Embed Size (px)
Citation preview

School of InformationUniversity of Michigan
SI 614Empirical observations of networks over time
(models to explain them another time)Perl tutorial
Lecture 13

Outline (networks over time)
university email network over time (recent Science article)
graphs over time (internet, citation, authorship, patents): densification & shrinking diameters

How does one choose new acquaintances in a social network?
triadic closure: choose a friend of friend homophily: choose someone with similar interests proximity: choose someone who is close spatially and
with whom you spend a lot of time seek novel information and resources
connect outside of circle of acquaintances span structural holes between people who don’t know each
other
sometimes social ties also dissolve avoid conflicting relationships reason for tie is removed: common interest, activity

Empirical analysis of an evolving social network
Gueorgi Kossinets & Duncan J. Watts Science, Jan. 6th, 2006
The data university email logs sender, recipient, timestamp
no content 43,553 undergraduate and graduate students, faculty, staff filtered out messages with more than 4 recipients (5% of
messages) 14,584,423 messages remaining sent over a period of 355 days
(2003-2004 school year)

weighted ties
wij = weight of the tie between individuals i and j m = # of messages from i to j in the time period between
(t-) and t “geometric rate” – because rates are multiplied together
high if email is reciprocated low if mostly one-way
serves as a relevancy horizon (30 days, 60 days…) 60 days chosen as window is study because rate of tie
formation stabilizes after 60 days sliding window: compare networks day by day (but each
day represents an overlapping 60 day window)

cyclic closure & focal closure
shortest path distance between i and j
new ties that appearedon day t ties that were there
in the past 60 days
number of common foci, i.e. classes

cyclic closure & focal closure
distance between two people in the email graph
pairs that attend one or more classes together
do not attend classes together
Individuals who share at least one class are three times more likely to start emailing each other if they have an email contact in common
If there is no common contact, then the probability of a new tie forming is lower, but ~ 140 times more likely if the individuals share a class than if they don’t
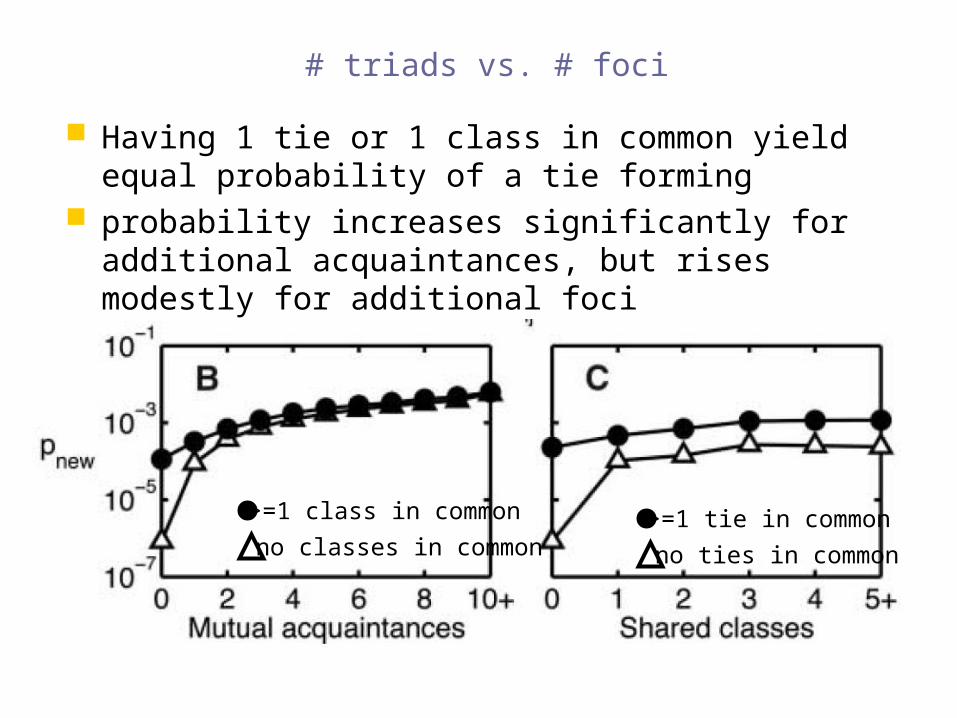
# triads vs. # foci
Having 1 tie or 1 class in common yield equal probability of a tie forming
probability increases significantly for additional acquaintances, but rises modestly for additional foci
>=1 tie in common
no ties in common
>=1 class in common
no classes in common
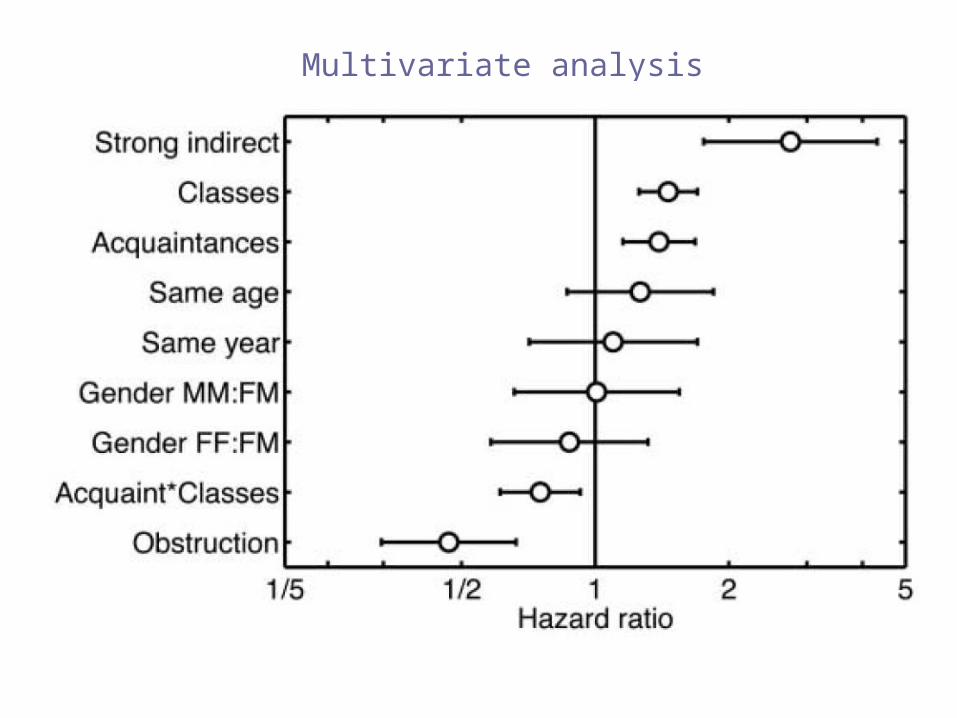
Multivariate analysis

the strength of ties
the stronger the ties, the greater the likelihood of triadic closure
bridges are on average weaker than other ties but bridges are more unstable:
may get stronger, become part of triads, or disappear

other observations
properties such as degree distribution, average shortest path, and size of giant component have seasonal variation (summer break, start of semester, etc.) appropriate smoothing window () needed
clustering coefficient, shape of degree distribution constant but rank of individuals changes over time

Graphs over time: Densification Laws, Shrinking Diameters and Possible Explanations
Jurij Leskovec, Jon Kleinberg, & Christos FaloutsosKDD’05
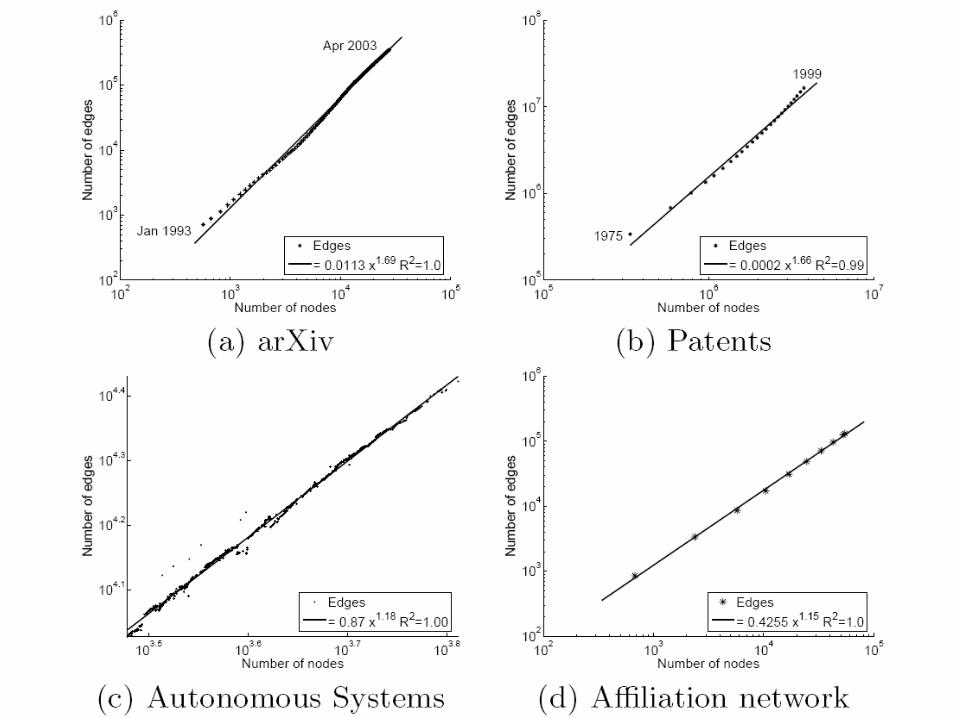
analysis of 4 large data sets of time show increase in average node degree a shrinking of the diameter
effective diameter defined as: distance d, such that 90% of pairs are within d hops of each
other more robust than diameter (maximum distance between any two
nodes) because it does not fall prey to degenerate structures such as extremely long chains
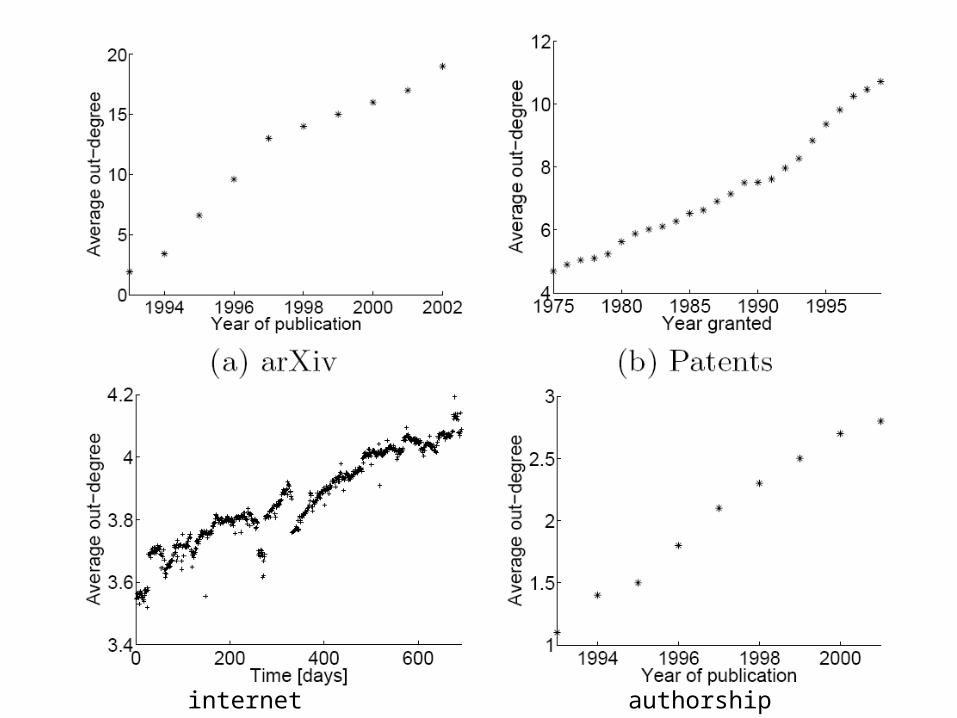
internet authorship


key observations
densification e(t) ~ n(t)
shrinking diameters even correcting for ‘phantom’ nodes – nodes that are not in the data
because they arrived before the period of study
models so far do not account for it Erdos-Renyi – grows as log(N) Scale free networks – log(log(N)) nothing accounts for shrinking
We’ll be covering two additional models in a couple of weeks community guided attachment forest fire model

Perl
Quick-and-dirty (or sophisticated and elegant) scripting language easily read in and parse text (do some simple counting up) output text in a different format
Choose a distribution of Perl usually already installed on campus unix/linux systems for windows/mac I would recommend ActivePerl (free, easy to
update/download modules) http://aspn.activestate.com/ASPN/Downloads/ActivePerl/
Lots of good online tutorials three Powerpoint presentations by Bridget Thomson McInnes
part 1: http://www.d.umn.edu/~bthomson/presentations/PerlPresentationPartI.ppt part 2: http://www.d.umn.edu/~bthomson/presentations/PerlPresentationPartII.ppt part 3: http://www.d.umn.edu/~bthomson/presentations/PerlPresentationPartIII.ppt

Converting a simple tab separated file into Pajek format
a simple tab separated fake file like the one I typed in from the survey
margaretcharles tanya
charles yan margaret
tanya margaret
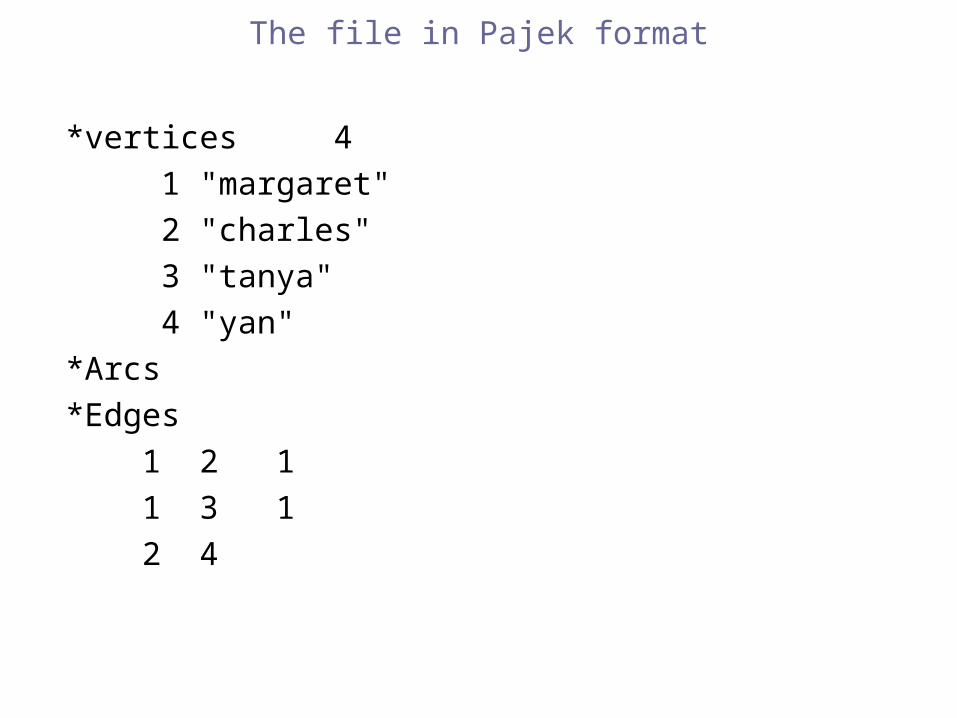
The file in Pajek format
*vertices 4
1 "margaret"
2 "charles"
3 "tanya"
4 "yan"
*Arcs
*Edges
1 2 1
1 3 1
2 4

the script (reading in the file)open(IN,“dummysocnet.txt") || die "could not open input file\n";
$i = 0;
while($line = <IN>) {
chomp($line);
($node,@links) = split(/\t/,$line);
if (!defined($number{$node})) {
$number{$node} = ++$i;
}
for $to (@links) {
if (!defined($number{$to})) {
$number{$to} = ++$i;
}
$pair{$node}{$to} = 1;
}
}
close(IN);
$n = $i;

the script (outputting the Pajek file)
open(OUT,"> dummysocnet.net");
print OUT "*vertices $n\n";
for $node (sort {$number{$a}<=>$number{$b};} keys %number) {
print OUT " ".$number{$node}." \"$node\"\n";
}
print OUT "*Arcs\n";
print OUT "*Edges\n";
for $from (keys %pair) {
for $to ( sort keys %{ $pair{$from} } ) {
if (!$havealready{$from}{$to}) {
print OUT " $number{$from} $number{$to} 1\n";
}
$havealready{$from}{$to} = 1;
$havealready{$to}{$from} = 1;
}
}
close(OUT);

Another example: creating a regular lattice
Creating the lattice$n = 100;
$k = 2;
for ($i = 0; $i < $n; $i++) {
for ($j = 1; $j <= $k; $j++) {
$ii = $i+$j;
$neighbor = $ii % $n;
$links{$i} .= "\t$neighbor";
$neighbor = ($i - $j);
if ($neighbor < 0) {
$neighbor = $n + $neighbor;
}
$links{$i} .= "\t$neighbor";
}
}

Outputting the regular lattice to Pajek
open(OUT,"> smallworld.net");print OUT "*vertices $n\n";
for ($i = 0; $i < $n; $i++) {$j = $i+1;print OUT " ".$j." \"$j\"\n";
}
print OUT "*Arcs\n";print OUT "*Edges\n";
for ($i = 0; $i < $n; $i++) {($null,@neighbors) = split(/\t/,$links{$i});$j = $i+1;for $neighbor (@neighbors) {
$nn = $neighbor+1;if ($j < $nn) {
print OUT " $j $nn 1\n";}
}}close(OUT);

messiest example: bipartite actor-movie networkfrom html files downloaded from the imdb database
files = `ls *.htm`;
@files = split(/\n/,$files);for $file (@files) {
open(IN,"$file")||die "couldn't open $file\n";$actor = $file;$actor =~ s/\..*//;$start = 0;while($line=<IN>) {
chomp($line);if ($line =~ /Actor<\/a> - filmography/) {
$start = 1;}if ($line =~ /Actress<\/a> - filmography/) {
$start = 1;}next if ($start == 0);if ($line =~ /<\/ol/) {
$start = 0;last;
}if ($line =~ /title\/[^\/]+\/\">([^<]+)/) {
$title = $1;$tnums{$actor} .= "\t$title";$actorsfortitle{$title} .= "\t$actor";
}}print "$tnums{$actor}\n";
}
read in multiple .htm files
identify the part of the file that contains the list of movies
for each movie in the list
add movie to list of movies for actor
add actor to list of actors for movie
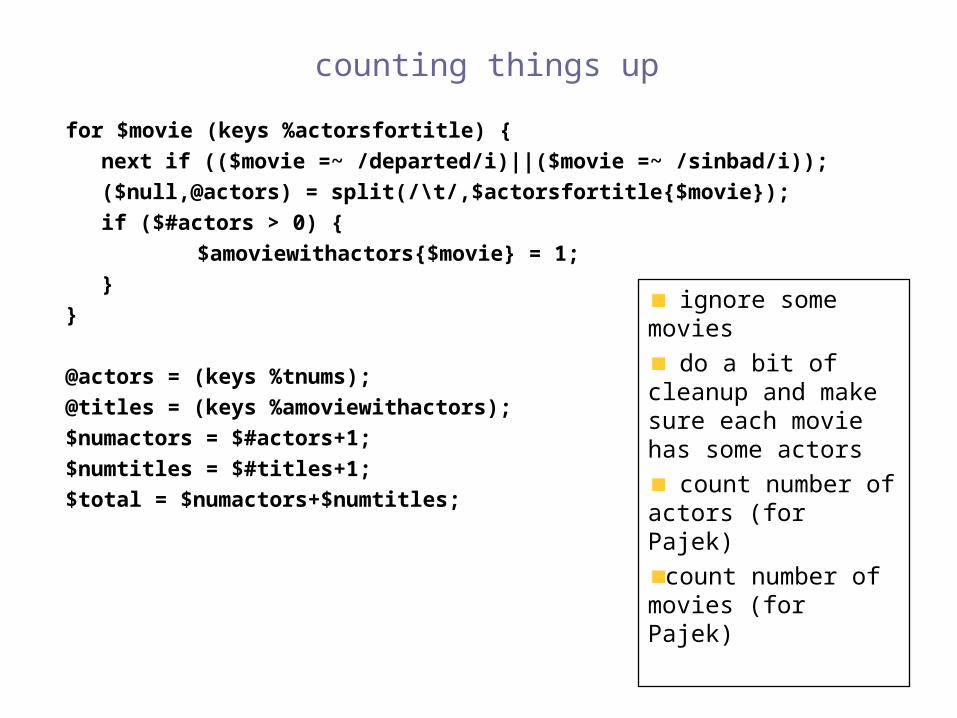
counting things up
for $movie (keys %actorsfortitle) {
next if (($movie =~ /departed/i)||($movie =~ /sinbad/i));
($null,@actors) = split(/\t/,$actorsfortitle{$movie});
if ($#actors > 0) {
$amoviewithactors{$movie} = 1;
}
}
@actors = (keys %tnums);
@titles = (keys %amoviewithactors);
$numactors = $#actors+1;
$numtitles = $#titles+1;
$total = $numactors+$numtitles;
ignore some movies
do a bit of cleanup and make sure each movie has some actors
count number of actors (for Pajek)
count number of movies (for Pajek)

defining movie and actor nodes for Pajek
open(OUT,"> actorsandmovies2.net");print OUT "*vertices $total $numactors\n";$i = 1;for $actor (@actors) {
print OUT " $i \"$actor\"\n";$vertexnum{$actor} = $i;$i++;
}
for $title (@titles) {print OUT " $i \"$title\"\n";$vertexnum{$title} = $i;$i++;
}

defining edges for Pajek
print OUT "*Arcs\n";print OUT "*Edges\n";
for $movie (keys %actorsfortitle) {next if (($movie =~ /departed/i)||($movie =~ /sinbad/i));($null,@actors) = split(/\t/,$actorsfortitle{$movie});if ($#actors > 0) {
print "$movie:$actorsfortitle{$movie}\n";for $actor (@actors) {
print OUT " $vertexnum{$actor} $vertexnum{$movie} 1\n";
}}
}close(OUT);

making a partition file for Pajek e.g. state where actor was born
if ($line =~ /BornWhere\?.*?([^,]*),([^,<]*)\</) {$actorstate{$actor} = $1;
}
$stateid = 0;for $actor (sort keys %actorstate) {
if (!defined($stateid{$actorstate{$actor}})) {$stateid{$actorstate{$actor}} = $stateid++;
}}
open(OUT,"> actorsandmovies.net");open(CLU,"> states.clu");print OUT "*vertices $total $numactors\n";print CLU "*vertices $numactors\n";$i = 1;for $actor (@actors) {
print OUT " $i \"$actor\"\n";print CLU " $stateid{$actorstate{$actor}}\n";$vertexnum{$actor} = $i;$i++;
}close(CLU);

output for movie data set
print "$actor\t$actorstate{$actor}\t$stateid{$actorstate{$actor}}\n";
EdwardNorton Massachusetts 2
GeorgeClooney Kentucky 3
SusanSarandon New York 4
MattDamon Massachusetts 2
MarkWahlberg Massachusetts 2
RichardGere Pennsylvania 6
BradPitt Oklahoma 0
JuliaRoberts Georgia 5
CatherineZetaJones Wales 1
JenniferLopez New York 4
the file states.clu now contains:
*vertices 10
2
3
4
2
2
6
0
5
1
4

Formatting data for guess
Use same actor dataset, this time pre-process to have a unimodal network of just actors
for $movie (keys %actorsfortitle) {
next if (($movie =~ /departed/i)||($movie =~ /sinbad/i));
($null,@actors) = split(/\t/,$actorsfortitle{$movie});
for $a1 (@actors) {
for $a2 (@actors) {
next if ($a1 ge $a2);
$nummovies{$a1}{$a2}++;
}
}
}
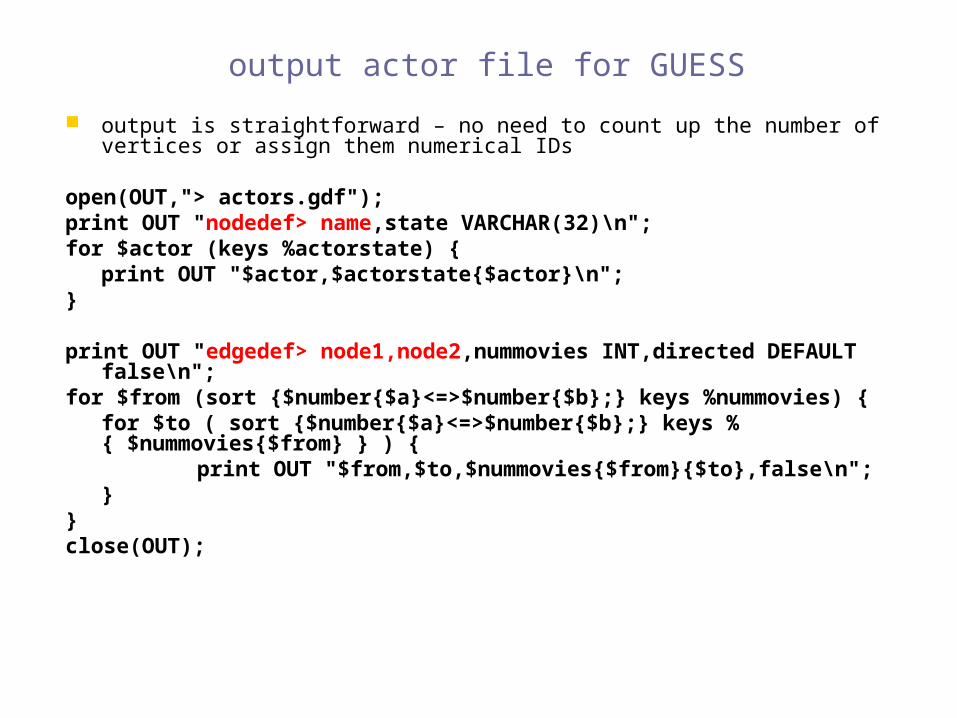
output actor file for GUESS
output is straightforward – no need to count up the number of vertices or assign them numerical IDs
open(OUT,"> actors.gdf");print OUT "nodedef> name,state VARCHAR(32)\n";for $actor (keys %actorstate) {
print OUT "$actor,$actorstate{$actor}\n";}
print OUT "edgedef> node1,node2,nummovies INT,directed DEFAULT false\n";
for $from (sort {$number{$a}<=>$number{$b};} keys %nummovies) {for $to ( sort {$number{$a}<=>$number{$b};} keys %{ $nummovies{$from} } ) {
print OUT "$from,$to,$nummovies{$from}{$to},false\n";}
}close(OUT);

the gdf file
nodedef> name,state VARCHAR(32)EdwardNorton, MassachusettsGeorgeClooney, KentuckySusanSarandon, New YorkMattDamon, MassachusettsMarkWahlberg, MassachusettsRichardGere, PennsylvaniaBradPitt, OklahomaJuliaRoberts, GeorgiaCatherineZetaJones, WalesJenniferLopez, New Yorkedgedef> node1,node2,nummovies INT,directed DEFAULT falseEdwardNorton,MarkWahlberg,1,falseEdwardNorton,RichardGere,1,falseEdwardNorton,JuliaRoberts,1,falseEdwardNorton,MattDamon,1,falseRichardGere,SusanSarandon,1,falseBradPitt,EdwardNorton,1,falseBradPitt,GeorgeClooney,3,falseBradPitt,SusanSarandon,1,falseBradPitt,JuliaRoberts,5,falseBradPitt,CatherineZetaJones,1,falseBradPitt,MattDamon,3,falseGeorgeClooney,MarkWahlberg,2,falseGeorgeClooney,JuliaRoberts,3,falseGeorgeClooney,JenniferLopez,1,falseGeorgeClooney,MattDamon,4,falseJuliaRoberts,RichardGere,2,falseJuliaRoberts,SusanSarandon,1,falseJuliaRoberts,MattDamon,4,falseJenniferLopez,RichardGere,1,falseJenniferLopez,SusanSarandon,1,falseJenniferLopez,MattDamon,1,falseCatherineZetaJones,GeorgeClooney,2,falseCatherineZetaJones,RichardGere,1,falseCatherineZetaJones,JuliaRoberts,2,falseCatherineZetaJones,MattDamon,1,false