Embed Size (px)
Citation preview

POLITECHNIKA WARSZAWSKA
WYDZIA ELEKTRYCZNY
INSTYTUT ELEKTROTECHNIKI TEORETYCZNEJI SYSTEMÓW INFORMACYJNO-POMIAROWYCH
PRACA DYPLOMOWA MAGISTERSKA
na kierunku INFORMATYKA
Zbigniew Przemysªaw KrólNr indeksu 170056
Przegl¡d i komputerowa implementacja algorytmów
genetycznych w oprogramowaniu edukacyjnym
Zakres pracy:
1. Zapoznanie z algorytmami genetycznymi2. Opis po»¡danej funkcjonalno±ci3. Przedstawienie rozwi¡zania implementacji4. Badania eksperymentalne.
Opiekun pracy
dr in». Krzysztof Siwek
Podpis i piecz¦¢
Kierownika Zakªadu Dydaktycznego
Warszawa, 16 listopada 2006Rok akademicki 2005/2006


Spis tre±ci
1 Wst¦p 11.1 Wst¦p . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 1
1.1.1 Obliczenia ewolucyjne . . . . . . . . . . . . . . . . . . . . . . 31.2 Cel pracy dyplomowej . . . . . . . . . . . . . . . . . . . . . . . . . . 4
2 Podstawowe zagadnienia 52.1 Metody przeszukiwania . . . . . . . . . . . . . . . . . . . . . . . . . . 52.2 Zalety i wady stosowania algorytmów genetycznych . . . . . . . . . . 62.3 Podstawowe poj¦cia . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62.4 Zagadnienia dotycz¡ce schematów . . . . . . . . . . . . . . . . . . . . 8
2.4.1 Schematy . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82.4.2 Zdolno±¢ schematów do przetrwania . . . . . . . . . . . . . . . 102.4.3 Bloki buduj¡ce . . . . . . . . . . . . . . . . . . . . . . . . . . 11
2.5 Tworzenie algorytmu genetycznego . . . . . . . . . . . . . . . . . . . 132.6 Staªe parametry charakteryzuj¡ce algorytm . . . . . . . . . . . . . . . 132.7 Zastosowania algorytmów genetycznych . . . . . . . . . . . . . . . . . 14
3 Algorytmy genetyczne i ich schemat dziaªania 163.1 Reprezentacja problemu: chromosom . . . . . . . . . . . . . . . . . . 16
3.1.1 Chromosomy binarne (BCD) . . . . . . . . . . . . . . . . . . . 173.1.2 Chromosomy kodowane metod¡ Graya . . . . . . . . . . . . . 173.1.3 Chromosomy kodowane logarytmiczne . . . . . . . . . . . . . 183.1.4 Chromosomy kodowane zmiennopozycyjnie . . . . . . . . . . . 18
3.2 Dziaªanie algorytmu genetycznego . . . . . . . . . . . . . . . . . . . . 183.3 Warunki stopu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 203.4 Metody generacji rozwi¡za« pocz¡tkowych . . . . . . . . . . . . . . . 203.5 Funkcja przystosowania . . . . . . . . . . . . . . . . . . . . . . . . . . 213.6 Operatory genetyczne . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.7 Operator selekcji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 223.8 Operator krzy»owania . . . . . . . . . . . . . . . . . . . . . . . . . . 263.9 Operator mutacji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 333.10 Operator inwersji . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 343.11 Skalowanie przystosowania . . . . . . . . . . . . . . . . . . . . . . . . 353.12 Specjalizacja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42
3.12.1 Migracja . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 433.12.2 Przenikanie . . . . . . . . . . . . . . . . . . . . . . . . . . . . 44
i

4 Opis funkcjonalno±ci i obsªugi programu 464.1 Zakªadka: Populacja . . . . . . . . . . . . . . . . . . . . . . . . . . . 464.2 Zakªadka: Operatory genetyczne . . . . . . . . . . . . . . . . . . . . . 484.3 Zakªadka: Obsªuga wyj±cia . . . . . . . . . . . . . . . . . . . . . . . . 544.4 Zakªadka: Wykresy i warunki stopu . . . . . . . . . . . . . . . . . . . 564.5 Panel sterowania dziaªaniem algorytmu . . . . . . . . . . . . . . . . . 58
5 Przedstawienie szczegóªów implementacji 595.1 Budowa programu . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.1.1 Przypadki u»ycia . . . . . . . . . . . . . . . . . . . . . . . . . 595.1.2 Pakiety programu . . . . . . . . . . . . . . . . . . . . . . . . . 59
5.2 W¡tki w ±rodowisku Swing . . . . . . . . . . . . . . . . . . . . . . . . 635.3 Zastosowane biblioteki . . . . . . . . . . . . . . . . . . . . . . . . . . 65
5.3.1 JEP - Java Expression Parser . . . . . . . . . . . . . . . . . . 655.3.2 JFreeChart . . . . . . . . . . . . . . . . . . . . . . . . . . . . 66
5.4 Zastosowane technologie . . . . . . . . . . . . . . . . . . . . . . . . . 685.4.1 XML . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 685.4.2 JavaBean . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 705.4.3 Javadoc . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72
5.5 Okno dialogowe pomocy . . . . . . . . . . . . . . . . . . . . . . . . . 735.6 Stosowane oprogramowanie . . . . . . . . . . . . . . . . . . . . . . . . 74
6 Badania eksperymentalne 766.1 Dziaªanie opracowanego programu . . . . . . . . . . . . . . . . . . . . 766.2 Badania eksperymentalne . . . . . . . . . . . . . . . . . . . . . . . . 77
6.2.1 Przykªad pierwszy - poszukiwanie maksimum funkcji . . . . . 776.2.2 Przykªad drugi - wyznaczenie liczby Pi . . . . . . . . . . . . . 886.2.3 Przykªad trzeci - projektowanie ltru dolnoprzepustowego . . 916.2.4 Inne przykªady testowe . . . . . . . . . . . . . . . . . . . . . . 94
7 Podsumowanie i wnioski ko«cowe 977.1 Realizacja celu pracy dyplomowej . . . . . . . . . . . . . . . . . . . . 977.2 Wªasne spostrze»enia i mo»liwo±ci dalszej rozbudowy . . . . . . . . . 97
Bibliograa 101


iv

Rozdziaª 1
Wst¦p
1.1 Wst¦p
Istnieje wiele metod rozwi¡zywania zada« optymalizacyjnych w celu doj±ciado satysfakcjonuj¡cego wyniku. Do rozwi¡zywania stosuje si¦ metody programowa-nia: dynamicznego, heurystycznego przeszukiwania, technik przeszukiwania i ogra-nicze«, itp. Wiele z rozwi¡zywanych zada« wymaga ogromnego nakªadu oblicze-niowego, a niektóre z nich s¡ NP-trudne. Nieraz rozwi¡zanie zadania jest na tylekosztowne i» praktycznie niemo»liwe jest jego rozwi¡zanie.
Jedn¡ z klas algorytmów sªu»¡cych do rozwi¡zywania trudnych problemów ob-liczeniowych s¡ algorytmy aproksymacyjne. S¡ one modelem maszynowego uczeniasi¦ wywodz¡cym swoje dziaªanie z mechanizmów ewolucji wyst¦puj¡cych w natu-rze. Dziaªaj¡ one poprzez stworzenie populacji osobników reprezentowanych przypomocy chromosomów. Osobniki przechodz¡ poprzez proces symulowanej ewolucji.Sªu»¡ do wyznaczania akceptowalnych rozwi¡za« przy pomocy akceptowalnej ilo±cioblicze«. Niestety, nie ma jeszcze metody pozwalaj¡cej na szybkie przej±cie od wy-ników quasi-optymalnych do prawdziwie optymalnych rozwi¡za«.
Do klas algorytmów aproksymacyjnych nale»¡ algorytmy losowe. S¡ one przy-datne w wypadkach rozwi¡zywania wielu typów zada« o wysokim stopniu kompli-kacji. Algorytmy genetyczne (AG) s¡ szczególn¡ losow¡ strategi¡ przeszukiwana.Za twórców matematycznej teorii algorytmów genetycznych uwa»a si¦ J. von Neu-manna oraz J. Hollanda. Od pocz¡tku lat pi¦¢dziesi¡tych, czyli wraz z pocz¡tkamiintensywnego rozwoju genetyki, rozpocz¦ªy si¦ próby zastosowania praw doboru na-turalnego w informatyce. Dobór naturalny zakªada wi¦ksze szanse przetrwania dlaosobników o najlepszym przystosowaniu.
Jednak przed dokªadniejszym omówieniem powy»szego tematu nale»y wspomnie¢o szerszej grupie, do której nale»¡ AG, mianowicie o Algorytmach Ewolucyjnych(AE). S¡ one szerszym terminem opisuj¡cym komputerowe znajdywanie rozwi¡-za« poprzez mechanizmy ewolucji odpowiednio zaprojektowane i zaimplementowanew programach komputerowych.
Algorytmy ewolucyjne to ogólny termin opisuj¡cy komputerowe systemy oblicze-niowe których implementacja oparta jest na mechanizmach ewolucji. Istniejekilka gªównych rodzajów algorytmów ewolucyjnych:
1

• algorytmy genetyczne,
• programowanie ewolucyjne,
• strategie ewolucyjne,
• systemy klasykuj¡ce,
• programowanie genetyczne.
Ka»dy z nich jako podstawow¡ koncepcj¦ swojego dziaªania wykorzystuje sy-mulacj¦ dziaªania ewolucji pewnych struktur przy pomocy operatorów, omó-wionych przeze mnie w dalszej cz¦±ci pracy takich, jak selekcja, mutacja i repro-dukcja (krzy»owanie). Proces zale»y od ocenianej przydatno±ci danych przed-stawicieli struktury w odniesieniu do symulowanego ±rodowiska.
Innymi sªowy algorytmy ewolucyjne charakteryzuj¡ si¦ ewoluowaniem zbio-rów przedstawicieli struktur danych zgodnie z dziaªaniem pewnych okre±lo-nych operatorów przeszukiwania - zwanych operatorami genetycznymi. Ka»dyz przedstawicieli podlega ocenie pod wzgl¦dem przystosowania do reguª oto-czenia. Warto±¢ ta ulega zmianie pod wpªywem wspomnianych operatorów,przy czym wi¦ksze szanse na rozwój w dalszych iteracjach posiadaj¡ obiektyo wy»szej warto±ci przydatno±ci do generacji optymalnego rozwi¡zania, gdy»tym wªa±nie jest owo przystosowanie. Zmiany zachodz¡ce prowadz¡ do heu-rystycznego przeszukiwania przestrzeni rozwi¡za«. Algorytmy te s¡ natomiastwystarczaj¡co rozbudowane by by¢ skutecznym mechanizmem adaptacyjnegoprzeszukiwania.
Algorytmy genetyczne s¡ podklas¡ algorytmów ewolucyjnych. Ich model dzia-ªania opiera si¦ na mechanizmie adaptacji skonstruowanym w oparciu o pro-cesy zaobserwowane w biologicznej ewolucji. Podstaw¡ jest, wspomniana w po-wy»szej denicji, konstrukcja populacji pewnych osobników, reprezentowanychprzez obiekty przynale»¡ce do pewnej struktury, w±ród których pod dziaªaniemokre±lonych operatorów symulowany jest proces ewolucji.
Algorytmy te s¡ u»ywane w wielu dziedzinach nauki (rozdziaª 2.7), w szczegól-no±ci jako metody optymalizacyjne w przypadku wielowymiarowych zagadnie«do obliczania rozwi¡za«, dla których nie istniej¡ dokªadne metody analityczne.
W podstawowym schemacie dziaªania reprezentantem jest tablica znaków (naj-cz¦±ciej binarna), natomiast podstawowe operatory genetyczne to krzy»owaniei mutacja. W przypadku algorytmów genetycznych tablice znakowe s¡ okre±lo-nej dªugo±ci, tak samo jak ilo±¢ dost¦pnych znaków (nazywana alfabetem).
Dziaªanie algorytmu przebiega iteracyjnie, a powtarzaj¡ce si¦ kroki wygl¡daj¡nast¦puj¡co:
okre±lenie przydatno±ci ka»dego z osobników populacji,
stworzenie nowego zbioru osobników (nowej populacji) poprzez operatory:
selekcji - proporcjonalnej do przydatno±ci,
krzy»owania,
mutacji.
2

zast¡pienie starej populacji now¡.
Pocz¡tkowy zbiór osobników generowany jest losowo, ewentualnie w sposóbukierunkowany przez znajomo±¢ problemu. Dalej przebiega ju» omówiony pro-ces adaptacji, a» do znalezienia satysfakcjonuj¡cego rozwi¡zania lub stwierdze-nia rozbie»no±ci algorytmu nie pozwalaj¡cej na skuteczne znalezienie rozwi¡-zania w sko«czonym czasie [13].
W wyniku dziaªania algorytmów genetycznych z przybli»onych rozwi¡za« po-wstaj¡ kolejne bardziej dokªadne rozwi¡zania. Nowe przybli»enia nie powstaj¡ lo-sowo, a przynajmniej w obr¦bie reguª wystarczaj¡cych by nie mo»na byªo ich za takieuzna¢, powstaj¡ w otoczeniu przybli»e« najbardziej obiecuj¡cych.
Pocz¡tkowo metody algorytmów genetycznych mo»na byªo podzieli¢ na dwiegªówne grupy:
• gªówny kierunek przeszukiwania wynikaª z wyznaczenia kombinacji najbardziejobiecuj¡cych rozwi¡za« - co za tym idzie, dokªadniejsza lokalizacja wcze±niejwykrytych ekstremów lokalnych funkcji dopasowania,
• przeszukanie caªej przestrzeni potencjalnych rozwi¡za« - maªo efektywne przydu»ych rozmiarach przestrzeni, zwykle niemo»liwe z praktycznego punktu wi-dzenia.
Obecne algorytmy z ró»n¡ intensywno±ci¡ ª¡cz¡ obie te techniki. Oczywi±cie w przy-padku istnienia konwencjonalnych (analitycznych) algorytmów do rozwi¡zania da-nego problemu uniwersalny algorytm genetyczny b¦dzie od nich gorszy.
Mo»na wyró»ni¢ cztery cechy odró»niaj¡ce algorytmy genetyczne od konwencjo-nalnych technik optymalizacji:
• operuj¡ na ci¡gach kodowych,
• dziaªaj¡ na populacjach punktów, a nie na pojedynczych punktach,
• poszukuj¡ metod¡ próbkowania (tak zwane ±lepe przeszukiwanie),
• stosuj¡ losowe reguªy wyboru.
1.1.1 Obliczenia ewolucyjne
Podstawowy podziaª dotycz¡cy oblicze« ewolucyjnych dzieli zagadnienia i spo-soby ich rozwi¡zania na:
• algorytmy genetyczne (genetic algorythm) [AG],
• strategie ewolucyjne (evolution strategies) [SE],
• programowanie ewolucyjne (evolutionary programming) [PE],
• programowanie genetyczne (genetic programming) [PG].
3

Moja praca dotyczy gªównie algorytmów genetycznych, jednak jej tematyka pokrywasi¦ te» cz¦±ciowo z zagadnieniami strategii ewolucyjnych. Zgodnie z denicjami za-czerpni¦tymi z [6]:
Algorytmy genetyczne (AG) zwykle przedstawiaj¡ rozwi¡zania dla chro-mosomów kodowanych binarnie i poszukiwania lepszych rozwi¡za«w przestrzeni genotypu prowadzone s¡ przy zastosowaniu operato-rów AG: selekcji, krzy»owania, i mutacji. Gªównym operatorem jest ope-rator krzy»owania.
Strategie ewolucyjne (SE) przedstawiaj¡ rozwi¡zania wyra»one przy po-mocy chromosomów kodowanych liczbami typu rzeczywistego (fenotyp)i poszukuj¡ lepszego rozwi¡zania w przestrzeni fenotypu z zastosowa-niem operatorów SE: krzy»owania i mutacji. Mutacja liczb typu rzeczy-wistego realizowana jest przez dodanie szumu gaussowskego. Strategieewolucyjne modykuj¡ odpowiednio wspóªczynniki dystrybucji Gaussaprowadz¡c do zbie»no±ci do globalnego optimum.
1.2 Cel pracy dyplomowej
Celem pracy dyplomowej jest:
• zapoznanie si¦ z zagadnieniami dotycz¡cymi algorytmów genetycznych,
• napisanie komputerowej implementacji programu do symulacji algorytmów ge-netycznych.
Napisany program, zgodnie z zaªo»eniami, powinien pozwala¢ na uruchamianiealgorytmów genetycznych o dowolnym wzorze funkcji przystosowania. Funkcja tamo»e by¢ okre±lona dowoln¡ ilo±ci¡ zmiennych. Wykonana implementacja powinnaumo»liwia¢ wybór jednego z kilku sposobów kodowania chromosomu i odpowied-nich ustawie« wybranych operatorów genetycznych i warunków stopu zale»nie odwybranego kodowania.
Powinien by¢ mo»liwy zapis i odczyt zarówno ustawie«, jak i zadanych populacji.Najlepiej do pliku, który mo»e by¢ otworzony w innym programie zewn¦trznym.Prócz tego program powinien umo»liwia¢ zapis wyników dziaªania algorytmu.
Dodatkowo architektura programu powinna umo»liwia¢ jest dalsz¡ rozbudow¦.
4

Rozdziaª 2
Podstawowe zagadnienia
2.1 Metody przeszukiwania
Metody przeszukiwania mog¡ by¢ stosowane w wypadku gdy istnieje wystarcza-j¡ca wiedza o danym problemie (mo»liwo±¢ stosowania efektywnych funkcji oceny)lub gdy zªo»ono±¢ problemu nie jest zbyt du»a. Rozwi¡zanie zadania jest cz¦stoprzeszukaniem zbioru wszystkich mo»liwych rozwi¡za«, zwanego przestrzeni¡ prze-szukiwania. Celem strategii przeszukiwania jest analizowanie elementów przestrzenizbioru potencjalnych rozwi¡za« w celu wyznaczenia podzbioru speªniaj¡cego okre-±lone warunki.
Ze wzgl¦du na sposób opisu zadania, zgodnie z tym co pisze Jerzy Cytowskiw [1], istotne s¡:
• sposób reprezentacji ka»dego z elementów zbioru (kod),
• metody obliczeniowe pozwalaj¡ce na wygenerowanie kolejnego elementuna podstawie danego elementu (operatory),
• metody wyboru operatorów spo±ród operatorów mo»liwych do zastosowania(strategie sterowania).
Wa»ne jest aby kod elementu byª jednoznaczny i uwzgl¦dniaª struktury zadania.Oznacza to, »e powinien reprezentowa¢ indywidualne cechy elementu oraz podzbiórpotencjalnych rozwi¡za« zwi¡zany z elementem.
W±ród metod przeszukiwania wyró»nia si¦ nast¦puj¡ce:
• strategia zachªanna (hill-climbing),
• strategia w gª¡b (depth-rst),
• strategia w gª¡b z iteracyjnym pogª¦bianiem (depth-rst interative-deepening),
• strategie heurystyczne,
• losowe algorytmy rozwi¡zywania zada«.
Wa»ne jest aby w przypadku algorytmów losowych speªnione zostaªy dwa warunki:
5

• dokªadne zbadanie najbardziej obiecuj¡cych obszarów przestrzeni (analizawielu reprezentantów), w algorytmach genetycznych sªu»y do tego mechanizmselekcji, a tak»e migracji i przenikania,
• ocena jak najwi¦kszej liczby potencjalnych rozwi¡za« poªo»onych w ró»nychobszarach przestrzeni, w przypadku algorytmów genetycznych sprzyja temumutacja i inwersja.
2.2 Zalety i wady stosowania algorytmów genetycz-
nych
Gªówne zalety wynikaj¡ce ze stosowania algorytmów genetycznych:
1. szybka zbie»no±¢ do bliskiego otoczenia globalnego optimum,
2. doskonaªe mo»liwo±ci przeszukiwania przestrzeni o zªo»onych przestrzeniachprzeszukiwania,
3. mo»liwo±¢ stosowania do przestrzeni poszukiwa«, w których nie ma mo»liwo±cizastosowania metod gradientowych.
Wadami natomiast s¡:
1. zbie»no±¢ w blisko±ci optimum globalnego staje si¦ bardzo wolna,
2. dziaªanie algorytmu genetycznego jest zauwa»alnie wolniejsze i mniej dokªadneni» metod analitycznych.
Nale»y zaznaczy¢ i» nie mo»na caªkowicie zaprzeczy¢ jakoby algorytmy ewolucyjnenie byªy losowym sposobem poszukiwaniem rozwi¡zania. Algorytmy ewolucyjne ko-rzystaj¡ z procesów stochastycznych jednak rezultat ich dziaªania jest znacz¡co nie-przypadkowy - to znaczy, znacznie lepszy ni» otrzymany tradycyjnymi metodamilosowymi.
2.3 Podstawowe poj¦cia
Zaznajamiaj¡c si¦ z zagadnieniami algorytmów genetycznych wa»ne jest pozna-nie poj¦¢ i terminologii wywodz¡cej si¦ z genetyki u»ywanej do ich opisu. Poni»ejprzedstawiam zebrane podstawowe poj¦cia, opracowane na podstawie [1, 2, 3, 5, 8],którymi posªuguj¦ si¦ w dalszej cz¦±ci mojej pracy.
Chromosom - uto»samiany jest z uszeregowanym liniowo ci¡giem kodowym (ªa«-cuch bitowy, wektor typu rzeczywistego, itp.) o okre±lonej dªugo±ci, no±nikjednoznacznej, uporz¡dkowanej informacji.
Gen - cecha, znak w ci¡gu kodowym, skªadowe kodu chromosomu.
Allel - odmiana genu (wariant cechy) - w przypadku algorytmów genetycznychz genami binarnymi 0 lub 1.
6

Fenotyp - zestaw cech danego osobnika podlegaj¡cych ocenie ±rodowiska, cechyujawniaj¡ce si¦ na zewn¡trz, rozwi¡zanie zadania.
Funkcja przystosowania - reprezentuje ±rodowisko zewn¦trzne, na jej podstawieosobnikom przypisuje si¦ odpowiedni¡ warto±¢ funkcji przystosowania, którajest odwzorowaniem ich przydatno±ci do rozwi¡zania okre±lonego zagadnienia.
Genotyp - struktura, informacja b¦d¡ca przepisem na utworzenie jednoznacznegofenotypu. Genotyp ulega zmianie pod wpªywem krzy»ówek i mutacji, zmianyte maj¡ charakter przypadkowy. W algorytmach genetycznych s¡ to poszcze-gólne ªa«cuchy, najcz¦±ciej - bitowe, np. 00101101. To wªa±nie genotyp jestobiektem, na którym dziaªaj¡ algorytmy genetyczne.
Osobnik - posiadacz genotypu i jednocze±nie powi¡zanego z nim fenotypu.
Populacja - podprzestrze« rozwi¡za«, zbiór okre±lonej liczby osobników, którzymog¡ wchodzi¢ ze sob¡ w interakcje.
Locus - miejsce wyst¦powania genu w chromosomie, miejsce w ªa«cuchu.
Epistaza - oznacza w przypadku algorytmów genetycznych nieliniowo±¢ - okre±le-nie na ile wpªyw jednego genu na dopasowanie ªa«cucha zale»y od warto±ciinnych genów. W terminologii biologicznej jest to wspóªdzielenie genów zloka-lizowanych w ró»nych miejscach wyst¦powania.
Generacja - iteracja pomiaru przystosowania i wygenerowania kolejnych populacji.
W przypadku terminologii dotycz¡cej programowania genetycznego pojawia si¦ nie-±cisªo±¢ j¦zykowa. Przejawia si¦ ona w nazywaniu zbioru genów, genotypu, osobni-kiem, czyli jednostk¡ tworz¡c¡ populacj¦. Jednocze±nie oczywistym jest i» w j¦zykucodziennym mówi¡c o osobniku my±limy o konkretnej osobie, zwierz¦ciu, a nie jegochromosomie. Jednak powy»sza rozbie»no±¢ jest caªkowicie usprawiedliwiona. W al-gorytmach genetycznych droga od genotypu do fenotypu jest zwykle jednoznaczniewyznaczon¡ procedur¡. W zwi¡zku z powy»szym nie±cisªo±¢ j¦zykowa o której pisz¦jest naturalna.
Denicja 1 (Przestrze« poszukiwa«) Je±li rozwi¡zanie problemu mo»e by¢ re-prezentowane schematem R (np. N parametrów rzeczywisto-liczbowych), wtedy prze-strze« poszukiwa« jest zbiorem wszystkich mo»liwych konguracji które mog¡ by¢przedstawione w R (w przypadku tego przykªadu N2).
Denicja 2 (Rozkªad normalny) Zmienna losowa posiada rozkªad normalny je-±li funkcja jej g¦sto±ci jest opisana wzorem (2.1).
f(x) =1√
2 · π · σ2· exp
−0, 5 · (x− µ)2
σ2, (2.1)
gdzie µ jest warto±ci¡ ±redni¡ zmiennej losowej x, natomiast σ jest odchyleniemstandardowym.
Denicja 3 (Odchylenie standardowe) Odchylenie standardowe jest miar¡ roz-pi¦to±ci zbioru danych. Miar¡ zmienno±ci zmiennej losowej.
7

2.4 Zagadnienia dotycz¡ce schematów
2.4.1 Schematy
Wa»ne miejsce w teorii algorytmów genetycznych zajmuje poj¦cie schematu.Schematy sªu»¡ do badania i klasykowania ci¡gów kodowych. S¡ tak»e podsta-wowym ±rodkiem analizy wpªywu selekcji i pozostaªych operatorów genetycznychna rozprzestrzenianie si¦ danych ukªadów chromosomów w populacji.
Wa»nym zagadnieniem dotycz¡cym teorii schematów jest spojrzenie na chro-mosom jako na wektor, który jest punktem w wielowymiarowej (lwymiarowej)przestrzeni rozwi¡za«. Ka»dy z genów reprezentuje jednocze±nie jeden z wymiarów(locus), a prócz tego jednocze±nie okre±lon¡ warto±¢ (allel). Schemat jest, w tymuj¦ciu, okre±lonym zestawem staªych warto±ci wybranych genów w chromosomie.Odpowiada to reprezentacji w postaci hiperpªaszczyzny w przestrzeni rozwi¡za«.
Schemat jest zbiorem wszystkich chromosomów które na okre±lonych pozycjachposiadaj¡ te same geny. W praktyce oznacza to wprowadzenie do alfabetu dodat-kowego symbolu nieistotne (*). Przykªadów jest niesko«czenie wiele, kilka z nichprzedstawiªem poni»ej.
*001 0001, 1001*00* 0000, 0001, 1000, 1001
1*0*11 100011, 100111, 110011, 110111*** 000, 001, 011, 010, 110, 100, 101, 111
Na powy»szych przykªadach mo»na ªatwo zaobserwowa¢ i»:
• dla ka»dego k-elementowego alfabetu istnieje (k + 1)l schematów, gdzie l jestliczb¡ genów,
• do ka»dego schematu pasuje dokªadnie 2r ªa«cuchów, gdzie r jest liczb¡ sym-boli nieistotne,
• do ka»dego ªa«cucha o dªugo±ci l pasuje 2l schematów,
• dla ka»dego ªa«cucha o dªugo±ci l istnieje 3l schematów,
• w populacji o liczno±ci n mo»e by¢ reprezentowanych od 2l do n · 2l ró»nychschematów.
Dla schematów istniej¡ dwie charakterystyczne wªasno±ci. S¡ nimi rz¡d i dªugo±¢deniuj¡ca.
Denicja 4 (Rz¡d) Rz¦dem schematu H (oznaczanym przez o(H)) okre±la si¦liczb¦ pozycji ustalonych w schemacie.
Przykªady:
H1 = (∗ ∗ ∗ ∗ 01∗) o(H1) = 2H2 = (1 ∗ 0 ∗ 01∗) o(H2) = 4H3 = (1111010) o(H3) = 7
8

Denicja 5 (Dªugo±¢ deniuj¡ca) Dªugo±¢ deniuj¡ca (rozpi¦to±¢, [2]) sche-matu H (oznaczana przez δ(H)) jest odlegªo±ci¡ mi¦dzy pierwsz¡ a ostatni¡ ustalon¡pozycj¡ schematu. Sªu»y ona do okre±lenia zawarto±ci informacji przechowywanychw schemacie.
Przykªady:
δ(H1) = 7− 6 = 1δ(H2) = 7− 2 = 5δ(H3) = 7− 1 = 6
Na podstawie powy»szych przykªadów mo»na zauwa»y¢, »e schemat z jedn¡ pozycj¡ustalon¡ ma dªugo±¢ deniuj¡c¡ równ¡ 0.
Zale»nie od dªugo±ci schematu ma on mniejsze lub wi¦ksze szanse na przetrwanie.Wzór (2.2) opisuje prawdopodobie«stwo zniszczenia schematu H (pd) na skutekkrzy»owania jednopunktowego.
pd(H) = δ(H)/(l − 1) (2.2)
Co za tym idzie prawdopodobie«stwo przetrwania schematu (ps) wyra»one jest wzo-rem (2.3).
ps(H) = 1− δ(H)/(l − 1) (2.3)
Poniewa» tylko niektóre chromosomy zostan¡ wybrane do krzy»owania, to prawdziweprawdopodobie«stwo przetrwania schematu wyra»one jest poprzez wzór (2.4), gdziepc jest prawdopodobie«stwem krzy»owania.
ps(H) = 1− pc · δ(H)/(l − 1) (2.4)
Jednak nie jest to jeszcze caªkowicie zgodne z rzeczywisto±ci¡. Wystarczy rozwa»y¢przykªad, gdzie chromosomy zapisane s¡ jako [0011], [0111] i [0001], gdy schemat H1
ma posta¢ [0 ∗ ∗1], to dowolnie krzy»uj¡c powy»szych osobników nie ma mo»liwo±cizniszczenia go, podczas gdy schemat H2 maj¡cy posta¢ [∗11∗] ma mniejsz¡ szans¦przetrwania. W zwi¡zku z tym potrzebna jest modykacja wzoru (2.4), dzi¦ki czemuotrzymywana jest ostateczna posta¢ (2.5).
ps(H) ≥ 1− pc · δ(H)/(l − 1) (2.5)
Mo»na stwierdzi¢, »e schematy s¡ podstaw¡ dziaªania algorytmów genetycznych.Podstawowe operacje wyst¦puj¡ce w algorytmach genetycznych, to: reprodukcja,
krzy»owanie i mutacja. Maj¡ one bezpo±redni wpªyw na reprodukcj¦ schematów.Efektem reprodukcji, jak ªatwo to zaobserwowa¢, jest wzrost ilo±ci dobrych sche-matów w populacji. Jest to oczywiste - osobniki b¦d¡ce ich nosicielami s¡ lepiejprzystosowane, wi¦c w zwi¡zku z tym charakteryzowane s¡ przez wi¦ksze prawdopo-dobie«stwo selekcji. Sama reprodukcja (selekcja elitarna) nie wnosi nowych elemen-tów do puli schematów. Dalej zachodzi krzy»owanie. Mo»e ono mie¢ destruktywnywpªyw na schemat. Poniewa» schemat ulega zniszczeniu je±li zostanie przeci¦ty, tooczywiste jest i» schemat jest tym trwalszy im mniejsza jego dªugo±¢ deniuj¡ca.
9

Mutacja o niewielkim nat¦»eniu ma znikomy wpªyw na schematy. Oczywi±cie imwi¦kszy jego rz¡d, tym wi¦ksza szansa, »e ulegnie zniszczeniu w trakcie ewentualnejmutacji.
W tym miejscu mo»na doj±¢ do do±¢ jasnego wniosku, do którego na podstawiepodobnego toku rozumowania doszedª Goldberg [2]:
Schematy o wysokim przystosowaniu i maªej rozpi¦to±ci [. . . ] propaguj¡si¦ z pokolenia na pokolenie w rosn¡cych wykªadniczo porcjach; wszystkoto odbywa si¦ równolegle, nie wymagaj¡c »adnej specjalnej organizacjiprogramu ani dodatkowej pami¦ci
Powy»sz¡ cech¦ algorytmów genetycznych nazywa si¦ ukryt¡ równolegªo±ci¡.Schematy mo»na rozpatrywa¢ jako hiperpªaszczyzny w przestrzeni rozwi¡za«.
Wymiarowo±¢ tych hiperpªaszczyzn zale»y bezpo±rednio od rz¦du i mo»e zosta¢ wy-ra»ona wzorem: n−o, gdzie n jest liczb¡ wymiarów przestrzeni rozwi¡za« (dªugo±ci¡chromosomu), natomiast o jest rz¦dem schematu.
Nale»y zauwa»y¢ i» warto±¢ schematu, w odniesieniu do rozwi¡zania optymal-nego w algorytmie genetycznym, nie opiera si¦ jedynie na warto±ci funkcji przysto-sowania. Oczywi±cie istotny jest fakt i» cenniejszy, z dwóch schematów o równymrz¦dzie, jest ten którego warto±¢ funkcji przystosowania jest wy»sza. Jednak prócztego wa»ny jest te» rz¡d schematu. Nale»y zauwa»y¢, »e schemat wy»szego rz¦du(np. o, w przestrzeni n-wymiarowej), z tak¡ sam¡ warto±ci¡ funkcji przystosowaniajak schemat rz¦du ni»szego (np. o − m, przy m > 0), jest bardziej warto±ciowygdy» jest odpowiednikiem hiperpªaszczyny o mniejszej liczbie wymiarów (n− o), cojest bli»sze konkretnemu rozwi¡zaniu (o m wymiarów), ni» schemat ni»szego rz¦du(n− o + m). W szczególno±ci schemat rz¦du równego dªugo±ci chromosomu, o naj-lepszym ze wszystkich schematów przystosowaniu b¦dzie rozwi¡zaniem najbardziejoptymalnym. W zwi¡zku z powy»szym poszukiwanie rozwi¡zania optymalnego mo»eby¢ jednocze±nie poszukiwaniem najlepszego schematu.
2.4.2 Zdolno±¢ schematów do przetrwania
W bie»¡cym podpunkcie przedstawi¦ niezwykle interesuj¡ce zagadnienie wspóª-czynnika przetrwania schematów (ang. survival rate). Zagadnienie to opisane zostaªowyczerpuj¡co w [8].
Mo»na rozwa»y¢ schemat H, który pozostaje powy»ej ±redniej przystosowaniaosobników o warto±¢ c. Przy tym ±rednie przystosowanie populacji wyra»one jestprzez f . Jak ªatwo da si¦ zauwa»y¢ ±rednie przystosowane osobników pasuj¡cychdo schematu H mo»na wyrazi¢ wzorem (2.6).
f(H) = (1 + c)f (2.6)
Zakªadaj¡c jedynie wyst¦powanie reprodukcji (przyjmuj¦ jako metod¦ selekcji se-lekcj¦ proporcjonaln¡) je±li przyj¡¢, »e m(H, t) odpowiada ilo±ci osobników repre-zentowanych przez schemat H w generacji t, to oczekiwana ilo±¢ reprezentantówpowy»szego schematu w generacji t+1 przedstawiona jest wzorem (2.7), i nazywany
10

jest równaniem wzrostu.
m(H, t + 1) = m(H, t)f(H)
f= (1 + c)m(H, t) (2.7)
Ze wzgl¦du na to, »e schemat H powoduje przystosowanie wy»sze od przeci¦tnego,w zwi¡zku z tym kolejna generacja posiada wi¦ksz¡ ilo±¢ osobników reprezentuj¡cychgo. Rozpatruj¡c przyrost ilo±ci reprezentantów z uwzgl¦dnieniem wpªywu krzy»owa-nia i mutacji (obydwa operatory dziaªaj¡ce jednopunktowo) powy»szy wzór przed-stawi¢ mo»na jako (2.8).
m(H, t + 1) ≥ m(H, t)f(H)
f
[1− pc
δ(H)
l − 1− pmo(H)
], (2.8)
gdzie pc jest prawdopodobie«stwem zaistnienia w nowej generacji na skutek krzy»o-wania, w odró»nieniu od reprodukcji, δ(H) jest dªugo±ci¡ deniuj¡c¡ (patrz denicja5) schematu H, l dªugo±ci¡ chromosomu, pm prawdopodobie«stwem mutacji, nato-miast o(H) jest rz¦dem schematu (patrz denicja 4).
Zaªo»one zostaªo, »e schemat H w wyniku krzy»owania lub mutacji zginie, odnosisi¦ to do cz¦±ci wzoru zawieraj¡cej prawdopodobie«stwo przetrwania schematu (2.5).Nie rozwa»yªem natomiast faktu powstania nowych chromosomów przynale»nychdo H. Jak wida¢ wyra¹nie w tym wypadku stosuje szacowanie dolne dla mo»liwo±ciprzetrwania schematu H. Dotyczy to szczególnie drugiego czªonu w nawiasie.
Je»eli za± chodzi o mutacj¦, to zostaªa zastosowana aproksymacja(1− pm)o(H) ∼= pmo(H), ze wzgl¦du na zaªo»enie, »e pm 1.
Jak wida¢ z (2.8) krótkie schematy (maªe δ(H)) niskiego rz¦du (maªe o(H))powy»ej ±redniej warto±ci przystosowania (wysokie f(H)/f) propagowane s¡ w ko-lejnych generacjach, i zgodnie z tym co pisze Falkenauer [8] i Goldberg [2], liczbaosobników reprezentuj¡cych dany schemat wzrasta wykªadniczo - o czym wspomnia-ªem ju» wcze±niej. Jest to tre±ci¡ twierdzenia o schematach.
Twierdzenie 1 (Twierdzenie o schematach) Krótkie schematy niskiego rz¦dui ocenione powy»ej ±redniej uzyskuj¡ wykªadniczo rosn¡c¡ liczb¦ ªa«cuchów w ko-lejnych pokoleniach.
Z powy»szego twierdzenia wynika, »e w przypadku gdy nie ma mo»liwo±ci za-stosowania metod analitycznych do rozwi¡zania problemu (np. optymalizacyjnego)nie ma lepszego sposobu przeszukiwania podprzestrzeni rozwi¡za« ni» algorytmygenetyczne.
2.4.3 Bloki buduj¡ce
Poniewa» krzy»owanie rozrywa ªa«cuchy obecne w chromosomie, powoduj¡c nisz-czenie dªugich schematów, ªatwo mo»na zauwa»y¢ i» krótsze schematy maj¡ znaczniewi¦ksze mo»liwo±ci przetrwania.
W zwi¡zku z powy»szym podpunktem od samego pocz¡tku dziaªania algorytmuwa»ne s¡ schematy o ponadprzeci¦tnym przystosowaniu. Krótkie schematy charakte-ryzuj¡ce si¦ ponadprzeci¦tnym przystosowaniem mog¡ by¢ postrzegane jako cegieªki
11

do budowy najlepiej przystosowanych osobników. Wªa±nie one nazywane s¡ blokamibuduj¡cymi.
Trudno±ci¡ na któr¡ napotyka si¦ w próbie skorzystania ze schematów jest ichilo±¢. Ze wzgl¦du na ni¡ niemo»liw¡ staje si¦ bezpo±rednia ocena ka»dego z nisko-rz¦dowych schematów.
Schemat jest reprezentowany przez hiperpªaszczyzn¦ w przestrzeni rozwi¡za«.Punkt, czyli w szczególno±ci rozwi¡zanie, jest miejscem gdzie przecinaj¡ si¦ hiper-pªaszczyzny. W zwi¡zku z powy»szym poszukiwanie optimum mo»e by¢ postrzeganejako poszukiwanie najlepszego schematu.
Emanuel Falkenauer [8] przedstawiª ciekawe wyprowadzenie ilo±ci potomków dlaponadprzeci¦tnie przystosowanych schematów. Na podstawie wyprowadze« zostaªsformuªowany wniosek, który pozwol¦ sobie tutaj przytoczy¢:
[. . . ] AG wykorzystuj¡ strategi¦ próbnej alokacji [. . . ] b¦d¡c¡ optymaln¡[w przypadku] nieuniknionej niepewno±ci, »e niezb¦dne b¦dzie przeszu-kiwanie ogromnych przestrzeni poszukiwa«.
Wynika z tego, »e w wypadku gdy wniosek ten daje si¦ zastosowa¢ algorytmy gene-tyczne s¡ najlepszym z mo»liwych sposobem przeszukiwania przestrzeni poszukiwa«.
W zwi¡zku z powy»szym mo»na stwierdzi¢ i» schematy trafnie opisuj¡ sposóbdziaªania algorytmów genetycznych, pomimo »e nie da si¦ ich bezpo±rednio wyko-rzysta¢ - cho¢ zostaªy skonstruowane metody na nich oparte (patrz krzy»owanieSimplex, w punkcie 3.8). Wniosek jaki z tego wypªywa jest taki, »e wybieraj¡c spo-sób kodowania chromosomów dla danego rozwi¡zania, a tak»e projektuj¡c operatorydziaªaj¡c na chromosomach, w celu optymalizacji nakªadów na poszukiwania wzgl¦-dem przeszukiwanego obszaru podprzestrzeni poszukiwa« nale»y bra¢ pod uwag¦schematy.
Twierdzenie 2 (Twierdzenie o blokach buduj¡cych) Algorytm genetycznyposzukuje dziaªania zbli»onego do optymalnego przez zestawianie krótkich, niskiegorz¦du schematów o du»ej wydajno±ci dziaªania, zwanych blokami buduj¡cymi.
Denicja 6 (Zwodzenie) Zwodzenie stan w którym ª¡czenie dobrych bloków bu-duj¡cych prowadzi do spadku warto±ci funkcji przystosowania. Jest przyczyn¡ nie-przydatno±ci okre±lonych algorytmów genetycznych do rozwi¡zywania niektórych pro-blemów.
Powy»sze zjawisko jest silnie poª¡czone z poj¦ciem epistazy. W przypadku wysokiejepistazy bloki buduj¡ce nie mog¡ si¦ formowa¢ i w efekcie tego zadanie jest zawodne.Istniej¡ metody post¦powania w tym przypadku. Poni»ej wymieniam i opisuj¦ jew skrócie.
1. zmiana sposobu kodowania, niezb¦dna jest do tego wst¦pna wiedza na tematproblemu,
2. u»ycie operatora inwersji, nie zawsze jest to jednak wystarczaj¡ce,
3. zastosowanie nieporz¡dnego algorytmu genetycznego, algorytmy te posiadaj¡kilka ciekawych wªa±ciwo±ci, jednak nie zajmowaªem si¦ nimi - po wi¦cej in-formacji odsyªam do [3] gdzie zostaªy dobrze opisane.
12

Denicja 7 (Dryf genowy) Dryf genowy jest procesem zmniejszania si¦ prawdo-podobie«stwa wyst¡pienia niektórych alleli. Zwi¦ksza si¦ ze wzrostem ilo±ci pokole«.Szybciej wyst¦puje w maªych populacjach. Mo»e prowadzi¢ do wygini¦cia okre±lonychalleli, przez to zmniejszaj¡c ró»norodno±¢ genetyczn¡ populacji.
2.5 Tworzenie algorytmu genetycznego
Tworzenie algorytmu genetycznego opiera si¦ na sze±ciu skªadowych:
1. odpowiednia reprezentacja rozwi¡zywanego problemu,
2. metoda generacji rozwi¡za« pocz¡tkowych,
3. funkcja przystosowania (sªu»y do oceny potencjalnych rozwi¡za«),
4. operatory genetyczne,
5. staªe parametry charakteryzuj¡ce dany algorytm - takie jak: rozmiar populacji,prawdopodobie«stwo stosowania operatorów genetycznych,
6. warunki zako«czenia dziaªania algorytmu.
2.6 Staªe parametry charakteryzuj¡ce algorytm
Nawet najprostszy algorytm genetyczny posiada zestaw parametrów, przez którejest charakteryzowany. Parametry te s¡ niezmienne podczas dziaªania algorytmui zale»nie od ich warto±ci algorytm mo»e by¢ bardzo przydatny do znalezienia roz-wi¡zania dla rozpatrywanego zagadnienia lub zupeªnie nieprzydatny. W niektórychimplementacjach prawdopodobie«stwo mutacji mo»e ulega¢ zmianie w kolejnych ge-neracjach - nale»y mie¢ to na uwadze, czasami zdarzaj¡ si¦ implementacje w którychrozmiar populacji lub nawet dªugo±¢ chromosomu osobników jest zmienna - s¡ tojednak przypadki szczególne i zwykle ±ci±le powi¡zane z rodzajem zadania do roz-wi¡zania którego stosowany jest algorytm. Algorytm mo»e by¢ bezwarto±ciowy zewzgl¦du na zachodz¡c¡ w nim rozbie»no±¢ lub cz¦stszy przypadek, zbie»no±¢ do lo-kalnego ekstremum.
Wyodr¦bniªem sze±¢ podstawowych grup i parametrów charakterystycznych:
• rodzaj kodowania chromosomu,
• dªugo±¢ chromosomu,
• rozmiar populacji i ich ewentualnego rozkªadu,
• wyst¦powanie podpopulacji (specjalizacja) i wykorzystanie operatora migracjilub przenikania,
• rodzaje stosowanych operatorów genetycznych (selekcja, krzy»owanie, muta-cja, inwersja),
13

• prawdopodobie«stwo zaj±cia mutacji,
• rodzaj wybranego skalowania.
Opis, sposób dziaªania i znaczenie powy»szych parametrów przedstawiªem w dal-szych cz¦±ciach mojej pracy.
2.7 Zastosowania algorytmów genetycznych
Algorytmy genetyczne posiadaj¡ rozliczne zastosowania. Wymieni¦ tutaj nie-które z nich, zaczerpni¦te z [10, 12, 13, 15].
• In»ynieria komputerowa: wykorzystanie AG w wi¦kszo±ci wszelkich rodzajówsystemów adaptacyjnych.
• In»ynieria komputerowa: u»ycie algorytmów genetycznych w systemach rozpo-znawania wzorców, ich rola polega tutaj na dokonywaniu klasykacji.
• In»ynieria komputerowa: wykrywanie brzegów obrazów, implementacja madwa zadania - sterowane lokalnym doborem parametrów ltracji obrazu; loka-lizacja punktów brzegowych.
• In»ynieria komputerowa: Algorytmy genetyczne wykorzystywane s¡ do asysto-wania sieciom neuronowym:
wybór cech lub transformacja przestrzeni cech u»ywanej przez klasyka-tor sieci neuronowej,
wybór sposobu uczenia lub parametrów steruj¡cych uczeniem,
analiza sieci neuronowych.
• In»ynieria: budowa samolotów niewykrywalnych przez radary - okre±lenie opty-malnego ksztaªtu.
• In»ynieria: budowa anten satelitarnych, okre±lenie optymalnego ksztaªtu po-trzebnego do maksymalizacji propagacji po»¡danego sygnaªu przy minimali-zacji zakªóce«.
• In»ynieria: wykorzystywane w systemach w których wyst¦puje problem opty-malizacyjny.
• In»ynieria: budowanie cyfrowych adaptacyjnych ltrów rekursywnych.
• In»ynieria: techniki efektywnego wykrywania, ±ledzenia i precyzyjnego okre-±lenia odlegªo±ci od podwodnych obiektów przy u»yciu - du»ych macierzy pa-sywnych sonarów, radarów, kamer wideo.
14

• Produkcja: optymalne wykorzystanie ci¦tych materiaªów, u»ycie algorytmówgenetycznych sprowadza si¦ do okre±lenia optymalnego ci¦cia elementów danejdªugo±ci w celu minimalizacji ilo±ci odpadków i jak najszybszego speªnieniaokre±lonych zamówie«; wycinanie zadanej ilo±ci ksztaªtów z jak najmniejszejpowierzchni materiaªu.
• Astronomia: obserwacje radarowe (ang. radar imaging) w radio-astronomii,u»ycie modulowanej fali radiowej odpowiedniej dªugo±ci pozwala na bardzoprecyzyjne okre±lenie powierzchni planet i asteroid, z powierzchni Ziemi - al-gorytmy genetyczne u»ywane s¡ tutaj do okre±lenia optymalnej dªugo±ci falii jej modulacji.
• Nauka: rozwi¡zywanie nieliniowych równa« ró»niczkowych wysokich rz¦dów.
• Robotyka: budowanie MOBOTów (ang. mobile robot - maszyna na wzór i po-dobie«stwo np. R2D2 lub C3PO z Gwiezdnych Wojen) czyli maszyn b¦d¡-cych w stanie porusza¢ si¦ w nieznanym, niepewnym ±rodowisku bez potrzebyu»ycia mapy. W zwi¡zku z tymi wymaganiami MOBOTy musz¡ by¢ w stanieprzystosowywa¢ si¦ do warunków panuj¡cych w otoczeniu i uczy¢ si¦ co mog¡zrobi¢ (np. przej±cie przez drzwi), a co jest niewykonalne (np. przej±cie przez±cian¦).
• Fizycy: modelowanie problemów ±wiata rzeczywistego zawieraj¡cych du»e ilo-±ci zmiennych, które w szczególno±ci na swój równolegªy charakter mog¡ by¢modelowane ªatwiej i szybciej przy pomocy algorytmów genetycznych.
• Biolodzy: wykorzystanie algorytmów genetycznych do modelowania zachowa-nia prawdziwych populacji.
• Chemicy i biochemicy: wykorzystanie algorytmów genetycznych do prowadze-nia bada« w celu wymy±lania nowych lub modykacji istniej¡cych produktówleczniczych.
Jednym z dobrze znanych problemów w których bardzo dobrze sprawuj¡ si¦algorytmy genetyczne s¡ zagadnienia szeregowania (ang. order based problems).
Przykªadem mo»e by¢ klasyczny problem komiwoja»era. Zadanie polega na od-wiedzeniu okre±lonej liczby miast w taki sposób by suma drogi byªa jak najkrótsza,przy czym miasta mog¡ by¢ poªo»one w dowolnych odlegªo±ciach od siebie.
15

Rozdziaª 3
Algorytmy genetyczne i ich schemat
dziaªania
3.1 Reprezentacja problemu: chromosom
Pierwsz¡ rzecz¡ przy tworzeniu algorytmu genetycznego jest okre±lenie kodowa-nia chromosomów. Musz¡ by¢ one kodowane ªa«cuchami sko«czonej dªugo±ci z okre-±lonego sko«czonego alfabetu. Najcz¦±ciej alfabet jest maªy. Zachodzi tutaj analogiado j¦zyka, gdzie ka»dy chromosom jest sªowem (ªa«cuchem znaków) skªadaj¡cym si¦z liter (znaków alfabetu), o czym pisze Michalewicz [3].
Dªugo±¢ chromosomu zale»na jest od wymaganej dokªadno±ci przybli»enia roz-wi¡zywanego zagadnienia oraz sposobu kodowania. Ka»dy punkt przestrzeni rozwi¡-za« reprezentowany jest przez jeden ªa«cuch. Algorytm genetyczny pracuje na tychwªa±nie reprezentacjach. W zwi¡zku z tym reprezentacja powinna by¢ odpowiedniodobrana.
Zgodne z prawidªami dziaªania algorytmów genetycznych istniej¡ dwie zasadykonstrukcji kodowania - zasada znacz¡cych cegieªek i zasada minimalnego alfabetu.Zostaªy one przedstawione przez Goldberga [2].
Zasada 1 (Zasada znacz¡cych cegieªek) Kod nale»y dobiera¢ w taki sposób,»eby schematy niskiego rz¦du i o maªej rozpi¦to±ci wyra»aªy wªasno±ci zadania orazpozostawaªy wzgl¦dnie niezale»ne od schematów o innych pozycjach ustalonych.
Zasada 2 (Zasada minimalnego alfabetu) Nale»y wybra¢ najmniejszy alfabetw którym dane zadanie wyra»a si¦ w sposób naturalny.
W zale»no±ci od dªugo±ci alfabetu zmienia si¦ te» mo»liwa liczba dost¦pnych od-wzorowa« na przestrze« rozwi¡za«, a co za tym idzie tak»e dªugo±¢ chromosomów.Wzór 3.1 przedstawia porównanie mo»liwej do odwzorowania liczb punktów w ªa«-cuchu 2-elementowym i k-elementowym, gdzie l i l′ s¡ odpowiednio - dªugo±ci¡ ci¡gubinarnego i dªugo±ci¡ sªowa w alfabecie k-elementowym.
2l = kl′ (3.1)
Wzór (k + 1)l′ opisuje liczb¦ dost¦pnych schematów dla alfabetu k-elementowego.
16

dziesi¦tne kodowanie Graya0 0001 0012 0113 0104 1105 1116 1017 100
Tablica 3.1: Przykªad warto±ci kodowania metod¡ Graya
Poprzez liniowe odwzorowanie przedziaªu < Pmin, Pmax > na zbiór nieujemnychliczb caªkowitych, z przedziaªu < 0, 2l − 1 > mo»na dokªadnie kontrolowa¢ zakresi precyzj¦ zmiennych decyzyjnych. Dokªadno±¢ reprezentacji (π) tego typu opisanajest wzorem przedstawionym poni»ej.
π =Pmax − Pmin
2l − 1(3.2)
Kod dla przypadków wieloparametrycznych konstruowany jest poprzez podziaª chro-mosomu na bloki odpowiedniej dªugo±ci - zale»nej od wymaganej ilo±ci punktówi dokªadno±ci reprezentacji. Bloki te w taki sam sposób odpowiadaj¡ powy»szymzasadom.
3.1.1 Chromosomy binarne (BCD)
Najcz¦±ciej stosowane s¡ geny binarne, ze wzgl¦du na uniwersalno±¢ tego roz-wi¡zania. Dla kodowania binarnego mo»liwe s¡ dwa gªówne rozwi¡zania kodowania:BCD (Binary Coded Decimals) i kodowanie Graya. Inny sposób kodowania, to ko-dowanie chromosomu przy pomocy tablicy zmiennych typu rzeczywistego.
Najbardziej popularnym typem kodowania chromosomów jest BCD [19].Przy innych ni» reprezentacja binarna konieczne jest skonstruowanie odpowied-
nich do danego typu genów operatorów. W mojej pracy przedstawiªem to zagadnie-nie na przykªadzie chromosomów wyra»onych tablic¡ zmiennych typu rzeczywistego,które dalej nazywa¢ b¦d¦ tak»e chromosomami kodowanymi zmiennoprzecinkowo.
3.1.2 Chromosomy kodowane metod¡ Graya
Jest to inny ni» BCD sposób kodowania binarnego. Zasada kodowania metod¡Graya zakªada, »e zmianie mi¦dzy kolejnymi warto±ciami podlega dokªadnie jedenbit. Co powoduje jego du»¡ przydatno±¢ w przypadku ukªadów cyfrowych [1, 19].Dla przykªadu w tablicy 3.1 przedstawiªem 3-bitowe kodowanie liczb od 0 do 7.
Operator mutacji przy zastosowaniu kodowania Graya gwarantuje wi¦ksz¡ dy-namik¦ przeszukiwania przestrzeni rozwi¡za«. Przykªadowe efekty mutacji pojedyn-czego genu ªa«cucha 000000, dla kodowania 6-bitowego w formie porównania z ko-dowaniem BCD, przedstawiªem w tabeli 3.2.
17

numer genu kod binarny kod Graya1 1 12 2 33 4 74 8 155 16 316 32 63
Tablica 3.2: Przedstawienie dynamiki przeszukiwania
Konwersja mi¦dzy powy»szym kodami odbywa si¦ w sposób przedstawiony wzo-rami (3.3) i (3.4) [30]:
Konwersja kodu binarnego (b) na kod Graya (g)
g = b XOR(b DIV 2) (3.3)
Konwersja kodu Graya (g) na binarny (b)
b = GRAY (g) =
g jesli g ∈ 0, 1g XOR GRAY (g DIV 2) dla g ≥ 2
(3.4)
3.1.3 Chromosomy kodowane logarytmiczne
Kodowanie logarytmiczne jest kolejnym ze sposobów kodowania binarnego.Liczba reprezentowana jest poprzez warto±¢ wyra»on¡ wzorem (3.5).
(−1)be(−1)a[bin]BCD (3.5)
Gdzie chromosomy maj¡ posta¢: ab[bin]BCD. Pierwsze dwa bity (a i b) nie maj¡bezpo±redniego powi¡zania z warto±ci¡, sªu»¡ jedynie do ustalenia znaku liczbyi znaku pot¦gi.
3.1.4 Chromosomy kodowane zmiennopozycyjnie
Dokªadno±¢ kodowania liczbami zmiennopozycyjnymi jest zwykle wy»sza od do-kªadno±ci kodowania bitowego [10]. Reprezentacja zmiennopozycyjna mo»e obejmo-wa¢ wi¦ksze dziedziny przestrzeni rozwi¡za«, na dodatek przy zachowaniu wi¦kszejdokªadno±ci. Przy u»yciu kodowania zmiennoprzecinkowego przestrze« poszukiwa«ma taki wymiar jak ilo±¢ zmiennych okre±laj¡cych badan¡ funkcj¦. Problem do-kªadno±ci reprezentacji sprowadza si¦ do czego± innego ni» w przypadku sposobówkodowania binarnego. Ograniczeniem nie jest przyj¦ta ilo±¢ bitów wektora, a rodzajprocesora i systemu operacyjnego - w chwili obecnej najcz¦±ciej 32 lub 64 bity.
3.2 Dziaªanie algorytmu genetycznego
Kolejne etapy dziaªania algorytmu genetycznego przedstawione s¡ na rysunku3.1.
18

Rysunek 3.1: Diagram dziaªania algorutmu genetycznego
19

W dalszej cz¦±ci mojej pracy omówiªem kolejne przedstawione etapy dziaªaniaalgorytmów genetycznych.
3.3 Warunki stopu
Dziaªanie algorytmów genetycznych mo»e odbywa¢ si¦ w niesko«czono±¢, a przy-najmniej na tyle dªugo by poprawa wyniku byªa niewspóªmierna do czasu dziaªania.W zwi¡zku z tym potrzebne jest okre±lenie warunków stopu, które w przypadkuspeªnienia którego± z nich doprowadz¡ do zako«czenia dziaªania algorytmu. Istniejekilka mo»liwo±ci wyj±cia z algorytmu. Mo»na próbowa¢ podzieli¢ je ze wzgl¦du na za-ko«czone sukcesem lub pora»k¡. Do pierwszej grupy nale»y:
• limit przystosowania - jest to przerwanie dziaªania algorytmu w momenciegdy przez najlepszego osobnika zostanie osi¡gni¦ta mniejsza lub równa zada-nej warto±¢ funkcji przystosowania. Wi¦cej na temat funkcji przystosowaniamo»na znale¹¢ w punkcie 3.5.
Natomiast do drugiej grupy - zako«czenia pora»k¡ - zaliczane jest wi¦cej warunków:
• osi¡gni¦cie zadanej ilo±ci generacji - okre±la maksymaln¡ ilo±¢ iteracji wykona-nych przez algorytm genetyczny, szczególnie przydatne gdy nie ma pewno±ci codo optymalnych ustawie« algorytmu genetycznego i poszukuje si¦ ich metod¡empiryczn¡, co cz¦sto ma miejsce,
• limit czasowy - okre±lenie maksymalnego czasu, przez jaki algorytm b¦dziedziaªa¢ przed zatrzymaniem, opcja przydatna gdy poszukiwany algorytm po-winien wpasowa¢ si¦ w naªo»one ograniczenia czasowe, co mo»e mie¢ miejscew rzeczywistych zastosowaniach,
• maksymalna ilo±¢ bezproduktywnych generacji - pozwala na okre±lenie ile ite-racji powinien wykona¢ algorytm w przypadku gdy nie nast¦puje poprawawyniku,
• czasowy limit bezczynno±ci - umo»liwia ustalenie przez ile czasu algorytm madziaªa¢ w przypadku braku poprawy wyniku funkcji przystosowania.
3.4 Metody generacji rozwi¡za« pocz¡tkowych
Dziaªanie algorytmu genetycznego rozpoczyna si¦ od utworzenia pocz¡tkowejpopulacji. Teoretyczne analizy algorytmów genetycznych stosuj¡ losow¡ generacj¦populacji pocz¡tkowej. Dzi¦ki temu mo»liwe jest jednoczesne przeszukiwanie roz-legªej przestrzeni. Poza tym pomaga to w unikni¦ciu zablokowania si¦ algorytmuw ekstremum lokalnym. W zastosowaniach praktycznych, np. optymalizacji, cz¦stostosuje si¦ inne sposoby takie jak metody deterministyczne. Dodatkowo przy do-brej znajomo±ci problemu, jak pisze Chippereld [11], mo»liwe jest dodanie kilkukonkretnych osobników o których wiadomo i» znajduj¡ si¦ w pobli»u ekstremum.
20

Mo»liwe jest tworzenie jednej populacji, jednak istnieje tak»e mo»liwo±¢ tworze-nia pod-populacji (ang. subpopulations) w ich obr¦bie osobnicy krzy»uj¡ si¦ mi¦-dzy sob¡ wedªug przyj¦tej reguªy i dziaªanie poszczególnych pod-populacji nie ró»nisi¦ niczym od pojedynczej, najcz¦±ciej spotykanej populacji. Jedyna ró»nica po-lega na przenoszeniu si¦ najlepszych osobników do s¡siednich populacji. Pozwala tona lepsze pokrycie przestrzeni rozwi¡za«, przy jednoczesnej zwi¦kszonej ochronieprzed zatrzymaniem algorytmu w optimum lokalnym [10].
Zagadnienia pod-populacji i migracji zostaªy szerzej opisane w dalszej cz¦±cipracy (rozdziaª 3.12.1).
Dla reprezentacji zmiennoprzecinkowej osobnicy populacji pocz¡tkowej genero-wani s¡ wedªug wzoru:
i(m) = (imax − imin) · random() + imin (3.6)
gdzie i(m) jest m-tym osobnikiem, imin jest doln¡ warto±ci¡ zakresu poszukiwa«,imax jest górn¡ warto±ci¡ zakresu poszukiwa«, natomiast random() jest generatoremliczb losowych o rozkªadzie jednorodnym, z przedziaªu < 0, 1 >.
3.5 Funkcja przystosowania
Funkcja przystosowania obliczana jest dla ka»dego osobnika w populacji. Od-zwierciedla jak bardzo dany osobnik, wzgl¦dem reszty populacji, zbli»yª si¦ do opti-mum. Jest przedstawieniem jako±ci rozwi¡zania reprezentowanego przez poszczegól-nego osobnika. Odwzorowuje ona chromosom na warto±¢ przystosowania, [3].
Funkcja przystosowania peªni znacz¡c¡ rol¦ w przebiegu dziaªania algorytmu ge-netycznego. W zwi¡zku z tym powinna by¢ odpowiednio dobrana. Powinna prowa-dzi¢ do oddzielenia chromosomów pozwalaj¡cych na najlepsze rozwi¡zanie problemui nie mo»e by¢ zbyt ostro selekcjonuj¡ca [13]. Wa»ne jest by, zgodnie wcze±niejszymipostulatami, pozwalaªa na zbadanie jak najwi¦kszego obszaru przestrzeni rozwi¡za«.
Funkcja przystosowania nie mo»e przyjmowa¢ warto±ci ujemnych, ze wzgl¦duna to i» jest ona nieujemnym kryterium jako±ci. W zwi¡zku z tym potrzebne jestprzeksztaªcenie funkcji celu w funkcj¦ przystosowania.
W przypadku algorytmów genetycznych przej±cie z zadania maksymalizacji zy-sku do zadania minimalizacji kosztu i vice versa, odbywa si¦ inaczej ni» w klasycz-nych badaniach operacyjnych. Temat te zostaª szerzej opisany przez Goldberga [2].
W zagadnieniach algorytmów genetycznych stosuje si¦ przedstawione poni»ejprzeksztaªcenie funkcji kosztu (g(x)) w funkcj¦ przystosowania (f(x)):
f(x) =
Cmax − g(x), je»eli g(x) < Cmax
0 w przeciwnym wypadku(3.7)
Wspóªczynnik kosztu maksymalnego (Cmax) mo»e by¢ dobrany na ró»ne sposoby:
• zosta¢ ustawiony na sztywno (np. wczytany z wej±cia),
• równy najwi¦kszej napotkanej dotychczasowo warto±ci,
• równy najwi¦kszej napotkanej dotychczasowo warto±ci w k ostatnich popula-cjach,
21

• waha¢ si¦ w zale»no±ci od wariancji rozpatrywanej populacji.
W zastosowaniach w których wyst¦puje funkcja zysku nie ma problemów z odpo-wiednim kierunkiem funkcji, jednak mog¡ by¢ problemy z ujemnymi warto±ciamifunkcji u»yteczno±ci (u(x)). Wzór (3.8), analogiczny do (3.7), przedstawia sposóbpoprawnego przewarto±ciowania funkcji u»yteczno±ci w funkcj¦ przystosowania:
f(x) =
u(x) + Cmin, je»eli u(x) + Cmin > 00 w przeciwnym wypadku
(3.8)
Wspóªczynnik kosztu minimalnego (Cmin) mo»e by¢ dobrany na ró»ne sposoby,o czym pisze Goldberg [2]:
• zosta¢ ustawiony na sztywno (np. wczytany z wej±cia),
• równy najmniejszej napotkanej dotychczasowo warto±ci,
• równy najmniejszej napotkanej dotychczasowo warto±ci w k ostatnich popula-cjach,
• waha¢ si¦ w zale»no±ci od wariancji rozpatrywanej populacji.
3.6 Operatory genetyczne
Operatory genetyczne s¡ ±ci±le powi¡zane ze sposobem reprezentacji chromo-somu.
Istniej¡ trzy podstawowe operatory genetyczne: operator selekcji, operator krzy-»owania i operator mutacji. Opisaªem je szerzej w kolejnych rozdziaªach - odpowied-nio: 3.7, 3.8 i 3.9.
Poza tym istniej¡ jeszcze rzadziej u»ywane operatory genetyczne takie jak: in-wersja, migracja, przenikanie. Dwa ostatnie z nich nale»¡ do grupy wprowadzaj¡cejdo zagadnie« populacji genetycznych termin specjalizacji. Informacje na ich tematmo»na znale¹¢ w rozdziaªach - odpowiednio: 3.10, 3.12.1 i 3.12.2. Zale»nie od wybra-nego typu operatora nale»y liczy¢ si¦ z charakterystycznymi mo»liwo±ciami i ogra-niczeniami ka»dego z nich.
3.7 Operator selekcji
Operator selekcji (czasem w literaturze dotycz¡cej algorytmów genetycznychokre±la si¦ selekcj¦ mianem reprodukcja) ma za zadanie wybór osobników do no-wej populacji promuj¡c jednocze±nie najlepszych osobników [7, 13]. Osobnicy posia-daj¡cy lepiej przystosowane chromosomy maj¡ wi¦ksze szanse przekazania swoichgenów.
Istnieje wiele, wr¦cz niesko«czona ilo±¢, ró»nych mechanizmów selekcji, [13]. Jed-nym ze sposobów ich usystematyzowania jest podziaª na selekcj¦ tward¡ (ang. hardselection) i selekcj¦ mi¦kk¡ (ang. soft selection). Poni»ej przedstawiam denicje obutych terminów, na podstawie [8].
22

Denicja 8 (selekcja twarda) Selekcja twarda polega na wspóªzawodnictwie mi¦-dzy osobnikami. Tylko najlepsze osobniki posiadaj¡ potomstwo. Co za tym idzie tylkoone maj¡ wpªyw na allele obecne w przyszªych pokoleniach.
Denicja 9 (selekcja mi¦kka) Selekcja mi¦kka jest mechanizmem który pozwalasªabiej przystosowanym osobnikom na umieszczenie swojego potomstwa w kolejnejgeneracji. Dzieje si¦ tak ze wzgl¦du na to i» ka»dy osobnik w populacji, niezale»nieod warto±ci funkcji przystosowania, posiada niezerowe prawdopodobie«stwo selekcji.
Do najcz¦±ciej stosowanych metod selekcji zalicza si¦:
• Selekcja elitarna,
• Selekcja proporcjonalna zwana tak»e "metod¡ koªa ruletki"(roulette wheel se-lection),
• Turniejowa (tournament selection),
• Równomierna,
• Stochastyczna równomierna,
• Reszta,
• Lepsza poªowa,
• Wybór losowy wedªug reszt z powtórzeniami,
• Deterministyczny.
Poni»ej omówiªem krótko ka»d¡ z nich, w celu uzupeªnienia informacji odsyªamdo [7, 9] oraz ¹ródeª wymienionych przy opisach.
Selekcja elitarna
Zwana tak»e elityzmem, jest mechanizmem zapewniaj¡cym przechodzeniedo nast¦pnych generacji osobników o najwy»szym przystosowaniu. Nie podlegaj¡oni dziaªaniu »adnych operatorów genetycznych, przechodz¡ bezpo±rednio (w lite-raturze dotycz¡cej algorytmów genetycznych mo»na si¦ tutaj spotka¢ z terminemklonowanie). Jest tutaj oczywiste i» w wypadku stosowania elityzmu najwy»sze przy-stosowanie w algorytmie genetycznym nie spada. Prowadzi to do szybszej zbie»no-±ci. W zwi¡zku z ró»nymi rodzajami problemów do których mo»e by¢ zastosowanyten sposób selekcji mo»e on zwi¦ksza¢ prawdopodobie«stwo znalezienia optymal-nego osobnika lub je zmniejsza¢. Ze wzgl¦du na ograniczenia tego sposobu selekcjii jednocze±nie jej niew¡tpliw¡ przydatno±¢ stosowana jest ona równolegle z innymimetodami, co zostaªo szerzej opisane w [7].
23

Rysunek 3.2: Selekcja proporcjonalna
Selekcja proporcjonalna ("Metoda koªa ruletki")
Metoda koªa ruletki wykorzystywana jest do wyselekcjonowania nc osobnikówz populacji licz¡cej L osobników. Zasada dziaªania opiera si¦ na tym, »e je±li osobnika posiada dwa razy lepsz¡ warto±¢ wspóªczynnika przystosowania ni» osobnik b,to wtedy osobnik a powinien reprodukowa¢ si¦ dwa razy cz¦±ciej ni» osobnik b.W zwi¡zku z powy»szym prawdopodobie«stwo selekcji jest adaptacje i opisane jestwzorem (3.9), i przedstawione na rysunku (3.2).
Pl/∑
l
Pl , gdzie Pl =minl′ (Jl′ )
Jl
, l, l′ ∈ 1, . . . , L (3.9)
Wa»nym aspektem dziaªania mechanizmu koªa ruletki jest fakt i» selekcja dokony-wana jest probabilistycznie, a nie deterministycznie. Oznacza to, »e fakt posiadaniaprzez danego osobnika najwy»szej warto±ci przystosowania w caªej populacji niegwarantuje i» zostanie on wybrany w którymkolwiek z dziaªa« mechanizmu. Pewnejest jedynie, »e statystycznie prawdopodobie«stwo »e zostanie wybrany jest propor-cjonalne do warto±ci jego funkcji przystosowania - najwy»sze, w danej populacji.
Selekcja deterministyczna
Metoda ta zapewnia i» osobniki posiadaj¡ce najwy»sze warto±ci przystosowa-nia zostan¡ wybrani do reprodukcji. Wybór deterministyczny odbywa si¦ poprzezpoliczenie prawdopodobie«stwa reprodukcji przedstawionego wzorem (3.10).
pi =fi∑fi
(3.10)
Nast¦pnie na podstawie prawdopodobie«stwa reprodukcji liczona jest, oczekiwanaliczba osobniów.
ei = pi · n (3.11)
Ka»dy osobnik otrzymuje tyle kopii ile wynosi cz¦±¢ caªkowita z ei. W kolejnymkroku cz¦±ci uªamkowe porz¡dkowane s¡ malej¡co i pozostaªe miejsca zapeªniane s¡osobnikami z góry listy.
24

Rysunek 3.3: Przedwczesna zbie»no±¢ selekcji deterministycznej
Ten sposób selekcji jest, wzgl¦dem innych, szybkobie»ny. Wad¡ natomiast jestfakt i» mo»e prowadzi¢ do przedwczesnej zbie»no±ci, to znaczy - algorytm mo»e za-trzyma¢ si¦ w ekstremum lokalnym, podczas gdy odrzucone zostaªy osobniki znajdu-j¡ce si¦ na zboczu prowadz¡cym do rozwi¡zania najlepszego globalnie. Zilustrowaªemto na rysunku 3.3, bª¡d tego typu okre±lany jest mianem bª¦du próbkowania (ang.sampling error).
Ze wzgl¦du na to i» populacja pocz¡tkowa generowana jest caªkowicie losowo,zupeªnie bez znajomo±ci problemu - ani obszarów, w których warto prowadzi¢ po-szukiwania, istnieje du»a szansa, »e w wi¦kszo±ci sytuacji gdzie stosowane s¡ algo-rytmy genetyczne doprowadzi do zdominowania populacji przez grup¦ osobnikównajlepiej w danej generacji przystosowanych. Przez to nast¡pi utrata zró»nicowaniaw populacji. Innymi sªowy wszyscy osobnicy stan¡ si¦ podobnie przystosowani, coza tym idzie b¦d¡ mie¢ wªa±ciwie takie same szanse na reprodukcj¦.
Turniejowa
Selekcja turniejowa przebiega w nast¦puj¡cy sposób: losowo wybiera si¦ dwóchlub wi¦cej osobników z caªej populacji. Porównuje si¦ wyniki ich funkcji przystoso-wania. Wybrany zostaje osobnik o najlepszej warto±ci funkcji przystosowania.
Stosowanie metody selekcji turniejowej daje szczególnie dobre efekty po dokona-niu skalowania przystosowania metod¡ rankingow¡ (patrz 3.11).
25

Równomierna
Polega na wyborze rodziców w sposób caªkowicie losowy, wedªug rozkªadu rów-nomiernego, zgodnie ze wzorem (3.12). Zaznacz¦ jednak, »e sposób ten w wi¦kszo±ciprzypadków nie jest u»ytecznym sposobem selekcji, co opisane jest w [8] i [18].
pi =1
N, ∀i ∈ 1, 2, . . . N (3.12)
Stochastyczna równomierna
Opisywana metoda selekcji jest, w przeciwie«stwie do np. selekcji koªem ruletki,selekcj¡ jednoprzebiegow¡. Wykorzystuje si¦ N wska¹ników, gdzie N jest oczekiwan¡liczb¡ osobników. Populacja jest ustawiana losowo i generowana jest losowa liczbaptr z przedziaªu < 0, suma/N >. Nast¦pnie wybierane jest N osobników przezwygenerowanie N wska¹ników odlegªych o 1, < ptr, ptr+1, . . . , ptr+N−1 >, i wybórosobników których przedziaª przystosowania przypada na pozycje wska¹ników.
Jej zalety polegaj¡ na stabilnych warunkach selekcji. Ka»dy osobnik ma gwaran-cj¦ zostania wybranym - nie mniej ni» bet(i)c razy i dokªadnie nie wi¦cej ni» det(i)erazy, gdzie et(i) jest oczekiwany prawdopodobie«stwem selekcji osobnika i.
Metoda ta jest szeroko u»ywana w algorytmach genetycznych.
Wybór losowy wedªug reszt z powtórzeniami
Pocz¡tek przebiega analogicznie do selekcji deterministycznej. Po przypisaniuosobników wedªug ich cz¦±ci caªkowitych, cz¦±ci uªamkowe u»ywane s¡ jako prawdo-podobie«stwa przy konstrukcji koªa rulety. Wybór pozostaªych osobników dokony-wany jest przy jego u»yciu [18, 8].
Lepsza poªowa
Lepsza, pod wzgl¦dem przystosowania, poªowa populacji zostaje przekopiowanado nowej populacji bez zmian. Pozostaªa cz¦±¢ (pop
2) poddawana jest dziaªaniu ope-
ratorów genetycznych [7].
Wyselekcjonowani osobnicy poddawani s¡ wpªywowi operatorów genetycznychdziaªaj¡cych z odpowiedni¡ cz¦stotliwo±ci¡.
3.8 Operator krzy»owania
Operator krzy»owania, nazywany tak»e operatorem rekombinacji, zamienia ªa«-cuchy genów mi¦dzy dwoma chromosomami. Jedna para chromosomów przechodziw drug¡, now¡ par¦, powstaª¡ na skutek zamiany bloków chromosomów w punk-cie ci¦cia. Najprostsz¡ metod¡ krzy»owania jest krzy»owanie jednopunktowe. Wybórmiejsca ci¦cia dokonywany jest losowo.
Dziaªanie tego operatora opiera si¦ na zªo»eniu i» cenne fragmenty genotypurozproszone s¡ w±ród cz¦±ci populacji. Mieszanie cz¦±ci chromosomów mi¦dzy osob-nikami i ª¡czenie ich losowo, z uwzgl¦dnieniem wyniku funkcji przystosowania, daw wyniku osobniki lepiej przystosowane.
26

Do±¢ dobrym zobrazowaniem tego rozumowania mo»e by¢ przykªad przytoczonyprzez Emanuela Falkenauera, [8]:
Zaªó»my, »e istnieje stado antylop i przyjmijmy, »e jedna z nichposiada dªugie nogi, pozwalaj¡ce na szybsz¡ ni» inni czªonkowie stadaucieczk¦ przed drapie»nikiem, podczas gdy inna posiada wyj¡tkowo do-bry wzrok, pozwalaj¡cy na ªatwiejsze odnalezienie po»ywienia ni» inne.Teraz gdy te dwie konkretne antylopy b¦d¡ mie¢ potomstwo, zajdziekrzy»owanie i chromosomy ich mªodych b¦d¡ zawiera¢ kawaªki chro-mosomów rodziców. To z kolei prowadzi do dziedziczenia cech rodzi-ców przez ich potomstwo, istnieje prawdopodobie«stwo, »e przynajmniejjedno z nich odziedziczy równocze±nie dªugie nogi od jednego z rodzi-ców i dobry wzrok od drugiego. W ten prosty sposób mªoda antylopab¦dzie lepsza [w znaczeniu przystosowania do przetrwania i co za tymidzie posiadania potomstwa] od ka»dego z rodziców.
Dzi¦ki temu w ±wiecie rzeczywistym najlepsze osobniki prze»ywaj¡ najdªu»ej i po-siadaj¡ najwi¦cej potomstwa. Natomiast w odniesieniu do algorytmów genetycz-nych, tylko one maj¡ potomstwo i s¡ dalej krzy»owane, niezale»nie od przyj¦tegomodelu selekcji zakªadam, i» najgorsze pod wzgl¦dem przystosowania osobniki po-siada¢ b¦d¡, co najwy»ej, bliskie zeru prawdopodobie«stwo krzy»owania. Prowadzito w kolejnych generacjach do pozostania najlepszych genów, z pocz¡tkowej puli.Na skutek dziaªania tego operatora, zarówno w ±wiecie rzeczywistym jak i w algo-rytmach genetycznych, dziaªa znacznie wi¦cej ni» jedynie prosta reguªa - przetrwaj¡tylko najlepiej przystosowani.
Wa»ne jest u±wiadomienie sobie i» krzy»owanie nie prowadzi do powstania no-wych cech. Nie oznacza to jednak, »e operator nie tworzy jednak czego± nowego.Istotnie, tworzy - zestawia dost¦pne, istniej¡ce cegieªki w nowym porz¡dku. Co od-nosi si¦ bezpo±rednio do teorii schematów (patrz punkt 2.4).
Niszcz¡ca natura krzy»owania bardziej wpªywa na powi¦kszenie przestrzeni po-szukiwa« ni» premiuje osobniki dobrze przystosowane. Dzi¦ki temu znacznie popra-wia si¦ dziaªanie algorytmu. W±ród metod krzy»owania wyró»nia si¦:
Krzy»owanie jednopunktowe
Krzy»owanie jednopunktowe (ang. simple arithmetic crossover) polega na krzy-»owaniu st
v i stw na k -tej pozycji. Wynikiem tej operacji jest potomstwo przedstawione
wzorem (3.13) gdzie warto±¢ k jest losowana z przedziaªu 2, . . . , N − 1. Obrazuje torysunek 3.4.
st+1v = (v1, . . . , vk, wk+1, . . . , wN)
st+1w = (w1, . . . , wk, vk+1, . . . , vN)
(3.13)
27

Rysunek 3.4: Sposób dziaªania krzy»owania jednopunktowego.
Rysunek 3.5: Sposób dziaªania krzy»owania wielopunktowego.
Krzy»owanie wielopunktowe
Krzy»owanie wielopunktowe przebiega w m punktach krzy»owania (ki takie,»e i ∈ 1, 2, . . . , N − 1, gdzie N jest dªugo±ci¡ chromosomu) które wybierane s¡ lo-sowo, bez powtórze« i ustawiane rosn¡co. Nast¦pnie wymieniane s¡ odcinki znaj-duj¡ce si¦ bezpo±rednio za nieparzystymi punktami krzy»owania. Przedstawiªem tona rysunku 3.5.
Krzy»owanie po±rednie
Krzy»owanie po±rednie (ang. uniform crossover) mo»na rozpatrywa¢ jako pe-wien szczególny przypadek krzy»owania wielopunktowego. Jednak o ile krzy»owanewielopunktowe okre±la punkty w których nast¦puje zamiana cz¦±ci chromosomu,to krzy»owanie po±rednie umo»liwia potencjalne dokonanie wymiany na dowolnymlocus.
Tworzona jest losowa maska krzy»owania tej samej dªugo±ci co chromosom. Najej podstawie okre±lane s¡ miejsca krzy»owania. Dziaªanie powy»szego operatorakrzy»owania mo»na prze±ledzi¢ na przykªadzie przedstawionym na rysunku 3.6. Dlapotomka O1 pobiera si¦ gen od rodzica P1 w przypadku wyst¡pienia 0 w mascei analogicznie, gen od rodzica P2 w przypadku wyst¡pienia 1. Dla drugiego potomkadziaªanie maski jest dokªadnie odwrotne. Sposobem wpªywania na dziaªanie tegooperatora jest ustawienie zadanego prawdopodobie«stwa zmiany warto±ci bitu maskipodczas jej tworzenia.
28

Rysunek 3.6: Sposób dziaªania krzy»owania po±redniego.
Rysunek 3.7: Efekt dziaªania krzy»owania z tasowaniem
Krzy»owanie z tasowaniem
Krzy»owanie z tasowaniem (ang. shue crossover) jest rodzajem krzy»owaniaz u»yciem jednego punktu. Zanim jednak nast¡pi krzy»owanie dokonywane jest lo-sowe mieszanie genów w chromosomach rodziców. Po operacji krzy»owania genyustawiane s¡ na poprzednich pozycjach. Sposób dziaªania tego rodzaju krzy»owaniazobrazowaªem na rysunku 3.7.
Ze wzgl¦du na efekty dziaªania zbli»one do krzy»owania wielopunktowego i po-±redniego nie b¦d¦ si¦ szerzej zajmowa¢ t¡ metod¡.
Krzy»owanie simplex
Wykorzystywana jest para rodziców lepszych (z wy»sz¡, z trzech, warto±ci¡funkcji przystosowania) i rodzic sªabszy. Krzy»owanie przebiega w taki sposób i»
29

Rysunek 3.8: Efekt dziaªania krzy»owania simplex
kolejne geny ustalane s¡ zgodnie ze wzorem (3.14), gdzie ot+1n jest n-tym bitem
potomka, natomiast vtn i wt
n to bity rodziców lepszych, utn to bit rodzica gorszego
i n ∈< 0, 1, . . . N >, gdzie N jest liczebno±ci¡ populacji.
ot+1n =
vt
n je»eli vtn 6= ut
n ∪ vtn = wt
n
wtn je»eli vt
n = utn
(3.14)
Sposób dziaªania przedstawiono na rysunku 3.8.Krzy»owanie simplex jest analogi¡ do nauki ze zªego zachowania lub inaczej na
podstawie bª¦dów. Jest ono oparte bezpo±rednio na teorii schematów i bloków bu-duj¡cych, które opisaªem w podrozdziale (2.4). Jest to bardzo interesuj¡cy operatorzaczerpni¦ty z [6].
Krzy»owanie dla reprezentacji zmiennoprzecinkowej
Dla reprezentacji binarnych opisany wy»ej sposób krzy»owania jest bardzo dobry,jednak nie jest on wystarczaj¡cy w przypadku reprezentacji z wykorzystaniem liczbrzeczywistych. Oczywistym tego powodem jest brak wprowadzania nowych informa-cji do genotypu. Zachodzi jedynie wymiana poszczególnych warto±ci (ma to ±cisªyzwi¡zek ze sposobem kodowania chromosomów kodowanych zmiennoprzecinkowo,o czym pisaªem wcze±niej (rozdziaª 3.1.4).
W zwi¡zku z tym opracowane zostaªy inne metody krzy»owania, bardziej efek-tywne w tym przypadku.
Krzy»owanie rozproszone
(ang. Intermediate recombination) Stosowane jest w wypadku zmiennoprzecin-kowego kodowania chromosomów. Potomstwo powstaje zgodnie ze wzorem (3.15),gdzie α jest wspóªczynnikiem skalowania wybranym losowo z pewnego przedziaªu,zwykle α ∈< 0; 1 >, wt+1
n i vt+1n n-tymi genami potomstwa, wt
n i vtn s¡ natomiast n-
tymi genami rodziców. Ka»da zmienna w potomku O1 powstaje zgodnie ze wzorem(3.15), przy czym dla ka»dej pary genów rodziców losowany jest nowy wspóªczynnikα.
vt+1n = vt
n · α∣∣wt
n − vtn
∣∣wt+1
n = wtn · α
∣∣vtn − wt
n
∣∣ (3.15)
30

Rysunek 3.9: Mo»liwy efekt dziaªania krzy»owania rozproszonego
Rysunek 3.10: Mo»liwy efekt dziaªania krzy»owania liniowego
Krzy»owanie rozproszone mo»e prowadzi¢ do powstania nowych osobników w ob-szarze zobrazowanym na rysunku 3.9. Decyduje o tym zakres wspóªczynnika α.
Krzy»owanie liniowe
Krzy»owanie liniowe (ang. line recombination) podobne jest do krzy»owania roz-proszonego, jednak z t¡ ró»nic¡, i» dla caªego chromosomu wykorzystywana jest razwylosowana warto±¢ α, o czym pisze Falkenauer w [8]. Na rysunku 3.10 przedsta-wiono ten wªa±nie sposób krzy»owania.
Natomiast Randy i Sue Ellen Haupt, w [10], przedstawiaj¡ troch¦ inny wzórna krzy»owanie liniowe mianowicie (3.16). Gdzie Ot+1
v i Ot+1w to chromosomy dzieci,
natomiast P tv i P t
w s¡ chromosomami rodziców, gdzie β jest wspóªczynnikiem z prze-dziaªu < 0; 1 > i jest losowany raz dla caªego osobnika.
Ot+1v = βP t
v + (1− β)P tw
Ot+1w = βP t
w + (1− β)P tv
(3.16)
Ze wzgl¦du na niemo»liwo±¢ wyj±cia z parametrami poza obszar obecnej popula-cji przydatna jest modykacja wzoru, gdy rozszerzanie przestrzeni poszukiwa« jestkonieczne. Tego typu modykacj¦ wprowadziª Wright, przedstawia to wzór (3.17).
31

Ot+1v = 0, 5 · P t
v + 0, 5 · P tw
Ot+1w = 1, 5 · P t
v − 0, 5 · P tw
Ot+1u = −0, 5 · P t
v + 1, 5 · P tw
(3.17)
W programie, który napisaªem wykorzystaªem wersj¦ krzy»owania liniowego za-proponowan¡ przez E.Falkenauera.
Krzy»owanie po±rednie
W krzy»owaniu po±rednim (heuristic crossover) dla reprezentacji zmiennoprze-cinkowej wyra»one jest wzorem (3.18). Gdzie wspóªczynnik α ∈< 0, 1 > i losowanyjest oddzielnie dla ka»dej pary genów.
vt+1n = αwt
n + (1− α)vtn
wt+1n = αvt
n + (1− α)wtn
(3.18)
Krzy»owanie ekstrapolacyjne
Krzy»owanie ekstrapolacyjne (an extrapolation method with a crossover method)zostaªo zaproponowane przez pa«stwo Haupt [10].
Zostaªo opracowane z my±l¡ o stworzeniu algorytmu krzy»owania opartegona krzy»owaniu binarnym. Pierwszym krokiem jest znalezienie punktu krzy»owaniazgodnie ze wzorem (3.19). Gdzie: roundup jest zaokr¡gleniem do warto±ci caªkowitej,natomiast n jest liczb¡ genów w chromosomie.
α = rounduprandom() · n (3.19)
Nast¦pnie dla rodziców opisanych wzorem (3.20), powstaj¡ dzieci zgodnie zewzorem (3.21), gdzie w punkcie krzy»owania warto±ci s¡ generowane wedªug wzoru(3.22).
stv = [vt
1, vt2, . . . v
tα, . . . vt
N ]
stw = [wt
1, wt2, . . . w
tα, . . . wt
N ](3.20)
st+1v = [vt+1
1 , vt+12 , . . . vt+1
∗ , . . . wt+1N ]
st+1w = [wt+1
1 , wt+12 , . . . wt+1
∗ , . . . vt+1N ]
(3.21)
vt+1∗ = vt
α − β[vtα − wt
α]
wt+1∗ = wt
α + β[wtα − vt
α](3.22)
Je»eli nie jest speªnione β > 1 potomstwo powstaje jedynie w granicach wyzna-czonych przez rodziców. Powy»szy operator generuje nowe chromosomy w bliskim
32

otoczeniu chromosomów wyj±ciowych. Dzieje si¦ tak na skutek dziedziczenia blokówgenów.
Badania pokazaªy, »e krzy»owanie i selekcja oparta na funkcji przystosowania s¡dwoma procesami, które w najwi¦kszym stopniu wi¡»¡ si¦ z teori¡ ewolucji.
Wi¦cej informacji zwi¡zanych z tym tematem mo»na znale¹¢ w [1, 6, 8, 10, 11,13].
3.9 Operator mutacji
Operator reprodukcji tworz¡cy nowy chromosom poprzez niewielkie zmiany chro-mosomu rodzica. Zmienia jeden lub wi¦cej genów w wybranym chromosomie. Dzi¦kitemu wprowadza ró»norodno±¢ w nowej populacji, gdy» nowy chromosom mo»e by¢bardzo odlegªy od chromosomu wyj±ciowego ze wzgl¦du na warto±¢ funkcji przysto-sowania. W zwi¡zku z tym, mimo i» operator ten jest bardzo przydatny, istniejepotrzeba ograniczenia jego dziaªana. Mutacja jest krokiem losowym i nie prowa-dzi bezpo±rednio do znalezienia rozwi¡zania optymalnego [1]. Zapobiega natomiasttworzeniu si¦ jednorodnych populacji osobników niezdolnych do reprodukcji prowa-dzonej do powstania odmiennych osobników. Prócz tego mutacja pomaga w od-tworzeniu cennego materiaªu genetycznego (0 lub 1 na odpowiednim loci) wyelimi-nowanego przez selekcj¦ i krzy»owanie. Prawdopodobie«stwo mutacji jest znaczniemniejsze ni» prawdopodobie«stwo krzy»owania, cho¢ nie dla ka»dego osobnika. Dlaprzykªadu w pozycji [2] proponowane prawdopodobie«stwo mutacji jest na pozio-mie jeden do tysi¡ca skopiowanych bitów, w [11] proponowane jest ustalenie gona poziomie 0,001 do 0,1. Cho¢ w niektórych przypadkach stosowana jest wy»szawarto±¢ prawdopodobie«stwa mutacji, nawet 0,25! Dobre efekty daje uzale»nienieprawdopodobie«stwa mutacji od warto±ci funkcji przystosowania osobnika. Dzi¦kitemu istnieje wi¦ksza szansa na ulepszenie sªabszych osobników przy zachowaniuniezmienionych osobników bardzo dobrze, na tle populacji, przystosowanych. Innymsposobem poprawy skuteczno±ci dziaªania mutacji jest uzale»nienie jej prawdopodo-bie«stwa od tego w której generacji zachodzi [13].
Wykorzystywane s¡ trzy poni»sze rodzaje mutacji:
Mutacja jednopunktowa
Mutacja ta stosowana jest w przypadku reprezentacji binarnej. Losowo wybranyelement vk, k ∈ 1, 2, . . . , N jest zast¦powany przez element o przeciwnej warto±ci.
Mutacja wielokrotna jednorodna
Jednopunktowa mutacja n losowo wybranych elementów, gdzie n zostaje ka»do-razowo losowo wybrane z przedziaªu 1, 2, . . . , N.
Mutacja gausoidalna
Rodzaj mutacji stosowany w przypadku kodowania zmiennoprzecinko-wego, [4], [7]. Wszystkie elementy chromosomu podlegaj¡ mutacji. Wynikiem jest
33

Rysunek 3.11: Dziaªanie operatora inwersji.
st+1v = (v
′1, . . . , v
′
k, . . . , v′m), gdzie v
′
k = vk + fk, k = 1, 2, . . . , N . Gdzie fk jest losow¡liczb¡ z dystrybucji Gaussa ze ±redni¡ zerow¡ i adaptacyjn¡ wariancj¡ σ2
k =T−tT
· (vmaxk −vmin
k )
3. Parametr modykuj¡cy mutacj¦ (σ2
k) dla tego operatora zmieniasi¦ wraz z kolejnymi iteracjami dziaªania algorytmu - krzywa Gaussa staje si¦ corazcie«sza. Przy czym fk(x), gdzie x to zmienna losowa z przedziaªu < 0, 1 >, wyra-»one jest wzorem (3.23). W którym zmienna µ = 0, 5 jest warto±ci¡ ±redni¡ zmiennejlosowej.
fk(xk) =1
σ√
2π· exp
(−(x− µ)2
2σ2
)(3.23)
3.10 Operator inwersji
Ostatnim z operatorów genetycznych, dziaªaj¡cych na pojedynczej populacji,jest operator inwersji. Gªównym zadaniem tego operatora jest zrównowa»enie nisz-cz¡cego schematy efektu krzy»owania. Poniewa» niektóre wªa±ciwo±ci przejawiaj¡si¦ poprzez wyst¦powanie zestawu genów, w szczególno±ci pary, w odpowiednimukªadzie zmiana kolejno±ci wyst¦powania dwóch genów mo»e prowadzi¢ do niespo-dziewanej poprawy przystosowania osobnika.
Dziaªanie operatora inwersji nie zmienia informacji zawartej w chromosomie.Jednak mo»e prowadzi¢ do polepszenia dziaªania operatora krzy»owania ze wzgl¦duna znoszenie efektu przerwania (efekt ten opisaªem przy okazji omawiania teoriischematów, w punkcie 2.4.1). Inwersja polega na zamianie miejscami kolejnych pargenów w losowo wybranym fragmencie chromosomu. Przedstawiªem to na rysunku3.11.
Mimo »e w literaturze zwykle pomija si¦ ten operator, to jego dziaªanie w po-ª¡czeniu z dziaªaniem krzy»owania jest nadzwyczaj skuteczne. Stosowanie inwersjipoprawia szybko±¢ zbie»no±ci algorytmu genetycznego, co potwierdziªem ekspery-mentalnie w dalszej cz¦±ci mojej pracy. Du»o na temat operatora inwersji piszeFalkenauer [8].
34

3.11 Skalowanie przystosowania
Wynik funkcji przystosowania nie zawsze odpowiada skalowaniu dla potrzebfunkcji selekcji [8]. Przykªadem mo»e by¢ sytuacja, gdy w populacji pojawia si¦kilku osobników z wysok¡ warto±ci¡ funkcji przystosowania na tle reszty z mier-nymi wynikami. W tym wypadku bezpo±rednie przyj¦cie wyniku funkcji przystoso-wania jako prawdopodobie«stwa selekcji (np. selekcja proporcjonalna) doprowadzido zdominowania populacji i zako«czenia dziaªania algorytmu w ekstremum lokal-nym. W zwi¡zku z tym bardzo przydatne jest tutaj zastosowanie operatora skalo-wania. Skalowanie ma bezpo±redni wpªyw na zbie»no±¢ algorytmu.
W dalszej cz¦±ci tego punktu omawiam dokªadniej wybrane metody skalowa-nia. Dodatkowo doª¡czyªem graczne przykªady skalowania warto±ci przykªadowejfunkcji przystosowania. Symulowana funkcja przystosowania jest symulowana wzo-rem (3.24), gdzie otrzymane warto±ci - odpowiednio: wygenerowane i posortowane -przedstawiªem na rysunkach 3.12 i 3.13.
Fi = 10 · rand()− 5 (3.24)
W celu szerszego zapoznania si¦ z zagadnieniem odsyªam do pozycji [6].
Funkcja skalowania okre±la funkcj¦ u»ywan¡ do skalowania otrzymanej war-to±ci funkcji przystosowania. Najcz¦±ciej u»ywane funkcje to:
Liniowa normalizacja
Wspomniana wcze±niej selekcja proporcjonalna (3.7) posiada niezaprzeczalne za-lety. Jej dziaªanie jest skuteczne, jednak istniej¡ powa»ne wady tej metody. Przed-stawiam je poni»ej:
1. Poprzez odwoªanie si¦ do natury b¦d¡cej inspiracj¡ dla algorytmów genetycz-nych pozostaje niew¡tpliw¡ prawd¡ stwierdzenie, »e osobnicy lepiej przysto-sowani powinni posiada¢ wi¦ksze szanse na przetrwanie i reprodukcj¦. Jednakstwierdzenie, »e jeden osobnik jest lepszy od drugiego 1,842 razy niekonieczniejest sensowne.
2. Ten sposób selekcji tworzy niejednorodny nacisk selektywny (ang. selectivepressure) - bardzo cz¦sto prowadzi do przedwczesnej zbie»no±ci na pocz¡tkudziaªana algorytmu i do utraty odpowiedniej promocji lepiej przystosowanychosobników pod koniec dziaªania - gdy wszyscy osobnicy posiadaj¡ takie samoprzystosowanie.
3. Nie jest konieczne by funkcja przystosowania miaªa jedynie warto±ci dodatnie,jednak jak okre±li¢ metod¦ dziaªania w przypadku pojawienia si¦ warto±cizerowych lub ujemnych? Zwykle dodana zostaje jednakowa warto±¢ do ka»dejz funkcji przystosowania, jednak prowadzi to do odej±cia od selekcji ±ci±leproporcjonalnej.
4. Podobny problem, do powy»szego, pojawia si¦ przy minimalizacji funkcji. Mo»-liwe s¡ dwa rozwi¡zania: 1/przystosowanie lub C − przystosowanie, przyj-mowane jest jako podstaw¦ selekcji - które jest skuteczniejsze?
35

Rysunek 3.12: Przykªadowe warto±ci do skalowania.
Rysunek 3.13: Przykªadowe warto±ci do skalowania (posortowane).
36

Powy»sze problemy, w wi¦kszo±ci, rozwi¡zuje stosowanie liniowej normalizacji.Jest to powszechna metoda - ze wzgl¦du na skuteczno±¢ i prostot¦. Dziaªanie me-tody przedstawia wzór (3.25), gdzie Fmax i Fmin s¡ odpowiednio - maksymalnymi minimalnym przystosowaniem w populacji. Bezpo±rednie wyniki F mapowane s¡na warto±ci F ′ z zakresu F ′
max, F ′min.
F ′i =
F ′max − F ′
min
Fmax − Fmin
· (Fi − Fmin) (3.25)
Nie rozwi¡zuje to jednak wszystkich problemów. Nie porusza w ogóle problemuminimalizacji. Nie jest tak»e jasno okre±lony sposób doboru F ′
max i F ′min.
Skalowanie rankingowe
Skalowanie rankingowe bazuje na pozycji wyniku osobnika w odniesieniu do ca-ªej populacji. Ka»demu osobnikowi (o numerze i) zostaje przydzielona ranga (Ri)w zale»no±ci od miejsca na posortowanej li±cie wyników funkcji przystosowania (Fi).Do skalowania wykorzystywany jest wzór (3.26).
F ′i =
F ′max − F ′
min
n·Ri (3.26)
Osobniki w populacji i ranga (R) liczona jest od zera (i ∈< 0, n)). Gdzie n jestrozmiarem populacji.
Przykªad: zostaje przydzielony wspóªczynnik prawdopodobie«stwa selekcji(100, 99, 98, 97, 96, . . .) osobnikom o nast¦puj¡cych wynikach funkcji przystosowania(98, 97, 91, 84, 80, . . .).
Innym rodzajem skalowania rankingowego jest sposób zaproponowany przez Ba-kera [7]:
F (xi) = 2− SP + 2(SP − 1) · xi − 1
Nind − 1(3.27)
Gdzie xi jest pozycj¡ w posortowanej populacji, Nind jest ilo±ci¡ osobników, SPjest selektywnym naciskiem o proponowanej warto±ci SP = 1, 1. Na rysunku3.14 przedstawiªem przykªadowy wynik skalowania rankingowego punktów z rysunku3.12.
Skalowanie rankingowe liniowe
Najlepszy osobnik otrzymuje warto±¢ s, gdzie s ∈< 1; 2 >. Najgorszy osobnikotrzymuje warto±¢ s − 2. Pozostali osobnicy otrzymuj¡ warto±ci opisane wzorem(3.28).
f(i) = s− (2i(s− 1))
(N − 1)(3.28)
Ten sposób skalowania sprawia, »e ±rednie prawdopodobie«stwo selekcji wynosi 1,dodatkowo ka»dy z osobników posiada tak¡ oczekiwan¡ ilo±¢ potomstwa ile wynosijego przeskalowana warto±¢ przystosowania.
Na rysunku 3.15 przedstawiªem przykªadowy wynik skalowania rankingowegoliniowego punktów z rysunku 3.12, dla wspóªczynnika s = 1, 2.
37

Rysunek 3.14: Przykªad dziaªania skalowania rankingowego.
Rysunek 3.15: Przykªad dziaªania skalowania rankingowego liniowego.
38

Rysunek 3.16: Przykªad dziaªania skalowania proporcjonalnego.
Skalowanie proporcjonalne
Sprawia i» prawdopodobie«stwo selekcji jest proporcjonalne do wyniku funkcjiprzystosowania. Istniej¡ dwa podstawowe powody, dla których powinno si¦ rozwa»y¢zastosowanie tej metody selekcji przed jej wykorzystaniem. Pierwszym jest szybkazbie»no±¢ na pocz¡tku dziaªania algorytmu, w efekcie czego ªatwo mo»e doj±¢ do do-minacji populacji przez najlepiej przystosowanych osobników. Drugi to wada tejmetody ujawniaj¡ca si¦ w wypadku starszej populacji posiadaj¡cej osobników przy-stosowanych na podobnym poziomie - premiowanie osobników najlepiej przystoso-wanych nie zachodzi wtedy w wystarczaj¡cym stopniu.
Na rysunku 3.16 przedstawiªem przykªadowy wynik skalowania proporcjonalnegopunktów z rysunku 3.12.
Skalowanie górne
Przeskalowuje osobników z najwy»sz¡ warto±ci¡ funkcji przystosowania w takisposób i» tylko okre±lona liczba osobników posiada potomstwo [8]. Prawdopodobie«-stwo selekcji w obu grupach jest takie samo, odpowiednio: 1/n i 0. Nale»y okre±li¢ilo±¢ osobników którzy maj¡ zosta¢ uwzgl¦dnieni w procesie selekcji. Mo»liwe s¡ dwasposoby deniowania cz¦±ci populacji:
• na sztywno (poprzez dokªadne sprecyzowanie ilo±ci osobników),
• pªynnie (poprzez okre±lenie odsetka populacji).
39

Rysunek 3.17: Przykªad dziaªania skalowania górnego.
Znacznie bardziej przydatny jest drugi z tych sposobów. Nie wprowadza on pro-blemów przy ±rodowisku z wspóªistniej¡cymi pod-populacjami o du»ej rozbie»no±ciilo±ci osobników. Prócz tego, w przypadku u»ycia oprogramowania korzystaj¡cegoz algorytmów genetycznych nie ma potrzeby ka»dorazowego korygowania wspóªczyn-nika przy zmianie ilo±ci osobników.
Na rysunku 3.17 przedstawiªem przykªadowy wynik skalowania górnego punktówz rysunku 3.12, dla 75% populacji.
Skalowanie liniowe
Wyra»a si¦ wzorem:F (x) = af(x) + b (3.29)
Gdzie a jest dodatnim (maksymalizacja) lub ujemnym (minimalizacja) wspóªczyn-nikiem skalowania, natomiast b ma za zadanie zapewnienie nieujemnego wyniku.Wa»ne jest by ±rednie przystosowanie po skalowaniu (Favg(x)) równe byªo ±redniemuprzystosowaniu pierwotnemu (favg(x)). Dzi¦ki temu zagwarantowane jest, »e osob-niki przeci¦tne b¦d¡ mie¢ ±rednio po jednym potomku w nast¦pnym pokoleniu.
redni¡ liczb¦ potomków osobnika o maksymalnym przystosowaniu pierwotnymmo»na kontrolowa¢ za pomoc¡ warunku (3.30).
Fmax(x) = Cmult · favg(x) (3.30)
Pojawiaj¡ si¦ trudno±ci ze stosowaniem wzoru (3.30) w przypadku dojrzaªych ge-neracji - ±rednia przystosowania pierwotnego przewa»aj¡cej wi¦kszo±ci osobników
40

Rysunek 3.18: Przykªad dziaªania skalowania liniowego.
bliska jest maksimum, jednak znacznie obni»aj¡ j¡ osobniki o kiepskim przysto-sowaniu (Goldberg [2] nazywa ich degeneratami). W takich wypadkach znaczniekorzystniejsze jest stosowanie alternatywnego warunku.
Fmin(x) = 0 (3.31)
Peter Hancock [5] przedstawia wzór (3.32) na skalowanie liniowe. Gdzie s jestwspóªczynnikiem spodziewanej liczby potomków i s ∈< 1, 2; 2, 0 >.
F (x) = 1 +(s− 1)(Fi − Fsr)
Fmax − Fsr
(3.32)
W efekcie dziaªania pojawiaj¡ si¦ osobnicy o przystosowaniu ujemnym. Jednymz rozwi¡za« w tym wypadku jest przyporz¡dkowanie im warto±ci zerowej. Jednaknie jest to najlepszym rozwi¡zaniem, gdy» potrzebne jest ponowne przeliczenie przy-stosowania i dodatkowo grozi to utrat¡ ró»norodno±ci w populacji. Inne podej±cie,przedstawione wzorem (3.33), to redukcja wspóªczynnika tak by tylko najgorsi osob-nicy otrzymali warto±¢ zerow¡.
s = 1 +(Fmax − Fsr)
Fsr − Fmin
(3.33)
Skalowanie liniowe mo»e prowadzi¢ do szybkiej przedwczesnej zbie»no±ci.Na rysunku 3.18 przedstawiªem przykªadowy wynik skalowania liniowego punk-
tów z rysunku 3.12, dla wspóªczynnika a = 1, 2.
41

Rysunek 3.19: Przykªad dziaªania skalowania wykªadniczego.
Skalowanie wykªadnicze
Najlepszy osobnik otrzymuje przystosowanie równe 1. Drugi pod wzgl¦dem przy-stosowania s, zwykle s = 0, 99. Trzeci s2 i tak dalej, a» do ostatniego - s(N−1).
W celu wyznaczenia oczekiwanej ilo±ci potomstwa trzeba podzieli¢ warto±¢ ka»-dego z osobników przez warto±¢ ±redniego przystosowania.
Na rysunku 3.19 przedstawiªem przykªadowy wynik skalowania wykªadniczegopunktów z rysunku 3.12.
Skalowanie pot¦gowe
Goldberg [2] pisze, i» wyra»a si¦ wzorem:
F (x) = f(x)k (3.34)
Gdzie wspóªczynnik k pozostaje najcz¦±ciej uzale»niony od rozpatrywanego zagad-nienia. Mo»e si¦ on zmieni¢ znacz¡co podczas dziaªania algorytmu genetycznego,zaw¦»aj¡c lub rozszerzaj¡c zakres warto±ci przystosowa«.
3.12 Specjalizacja
Specjalizacja jest w algorytmach genetycznych odpowiednikiem izolacji geogra-cznej [11]. Wyst¦puje gdy równolegle ewoluuje wi¦cej ni» jedna populacja i w ka»-dej z nich osobnicy mog¡ ª¡czy¢ si¦, i wymienia¢ materiaªem genetycznym, jedynie
42

Rysunek 3.20: Dziaªanie operatora migracji
ze sob¡. W wyniku tego pod-populacje ró»ni¡ si¦ mi¦dzy sob¡ w charakterystyce. Do-br¡ analogi¡ mo»e by¢ tak»e spojrzenie na pod-populacje jako na odr¦bne gatunki.Technika ta sprawdza si¦ w przypadku poszukiwania kilku rozwi¡za« dla jednegoproblemu lub mo»e sªu»y¢ utrzymaniu ró»norodno±ci w przestrzeni poszukiwa«.
3.12.1 Migracja
Migracja jest przemieszczaniem si¦ osobników mi¦dzy pod-populacjami wyst¦pu-j¡cymi w algorytmie genetycznym [17]. Co jaki± okre±lony czas nast¦puje migracja.Mo»liwe s¡ dwie ±cie»ki post¦powania:
- najlepsze osobniki jednej populacji zast¦puj¡ najsªabsze osobniki w drugiejpopulacji,
- losowo, wedªug rozkªadu równomiernego, wybrane osobniki emigruj¡ do innejpod-populacji i zast¦puj¡ emigrantów.
Migracja mo»e zachodzi¢ mi¦dzy losowo wybranymi pod-populacjami i mi¦dzy pod-populacj¡ nast¦pn¡/poprzedni¡, lub tylko druga z mo»liwo±ci. W [11] Chippereldproponuje model z losowym wyborem pod-populacji, taki jak przedstawiªem na ry-sunku 3.20. Dzi¦ki migracji zachodzi wymiana materiaªu genetycznego mi¦dzy pod-populacjami.
Na rysunku przedstawiªem schemat siedmiu pod-populacji. Widoczna jest mi-gracja jednostronna, kolejno → GA1 −→ GA2 −→ . . . GA7 −→.
Dziaªanie migracji mo»e by¢ kontrolowane przez poni»sze parametry.
• Kierunek - migracja mo»e zaj±¢ w jednym lub dwóch kierunkach.
43

w przód migracja odbywa si¦ w kierunku nast¦pnej pod-populacji.W tym przypadku osobniki z n-tej pod-populacji migruj¡ do (n+1)-tejpod-populacji.
obustronniemigracja odbywa si¦ w dwie strony. W tym przypadku osob-niki migruj¡ do (n+1)-ej i (n-1)-ej pod-populacji.
W przypadku skrajnych pozycji wektora pod-populacji migracja zachodziod ostatniej do pierwszej pod-populacji i vice versa. Ten proces nazywany jestzawijaniem pod-populacji (ang. migration wrapping), aby mu zapobiec nale»yustawi¢ rozmiar ostatniej pod-populacji jako zerowy.
• Cz¦±¢ oznacza jak du»a cz¦±¢ osobników przechodzi mi¦dzy populacjamiw momencie migracji. Warto±¢ ta odnosi si¦ do mniejszej z populacji bio-r¡cej udziaª w migracji. Osobniki migruj¡ce z jednej pod-populacji do drugiejs¡ przenoszone, nie kopiowane.
• Przedziaª okre±la jak wiele generacji upªywa mi¦dzy migracjami. W przy-padku ustawienia Przedziaªu na warto±¢ 20 migracja mi¦dzy populacjami b¦-dzie zachodzi¢ co ka»de 20 generacji.
3.12.2 Przenikanie
Innym mechanizmem przemieszczania si¦ materiaªu genetycznego jest przeni-kanie. Podczas gdy migracja wprowadza nieci¡gªo±ci w pod-populacjach, zwi¡zanez przemieszczaniem osobników. Operator przenikania opiera si¦ na kopiowaniu osob-ników i przekazywaniu ich do s¡siednich pod-populacji [17].
Pod-populacje umieszczone s¡ analogicznie do przypadku migracji. Przenikanieodbywa si¦ co zadany okres czasu, jedynie mi¦dzy s¡siaduj¡cymi pod-populacjami.Rysunek 3.21 reprezentuje nast¦puj¡cy przykªad:
Osobnik z populacji Pop.1 zostanie skopiowany do populacji Pop.2, osob-nik z Pop.2 do Pop.3, . . . osobnik z Pop.7. do Pop.1.
Analogicznie do migracji przenikanie tak»e mo»e zachodzi¢ obustronnie. Wynikiemdziaªania tej operacji jest zwi¦kszenie ilo±ci osobników w populacjach. Najprostszymrozwi¡zaniem tego problemu jest zastosowanie odpowiedniej metody selekcji.
Modele implementuj¡ce przenikanie odznaczaj¡ si¦ mniejszym ziarnem ni» mo-dele migracyjne. Najprostszym mechanizmem wspieraj¡cym dziaªanie przenikaniajest implementacja algorytmu najbli»szego s¡siedztwa, przedstawionego powy»ej.Jednak w przypadku obu modeli (tak»e migracji) mo»liwe jest ustawienie dodat-kowych dróg przemieszczenia - mi¦dzy pod-populacjami nies¡siaduj¡cymi ze sob¡.
Algorytm ten w wielu przypadkach wykazuje si¦ wi¦ksz¡ efektywno±ci¡ dziaªaniani» algorytmy globalne czy migracyjne przy zbli»onej liczbie osobników. Jako wy-znacznik efektywno±ci wzi¦to w tym wypadku pod uwag¦ pr¦dko±¢ odnajdywaniaoptymalnego rozwi¡zania, liczon¡ w iteracjach oraz wielko±¢ przeszukiwanej pod-przestrzeni. Pisze o tym Chippereld w [11].
44

Rysunek 3.21: Dziaªanie operatora przenikania
45

Rozdziaª 4
Opis funkcjonalno±ci i obsªugi
programu
W tym rozdziale opisaªem funkcjonalno±¢ i sposób obsªugi programu. Ka»d¡z funkcji programu omówiªem w sposób wystarczaj¡cy do korzystania z jego peªnejfunkcjonalno±ci.
4.1 Zakªadka: Populacja
Zakªadka Populacja (rysunek 4.1) sªu»y do ustawienia opcji:
• funkcji przystosowania i zakresów zmiennych,
• kodowania i ewentualnego sposobu (dªugo±ci) reprezentacji zmiennych,
• ustawie« populacji.
Ustawienia zadania
• Wzór funkcji przystosowania pole umo»liwiaj¡ce wpisanie wzoru funkcjiprzystosowania, gdzie lista dost¦pnych funkcji matematycznych znajduje si¦w tabeli 5.1, prócz tego dost¦pne s¡ staªe pi i e.Program realizuje poszukiwanie maksimum. Oznacza to potrzeb¦ przeksztaª-cenia wzoru funkcji w przypadku potrzeby dokonania minimalizacji. Dokonujesi¦ tego cho¢by poprzez zmian¦ znaku.
• Podziaª chromosomu pole dost¦pne przy kodowaniach binarnych, sªu»ydo okre±lenia ile bitów reprezentuje kolejne zmienne. Gdzie zmienne s¡ ko-lejnymi zmiennymi wzoru funkcji przystosowania. Kolejne warto±ci oddzielanes¡ znakiem -.
• Zakres warto±ci przedziaªów pole sªu»¡ce do okre±lenia przedziaªu ogra-niczaj¡cego kolejne zmienne. Przedziaªy musz¡ by¢ poprawnie zapisane, tzn.w formie (a; b), gdzie a i b s¡ warto±ciami ograniczenia, odpowiednio: dolnegoi górnego, przedziaªu.
46

Rysunek 4.1: Wygl¡d zakªadki Populacja.
47

• Rodzaj kodowania chromosomu lista sªu»¡ca do wyboru odpowiedniegokodowania. Dost¦pne s¡ nast¦puj¡ce typy kodowania:
Binarny (kodowanie BCD)
Binarny (kodowanie Graya)
Rzeczywisty
Dodatkowo istniej¡ jeszcze dwa pola - dªugo±¢ chromosomu i dokªadno±¢ -pozwalaj¡ce na odczyt aktualnej dªugo±ci chromosomu i dokªadno±ci reprezentacjizmiennej (w przypadku kodowania binarnego).
Ustawienia populacji
• Ilo±¢ osobników pole pozwala na okre±lenie ilo±ci osobników w populacji. Je-±li wprowadzonych zostanie kilka warto±ci stworzone zostan¡ pod-populacje.W tym wypadku liczby odpowiadaj¡ za liczebno±¢ ka»dej z nich. Kolejne war-to±ci oddzielane s¡ znakiem −. Ograniczeniem jest minimalna warto±¢ 2 osob-ników.
4.2 Zakªadka: Operatory genetyczne
Zakªadka Operatory genetyczne (rysunek 4.2) sªu»y do ustawienia opcji dla ope-ratorów:
• selekcji,
• skalowania,
• mutacji,
• krzy»owania,
• inwersji,
• specjalizacji.
Opcje operatora selekcji
Funkcja selekcji wybiera, na podstawie przeskalowanych warto±ci funkcji przy-stosowania, rodziców do tworzenia kolejnej generacji.
Wybór funkcji selekcji dokonywany jest w polu Rodzaj selekcji Mo»liwy jestwybór nast¦puj¡cych funkcji:
• Proporcjonalna zwana tak»e metod¡ koªa ruletki , budowany jest odcinekpodzielony proporcjonalnie do wyników funkcji przystosowania kolejnych osob-ników. Losuje si¦ liczb¦ z zakresu odcinka i na tej podstawie dokonywany jestwybór rodzica.
48
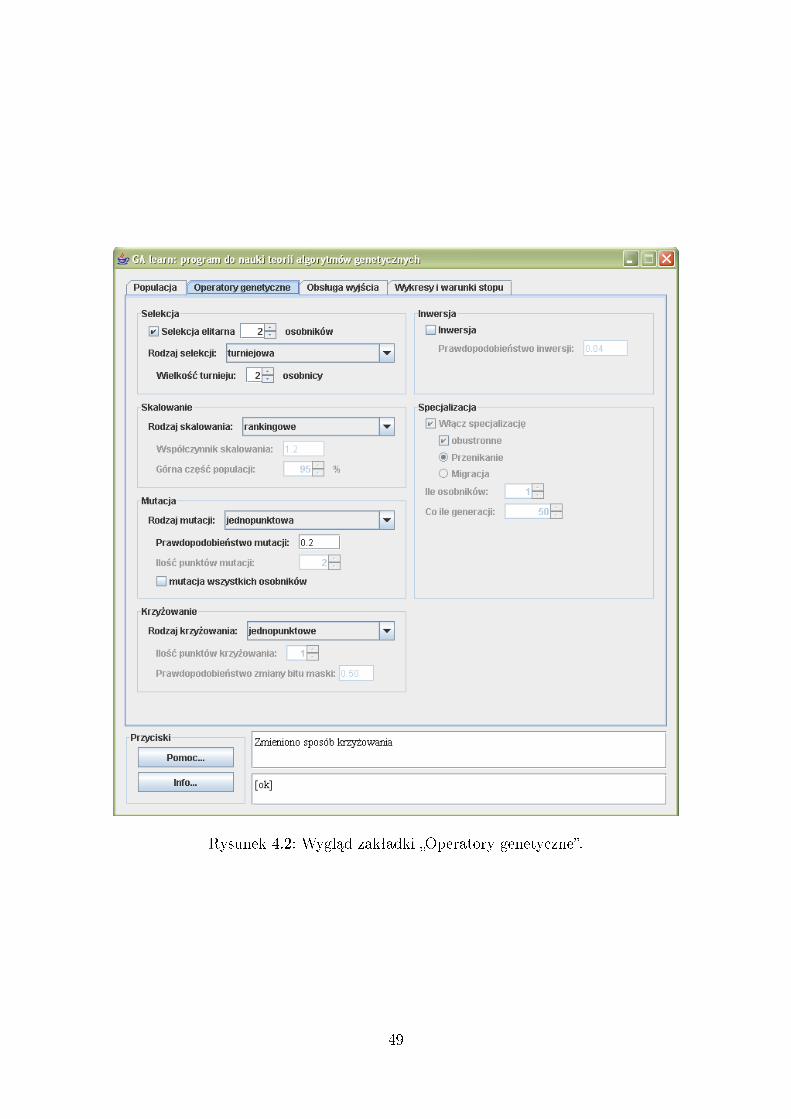
Rysunek 4.2: Wygl¡d zakªadki Operatory genetyczne.
49

• Deterministyczna Metoda ta zapewnia i» osobniki posiadaj¡ce najwy»-sze warto±ci przystosowania zostan¡ wybrani do reprodukcji. Wybór deter-ministyczny odbywa si¦ poprzez policzenie prawdopodobie«stwa reprodukcjiwprost proporcjonalne do warto±ci funkcji przystosowania. Ka»dy osobnikotrzymuje tyle kopii ile wynosi cz¦±¢ caªkowita z oczekiwanej ilo±ci potom-stwa. W kolejnym kroku cz¦±ci uªamkowe porz¡dkowane s¡ malej¡co i pozo-staªe miejsca zapeªniane s¡ osobnikami z góry listy.
• Turniejowa losowani s¡ osobnicy, losowanie ma charakter rozkªadu równo-miernego, na rodzica wybierany jest najlepszy z nich - decyduje warto±¢ funkcjiprzystosowania. Poprzez Wielko±¢ turnieju ustala si¦ ilo±¢ jednorazowo loso-wanych osobników.
• Stochastyczna równomierna - tworzony jest odcinek dzielony na pod-odcinki odpowiadaj¡ce kolejnym osobnikom, proporcjonalne do ich przystoso-wania. Algorytm przechodzi po caªej dªugo±ci krokami równej dªugo±ci. Miejscestartu jest liczb¡, mniejsz¡ ni» dªugo±¢ kroku, losow¡ o rozkªadzie równomier-nym. Przy ka»dym kroku wybierany jest odpowiedni osobnik.
• Wybór losowy wedªug reszt z powtórzeniami przepisuje rodzicówna podstawie caªkowitych cz¦±ci przeskalowanych warto±ci przystosowania. Dozapeªnienia pozostaªych miejsc wykorzystywany jest algorytm koªa rulety (se-lekcja proporcjonalna).
• Równomierna rodzice wybierani s¡ caªkowicie losowo z rozkªadu równomier-nego. Sposób ten zwykle nie jest u»ytecznym sposobem selekcji.
Opcja selekcja elitarna pozwala na wª¡czenie bezpo±redniego przeniesienia, okre±lo-nej liczby, najlepszych osobników bezpo±rednio do nowej populacji. Nie podlegaj¡oni wtedy »adnym zmianom, chyba »e jest to ustawione w innych opcjach (mutacjawszystkich osobników).
Opcje operatora skalowania przystosowania
Funkcja skalowania przeksztaªca wyniki zwracane przez funkcj¦ przystosowaniado warto±ci przydatnych dla funkcji selekcji.
Rodzaj skalowania okre±la funkcj¦ u»ywan¡ do skalowania. Dost¦pne s¡ na-st¦puj¡ce funkcje:
• Rankingowe bazuje na pozycji wyniku osobnika w odniesieniu do caªej popu-lacji. Ranga osobnika jest jego pozycj¡ w±ród posortowanych wyników funkcjiprzystosowania caªej populacji.
• Rankingowe liniowe bazuje na pozycji wyniku osobnika w odniesieniu do caªejpopulacji. Liniowo±¢ uzyskana jest poprzez u»ycie odpowiedniego wspóªczyn-nika.
• Proporcjonalne sprawia i» prawdopodobie«stwo selekcji jest proporcjonalnedo wyniku funkcji przystosowania.
50

• Górne przeskalowuje osobników z najwy»sz¡ warto±ci¡ funkcji przystosowaniaw taki sposób i» tylko okre±lona liczba osobników posiada potomstwo. Praw-dopodobie«stwo selekcji w obu grupach jest takie samo, odpowiednio: 1/n i 0.Nale»y okre±li¢ ilo±¢ osobników którzy zostan¡ uwzgl¦dnieni w procesie selek-cji. Dokonywane jest to poprzez okre±lenie procentowej warto±ci górnej cz¦±cipopulacji w polu górna cz¦±¢ populacji. Wynik niecaªkowity ilo±ci osobni-ków zaokr¡glany jest w dóª.
• Liniowe dokonuje skalowania przy zastosowaniu funkcji liniowej o zadanymwspóªczynniku skalowania, zwykle z przedziaªu < 1; 2 >.
• Wykªadnicze dokonywane jest na podstawie funkcji wykªadniczej. Najlepszyosobnik otrzymuje warto±¢ przystosowania równ¡ 1, nast¦pni kolejne caªkowitepot¦gi wspóªczynnika s=0,99.
Opcje operatora mutacji
Funkcja mutacji wprowadza niewielkie losowe zmiany w±ród osobników nale»¡-cych do populacji. Zapewnia to genetyczne zró»nicowanie i pozwala na przeszukaniewi¦kszej przestrzeni rozwi¡za«. Funkcja ustalaj¡ca sposób dziaªania mutacji usta-wiana jest w polu rodzaj mutacji, natomiast prawdopodobie«stwo w polu prawdo-podobie«stwo mutacji. Operacja ta ma ró»n¡ posta¢ zale»nie od sposobu kodo-wania osobników. Do wyboru pozostaj¡ nast¦puj¡ce mo»liwo±ci:
• Jednopunktowa (kodowanie binarne) proces przebiega dwustopniowo,w pierwszym kroku porównuje si¦ liczb¦ losow¡ z rozkªadu równomiernego,z prawdopodobie«stwem mutacji w celu ustalenia czy osobnik zostanie zmuto-wany. W drugim kroku losowana jest pozycja w chromosomie na której zajdziemutacja.
• Wielokrotna (kodowanie binarne) Proces pocz¡tkowy jest identyczny jak dlaprzypadku jednopunktowego. Jednak losowana jest tak»e liczba miejsc na któ-rych zajdzie mutacja, gdzie minimalna ilo±¢ to 1 natomiast maksymalna okre-±lona jest w polu ilo±¢ punktów mutacji.
• Gausoidalna (kodowanie zmiennoprzecinkowe) dodaje losow¡ liczb¦ do ka»-dej pozycji w wektorze danego osobnika. Liczba wybierana jest wedªug roz-kªadu równomiernego z rozkªadu Gaussa, centrowanego na zerze. Wariancjarozkªadu zmienia si¦ z przebiegiem dziaªania algorytmu - im dªu»sze dziaªanietym wi¦ksze zaw¦»enie wariancji.
Przeª¡cznik mutacja wszystkich osobników pozwala na wª¡czenie, opcji mutacjitak»e osobników podlegaj¡cych selekcji elitarnej. Korzystanie z tej opcji, w niektó-rych szczególnych przypadkach, mo»e doprowadzi¢ do utraty cennych dla ±rodowiskaosobników.
51

Opcje operatora krzy»owania
Krzy»owanie to operacja poª¡czenia co najmniej dwóch osobników, prowadz¡cado powstania nowych osobników do kolejnej generacji. Operacja ta, podobnie jakmutacja ze wzgl¦du na ±cisª¡ zale»no±¢ z reprezentacj¡ ka»dego genu, ma ró»n¡posta¢ zale»nie od sposobu kodowania osobników.
Mo»liwe jest ustawienie funkcji dokonuj¡cej krzy»owania w polu Funkcja krzy»o-wania. Do wyboru s¡ nast¦puj¡ce mo»liwo±ci:
• Jednopunktowe (kodowanie binarne) losowana jest liczba caªkowita l z prze-dziaªu <1,n>, gdzie n jest ilo±ci¡ zmiennych wektora genotypu. Pozycje wek-tora pierwszego rodzica o indeksie mniejszym lub równym l i cz¦±¢ wektoradrugiego rodzica o indeksie wi¦kszym ni» l tworzy jednego nowego osobnika,natomiast pozostaªe cz¦±ci wektorów (pocz¡tek drugiego z wektorów i koniecpierwszego) tworz¡ drugiego z nowych osobników. Patrz punkt 3.8.
• Wielopunktowe (kodowanie binarne) Przebiega tak samo jak krzy»owaniejednopunktowe, z tym, »e przebiega w ilo±ci punktów okre±lonych w polu ilo±¢punktów krzy»owania.
• Po±rednie (kodowanie binarne) polega na tworzeniu losowego wektora ma-ski, jest to wektor binarny o dªugo±ci wektora genotypu. Na podstawie tegowektora, i jego inwersji (tzn. wektor powstaj¡cy z zanegowania wszystkich po-zycji wektora wyj±ciowego), wybiera si¦ elementy wektorów genotypów oburodziców do wymiany. Dla pierwszego z dzieci bierze si¦ te pozycje z wektorapierwszego rodzica na których w masce wyst¦puje 1 i od drugiego rodzica tepozycje wektora na których w masce wyst¦puje 0.
• Simplex (kodowanie binarne) zwane jest tak»e krzy»owaniem z nauk¡ ze zªegozachowania, bierze w nim udziaª trzech rodziców - dwóch lepszych i jedengorszy (pod wzgl¦dem warto±ci funkcji przystosowania), natomiast efektemjest jeden osobnik potomstwa. Sama procedura przebiega w ten sposób, »e dlaka»dego genu wybiera si¦ gen tego rodzica lepszego który posiada gen innyni» rodzic gorszy, chyba »e wszyscy trzej posiadaj¡ taki sam.
• Rozproszone (kodowanie zmiennoprzecinkowe) dzieci tworzone przez zasto-sowanie ±redniej wa»onej rodziców. Rodzice wyznaczaj¡ hiperkostk¦ w którejtworz¡ przeciwne wierzchoªki. Losowany wspóªczynnik jest staªy dla danegoosobnika. Je±li wspóªczynnik zawiera si¦ w przedziale <0,1> to w tym wy-padku dzieci znajduj¡ si¦ wewn¡trz hiperkostki. Natomiast je±li wspóªczynnik(kodowanie zmiennoprzecinkowe) jest wi¦kszy, to mog¡ znajdowa¢ si¦ pozani¡.
• Liniowe (kodowanie zmiennoprzecinkowe) tworzy dzieci le»¡ce na linii zawie-raj¡cej dwójk¦ rodziców, mniejsza odlegªo±¢ od rodziców z lepsz¡ warto±ci¡przystosowania i wi¦ksza od rodziców z gorsz¡ warto±ci¡ przystosowania. Jestlosowany jeden wspóªczynnik dla caªego osobnika.
52

• Po±rednie (kodowanie zmiennoprzecinkowe) dzieci tworzone przez zastoso-wanie ±redniej wa»onej rodziców. Rodzice wyznaczaj¡ hiperkostk¦ w którejtworz¡ przeciwne wierzchoªki. Dla ka»dego kolejnego genu losowany jest nowywspóªczynnik. Je±li wspóªczynnik zawiera si¦ w przedziale <0,1> to w tym wy-padku dzieci znajduj¡ si¦ wewn¡trz hiperkostki. Natomiast je±li wspóªczynnikjest wi¦kszy, to mog¡ znajdowa¢ si¦ poza ni¡.
• Ekstrapolacyjne (kodowanie zmiennoprzecinkowe) oparte jest na binarnymkrzy»owaniu jednopunktowym. Losowany jest punkt krzy»owania, w którymgeny dzieci s¡ wynikow¡ genów obydwu rodziców natomiast cz¦±¢ przedi po punkcie krzy»owania pochodzi bezpo±rednio odpowiednio od pierwszegoi od drugiego z rodziców dla pierwszego potomka, i odwrotnie dla drugiego.
Opcje inwersji
Inwersja jest operatorem genetycznym stosowanym w przypadku kodowania bi-narnego. Jej zadaniem jest zapobieganie utracie cennych zestawów genów. Poniewa»niektóre cechy przejawiaj¡ si¦ poprzez wyst¦powanie okre±lonego zestawu kolejnychgenów to krzy»owanie ma cz¦sto niszcz¡cy wpªyw szczególnie na dªu»sze schematy.Prawdopodobie«stwo inwersji jest zwykle du»o mniejsze (zwykle o rz¡d wielko-±ci) ni» prawdopodobie«stwo mutacji.
Inwersja nie zachodzi dla osobników podlegaj¡cych selekcji elitarnej i przemiesz-czanych w obr¦bie specjalizacji. Co wynika bezpo±rednio z przyczyny dla której jeststosowana.
Opcje migracji
Migracja jest przemieszczaniem si¦ osobników mi¦dzy pod-populacjami tworzo-nymi przez algorytm w wypadku wpisania wektora w pole Rozmiar populacji (patrzpunkt 4.1, na stronie 48). Co jaki± okre±lony czas najlepsze osobniki jednej popula-cji zast¦puj¡ najsªabsze osobniki w drugiej populacji. Dziaªanie migracji mo»e by¢kontrolowane przez poni»sze parametry.
• Kierunek - migracja mo»e zaj±¢ w jednym lub dwóch kierunkach.
w przód migracja odbywa si¦ w kierunku nast¦pnej pod-populacji.W tym przypadku osobniki z n-tej pod-populacji migruj¡ do (n+1)-tejpod-populacji.
obustronniemigracja odbywa si¦ w dwie strony. W tym przypadku osob-niki migruj¡ do (n+1)-tej i (n-1)-tej pod-populacji.
W przypadku skrajnych pozycji wektora pod-populacji migracja zachodziod ostatniej do pierwszej pod-populacji i vice versa. Ten proces nazywany jestzawijaniem pod-populacji, aby mu zapobiec nale»y ustawi¢ rozmiar ostatniejpod-populacji jako zerowy.
• Pole ile osobników oznacza jak du»a cz¦±¢ osobników przechodzi mi¦dzy po-pulacjami w momencie migracji. Warto±¢ ta odnosi si¦ do mniejszej z populacji
53

bior¡cej udziaª w migracji. Osobniki migruj¡ce z jednej pod-populacji do dru-giej s¡ kopiowane (klonowanie), nie przenoszone.
• Pole co ile migracja okre±la jak wiele generacji upªywa mi¦dzy migracjami.W przypadku ustawienia na warto±¢ 20 migracja mi¦dzy populacjami b¦dziezachodzi¢ co ka»de 20 generacji. Wa»ny jest dobór odpowiednio du»ego pa-rametru aby miaªo szans¦ wyksztaªci¢ si¦ rzeczywiste zró»nicowanie mi¦dzypod-populacjami.
4.3 Zakªadka: Obsªuga wyj±cia
Zakªadka Obsªuga wyj±cia (rysunek 4.3) sªu»y do ustawienia opcji:
• zapisu wyników dziaªania algorytmu,
• zapisu/odczytu ustawie« domy±lnych,
• zapisu/odczytu ustawie«,
• generacji/odczytu okre±lonego ±rodowiska.
Ustawienia algorytmu
Po wyborze pliku, przy pomocy dialogu otwieranego po naci±ni¦ciu przyciskuWybierz plik..., istnieje mo»liwo±¢ zapisu danych do pliku lub odczytu danych.Formatem zapisu jest XML.
Ustawienia domy±lne
Po naci±ni¦ciu przycisku Zapisz dokonywany jest zapis ustawie« do pliku do-my±lne.xml. Je»eli plik taki istnieje w katalogu programu aktywny jest wtedy przy-cisk Przywró¢, który powoduje odczytanie danych z pliku i ustawienie parametrówprogramu.
Dane wej±ciowe
Kontrolki znajduj¡ce si¦ na tym panelu pozwalaj¡ na wygenerowanie lub odczytnowego ±rodowiska z pliku, a tak»e zapisanie go do wybranego pliku. Dodatkowekontrolki pozwalaj¡ na zapis wszystkich ustawie« programu (zapisz z wszystkimiustawieniami), a tak»e u»ycie wygenerowanego/odczytanego ±rodowiska w uru-chamianym algorytmie. Nie jest to jednak mo»liwe po zmianie ustawie« zadanialub populacji, od których bezpo±rednio zale»¡ osobnicy ±rodowiska.
Zapis wyników dziaªania algorytmu
Kontrolki na tym panelu pozwalaj¡ na zapis efektu dziaªania algorytmu do wy-branego pliku. Po wyborze pliku mo»liwe jest wª¡czenie zapisu (Zapisuj kolejnepopulacje). Nale»y dokona¢ wyboru, czy zapisywa¢ wszystkie generacje, czy
54

Rysunek 4.3: Wygl¡d zakªadki Obsªuga wyj±cia.
tylko kra«cowe wtedy zapisywana jest jedynie generacja pocz¡tkowa i ostatnia.Nale»y wzi¡¢ przy tym pod uwag¦ i» przykªadowy algorytm z kodowaniem binarnymo dªugo±ci chromosomu 26 genów, dla 20 osobników w 100 generacjach, przy zapisiewarto±ci funkcji przystosowania tworzy plik wielko±ci 200kB.
Domy±lnie zapisywane s¡ tylko warto±ci chromosomu, dodatkowo mo»na wª¡czy¢:zapisz warto±¢ przystosowania, zapisz reprezentowane punkty, zapisz ilo±¢selekcji. Mo»liwe jest wymuszenie zapisu jedynie lidera ka»dej populacji (zapisztylko lidera. Dodatkowo mo»na zapisa¢ wyniki z ustawieniami programu (zapiszustawienia algorytmu).
Opcja zapisu osobników do pliku jest bardzo przydatna przy dokªadnym ±ledze-niu mechanizmu dziaªania dla maªych populacji przy niewielkiej ilo±ci iteracji.
55

Rysunek 4.4: Wygl¡d zakªadki Wykresy i warunki stopu.
4.4 Zakªadka: Wykresy i warunki stopu
Zakªadka Wykresy i warunki stopu (rysunek 4.4) sªu»y do ustawienia opcji:
• wykresów które maj¡ by¢ wy±wietlane,
• mechanizmu dziaªania algorytmu,
• warunków stopu.
Ustawienia wykresów
Funkcje rysowania umo»liwiaj¡ przegl¡d wykresów dziaªania algorytmu gene-tycznego w ró»nych jego aspektach.
56

• Najlepsze przystosowanie zaznacza najlepsz¡ warto±¢ funkcji w danej ge-neracji.
• rednia odlegªo±¢ w populacji wykre±la ±redni¡ odlegªo±¢ mi¦dzy osobni-kami w populacji dla kolejnych generacji.
• Przystosowanie osobników wykre±la histogram przedstawiaj¡cy wyniki dlakolejnych generacji.
• Warunki stopu wykre±la poziom speªnienia konkretnych warunków stopu.
• Min/Max/r przystosowania wykre±la minimaln¡, maksymaln¡ i ±redni¡warto±¢ przystosowania w ka»dej generacji.
• Selekcja wykre±la histogram rodziców. Pokazuje którzy rodzice przyczyniaj¡sie do powstania ka»dej z generacji.
Rozmiar okna wykresów
Umo»liwia ustawienie wybranej wielko±ci ekranu wy±wietlania.
• Automatyczny rozmiar ekranu zostanie ustawiony na domy±lne warto±ci.
• Zadany umo»liwia dokªadne okre±lenie szeroko±ci i wysoko±ci okna.
• Peªny ekran wykresy wy±wietlane s¡ w trybie peªnoekranowym.
Warunki stopu
Warunki stopu okre±laj¡ w jakim wypadku dziaªanie algorytmu zostanie prze-rwane.
• Maksymalna ilo±¢ generacji okre±la maksymaln¡ ilo±¢ iteracji wykonanychprzez algorytm genetyczny.
• Maksymalna ilo±¢ bezproduktywnych generacji umo»liwia ustalenieprzez ile generacji nie poprawiaj¡cych wyniku funkcji przystosowania algo-rytm ma dziaªa¢.
• Maksymalny czas okre±la maksymalny czas, w sekundach, przez jaki algo-rytm b¦dzie dziaªa¢ przed zatrzymaniem.
• Oczekiwana warto±¢ przystosowania algorytm przerywa dziaªanie w mo-mencie gdy najlepsza warto±¢ funkcji przystosowania osi¡gnie warto±¢ wi¦ksz¡lub równ¡ warto±ci danej.
57

a) b) c) d)
Rysunek 4.5: Przykªadowe mo»liwo±ci stanu panelu sterowania dziaªaniem algo-rytmu: a) algorytm wª¡czony bez opó¹nienia, b) algorytm wª¡czonym opó¹nie-niem, c) zatrzymanie dziaªania algorytmu, d) algorytm uruchomiony z opcj¡ po-twierdzania kolejnych generacji.
4.5 Panel sterowania dziaªaniem algorytmu
Panel sterowania dziaªaniem algorytmu dost¦pny jest po uruchomieniu algo-rytmu genetycznego. Jego zadaniem jest umo»liwienie kontroli nad wykonywaniemkolejnych iteracji, dzi¦ki czemu mo»liwa jest bardziej wnikliwa analiza przebiegaj¡-cych procesów. Panel sªu»y do:
• wy±wietlania bie»¡cej generacji,
• wy±wietlania najlepszego przystosowania,
• przerwania dziaªania algorytmu,
• wª¡czenia/wyª¡czenia opó¹nienia mi¦dzy kolejnymi generacjami (je±li algo-rytm uruchomiony z opó¹nieniem),
• chwilowego zatrzymania dziaªania algorytmu,
• potwierdzania ka»dej z kolejnych generacji (je±li wª¡czono dziaªanie krokowew zakªadce Wykresy i warunki stopu).
Wi¦cej informacji na temat opó¹nienia i dziaªania krokowego algorytmu zna-le¹¢ mo»na w rozdziale 4.4.
Podstawa funkcjonalno±ci programu opracowana zostaªa na podstawie toolboxuGATools [17] programu MatLab 7.0.1. Opracowany przeze mnie program implemen-tuje funkcje tego toolboxu, jak równie» zawiera nowe funkcje i posiada rozszerzonemo»liwo±ci.
58

Rozdziaª 5
Przedstawienie szczegóªów
implementacji
5.1 Budowa programu
5.1.1 Przypadki u»ycia
Na rysunku 5.1 przedstawiªem diagram przypadków u»ycia programu. Nie b¦d¦tutaj skupiaª si¦ na szczegóªach, które opisaªem dokªadnie w rozdziale 4.
5.1.2 Pakiety programu
Program skªada si¦ z trzech pakietów. Podziaª ten jest naturaln¡ konsekwencj¡wymaganej funkcjonalno±ci programu oraz umo»liwienia ªatwej ewentualnej pó¹-niejszej rozbudowy lub wykorzystania której± z cz¦±ci. Podziaª przedstawiony zostaªna rysunku 5.2. Poszczególne pakiety tworz¡ logiczne cz¦±ci:
• GA_engine - cz¦±¢ obliczeniowa: tworzenie ±rodowiska zªo»onego z pod-populacji okre±lonych ilo±ci osobników i wykonywanie kolejnych iteracji zgod-nie z ustawionymi parametrami ±rodowiska i operatorów genetycznych (rysu-nek 5.3).
• GA_program - pakiet zawieraj¡cy klas¦ uruchomieniow¡ (GA_learn),klas¦ wykorzystywan¡ do ustawienia i wª¡czenia algorytmu genetycznego(Sterowanie) cz¦±ci interfejsu gracznego sªu»¡ce do wy±wietlania wykresów,wy±wietlania wyników, wy±wietlania numeru generacji i kontroli przebiegu al-gorytmu (rysunek 5.4).
• GA_UI - pakiet obsªugi interfejsu gracznego: klasy o nazwach Panel∗ s¡Beanami b¦d¡cymi poszczególnymi cz¦±ciami gªównego okna, okna dialogowe(DialogInfo i DialogHelp, odpowiednio - informacji o programie i pomocy),gªówn¡ klas¡ pakietu (UI_GA_learn) która korzysta z klasy obsªugi w¡tkówSwingWorker do uruchomienia klasy Sterowanie pakietu GA_program (ry-sunek 5.5).
59
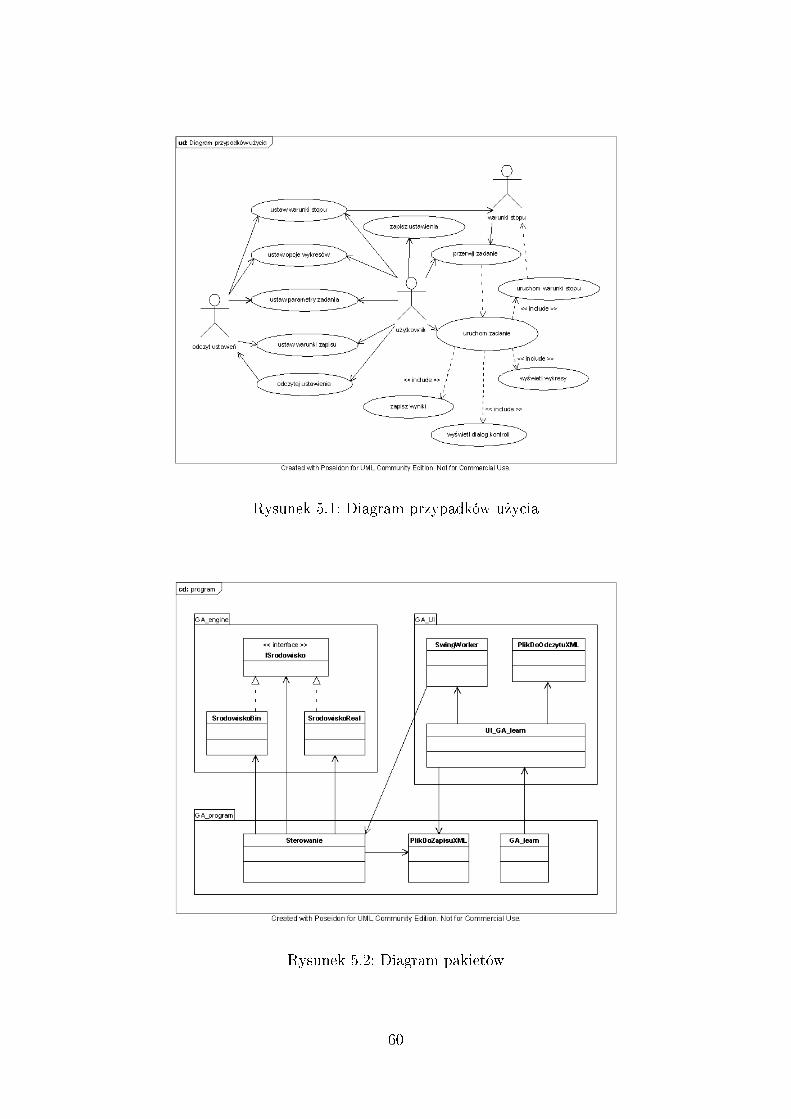
Rysunek 5.1: Diagram przypadków u»ycia
Rysunek 5.2: Diagram pakietów
60

Rysunek 5.3: Diagram klas pakietu GA_engine
Rysunek 5.4: Diagram klas pakietu GA_program
61

Rysunek 5.5: Diagram klas pakietu GA_UI
62

5.2 W¡tki w ±rodowisku Swing
Event-Dispatching Thread
Czasochªonno±¢ oblicze« algorytmu genetycznego nale»y uwzgl¦dni¢ szczególniew sposobie dziaªania ±rodowiska gracznego. Obsªuga zdarze« i rysowane kompo-nentów w Java Swing korzystaj¡ z jednego w¡tku zwanego event-dispatching thread.To zapewnia zako«czenie dziaªania obsªugi ka»dego zdarzenia przed rozpocz¦ciemobsªug nast¦pnego i uniemo»liwia zakªócenie rysowania przez wywoªane obsªugi zda-rze«. Aby unikn¡¢ zakleszczenia nale»y podj¡¢ szczególne ±rodki ostro»no±ci zmie-rzaj¡ce do zapewnienia by wszystkie komponenty i modele Swing byªy tworzone,modykowane i wykonywane tylko z event-dispatching thread.
U»ycie metody invokeLater
Mo»na wywoªa¢ invokeLater z ka»dego w¡tku, który wymaga event-dispatchingthread do wykonania okre±lonego kodu. Trzeba umie±ci¢ kod w metodzie run obiektuRunnable i u»y¢ tego obiekty jako argumentu wywoªania invokeLater. MetodainvokeLater nie czeka na zako«czenie dziaªania kodu przez event-dispatching threadtylko powraca natychmiastowo. Poni»ej przedstawiam przykªad wykorzystania me-tody invokeLater.
Listing 5.1: u»ycie metody invokeLater
1 Runnable updateAComponent = new Runnable ( ) 2 public void run ( ) component . doSomething ( ) ; 3 ;4 Sw i n gU t i l i t i e s . invokeLater ( updateAComponent ) ;
U»ycie metody invokeAndWait
Metoda invokeAndWait jest bardzo podobna do invokeLater, z t¡ tylko ró»nic¡»e nie powraca do czasu zako«czenia dziaªania kodu przez event-dispatching thread.Kiedy tylko jest to mo»liwe nale»y korzysta¢ z invokeLater zamiast invokeAndWait- w przeciwnym wypadku nale»y liczy¢ si¦ z istnieniem mo»liwo±ci wyst¡pieniazakleszczenia. Je±li jednak u»ycie invokeAndWait jest niezb¦dne nale»y upew-ni¢ si¦, »e nie zakªada blokad na obiekty których mog¡ potrzebowa¢ inne w¡tkiprzed zako«czeniem dziaªania metody. Poni»ej przedstawiam przykªad dziaªaniainvokeAndWait.
Listing 5.2: u»ycie metody invokeAndWait
1 void showHel loThereDialog ( ) throws Exception 2 Runnable showModalDialog = new Runnable ( ) 3 public void run ( ) 4 JOptionPane . showMessageDialog (myMainFrame , "He l lo
There" ) ;5 6 ;7 Sw i n gU t i l i t i e s . invokeAndWait ( showModalDialog ) ;
63

8
U»ycie w¡tków dla poprawienia wydajno±ci
W¡tki u»yte poprawnie mog¡ prowadzi¢ do poprawy wydajno±ci. Wa»na jestjednak rozwaga podczas u»ycia ich w programach Swing. W¡tki mog¡ prowadzi¢tak»e do uproszczenia kodu programu. Podstawowe sytuacje kiedy warto ich u»ywa¢,to:
• dªugotrwaªe operacje obliczeniowe, operacje blokuj¡ce dost¦p lub dªugotrwalekorzystaj¡ce z sieci, dysku lub innych urz¡dze« I/O,
• dªugotrwaªe operacje obliczeniowe, które mo»na przenie±¢ z event-dispatchingthread, tak by GUI pozostawaªo aktywne,
• potrzeba powtarzania jakiego± dziaªania co okre±lony czas, np. aktualizacjastanu stopera,
• oczekiwanie na powiadomienie z innego programu.
Ze wzgl¦du na ªatwo±¢ popeªnienia bª¦du podczas implementacji w¡tków w Swing,warto wykorzysta¢ istniej¡ce klasy narz¦dziowe. Przykªadem takiej klasy mo»e by¢SwingWorker.java. Dziaªanie tej klasy polega na stworzeniu w¡tku do uruchomieniaw nim czasochªonnego kodu. Dodatkowo umo»liwia wykonanie dodatkowego koduw event-dispatching thread, po zako«czeniu pierwszego.
W moim programie postanowiªem skorzysta¢ z powy»szej klasy w celu urucho-mienia silnika obliczeniowego dla algorytmu genetycznego. Klasa okazaªa si¦ dziaªa¢bardzo dobrze i w peªni speªniªa moje oczekiwania. W kolejnym punkcie opisaªemsposób jej wykorzystania.
U»ycie klasy SwingWorker
Klasa SwingWorker nie nale»y do pakietu Swing, wymagane jest pobranie jejz [22] lub innego ¹ródªa. Wykorzystanie SwingWorker polega na stworzeniu pod-klasy implementuj¡cej metod¦ construct, która zawiera wstawiony kod do wyko-nania. SwingWorker tworzy w¡tek jednak nie rozpoczyna jego dziaªania. W celurozpocz¦cia dziaªania w¡tku nale»y wywoªa¢ metod¦ start, gdzie wywoªywana jestmetoda construct.
Poni»ej przedstawiam fragment kodu uruchomienia algorytmu genetycznego.
Listing 5.3: fragment kodu UI_GA_learn.java
1 i f ( worker !=null ) 2 worker . i n t e r r up t ( ) ;3 wypiszStan ( "Przerwano d z i a ª a n i e algorytmu .
Uruchomiono ponownie . . . " ) ;4 else wypiszStan ( "Uruchomiono : algorytm . . . " ) ;5
6 worker = new SwingWorker ( ) 7 Sterowanie s t e r ;
64

8 public void i n t e r r up t ( ) 9 // System . err . p r i n t l n (" s d f s a d f g a s d f g ") ;10 s t e r . p r z e rw i j ( ) ;11 12 public Object cons t ruc t ( ) 13 /∗ tu j e s t kod ∗/14 15 ;16 worker . s t a r t ( ) ;
Szczegóªowe informacje na temat u»ycia w¡tków w ±rodowisku Swing mo»naznale¹¢ w [22].
5.3 Zastosowane biblioteki
W projekcie korzystaªem z gotowych darmowych bibliotek. U»yªem ich do parso-wania wzorów matematycznych (Java Expression Parser) i do rysowania wykresów(JFreeChart). Poni»ej opisaªem wymienione biblioteki, aspekty dotycz¡ce ich do-st¦pno±ci i stosowania.
5.3.1 JEP - Java Expression Parser
Opis
Strona producenta: http://www.singularsys.com/jep/Wykorzystana wersja: 2.4.0 (released 2006/04/01)
JEP jest bibliotek¡ sªu»¡c¡ do parsowania i sprawdzania poprawno±ci wzorówmatematycznych. Dzi¦ki jej zastosowaniu istnieje mo»liwo±¢ wprowadzania dowol-nych funkcji matematycznych w postaci zmiennej typu String do wykorzystaniaw programie. Biblioteka JEP obsªuguje wprowadzanie zdeniowanych zmiennych,staªych i wzorów. Uwzgl¦dnia przy tym wykorzystanie wielu funkcji matematycz-nych, co przedstawiªem szerzej w podpunkcie Dost¦pne funkcje. Poni»ej wymieni-ªem w punktach mo»liwo±ci i zalety biblioteki.
• maªy rozmiar (plik jar ma obj¦to±¢ jedynie 75kB ),
• wspiera u»ycie wyra»e« algebry boolowskiej (!, &&, ||, <, >, !=, ==, >=i <=),
• szybkie dziaªanie (wyra»enie mo»e zosta¢ szybko przeliczone dla innych war-to±ci zmiennych),
• wsparcie dla podstawowych funkcji matematycznych,
• mo»liwo±¢ rozszerzenia przez zdeniowanie funkcji u»ytkownika,
• przedeniowane staªe, takie jak π i liczba Eulera e,
• wsparcie dla ªa«cuchów znakowych, liczb zespolonych i wektorów,
65

• wsparcie dla wnioskowanego mno»enia (mo»liwo±¢ u»ycia 3x zamiast 3*x),
• przy obliczeniach umo»liwia wybór mi¦dzy zadeklarowanymi i nie zadeklaro-wanymi zmiennymi,
• peªna kompatybilno±¢ z Java 1.2 (biblioteka przekompilowana z u»yciem SunJDK 1.2.2),
• wsparcie dla znaków typu Unicode (wª¡czaj¡c greckie symbole),
• obszerna i wyczerpuj¡ca dokumentacja,
• biblioteka jest darmowa (dystrybuowana na licencji GPL).
Licencja
JEP jest bibliotek¡ która dystrybuowana jest na zasadzie dwóch licencji GNUGeneral Public License (GPL) i JEP Commercial License. Poniewa» licencja GPLmo»e by¢ zbyt restrykcyjna do zastosowa« w konkretnej aplikacji dost¦pna jest tak»elicencja komercyjna.
Wi¦cej na temat licencji GPL mo»na znale¹¢ pod adresem:http://www.gnu.org/licenses/gpl.html
Dost¦pne funkcje
W tabeli 5.1, przedstawiam list¦ funkcji dost¦pnych w bibliotece JEP. Ograni-czyªem si¦ do wymienienia jedynie funkcji dla liczb rzeczywistych i zespolonych.Dodatkowo biblioteka umo»liwia tak»e tworzenie wªasnych funkcji. Jednak nie byªopotrzeby stosowania tej cechy biblioteki.
5.3.2 JFreeChart
Opis
Strona producenta: http://www.jfree.org/jfreechart/Wykorzystana wersja: 0.9.18
JFreeChart jest darmow¡ bibliotek¡ napisan¡ caªkowicie w j¦zyku Java. Pozwalaw ªatwy i prosty sposób na wy±wietlanie zaawansowanych wykresów o profesjo-nalnym wygl¡dzie. Dzi¦ki temu, po opanowaniu podstaw biblioteki, staje si¦ mo»-liwe rozwijanie konkretnego zagadnienia bez zbytniego zagª¦biania si¦ w tworzenie±rodowiska do wy±wietlania wykresów. Ze wzgl¦du na bardzo du»¡ ilo±¢ rodzajówwykresów mo»na znale¹¢ odpowiedni do ka»dego nie-specjalistycznego zagadnienia.Poza tym wykresy mo»na dostosowywa¢ do swoich potrzeb, ª¡czy¢ ze sob¡ i daje toznacznie wi¦ksze mo»liwo±ci do ewentualnego wykorzystania. Poni»ej wymieniªemw punktach podstawowe cechy i zalety biblioteki.
• spójne i dobrze udokumentowane API,
66

funkcja symbolliczba
double zespolonasinus sin(x) tak tak
cosinus cos(x) tak taktangens tan(x) tak takarc sinus asin(x) tak tak
arc cosinus acos(x) tak takarc tangens atan(x) tak takarc tangens
atan2(y, x) tak nie(z 2 parametrami)sinus hiperboliczny sinh(x) tak tak
cosinus hiperboliczny cosh(x) tak taktangens hiperboliczny tanh(x) tak takarc sinus hiperboliczny asinh(x) tak tak
arc cosinus hiperboliczny acosh(x) tak takarc tangens hiperboliczny atanh(x) tak tak
logarytm naturalny ln(x) tak taklogarytm dziesi¦tny log(x) tak tak
wykªadnicza (ex) exp(x) tak takwarto±¢ bezwzgl¦dna abs(x) tak takliczba losowa z [0;1] rand() tak tak
reszta z dzielenia mod(x,y)=x%y tak takpierwiastek sqrt(x) tak tak
suma sum(x,y,z) tak takinstrukcja warunkowa if(warunek) tak takzamiana na ªa«cuch str(x) tak tak
wspóªczynnik dwumianowy binom(n,i)dla warto±ci
niecaªkowitych
Tablica 5.1: Lista funkcji dost¦pnych w bibliotece JEP.
67

• wsparcie dla szerokiego wachlarza ró»nych typów wykresów,
• elastyczny projekt, ªatwy w rozszerzaniu i mog¡cy by¢ stosowany zarównow aplikacjach klienckich, jak i serwerowych,
• wsparcie dla wielu typów wyj±ciowych (komponenty Swing, obrazy - wª¡czaj¡cPNG i JPEG, graka wektorowa - wª¡czaj¡c PDF, EPS i SVG),
• biblioteka jest darmowa (na licencji LGPL).
Powa»n¡ niedogodno±ci¡ podczas korzystania z tej biblioteki jest fakt i» nie nale»yona do oprogramowania open source. Ze wzgl¦du na licencj¦ sama biblioteka jestdarmowa, jednak za dokumentacj¦ i przykªady nale»y zapªaci¢. W zwi¡zku z czympodczas pisania programów z jej u»yciem, w przypadku ograniczonych ±rodków -nansowych, przydatne staje si¦ przeszukiwanie forów internetowych i stron www.W momencie gdy powy»sze ograniczenia nie s¡ istotne dost¦pny jest podr¦cznikzawieraj¡cy 530 stron dokumentacji i przykªadów. Napisany zostaª przez DavidaGilbert'a, twórc¦ JFreeChart, i b¦d¡c sprzedawanym przez rm¦ nale»¡c¡ do niego(Object Renery Limited) stanowi gªówne ¹ródªo dochodu na rozwijanie biblioteki.W chwili obecnej dost¦pna jest wersja 1.0.2 tej biblioteki.
Licencja
Szerzej na temat sposobu licencjonowania i niedogodno±ci z tym zwi¡zanychnapisaªem we wcze±niejszym punkcie. Wi¦cej na temat licencji Lesser General PublicLicense mo»na znale¹¢ pod adresem:http://www.gnu.org/licenses/lgpl.html
Wymagania
JFreeChart wymaga stosowania platformy Java 2 (JDK w wersji 1.3 lub pó¹niej-szej).
5.4 Zastosowane technologie
5.4.1 XML
XML inaczej Extensible Markup Language jest prostym, otwartym formatemtekstowym. Wywodzi si¦ od SGML (Standard Generalized Markup Language (ISO8879), format powstaªy w 1986 roku). Powstaª jako format maj¡cy sprosta¢ zada-niom wymiany ró»norodnych danych gªównie w sieci Internet. Prace nad opracowa-niem tego formatu prowadziªo W3C [31].
Skªadnia XML jest bardzo podobna do HTML, z t¡ ró»nic¡ i» XML nie mazdeniowanych »adnych znaczników. Zamiast tego, zale»nie od potrzeb, tworzones¡ odpowiednie znaczniki odpowiadaj¡ce odpowiedniemu zastosowaniu. W formacieXML uj¦ta jest idea DTD (Document Type Denition - plik zawieraj¡cy denicjeelementów, atrybutów i encji), pliku okre±laj¡cego zestaw znaczników do rozwi¡zania
68

okre±lonego problemu oraz tego w jaki sposób znaczniki mog¡ by¢ zagnie»d»anei jakie mog¡ posiada¢ atrybuty.
Poni»ej przedstawiam dziesi¦¢ punktów które ogólnie opisuj¡ standard XML [32]:
1. XML sªu»y do przechowywania ustrukturyzowanych danych - czyli wi¦kszo±cidanych jakie przetwarzane s¡ przez oprogramowanie,
2. XML wygl¡da troch¦ podobnie do HTML - jednak w odró»nieniu od niegoznaczniki maj¡ jedynie na celu oddzielenie od siebie danych,
3. XML jest tekstem jednak nie jest przeznaczony do czytania - ta cecha pozwalajednak na ewentualne zajrzenie w kod w przypadku gdy plik ulegª uszkodzeniu(specykacja zakªada, »e programy nie parsuj¡ niepoprawnych plików XML),
4. XML jest z zaªo»enia rozwlekªy - dzieje si¦ tak poniewa» jest formatem tek-stowym, przy obecnych cenach dysków i mo»liwo±ciach kompresji w locie niejest to utrudnieniem, natomiast korzy±ci s¡ niew¡tpliwe,
5. XML jest caª¡ rodzin¡ technologii - w skªad wchodz¡ takie technologie jakXPointer, CSS, XSL (XSLT), DOM, i inne,
6. XML jest nowy, ale nie zbyt-nowy - powstaª w 1998 jednak wywodzi si¦z SGML powstaªego na pocz¡tku lat '80tych,
7. XML prowadzi HTML do XHTML - najpopularniejsze zastosowanie XML jakoformatu dokumentu,
8. XML jest modularny - pozwala na stworzenie nowego formatu przez ª¡czeniei ponowne u»ycie ju» istniej¡cych,
9. XML jest podstaw¡ RDF (Resource Description Framework) i Semantic Web- wspomaga opisywanie zasobów i tworzenie aplikacji meta-danowych,
10. XML jest wolny od licencji, niezale»ny platformowo i dobrze wspierany - dzi¦kitemu tworzonych jest coraz wi¦cej narz¦dzi, w tym darmowych, które mo»nawykorzysta¢ przy tworzeniu aplikacji opartych o XML.
Du»¡ zalet¡ XML jest fakt i» jest on zapisywany w formacie ASCII. Je±li to po-trzebne mo»e by¢ edytowany w dowolnym edytorze. Prócz tego przegl¡danie plikóww formacie XML mo»liwe jest przy u»yciu edytora plików tekstowych (np. Notepadlub Vi), ale znacznie lepiej nadaj¡ si¦ do tego przegl¡darki internetowe. Szczególniechc¦ zwróci¢ tu uwag¦ na przegl¡dark¦ Firefox, w która dzi¦ki wªa±ciwej interpreta-cji formatu umo»liwia zwijanie i rozwijanie gaª¦zi struktury. Zapewnia to znaczn¡prostot¦ czytania i przegl¡dania wyników.
69

5.4.2 JavaBean
W wielu ±rodowiskach programowania (Borland Delphi, Microsoft Visual Stu-dio .Net, NetBeans) interfejsy graczne tworzy si¦ gracznie, gªównie przy pomocymyszy - ten sposób programowania zwany jest programowaniem gracznym. Ponie-wa» interfejsy graczne buduje si¦ z komponentów, które posiadaj¡ swoje wªa±ci-wo±ci, posiadaj¡ metody obsªugi i generuj¡ zdarzenia, najlepsz¡ mo»liwo±ci¡ jestª¡czenie ich w wi¦ksze caªo±ci, które b¦d¡ mogªy by¢ powielane bez potrzeby two-rzenia caªego kodu ich obsªugi za ka»dym razem od nowa. W celu umo»liwienia tegopowstaªa konwencja nazewnicza pozwalaj¡ca tworzy¢ obiekty które pó¹niej mo»nawykorzysta¢ w ±rodowisku programowania wizualnego. W skrócie: ka»da wªa±ciwo±¢obiektu klasy Abc (zwanego beanem) posiada metody getAbc() i setAbc(), któreumo»liwiaj¡ do niej dost¦p, metody zewn¦trzne nietrzymaj¡ce tej konwencji musz¡by¢ zadeklarowane jako publiczne. Dzi¦ki temu mo»liwe jest automatyczne - bezodwoªywania si¦ do kodu - tworzenie zestawu arkusza wªa±ciwo±ci i obsªugiwanychzdarze«.
Ze wzgl¦du na rozbudowany interfejs graczny zostaªa znaczne rozbudowaniaklasa tego» interfejsu. W zwi¡zku z tym podzielenie logicznie powi¡zanych ze sob¡komponentów okna staªo si¦ naturalnym i oczywistym rozwi¡zaniem. Do tego celuwykorzystany zostaª mechanizm JavaBean.
W celu wi¦kszego uproszczenia u»ycia wszystkie Beany zaimplementowanew moim programie posiadaj¡ wspólne co najmniej dwie metody:
• public void setValue(int obiekt,String wartosc)
• public String getStringValue(int obiekt) throws IndexOutOfBoundsException
Gdzie jako obiekt wstawiana jest jedna ze staªych reprezentuj¡cych dost¦pne obiektyBeana. Dzi¦ki temu kod w klasie obsªugi interfejsu gracznego jest znacznie czytel-niejszy, czego przykªad przedstawiam poni»ej na wycinkach metod: zapisuj¡cej usta-wienia do pliku (listing 5.4) i przywracaj¡cej ustawienia po odczycie z pliku (listing5.5) - gdzie el jest tablic¡ odczytanych ustawie«. Znaki //[...] oznaczaj¡ pomini¦tefragmenty kodu.
Listing 5.4: Wycinek metody zapisu ustawie«
1 private void zap i s zUstawien ia (PlikDoZapisuXML p l i k )throws ExBladZapisuPliku
2 p l i k . zapiszPoczatekGaleziXML ( " ustawien ia " ) ;3 zap i szUstawien iaZadania ( p l i k ) ;4 // <ed i to r−f o l d d e f a u l t s t a t e="co l l a p s e d " desc="
us tawien ia : s e l e k c j i ">5 p l i k . zapiszPoczatekGaleziXML ( "
u s t aw i en i a_s e l e k c j i " ) ;6 p l i k . zapiszElementXML ( " jcm_selekc ja " ,7 pane lS e l ek c j a1 . ge tSt r ingValue (
pane lS e l ek c j a1 .SELEKCJA_RODZAJ) ) ;8 p l i k . zapiszElementXML ( " j cb_se l ek c j a_e l i t a rna " ,9 pane lS e l ek c j a1 . ge tSt r ingValue (
pane lS e l ek c j a1 .SELEKCJA_ELITARNA) ) ;
70

10 p l i k . zapiszElementXML ( "j s_se l ekc ja_e l i t a rna_osobn i cy " ,
11 pane lS e l ek c j a1 . ge tSt r ingValue (pane lS e l ek c j a1 .SELEKCJA_ILOSC_OSOBNIKOW) ) ;
12 p l i k . zapiszKoniecGaleziXML ( ) ;13 // </ed i to r−f o l d >14 // <ed i to r−f o l d d e f a u l t s t a t e="co l l a p s e d " desc="
us tawien ia : ska lowania ">15 p l i k . zapiszPoczatekGaleziXML ( "
ustawienia_skalowania " ) ;16 p l i k . zapiszElementXML ( " jcm_skalowanie" ,17 panelSkalowanie1 . ge tSt r ingValue (
panelSkalowanie1 .SKALOWANIE_RODZAJ) ) ;18 p l i k . zapiszElementXML ( "
jt f_skalowanie_wspolczynnik " ,19 panelSkalowanie1 . ge tSt r ingValue (
panelSkalowanie1 .SKALOWANIE_WSPOLCZYNNIK) ) ;
20 p l i k . zapiszElementXML ( " js_skalowanie_gorna_czesc" ,
21 panelSkalowanie1 . ge tSt r ingValue (panelSkalowanie1 .SKALOWANIE_GORNA_CZESC) ) ;
22 p l i k . zapiszKoniecGaleziXML ( ) ;23 // </ed i to r−f o l d >24 // [ . . . ]25
Listing 5.5: Wycinek metody przywrócenia ustawie«
1 private void przywrocUstawienia ( S t r ing [ ] [ ] e l ) 2 for ( int i =0; i<e l [ 0 ] . l ength ; i++) // p ¦ t l a
c z y t an ia i~us tawien ia war to ±c i odpowiednichob iek tów
3 // [ . . . ]4 // <ed i to r−f o l d d e f a u l t s t a t e="co l l a p s e d " desc="
us tawien ia : s e l e k c j i ">5 i f ( e l [ 0 ] [ i ] . equa l s ( " jcm_selekc ja " ) )6 pane lS e l ek c j a1 . setValue ( pane lSe l ek c j a1 .
SELEKCJA_RODZAJ, e l [ 1 ] [ i ] ) ;7 i f ( e l [ 0 ] [ i ] . equa l s ( " j cb_se l ek c j a_e l i t a rna " )
)8 pane lS e l ek c j a1 . setValue ( pane lSe l ek c j a1 .
SELEKCJA_ELITARNA, e l [ 1 ] [ i ] ) ;9 i f ( e l [ 0 ] [ i ] . equa l s ( "
j s_se l ekc ja_e l i t a rna_osobn i cy " ) )
71

10 pane lS e l ek c j a1 . setValue ( pane lSe l ek c j a1 .SELEKCJA_ILOSC_OSOBNIKOW, e l [ 1 ] [ i ] ) ;
11 // </ed i to r−f o l d >12 // <ed i to r−f o l d d e f a u l t s t a t e="co l l a p s e d " desc="
us tawien ia : ska lowania ">13 i f ( e l [ 0 ] [ i ] . equa l s ( " jcm_skalowanie" ) )14 panelSkalowanie1 . setValue (
panelSkalowanie1 .SKALOWANIE_RODZAJ, e l[ 1 ] [ i ] ) ;
15 i f ( e l [ 0 ] [ i ] . equa l s ( "jt f_skalowanie_wspolczynnik " ) )
16 panelSkalowanie1 . setValue (panelSkalowanie1 .SKALOWANIE_WSPOLCZYNNIK, e l [ 1 ] [ i ] ) ;
17 i f ( e l [ 0 ] [ i ] . equa l s ( "js_skalowanie_gorna_czesc " ) )
18 panelSkalowanie1 . setValue (panelSkalowanie1 .SKALOWANIE_GORNA_CZESC, e l [ 1 ] [ i ] ) ;
19 // </ed i to r−f o l d >20 // [ . . . ]21
5.4.3 Javadoc
Javadoc jest narz¦dziem do tworzenia dokumentacji w HTML. Dokumenty two-rzone s¡ na podstawie odpowiednio sformatowanych komentarzy w kodzie ¹ródªo-wym. Javadoc mo»e by¢ ±ci¡gni¦ty jedynie jako cz¦±¢ Java 2 SDK.
Narz¦dzie to jest bardzo przydatne w tworzeniu jasnej i spójnej dokumentacjiklas programu lub biblioteki. Kod ¹ródªowy musi by¢ odpowiednio komentowany bymo»na byªo wygenerowa¢ z niego dokumentacj¦, komentarze te swobodnie wspóªist-niej¡ z innymi - zwyczajnymi komentarzami.
Zdecydowaªem si¦ na dokumentacj¦ kodu mojego programu w ten wªa±nie sposóbze wzgl¦du na kilka cech:
• wspomnian¡ ju» wcze±niej - prostot¦,
• niezwykª¡ przejrzysto±¢ i spójno±¢ tego typu dokumentacji,
• mo»liwo±¢ tworzenia i wykorzystania jej na bie»¡co w ±rodowisku NetBeans,
• fakt i» ten typ dokumentacji jest standardem dla j¦zyka Java.
Wi¦cej informacji na temat sposobu tworzenia dokumentacji w Javadoc mo»naznale¹¢ na stronach www pod adresem [23] oraz [24].
Dodatkowo ±rodowisko NetBeans umo»liwia zwijanie fragmentów kodu poprzezu»ycie odpowiednio formatowanych komentarzy. Przykªadem jest linia 4 z lini¡ 11w listingu 5.5.
72

5.5 Okno dialogowe pomocy
Ze wzgl¦du na fakt i» program napisany jako cz¦±¢ mojej pracy jest programemedukacyjnym od samego pocz¡tku jego powstawania byªo oczywiste i» istotnymelementem b¦dzie w nim pomoc. Przy tworzeniu pomocy postawiªem sobie dwazaªo»enia prostota i efektywno±¢.
Okno dialogu pomocy zawiera cztery komponenty dwa przyciski (Wstecz i Doprzodu) oraz dwa obiekty typu JEdtorPane (menu i obszar wy±wietlania zawarto±cipomocy). W zwi¡zku z tym wida¢, »e pierwsze zaªo»enie jest speªnione.
U»ycie obiektów typu JEdtorPane, do±¢ proste w implementacji, pozwoliªona wykorzystanie mechanizmów dziaªania j¦zyka HTML. Dzi¦ki temu speªniªemte» drugie zaªo»enie dzi¦ki mo»liwo±ci u»ycia hiperª¡cz nawigowanie po tek±ciepomocy i przegl¡danie go jest intuicyjne.
U»ycie samego obiektu JEdtorPane nie stwarza jeszcze mo»liwo±ci korzystaniaz HTML. Nale»y ustawi¢ odpowiedni rodzaj zawarto±ci (linia 5 i 6 listingu 5.6). Dal-szym krokiem jest ustawienie strony pocz¡tkowej, a tak»e dodanie metody obsªugizdarzenia u»ycia hiperª¡cza.
Listing 5.6: Obsªuga inicjalizacji pomocy
1 private void loadHelp ( ) 2 try 3 St r ing userDir = System . getProperty ( " user . d i r " ) ;4
5 jepMenu . setContentType ( " tex t /html" ) ;6 jepHelp . setContentType ( " tex t /html" ) ;7 jepHelp . setPage ( " f i l e :/// "+userDir . concat ( "/ help
/ index . html" ) ) ;8 h i s t o r y [0 ]=new St r ing ( " f i l e : /// "+userDir . concat (
"/ help / index . html" ) ) ;9 jepMenu . setPage ( " f i l e : /// "+userDir . concat ( "/ help
/menu . html" ) ) ;10 jepMenu . addHyper l inkLi s tener ( this ) ;11 jepHelp . addHyper l inkLi s tener ( this ) ;12 13 catch ( IOException e ) 14 System . out . p r i n t l n ( e . getMessage ( ) ) ;15 16
Samo wy±wietlenie nowej strony po u»yciu hiperª¡cza widoczne jest na listingu5.7 w linii 5. Prócz tego do tablicy historii przegl¡dania stron dodawana jest nowastrona co nast¦puje w kolejnej linii.
Listing 5.7: Obsªuga u»ycia hipreª¡cza
1 public void hyperl inkUpdate ( Hyperl inkEvent event ) 2 i f ( event . getEventType ( ) == Hyperl inkEvent . EventType .
ACTIVATED)
73

3 try 4 jepHelp . setPage ( event . getURL ( ) ) ;5 addNext ( event . getURL ( ) . getPath ( ) ) ;6 catch ( IOException i o e ) 7 System . out . p r i n t l n ( "Bª¡d : "+i o e . getMessage ( ) ) ;8 9 10
Niew¡tpliwym atutem takiego sposobu implementacji pomocy jest istnienia po-mocy niezale»nie od programu. Dzi¦ki temu mo»na dokonywa¢ w niej zmian bez po-trzeby ponownej kompilacji programu. Poza tym mo»liwe jest, niewykorzystywanew tym przypadku, odwoªanie si¦ do plików umieszczonych w sieci Internet/Intranet.Daje to dodatkowe mo»liwo±ci na przykªad w przypadku tworzenia ±rodowisk opar-tych o architektur¦ klient-serwer, gdzie zale»nie od potrzeb mo»na udost¦pnia¢ je-dynie okre±lone fragmenty pomocy.
Wi¦cej na temat u»ycia HTML w obiektach Swing i JEditorPane mo»na znale¹¢w [27] i [28].
5.6 Stosowane oprogramowanie
Przy projektowaniu programu, jego tworzeniu i pisaniu pracy korzystaªem z na-st¦puj¡cego oprogramowania:
• MikTeX 2.4.1705,
• TeXnicCenter 1 Beta 6.51,
• Inkscape 0.43,
• biblioteki Java (1.5.0_03),
• NetBeans IDE 5.0,
• MS-Windows XP Prof. (z SP2),
• MatLab wersja 7,
• Poseidon for UML comunity edition 4.2.1-0,
• PsPad freeware editor 4.5.1 (2270).
Znaczna wi¦kszo±¢ z powy»szego oprogramowania to produkty typu freeware. Wartozainteresowa¢ si¦ programem Inkscape (http://www.inkscape.org/), który nie jestszeroko rozpowszechniony i jest maªo znany. Otwiera on pliki wielu formatów gra-cznych. Posiada mo»liwo±¢ zapisu rysunków do takich formatów jak SVG, PS, EPS,PNG. W zwi¡zku z tym jest do±¢ przydatny do wykonania rysunków o ±rednim stop-niu rozbudowania.
Drugim z programów, na który pragn¦ zwróci¢ nawet wi¦ksz¡ uwag¦, jest fre-ewareowy PsPad (http://www.pspad.com/en/). Jest to bardzo rozbudowany edytor
74

który wykorzystaªem do napisania pomocy do mojego programu. Posiada on wieleprzydatnych opcji, takich jak kolorowanie skªadni, rozbudowany podgl¡d dla pli-ków html, rozbudowan¡ pomoc i wsparcie dla wielu formatów (C/C++, PHP, Perl,SQL, HTML, XHTML, CSS, XML, Java, JavaScript, i jeszcze wielu innych).
75

Rozdziaª 6
Badania eksperymentalne
6.1 Dziaªanie opracowanego programu
Dziaªanie programu jest w peªni zgodne z wcze±niejszymi zaªo»eniami. Dodat-kowo w trakcie implementacji i wst¦pnego testowania zostaªo rozbudowanych kilkafunkcji programu zostaªo rozbudowane w zwi¡zku z ich u»yteczno±ci¡ lub prawdo-podobn¡ przyszª¡ przydatno±ci¡ nowej funkcjonalno±ci.
Mo»liwe jest:
• wybór ró»nego sposobu kodowania,
• zapis funkcji przystosowania przy pomocy dowolnego wzoru matematycznego,
• precyzyjne okre±lenie przedziaªów zmiennych,
• dobór dokªadno±ci reprezentacji (dla kodowania binarnego),
• kilka sposobów selekcji,
• kilka sposobów skalowania,
• kilka sposobów krzy»owania - zale»nie od kodowania,
• kilka sposobów mutacji - zale»nie od kodowania,
• kilka rodzajów wykresów przebiegu dziaªania,
• mo»liwo±¢ opó¹nienia mi¦dzy iteracjami lub potwierdzenia co krok,
• ró»ne sposoby deklaracji warunków stopu,
• wiele innych - bardziej szczegóªowych opcji.
W rozdziale 4 opisaªem szczegóªowo opcje programu.
76

6.2 Badania eksperymentalne
W tym punkcie przedstawione zostaªy wyniki dziaªania programu (GA_learn)napisanego w efekcie zapoznania si¦ z zagadnieniami dotycz¡cymi algorytmów ge-netycznych, opisanymi szczegóªowo w rozdziale 3. Cz¦±¢ przykªadów zostaªa za-czerpni¦tych z literatury wymienionej w bibliograi oraz stron WWW. Zostaªy wy-brane szczególnie reprezentatywne przykªady funkcje posiadaj¡ce ekstrema glo-balne trudne lub wr¦cz niemo»liwe do znalezienia metodami analitycznymi. Na ko-niec dodany zostaª przykªad projektowania ltrów przy zastosowaniu algorytmówgenetycznych.
6.2.1 Przykªad pierwszy - poszukiwanie maksimum funkcjidwóch zmiennych
Przykªad pierwszy przedstawia poszukiwanie maksimum funkcji dwóch zmien-nych. Funkcja przedstawiona jest wzorem (6.1).
f(x1, x2) = 21, 5 + x1 · sin(4πx1) + x2 · sin(20πx2)
−3, 0 ≤ x1 ≤ 12, 1
4, 1 ≤ x2 ≤ 5, 8
(6.1)
Poni»ej przedstawiono szereg testów przeprowadzonych przy u»yciu programuGA_learn.
Okre±lenie minimalnej liczby osobników
W tabeli 6.1 przedstawiono zestawienie efektywno±ci dziaªania algorytmu dlaró»nych wielko±ci populacji, te same warto±ci znajduj¡ si¦ na wykresach na rysunku6.2. Jako wynik ekstremalny, otrzymany z trzech prób na populacjach o rozmiarze1000 osobników, przyj¦to warto±¢ przystosowania 38,8499. W zwi¡zku z tym prze-prowadzono szereg prób maj¡cych na celu ustalenie optymalnej wielko±ci populacji.
Nale»y zwróci¢ uwag¦, na to i» w przypadku wykonywanych tutaj testów porów-nywane s¡ tak naprawd¦ najlepsze przystosowania, a nie przystosowania jak mog¡to sugerowa¢ np. nazwy u»ywane w tabelach.
Przeprowadzono po 15 prób dla ka»dej z liczebno±ci populacji, przy pozostaªychustawieniach ±rodowiska:
• wzór i zakres przedziaªów: j.w.,
• podziaª chromosomu: 14-12 (precyzja reprezentacji zmiennych: 14 bitówna pierwsz¡ i 12 bitów na drug¡),
• populacje: jedna populacja,
• skalowanie: rankingowe,
• selekcja: proporcjonalna + 1 osobnik elity,
77

Rysunek 6.1: Funkcja opisana wzorem (6.1)
• mutacja: jednopunktowa (prawdopodobie«stwo 0,15),
• krzy»owanie: jednopunktowe,
• specjalizacja: n.d.,
• przy ograniczeniu: do 250 bezproduktywnych generacji.
Na podstawie bada« ustalono, i» najni»szy wspóªczynnik ceny (wyra»ony wzorem(6.2)) osi¡gn¦ªo ±rodowisko zawieraj¡ce 15 osobników.
wc =se · ng
fsum
(6.2)
Gdzie:
• wc wspóªczynnik ceny
• se wielko±¢ ±rodowiska
• ng suma ilo±ci generacji
• fsum suma przystosowania
78

Rysunek 6.2: Okre±lenie minimalnej liczby osobników
liczebn
o±¢pop
ulacji
±r.ilo±¢gene
racji
min.ilo
±¢gene
racji
max
.ilo
±¢gene
racji
±r.przystosow
anie
min.przystosow
anie
max
.przystosow
anie
wspóªczyn
nikceny
200 31.93 5 109 38.8492 38.8388 38.8499 164.3965100 41.13 13 100 38.7178 37.8499 38.8499 106.238850 81.27 6 405 38.2396 37.1450 38.8499 106.259925 71.07 13 340 37.8377 34.8023 38.8499 46.954915 73.00 9 298 36.7916 32.9886 38.7386 29.76227 158.53 19 573 35.0704 28.2708 38.3358 31.6430
Tablica 6.1: Okre±lenie minimalnej liczby osobników
79

Jednak ilo±¢ 15 osobników jest niewystarczaj¡ca ze wzgl¦du na fakt nieosi¡gni¦ciaekstremum podczas »adnej z prób. Wystarczaj¡cym okazaªo si¦ ±rodowisko z popula-cj¡ 25 osobników, gdzie osi¡gni¦te zostaªo ekstremum. Postanowiono dalsze badaniaprzeprowadza¢ na ±rodowisku 25 osobników.
Porównanie wyników dla ró»nego rozkªadu osobników
Poni»ej przeprowadzono badana dotycz¡ce optymalnego rozkªadu osobnikówna pod-populacje. Wprowadzenie ró»nych pod-populacji przydatne jest do:
• poszukiwania wi¦cej ni» jednego ekstremum,
• zachowania wi¦kszej ró»norodno±ci genetycznej.
W tym wypadku zostaªa wykorzystana druga z tych wªa±ciwo±ci.Na rysunku 6.3 i w tabeli 6.2 przedstawiono wyniki bada«. Na ka»dym z ustawie«
±rodowiska zostaªo poczynione 15 prób obliczeniowych. W wyniku tego okre±lonowarto±ci minimalne, maksymalne i ±rednie. Pozostaªe ustawienia ±rodowiska byªynast¦puj¡ce:
• wzór i zakres przedziaªów: j.w.,
• podziaª chromosomu: 14-12,
• populacje: jedna populacja 20 osobników,
• skalowanie: rankingowe,
• selekcja: proporcjonalna + 1 osobnik elity,
• mutacja: jednopunktowa (prawdopodobie«stwo 0,15),
• krzy»owanie: jednopunktowe,
• specjalizacja: przenikanie obustronne,
• przy ograniczeniu: do 250 bezproduktywnych generacji.
Nale»y zwróci¢ uwag¦ na fakt i» w tym wypadku wzór na wspóªczynnik ceny wy-ra»a si¦ wzorem 6.3, obrazuje on zró»nicowanie nakªadu obliczeniowego w stosunkudo otrzymanego wyniku. Wzór zmieniono (w odniesieniu do 6.2) ze wzgl¦du na toi» w tym wypadku ilo±¢ wszystkich osobników jest staªa.
wc =ng
fsum
(6.3)
Gdzie:
• wc wspóªczynnik ceny
• ng suma ilo±ci generacji
• fsum suma przystosowania
80

Rysunek 6.3: Porównanie wyników dla ró»nego rozkªadu osobników
rozkªadpop
ulacji
±r.ilo±¢gene
racji
wzgl.±r.ilo
±¢gene
racji
min.ilo
±¢gene
racji
max
.ilo
±¢gene
racji
±r.przystosow
anie
min.przystosow
anie
max
.przystosow
anie
wspóªczyn
nikceny
25 71.13 71.1333 13 340 37.8377 34.8023 38.8499 1.880013-12 143.40 93.4000 51 401 37.7009 34.1713 38.8499 3.80368-8-9 171.20 121.2000 51 600 38.0232 34.3387 38.8499 4.50256-6-6-7 216.87 116.8667 100 400 38.3247 37.2502 38.8388 5.65875-5-5-5-5 256.67 156.6667 101 501 38.1189 36.5897 38.8499 6.73334-4-4-4-4-5 371.87 221.8667 150 927 38.4628 37.9388 38.8499 9.6682
Tablica 6.2: Porównanie wyników dla ró»nego rozkªadu osobników
81

Dodatkowo wprowadzono wzgl¦dn¡ ±redni¡ ilo±¢ generacji. Poniewa» ilo±¢ gene-racji bezproduktywnych liczona jest zbiorczo dla wszystkich pod-populacji, wynikaz tego, i» w ogólnym wypadku warunek stopu nie mo»e by¢ speªniony tak dªugojak trwa przej±cie najlepszych osobników z wiod¡cej populacji. Przy obustronnymoperatorze przenikania zajmuje to dokªadnie T = roundup((np − 1)/2) · t, gdzieT jest czasem liczonym w ilo±ciach generacji, np jest liczb¡ populacji, natomiast todst¦pem czasu mi¦dzy dokonaniem specjalizacji. Jest to wzór dla przypadku gdywarto±¢ ilo±ci bezproduktywnych populacji jest wi¦ksza od t.
To wªa±nie z powodu opisanego powy»ej sztucznego wydªu»enia czasu orazwzgl¦dnie du»ego prawdopodobie«stwa mutacji (0,15) du»a ilo±¢ maªych populacjiotrzymuje lepsze, pod wzgl¦dem ±redniej warto±ci przystosowania, wyniki. Wyra¹niejednak wida¢ jakim nakªadem kosztu obliczeniowego.
Wynika st¡d wniosek i» je±li wzi¡¢ pod uwag¦ szybko±¢ znajdowania rozwi¡zanianajlepszy jest wariant 25 osobników w jednej populacji, przy czym dopiero cztero-krotnie bardziej kosztowna obliczeniowo opcja 5-5-5-5 gwarantuje uzyskanie lepszegominimalnego, maksymalnego jak równie» ±redniego przystosowania. Tak wi¦c roz-kªad osobników nale»y dobra¢ ze szczególnym uwzgl¦dnieniem danego zastosowaniai mo»liwo±ci czasowo-obliczeniowych.
Porównanie wyników dla ró»nych ustawie« mutacji
Na rysunku 6.4 i w tabeli 6.3 przedstawiono wyniki bada«. Na ka»dym z ustawie«±rodowiska poczyniono 15 prób obliczeniowych. W wyniku tego okre±lono warto±ciminimalne, maksymalne i ±rednie. Pozostaªe ustawienia ±rodowiska byªy nast¦pu-j¡ce:
• wzór i zakres przedziaªów: j.w.,
• kodowanie: BCD,
• podziaª chromosomu: 14-12,
• populacje: jedna populacja 20 osobników,
• skalowanie: rankingowe,
• selekcja: proporcjonalna + 1 osobnik elity,
• mutacja: dziaªanie na ka»dym z osobników, prawdopodobie«stwo mu-tacji 0,15,
• krzy»owanie: jednopunktowe,
• specjalizacja: przenikanie obustronne,
• przy ograniczeniu: do 250 bezproduktywnych generacji.
Na podstawie bada« wida¢ wyra¹nie, »e w ka»dym z bada« osi¡gni¦te zostaªomaksymalne przystosowanie. Nie jest to zaskoczeniem zwa»ywszy na fakt stosowaniaselekcji elitarnej. Najwy»sze ±rednie przystosowanie osi¡gni¦te zostaªo przy mutacji
82

Rysunek 6.4: Porównanie wyników dla ró»nych ustawie« mutacji
rodz
ajmutacji
±r.ilo±¢gene
racji
min.ilo
±¢gene
racji
max
.ilo
±¢gene
racji
±r.przystosow
anie
min.przystosow
anie
max
.przystosow
anie
wspóªczyn
nikceny
jednopunktowa 71.13 13 340 37.8377 34.8023 38.8499 1.88002-punktowa 272.67 64 476 38.7950 38.4481 38.8499 7.02846-punktowa 282.60 62 776 38.7400 38.3456 38.8499 7.29488-punktowa 359.60 63 569 38.7639 38.3499 38.8499 9.2767
Tablica 6.3: Porównanie wyników dla ró»nych ustawie« mutacji
83

2-punktowej. Dodatkowo wart uwagi jest fakt i» minimalne przystosowania z ka»dej,z 15 prób, dla ±rodowisk z mutacj¡ wielopunktow¡, s¡ znacznie wy»sze od to»samejwarto±ci dla ±rodowiska z mutacj¡ jednopunktow¡. Co naturalne okupione jest to conajmniej czterokrotnie, a» do pi¦ciokrotnie - dla ±rodowiska z mutacj¡ 8-punktow¡,wi¦ksz¡ ±redni¡ ilo±ci¡ iteracji. Czego odbicie wida¢ na warto±ciach wspóªczynnikaceny.
Konkluzja jest tutaj nast¦puj¡ca w przypadku wzgl¦dnie nieograniczonych za-sobów najbardziej korzystne jest stosowanie mutacji 2-punktowej. Jednak w przy-padku silnych ogranicze« czasowych i mniejszego nacisku na precyzj¦ otrzymanegowyniku najwi¦ksz¡ opªacalno±¢ gwarantuje zastosowanie ±rodowiska z mutacj¡ jed-nopunktow¡. W przypadkach po±rednich nale»y dokona¢ bardziej szczegóªowej ana-lizy lub, je±li to wystarczy, oprze¢ si¦ na danych które zebraªem w powy»szychbadaniach.
Porównanie wyników dla ró»nego rodzaju kodowania
Na rysunku 6.5 i w tabeli 6.4 przedstawiono wyniki bada«. Na ka»dym z ustawie«±rodowiska zostaªo poczynione 15 prób obliczeniowych. W wyniku tego okre±lonowarto±ci minimalne, maksymalne i ±rednie. Pozostaªe ustawienia ±rodowiska byªynast¦puj¡ce:
• wzór i zakres przedziaªów: j.w.,
• podziaª chromosomu: 14-12,
• populacje: jedna populacja 20 osobników,
• skalowanie: rankingowe,
• selekcja: proporcjonalna + 1 osobnik elity,
• mutacja: 2-punktowa (za wyj¡tkiem pierwszych prób gdzie jest tozaznaczone) (prawdopodobie«stwo 0,15),
• krzy»owanie: jednopunktowe,
• specjalizacja: przenikanie obustronne,
• przy ograniczeniu: do 250 bezproduktywnych generacji.
Na podstawie wyników przedstawionych w tabeli 6.4 wida¢ wyra¹nie i» najlep-sze wyniki, w tym rodzaju zada«, uzyskaªy ±rodowiska stosuj¡ce kodowanie binarnemetod¡ Graya. Przy czym w tym wypadku zastosowanie inwersji dziaªaªo niekorzyst-nie - je±li chodzi o warto±ci wyników. Jest jednak dobrze widoczna poprawa czasudziaªania, i co za tym idzie ni»sza warto±¢ wspóªczynnika ceny.
Najsªabsze efekty, je±li chodzi o warto±¢ funkcji przystosowania, osi¡gn¦ªy popu-lacje binarne z mutacj¡ jednorodn¡. Jednak, co jest do przewidzenia w przypadkumniejszych ilo±ci mutacji, ten sposób kodowania prowadziª do najszybszej zbie»no±ci,niekoniecznie do warto±ci ekstremalnej.
84

Rysunek 6.5: Porównanie wyników dla ró»nego rodzaju kodowania
rodz
ajko
dowan
ia
±r.ilo±¢gene
racji
min.ilo
±¢gene
racji
max
.ilo
±¢gene
racji
±r.przystosow
anie
min.przystosow
anie
max
.przystosow
anie
wspóªczyn
nikceny
binarne (BCD)71.13 13 340 37.8377 34.8023 38.8499 1.8800
(m.jednopunktowa)binarne (BCD) 272.67 64 476 38.7950 38.4481 38.8499 7.0284binarne (Gray'a) 384.73 77 813 38.8474 38.8388 38.8499 9.9037binarne (Gray'a)
242.93 88 401 38.7959 38.4502 38.8499 6.2618(inwersja)
zmiennoprzecinkowe 118.00 18 315 38.5496 38.2736 38.7311 3.0610
Tablica 6.4: Porównanie wyników dla ró»nego rodzaju kodowania
85

Kodowanie zmiennoprzecinkowe charakteryzuje si¦ do±¢ szybk¡ zbie»no±ci¡.Dzi¦ki temu, mimo nieosi¡gni¦cia - ani razu - maksimum globalnego ogólny rezultatw postaci ±redniego przystosowania nie jest zªy. Warto zwróci¢ uwag¦ na jednocze-sn¡ nisk¡ warto±¢ wspóªczynnika ceny. Jest to informacja o potencjalnej przydatno±citego rodzaju kodowania w przypadku zada« w których zagadnieniem priorytetowymjest czas, czy patrz¡c inaczej - moc obliczeniowa. Przy czym godny podkre±leniajest fakt najni»szej warto±ci maksymalnej ilo±ci generacji. Pozwala, to na podstawierozs¡dnej ilo±ci prób, na wyci¡gni¦cie dodatkowego wniosku o wysokiej stabilno±cidziaªania tego typu ±rodowisk.
Przedstawienie efektów dziaªania selekcji równomiernej
Na rysunku 6.6 i w tabelach 6.5 i 6.6 przedstawiono wyniki bada«. Na ka»dymz ustawie« ±rodowiska zostaªo poczynione 6 prób obliczeniowych. Liczb¦ t¡ uznanoza optymaln¡ w zwi¡zku z otrzymywanymi rezultatami dziaªania, które przedsta-wiono w dalszej cz¦±ci. W wyniku tego okre±lono warto±ci minimalne, maksymalnei ±rednie, jednak jedynie dla przystosowania odno±nie ilo±ci populacji: patrz opiswyników. Ustawienia ±rodowiska byªy nast¦puj¡ce:
• wzór i zakres przedziaªów: j.w.,
• podziaª chromosomu: 14-12,
• populacje: jedna populacja 20 osobników,
• skalowanie: rankingowe,
• selekcja: proporcjonalna (patrz: tabela 6.5),
• mutacja: 2-punktowa wszystkich osobników (prawdopodobie«stwo0,15),
• krzy»owanie: jednopunktowe,
• specjalizacja: przenikanie obustronne,
• przy ograniczeniu: do 250 bezproduktywnych generacji.
Przeprowadzono jedynie po 6 prób, ze wzgl¦du na fakt i» »adno z dwóch ±rodo-wisk nie zachowywaªo si¦ stabilnie. wiadczy o tym zatrzymanie po 5000 generacji,która to warto±¢ byªa warto±ci¡ graniczn¡ (pierwszy warunek stopu). W zwi¡zkuz tym przyj¦to, i» ustawienia zastosowanie w tych ±rodowiskach nie nadaj¡ si¦ do u»y-cia w przypadku tego typu zada«.
Zastosowanie selekcji elitarnej znacznie poprawiªo uzyskiwane wyniki, jednaknadal nie s¡ one zadowalaj¡ce. Istnieje du»a grupa ±rodowisk, które spisuj¡ si¦ lepiejw tego typu zadaniach.
86

Rysunek 6.6: Przedstawienie efektów dziaªania selekcji równomiernej
selekcja ±rednie minimalne maksymalneelitarna przystosowanie przystosowanie przystosowanietak 38.1569 36.4129 38.8375nie 27.9898 25.0484 32.4447
Tablica 6.5: Przedstawienie efektów dziaªania selekcji równomiernej
z selekcj¡ bez selekcjielitarn¡ elitarnej38.8375 25.048438.3051 25.175938.8080 26.731837.7685 31.195238.8095 32.444736.4129 27.3427
Tablica 6.6: Zestawienie efektów dziaªania selekcji równomiernej
87

6.2.2 Przykªad drugi - wyznaczenie liczby Pi
Drugi z przykªadów jest poszukiwaniem najlepszego przybli»enia, przy pomocyuªamka zwykªego, warto±ci liczby π. Ze wzgl¦du na natur¦ zadania mo»liwe jeststosowanie jedynie liczb binarnych.
Wykres funkcji przedstawionej wzorem (6.4) znajduje si¦ na rysunku 6.7.
f(x1, x2) = −abs(π − x1
x2
)
1 ≤ x1 ≤ 1024
1 ≤ x2 ≤ 1024
(6.4)
Ze wzgl¦du na rozpi¦to±¢ zakresów warto±ci jest on maªo czytelny, w zwi¡zkuz tym na rysunku 6.8 umieszczono fragment wykresu. Widoczne na nim maksimumjest trudne do wykrycia metodami analitycznymi. Poni»ej przedstawiono wynikiposzukiwania maksimum przy wykorzystaniu ró»nych metod selekcji i kodowania.
Poszukiwanie optymalnych metod selekcji i kodowania
Ze wzgl¦du na skomplikowany przykªad obliczeniowy wa»ne jest odpowiednieustawienie algorytmu genetycznego. Dla danego przykªadu postanowiono przepro-wadzi¢ zestawienie metod selekcji i kodowania (zarówno kodowania BCD jak i ko-dowania Graya). Badane selekcje to:
• selekcja: proporcjonalna,
• selekcja: deterministyczna,
• selekcja: turniejowa (2 osobników),
• selekcja: stochastyczna równomierna,
• selekcja: losowa wedªug reszty z powtórzeniami,
• selekcja: równomierna.
Pozostaªe ustawienia algorytmu, to:
• wzór i zakres przedziaªów: j.w.,
• podziaª chromosomu: 10-10,
• populacje: jedna populacja 100 osobników,
• skalowanie: rankingowe,
• selekcja elitarna: 1 osobnik,
• mutacja: wielopunktowa (2 punkty, prawdopodobie«stwo 0,15),
• krzy»owanie: jednopunktowe,
88

Rysunek 6.7: Funkcja opisana wzorem (6.4).
Rysunek 6.8: Wycinek funkcji opisanej wzorem (6.4).
89

selekcja
±r.ilo±¢gene
racji
min.ilo
±¢gene
racji
max
.ilo
±¢gene
racji
±r.przystosow
anie
min.przystosow
anie
max
.przystosow
anie
wspóªczyn
nikceny
kodowanie
BCD
proporcjonalna 13.73 2 37 -1.6153 -5.670 -0.3825 0.4991deterministyczna 54.07 0 157 -9.6150 -52.2902 -0.0027 11.6967turniejowa (2) 22.80 2 89 -1.5098 -5.8744 -0.0027 0.7745stochastyczna
99.07 5 265 -4.8878 -12.6449 -0.0027 10.8950równomierna
losowa wg.reszty62.07 4 237 -6.2113 -17.3251 -0.3825 8.6741
z powtórzeniamirównomierna 204.40 1 658 -0.7875 -2.1334 -0.0027 3.6219
kodowanie
Graya
proporcjonalna 37.40 11 237 -1.2332 -2.255 -0.3825 1.0377deterministyczna 65.27 12 227 -2.6830 -12.4178 -0.0027 3.9400turniejowa (2) 35.60 7 205 -1.2647 -2.1334 -0.0027 1.0130stochastyczna
102.07 10 318 -2.0558 -8.3220 -0.3825 4.7210równomierna
losowa wg.reszty53.67 0 151 -1.9147 -7.4758 -0.0027 2.3119
z powtórzeniamirównomierna 192.73 9 793 -1.1228 -3.428 -0.0027 4.8690
·10−4 ·10−4 ·10−4
Rysunek 6.9: Zestawienie wyników.
90

• specjalizacja: n.d.,
• przy ograniczeniu: do 250 bezproduktywnych generacji.
Na podstawie wyników w tabeli 6.9 mo»na zaobserwowa¢ i» nadspodziewaniedobre rezultaty zostaªy uzyskane przy zastosowaniu selekcji równomiernej. Jest to±ci±le zwi¡zane z rozkªadem warto±ci funkcji przystosowania. Dodatkowo wart uwagijest fakt i» ten sposób selekcji, cho¢ najlepszy, okazaª si¦ bardziej kosztowny (funkcjawspóªczynnika ceny wyra»ona jest wzorem (6.5)) w przypadku kodowania Graya.Jednocze±nie byª on najbardziej kosztownym ze sposobów selekcji, w tym wypadkukodowania, podczas gdy w przypadku kodowania BCD koszt tego sposobu selekcjilokowaª si¦ poni»ej ±redniego kosztu.
wc = −ng · fsum (6.5)
Gdzie:
• wc wspóªczynnik ceny
• ng suma ilo±ci generacji
• fsum suma przystosowania
Zgodnie z oczekiwaniami kodowanie Graya okazaªo si¦ skuteczniejsze jednak wol-niejsze, cho¢ nie we wszystkich przypadkach selekcji. Dla obu metod kodowania je-dynie dla trzech rodzajów selekcji (deterministycznej, turniejowej i równomiernej)udaªo si¦ uzyska¢ warto±¢ rzeczywistego ekstremum (w cho¢ jednej z 15 prób).
W obu przypadkach najsªabsze efekty osi¡gni¦te zostaªy przy zastosowaniu se-lekcji deterministycznej. Prawdopodobnie spowodowane jest to przez fakt szybko-zbie»no±ci tej selekcji, o czym wspomniano w punkcie 3.7 pracy.
6.2.3 Przykªad trzeci - projektowanie ltru dolnoprzepusto-wego
Przykªad trzeci przedstawia u»ycie programu GA_learn do projektowania ltrudolnoprzepustowego. Schemat ltru dolnoprzepustowego znajduje si¦ na rysunku6.10. Funkcja transmitancji projektowanego ltru przedstawiona jest wzorem (6.6).
T (s) =1
sR1C4(sR4C3 + 1)(sR3C2 + 1)(sR2C1 + 1)= . . .
=1
s4R1R2R3R4C1C2C3C4 + s3(R1R3R4C2C3C4 + R1R2R4C1C3C4 + R1R2R3C1C2C4)+
+s2(R1R4C3C4 + R1R3C2C4 + R1R2C1C4) + sR1C4
(6.6)
Uproszczenie wzoru (6.6) prowadzi do wzoru (6.7).
91

Rysunek 6.10: Schemat ltru dolnoprzepustowego o transmitancji opisanej wzo-rem (6.6).
T (s) =1
s4a4 + s3a3 + s2a2 + sa1
a4 = R1R2R3R4C1C2C3C4
a3 = R1R3R4C2C3C4 + R1R2R4C1C3C4 + R1R2R3C1C2C4
a2 = R1R4C3C4 + R1R3C2C4 + R1R2C1C4
a1 = R1C4
(6.7)
Projektowanie ltru opiera si¦ na znalezieniu warto±ci elementów skªadowychltru (R i C) na podstawie zadanej transmitancji. W zwi¡zku z tym nale»y, ana-logicznie do przykªadu z punktu 6.2.2, utworzy¢ funkcj¦ pozwalaj¡c¡ na porówna-nie ltru zaprojektowanego z zadanym. Funkcja ta w wyniku daje liczb¦, jest onawspóªczynnikiem podobie«stwa, do wyznaczenia tej funkcji mo»na u»y¢ wzoru (6.7).W tym celu zostaje przeksztaªcony do wzoru (6.8).
g(a1, a2, a3, a4) = −(|a4 − a4|2 + |a3 − a3|2 + |a2 − a2|2 + |a1 − a1|2) (6.8)
Gdzie g(a1, a2, a3, a4) jest wzorem na wspóªczynnik podobie«stwa, czyli funkcj¡której maksimum jest poszukiwane. Wspóªczynniki an s¡ skªadowym transmitan-cji poszukiwanego ltru, dodpowiadaj¡cym an, gdzie n ∈ 1, 2, 3, 4. Ze wzgl¦duna charakter wzoru (6.8), którego wynik jest liczb¡ rzeczywist¡, mo»e on zosta¢wykorzystany jako funkcja przystosowania.
W tabeli 6.11 przedstawiono warto±ci zadane (indeks z) ltru w zestawieniuz otrzymanymi, w wyniku dziaªania algorytmu genetycznego, warto±ciami zapro-jektowanymi (indeks p). Dodatkowo policzono procentow¡ zmian¦ w warto±ciachposzczególnych elementów, co wyra¹niej obrazuje efekt projektowania z wykorzy-staniem algorytmu genetycznego.
Podczas projektowania wykorzystano algorytm genetyczny o nast¦puj¡cych usta-wieniach ±rodowiska:
• wzór i zakres przedziaªów: opisany wzorem (6.8),
• podziaª chromosomu: 12-12-12-12-12-12-12-12 (precyzja reprezentacjizmiennych: 12 bitów na parametr),
92

rezystancja pojemno±¢
zada
na
zaprojektowan
a
ró»n
icaprocentowa
zada
na
zaprojektowan
a
ró»n
icaprocentowa
R1z = 10000 Ω R1p = 9767 Ω 2,3% C1z = 4, 7 µF C1p = 4, 4 µF 6,5%R2z = 45000 Ω R2p = 50460 Ω -12,1% C2z = 1, 7 µF C2p = 1, 9 µF -10,6%R3z = 13000 Ω R3p = 17370 Ω -33,6% C3z = 8, 2 µF C3p = 8, 8 µF -7,8%R4z = 20000 Ω R4p = 18560 Ω 7,2% C4z = 2, 8 µF C4p = 3, 2 µF -13,6%
Rysunek 6.11: Zestawienie warto±ci elementów skladowych ltrów - warto±ci zadanei zaprojektowane
• populacje: jedna populacja (40 osobników),
• skalowanie: rankingowe,
• selekcja: proporcjonalna + 1 osobnik elity,
• mutacja: 2-punktowa (prawdopodobie«stwo 0,10),
• krzy»owanie: jednopunktowe,
• przy ograniczeniu: do 100 bezproduktywnych generacji.
Po 86 generacjach, w wyniku dziaªania opisanego powy»ej algorytmu genetycz-nego, obliczono warto±ci elementów elektronicznych skªadaj¡cych si¦ na poszuki-wany ltr dolnoprzepustowy. Warto±ci te przedstawione zostaªy w tabeli 6.11. Jakwida¢ na podstawie porównania dla wi¦kszo±ci z nich warto±ci ró»ni¡ si¦ okoªo 10%wzgl¦dem warto±ci oczekiwanych. Natomiast warto±¢ maksymalizowanej funkcji wy-ra»onej wzorem (6.8) wyniosªa przy tym g = −9, 479 · 10−6.
Wykres transmitancji ltrów przedstawiony jest na rysunku 6.12a. Na ry-sunku 6.12b przedstawiono procentow¡ ró»nic¦ mi¦dzy warto±ci¡ transmitancji dlaltru zadanego, a zaprojektowanego. Jak wida¢ nawet w maksimum wykresu nieprzekracza ona 8%.
Nale»y zwróci¢ uwag¦ na rozmiar przestrzeni rozwi¡za« która dotyczyªa tegoproblemu obliczeniowego. Chromosomy kodowane s¡ binarnie i maj¡ po 12 bitówdokªadno±ci na zmienn¡. W zwi¡zku z tym jedna zmienna generuje przestrze« roz-wi¡za« wielko±ci 212 = 4096. Co wi¦cej, funkcja której ekstremum byªo poszuki-wane jest funkcj¡ o±miu zmiennych. W zwi¡zku z tym zupeªna przestrze« rozwi¡za«funkcji wynosi 40968 = 7.9228 · 1028. Jak wida¢ ilo±¢ punktów jest na tyle du»a, i»metody typu brute force s¡ w tym wypadku bezu»yteczne. Wida¢ wyra¹nie przy-datno±¢ wykorzystania algorytmów genetycznych w obliczeniach projektowych.
93

a) b)
Rysunek 6.12: Efekt projektowania ltru: a) wykresy transmitancji obu ltrów,b) procentowa ró»nica wartosci transmitancji.
6.2.4 Inne przykªady testowe
Poni»ej przedstawiono jeszcze kilka innych przykªadów funkcji testowych do-tycz¡cych zagadnie« poszukiwania ekstremum. Zostaªy one wykorzystane podczastestowania, w ró»nych kolejnych fazach pisania programu.
f(x1, x2) = x1 · x2 · cos(x2) · sin(x1)
0 ≤ x1 ≤ 10
0 ≤ x2 ≤ 10
(6.9)
f(x1, x2) =
=((x1 + 0, 5)2 + 2(x2 − 0, 5)2 − 0, 3cos(3x1)− 0, 4cos(4x2) + 0, 8)−1
− 5 ≤ x1 ≤ 5
− 5 ≤ x2 ≤ 5
(6.10)
f(x1) = x1 · sin(10πx1) + 1
0 ≤ x1 ≤ 1(6.11)
94

Rysunek 6.13: Funkcja opisana wzorem (6.9).
Rysunek 6.14: Funkcja opisana wzorem (6.10).
95

Rysunek 6.15: Funkcja opisana wzorem (6.11).
96

Rozdziaª 7
Podsumowanie i wnioski ko«cowe
7.1 Realizacja celu pracy dyplomowej
Osi¡gni¦ty zostaª cel jakim byªo napisanie komputerowej implementacji pro-gramu do symulacji algorytmów genetycznych. Napisany program, zgodnie z za-ªo»eniami, pozwala na uruchamianie algorytmów genetycznych o dowolnym wzorzefunkcji przystosowania. Funkcja mo»e posiada¢ dowoln¡ ilo±¢ zmiennych o zadanychnazwach, z wyj¡tkiem nazw funkcji wymienionych w tabeli 5.1 i dwóch staªych. Mo»-liwy jest wybór jednego z trzech sposobów kodowania chromosomu i odpowiednichustawie« wybranych operatorów genetycznych, warunków stopu i opcji rysowaniawykresów.
Mo»liwy jest zapis i odczyt zarówno ustawie«, jak i zadanych populacji. Prócztego program umo»liwia zapis wyników dziaªania algorytmu, z zadanymi informa-cjami dodatkowymi.
Dodatkowo program zostaª podzielony na trzy pakiety. Dzi¦ki temu mo»liwe jestnapisanie dodatkowego interfejsu gracznego i uruchomienie w nim cz¦±ci oblicze-niowej. Dzi¦ki temu w do±¢ prosty sposób mo»liwa jest dalsza rozbudowa.
Prócz tego zebrano i przedstawiªem kluczowe zagadnienia dotycz¡ce teorii algo-rytmów genetycznych.
7.2 Wªasne spostrze»enia i mo»liwo±ci dalszej roz-
budowy
Celem mojej pracy byª przegl¡d algorytmów genetycznych i stworzenie na tejpodstawie komputerowej implementacji programu do symulacji algorytmów gene-tycznych. Efektem mojej pracy jest program umo»liwiaj¡cy praktyczne badaniepodstawowych, jak i rzadziej spotykanych, zagadnie« dotycz¡cych algorytmów ge-netycznych.
Mimo wielu dni po±wi¦conych na zgª¦bianie tematu pozostaªy jeszcze zagadnie-nia nie uj¦te w mojej pracy. Oczywi±cie niektóre z nich zostaªy celowo pomini¦te,w zwi¡zku z marginaln¡ przydatno±ci¡. Pozostaªo kilka interesuj¡cych zagadnie« ta-kich jak cho¢by kodowanie logarytmiczne, algorytmy wykorzystuj¡ce zmienn¡ ilo±¢osobników w populacji lub zmienn¡ dªugo±¢ chromosomu, wspomniane w [9, 12]. Nie
97

s¡ to jednak wszystkie zagadnienia o jakie mo»na rozszerzy¢ dziaªanie programu.W przypadku chromosomów kodowanych binarnie mo»liwe jest u»ycie podpopulacjikodowanych na ró»ne sposoby, co wi¦cej nawet z wykorzystaniem ró»nych podstawo-wych ustawie« operatorów genetycznych. By¢ mo»e jest to dobry sposób na zwi¦k-szenie generalizacji i skuteczno±ci dziaªania algorytmu. Niestety w przestudiowanejliteraturze nie znalazªem wzmianek na temat bada« w tym kierunku, cho¢ wydaj¡si¦ obiecuj¡ce.
98

Bibliograa
[1] Jerzy Cytowski Algorytmy genetyczne - podstawy i zastosowania, 1996,Akademicka Ocyna Wydawnica PLJ, Warszawa
[2] Dawid E. Goldberg Algorytmy genetyczne i ich zastosowania, 1995, Wydaw-nictwo Naukowo-Techniczne, Warszawa
[3] Zbigniew Michalewicz Algorytmy genetyczne + struktury danych = progra-mowanie ewolucyjne, 2003, wydanie trzecie, poprawione i rozszerzone, Wydaw-nictwo Naukowo-Techniczne, Warszawa
[4] Lance D. Chambers (edited by) The Practical Handbook of Genetic Algori-thms, Aplications - Volume I, 2001, second edition, Chapman & Hall/CRC,
[5] Lance D. Chambers (edited by) The Practical Handbook of Genetic Algori-thms, Aplications - Volume II, 2001, second edition, Chapman & Hall/CRC,
[6] Da Ruan (edited by) Intelligent hybrid systems - fuzzy logic, neural networks,and genetic algorythms, 1997, Kluwer Academc Publishers
[7] John R. Koza, Davig E. Goldberg, David B. Fogel, Rick L. Riolo (edited by) Genetic programming 1996 - proceedings of the rst annual conference, 1996,Massachusetts Institute of Technology
[8] Emanuel Falkenauer Genetic algorithms and grouping problems, 1998, JohnWiley & Sons Ltd., West Sussex, England
[9] K. F. Man Genetic algorithms, concepts and designs, 1999, K. S. Tan andS. Kwong, Springer,
[10] Randy L. Haupt, Sue Ellen Haupt Practical genetic algorithms, 1998, JohnWiley & Sons Ltd.
[11] A. M. S. Zalzala and . J. Fleming (edited by) Genetic algorithms in engine-ering systems, 1997, The Institution of Electrical Engineers, London, UnitedKingdom
[12] L. Darrell Whitley, J. David Schaer International Workshop on combi-nations of Genetic Algorythms and Neural Networks, 1992, IEEE ComuterSociety Press
99

[13] Heitkoetter, Joerg and Beasley, David, eds. The Hitchhiker's Guide to Evo-lutionary Computation: A list of Frequently Asked Questions (FAQ), 2001
[14] Mitchell Melanie An Introduction to Genetic Algorithms, 1999, A BradfordBook The MIT Press
[15] D.Dasgupta, Z.Michalewicz Evolutionary algorithms in engineering aplica-tions, 1997, Springer
[16] K.Miettinen, P.Neittaanmäki, M.M.Mäkelä, J.Périaux Evolutionary algori-thms in engineering and computer sience, 1999, John Wiley & Sons Ltd.,
[17] Genetic Algorithm and Direct Search Toolbox for use with MATLAB, User'sGuide Version 2, 2005, The MathWorks, Wrzesie«
[18] dr in». Mirosªaw Parol - wykªady z zagadnie« algorytmów ewolucyjnych - III rokkierunku Informatyka, semestr zimowy 2003/2004, naWydziale Elektrycznyczm(Politechnika Warszawska)
[19] prof. dr in». Henryk Supronowicz - wykªady z zagadnie« techniki cyfrowej - IIrok kierunku Informatyka, semestr zimowy 2002/2003, na Wydziale Elektrycz-nyczm (Politechnika Warszawska)
[20] Bruce Eckel Thinking in Java, 2003, wydanie 3, Helion
[21] Martin Fowler, Kendall Scott UML w kropelce, 2002, wydanie 1, Ocyna wy-dawnicza LPT, Warszawa
[22] Using Other Swing Features - How to Use Threads, data /2006.10.07:23/,http://java.sun.com/docs/books/tutorial/uiswing/misc/threads.html
[23] How to Write Doc Comments for the Javadoc Tool, data /2006.10.07:23/,http://java.sun.com/j2se/javadoc/writingdoccomments/index.html
[24] javadoc - The Java API Documentation Generator, data /2006.10.07:23/,http://java.sun.com/j2se/1.4.2/docs/tooldocs/windows/javadoc.html
[25] Lesson: Using Swing Components, data /2006.10.07:23/,http://java.sun.com/docs/books/tutorial/uiswing/components/index.html
[26] A Visual Index to the Swing Components, data /2006.10.07:23/,http://java.sun.com/docs/books/tutorial/uiswing/components/components.html
[27] Using HTML in Swing Components, data /2006.10.07:23/,http://java.sun.com/docs/books/tutorial/uiswing/components/html.html
[28] How to Use Editor Panes and Text Panes, data /2006.10.07:23/,http://java.sun.com/docs/books/tutorial/uiswing/components/editorpane.html
[29] Strona na temat algorytmów genetycznych (podstawy), data /2006.10.07:23/,http://panda.bg.univ.gda.pl/ sielim/genetic/
100

[30] Gray code: denitions and much more, data /2006.10.07:23/,http://www.answers.com/main/ntquery;jsessionid=r9a4cudhnf61?tname=gray-code&sbid=lc06b
[31] Elliotte Rusty Harold, Processing XML with Java, data /2006.10.07:23/, [po-sta¢ elektroniczna]
[32] XML in 10 points, data /2006.10.07:23/,http://www.w3.org/XML/1999/XML-in-10-points.html
[33] comp.lang.java.gui - lista dyskusyjna dotycz¡ca programowania gracznego in-terfejsu u»ytkownika w j¦zyku Java,
[34] pl.comp.lang.java - lista dyskusyjna dotycz¡ca programowania w j¦zyku Java,
[35] comp.lang.java - lista dyskusyjna dotycz¡ca programowania w j¦zyku Java,
[36] Marcin K¦dziorek Rozproszona implementacja algorytmu genetycznego wjezyku Java, 2003, Politechnika Warszawska, Wydziaª Elektryczny
101





























