from an eXtremely Distributed Project", In Proceedings of the conference on AGILE 2006, publisher IEEE Computer Society
Jang, C.; Steinfield, C. and Pfaff, B. (2002). "Virtual team awareness and groupware support: an evaluation of the teamSCOPE system". International Journal of Human Computer Studies, Academic Press, Inc., 56, 109-126
Kagdi, H. H.; Hammad, M. and Maletic, J. I. (2008) "Who can help me with this source code change?" ICSM, IEEE, 157-166
Larman, C. (2004) Applying UML and Patterns : An Introduction to Object-Oriented Analysis and Design and Iterative Development (3rd Edition) Prentice Hall PTR
Layman, L.; Williams, L.; Damian, D. and Bures, H. (2006) "Essential communication practices for Extreme Programming in a global software development team". Information and Software Technology, 48, 781 - 794
Loh, S. (2001) "Abordagem Baseada em Conceitos para Descoberta de Conhecimento em Textos" Universidade Federal do Rio Grande do Sul
Mangan, M. A. S.; Borges, M. R. S. and Werner, C. M. L. (2004) "A middleware to increase awareness in distributed software development workspaces". Proceedings - WebMedia and LA-Web 2004, 62 - 64

74
Mcdonald, D. and Mcdonald, D. W. (2001) "Evaluating Expertise Recommendations" Proceedings of the 2001 International ACM SIGGROUP Conference on Supporting Group Work, Press, 214-223
McDonald, D. W. and Ackerman, M. S. (2000) "Expertise recommender: a flexible recommendation system and architecture" CSCW '00: Proceedings of the 2000 ACM conference on Computer supported cooperative work, ACM, 231-240
Minto, S. and Murphy, G. C. (2007) "Recommending Emergent Teams" ICSEW '07: Proceedings of the 29th International Conference on Software Engineering Workshops, IEEE Computer Society, 5
Moe, N. B. and Smite, D. (2007) "Understanding lacking trust in global software teams: A multi-case study". Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 4589 NCS, 20 - 34
Moraes, A. K. O. (2007) "Uma Proposta de Processo de Software para Fábricas de Software de Código Aberto". Dissertação de Mestrado. Centro de Informática, Universidade Federal de Pernambuco.
Paasivaara, M. and Lassenius, C. (2003) "Collaboration practices in global interorganizational software development projects". Software Process Improvement and Practice, 8, 183 - 199
Parvathanathan, K. et al (2007), "Global Development and Delivery in Practice Experiences of the IBM Rational India Lab". International Technical Support Organization, IBM
Petry, H. (2007) "ICARE: um sistema de recomendação de especialistas sensível a contexto" Universidade Federal de Pernambuco
Ramesh, B.; Cao, L.; Mohan, K. and Xu, P. (2006) "Can distributed software development be agile?". Communications of the ACM, 49, 41 - 46
Robillard, M. P. (2008) "Topology analysis of software dependencies" ACM Trans. Softw. Eng. Methodol., ACM, 17, 1-36
Sakthivel, S. (2005) "Virtual workgroups in offshore systems development". Information and Software Technology, 47, 305 - 318
Sakuda, L. O. ; Vasconcelos, F. C. (2005) "Teletrabalho: Desafios e Perspectivas" O&S. Organizações & Sociedade , Salvador, BA, v. 33, p. 39-50.
Sim, Y.-W. and Crowder, R. (2004) "Evaluation of an Approach to Expertise Finding." PAKM, Springer, 3336, 141-152
Sindhgatta, R. (2008) "Identifying domain expertise of developers from source code" KDD '08: Proceeding of the 14th ACM SIGKDD international conference on Knowledge discovery and data mining, ACM, 981-989
Smite, D. (2006) "Global software development projects in one of the biggest companies in Latvia: Is geographical distribution a problem?" Software Process Improvement and Practice, 11, 61 - 76
Sommerville, I. (2003) Engenharia de Software (6ª Edição) Addison-Wesley Pub. Co. São Paulo
Steinfield, C. et al. (2002) "Communication and collaboration processes in global virtual teams", Unpublished INTEnD report, Michigan State University, East Lansing, Michigan
Terveen, L. and Hill, W. (2001) "Beyond Recommender Systems: Helping People Help Each Other"
Thissen, M. R.; Page, J. M.; Bharathi, M. C. and Austin, T. L. (2007) "Communication tools for distributed software development teams". Proceedings of the 2007 ACM SIGMIS Computer Personnel Research Conference: The Global Information Technology Workforce, SIGMIS-CPR 2007, 28 - 35
Vivacqua, A. and Lieberman, H. (2000) "Agents to assist in finding help" CHI '00: Proceedings of the SIGCHI conference on Human factors in computing systems, ACM, 65-72

75
Vivacqua, A. S. (1999) "Agents for Expertise Location" In Proc. 1999 AAAI Spring Symposium Workshop on Intelligent Agents in Cyberspace, 9-13
Webster, J. and Watson, R. T. (2002) "Analyzing the Past to Prepare for the Future: Writing a Literature Review". MIS Quarterly, 26, 13-23
Wives, L. K. (1999) "Um estudo sobre Agrupamento de Documentos Textuais em Processamento de Informações não Estruturadas Usando Técnicas de Clustering" Universidade Federal do Rio Grande do Sul
Wives, L. K. (2002) "Tecnologias de Descoberta de Conhecimento em Textos Aplicadas à Inteligência Competitiva". Exame De Qualificação. Universidade Federal do Rio Grande do Sul
Wohlin, C.; Runeson, P.; Host, M.; Ohlsson, C.; Regnell, B. and Wesslén, A. (2000) "Experimentation in Software Engineering: an Introduction" Kluver Academic Publishers
Xiaohu, Y.; Bin, X.; Zhijun, H. and Maddineni, S. R. (2004) "Extreme programming in global software development" Canadian Conference on Electrical and Computer Engineering, 4, 1845 - 1848
Ye, Y.; Nakakoji, K. and Yamamoto, Y. (2007) "Reducing the Cost of Communication and Coordination in Distributed Software Development." SEAFOOD, Springer, 4716, 152-169
Ye, Y.; Yamamoto, Y.; Nakakoji, K.; Nishinaka, Y. and Asada, M. Amaral, V. (2007) "Searching the library and asking the peers: learning to use Java APIs on demand". PPPJ, ACM, 272, 41-50

76
Apêndice A – Protocolo de Revisão
Sistemática
Objetivo
O objetivo inicial desta pesquisa consiste em levantar os conceitos envolvidos na
Gerência de Comunicação, assim como, as experiências desta área em projetos de
desenvolvimento de softwares com equipes distribuídas (técnicas, processos, ferramentas
utilizadas e dificuldades encontradas).
1. Formulação da pergunta
1. Quais são os conceitos envolvidos na gerência da comunicação?
2. Quais as dificuldades encontradas na comunicação em equipes de projetos de
software distribuídas?
3. Em projetos de desenvolvimento com ambientes fisicamente distribuídos existem
processos, técnicas ou ferramentas para obter-se uma efetiva comunicação?
a. Em caso positivo, quais foram os processos, técnicas ou ferramentas
adotadas?
b. E quais são os seus pontos positivos e negativos?
1.1. Qualidade e Amplitude
Intervenção
Avaliação de processos, técnicas e ferramentas utilizadas por equipes distribuídas
que contribuíram Gerência de Comunicação.
Efeito

77
Encontrar possíveis processos, técnicas ou ferramentas que possibilitem uma efetiva
comunicação em ambientes distribuídos e dar fundamentos necessários para conduzir um
estudo mais profundo em como ter uma gerência de comunicação integrada com a gerência
de conhecimento em ambientes distribuídos.
População
Equipes de desenvolvimento de software distribuídas.
Aplicação
Projetos de desenvolvimento de softwares em ambientes distribuídos.
Palavras - Chave
• Intervenção
Processo – Process, Method, Methodology, Technique, Approach
Técnicas – Mechanism, Strategy
Ferramentas – Tool
Gerência de Comunicação – Communication, Communication Management,
Coordination Management
• População
Equipes distribuídas de desenvolvimento de software
Desenvolvimento Distribuído - Distributed software development, global software
development, virtual organization
Equipes distribuídas - global team, distributed team, dispersed team, virtual team
1.2. Definição de critérios de seleção de fontes

78
Os artigos devem estar disponíveis na web: com a possibilidade de mecanismos de
busca através de palavras-chave e com garantia de resultados únicos ao mesmo conjunto de
palavras-chave.
Os artigos também podem ser obtidos por pessoas com experiência no assunto.
Linguagem de estudo
Inglês - Por ser considerada a língua padrão na Engenharia de Software
1.3. Identificação das fontes
Métodos de pesquisa em fontes
Pesquisas através de mecanismos de busca e debates com especialistas.
String de busca
(Process OR Method OR Methodology OR Technique OR Approach OR Mechanism OR
Strategy OR Tool) AND ("Communication" OR "communication Management" OR
"coordination management") AND ("distributed software development" OR "global software
development" OR "virtual software organization" OR "global software team" OR "distributed
software team" OR "dispersed software team" OR "virtual software team")
Fonte utilizada
Engineering Village

79
2. Seleção dos estudos
2.1. Definição dos estudos
Definição dos critérios de inclusão ou exclusão dos estudos
Os artigos devem:
• Estar disponíveis na web;
• Ser escritos em Inglês;
• Abordar conceitos empregados na Gerência de Comunicação e Conhecimento;
• Abordar os processos, técnicas ou ferramentas utilizadas em projetos fisicamente
distribuídos e relatar como foi a experiência.
A escala envolvida nos critérios envolve duas opções: Sim ou Não.
Definição dos tipos de estudos
Todos os tipos de estudos coletados para a pesquisa serão considerados.
Procedimento para a seleção dos estudos
O processo de seleção seguirá os seguintes passos:
1. O pesquisador executa as strings de busca em cada uma das fontes selecionadas;
2. Os artigos são obtidos da fonte e documentados na lista de artigos encontrados,
presentes no formulário de condução da revisão;
3. Para selecionar os estudos iniciais, os abstracts e conclusões de todos os estudos
obtidos serão lidos e verificados através dos critérios de inclusão e exclusão
estabelecidos;

80
4. Os artigos incluídos e excluídos são documentados na lista de artigos incluídos e na
lista de artigos excluídos, respectivamente, presentes no Formulário de Condução da
Revisão, juntamente com a justificativa de sua inclusão ou exclusão.
5. Os artigos incluídos são avaliados mediante a leitura do artigo inteiro; os artigos
incluídos são documentados no Formulário de Seleção de Estudos e encaminhados
para a avaliação da qualidade dos estudos primários. Os artigos excluídos são
documentados na lista de artigos excluídos junto com a justificativa de exclusão.
2.2. Executar seleção
Inicial seleção dos estudos
A lista de estudos estará contida no formulário de condução da revisão
Avaliação da qualidade dos estudos
Aqui será utilizado o formulário de extração de dados e matriz de conceitos

81
3. Extração da informação
3.1. Definição do critério de inclusão e exclusão de
informações
As informações extraídas dos estudos devem conter conceitos, processos, técnicas ou
ferramentas envolvidas na gestão da comunicação ou conhecimento.
3.2. Formas de extração de dados
Para cada estudo selecionado, durante a execução do processo de avaliação da qualidade
dos estudos primários, será preenchida uma cópia do formulário de extração de dados e
checados os seguintes itens encontrados em matrizes:
• Conceitos;
• Dificuldades de comunicação;
• Processos, técnicas, ferramentas e seus pontos positivos e negativos.
Formulários
Para possibilitar a documentação da revisão sistemática, facilitando a extração e
sumarização dos dados, foram elaborados os seguintes formulários:
Formulário de Condução da Revisão:
Formulário contendo campos para a armazenagem de informações sobre a fonte onde a
busca foi realizada, a data de realização da busca, as combinações de palavras-chave que
proporcionaram a busca dos artigos e a lista dos artigos encontrados.
Formulário de Seleção de Estudos:

82
Formulário contendo campos que informem: nome do artigo, lista de autores, data de sua
publicação, veículo de publicação do artigo, fonte de onde foi obtido e situação do artigo
(pendente, incluído e excluído).
Formulário de Extração de Dados:
Formulário contendo campos para o resumo do artigo, objetivo do estudo, descrição do
estudo experimental, resultados do estudo, além de comentários adicionais do pesquisador
que extraiu os dados, entre outros.

83
Apêndice B – Formulário de condução
da revisão sistemática
Lista de artigos encontrados com a busca realizada no Engineering Village no dia onze de
abril de 2008.
Artigos aprovados
Ali Babar, M.; Verner, J. M. and Nguyen, P. T. Establishing and maintaining trust in software
outsourcing relationships: An empirical investigation Journal of Systems and Software, 2007,
80, 1438 - 1449
Aranda, G. N.; Cechich, A.; Vizcaino, A. and Piattini, M. Technology selection to improve
global collaboration Proceedings - 2006 IEEE International Conference on Global Software
Engineering, ICGSE 2006, 2006, 223 - 230
Canfora, G.; Cimitile, A.; Di Lucca, G. A. and Visaggios, C. A. How distribution affects the
success of pair programming International Journal of Software Engineering and Knowledge
Engineering, 2006, 16, 293 - 313
Damian, D.; Lanubile, F. and Mallardo, T. On the need for mixed media in distributed
requirements negotiations IEEE Transactions on Software Engineering, 2008, 34, 116 - 132
Espinosa, J. A. and Carmel, E. The effect of time separation on coordination costs in global
software teams: A dyad model Proceedings of the Hawaii International Conference on
System Sciences, 2004, 37, 683 - 692
Espinosa, J. A. and Carmel, E. The impact of time separation on coordination in global
software teams: A conceptual foundation Software Process Improvement and Practice,
2003, 8, 249 - 266

84
Gilbert, E. and Karahalios, K. CodeSaw: A social visualization of distributed software
development Lecture Notes in Computer Science (including subseries Lecture Notes in
Artificial Intelligence and Lecture Notes in Bioinformatics), 2007, 4663 NCS, 303 - 316
Gutwin, C.; Penner, R. and Schneider, K. Group awareness in distributed software
development Proceedings of the ACM Conference on Computer Supported Cooperative
Work, CSCW, 2004, 72 - 81
Gutwin, C.; Schneider, K.; Paquette, D. and Penner, R. Supporting group awareness in
distributed software development Lecture Notes in Computer Science, 2005, 3425, 383 - 397
Herbsleb, J.; Mockus, A.; Finholt, T. and Grinter, R. An empirical study of global software
development: Distance and speed Proceedings - International Conference on Software
Engineering, 2001, 81 - 90
Herbsleb, J. D. and Mockus, A. An empirical study of speed and communication in globally
distributed software development IEEE Transactions on Software Engineering, 2003, 29, 481
- 494
Layman, L.; Williams, L.; Damian, D. and Bures, H. Essential communication practices for
Extreme Programming in a global software development team Information and Software
Technology, 2006, 48, 781 - 794
Lopes, L.; Prikladnicki, R.; Audy, J. L. N. and Majdenbaum, A. Distributed requirements
specification: Minimizing the effect of geographic dispersioni ICEIS 2004 - Proceedings of the
Sixth International Conference on Enterprise Information Systems, 2004, 531 - 534
Mangan, M. A. S.; Borges, M. R. S. and Werner, C. M. L. A middleware to increase awareness
in distributed software development workspaces Proceedings - WebMedia and LA-Web
2004, 2004, 62 - 64
Moe, N. B. and Smite, D. Understanding lacking trust in global software teams: A multi-case
study Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial
Intelligence and Lecture Notes in Bioinformatics), 2007, 4589 NCS, 20 - 34

85
Paasivaara, M. and Lassenius, C. Collaboration practices in global inter-organizational
software development projects Software Process Improvement and Practice, 2003, 8, 183 -
199
Ramesh, B.; Cao, L.; Mohan, K. and Xu, P. Can distributed software development be agile?
Communications of the ACM, 2006, 49, 41 - 46
Rocha De Faria, H. and Adler, G. Architecture-centric global software processes Proceedings -
2006 IEEE International Conference on Global Software Engineering, ICGSE 2006, 2006, 241 -
242
Sakthivel, S. Virtual workgroups in offshore systems development Information and Software
Technology, 2005, 47, 305 - 318
Smite, D. Global software development projects in one of the biggest companies in Latvia: Is
geographical distribution a problem? Software Process Improvement and Practice, 2006, 11,
61 - 76
Thissen, M. R.; Page, J. M.; Bharathi, M. C. and Austin, T. L. Communication tools for
distributed software development teams Proceedings of the 2007 ACM SIGMIS Computer
Personnel Research Conference: The Global Information Technology Workforce, SIGMIS-CPR
2007, 2007, 2007, 28 - 35
Wongthongtham, P.; Chang, E. and Dillon, T. Towards 'ontology'-based software engineering
for multi-site software development 2005 3rd IEEE International Conference on Industrial
Informatics, INDIN, 2005, 2005, 362 - 365
Wongthongtham, P.; Chang, E.; Dillon, T. and Sommerville, I. Ontology-based multi-site
software development methodology and tools Journal of Systems Architecture, 2006, 52,
640 - 653
Xiaohu, Y.; Bin, X.; Zhijun, H. and Maddineni, S. R. Extreme programming in global software
development Canadian Conference on Electrical and Computer Engineering, 2004, 4, 1845 -
1848

86
Ye, Y.; Nakakoji, K. and Yamamoto, Y. Reducing the cost of communication and coordination
in distributed software development Lecture Notes in Computer Science (including subseries
Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2007, 4716 NCS,
152 - 169
Ågerfalk, P. J. and Fitzgerald, B. Flexible and distributed software processes: Old petunias in
new bowls? Communications of the ACM, 2006, 49, 27 – 34
Artigos reprovados
Aranda, G. N.; Vizcaino, A.; Cechich, A. and Piattini, M. How to choose groupware tools
considering stakeholders' preferences during requirements elicitation? Lecture Notes in
Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture
Notes in Bioinformatics), 2007, 4715 NCS, 319 - 327
Canfora, G. and De Lucia, A. Workshop on cooperative supports for distributed software
engineering processes Proceedings - IEEE Computer Society's International Computer
Software and Applications Conference, 2002, 1047 - 1048
Ebert, C.; Parro, C.; Suttels, R. and Kolarczyk, H. Improving validation activities in a global
software development Proceedings - International Conference on Software Engineering,
2001, 545 - 554
Goldmann, S. and Kotting, B. Software engineering over the internet IEEE Internet
Computing, 1999, 3, 93 - 94
Kaiser, G. E. and Dossick, S. E. Workgroup middleware for distributed projects Proceedings of
the Workshop on Enabling Technologies: Infrastructure for Collaborative Enterprises, WET
ICE, 1998, 63 - 68
Mak, D. K. and Kruchten, P. B. Task coordination in an agile distributed software
development environment Canadian Conference on Electrical and Computer Engineering,
2007, 606 - 611
Maurer, F. 4th ICSE workshop on "Software Engineering over the Internet" Proceedings -
International Conference on Software Engineering, 2001, 751 - 752

87
Nakamura, K.; Fujii, Y.; Kiyokane, Y.; Nakamura, M.; Hinenoya, K.; Peck, Y. H. and Choon-Lian,
S. Distributed and concurrent development environment via sharing design information
Proceedings - IEEE Computer Society's International Computer Software and Applications
Conference, 1997, 274 - 279
Paasivaara, M. and Lassenius, C. Could global software development benefit from agile
methods? Proceedings - 2006 IEEE International Conference on Global Software Engineering,
ICGSE 2006, 2006, 109 - 113
Rodriguez, F.; Geisser, M.; Berkling, K. and Hildenbrand, T. Evaluating collaboration
platforms for offshore software development scenarios Lecture Notes in Computer Science
(including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in
Bioinformatics), 2007, 4716 NCS, 96 - 108
Sa, J. and Maslova, E. A unified process support framework for global software development
Proceedings - IEEE Computer Society's International Computer Software and Applications
Conference, 2002, 1065 - 1070
Stack, B. M. and Jenks, S. F. A middleware architecture to facilitate distributed programming
Proceedings of the International Conference on Parallel and Distributed Processing
Techniques and Applications, 2003, 1, 201 - 207
Wongthongtham, P.; Chang, E. and Dillon, T. Multi-site distributed software development:
Issues, solutions, and challenges Lecture Notes in Computer Science (including subseries
Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics), 2007, 4706 NCS,
346 - 359
Wongthongtham, P.; Chang, E. and Dillon, T. Methodology for multi-site software
engineering using Ontology Proceedings of the International Conference on Software
Engineering Research and Practice, SERP'04, 2004, 2, 477 - 482
Yau, S. S. and Xia, B. Object-oriented distributed component software development based on
CORBA Proceedings - IEEE Computer Society's International Computer Software and
Applications Conference, 1998, 246 - 251

88
Proceedings of the 2007 ACM SIGMIS Computer Personnel Research Conference: The Global
Information Technology Workforce, SIGMIS-CPR 2007 Proceedings of the 2007 ACM SIGMIS
Computer Personnel Research Conference: The Global Information Technology Workforce,
SIGMIS-CPR 2007, 2007, 2007, 234
Software Engineering Approaches for Offshore and Outsourced Development: First
International Conference, SEAFOOD 2007 Revised Papers Lecture Notes in Computer Science
(including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in
Bioinformatics), 2007, 4716 NCS, 109
Pimentel, M.G.C.;Munson, E. (ed.) Proceedings - WebMedia and LA-Web 2004 Proceedings -
WebMedia and LA-Web 2004, 2004, 175





























