Embed Size (px)
Citation preview

Nekaj resenih nalog iz statistike in pripadajoce teorijeMatematika s statistiko, 1. letnik biokemije UN
25. maj 2009
1 Intervalno ocenjevanje
Naj bo slucajna spremenljivka X porazdeljena normalno s parametroma a in σ (a je ma-tematicno upanje spremenljivke X, σ2 pa disperzija). V statistiki ponavadi ta parametranista znana, saj imamo na voljo le vzorec podatkov x1, x2, . . . , xn za X. Za te podatke lahkotockovno ocenimo vrednosti parametrov a in σ. Za tockovno oceno matematicnega upanjaizberemo kar aritmeticno sredino danega vzorca:
x =x1 + x2 + . . .+ xn
n. (1)
Tockovno oceno disperzije dobimo iz obrazca
s2 =1
n− 1
n∑i=1
(xi − x)2. (2)
Namesto tockovne ocene nekega parametra populacije lahko navedemo le interval na realniosi, na katerem z doloceno, v naprej predpisano verjetnostjo lezi prava vrednost parametra.Predpisano verjetnost imenujemo stopnja zaupanja in jo oznacimo z 1−α. Pri tem parametruα pravimo stopnja znacilnosti. Najpogostejse vrednosti za α so 0.05, 0.01 in vcasih 0.001.Dobljenemu intervalu pravimo interval zaupanja.
Recimo, da imamo vzorec x1, x2, . . . , xn za X ∼ N(a, σ). Parametra a ne poznamo,zelimo pa dolociti interval, na katerem a lezi z verjetnostjo 1− α. Locimo dve moznosti:
1. Ce je parameter σ znan, potem je interval zaupanja za a
[x− zασ√n, x+ zα
σ√n
], (3)
kjer je x vzorcno povprecje (gl. obrazec (1)), n stevilo podatkov v vzorcu, vrednost zαpa dobimo, ce resimo enacbo
Φ(zα) =1− α
2(4)
s pomocjo tabele 1.
2. Pogosto se zgodi, da tudi parameter σ ni znan. V tem primeru se a z verjetnostjo 1−αnahaja na intervalu
[x− tαs√n, x+ tα
s√n
], (5)
kjer je tα vrednost, ki jo dobimo iz tabele 2 pri stopnji znacilnosti α in n−1 prostostnihstopnjah. Vrednosti x in s dobimo s pomocjo obrazcev (1) in (2).
Naloga 1. Doloci interval zaupanja za matematicno upanje slucajne spremenljivke X, kije normalno porazdeljena z disperzijo σ2 = 9, ce smo za vzorec s 100 elementi izracunalipovprecno vrednost x = 5 in je stopnja zaupanja 0.99.
1

Resitev. Parameter σ je znan (σ = 3), n = 100, stopnja znacilnosti pa je α = 1−0.99 = 0.01.Parameter z0.01 dolocimo, ce resimo enacbo (4) za α = 0.01, torej Φ(z0.01) = 0.495. V tabeli1 med podatki poiscemo vrednost, ki je cim blizje vrednosti 0.495 in preberemo, pri kateremx je dosezena. Tako dobimo zα. V nasem primeru dobimo z0.01 = 2.57 (natancnejso resitevz0.01 = 2.575 lahko dobimo z linearno interpolacijo; gl. dodatek o uporabi tabel). Intervalzaupanja je torej - gl. (3):[
5− 2.57 · 3√100
, 5 + 2.57 · 3√100
]= [4.226, 5.774].
�
Naloga 2. V laboratoriju so opravili 10 meritev koncentracije prahu v zraku. Dobili sonaslednje vrednosti (v mg/m3):
3.8 3.8 3.9 3.5 3.6 3.8 4.0 3.5 3.7 3.9 .
Slucajna spremenljivka X, ki meri koncentracijo prahu, je lognormalno porazdeljena (to po-meni, da je logaritem te slucajne spremenljivke normalno porazdeljena slucajna spremen-ljivka). Doloci interval zaupanja pri 95% zanesljivosti. Ali lahko s 95% zanesljivostjo trdimo,da koncentracija prahu ne presega 4 mg/m3?
Resitev. Ce spremenljivka X oznacuje koncentracijo prahu v zraku, potem je Y = lnX nor-malno porazdeljena slucajna spremenljivka, zato bomo najprej izracunali interval zaupanjaza Y . Podatke za vzorec od Y dobimo tako, da logaritmiramo tiste od X:
xi yi = lnxi (yi − y)2
3.8 1.3350 0.000203.8 1.3350 0.000203.9 1.3610 0.000163.5 1.2528 0.004603.6 1.2809 0.001603.8 1.3350 0.000204.0 1.3863 0.004303.5 1.2528 0.004603.7 1.3083 0.000153.9 1.3610 0.00016
13.2080 0.00210
Po formuli (1) izracunamo srednjo vrednost y, po formuli (2) pa cenilko za standardni odklons (tabeli smo dodali se stolpec za kvadrate odklonov (yi − y)2):
y =1n
n∑i=1
yi =13.2080
10= 1.3208
s2 =1
n− 1
n∑i=1
(yi − y)2 =0.00210
9= 0.00023,
torej je s = 0.048. Ker parameter σ ni znan, interval zaupanja za Y pri α = 0.05 izracunamopo formuli (5). Pri tem vrednost t0.05 dolocimo s pomocjo tabele 2 pri α = 0.05 in n− 1 = 9prostostnih stopnjah; dobimo t0.05 = 2.26. Interval zaupanja za Y torej je
[1.3208− 2.26 · 0.048√10
, 1.3208 + 2.26 · 0.048√10
] = [1.2865, 1.3551].
Interval zaupanja za spremenljivko X dobimo, ce antilogaritmiramo meje intervala za Y (lnje strogo narascajoca funkcija). Interval, ki ga dobimo, je [e1.2865, e1.3551] = [3.6201, 3.8771].Povprecna koncentracija prahu torej s 95% verjetnostjo lezi na tem intervalu, torej lahko zenako gotovostjo trdimo, da ne presega 4 mg/m3. �
2

2 Testiranje hipotez za srednjo vrednost in standardniodklon
Statisticna hipoteza je vsaka domneva o tipu porazdelitvenega zakona slucajne spremenljivkeX, ki oznacuje neko lastnost populacije. Hipoteza, ki jo preucujemo, se imenuje nicelnahipoteza H0, vsaka druga mozna hipoteza pa je alternativna hipoteza H1. V splosnem te-stiramo hipoteze na naslednji nacin: Izberemo slucajni vzorec podatkov x1, x2, . . . , xn zaspremenljivko X. Nato izberemo testno statistiko U = U(X1, X2, . . . , Xn), ki meri, kakodobro drzi hipoteza, in kriticno obmocje, podmnozico v zalogi vrednosti te statistike. Toobmocje je odvisno od vrste testa in stopnje znacilnosti α. Nato izracunamo vrednost sta-tistike u = U(x1, x2, . . . , xn) na danem vzorcu. Ce vrednost u pade v kriticno obmocje,hipotezo H0 zavrnemo, ce pa je u zunaj kriticnega obmocja, H0 sprejmemo oziroma recemo,da se eksperimentalni podatki ne razlikujejo znacilno od podanih.
Test hipoteze je dvostranski, ce je kriticno obmocje sestavljeno iz dveh polodprtih inter-valov. Tak test imamo tedaj, ko preucujemo, ali se vrednosti vzorca znacilno razlikujejo odparametra, ki ga preucujemo, pri tem pa nam je vseeno, ali so vrednosti znacilno vecje aliznacilno manjse. Ce je kriticno obmocje testa en sam polodprti interval, je test enostranski.
Za X ∼ N(a, σ) bomo obravnavali naslednje parametricne teste za matematicno upanjea pri stopnji znacilnosti α:
1. Parameter σ je znan, testiramo pa hipotezo H0(a = a0), kjer je a0 dana vrednost.Tu za testno statistiko uporabimo Z = X−a0
σ
√n (zato temu testu vcasih pravimo tudi
Z-test). Ce jo izracunamo na vzorcu x1, x2, . . . , xn, dobimo
z =x− a0
σ
√n. (6)
Kriticno obmocje je odvisno od izbire alternativne hipoteze:
(a) Dvostranski test H0(a = a0) proti H1(a 6= a0);Kriticno vrednost zα dobimo, ce resimo enacbo
Φ(zα) =1− α
2(7)
s pomocjo tabele 1. Hipotezo H0 zavrnemo, ce je |z| ≥ zα.(b) Enostranski test H0(a = a0) proti H1(a ≤ a0);
Kriticno vrednost zα dobimo, ce resimo enacbo
Φ(zα) = α− 12
(8)
s pomocjo tabele 1. Hipotezo H0 zavrnemo, ce je z ≤ zα.(c) Enostranski test H0(a = a0) proti H1(a ≥ a0);
Kriticno vrednost zα dobimo, ce resimo enacbo
Φ(zα) =12− α (9)
s pomocjo tabele 1. Hipotezo H0 zavrnemo, ce je z ≥ zα.
2. Parameter σ je neznan, testiramo pa hipotezo H0(a = a0), kjer je a0 dana vrednost.Tu za testno statistiko uporabimo T = X−a0
s
√n (zato temu testu vcasih pravimo tudi
t-test). Ce jo izracunamo na vzorcu x1, x2, . . . , xn, dobimo
t =x− a0
s
√n. (10)
Kriticno obmocje je odvisno od izbire alternativne hipoteze:
3

(a) Dvostranski test H0(a = a0) proti H1(a 6= a0);Kriticno vrednost tα dobimo iz
P (|T | ≥ tα) = α (11)
pri n − 1 prostostnih stopnjah s pomocjo tabele 2. Hipotezo H0 zavrnemo, ce je|t| ≥ tα.
(b) Enostranski test H0(a = a0) proti H1(a ≤ a0);Kriticno vrednost t2α dobimo iz
P (|T | ≥ t2α) = 2α (12)
pri n − 1 prostostnih stopnjah s pomocjo tabele 2. Hipotezo H0 zavrnemo, ce jet ≤ −t2α.
(c) Enostranski test H0(a = a0) proti H1(a ≥ a0);Kriticno vrednost t2α dobimo iz
P (|T | ≥ t2α) = 2α (13)
pri n − 1 prostostnih stopnjah s pomocjo tabele 2. Hipotezo H0 zavrnemo, ce jet ≥ t2α.
Naloga 3. Povprecna zivljenjska doba 100 nakljucno izbranih zarnic je 1570 ur s standardnimodklonom 120 ur.
(a) Preveri hipotezo, da je povprecna zivljenjska doba zarnic v celotni proizvodnji 1600 urpri stopnji znacilnosti α = 0.05.
(b) Preveri hipotezo H0(a = 1600) proti H1(a ≤ 1600).
(c) Preveri hipotezo H0(a = 1600) proti H1(a ≥ 1600).
Resitev. Prepisimo podatke: x = 1570, n = 100, σ = 120. Testiramo hipotezo H0(a = 1600)(torej je a0 = 1600) proti alternativnim hipotezam. Ker je parameter σ znan, uporabimoZ-test. Najprej izracunajmo testno statistiko na vzorcu po enacbi (6):
z =x− a0
σ
√n =
1570− 1600120
·√
100 = −2.5.
V (a) testiramo H0(a = 1600) proti H1(a 6= 1600), zato uporabimo dvostranski test. Kriticnovrednost z0.05 dolocimo, ce resimo enacbo (7) za α = 0.05. Dobimo Φ(z0.05) = 0.475, odkoder s pomocjo tabele 1 dobimo z0.05 = 1.96. Ker je v nasem primeru |z| > z0.05, hipotezoH0 zavrnemo, torej lahko s 95% gotovostjo trdimo, da se povprecna zivljenjska doba zarnicznacilno razlikuje od 1600 ur.
V (b) kriticno vrednost z0.05 dolocimo iz enacbe (8); dobimo Φ(z0.05) = −0.45. Iz tabele1 dobimo z0.05 = −1.65 (tukaj upostevamo Φ(−z) = −Φ(z)). Ker je z ≤ zα, hipotezo H0
zavrnemo.
V (c) kriticno vrednost z0.05 dolocimo iz enacbe (9); dobimo Φ(z0.05) = 0.45. Iz tabele1 dobimo z0.05 = 1.65. Ker je z < zα, hipoteze H0 ne zavrnemo. Z verjetnostjo 0.95 lahkotrdimo, da je povprecna zivlj. doba zarnic znacilno manjsa od 1600 ur. �
Naloga 4. Stroj polni 33 kilogramske vrece s hidrirnim apnom. Ali nam vzorec desetihslucajno izbranih tehtanj, navedenih v spodnji tabeli, s stopnjo znacilnosti α = 0.01 zagotavlja,da vreca v povprecju res tehta 33 kilogramov, ce je masa vrece normalno porazdeljena slucajnaspremenljivka s standardnim odklonom σ = 0.3.
32.92 32.50 32.80 33.52 32.49 32.62 33.40 33.09 33.44 33.10
4

Resitev. Preizkusamo hipotezo H0(a = 33) proti hipotezi H1(a 6= 33), pri cemer je stan-dardni odklon znan. Najprej izracunamo povprecje za vzorec in dobimo x = 33.033. Testnastatistika je
z =x− a0
σ
√n =
33.033− 330.3
√10 = 0.35.
Kriticno vrednost z0.01 dobimo iz iz enacbe (7) za α = 0.01, torej resujemo enacbo Φ(z0.01) =0.495. Iz tabele za funkcijo Φ dobimo priblizno resitev z0.01 = 2.57. Ker je |z| < zα, hipotezeH0 ne zavrnemo, torej lahko pri stopnji znacilnosti 0.01 (se pravi z verjetnostjo 0.99) trdimo,da je povprecna masa vrece dejansko 33 kilogramov. �
Naloga 5. V okolici nekega zdravilisca so enajst zaporednih dni merili hrup in dobili nasle-dnje podatke (v decibelih):
46.20 46.52 46.47 46.05 46.89 46.97 46.10 46.64 46.29 46.03
Ali lahko na osnovi dobljenih podatkov sklepamo, da je povprecna vrednost hrupa pri stopnjiznacilnosti α = 0.001 enaka 46.5 dB, ce predpostavimo da imamo lahko preucevano kolicinoza normalno porazdeljeno slucajno spremenljivko?
Resitev. Slucajna spremenljivka X, ki meri hrup v okolici zdravilisca, je porazdeljena pozakonu N(a, σ), vendar pa v tem primeru standardnega odklona σ ne poznamo. Zato bomoσ ocenili iz vzorca (se pravi, izracunali bomo s) in uporabili t-test za testiranje hipotezeH0(a = 46.5) proti hipotezi H1(a 6= 46.5). Najprej izracunamo povprecje vzorca: x = 46.277.V pomoc racunanju parametra s napravimo naslednjo tabelo:
xi (xi − x)2
46.20 0.00592946.52 0.05904946.47 0.03724946.05 0.05152946.89 0.37576946.97 0.48024946.10 0.03132946.64 0.13176946.29 0.00016946.03 0.061009
Σ = 464.16 Σ = 1.23405
Iz formule (2) sedaj dobimo:
s2 =1
n− 1
n∑i=1
(xi − x)2 =110· 1.23405 = 0.123405,
torej je s = 0.351. Vrednost statistike t je zato
t =x− a0
s
√n =
46.277− 46.50.351
√11 = −2.107.
Kriticno vrednost tα dobimo tako, da resimo enacbo P (|T | ≥ tα) = α pri f = n − 1 = 10prostostnih stopnjah. Iz tabele preberemo, da je t0.001 = 4.59. Ker je | − 2.107| < 4.59,hipoteze ne zavrnemo; vzorcne meritve hrupa se ne razlikujejo bistveno od 46.5 dB. �
3 t-test pri parnih, med seboj odvisnih vzorcih
Doslej smo obravnavali analizo kvantitativnih podatkov na med seboj neodvisnih vzorcih.Pogosto pa imamo opravka s podatki, dobljenimi v parnih poskusih. V takem primeru imavsak podatek v enem vzorcu svoj par v drugem vzorcu.
5

Postopek resevanja takih problemov je preprost. Upostevamo le razliko podatkov vposameznem paru. Ce testiramo hipotezo srednjih vrednostih, je nicelna domneva vednoH0(a = 0). Za testiranje uporabimo t-test.
Naloga 6. Pri dveh proizvodnih postopkih, A in B, merimo produktivnost delavcev. Izberemo10 nakljucnih delavcev in dobimo naslednje podatke (st. izdelkov na uro):
A 12 7 9 12 15 9 8 13 12 7B 11 10 14 15 12 11 7 14 11 9
(a) Preveri hipotezo, da je produktivnost po postopku A bistveno razlicna od produktivnostipri postopku B.
(b) Preveri, ali je produktivnost pri postopku A bistveno manjsa kot pri postopku B.
Stopnja znacilnosti naj bo α = 0.01.
Resitev. Slucajna spremenljivka, ki bo merila razlike v produktivnosti med postopkomaA in B, bo kar razlika, torej X = B − A. Poleg tega opazimo, da standardni odklon σ niznan, zato bomo napravili t-test.
A B xi = B −A (xi − x)2
12 11 -1 47 10 3 49 14 5 1612 15 3 415 12 -3 169 11 2 18 7 -1 413 14 1 012 11 -1 47 9 2 1
10 54
Po formuli (1) izracunamo srednjo vrednost za vzorec xi; dobimo x = 1. Parameter sizracunamo po formuli (2): s2 = 54/9 = 6, torej je s =
√6. Ker preverjamo hipotezo, ali
se produktivnost postopka A razlikuje od produktivnosti postopka B, v resnici za slucajnospremenljivko X preverjamo hipotezo H0(a = 0) proti alternativnim hipotezam (torej jea0 = 0). Izracunajmo najprej testno statistiko na vzorcu po enacbi (10):
t =x− a0
s
√n =
1− 0√6·√
10 = 1.29.
V (a) preverjamo hipotezo H0(a = 0) proti hipotezi H1(a 6= 0). Kriticno vrednost t0.01dobimo s pomocjo (11) pri α = 0.01 in n − 1 = 9 prostostnih stopnjah; dobimo torejP (|T | ≥ t0.01) = 0.01. Iz tabele 2 preberemo t0.01 = 3.25. Ker je |t| < t0.01, hipotezeH0 ne zavrnemo.
V (b) preverjamo hipotezo H0(a = 0) proti hipotezi H1(a ≥ 0). Kriticno vrednost t2·0.01dobimo s pomocjo (13) pri α = 0.01 in n − 1 = 9 prostostnih stopnjah; dobimo torejP (|T | ≥ t0.02) = 0.02. Iz tabele 2 preberemo t0.02 = 2.82. Ker je t < t0.02, hipoteze H0
ne zavrnemo. �
4 χ2 test porazdelitve
Test χ2 (hi kvadrat) se pogosto uporablja pri statisticni obdelavi podatkov, kadar zelimovedeti, ali se ugotovljene frekvence razlikujejo od frekvenc, ki bi jih pricakovali na temelju
6

hipoteze. Postopek je naslednji. Za vsak razred najprej dolocimo ugotovljeno frekvenco fuin pricakovano (teoreticno) frekvenco fp. Nato izracunamo naslednjo vsoto (sestevamo povseh razredih):
χ2 =∑ (fu − fp)2
fp.
Preizkus se uporablja pri analizi enega ali vec nakljucnih vzorcev. Frekvence, s katerimiracunamo, so absolutne. Vzorci morajo biti dovolj veliki. Empiricno pravilo je, da mora bitienot vsaj 40, vsaj 80 odstotkov razredov pa mora imeti frekvenco vsaj 5. Vcasih je zatopotrebno razrede zdruziti.
Kadar imamo podatke o frekvenci dolocenega razreda v vzorcu in zelimo ugotoviti, ali sete frekvence znacilno razlikujejo od pricakovanih, postavimo nicelno domnevo, da je relativnafrekvenca π v populaciji enaka pricakovani frekvenci π0, torej H0(π = π0). Na osnovi vzorcaizracunamo χ2, nato pa ga primerjamo s kriticno vrednostjo χ2
α, ki jo dobimo iz Tabele 3 prim− 1 prostostnih stopnjah; pri tem je m stevilo razredov v vzorcu. Ce je χ2 > χ2
α, nicelnohipotezo zavrnemo.
Naloga 7. Za neko boleznijo je do sedaj umiralo 40 odstotkov vseh bolnikov. Na kliniki z52 bolniki s to boleznijo so preizkusili novo metodo zdravljenja in je umrlo le 7 bolnikov. Alilahko z manj kot 1% tveganjem trdimo, da je nova metoda ucinkovitejsa kot dosedanje?
Resitev. Imamo dva razreda, to so ozdravljeni in umrli bolniki. Na kliniki je prvih 45,drugih 7. To sta ugotovljeni frekvenci za ta razreda. Pricakovani frekvenci bi bili 0.6·52 = 31.2za ozdravljene in 0.4 · 52 = 20.8 za umrle. Naredimo tabelo:
fu fpozdravljeni 45 31.2
umrli 7 20.8
Testiramo H0(π = 0.4) proti H1(π 6= 0.4). Izracunamo χ2:
χ2 =(45− 31.2)2
31.2+
(7− 20.8)2
20.8= 15.260.
α = 0.01, χ2α pri 2 − 1 = 1 prostostni stopnji je χ2
0.01 = 6.635. Ker je χ2 > χ20.01, H0
zavrnemo, torej je nova metoda ucinkovitejsa. �
Naloga 8. Igralno kocko smo vrgli 100 krat in dobili naslednjo porazdelitev stevila pik: 20krat 1 piko, 17 krat 2 piki, 10 krat 3 pike, 15 krat 4 pike, 16 krat 5 pik in 22 krat 6 pik.Preskusi na stopnji znacilnosti 0.05 domnevo, da smo metali posteno kocko.
Resitev. Teoreticne frekvence za posamezno st. pik so fp = 100/6 ≈ 16.7. Dobimotabelo:
st. pik fu fp1 20 16.72 17 16.73 10 16.74 15 16.75 16 16.76 22 16.7
Hipoteza H0 je, da je kocka postena. Eksperimentalna vrednost statistike χ2 je χ2 =∑6i=1
(fu−fp)2
fp= 5.24, kriticno vrednost pa dolocimo iz tabele pri f = 6 − 1 = 5 prosto-
stnih stopnjah, torej χ20.05 = 11.070. Hipoteze H0 zato ne zavrnemo. �
7

5 Povezanost dveh slucajnih spremenljivk, regresijskapremica
Pogosto srecujemo probleme, v katerih nas zanima medsebojna zveza dveh slucajnih spre-menljivk X in Y . Ce iz podatkov vzorca opazimo, da so linearno povezani, lahko izracunamoregresijsko premico, t.j., premico, ki se po principu najmanjsih kvadratov najbolje prilegapodatkom.
Ce imamo vzorca x in y velikosti n, potem ima regresijska premica enacbo y = ax + b,kjer je
a =
n∑i=1
xiyi − nxyn∑i=1
(xi − x)2=
n∑i=1
xiyi − nxy
(n− 1)s2x
inb = y − ax.
Naloga 9. V Angliji je bilo med leti 1999 in 2003 v kemijski industriji naslednje stevilopozarov z nastalo skodo v milijonih funtov:
leto 1999 2000 2001 2002 2003st. pozarov 51 53 44 67 65
skoda 4.4 3.1 3.2 6.2 6.2
Zapisi enacbo regresijske premice. Koliksno skodo lahko pricakujemo v primeru, da bo v enemletu 70 pozarov?
Resitev. Naj bo x stevilo pozarov, y pa skoda. Podatke lahko prepisemo v
x y51 4.453 3.144 3.267 6.265 6.2
Dobimo
a =
n∑i=1
xiyi − nxyn∑i=1
(xi − x)2=
1347.9− 5 · 56 · 4.62(−5)2 + (−3)2 + (−12)2 + 112 + 92
= 0.143
inb = y − ax = 4.62− 0.143 · 56 = −3.388.
Regresijska premica ima enacbo y = 0.143x − 3.388. Za x = 70 pozarov dobimo y =0.143 · 70− 3.388 ≈ 6.6 milijonov funtov letne skode. �
Za natancnejse ugotavljanje povezanosti spremenljivk uporabljamo metodo korelacije. Zaslucajne spremenljivke, ki so priblizno normalno porazdeljene, lahko uporabimo Pearsonovkoeficient korelacije. Naj bosta x in y spet vzorca velikosti n. Najprej izracunamo kovarianco
Cxy =
n∑i=1
xiyi − nxy
n− 1.
Pearsonov koeficient korelacije se potem izracuna po formuli
r =Cxysxsy
=
n∑i=1
xiyi − nxy√n∑i=1
x2i − nx2 ·
√n∑i=1
y2i − ny2
.
8

r zavzame vrednosti med −1 in 1. V grobem, ce je r blizu −1, govorimo o negativni povezano-sti, za r blizu 1 imamo pozitivno povezanost, vrednosti r blizu 0 pa nakazujejo, da spremen-ljivki nista povezani. Ce zelimo dejansko ugotoviti, ali je povezanost znacilna, izracunamotestno statistiko
t = r
√n− 21− r2
,
nato pa poiscemo kriticno vrednost tα iz tabele za t-porazdelitev (Tabela 2) pri f = n − 2prostostnih stopnjah. Nicelna hipoteza H0 je, da spremenljivki nista povezani. Ce je t > tα,hipotezo H0 zavrnemo, torej lahko pri danem tveganju trdimo, da je povezanost znacilna.
Naloga 10. Raziskava naj bi pokazala, ali je krvni pritisk pri zenskah odvisen od starosti.Izbran je bil nakljucni vzorec 22 zensk, ki so jim merili krvni pritisk. Dobljeni so bilo naslednjipodatki:
leta mm Hg22 13123 12824 11627 10628 11430 11732 12235 12140 14741 13946 137
leta mm Hg49 13350 18351 13051 14452 12856 14557 14159 15763 15571 17277 178
Ali lahko z manj kot 5% tveganjem trdimo, da sta starost zensk in krvni pritisk povezana?
Resitev. Naj bo x starost, y pa krvni tlak. Imamo n = 22 podatkov, α = 0.05. Najprejizracunamo naslednje vrednosti: ∑
xi = 984,∑x2i = 49260,∑yi = 3044,∑y2i = 430192,∑
xiyi = 141594
Dobimo x = 44.73, y = 138.36. Od tod lahko izracunamo Pearsonov koeficient korelacije:
r =
n∑i=1
xiyi − nxy√n∑i=1
x2i − nx2 ·
√n∑i=1
y2i − ny2
= 0.79.
Testna statistika je
t = r
√n− 21− r2
= 5.7,
kriticna vrednost tα pri f = n − 2 = 20 prostostnih stopnjah pa je t0.01 = 2.09. Ker jet > t0.01, z manj kot 5% tveganjem zavrnemo nicelno domnevo H0, torej lahko trdimo, dasta starost in krvni pritisk pri zenskah znacilno povezana. �
9
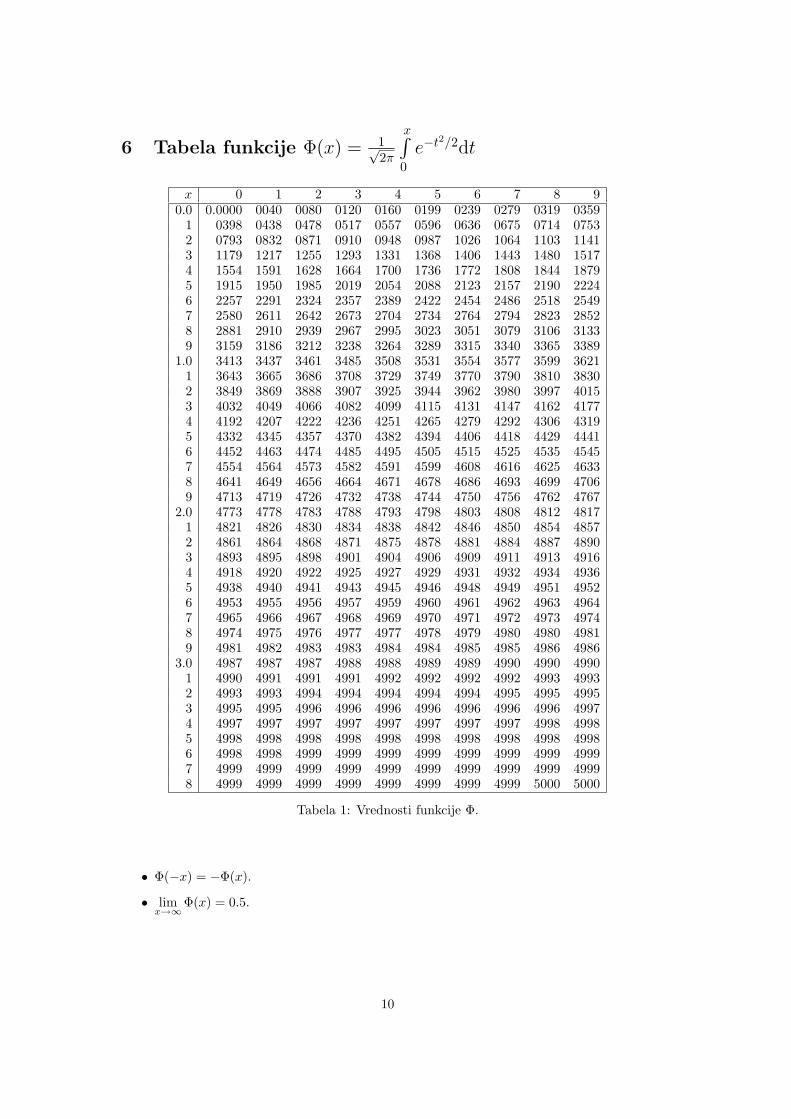
6 Tabela funkcije Φ(x) = 1√2π
x∫0e−t
2/2dt
x 0 1 2 3 4 5 6 7 8 90.0 0.0000 0040 0080 0120 0160 0199 0239 0279 0319 0359
1 0398 0438 0478 0517 0557 0596 0636 0675 0714 07532 0793 0832 0871 0910 0948 0987 1026 1064 1103 11413 1179 1217 1255 1293 1331 1368 1406 1443 1480 15174 1554 1591 1628 1664 1700 1736 1772 1808 1844 18795 1915 1950 1985 2019 2054 2088 2123 2157 2190 22246 2257 2291 2324 2357 2389 2422 2454 2486 2518 25497 2580 2611 2642 2673 2704 2734 2764 2794 2823 28528 2881 2910 2939 2967 2995 3023 3051 3079 3106 31339 3159 3186 3212 3238 3264 3289 3315 3340 3365 3389
1.0 3413 3437 3461 3485 3508 3531 3554 3577 3599 36211 3643 3665 3686 3708 3729 3749 3770 3790 3810 38302 3849 3869 3888 3907 3925 3944 3962 3980 3997 40153 4032 4049 4066 4082 4099 4115 4131 4147 4162 41774 4192 4207 4222 4236 4251 4265 4279 4292 4306 43195 4332 4345 4357 4370 4382 4394 4406 4418 4429 44416 4452 4463 4474 4485 4495 4505 4515 4525 4535 45457 4554 4564 4573 4582 4591 4599 4608 4616 4625 46338 4641 4649 4656 4664 4671 4678 4686 4693 4699 47069 4713 4719 4726 4732 4738 4744 4750 4756 4762 4767
2.0 4773 4778 4783 4788 4793 4798 4803 4808 4812 48171 4821 4826 4830 4834 4838 4842 4846 4850 4854 48572 4861 4864 4868 4871 4875 4878 4881 4884 4887 48903 4893 4895 4898 4901 4904 4906 4909 4911 4913 49164 4918 4920 4922 4925 4927 4929 4931 4932 4934 49365 4938 4940 4941 4943 4945 4946 4948 4949 4951 49526 4953 4955 4956 4957 4959 4960 4961 4962 4963 49647 4965 4966 4967 4968 4969 4970 4971 4972 4973 49748 4974 4975 4976 4977 4977 4978 4979 4980 4980 49819 4981 4982 4983 4983 4984 4984 4985 4985 4986 4986
3.0 4987 4987 4987 4988 4988 4989 4989 4990 4990 49901 4990 4991 4991 4991 4992 4992 4992 4992 4993 49932 4993 4993 4994 4994 4994 4994 4994 4995 4995 49953 4995 4995 4996 4996 4996 4996 4996 4996 4996 49974 4997 4997 4997 4997 4997 4997 4997 4997 4998 49985 4998 4998 4998 4998 4998 4998 4998 4998 4998 49986 4998 4998 4999 4999 4999 4999 4999 4999 4999 49997 4999 4999 4999 4999 4999 4999 4999 4999 4999 49998 4999 4999 4999 4999 4999 4999 4999 4999 5000 5000
Tabela 1: Vrednosti funkcije Φ.
• Φ(−x) = −Φ(x).
• limx→∞
Φ(x) = 0.5.
10
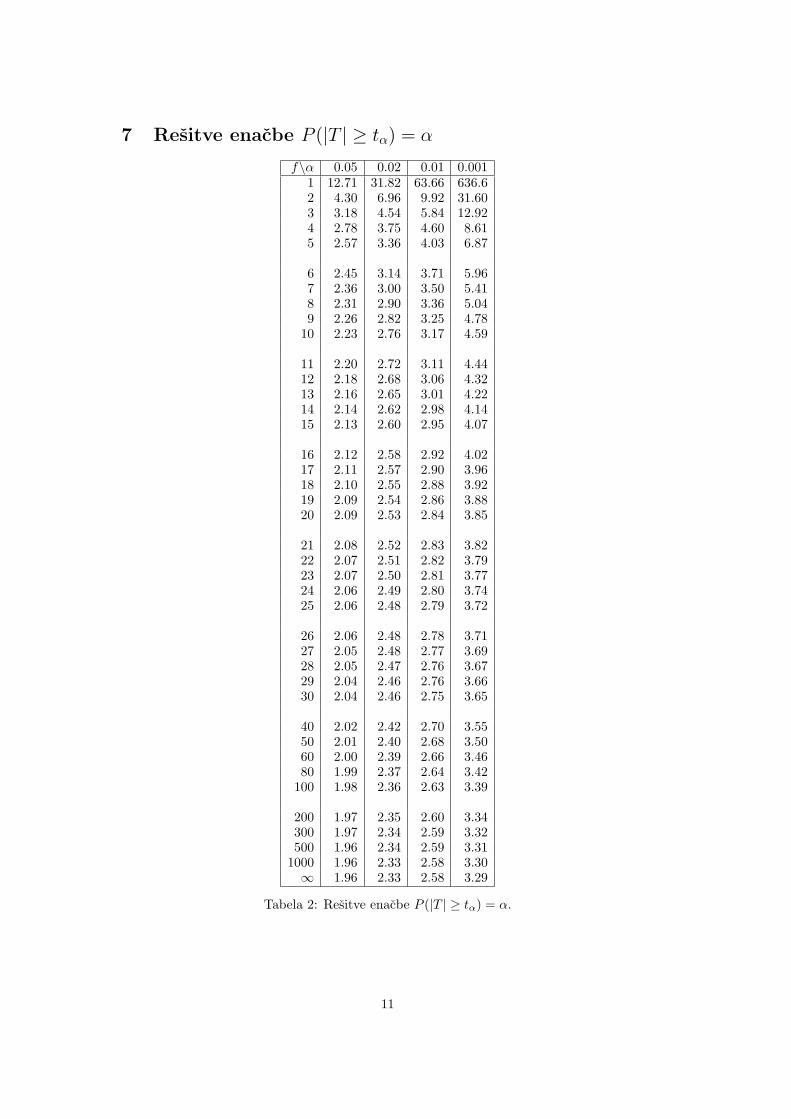
7 Resitve enacbe P (|T | ≥ tα) = α
f\α 0.05 0.02 0.01 0.0011 12.71 31.82 63.66 636.62 4.30 6.96 9.92 31.603 3.18 4.54 5.84 12.924 2.78 3.75 4.60 8.615 2.57 3.36 4.03 6.87
6 2.45 3.14 3.71 5.967 2.36 3.00 3.50 5.418 2.31 2.90 3.36 5.049 2.26 2.82 3.25 4.78
10 2.23 2.76 3.17 4.59
11 2.20 2.72 3.11 4.4412 2.18 2.68 3.06 4.3213 2.16 2.65 3.01 4.2214 2.14 2.62 2.98 4.1415 2.13 2.60 2.95 4.07
16 2.12 2.58 2.92 4.0217 2.11 2.57 2.90 3.9618 2.10 2.55 2.88 3.9219 2.09 2.54 2.86 3.8820 2.09 2.53 2.84 3.85
21 2.08 2.52 2.83 3.8222 2.07 2.51 2.82 3.7923 2.07 2.50 2.81 3.7724 2.06 2.49 2.80 3.7425 2.06 2.48 2.79 3.72
26 2.06 2.48 2.78 3.7127 2.05 2.48 2.77 3.6928 2.05 2.47 2.76 3.6729 2.04 2.46 2.76 3.6630 2.04 2.46 2.75 3.65
40 2.02 2.42 2.70 3.5550 2.01 2.40 2.68 3.5060 2.00 2.39 2.66 3.4680 1.99 2.37 2.64 3.42
100 1.98 2.36 2.63 3.39
200 1.97 2.35 2.60 3.34300 1.97 2.34 2.59 3.32500 1.96 2.34 2.59 3.31
1000 1.96 2.33 2.58 3.30∞ 1.96 2.33 2.58 3.29
Tabela 2: Resitve enacbe P (|T | ≥ tα) = α.
11
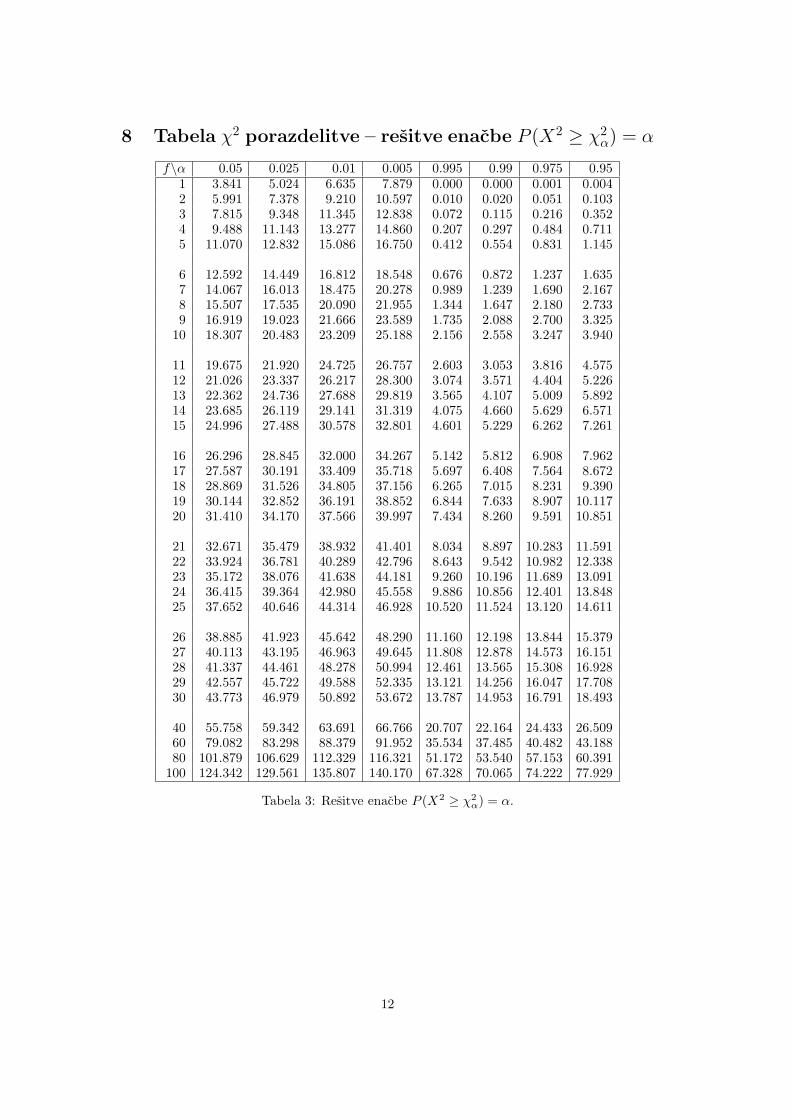
8 Tabela χ2 porazdelitve – resitve enacbe P (X2 ≥ χ2α) = α
f\α 0.05 0.025 0.01 0.005 0.995 0.99 0.975 0.951 3.841 5.024 6.635 7.879 0.000 0.000 0.001 0.0042 5.991 7.378 9.210 10.597 0.010 0.020 0.051 0.1033 7.815 9.348 11.345 12.838 0.072 0.115 0.216 0.3524 9.488 11.143 13.277 14.860 0.207 0.297 0.484 0.7115 11.070 12.832 15.086 16.750 0.412 0.554 0.831 1.145
6 12.592 14.449 16.812 18.548 0.676 0.872 1.237 1.6357 14.067 16.013 18.475 20.278 0.989 1.239 1.690 2.1678 15.507 17.535 20.090 21.955 1.344 1.647 2.180 2.7339 16.919 19.023 21.666 23.589 1.735 2.088 2.700 3.325
10 18.307 20.483 23.209 25.188 2.156 2.558 3.247 3.940
11 19.675 21.920 24.725 26.757 2.603 3.053 3.816 4.57512 21.026 23.337 26.217 28.300 3.074 3.571 4.404 5.22613 22.362 24.736 27.688 29.819 3.565 4.107 5.009 5.89214 23.685 26.119 29.141 31.319 4.075 4.660 5.629 6.57115 24.996 27.488 30.578 32.801 4.601 5.229 6.262 7.261
16 26.296 28.845 32.000 34.267 5.142 5.812 6.908 7.96217 27.587 30.191 33.409 35.718 5.697 6.408 7.564 8.67218 28.869 31.526 34.805 37.156 6.265 7.015 8.231 9.39019 30.144 32.852 36.191 38.852 6.844 7.633 8.907 10.11720 31.410 34.170 37.566 39.997 7.434 8.260 9.591 10.851
21 32.671 35.479 38.932 41.401 8.034 8.897 10.283 11.59122 33.924 36.781 40.289 42.796 8.643 9.542 10.982 12.33823 35.172 38.076 41.638 44.181 9.260 10.196 11.689 13.09124 36.415 39.364 42.980 45.558 9.886 10.856 12.401 13.84825 37.652 40.646 44.314 46.928 10.520 11.524 13.120 14.611
26 38.885 41.923 45.642 48.290 11.160 12.198 13.844 15.37927 40.113 43.195 46.963 49.645 11.808 12.878 14.573 16.15128 41.337 44.461 48.278 50.994 12.461 13.565 15.308 16.92829 42.557 45.722 49.588 52.335 13.121 14.256 16.047 17.70830 43.773 46.979 50.892 53.672 13.787 14.953 16.791 18.493
40 55.758 59.342 63.691 66.766 20.707 22.164 24.433 26.50960 79.082 83.298 88.379 91.952 35.534 37.485 40.482 43.18880 101.879 106.629 112.329 116.321 51.172 53.540 57.153 60.391
100 124.342 129.561 135.807 140.170 67.328 70.065 74.222 77.929
Tabela 3: Resitve enacbe P (X2 ≥ χ2α) = α.
12

9 Navodila za uporabo tabel
Primer 1. Koliko je Φ(2.45)? In koliko Φ(−2.45)? Koliko pa je Φ(5.23)?
Φ(2.45): V tabeli funkcije Φ v skrajno levem stolpcu poiscemo vrstico, v kateri je 2.4.Nato se premaknemo v stolpec s stevilko, ki oznacuje drugo decimalko, torej v stolpec z za-poredno stevilko 5. Vrednost, ki jo tam preberemo, nam doloca decimalke rezultata. Dobimotorej Φ(2.45) = 0.4929. Shematicno postopek izgleda takole:
x 0 1 2 3 4 5 6 7 8 90.0
...2.0
...4 4929...
Φ(−2.45): Upostevamo, da je Φ(−x) = −Φ(x), torej je Φ(−2.45) = −Φ(2.45) = −0.4929.Φ(5.23): Vrednosti za Φ(5.23) v tabeli ni, upostevamo pa lahko da je Φ(x) za ,,velike” xpriblizno enaka 0.5. Zato Φ(5.23) = 0.5.
Primer 2. Resi enacbo Φ(x) = 0.2345.
Tu je potrebno postopati obratno kot pri Primeru 1. Znotraj tabele poiscemo vrednost,ki je najblize vrednosti 0.2345:
x 0 1 2 3 4 5 6 7 8 90.0
...6 2324 2357 2389...
Iz tabele sedaj preberemo, da vrednost 0.2357 dobimo, ce izracunamo Φ(0.63), zato je pri-blizna resitev enacbe Φ(x) = 0.2345 enaka x = 0.63. Ce zelimo natancnejso resitev, lahkouporabimo linearno interpolacijo. V tabeli funkcije Φ poiscemo najvecji a, za katerega jeΦ(a) < 0.2345, ter najmanjsi b, za katerega je Φ(b) > 0.2345. Iz tabele preberemo:
a = 0.62, Φ(0.62) = 0.2324,b = 0.63, Φ(0.63) = 0.2357.
Vrednost za x sedaj dobimo iz
x = a+b− a
Φ(b)− Φ(a)(Φ(x)− Φ(a)) = 0.62 +
0.63− 0.620.2357− 0.2324
(0.2345− 0.2324) = 0.6267.
Primer 3. Poisci resitev enacbe P (|T | ≥ tα) = α pri α = 0.05 in 15 prostostnih stopnjah.
Tu uporabimo tabelo za t-porazdelitev. V skrajno levem stolpcu je navedeno steviloprostostnih stopenj f (v nasem primeru je f = 15). V ustrezni vrstici poiscemo stolpec zustrezno α in odcitamo vrednost za tα:
f\α 0.05 0.02 0.01 0.0011...
15 2.13...
Dobimo torej t0.05 = 2.13.
13





























