Embed Size (px)
Citation preview

The flight of the Condor - a decade of High
Throughput Computing
Miron LivnyComputer Sciences DepartmentUniversity of Wisconsin-Madison

www.cs.wisc.edu/condor
Remember!› There are no silver bullets.
› Response time = Queuing Time + Execution Time.
› If you believe in parallel computing you need a very good reason for not using an idle resource.
› Debugging complex parallel applications is not fun.

www.cs.wisc.edu/condor
Background and
motivation …

www.cs.wisc.edu/condor
“ … Since the early days of mankind the primary motivation for the establishment of communities has been the idea that by being part of an organized group the capabilities of an individual are improved. The great progress in the area of inter-computer communication led to the development of means by which stand-alone processing sub-systems can be integrated into multi-computer ‘communities’. … “
M. Livny, “ Study of Load Balancing Algorithms for Decentralized Distributed Processing Systems.”, Ph.D thesis, July 1983.

www.cs.wisc.edu/condor
The growing gap between
what we ownand what
each of us can access

www.cs.wisc.edu/condor
Distributed OwnershipDue to dramatic decrease in the cost-performance ratio of hardware, powerful computing resources are owned today by individuals, groups, departments, universities…
Huge increase in the computing capacity owned by the scientific community
Moderate increase in the computing capacity accessible by a scientist

www.cs.wisc.edu/condor
What kind of Computing?
High Performance Computing Other

www.cs.wisc.edu/condor
How aboutHigh Throughput Computing
(HTC)?I introduced the term HTC in a seminar at the NASA Goddard Flight Center in July of ‘96 and a month later at the European Laboratory for Particle Physics (CERN).
HTC paper in HPCU News 1(2), June ‘97. HTC interview in HPCWire, July ‘97. HTC part of NCSA PACI proposal Sept. ‘97 HTC chapter in “the Grid” book, July ‘98.

www.cs.wisc.edu/condor
High Throughput Computing
is a24-7-365activity
FLOPY (60*60*24*7*52)*FLOPS

www.cs.wisc.edu/condor
A simple scenario of a High Throughput Computing (HTC)
user with a very simple application and one
workstation on his/her desk

www.cs.wisc.edu/condor
The HTC ApplicationStudy the behavior of F(x,y,z) for 20 values of x, 10 values of y and 3 values of z (20*10*3 = 600) F takes on the average 3 hours to compute
on a “typical” workstation (total = 1800 hours) F requires a “moderate” (128MB) amount of
memory F performs “little” I/O - (x,y,z) is 15 MB and
F(x,y,z) is 40 MB

www.cs.wisc.edu/condor
What we have hereis a
Master Worker Application!

www.cs.wisc.edu/condor
Master-Worker ParadigmMany scientific, engineering and commercial applications (Software builds and testing, sensitivity analysis, parameter space exploration, image and movie rendering, High Energy Physics event reconstruction, processing of optical DNA sequencing, training of neural-networks, stochastic optimization, Monte Carlo...) follow the Master-Worker (MW) paradigm where ...

www.cs.wisc.edu/condor
Master-Worker Paradigm… a heap or a Directed Acyclic Graph (DAG) of tasks is assigned to a master. The master looks for workers who can perform tasks that are “ready to go” and passes them a description (input) of the task. Upon the completion of a task, the worker passes the result (output) of the task back to the master.
Master may execute some of the tasks. Master maybe a worker of another master. Worker may require initialization data.

www.cs.wisc.edu/condor
Master-Worker computing is Naturally Parallel.
It is by no means Embarrassingly
Parallel. As you will see, doing it
right is by no means trivial.Here are a few challenges ...

www.cs.wisc.edu/condor
Dynamic or Static?This is the key question one faces when building a MW application. How this question is answered has an impact on The algorithm Target architecture Resources availability Quality of results Complexity of implementation

www.cs.wisc.edu/condor
How do the Master and Worker Communicate?
Via a shared/distributed file/disk system using reads and writes or
Via a message passing system (PVM-MPI) using sends and receives or
Via a shared memory using loads, stores and semaphores.

www.cs.wisc.edu/condor
How many workers?
One per task?One per CPU allocated to the
master?N(t) depending on the dynamic
properties of the “ready to go” set of tasks?

www.cs.wisc.edu/condor
Job Parallel MW
Master and workers communicate via the file system.
Workers are independent jobs that are submitted/started, suspended, resumed and cancelled by the master.
Master may monitor progress of jobs and availability of resources or just collect results at the end.

www.cs.wisc.edu/condor
Building a basic Job Parallel Application
1. Create n directories.2. Write an input file in each directory.3. Submit a cluster of n job.4. Wait for the cluster to finish.5. Read an output file from each
directory.

www.cs.wisc.edu/condor
Task Parallel MW Master and workers exchange data via
messages delivered by a message passing system like PVM or MPI.
Master monitors availability of resources and expends or shrinks the resource pool of the application accordingly.
Master monitors the “health” of workers and redistribute tasks accordingly.

www.cs.wisc.edu/condor
Our Answerto High Throughput MW Computing

www.cs.wisc.edu/condor
“… Modern processing environments that consist of large collections of workstations interconnected by high capacity network raise the following challenging question: can we satisfy the needs of users who need extra capacity without lowering the the quality of service experienced by the owners of under utilized workstations? … The Condor scheduling system is our answer to this question. … “
M. Litzkow, M. Livny and M. Mutka, “Condor - A Hunter of Idle Workstations”, IEEE 8th ICDCS, June 1988.

www.cs.wisc.edu/condor
The Condor System A High Throughput Computing system that supports
large dynamic MW applications on large collections of distributively owned resources developed, maintained and supported by the Condor Team at the University of Wisconsin - Madison since ‘86. Originally developed for UNIX workstations. Fully integrated NT version in advance testing. Deployed world-wide by academia and industry. A 600 CPU system at U of Wisconsin Available at www.cs.wisc.edu/condor.

www.cs.wisc.edu/condor
Selected sites (18 Nov 1998 10:21:13)
Name Machine Running IdleJobs HostsTotalRNI core.rni.helsinki.fi 9 9 17dali.physik.uni-l dali.physik.uni-leipzig.de 1 0 23Purdue ECE drum.ecn.purdue.edu 4 9 4ICG TU-Graz fcggsg06.icg.tu-graz.ac.at 0 0 47TU-Graz Physikstu fubphpc.tu-graz.ac.at 0 8 5PCs lam.ap.polyu.edu.hk 7 5 8C.O.R.E. Digital latke.coredp.com 7 45 26legba legba.unsl.edu.ar 0 0 5ictp-test mlab-42.ictp.trieste.it 18 0 26CGSB-NLS nls7.nlm.nih.gov 4 1 8UCB-NOW now.cs.berkeley.edu 3 3 5INFN - Italy venus.cnaf.infn.it 31 61 84NAS CONDOR POOL win316.nas.nasa.gov 6 0 20

www.cs.wisc.edu/condor
“… Several principals have driven the design of Condor. First is that workstation owners should always have the resources of the workstation they own at their disposal. … The second principal is that access to remote capacity must be easy, and should approximate the local execution environment as closely as possible. Portability is the third principal behind the design of Condor. … “
M. Litzkow and M. Livny, “Experience With the Condor Distributed Batch System”, IEEE Workshop on Experimental Distributed Systems, Huntsville, AL. Oct. 1990.

www.cs.wisc.edu/condor
Key Condor Mechanisms› Matchmaking - enables requests for services and
offers to provide services find each other (ClassAds).
› Checkpointing - enables preemptive resume scheduling (go ahead and use it as long as it is available!).
› Remote I/O - enables remote (from execution site) access to local (at submission site) data.
› Asynchronous API - enables management of dynamic (opportunistic) resources.
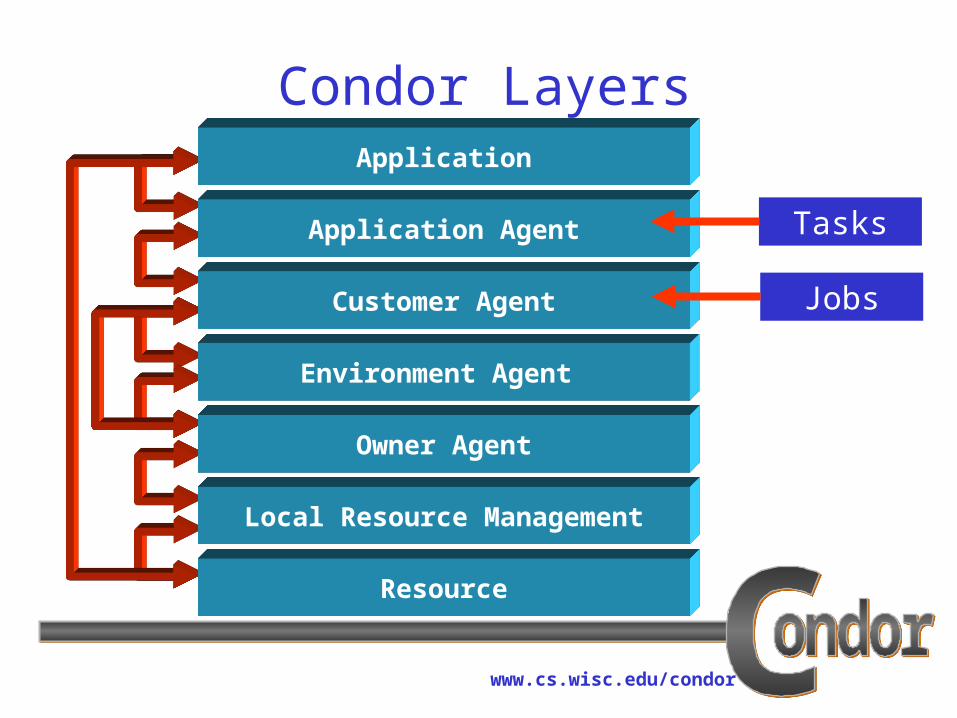
www.cs.wisc.edu/condor
Resource
Local Resource Management
Owner Agent
Environment Agent
Customer Agent
Application Agent
Application
Condor Layers
Tasks
Jobs

www.cs.wisc.edu/condor
Condor MW services› Checkpointing of Job Parallel (JP) workers
› Remote I/O for master-worker communication
› Log files for JP workers
› Management of large (10K) numbers of jobs
› Process management for dynamic PVM applications
› A DAGMan (Directed Acyclic Graph Manager)
› Access to large amounts of computing power

www.cs.wisc.edu/condor
Condor System Structure
Submit Machine Execution Machine
Collector
CA[...A]
[...B]
[...C]
CN
RA
Negotiator
Customer Agent Resource Agent
Central Manager

www.cs.wisc.edu/condor
Advertising Protocol
CA[...A]
[...B]
[...C]
CN
RA
[...N]
[...M]
[...M]

www.cs.wisc.edu/condor
Advertising Protocol
CA[...A]
[...B]
[...C]
CN
RA
[...M]
[...N]

www.cs.wisc.edu/condor
Matching Protocol
CA[...A]
[...B]
[...C]
CN
RA
[...M]
[...N]

www.cs.wisc.edu/condor
Claiming Protocol
CA[...A]
[...C]
CN
RA
[...S]

www.cs.wisc.edu/condor
Remote Execution
Executable
Checkpoint
Input Files
Output Files
Network
*May be distributed.
Customer File System* Remote Workstation
Memory
CPU
File Syste
m
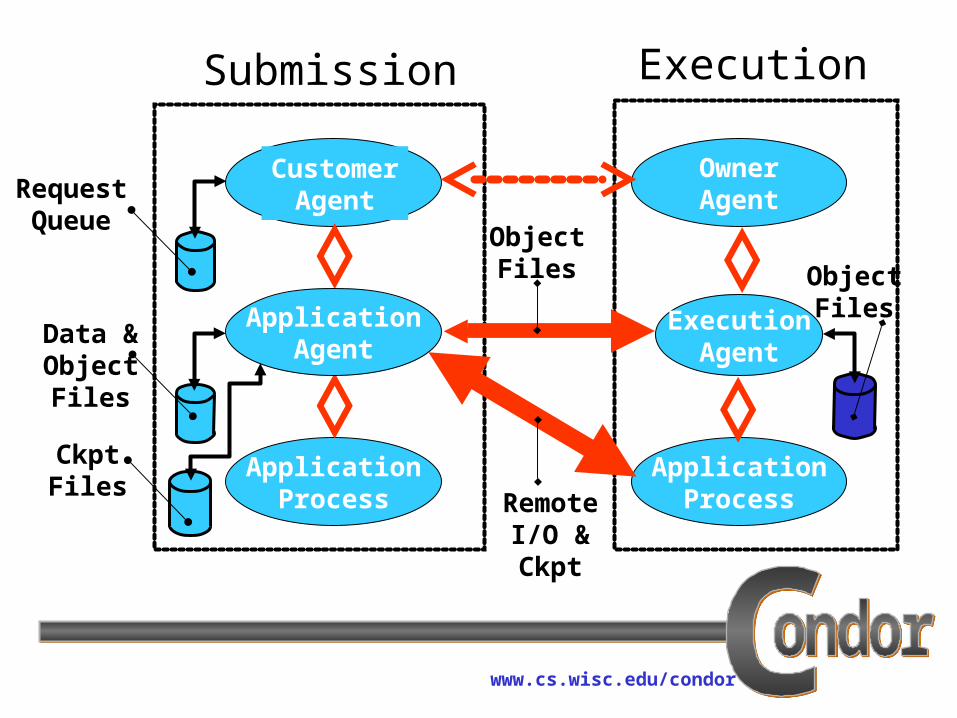
www.cs.wisc.edu/condor
OwnerAgent
ExecutionAgent
ApplicationProcess
CustomerAgent
ApplicationProcess
ApplicationAgent
RequestQueue
Data &ObjectFiles
CkptFiles
ObjectFiles
RemoteI/O &Ckpt
ObjectFiles
Submission Execution

www.cs.wisc.edu/condor
Workstation Cluster Workshop December 1992

www.cs.wisc.edu/condor
We have users that ...
› … have job parallel MW applications with more than 5000 jobs.
› … have task parallel MW applications with more than 100 tasks.
› … run their job parallel MW application for more than six month.
› … run their task parallel MW application for more than four weeks.

www.cs.wisc.edu/condor
executable = workerrequirement =( (OS == “Linux2.2”)
&& Memory >= 64))initialdir = worker_dir.$(process)input = inoutput = outerror = errlog = logqueue 1000
executable = workerrequirement =( (OS == “Linux2.2”)
&& Memory >= 64))initialdir = worker_dir.$(process)input = inoutput = outerror = errlog = logqueue 1000
A Condor Job-Parallel Submit File

www.cs.wisc.edu/condor
Material Sciences MW Application
Potential = startFOR cycle = 1 to 36
FOR location = 1 to 31totalEnergy =+ Energy(location,potential)
END
potential = F(totalEnergy)END
Potential = startFOR cycle = 1 to 36
FOR location = 1 to 31totalEnergy =+ Energy(location,potential)
END
potential = F(totalEnergy)END
Implemented as a PVM application with the Condor MW services. Two traces (execution and performance) visualized by DEVise.
WorkerTasks
MasterTasks

www.cs.wisc.edu/condor
Logicalworker
ID
36*31Worker
Tasks
NodeUtilization
# ofWorkers
OneCycle(31
worker
tasks)
TaskDuration
vs.Location
Time(total 6 hours)
FirstAllocation
SecondAllocation
ThirdAllocation Preemption

www.cs.wisc.edu/condor
… back to the user withthe 600 jobs and
only one workstation to run them

www.cs.wisc.edu/condor
First step - get organized!› Turn your workstation into a single node
“Personal” Condor pool
› Write a script that creates 600 input files for each of the (x,y,z) combinations
› Submit a cluster of 600 jobs to your personal Condor pool
› Write a script that monitors the logs and collects the data from the 600 output files
› Go on a long vacation … (2.5 months)

www.cs.wisc.edu/condor
Your Personal Condor will ...
› ... keep an eye on your jobs and will keep you posted on their progress
› ... implement your policy on when the jobs can run on your workstation
› ... implement your policy on the execution order of the jobs
› .. add fault tolerance to your jobs
› … keep a log of your job activities

www.cs.wisc.edu/condor
yourworkstation
personalCondor
600 Condorjobs

www.cs.wisc.edu/condor
… and what about theunderutilized workstation in the next office or the one in the class room
downstairs or the Linux cluster node in the other building or the O2K node at the other side of town
or …

www.cs.wisc.edu/condor

www.cs.wisc.edu/condor
Second step - become a scavenger
› Install Condor on the machine next door.
› Install Condor on the machines in the class room.
› Configure these machines to be part of your Condor pool
› Go on a shorter vacation ...

www.cs.wisc.edu/condor
yourworkstation
personalCondor
600 Condorjobs
GroupCondor

www.cs.wisc.edu/condor
Third step - Take advantage of your
friends
› Get permission from “friendly” Condor pools to access their resources
› Configure your personal Condor to “flock” to these pools
› reconsider your vacation plans ...

www.cs.wisc.edu/condor
yourworkstation
friendly Condor
personalCondor
600 Condorjobs
GroupCondor

www.cs.wisc.edu/condor

www.cs.wisc.edu/condor
Forth Step - Think big!› Get access (account(s) + certificate(s))
to a Globus managed Grid
› Submit 599 “To Globus” Condor glide-in jobs to your personal Condor
› When all your jobs are done, remove any pending glide-in jobs
› Take the rest of the afternoon off ...

www.cs.wisc.edu/condor
yourworkstation
friendly Condor
personalCondor
600 Condorjobs
Globus Grid
PBS LSF
Condor
GroupCondor
599 glide-ins

www.cs.wisc.edu/condor
Simple is not only
beautiful it can be very effective





























