Embed Size (px)
Citation preview

Precise News Video Text Detection and
Text Extraction Based on
Multiple Frames Integration
Advisor: Dr. Shwu-Huey Yen
Student: Hsiao-Wei Chang
1

2
Outline
1 Introduction
2 Related work
3 Edge detection
4 Proposed Method
5 Experimental Results
6 Conclusion

1 Introduction
Video text can be scene text or caption text. Caption text, static or scrolling, is superimposed in a later stage of videos producing. Most static texts provide concise and direct description of the content presented in news video.
3

The procedure of video textual information extraction can be divided into two categories; detection and extraction.
4

2 Related work
Video text detection methods can be classified into three classes.
The first class is texture-based.
The second class presumes that a text string contains a uniform color.
The third class is edge-based.
5

Text extraction methods can be classified into two classes.
The first class is global .
The second class is local.
6

Niblack proposed calculating the threshold value by shifting a window across the image. The threshold is determined by the following formula:
T(x,y) = m(x,y) + k * s(x,y),
where m(x,y) and s(x,y) are local mean and standard deviation values, respectively. The value of k is a parameter.
7

Sauvola established on Niblack’s algorithm. The threshold is determined by the following formula:
T(x,y) = m(x,y) * (1 + k * (s(x,y)/R - 1))
where m(x,y) and s(x,y) are as in Niblack's formula. R is the dynamic range of standard deviation, and a parameter k.
8
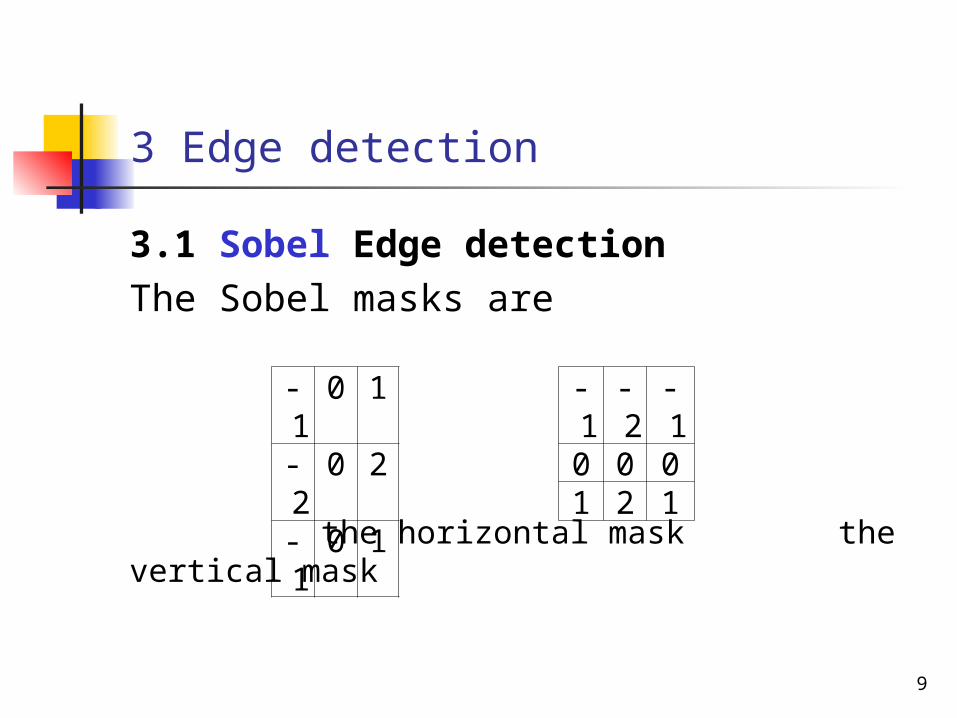
3 Edge detection
3.1 Sobel Edge detection
The Sobel masks are
the horizontal mask the vertical mask
9
-1 0 1-2 0 2-1 0 1
-1 -2 -10 0 01 2 1

The magnitude of the gradient is then calculated using the formula:
10
22yx GGG

3.2 Canny edge detection
The Canny algorithm contains three parameters.
The size of the Gaussian filter.
Thresholds: the use of two thresholds with hysteresis allows more flexibility than in a single-threshold approach.
11

(a) original image (b) Sobel edge (c) Canny edge
(a) original image (b) Sobel edge (c) Canny edge
12

4 The Proposed Method
4.1 Text Detection
People need 2 seconds or more to process a complex scene. Thus, if videos are played f frames per second, we are interested in video texts focusing on a fixed location for at least 2f consecutive frames. Let k be the nearest integer that is not less than f.
13

On the mth round, four reference frames on frames (m-1)k+i, i= 1, k/3, 2k/3, 3k/3 are chosen. We set h and w are the height and width of the character size.
14
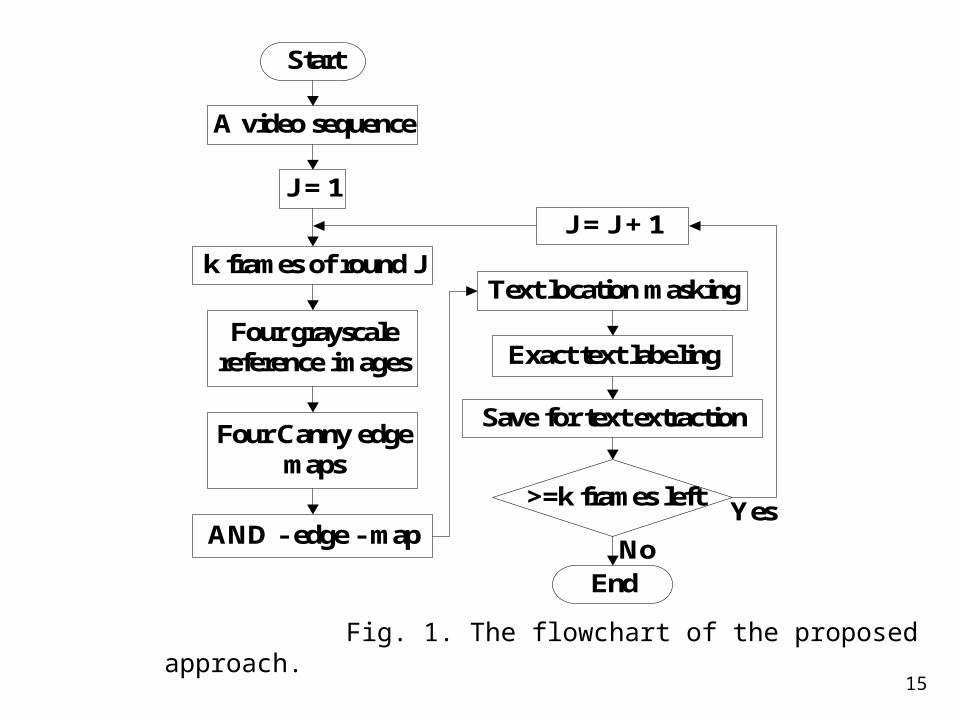
Fig. 1. The flowchart of the proposed approach.
15
Start
A video sequence
J = 1
k frames of round J
Four grayscale reference images
Four Canny edge maps
AND - edge - map
Text location masking
Exact text labeling
Save for text extraction
>=k frames left
J = J + 1
End
Yes
No

Step 1: Get four reference frames from the given one round of video frames and transform them into grayscale images. We use Eq.(1) to accomplish this.
(1)
where Y is the intensity value.
16
BGRY 114.0587.0299.0

17
(a
Fig. 2. Four color reference frames.

18
Fig. 3. Four grayscale reference images.

Step 2: Execute the edge detection. The Canny edge detector is applied on each grayscale image yielding an edge map. A simple line deletion (horizontal and vertical) is followed if a line is too long.
19

20
Fig. 4. Four Canny edge detection maps after removing lines that are too long.

Step 3: Do logical AND on Canny edge maps. Note that after AND operation, a position (i, j) is true (an edge pixel) if all four Canny edge maps are true at (i, j).
21

22
Fig. 5. The AND-edge-map: the result after taking AND operation on four Canny edge maps of Fig. 4.

Step 4: Mask text location. A three-stage technique is designed to find the text mask. (a) A window the size of w h (presumed character size) slides from left to right (per column) and top to bottom (per row) on the AND-edge-map.
23

The value of BWT represents the transitions from black to white or from white to black.
where b()=1 if it is black and 0 otherwise. If BWT is larger than the threshold TBWT , this window is masked.
24
)|),1(),(|()|)1,(),(|(1
0
1
1
1
0
1
1
w
j
h
i
h
i
w
j
jibjibjibjibBWT

25
(a) (b)
Fig. 6. (a) Edge of the string. (b) Edge of English letter “I”.

The threshold TBWT depends on the character size. “I” is the one with the least black-and-white transitions in English letters. Figure 6 shows each letter has dimension approximately 1018 and the BWT in Fig. 6(b) is 72 which is 0.4 of 1018. The experimental results on many multilingual video texts are satisfying when is 0.35, TBWT = (wh).
26

(b) The rough mask is examined. A horizontal line segment of length w comprising points on (i, j), …, (i+w-1, j) will be eliminated if neither of these points is an edge; and a vertical line segment of length h comprising points on (i, j), …, (i, j+h-1) will be eliminated if neither of them is an edge point.
27

(c) Considering the different background and various contrast in reference frames, the results of the Canny edge detector of the same text on different frames may differ in a few pixels. This usually causes characters to lose some pixels in the AND-operation.
28

To alleviate this problem, a morphological compensated image M is obtained by first applying a closing. Isolated blobs of small size are removed followed by a dilation to extend the text region.

30
(a) The obtained rough mask (b) Non-text pixels removal
(c) Isolated noises removal (d) Morphological compensation

Step 5: Exact text location. To do the refinement, we examine every white pixel. If a white pixel is located on (i, j) position, then points located on top, bottom, left, and right of (i, j) position of the edge map will be examined.
31

In checking the upward direction, on the binary edge map, if (i, j-1), (i, j-2), …, (i, j-k+1) points are all white and (i, j-k) is the first edge pixel (black point), then every point on (i, j-1), (i, j-2), …, (i, j-k+1) in the rough text (grayscale) image must be non-text accordingly. Thus, any non-white pixels will be converted into white in the rough text image.
32
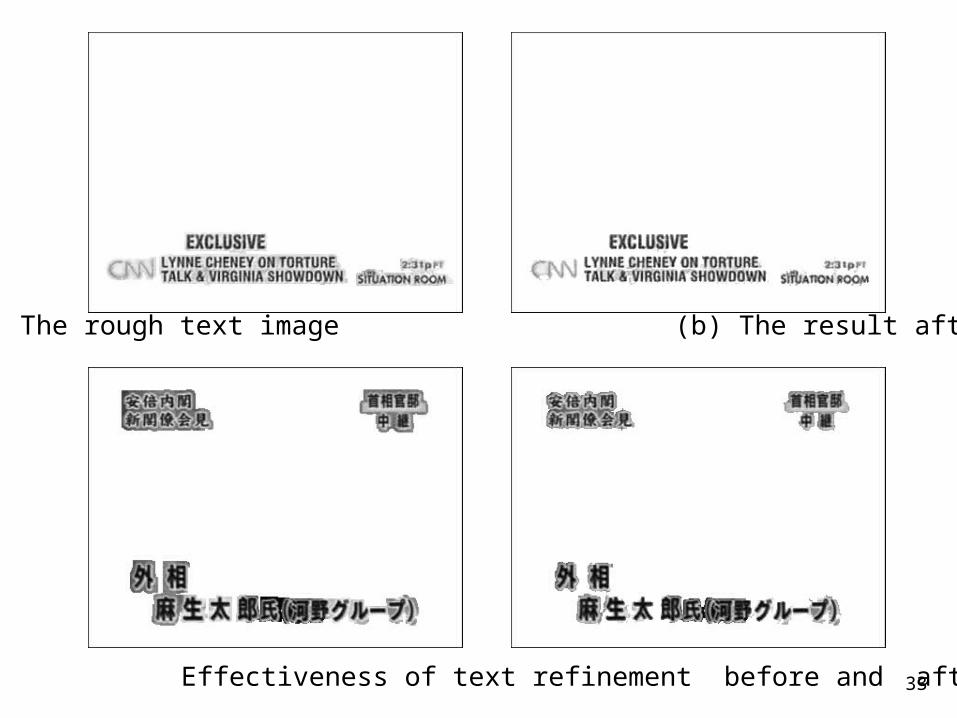
33
(a) The rough text image (b) The result after refinement
Effectiveness of text refinement before and after.

Finally, to label the detected texts, we do a simple binarization on the refined text image followed by a morphological operation to connect texts that are close to each other.

35
Fig. 9. Some results of our method.

36
4.2 Text Extraction
The flowchart of the proposed approach is given in Fig. 12.

37
Start
Get a text detected box
Extend boundary
Transform Color image into grayscale image
Create Canny edge map
End
Get B from line-traversing
Does B cover entire range of histogram
modify the background pixel
intensity
Get the threshold T
No
Yes
Fig. 12. The flowchart of the proposed approach

38
First, for video text which is captured in a tightly bounded, we extend both the upper and lower boundary of the box at least 1 pixel to ensure that sufficient pixels are included for the application of Canny edge detector.

We compare the pixel intensity of each column both from top to bottom and from bottom to top until we reach the pixel position identified as Canny edge or the end of the boundary if there is no Canny edge. When the comparison is complete, we get the range of the background intensity.
39

Let bmin and bmax be the least and the largest intensity values for those encountered pixels. The range of the background intensity is thus defined as B = [bmin, bmax]. It is possible that B covers the entire range of the intensity. According to B, we will discuss the binarization in two cases.
40

Case (1): B does not cover the entire range of the histogram.
We use the interval B to determine the range of foreground intensity F. Since text polarity is initially unknown, the midpoint of B can be used to estimate the foreground intensity.
41

If intensity of the midpoint of B is bright (>128), then the text is positive polarity, and negative polarity otherwise.
42
,otherwise]255,1[
,128)(]1,0[
max
maxmin21
min
b
bbbF
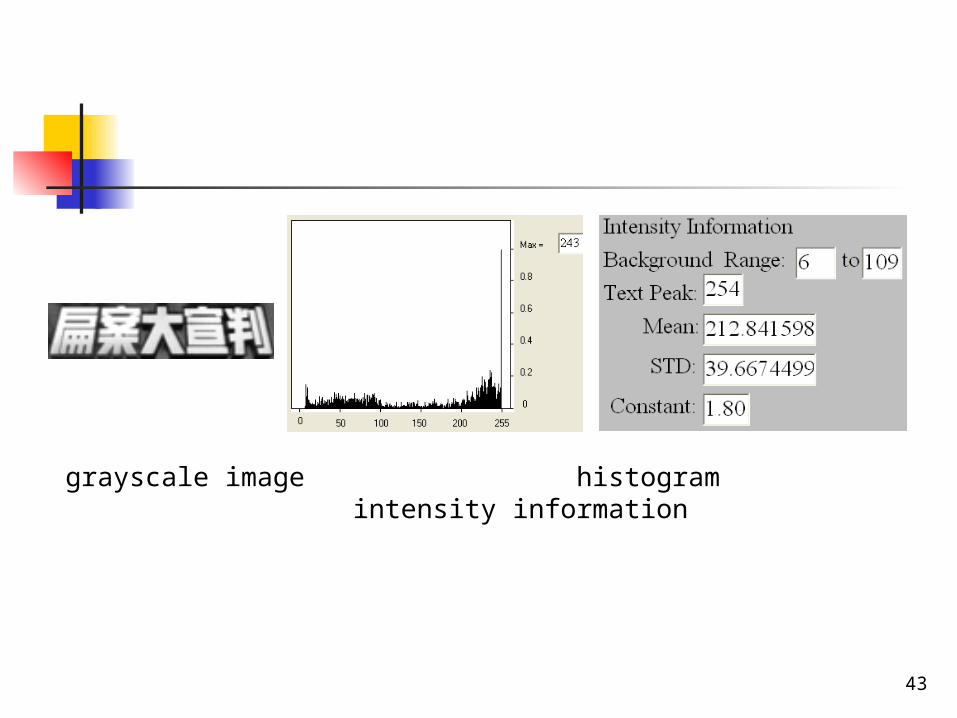
43
grayscale image histogram intensity information

44
[0, ] if it is positive polarity (dark text),
[ , 255] otherwise,
p kT
p k
where p and are the peak and the standard deviation of F, and k is a constant. In our experiments, k is set as 1.80.
we define the text intensity T as

45
(a) (b) (c)
(d) (e) (a) original image, (b) extended image, (c) grayscale image, (d) Canny edge map, (e) final image for OCR.

Case (2): B covers the entire range of the histogram.
Fig. 15. original image
Otsu Lin Niblack Sovola
Fig. 16. binarization results
46

To solve this problem, we reverse the refined image to recover the original text polarity. Repeat the steps, i.e., producing histogram, Canny edge map, and the background range B on this reversed image. Now, the background intensity range B is [0, 97].
47

refined image reverse Canny map
histogram intensity information
48

For each background pixel P, if its intensity is within the range of text intensity T, then its intensity value will be replaced by
where I(P) is the intensity of P.
49
255 if it is positive polarity,( )
0 otherwise,I P

(a) (b)
Fig. 20. (a) modify background intensities of Fig. 15;
(b) proposed algorithm binarization result
50

5 The Experimental Results
5.1 Text Detection Results
The proposed text detection algorithm was evaluated on multilingual videos clips for a total of approximately 30 minutes. All of these videos have a resolution of 400300 and a frame rate 29.97 per second. The presumed largest character size wh was set to be 2020 and in TBWT was set to be 0.35.
51

52
(a) (b) (c) Fig. 22.Three bounding boxes for the same text from large to small.
(a) (b) (c)
(d) (e) Fig. 23. Detected boxes (in yellow) for a ground truth text (in blue) that (a)
and (b) fail to detect, (c)~(e) truly detect it but only (e) accurately matched.

In Fig. 22. the dimensions of bounding boxes are 8820, 8618, and 8416 for (a), (b), (c) respectively. Any of them are perfect, but the area in (c) is only 76.4% of that in (a). To accommodate these cases, we take the medium bounding box, the one in (b), as the ground truth.
53

A detected box truly detects the texts if the area ratio r, defined in (3), is at least 50%.
54
)__(
)__(
BOXGBOXDArea
BOXGBOXDArear
(3)
where D_BOX is a detected box, like yellow boxes in Fig. 23, G_BOX is the ground truth text box, like blue boxes in Fig. 23.

To focus the bounding preciseness, if the area ratio r is at least 80% we say the text is accurately detected. We use recall (R), precision (P), and quality of bounding preciseness (Q) to measure the efficacy of algorithms as in (14), (15), (16).
55

(14)
(15)
(16)
56
)__(#)__(#
)__(#
)_(#
)__(#
FBOXDTBOXD
TBOXD
BOXD
TBOXDP
)__(#
)___(#
TBOXD
TBOXDAcuQ
)_(#
)__(#
BOXG
TBOXDR

57
(a) (b)
(c) (d) Fig. 24. The ambiguities in defining a ground truth for “TALK & VIRGINIA SHOWDOWN”.

Take characters “TALK & VIRGINIA SHOWDOWN” in Fig. 24 as an example. We accept all (a)~(d) cases to be ground truths. However, cases (a) and (b) are better because detected regions should be as tight as possible.
58

59
(a) (b)
(c) (d)

60
(e) (f)
Fig. 25. Some results of our method(size 400x300). (a) and (b) are CNN videos, (c) ESPN video, (d) NHK video from Japan, (e) and (f) are two different news videos from Taiwan.

Table 1. Results on Different Video sources
Video Sources
Type/LanguageLengthmin sec
# of G. boxes
D_BOX_F D_BOX_T
# of False Alarms
# of boxes w.r < 50%
# of boxes w.50% r < 80%
# of boxes w.r 80%
CNN News/English 9’16” 404 0 4 9 391
ESPN Sport/English 5’07” 111 2 11 29 71
NHK News/Japanese 5’35” 310 0 0 0 310
ETTV News/Chinese 5’29” 939 0 0 27 912
TVBS News/Chinese 4’51” 1340 0 64 57 1219
Total --/-- 30’18” 3104 2 79 122 2903
61
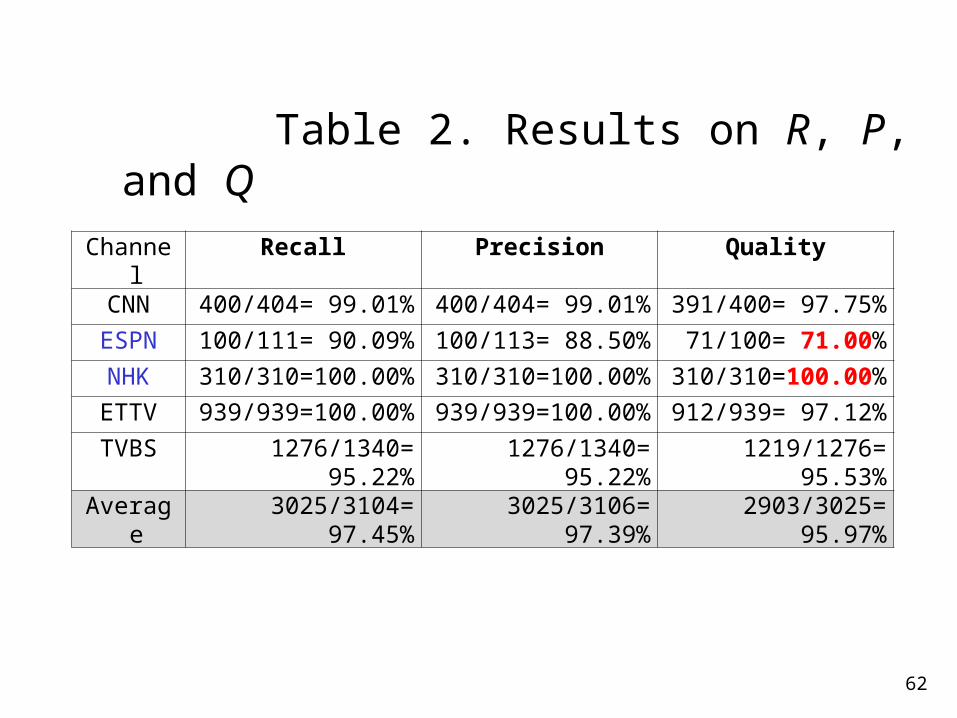
Table 2. Results on R, P, and Q
Channel Recall Precision Quality
CNN 400/404= 99.01% 400/404= 99.01% 391/400= 97.75%
ESPN 100/111= 90.09% 100/113= 88.50% 71/100= 71.00%
NHK 310/310=100.00% 310/310=100.00% 310/310=100.00%
ETTV 939/939=100.00% 939/939=100.00% 912/939= 97.12%
TVBS 1276/1340= 95.22% 1276/1340= 95.22% 1219/1276= 95.53%
Average 3025/3104= 97.45% 3025/3106= 97.39% 2903/3025= 95.97%
62

We summarize the contributions of the proposed algorithm in the following:
Precise boxes. Positive and negative text polarities. The alignment and the length of text strings. Sizes, fonts, and multi-color characters.

The worst experimental result is the ESPN video due to the small, isolated, and sparsely located characters. We repeated the experiment with a presumed character size of wh to be halved (1010).
64

65
Fig. 28. Some results of other’s method. (a) Hua et al., 2001, (b) Wang et al., 2004, (c) Anthimopoulos et al., 2008, (d) Huang et al., 2008.
(a) (b)
(c) (d)
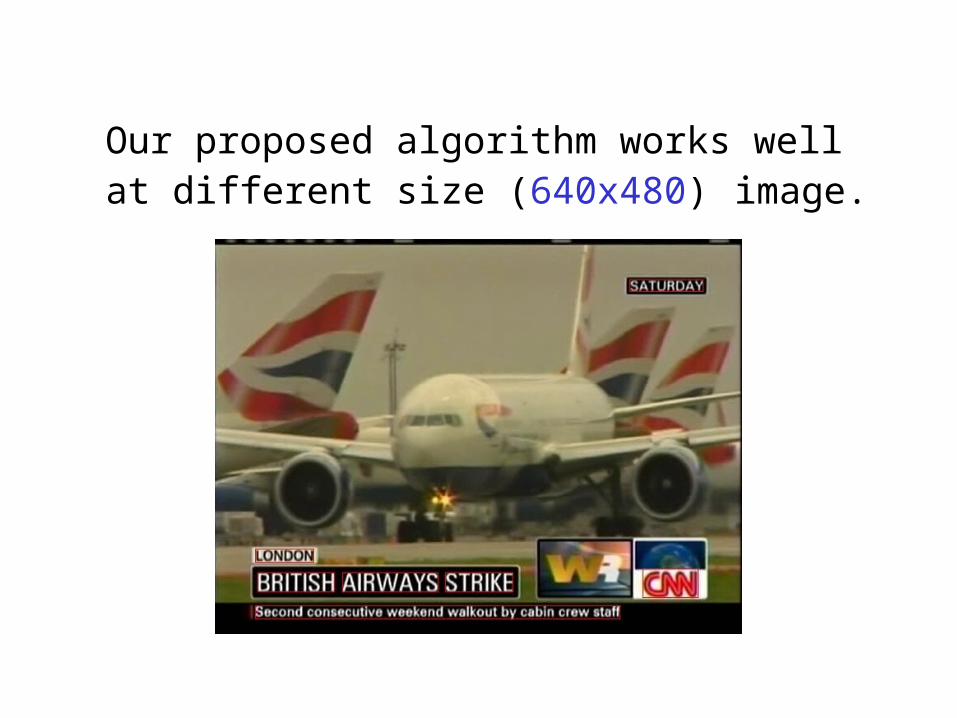
Our proposed algorithm works well at different size (640x480) image.

5.2 Text Extraction Results
We evaluated the performance of our proposed method comparing with Otsu, Lin, Niblack, and Sauvola methods.

Niblack’s method Sauvola’s method our method
original image Otsu’s method Lin’s method

69
Niblack’s Sauvola’s our methodw=20, k=0.2 w=20, k=0.2
original image Otsu’s method Lin’s method

original image Otsu’s method Lin’s method
Niblack’s method Sauvola’s method our method

71
Niblack’s method (cited from [30]) [25] approach (cited from [30])
our method
original image (cited from [30]) [30] approach (cited from [30])

72
original image (cited from [29]) Otsu’s method
Lin’s method Niblack’s method (cited from [29])
Sauvola’s method (cited from [29]) adaptive Niblack’s (cited from [29])
adaptive Sauvola’s (cited from [29]) our method

73
original image (cited from [29]) Otsu’s mehod
Sauvola’s method (cited from [29]) adaptive Niblack’s (cited from [29])
adaptive Sauvola’s (cited from [29]) our method
Lin’s method Niblack’s method (cited from [29])

6 Conclusion
We proposed a general text detection algorithm that is applicable to multilingual news videos without any limitations on text colors, fonts or sizes, alignments, or length of text strings. This algorithm has excellent performances in recall (R), precision (P), and quality of bounding preciseness (Q).
74

For text extraction, our proposed method has the merits both from global and adaptive methods. It is parameter-free, computation efficient and robust to various video text including color, font size, alignment.

Thank you !





























