Embed Size (px)
Citation preview

HIGHER EDUCATION DATA & INFORMATION IMPROVEMENT PROGRAMME
Higher Education Data and Information Improvement Programme
Project: Data Language
Straw Man Logical Student Data Model
Discussion Paper January 2016

Page 2 of 14
Contents
1. Context ..................................................................................................................................................................... 3
1.1 About the Data Language project ................................................................................................................. 3
1.2 About Data Futures....................................................................................................................................... 3
1.3 About this paper ........................................................................................................................................... 3
2. Guide to the Straw Man Data Model ....................................................................................................................... 4
2.1 About the data model ......................................................................................................................................... 4
2.2 Reading the data model ..................................................................................................................................... 4
2.3 Some principles .................................................................................................................................................. 4
2.4 How the data model is structured ...................................................................................................................... 5
2.5 Areas for discussion ............................................................................................................................................ 7
2.6 Prompts for feedback ......................................................................................................................................... 9
2.7 Next steps ........................................................................................................................................................... 9
3. Straw Man Logical Student Data Model ................................................................................................................. 10
3.1 Full model ......................................................................................................................................................... 10
3.2 Person element ................................................................................................................................................. 11
3.3 Instance element .............................................................................................................................................. 12
3.4 Curriculum element .......................................................................................................................................... 13
3.5 Provider element .............................................................................................................................................. 14

Page 3 of 14
1. Context
1.1 About the Data Language project The Data Language project is a HEDIIP project that will define a common HE student dataset with a supporting set of agreed data definitions. This will deliver a key element of the New Landscape. The project commenced at the beginning of November 2015 and meetings have been taking place with HE providers and a number of key data collectors across the UK. These meetings have been exploring current student data requirements, future student data requirements, and data language. The project is focusing on student and curriculum data as this encompasses the largest collections and will therefore have the most significant impact on the landscape. The new dataset and definitions will be used by HESA as part of the implementation of Data Futures, but they will also be designed to be used more widely by other organisations collecting or transferring data about Higher Education students and their courses.
1.2 About Data Futures Data Futures is a fundamental redesign of current HESA systems, aimed at delivering significant efficiencies for HE providers through the rationalisation of the returns process, faster data processing times, and the collection and delivery of data in-year. The intention is that the new data language should be used in Data Futures, but HESA Data Futures will not be the only user of the data language as other organisations will continue to collect data direct from providers.
The new data language is not exclusively intended for use by HESA; it may contain entities or attributes which HESA will not collect. If the HEDIIP vision is achieved, then HESA may come to collect those data in future as more collectors rely on the transformed HESA for their routine data collection. This will meet the principle of ‘collect once: use many times’. However inclusion of an attribute or entity in the data model does not imply that it will be collected by HESA following Data Futures.
HESA has recently consulted about Data Futures. The consultation documents and more information about the Data Futures programme are available to view on the HESA website at www.hesa.ac.uk/datafutures. The consultation closed on 18 December 2015, and HESA will publish the outcomes shortly.
1.3 About this paper This is a paper to generate discussion on the straw man logical student data model, developed by the project team as an early proposal for the common HE student dataset. It is however not a formally-approved policy statement of the HEDIIP Programme, HESA, any funding body or data collector, or anyone else. This paper will hopefully aid your understanding of where we have sound ideas that need further refinement, and where our ideas themselves may need further work, and you can shape your feedback accordingly. The document begins with a guide to the data model and is followed by the full model and different elements of the full model, for example Person and Provider.
Some of the material in this paper has previously been published by the project, for instance in the draft glossary of terms. Repeating that material isn’t meant to imply that the project has stopped taking feedback on it. The intention is only to have a document which can be read without cross-reference to other documents. Indicated at the end of this paper are some areas where we would particularly appreciate feedback, however we are also still very open to feedback on the terms used, their definition, or any other items about the data language which seem relevant to you.
You can publicly post your feedback on the Data Language discussion page of the website. Alternatively you can email the HEDIIP Programme at [email protected]. We would appreciate any feedback by Monday 29 February.

Page 4 of 14
2. Guide to the Straw Man Data Model
2.1 About the data model The Data Language project took the view early on that in order to produce the best results – i.e. the most widely used model – the project should engage with data collectors and providers on an ongoing basis. In November and December 2015 the project team met with representatives of over seventy organisations to understand data requirements, learn from current experience and explore principles and options for change. The result of that work is a data model which – we believe – is based on the principles discussed and meets the requirements of a wider range of stakeholders than any existing model.
As that timetable indicates, this is not a well-developed proposal for change. Instead this is explicitly a straw man data model designed to elicit further feedback. However it does represent the current thinking of the project team about the shape a new model could take. It is the outline of a possible proposal.
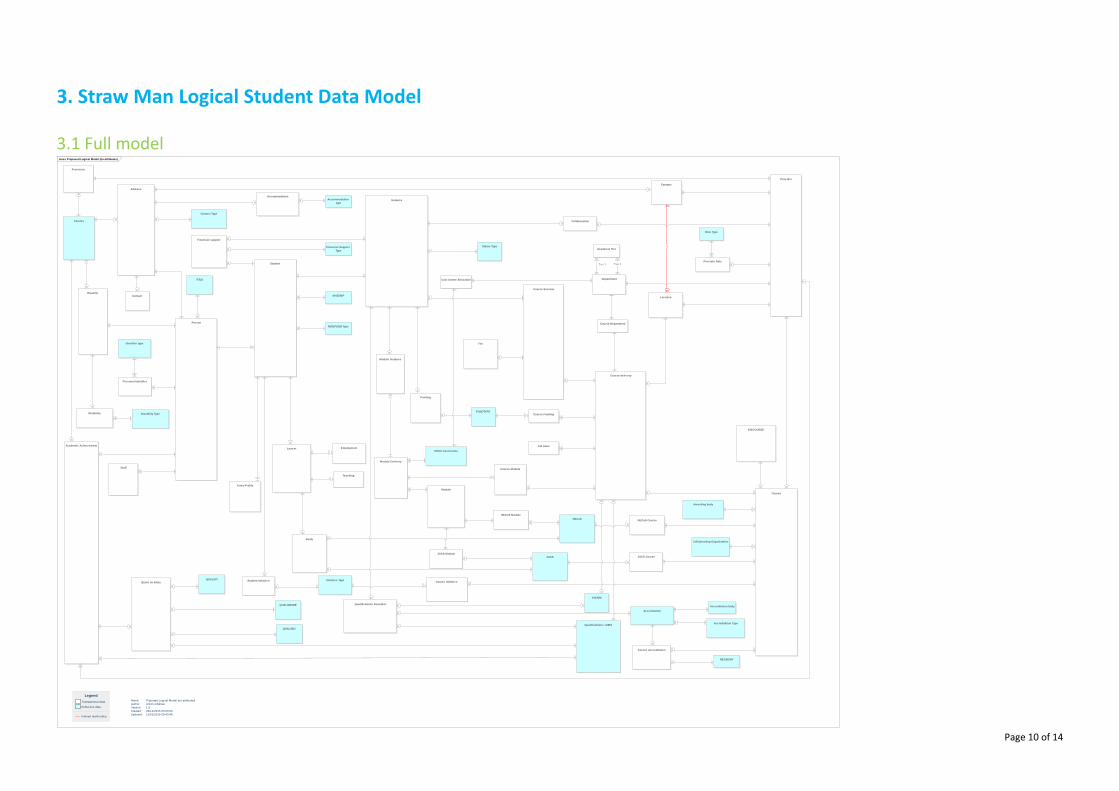
2.2 Reading the data model The straw man model is published as a 'crow's foot' entity relationship diagram. This kind of presentation is familiar to anyone who has worked with the existing HESA data collections, and shows the logical relationships between entities clearly. The main change made from previous practice is explicitly to show reference data in the model (the blue boxes) rather than showing these data only in the definitions of the relevant attributes. While this makes the diagram busier, we believe it is important to draw out all the interconnections between what have previously been separate data collection streams.
A single view of the entire model has been published, and also views of the parts of the model concerned with curriculum, people, instances, and providers. These are different views of the same model. You will not find anything on the curriculum, person, instance or provider view that is not in the full view, but it may be more convenient to use just the part of the model you are particularly interested in examining at any one time.
The attributes associated with each entity have not been published. We certainly recognise the importance of doing this as soon as possible, but are still working through some parts of the model to identify what attributes are required. The decision was taken not to delay publishing the straw man itself until the project is ready to publish the attributes too.
2.3 Some principles The data language is based on principles discussed with a wide range of stakeholders. The ones that are particularly important to the straw man model are:
A single, integrated data language and model. We propose to replace special-purpose returns (such as the
HESA Student, KIS, Institutional Profile, or the ITT) with a single, integrated data language and model so
that data can be collected once, and used many times (this is not a proposal to amalgamate all HESA
returns into one.)
Data captured will be appropriately modelled to reflect the logical state as closely as possible.
Calculated fields (such as TYPEYR or MODOUT) will be replaced by administrative data (e.g. session start
and end dates, module marks) that would allow the relevant calculations to be performed by HESA or by
data users.
Project discussions to date have suggested that these principles are broadly supported by data collectors and providers, but how far we can develop some of these principles still remains to be seen. For instance it may be possible to eliminate the KIS Course Stage entities completely if we are able to collect the teaching and assessment data that relate to specific modules.

Page 5 of 14
2.4 How the data model is structured The model has a series of entities which collect information about the provider and its curriculum offer to students. These are the Provider, Department, Campus, Course, Course Accreditation, Course Initiative, Course Delivery, Course Session, Module, Module Delivery, Course Module, Course Subject and Module Subject. The KIS Course is still shown, but with further development we hope to be able to eliminate it, or perhaps make it optional for providers who are not able to complete all the relevant modular data. All of these provider and curriculum data can be reported without the need for any student to enrol on any course. It is therefore possible for them to be reported far in advance of traditional HESA student deadlines. Many of these data are already collected long before students enrol – for instance by UCAS or the SLC in order to populate their course databases. The model has a further series of entities which relate to the individual person who falls within the coverage statement. These are the Person, the roles that Person may take (Staff, Student, Leaver) and related data. While the Staff Return is not within scope for the Data Language project, many students are also staff so the link to staff data is important. A Person has Equality data, Academic Achievement, which allows a consistent description of that person to be maintained across time as they potentially study with more than one provider, and Address(es). The Student entity captures that Person’s engagement with a particular provider to pursue a particular Course, and has an Entry Profile. The Student may also have Financial Support or Student Initiative entities to report relevant support they have received. This Student entity more closely matches the Instance concept within the current HESA Student return. Students are linked to curriculum through the Instance and Module Instance entities. A Student will have one Instance for each Course Session which they undertake, and one Module Instance for each Module Delivery which they undertake. The Qualification Awarded and related Accreditation are also linked to the Instance, as we recognise that the qualifications awarded to a student may not be those originally aimed at. Curriculum The curriculum model is hierarchical with a Course consisting of one or many Course Deliveries, each with one or many Course Sessions. In parallel a Module has one or may Module Deliveries. The relationship between Courses and Modules is not hierarchical. Course Deliveries are linked to Module Deliveries through the Course Module entity, which permits a many:many relationship between Courses and Modules.
The Course is an approved programme of study that provides a coherent learning experience and leads to
a qualification at HE level or credit towards a qualification at HE level. A course will have one (or possibly
more than one) programme specification (i.e. a published statement about the intended learning
outcomes, containing information about teaching and learning methods, support and assessment
methods, and how individual units relate to levels of achievement). It is a persistent entity and would
normally be expected to link course delivery records over many years. The Course is not closely defined,
and providers will have some flexibility to aggregate their curriculum into Courses that make sense to
them. The main limitation on this being that Accreditation information is held at the Course level.
The Course Delivery is the specific offer of a Course to Students. It therefore has a specific start date,
expected end date, location, mode, entry qualifications and (usually) a specific course aim. One course
delivery must exist for each offer made in the provider’s prospectus. A course may have any number of
course deliveries. Students will be associated with a single course delivery throughout their study unless
they choose (and are permitted) to transfer. This definition is close to the UCAS course definition, and we
would expect a 1:1 link between UCAS courses and Course Deliveries in the data language.
The Course Session specifies the specific session of a Course on which a Student is enrolled at any one
time. A Student may be associated with several Course Sessions over their engagement with a Course, but
only one at any one time. Course Sessions will usually be year-long (except for the last Course Session in
any Course Delivery, which may be shorter). Where there is a progression decision made by the provider
within the Course Delivery, which determines whether the Student is permitted to progress to the next

Page 6 of 14
stage of the course, a new Course Session must be created to represent this. However progression is not
necessary to the definition of the Course Session where the structure of the Course does not require
progression decisions (for instance where the provider operates a bare credit accumulation model).
While the structure of the curriculum entities (a persistent Course with specific entry points (Course Deliveries) and enrolment sessions (Course Sessions)) is similar to that used by many institutions, the definition of the Course Delivery is firmly fixed to the offer made to potential applicants, and not the internal structure used by institutions to deliver that offer. For instance an institution might use a single course code to group together students pursuing many different, but related, qualification aims – BSc Computing, BSc Information Technology, and BSc Computing and Web Development. These must all be separate Course Deliveries in the data language, because each Course Delivery may only have one Course Aim.
A Module is a self-contained, formally structured unit of study, with a coherent and explicit set of learning outcomes and assessment criteria. A Module is a persistent entity and would normally be expected to link Module Delivery records over many years. Note that whilst the Module has defined learning outcomes (this is the QAA definition of a Module), the specific assessment methodology is defined at the Module Delivery level. Different deliveries of the same Module could use a different mix of exams and coursework, for instance.
The Module Delivery is the specific offer of a module to students. It therefore has a specific start date, end date, assessments, language of instruction and teaching load.
As there is no concept of progression within Modules (by definition, because they are units of study) there is one level less in the hierarchy of modular entities.
People The straw man model introduces a Person entity to describe a single individual. This is necessary because some intended future uses of data make it much more important to track individuals across interaction with many providers. We are also considering whether Students in some collaborative arrangements should be returned by more than one provider for the same Course. The Person entity also offers the opportunity to clarify the link with staff data, where the same individual may be both a staff member and a student, either at the same provider or at different providers.
A Person is a natural person.
A Student is a Person undertaking a Course Delivery. One Person may therefore be more than one
Student if more than one Course Delivery is undertaken.
A Leaver is a Student who has permanently ended their engagement with a Course Delivery. A Leaver may
go on to undertake employment, study or teaching. This definition is broader than the current DLHE
population, but this is not meant to imply a change to the population of Leavers surveyed in DLHE.
Instances Instances provide the resolution between people and the curriculum they study.
An Instance is the specific programme of activity agreed between a Student and a provider at enrolment
or re-enrolment. It is therefore the resolution between a Student and a set of course and module
sessions. This is a fairly radical change from the use of the term ‘instance’ in the current HESA Student
collection. It is closer to the concept of ‘year of instance’ which is used in the HESA Student, although it is
not formally an entity in that collection.
A Module Instance is the outcome of a Student’s engagement with a Module Delivery.

Page 7 of 14
2.5 Areas for discussion Complexity At first sight this new data model looks more complex than the current model. This is for two reasons:
The new model covers more ground. This model covers the HESA Student, ITT, AP Student, KIS,
Institutional Profile, and makes links to the DLHE and Staff returns. As far as we are aware, a data model
covering this much ground has not been published before;
The old model hid a lot of complexity. This happened in three ways. Firstly very complex concepts were
expressed as a single, simple attribute (e.g. TYPEYR). Secondly, key concepts were not formally
represented in the model (FUNDCOMP relates to a year of instance, and STULOAD relates to a HESA year,
but both are shown in the model as attributes of the same entity). Thirdly, reference data were not
shown explicitly.
We believe the new approach delivers three major benefits:
Reducing reliance on the tacit knowledge of key individuals – currently a significant risk for many
providers;
Simpler operation;
More useful data.
To show what we mean by ‘simpler operation’ and ‘more useful data’, consider TYPEYR. To replace TYPEYR we need a new entity – the Course Session – with new attributes (in this case, start and end dates). The Course Session is effectively a programme year. So instead of having to calculate TYPEYR for each instance (which is often only possible at the end of the year once you know that an individual student has not withdrawn), providers only have to report when their teaching on each course starts and stops (which is known well in advance). The dates are also more useful to a wider group of data collectors than the TYPEYR value. The Personal Learner Record (PLR) With the wider adoption of the ULN in the HE sector, there has been a proposal to use the HESA data to populate the Personal Learner Record (PLR). This would have significant potential benefits for providers and graduates:
Graduates would have a persistent, trusted, public verification of their award, even if their HE provider
were subsequently to go out of business;
Providers would be able to reduce, and perhaps eliminate, the resources currently taken up providing
replacement transcripts and verification of qualifications for graduates.
In order to achieve this however, we need to collect much more detailed information about qualifications awarded and transcripts. Much of this information will also be needed for other uses (e.g. by PSRBs who need to know precisely which graduates are eligible for membership). The implications of this would be:
Qualifications data structured much more like KIS, and much less like the HESA Student COURSEAIM;
Defining the transcript, probably in pdf form, as an attribute of the qualification awarded (the alternative
would be to collect structured data to allow the transcript to be recreated, but this would be challenging);
Collecting detailed data about the regulatory status of qualifications awarded – and not just courses
offered as at present.
This seems to be the minimum dataset which could make the PLR a useful source of qualifications data. Currently, the data language does not include scope to capture the additional Higher Education Achievement Record (HEAR) data beyond the award and transcript. Degree awarding institutions may have views on whether awards for publication in the PLR should be returned by the HE provider or the degree-awarding institution, where the two are different.

Page 8 of 14
Accreditation PSRBs use a variety of language to describe the different things they do to courses and students (e.g. accredit, admit, recognise, etc.), we have used the blanket term ‘accreditation’ to describe any of these, as this reflects current HESA practice in KIS. Enhanced accreditation data are needed both for the PLR purpose and to make the data language useful for the many PSRBs who currently collect data about the HE sector. Data about PSRB regulation is currently held in three main ways:
The KIS data includes detailed statements about the regulation of particular KIS Courses using the
Accreditation entity. The precise wording of these statements is agreed with the relevant PSRB;
In the HESA Student data courses for medical, dental, health and social care, and veterinary students are
identified using a field called REGBODY. REGBODY only provides values for PSRBs that regulate health and
social care professions, not for any others;
In the HESA Student data there are separate codes which identify those qualifications that
o Lead towards registration with the General Teaching Council;
o Lead towards registration with the Architects Registration Board; or
o Lead towards obtaining eligibility to register to practice with a health or social care or veterinary
statutory regulatory body (which body should in turn be clear from the REGBODY value returned
for the course which the student is studying).
Other regulated qualifications are not separately identified. A separate code is returned (a) for the qualification which the course is aimed at and (b) for the qualification actually achieved, so in principle students who aimed for a regulated qualification but gained an unregulated qualification instead can be recognised by the use of different codes for the qualification aim and the achieved qualification. We believe that the regulatory information about qualifications can be formed in the same way as the current KIS Accreditation entity (i.e. one data item specifying the PSRB, and another specifying the relevant statement, with possibly a third to specify whether this statement appears on the certificate). This is the way the straw man data model is structured. The straw man does not allow us to separately identify students on accredited courses who are still studying but are no longer eligible for an accredited award (this can happen where the PSRB has stricter rules about plagiarism or reassessment than the HE provider, for instance). The straw man does not allow us to hold information about accredited modules. Institutional Structures The straw man model has inherited the current Institutional Profile method for describing institutional structures, in which Departments are the entities, and higher organisations (such as Schools and Faculties) are reported against those departments using the Tier 1 and Tier 2 attributes. This meets the current requirement to understand the allocation of departments to academic cost centres for funding purposes. This project proposes a Course Department link that would allow a wider range of data to be reported about Departments. This would allow HESA data to be used to answer questions like ‘How many students are there in the Department of Engineering at Poppleton’, but potentially a different structure would allow more complete reporting of institutional structures, and therefore more precise relation of the data language to actual provider structures.
The Academic Tier entity must link to at least one Department, so there is no option for providers to
report a School with no constituent academic Departments (such as a Graduate School).
Module Deliveries are linked to Cost Centres, rather than directly to Departments.
Some PSRBs require more detailed data about the staff actually teaching on accredited courses, and providers in England, if not the rest of the UK, have a requirement to publish this information for consumer protection reasons. It may therefore be beneficial to have a capability to link staff to the Module Deliveries they teach.

Page 9 of 14
Fees The project has created a Fee entity which relates to the Course Session and is therefore a piece of curriculum data – data that can be gathered in advance of any particular student enrolling. The intention of this is to gather as much information as possible about fees and fee-related information as curriculum data rather than individual data. However we are aware that many providers have complicated fee structures, and this proposal might not work so well in practice.
2.6 Prompts for feedback We welcome all kinds of feedback but we would particularly welcome feedback on:
The presentation of PSRB-related information. Because of the large volume of PSRBs collecting data,
meeting the needs of as many PSRBs as possible is vital to the success of the HEDIIP vision.
The population of the PLR. While this is not a short-term objective, it potentially has a big impact on the
data model.
The proposed curriculum structure, especially whether providers would be able to work within the Course
Delivery/Course Session model.
You can publicly post your feedback on the Data Language discussion page of the website. Alternatively you can email the HEDIIP Programme at [email protected]. We would appreciate any feedback by Monday 29 February.
2.7 Next steps The project will be using your feedback in order to inform further development of the data model. Another round of HE Provider workshops will be taking place at the end of February and this will provide an opportunity to discuss the model and feedback in a more discursive environment. The project will also continue to meet with data collectors to discuss the model in detail. A later iteration of the model will be presented during conference season (March).
Page 10 of 14
3. Straw Man Logical Student Data Model 3.1 Full model
class Proposed Logical Model (no attributes)
Person
Address
Equality
Staff
Student
Leav er Employment
Teaching
Study
Course
Course Module
Module
Module Instance
Prov ider
Instance
Entry Profile
Funding
Accreditation
Campus
Course Initiativ e
Academic Achiev ement
Course Session
Qualifications / AIMS
Course deliv ery
Location
AccommodationAccommodation
type
Collaboration
Disability Type
Fee
NHSEMP
Prov ision
Cost Centre Allocation
Country
TITLE
Collaborating Organisation
Accreditation body
Course Accreditation
Awarding body
FUNDTYPE
REGBODY
Prov ider Role
Role Type
NIDEPEND Type
Identifier type
Personal Identifier
QUALGRADE
QUALSIT
QUALSBJ
Quals on Entry
Financial support
Financial Support
Type
Qualifications Awarded
KISCOURSE
ILR Aims
Initiaitv e Type
Module Deliv ery
HECoS
HECoS Module
HECoS Course
JACS JACS CourseJACS Module
HESA Cost Centre
Course Department
Contact Type
Student Initiativ e
Disability
Accreditation Type
Department
Academic Tier
Course Funding
Status Type
KISAIM
Contact
Name: Proposed Logical Model (no attributes)
Author: simon.robshaw
Version: 1.0
Created: 26/11/2015 00:00:00
Updated: 11/01/2016 09:43:46
Transactional data
Reference data
Inferred realtionship
Legend
Tier 1 Tier 2
?

Page 11 of 14
3.2 Person element
class Person (no attributes)
Disability Type
Address
Employment
Academic
Achiev ement
Equality
Identifier type
Leav er
Person
Personal Identifier
Quals on Entry
Student
Staff
Study
TITLE
Teaching
Entry Profile
Disability
Name: Person (no attributes)
Author: simon.robshaw
Version: 1.0
Created: 04/01/2016 00:00:00
Updated: 11/01/2016 09:43:46
Campus
Activ ity
HESA Cost Centre
Staff Contract
Contact Contact Type
Transactional data
Reference data
Legend

Page 12 of 14
3.3 Instance element
class Instance (no attributes)
Accommodation Accommodation type
Course Session
Entry Profile
Student Initiativ e
Student
Qualifications Awarded
Module Instance
Instance
Address
Financial support
Financial Support Type
Funding
NHSEMP
NIDEPEND Type
Collaboration
Name: Instance (no attributes)
Author: simon.robshaw
Version: 1.0
Created: 04/01/2016 00:00:00
Updated: 11/01/2016 09:43:47
FUNDTYPE
Status Type
Person
Transactional data
Reference data
Legend

Page 13 of 14
3.4 Curriculum element
class Curriculum (no attributes)
Accreditation
Accreditation body
Awarding body
Collaborating
Organisation
Course
Course Accreditation
Course Session
Course Module
Course deliv ery
ILR Aims
Initiaitv e TypeCourse Initiativ e
KISCOURSE
Location
Module Deliv ery
Module
Module Instance
REGBODY
Qualifications / AIMS
JACS Course
HECoS Course
HECoS
HECoS Module
JACSJACS Module
Accreditation Type
FUNDTYPE Prov ider
Course Department
Name: Curriculum (no attributes)
Author: simon.robshaw
Version: 1.0
Created: 04/01/2016 00:00:00
Updated: 11/01/2016 09:43:46
Instance
Course Funding
KISAIM
HESA Cost
Centre
Transactional data
Reference data
Legend

Page 14 of 14
3.5 Provider element
class Prov ider (no attributes)
Cost Centre
Allocation
Address Contact Type
Campus
Country
Location
Prov ider
Prov ider Role
Prov ision
Role Type
Collaboration
Name: Provider (no attributes)
Author: simon.robshaw
Version: 1.0
Created: 04/01/2016 00:00:00
Updated: 11/01/2016 09:43:47
HESA Cost Centre
Department Academic Tier
Transactional data
Reference data
Inferred Relationship
Legend
Tier 1
?
Tier 2





























