Embed Size (px)
Citation preview

Psychological ReviewV O L U M E 8 5 N U M B E R 5 S E P T E M B E R 1 9 7 8
Toward a Model of Text Comprehension and Production
Walter KintschUniversity of Colorado
Teun A. van DijkUniversity of Amsterdam,
Amsterdam, The Netherlands
The semantic structure of texts can be described both at the local microleveland at a more global macrolevel. A model for text comprehension based on thisnotion accounts for the formation of a coherent semantic text base in terms ofa cyclical process constrained by limitations of working memory. Furthermore,the model includes macro-operators, whose purpose is to reduce the informationin a text base to its gist, that is, the theoretical macrostructure. These opera-tions are under the control of a schema, which is a theoretical formulation ofthe comprehender's goals. The macroprocesses are predictable only when thecontrol schema can be made explicit. On the production side, the model is con-cerned with the generation of recall and summarization protocols. This processis partly reproductive and partly constructive, involving the inverse operationof the macro-operators. The model is applied to a paragraph from a psycho-logical research report, and methods for the empirical testing of the modelare developed.
The main goal of this article is to describethe system of mental operations that underliethe processes occurring in text comprehensionand in the production of recall and summariza-tion protocols. A processing model will beoutlined that specifies three sets of operations.First, the meaning elements of a text become
This research was supported by Grant MH1S872from the National Institute of Mental Health to thefirst author and by grants from the NetherlandsOrganization for the Advancement of Pure Researchand the Faculty of Letters of the University of Amster-dam to the second author.
We have benefited from many discussions with mem-bers of our laboratories both at Amsterdam andColorado and especially with Ely Kozminsky, who alsoperformed the statistical analyses reported here.
Requests for reprints should be sent to WalterKintsch, Department of Psychology, University ofColorado, Boulder, Colorado 80309.
organized into a coherent whole, a processthat results in multiple processing of someelements and, hence, in differential retention.A second set of operations condenses the fullmeaning of the text into its gist. These pro-cesses are complemented by a third set ofoperations that generate new texts from thememorial consequences of the comprehensionprocesses.
These goals involve a number of more con-crete objectives. We want first to be able togo through a text, sentence by sentence,specifying the processes that these sentencesundergo in comprehension as well as the out-puts of these processes at various stages ofcomprehension. Next, we propose to analyzerecall protocols and summaries in the same wayand to specify for each sentence the operationsrequired to produce such a sentence. The
Copyright 1978 by the American Psychological Association, Inc. 0033-295X/78/8505-0363$00.75
363

364 WALTER KINTSCH AND TEUN A. VAN DIJK
model is, however, not merely descriptive. Itwill yield both simulated output protocolsthat can be qualitatively compared withexperimental protocols and detailed predic-tions of the frequencies with which proposi-tions from the text as well as certain kinds ofinferences about it appear in experimentalprotocols, which can then be tested with con-ventional statistical methods.
LaBerge and Samuels (1974), in their in-fluential article on reading processes, haveremarked that "the complexity of the compre-hension operation appears to be as enormousas that of thinking in general" (p. 320). Aslong as one accepts this viewpoint, it would befoolish to offer a model of comprehensionprocesses. If it were not possible to separateaspects of the total comprehension process forstudy, our enterprise would be futile. Webelieve, however, that the comprehensionprocess can be decomposed into components,some of which may be manageable at present,while others can be put aside until later.
Two very important components will beexcluded from the present model. First, themodel will be concerned only with semanticstructures. A full grammar, including a parser,which is necessary both for the interpretationof input sentences and for the production ofoutput sentences, will not be included. Infact, no such grammar is available now, noris there hope for one in the near future. Hence,the model operates at the level of assumedunderlying semantic structures, which wecharacterize in terms of propositions. Further-more, comprehension always involves knowl-edge use and inference processes. The modeldoes not specify the details of these processes.That is, the model only says when an inferenceoccurs and what it will be; the model does notsay how it is arrived at, nor what preciselywas its knowledge base. Again, this restrictionis necessary because a general theory of in-ference processes is nowhere in sight, and thealternative of restricting the model to a smallbut manageable base has many disadvantages.
Comprehension can be modeled only if weare given a specific goal. In other words, wemust know the control processes involved incomprehension. Frequently, these are illspecified, and thus we must select cases wherewell-defined control processes do exist, prefer-
ably ones that are shared by many readers inorder to make feasible the collection of mean-ingful data. Hence, we shall emphasize theprocessing of certain conventional text types,such as stories.
Comprehension is involved in reading as wellas in listening, and our model applies to both.Indeed, the main differences between readingand listening occur at levels lower than theones we are concerned with (e.g., Kintsch &Kozminsky, 1977; Sticht, in press). We aretalking here, of course, about readers for whomthe decoding process has become automated,but the model also has implications for readerswho still must devote substantial resources todecoding.
One of the characteristics of the presentmodel is that it assumes a multiplicity ofprocesses occurring sometimes in parallel,sometimes sequentially. The fact that, phe-nomenologically, comprehension is a verysimple experience does not disprove this no-tion of multiple, overlapping processes. Per-ception is likewise a unitary, direct experience;but when its mechanisms are analyzed at thephysiological and psychological levels, theyare found to consist of numerous interactingsubprocesses that run off rapidly and withvery little mutual interference. Resourcesseem to be required only as attention, con-sciousness, decisions, and memory becomeinvolved; it is here that the well-knowncapacity limitations of the human systemseem to be located rather than in the actualprocessing. Thus, in the comprehension modelpresented below, we assume several complexprocesses operating in parallel and interactivelywithout straining the resources of the system.Capacity limitations become crucial, however,when it comes to the storage of information inmemory and response production. That sucha system is very complex should not in itselfmake it implausible as an account of compre-hension processes.
The organization of this article is as follows.First, the semantic structure of texts, includ-ing their macrostructure, is discussed briefly,mainly with reference to our previous work.Then, a psychological processing model isdescribed that is based on these ideas abouttext structure. While related, the functions ofthese two enterprises are rather different. The

TEXT COMPREHENSION AND PRODUCTION 365
structural theory is a semiformal statementof certain linguistic intuitions, while the pro-cessing model attempts to predict the contentsof experimental protocols. Therefore, theymust be evaluated in rather different ways.Finally, some preliminary applications andtests of the processing model are described,and some linguistic considerations are raisedthat may guide future extensions of it.
Semantic Structures
We assume that the surface structure of adiscourse is interpreted as a set of proposi-tions. This set is ordered by various semanticrelations among the propositions. Some of theserelations are explicitly expressed in the surfacestructure of the discourse; others are inferredduring the process of interpretation with thehelp of various kinds of context-specific orgeneral knowledge.
The semantic structure of a discourse ischaracterized at two levels, namely, at thelevels of microstructure and of macrostructure.The microstructure is the local level of thediscourse, that is, the structure of the in-dividual propositions and their relations. Themacrostructure is of a more global nature,characterizing the discourse as a whole. Theselevels are related by a set of specific semanticmapping rules, the macrorules. At both levels,we provide an account of the intuitive notionof the coherence of a discourse: A discourse iscoherent only if its respective sentences andpropositions are connected, and if thesepropositions are organized globally at themacrostructure level.
Microstructure of Discourse
In our earlier work (Kintsch, 1974; vanDijk, 1972,1977d), we attempted to character-ize the semantic structure of a discourse interms of an abstract text base. The presentarticle will shift attention to the more specificproperties of comprehension, that is, to theways a language understander actually con-structs such a text base.
Text bases are not merely unrelated listsof propositions; they are coherent, structuredunits. One way to assign a structure to a textbase may be derived from its referential
coherence: We establish a linear or hierarchicalsequence of propositions in which coreferentialexpressions occur. The first (or superordinate)of these propositions often appears to have aspecific cognitive status in such a sequence,being recalled two or three times more oftenthan other propositions (see Kintsch, 1974).Clearly, a processing model must account forthe superior recall of propositions that func-tion as superordinates in the text-basestructure.
Inferences
Natural language discourse may be con-nected even if the propositions expressed by thediscourse are not directly connected. Thispossibility is due to the fact that languageusers are able to provide, during comprehen-sion, the missing links of a sequence on thebasis of their general or contextual knowledgeof the facts. In other words, the facts, asknown, allow them to make inferences aboutpossible, likely, or necessary other facts and tointerpolate missing propositions that may makethe sequence coherent. Given the generalpragmatic postulate that we do not normallyassert what we assume to be known by thelistener, a speaker may leave all propositionsimplicit that can be provided by the listener.An actual discourse, therefore, normally ex-presses what may be called an implicit textbase. An explicit text base, then, is a theoreticalconstruct featuring also those propositionsnecessary to establish formal coherence. Thismeans that only those propositions are inter-polated that are interpretation conditions, forexample, presuppositions of other propositionsexpressed by the discourse.
Macrostructure of Discourse
The semantic structure of discourse must bedescribed not only at the local microlevel butalso at the more global macrolevel. Besidesthe purely psychological motivation for thisapproach, which will become apparent belowin our description of the processing model,the theoretical and linguistic reasons for thislevel of description derive from the fact thatthe propositions of a text base must be con-nected relative to what is intuitively called a

366 WALTER KINTSCH AND TEUN A. VAN DIJK
topic of discourse (or a topic of conversation),that is, the theme of the discourse or a fragmentthereof. Relating propositions in a local manneris not sufficient. There must be a global con-straint that establishes a meaningful whole,characterized in terms of a discourse topic.
The notion of a discourse topic can be madeexplicit in terms of semantic macrostructures.Like other semantic structures, these macro-structures are described in terms of proposi-tions and proposition sequences. In order toshow how a discourse topic is related to therespective propositions of the text base, wethus need semantic mapping rules with micro-structural information as input and macro-structural information as output. Such macro-rules, as we call them, both reduce andorganize the more detailed information of themicrostructure of the text. They describe thesame facts but from a more global point ofview. This means, for instance, that we mayhave several levels of macrostructure; macro-rules may apply recursively on sequences ofmacropropositions as long as the constraintson the rules are satisfied.
The general abstract nature of the macro-rules is based on the relation of semantic en-tailment. That is, they preserve both truthand meaning: A macrostructure must be im-plied by the (explicit) microstructure fromwhich it is derived. Note that in actual pro-cessing, as we will see, macrostructures mayalso be inferred on the basis of incompleteinformation.
The basic constraint of the macrorules isthat no proposition may be deleted that is aninterpretation condition of a following proposi-tion of the text. In fact, this also guaranteesthat a macrostructure itself is connected andcoherent.
A formal description of the macrorules willnot be given here. We shall merely mentionthem briefly in an informal way (for details,see van Dijk, 1977b, 1977d).
1. Deletion. Each proposition that isneither a direct nor an indirect interpretationcondition of a subsequent proposition may bedeleted.
2. Generalization. Each sequence of propo-sitions may be substituted by the generalproposition denoting an immediate superset.
3. Construction. Each sequence of proposi-
tions may be substituted by a proposition de-noting a global fact of which the facts denotedby the microstructure propositions are normalconditions, components, or consequences.
The macrorules are applied under the con-trol of a schema, which constrains their opera-tion so that macrostructures do not becomevirtually meaningless abstractions or general-izations.
Just as general information is needed toestablish connection and coherence at themicrostructural level, world knowledge is alsorequired for the operation of macrorules. Thisis particularly obvious in Rule 3, where ourframe knowledge (Minsky, 1975) specifieswhich facts belong conventionally to a moreglobal fact, for example, "paying" as a normalcomponent of both "shopping" and "eating ina restaurant" (cf. Bobrow & Collins, 1975).
Schematic Structures of Discourse
Typical examples of conventional schematicstructures of discourse are the structure of astory, the structure of an argument, or thestructure of a psychological report. Thesestructures are specified by a set of character-istic categories and a set of (sometimes re-cursive) rules of formation and transforma-tion defining the canonical and possible order-ing of the categories (e.g., van Dijk, 1976,in press).
Schematic structures play an important rolein discourse comprehension and production.Without them, we would not be able to explainwhy language users are able to understand adiscourse as a story, or why they are able tojudge whether a story or an argument is cor-rect or not. More specifically, we must beable to explain why a free-recall protocol or asummary of a story also has a narrativestructure, or why the global structure of apsychological paper is often conserved in itsabstract (cf. Kintsch & van Dijk, 1975; vanDijk & Kintsch, 1977). Furthermore, schematicstructures play an important control functionin the processing model to be described below,where they are used not only in connection withconventional texts but also to representidiosyncratic personal processing goals. Theapplication of the macrorules depends ,onwhether a given proposition is or is not judged

TEXT COMPREHENSION AND PRODUCTION 367
to be relevant in its context, with the schemaspecifying the kind of information that is to beconsidered relevant for a particular compre-hension task.
Process Model
Forming Coherent Text Bases
The model takes as its input a list of pro-positions that represent the meaning of a text.The derivation of this proposition list from thetext is not part of the model. It has been de-scribed and justified in Kintsch (1974) andfurther codified by Turner and Greene (inpress). With some practice, persons using thissystem arrive at essentially identical pro-positional representations, in our experience.Thus, the system is simple to use; and whileit is undoubtedly too simple to capture nuancesof meaning that are crucial for some linguisticand logical analyses, its robustness is wellsuited for a process model. Most important,this notation can be translated into othersystems quite readily. For instance, one couldtranslate the present text bases into thegraphical notation of Norman and Rumelhart(1975), though the result would be quitecumbersome, or into a somewhat more sophisti-cated notation modeled after the predicatecalculus, which employs atomic propositions,variables, and constants (as used in van Dijk,1973). Indeed, the latter notation mayeventually prove to be more suitable. Theimportant point to note is simply that al-though some adequate notational system forthe representation of meaning is required, thedetails of that system often are not crucialfor our model.
Prepositional Notation
The prepositional notation employed belowwill be outlined here only in the briefest possibleway. The idea is to represent the meaning ofa text by means of a structured list of proposi-tions. Propositions are composed of concepts(the names of which we shall write in capitalletters, so that they will not be confused withwords). The composition rule states that eachproposition must include first a predicate, orrelational concept, and one or more arguments.
The latter may be concepts or other embeddedpropositions. The arguments of a propositionfulfill different semantic functions, such asagent, object, and goal. Predicates may berealized in the surface structure as verbs,adjectives, adverbs, and sentence connectives.Each predicate constrains the nature of theargument that it may take. These constraintsare imposed both by linguistic rules and generalworld knowledge and are assumed to be apart of a person's knowledge or semanticmemory.
Propositions are ordered in the text baseaccording to the way in which they are ex-pressed in the text itself. Specifically, theirorder is determined by the order of the wordsin the text that correspond to the preposi-tional predicates.
Text bases must be coherent. One of thelinguistic criteria for the semantic coherenceof a text base is referential coherence. In termsof the present notational system, referentialcoherence corresponds to argument overlapamong propositions. Specifically, (P, A, B) isreferentially coherent with (R, B, C) becausethe two propositions share the argument B,or with (Q, D, (P, A, B)) because one proposi-tion is embedded here as an argument intoanother. Referential coherence is probably themost important single criterion for the co-herence of text bases. It is neither a necessarynor a sufficient criterion linguistically. How-ever, the fact that in many texts other factorstend to be correlated with it makes it a usefulindicator of coherence that can be checkedeasily, quickly, and reliably. We therefore pro-pose the following hypothesis about textprocessing: The first step in forming a coherenttext base consists in checking out its referentialcoherence; if a text base is found to be refer-entially coherent, that is, if there is someargument overlap among all of its propositions,it is accepted for further processing; if gapsare found, inference processes are initiated toclose them; specifically, one or more proposi-tions will be added to the text base that makeit coherent. Note that in both cases, the argu-ment-referent repetition rule also holds forarguments consisting of a proposition, therebyestablishing relations not only between in-dividuals but also between facts denoted bypropositions.

368 WALTER KINTSCH AND TEUN A. VAN DIJK
Processing Cycles
The second major assumption is that thischecking of the text base for referential co-herence and the addition of inferences wherevernecessary cannot be performed on the textbase as a whole because of the capacitylimitations of working memory. We assumethat a text is processed sequentially from left toright (or, for auditory inputs, in temporalorder) in chunks of several propositions at atime. Since the proposition lists of a text baseare ordered according to their appearance inthe text, this means that the first n\ proposi-tions are processed together in one cycle, thenthe next «2 propositions, and so on. It is un-reasonable to assume that all M»S are equal.Instead, for a given text and a given compre-hender, the maximum w, will be specified.Within this limitation, the precise number ofpropositions included in a processing chunkdepends on the surface characteristics of thetext. There is ample evidence (e.g., Aaronson& Scarborough, 1977; Jarvella, 1971) thatsentence and phrase boundaries determine thechunking of a text in short-term memory. Themaximum value of w», on the other hand, is amodel parameter, depending on text as wellas reader characteristics.1
If text bases are processed in cycles, it be-comes necessary to make some provision inthe model for connecting each chunk to theones already processed. The following assump-tions are made. Part of working memory is ashort-term memory buffer of limited size s.When a chunk of n( propositions is processed,s of them are selected and stored in the buffer.2
Only those s propositions retained in the bufferare available for connecting the new incomingchunk with the already processed material. Ifa connection is found between any of the newpropositions and those retained in the buffer,that is, if there exists some argument overlapbetween the input set and the contents of theshort-term memory buffer, the input isaccepted as coherent with the previous text.If not, a resource-consuming search of allpreviously processed propositions is made. Inauditory comprehension, this search rangesover all text propositions stored in long-termmemory. (The storage assumptions are detailedbelow.) In reading comprehension, the searchincludes all previous propositions because even
those propositions not available from long-term memory can be located by re-reading thetext itself. Clearly, we are assuming here areader who processes all available information;deviant cases will be discussed later.
If this search process is successful, that is, ifa proposition is found that shares an argumentwith at least one proposition in the input set,the set is accepted and processing continues.If not, an inference process is initiated, whichadds to the text base one or more propositionsthat connect the input set to the already pro-cessed propositions. Again, we are assuminghere a comprehender who fully processes thetext. Inferences, like long-term memorysearches, are assumed to make relativelyheavy demands on the comprehender's re-sources and, hence, contribute significantly tothe difficulty of comprehension.
Coherence Graphs
In this manner, the model proceeds throughthe whole text, constructing a network ofcoherent propositions. It is often useful torepresent this network as a graph, the nodesof which are propositions and the connectinglines indicating shared referents. The graphcan be arranged in levels by selecting thatproposition for the top level that results inthe simplest graph structure (in terms of somesuitable measure of graph complexity). Thesecond level in the graph is then formed by allthe propositions connected to the top level;propositions that are connected to any proposi-
1 Presumably, a speaker employs surface cues tosignal to the comprehender an appropriate chunk size.Thus, a good speaker attempts to place his or hersentence boundaries in such a way that the listener canuse them effectively for chunking purposes. If aspeaker-listener mismatch occurs in this respect, com-prehension problems arise because the listener cannotuse the most obvious cues provided and must rely onharder-to-use secondary indicators of chunk boundaries.One may speculate that sentence grammars evolvedbecause of the capacity limitations of the humancognitive system, that is, from a need to packageinformation in chunks of suitable size for a cyclicalcomprehension process.
2 Sometimes a speaker does not entrust the listenerwith this selection process and begins each new sentenceby repeating a crucial phrase from the old one. Indeed,in some languages such "backreference" is obligatory(Longacre & Levinsohn, 1977).

TEXT COMPREHENSION AND PRODUCTION 369
tion at the second level, but not to the first-level proposition, then form the third level.Lower levels may be constructed similarly.For convenience, in drawing such graphs, onlyconnections between levels, not within levels,are indicated. In case of multiple between-level connections, we arbitrarily indicate onlyone (the first one established in the processingorder). Thus, each set of propositions, depend-ing on its pattern of interconnections, can beassigned a unique graph structure.
The topmost propositions in this kind ofcoherence graph may represent presuppositionsof their subordinate propositions due to thefact that they introduce relevant discoursereferents, where presuppositions are importantfor the contextual interpretation and hence fordiscourse coherence, and where the number ofsubordinates may point to a macrostructuralrole of such presupposed propositions. Notethat the procedure is strictly formal: There isno claim that topmost propositions are alwaysmost important or relevant in a more intuitivesense. That will be taken care of with themacro-operations described below.
A coherent text base is therefore a con-nected graph. Of course, if the long-termmemory searches and inference processesrequired by the model are not executed, theresulting text base will be incoherent, that is,the graph will consist of several separateclusters. In the experimental situations we areconcerned with, where the subjects read thetext rather carefully, it is usually reasonableto assume that coherent text bases areestablished.
To review, so far we have assumed a cyclicalprocess that checks on the argument overlapin the proposition list. This process is auto-matic, that is, it has low resource require-ments. In each cycle, certain propositions areretained in a short-term buffer to be connectedwith the input set of the next cycle. If no con-nections are found, resource-consuming searchand inference operations are required.
Memory Storage
In each processing cycle, there are »,-propositions involved, plus the s propositionsheld over in the short-term buffer. It isassumed that in each cycle, the propositions
currently being processed may be stored inlong-term memory and later reproduced in arecall or summarization task, each with proba-bility p. This probability p is called thereproduction probability because it combinesboth storage and retrieval information. Thus,for the same comprehension conditions, thevalue of p may vary depending on whetherthe subject's task is recall or summarizationor on the length of the retention interval. Weare merely saying that for some comprehen-sion-production combination, a proposition isreproduced with probability p for each time ithas participated in a processing cycle. Since ateach cycle a subset of s propositions is selectedand held over to the next processing cycle,some propositions will participate in more thanone processing cycle and, hence, will havehigher reproduction probabilities. Specifically,if a proposition is selected k — 1 times forinclusion in the short-term memory buffer, ithas k chances of being stored in long-termmemory, and hence, its reproduction proba-bility will be 1 - (1 - p)k.
Which propositions of a text base will bethus favored by multiple processing dependscrucially on the nature of the process thatselects the propositions to be held over fromone processing cycle to the next. Variousstrategies may be employed. For instance, the5 buffer propositions may be chosen at random.Clearly, such a strategy would be less thanoptimal and result in unnecessary long-termmemory searches and, hence, in poor readingperformance. It is not possible at this time tospecify a unique optimal strategy. However,there are two considerations that probablycharacterize good strategies. First, a goodstrategy should select propositions for thebuffer that are important, in the sense thatthey play an important role in the graphalready constructed. A proposition that isalready connected to many other propositionsis more likely to be relevant to the next inputcycle than a proposition that has played a lesspivotal role so far. Thus, propositions at thetop levels of the graph to which many othersare connected should be selected preferentially.Another reasonable consideration involvesrecency. If one must choose between twoequally important propositions in the senseoutlined above, the more recent one might be

370 WALTER KINTSCH AND TEUN A. VAN DIJK
expected to be the one most relevant to thenext input cycle. Unfortunately, these con-siderations do not specify a unique selectionstrategy but a whole family of such strategies.In the example discussed in the next section,a particular example of such a strategy will beexplored in detail, not because we have anyreason to believe that it is better than somealternatives, but to show that each strategyleads to empirically testable consequences.Hence, which strategy is predominantly usedin a given population of subjects becomes anempirically decidable issue because eachstrategy specifies a somewhat differentpattern of reproduction probabilities over thepropositions of a text base. Experimentalresults may be such that only one particularselection strategy can account for them, orperhaps we shall not be able to discriminateamong a class of reasonable selection strategieson the basis of empirical frequency distribu-tions. In either case, we shall have the in-formation the model requires.
It is already clear that a random selectionstrategy will not account for paragraph recalldata, and that some selection strategy in-corporating an "importance" principle is re-quired. The evidence comes from work onwhat has been termed the "levels effect"(Kintsch & Keenan, 1973; Kintsch et al.,1975; Meyer, 1975). It has been observed thatpropositions belonging to high levels of a text-base hierarchy are much better recalled (bya factor of two or three) than propositions lowin the hierarchy. The text-base hierarchies inthese studies were constructed as follows. Thetopical proposition or propositions of aparagraph (as determined by its title orotherwise by intuition) were selected as thetop level of the hierarchy, and all thosepropositions connected to them via argumentoverlap were determined, forming the nextlevel of the hierarchy, and so on. Thus, thesehierarchies were based on referential coherence,that is, arguments overlap among proposi-tions. In fact, the propositional networksconstructed here are identical with thesehierarchies, except for changes introduced bythe fact that in the present model, coherencegraphs are constructed cycle by cycle.
Note that the present model suggests aninteresting reinterpretation of this levels effect.
Suppose that the selection strategy, as dis-cussed above, is indeed biased in favor ofimportant, that is, high-level propositions.Then, such propositions will, on the average,be processed more frequently than low-levelpropositions and recalled better. The betterrecall of high-level propositions can then beexplained because they are processed dif-ferently than low-level propositions. Thus,we are now able to add a processing explana-tion to our previous account of levels effects,which was merely in terms of a correlationbetween some structural aspects of texts andrecall probabilities.
Although we have been concerned here onlywith the organization of the micropropositions,one should not forget that other processes,such as macro-operations, are going on at thesame time, and that therefore the buffer mustcontain the information about macroproposi-tions and presuppositions that is required toestablish the global coherence of the dis-course. One could extend the model in thatdirection. Instead, it appears to us worth-while to study these various processing com-ponents in isolation, in order to reduce thecomplexity of our problem to manageableproportions. We shall remark on the feasibilityof this research strategy below.
Testing the Model
The frequencies with which different textpropositions are recalled provide the majorpossibility for testing the model experi-mentally. It is possible to obtain good esti-mates of such frequencies for a given popula-tion of readers and texts. Then, the best-fitting model can be determined by varyingthe three parameters of the model—n, themaximum input size per cycle; s, the capacityof the short-term buffer; and p, the reproduc-tion probability—at the same time exploringdifferent selection strategies. Thus, whichselection strategy is used by a given popula-tion of readers and for a given type of textbecomes decidable empirically. For instance,in the example described below, a selectionstrategy has been assumed that emphasizesrecency and frequency (the "leading-edge"strategy). It is conceivable that for collegestudents reading texts rather carefully underlaboratory conditions, a fairly sophisticated

TEXT COMPREHENSION AND PRODUCTION 371
strategy like this might actually be used (i.e.,it would lead to fits of the model detectablybetter than alternative assumptions). At thesame time, different selection strategies mightbe used in other reader populations or underdifferent reading conditions. It would beworthwhile to investigate whether there arestrategy differences between good and poorreaders, for instance.
If the model is successful, the values of theparameters s, n, and p, and their dependenceon text and reader characteristics might alsoprove to be informative. A number of factorsmight influence s, the short-term memorycapacity. Individuals differ in their short-termmemory capacity. Perfetti and Goldman(1976), for example, have shown that goodreaders are capable of holding more of a textin short-term memory than poor readers. Atthe same time, good and poor readers did notdiffer on a conventional memory-span test.Thus, the differences observed in the readingtask may not be due to capacity differencesper se. Instead, they could be related to theobservation of Hunt, Lunneborg, and Lewis(1975) that persons with low verbal abilitiesare slower in accessing information in short-term memory. According to the model, acomprehender continually tests input proposi-tions against the contents of the short-termbuffer; even a slight decrease in the speedwith which these individual operations areperformed would result in a noticeable de-terioration in performance. In effect, loweringthe speed of scanning and matching operationswould have the same effect as decreasing thecapacity of the buffer.
The buffer capacity may also depend on thedifficulty of the text, however, or more pre-cisely, on how difficult particular readers finda text. Presumably, the size of the bufferdepends, within some limits, on the amount ofresources that must be devoted to other as-pects of processing (perceptual decoding, syn-tactic-semantic analyses, inference generation,and the macro-operations discussed below).The greater the automaticity of these processesand the fewer inferences required, the largerthe buffer a reader has to operate with.Certainly, familiarity should have a pro-nounced effect on n, the number of propositionsaccepted per cycle. The process of construct-
ing a text base is perhaps best described asapperception. That is, a reader's knowledgedetermines to a large extent the meaning thathe or she derives from a text. If the knowledgebase is lacking, the reader will not be able toderive the same meaning that a person withadequate knowledge, reading the same text,would obtain. Unfamiliar material would haveto be processed in smaller chunks than familiarmaterial, and hence, n should be directlyrelated to familiarity. No experimental testsof this prediction appear to exist at present.However, other factors, too, might influence n.Since it is determined by the surface form of thetext, increasing the complexity of the surfaceform while leaving the underlying meaningintact ought to decrease the size of the pro-cessing chunks. Again, no data are presentlyavailable, though Kintsch and Monk (1972)and King and Greeno (1974) have reportedthat such manipulations affect reading times.
Finally, the third parameter of the model,p, would also be expected to depend on famili-arity for much the same reasons as s: Themore familiar a text, the fewer resources arerequired for other aspects of processing, andthe more resources are available to storeindividual propositions in memory. The valueof p should, however, depend above all on thetask demands that govern the comprehensionprocess as well as the later production process.If a long text is read with attention focusedmainly on gist comprehension, the probabilityof storing individual propositions of the textbase should be considerably lower than whena short paragraph is read with immediate recallinstructions. Similarly, when summarizing atext, the value of p should be lower than inrecall because individual micropropositions aregiven less weight in a summary relative tomacropropositions.
Note that in a model like the present one,such factors as familiarity may have rathercomplex effects. Not only can familiar materialbe processed in larger chunks and retainedmore efficiently in the memory buffer; if atopic is unfamiliar, there will be no frame avail-able to organize and interpret a given proposi-tion sequence (e.g., for the purpose of generat-ing inferences from it), so readers might con-tinue to pick up new propositions in the hopeof finding information that may organize what

372 WALTER KINTSCH AND TEUN A. VAN DIJK
they already hold in their buffer. If, however,the crucial piece of information fails to arrive,the working memory will be quickly overloadedand incomprehension will result. Thus, famili-arity may have effects on comprehension notonly at the level of processing considered here(the construction of a coherent text base) butalso at higher processing levels.
Readability
The model's predictions are relevant notonly for recall but also for the readability oftexts. This aspect of the model has been ex-plored by Kintsch and Vipond (1978) and willbe only briefly summarized here. It was notedthere that conventional accounts of readabilityhave certain shortcomings, in part becausethey do not concern themselves with theorganization of long texts, which might beexpected to be important for the ease ofdifficulty with which a text can be compre-hended. The present model makes some pre-dictions about readability that go beyond theaetraditional accounts. Comprehension in thenormal case is a fully automatic process, thatis, it makes low demands on resources. Some-times, however, these normal processes areblocked, for instance, when a reader mustretrieve a referent no longer available in his orher working memory, which is done almostconsciously, requiring considerable processingresources. One can simulate the comprehen-sion process according to the model and deter-mine the number of resource-consuming opera-tions in this process, that is, the number oflong-term memory searches required and thenumber of inferences required. The assumptionwas made that each one of these operationsdisrupts the automatic comprehension pro-cesses and adds to the difficulty of reading.On the other hand, if these operations arenot performed by a reader, the representationof the text that this reader arrives at will beincoherent. Hence, the retrieval of the textbase and all performance depending on itsretrieval (such as recall, summarizing, orquestion answering) will be poor. Texts re-quiring many operations that make high de-mands on resources should yield either in-creased reading times or low scores on com-prehension tests. Comprehension, therefore,
must be evaluated in a way that considersboth comprehension time and test perfor-mance because of the trade-off between thetwo. Only measures such as reading time perproposition recalled (used in Kintsch et al.,1975) or reading speed adjusted for compre-hension (suggested by Jackson & McClelland,1975) can therefore be considered adequatemeasures of comprehension difficulty.
The factors related to readability in themodel depend, of course, on the input sizeper cycle («) and the short-term memorycapacity (s) that are assumed. In addition,they depend on the nature of the selectionstrategy used, since that determines whichpropositions in each cycle are retained in theshort-term buffer to be interconnected withthe next set of input propositions. A readerwith a poor selection strategy and a smallbuffer, reading unfamiliar material, mighthave all kinds of problems with a text thatwould be highly readable for a good reader.Thus, readability cannot be considered aproperty of texts alone, but one of the text-reader interaction. Indeed, some preliminaryanalyses reported by Kintsch and Vipond(1978) show that the readability of some textschanges a great deal as a function of the short-term memory capacity and the size of inputchunks: Some texts were hard for all param-eter combinations that were explored; otherswere easy in every case; still others could beprocessed by the model easily when short-termmemory and input chunks were large, yetbecame very difficult for small values of theseparameters.
Macrostructure of a Text
Macro-operators transform the propositionsof a text base into a set of macropropositionsthat represent the gist of the text. They do soby deleting or generalizing all propositionsthat are either irrelevant or redundant and byconstructing new inferred propositions. "De-lete" here does not mean "delete from memory"but "delete from the macrostructure." Thus,a given text proposition—a microproposition—may be deleted from the text's macrostructurebut, nevertheless, be stored in memory andsubsequently recalled as a microproposition.

TEXT COMPREHENSION AND PRODUCTION 373
Role of the Schema
The reader's goals in reading control theapplication of the macro-operators. The formalrepresentation of these goals is the schema.The schema determines which microproposi-tions or generalizations of micropropositionsare relevant and, thus, which parts of the textwill form its gist.
It is assumed that text comprehension isalways controlled by a specific schema. How-ever, in some situations, the controlling schemamay not be detailed, nor predictable. If areader's goals are vague, and the text that heor she reads lacks a conventional structure,different schemata might be set up by dif-ferent readers, essentially in an unpredictablemanner. In such cases, the macro-operationswould also be unpredictable. Research on com-prehension must concentrate on those caseswhere texts are read with clear goals that areshared among readers. Two kinds of situationsqualify in this respect. First of all, there area number of highly conventionalized texttypes. If a reader processes such texts in ac-cordance with their conventional nature,specific well-defined schemata are obtained.These are shared by the members of a givencultural group and, hence, are highly suitablefor research purposes. Familiar examples ofsuch texts are stories (e.g., Kintsch & van Dijk,1975) and psychological research reports(Kintsch, 1974). These schemata specifyboth the schematic categories of the texts (e.g.,a research report is supposed to containintroduction, method, results, and discussionsections), as well as what information in eachsection is relevant to the macrostructure (e.g.,the introduction of a research report mustspecify the purpose of the study). Predictionsabout the macrostructure of such texts re-quire a thorough understanding of the natureof their schemata. Following the lead ofanthropologists (e.g., Colby, 1973) and lin-guists (e.g., Labov & Waletzky, 1967), psy-chologists have so far given the most attentionto story schemata, in part within the presentframework (Kintsch, 1977; Kintsch & Greene,1978; Poulsen, Kintsch, Kintsch, & Premack,in press; van Dijk, 1977b) and in part withinthe related' 'story grammar" approach (Mand-ler & Johnson, 1977; Rumelhart, 1975; Stein& Glenn, in press).
A second type of reading situation wherewell-defined schemata exist comprises thosecases where one reads with a special purposein mind. For instance, Hayes, Waterman, andRobinson (1977) have studied the relevancejudgments of subjects who read a text with aspecific problem-solving set. It is not necessarythat the text be conventionally structured.Indeed, the special purpose overrides whatevertext structure there is. For instance, one mayread a story with the processing controllednot by the usual story schema but by somespecial-purpose schema established by taskinstructions, special interests, or the like.Thus, Decameron stories may be read not forthe plot and the interesting events but be-cause of concern with the role of women infourteenth-century Italy or with the attitudesof the characters in the story toward moralityand sin.
There are many situations where compre-hension processes are similarly controlled. Asone final example, consider the case of readingthe review of a play with the purpose of de-ciding whether or not to go to that play.What is important in a play for the particularreader serves as a schema controlling the gistformation: There are open slots in this schema,each one standing for a property of plays thatthis reader finds important, positively ornegatively, and the reader will try to fill theseslots from the information provided in thereview. Certain propositions in the text baseof the review will be marked as relevant andassigned to one of these slots, while others willbe disregarded. If thereby not all slots arefilled, inference processes will take over, andan attempt will be made to fill in the missinginformation by applying available knowledgeframes to the information presented directly.Thus, while the macro-operations themselvesare always information reducing, the macro-structure may also contain information notdirectly represented in the original text base,when such information is required by the con-trolling schema. If the introduction to a re-search report does not contain a statement ofthe study's purpose, one will be inferred ac-cording to the present model.
In many cases, of course, people readloosely structured texts with no clear goalsin mind. The outcome of such comprehension

374 WALTER KINTSCH AND TEUN A. VAN DIJK
processes, as far as the resulting macrostruc-ture is concerned, is indeterminate. We believe,however, that this is not a failure of the model:If the schema that controls the macro-opera-tions is not well denned, the outcome will behaphazard, and we would argue that noscientific theory, in principle, can predict it.
Macro-operators
The schema thus classifies all propositionsof a text base as either relevant or irrelevant.Some of these propositions have generaliza-tions or constructions that are also classifiedin the same way. In the absence of a generaltheory of knowledge, whether a microproposi-tion is generalizable in its particular context orcan be replaced by a construction must bedecided on the basis of intuition at present.Each microproposition may thus be eitherdeleted from the macrostructure or included inthe macrostructure as is, or its generalizationor construction may be included in the macro-structure. A proposition or its generalization/construction that is included in the macro-structure is called a macroproposition. Thus,some propositions may be both micro- andmacropropositions (when they are relevant);irrelevant propositions are only microproposi-tions, and generalizations and constructionsare only macropropositions.3
The macro-operations are performed proba-bilistically. Specifically, irrelevant micropro-positions never become macropropositions.But, if such propositions have generalizationsor constructions, their generalizations or con-structions may become macropropositions,with probability g when they, too, are ir-relevant, and with probability m when theyare relevant. Relevant micropropositions be-come macropropositions with probability m;if they have generalizations or constructions,these are included in the macrostructure, alsowith probability m. The parameters m and gare reproduction probabilities, just as p in theprevious section: They depend on both storageand retrieval conditions. Thus, m may besmall because the reading conditions did notencourage macroprocessing (e.g., only a shortparagraph was read, with the expectation ofan immediate recall test) or because the pro-duction was delayed for such a long time that
even the macropropositions have beenforgotten.
Macrostructures are hierarchical, and hence,macro-operations are applied in several cycles,with more and more stringent criteria of rele-vance. At the lowest level of the macro-structure, relatively many propositions areselected as relevant by the controlling schemaand the macro-operations are performed ac-cordingly. At the next level, stricter criteriafor relevance are assumed, so that only someof the first-level macropropositions are re-tained as second-level macropropositions. Atsubsequent levels, the criterion is strengthenedfurther until only a single macroproposition(essentially a title for that text unit) remains.A macroproposition that was selected asrelevant at k levels of the hierarchy has there-fore a reproduction probability of 1— (1 —m)*,which is the probability that at least one of thek times that this proposition was processedresults in a successful reproduction.
Production
Recall or summarization protocols obtainedin experiments are texts in their own right,satisfying the general textual and contextualconditions of production and communication.A protocol is not simply a replica of a memoryrepresentation of the original discourse. On thecontrary, the subject will try to produce a newtext that satisfies the pragmatic conditions ofa particular task context in an experiment orthe requirements of effective communicationin a more natural context. Thus, the languageuser will not produce information that he orshe assumes is already known or redundant.Furthermore, the operations involved in dis-course production are so complex that thesubject will be unable to retrieve at any onetime all the information that is in principleaccessible to memory. Finally, protocols willcontain information not based on what thesubject remembers from the original text, but
3 Longacre and Levinsohn (1977) mention a languagethat apparently uses macrostructure markers in thesurface structure: In Cubeo, a South American Indianlanguage, certain sentences contain a particular particle;stringing together the sentences of a text that aremarked by this particle results in an abstract or sum-mary of the text.

TEXT COMPREHENSION AND PRODUCTION 375
consisting of reconstructively added details,explanations, and various features that are theresult of output constraints characterizingproduction in general.
Optional transformations. Propositionsstored in memory may be transformed invarious essentially arbitrary and unpredictableways, in addition to the predictable, schema-controlled transformations achieved throughthe macro-operations that are the focus of thepresent model. An underlying conception maybe realized in the surface structure in a varietyof ways, depending on pragmatic and stylisticconcerns. Reproduction (or reconstruction) ofa text is possible in terms of different lexicalitems or larger units of meaning. Transforma-tions may be applied at the level of the micro-structure, the macrostructure, or the schematicstructure. Among these transformations onecan distinguish reordering, explication ofcoherence relations among propositions, lexicalsubstitutions, and perspective changes. Thesetransformations may be a source of errors inprotocols, too, though most of the time theypreserve meaning. Whether such transforma-tions are made at the time of comprehension,or at the time of production, or both cannot bedecided at present.
A systematic account of optional transforma-tions might be possible, but it is not necessarywithin the present model. It would make analready complex model and scoring systemeven more cumbersome, and therefore, wechoose to ignore optional transformations inthe applications reported below.
Reproduction. Reproduction is the simplestoperation involved in text production. Asubject's memory for a particular text is amemory episode containing the following typesof memory traces: (a) traces from the variousperceptual and linguistic processes involved intext processing, (b) traces from the compre-hension processes, and (c) contextual traces.Among the first would be memory for the type-face used or memory for particular words andphrases. The third kind of trace permits thesubject to remember the circumstances inwhich the processing took place: the laboratorysetting, his or her own reactions to the wholeprocedure, and so on. The model is not con-cerned with either of these two types ofmemory traces. The traces resulting from the
comprehension processes, however, are speci-fied by the model in detail. Specifically, thosetraces consist of a set of micropropositions.For each microproposition in the text base,the model specifies a probability that it willbe included in this memory set, depending onthe number of processing cycles in which itparticipated and on the reproduction param-eter p. In addition, the memory episode con-tains a set of macropropositions, with theprobability that a macroproposition is includedin that set being specified by the parameter m.(Note that the parameters m and p can only bespecified as a joint function of storage andretrieval conditions; hence, the memory con-tent on which a production is based must alsobe specified with respect to the task demandsof a particular production situation.)
A reproduction operator is assumed thatretrieves the memory contents as describedabove, so that they become part of the subject'stext base from which the output protocol isderived.
Reconstruction. When micro- or macro-information is no longer directly retrievable,the language user will usually try to recon-struct this information by applying rules ofinference to the information that is stillavailable. This process is modeled with threereconstruction operators. They consist of theinverse application of the macro-operators andresult in the reconstruction of some of theinformation deleted from the macrostructurewith the aid of world knowledge: (a) additionof plausible details and normal properties, (b)particularization, and (c) specification ofnormal conditions, components, 01 conse-quences of events. In all cases, errors may bemade. The language user may make guessesthat are plausible but wrong or even givedetails that are inconsistent with the originaltext. However, the reconstruction operatorsare not applied blindly. They operate underthe control of the schema, just as in the case ofthe macro-operators. Only reconstructions thatare relevant in terms of this control schemaare actually produced. Thus, for instance,when "Peter went to Paris by train" is aremembered macroproposition, it might beexpanded by means of reconstruction opera-tions to include such a normal component as"He went into the station to buy a ticket,"

376 WALTER KINTSCH AND TEUN A. VAN DIJK
but it would not include irrelevant reconstruc-tions such as "His leg muscles contracted."The schema in control of the output operationneed not be the same as the one that controlledcomprehension: It is perfectly possible to lookat a house from the standpoint of a buyer andlater to change one's viewpoint to that of aprospective burglar, though different informa-tion will be produced than in the case when nosuch schema change has occurred (Anderson& Pichert, 1978).
Metastatements. In producing an outputprotocol, a subject will not only operatedirectly on available information but will alsomake all kinds of metacomments on thestructure, the content, or the schema of thetext. The subject may also add comments,opinions, or express his or her attitude.
Production plans. In order to monitor theproduction of propositions and especially theconnections and coherence relations, it mustbe assumed that the speaker uses the availablemacropropositions of each fragment of thetext as a production plan. For each macro-proposition, the speaker reproduces or recon-structs the propositions dominated by it.Similarly, the schema, once actualized, willguide the global ordering of the productionprocess, for example, the order in which themacropropositions themselves are actualized.At the microlevel, coherence relations willdetermine the ordering of the propositions tobe expressed, as well as the topic-commentstructure of the respective sentences. Both atthe micro- and macrolevels, production isguided not only by the memory structure ofthe discourse itself but also by general knowl-edge about the normal ordering of events andepisodes, general principles of ordering ofevents and episodes, general principles ofordering of information in discourse, andschematic rules. This explains, for instance,why speakers will often transform a non-canonical ordering into a more canonical one(e.g., when summariziing scrambled stories,as in Kintsch, Mandel, & Kozminsky, 1977).
Just as the model of the comprehensionprocess begins at the propositional level ratherthan at the level of the text itself, the produc-tion model will also leave off at the proposi-tional level. The question of how the textbase that underlies a subject's protocol is
transformed into an actual text will not beconsidered here, although it is probably a lessintractable problem than that posed by theinverse transformation of verbal texts intoconceptual bases.
Text generation. Although we are con-cerned here with the production of second-order discourses, that is, discourses with re-spect to another discourse, such as free-recallprotocols or summaries, the present model mayeventually be incorporated into a more generaltheory of text production. In that case, thecore propositions of a text would not be aset of propositions remembered from somespecific input text, and therefore newmechanisms must be described that wouldgenerate core propositions de novo.
Processing Simulation
How the model outlined in the previoussection works is illustrated here with a simpleexample. A suitable text for this purpose mustbe (a) sufficiently long to ensure the involve-ment of macroprocesses in comprehension; (b)well structured in terms of a schema, so thatpredictions from the present model becomepossible; and (c) understandable withouttechnical knowledge. A 1,300-word researchreport by Heussenstam (1971) called "Bumper-stickers and the Cops," appeared to fill theserequirements. Its structure follows the con-ventions of psychological research reportsclosely, though it is written informally, with-out the usual subheadings indicating methods,results, and so on. Furthermore, it is con-cerned with a social psychology experimentthat requires no previous familiarity witheither psychology, experimental design, orstatistics.
We cannot analyze the whole report here,though a tentative macroanalysis of "Bumper-stickers" has been given in van Dijk (in press).Instead, we shall concentrate only on its firstparagraph:
A series of violent, bloody encounters between policeand Black Panther Party members punctuated theearly summer days of 1969. Soon after, a group ofBlack students I teach at California State College, LosAngeles, who were members of the Panther Party,began to complain of continuous harassment by lawenforcement officers. Among their many grievances,they complained about receiving so many traffic

TEXT COMPREHENSION AND PRODUCTION 377
citations that some were in danger of losing their driv-ing privileges. During one lengthy discussion, werealized that all of them drove automobiles with PantherParty signs glued to their bumpers. This is a report ofa study that I undertook to assess the seriousness oftheir charges and to determine whether we were hearingthe voice of paranoia or reality. (Heussenstam, 1971,p. 32)
Our model does not start with this text butwith its semantic representation, presented inTable 1. We follow here the conventions ofKintsch (1974) and Turner and Greene (inpress). Propositions are numbered and are listedconsecutively according to the order in whichtheir predicates appear in the English text.Each proposition is enclosed by parenthesesand contains a predicate (written first) plusone or more arguments. Arguments are con-cepts (printed in capital letters to distinguishthem from words) or other embedded proposi-tions, which are referred to by their number.Thus, as is shown in Table 1, (COMPLAIN,STUDENT, 19) is shorthand for (COMPLAIN,STUDENT, (HARASS, POLICE, STUDENT)). Thesemantic cases of the arguments have not beenindicated in Table 1 to keep the notationsimple, but they are obvious in most instances.
Some comments about this representationare in order. It is obviously very "surfacy"and, in connection with that, not at all un-ambiguous. This is a long way from a precise,logical formalism that would unambiguouslyrepresent "the meaning" of the text, preferablythrough some combination of elementarysemantic predicates. The problem is not onlythat neither we nor anyone else has everdevised an adequate formalism of this kind;such a formalism would also be quite inap-propriate for our purposes. If one wants todevelop a psychological processing model ofcomprehension, one should start with a non-elaborated semantic representation that isclose to the surface structure. It is then thetask of the processing model to elaborate thisrepresentation in stages, just as a reader startsout with a conceptual analysis directly basedon the surface structure but then constructsfrom this base more elaborate interpretations.To model some of these interpretative processesis the goal of the present enterprise. Theseprocesses change the initial semantic repre-sentation (e.g., by specifying coherence rela-tions of a certain kind, adding required in-
Table 1Proposition List for the Bumper stickersParagraph
Propositionnumber
1234
567
89
10111213
14
IS16171819
202122232425262728
293031323334353637
383940414243444546
Proposition
(SERIES, ENCOUNTER)(VIOLENT, ENCOUNTER)(BLOODY, ENCOUNTER)(BETWEEN, ENCOUNTER, POLICE,
BLACK PANTHER)(TIME: IN, ENCOUNTER, SUMMER)(EARLY, SUMMER)(TIME: IN, SUMMER, 1969)
(SOON, 9)(AFTER, 4, 16)(GROUP, STUDENT)(BLACK, STUDENT)(TEACH, SPEAKER, STUDENT)(LOCATION: AT, 12, CAL STATE
COLLEGE)(LOCATION : AT, CAL STATE COLLEGE,
LOS ANGELES)(IS A, STUDENT, BLACK PANTHER)(BEGIN, 17)(COMPLAIN, STUDENT, 19)(CONTINUOUS, 19)(HARASS, POLICE, STUDENT)
(AMONG, COMPLAINT)(MANY, COMPLAINT)(COMPLAIN, STUDENT, 23)(RECEIVE, STUDENT, TICKET)(MANY, TICKET)(CAUSE, 23, 27)(SOME, STUDENT)(IN DANGER OF, 26, 28)(LOSE, 26, LICENSE)
(DURING, DISCUSSION, 32)(LENGTHY, DISCUSSION)(AND, STUDENT, SPEAKER)(REALIZE, 31, 34)(ALL, STUDENT)(DRIVE, 33, AUTO)(HAVE, AUTO, SIGN)(BLACK PANTHER, SIGN)(GLUED, SIGN, BUMPER)
(REPORT, SPEAKER, STUDY)(DO, SPEAKER, STUDY)(PURPOSE, STUDY, 41)(ASSESS, STUDY, 42, 43)(TRUE, 17)(HEAR, 31, 44)(OR, 45, 46)(OF REALITY, VOICE)(OF PARANOIA, VOICE)
Note, Lines indicate sentence boundaries. Proposi-tions are numbered for eace of reference. Numbers aspropositional arguments refer to the proposition withthat number.

378 WALTER KINTSCH AND TEUN A. VAN DIJK
Cycle 1; Buffer 0' Input' P1-7.
Cycle 2- Buffer P3,4,5,7* Input' P8-I9.35 7
Cycle 3* Buffer P4, 9, 15, 19' Input* P20-28.
2
Cycle 4* Buffer P4,9,I5,I9* Input* P29-37.
32 - 29 30
Cycle 5* Buffer* P4, 19,36,37* Input* P38-46.
Figure 1. The cyclical construction of the coherencegraph for the propositions (P) shown in Table 1.
ferences, and specifying a macrostructure)toward a deeper, less surface-dependent struc-ture. Thus, the deep, elaborated semanticrepresentation should stand at the end ratherthan at the beginning of a processing model,though even at that point some vagueness and
ambiguity may remain. In general, neitherthe original text nor a person's understandingof it is completely unambiguous.
This raises, of course, the question of whatsuch a semantic representation represents.What is gained by writing (COMPLAIN, STU-DENT) rather than The students complained?Capitalizing complain and calling it a conceptrather than a word explains nothing in itself.There are two sets of reasons, however, whya model of comprehension must be based on asemantic representation rather than directlyon English text. The notation clarifies whichaspects of the text are important (semanticcontent) and which are not (e.g., surfacestructure) for our purpose; it provides a unitthat appears appropriate for studying com-prehension processes, that is, the proposition(see Kintsch & Keenan, 1973, for a demon-stration that number of propositions in asentence rather than number of words deter-mines reading time); finally, this kind of nota-tion greatly simplifies the scoring of experi-mental protocols in that it establishes fairlyunambiguous equivalence classes within whichparaphrases can be treated interchangeably.
However, there are other even more impor-tant reasons for the use of semantic representa-tions. Work that goes beyond the confines ofthe present article, for example, on the organi-zation of text bases in terms of fact frames andthe generation of inferences from such knowl-edge fragments, requires the development ofsuitable representations. For instance, COM-PLAIN is merely the name of a knowledgecomplex that specifies the normal uses of thisconcept, including antecedents and conse-quences. Inferences can be derived from thisknowledge complex, for example, that thestudents were probably unhappy or angry orthat they complained to someone, with thetext supplying the professor for that role. Oncea concept like COMPLAIN is elaborated in thatway, the semantic notation is anything butvacuous. Although at present we are not con-cerned with this problem, the possibility forthis kind of extension must be kept open.
Cycling
The first step in the processing model is toorganize the input propositions into a co-herent graph, as illustrated in Figure 1. It was

TEXT COMPREHENSION AND PRODUCTION 379
assumed for the purpose of this figure thatthe text is processed sentence by sentence.Since in our example the sentences are neithervery short nor very long, this is a reasonableassumption and nothing more complicated isneeded. It means that «,-, the number of inputpropositions processed per cycle, ranges be-tween 7 and 12.
In Cycle 1 (see Figure 1), the buffer isempty, and the propositions derived from thefirst sentence are the input. P4 is selected asthe superordinate proposition because it isthe only proposition in the input set that isdirectly related to the title: It shares with thetitle the concept POLICE. (Without a title,propositions are organized in such a way thatthe simplest graph results.) PI, P2, P3, and PSare directly subordinated to P4 because of theshared argument ENCOUNTER; P6 and P7 aresubordinated to P5 because of the repetitionof SUMMER.
At this point, we must specify the short-termmemory assumptions of the model. For thepresent illustration, the short-term memorycapacity was set at j = 4. Although this seemslike a reasonable value to try, there is noparticular justification for it. Empiricalmethods to determine its adequacy will bedescribed later. We also must specify somestrategy for the selection of the propositionsthat are to be maintained in the short-termmemory buffer from one cycle to the next. Aswas mentioned before, a good strategy shouldbe biased in favor of superordinate and recentpropositions. The "leading-edge strategy,"originally proposed by Kintsch and Vipond(1978), does exactly that. It consists of thefollowing scheme. Start with the top proposi-tion in Figure 1 and pick up all propositionsalong the graph's lower edge, as long as eachis more recent than the previous one (i.e., theindex numbers increase); next, go to the highestlevel possible and pick propositions in orderof their recency (i.e., highest numbers first);stop whenever s propositions have beenselected. In Cycle 1, this means that the pro-cess first selects P4 ,then PS and P7, which arealong the leading edge of the graph; thereafter,it returns to Level 2 (Level 1 does not containany other not-yet-selected propositions) andpicks as a fourth and final proposition themost recent one from that level, that is, P3.
Figure 2. The complete coherence graph. (Numbersrepresent propositions. The number of boxes representsthe number of extra cycles required for processing.)
Cycle 2 starts with the propositions carriedover from Cycle 1; P9 is connected to P4, andP8 is connected to P9; the next connection isformed between P4 and PIS because of thecommon argument BLACK PANTHER; P19 alsoconnects to P4 because of POLICE; P10, Pll,P12, and PI 7 contain the argument STUDENTand are therefore connected to PIS, whichfirst introduced that argument. The construc-tion of the rest of the graph as well as the otherprocessing cycles should now be easy to follow.The only problems arise in Cycle 5, where theinput propositions do not share a commonargument with any of the propositions in thebuffer. This requires a long-term memorysearch in this case; since some of the input

380 WALTER KINTSCH AND TEUN A. VAN DIJK
REPORT SCHEMA
INTRODUCTION'(DO, $, ) (EXPERIMENT METHOD RESULTS DISCUSSIONSTUDY
$
SETTING'<$> LITER/MIRE'($) PURPOSE'(PURPOSE, ^EXPERIMENT, (FIND OUT, (CAUSE, $ , $ ) ) >STUDYI $
(TINE<$,$)
not' $ , $ >
($) (S) ($)
Figure 3. Some components of the report schema. (Wavy brackets indicate alternatives. $ indicatesunspecified information.)
propositions refer back to PI7 and P31, thesearch leads to the reinstatement of these twopropositions, as shown in Figure 1. Thus, themodel predicts that (for the parameter valuesused) some processing difficulties should occurduring the comprehension of the last sentence,having to do with determining the referentsfor "we" and "their charges."
The coherence graph arrived at by means ofthe processes illustrated in Figure 1 is shown inFigure 2. The important aspects of Figure 2are that the graph is indeed connected, that is,the text is coherent, and that some proposi-tions participated in more than one cycle.This extra processing is indicated in Figure 2by the number of boxes in which each proposi-tion is enclosed: P4 is enclosed by fourboxes, meaning that it was maintained duringfour processing cycles after its own input cycle.Other propositions are enclosed by three, two,one, or zero boxes in a similar manner. Thisinformation is crucial for the model because itdetermines the likelihood that each proposi-tion will be reproduced.
Schema
Figure 3 shows a fragment of the reportschema. Since only the first paragraph of areport will be analyzed, only information inthe schema relevant to the introduction of areport is shown. Reports are conventionallyorganized into introduction, method, results,and discussion sections. The introductionsection must specify that an experiment, or
an observational study, or some other type ofresearch was performed. The introduction con-tains three kinds of information: (a) the settingof the report, (b) literature references, and (c)a statement of the purpose (hypothesis) of thereport. The setting category may further bebroken down into location and time ($ signsindicate unspecified information). The litera-ture category is neglected here because it isnot instantiated in the present example. Thepurpose category states that the purpose ofthe experiment is to find out whether somecausal relation holds. The nature of thiscausal relation can then be further elaborated.
Macro-operations
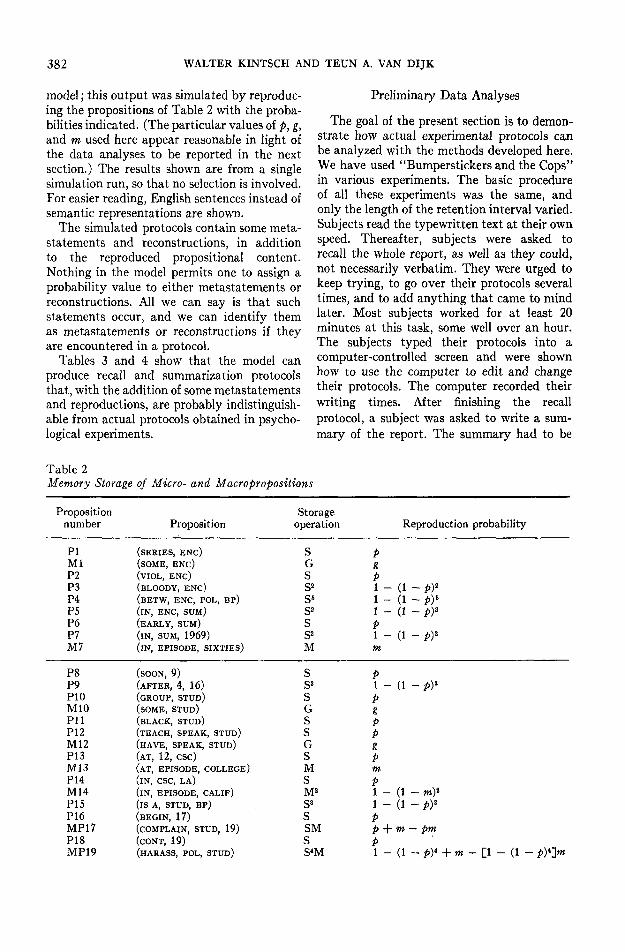
In forming the rnacrostructure, micropro-positions are either deleted, generalized, re-placed by a construction, or carried over un-changed. Propositions that are not generalizedare deleted if they are irrelevant; if they arerelevant, they may become macropropositions.Whether propositions that are generalizedbecome macropropositions depends on therelevance of the generalizations: Those thatare relevant are included in the macrostructurewith a higher probability than those that arenot relevant. Thus, the first macro-operationis to form all generalizations of the micro-propositions. Since the present theory lacks aformal inference component, intuition mustonce again be invoked to provide us with therequired generalizations. Table 2 lists thegeneralizations that we have noted in the text

TEXT COMPREHENSION AND PRODUCTION 381
base of the Bumperstickers paragraph. Theyare printed below their respective micro-propositions and indicated by an "M." Thus,PI (SERIES, ENCOUNTER) is generalized to Ml(SOME, ENCOUNTER).
In Figure 4, the report schema is applied toour text-base example in order to determinewhich of the propositions are relevant andwhich are not. The schema picks out thegeneralized setting statements—that the wholeepisode took place in California, at a college,and in the sixties. Furthermore, it selects thatan experiment was done with the purpose offinding out whether Black Panther bumper-stickers were the cause of students receiving traffictickets. Associated with the bumper stickers isthe fact that the students had cars with thesigns on them. Associated with the tickets ismany tickets, and that the students complainedabout police harassment. Once these proposi-tions have been determined as relevant, astricter relevance criterion selects not allgeneralized setting information, but only themajor setting (in California), and not allantecedents and consequences of the basiccausal relationship, but only its major com-ponents (bumperstickers lead to tickets). Finally,at the top level of the macrostructure hier-archy, all the information in the introductionis reduced to an experiment was done. Thus,some propositions appear at only one level ofthe hierarchy, others at two levels, and oneat all three levels. Each time a proposition isselected at a particular level of the macro-structure, the likelihood that it will later berecalled increases.
The results of both the micro- and macro-processes are shown in Table 2. This tablecontains the 46 micropropositions shown inTable 1 and their generalizations. Macro-
propositions are denoted by M in the table;micropropositions that are determined to berelevant by the schema and thus also functionas macropositions are denoted by MP.
The reproduction probabilities for all thesepropositions are also derived in Table 2. Threekinds of storage operations are distinguished.The operation S is applied every time a(micro-) proposition participates in one of thecycles of Figure 1, as shown by the number ofboxes in Figure 2. Different operators apply tomacropropositions, depending on whether ornot they are relevant. If a macropropositionis relevant, an operator M applies; if it isirrelevant, the operator is G. Thus, the repro-duction probability for the irrelevant macro-proposition some encounters is determined byG; but for the relevant in the sixties, it isdetermined by M. Some propositions can bestored either as micro- or macropropositions;for example, the operator SM2 is applied toMP23 — S because P23 participates in oneprocessing cycle and M2 because M23 isincorporated in two levels of the macro-structure.
The reproduction probabilities shown in thelast column of Table 2 are directly determinedby the third column of the table, with p, g,and m being the probabilities that each applica-tion of S, G, and M, respectively, results in asuccessful reproduction of that proposition.It is assumed here that S and M are statisticallyindependent.
Production
Output protocols generated by the modelare illustrated in Tables 3 and 4. Strictlyspeaking, only the reproduced text basesshown in these tables are generated by the
(LK>
HOC' AT, COLLEGE)(TIME • IN, SIXTIES)
(PURPOSE, at, (ASSESS, (CAUSE, IBLAMPANTHER, SUHPERSTICKERI (RECEIVE, STUDENT, TICKETS))))
(HAVE, STUDENT, AUTO)(HAVE, (AUTO ,SICN)
[STUDENT
(CDWLAIN, STUDENT,(HARASS, POUCE,STUDENT))INANV, TICKET)
Figure 4. The macrostructure of the text base shown in Table 1. (Wavy brackets indicate alternatives.)
382 WALTER KINTSCH AND TEUN A. VAN DIJK
model; this output was simulated by reproduc-ing the propositions of Table 2 with the proba-bilities indicated. (The particular values of p, g,and m used here appear reasonable in light ofthe data analyses to be reported in the nextsection.) The results shown are from a singlesimulation run, so that no selection is involved.For easier reading, English sentences instead ofsemantic representations are shown.
The simulated protocols contain some meta-statements and reconstructions, in additionto the reproduced prepositional content.Nothing in the model permits one to assign aprobability value to either metastatements orreconstructions. All we can say is that suchstatements occur, and we can identify themas metastatements or reconstructions if theyare encountered in a protocol.
Tables 3 and 4 show that the model canproduce recall and summarization protocolsthat, with the addition of some metastatementsand reproductions, are probably indistinguish-able from actual protocols obtained in psycho-logical experiments.
Preliminary Data Analyses
The goal of the present section is to demon-strate how actual experimental protocols canbe analyzed with the methods developed here.We have used "Bumperstickers and the Cops"in various experiments. The basic procedureof all these experiments was the same, andonly the length of the retention interval varied.Subjects read the typewritten text at their ownspeed. Thereafter, subjects were asked torecall the whole report, as well as they could,not necessarily verbatim. They were urged tokeep trying, to go over their protocols severaltimes, and to add anything that came to mindlater. Most subjects worked for at least 20minutes at this task, some well over an hour.The subjects typed their protocols into acomputer-controlled screen and were shownhow to use the computer to edit and changetheir protocols. The computer recorded theirwriting times. After finishing the recallprotocol, a subject was asked to write & sum-mary of the report. The summary had to be
Table 2Memory Storage of Micro- and Macropropositions
Propositionnumber
PIMlP2P3P4PSP6P7M7
P8P9P10M10PllP12M12P13M13P14M14P15P16MP17P18MP19
Proposition
(SERIES, ENC)(SOME, ENC)(VIOL, ENC)(BLOODY, ENC)(BETW, ENC, POL, BP)(IN, ENC, SUM)(EARLY, SUM)(IN, SUM, 1969)(IN, EPISODE, SIXTIES)
(SOON, 9)(AFTER, 4, 16)(GROUP, STUD)(SOME, STUD)(BLACK, STUD)(TEACH, SPEAK, STUD)(HAVE, SPEAK, STUD)(AT, 12, esc)(AT, EPISODE, COLLEGE)(IN, esc, LA)(IN, EPISODE, CALIF)(is A, STUD, BP)(BEGIN, 17)(COMPLAIN, STUD, 19)(CONT, 19)(HARASS, POL, STUD)
Storageoperation
SGSS2
S6
S2
SS2
M
SS»SGSSGSMSM2
S8
SSMSS4M
PgP1 -1 —1 -P1 -m
P1 -PgPPgPmP1 -1 -PP +P1 -
Reproduction probability
(1 - py(1 - #)•(1 - py
(1 - p)*
(l - py
(1 - my(i - pym — pm
(1 - /> )«+ m - [1 - (1 - py^m

TEXT COMPREHENSION AND PRODUCTION 383
Table 2 (continued)
Propositionnumber
P20P21P22MP23MP24P25P26P27P28
P29P30P31P32P33P34M34MP35MP36
P37M37
P38MP39MP40MP41MP42P43P44P4SP46
Proposition
(AMONG, COMP)(MANY, COMP)(COMPLAIN, STUD, 23)(RECEIVE, STUD, TICK)(MANY, TICK)(CAUSE, 23, 27)(SOME, STUD)(IN DANGER, 26, 28)(LOSE, 26, Lie)
(DURING, DISC)(LENGTHY, DISC)(AND, STUD, SPEAK)(REALIZE, 31, 34)(ALL, STUD)(DRIVE, 33, AUTO)(HAVE, STUD, AUTO)(HAVE, AUTO/STUD, SIGN)(BP, SIGN)
(GLUED, SIGN, BUMP)(ON, SIGN, BUMP)
(REPORT, SPEAK, STUDY)(DO, SPEAK, STUDY)(PURPOSE, STUDY, 41)(ASSESS, STUDY, 42, 43)(TRUE, 17)/(CAUSE, 36, 23)(HEAR, 31, 44)(OR, 45, 46)(OF REALITY, VOICE)(OF PARANOIA, VOICE)
Storageoperation
SSSSM2
SMSSSS
SSSSSSMSMS2M2
SM2
SSM3
SM2
SM2
SM2
SSSS
PPPP +P +PPPP
PPPPPPmP +1 -
—P1 —
PP +P +P +P +PPPP
Reproduction probability
1 _ (1 _ m)2 _ p£i - (1 - w)2]m — pm
m — pm(1 - p)* + 1 - (1 - m)2
[1 - (1 - £)2] X C1 - (1 - OT)2J
(1 - w)2
1 - (1 - m)3 - p[l - (1 - >w)3]1 - (1 - w)2 - p[\ - (1 - w)2]1 - (1 - w)2 - p\_\ - (1 - w)2]1 - (1 - w)2 - p{\ - (1 - w)2]
Note. Lines show sentence boundaries. P indicates a microproposition, M indicates a macroproposition, andMP is both a micro- and macroproposition. S is the storage operator that is applied to micropropositions, Gis applied to irrelevant macropropositions, and M is applied to relevant macropropositions.
between 60 and 80 words long to facilitatebetween-subjects comparisons. The computerindicated the number of words written to avoidthe distraction of repeated word counts. Allsubjects were undergraduates from the Uni-versity of Colorado and were fulfilling acourse requirement.
A group of 31 subjects was tested immedi-ately after reading the report. Another groupof 32 subjects was tested after a 1-monthretention interval, and 24 further subjectswere tested after 3 months.
Some statistics of the protocols thus ob-tained are shown in Table 5. Since the sum-maries were restricted in length, the fact thattheir average length did not change appreciably
over a 3-month period is hardly remarkable.But note that the overall length of the free-recall protocols declined only by about athird or quarter with delay. Obviously, sub-jects did very well even after 3 months,at least in terms of the number of wordsproduced. If we restrict ourselves to the firstparagraph of the text and analyze proposi-tionally those portions of the recall protocolsreferring to that paragraph, we arrive at thesame conclusions. Although there is a (sta-tistically significant) decline over delay in thenumber of propositions in the protocols thatcould be assigned to the introduction category,the decline is rather moderate.
While the output changed relatively little

384 WALTER KINTSCH AND TEUN A. VAN DIJK
Table 3A Simulated Recall Protocol
Reproduced text base
PI, P4, M7, P9, P13, P17, MP19, MP35, MP36, M37, MP39, MP40, MP42
Text base converted to English, with reconstructions italicized
In the sixties (M7), there was a series (PI) of riots between the police and the Black Panthers (P4). Thepolice did not like 'the Black Panthers (normal consequence of 4). After that (P9), students who were enrolled(normal component of 13) at the California State College (P13) complained (P17) that the police were har-assing them (P19). They were stopped and had to show their driver's license (normal component of 23). Thepolice gave them trouble (P19) because (MP42) they had (MP35) Black Panther (MP36) signs on theirbumpers (M37). The police discriminated against these students and violated their civil rights (particularizationof 42). They did an experiment (MP39) for this purpose (MP40).
Note. The parameter values used were pfrom Table 2.
.10, g = .20, and m = .40. P, M, and MP identify propositions
in quantity, its qualitative composition changeda great deal. In the recall protocols, the propor-tion of reproductive propositions in the totaloutput declined from 72% to 48%, while atthe same time, reconstructions almost doubledtheir contribution, and metastatements quad-rupled theirs.4 These results are shown inFigure 5; they are highly significant sta-tistically, X2(4) = 56.43. As less material fromthe text is reproduced, proportionately morematerial is added by the production processesthemselves. Interestingly, these productionprocesses operated quite accurately in thepresent case, even after 3 months: Errors, thatis, wrong guesses or far-fetched confabulations,occurred with negligible frequency at alldelay intervals (1%, 0%, and 1% for zero,1-month, and 3-month delays, respectively).
Table 4A Simulated Summary
Reproduced text baseM14, M37, MP39, MP40
Text base converted to English,with metastatements and recon-
structions italicized
This report was about (metastatement) an experimentdone (MP39) in California (M'lf). It was done(MP39) in order to (MP40) protect students fromdiscrimination (normal consequence of 41).
Note. The parameter values used were p = .01,g = .05, and m = .30. M and MP identify proposi-tions from Table 2.
For the summaries, the picture is similar,though the changes are not quite as pro-nounced, as shown in Figure 6. The contribu-tion of the three response categories to thetotal output still differs significantly, however,X2(4) = 16.90, p = .002. Not surprisingly,summaries are generally less reconstructivethan recall. Note that the reproductive com-ponent includes reproductions of both micro-and macropropositions!
We have scored every statement that couldbe a reproduction of either a macro- or micro-proposition as if it actually were. This is, ofcourse, not necessary: It is not only possiblebut quite probable that some of the statementsthat we regarded as reproductive in originare reconstructions that accidentally duplicateactual text propositions. Thus, our estimates ofthe reproductive components of recall andsummarization protocols are in fact upperbounds.
Protocol Analyses
In order to obtain the data reported above,all protocols had to be analyzed proposi-
* Metastatements seem to be most probable whenone has little else to say: Children use such statementsmost frequently when they talk about something theydo not understand (e.g., Poulsen et al, in press), andthe speech of aphasics is typically characterized by suchsemantically empty comments (e.g., Luria & Tsvet-kova, 1968). In both cases, the function of thesestatements may be to maintain the communicativerelationship between speaker and listener. Thus, theirfunction is a pragmatic one.

TEXT COMPREHENSION AND PRODUCTION 385
IUU
90
80
1 7°
1 6°I 50%t 40
& 30
20
10
0
Figure 5and metretentioi
1 1 1
^^Reproductions
^^^ ReconstructionsV
— MetQ^ —
IMMEDIATE ONE THREEMONTH MONTH
Retention Interval
Proportion of reproductions, reconstructions,astatements in the recall protocols for threei intervals.
Table 5Average Number of Words and Propositions ofRecall and Summarization Protocols as aFunction of the Retention Interval
No. words No. propositionsProtocol and (total (1st paragraph
retention interval protocol) only)
RecallImmediate 363 17.31 month 225 13.23 months 268 14.8
SummariesImmediate 75 8.41 month 76 7.43 months 72 6.2
(d) errors and unclassifiable statements (notrepresented in the present protocol).
Note that the summary is, for the most part,a reduced version of the recall protocol; onthe other hand, the second proposition of thesummary that specifies the major setting didnot appear in the recall. Clearly, the recall
tionally. An example of how this kind ofanalysis works in detail is presented in Tables6 and 7, for which one subject from the im-mediate condition was picked at random. Therecall protocol and the summary of this sub-ject are shown, together with the propositionalrepresentations of these texts. In construct-ing this representation, an effort was made tobring out any overlap between the proposi-tional representation of the original text andits macrostructure (see Table 2) and the pro-tocol. In other words, if the protocol containeda statement that was semantically (notnecessarily lexically) equivalent to a textproposition, this text proposition was used inthe analysis. This was done to simplify theanalysis; as mentioned before, a fine-grainedanalysis distinguishing optional meaning-pre-serving transformations would be possible.
Each protocol proposition was then assignedto one of four response categories: (a) repro-ductions (the index number of the reproducedproposition is indicated), (b) reconstructions(the source of the reconstruction is notedwherever possible), (c) metastatements, and
at
J8
1
1I
IUU
90
80
70
60
50
40
30
20
10
n
1 1 1
— —
_ *~~ — o^Reproductions
_ >o _
— _
— —
— Reconstructions^ ——- • -oo
- Metc .̂ -
? f 1IMMEDIATE ONE THREE
MONTH MONTH
Retention Interval
Figure 6. Proportion of reproductions, reconstructions,and metastatements in the summaries for three reten-tion intervals.

386 WALTER KINTSCH AND TEUN A. VAN DIJK
Table 6Recall Protocol and Its Analysis From a Randomly Selected Subject
Recall protocol
The report started with telling about the Black Panther movement in the 1960s. A professor was tellingabout some of his students who were in the movement. They were complaining about the traffic tickets theywere getting from the police. They felt it was just because they were members of the movement. The pro-fessor decided to do an experiment to find whether or not the bumperstickers on the cars had anything todo with it.
Propositionnumber Proposition Classification
1 (START WITH, REPORT, 2)2 (TELL, REPORT, BLACK PANTHER)3 (TIME : IN, BLACK PANTHER, SIXTIES)
Schematic metastatementSemantic metastatementM7
4 (TELL, PROFESSOR, STUDENT)5 (SOME, STUDENT)6 (HAVE, PROFESSOR, STUDENT)7 (IS A, STUDENT, BLACK PANTHER)
Semantic metastatementM10M12PIS (lexical transformation)
(COMPLAIN, STUDENT, 9)(RECEIVE, STUDENT, TICKET, POLICE)
MP17MP23 (specification of component)
1011
12131415161718
(FEEL, STUDENT)(CAUSE, 7, 9)
(DECIDE, PROFESSOR, 13)(DO, PROFESSOR, EXPERIMENT)(PURPOSE, 13, IS)(ASSESS, 16)(CAUSE, 17, 9)(ON, BUMPER, SIGN)(HAVE, AUTO, SIGN)
Specification of condition ofMP42
Specification of condition ofMP39MP40MP41MP42M37MP35
MP17
MP39
Note. Only the portion referring to the first paragraph of the text is shown. Lines indicate sentence bound-aries. P, M, and MP identify propositions from Table 2.
protocol does not reflect only what is stored inmemory.
Statistical Analyses
While metastatements and reconstructionscannot be analyzed further, the reproductionspermit a more powerful test of the model.If one looks at the pattern of frequencieswith which both micro- and macroproposi-tions (i.e., Table 2) are reproduced in thevarious recall conditions, one notes thatalthough the three delay conditions differamong each other significantly [minimum<(54) = 3.67], they are highly correlated:Immediate recall correlates .88 with 1-monthrecall and .77 with 3-month recall; the twodelayed recalls correlate .97 between eachother. The summaries are even more alike at
the three retention intervals. They do notdiffer significantly [maximum <(54) = 1.99],and the intercorrelations are .92 for immediate/1-month, .87 for immediate/3-month, and .94for l-month/3-month recall. These high cor-relations are not very instructive, however,because they hide some subtle but consistentchanges in the reproduction probabilities. Amore powerful analysis that brings out thesechanges is provided by the model.
The predicted frequencies for each micro-and macroproposition are shown in Table 3as a function of the parameters p, g, and m.These equations are, of course, for a specialcase of the model, assuming chunking bysentences, a buffer capacity of four proposi-tions, and the leading-edge strategy. It is,nevertheless, worthwhile to see how well thisspecial case of the model can fit the data ob-

TEXT COMPREHENSION AND PRODUCTION 387
Table 7Summary and Its Analysis From the Same Randomly Selected Subject as in Table 6
Summary
This report was about an experiment in the Los Angeles area concerning whether police were giving outtickets to members of the Black Panther Party just because of their association with the party.
Propositionnumber
123456
Proposition
(IS ABOUT, REPORT, EXPERIMENT)(LOC: IN, 1, LOS ANGELES)(PURPOSE, EXPERIMENT, 4)(CAUSE, 5, 6)(IS A, SOMEONE, BLACK PANTHER)(GIVE, POLICE, TICKET, SOMEONE)
Classification
Semantic metastatementM14MP40MP42P15MP23 (lexical transformation)
Note. Only the portion referring to the first paragraph of the text is shown. P, M, and MP identify proposi-tions from Table 2.
tained from the first paragraph of Bumper-stickers when the three statistical parametersare estimated from the data. This was doneby means of the STEPIT program (Chandler,1965), which for a given set of experimentalfrequencies, searches for those parametervalues that minimize the chi-squares betweenpredicted and obtained values. Estimatesobtained for six separate data sets (threeretention intervals for both recall and sum-maries) are shown in Table 8. We first notethat the goodness of fit of the special case ofthe model under consideration here was quitegood in five of the six cases, with the obtainedvalues being slightly less than the expectedvalues.5 Only the immediate recall data
Table 8Parameter Estimates and Chi-SguareGoodness-of-Fit Values
Protocol andretention interval
RecallImmediate1 month3 months
SummariesImmediate1 month3 months
P
.099
.032
.018
.015
.024
.001
m
.391
.309
.321
.276
.196
.164
$
.198
.097
.041
.026
.040
.024
X2(50)
88.34*46.0837.41
30.1146.4630.57
could not be adequately fit by the model inits present form, though even there thenumerical value of the obtained goodness-of-fit statistic is by no means excessive. (Theproblems are caused mostly by two datapoints: Subjects produced Pll and P33 withgreater frequency than the model could accountfor; this did not happen in any of the otherdata sets.)
Perhaps more important than the goodness-of-fit statistics is the fact that the pattern ofparameter estimates obtained is a sensibleand instructive one: In immediate recall, theprobability of reproducing micropropositions(p) is about five times as high as after 3months; the probability of reproducing ir-relevant generalizations (g) decreases by asimilar factor; however, the likelihood thatmacropropositions are reproduced (m) changesvery little with delay. In spite of the highcorrelations observed between the immediaterecall and 3-month delayed recall, the forget-ting rates for micropropositions appear to beabout four times greater than that for macro-propositions! In the summaries, the same kindof changes occur, but they are rather less pro-nounced. Indeed, the summary data from allthree delay intervals could be pooled and fitted
Note. The average standard errors are .003 for p,.023 for ih, and .025 for $, respectively.*p < .001.
6 Increasing (or decreasing) all parameter values inTable 8 by 33% yields statistically significant in-creases in the chi-squares. On the other hand, the in-creases in the chi-squares that result from 10% changesin the parameter values are not sufficiently large to bestatistically significant.

388 WALTER KINTSCH AND TEUN A. VAN DIJK
by one set of parameter values with littleeffect on the goodness of fit. Furthermore,recall after 3 months looks remarkably likethe summaries in terms of the parameterestimates obtained here.
These observations can be sharpened con-siderably through the use of a statisticaltechnique originally developed by Neyman(1949). Neyman showed that if one fits amodel with some set of r parameters, yieldinga X2(« — r), and then fits the same data setagain but with a restricted parameter set ofsize q, where q < r, and obtains a X2(« — q),X2(w — r) — X2(n — q) also has the chi-squaredistribution with r— q degrees of freedom underthe hypothesis that the r — q extra parametersare merely capitalizing on chance variationsin the data, and that the restricted model fitsthe data as well as the model with moreparameters. Thus, in our case, one can ask,for instance, whether all six sets of recall andsummarization data can be fitted with one setof the parameters p, m, and g, or whetherseparate parameter values for each of the sixconditions are required. The answer is clearlythat the data cannot be fitted with one singleset of parameters, with the chi-square for theimprovement obtained by separate fits, X2(15)= 272.38. Similarly, there is no single set ofparameter values that will fit the three recallconditions jointly, X2(6) = 100.2. However,single values of p, m, and g will do almost aswell as three separate sets for the summarydata. The improvement from separate sets isstill significant, X2(6) = 22.79, .01 < p < .001,but much smaller in absolute terms (thiscorresponds to a normal deviate of 3.1, whilethe previous two chi-squares translate into zscores of 16.9 and 10.6, respectively). Indeed,it is almost possible to fit jointly all three setsof summaries and the 3-month delay recalldata, though the resulting chi-square for thesignificance of the improvement is againsignificant statistically, X2(9) = 35.77, p<.GOi.The estimates that were obtained when allthree sets of summaries were fitted witha single set of parameters were p = .018,m = .219, and g = .032; when the 3-monthrecall data were included, these values changedto £ = .018, m = .243, and g = .034.
The summary data can thus be described interms of the model by saying that over 70%
of the protocols consisted of reproductions,with the remainder being mostly reconstruc-tions and a few metastatements. With delay,the reproductive portion of these protocolsdecreased but only slightly. Most of the re-productions consisted of macropropositions,with the reproduction probability for macro-propositions being about 12 times that formicropropositions. For recall, there were muchmore dramatic changes with delay: For im-mediate recall, reproductions were three timesas frequent as reconstructions, while theircontributions are nearly equal after 3 months.Furthermore, the composition of the repro-duced information changes very much: Macro-propositions are about four times as importantas micropropositions in immediate recall;however, that ratio increases with delay, soafter 3 months, recall protocols are very muchlike summaries in that respect.
It is interesting to contrast these resultswith data obtained in a different experiment.Thirty subjects read only the first paragraphof Bumperstickers and recalled it in writingimmediately. The macroprocesses described bythe present model are clearly inappropriatefor these subjects: There is no way thesesubjects can construct a macrostructure asoutlined above, since they do not even know-that what they are reading is part of a researchreport! Hence, one would expect the patternof recall to be distinctly different from thatobtained above; the model should not fit thedata as well as before, and the best-fittingparameter estimates should not discriminatebetween macro- and micropropositions.Furthermore, in line with earlier observations(e.g., Kintsch et al., 1975), one would expectmost of the responses to be reproductive. Thisis precisely what happened: 87% of the pro-tocols consisted of reproductions, 10% re-constructions, 2% metastatements, and 1%errors. The total number of propositions pro-duced was only slightly greater (19.9) thanimmediate recall of the whole text (17.3; seeTable 5). The correlation with immediaterecall of the whole text was down to r = .55;with the summary data, there was even lesscorrelation, for example, r = .32, for the3-month delayed summary. The model fitwas poor, with a minimum chi-square of 163.72for 50 df. Most interesting, however, is the

TEXT COMPREHENSION AND PRODUCTION 389
fact that the estimates for the model param-eters p, m, and g that were obtained were notdifferentiated: j> = .33, m = .30, | = .36.Thus, micro- and macroinformation is treatedalike here—very much unlike the situationwhere subjects read a long text and engage inschema-controlled macro-operations!
While the tests of the model reported herecertainly are encouraging, they fall far shortof a serious empirical evaluation. For thispurpose, one would have to work with at leastseveral different texts and different schemata.Furthermore, in order to obtain reasonablystable frequency estimates, many more proto-cols should be analyzed. Finally, the generalmodel must be evaluated, not merely a specialcase that involves some quite arbitrary assump-tions.6 However, once an appropriate dataset is available, systematic tests of theseassumptions become feasible. Should themodel pass these tests satisfactorily, it couldbecome a useful tool in the investigation ofsubstantive questions about text comprehen-sion and production.
General Discussion
A processing model has been presented herefor several aspects of text comprehension andproduction. Specifically, we have been con-cerned with problems of text cohesion and gistformation as components of comprehensionprocesses and the generation of recall and sum-marization protocols as output processes. Ac-cording to this model, coherent text bases areconstructed by a process operating in cyclesand constrained by limitations of workingmemory. Macroprocesses are described thatreduce the information in a text base throughdeletion and various types of inferences to itsgist. These processes are under the control ofthe comprehender's goal, which is formalized inthe present model as a schema. The macro-processes described here are predictable onlyif the controlling schema can be made explicit.Production is conceived both as a process ofreproducing stored text information, whichincludes the macrostructure of the text, andas a process of construction: Plausible in-ferences can be generated through the inverseapplication of the macro-operators.
This processing model was derived from theconsiderations about semantic structures
sketched at the beginning of this article. There,we limited our discussion to points that weredirectly relevant to our processing model.The model, as developed here, is, however, nota comprehensive one, and it now becomesnecessary to extend the discussion of semanticstructures beyond the self-imposed limits wehave observed so far. This is necessary for tworeasons: (a) to indicate the directions thatfurther elaborations of the model might takeand (b) to place what we have so far into abroader context.
Coherence
Sentences are assigned meaning and refer-ence not only on the basis of the meaning andreference of their constituent components butalso relative to the interpretation of other,mostly previous, sentences. Thus, each sen-tence or clause is subject to contextual inter-pretation. The cognitive correlate of this ob-servation is that a language user needs torelate new incoming information to the in-formation he or she already has, either fromthe text, the context, or from the languageuser's general knowledge system. We havemodeled this process in terms of a coherentprepositional network: The referential identityof concepts was taken as the basis of the co-
6 We have used the leading-edge strategy here be-cause it was used previously by Kintsch and Vipond(1978). In comparison, for the data from the immedi-ate-summary condition, a recency-only strategy in-creases the minimum chi-square by 43%, while alevels-plus-primacy strategy yields an increase of 23%(both are highly significant). A random selectionstrategy can be rejected unequivocally, xs(34) = 113.77.Of course, other plausible strategies must be investi-gated, and it is quite possible that a better strategythan the leading-edge strategy can be found. However,a systematic investigation would be pointless with onlya single text sample.
Similar considerations apply to the determination ofthe buffer capacity, s. The statistics reported above werecalculated for an arbitrarily chosen value of s = 4.For s = 10, the minimum chi-square increasesdrastically, and the model no longer can fit the data.On the other hand, for s = 1, 2, or 3, the minimumchi-squares are only slightly larger than those reportedin Table 8 (though many more reinstatement searchesare required during comprehension for the smallervalues of s). A more precise determination of the buffercapacity must be postponed until a broader data basebecomes available.

390 WALTER KINTSCH AND TEUN A. VAN DIJK
herence relationships among the propositionsof a text base. While referential coherence isundoubtedly important psychologically, thereare other considerations that need to be ex-plicated in a comprehensive theory of textprocessing.
A number of experimental studies, follow-ing Haviland and Clark (1974), demonstratevery nicely the role that referential coherenceamong sentences plays in comprehension.However, the theoretical orientation of thesestudies is somewhat broader than the one wehave adopted above. It derives from the workof the linguists of the Prague School (e.g.,Sgall & Hajicova, 1977) and others (e.g.,Halliday, 1967) who are concerned with thegiven-new articulation of sentences, as it isdescribed in terms of topic-comment andpresupposition-assertion relations. Within psy-chology, this viewpoint has been expressedmost clearly by Clark (e.g., Clark, 1977).Clark's treatment of the role of the "given-newcontract" in comprehension is quite consistentwith the processing model offered here. Refer-ential coherence has an important function inClark's system, but his notions are not limitedto it, pointing the way to possible extensionsof the present model.
Of the two kinds of semantic relations thatexist among propositions, extensional andintensional ones, we have so far restrictedourselves to the former. That is, we haverelated propositions on the basis of theirreference rather than their meaning. In thepredicate logical notation used here, this kindof referential relation is indicated by commonarguments in the respective propositions. Innatural surface structures, referential identityis most clearly expressed by pronouns, other"pro" forms, and definite articles. Note thatreferential identity is not limited to individuals,such as discrete objects, but may also be basedon related sets of propositions specifying prop-erties, relations, and events, or states of affairs.Identical referents need not be referred to withthe same expressions: We may use the expres-sions "my brother," "he," "this man," or"this teacher" to refer to the same individual,depending on which property of the individualis relevant in the respective sentences of thediscourse.
Although referential identity or other refer-
ential relationships are frequent concomitantproperties of coherence relations betweenpropositions of a text base, such relations arenot sufficient and sometimes not even neces-sary. If we are talking about John, for instance,we may say that he was born in London, thathe was ill yesterday, or that he now smokes apipe. In that case, the referential individualremains identical, but we would hardly saythat a discourse mentioning these facts abouthim would by this condition alone be coherent.It is essential that the facts themselves berelated. Since John may well be a participantin such facts, referential identity may be anormal feature of coherence as it is establishedbetween the propositions taken as denotingfacts.
Facts
The present processing model must thereforebe extended by introducing the notion of"facts." Specifically, we must show how thepropositions of a text base are organized intohigher-order fact units. We shall discuss heresome of the linguistic theory that underliesthese notions.
The propositions of a text base are con-nected if the facts denoted by them are related.These relations between facts in some possibleworld (or in related possible worlds) aretypically of a conditional nature, where theconditional relation may range from possi-bility, compatibility, or enablement via proba-bility to various kinds of necessity. Thus, onefact may be a possible, likely, or necessarycondition of another fact; or a fact may be apossible, likely, or necessary consequence ofanother fact. These connection relations be-tween propositions in a coherent text base aretypically expressed by connectives such as"and," "but," "because," "although," "yet,""then," "next," and so on.
Thus, facts are joined through temporalordering or presuppositional relationships toform more complex units of information. Atthe same time, facts have their own internalstructure that is reflected in the case structureof clauses and sentences. This framelikestructure is not unlike that of propositions,except that it is more complex, with slots thatassign specific roles to concepts, propositions,and other facts. The usual account of such

TEXT COMPREHENSION AND PRODUCTION 391
structures at the level of sentence meaning isgiven in terms of the following:
1. state/event/action (predicate)2. participants involved (arguments)
a. agent (s)b. patient (s)c. beneficiaryd. object(s)e. instrument (s)
and so on
3. circumstantials
a. timeb. placec. directiond. origine. goal
and so on
4. properties of 1, 2, and 35. modes, moods, modalities.
Without wanting to be more explicit or com-plete, we surmise that a fact unit would featurecategories such as those mentioned above. Thesyntactic and lexical structure of the clausepermits a first provisional assignment of sucha structure. The interpretation of subsequentclauses and sentences might correct thishypothesis.
In other words, we provisionally assume thatthe case structure of sentences may have pro-cessing relevance in the construction of complexunits of information. The propositions playthe role of characterizing the various proper-ties of such a structure, for example, specifyingwhich agents are involved, what their respec-tive properties are, how they are related,and so on. In fact, language users are able toderive the constituent propositions from once-established fact frames.
We are now in a position to better under-stand how the content of the proposition in atext base is related, namely, as various kindsof relations between the respective individuals,properties, and so on characterizing the con-nected facts. The presupposition-assertionstructure of the sequence shows how new factsare added to the old facts; more specifically,each sentence may pick out one particularaspect, for example, an individual or propertyalready introduced before, and assign it furtherproperties or introduce new individuals relatedto individuals introduced before (see Clark,1977; van Dijk, 1977d).
It is possible to characterize relations be-
tween propositions in a discourse in morefunctional terms, at the pragmatic or rhetoricallevels of description. Thus, one propositionmay be taken as a "specification," a "correc-tion," an "explanation," or a "generalization"of another proposition (Meyer, 1975; van Dijk,1977c, 1977d). However, we do not yet have anadequate theory of such functional relations.
The present model was not extended beyondthe processes involved in referential coherenceof texts because we do not feel that theproblems involved are sufficiently well under-stood. However, by limiting the processingmodel to coherence in terms of argumentrepetition, we are neglecting the importantrole that fact relationships play in comprehen-sion. For instance, most of the inferences thatoccur during comprehension probably derivefrom the organization of the text base into factsthat are matched up with knowledge framesstored in long-term memory, thus providinginformation missing in the text base by a pro-cess of pattern completion, or "default assign-ments," in Minsky's terminology (Minsky,1975). Likewise, the fate of inconsistent in-formation might be of interest in a text, forexample, whether it would be disregarded inrecall or, on the contrary, be particularly wellreported because of the extra processing itreceives. Finally, by looking at the organiza-tion of a text base in terms of fact relations,a level of representation is obtained that cor-responds to the "knowledge structures" ofSchank and Abelson (1977). Schank andAbelson have argued convincingly that sucha level of representation is necessary in order toaccount for full comprehension. Note, how-ever, that in their system, as in the presentone, that level of representation is built onearlier levels (their microscopic and macro-scopic conceptual dependency representations,which correspond loosely to our microstructureand macrostructure).
Limitations and Future Directions
Other simplifying assumptions made in thecourse of developing this model should like-wise be examined. Consider first the relation-ship between a linguistic text grammar and atext base actually constructed by a reader orlistener. In general, the reader's text base willbe different from the one abstractly specified

392 WALTER KINTSCH AND TEUN A. VAN DIJK
by a text grammar. The operations and strate-gies involved in discourse understanding arenot identical to the theoretical rules and con-straints used to generate coherent text bases.One of the reasons for these differences lies inthe resource and memory limitations of cogni-tive processes. Furthermore, in a specificpragmatic and communicative context, alanguage user is able to establish textual co-herence even in the absence of strict, formalcoherence. He or she may accept discoursesthat are not properly coherent but that arenevertheless appropriate from a pragmatic orcommunicative point of view. Yet, in thepresent article, we have neglected thoseproperties of natural language understandingand adopted the working hypothesis that fullunderstanding of a discourse is possible at thesemantic level alone. In future work, a dis-course must be taken as a complex structure ofspeech acts in a pragmatic and social context,which requires what may be called pragmaticcomprehension (see van Dijk, 1977a, on theseaspects of verbal communication).
Another processing assumption that mayhave to be reevaluated concerns our decision todescribe the two aspects of comprehensionthat the present model deals with—the co-herence graph and the macrostructure—as ifthey were separate processes. Possible inter-actions have been neglected because each ofthese processes presents its own set of problemsthat are best studied in isolation, without theadded complexity of interactive processes.The experimental results presented above areencouraging in this regard, in that they indicatethat an experimental separation of these sub-processes may be feasible: It appears that re-call of long tests after substantial delays, aswell as summarization, mostly reflects themacro-operations; while for immediate recallof short paragraphs, the macroprocesses playonly a minor role, and the recall pattern ap-pears to be determined by more local con-siderations. In any case, trying to decomposethe overly complex comprehension probleminto subproblems that may be more accessibleto experimental investigation seems to be apromising approach. At some later stage, how-ever, it appears imperative to analyzetheoretically the interaction between these twosubsystems and, indeed, the other components
of a full-fledged comprehension model, suchas the text-to-text-base translation processesand the organization of the text base in termsof facts.
There are a number of details of the modelat its present stage of development that couldnot be seriously defended vis-a-vis sometheoretical alternatives. For instance, we haveassumed a limited-capacity, short-term bufferin the manner of Atkinson and Shiffrin (1968).It may be possible to achieve much the sameeffect in a quite different way, for example, byassuming a rapidly decaying, spreading activa-tion network, after Collins and Loftus (1975)and Anderson (1977). Similarly, if one grantsus the short-term buffer, we can do no morethan guess at the strategy used to selectpropositions to be maintained in that buffer.That is not a serious problem, however, be-cause it is open to empirical resolution withpresently available methods, as outlined inthis article. Indeed, the main value of thepresent model is that it is possible to formulateand test empirically various specific hypothesesabout comprehension processes. Some ratherpromising initial results have been reportedhere as illustrations of the kind of questionsthat can be raised with the help of the model.Systematic investigations using these methodsmust, of course, involve many more texts andseveral different text types and will require anextended experimental effort. In addition,questions not raised here at all will have to beinvestigated, such as the possible separation ofreproduction probabilities into storage andretrieval components.
To understand the contribution of thismodel, it is important to be clear about itslimitations. The most obvious limitation of themodel is that at both input and output itdeals only with semantic representations, notwith the text itself. Another restriction isperhaps even more serious. The model stopsshort of full comprehension because it does notdeal with the organization of the prepositionaltext base into facts. Processing proceeds onlyas far as the coherence graph and the macro-structure; the component that interpretsclusters of propositions as facts, as outlinedabove, is as yet missing. General world knowl-edge organized in terms of frames must play acrucial role in this process, perhaps in the

TEXT COMPREHENSION AND PRODUCTION 393
manner of Charniak (1977). Note that thiscomponent would also provide a basis for atheory of inference, which is another missinglink from our model of macro-operations.
In spite of these serious limitations, thepresent model promises to be quite useful, evenat its present stage of development. As long as"comprehension" is viewed as one undif-ferentiated process, as complex as "thinkingin general," it is simply impossible to formulateprecise, researchable questions. The modelopens up a wealth of interesting and significantresearch problems. We can ask more refinedquestions about text memory. What about thesuggestion in the data reported above that gistand detailed information have different decayrates? Is the use of a short-term buffer in anyway implicated in the persistent finding thatphonological coding during reading facilitatescomprehension (e.g., Perfetti & Lesgold,1978)? One can begin to take a new look atindividual differences in comprehension: Canthey be characterized in terms of buffer size,selection strategies, or macroprocesses? De-pending on the kind of problem a particularindividual may have, very different educationalremedies would be suggested! Similarly, wemay soon be able to replace the traditionalconcept of readability with the question"What is readable for whom and why?" andto design texts and teaching methods in such away that they are suited to the cognitive pro-cessing modes of particular target groups. Thus,the model to some extent makes up in promisefor what it lacks in completeness.
References
Aaronson, D., & Scarborough, H. S. Performancetheories for sentence coding: Some quantitativemodels. Journal of Verbal Learning and Verbal Be-havior, 1977,16, 277-303.
Anderson, J. R. Language, memory and thought. Hills-dale, N.J.: Erlbaum, 1977.
Anderson, R. C., & Pichert, J. W. Recall of previouslyunrecallable information following a shift in per-spective. Journal of Verbal Learning and Verbal Be-havior, 1978, 17, 1-12.
Atkinson, R. C., & Shiffrin, R. M. Human memory: Aproposed system and its control processes. In K. W.Spence & J. T. Spence (Eds.), The psychology oflearning and motivation: Advances in research andtheory (Vol. 2). New York: Academic Press, 1968.
Bobrow, D., & Collins, A. (Eds.). Representation andunderstanding: Studies in cognitive science. NewYork: Academic Press, 1975.
Chandler, P. J. Subroutine STEPIT: An algorithmthat finds the values of the parameters which minimizea given continuous function. Bloomington: IndianaUniversity, Quantum Chemistry Program Exchange,1965.
Charniak, E. A framed PAINTING : The representation ofa common sense knowledge fragment. CognitiveScience, 1977, 1, 335-394.
Clark, H. H. Inferences in comprehension. In D. La-Berge & S. J. Samuels (Eds.), Basic processes inreading. Hillsdale, N.J.: Erlbaum, 1977.
Colby, B. N. A partial grammar of Eskimo folktales.American Anthropologist, 1973, 75, 645-662.
Collins, A. M., & Loftus, E. F. A spreading activationtheory of semantic processing. Psychological Review,1975, 82, 407-128.
Halliday, M. A. K. Notes on transitivity and theme inEnglish. Journal of Linguistics, 1967, 3, 199-244.
Haviland, S. E., & Clark, H. H. What's new? Acquiringnew information as a process in comprehension.Journal of Verbal Learning and Verbal Behavior,1974, A?, 512-521.
Hayes, J. R., Waterman, D. A., & Robinson, C. S.Identifying the relevant aspects of a problem text.Cognitive Science, 1977, 1, 297-313.
Heussenstam, F. K. Bumperstickers and the cops.Transactions, 1971, 8, 32-33.
Hunt, E., Lunneborg, C., & Lewis, J. What does itmean to be high verbal? Cognitive Psychology, 1975,7, 194-227.
Jackson, M. D., & McClelland, J. L. Sensory and cogni-tive determinants of reading speed. Journal of VerbalLearning and Verbal Behavior, 1975, 14, 556-574.
Jarvella, R. J. Syntactic processing of connected speech.Journal of Verbal Learning and Verbal Behavior,1971, 10, 409-416.
King, D. R. W., & Greeno, J. G. In variance of inferencetimes when information was presented in differentlinguistic formats. Memory &• Cognition, 1974, 2,233-235.
Kintsch, W. The representation of meaning in memory.Hillsdale, N.J.: Erlbaum, 1974.
Kintsch, W. On comprehending stories. In M. A. Just& P. Carpenter (Eds.), Cognitive processes in compre-hension. Hillsdale, N.J.: Erlbaum, 1977.
Kintsch, W., & Greene, E. The role of culture specificschemata in the comprehension and recall of stories.Discourse Processes, 1978, 1, 1—13.
Kintsch, W., & Keenan, J. M. Reading rate as a func-tion of the number of propositions in the base struc-ture of sentences. Cognitive Psychology, 1973, 5,257-274.
Kintsch, W., & Kozminsky, E. Summarizing storiesafter reading and listening. Journal of EducationalPsychology, 1977, 69, 491-499.
Kintsch, W., Kozminsky, E., Streby, W. J., McKoon,G., & Keenan J. M. Comprehension and recall oftext as a function of content variables. Journal ofVerbal Learning and Verbal Behavior, 1975, 14,196-214.
Kintsch, W., Mandel, T. S., & Kozminsky, E. Sum-marizing scrambled stories. Memory & Cognition,1977, 5, 547-552.
Kintsch, W., & Monk, D. Storage of complex informa-

394 WALTER KINTSCH AND TEUN A. VAN DIJK
tion in memory: Some implications of the speedwith which inferences can be made. Journal ofExperimental Psychology, 1972, 94, 25-32.
Kintsch, W,, & van Dijk, T. A. Comment on se rapelleet on re'sume des histoires. Langages, 1975,40,98-116.
Kintsch, W., & Vipond, D. Reading comprehensionand readability in educational practice and psycho-logical theory. In L. G. Nilsson (Ed.), Memory:Processes and problems. Hillsdale, N.J.: Erlbaum,1978.
LaBerge, D., & Samuels, S. J. Toward a theory ofautomatic information processing in reading. Cogni-tive Psychology, 1974, 6, 293-323.
Labov, W. J., & Waletzky, J. Narrative analysis:Oral versions of personal experience. In J. Helm(Ed.), Essays on the verbal and visual arts, Seattle:Washington University Press, 1967.
Longacre, R., & Levinsohn, S. Field analysis of dis-course. In W. U. Dressier (Ed.), Current trends intextlinguistics. Berlin, West Germany: de Gruyter,1977.
Luria, A. R., & Tsvetkova, L. S. The mechanism of"dynamic aphasia." Foundations of Language, 1968,4, 296-307.
Handler, J. M., & Johnson, N. J. Remembrance ofthings parsed: Story structure and recall. CognitivePsychology, 1977, 9, 111-151.
Meyer, B. The organization of prose and its effect uponmemory. Amsterdam, The Netherlands: NorthHolland, 1975.
Minsky, M. A framework for representing knowledge.In P. Winston (Ed.), The psychology of computervision. New York: McGraw-Hill, 1975.
Neyman, J, Contribution to the theory of the test. InJ. Neyman (Ed.), Proceedings of the Berkeley Sym-posium on Mathematical Statistics and Probability.Berkeley: University of California Press, 1949.
Norman, D. A., & Rumelhart, D. E. Explorations incognition. San Francisco: Freeman, 1975.
Perfetti, C. A., & Goldman, S. R. Discourse memoryand reading comprehension skill. Journal of VerbalLearning and Verbal Behavior, 1976, 15, 33-42.
Perfetti, C. A., & Lesgold, A. M. Coding and compre-hension in skilled reading and implications forreading instruction. In L. B. Resnick & P. Weaver(Eds.), Theory and practice in early reading. Hillsdale,N.J.: Erlbaum, 1978.
Poulsen, D., Kintsch, E., Kintsch, W., & Premack, D.Children's comprehension and memory for stories.Journal of Experimental Child Psychology, in press.
Rumelhart, D. E. Notes on a schema for stories. In D.
Bobrow & A. Collins (Eds.), Representation andunderstanding: Studies in cognitive science. New York:Academic Press, 1975.
Schank, R., & Abelson, R. Scripts, plans, goals, andunderstanding. Hillsdale, N.J.: Erlbaum, 1977.
Sgall, P., & Hajifova, W. E. Focus on focus. ThePrague Bulletin of Mathematical Linguistics, 1977,28, 5-54.
Stein, N. L., & Glenn, C. F. An analysis of story com-prehension in elementary school children. In R.Freedle (Ed.), Multidisciplinary approaches to dis-course processing. Hillsdale, N.J.: Ablex, in press.
Sticht, T. Application of the audread model to readingevaluation and instruction. In L. Resnick & P.Weaver (Eds.), Theory and practice in early reading.Hillsdale, N.J.: Erlbaum, in press.
Turner, A., & Greene, E. The construction of a pro-positional text base. JSAS Catalog of Selected Docu-ments in Psychology, in press.
van Dijk, T. A. Some aspects of text grammars. TheHague, The Netherlands: Mouton, 1972.
van Dijk, T. A. Text grammar and text logic. In J. S.Petofi & H. Rieser (Eds.), Studies in text grammar.Dodrecht, The Netherlands: Reidel, 1973.
van Dijk, T. A. Philosophy of action and theory ofnarrative. Poetics, 1976, 5, 287-338.
van Dijk, T. A. Context and cognition: Knowledgeframes and speech act comprehension. Journal ofPragmatics, 1977, /, 211-232. (a)
van Dijk, T. A. Macro-structures, knowledge frames,and discourse comprehension. In M. A. Just & P.Carpenter (Eds.), Cognitive processes in comprehen-sion. Hillsdale, N.J.: Erlbaum, 1977. (b)
van Dijk, T. A. Pragmatic macro-structures in dis-course and cognition. In M. de Mey et al. (Eds.),Communication and cognition. Ghent, Belgium:University of Ghent, 1977. (c)
van Dijk, T. A. Text and context: Explorations in thesemantics and pragmatics of discourse. London,England: Longmans, 1977. (d)
van Dijk, T. A. Recalling and summarizing complexdiscourse. In W. Burghardt & K. Holker (Eds.),Text processing. Berlin, West Germany: de Gruyter,in press.
van Dijk, T. A., & Kintsch, W. Cognitive psychologyand discourse. In W. Dressier (Ed.), Current trends intextlinguistics. Berlin, West Germany: de Gruyter,1977.
Received January 3, 1978 •





























