Embed Size (px)
Citation preview

Time Optimization of HEVC Encoder over X86 Processors using SIMD
Kushal Shah1000857252
Advisor: Dr. K. R. Rao
Spring 2013Multimedia Processing EE5359

Objective
• With a lot of enhanced coding tools introduced, HEVC is expected to achieve 50% bit rate reductions at similar mean opinion score (MOS) compared with the previous standard H.264/AVC.
• However, the computational complexity of HEVC has greatly increased, making encoding speed a serious problem in the implementation of HEVC.[2]

Overview of HEVC[1]
• High Efficiency Video Coding (HEVC) is the newest video coding standard of the ITU-T Video Coding Experts Group and the ISO/IEC Moving Picture Experts Group.
• The main goal of the HEVC standardization effort is to enable significantly improved compression performance relative to existing standards—in the range of 50% bit-rate reduction for equal perceptual video quality.
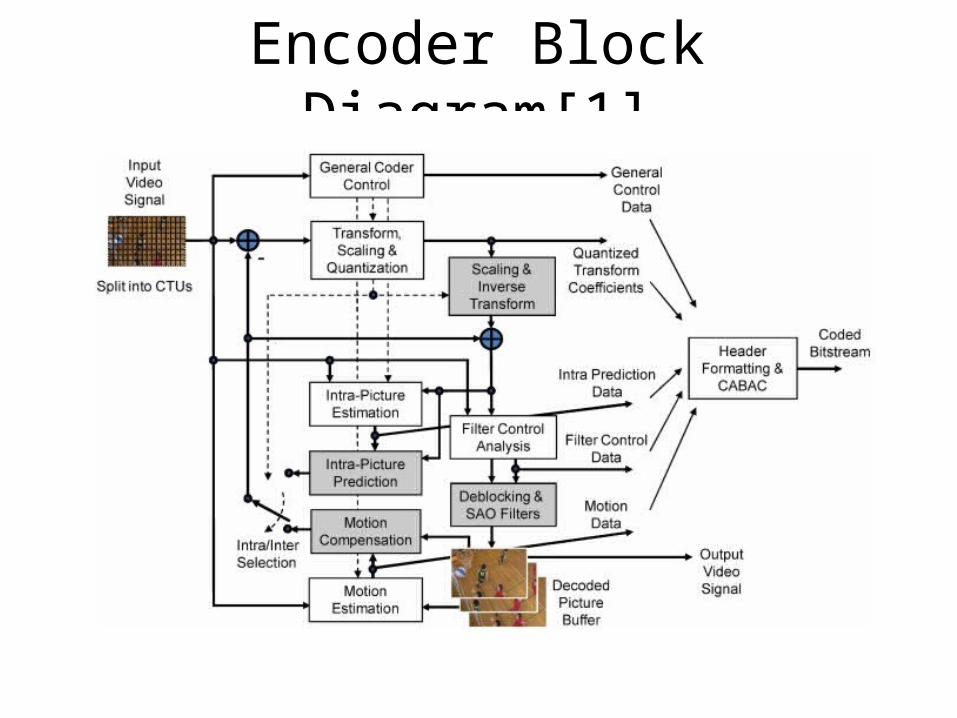
Encoder Block Diagram[1]

Macroblocks in HEVC[5]

Time Analysis of HEVC Encoder[2][3]

Time Analysis of HEVC Encoder[2][3]
• HEVC utilizes a quadtree structure [4] to support large and flexible block sizes.
• The size of a coding unit (CU) can be 64x64, 32x32, 16x16 and 8x8. Each CU is split into one or more prediction units (PU) and transform units (TU).
• For PU, the width and height of a PU varies from 4 to 64, indicating that the blocks to be processed in motion compensation (MC) can be as large as 64x64.

Time Analysis of HEVC Encoder[2][3]
• In motion estimation (ME), sum of absolute differences (SAD) and sum of absolute transformed differences (SATD) of different block sizes are calculated.
• Due to the flexible block structure, each 4x4 block will be calculated several times from 4x4 to 64x64 ME, which can be quite time-consuming.

Motion Compensation
• 8-Tap Interpolation Filter:

Intel SSE Instruction[6]
• Streaming SIMD Extensions (SSE) is the SIMD instruction set extension over the x86 architecture. It is further enhanced to SSE2, SSE3, SSSE3 and SSE4 subsequently.
• SSE contains eight 128-bit registers originally, known as XMM0 through XMM7. And the number of register is extended to sixteen in AMD64.
• Each 128-bit register can be divided into two 64-bit integers, four 32-bit integers, eight 16-bit short integers or sixteen 8-bit bytes.
• With SSE series instructions, several XMM registers can be operated at the same time, indicating considerable data-level parallelism.

Intel SSE Instruction[6]
• The PMADDUBSW instruction takes two 128-bit SSE registers as operands, with the first one containing sixteen unsigned 8-bit integers, and the second one containing sixteen signed 8-bit integers. With this instruction, we only need to sum the values in the result register to get the final results.

Intel SSE Instruction[6]
• The PMADDW instruction takes two 64-bit SSE registers as operands, with the first one containing eight unsigned 8-bit integers, and the second one containing eight signed 8-bit integers. This instruction adds and concatenates values of this two operands.

Calculating MC Vectors

Abbreviation• SIMD : Single Instruction Multiple Data• ME: Motion Estimation • SAD: Sum of Absolute Differences • SATD: Sum of Absolute Transformed Differences (SATD) • CTU: Coding Tree Unit• CB: Coding Block• PB: Prediction Unit• TB: Transform Unit

References[1] G. J. Sullivan, J.-R. Ohm, W.-J. Han, and T. Wiegand, “Overview of the High Efficiency Video Coding (HEVC) standard,” IEEE Trans. Circuits Syst. Video Technol., vol. 22, no. 12, pp. 1648–1667, Dec. 2012.[2] Keji Chen, Yizhou Duan, Leju Yan, Jun Sun and Zongming Guo, “Efficient SIMD Optimization of HEVC Encoder over X86 Processors ,” Institute of Computer Science and Technology, Peking University, Beijing 100871, China.[3] JCT-VC, “HM6: High Efficiency Video Coding (HEVC) Test Model 6 Encoder Description,”JCTVC-H1002, Feb. 2012.[4] D. Marpe et al., “Video compression using nested quadtree structures, leaf merging, and improved techniques for motion representation and entropy coding,” IEEE Trans. Circuits Syst. Video Technol., vol. 20, no. 12, pp. 1676 –1687, Dec. 2010.[5] http://codesequoia.wordpress.com/2012/10/28/hevc-ctu-cu-ctb-cb-pb-and-tb/[6] Intel Corp., Intel® 64 and IA-32 Architectures Software Developers Manual

THANK YOU





























