Embed Size (px)
DESCRIPTION
Regresion Lineal y No Lineal
Citation preview

ESTRATEGIAS Y DISEÑOS AVANZADOS DE INVESTIGACIÓN SOCIAL
Titular: Agustín Salvia
ANÁLISIS DE MODELOS DE REGRESION LINEAL (2° PARTE)
SEMINARIO DE POSGRADO

Problemas de Causalidad
El investigador suele tener razones teóricas o prácticas para creer que determinada variable es causalmente dependiente de una o más variables distintas.
Si hay suficientes observaciones empíricas sobre estas variables, el análisis de regresión es un método apropiado para describir la estructura, fuerza y sentido exacto de esta asociación.
Modelos de Regresión Lineal

Problemas de Causalidad
El modelo permite diferenciar variables explicativas, independientes o predictivas (métricas), variables a explicar o dependientes, y variables control o intervinientes (métricas o transformadas en variables categoriales).
La distinción entre variables dependientes e independientes debe efectuarse con arreglo a fundamentos teóricos, por conocimiento o experiencia y estudios anteriores.
Métodos de tipo: Y : f (X, є) / Y = B1X1 + U
Modelos de Regresión Lineal

Modelos de Regresión Lineal
Estima la fuerza o bondad explicativa del modelo teórico independientemente de las características de las variables introducidas
Predice el valor medio que puede asumir la variable Y dado un valor de X (regresión a la media) bajo un intervalo de confianza
Estima el efecto neto de cada una de las variables intervinientes sobre la variable dependiente (control sobre los demás efectos suponiendo independencia entre las variables predictivas).
Respuestas Metodológicas

Modelos de Regresión Lineal
El objetivo de la técnica de regresión es establecer la relación estadística que existe entre la variable dependiente (Y) y una o más variables independientes (X1, X2,… Xn). Para poder realizar esto, se postula una relación funcional entre las variables. Debido a su simplicidad analítica, la forma que más se utiliza en la práctica es la relación lineal:
ŷ= b0 + b1x1 +… bnxn
donde los coeficientes b0 y b1, … bn, son los factores que definen la variación promedio de y, para cada valor de x. Estimada esta función teórica a partir de los datos, cabe preguntarse qué tan bien se ajusta a la distribución real.
Función Lineal de Regresión
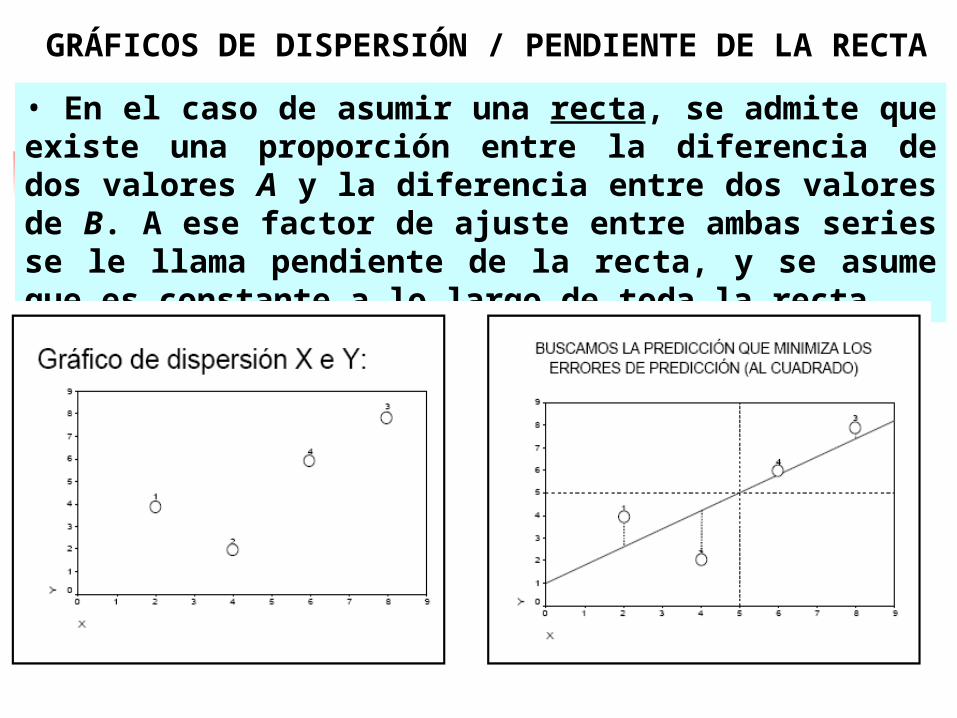
• En el caso de asumir una recta, se admite que existe una proporción entre la diferencia de dos valores A y la diferencia entre dos valores de B. A ese factor de ajuste entre ambas series se le llama pendiente de la recta, y se asume que es constante a lo largo de toda la recta.
GRÁFICOS DE DISPERSIÓN / PENDIENTE DE LA RECTA

Modelos de Regresión Lineal
- El parámetro b0, conocido como la “ordenada en el origen,” nos indica cuánto es Y cuando X = 0. El parámetro b1, conocido como la “pendiente,” nos indica cuánto aumenta Y por cada aumento en X.
- La técnica consiste en obtener estimaciones de estos coeficientes a partir de una muestra de observaciones sobre las variables Y y X.
- En el análisis de regresión, estas estimaciones se obtienen por medio del método de mínimos cuadrados. Logradas estas estimaciones se puede evaluar la bondad de ajuste y significancia estadística.
Función Lineal de Regresión
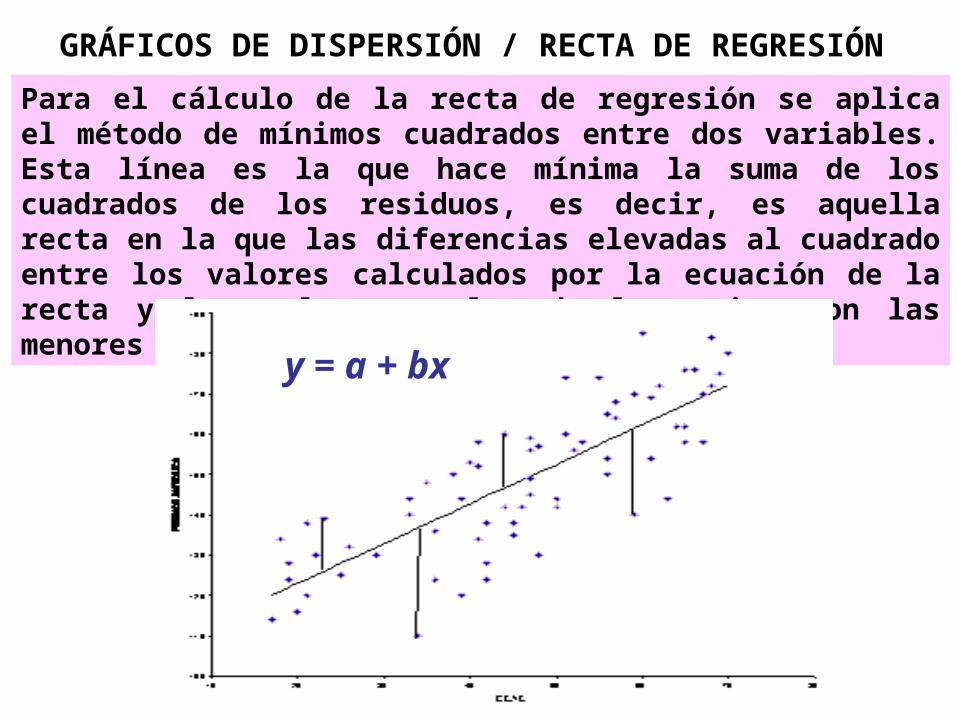
Para el cálculo de la recta de regresión se aplica el método de mínimos cuadrados entre dos variables. Esta línea es la que hace mínima la suma de los cuadrados de los residuos, es decir, es aquella recta en la que las diferencias elevadas al cuadrado entre los valores calculados por la ecuación de la recta y los valores reales de la serie, son las menores posibles.
GRÁFICOS DE DISPERSIÓN / RECTA DE REGRESIÓN
y = a + bx

Modelos de Regresión Lineal
Una pregunta importante que se plantea en el análisis de regresión es la siguiente: ¿Qué parte de la variación total en Y se debe a la variación en X? ¿Cuánto de la variación de Y no explica X?
El estadístico que mide esta proporción o porcentaje se denomina coeficiente de determinación (R2). Si por ejemplo, al hacer los cálculos respectivos se obtiene un valor de 0.846. Esto significa que el modelo explica el 84.6 % de la variación de la variable dependiente.
Función Lineal de Regresión

Se supone que la forma funcional que relaciona la variable DEPENDIENTE con la/las variables explicativas es de tipo LINEAL.
Las variables explicativas deben ser entre sí INDEPENDIENTES.
La CONSTANTE (b0) no sólo expresa el valor estimado de y en la ordenada al origen, sino también el conjunto de los errores no lineales y desconocidos del modelo.
Modelos de Regresión LinealRequisitos Estadísticos del Método

La variable aleatoria є (error) debe ser estadísticamente independiente de los valores de X y tener una distribución normal con una media igual a cero (supuesto 1 y 2).
Cualquier par de errores, єi y єj deben ser estadísticamente independientes entre sí, es decir que su covarianza debe ser igual a 0 (supuesto 3)
Las variables aleatorias єj deben tener una varianza finita σ2 que es constante para todos los valores de xj . (Supuesto 4 o de homocedasticidad)
Modelos de Regresión LinealSupuestos del Método de Regresión

Se evalúa la bondad de ajuste del modelo teórico a a través del coeficiente de determinación R2
La capacidad explicativa del modelo se hace a partir del método de mínimos cuadrados (ANOVA), cuyo resultado es testeado a través de F de Fisher
Predice los valores de la variable dependiente a partir de estimar el valor del coeficiente (B), el error estándar (S) y el coeficiente R parcial (BETA) de cada una de las variables y de la Constante
Mide la fuerza, sentido y significancia estadística de las variables del modelo sobre la variable dependiente a través de la prueba t de Student
Modelos de Regresión LinealSalidas Estadísticas del Método
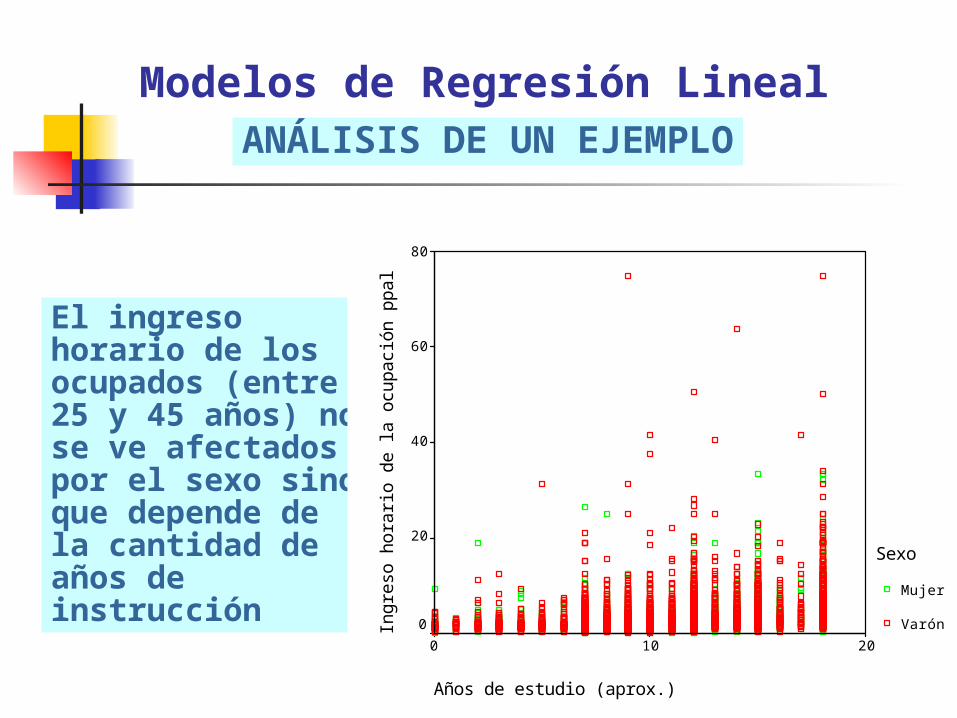
El ingreso horario de los ocupados (entre 25 y 45 años) no se ve afectados por el sexo sino que depende de la cantidad de años de instrucción
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Años de estudio (aprox.)
20100
Ing
reso
ho
rari
o d
e la
ocu
pa
ció
n p
pa
l
80
60
40
20
0
Sexo
Mujer
Varón
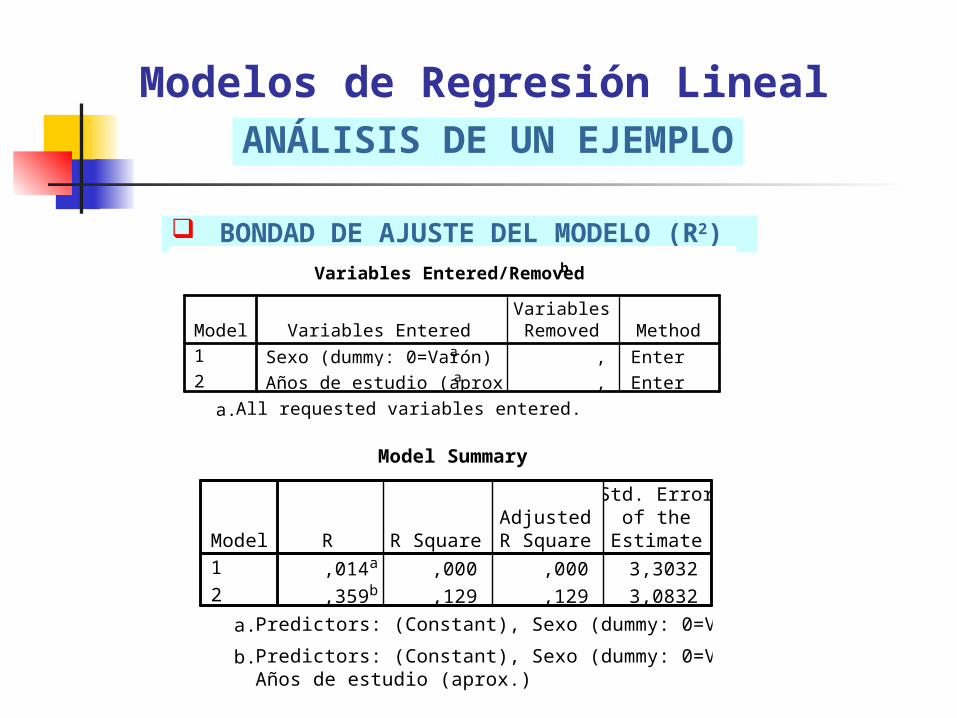
BONDAD DE AJUSTE DEL MODELO (R2)
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Variables Entered/Removedb
Sexo (dummy: 0=Varón)a , Enter
Años de estudio (aprox.)a , Enter
Model1
2
Variables EnteredVariablesRemoved Method
All requested variables entered.a.
Dependent Variable: Ingreso horario de la ocupación ppalb. Model Summary
,014a ,000 ,000 3,3032
,359b ,129 ,129 3,0832
Model1
2
R R SquareAdjustedR Square
Std. Errorof the
Estimate
Predictors: (Constant), Sexo (dummy: 0=Varón)a.
Predictors: (Constant), Sexo (dummy: 0=Varón),Años de estudio (aprox.)
b.
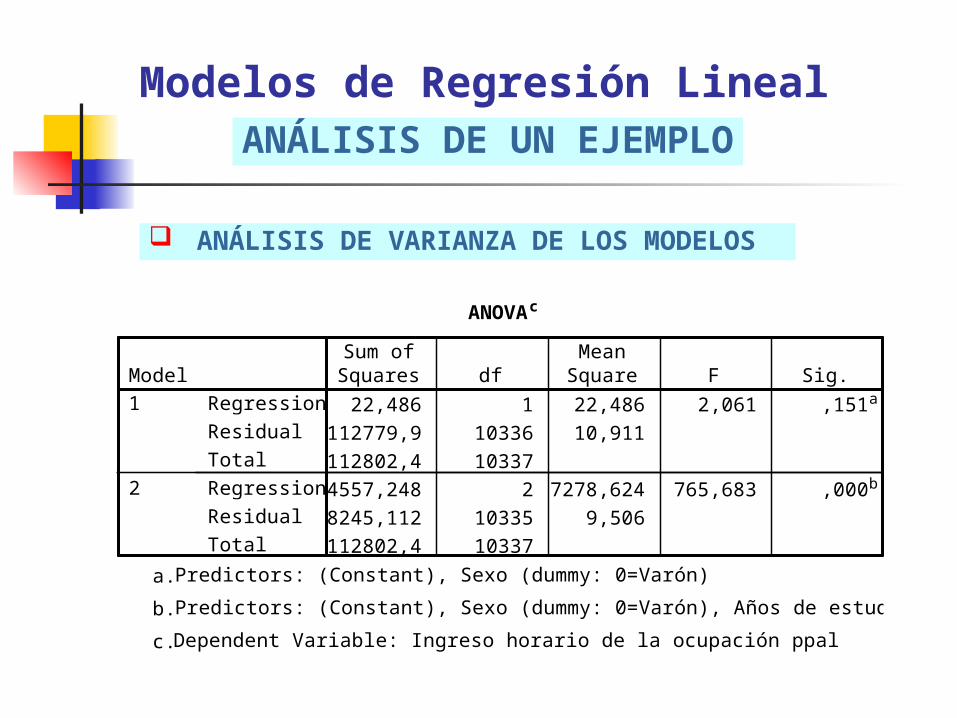
ANÁLISIS DE VARIANZA DE LOS MODELOS
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
ANOVAc
22,486 1 22,486 2,061 ,151a
112779,9 10336 10,911
112802,4 10337
14557,248 2 7278,624 765,683 ,000b
98245,112 10335 9,506
112802,4 10337
Regression
Residual
Total
Regression
Residual
Total
Model1
2
Sum ofSquares df
MeanSquare F Sig.
Predictors: (Constant), Sexo (dummy: 0=Varón)a.
Predictors: (Constant), Sexo (dummy: 0=Varón), Años de estudio (aprox.)b.
Dependent Variable: Ingreso horario de la ocupación ppalc.
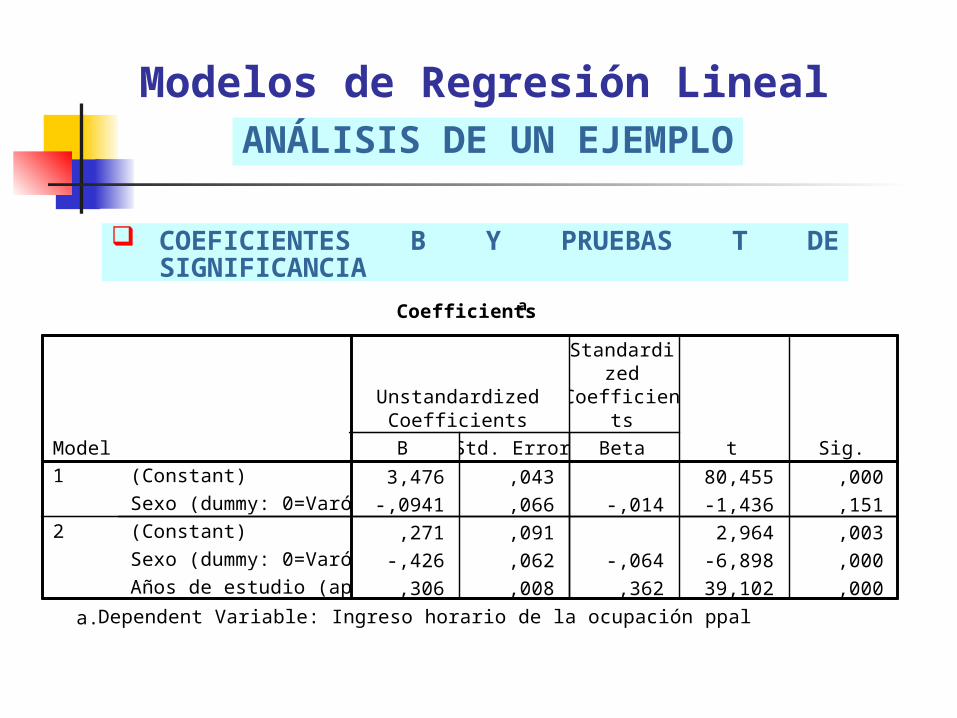
COEFICIENTES B Y PRUEBAS T DE SIGNIFICANCIA
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Coefficientsa
3,476 ,043 80,455 ,000
-,0941 ,066 -,014 -1,436 ,151
,271 ,091 2,964 ,003
-,426 ,062 -,064 -6,898 ,000
,306 ,008 ,362 39,102 ,000
(Constant)
Sexo (dummy: 0=Varón)
(Constant)
Sexo (dummy: 0=Varón)
Años de estudio (aprox.)
Model1
2
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: Ingreso horario de la ocupación ppala.

MULTICOLINEALIDAD: a través de matrices de correlación simple entre las variables independientes. Solución: Seleccionar variables independiente con baja correlación entre sí y/o transformar en variables dummy no colineales.
NORMALIDAD DE LOS RESIDUOS: a través de un gráfico de de distribución de los residuos. Solución: eliminación de datos outliers.
HETEROSCEDASTICIDAD: a través de gráficos de residuos є para cada valor de ŷ. Solución: Eliminación de casos outliers, tranformación de las variables independientes y/o estandarización de la variable dependiente Y.
AUTOCORRELACIÓN DE ERRORES: a través de la prueba Durbin-Watson / el valor 2 indica no autocorrelación. Solución: Corrección de observaciones o eliminación de datos.
Modelos de Regresión LinealControl de Supuestos

Modelos de Regresión No LinealAjustes Estadísticos del Método
La regresión lineal no siempre da buenos resultados, porque a veces la relación entre Y y X no es lineal sino que exhibe algún grado de curvatura. La estimación directa de los parámetros de funciones no-lineales es un proceso complicado. No obstante, a veces se pueden aplicar las técnicas de regresión lineal por medio de transformaciones de las variables originales.
¿Cómo ajustar modelos de regresión lineal cuando la función no es lineal?

AJUSTE DE VARIABLES A FUNCIONES NO LINEALES
• Hacer el diagrama de dispersión de las dos variables y evaluar si el patrón resultante sigue la forma lineal o alguna otra función.
• Identificada dicha función, substituir los valores de una variable con sus valores cuadrados, raíz cuadrada, logarítmicos o con alguna otra modificación, y hacer de nuevo la matriz de correlación.
• Identificar la función que mejor ajuste por medio de un paquete estadístico y determinar los coeficientes para la construcción de esa ecuación.
Exponencial:
y = a + bx
Polinómica:
y = a + b x + c x2
Logarítmica:
y = a + log b x
FUNCIONES NO LINEALES
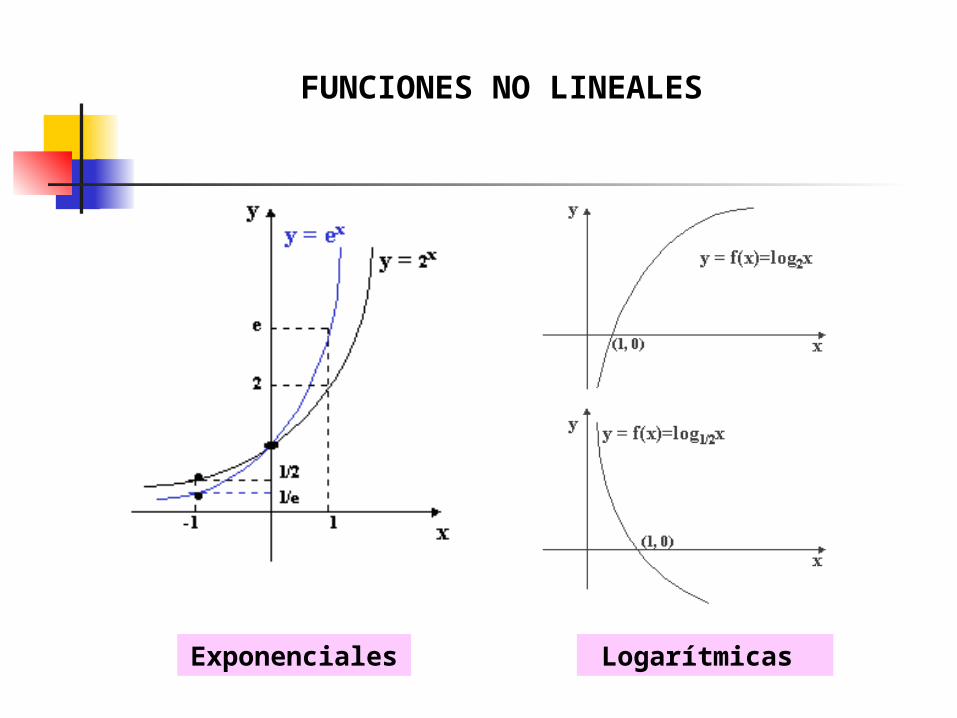
FUNCIONES NO LINEALES
Exponenciales Logarítmicas

Modelos de Regresión No LinealAjustes Estadísticos del Método
Si aplicamos logaritmos, esta función también puede ser expresada como: log(Y) = log(A) + b.log(X). En lugar de calcular la regresión de Y contra X, calculamos la regresión del logaritmo de Y contra el logaritmo de X. Este modelo es interesante, porque el exponente b en una función exponencial mide la elasticidad de Y respecto de X.
Una función no-lineal que tiene muchas aplicaciones es la función exponencial:
Y = AXb
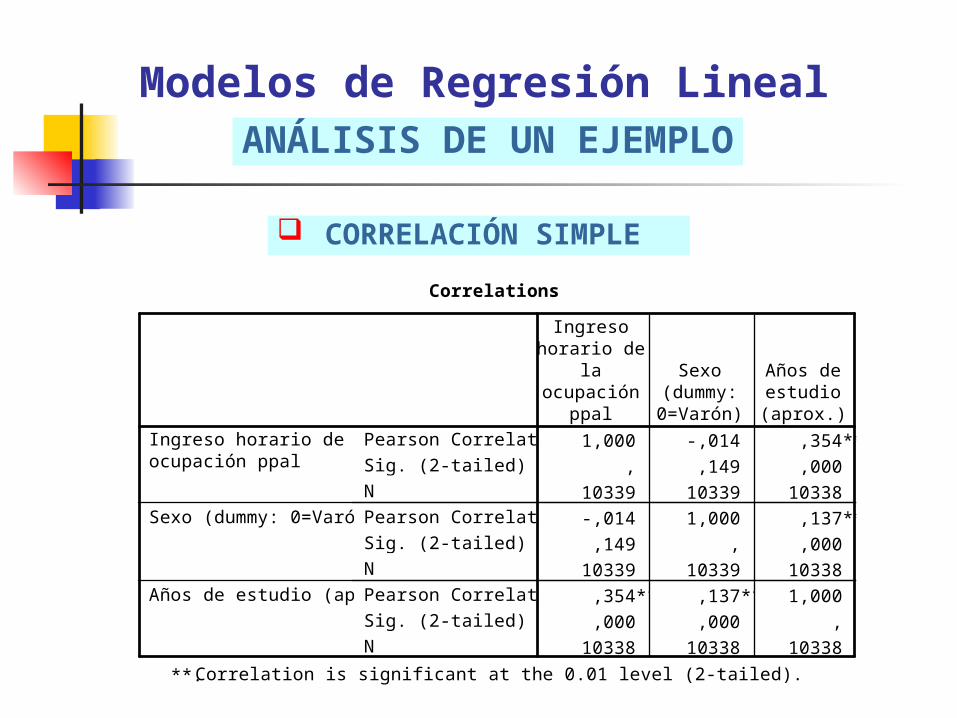
CORRELACIÓN SIMPLE
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Correlations
1,000 -,014 ,354**
, ,149 ,000
10339 10339 10338
-,014 1,000 ,137**
,149 , ,000
10339 10339 10338
,354** ,137** 1,000
,000 ,000 ,
10338 10338 10338
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Ingreso horario de laocupación ppal
Sexo (dummy: 0=Varón)
Años de estudio (aprox.)
Ingresohorario de
laocupación
ppal
Sexo(dummy:0=Varón)
Años deestudio(aprox.)
Correlation is significant at the 0.01 level (2-tailed).**.
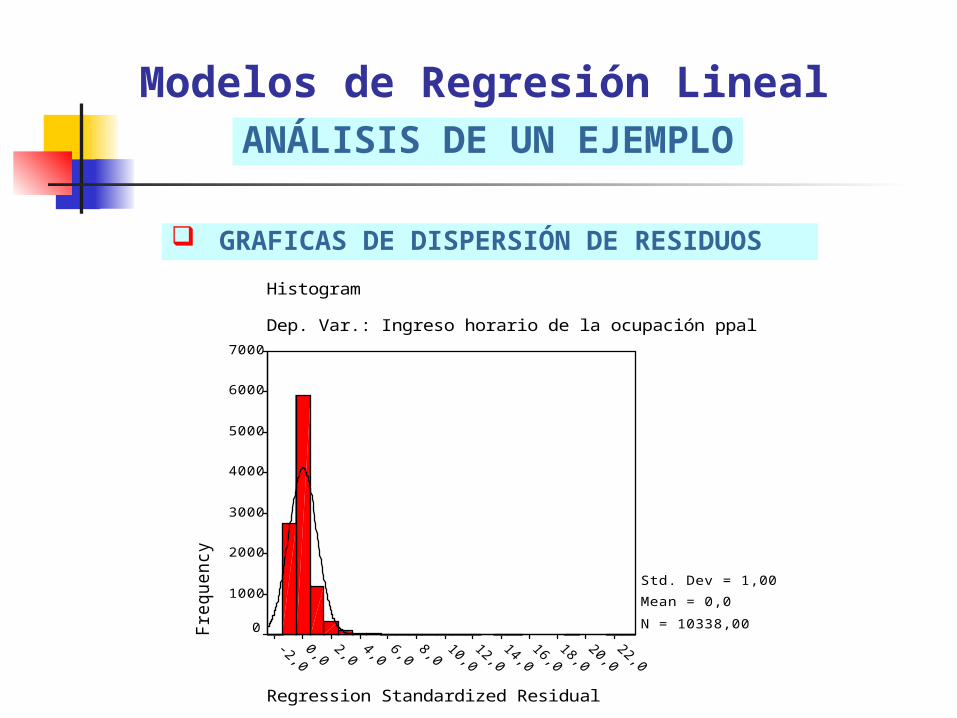
GRAFICAS DE DISPERSIÓN DE RESIDUOS
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Regression Standardized Residual
Histogram
Dep. Var.: Ingreso horario de la ocupación ppal
Fre
qu
en
cy
7000
6000
5000
4000
3000
2000
1000
0
Std. Dev = 1,00
Mean = 0,0
N = 10338,00
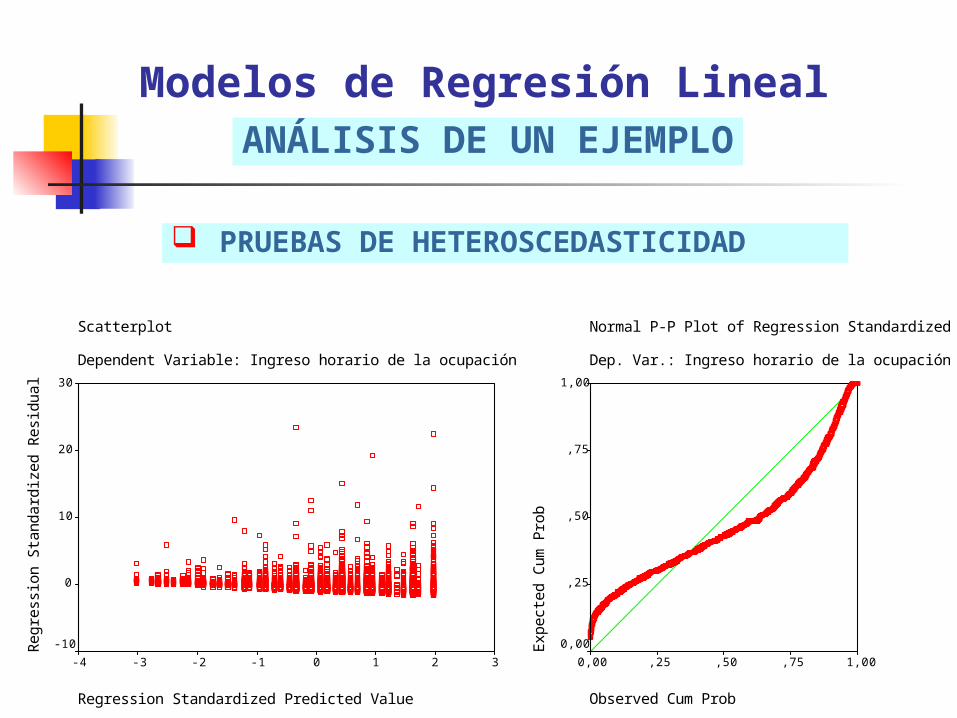
PRUEBAS DE HETEROSCEDASTICIDAD
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Normal P-P Plot of Regression Standardized Res.
Dep. Var.: Ingreso horario de la ocupación ppal
Observed Cum Prob
1,00,75,50,250,00
Exp
ect
ed
Cu
m P
rob
1,00
,75
,50
,25
0,00
Scatterplot
Dependent Variable: Ingreso horario de la ocupación ppal
Regression Standardized Predicted Value
3210-1-2-3-4
Re
gre
ssio
n S
tan
da
rdiz
ed
Re
sid
ua
l
30
20
10
0
-10

DURBIN WATSON: EVALUACIÓN DE AUTOCORRELACIÓN
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Model Summaryb
,359a ,129 ,129 3,0832 1,707Model1
R R SquareAdjustedR Square
Std. Errorof the
EstimateDurbin-W
atson
Predictors: (Constant), Sexo (dummy: 0=Varón), Años de estudio(aprox.)
a.
Dependent Variable: Ingreso horario de la ocupación ppalb.

Modelos de Regresión Lineal
Eliminar casos OUTLIERS que afectan la distribución.
Recodificación de las variables independientes y/o transformación LOGÍSTICA de la variable dependiente.
Estratificación del análisis a partir de usar una variable independiente como CRITERIO PARA DIVIDIR a la población en grupos comparables.
¿QUÉ HACER FRENTE A LOS SESGOS DE ESTIMACIÓN?
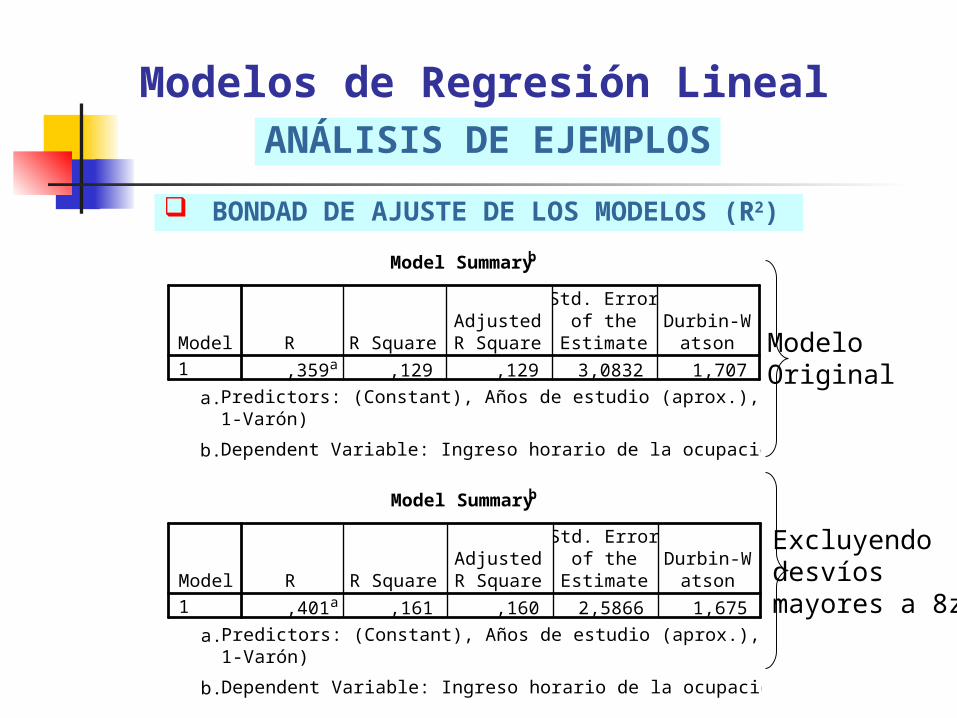
BONDAD DE AJUSTE DE LOS MODELOS (R2)
Modelos de Regresión LinealANÁLISIS DE EJEMPLOS
Model Summaryb
,359a ,129 ,129 3,0832 1,707Model1
R R SquareAdjustedR Square
Std. Errorof the
EstimateDurbin-W
atson
Predictors: (Constant), Años de estudio (aprox.), Sexo (dummy1-Varón)
a.
Dependent Variable: Ingreso horario de la ocupación ppalb.
ModeloOriginal
Model Summaryb
,401a ,161 ,160 2,5866 1,675Model1
R R SquareAdjustedR Square
Std. Errorof the
EstimateDurbin-W
atson
Predictors: (Constant), Años de estudio (aprox.), Sexo (dummy1-Varón)
a.
Dependent Variable: Ingreso horario de la ocupación ppalb.
Excluyendodesvíosmayores a 8z

BONDAD DE AJUSTE DEL MODELO (R2)
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Variabledependientelogaritmoing. horario
Model Summaryc
,021a ,000 ,000 ,7307
,422b ,178 ,178 ,6625 1,622
Model1
2
R R SquareAdjustedR Square
Std. Errorof the
EstimateDurbin-W
atson
Predictors: (Constant), Sexo (dummy 1-Varón)a.
Predictors: (Constant), Sexo (dummy 1-Varón), Años de estudio(aprox.)
b.
Dependent Variable: L_INGHORc.
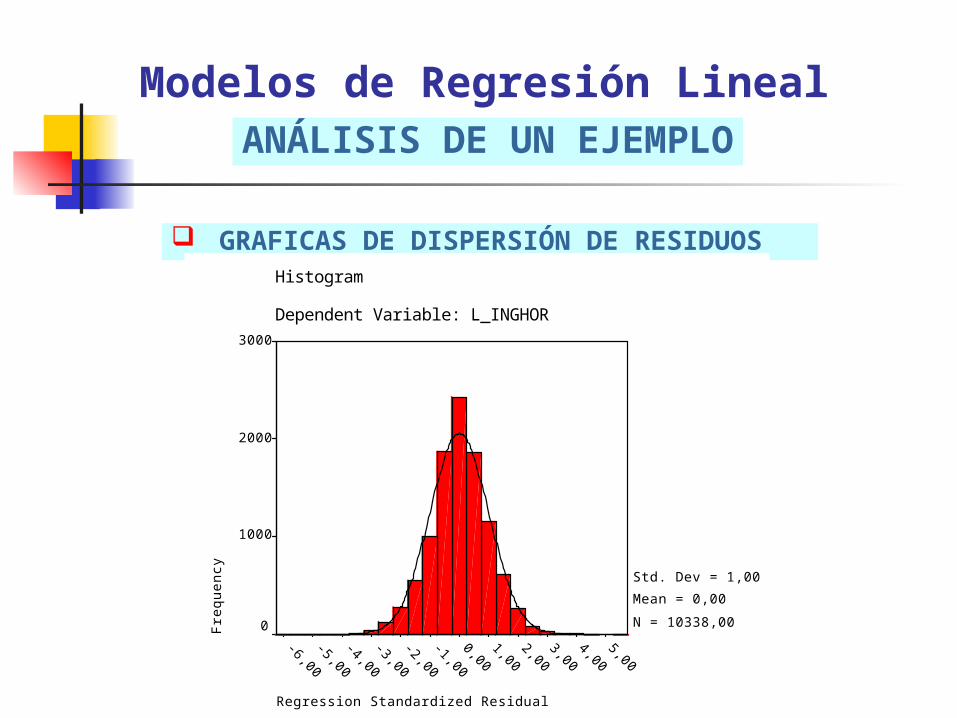
GRAFICAS DE DISPERSIÓN DE RESIDUOS
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Regression Standardized Residual
5,004,00
3,002,00
1,000,00
-1,00-2,00
-3,00-4,00
-5,00-6,00
Histogram
Dependent Variable: L_INGHOR
Fre
quen
cy
3000
2000
1000
0
Std. Dev = 1,00
Mean = 0,00
N = 10338,00
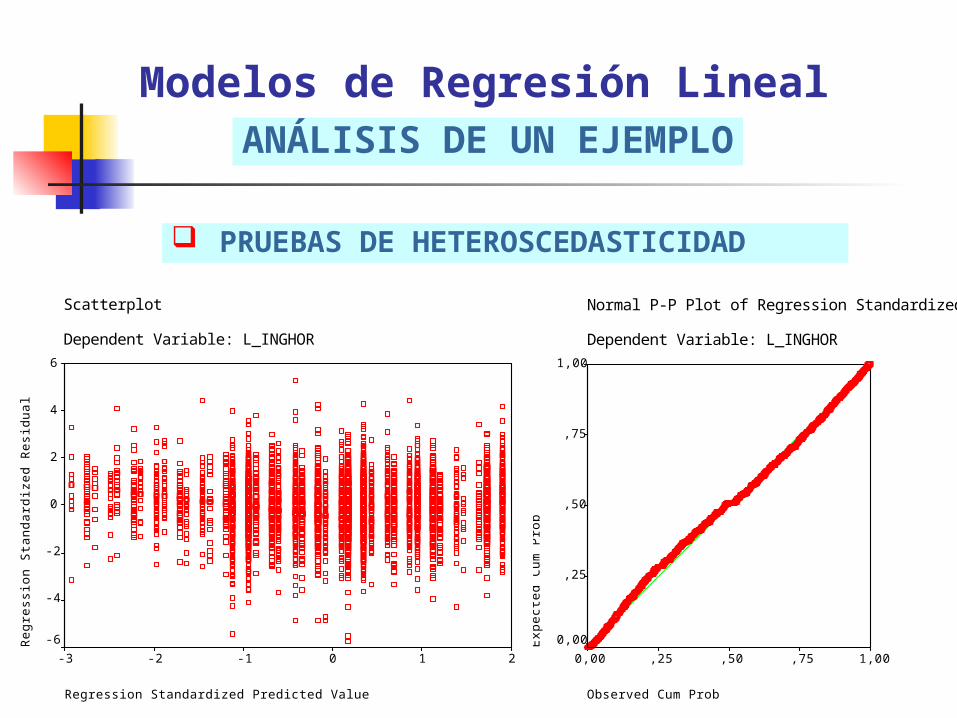
PRUEBAS DE HETEROSCEDASTICIDAD
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Normal P-P Plot of Regression Standardized Residual
Dependent Variable: L_INGHOR
Observed Cum Prob
1,00,75,50,250,00
Exp
ecte
d C
um P
rob
1,00
,75
,50
,25
0,00
Scatterplot
Dependent Variable: L_INGHOR
Regression Standardized Predicted Value
210-1-2-3
Reg
ress
ion
Sta
ndar
dize
d R
esid
ual
6
4
2
0
-2
-4
-6
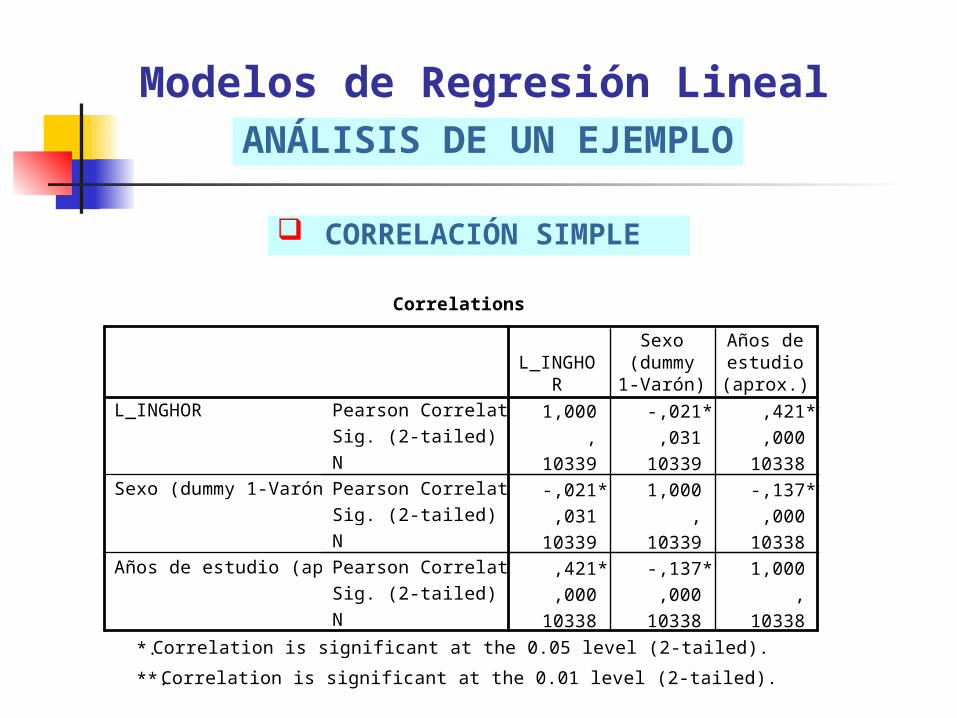
CORRELACIÓN SIMPLE
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Correlations
1,000 -,021* ,421**
, ,031 ,000
10339 10339 10338
-,021* 1,000 -,137**
,031 , ,000
10339 10339 10338
,421** -,137** 1,000
,000 ,000 ,
10338 10338 10338
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
Pearson Correlation
Sig. (2-tailed)
N
L_INGHOR
Sexo (dummy 1-Varón)
Años de estudio (aprox.)
L_INGHOR
Sexo(dummy1-Varón)
Años deestudio(aprox.)
Correlation is significant at the 0.05 level (2-tailed).*.
Correlation is significant at the 0.01 level (2-tailed).**.
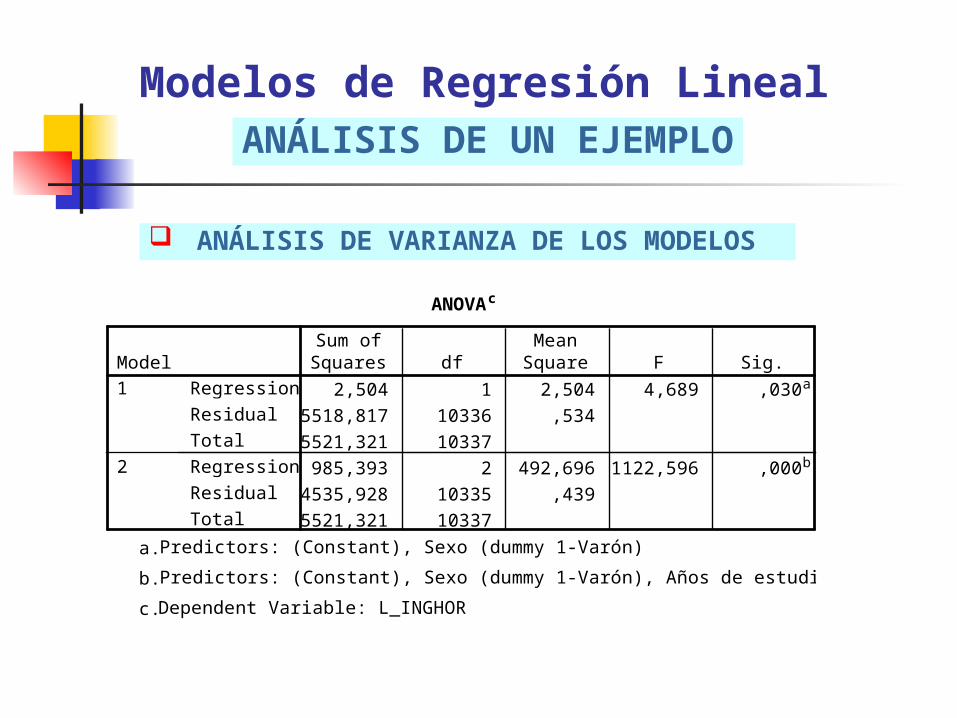
ANÁLISIS DE VARIANZA DE LOS MODELOS
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
ANOVAc
2,504 1 2,504 4,689 ,030a
5518,817 10336 ,534
5521,321 10337
985,393 2 492,696 1122,596 ,000b
4535,928 10335 ,439
5521,321 10337
Regression
Residual
Total
Regression
Residual
Total
Model1
2
Sum ofSquares df
MeanSquare F Sig.
Predictors: (Constant), Sexo (dummy 1-Varón)a.
Predictors: (Constant), Sexo (dummy 1-Varón), Años de estudio (aprox.)b.
Dependent Variable: L_INGHORc.
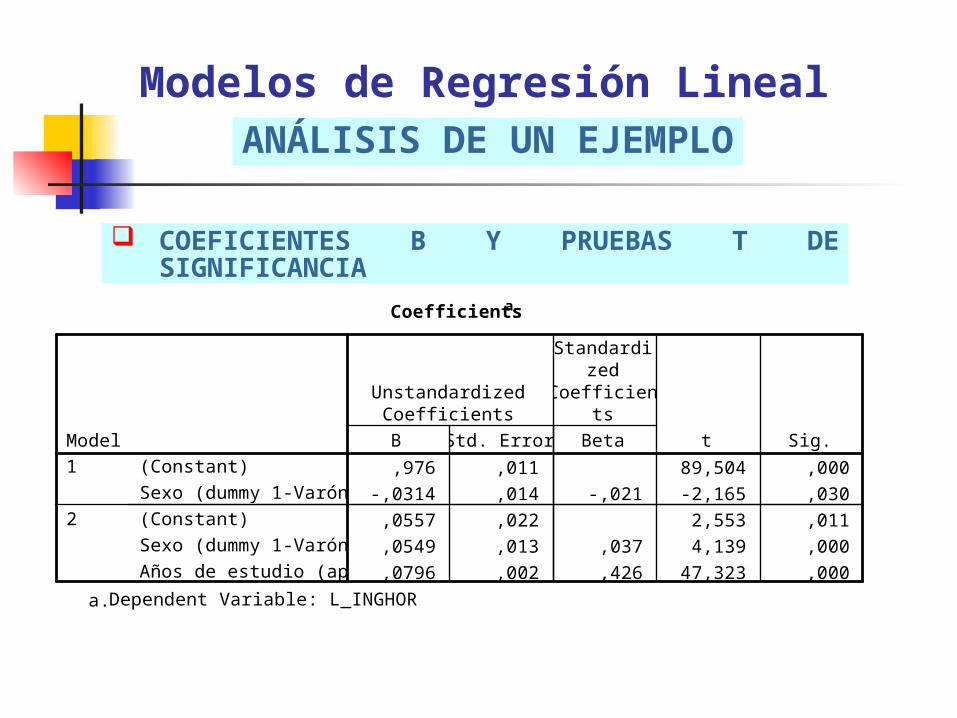
COEFICIENTES B Y PRUEBAS T DE SIGNIFICANCIA
Modelos de Regresión LinealANÁLISIS DE UN EJEMPLO
Coefficientsa
,976 ,011 89,504 ,000
-,0314 ,014 -,021 -2,165 ,030
,0557 ,022 2,553 ,011
,0549 ,013 ,037 4,139 ,000
,0796 ,002 ,426 47,323 ,000
(Constant)
Sexo (dummy 1-Varón)
(Constant)
Sexo (dummy 1-Varón)
Años de estudio (aprox.)
Model1
2
B Std. Error
UnstandardizedCoefficients
Beta
Standardized
Coefficients
t Sig.
Dependent Variable: L_INGHORa.














