Embed Size (px)
Citation preview

Query Optimization, Concludedand Concurrency Control
Zachary G. IvesUniversity of Pennsylvania
CIS 650 – Implementing Data Management Systems
February 2, 2005

2
Administrivia
The next assignment: Read and summarize the ARIES paper,
Sections 1.1, 3-6
Talk by Morgan Stanley: “Information Security Challenges in Financial Services IT” Thursday (tomorrow), 6:30PM, L101 Pizza, plus USB flash drives for 1st 50 students (Mostly interested in recruiting…)

3
Today’s Trivia Question

4
Optimizer Generators
Idea behind EXODUS and Starburst:Build a programming language for writing custom optimizers!
Rule-based or transformational language Describes, using declarative template and conditions,
an equivalent expression
EXODUS: compile an optimizer based on a set of rules
Starburst: run a set of rules in the interpreter; a client could customize the rules

5
Starburst Pros and Cons
Pro: Stratified search generally works well in practice – DB2
UDB has perhaps the best query optimizer out there Interesting model of separating calculus-level and
algebra-level optimizations Generally provides fast performance
Con: Interpreted rules were too slow – and no database user
ever customized the engine! Difficult to assign priorities to transformations Some QGM transformations that were tried were difficult
to assess without running many cost-based optimizations
Rules got out of control

6
The EXODUS and Volcano Optimizer Generators
Part of a “database toolkit” approach to building systems A set of libraries and languages for building
databases with custom data models and functionalities
(rules in “E”)
(EXODUS)
(MyQL) (MyDB plan)
(gcc)

7
EXODUS/Volcano Model
Try to unify the notion of logical-logical transformations and logical-physical transformations No stratification as in Starburst – everything is
transformations Challenge: efficient search – need a lot of
pruning EXODUS: used many heuristics, something called a
MESH Volcano: branch-and-bound pruning, recursion +
memoization

8
Example Rules
Physical operators:%operator 2 join%method 2 hash_join loops_join cartesian_product
Logical-logical transformations:join (1,2) ->’ join(2,1)
Logical-physical transformations:join (1,2) by hash_join (1,2)
Can get quite hairy:join 7 (join 8 (1,2), 3) <-> join 8(1, join 7 (2,3))
{{#ifdef FORWARDif (NOT cover_predicate (OPERATOR_7 oper_argument, INPUT_2 oper_property, INPUT_3 oper_property))
REJECT…
9
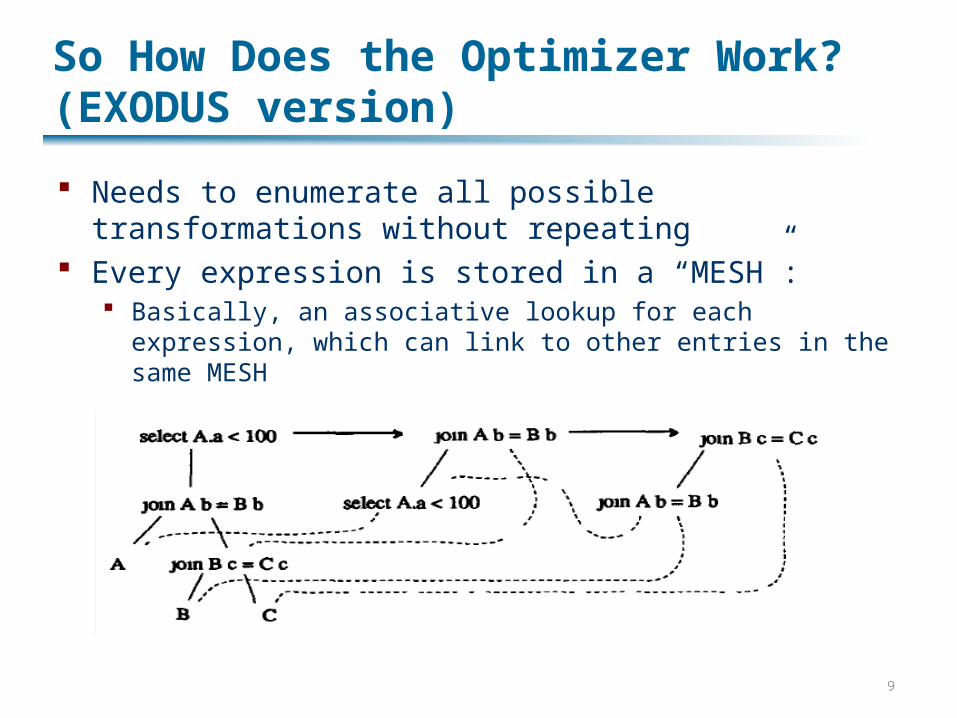
So How Does the Optimizer Work?(EXODUS version)
Needs to enumerate all possible transformations without repeating
Every expression is stored in a “MESH”: Basically, an associative lookup for each expression,
which can link to other entries in the same MESH

10
Search in EXODUS
Apply a transformation, see if it produces a new node If so:
Find cheapest implementation rule Also apply all relevant transformation rules, add results to
OPEN set Propagate revised cost to parents (reanalyze) Check parents for new transformation possibilities (rematch)
Heuristics to guide the search in the OPEN set: “Promise” – an “expected cost factor” for each transformation
rule, based on analysis of averages of the optimizer’s cost model results
Favor items with high expected payoff over the current cost Problem: often need to apply 2 rules to get a benefit; use
heuristics Once a full plan is found, optimizer does hill climbing,
only applying a limited set of rules

11
Pros and Cons of EXODUS Pros:
Unified model of optimization is powerful, elegant Very extensible architecture
Cons: Combined logical and physical expressions in the same MESH
equivalent logical plans with different physical operators (e.g., merge vs. hash joins) were kept twice
Physical properties weren’t handled well sort enforcers were seldom applied since they didn’t pay off
immediately – had to hack them into sort-merge join Hard-coded transformation, then algorithm selection, cost
analysis always applied even if not part of the most promising expression applied based on perceived benefit – biased towards larger
expressions, which meant repeated re-optimization Cost wasn’t very generic a concept

12
Volcano, Successor to EXODUS(Shouldn’t it be LEVITICUS?)
Re-architected into a top-down, memoized engine Depth-first search – allows branch-and-bound pruning
FindBestPlan takes logical expression, physical properties, cost bound: If already computed, return Else compute set of possible “moves”:
Logical-logical rule Compliant logical-physical rule Enforcer
Insert logical expression into lookup table Insert physical op, plan into separate lookup table Return best plan and cost
More generic notions of properties and enforcers (e.g., location, SHIP), cost (an ADT)

13
EXODUS, Revision 3: Cascades
Basically, a cleaner, more object-oriented version of the Volcano engine
Rumor has it that MS SQL Server is currently based on a (simplified and streamlined) version of the Volcano/Cascades optimizer generator

14
Optimization Evaluation
So, which is best? Heuristics plus join-based enumeration
(System-R) Stratified, calculus-then-algebraic (Starburst)
Con: QGM transformations are almost always heuristics-based
Pro: very succinct transformations at QGM level
Unified algebraic (Volcano/Cascades) Con: many more rules need to be applied to get
effect of QGM rewrites Pro: unified, fully cost-based model

15
Switching Gears…
You now know how to build a query-only DBMS, from physical page layout through query optimization
… But what if we want to build an updatable DBMS? The major issues: concurrency (today) and
recovery (next time)

16
Recall the Fundamental Concepts of Updatable DBMSs
ACID properties: atomicity, consistency, isolation, durability
Transactions as atomic units of operation always commit or abort can be terminated and restarted by the DBMS
– an essential property typically logged, as we’ll discuss later
Serializability of schedules

17
Serializability and Concurrent Deposits
Deposit 1 Deposit 2read(X.bal) read(X.bal)X.bal := X.bal + $50 X.bal:= X.bal + $10write(X.bal) write(X.bal)

18
Violations of Serializability
Dirty data: data written by an uncommitted transaction; a dirty read is a read of dirty data (WR conflict)
Unrepeatable read: a transaction reads the same data item twice and gets different values (RW conflict)
Phantom problem: a transaction retrieves a collection of tuples twice and sees different results

19
Two Approaches to Serializability (or other Consistency Models)
Locking – a “pessimistic” strategy First paper (Gray et al.): hierarchical locking,
plus ways of compromising serializability for performance
Optimistic concurrency control Second paper (Kung & Robinson): allow writes
by each session in parallel, then try to substitute them in (or reapply to merge)

20
Locking
A “lock manager” that grants and releases locks on objects
Two basic types of locks: Shared locks (read locks): allow other shared locks to be
granted on the same item Exclusive locks (write locks): do not coexist with any other
locks
Generally granted in two phase locking model: Growing phase: locks are granted Shrinking phase: locks are released (no new locks
granted) Well-formed, two-phase locking guarantees serializability
(Note that deadlocks are possible in this model!)

21
Gray et al.: Granularity of Locks
For performance and concurrency, want different levels of lock granularity, i.e., a hierarchy of locks: database extent table page row attribute
But a problem arises: What if T1 S-locks a row and T2 wants to X-lock a table? How do we easily check whether we should give a lock to
T2?

22
Intention Locks
Two basic types: Intention to Share (IS): a descendant item will be
locked with a share lock Intention Exclusive lock: a descendant item will be
locked with an exclusive lock Locks are granted top-down, released bottom-up
T1 grabs IS lock on table, page; S lock on row T2 can’t get X-lock on table until T1 is done
But T3 can get an IS or S lock on the table

23
Lock Compatibility Matrix
IS IX S SIX X
IS Y Y Y Y N
IX Y Y N N N
S Y N Y N N
SIX Y N N N N
X N N N N N

24
Lock Implementation
Maintain as a hash table based on items to lock Lock/unlock are atomic operations in critical
sections First-come, first-served queue for each locked
object All adjacent, compatible items are a compatible group The group’s mode is the most restrictive of its members
What if a transaction wants to convert (upgrade) its lock? Should we send it to the back of the queue? No – will almost assuredly deadlock! Handle conversions immediately after the current group

25
Degrees of Consistency
Full locking, guaranteeing serializability, is generally very expensive
So they propose several degrees of consistency as a compromise (these are roughly the SQL isolation levels): Degree 0: T doesn’t overwrite dirty data of other
transactions Degree 1: above, plus T does not commit writes before
EOT Degree 2: above, plus T doesn’t read dirty data Degree 3: above, plus other transactions don’t dirty any
data T read

26
Degrees and Locking
Degree 0: short write locks on updated items
Degree 1: long write locks on updated items
Degree 2: long write locks on updated items, short read locks on read items
Degree 3: long write and read locks
Does Degree 3 prevent phantoms? If not, how do we fix this?

27
What If We Don’t Want to Lock?
Conflicts may be very uncommon – so why incur the overhead of locking? Typically hundreds of instructions for every
lock/unlock Examples: read-mostly DBs; large DB with few
collisions; append-mostly; hierarchical data
Proposition – break lock into three phases: Read – and write to private copy of each page (i.e.,
copy-on-write) Validation – make sure no conflicts between
transactions Write – swap the private copies in for the public ones

28
Validation
Goal: guarantee that only serializable schedules result in merging Ti and Tj writes
Approach: find an equivalent serializable schedule: Assign each transaction a number Ensure equivalent serializable schedule as follows:
If TN(Ti) < TN(Tj) then we must satisfy one of:
1. Ti finishes writing before Tj starts reading (serial)
2. WS(Ti) disjoint from RS(Tj) and Ti finishes writing before Tj writes
3. WS(Ti) disjoint from RS(Tj) and WS(Ti) disjoint from WS(Tj), and Ti finishes read phase before Tj completes its read phase

29
Why Does This Work?
Condition 1 – obvious since it’s serial Condition 2:
No W-R conflicts since disjoint In all R-W conflicts, Ti precedes Tj since Ti reads before it
writes (and that’s before Tj)
In all W-W conflicts, Ti precedes Tj
Condition 3: No W-R conflicts since disjoint No W-W conflicts since disjoint In all R-W conflicts, Ti precedes Tj since Ti reads before it
writes (and that’s before Tj)

30
The Achilles Heel
How do we assign TNs? Not optimistically – they get assigned at the
end of read phase Note that we need to maintain all of the read
and write sets for transactions that are going on concurrently – long-lived read phases cause difficulty here Solution: bound buffer, abort and restart
transactions when out of space Drawback: starvation – need to solve by locking the
whole DB!

31
Serial Validation Simple: writes won’t be interleaved, so test
1. Ti finishes writing before Tj starts reading (serial)2. WS(Ti) disjoint from RS(Tj) and Ti finishes writing before Tj
writes Put in critical section:
Get TN Test 1 and 2 for everyone up to TN Write
Long critical section limits parallelism of validation, so can optimize: Outside critical section, get a TN and validate up to there Before write, in critical section, get new TN, validate up to
that, write Reads: no need for TN – just validate up to highest
TN at end of read phase (no critical section)

32
Parallel Validation
For allowing interleaved writes Save active transactions (finished reading, not
writing) Abort if intersect current read/write set Validate:
CRIT: Get TN; copy active set; add self to active set Check (1), (2) against everything from start to finish Check (3) against all active set If OK, write CRIT: Increment TN counter, remove self from active
Drawback: might conflict in condition (3) with someone who gets aborted

33
Who’s the Top Dog?Optimistic vs. Non-Optimistic
Drawbacks of the optimistic approach: Generally requires some sort of global state,
e.g., TN counter If there’s a conflict, requires abort and full
restart
Study by Agrawal et al. comparing optimistic vs. locking: Need load control with low resources Locking is better with moderate resources Optimistic is better with infinite or high
resources

34
Reminder
The next assignment: Read and summarize the ARIES paper,
Sections 1.1, 3-6





























