Embed Size (px)
Citation preview

Liāna Natenadze
Pacientu reģistrēšanas poliklīnikā datu konceptuālais modelis
Rīga 2009.

SATURS
UZDEVUMA NOSTĀDNE...............................................................................................5
1. PRIEKŠMETISKĀS VIDES APRAKSTS.............................................................6
1.1 Problēmsfēras apraksts............................................................................6
1.2 Datu plūsmas diagramma........................................................................6
1.3 Datu subjektīva grupēšana......................................................................9
2. EER DIAGRAMMA (KONCEPTUĀLAIS MODELIS).....................................12
2.1 Konceptuālā modeļa elementi...............................................................12
2.2 EER diagramma....................................................................................13
2.3 Konceptuālā modeļa definējumi............................................................15
2.3.1. Unārā saite...............................................................................................15
2.3.2. Binārā saite (N:M, 1:N, 1:1)....................................................................15
2.3.3. Ternārā saite............................................................................................16
2.3.4. Dati saitē..................................................................................................16
2.3.5. Vājā realitāte...........................................................................................17
2.3.6. Klasifikācija (pilnā).................................................................................17
2.3.7. Superrealitāte...........................................................................................18
2.3.8. Mantošana (.............................................................................................19
3. TRANSFORMĀCIJA RDB STRUKTŪRĀ.........................................................20
3.1 Tipiskie transformāciju piemēri............................................................20
3.2 Elementu transformācijas realizācija....................................................23
3.2.1. Unārās saites transformācija...................................................................23
3.2.2. Ternārās saites transformācija................................................................24
3.2.3. Superrealitātes transformācija................................................................26
3.2.4. Vājās realitātes transformācija................................................................28
3.2.5. Pilnās klasifikācijas transformācija........................................................29
3.2.6. Mantošanas (specializācijas) transformācija..........................................31
3.2.7. Pārējo saišu transformācija.....................................................................32
3.2.8. Kopīgais RDB loģiskais modelis..............................................................32
4. NORMĀLFORMU PĀRBAUDE........................................................................34
4.1 1 Normālformas pārbaude.....................................................................34
2

4.2 2 Normālformas pārbaude.....................................................................34
4.3 3 Normālformas un Boisa – Kodda normālformas pārbaude................35
4.3.1. Tabulas T_Izmeklejumi pārbaude............................................................36
4.3.2. Tabulas T_Personas pārbaude................................................................37
4.3.3. Tabulu T_Diagnosti, T_Specialisti, T_RajonaArsti pārbaude................39
4.3.4. Pārveidotais kopējais modelis.................................................................40
5. SQL KODA REALIZĒŠANA..............................................................................42
5.1 Tabulu izveide.......................................................................................42
5.2 Klasteru izveide.....................................................................................46
5.3 Virkņu izveide.......................................................................................47
5.4 Skatu izveide.........................................................................................48
5.5 Sinonīmu izveide...................................................................................49
5.6 Dinamisko ierobežojumu (trigeru) izveide...........................................49
5.7 Glabāšanas procedūras izveide..............................................................50
SECINĀJUMI...............................................................................................................51
INFORMĀCIJAS AVOTI............................................................................................52
3

PRIEKŠMETISKĀS VIDES APRAKSTS
1.1. Problēmsfēras apraksts
Darba apskatīta problēmas vide ir saistīta ar pacientu reģistrēšanu
poliklinikā, kā arī izmeklējumu diagnožu rezultātu fiksēšana. Poliklinikas
adminstrācija reģistrē pacientu personas datus, reģistrē pacienta kartes. Ka arī
pieraksta pacientus pie ārstiem–speciālistiem, piesaistā katram pacienta rajona
ārstu, atbilstoši deklarētai adresei. Ārstēšanas shemu fiksēšana, slimības lapu
veidošana, recepšu un reķinu izrakstīšana.
1.2. Datu plūsmas diagramma
Datu plūsmas diagrammā izmantotas sekojošas notācijas – ārējās vides
realitāte, funkcija, datu krātuve un bulta, kas savieno šos objektus savā starpā,
norādot saites. DPD tiek veidota Visio 2000 vidē, ar sekojošiem apzīmejumiem:
Ārējās vides realitāte (aktieris), kas ietekmē informācijas
sistēmas darbību un kalpo kā datu avots šajā sistēmā.
Datu krātuve – datu izvietošana.
Datu plūsma starp dažādiem sistēmas objektiem: starp
procesiem, datu krātuvēm un ārējām realitātēm.
Funkcijas – ieejas informāciju
pārvērš izejas informācijā. Procesa apzīmējumā iekļauts procesa numurs
(Fn), procesa nosaukums, ieejas datu saraksts, izejas datu saraksts.
D – Dati;
F – Funkcija;
V – Vaicājums;
A – Atbilde.
4

5
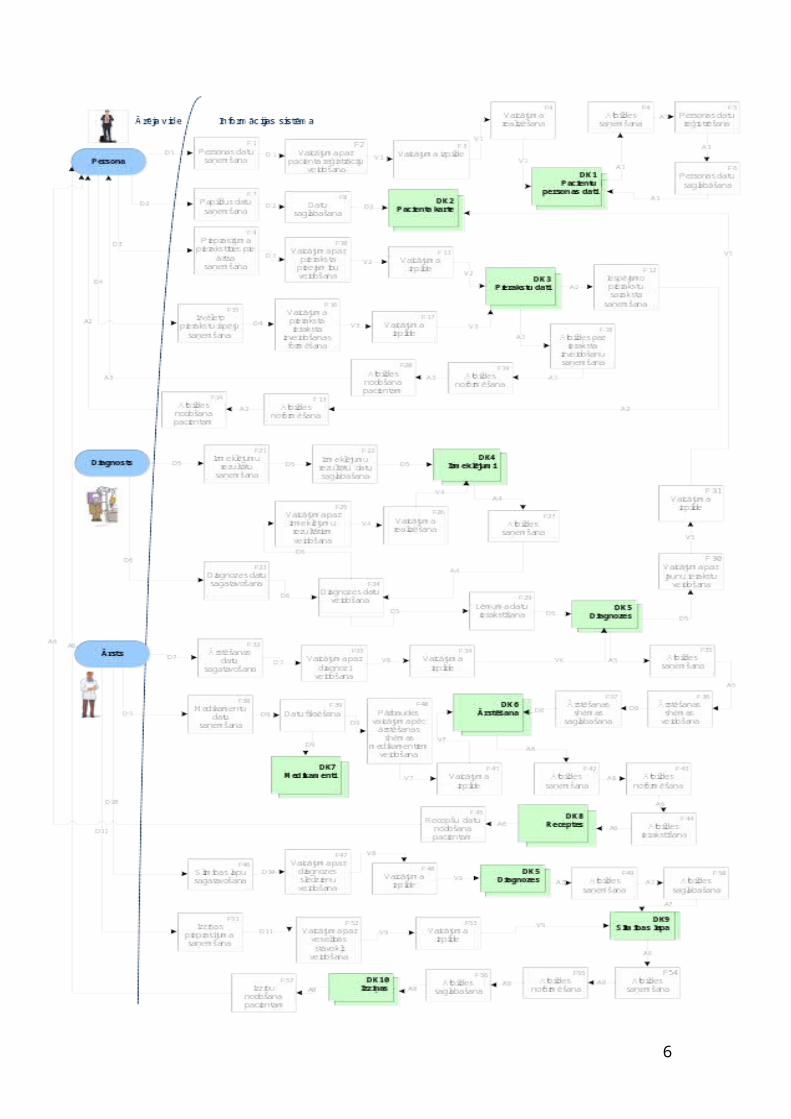
DPD parāda ar kāda tipa datiem operē poliklinikas sistēma, no kādiem
ārējiem datu avotiem šī informācija tiek iegūta, kādos procesos datu plūsma
sadalās un kur sistēmā glabājas apstrādātie dati. Sistēmas ieejas dati ir pacientu
personas dati, izmeklējumu un diagnosticēšanas rezultāti, ka arī pierakstu,
medikamentu dati.
Ārējas realitātes:
Poliklinikas darbības sistēma satur 3 ārējas realitātes:
Persona – jebkurš cilvēks, kas ir potenciāls poliklinikas pacients;
Diagnosts–poliklinikas ārsts-diagnosts;
Ārsts – poliklinikas ārsts.
Datu krātuves:
Sistēma satur 9 datu krātuves, kas ir apzīmētas DKn, kur DK atšifrējas kā
datu krātuve un n – glabātuves kārtas numurs:
DK1. pacienta personas dati – pacienta personas datu krātuve;
DK2. pacienta karte – papildus datu par (fiziskie parametri) krātuve;
DK3. pierakstu dati – pieraksti pie ārstiem;
DK4. izmeklējumi – pacienta laboratorisko izmeklējumu rezultātu krātuve;
DK5. diagnozes – pacienta diagnožu slēdznienu krātuve;
DK6. ārstēšana – ārstēšanas shēmu krātuve;
DK7. medikamenti – izrakstītie medikamenti ;
DK8. receptes – medikamentu recepšu datu krātuve;
DK9. slimības lapa – veselības stāvokļu datu krātuve;
Datu plūsmas:
Sistēma satur 29 datu plūsmas, izdalītas 57 funkcijas. Tātad sistēmā eksistē sekojošas datu plūsmas:
D1 d1 – vārds, uzvārds d2 – personas kods d3 – adrese d4 – tālrunis;
V1 d2 ;
A1 d1 d2 d3 d4;
D2 d5 – numurs
d6 – dzimums d7 – vecums;
D3 d8 - ārsts d9 – pieraksta datums d10 – pieraksta laiks;
V2 d8 d9 d10
A2 d9 d10;
D4
6

d9 d10;
V3 d9 d10;
A3 d9 d10;
D5 d11 – nosaukums d12 – analīzes datums d13 – vērtība;
D6 d14 – numurs d15 – datums d16 – slēdziens;
V4 d17 – pamats;
A4 d17;
D5 d14 d15 d16 d17;
V5 d14 d15 d16 d17;
D7 d18 – veids d19 – medikamenti d20 – kurss;
V6
d21 – pamats;A5
d21;D8
d18 d19 d20 d21;
D9 d22 – nosaukums d23 – kategorija d24 – daudzums;
V7 d25 – numurs;
A6 d25;
D10 d26 – numurs d27 – datums;
V8 d28 – pamatojums;
A7 d28;
D11 d29 – numurs d30 – datums;
V9 d31 – slēdziens;
A8 d31 ;
1.3. Datu subjektīva grupēšana
Subjektīvi veicot būtiskāko datu grupēšanu, tiek izdalītas sekojošas
realitātes, kurām šie dati pieder. Jāmin, ka par realitātēm kļuva galvenokārt visas
DPD datu krātuves un ārējas realitātes, ērtības labā izlaižot vārdu “dati”
realitātēm, jo tāpat skaidrs, ka katra no tām glabā datus.
Nr. Realitātes
nosaukums
Atribūti
7

R1 Persona vārds uzvārds personas kods adrese tālrunis
R2 Pacienta karte numurs reģistrācijas datums vecums dzimums diagnoze ārstēšanas shēma slimības lapas numurs
R3 Diagnosts vārds uzvārds personas kods tālrunis speciālizācija
R4 Diagnoze izniegšanas datums diagnozes rezultāts
R5 Izmeklējums kategorija nosaukums datums vērtība
R6 Slimības lapa numurs pamatojums slēdznienam slēdziens
R8 Ārstēšana tips medikamenti kursa ilgums
R9 Medikaments nosaukums derības tērmiņš kategorija ražotājs cena
R10 Pieraksts numurs datums laiks
R11 Ārsts vārds uzvārds personas kods amats rajons specializācija
R12 Recepte recepta numurs izsniegšanas datums arstnieciska forma
Protams, šie datu elementi ir tikai uzmetums, meģinājums pārskaitīt
būtisko datu kopu un to piederību. Un tagad, kad ir definētas notācijas, izveidota
DPD un ir subjektīvi sagrupēti dati, var sākt veidot datu bāzes konceptuālo
8

modeli, jeb EER diagrammu.
Talākājā projektēšana var tikt pievienotas vēl dažas realitātes. Piemērām,
realitāti „Ārsts”, būtu labi sadalīt atsevišķi uz „Rajona ārsts” (kurš ir atbildīgs par
konkrētiem pacientiem, pēc deklarētas adreses principā, un pie kurā nav
jāpierakstās), un uz „Specialists” (šauras specializācijas ārsts, pie kura ir
jāpierakstās).
Ar sadalīšanu var arī panākt medikamentu šķīrošanu uz bezmaksas un
maksas medikamentiem ( par kuriem ir jāveido atsevīšķo reķinu).
9

2. EER DIAGRAMMA (KONCEPTUĀLAIS MODELIS)
Balstoties uz poliklinikas datu plūsmas diagrammas pamata, mēģināsim
izprojektēt konceptuālo modeli, izmantojot EER diagrammu ar P. Čena notāciju.
2.1. Konceptuālā modeļa elementi
Topošajam konceptuālajam modelim ir sekojoši elementi:
unāra saite:
bināra saite:
ternāra saite:
dati saitē:
vājā realitāte:
klasifikācija:
10

superrealitāte:
mantošana (vispārinājums, specializācija, agregācija vai kompozīcija):
2.2. EER diagramma
Sākumā apskatīsim pašu diagrammu. Vēlāk, apskatīsim atkārtoti secīgi
katru no elementiem un definēsim to esamību diagrammā ar nedaudz sīkāku un
detalizētāku izpēti. EER diagrammas attēlā pagaidām nav attēloti realitāšu un
saišu atribūti. Tas ir ar tādu nolūku, lai varētu labāk apskatīt diagrammas saturu,
t.i. lai būtu pārskatāma diagramma.
11

14

Nākošais solis ir katra atsevišķa elementa sīkāka izpēte. Turklāt, šeit būs iespēja
pārliecināties, ka visi vajadzīgie elementi ir izmantoti uzdevuma realizēšanas gaitā.
2.3. Konceptuālā modeļa definējumi
Balstoties uz Poliklinikas Datu Plūsmas Diagrammu, un uz izprojektētā
konceptuālā modeļa, kurā ir izmantota P. Čena notācija, mēģināsim apskatīt modeļa
loģisko struktūru.
2.3.1. Unārā saite
Unāra saite ir saite, kas saista realitāti R1 ar to pašu realitāti R1. Lai labāk
saprastu šo definējumu, apskatīsim
Tas nozīme, ka ir nodaļas vadītāji, kuriem ir viens vai vairāki ārsti pakārtojumā,
vai arī nav neviena ārsta, gadījumā, kad runa iet par šauras speciālizācijas jomam. Tātad,
vienam ārstam var būt nodaļas vadītājs vai arī viņš pats var būt nodaļas vadītājs.
2.3.2. Binārā saite (N:M, 1:N, 1:1)
Bināra saite ir divu dažādu realitāšu saite. Apskatīsim vienu no piemēriem.
Tātad eksistē realitāte „Ārstēšana” (ārstēšanas shēmas noradījums) un realitāte
„Medikaments”. Katrai ārstēšanas shēmai, var tikt izrakstīti vairāki medikamenti. Un
otrādi – viens medikaments var būt izrakstīts vairāku ārstēšanas shēmu ietvaros. Tas ir

viens bināra saite daudzi pret daudziem (N:M). Bināra saite var arī eksistēt starp
realitāti un superrealitāti, klasifikācijas vai mantošanas apakšrealitāti, u.t.t.
2.3.3. Ternārā saite
Ternārā saite eksistē starp trim realitātēm, lai sasaistītu tās visas, veidojot
vienu veselu saiti. Šī saitē ir sarežģītākā par bināro saiti, tāpēc apskatīsim vienu
piemēru.
Tātad mums ir trīs realitātes, kas ir sasaistītas, veidojot savā starpā ternāro saiti.
Šīs ternāras saites jēga ir sekojoša – diagnosts (pirmā realitāte), balstoties uz
izmeklējumu rezultātiem (otrā realitāte) noteic diagnozi (trešā realitāte). Pie tam,
diagnosts var noslēgt vairākas diagnozes, balstoties uz vairākiem izmeklējumiem.
Diagnozes konstatēšanai var būt izmantoti vairāku izmeklējumu rezultāti, un neviena
diagnoze nevar būt konstatēta bez diagnosta palīdzības un ne balstoties uz izmeklējumu
rezultātiem. Taču izmeklējums var būt neizmantots diagnozes noteikšanai, gadījumā, ja
tas nav būtisks, vai nu iepriekšējo izmeklējumu (to skaits var būt liels) rezultāti dod
pamatojumu, diagnozes noteikšanai.
2.3.4. Dati saitē
Kā liecina pats nosaukums , dati, kas parasti pieder konkrētai realitātei, tagad
būs arī saitē. Apskatīsim vienu piemēru.
16

Kā redzams attēlā , saitei starp realitātēm medikaments un recepte ir savs
atribūts , kas tieši pieder saitei.
2.3.5. Vājā realitāte
Vājā realitāte ir tāda realitāte, kura bez realitātēm, kas ir saistītas ar šo vājo
realitāti, dod bezjēdzīgus, „tukšus” datus. Tagad apskatīsim vienu no realizētajiem
piemēriem.
Tātad realitāte „Recepte” ir vājā realitāte, jo bez datiem saitēs un realitāti
„Medikaments” un superrealitāti „Pacients”, vājai realitātei ir bezjēdzīgi, „tukši” dati. Īsāk
sakot, realitātes „Recepte” pastāvēšana ir bezjēdzīga, ja nav medikamenta, ko izrakstīt
un nav pacineta, kam recepte ir domāta.
2.3.6. Klasifikācija (pilnā)
Kā jau bija minēts iepriekš, klasifikācija var būt pilna vai arī nepilna. Pēc būtības
atšķirība starp pilno un nepilno klasifikāciju ir sekojoša:
Ja klasifikācija ir pilna, tad ir apskatītas un definētas visas realitātes lomas
(piemēram, ja mums ir realitāte „Medikament”, tad pilna klasifikācija varētu būt „Maksas
Medikaments”, „Bezmaksas Medikaments”). Tātad, galvenajā realitātē (Medikaments),
zem atribūta kategorija ir tikai divi iespējamie varianti (‘maksas’, ‘bezmaksas’)
Ja klasifikācija ir nepilna, tad ir definētas dažas vai ne visas realitātes lomas
(piemēram, ja mums ir realitāte „Profesors”, tad nepilna klasifikācija varētu būt
„Asocietais profesors”, bet pārējie realitāte „Profesors” atribūta „grads” dati varētu būt
nesašķiroti, jo piemēram, pēc būtības mus iznteresē tikai asocieti profesori. Tagad par
piemēru no mūsu procesa, kur ir realizēta pilnā klasifikācija.
17

Šajā gadījumā, kā jau minēju, realitātē „Medikaments” zem atribūta „kategorija” ir
tikai divi varianti, pēc kuriem arī tiek veikta klasifikācija – vai nu medikaments ir
bezmaksas, un tad tam ir 100% atlaide, vai arī maksas, tad pacientam tiek izrakstīts
rēķins.
2.3.7. Superrealitāte
Superrealitāte, savukārt, ir divu vai vairāku realitāšu apvienojums ar mērķi
definēt vienu veselu realitāti. Kā piemērs varētu definēt dokumentu kopu, kas ir
vajadzīga pieteicoties darbā, jo neviens neiesniedz tikai CV vai tikai pieteikuma vēstuli ,
bet gan iesniedz abus šos dokumentus. Tieši tāpēc, pēc līdzīga iemesla tiek definēta
superrealitāte „Pacients” .
Tātad mums ir realitāte „Persona”, ka arī realitāte „Pacienta Karte”. Kopā šīs divas
realitātes veido superrealitāti „Pacients”.
18

2.3.8. Mantošana
Mantošana ļauj „bērnu” realitātēm mantot vai pārņemt īpašības no realitātēm,
kuri ir „vecāki”. Tātad, ja ir realitāte R1 ar četriem atribūtiem, kurai ir divas
realitātes R2 un R3, kas ir bērni, tad realitātes R2 un R3 pārņems R1 četrus
atribūtus. Pie tam, „bērnu” realitātes var pieņemt sev arī papildus atribūtus, bez tiem, ko
ir mantojuši no „vecāku” realitātes. Šajā gadījumā izmantojamā mantošana ir
„Specializācija”, kas nozīmē to, ka „bērnu” realitātes specializē „vecāku” realitāti, t.i.,
„vecāku” realitāte pie saviem jau esošajiem atribūtiem pieņem vēl „bērnu” atribūtus.
Apskatīsim piemēru.
Tātad mums ir realitāte „Ārsts”, ka arī divas realitātes „bērni” t.i. realitāte „Rajona
Ārsts” un „Specialists”, kas manto visus atribūtus no realitātes „Ārsts”. Līdz ar to mums ir
variants, kad augstākā līmeņa realitāte manto zemākā līmeņa atribūtus.
Tagad, kad ir izveidota datu plūsmas diagramma, ir izveidots konceptuālais modelis,
varam pāriet pie vienas no sarežģītākajām darba uzdevuma daļas - pāriet pie loģiska
modeļa – pārveidot EER diagrammu par tabulām, skatiem, objektiem utt.
19

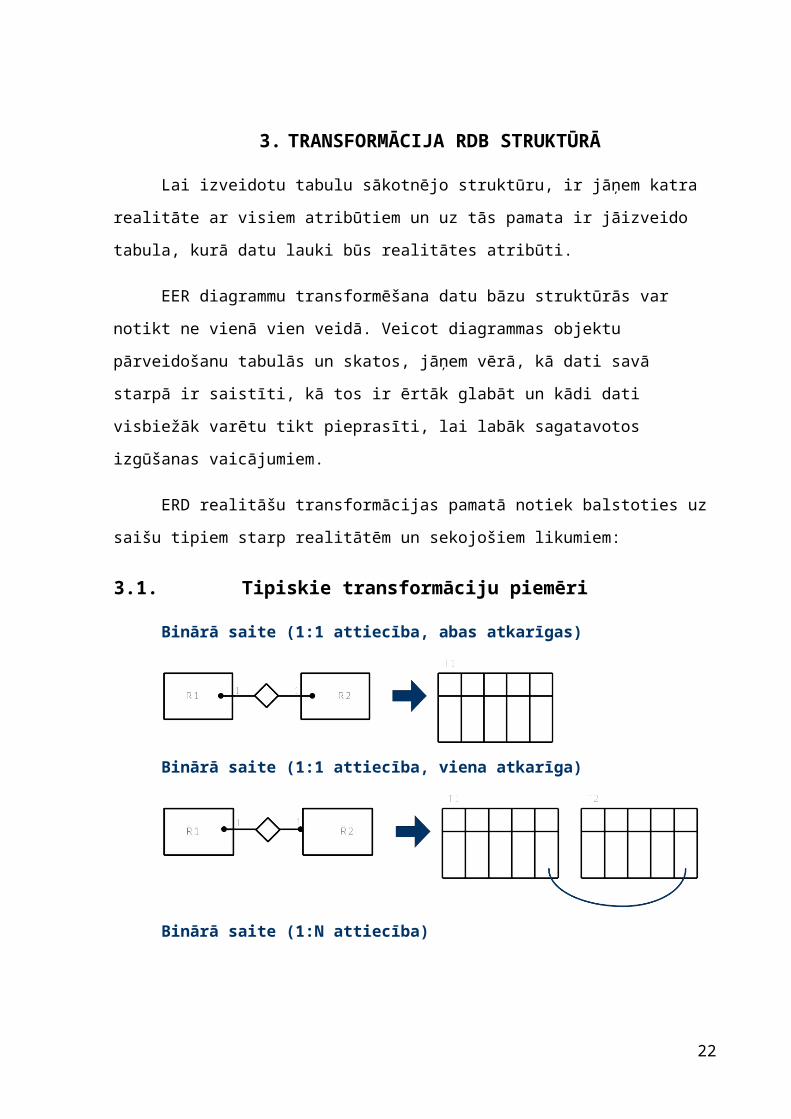
3. TRANSFORMĀCIJA RDB STRUKTŪRĀ
Lai izveidotu tabulu sākotnējo struktūru, ir jāņem katra realitāte ar visiem
atribūtiem un uz tās pamata ir jāizveido tabula, kurā datu lauki būs realitātes atribūti.
EER diagrammu transformēšana datu bāzu struktūrās var notikt ne vienā vien
veidā. Veicot diagrammas objektu pārveidošanu tabulās un skatos, jāņem vērā, kā dati
savā starpā ir saistīti, kā tos ir ērtāk glabāt un kādi dati visbiežāk varētu tikt pieprasīti,
lai labāk sagatavotos izgūšanas vaicājumiem.
ERD realitāšu transformācijas pamatā notiek balstoties uz saišu tipiem starp
realitātēm un sekojošiem likumiem:
3.1. Tipiskie transformāciju piemēri
Binārā saite (1:1 attiecība, abas atkarīgas)
Binārā saite (1:1 attiecība, viena atkarīga)
Binārā saite (1:N attiecība)
Binārā saite (N:M attiecība)
20

Unārā saite (1:N attiecība)
Klasifikācija
Superrealitāte
Mantošana (Specializācija)
21

Vājā realitāte
Ternārā saite
1. variants:
2. variants:
22

Dati saitē
1. variants:
2. variants:
3.2. Elementu transformācijas realizācija
Tagad, kad mums ir pilnīgi definēta EER diagramma, var ķerties pie
transformācijas loģiskajā modelī. Lai labāk saprastu katru EER diagrammas daļu,
apskatīsim katru elementu (unāra saite, bināra saite utt.) atsevišķi. Pēc tam mēģināsim
savienot visas transformācijas kopā, izveidojot kopīgo RDB loģisko modeli. Gribētu
piebilst to, ka Datu saitēs transformācija uzreiz tiks veikta, realizējot pārējo elementu
transformācijas. Pie tam, ar katru nākošo transformāciju tabulu struktūra var mainīties,
jo iespējams tabulās var būt tikt pievienoti lauki no saitēm, kuras saista jau izskatīto
realitāti ar kādu no vēl pirms tam neizskatītām realitātēm.
3.2.1. Unārās saites transformācija
Lai labāk saprastu unāras saites transformāciju, attēlosim sākuma elementu
23

Tātad, attēlosim realitāti „Ārsts” kā tabulu. Tā kā unāra saite ir saite, kas savieno
vienu un to pašu realitāti, pie tam ar attiecību 1:N – tad izveidosim tabulai pievienosim
saites atribūtu „nodaļas vadītaja numurs”, tādā veidā definējot gan attiecību 1:N, gan arī
pašu tabulu.
Uzskatamāk, ar primāro un ārējām atslēgām, to varētu attēlot sekojošā veidā:
3.2.2. Ternārās saites transformācija
Lai labāk saprastu ternārās saites transformāciju, attēlosim sākuma elementus.
Pirmā ternārā saite:
24

Ternārās saites transformācija tiek realizēta veidojot trīs tabulas katrai
realitātei, tiek veidots arī skats, kas palīdz attēlot un savienot trīs galvenās tabulas. Vēl
viens variants ir pievienot papildus atslēgas katrai no tabulām, tādējādi savienojot
katru no tabulām ar divām citām, taču šis variants nav efektīvs. Tātad, izmantojot pirmo
variantu, iegūstam sekojošas tabulu struktūras:
Un loģiskais modelis:
25
Otrā ternārā saite:
Šī saite realizēta tādā pašā veidā, ka iepriekšēja:
Tagad mēģināsim attēlot šīs struktūras nedaudz pārskatāmāk:
26

Izveidotajos skatos varam redzēt, ka lauki iekš tā tiek ņemti no citām tabulām
(sākumlauku nosaukumi ir attēloti iekavās, norādot to lauku, kurš tiek izmantots no
citas tabulas).
3.2.3. Superrealitātes transformācija
Lai labāk saprastu superrealitātes transformāciju, attēlosim sākuma elementus:
Superrealitātes transformāciju arī var realizēt dažādos veidos. Viens veids – veidot
skatu, apvienojot divu tabulu datus. Cits veids – veidot jaunu tabulu, kas saturēs divu
tabulu datus, ka arī citus datus. Ir iespējami arī citi varianti. Kuru variantu izvēlēties ir
atkarīgs no situācijas. Izveidotajai EER diagrammai izmantosim otro variantu, jo tad, ja
mēs veidosim skatu, tam nevarēs būt, līdz ar to – veidosim trīs tabulas. Tomēr, vēl
labākais risinājums šajā gadījumā būs, izveidot superrealitāti kā starptabulu, kura saista
personas un viņa pacienta kartes, un klāt vēl izveidosim skatu „Skats_Pacienti”, kurš arī
tieši saturēs abu realitāšu atribūtus. Līdz ar to, mēs apvienojam abus paņēmienus
superrealitāšu realizēšanā. Realizācija ir apskatāma zemāk:
27

Tātad, varam redzēt, ka ir izveidota tabula, kurā ir gan personas dati, gan dati par
šo personu pacientu kartem. Tagad mēģināsim attēlot šīs struktūras nedaudz
pārskatāmāk, izmantojot gan ārējās, gan primārās atslēgas:
3.2.4. Vājās realitātes transformācija
Lai labāk saprastu vājās realitātes transformāciju, attēlosim sākuma elementus:
28

Vāja realitāte kļūs par tabulu „Medikament” un „Pacients” starptabulu. Realizācija
zemāk:
Tagad mēģināsim attēlot šīs struktūras nedaudz pārskatāmāk, izmantojot gan
ārējās, gan primārās atslēgas
29

Pašlaik šī vājā realitāte, kura tagad ir tabula „T_Receptes” ir tā, kura savā starpā
saista pacientu un medikamentu tabulas. Šī savienošanās notika tādā veidā, ka vājās
realitātes tabula pieņēma sevī identifikatorus no pārējām divām tabulām.
3.2.5. Pilnās klasifikācijas transformācija
Lai labāk saprastu pilnās klasifikācijas transformāciju, attēlosim sākuma
elementus:
30

Tagad varam apskatīt klasifikāciju. Tā kā klasifikācija ir diezgan sarežģīta
struktūra, tad svarīgi ir atcerēties to, ka pilno klasifikāciju realizē kā tabulu ar diviem
skatiem, pie tam, skati manto, šajā gadījumā, trīs tabulas atribūtus, jo pēc ceturtā
atribūta notiek pati klasifikācija. Tātad, tabulas un skatu struktūras realizāciju var
aplūkot.
Šeit varam redzēt, ka ir jauna tabula un divi skati, kuri manto visus atribūtus,
izņemot to, pēc kura notiek klasifikācija. Uzreiz, paredzot datu dublēšanu, izņemsim no
tabulas „T_Medikamenti” datus, kuri dublējas pārējās realitātēs. Klasificēšanas nolūkiem
tiks izmantoti skati.
Taču sākumā pēc būtības izveidosim pašas tabulas ar maksas un bezmaksas
medikamentiem. Bet tikai pēc tam izveidosim arī skatus.
Tagad mēģināsim attēlot šīs struktūras nedaudz pārskatāmāk
31

3.2.6. Mantošanas (specializācijas) transformācija
Lai labāk saprastu mantošanas transformāciju, attēlosim sākuma elementus:
Mantošanu transformēšanas shēma ir divas tabulas un skats. Bet ta kā, zināms ka
dažas tabulas atsaucas tieši uz realitāti „Ārsts”, tad arī šajā gadījumā būs loģiskāk veidot
3 tabulas:
Veidojot loģisko modeli, tikko noteiktai struktūrai, ir jāatrod risinājumu sekojošai
problēmai. Tabula T_Arsti satur unaro saiti. Problēmas atrisināšanai labākais manuprāt
variants ir sekojošs, ar nosacījumu, ka rajona ārstiem ir sava atsevišķa struktūra un
32

specialistiem savā. Un ārsts specialists nevar būt par nodaļas vadītāju rajona ārstam:
3.2.7. Pārējo saišu transformācija
Vēl daži pārviedojumi, kas tiek attēloti fragmentiski.
Saite starp T_Pacienti, T_Pieraksti un T_Specialisti:
Saite starp T_Pacienti un T_Rajona_Arsti:
33

3.2.8. Kopīgais RDB loģiskais modelis
34

33

4. NORMĀLFORMU PĀRBAUDE
Datu bāze var tikt uzskatīta par normalizēto, ja tās tabulas (vai lielāka daļa no
tabulam) ir piedavātas, kaut minimāli, 3 normālformā (3NF). Bieži vien, daudzas tabulas
tiek normalizētas līdz 4 normālfromai (4NF), bet dažreiz, prētēji, notiek denormalizācija.
Normalizācijas galvenais mērķis – informācijas dublēšanas un redundances
novēršana, kas savukārt ļauj nodrošināt datu bāzi, no loģisko un strukturālo problēmu
rašanam, ko sauc par datu anomalijam.
4.1. 1 Normālformas pārbaude
1 Normālforma (1NF) – tabula atrodas 1NF , ja katrs tabulas atribūts ir atomārs.
„Atomars atribūts” nozīme, ka atribūts var saturēt tikai vienu vērtību. Līdz ar to 1NF:
aizliedz atkartotās kolonnas (kas satur vienādu pēc jēgas informāciju);
aizliedz daudzējādas ( ) kolonnas ( kas saturмножественные
saraksta tipa vērtības);
pieprasa noteikt tabulai primāro atslēgu.
Saskaņā ar 1NF prasībam, projektējamā datu bāze visas tabulas atrodas 1NF.
4.2. 2 Normālformas pārbaude
2 Normālforma (2NF) – tabula atrodas 2NF, ja ta atrodas 1NF un pie tam katrs
tabulas atribūts, kas nav primāra atslēga, funkcionāli pilnīgi ir atkarīgs no primāras
atslegas kopumā, bet nav funkcionāli atkarīgs no kādas primāra atslēga sastāvdaļas. Tas
nozīme, kā gadījumā, kad tabula atrodas 1NF un primāra atslēga tai sastāv no vienas
kolonnas, tas automatiski atrodās 2NF.
Apskatīsim 2NF būtību konkrētājā piemērā. Paņemsim kādu no tabulam, no
projektējamas datu bāzes.
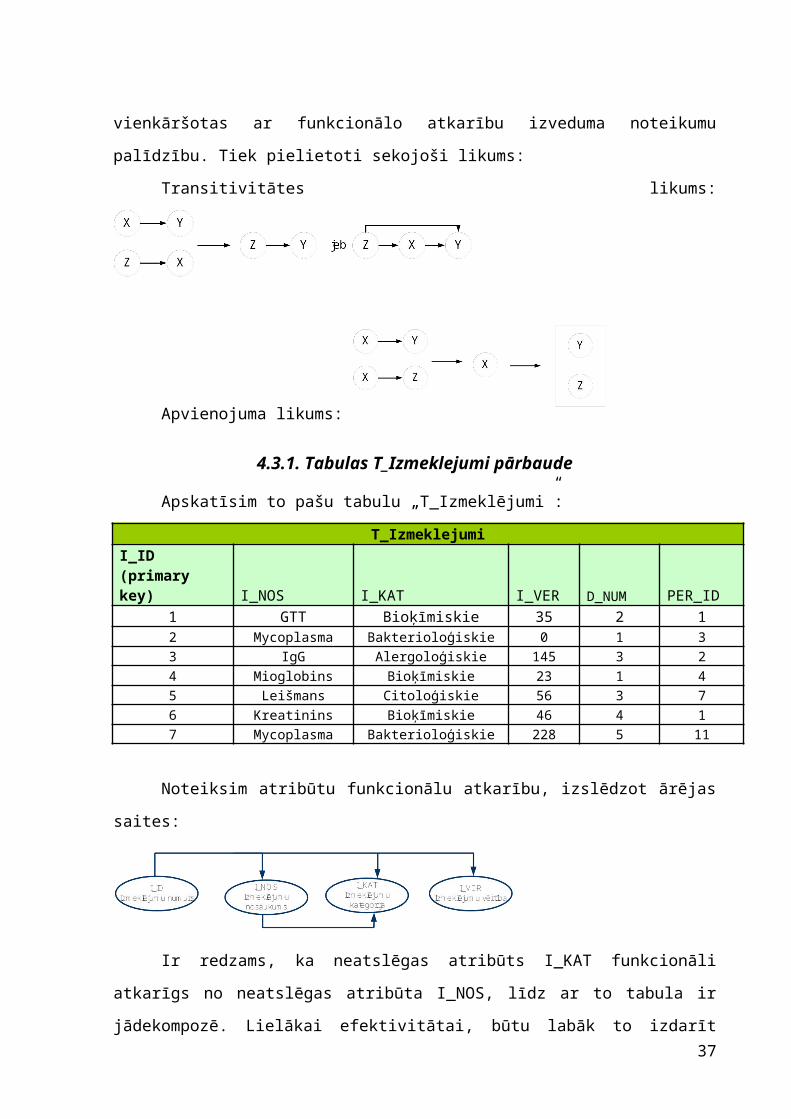
T_IzmeklejumiI_ID (primary key) I_NOS I_KAT I_VER D_NUM PER_ID
1 GTT Bioķīmiskie 35 2 12 Mycoplasma Bakterioloģiskie 0 1 33 IgG Alergoloģiskie 145 3 24 Mioglobins Bioķīmiskie 23 1 45 Leišmans Citoloģiskie 56 3 76 Kreatinins Bioķīmiskie 46 4 17 Listeria Bakterioloģiskie 228 5 3
34

Uzmanīgi apskatīsim šo tabulu: tai ir viena primāra atslēga, kas jau garantē to
faktu kā tabula atrodas 2NF. Un to fukcionāla atkarība izskatās šādi:
Bet ja pieņemt, ka šajā tabulā būtu salikta primāra atslēga (I_ID, I_NOS) , jeb
izmeklējuma numurs un izmeklējuma nosaukums, tad situācija kļūtu pavisam citāda.
Ir redzāms, kā atribūts I_KAT, jeb izmeklējumu kategorija ir atkarīgs no saliktas
primāras atslēgas tikai vienas daļas: no lauka I_NOS, izmeklējumu nosaukums, līdz ar to
ir skaidri redzams kā, šī tabula neatrodas 2NF, un tai ir nepieciešama dekompozīcija.
Taču tā kā šai tabulai īstenībā nav saliktas primāras atslēgas, tad uzskatīsim, ka tā
atrodas 2NF, jo visi atribūti ir atkarīgi no primāras atslēgas, un tai nav nepieciešama
dekompozīcija tik tālu, un ķersimies klāt 3NF un Boisa-Kodda NF pārbaudei, kur būs
redzāms, kāpec un kā šai tabulai ir jāizskatās.
Tātād, parējas tabulas nav vērts pārbaudīt atbilstībā pret 2NF, jo tiem visiem nav
saliktas primāras atslēgas.
4.3. 3 Normālformas un Boisa – Kodda normālformas pārbaude
3 Normālforma (3NF) – tabula atrodas 3NF, ja ta atrodas 2NF un pie tam
jebkurš tās neatslēgas atribūts funkcionāli atkarīgs „tikai” no primāras atslēgas.
Risinot lielāku daļu no praktiskiem uzdevumiem, normalizēšana līdz 3NF ir
pietekama.
Boisa – Kodda Normālforma (BCNF) – tabula atrodas BCNF, ja ta atrodas 3NF
un pie tam, neeksistē primāras atslēgas atribūtu funkcionālas atkarības no neatslēgas 35

atribūtiem. Ja tabula satur vairākus determinantus, tad tiem visiem jābūt iespējamam
primārās atslēgas kandidātam. Praktiski Boisa- Kodda normālforma tiek izmantota 3NF
pārbaudei.
Tabulu struktūru ir iespējams pārbaudīt ar funkcionālas atkarības diagrammas
palīdzību. Sarežģītās diagrammas tiek vienkāršotas ar funkcionālo atkarību izveduma
noteikumu palīdzību. Tiek pielietoti sekojoši likums:
Transitivitātes likums:
Apvienojuma likums:
4.3.1. Tabulas T_Izmeklejumi pārbaude
Apskatīsim to pašu tabulu „T_Izmeklējumi”:
T_IzmeklejumiI_ID (primary key) I_NOS I_KAT I_VER D_NUM PER_ID
1 GTT Bioķīmiskie 35 2 12 Mycoplasma Bakterioloģiskie 0 1 33 IgG Alergoloģiskie 145 3 24 Mioglobins Bioķīmiskie 23 1 45 Leišmans Citoloģiskie 56 3 76 Kreatinins Bioķīmiskie 46 4 17 Mycoplasma Bakterioloģiskie 228 5 11
Noteiksim atribūtu funkcionālu atkarību, izslēdzot ārējas saites:
Ir redzams, ka neatslēgas atribūts I_KAT funkcionāli atkarīgs no neatslēgas
atribūta I_NOS, līdz ar to tabula ir jādekompozē. Lielākai efektivitātai, būtu labāk to
izdarīt sekojošā veidā:
36

Visiem izmeklējumiem piešķirt savu unikālo kodu, kas darbosies poliklinikas
iekšējā sistēmā, aipildot otru tabulu ar visam iespējamam un zināmam analīzem. Tada
veidā būs iespējams izvairīties no informācijas redundances, samazināt kļūdu skaitu un
palielināt efektivitāti. Rezultātā divas tabulas izskatīsies šādi:
Pārveidojam arī loģisko modeli:
Tagad šīs tabulas atbilst 3NF un BCNF.
4.3.2. Tabulas T_Personas pārbaude
Apskatīsim tabulu T_Persona:
T_PersonasPER_ID PER_VAR PER_UZV PER_KODS PER_ADR PER_TAL
1 Jānis Ozols 230684-19227 Skanstas 13-23 267583302 Ivars Zars 020476-17273 Jelgavas 1-43 287644223 Aleksandrs Koks 160888-28374 Dzelzavas4-6 21837475
37

Tagad apskatisīm atribūtu funkcionālas atkarības diagrammu:
Ka var redzēt, šajā tabulā divi atribūti varētu būt primāras atslēgas. Tas ir PER_ID
personas numurs, no kura funkcionāli atkarīgi ir pilnīgi visi atribūti, un PER_KODS
personālais kods, kas pats par sevi ir unikāls katram cilvēkam un no kura ir atkarīgi
cilvēka vārds, uzvārds, deklarēta adrese un tālrunis. Tatād šī tabula netbilst BCNF
prasībam.
Tabula „T_Personas” ir jāsadala divās tabulās tā, lai nošķirtu datus par pašu
personu un personu, kas ir reģistrēts poliklinikā.
Tātad, veiksim tabulas atdalīšanu jeb dekompozīciju. Lai novērstu transitivitāti
datu grupām, izveidosim jaunas tabulas: „T_PersonasDati”, kura saturēs informāciju par
personu kā tādu un tabula „T_Personas” paliks par tabulu, kura kalpo kā informācija par
personu, kura ir reģistrēta poliklinikā.
Tātad, apskatīsimies, kā tas izskatīsies tad, kad tiks veidotas tabulas
Pārveidojam arī loģisko modeli:
38

4.3.3. Tabulu T_Diagnosti, T_Specialisti, T_RajonaArsti pārbaude
Visas šīs tabulas netbilsts 3NF un BCNF ta paša iemesla deļ, ka iepriekšēja tabula
T_Personas. Visās tabulās ir atribūts personas kods. Un šo tabulu dekompozīcija būtu
pilnīgi vienāda ar iepriekšējo piemēru. Tomēr šo problēmu līdzības deļ, arī risinājumu
būtu racionālāk atrast vienu.
Tā kā visas šīs trīs tabulās glabājās dati par ārstiem, kam ir noteikti un vieni un
tie paši kopīgie atribūti, tad līdzīgi tabulai „T_PersonasDati”, tabula
„T_MedPersonalaDati” varētu saturēt datus par visiem šiem cilvēkiem neatkarīgi no ta,
vai tas ir ārsts, vai arī diagnosts, bet pašās tabulas glabāsies atsevišķi atribūti.
Šo tabulu dekompozīcija izskatīsies šādi:
Pārveidojam arī loģisko modeli:
39

4.3.4. Pārveidotais kopējais modelis
Izskatās, ka visas pārējas tabulas atbilst prasībam un var attēlot kopējo
pārveidoto modeli:
40

41

5. SQL KODA REALIZĒŠANA
Darba pedējā daļā meģinasim realizēt tikko izprojektēto datu bāzes struktūru ar
SQL koda palidzību Oracle DBVS. RDB struktūras realizācijas gaitā jābūt realizētiem:
Tabulam ar lauku ierobežojumiem;
Skatiem;
Sinonīmiem;
Virknem;
Klasteriem;
Dinamiskiem ierobežojumiem (trigerus);
Glabāšanas procedūram.
5.1. Tabulu izveide
SQL koda realizēšanai izmantots Notepad ++. Sākumā definējam tabulas un arī
uzreiz definējam ierobežojumus – primārās atslēgas tabulās, saites uz citām tabulām:
T_PersonasDatu tabula CREATE TABLE T_PersonasDati(
per_kods number(12) constraint c2_per_kods primary key,per_var varchar2(20) constraint c2_per_var not null,per_uzv varchar2(20) constraint c2_per_uzv not null,per_adr varchar2(20) constraint c2_per_adr not null,per_tal number(10) constraint c2_per_tal not null)cluster Personas (per_kods) /
T_Personas tabulaCREATE TABLE T_Personas (per_id number(3) constraint c1_per_id primary key,per_kods number(12) constraint cl_per_kods unique not null,constraint saite_per_perkods foreign key(per_kods) references T_PersonasDati(per_kods) ON DELETE CASCADE)cluster Personas (per_kods)/
T_pacKartes tabulaCREATE TABLE T_PacKartes (pack_id number(3) constraint c_pack_id primary key,pack_reg date constraint c_pack_reg not null,pack_dia_dat date constraint c_dia_dat not null,per_id number(3) constraint c_per_id unique not null,dia_id number(4) constraint c_dia_id not null,constraint saite_per_id foreign key(per_id) references T_Personas(per_id) ON DELETE CASCADE,constraint saite_dia_id foreign key(dia_id) references T_Diagnozes(dia_id) ON DELETE CASCADE)cluster Personas (per_kods) /
42

T_Pacienti tabulaCREATE TABLE T_Pacienti (pac_id number(4) constraint c3_pac_id primary key,pac_dzim char(1) constraint c3_pac_dzim not null,pac_vec number(3) constraint c3_pac_vec not null,per_id number(3) constraint c3_per_id unique not null,pack_id number(5) constraint c3_pack_id unique not null,ra_id number(3) constraint c3_ra_id not null,constraint saite_per_id foreign key(per_id) references T_Personas(per_id) ON DELETE CASCADE,constraint saite_pack_id foreign key(pack_id) references T_PacientuKartes(pack_id) ON DELETE CASCADE,constraint saite_ra_id foreign key(ra_id) references T_RajonaArsti(ra_id) ON DELETE CASCADE)cluster Pacienti (pac_id)/
T_SlimibasLapa tabulaCREATE TABLE T_SlimibasLapa (sl_id number(3) constraint c_sl_id primary key, sl_izsndat date constraint c_sl_izsndat not null,sl_atbr varchar2(10) constraint c_sl_atbr not null,dia_id number (4) constraint sl_dia_id not null,pac_id number(4) constraint unique not null,constraint saite_dia_id foreign key(dia_id) references T_Diagnozes(dia_id) ON DELETE CASCADE,constraint saite_pac_id foreign key(pac_id) references T_Pacienti(pac_id) ON DELETE CASCADE)cluster Pacienti (pac_id) /
T_Pieraksti tabulaCREATE TABLE Pieraksti (pie_id number(6) constraint c_pie_id primary key,pie_dat date constraint c_pie_dat not null,pie_laiks date constraint c_pie_laiks not null,pac_id number(4) constraint c_pac_id not null,sa_id number(3) constraint c_sa_id not null,constraint saite_sa_id foreign key(sa_id) references T_Specialisti(sa_id) ON DELETE CASCADE,constraint saite_pac_id foreign key(pac_id) references T_Pacienti(pac_id) ON DELETE CASCADE)cluster Pacienti (pac_id) /
T_MedPersonalaDati tabulaCREATE TABLE T_MedPersonalaDati(mper_kods number(12) constraint c_mper_kods primary key,mper_var varchar2(20) constraint c_mper_var not null,mper_uzv varchar2(20) constraint c_mper_uzv not null,mper_adr varchar2(20) constraint c_mper_adr not null,mper_tal number(10) constraint c_mper_tal not null)cluster MedPersonals (mper_kods)/
T_Arsti tabula
43
CREATE TABLE T_Arsti (a_id number(3) constraint c7_a_id primary key) /
T_RajonaArsti tabulaCREATE TABLE T_RajonaArsti (ra_id number(3) constraint c5_ra_id primary key,ra_amats varchar2(15) constraint c5_ra_amats not null,ra_rajons varchar2(15) constraint c5_ra_rajons not null,ra_nodvad number(3) constraint c5_ra_nodvad not null,a_id number(3) constraint c5_a_id unique not null,mper_kods number(12) constraint c5_mper_kods unique not null,constraint saite_ra_nodvad foreign key(ra_nodvad) references T_RajonaArsti(ra_id) ON DELETE CASCADE,constraint saite_a_id foreign key(a_id) references T_Arsti(a_id) ON DELETE CASCADE,constraint saite_mperkods foreign key(mper_kods) references T_MedPersonalaDati(per_mkods) ON DELETE CASCADE)cluster MedPersonals (mper_kods)/
T_Specialisti tabulaCREATE TABLE T_Specialisti (sa_id number(3) constraint c6_sa_id primary key,sa_amats varchar2(15) constraint c6_sa_amats not null,sa_nodvad varchar2(15) constraint c6_sa_nodvad not null,a_id number(3) constraint c6_a_id unique not null,mper_kods number(12) constraint c6_mper_kods unique not null,constraint saite_sa_nodvad foreign key(sa_nodvad) references T_RajonaArsti(sa_id) ON DELETE CASCADE,constraint saite_a_id foreign key(a_id) references T_Arsti(a_id) ON DELETE CASCADE,constraint saite_per_perkods foreign key(mper_kods) references T_MedPersonalaDati(per_mkods) ON DELETE CASCADE)cluster MedPersonals (mper_kods)/
T_Diagnosti tabulaCREATE TABLE T_Diagnosti (d_id number(3) constraint c4_d_id primary key,d_spec varchar2(20) constraint c4_d_spec not null,mper_kods number(12) constraint c4_mper_kods unique not null,constraint saite_per_perkods foreign key(mper_kods) references T_MedPersonalaDati(per_mkods) ON DELETE CASCADE)cluster MedPersonals (mper_kods)/
T_Medikamenti tabulaCREATE TABLE T_Medikamenti (m_id number(4) constraint c_m_id primary key,m_kat varchar2(9) constraint c_m_kat CHECK (m_kat IN (‘maksas’, ‘bezmaksas’)))cluster Medikamenti (m_id) /
T_MaksasMedikamenti tabulaCREATE TABLE T_MaksasMedikamenti (mm_id number(4) constraint c_mm_id primary key,mm_nos varchar2(20) constraint c_mm_nos not null,mm_cena varchar2(6) constraint c_mm_cena not null,mm_atl varchar2(4),
44

m_id number(4) constraint c_m_id not null,constraint saite_m_id foreign key(m_id) references T_Medikamenti(m_id) ON DELETE CASCADE)cluster Medikamenti (m_id) /
T_BezmaksasMedikamenti tabulaCREATE TABLE T_BezmaksasMedikamenti (bm_id number(4) constraint c_bm_id primary key,bm_nos varchar2(20) constraint c_bm_nos not null,bm_cena varchar2(6) constraint c_bm_cena not null,bm_atl varchar2(4) constraint c_bm_atl not null,m_id number(4) constraint c_m_id not null,constraint saite_m_id foreign key(m_id) references T_Medikamenti(m_id) ON DELETE CASCADE)cluster Medikamenti (m_id) /
T_Rekini tabulaCREATE TABLE T_Rekini (rek_id number(5) constraint c_rek_id primary key,pac_id number(4) constraint c_pac_id not null,mm_id number(4) constraint c_mm_id not null,constraint saite_pac_id foreign key(pac_id) references T_Pacienti(pac_id) ON DELETE CASCADE,constraint saite_mm_id foreign key(mm_id) references T_MaksasMedikamenti(mm_id) ON DELETE CASCADE)
T_Receptes tabulaCREATE TABLE T_Receptes (r_id number(5) constraint c_r_id primary key,r_aforma varchar2(15),r_izsndat date constraint c_r_izndat not null,m_id number(4) constraint c_m_id not null,pac_id number(4) constraint c_pac_id not null,constraint saite_pac_id foreign key(pac_id) references T_Pacienti(pac_id) ON DELETE CASCADE,constraint saite_m_id foreign key(m_id) references T_Medikamenti(m_id) ON DELETE CASCADE)cluster Medikamenti (m_id) /
T_Diagnozes tabulaCREATE TABLE T_Diagnozes (dia_id number(4) constraint c_dia_id primary key,dia_nos varchar2(20) constraint c_dia_nos not null,dia_ats varchar2(20) constraint c_dia_ats not null,d_id number(3) constraint c_d_id not null,i_id number(3) constraint c_i_id not null,a_id number(3) constraint c_a_id not null,constraint saite_d_id foreign key(d_id) references T_diagnosti(d_id) ON DELETE CASCADE,constraint saite_i_id foreign key(i_id) references T_Izmeklejumi(i_id) ON DELETE CASCADE,constraint saite_a_id foreign key(a_id) referneces T_Arsti(a_id) ON DELETE CASCADE)
45

T_Izmeklejumi tabulaCREATE TABLE T_Izmeklejumi (i_id number(3) constraint c_i_id primary key,i_ver varchar2(5) constraint c_i_ver not null,d_id number(3) constraint c_d_id not null,per_id number(4) constraint c_per_id not null,iz_kods number(3) constraint c_iz_kods not null,constraint saite_d_id foreign key(d_id) references T_Diagnosti(d_id) ON DELETE CASCADE,constraint saite_per_id foreign key(per_id) references T_Personas(per_id) ON DELETE CASCADE,constraint saite_iz_kods foreign key(iz_kods) references T_IzmeklejumuDati(iz_kods) ON DELETE CASCADE) /
T_IzmeklejumuDati tabulaCREATE TABLE T_IzmeklejumuDati (iz_kods number(3) constraint c_iz_kods primary key,iz_nos varchar2(20) constraint c_iz_nos not null,iz_kat varchar2(20) constraint c_iz_kat not null) /
T_ArstesanasSH tabulaCREATE TABLE T_ArstesanasSH (ar_id number(3) constraint c_ar_id primary key,ar_tips varchar2(20) constraint c_ar_tips not null,ar_ilg varchar2(20) constraint c_ar_ilg not null,a_id number(3) constraint c_a_id not null,dia_id number(4) constraint c_dia_id not null,constraint saite_a_id foreign key(a_id) references T_Arsti(a_id) ON DELETE CASCADE,constraint saite_dia_id foreign key(dia_id) references T_Diagnozes(dia_id) ON DELETE CASCADE) /
T_Sasaistes tabulaCREATE TABLE T_Sasaistes (s_sas_id number(5) constraint c_ssas_id primary key,m_id number(3) constraint c_m_id not null,ar_id number(3) constraint c_ar_id not null,constraint saite_m_id foreign key(m_id) references T_Medikamenti(m_id) ON DELETE CASCADE,constraint saite_ar_id foreign key(ar_id) references T_ArstesanasSH(ar_id) ON DELETE CASCADE) /
5.2. Klasteru izveide
Klasteris tiek izmantots loģiski saistīto tabulu sasaitei fiziskā struktūrā. Galvenais
iemesls, sarežģīto vaicājumu izpildes paātrināšanai. Piemēram, realizēsim 4 klasterus:
klasteris Medikamenti
CREATE CLUSTER Medikamenti(m_id NUMBER(3))
46

SIZE 512storage (INITIAL 512k NEXT 64k) /
klasteris MedPersonals
CREATE CLUSTER MedPersonals(mper_kods NUMBER(3))SIZE 512storage (INITIAL 512k NEXT 64k) /
klasteris Pacientu
CREATE CLUSTER Pacienti(pac_id NUMBER(3))SIZE 512storage (INITIAL 512k NEXT 64k) /
klasteris Personas
CREATE CLUSTER Personas(per_kods NUMBER(3))SIZE 512storage (INITIAL 512k NEXT 64k) /
5.3. Virkņu izveide
Virknes tiek izmantotas identifikatoru definešanai tabulās. Piemēram, izveidosim
tikai dažas virknes, bet principā varētu definēt virkni katrai tabulai, kurā eksistē
identifikators:
CREATE SEQUENCE rekini_keyINCREMENT BY 1START WITH 1maxvalue 999minvalue 1nocyclecache 5 /
CREATE SEQUENCE receptes_keyINCREMENT BY 1START WITH 1maxvalue 999minvalue 1nocyclecache 5 /
CREATE SEQUENCE izmeklejumi_keyINCREMENT BY 1START WITH 1maxvalue 999minvalue 1nocyclecache 5 /
CREATE SEQUENCE pieraksti_keyINCREMENT BY 1START WITH 1maxvalue 999minvalue 1nocyclecache 5 /
47

5.4. Skatu izveide
Skats – tas ir virtuāla tabula, kas fiziski neeksistē datu bāzē, bet kura eksistē
lietotāja uzskatā par datu loģisko struktūru. Virtuāla tabula nesatur faktiskus datus, bet
ir realizēta kā vaicājums eksistejošiem datu bāzes tabulam. Virtuālas tabulas tiek
izmantotas būtībā, lai realizētu datu ārējas shēmas. Piemēram, realizēsim visus skatus,
kas tika definēti projektējamā datu bāzē:
skats PacientiCREATE OR REPLACE VIEW Skats_Pacienti (pacienta numurs, dzimums, vecums, kartes numurs, registracija, personalais kods,vards, uzvards, adrese, talrunis ) ASSELECT A.pac_id, A.pac_dzim, A.pac_vec, C.pack_id, C.pack_reg, G.per_kods, G.per_var, G.per_uzv, G.per_adr, G.per_talFROM T_Pacienti A, T_PacKartes C,
(SELECT B.per_id, D.per_kods, D.per_var, D.per_uzv, D.per_adr, D.per_tal FROM T_Personas B, T_PersonasDati D WHERE B.per_kods=D.per_kods) AS G
WHERE A.per_id=G.per_id AND A.per_id=C.per_id AND G.per_id=C.per_id/
skats MaksasCREATE OR REPLACE VIEW Maksas(medikamenta numurs, nosaukums, cena, atlaide) ASSELECT A.m_id, B.m_nos, B.m_cena, B.m_atlFROM T_Medikamenti A, T_MaksasMedikamenti BWHERE A.m_id=B.m_id
skats BezmaksasCREATE OR REPLACE VIEW Bezmaksas(medikamenta numurs, nosaukums, cena, atlaide) ASSELECT A.m_id, B.m_nos, B.m_cena, B.m_atlFROM T_Medikamenti A, T_BezmaksasMedikamenti BWHERE A.m_id=B.m_id
skats Arstesana_pec_diagnozesCREATE OR REPLACE VIEW Arstesana_pec_diagnozes(arestesana, arts, diagnoze, nosaukums) ASSELECT A.ar_id, B.a_id, C.dia_id, C.dia_nosFROM T_ArstesanasSH A, T_Arsti B, T_Diagnozes CWHERE A.a_id=B.a_id AND A.a_id=C.a_id AND B.a_id=C.a_id
skats Diagnoze_pec_izmeklejumiemCREATE OR REPLACE VIEW Diagnoze_pec_izmeklejumiem(diagnoze, nosaukums, izmeklejums, diagnosts) ASSELECT A.dia_id, A.dia_nos, B.i_id, C.d_idFROM T_Diagnozes A, T_Izmeklejumi B, T_Diagnosti CWHERE A.d_id =B.d_id AND A.d_id =C.d_id AND B.d_id =C.d_id
48

5.5. Sinonīmu izveide
Sinonīmi ļauj programmām strādāt bez modificēšanas neatkarīgi no tā, kuram
lietotājam pieder tabula vai skats un nestatoties uz to, kurai datubāzei pieder tabula vai
skats. Sinonīms ir tabulas, skata, virknes, cita sinonīma, procedūras vai cita Oracle
objekta pseidonims. Piemērām izveidosim trīs sinonīmus, kuri balstās uz iepriekš
definētajiem skatiem:
sinonīms Sk_Pacienti_SynCREATE PUBLIC SYNONYM Sk_Pacienti_Syn FOR Skats_Pacienti /
sinonīms Maksas_SynCREATE PUBLIC SYNONYM Maksas_Syn FOR Maksas /
sinonīms Bezmaksas_SynCREATE PUBLIC SYNONYM Bezmaksas_Syn f FOR Bezmaksas /
5.6. Dinamisko ierobežojumu (trigeru) izveide
Trigeris – ir īpaša tipa glabāšanas procedūra, kuru lietotājs neizsauc pats, bet kuru
izpildi nosaka kāda notikuma iestašāna (pēc būtības INSERT, DELETE, UPDATE
komandu izpilde) Trigerus izmanto lai nodrošināt datu integritāti. Serveris automātiski
palaiž trigeru, katru reizu kad tiek veiktas izmaiņas tabulā, ar kuru trigeris ir saistīts.
Piemēram, izveidosim trigerus, kas neļaus veikt jebkādas modificēšanas tabulas
T_Pieraksti un T_Receptes, brīvdienās:
trigeris EditPierakstiCREATE OR REPLACE TRIGGER Edit_Pierakstibefore delete or update or insert on T_Pierakstideclarelietotaj_kl exception;beginif substr(user,1,6)<>'ADMINISTRATORS' thenraise lietotaj_kl;end if;exceptionwhen lietotaj_kl thenraise_application_error (-20006,'Jus nevarat veikt izmainas saja tabula!');end; /
trigeris EditReceptesCREATE OR REPLACE TRIGGER Edit_Receptesbefore delete or update or insert on T_Receptesdeclarelietot_kl exception;beginif substr(user,1,6)<>'ADMINISTRATORS' then
49

raise lietot_kl;end if;exceptionwhen lietot_kl thenraise_application_error (-20006,'Jus nevarat veikt izmainas saja tabula!');end; /
5.7. Glabāšanas procedūras izveide
Glabāšānas procedūra – ta ir viena var vairākas SQL – konstrukcijas, kas ir
ierakstītas datu bāzē. Parasto SQL vaicājumu izpildes atļaušana lielam lietotāju skaitam,
var izraisīt vairākas problēmas, līdz ar to vairāku glabašanas procedūru veidošana
(analoģiski selectam), var dod iespeju pilnīgi atsakties no parasto vaicajumu lietošanas.
Šī pieeja nodrošina darba stabilitāti un drošību, pie tam pastāv vēl daži iemesli
glabāšanas procedūru realizēšanai – ātra izpilde, lielo uzdevumu sadalīšana mazos
moduļos, tīkla slodzes samazināšana u.t.t.
Tatād par glabāšanas procedūru var kļūt jebkurš parastais vaicājums. Vienkāršam
piemēram, izveidosim glabašanas procedūru, kura izvadīs nosaukumus un cenas visiem
medikamentiem, ko ir pircis pacients ar identifikācijas numuru 1 :
CREATE OR REPLACE PROCEDURE PacMedISBEGINSELECT B.pac_id, A.nosaukums, A.cenaFROM T_Pacienti B,
(SELECT A.pac_id AS pacients, B.mm_nos AS nosaukums, B.mm_cena AS cena FROM T_Rekins A, T_MaksasMedikaments B WHERE A.mm_id=B.mm_id) AS A
WHERE B.pac_id=A.pac_id AND B.pac_id = 1END/
50

INFORMĀCIJAS AVOTI
1. J.Eiduks, 2008./2009.māc.g. Izdales materiāli no diska
2. „Data Base Design for Smarties” Robert J. Muller
3. http://www.interface.ru/home.asp?artId=2805
4. http://www.cs.ifmo.ru/education/documentation/dbguide/index.shtml
5. http://www.wwwmaster.ru/article.php?nart=21
6. http://ms.by.ru/HTML/19.htm
7. http://club.shelek.ru/viewart.php?id=177
8. http://dic.academic.ru/dic.nsf/ruwiki/118395
9. http://www.delphikingdom.com/asp/viewitem.asp?catalogid=95
10. http://www.parallel.ru/docs/www.citforum.ru/database/dblearn/dblearn06.shtml
51

























