Embed Size (px)
Citation preview

The Kangaroo Approachto Data Movement
on the Grid
Jim Basney, Miron Livny, Se-Chang Son, and Douglas Thain
Condor ProjectUniversity of Wisconsin

Outline
A Vision of Grid Data Movement Architecture and Example Semantics and Design Necessary Mechanisms The First Hop What Next?

An Old Problem Run programs that make use of
CPUs and storage in separate locations.
There are basic, working solutions to this problem, but they do not address many of its subleties.

The Problem is Not Trivial Distributed systems are subject to failures that
most applications are not designed to handle.• “Oops, a router died.”• “Oops, the switch is in half-duplex mode.”• “Oops, I forgot to start one server.”• “Oops, I forgot to update my AFS tokens.”
We want to avoid wasting resources (cpu, network, disk) that charge for tenancy.
• Co-allocation is a common solution, but external factors can get in the way.
• Co-allocation in and of itself is wasteful!• Can’t we overlap I/O and cpu?
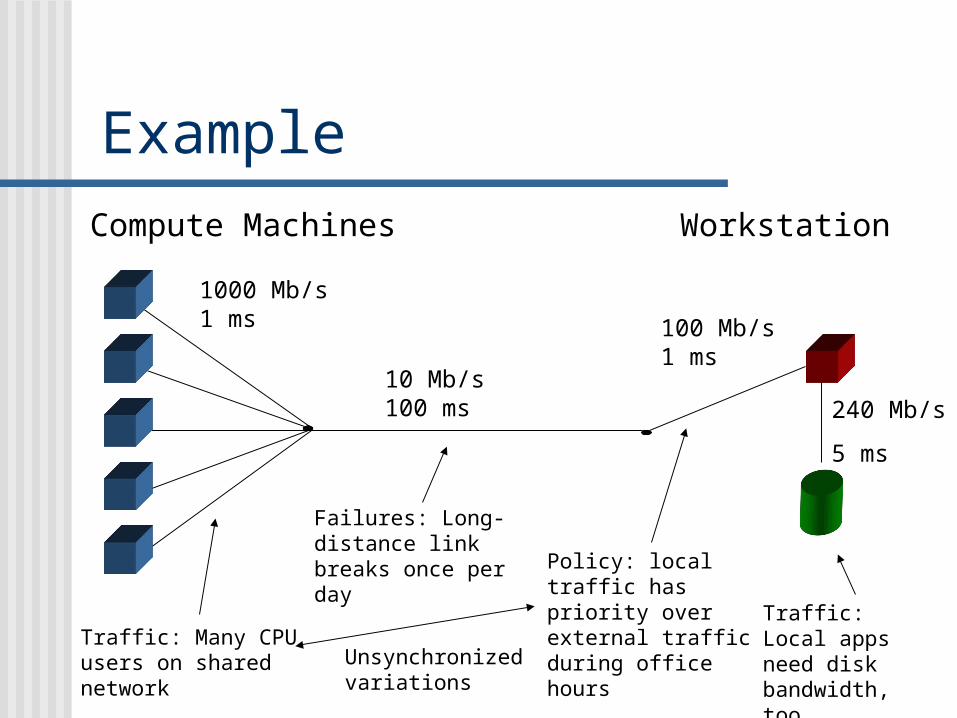
ExampleCompute Machines Workstation
1000 Mb/s1 ms
240 Mb/s
5 ms
10 Mb/s100 ms
100 Mb/s1 ms
Traffic: Many CPU users on shared network
Failures: Long-distance link breaks once per day Policy: local traffic
has priority over external traffic during office hours
Traffic: Local apps need disk bandwidth, too.Unsynchronized
variations

What’s inOur Toolbox? Partial File Transfer:
Condor Remote I/O Storage Resource Broker (SRB) (NFS?)
Whole file transfer: Globus GASS FTP, GridFTP (AFS?)
It’s not just what you move, but when you move it.
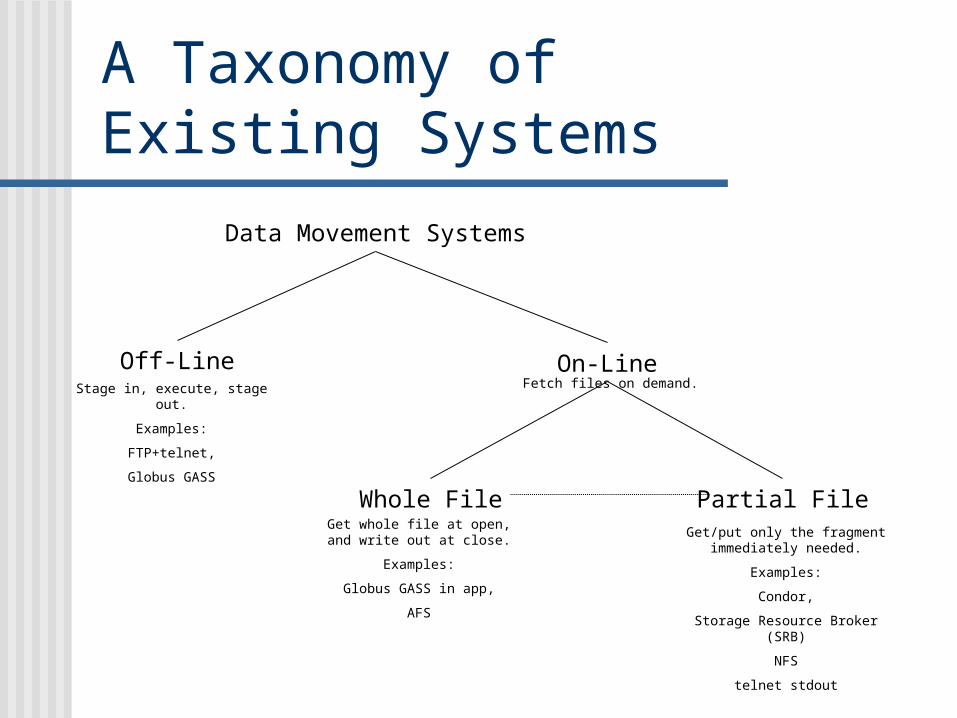
A Taxonomy ofExisting Systems
Whole File
Data Movement Systems
Off-LineStage in, execute, stage out.
Examples:
FTP+telnet,
Globus GASS
On-LineFetch files on demand.
Get whole file at open, and write out at close.
Examples:
Globus GASS in app,
AFS
Partial FileGet/put only the fragment
immediately needed.
Examples:
Condor,
Storage Resource Broker (SRB)
NFS
telnet stdout

Offline I/O Benefits:
Makes good throughput by pipelining. Co-allocation of cpu and network not needed. Easy to schedule.
Drawbacks: Must know needed files in advance. Co-use of cpu and network not possible. Must pull/push whole file, even when only
partial is needed.

Online I/O Benefits:
Need not know I/O requirements up front. (Some programs compute file names.)
Gives user incremental results. (Partial) Only moves what is actually used.
Drawbacks: Very difficult to schedule small or un-
announced operations. (Partial) Stop-and-wait does not scale to high
latency networks.

Problems with Both Error handling
GASS, AFS - close fails?!? Condor - disconnect causes rollback
The longer the distance, the worse the performance Drop rate is multiplied with each additional link. Latency increases with each link. TCP throughput is limited to the slowest link.
Resource allocation Network allocation is done end-to-end. CPU and I/O rarely overlap.

Our Vision
A no-futz wide-area data movement system that provides end-to-end reliability, maximizes throughput, and adapts to local conditions and policies.
Basic idea: Add buffers. Add a process to oversee.
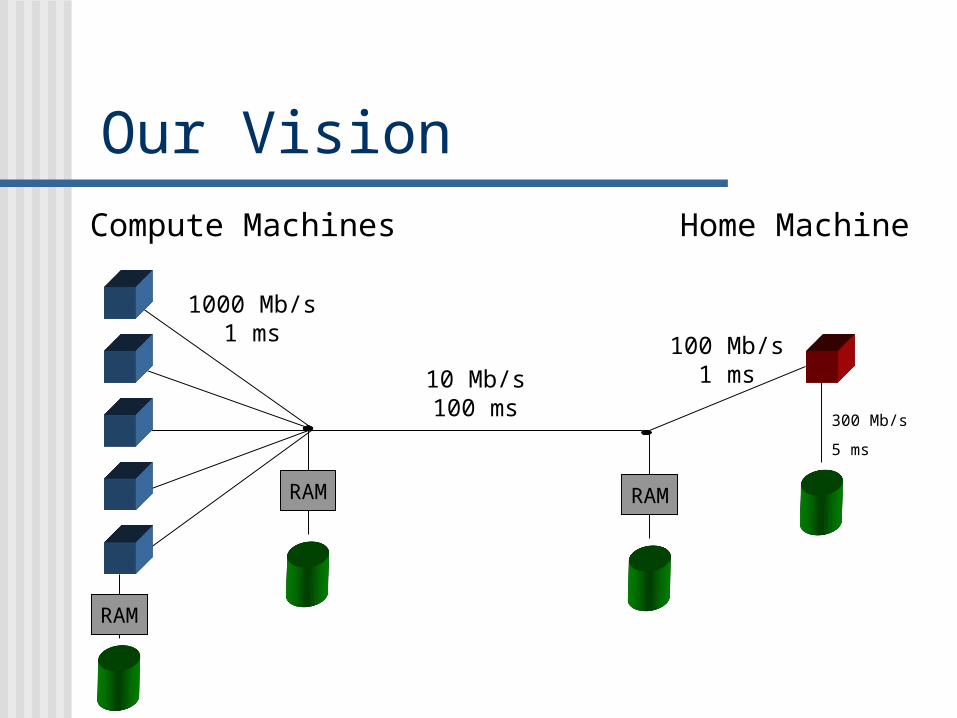
Our VisionCompute Machines Home Machine
1000 Mb/s1 ms
300 Mb/s
5 ms
10 Mb/s100 ms
100 Mb/s1 ms
RAM
RAM
RAM
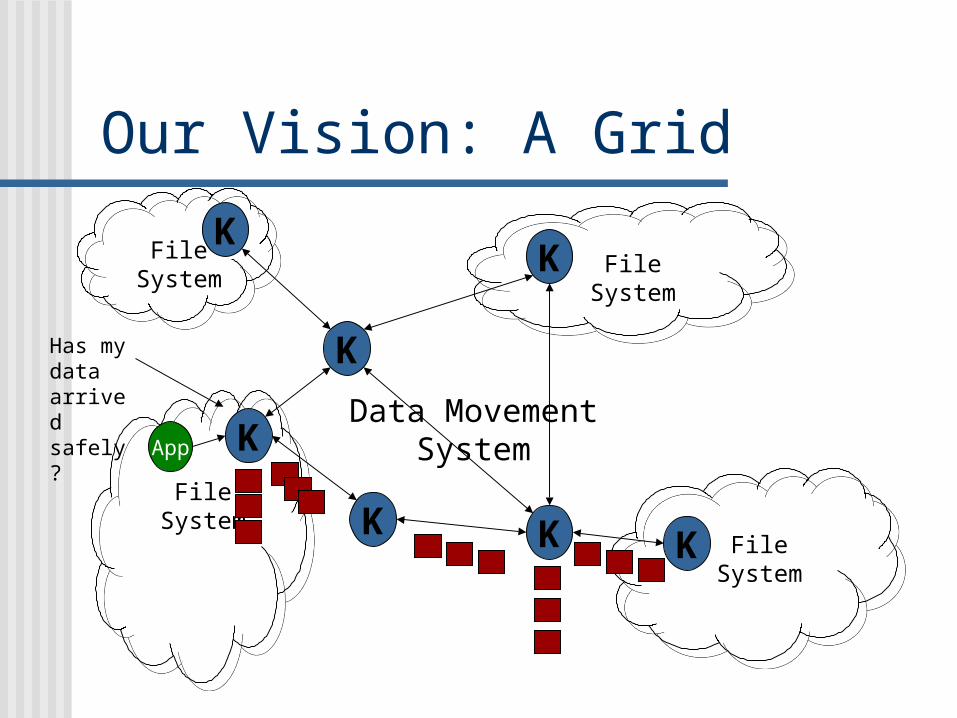
Our Vision: A Grid
FileSystem
FileSystem
FileSystem
FileSystem
KKK
K
K
KK
Data MovementSystemApp
Has my data arrived safely?

Our Vision
Requirements: Must be “fire-and-forget.” Relieve the
application of error handling! Robust wrt to machine and software crashes. (No-futz)
Must provide incremental output results. Hide latency from applications by overlapping
I/O and cpu. Maximize use of resources (cpu, network,
disk) when available, and evacuate same when required.

Our Vision Concessions:
No inter-process consistency needed. Increased latency of actual data
movement is acceptable.

The First Hop A working test bed that validates the core
architecture. Supports applications using standard POSIX
operations. Concentrate on write-behind because it
doesn’t require speculation. Leave room in the architecture to experiment
with read-ahead. Preview of results:
Small scale, overlapping is slower. Large scale, overlapping is faster.

Outline
A Vision of Grid Data Movement Architecture and Example Necessary Mechanisms Semantics and Design The First Hop What Next?

Architecture Layers
Application Adaptation Consistency Transport
Example
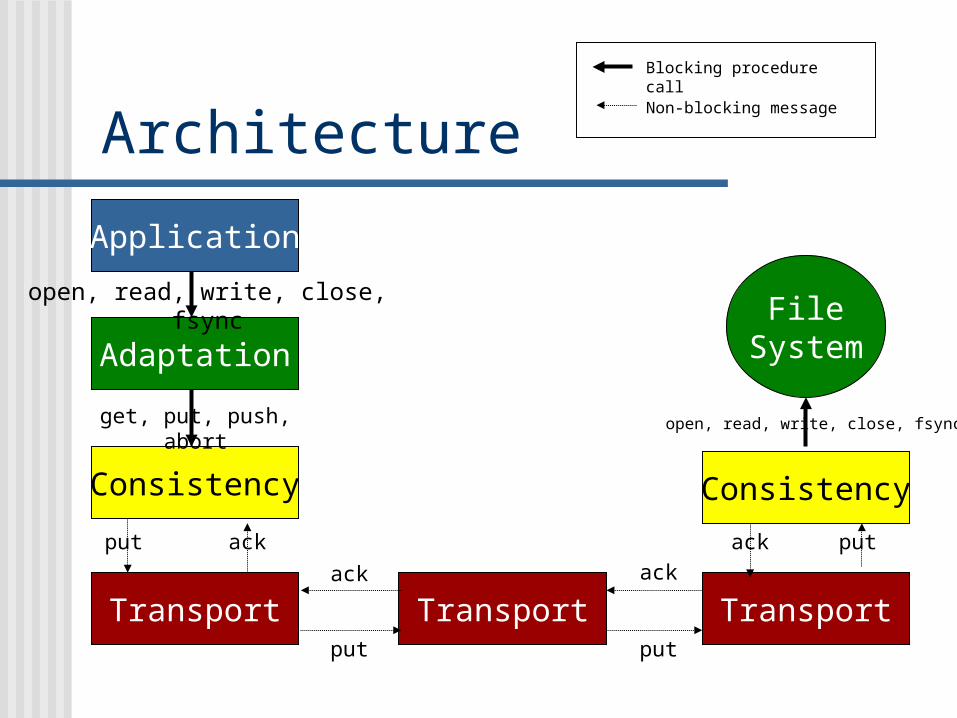
Architecture
Transport
Consistency
Adaptation
open, read, write, close, fsync
get, put, push, abort
put
Application
Transport Transport
Consistency
ack ack put
FileSystem
open, read, write, close, fsync
Blocking procedure call
Non-blocking message
put
ack ack
put

Transport Layer Interface
Send message, query route, query status Semantics
Ordering - None (or worse!) Reliability - Likely, but not guaranteed. Duplication - Unlikely, but possible.
Performance Uses all available resources (net, mem, disk) to
maximize throughput. Subject to local conditions (traffic, failures) and
policies (priority, bw limits)
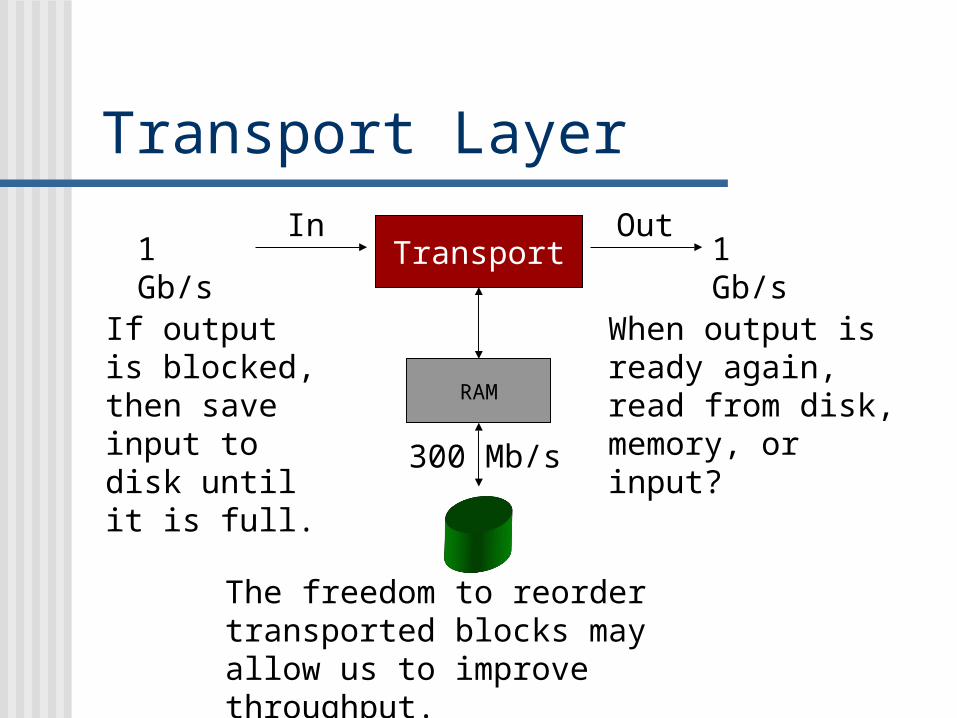
Transport Layer
Transport
RAM
1 Gb/s 1 Gb/s
300 Mb/s
If output is blocked, then save input to disk until it is full.
When output is ready again, read from disk, memory, or input?
In Out
The freedom to reorder transported blocks may allow us to improve throughput.

Consistency Layer Interface
Get block, put block, sync file, abort file Semantics
Ordering - Order preserving or not? Reliability - Detects success Duplication - Delivers at most once
Performance Must cache dirty blocks until delivered Might cache clean blocks Might speculatively read clean blocks
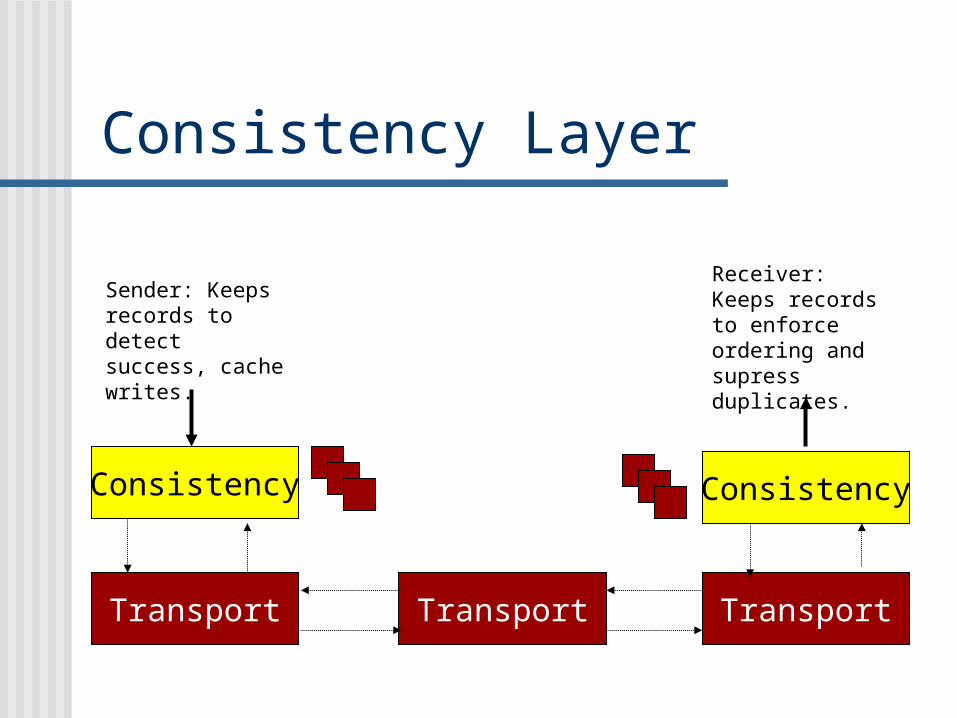
Consistency Layer
Transport
Consistency
Transport Transport
Consistency
Sender: Keeps records to detect success, cache writes.
Receiver: Keeps records to enforce ordering and supress duplicates.

Adaptation Layer Converts POSIX operations into Kangaroo
operations Open
O_CREAT, always succeeds Otherwise, checks for existence with a ‘get’
Read = kangaroo get Write = kangaroo put Close = NOP Fsync = kangaroo sync
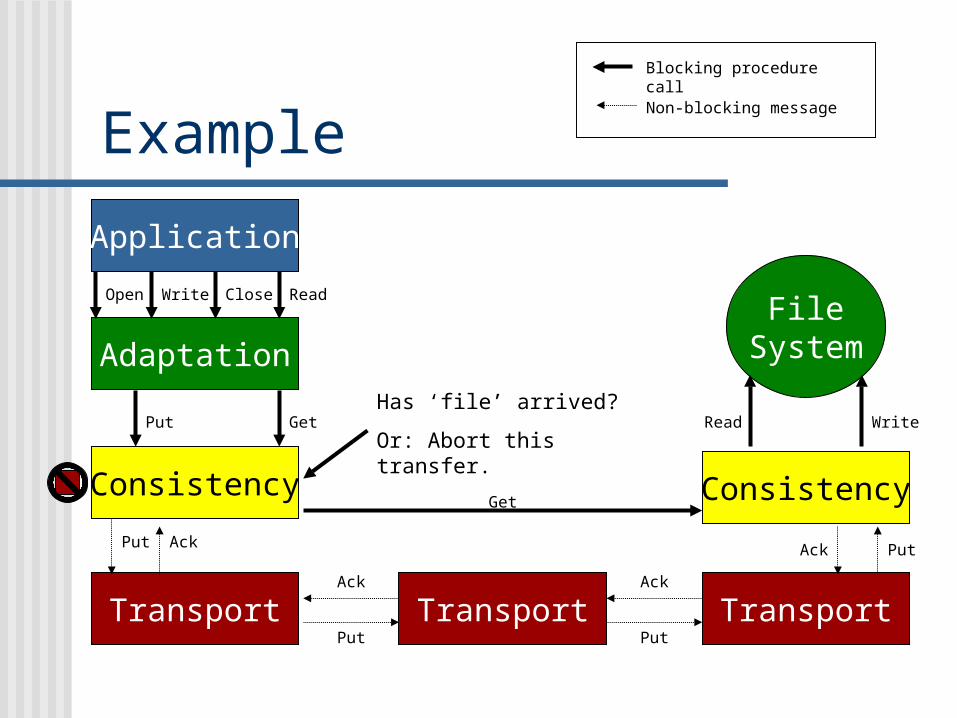
Example
Transport
Consistency
Adaptation
Application
Transport Transport
Consistency
FileSystem
Blocking procedure call
Non-blocking message
Open Write Close
Put
Put
Put Put
PutAck
AckAck
Ack
Has ‘file’ arrived?
Or: Abort this transfer.
Read
Get Read Write
Get

Outline
A Vision of Grid Data Movement Architecture and Example Semantics and Design Necessary Mechanisms The First Hop What Next?

Semantics and Design A data movement system is a bridge
between file systems. It addresses many of the same
issues as file systems: Consistency Committal Ordering Replication

Consistency Single Node
A put/get blocks until the local server has atomically accepted it.
Multiple processes that are externally synchronized will see a consistent view.
Multiple Nodes No guarantees unless you use an explicit sync. This is reasonable in a Grid environment,
because most users make use of a wide-area scheduler to partition jobs and data.

Commital Possible meanings of commit:
Force this data to the safest medium available.
Make these changes visible to others. Make this data safe from a typical crash.
Possible implementations in Kangaroo: Push all the way to target, and force to disk
(tape?) Push to the target server. Push to the nearest disk.

Commital Safest choice is to implement the most
conservative -- push all the way to the server, and force it to disk there.
Some applications may want the more relaxed meanings.
POSIX only provides one interface: fsync().
Easy solution: implement all three, and provide a flexible binding in the Adaptation layer.

Ordering Does the system commit operations in the
same order they were sent? Relaxed -- no ordering
Satisifies large majority of apps that do not overlap writes.
Interesting case of output log files. Need to wait max TTL before re-using an output file
name Strict -- exact ordering, enforced at recvr
Increases queue lengths everywhere. Doesn’t burden user with determining if application
is safe to relax.

Strict Ordering Algorithm Much like TCP:
Sender keeps copies of data blocks until they are acknowledged.
Receiver sends cumulative acks and commits unbroken sequences.

Strict Ordering Algorithm But some differences from TCP:
No connection semantics. Block ID is (birthday,sequence). Receiver keeps on disk last ack’d ID of all
senders it has ever talked to. If sender reboots:
• Compute the next ID from blocks on disk• If none, reset b to current time, s to 0
If receiver reboots:• Last recvd ID of all senders is on disk.• Garbage problem: fix with a long receiver timeout +
reset message causes sender to start over.

Replication Issues We would like to delete data stored at the
sender ASAP, but… Do I Trust this Disk?
Buffer Storage - Could disappear at any time. Reliable Storage - No deliberate destruction.
Reliability is not everything If delivery is highly likely and recomputation is
relatively cheap, then losing data is acceptable… but only if delivery failure is detectable!
Reliability = More copies. User should be able to configure a range from “most
reliable” to “fewest copies.”

Replication Issues End-to-End Argument:
Regardless of whatever duplication is done internally for performance or reliability, only the end points can be responsible for ensuring (or detecting) correct delivery.
So, the sender must retain a record of what was sent, even if it does not retain the actual data.

Replication Techniques Pass the Buck Hold the Phone Don’t Trust Strangers
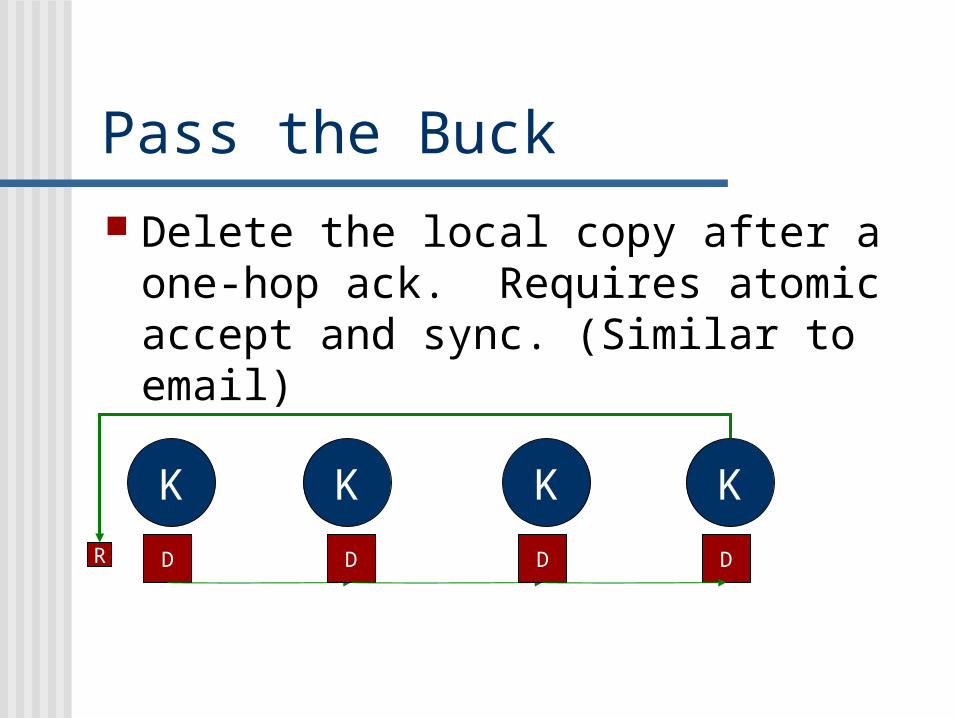
Pass the Buck Delete the local copy after a one-hop
ack. Requires atomic accept and sync. (Similar to email)
K K K K
R DD D D
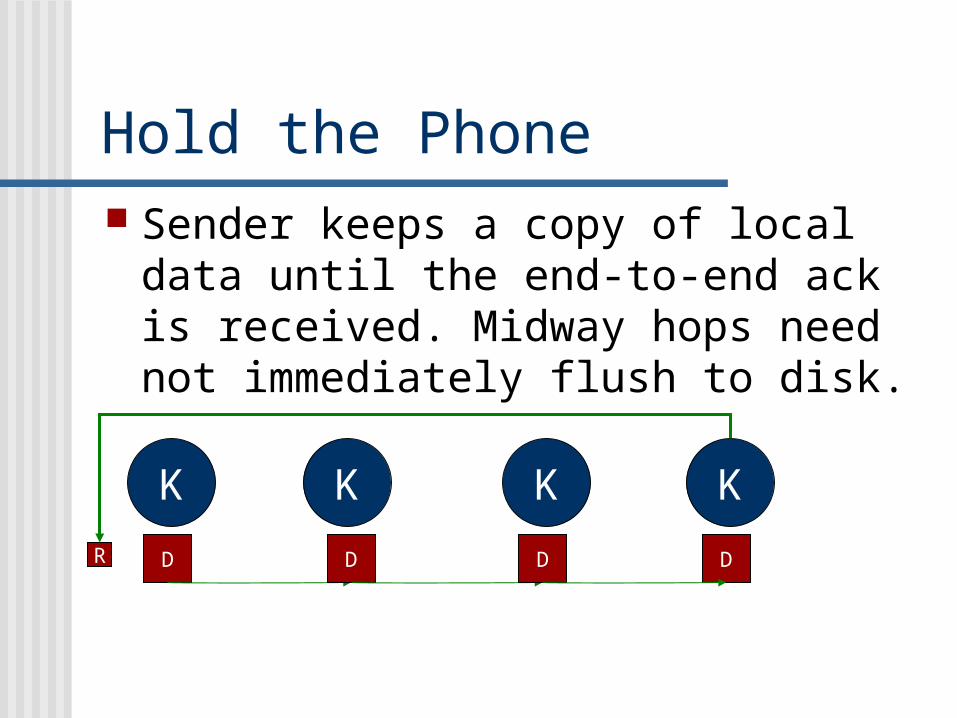
Hold the Phone Sender keeps a copy of local data
until the end-to-end ack is received. Midway hops need not immediately flush to disk.
K K K K
R DD D D

Don’t Trust Strangers If the sender determines the
receiver to be reliable, then delete, otherwise hold.
K K K KR DD I trust
you.No, you are just buffer.
D I trust you.DR

Replication Comparison
Pass the Buck Evacuates source ASAP. One copy of data. Dirty reads must hop through all nodes. No retry of failures. (Success still likely.)
Hold the Phone Evacuates source more slowly. Two copies. Dirty reads always satisfied at source. Sender can retry failures.
Don’t Trust Strangers Evacuates source like PTB, but still 2 copies. Dirty reads hop. Retries done midway.

Outline
A Vision of Grid Data Movement Architecture and Example Necessary Mechanisms Semantics and Design The First Hop What Next?

Necessary Mechanisms Adaptation Layer
Needs a tool for trapping and rerouting an application’s I/O calls without special privileges: Bypass
Transport Layer Needs a tool for detecting network
conditions and enforcing policies: Cedar

Bypass General-purpose tool for trapping and
redirecting standard library procedures. Trap all I/O operations. Those involving
Kangaroo are sent to Adaptation layer. Otherwise, execute without modification.
Can be applied at run-time to any dynamically-linked program: vi kangaroo://home.cs.wisc.edu/tmp/file grep thain gsiftp://ftp.cs.wisc.edu/etc/passwd gcc http://www/example.c -o
kangaroo://home/output

Cedar Standard socket abstraction. Enforces limits on how much bandwidth
can be consumed across multiple times scales.
Also measures congestion and reports to locally-determined manager.
Example: If conditions are good, do not exceed 10Mb/s. If there is competition for the link, fall back to
no more than 1Mb/s.

Why Limit Bandwidth? Isn’t TCP flow control sufficient?
An overloaded receiver can squelch a sender with back-pressure.
Competing TCPs will tend to split the available bw equally.
No. Three reasons: To enforce local policies on resources consumed
by visiting processes. To clamp processes competing for a single
resource. To leave some bandwidth available for small-scale
unscheduled operations.

Outline
A Vision of Grid Data Movement Architecture and Example Semantics and Design Necessary Mechanisms The First Hop What Next?

The First Hop We have implemented a kangaroo testbed
which has most of the critical features: Each node runs a kangaroo_server process
which accepts messages on TCP and UNIX-domain sockets.
Outgoing data is placed into a spool dir in the file system for a kangaroo_mover process to pick it up and send it out.
Bypass is used to attach unmodified UNIX applications to a libkangaroo.a which contacts the local server to execute puts and gets.

The First Hop Several important elements are yet to be
implemented: Only one sync algorithm
• push to server but not to disk Only one replication algorithm:
• hold the phone Consistency layer detects delivery success,
but does not timeout and retry. Receiver implements only relaxed ordering. Reads are implemented simply as minimal
blocking RPCs to the target server.

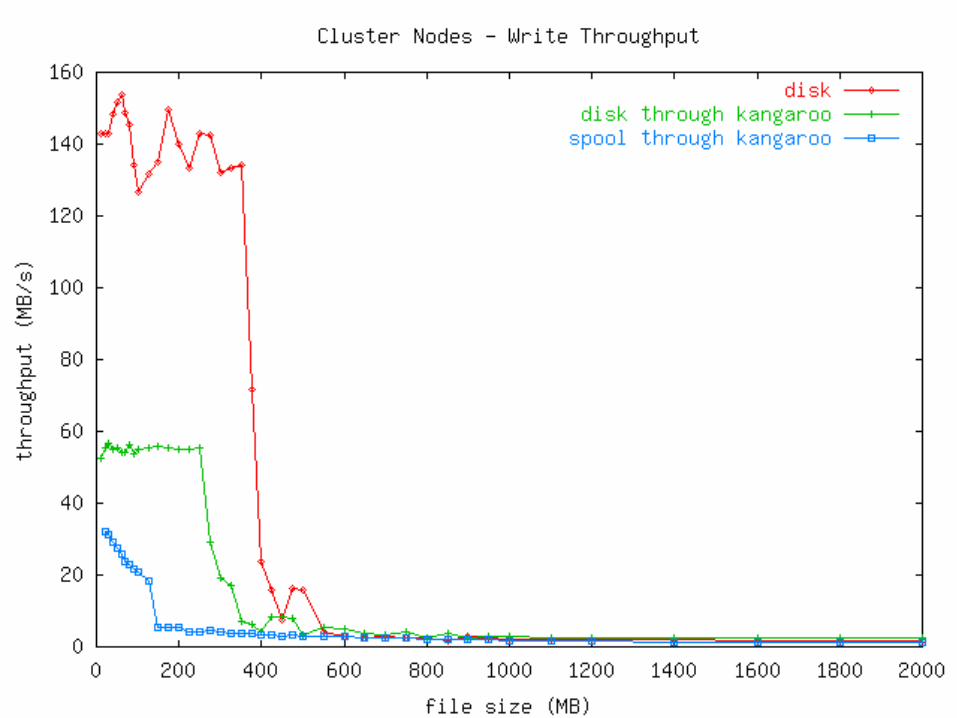
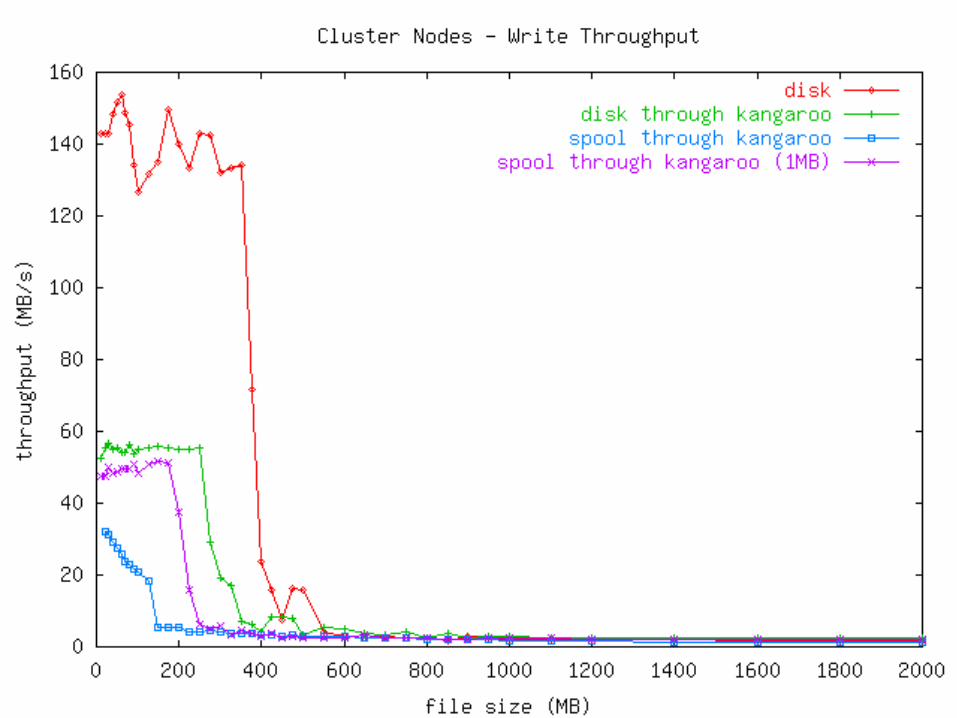
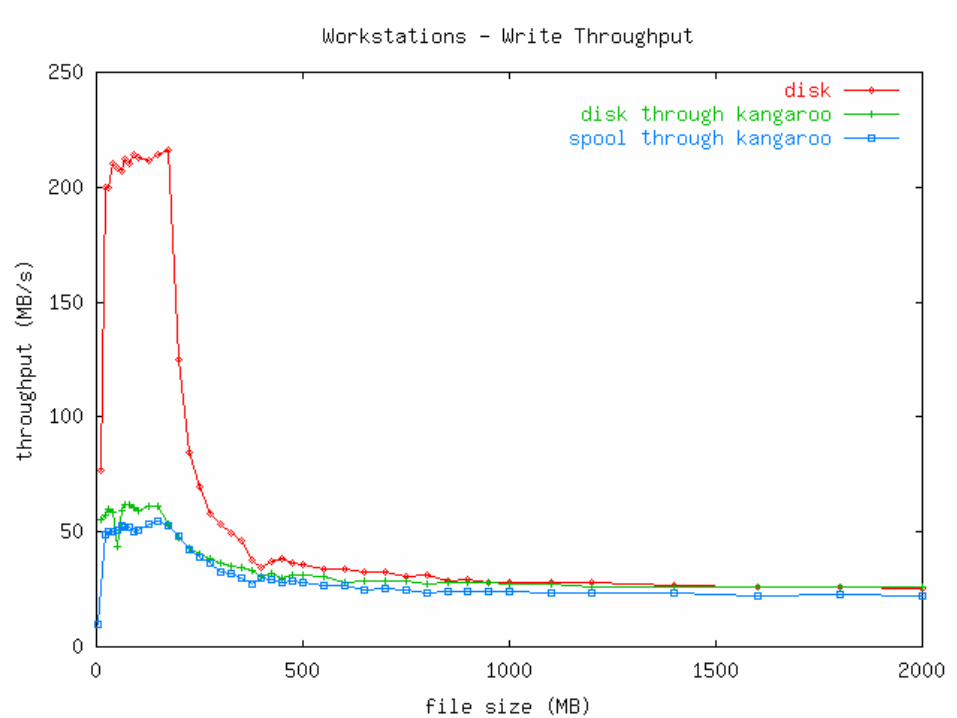
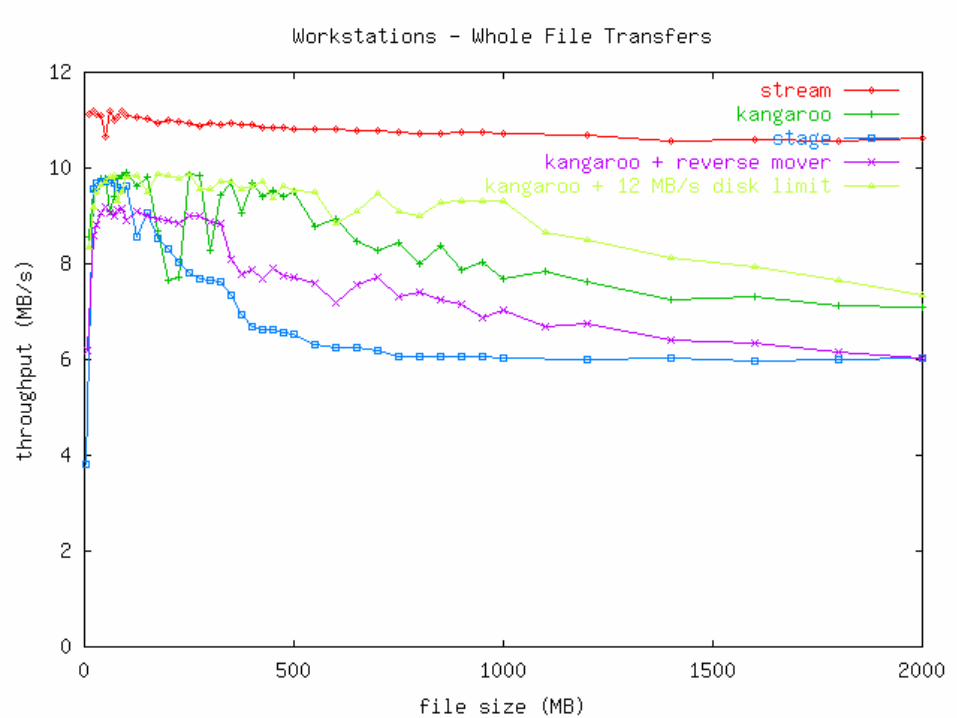
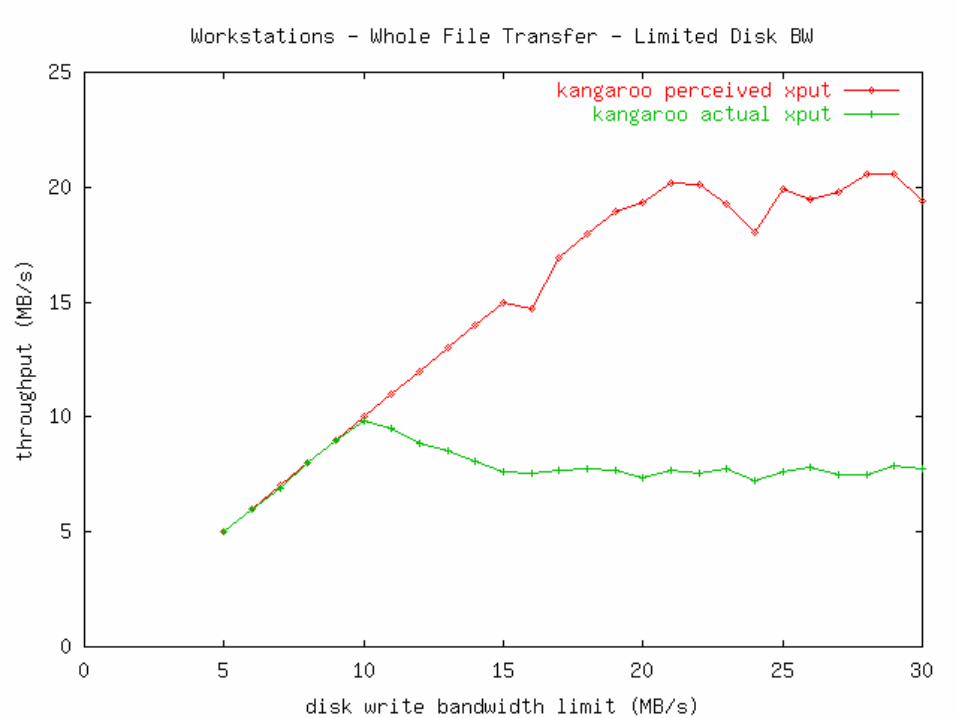
Measurements Micro: How fast can an app write output?
• Plain file• Plain file through Kangaroo• Kangaroo
Mini: How fast can output be moved?• Online: Stream from memory to network.• Offline: Stage to disk, then write to network.• Kangaroo
Macro: How fast can we run an event-processing program?
• Online: Read and write over network.• Offline: Stage input, run program, stage output.• Kangaroo

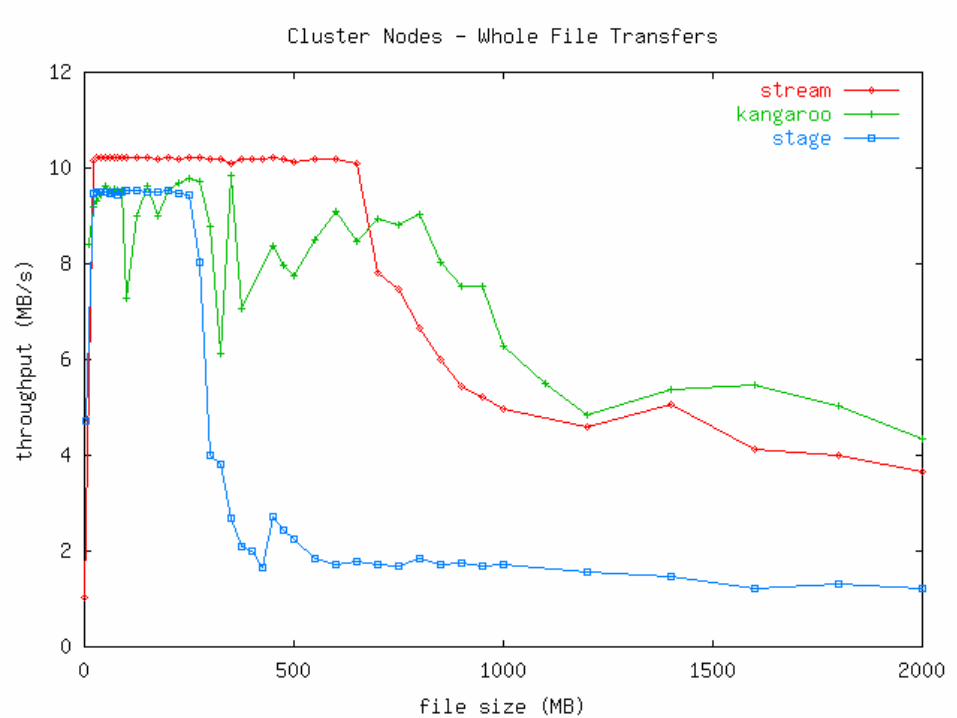
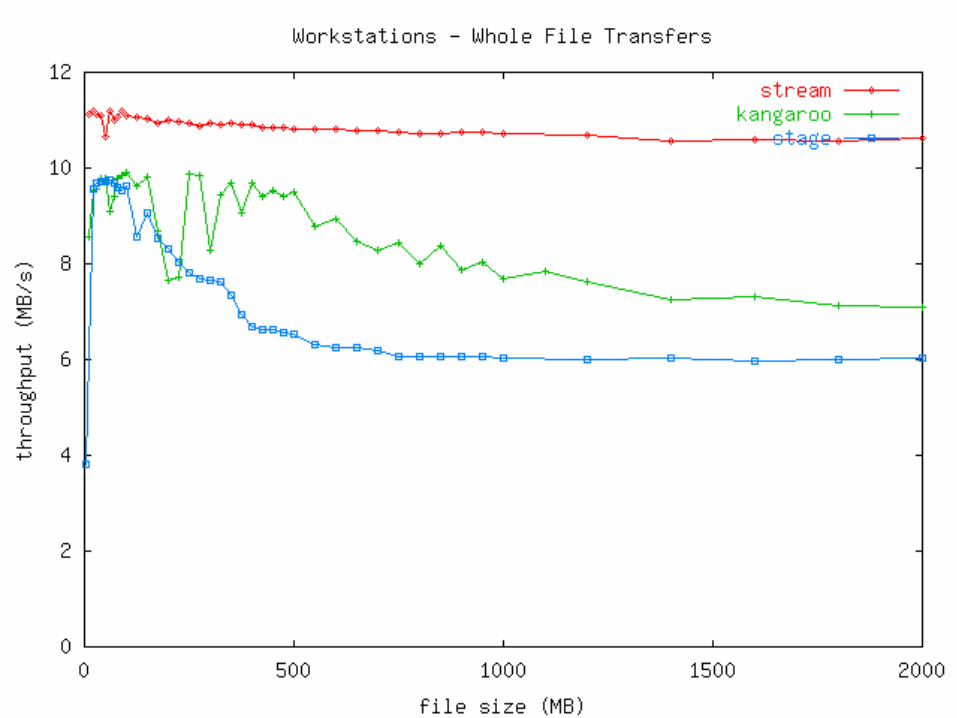
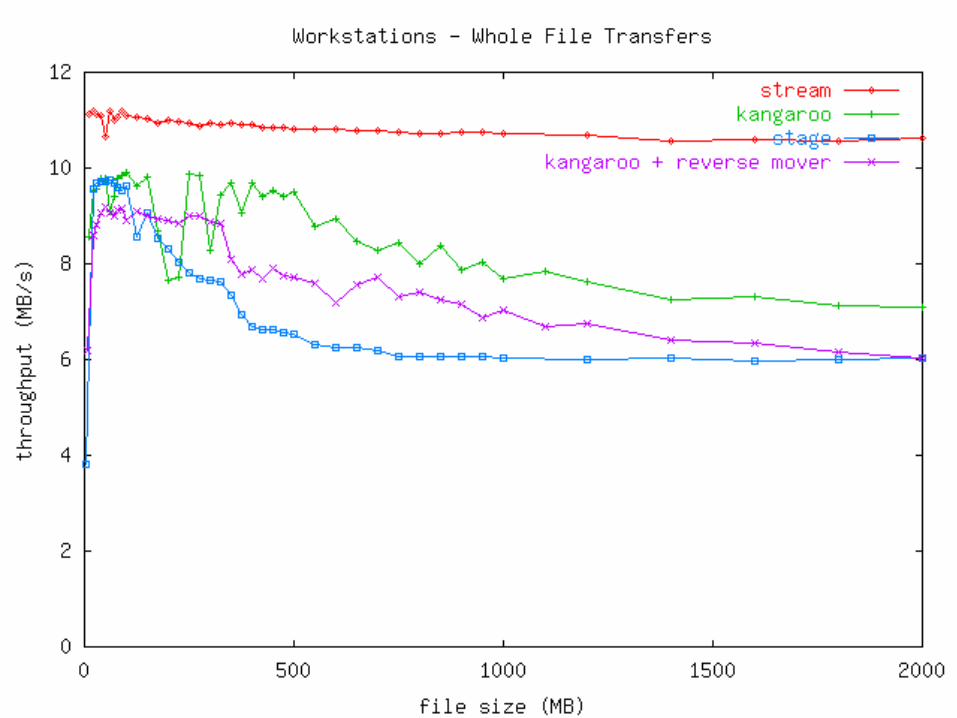
Measurements Two types of machines used:
Disk>Network (Linux Workstations)• 100 Mb/s switched Ethernet• 512 MB RAM• 10.2 GB Quantum Fireball Plus LM
• Ultra ATA/66, 7200 RPM, 2MB cache• 650 MHz P3
Network>Disk (Linux Cluster Nodes)• 100 Mb/s switched Ethernet• 1024 MB RAM• 9.1 GB IBM 08L8621
• Ultra2 Wide SCSI-3, 10000 RPM, 4MB cache• 2 * 550 MHz P3 Xeon

Macrobenchmark:Event Processing A fair number of standard, but non-
Grid-aware, applications look like this: For I=1 to N
• Read input• Compute results• Write output
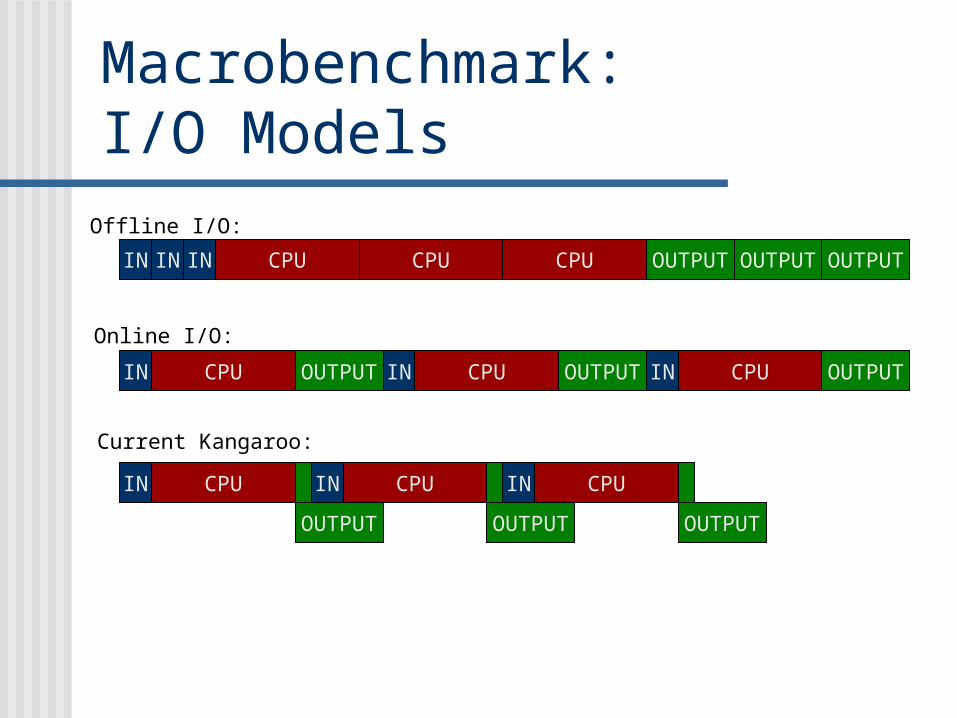
Macrobenchmark:I/O Models
IN CPUIN OUTPUTOUTPUTCPU CPU OUTPUT
IN CPUINOUTPUT OUTPUTCPU CPU OUTPUTIN
IN
IN CPUIN
OUTPUT OUTPUT
CPU CPU
OUTPUT
Online I/O:
Offline I/O:
Current Kangaroo:
IN

Macrobenchmark:Event Processing
Synthetic Example: Ten loops of:
• 1 MB input• 15 seconds CPU• 100 MB output
Results on workstations: Offline: 289 seconds (disk bound) Online: 249 seconds (network bound) Kangaroo: 183 seconds

Summary Micro view: Kangaroo imposes a severe
penalty, due to additional memory copies and contention for disk and directory ops.
Mini view: Kangaroo is competitive with staging and streaming, depending on the circumstances.
Macro view: Kangaroo provides a big win when there is ample opportunity to overlap CPU and I/O.

Outline
A Vision of Grid Data Movement Architecture and Example Semantics and Design Necessary Mechanisms The First Hop What Next?

Implementation Details Error Reporting
“Where is my data?” Acute failures should leave an error
record that can be queried. Chronic failures should trigger e-mail.
Strict Ordering Read-Ahead

Research Issues Prioritizing Reads over Writes
Easy to do at a single node. Hard to synchronize between several.
Virtual Memory Need a disk system optimized for read-once, write-
once, delete-once. Interaction with CPU scheduling
Long delay for input? Start another job. Multi-Hop Staging
Probably a win for buffering between mismatched networks. Where is the boundary?

Conclusion We have built a naïve
implementation of Kangaroo using existing building blocks.
Despite its inefficiencies, the benefits of write-behind can be a big win.
Many open research issues!





























