Embed Size (px)
Citation preview

TEMA 1: CONCEPTOS BÁSICOS DE PARALELISMO Y ANÁLISIS DE PRESTACIONES
SISTEMAS PARALELOS Y DISTRIBUIDOSwww.atc.us.es
Dpto. de Arquitectura y Tecnología de Computadores. Universidad de Sevilla
1

Arquitectura: Visiones clásica y actual• Visión clásica: Juegos de instrucciones
(Instruction Set Architecture (ISA)– Ej: decisiones sobre ISA: registros, direccionamiento,
operandos, tipos de instr. , etc– CISC (Computador de repertorio complejo de
instrucciones)– RISC (Computador de repertorio reducido de
instrucciones, posteriormente, instrucciones sencillas)
• Visión “Actual” : Requisitos de la máquina de destino (target machine)– Ej: maximizar rendimiento pero con restricciones de:
coste, potencia, disponibilidad, herramientas software, etc.
2

Ejercicio sobre arquitectura• ¿Cuál de las 2 opciones es más correcta?
1. Interesa dominar todos los tipos de arquitectura
2. Interesa concentrarse en la arquitectura actual de más prestaciones o rendimiento
• Ej: Proc. Vectoriales en ediciones H&P
SPD. Tema 1. 3

Leyes y principios de Arquitectura• LEMA: analizar código y sistemas
– puede haber comportamientos no intuitivos
• Ley de Moore (y similares)• Ley de Amdahl• Ley de localidad 10/90• Componentes del tiempo de ejecución de
un programa
SPD. Tema 1. 4
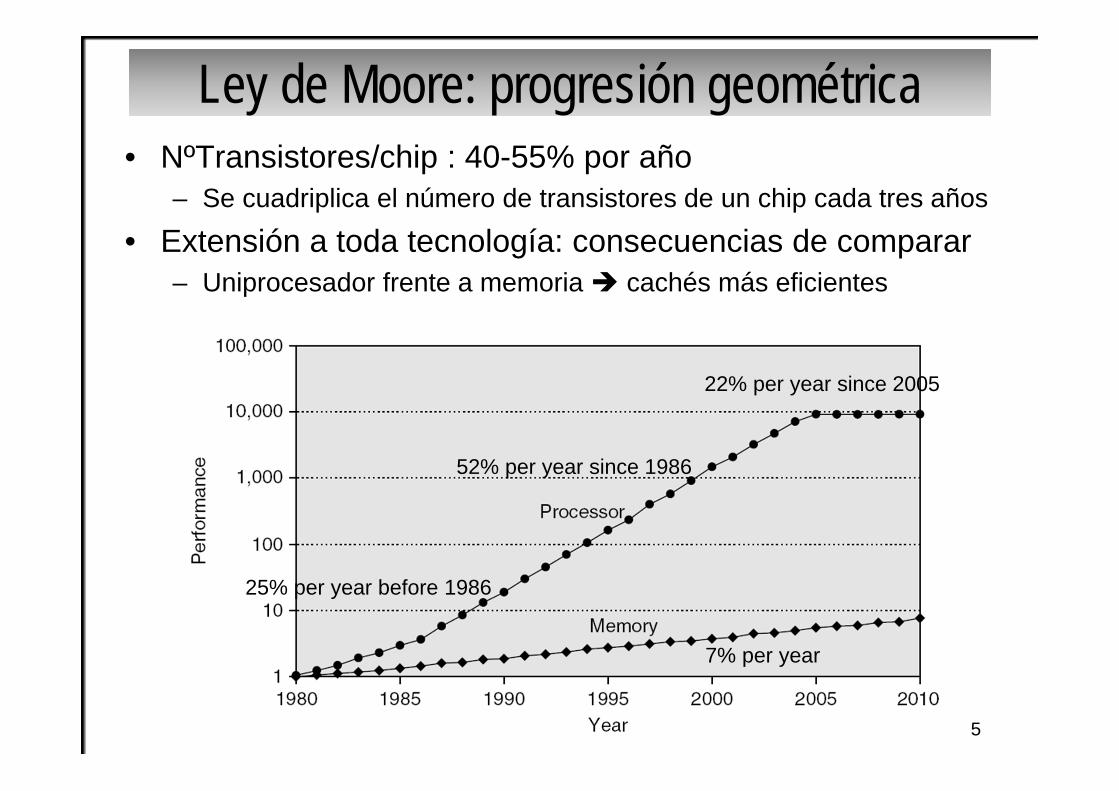
Ley de Moore: progresión geométrica• NºTransistores/chip : 40-55% por año
– Se cuadriplica el número de transistores de un chip cada tres años
• Extensión a toda tecnología: consecuencias de comparar– Uniprocesador frente a memoria cachés más eficientes
5
7% per year
25% per year before 1986
52% per year since 1986
22% per year since 2005

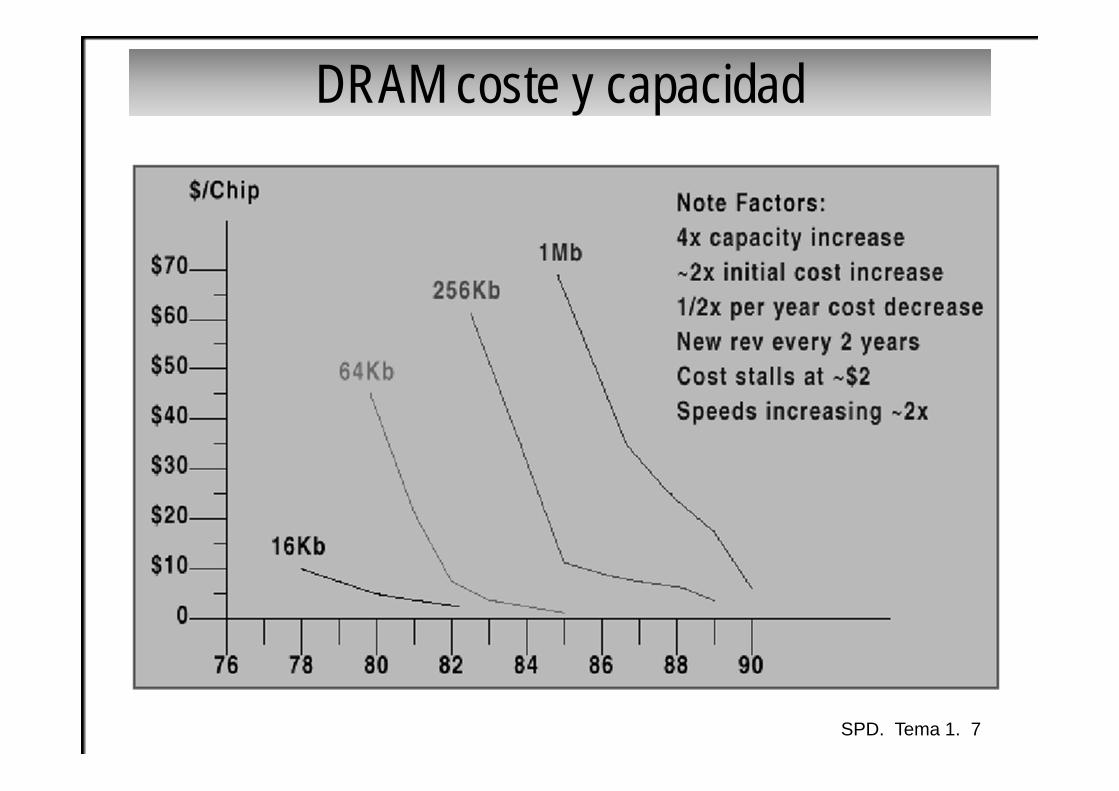
Tendencias tecnológicas: coste y capacidad (2007-2012)
SPD. Tema 1. 6
• Integrated circuit technology– Transistor density: 35%/year– Die size: 10-20%/year– Integration overall: 40-55%/year
• DRAM capacity: 25-40%/year (slowing)
• Flash capacity: 50-60%/year– 15-20X cheaper/bit than DRAM
• Magnetic disk technology: 40%/year– 15-25X cheaper/bit then Flash– 300-500X cheaper/bit than DRAM
DRAM coste y capacidad
SPD. Tema 1. 7
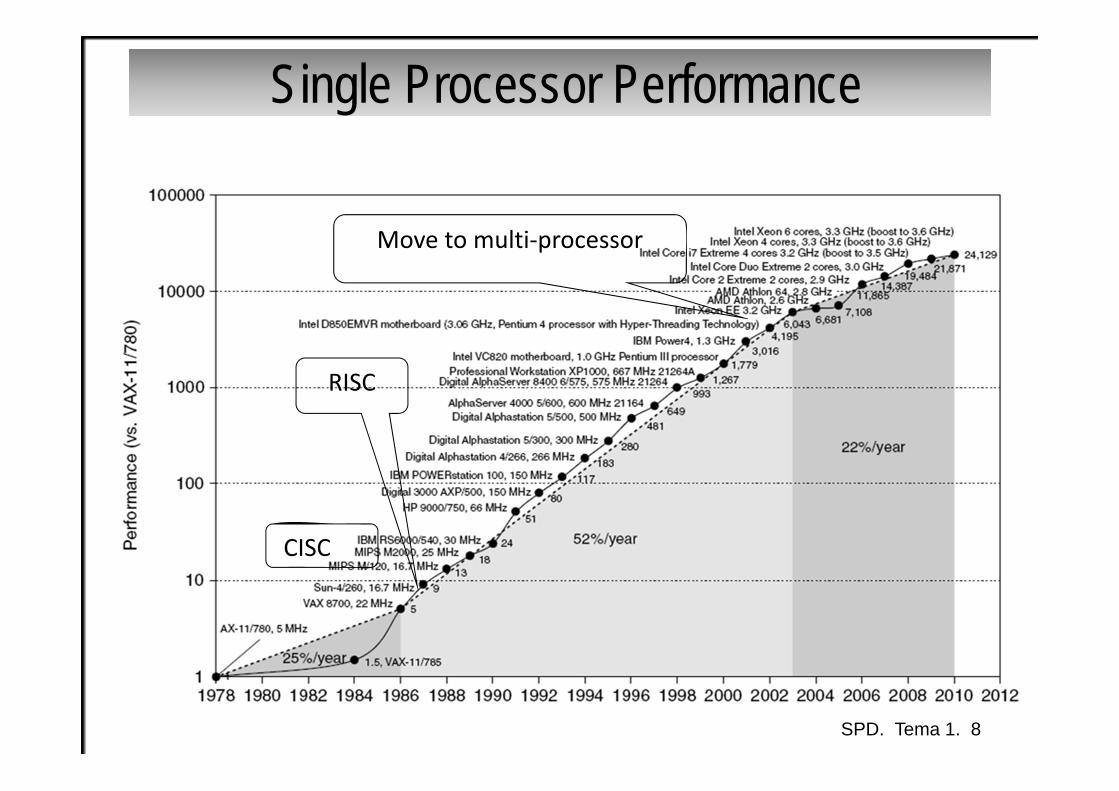
Single Processor Performance
SPD. Tema 1. 8
Move to multi‐processor
RISC
CISC
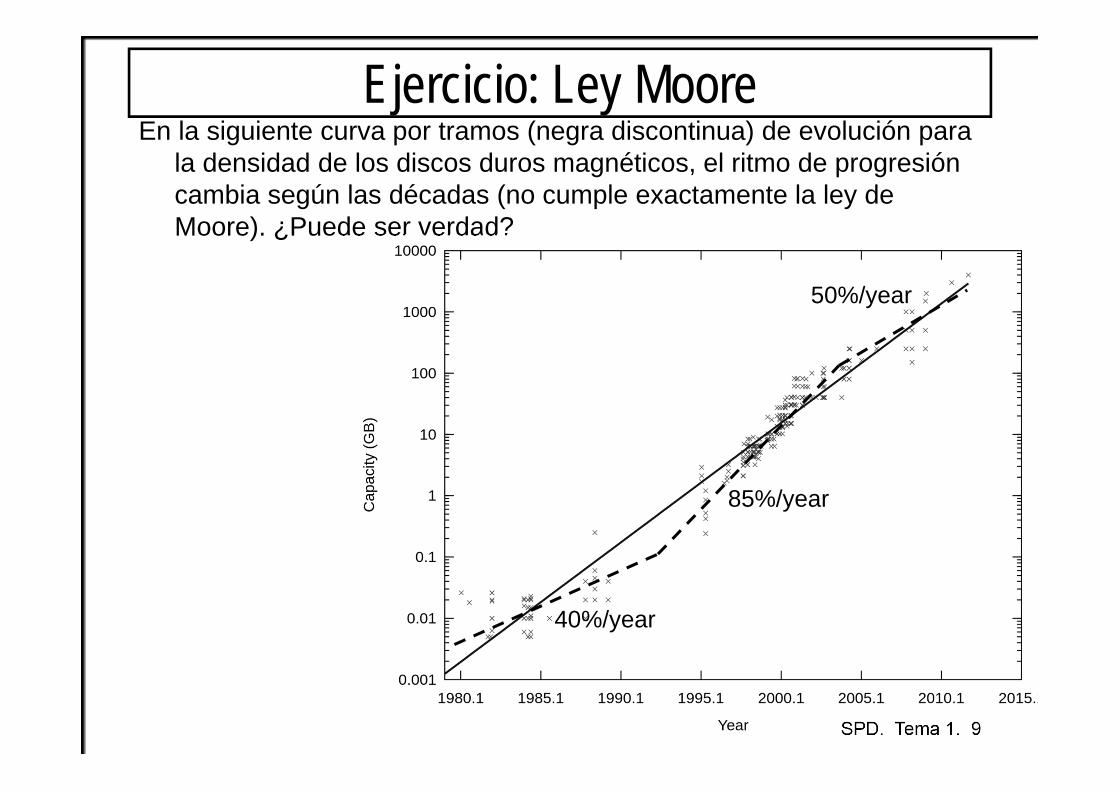
Ejercicio: Ley MooreEn la siguiente curva por tramos (negra discontinua) de evolución para
la densidad de los discos duros magnéticos, el ritmo de progresión cambia según las décadas (no cumple exactamente la ley de Moore). ¿Puede ser verdad?
SPD. Tema 1. 9
85%/year
50%/year
40%/year
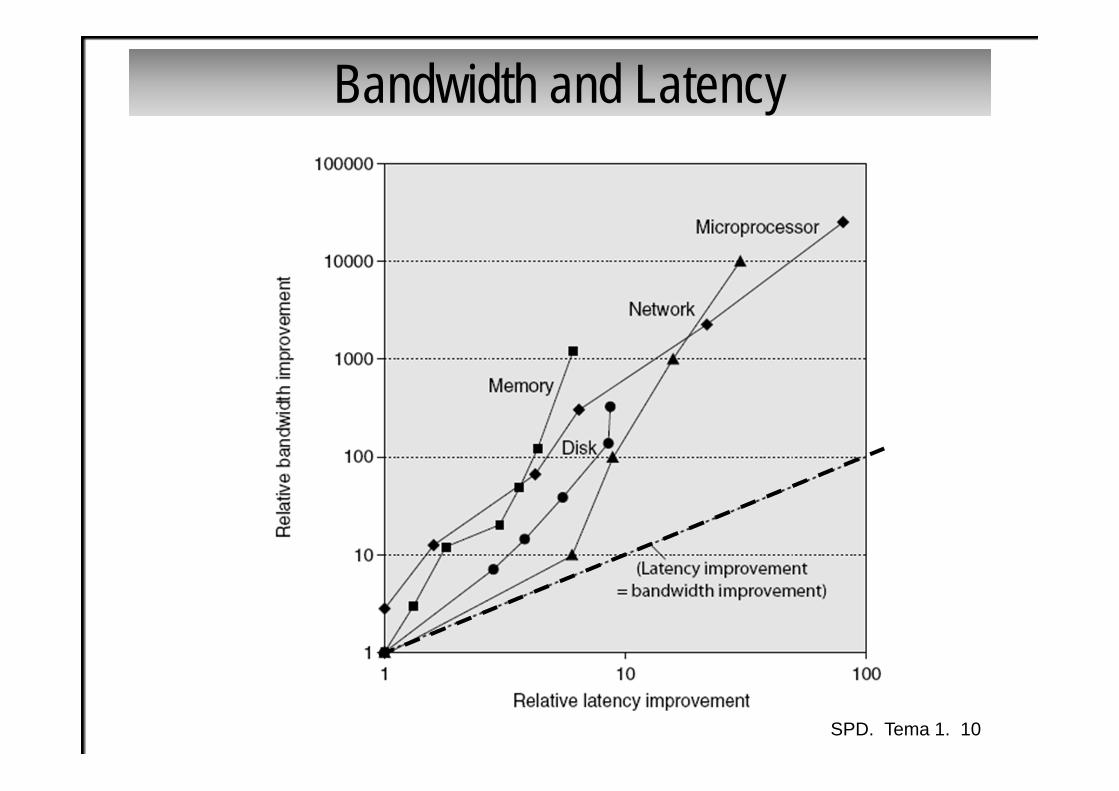
Bandwidth and Latency
SPD. Tema 1. 10

Ejercicio: Bandwidth and Latency• Definir grosso modo:
– Bandwidth – Latency
SPD. Tema 1. 11
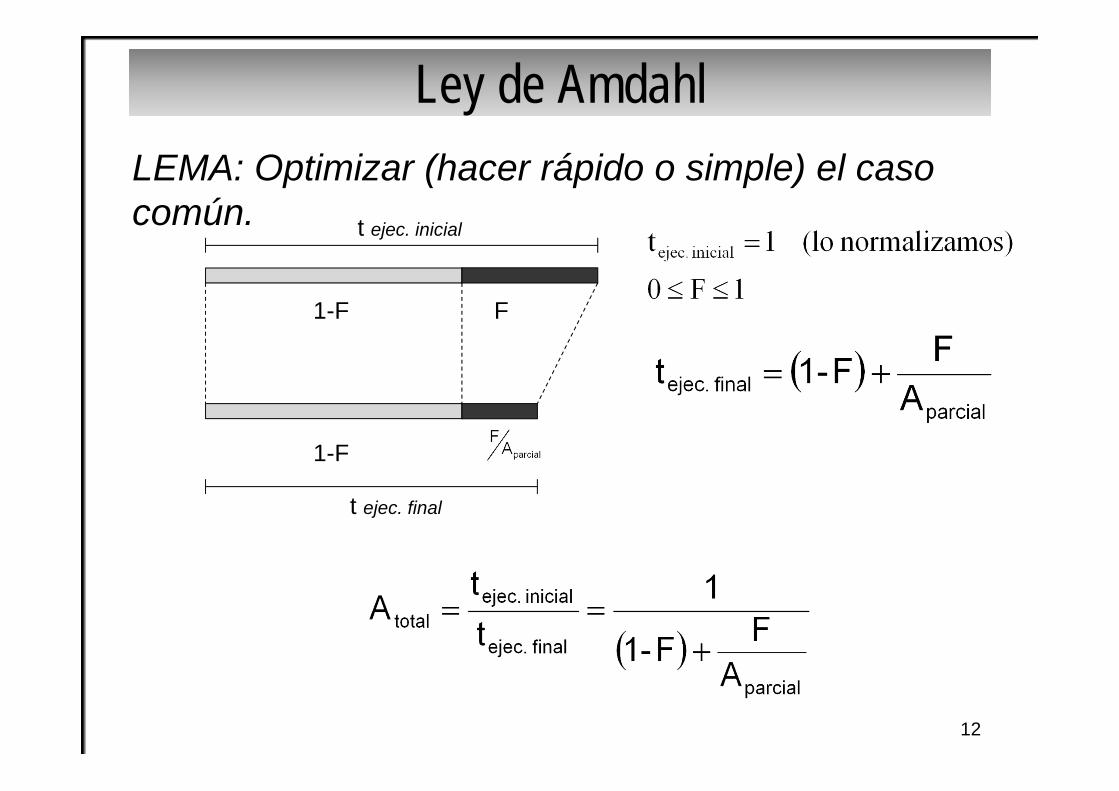
Ley de Amdahl
12
t ejec. inicial
t ejec. final
1-F
1-F
F
LEMA: Optimizar (hacer rápido o simple) el caso común.

Principio de localidad • Temporal • Espacial• Regla empírica, 90% del tiempo de
ejecución en el 10% del código y datos• Importante orden accesos a memoria
13
EJERCICIO: ¿Por qué casi todos los computadores actuales tienen varios niveles de caché (Jerarquía de memoria)?

EJERCICIO: ley de Amdahl y Ley 10/90• Teniendo en cuenta la ley de Amdahl y la
10/90, si se quiere optimizar un programa que conviene más:– Optimizar todo el código para ir ganando
aceleración en todos los sitios– Concentrarse en los bucles – Optimizar los accesos a memoria de datos (p.
ej. reordenar accesos a caché)
• Justificar la respuesta.
SPD. Tema 1. 14
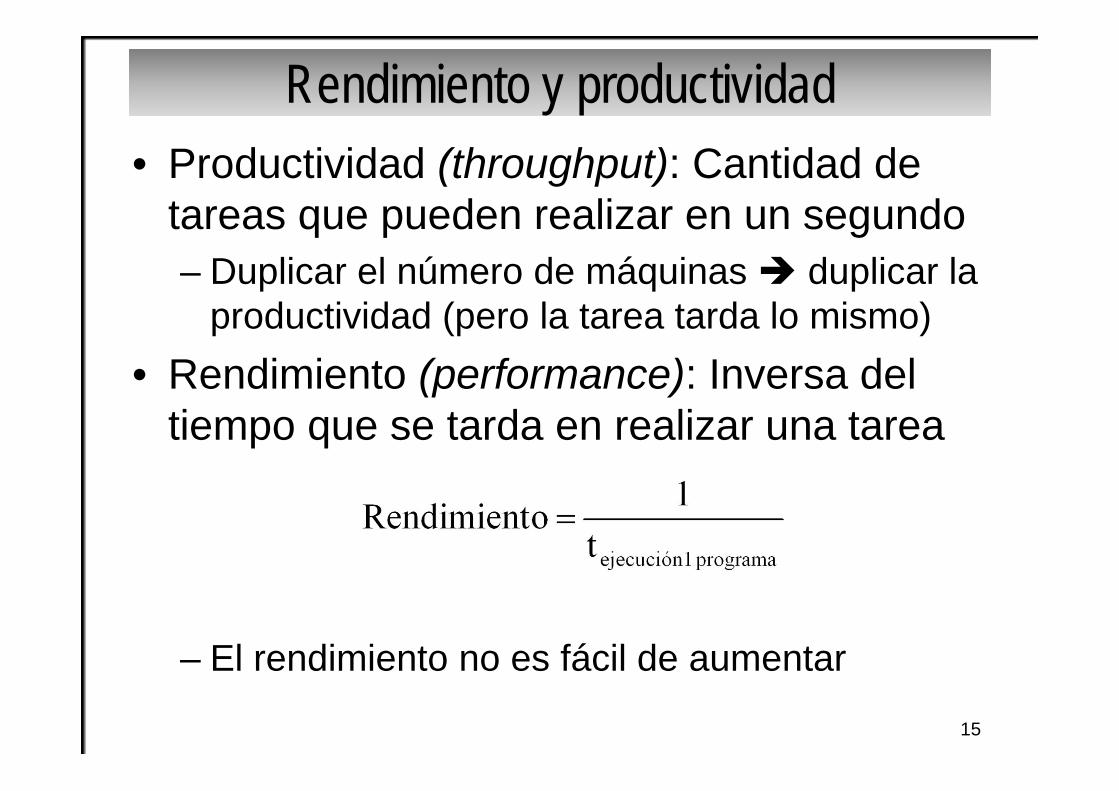
• Productividad (throughput): Cantidad de tareas que pueden realizar en un segundo– Duplicar el número de máquinas duplicar la
productividad (pero la tarea tarda lo mismo)• Rendimiento (performance): Inversa del
tiempo que se tarda en realizar una tarea
– El rendimiento no es fácil de aumentar
Rendimiento y productividad
15
16
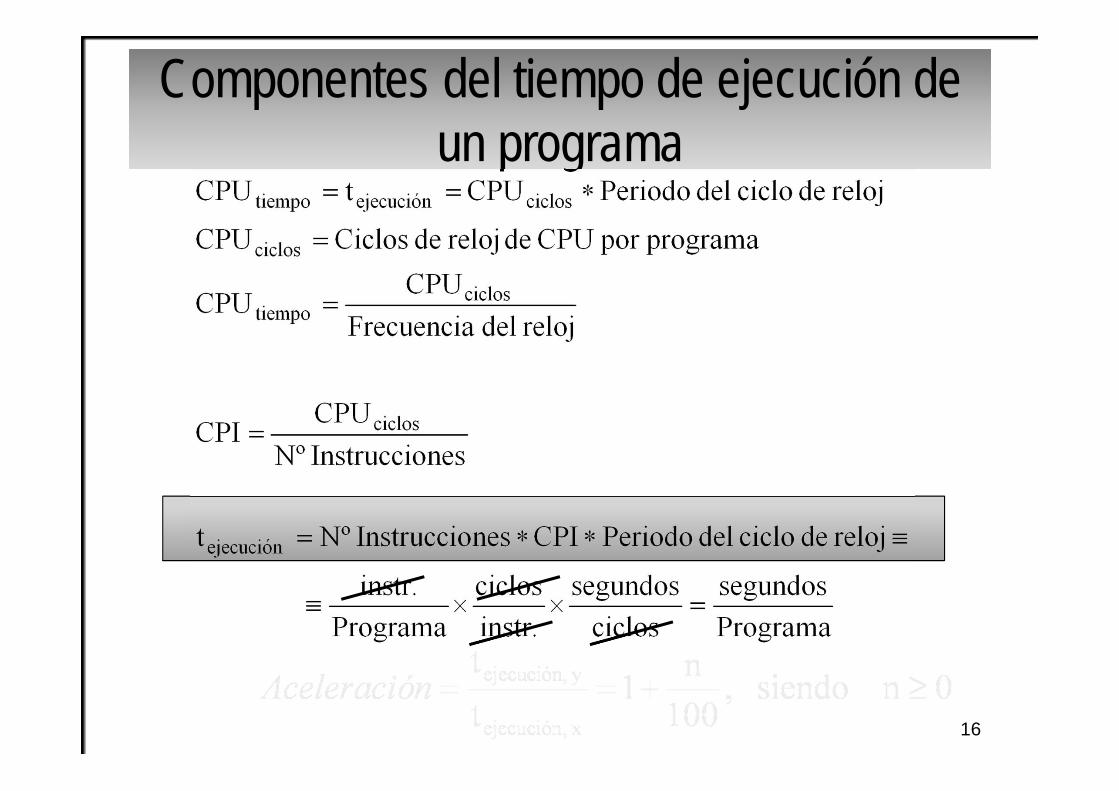
Componentes del tiempo de ejecución de un programa

EJERCICIO: Ley AmdahlSupongamos que consigo paralelizar el 50% de un
programa, de forma que se pueden ejecutar en 10 procesadores a la vez obteniendo una aceleración parcial de 10. ¿Cuál sería la aceleración total?a) Cercana a 10 vecesb) 50%*10= 5 vecesc) En torno a 80%d) Ninguna de las anteriores
SPD. Tema 1. 17

CPI: magnitud arquitectónica
18
Casi “Data Flow Limit” (límite del flujo de datos) • Sólo “se ven” las dependencias reales
¿Qué factores limitan más el rendimiento?• CPIcontrol: predicción de saltos. • CPImemoria: Accesos a memoria de datos (cachés)
Aumentar Rendimiento : más paralelismo
EJERCICIO: ¿Cómo obtener más rendimiento? ¿comprarse otra máquina o pensar en lo anterior?

Magnitudes de rendimiento• Muy usadas pero no son exactas
– MIPS: Millones de instrucciones por segundo– MFLOPs (GFLOPs): Millones (G) de
operaciones en coma flotante por segundo• Sólo + - * / y transcendentes • Para código científico
• Mejor: Medias de Colección benchmarks– Standard Performance Evaluation Corporation
(SPEC)• SPECint (programas enteros)• SPECfp (programas F.P.)
SPD. Tema 1. 19

Tipos de paralelismo• PARALELISMO A NIVEL DE INSTRUCCIONES
(ILP) • PARALELISMO A NIVEL DE DATOS (DLP) • PARALELISMO A NIVEL DE HILOS, TAREAS
(TLP) • PARALELISMO A NIVEL DEPETICIONES
(RLP)
• LEMA: “Actualmente el paralelismo es casi la única forma de aumentar rendimiento y/o productividad”
SPD. Tema 0. 20
F1 F2 F3 F4
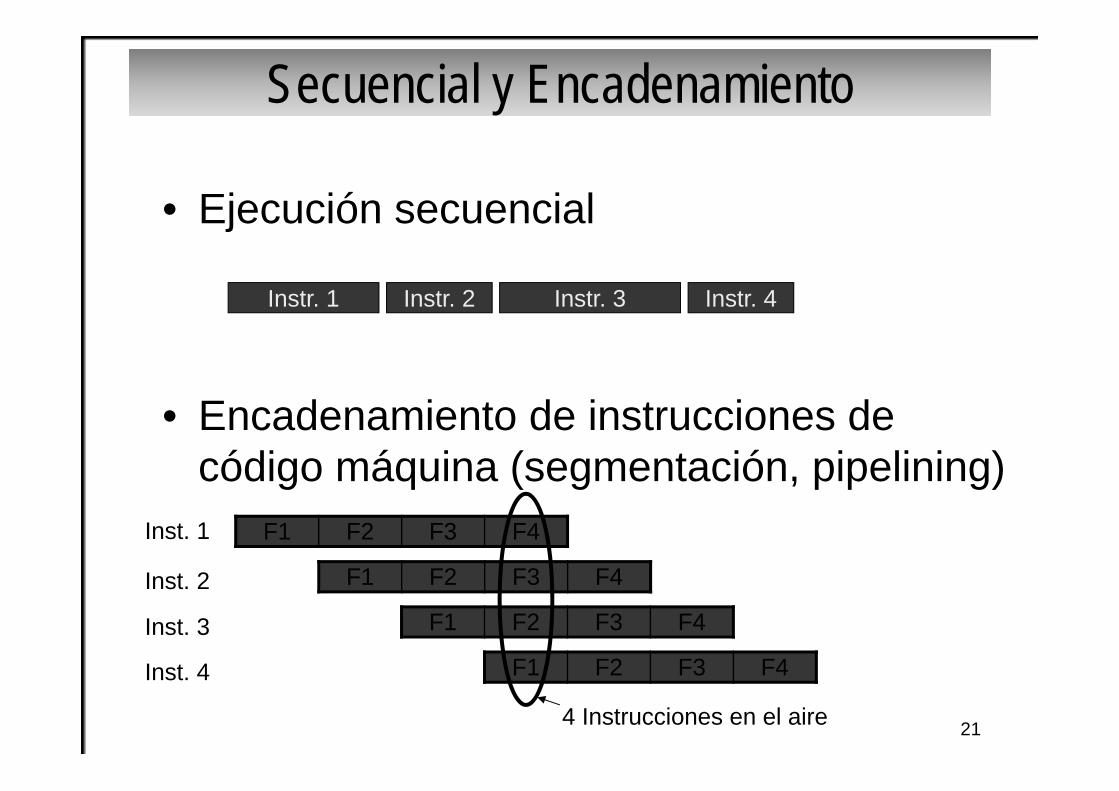
Secuencial y Encadenamiento
21
• Ejecución secuencial
• Encadenamiento de instrucciones de código máquina (segmentación, pipelining)
Instr. 1 Instr. 2 Instr. 3 Instr. 4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
Inst. 1
Inst. 2
Inst. 3
Inst. 4
4 Instrucciones en el aire
22
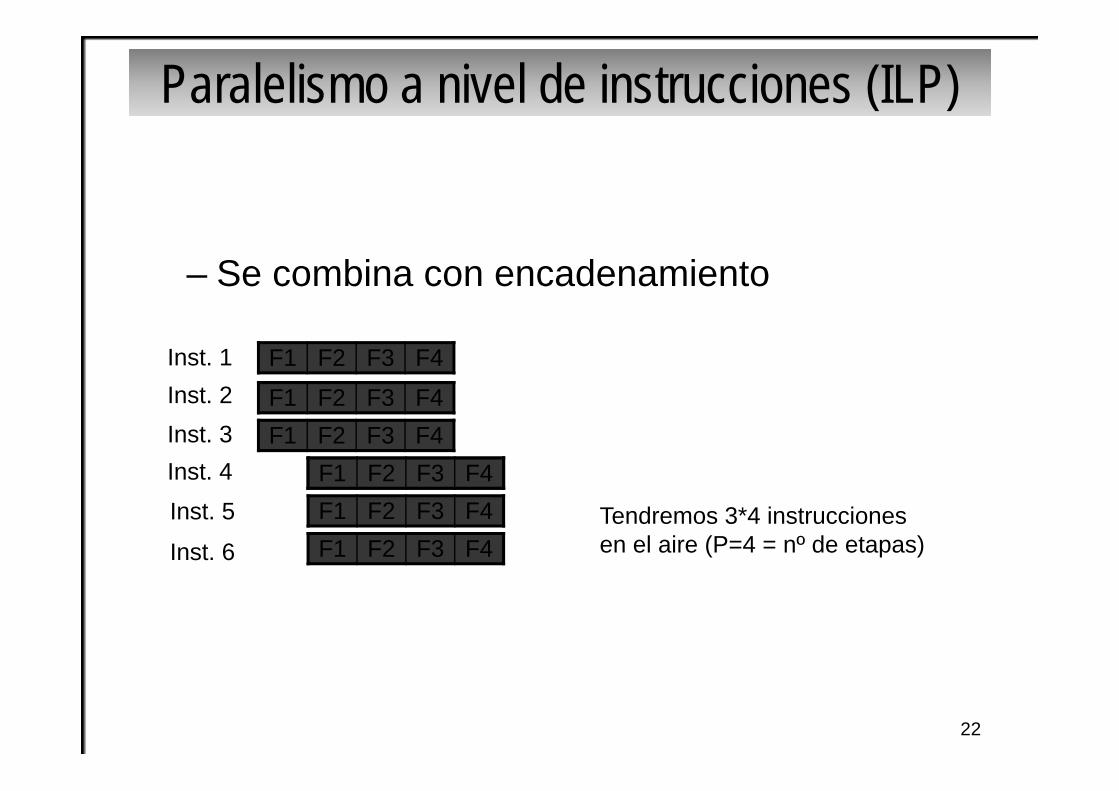
Paralelismo a nivel de instrucciones (ILP)
– Se combina con encadenamiento
F1 F2 F3 F4Inst. 1Inst. 2Inst. 3Inst. 4
F1 F2 F3 F4F1 F2 F3 F4
F1 F2 F3 F4F1 F2 F3 F4F1 F2 F3 F4F1 F2 F3 F4
Inst. 5
Inst. 6Tendremos 3*4 instruccionesen el aire (P=4 = nº de etapas)

23
Paralelismo a nivel de datos (DLP)– procesamiento vectorial– la misma operación sobre muchos datos (p.e. sumar 2
vectores). – Típico en programas multimedia, científicos y de
transacciones (bancos, comercios, comunicaciones, etc.)
F1 F2 F3 F4F3Inst. 1
Inst. 2
Inst. 3
Inst. 4
Inst. 5
Inst. 6
F1 F2 F3 F4F3
F1 F2 F3 F4F3
F1 F2 F3 F4F3
F1 F2 F3 F4F3
F1 F2 F3 F4F3

EJERCICIO: COMENTARIO TEXTOFrom H&P 2012.The switch to multiple processors per chip around 2005 did
not come from some breakthrough that dramatically simplified parallel programming or made it easy to build multicore computers.
The change occurred because there was no other option due to the ILP walls and power walls.
Performance is now a programmer’s burden. The programmer era of relying on hardware designers to make their programs go faster without lifting a finger is officially over. If programmers want their programs to go faster with each generation, they must make their programs more parallel.
The popular version of Moore’s law—increasing performance with each generation of technology—is now up to programmers. SPD. Tema 1. 24
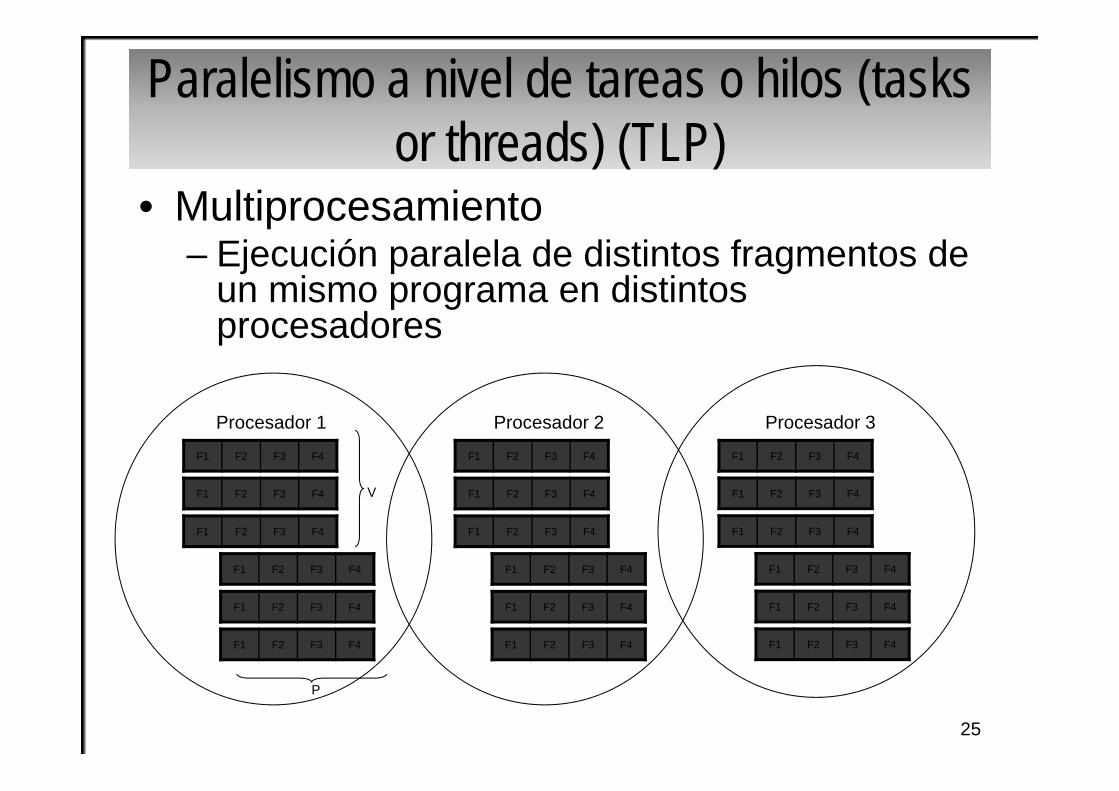
Paralelismo a nivel de tareas o hilos (tasksor threads) (TLP)
• Multiprocesamiento – Ejecución paralela de distintos fragmentos de
un mismo programa en distintos procesadores
25
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
F1 F2 F3 F4
Procesador 2Procesador 1 Procesador 3
P
V
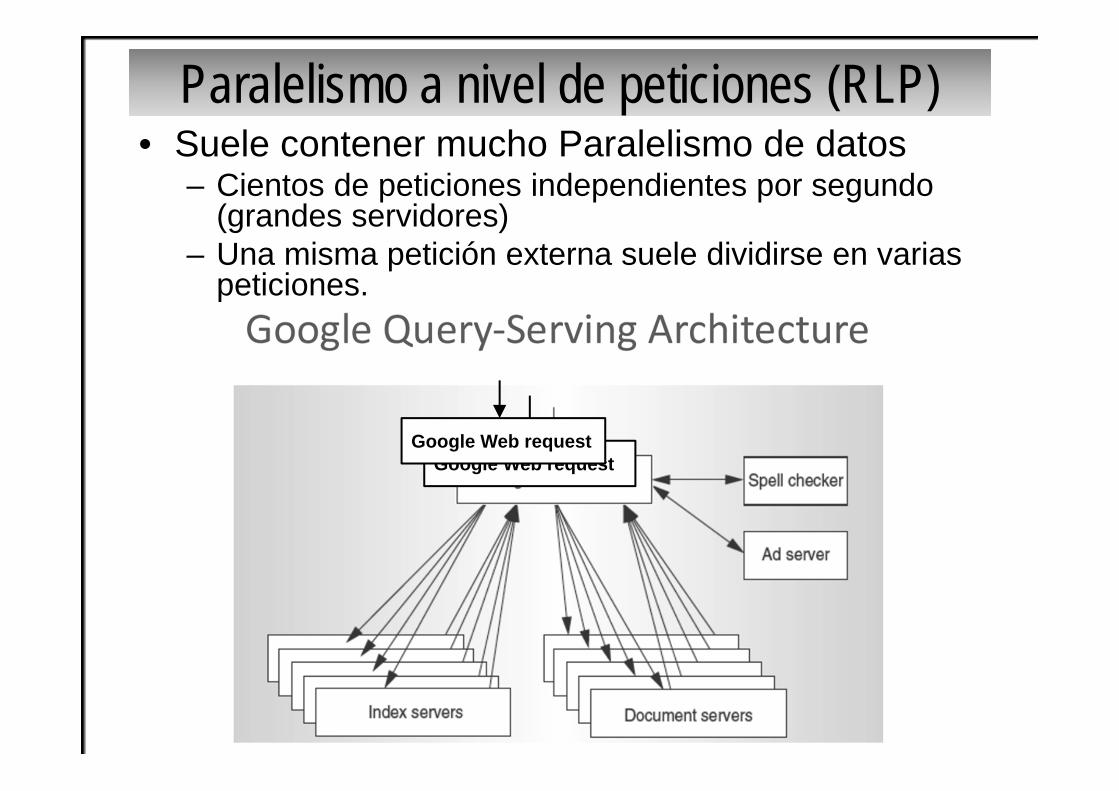
Paralelismo a nivel de peticiones (RLP)• Suele contener mucho Paralelismo de datos
– Cientos de peticiones independientes por segundo (grandes servidores)
– Una misma petición externa suele dividirse en varias peticiones.
Google Web requestGoogle Web request

EJERCICIO
• Hallar el número de instr. en vuelo (activas en cualquier fase en un ciclo) del diagrama de Multiprocesamiento.
• Hallar número de operaciones por ciclo si además hay DLP con 2 operaciones a la vez en F3.
SPD. Tema 1. 27

CONCEPTOS BÁSICOS• Resumen de conceptos de cada tema
– ILP– DLP– TLP/RLP
SPD. Tema 1. 28

Límites del ILP• ILP: Paralelismo a nivel de instrucciones• Se han acercado al Data Flow Limit, límite del
flujo de datos • ¿Qué dos factores limitan más el paralelismo
ILP extraíble en benchmarks reales?– Fallos en la predicción de saltos.
• BTB cada vez más sofisticada, compleja y grande.
– Accesos a memoria de datos (caché): • Aunque AB altísimo• Latencia de acceso decrece poco• Muchos accesos
SPD. Tema 1. 29

Técnicas Estáticas vs. Dinámicas• Estática: compilador/programador• Dinámica: procesador en t de ejecución• PLANIFICACIÓN (reordenación de
instrucciones o Scheduling) ESTÁTICA– Compiladores avanzados: En teoría se puede extraer
Alto Rendimiento del Scheduling Dinámico– Ej. Desenrollado de bucles y otros
• PLANIFICACIÓN DINÁMICA– Algoritmo en hardware. Muy sofisticado. – IDEA: Apuntar la información de dependencias en
registros ocultos y esperar a que llegue el dato. – Scheduling Dinámico muy eficiente
SPD. Tema 1. 30

Ej. DESENROLLADO DE BUCLESfor (i=0 ; i<M ; i++)
y[i]= x[i] * s;
//Planif. estática otra forma:
for (i=0 ; i<M ; i+=4 ) {y[i+0]= x[i+0] * s ;y[i+1]= x[i+1] * s ;y[i+2]= x[i+2] * s ;y[i+3]= x[i+3] * s ;
}SPD. Tema 1. 31

ARQUITECTURAS MICROPROC.: Tres Modelos• Reducir CPI: Superescalares.
– ejecutan varias instr/ciclo.– Técnicas Dinámicas Sofisticación
• Reducir Ninst LIW o VLIW (“Very Long Instruction Word”): – Macroinstrucciones preparadas estáticamente con
varias operaciones dentro.– Técnicas Estáticas Dependencia del compilador
• Reducir τ “superpipeline”, supersegmentadoo superencadenado.– Más etapas en la cadena – Más consumo energía
SPD. Tema 1. 32

CPU actuales alto rendimiento• Procesadores GPP (General Purpose
Processor): muy sofisticados. – POWER7 (IBM,Freescale y otros)– Core (Intel)– Sempron, Phenom , Fusion (AMD)
• Procesadores para empotrados: VLIW o superescalares sencillos para DSP, PDAs, smartphones.– ARM v7 Cortex (especificación)– OMAP3 processors (Texas Instr.)– MSC81xx (Freescale) multi-core DSP.
SPD. Tema 1. 33
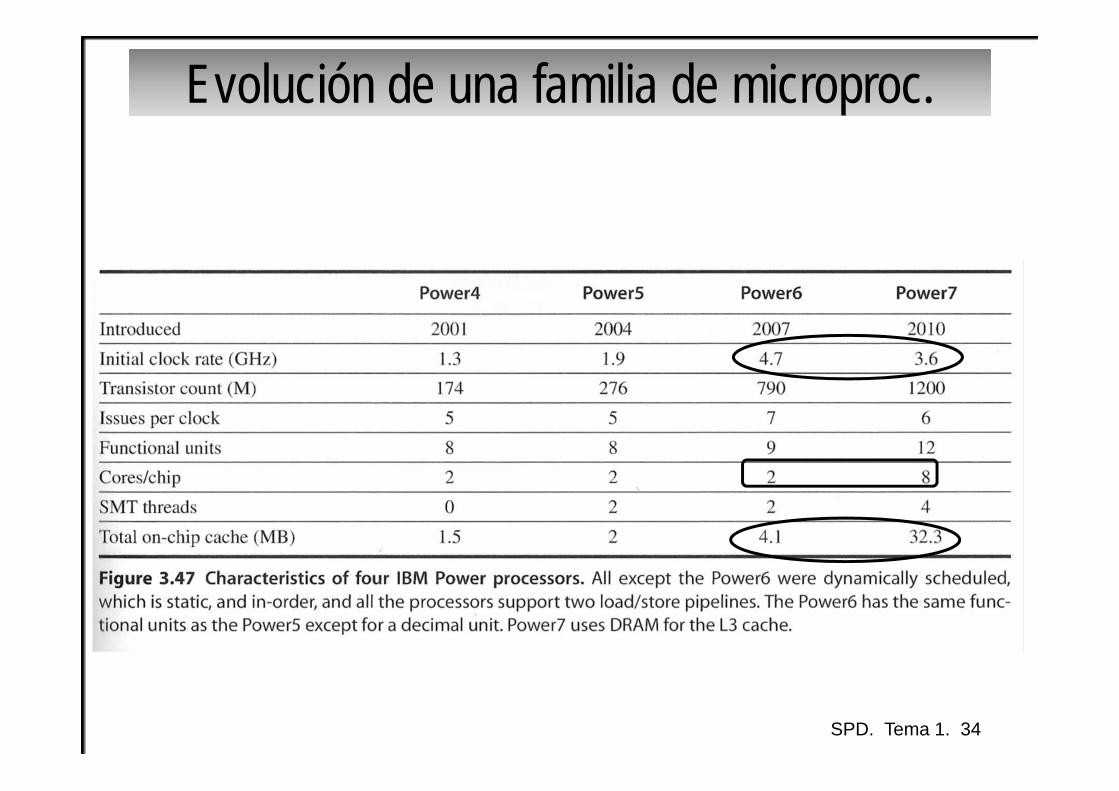
Evolución de una familia de microproc.
SPD. Tema 1. 34

Utilidad de DLP• DLP: Paralelismo a nivel de datos: vectorización• Aplicaciones
– Multimedia: tratamiento de imágenes, sonido – Científico: Cálculo matricial, vectorial, resolución
ecuaciones,…– Transacciones: (bancos, comercios, comunicaciones,…)
• Sistemas – Empotrados (tb genéricos) – GPU: Graphics Proc. Units (tarjetas gráficas)– Supercomputadores científicos
• Punto débil: – es difícil “vectorizar” – juego de instrucciones cambia cada varios años: cambio
de librerías, cambio en vectorizaciónSPD. Tema 1. 35

TLP• TLP: Paralelismo a nivel de tareas/hilos• PUNTO DÉBIL EXTRACCIÓN DE PARALELISMO:
– “Artesanal”– Automática sólo si es evidente– Difícil analizar si una aplicación es paralelizable.
• PUNTOS CLAVE EN EL DISEÑO:– Red de interconexión – La forma de organizar la jerarquía de memoria
SPD. Tema 1. 36
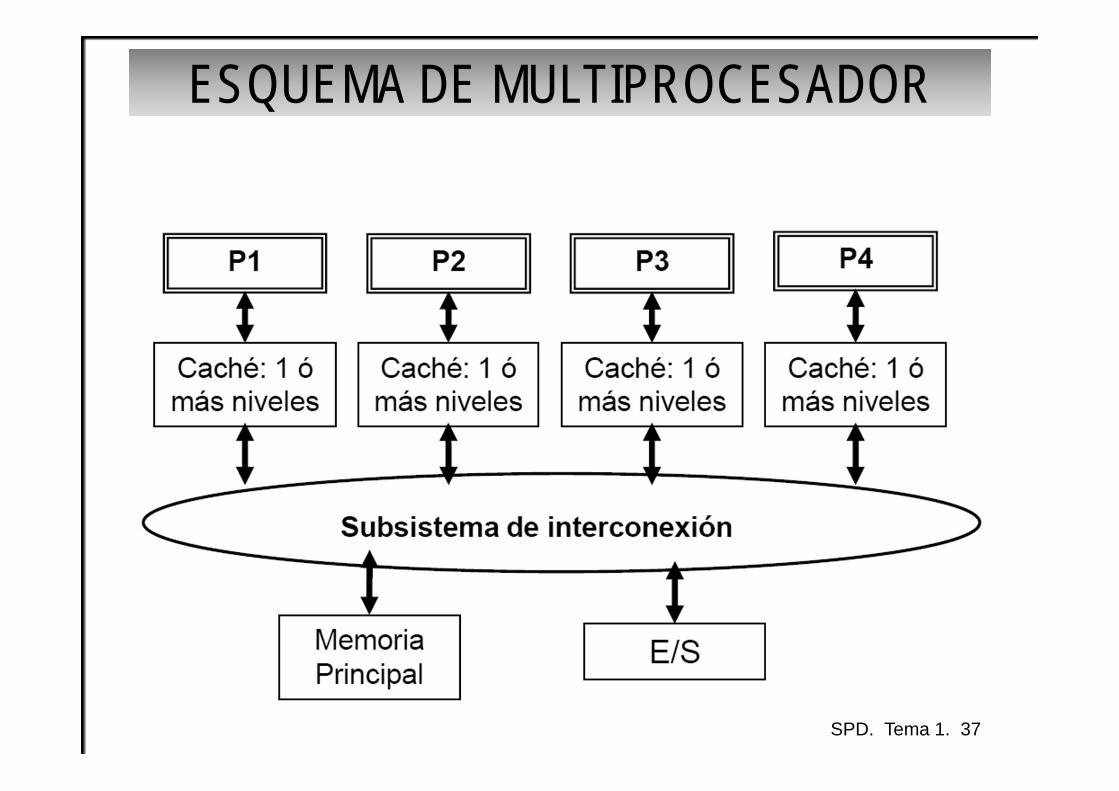
ESQUEMA DE MULTIPROCESADOR
SPD. Tema 1. 37

Disposición lógica de la memoria• Espacio de direcciones compartido (todos
los multicore actuales) – Herramienta OpenMP: directivas o extensiones a
lenguajes de programación Fortran, C, C++.
• Espacio de direcciones disjuntos: clustersde computación.– Librería Message Passing Interface (MPI):
especificación para librerías de paso de mensajes
SPD. Tema 1. 38

RLP• RLP: Paralelismo a nivel de peticiones• Paralelismo evidente en (servidores):
– Carga de tareas variadas – Procesado de transacciones (base de datos,
búsqueda internet, etc.) • Necesitan herramientas (clave):
– Balanceo de carga– Virtualización
• Aparecen nuevos retos:– Alta Disponibilidad– Reducción costes– Reducir Consumo energético. SPD. Tema 1. 39





























