Embed Size (px)
Citation preview

WYDZIAŁ ELEKTROTECHNIKI, AUTOMATYKI,
INFORMATYKI I ELEKTRONIKI
KATEDRA TELEKOMUNIKACJI
Praca dyplomowa
magisterska
Imię i nazwisko Adam Pyka
Kierunek studiów Elektronika i Telekomunikacja
Temat pracy dyplomowej Przenośny system detekcji
i rozpoznawania znaków drogowych
Opiekun pracy dr inż. Jakub Gałka
Kraków, rok 2011

Oświadczam, świadomy odpowiedzialności karnej za poświadczenie nieprawdy,
że niniejszą pracę dyplomową wykonałem osobiście i samodzielnie i że nie korzystałem
ze źródeł innych niż wymienione w pracy.

Szczególne wyrazy podziękowania chciałbym skierować
w stronę promotora dr inż. Jakuba Gałki za okazaną
cierpliwość, nieocenioną pomoc i wsparcie jakiego
udzielił mi w czasie pisania pracy.

Niniejszą pracę chciałbym dedykować mojej żonie,
która wierzyła we mnie nawet gdy ja zwątpiłem.

Spis treści
1. Wstęp
1.1 Cel pracy …………………………………………………………………. 1
1.2 Zakres pracy ……………………………………………………………… 1
2. Wprowadzenie do świata obrazów …………………………………………… 3
2.1 Przestrzenie barw …………………………………………………………. 3
2.2 Reprezentacja obrazów …………………………………………………… 5
3. Przekształcenia i analiza obrazów ……………………………………………. 7
3.1 Przekształcenia geometryczne ……………………………………………. 7
3.2 Przekształcenia punktów …………………………………………………. 8
3.2.1 Histogram i wyrównanie histogramu ……………………………… 8
3.2.2 Korekcja gamma …………………………………………………... 10
3.2.3 Binaryzacja ………………………………………………………… 11
3.3 Przekształcenia kontekstowe ……………………………………………… 12
3.3.1 Splot ………………………………………………………………. 13
3.3.2 Filtry 2-D ………………………………………………………….. 14
3.3.2.1 Filtry dolnoprzepustowe ………………………………………. 15
3.3.2.2 Filtry górnoprzepustowe ………………………………………. 16
3.4 Przekształcenia morfologiczne ……………………………………………. 20
3.4.1 Erozja ……………………………………………………………… 20
3.4.2 Dylatacja …………………………………………………………… 21
3.4.3 Otwarcie i zamknięcie ……………………………………………… 22
3.4.4 Detekcja ekstremów: Top-Hat, Bottom-Hat ……………………….. 23
3.4.5 Ścienianie i pogrubianie …………………………………………… 24
3.4.6 Szkieletyzacja i obcinanie gałęzi …………………………………… 25
3.4.7 Trafi - nie trafi ……………………………………………………… 27
3.5 Analiza obrazów …………………………………………………………… 28
3.5.1 Segmentacja i numerowanie ……………………………………….. 28
3.5.2 Współczynniki kształtu …………………………………………….. 29
3.5.3 Momenty główne i centralne ………………………………………. 31
4. Praktyczne wykorzystanie przekształceń- znajdowanie znaków w obrazie …… 32
4.1 ROI („Region Of Interest ”) charakter i właściwości znaków …………….. 32
4.2 Stosowane metody detekcji znaków ………………………………………. 33
4.2.1 Analiza kształtów …………………………………………………... 34
4.2.2 Analiza koloru ……………………………………………………… 38
4.2.3 Porównanie metod …………………………………………………. 40
4.3 Zastosowana metoda detekcji znaków …………………………………….. 41
5. Rozpoznawanie obrazów i metody klasyfikacji wzorców …………………….. 46
5.1 Metody bezpośredniej analizy obrazu ……………………………………… 46
5.2 Metody oparte o generację wektora cech ………………………………….. 48
5.2.1 Powszechnie znane sposoby generowania wektora cech …………… 49
5.2.2 Zastosowana metoda ekstrakcji cech ………………………………. 50
5.3 Klasyfikatory ………………………………………………………………. 52
5.3.1 Maszyna wektorów wspierających SVM …………………………... 53
5.3.2 SVM liniowo separowalnego zbioru wzorców …………………….. 54
5.3.3 SVM nieliniowo separowalnego zbioru wzorców …………………. 57
6. Skuteczność algorytmów ………………………………………………………. 62
6.1 Skuteczność detektora ……………………………………………………... 62
6.2 Skuteczność rozpoznawania ……………………………………………….. 67

6.3 Podsumowanie wyników ………………………………………………….. 71
7. Opis programu …………………………………………………………………. 73
7.1 Obsługa programu …………………………………………………………. 73
7.2 Ważniejsze części i funkcje programu …………………………………….. 77
Dodatek- Porównanie współczynników kształtu oraz momentów geometrycznych …… 83
Literatura ………………………………………………………………………………. 87

Wykaz ważniejszych oznaczeń
i,j- indeksy
O- obraz źródłowy
O’- obraz wynikowy
O(i,j)- piksel obrazu źródłowego
- wynik splotu sygnału ciągłego
- wynik splotu sygnału dyskretnego
- sygnał ciągły
- histogram
- dystrybuanta histogramu
- współczynniki filtru, rozmiar VC
γ - współczynnik korekcji gamma, parametr w SVM
- współczynnik zawartości
- współczynnik centryczności
- współczynnik Fereta
- współczynnik prostokątności
- współczynnik cyrkularności
- współczynnik Malinowskiej
- współczynnik Blair-Bliss
- współczynnik Danielssona
- współczynnik Haralicka
- moment główny
- moment centralny
- moment centralny znormalizowany
- niezmienniki momentowe
N- liczba klas, liczba elementów
ci- klasy w SVM
CI, CJ klasy konkurencyjne w SVM
- wektor
- wektor wynikowy funkcji rozpoznawania znaków
- zbiór punktów głosowania
- odległość
- macierz współczynników hiperpłaszczyzny
- liczba wzorców, długość
- odległość pomiędzy hiperpłaszczyznami
- funkcja rozdzielająca
- próg binaryzacji

Wykaz ważniejszych akronimów
RGB- przestrzeń barw ang. Red Green Blue
HSV – przestrzeń barw ang. Hue Saturation Value
YUV- przestrzeń barw
CIEXYZ- przestrzeń barw
ROI- obszar zainteresowania ang. Region Of Interest
SKIZ- szkieletyzacja bez stykania obszarów
SVM- maszyna wektorow wspierajacych ang. Support Vector Machine
FRST- szybka transformata radialna ang. Fast Radial Symetry Transform
LUT - operacja odczytu z tablicy ang. Look Up Table
NN- metoda klasyfikacji ang. Nearest Neighbour
k-NN- metoda klasyfikacji ang. k-Nearest Neighbours
NM- metoda klasyfikacji ang. Nearest Mode
MAC - operacja pomnóż i sumuj
FPGA- uklady programowalne
SIFT- ang. Scale Invariant Feature Transform
SURF- ang. Speeded Up Robust Features
PCA- ang. Principal Components Analisis
VC- rozmiar Vapnika-Czervonenkisa

Przenośny system detekcji i rozpoznawania znaków drogowych
1
1.Wstęp
Według najnowszych danych liczba samochodów w 2010 roku osiągnęła pułap
900 milionów. Jeżeli bieżący trend zostanie zachowany, to w ciągu następnych 30 lat liczba
ta ulegnie podwojeniu. Tak duża liczba samochodów przyczynia się do coraz większej liczby
wypadków drogowych oraz potencjalnych sytuacji zagrożenia zdrowia i życia podróżujących.
Koncerny samochodowe coraz większą wagę przywiązują do bezpieczeństwa ich produktów.
Samochód XXI wieku jest wyposażony w systemy awaryjnego hamowania, wyprowadzania z
poślizgu, rozpoznawania przeszkód na drodze oraz wiele innych. Systemami, które są
aktualnie wprowadzane do najnowocześniejszych pojazdów są systemy rozpoznawania
sytuacji drogowych w tym także systemy rozpoznawania znaków. Tematem detekcji i
rozpoznawania znaków drogowych nauka zajmuje się od dawna. Powstało wiele prac w tym
temacie, niektóre zostały nawet zastosowane w produkcji seryjnej w samochodach grupy
Volvo. Możliwość zainstalowania w samochodzie urządzeń rozpoznających znaki drogowe i
ostrzegające o potencjalnych sytuacjach niebezpiecznych z pewnością przyczyni się do
poprawy bezpieczeństwa na drogach.
1.1 Cel pracy
Celem pracy jest zbudowanie algorytmu umożliwiającego znalezienie w nieruchomym
obrazie znaku drogowego, a następnie jego rozpoznanie. System w wersji podstawowej
powinien znajdować i rozpoznawać znaki drogowe grupy B -znaki zakazu. W wersji
rozszerzonej powinien też reagować na wybrane znaki pozostałych grup. Algorytm powinien
cechować się jak największą skutecznością detekcji znaków i prawidłowym ich
rozpoznawaniem.
1.2 Budowa pracy
Praca składa się z sześciu rozdziałów opisujących najważniejsze aspekty
przetwarzania obrazów i ich wykorzystanie w rozpoznawaniu obrazów. Uzupełnieniem pracy
jest rozdział siódmy oraz dodatek.
Rozdział pierwszy stanowi wstęp do pracy, gdzie omówiony jest cel pracy.
Rozdział drugi stanowi wprowadzenie do przetwarzania obrazów, omówione są w nim
między innymi przestrzenie barw, oraz podstawowe informacje o obrazach.
W rozdziale trzecim omówione są przekształcenia geometryczne, punktowe,
kontekstowe i morfologiczne. Wszystkie zostały poparte przykładami i opisane pod
względem ich wykorzystania w obróbce obrazów. Rozdział kończy się podstawami analizy
obrazu, między innymi poruszone zostały operacje segmentacji, współczynniki kształtu i
niezmienniki momentowe.
Rozdział czwarty rozpoczyna omówienie głównego tematu pracy, poruszone są w nim
zagadnienia obszarów zainteresowania i stosowane metody detekcji znaków. W pierwszej
części rozdziału przytoczone zostały sposoby detekcji znaków stosowane w innych pracach
naukowych w tej tematyce. Wprowadzony został także podział metod detekcji i szczegółowo
zaprezentowano metodę detekcji znaków w oparciu o analizę kształtu. Druga część rozdziału
to omówienie zastosowanego w pracy rozwiązania problemu detekcji.

Przenośny system detekcji i rozpoznawania znaków drogowych
2
Metody rozpoznawania znaków, a także towarzyszące im pojęcia i algorytmy zostały
zaprezentowane w rozdziale piątym. Wymienione zostały sposoby generowania wektorów
cech oraz realizacje klasyfikatorów. Rozdział kończy się propozycją budowy i zasady
działania modułu rozpoznawania znaków.
Szósty rozdział jest podsumowaniem pracy pod względem osiągniętych rezultatów i
uzyskanej skuteczności działania. Wyniki zostały zestawione z tymi otrzymywanymi w
innych pracach na ten temat.
W rozdziale siódmym omówione zostały algorytmy i rozwiązania zastosowane w
programie komputerowym. Pierwsza część tego rozdziału jest opisem interfejsu
użytkownika, w drugiej przytoczone zostały główne części programu.
Jako dodatek do pracy zostały przeanalizowane wybrane współczynniki kształtu oraz
niezmienniki momentowe stosowane w określaniu kształtu figur geometrycznych.

Przenośny system detekcji i rozpoznawania znaków drogowych
3
2.Wprowadzenie do świata obrazów
W tej pracy pod pojęciem obrazu będzie rozumiany zbiór liczb uszeregowanych do
postaci dwu lub trzy wymiarowej macierzy. Zbiór ten będzie najczęściej cyfrową
reprezentacją obrazu w sensie pewnej scenerii. Za pomocą odpowiednich narzędzi możliwe
będzie odtworzenie tej scenerii i wyświetlenie na ekranie komputera. Obrazy- sceny należy
oczywiście w pierwszej kolejności wprowadzić do świata cyfrowego i przekształcić do
wymaganej postaci macierzowej. Służy do tego wiele rodzajów przetworników,
najpopularniejszymi są matryce optoelektroniczne CCD stosowane w kamerach i aparatach
fotograficznych. Z przekształceniem takim wiąże się wiele aspektów technicznych, spośród
których należy wymienić:
Rozdzielczość bitowa i sposób reprezentacji. Sposób reprezentacji mówi o zdolności
matrycy do wytwarzania obrazów kolorowych (trójwymiarowa macierz) lub
monochromatycznych (macierze dwuwymiarowe). Rozdzielczość bitowa natomiast
mówi jak dokładnie urządzenie jest w stanie reprezentować rzeczywiste kolory sceny,
którą ”obserwuje”.
Rozdzielczość przestrzenna. W aparacie fotograficznym lub kamerze pewna
obserwowana przestrzeń przeskalowana przez zbiór soczewek pada na jeden element
światłoczuły matrycy CCD. Ważne jest więc jak duży obszar przestrzeni jest
reprezentowany przez jeden piksel obrazu. Parametr zdefiniowany w celu
ilościowego opisu tego faktu, to stosunek całkowitej powierzchni matrycy, do ilości
komórek jaką zawiera, a nazywany jest rozdzielczością przestrzenna. Najczęściej im
większa rozdzielczość przestrzenną (większa liczba pikseli przetwornika), tym
mniejszy obszar oddziałuje na jeden piksel i reprezentacja w świecie cyfrowym jest
dokładniejsza.
Rozdzielczość czasowa. Parametr ten mówi jak często odświeżany jest obraz, tzn. jak
często następuje aktualizacja danych. Zbyt częste odświeżanie wiąże się z natłokiem
informacji przekazywanych do dalszych urządzeń z którymi matryca współpracuje.
Zbyt rzadkie odświeżanie powoduje utratę płynności obserwowanego obrazu i w
skrajnych przypadkach wiąże się z niemożliwością prawidłowego odtworzenia sceny.
O metodach pozyskiwania obrazów można dowiedzieć się więcej z [1] oraz [3].
2.1 Przestrzenie barw
Postrzegany przez człowieka kolor związany jest z długością fali padającego światła.
Żeby rozpoznać i zapisać ten kolor w postaci danych cyfrowych konieczne jest jego rozbicie
na kilka składowych i zmierzenie ich natężenia. Najczęściej stosowanymi składowymi są
kolory czerwony, zielony i niebieski. Oznacza to, że pojedynczy obraz kolorowy to w istocie
trzy obrazy monochromatyczne dla tych trzech składowych. Mogą one być przekazywane do
dalszego przetwarzania bezpośrednio lub po przekształceniu. Ze sposobem reprezentacji
koloru wiąże się tzw. przestrzeń barw czyli forma w jakiej informacja o kolorze jest
przekazywana. Do najpowszechniejszych przestrzeni barw należą:
RGB (ang. „Red Green Blue”) Informacja o kolorze jest przekazywana bezpośrednio.
Trzema składowymi są czerwony zielony i niebieski. Model ten jest stosowany
najczęściej w monitorach komputerów oraz różnego rodzaju wyświetlaczach. Jest on
zależny od urządzenia (ang. „device dependent”), co oznacza, że ta sama barwa może

Przenośny system detekcji i rozpoznawania znaków drogowych
4
nieco inaczej wyglądać na różnych urządzeniach. Do zapisu najczęściej jest używany
format 24 bitowy, co oznacza, że każdy kolor ma 256 poziomów intensywności.
Rys. 2.1 Przestrzeń RGB [33]
CMYK (ang. „Cyan Magenta Yellow blacK”) Istotą uzyskiwania kolorów w
przestrzeni CMYK jest filtrowanie światła białego i obserwowanie wyników tej
filtracji.. Naniesienie trzech filtrów składowych CMY daje w efekcie filtr tłumiący
wszystkie długości fali, a więc kolor czarny. Jednakże takie rozwiązanie byłoby
marnotrawstwem i do przestrzeni została dołożona jeszcze jedna składowa- czarny.
Kolor biały jest w istocie brakiem filtru. Przestrzeń ta wykorzystywana jest w
poligrafii i drukarkach komputerowych.
Rys. 2.2 Przestrzeń CMYK [33]
HSV (ang. „Hue”„Saturation”„Value”) Jest transformatą przestrzeni RGB do postaci
biegunowej, która jest łatwiejsza w obróbce komputerowej.
Rys. 2.3 Przestrzeń HSV [33]

Przenośny system detekcji i rozpoznawania znaków drogowych
5
Składowa „Hue” odpowiada za barwę światła z koła barw i jest wyrażana, jako kąt w
zakresie 0-3600 składowa „Value” mówi o intensywności światła białego, natomiast
„Saturation” o intensywności barwy. W modelu tym, żeby przykładowo rozjaśnić
kolor wystarczy zmienić tylko składową V, podobnie żeby zmienić intensywność
koloru wystarczy zmienić składową S. Modelem bardzo podobnym do HSV jest
model HSL (ang. „Hue” „Saturation” „Lightness”) i różni się on tym, że L=1
zapewnia światło białe niezależnie od wartości S.
YUV model ten był używany podczas wymiany telewizorów czarno-białych na
kolorowe. Składowa Y odpowiadająca za luminancje określa odcień szarości,
składowe U i V to różnice pomiędzy odpowiednio kolorem niebieskim a luminancją
oraz kolorem czerwonym a luminancja. Telewizory czarnobiałe odbierały tylko
sygnał Y, kolorowe natomiast na podstawie wszystkich trzech składowych odtwarzały
przestrzeń RBG.
CIEXYZ model ten jest wyjściowym do modeli CIELUV oraz CIELab i został
opracowany przez Międzynarodową Komisję Oświetleniową. Model ten zbudowany
dla najlepszego modelowania ludzkiego oka uwzględnia tzw. sprawności wizualne.
Przestrzeń ta jest najobszerniejsza tzn. umożliwia zapisanie największej ilości
kolorów.
Z punktu widzenia nimniejszej pracy najistotniejszymi przestrzeniami barw są RGB i HSV
gdyż za ich pomocą można w prosty sposób wyznaczać obszary, w których
najprawdopodobniej znajdują sie znaki drogowe. Będą to obszary o określonych wartościach
składowych R, G i B czy H, S i V.
2.2 Reprezentacja obrazów
Obrazy w pamięci komputera mogą być przechowywane w dwojaki sposób, w tzw.
postaci wektorowej lub rastrowej. Sposób reprezentacji zależy od źródła pochodzenia obrazu
i ewentualnych operacji, jakie zostały na nim przeprowadzone.
Grafika wektorowa to w istocie zbiór pewnych równań które opisują pojedyncze
elementy obrazu. Równanie takie zapisane jest w postaci współcznników i zebrane w jeden
element –wektor. Z każdym takim równaniem związany jest kolor obiektu jego wielkość i
położenie. Programy przetwarzające takie obrazy w istocie wyznaczają rozwiązania tych
równań i na ich podstawie tworzą prezentowaną grafikę- obliczają wartości kolorów
poszczególnych pikseli. Edytowanie obrazu polega na zmianie współczynników w wektorze.
Zaletą tego rodzaju obrazów jest niezależność dokładności od rozmiarów obrazu, dowolne
przeskalowanie nie powoduje utraty wyrazistości i ilości przedstawionych szczegółów.
Przykładami takich obrazów są Cliparty z pakietu programów Microsoft Office.
Grafika rastrowa jest zapisaniem wartości każdego piksela obrazu w nośniku danych.
Grafiką taką są wszelakiego rodzaju zdjęcia i filmy i jest ona nieodporna na skalowanie i
wszelkie transormacje. Oznacza to, że zmiana rozmiarów obrazu wiąże się z utratą części
danych, a co za tym idzie dokładności obrazu. W nimniejszej pracy stosowany będzie tylko
ten sposób zapisu obrazów.

Przenośny system detekcji i rozpoznawania znaków drogowych
6
Ze sposobem zapisu grafiki rastrowej w nośnikach danych związany jest tzw. format
zapisu. Obrazy mogą zostać zapisane w sposób bezpośredni tj. zapisana jest wartość każdego
piksela obrazu bez jakiejkolwiek ich obróbki i wtedy format to mapa bitowa (ang. „bitmap”).
Obraz zapisany w ten sposób zajmuje najwięcej miejsca w pamięci komputera. Możliwe jest
także zapisanie obrazów w postaci przetworzonej. Transformacje mają najczęściej na celu
zmniejszenie ilości niezbędnego miejsca w pamięci potrzebnego na przechowanie takiego
obrazu. Rozróżniane są przy tym dwa rodzaje kompresji, stratna i bezstratna. Kompresja
stratna, to taka w której tracona jest pewna część informacji, a więc dokładność obrazu,
najpopularniejszym formatem tego rodzaju przekształcenia jest JPEG. Kompresja bezstratna
oznacza, że obraz nie traci szczegółów a mimo to zajmuje mniej miejsca niż mapa bitowa.
Najpopularniejszymi formatami tej kompresji są TIFF oraz PNG.
W tej pracy wykorzystywano obrazy zapisane w formacie JPEG.

Przenośny system detekcji i rozpoznawania znaków drogowych
7
3.Przekształcenia i analiza obrazazów
Obraz można traktować jako macierz z zapisanymi w niej liczbami określającymi
intensywność barwy każdego punktu. Macierze te można poddać przekształceniom
matematycznym, spośród których w tym rozdziale zostanie przedstawionych kilka
podstawowych. Szczegółowe informacje na temat przekształceń obrazów wraz ze
stosownymi wzorami mogą być znalezione w [1]. Do podstawowych przekształceń na
obrazach zalicza się przekształcenia:
geometryczne
punktowe
kontekstowe
morfologiczne
widmowe czyli wszystkie przekształcenia w dziedzinie częstotliwości
wykorzystujące zarówno transformatę Fouriera, jak i Falkową. Przekształcenia te
jako jedyne nie będą omawiane w tej pracy. Bardzo przystępne informacje na temat
obu transformat można znaleźć w [2].
W kolejnych podrozdziałach w sposób skrótowy są opisane podstawowe z czterech
wymienionych powyżej przekształceń.
3.1 Przekształcenia geometryczne
Przekształcenia geometryczne, to przekształcenia polegające na obrotach, zmianach
rozmiarów, miejscowych zmianach skali itp. Są one wykorzystywane w systemach akwizycji
obrazów (kamerach, skanerach itp.) do korekcji błędów powstałych przez nieidealne układy
optyczne tych urządzeń. Ponadto są czasem niezbędne jako początkowe transformacje w
wizyjnych systemach pomiarowych. Poniżej przedstawiono kilka takich przekształceń.
Rys. 3.1 Obrót

Przenośny system detekcji i rozpoznawania znaków drogowych
8
Rys. 3.2 Zmiana rozmiarów
Rys.3.3 Lokalna zmiana skali
(od lewej: oryginał, zmiana skali osi Y, zmiana skali osi X i Y)
Przekształcenia te są proste w realizacji i nie wymagają opisu, większość programów
do obróbki graficznej oraz języków programowania posiada niezbędne biblioteki do
wykonania takich zmian. Przekształcenia te wymagają przeliczenia wartości każdego punktu
w obrazie. Realizuje się to najczęściej metodą aproksymacji liniowej na podstawie sąsiednich
punktów. Teoretycznie możliwe jest przywrócenie pierwotnego obrazu, jednakże
transformata taka wiąże się z utratą części danych, a więc jej cofnięcie poskutkuje utratą
rozdzielczości.
3.2 Przekształcenia punktowe
Są to operacje wykonywane na pojedynczych punktach obrazu. Nie zmieniają one
rozmiarów czy skali obrazu, a jedynie stopień jasności, kontrast bądź w przypadku obrazów
kolorowych nasycenie barw. Najczęściej wykorzystywaną korekcją obrazu należącą do tej
grupy jest tzw. wyrównanie histogramu. Do tych przekształceń zaliczane są także łączenie
(sumowanie) dwu i więcej obrazów w jeden.
3.2.1 Histogram i wyrównanie histogramu
Pojęcie histogramu zostanie wyjaśnione w odniesieniu do obrazów
monochromatycznych (w skali szarości) gdyż będzie to bardziej przystępne i przejrzyste.
Stosowane poniżej sformułowania stopnia szarości i jasności należy rozumieć następująco.
Stopień szarości to nasycenie obrazu (punktu) kolorem czarnym, natomiast stopień jasności

Przenośny system detekcji i rozpoznawania znaków drogowych
9
to nasycenie kolorem białym. Większy stopień jasności to mniejszy stopień szarości i
odwrotnie.
Histogram– jest to najczęściej wykres słupkowy mówiący ile w obrazie jest punktów o
danym stopniu szarości w stosunku do liczby wszystkich punktów obrazu. Zliczania punktów
dokonuje się dla każdego poziomu jasności, czyli w przypadku obrazu wykorzystującego 8-
bitową reprezentacje dokonywanych jest 256 zliczeń.
Wyrównanie histogramu– Polega na takiej zmianie jasności pikseli obrazu, aby w
jednakowych zakresach histogramu liczba pikseli była zbliżona. Operację tę realizuje się na
podstawie dystrybuanty histogramu opisanej wzorem (3.1a)
(3.1a)
gdzie jest wartością histogramu dla i tego stopnia szarości, a N jest liczbą pikseli w
obrazie
Dystrybuanta określa ilość pikseli o stopniu jasności mniejszym lub równym i w
odniesieniu do liczby wszystkich pikseli obrazu N. Wyrównanie histogramu może być
opisane wzorem (3.1b)
(3.1b)
gdzie to pierwsza niezerowa wartość dystrybuanty, k- liczba stopni szarości
Na rysunku 3.4 przedstawiony został obraz oryginalny wraz z histogramem po prawej
stronie. Na rysunku 3.5 przedstawiony jest ten sam obraz po wyrównaniu histogramu oraz
jego histogram po prawej.
Rys. 3.4 Obraz oryginalny i jego histogram

Przenośny system detekcji i rozpoznawania znaków drogowych
10
Rys.3.5 Obraz po wyrównaniu histogramu i jego histogram.
Porównując powyższe rysunki widać jak zmienia się obraz po wyrównaniu
histogramu i na czym ono polega. Widać znaczną poprawę dynamiki obrazu, chodź jest ona
okupiona większą ziarnistością obrazu. Efekt operacji w postaci histogramu jest bardziej
równomierny, a liczba pikseli w równych przedziałach jest do siebie zbliżona.
3.2.2 Korekcja gamma
Operacja ta zmienia kontrast obrazu poprzez modyfikację wartości jasności danego
piksela według poniższego wzoru:
(3.2a)
gdzie: –piksel wynikowy, –piksel źródłowy, γ- współczynnik korekcji
Obraz po korekcji musi zostać unormowany, i w przypadku stosowania 24 bitowego
zapisu obrazów kolorowych korekcja gamma z normalizacją może być opisana wzorem:
(3.2b)
Korekcja gamma jest operacją nieliniową, ale odwracalną, czyli istnieje możliwość
przywrócenia oryginalnego wyglądu obrazu. W przypadku obrazów kolorowych teoretycznie
można dokonać korekcji każdego koloru składowego w przestrzeni RGB osobno i z inną
wartością współczynnika. W praktyce jednak stosuje się taki sam współczynnik do
wszystkich kolorów. Wynik korekcji gamma dla γ=1.5 przedstawia rysunek 3.6.

Przenośny system detekcji i rozpoznawania znaków drogowych
11
Rys. 3.6 Obraz oryginalny po lewej i po korekcji gamma po prawej.
Jak widać korekcja gamma może w znaczny sposób poprawić postrzeganą jakość
obrazu. Jest to druga po wyrównaniu histogramu podstawowa operacja wykorzystywana do
poprawy jakości obrazów. Praktyczna poprawa odbywa się dwuetapowo, w pierwszym kroku
dokonujemy wyrównania histogramu, w wyniku czego wykorzystany jest cały zakres
jasności. W drugim kroku dokonujemy korekcji gamma zmieniającej kontrast obrazu.
3.2.3 Binaryzacja
Operacja ta polega na utworzeniu na podstawie obrazu monochromatycznego lub
kolorowego obrazu binarnego. Obraz binarny to taki w którym wyróżniamy tylko dwa
skrajne poziomy szarości, czyli czarny lub biały, jest on więc zapisany z wykorzystaniem
jednobitowej reprezentacji punktu. Binaryzacji dokonuje się porównując jasność piksela z
pewną ustaloną dla całego obrazu wartością progową, lub lokalną wartością progową
obliczaną dla otoczenia analizowanego piksela w obrazie źródłowym. Jeżeli piksel jest
jaśniejszy to w obrazie binarnym w tym miejscu wstawiana jest „1” natomiast jeżeli jest
ciemniejszy to „0”. Globalną wartość progową można dobrać w sposób dowolny, w praktyce
jednak dobiera się ją na podstawie histogramu. Binaryzacja służy do wytwarzania tzw. masek
lub wydobywania pewnej informacji z obrazu. Poniżej został przytoczony przykład
zastosowania binaryzacji.
W przytoczonym przykładzie założono, że koniecznym jest wyznaczenie obszarów
pokrytych śniegiem. Dla ułatwienia proces ten został przeprowadzony dla obrazu
monochromatycznego. W pierwszej kolejności wyznaczony został histogram obrazu
przedstawiony na rysunku 3.7.
Na histogramie zaznaczone są kolorem czerwonym dwie wartości jasności, obie wyznaczają
progi binaryzacji. Próg zaznaczony kreską pionową jest wyznaczony według powszechnie
stosowanego algorytmu środka ciężkości. W podejściu tym próg binaryzacji jest obliczany
jako lokalne minimum rozgraniczające dwie równoliczne grupy. Oznacza to, że liczba pikseli
po lewej stronie progu jest równa liczbie pikseli po jego stronie prawej. Jest to metoda
dobierania progu bez uwzględnienia zawartości rysunku (tego co przedstawia). Drugi próg
oznaczony kropką wyznaczony jest w sposób analogiczny do pierwszego (jako wartość
pomiędzy dwoma skupiskami jasności) ale w tym przypadku nie jest zachowany warunek
równości liczby pikseli po obu jego stronach. Próg ten dobrany jest z uwzględnieniem
zawartości rysunku.
Pierwsza metoda jest łatwa do zaimplementowania w algorytmach samoczynnie
tworzących obrazy binarne, druga wymaga interwencji człowieka. Na rysunku 3.8

Przenośny system detekcji i rozpoznawania znaków drogowych
12
przedstawione są obrazy binarne wyznaczone obiema metodami. W przypadku stosowania
drugiej metody dokładność działania jest nieco lepsza- zaznaczony jest dach.
Rys. 3.7 Obraz wyjściowy i jego histogram
Rys.3.8 Obraz binarny wyznaczony pierwszą metodą po lewej i drugą metodą po prawej.
Przekształcenia punktowe stanowią bardzo liczną grupę. Przedstawione w pracy
przykłady są fundamentalnymi w tej grupie przekształceń. Pozostałymi często stosowanymi
metodami są łączenie dwóch obrazów, dodawanie stałej do obrazu itp.
3.3 Przekształcenia kontekstowe
Przekształcenia kontekstowe, to takie które zmieniają jasność piksela w zależności od
jego dotychczasowej wartości ale także z uwzględnieniem jasności sąsiednich pikseli. Pod

Przenośny system detekcji i rozpoznawania znaków drogowych
13
pojęciem przekształceń kontekstowych głównie kryje się różnego rodzaju filtracja obrazów.
W kolejnych podrozdziałach przytoczone są podstawy filtracji oraz dwa najpopularniejsze
typy filtrów dolno i górnoprzepustowy.
3.3.1. Splot
Splot dwu funkcji może być opisany następującym wzorem:
(3.3)
gdzie y(t) jest wynikiem splotu, x( jest funkcją splataną, a h(t-τ) funkcją splatającą, bądź
inaczej h(t-τ) to odpowiedź impulsowa filtru, natomiast x(τ) to sygnał filtrowany.
W jednowymiarowej dziedzinie dyskretnej splot można przedstawić równaniem 3.4.
(3.4)
Graficzna interpretacja wzoru 3.4 może być przedstawiona jak na rysunku 3.9, gdzie
h(0), h(1) i h(2) to współczynniki filtru, x(i) to kolejne dane źródłowe, a y(i) to wynik
działania funkcji splatającej.
Rys. 3.9 Splot w dziedzinie dyskretnej
Ważnym czynnikiem jest numeracja współczynników filtru i kolejnych próbek
sygnału wejściowego. Pierwszy współczynnik filtru h(0) jest zawsze mnożony przez
najnowszą próbkę sygnału, drugi współczynnik filtru przez poprzednia itd. Zsumowany
wynik mnożeń stanowi najnowszą próbkę sygnału wyjściowego.
W przypadku obrazów sygnał wejściowy i wyjściowy są dwuwymiarowe, a więc i filtr
musi być dwuwymiarowy1. Splot w dwuwymiarowej przestrzeni dyskretnej może być
opisany wzorem 3.5
(3.5)
1 Istnieje możliwość filtrowania obrazów filtrami jednowymiarowymi. Zagadnienie opisane w [2]

Przenośny system detekcji i rozpoznawania znaków drogowych
14
W filtrach 2-D element dla którego realizowana jest w danej chwili filtracja znajduje
się w środku filtru- czerwony kwadrat na rysunku 3.10. Filtr natomiast zbudowany jest wokół
tego elementu – żółty kwadrat. Tym samym naturalnym wydaje się stosowanie filtrów o
nieparzystej liczbie kolumn i wierszy.
Przedstawione we wzorze 3.5 sumowanie przebiega w zakresie od minus do plus
nieskończoności. W praktyce jednak filtracja realizowana jest w zakresie obrazu, żaden
współczynnik filtru nie wystaje poza obszar obrazu. Obraz po filtracji jest więc w sposób
naturalny mniejszy od obrazu źródłowego. Uzyskanie obrazu o takich samych rozmiarach
realizowane jest na kilka sposobów. Możliwe jest poszerzenie obrazu źródłowego o
wymaganą rozmiarem filtru ilość pikseli brzegowych, lub poszerzenie wyniku.
Rys. 3.10 Filtracja 2-D
Problem filtrowania próbek brzegowych oraz powód stosowania i realizacja
stałoprzecinkowych współczynników filtru jest omówiony w [1], natomiast szczegółowe
informacje o filtrowaniu 1-D i 2-D jak również projektowanie filtrów zawarte są w [2]. W
przypadku prostego przetwarzania obrazów stosuje się filtry 9-cio elementowe (3×3) oraz 25-
cio elementowe (5×5) gdyż dają one zadowalające wyniki i nie wymagają zbyt dużej liczby
obliczeń do wyznaczenia pojedynczej próbki sygnału.
3.3.2 Filtry 2-D
Podobnie jak w przypadku filtrów jednowymiarowych filtry dwuwymiarowe dzielimy
ze względu ułożenie pasma przepustowego na:
dolnoprzepustowe
górnoprzepustowe- gradienty
specjalne- medianowe, nieliniowe i inne
Pojęcie częstotliwości w obrazach wiąże się ze zmianami poziomów szarości w
obrazie. Obszar w którym występuje częsta zmiana poziomu jasności zawiera w dużej części
składowe wysokoczęstotliwościowe. Natomiast obszar który przedstawia jednorodne duże
powierzchnie zawiera głównie składowe niskoczęstotliwościowe. W przedstawionym na
rysunku 3.11 obrazie składowe niskie częstotliwości będą związane z dachem chatki oraz
łąką przed chatką. Wysokie częstotliwości będą natomiast skojarzone z obszarem lasu.

Przenośny system detekcji i rozpoznawania znaków drogowych
15
3.3.2.1 Filtry dolnoprzepustowe:
Rys.3.11 Obraz po filtracji filtrem uśredniającym 3×3
Rys. 3.12 Obraz po filtracji filtrem uśredniającym 5×5

Przenośny system detekcji i rozpoznawania znaków drogowych
16
Rys. 3.13 Filtr uśredniający 5×5 oraz 3×3
Filtry uśredniające są najprostszą odmianą filtrów dolnoprzepustowych, zastosowanie
takiego filtru powoduje, że analizowany piksel przyjmuje wartość średnią spośród jego
sąsiadów. Innym bardzo popularnym filtrem dolnoprzepustowym jest filtr Gausa który
zazwyczaj mniej degraduje obraz niż filtr uśredniający. Przykładowy filtr Gausa oraz efekt
jego działania jest przedstawiony na rysunku 3.14
Rys 3.14 Obraz oryginalny po lewej oraz po filtracji filtrem Gaussa
3.3.2.2 Filtry górnoprzepustowe
Filtry górnoprzepustowe znalazły szczególne zastosowanie jako metoda wydobywania
krawędzi z obrazu. Rozróżniane są dwa sposoby wydobywania krawędzi gradienty i
laplasjany. Oba sprowadzają się do wyznaczenia odpowiednich współczynników filtrów.
Wyprowadzenia stosownych wzorów i uzasadnienie podaje [1]. Ponadto filtry tego typu
mogą wydobywać z obrazu kontury kierunkowe tzn. wzdłuż zadanej osi lub ogólne- bez
wyróżnionego kierunku. Poniżej przedstawione są przykładowe filtry wraz z wynikami ich
działania.

Przenośny system detekcji i rozpoznawania znaków drogowych
17
Rys. 3.15 Wynik działania filtru Prewitt-a w kierunku horyzontalnym i jego maski
Rys. 3.16 Wynik działania filtru Sobela w kierunku horyzontalnym i jego maski

Przenośny system detekcji i rozpoznawania znaków drogowych
18
Rys. 3.17 Wynik działania gradientu Robertsa oraz jego maski
Wszystkie przytoczone filtry były kierunkowymi tzn. wykrywały krawędzie w
zadanym kierunku. Takie filtry są przydatne wszędzie tam, gdzie poszukiwane obiekty są
zbudowane z odcinków liniowych. Przykładem takich obiektów mogą być linie rozdzielające
pasy na jezdni, pasy dla pieszych itd. Jeżeli natomiast poszukiwane obiektów nie mają
zadanego kierunku to ich krawędzie można wyznaczyć w oparciu o powyższe maski sumując
wyniki dla kierunków poziomego i pionowego. Sumowanie to można zrealizować na kilka
sposobów, dwa najważniejsze sposoby to sumowanie modułów lub wykorzystanie metryki
Euklidesowej. Powstały w ten sposób filtr jest nieliniowy. Rysunek 3.15 przedstawia obraz
konturowy będący wynikiem filtracji liniowej w kierunku horyzontalnym. Rysunki 3.16 i
3.17 przedstawiają obrazy konturowe będące wynikiem filtracji nieliniowej. Innym sposobem
znajdowania krawędzi bez uwzględniania kierunku są laplasjany przykład działania takiego
filtru przedstawiony jest na rysunku 3.18.

Przenośny system detekcji i rozpoznawania znaków drogowych
19
Rys. 3.18 Wynik działania Laplasjanu oraz jego maska.
Prócz zaprezentowanych podstawowych filtrów dolno i górno przepustowych, ważną
grupą są tzw. filtry medianowe. (w uporządkowanym rosnąco ciągu liczb mediana jest
wartością środkową). Działają one podobnie do filtrów uśredniających, z tą różnicą, że do
obliczenia wartości piksela on sam nie jest brany pod uwagę. Obliczana jest mediana ze
wszystkich pikseli z wyjątkiem środkowego, następnie jest ona porównywana z wartością
środkowego piksela (dla którego jest obliczany wynik). Jeżeli wartość środkowego piksela
odbiega znacząco od obliczonej mediany, to wartość tego piksela jest zamieniana na wartość
mediany. Jeżeli wartości środkowa i mediana są zbliżone to piksel ten pozostaje
niezmieniony. Filtry medianowe, mają tą przewagę na uśredniającymi, że nie rozmywają
krawędzi obrazu, bardzo skutecznie natomiast usuwają z niego różnego rodzaju artefakty.
Wynik działania filtru medianowego przedstawiony jest na rysunku 3.19
Rys.3.19 Obraz zakłócony po lewej i wynik filtracji medianowej tego obrazu po prawej

Przenośny system detekcji i rozpoznawania znaków drogowych
20
Do filtrów nieliniowych należą także filtry minimalne i maksymalne w których
analizowany piksel przyjmuje wartość maksymalną lub minimalną ze swojego otoczenia.
Istnieją także filtry specjalizowane do indywidualnych przypadków i potrzeb. Filtry te na
ogół nie podpadają pod żadne kryteria, a ich charakterystyka częstotliwościowa jest na ogół
dość skomplikowana. Nie sposób więc przytoczyć tu jakiekolwiek uogólnione przykłady. Z
uwagi na ogólny charakter pracy interesującym filtrem jest filtr poprawiający ostrość obrazu
rejestrowanego przez kamerę umieszczoną w samochodzie. Filtr taki można byłoby
sklasyfikować jako szczególny przypadek filtru górnoprzepustowego.
3.4 Przekształcenia morfologiczne
Przekształcenia morfologiczne są podstawowymi przekształceniami stosowanymi w
przetwarzaniu i analizie obrazów. Pozwalają one na modyfikacje kształtu obiektów w obrazie
celem ustalenia relacji pomiędzy nimi. Podstawą przekształceń morfologicznych jest tzw.
element strukturalny, czyli ruchoma macierz przemieszczająca się po pikselach obrazu.
Element ten może przyjmować w zasadzie dowolny kształt (w macierzy elementy nienależące
do kształtu mają wartość zerową) oraz dowolną wielkość. Od jego kształtu i rozmiarów
zależeć będą właściwości operacji morfologicznych oraz wynik ich przeprowadzenia. W
praktyce najczęściej stosuje się z elementy strukturalne kwadratowe o wymiarach 3×3, 5×5,
7×7 itd.
Przekształcenia morfologiczne polegają w ogólności na przesuwaniu po obrazie
elementu strukturalnego i porównaniu go z pikselami w obrazie, a następnie wykonaniu
prostych operacji zależnych od wyniku tego porównania. Tak jak w przypadku filtrów,
wszelakie zmiany w obrazie dokonywane są tylko dla piksela odpowiadającego środkowemu
składnikowi elementu strukturalnego. Przekształcenie morfologiczne różnią się zasadniczo od
wszystkich dotychczas przedstawionych przekształceń, gdyż w zależności od wyniku
porównania elementu strukturalnego z obrazem odpowiedni piksel może być zmieniony lub
nie. W operacjach morfologicznych możliwa jest realizacja jednego z dwóch scenariuszy w
zależności od wyniku porównania. Tak duże możliwości okupione są jednak złożonością
obliczeniową i koniecznością stosowania jednostek o dużej mocy obliczeniowej. Operacje
morfologiczne przeprowadza się najczęściej na obrazach binarnych na których przedstawione
są pewne obiekty. Operacja najczęściej odnosi się do tych obiektów i ma je ukształtować w
pożądany sposób.
3.4.1 Erozja
Erozja jest operacją, która przeprowadzona na obiekcie spowoduje, że zostanie
wygładzony jego brzeg. Wszystkie artefakty wystające poza obrys główny obiektu zostaną
usunięte. Wielkości elementów usuwanych zależą od rozmiarów elementu strukturalnego.
Poniżej przytoczona jest jedna z wielu definicji erozji.
Przyjmijmy, że istnieje pewna figura X i element strukturalny E
o środku w punkcie centralnym tego elementu. Erozją figury X
elementem strukturalnym E jest zbiór wszystkich punktów centralnych
elementów E, które w całości mieszczą się we wnętrzu figury X.

Przenośny system detekcji i rozpoznawania znaków drogowych
21
Wynikiem erozji jest zawsze figura o mniejszej powierzchni (w sensie ilości pikseli)
niż figura wyjściowa. Najprostszym elementem strukturalnym erozji jest macierz samych
jedynek. Przykładową erozję przedstawia poniższy rysunek.
Rys. 3.19 Figura wyjściowa po lewej, w środku figura po jednej erozji elementem
strukturalnym 3×3, z prawej figura po wykonaniu pięciu erozjach tym samym elementem
Erozję można traktować jako filtr minimalny tj. taki, który każdemu elementowi
przypisuje wartość minimalną z jego otoczenia. Otoczenie jest zdefiniowane przez wielkość
elementu strukturalnego. Takie podejście pozwala na realizację tego przekształcenia dla
obrazów monochromatycznych i kolorowych. W przypadku tych ostatni należy wykonać
niezależnie erozje dla każdej składowej w przestrzeni RGB.
Podstawowymi własnościami erozji są:
generalizacja obszarów poprzez usuwanie drobnych wypustek
usuwanie pojedynczych odizolowanych obszarów
zmniejszanie powierzchni
erozja podłużnym elementem strukturalnym wydobywa z obrazu fragmenty o
zgodnym kierunku.
3.4.2 Dylatacja
Dylatacja jest przekształceniem odwrotnym do erozji, które w ogólności można
zdefiniować w następujący sposób:
Przyjmijmy, że istnieje figura X i element strukturalny E o środku
w punkcie centralnym tego elementu. Dylatacją figury X elementem
E jest zbiór wszystkich środków elementów E, których chociaż
jeden punkt należy do figury X.
Wynikiem dylatacji jest zawsze figura większa w sensie ilości pikseli, niż figura
początkowa. Elementem strukturalnym w tej operacji jest macierz składająca się z samych
jedynek. Efekt dylatacji elementem o rozmiarach 3×3 jest przedstawiony na poniższym
rysunku.

Przenośny system detekcji i rozpoznawania znaków drogowych
22
Rys. 3.20 Obraz oryginalny po lewej, po wykonaniu pojedynczej dylatacji
w środku i po wykonaniu pięciu dylatacji po prawej.
Dylatację przez analogię do erozji można traktować jako filtr maksymalny, tj. taki,
który każdemu elementowi przypisuje wartość maksymalną z jego otoczenia. Wielkość
otoczenia zależy od rozmiarów elementu strukturalnego. Dylatację tak samo jak erozję można
w tym kontekście stosować do obrazów monochromatycznych i kolorowych.
Podstawowymi własnościami dylatacji są:
— usuwanie z figury wąskich wcięć i zamykanie małych (w porównaniu z elementem
strukturalnym) zatok
— uwypuklanie drobnych odizolowanych obszarów
—zwiększanie powierzchni
— łącznie bliskich obszarów w jeden
Istnieje pewna odmiana dylatacji zwana dylatacją bez stykania krawędzi (ang. „SKeleton by
Influence Zone”) która zapewnia, że dwa sąsiadujące ze sobą obszary nie zostaną połączone
w jeden. Dylatacja ta będzie podana w tzw. Alfabecie Golay’a na końcu tego rozdziału.
3.4.3 Otwarcie i zamknięcie
Operacje otwarcia i zamknięcia składają się z dwu powyższych przekształceń.
Otwarcie to w pierwszej kolejności erozja, a następnie dylatacja. Zamknięcie odwrotnie, czyli
w najpierw dylatacja, a następnie erozja obrazu. Obie operacje niezmienianą znacząco
rozmiarów i kształtu figury (pod warunkiem, że są wykonane tym samym elementem
strukturalnym), usuwają z niego natomiast pewne zniekształcenia powierzchni. Otwarcie
niweluje drobne wypustki wystające poza główne ciało figury, zamknięcie natomiast
eliminuje wcięcia w figurze. Właściwości te, wynikają z własności pierwszej operacji w obu
przekształceniach. Drugie przekształcenie ma zazwyczaj na celu zniwelować zmianę
powierzchni i kształtu figury jaka wiąże się z wykonaniem pierwszej operacji. Na poniższym
rysunku przedstawione są wyniki obu przekształceń.

Przenośny system detekcji i rozpoznawania znaków drogowych
23
Rys. 3.21 Wynik operacji otwarcia po lewej i zamknięcia po prawej elementem strukturalnym
o rozmiarze 3×3
3.4.4 Detekcja ekstremów: Top-hat, Bottom-hat
Wśród operacji morfologicznych istnieją dwa przekształcenia wykrywające ekstrema
obiektów czyli jego „ostre końce”. Czubek kapelusza (Top-hat) jest operacją wykrywającą
ekstrema „wystające” poza obszar główny figury. Przekształcenie to polega na wykonaniu
otwarcia figury, a następnie odjęciu obrazu początkowego i przeprowadzeniu binaryzacji.
Spód kapelusza (Bottom-hat) jest operacją znajdowania ekstremów wewnętrznych obszarów.
Dokonuje się tego przeprowadzając binaryzację różnicy pomiędzy obrazem poddanym
zamknięciu i oryginalnym.
Rys. 3.22 Wyniki operacji Top-hat po lewej i Bottom-hat po prawej
Operacja otwarcia kapelusza daje podobny rezultat to wykrywania krawędzi przy
użyciu laplasjanu. W tym przypadku wynik jest jednak silnie zależny od wybranego elementu
strukturalnego (jego kształtu i rozmiarów) a także od progu binaryzacji. Poniższy rysunek
przedstawia wynik operacji Top-hat elementem strukturalnym (macierz składająca się z
samych jedynek) o wymiarach 3×3 i laplasjanu.

Przenośny system detekcji i rozpoznawania znaków drogowych
24
Rys. 3.23 Wynik operacji Top-hat po lewej i laplasjanu po prawej.
3.4.5 Ścienianie i pogrubianie
Ścienianie jest operacją wykrywającą kontury obszarów. Polega ono na porównaniu
pikseli obrazu z elementem strukturalnym. Jeżeli układ pikseli jest zgodny, to pozostawiamy
obraz bez zmian. Jeżeli natomiast piksele obrazu nie zgadają się ze wzorcem zapisanym w
elemencie strukturalnym to piksel obrazu odpowiadający elementowi środkowemu
zmieniamy na „0”. W ścienianiu używane są elementy strukturalne przedstawione na rysunku
3.24, chociaż w praktyce stosuje się także wiele innych.
Rys. 3.24 Elementy strukturalne używane w operacji ścieniania
Operację ścieniania wykonuje się iteracyjnie, co oznacza, że rezultat poprzedniej
operacji jest obrazem źródłowym dla następnej. Pętla jest przerywana gdy obraz wynikowy
jest taki sam jak źródłowy. Rysunek 3.25 przedstawia wynik działania ścieniania.

Przenośny system detekcji i rozpoznawania znaków drogowych
25
Rys. 3.25 Wynik ścieniania
Podobnie jak w przypadku erozji i dylatacji, także ścienianie ma operację odwrotną w
postaci pogrubiania. Operacją pogrubiania polega na porównaniu pikseli obrazu ze wzorcem
zapisanym w elemencie strukturalnym i na podstawie tego porównania wykonaniu jednej z
dwu czynności. Jeżeli układ pikseli jest zgodny, to piksel obrazu odpowiadający środkowi
elementu strukturalnego jest zmieniany na „1”, jeżeli zgodności nie ma to pozostawiamy on
jest bez zmian. Elementy strukturalne używane przy pogrubianiu to między innymi te
przedstawione na rysunku 3.26.
Rys. 3.26 Elementy strukturalne pogrubiania.
W celu otrzymania spodziewanych wyników operacje morfologiczne należy przeprowadzać
jednakowo dla każdego brzegu figury. Żeby zrobić to prawidłowo należy czterokrotnie
przeprowadzić jedną operacje, za każdym razem z elementem strukturalnym „dopasowanym”
do odpowiedniego brzegu. Dlatego też elementami strukturalnymi w wielu przekształceniach
morfologicznych jest jedna (bądź kilka zdecydowanie różnych) macierz, obracana o 900 przy
realizowaniu operacji danego brzegu.
3.4.6 Szkieletyzacja i obcinanie gałęzi
Szkieletem figury jest najmniejszy zbiór punktów, które w pełni opisują jej kształt i
właściwości. Graficznie jest to zbiór punktów równoodległych od brzegów figury.
Szkieletyzację wykonuje się jako ścienianie elementem strukturalnym o następującym
wzorcu:

Przenośny system detekcji i rozpoznawania znaków drogowych
26
Rys.3.27 Element strukturalny szkieletyzacji.
Obraz oryginalny i jego szkielet przedstawione są na rysunku 3.28:
Rys. 3.28 Obraz oryginalny i jego szkielet.
W większości przypadków obraz szkieletowy posiada gałęzie pochodzące z różnego
rodzaju zakłóceń obrazu oryginalnego. Litery powyższego obrazu zostały celowo zakłócone,
żeby pokazać jak wyglądają gałęzie i jakie zniekształcenia je generują. Najsłabiej zakłócona
została litera „G” jednakże charakter tych zakłóceń jest najbardziej uciążliwy, dlatego też
szkielet tej litery jest skomplikowany. Można by było uniknąć tego rodzaju zakłóceń stosując
przed szkieletyzacją operację zamknięcia (w przypadku litery „G”) oraz otwarcia (w
przypadku litery „A”). Litera „H” jest zakłócona w nieco inny sposób niż dwie poprzednie, i
tutaj zamknięcie i otwarcie nie zniweluje powstałych „gałęzi” i trzeba je usunąć ze szkieletu.
Służy do tego operacja usuwania gałęzi, która podobnie jak szkieletyzacja jest w zasadzie
operacją ścieniania, ze specjalnie do tego przeznaczonym elementem strukturalnym.
Obcinanie gałęzi jest realizowane w pętli której liczba iteracji zależna jest od użytkownika.
Rys. 3.29 Szkielet bezpośrednio po operacji szkieletyzacji po lewej, oraz po obcinaniu gałęzi
wykonanemu 30-to krotnie po prawej.
W przypadku obrazu przedstawionego na rysunku 3.29 przed dkonaniem operacji
szkieletyzacji zrealizowana została operacji zamknięcia i otwarcia elementem strukturalnym
o wymiarach 3×3 piksele. Operacje te pomogły w sposób znaczący (szczególnie zamknięcie)
i szkielety są dużo mniej skomplikowane.

Przenośny system detekcji i rozpoznawania znaków drogowych
27
3.4.7 Trafi- nie trafi
Przekształcenie trafi nie trafi jest najprostszym ze wszystkich dotychczas
przedstawionych przekształceń i jest też najbardziej uniwersalnym narzędziem. Polega ono,
jak wszystkie operacje morfologiczne, na porównaniu obrazu z elementem strukturalnym.
Jeżeli wynik tego porównania jest pozytywny (obszary są zgodne) to piksel wskazywany
przez środek elementu strukturalnego jest zmieniany na „1”, jeżeli wynik porównania jest
negatywny, to odpowiedni piksel otrzymuje wartość „0”. Odpowiednio dobrany element
strukturalny może zmienić tą operację w erozję, dylatację itd.
Przedstawione powyżej operacje morfologiczne są podstawowymi, a wyniki tych
operacji w dużym stopniu zależą od elementu strukturalnego, jego wielkości i wzorca w nim
zapisanego. Przy podawaniu definicji przekształceń morfologicznych, istotnym czynnikiem
jest położenie środka elementu strukturalnego. W praktyce, jeżeli nie znajduje się on w
punkcie centralnym, to obraz wynikowy jest przesunięty względem wyjściowego o
odpowiedni wektor. Wynik operacji może się w tym przypadku różnić od oczekiwanego.
W celu uszeregowania operacji morfologicznych i określeniu wyników jakie dzięki
nim można uzyskać, zestawia się je w tabeli. Tabela ta w literaturze powszechnie znana jest
pod nazwą „Alfabet Golay’a” i jest przedstawiona poniżej. Tabela ta w całości pochodzi
z [1]
Tab. 3.1 Alfabet Golay’a
Symbol Element strukturalny Ścienianie Pogrubianie Trafi- nie trafi
C
Wypukłe
otoczenie
D
Marker lub
centroid
Przybliżenie
wypukłego
otoczenia
E
Obcinanie
gałęzi
SIKZ (LC a
następnie EC)
Detekcja
punktów
końcowych
F
Detekcja
punktów
potrójnych
H
Detekcja
brzegu Erozja
I
Detekcja
odizolowanych
punktów
L
Szkieletyzacja SKIZ (L
C a
następnie EC)
M
Szkieletyzacja
Pogrubianie
izolowanych
punktów
R
Erozja
liniowa
Dylatacja
liniowa

Przenośny system detekcji i rozpoznawania znaków drogowych
28
3.5 Analiza obrazu
Analiza obrazu jest procesem polegającym w ogólności na wydobyciu z niego
informacji istotnych ze względu na realizowane zadanie. Informacje te mogą być zarówno
końcowym efektem całego procesu przetwarzania, jak również informacją pośrednią w
jednym z etapów procesu obróbki. Zazwyczaj ilość danych jaka powstaje (na podstawie
obrazu poddawanego analizie) jest dużo mniejsza od tej dotychczas przetwarzanej. Dzieje się
tak ponieważ powstające informacje są opisem matematycznym obiektów w obrazie
źródłowym, a nie tymi obiektami. Proces ten jest jednak złożony i może wymagać dużych
nakładów obliczeniowych. Nie mniej istnieją przekształcenia klasyczne, które są
przedstawione w kolejnych podrozdziałach.
3.5.1 Segmentacja i numerowanie
Segmentacja jest procesem wyodrębniania z obrazu poszczególnych obszarów, na
podstawie arbitralnie dobranego kryterium. Kryterium takim może być zarówno kolor jak i
faktura czy stopień jasności obszarów. Wynikiem końcowym procesu segmentacji jest obraz
binarny, w którym obszary o jasności „1” odpowiadają obiektom w obrazie. Istnieje
możliwość ponumerowania znalezionych w procesie segmentacji obszarów. Operację taką
nazywamy indeksowaniem ang. indexing. Jej wynikiem jest obraz monochromatyczny, w
którym jednorodne odizolowane od siebie pola przyjmują kolejny numer w procesie
wyliczania. Istnieje kilka sposobów realizowania procesu segmentacji, z których
najważniejszymi są:
Segmentacja przez rozrost obszaru. Segmentacja taka rozpoczyna się z dowolnego
miejsca w obrazie, które spełnia zadane kryterium. Miejsce to jest oznaczane w
obrazie wynikowym (początkowo składającym się z samych zer) poprzez ustawienie
wartości piksela na „1”.Do obszaru dołączane są wszystkie piksele sąsiadujące, które
spełniają to samo kryterium. Proces jest kontynuowany dopóki wszystkie piksele
sąsiadujące i jednocześnie spełniające kryterium nie zostaną dołączone. Proces
segmentacji realizowany jest dla wszystkich pikseli obrazu źródłowego. Końcowym
etapem tej części jest maska wycinająca całe obiekty.
Segmentacja przez podział obszaru. Ten rodzaj procesu segmentacji polega na
kolejnych podziałach obrazu źródłowego na części, a następnie sprawdzeniu czy
obszary które zostały podzielone spełniają kryterium jednorodności. Jeżeli nie to
obszar zostaje poddany dalszemu podziałowi. Jeżeli natomiast kryterium jest
spełnione, to w obrazie wynikowym analogiczne piksele przyjmują wartość „1”. W
końcowym etapie wszystkie stykające się obszary są łączone w jeden i nadawana jest
im kolejna wartość związana z procesem indeksacji. Podział obszaru może być stały
tzn. zawsze jest on dzielony w ten sam sposób (przykładowo na 4 części) lub
dynamiczny gdzie za każdym razem sposób podziału jest dobierany. Podział
dynamiczny może być realizowany w oparciu o wynik działania gradientu, która to
operacja rozgranicza różniące się od siebie obszary.
Inne. Powszechnie stosowanymi sposobami segmentacji, są też algorytmy oparte na
klasyfikatorach. W takim przypadku obraz w pierwszej kolejności jest
przekonwertowywany do innej przestrzeni barw (przykładowo HSV lub CIExyz), aby
następnie przy użyciu klasyfikatorów wydzielić obszary zainteresowania. Na koniec
dokonuje się konwersji do wyjściowej przestrzeni barw (najczęściej RGB).

Przenośny system detekcji i rozpoznawania znaków drogowych
29
Segmentacja jest bardzo skutecznym sposobem interpretowania zawartości obrazu i
wyodrębniania w nim obiektów o zadanych cechach. Często w przypadku analizowania
złożonych obrazów, po pierwszej segmentacji, przeprowadza się ją jeszcze raz z nieco
osłabionym kryterium. W tym przypadku nie rozpatruje się jednak całego obrazu, a tylko
obszary przylegające do znalezionych w pierwszym etapie obiektów. Podejście takie ma
swoje uzasadnienie w przypadku nierównomiernego oświetlenia obiektów, bądź innego
rodzaju zakłóceń.
Szczegółowa realizacja indeksowania jest przedstawiona w [1]. W obrazie
przedstawionym na rysunku 3.31 w pierwszej kolejności zrealizowana została segmentacja, a
następnie indeksacja obiektów.
Rys. 3.31 Obraz oryginalny po lewej oraz po wykonaniu
segmentacji i numerowaniu po prawej
Przedstawione powyżej operacje nie opisują obiektów znajdujących się w obrazie, nie
mniej są istotne przed przystąpieniem do tego opisu.
3.5.2 Współczynniki kształtu
Do opisu matematycznego obiektów służą różnego rodzaju współczynniki. Wśród
nich rozróżniamy współczynniki kształtu, momenty bezwładności i inne. Kilka
podstawowych współczynników przedstawiono poniżej.
pole powierzchni- jest w zasadzie ilością pikseli obiektu.
długość konturu
zawartość
(3.7)
gdzie L jest długością konturu obiektu, a S powierzchnią tego obiektu.
centryczność
(3.8)
gdzie LH jest odległością od środka ciężkości obiektu do dalej położonego końca w
osi poziomej, a LV jest odległością od środka ciężkości obiektu do dalej położonego
końca w osi pionowej.

Przenośny system detekcji i rozpoznawania znaków drogowych
30
współczynnik Fereta
(3.9)
gdzie DH jest rozpiętością figury w poziomie, a DV jest rozpiętością figury w pionie.
prostokątność
(3.10)
gdzie S jest polem obiektu, a PP jest polem najmniejszego prostokąta opisanego na
figurze.
współczynnik cyrkularności
(3.11)
współczynnik Malinowskiej. Mierzy stopień krągłości obiektu, i jest niezależny od
wielkości.
(3.12)
Powyższe współczynniki są szybko wyznaczalne, okupione to jest jednak małą
dokładnością opisu. W przypadku tych współczynników zmiana rozmiarów, czy ułożenia
(szczególnie obrót) obiektu powodują zmianę wartości tych współczynników. Ponadto
wartości współczynników nie wykazują dużej zmienności dla podobnych figur (przykładowo
ośmiokąt i koło). Nieco bardziej skomplikowane i dłuższe w wyznaczaniu są współczynniki o
wzorach 3.13 do 3.15
współczynnik Blair -Bliss Mierzy stopień wydrążenia obiektu, jest niezależny od
wielkości i unormowany.
(3.13)
gdzie ri jest odległością piksela od środka ciężkości obiektu, sumowania dokonujemy
po wszystkich pikselach obiektu wyliczanych przez i.
współczynnik Danielssona
(3.14)
gdzie li jest minimalną odległością piksela obiektu od konturu tego obiektu, a S jest
powierzchnią obiektu.
współczynnik Haralicka
(3.15)
gdzie di jest odległością i-tego piksela konturu od środka ciężkości figury, a n liczbą
pikseli konturu.

Przenośny system detekcji i rozpoznawania znaków drogowych
31
3.5.3 Momenty główne i centralne
Prócz współczynników kształtu do opisu matematycznego obiektów mogą służyć tzw.
momenty oraz niezmienniki momentowe. Wzory opisujące te wielkości są w ogólności
dobrze znane i stosowane w wielu dziedzinach nauki, (najszerzej są stosowane w mechanice).
Poniżej przytoczone są wzory definiujące momenty w dziedzinie dyskretnej.
momenty główne
(3.16)
Rząd momentu określają p i q i dla pq=00 mamy moment rzędu 0 który jest polem
powierzchni figury. Momenty rzędu 1 czyli 01 i 10 określają położenie środka
ciężkości figury względem osi X i Y a współrzędne tego środka można wyznaczyć
stosując wzór 3.17
(3.17)
momenty centralne
(3.18)
Moment centralny rzędu trzeciego opisuje (przez analogię do statystyki)
„atrakcyjność” konturu, czyli jak bardzo jest on różny od okręgu. Moment rzędu
trzeciego mówi o stopniu symetryczności figury.
moment centralny znormalizowany
(3.19)
niezmienniki momentowe (3.20a)
(3.20b)
(3.20c)
(3.20d)
Niezmienników momentowych jest wiele więcej, a wzory je opisujące można znaleźć
w bogatej literaturze matematycznej. Często jednak podaje się je w innych formach i stosując
inne oznaczenia. Najczęściej przytaczanym jest niezmiennik opisany wzorem 3.20d i
występuje on pod symbolem M7 lub W7. Wszystkie mają jedną wspólną cechę, ich wartość
jest stała bez względu na położenie, obrót i wielkości figury którą opisują. W dodatku
przedstawione jest badanie wartości niezmienników momentowych oraz wybranych
współczynników kształtu w zależności od figury jaką opisują.

Przenośny system detekcji i rozpoznawania znaków drogowych
32
4. Praktyczne wykorzystanie przekształceń-
znajdowanie znaków w obrazie
W pierwszej części tego rozdziału przedstawione zostaną metody znajdowania znaków
w obrazie lub sekwencjach obrazów. Przytoczone metody analizy koloru i kształtu,
w szczególności metoda transformaty radialnej, maszyna SVM zaprezentowana przez
dr Bogusława Cyganka w [9], oraz zastosowany w pracy algorytm są redagowane na
podstawie znalezionych opracowań tych metod. Dwie spośród nich zostały
zaimplementowane w Matlabie i sprawdzone pod względem poprawności działania, obie są
szczegółowo omówione w odpowiednich podrozdziałach.
4.1 ROI (ang. „Region Of Interest” ) charakter i właściwości znaków
Pojęcie ROI często jest wykorzystywane przy przetwarzaniu oraz analizie obrazów
i najogólniej oznacza fragmenty obrazu istotne z punktu widzenia realizowanego zadania. W
przypadku niniejszej pracy ROI będzie określało obszary w których znajdują się znaki
drogowe. Moduł detekcji ma za zadanie obszary te w obrazie wejściowym odnaleźć i
przekazać w odpowiedniej formie do dalszego przetwarzania.
W pierwszej kolejności należy więc określić podstawowe cechy jakie opisują znaki drogowe
z trzech grup A, B i C aby prawidłowo zaprojektować moduł detektora.
Znaki drogowe w Polsce a także na świecie są unormowane, i choć ich kształt i kolor
jest w wielu krajach nieco inny, to można wyznaczyć ich podstawowe cechy:
do znaków stosowane są proste figury geometryczne takie jak okrąg, prostokąt, trójkąt
równoramienny, ośmiokąt foremny oraz rąb.
znaki zakazu są okrągłe, mają czerwone obramowanie i biały lub żółty środek
(przykładowo znak „Zakaz wjazdu”)
znak stop na całym świecie jest czerwonym ośmiokątem z napisem „STOP” w środku.
znaki ostrzegawcze mają kształt trójkąta z czerwonym obramowaniem i żółtym lub
białym wnętrzem, w którym czarnym kolorem jest oznaczony obiekt lub zjawisko do
którego znak się odnosi i przed którym przestrzega.
znaki nakazujące kierunek jazdy, a także informujące o organizacji ruchu na drodze są
koloru niebieskiego z białym lub czarno-białym rysunkiem w środku.
Na podstawie zebranych obrazów prezentujących znaki w różnych otoczeniach,
warunkach oświetleniowych i sytuacjach drogowych, wyznaczono histogramy kolorów
występujących w znakach. Zbiór testowy nie jest duży i zawiera 100 znaków, dlatego też
wyniki tej analizy zestawiono z wynikami przedstawionymi w [4]. We wnioskowaniu tym
wykorzystano reprezentację w przestrzeni HSV, a wyniki przedstawia rysunek 4.1. Przyjęto,
że zbiór ten stanowi pewnego rodzaju wzorzec, na którym będzie się opierała analiza
przedstawiona w części 4.3 tego rozdziału. Grupa testowa składa się ze znaków „dobrej
jakości” tzn. takich które nie są wyblakłe, pomalowane na inny kolor lub widziane przez filtr
koloru. Nie mniej istnieją znaki, których kolory zupełnie nie „pasują” do zaprezentowanych
tu przykładów, w algorytmach analizujących kolory zostaną one więc odrzucone. Częstym
przypadkiem, w którym kolor znaku nie pasuje do zaprezentowanych tu wzorców jest
oświetlenie obiektywu kamery przez słońce, lub nadjeżdżający z naprzeciwka samochód. W
takim przypadku postrzeganie kamery zostaje zakłócone i znak o prawidłowych barwach jest
widziany jako niepoprawny kolorystycznie.

Przenośny system detekcji i rozpoznawania znaków drogowych
33
Rys. 4.1 Histogramy składowych H i S znaków drogowych
Wspomniane wcześniej proste figury geometryczne, jakie są wykorzystane w znakach
drogowych, mogą ulec wypatrzeniu. Najprostszym przypadkiem zniekształcenia jest
obserwowanie znaku pod kątem, wtedy nawet bardzo regularny i dobry znak nie posiada
wystarczającej liczby osi symetrii. Może to zaowocować odrzuceniem takiego obiektu
w algorytmach opartych o analizę kształtu. Znaki mogą być także obrócone względem
swojego prawidłowego ułożenia, albo zniszczone przez chuliganów lub na skutek wypadków
drogowych. Istotną sprawą, jaką należy rozpatrzyć, jest zasadność znajdowania takich
zniekształconych znaków w obrazie poddawanym analizie
4.2 Stosowane metody detekcji znaków
Istnieje wiele metod wyznaczania obszarów zainteresowania w obrazie, dzielą się one
na trzy podstawowe grupy:
Metody oparte o analizę kształtu.
Metody oparte o analizę koloru i/lub tekstury
Mieszane
W rozpoznawaniu znaków najbardziej popularne są metody realizowane w oparciu
o analizę kolorystyczną a także mieszane. Rzadko stosowane są metody oparte o analizę
kształtu, mimo to detektor taki został zbudowany przez Gareth Loy i Nick Barnes
i przedstawiony w [14]. Autorzy przy realizowaniu projektu wykorzystali Szybką
Symetryczną Transformatę Radialną (ang. „Fast Radial Symetry Transform”) która
umożliwia znalezienie w obrazie obiektów symetrycznych lub symetrycznie względem siebie
ułożonych. Opis dość prostego przypadku „FRST” znajduje się między innymi w [15].
Popularność metod wykorzystujących kolor do detekcji znaków wynika z mnogości
narzędzi i przekształceń możliwych do wykorzystania. Duża liczba przestrzeni barw,

Przenośny system detekcji i rozpoznawania znaków drogowych
34
począwszy od RGB i HSV po bardzo zaawansowane, jak CIECAM97 w połączeniu z
różnorodnością narzędzi grafiki komputerowej sprawia, że analiza kolorystyczna jest
powszechnie stosowana. Metody i algorytmy działania przy analizie kolorów zostały na
przestrzeni lat dopracowane, a wyniki ich działania są powtarzalne i z góry znane.
W przypadku metod opartych o analizę kształtu istnieje zaledwie kilka przekształceń
umożliwiających realizację detektorów tym sposobem. Do najpowszechniejszych należą
Transformata Hougha i wspomniana wyżej transformata radialna, oba przekształcenia są
jednak czasochłonne i wymagają sporego nakładu obliczeniowego. W następnych
podrozdziałach przedstawione są detektory zbudowane z wykorzystaniem obu podejść, a na
koniec są one ze sobą porównane.
4.2.1 Analiza kształtów
W pracy podjęto próby zrealizowania programu podobnego do tego przedstawionego
w [14]. Próby te nie przyniosły jednak zadowalających wyników, co spowodowało, że
zaniechano dalszej pracy nad tym algorytmem na rzecz innego przedstawionego w rozdziale
4.3. W przytaczanej pracy [14] szybka transformata radialna została nieco zmodyfikowana i
udoskonalona pod względem przydatności do stawianego jej zadania.
Zagadnienie odnajdowania i rozpoznawania znaków w oparciu o kształt figur wymaga
wprowadzenia pojęcia metryki. Przestrzeń, w której metrykę tą należy zdefiniować jest
przestrzenią typu lub , co powoduje, że najczęściej stosowane są powszechnie znane
metryki: Euklidesowa i wartości bezwzględnej. W pracy zastosowano metrykę Euklidesową,
a poniżej przedstawiono kolejne etapy działania algorytmu.
Obraz krawędziowy. Pierwszą operacją w algorytmie jest wytworzenie obrazu
krawędziowego. Obraz taki uzyskiwany jest poprzez filtrację w przestrzeni RGB
maską Sobela.
Gradient. Następnie dla każdego piksela obrazu krawędziowego określana jest
wartość oraz kąt gradientu. Kąt jest zapisany jako dwuelementowy unormowany
wektor , a składowe w sposób pośredni określają jego wartość. Analiza
wektorowa pozwala tak zapisany kąt obracać, przykładowo obrót o kąt 900 to
przypisanie
W dalszej kolejności następuje progowanie, które z obrazu krawędziowego usuwa
piksele o małej wartości pozostawiając tym samym proste związane z gwałtownymi
zmianami barwy w obrazie źródłowym.
Proste głosujące. Wektor piksela wyznacza prostą prostopadłą do linii
krawędziowej na której leży. Następnie na prostej tej w odległości od piksela i w
kierunku wskazywanym przez tworzony jest punkt , a po przeciwnej stronie
piksela w takiej samej odległości punkt . Tym sposobem punkty i leżą na
jednej prostej prostopadłej do linii krawędziowej w punkcie . Punkty i są
środkami odcinków odpowiednio i , które z kolei są równoległe względem siebie
i względem stycznej do linii krawędziowej w punkcie . Ułożenie punktów , i
oraz prostych i przedstawione jest na rysunku 4.2.

Przenośny system detekcji i rozpoznawania znaków drogowych
35
Rys. 4.2 Punkty i proste głosujące.
Długość odcinków i zależy od kształtu poszukiwanego obiektu oraz aktualnej
wartości odległości i są one wyznaczane na podstawie
(4.1a)
gdzie oznacza ilość boków poszukiwanego kształtu, przykładowo dla trójkąta
Głosowanie. W obrazie wynikowym punkty pokrywające się z lub są punktami
głosującymi. Te leżące w odległości mniejszej niż od odpowiednio lub głosują
pozytywnie (+1) a te bardziej odległe negatywnie (-1). Zbiory punktów głosujących
pozytywnie i negatywnie mogą być zapisane jako [14]
(4.1b)
gdzie oznacza odległość między punktami i , a według [14]
Liczenie głosów. Głosowanie jest przeprowadzane dla każdego piksela w obrazie
krawędziowym, a głosy poszczególnych głosowań są sumowane i stanowią wynik
działania pojedynczej iteracji algorytmu. Piksel obrazu wynikowego zbierze zatem
wiele głosów pozytywnych tylko wtedy, gdy wiele pikseli obrazu krawędziowego
będzie miało swoje wektory skierowane w jego stronę, lub w stronę przeciwną.
Piksel wynikowy z dużą ilością głosów pozytywnych jest pretendentem na środek
znaku. Jednakże ze względu na fakt, że nie jest znany a priori rozmiar i kształt znaku,
głosowanie należy przeprowadzić wielokrotnie dla różnych wartości i a
poszczególne obrazy wynikowe ze sobą zsumować. Wynik działania algorytmu dla
pojedynczej iteracji jest przedstawiony na rysunku 4.3.

Przenośny system detekcji i rozpoznawania znaków drogowych
36
Rys. 4.3 Wynik działania operacji znajdowania środka znaku na podstawie modułu gradientu.
Obraz kątowy. Autorzy [14] podają, że w algorytmie obliczany jest także drugi obraz
wynikowy. Każdy znak składa się ze skończonej liczby odcinków prostych, które są
usytuowane względem siebie o z góry znany kąt. Kąt ten jest określony jako [14]
(4.2)
Informacja ta jest wykorzystana, przy tworzeniu drugiego obrazu wynikowego. Kąt
każdego gradientu jest przemnażany, przez –liczbę brzegów poszukiwanej figury
(3 dla trójkąta, 4 dla prostokąta itd.) z uwzględnieniem okresowości miary kątowej
tzn. kąt przyjmuje wartości z zakresu [0- 3600]. Powstały w ten sposób wektor jest
analogicznie jak w pierwszym obrazie wynikowym, głosem oddawanym na
odcinakach głosowania i . Głos ten jest pozytywnym, wtedy moduł wektora
jest dodawany, lub negatywnym kiedy jest on odejmowany od obrazu. Granice
głosowania pozytywnego i negatywnego są takie same jak w pierwszym obrazie
wynikowym. Drugi obraz wynikowy mówi zatem o rozmieszczeniu względem siebie
linii krawędziowych, a więc o kształcie figury. Tak samo jak w pierwszej części
algorytmu analizę należy przeprowadzić kilkakrotnie dla różnych wartości odległości
i poszukiwanego kształtu (zmiennej ). Przykładowy drugi obraz wynikowy
pokazany jest na rysunku 4.4.

Przenośny system detekcji i rozpoznawania znaków drogowych
37
Rys.4.4 Wynik operacji znajdowania środka znaku na podstawie kąta.
Końcowym etapem procesu znajdowania znaków tą metodą jest wyznaczenie środka znaku na
podstawie dwu obrazów wynikowych. W tym celu należy unormowane wartości pikseli obu
obrazów wymnożyć przez siebie, a następnie odnaleźć w obrazie piksele o wartości zbliżonej
do 1. Obrazy wynikowe pierwszy i drugi wyznacza się równolegle w jednym obiegu pętli
analizującej wszystkie piksele. Wynik końcowy przedstawiony jest na rysunku 4.5 gdzie
poszukiwanie było przeprowadzone dla znaku ostrzegawczego.
Najpoważniejszą wadą tej metody, poza dość dużym obciążeniem jednostki
obliczeniowej jest problem z normowaniem kolejnych obrazów. Na etapie prób i testowania
algorytmu nie udało się znaleźć prawidłowej funkcji normalizującej, a jedynie pewne
niedoskonale oszacowania. Każdy obraz należy przeanalizować kilkakrotnie, dla różnych
wartości odległości R ze wzoru (4.1a) oraz dla różnych wartości parametru n ze wzoru (4.2).
Analiza ta jest długotrwała i w efekcie nie daje zadowalających wyników, co było powodem
dla którego zaniechano dalszych prac nad tym algorytmem.
Rys.4.5 Wynik końcowy metody

Przenośny system detekcji i rozpoznawania znaków drogowych
38
4.2.2 Analiza koloru
Drugą grupę metod detekcji znaków i wyznaczania rejonów zainteresowania stanowią
metody oparte o analizę kolorów i faktury. Sposobów realizacji detektorów znaków tą metodą
jest wiele, a poniżej przedstawionych jest kilka przykładowych. Różnią się one podejściem
autora, stopniem skomplikowania, a także formalizmem matematycznym. Niektóre bowiem
opierają się o analizę matematyczną obrazu jako macierzy liczb, podczas gdy inne oparte są o
„wyczucie” autora. Poniżej przytoczone zostały skrótowe opisy kilku interesujących metod.
Metoda znajdowania znaków przedstawiona w [10] jest realizowana z
wykorzystaniem przestrzeni CIELab. W pracy tej zastosowano rozpoznawanie oparte o
Gaussowskie modele znaków. Model taki przewiduje, że dla każdego koloru jaki występuje
w znakach wyznaczona jest wartość oczekiwana oraz macierz kowariancji. Rozpoznawanie
znaków oparte jest o zmodyfikowaną wersję klasyfikatora Bayesa. Wynikiem klasyfikacji są
oznaczone obszary znaków, które podlegają dalszemu przetwarzaniu. Ponadto po poprawnym
znalezieniu i rozpoznaniu znaku następuje aktualizacja modelu, dzięki czemu dostosowuje się
on samoczynnie do znaków występujących w rzeczywistości. Wszystkie oznaczone piksele są
następnie poddawane indeksowaniu czyli łączeniu w spójne obszary będące regionami
zainteresowania ROI. Autorzy projektu wykorzystują także charakter danych napływających
z kamery, należy bowiem pamiętać, że analizowane są nie pojedyncze obrazy, ale ich serie
czasowe i fakt ten został wykorzystany. W pracy zrealizowano bowiem śledzenie znaków, co
oznacza, że nawet pojedyncze błędne rozpoznanie nie powoduje utraty funkcjonalności.
W pracy Michaela Shneiera [11] operacje realizowane są w przestrzeni RGB. W
pierwszej kolejności wyznaczany jest stosunek zawartości barw względem siebie, następnie
trzy obrazy wynikowe tj. R/G, G/B i R/B są jednocześnie poddawane binaryzacji
z odpowiednimi progami. Zastosowane progi nie są krytyczne tzn. powinny mieć
odpowiednie wartości, jednak niewielkie ich odchyłki nie wpływają na działanie algorytmu.
Wynikiem tych operacji jest obraz binarny, w którym znajdują się pola odpowiadające
kandydatom na znaki, przy czym wszystkie rodzaje znaków znajdują się w jednym obrazie.
Istnieje także możliwość otrzymania osobnych obrazów dla każdego rodzaju znaku (bazując
na ich kolorach). W takim przypadku konieczna jest jednak oddzielna binaryzacja obrazów
R/G G/B i R/B. Autor zastosował pierwsze podejście, z jednym obrazem binarnym. W
następnej kolejności należy wykonać erozję w celu usunięcia zakłóceń w postaci niewielkich
pól pikseli, oraz trzykrotną dylatację mającą na celu wypełnienie nieciągłości znaków. Istnieje
bowiem zagrożenie, że w wyniku nierównomiernego oświetlenia, bądź częściowego
zasłonięcia znaku jego kształt będzie nieregularny, a pole niejednorodne. Tak przygotowany
obraz podlega segmentacji i indeksacji. Każdemu segmentowi są następnie
przyporządkowywane parametry, autor zastosował następujące: „centroid” (w niniejszej
pracy parametr ten jest nazwany środkiem ciężkości obiektu), pole powierzchni, najmniejszy
prostokąt opisany na figurze (ang. „bounding box”) . Parametry te wykorzystane są przy
selekcji obiektów, odrzucane są te o zbyt małym lub zbyt dużym polu powierzchni, których
„bounding box” jest zanadto prostokątny, lub których położenie w obrazie nie pasuje do
miejsca, gdzie znaki zazwyczaj występują. Pozostają więc tylko obiekty, które
najprawdopodobniej reprezentują znaki, i to one są poddawane dalszemu przetwarzaniu.
Obiekty, które zostały sklasyfikowane jako zawierające znaki są śledzone w kolejnych
obrazach napływających z kamery, jeżeli w pięciu kolejnych klatkach obiekt jest rozpoznany
jako zawierający znak, to tworzy on dla tego znaku maskę wycinającą. Przedstawiony
algorytm jest więc bardzo prosty, i jak podaje autor, daje dość dobre wyniki.
Najbardziej zaawansowany algorytm detekcji znaków z jakim spotkał się autor tej
pracy został przedstawiony w [12]. Procedura ta zrealizowana jest w oparciu o detektory
kolorów i kształtu. Regiony zainteresowania wyznaczane są na podstawie kolorów w

Przenośny system detekcji i rozpoznawania znaków drogowych
39
przestrzeni HSV. W pierwszej kolejności dokonywana jest binaryzacja na podstawie dwu
składowych H i S z progami TH i TS, następnie obszar ten uzupełnia się o piksele należące do
znaku. Uzupełnienie to także jest procesem binaryzacji, ale z progami tH i tS mniejszymi od
tych w pierwszym podejściu i przy zachowaniu warunku sąsiedztwa. Pikselom zostaje
przypisana wartość „1” w procesie binaryzacji, jeżeli ich składowe H i S przekraczają progi tH
i tS oraz gdy w najbliższym sąsiedztwie znajdują się piksele, które w pierwszym podejściu
zostały sklasyfikowane jako należące do znaku. Tak powstały obraz binarny jest dzielony na
obszary zewnętrza i wnętrza znaku. Obszary zewnętrzne to takie, które mają „połączenie” z
brzegiem obrazu, tzn. istnieje ciągła ścieżka prowadząca od piksela do co najmniej jednego
brzegu obrazu. Jak podaje autor wyznaczanie zewnętrza rozpoczynane jest od brzegów
obrazu przemieszczając się w kierunku jego środka i oznaczając piksele (którym w obrazie
binarnym odpowiadają „0”) jako zewnętrzne. Jeżeli ścieżka trafi w piksele sklasyfikowane w
pierwszej części jako „1” (brzeg znaku) to zostają one ominięte bez zaznaczenia. Procedura
kontynuowana jest, aż do środka obrazu, a jej wynikiem jest powstały obszar zewnętrza. Jako
wnętrze traktowana jest pozostała część obrazu. Kolejnym etapem jest znalezienie krawędzi
rozdzielającej zewnętrze od wnętrza znaku czyli jego brzegu, zrealizowane to jest na zasadach
sąsiedztwa. Brzegiem jest ten piksel wnętrza, którego chociaż jeden sąsiad należy do
zewnętrza znaku (od którego rozpoczyna się procedura). Następnie dokonywana jest
indeksacja wyznaczonych krawędzi i do każdej z nich dopasowywany zostaje kontur znaku.
Jeżeli dopasowanie jest zgodne tzn. różnica pomiędzy krawędzią, a kształtem dopasowującym
jest niewielka to obszar ten jest rozpoznany jako znak. Dopasowanie kształtów dokonywane
jest na podstawie „rogów” figury (patrz 3.4.4 operacja „Top-Hat”) i układu linii łączących
sąsiadujące ze sobą punkty. Ponieważ autor skupiał się w prezentowanym algorytmie na
znakach trójkątnych, toteż etap dopasowania kształtu nie uwzględnia znaków okrągłych
(które nie mają wierzchołków). Zaprezentowane podejście ma tą przewagę nad pozostałymi,
że umożliwia znalezienie znaku na tle obszaru o takim samym kolorze jak brzeg znaku.
Innowacyjne podejście do problemów detekcji znaków przedstawione jest w [9] autor
dr Cyganek w swojej pracy realizuje wstępne przetwarzanie prowadzące do wyznaczenia
obszarów zainteresowania w jednym etapie. Do obrazu wejściowego w przestrzeni RGB
zastosowana jest maszyna wektorów wspierających (ang. „Support Vector Machine”), która
jako wynik swojej pracy przedstawia obraz z zaznaczonymi obszarami znaków. Maszyna ta
analizuje układ pikseli i na podstawie ich koloru i ułożenia odnajduje w obrazie wejściowym
obszary zainteresowania, autor etap ten nazywa segmentacją kolorów. Następnie znalezione
obiekty są poddawane adaptacyjnemu dopasowaniu kształtu, etap ten generuje opis
właściwości geometrycznych obiektów, a więc możliwe jest odrzucenie obiektów, które nie
pasują kształtem do znaków. Wszystkie pozostałe obiekty są rejestrowane, oraz dla każdego z
nich są tworzone macierze przekształcenia afinicznego, które będą wykorzystane na etapie
klasyfikacji. Tak przygotowane obiekty są następnie poddawane transformacji Log- polar,
oraz binaryzacji. Autor zastosował binaryzację adaptacyjną, w której próg leży pomiędzy
wartością jasności piksela równą 128 a maksimum występującym w histogramie.
Z powstałego obrazu binarnego wydobywane są cechy, które będą podlegały klasyfikacji w
bloku klasyfikacji.

Przenośny system detekcji i rozpoznawania znaków drogowych
40
4.2.3 Porównanie metod
Na podstawie przytoczonych tu przykładów, a także ich realizacji w Matlabie można
wysnuć pewne wnioski dotyczące skuteczności oraz szybkości działania przedstawionych
metod detekcji.
Algorytmy badające kształt są skomplikowane matematycznie, wymagają analizy
wzorów i poprawnej interpretacji wyników najczęściej przy tym nie posiadających
interpretacji fizycznej. Podejście to zawiera jednakże stosunkowo niewielką ilość operacji
składowych. Przedstawiona metoda zmodyfikowanej Szybkiej Transformaty Radialnej była
czasochłonna i w rezultacie nie dawała satysfakcjonujących wyników.
Przytoczone metody znajdowania rejonów zainteresowania oparte o analizę kolorów
dawały lepsze wyniki, niż wspomniana wyżej metoda. Na podstawie, przedstawionej
w następnym podrozdziale implementacji można powiedzieć, że metody wykorzystujące
analizę kolorów są dużo szybsze. Ilość pojedynczych prostych operacji, jakie należy
przeprowadzić jest jednak stosunkowo duża, a niektóre z nich są wprowadzone w celu
usunięcia wad poprzednio wykonanej. Początkowe operacje w tych algorytmach są
stosunkowo proste, polegają na zamianie przestrzeni barw, filtracji, binaryzacji itd. Problemy
pojawiają się natomiast w dalszych częściach algorytmów, gdzie należałoby odrzucić obiekty
nie pasujące do znaków. „Czyste” sposoby wyznaczania ROI na podstawie koloru tego nie
realizują. Powoduje to, że do dalszego przetwarzania przekazywana jest duża liczba obiektów
nie będących znakami (ang, „false positive”). Problem ten, a także wiele innych (z jakimi
spotkał się autor pracy podczas budowy algorytmu), we wszystkich przytoczonych wyżej
przykładach zostały rozwiązane poprzez wprowadzenie bloku analizującego kształt. Autor
także zastosował to podejście wprowadzając na samym końcu blok klasyfikatora SVM. Tym
sposobem w algorytmie analizującym kolor znalazł się blok analizy kształtu, a cała metoda
należy w zasadzie do grupy metod mieszanych. Należy tu jednak zaznaczyć granicę pomiędzy
metodami. W metodach opartych o analizę kształtu, operacje matematyczne są wykonywane
dla całego obrazu wejściowego, bez dzielenia go na części. W metodach analizy koloru
wszystkie operacje są realizowane ze względu na barwę i dążą do wyznaczenia interesujących
obszarów. Najlepszym, i najczęściej stosowanym sposobem zbudowania detektora, jest
zastosowanie metod łączonych tzn. zastosowanie metod analizy koloru i kształtu
jednocześnie. W algorytmach zbudowanych według tej idei początkową operacją jest
zmniejszenie liczby danych poprzez analizę kolorów, i wybranie z obrazu wejściowego tylko
tych obiektów, które mają odpowiednią barwę. Dopiero tak przygotowane dane są dzielone na
podobszary i podlegają analizie kształtu, która w tym przypadku jest bardzo skutecznym
narzędziem. Określa ona czy dany obiekt znaleziony w pierwszej części jest zbliżony
kształtem do figur znaków, i odpowiednie obiekty stanowią odpowiedź detektora. Metody
wymienione jako analizujące kształt nie uwzględniają tej pierwszej operacji (ograniczania
liczby danych), lecz od razu skupiają się na poszukiwaniu figur geometrycznych, przez co są
dużo bardziej skomplikowane.

Przenośny system detekcji i rozpoznawania znaków drogowych
41
4.3 Zastosowana metoda detekcji znaków
W pracy zastosowano metodę detekcji znaków należącą do grupy mieszanej
tj. wykorzystującej jednocześnie analizę koloru i kształtu. Podejście takie pozwala
wykorzystać walory obu tych sposobów i dzięki temu istnieją realne szanse na zwiększenie
skuteczności i szybkości działania. W pracy wykorzystano algorytm oparty o ten
zaprezentowany przez „Saturnino Maldonado Bascon, i innych” i przedstawiony w [13].
Schemat blokowy przedstawiający idee działania znajduje się na rysunku. 4.6
Operacje
morfologiczne II
Wektory
brzegowe
Rozdzielanie
obszarów
Sprawdzenie
kształtu- SVM
Sumowanie
obrazów
Operacje
morfologiczne ILUT
Funkcje
przynależności
RGB do HSV
Obraz
wejściowy
Wycięcie
obszaru znaku
Obraz
wyjściowy
Rys. 4.6 Schemat ideowy bloku detektora
W pierwszej kolejności realizowana jest zmiana przestrzeni barw z RGB na HSV.
Algorytm do tego służący opisano w [20], [21], [8]. Powszechnie dostępne są też aplikacje
prezentujące taką zamianę, a także gotowe funkcje napisane w różnych językach
programowania. Konwersję taką można zapisać wzorami (4.3) [8].
(4.3)
gdzie

Przenośny system detekcji i rozpoznawania znaków drogowych
42
Następnym etapem jest znalezienie obszarów o kolorach zbliżonych do tych
występujących w znakach. W rozdziale 4.1 przedstawiono histogramy składowych h i s
znaków i na tej podstawie oraz na postawie wykonanych testów wyznaczono funkcje
przynależności (ang. Membeship function) przedstawione na rysunku 4.7.
Rys 4.7 Funkcje przynależności dla składowych h i s dla trzech kolorów znaków
W celu wyznaczenia obszarów zainteresowania posłużono się metodą odczytu
wartości z tablicy LUT (ang. „Look Up Table”). Składowa h każdego piksela jest
interpretowana jako adres w tablicy z której odczytywana jest przynależność tego piksela do
znaku. W tablicy tej zapisane są kolejne wartości funkcji przynależności, a każdy rodzaj
znaku (grupy A, B, C i D) ma swoja tablicę. Jeżeli analizowany piksel posiadał składową h o
wymaganej wartości, to odczytana wartość wynosi 1, jeżeli wartość ta nie odpowiadała
kolorowi znaku, to odczytane zostało 0. Operację LUT przeprowadza się analogicznie dla
składowej s wykorzystując odpowiednie tablice z funkcjami przynależności. W celu
znalezienia w jednym obrazie znaków wszystkich grup (A, B, C i D) konieczne jest więc
przeprowadzenie operacji odczytu z tabeli- LUT sześciokrotnie. Następnie dla każdego koloru
wymnażane ze sobą są odpowiedzi poszukiwania dla składowych h i s co w rezultacie
skutkuje powstaniem trzech obrazów częściowych. Podejście takie gwarantuje, że znalezione
obszary zainteresowania mają obie składowe o odpowiednich wartościach, a więc z dużym
prawdopodobieństwem są to znaki.
Kolejnym etapem jest operacja zamknięcia i otwarcia przeprowadzana w celu
usunięcia zakłóceń i nieciągłości w znalezionych obszarach. Operacja ta jest przeprowadzana
na każdym z trzech obrazów częściowych. Następnie są one ze sobą sumowane i poddawane
operacji otwarcia po raz drugi, żeby usunąć pozostałe zakłócenia. W rozdziale 6.1 jest
przeprowadzana analiza wpływu operacji morfologicznych na obrazie na skuteczność
działania algorytmu. Na rysunku 4.8 przedstawiony jest przykładowy obraz oraz jego trzy
obrazy częściowe. W obrazach częściowych zostały odwrócone kolory tzn. czarne obszary
odpowiadają teraz wartościom 1, białe natomiast wartościom 0. Zamiana ta została dokonana
celem poprawienia czytelności wyników.

Przenośny system detekcji i rozpoznawania znaków drogowych
43
Rys 4.8 Obraz oryginalny oraz jego trzy obrazy częściowe
Obrazy częściowe przedstawiają nie tylko obszary znaków, ale również tych
przedmiotów, których kolor był zbliżony do kolory znaku i został zakwalifikowany jako
potencjalny znak. W zależności od oświetlenia obrazu, a także treści znaku mogą się pojawić
również odbicia i refleksy, których kolor będzie zbliżony do kolorów poszukiwanych znaków.
W takim przypadku zakłócone mogą być wszystkie trzy obrazy częściowe.
Przygotowany w pierwszej części algorytmu obraz zajmuje dużo mniejszy obszar w
pamięci komputera, i zarazem dostęp do niego jest dużo szybszy. Dogodniejszy są więc
bardziej skomplikowane operacje, spośród których pierwszą jest indeksacja. Zaznaczone
obszary są w dalszej kolejności sprawdzane pod względem prostokątności i powierzchni. Dla
obszarów o powierzchni z przedziału 500 do 100 tys. pikseli i stopniu prostokątności od 0.8
do 2.1 są wyznaczane wektory brzegowe. Idea budowy wektora przedstawiona jest na
rysunku 4.9.
4.9 Wektory brzegowe

Przenośny system detekcji i rozpoznawania znaków drogowych
44
Wektor brzegowy to zbiór odległości brzegu figury od brzegu najmniejszego prostokątnego
obrysu wyznaczana w kierunku pionowym lub poziomym. W celu wyznaczenia tych
odległości skaluje się wybrany obszar do rozmiarów odpowiadających długości wektora.
Wyznaczenie zestawu wektorów o długościach 50 elementów każdy wymaga przeskalowania
obszaru do rozmiarów 50×50 pikseli. W pierwszej kolejności brane pod uwagę są dwa górne
wektory, a więc opisujące figurę po bokach. Na podstawie tych wektorów sprawdzane jest
czy obszar nie przedstawia dwóch znaków wobec których nie zachowano rygorów
odległościowych. Wektory te można traktować jako zbiór wartości pewnej funkcji odcinkami
liniowej. Na podstawie kilku pierwszych wartości wyznaczany jest współczynnik
kierunkowy, a następnie dokonywane jest sprawdzenie, czy wartość następnego elementu jest
zgodna z przewidywaniami z dokładnością do kilku pikseli. Współczynnik kierunkowy jest z
każdym krokiem uaktualniany tak, żeby prognozowanie było prawidłowe nawet dla okręgu.
Jeżeli wartości kolejnych pikseli są zgodne z prognozą, to obszar przedstawia tylko jedną
figur. Jeżeli wartości te odbiegają od przewidywań, to obraz jest rozdzielany. Obraz binarny
oraz wynik działania bloku rozdzielania pokazane są na rysunku 4.10. Jeżeli rozdzielono
obszar, to wektory brzegowe wyznaczone są ponownie dla obu jego części, jeżeli nie to
pozostają one aktualne.
Rys 4.10 Wynik rozdzielania
Ostatnim etapem pracy bloku detektora jest analiza kształtu znalezionych obszarów. Jest ona
realizowana w oparciu wyznaczone wektory brzegowe z użyciem czterech maszyn wektorów
wspierających SVM. Weryfikacja ta jest oparta o głosowanie, a w literaturze sposób ten
nazwany jest klasyfikatorem głosującym (ang. „Voting classifier”). Każda z maszyn SVM
analizuje wektory brzegowe, które są do niej na stałe przypisane. Oznacza to że maszyna N
analizuje tylko wektory pionowe tworzone od góry obszaru itd. Idea działania maszyny SVM
przedstawiona jest w rozdziale 5.3 Na rysunku 4.11 przedstawiona jest schematyczna budowa
klasyfikatora głosującego. Każdy SVM weryfikuje swój wektor i wystawia kod znaku jaki
rozpoznał, kod ten stanowi numer komórki w wektorze wyjściowym. Początkowo zerowe
wartości elementów wektora wyjściowego są teraz inkrementowane zgodnie z głosami
maszyn SVM. Każdy element wektora jest tyle razy inkrementowany ile maszyn na niego
wskazywało. Jeżeli element otrzymał co najmniej trzy głosy to jest to interpretowane jako
rozpoznanie kształtu i obiekt dla którego było przeprowadzane sprawdzenie otrzymuje status
figury geometrycznej. Następnie poza blokiem detektora figura ta jest wycinana z obrazu
źródłowego i przekazywana do bloku rozpoznawania zawartości. Metoda rozpoznawania jest
opisana w rozdziale 5.2.2 oraz 5.3

Przenośny system detekcji i rozpoznawania znaków drogowych
45
SVM - S
SVM - N
SVM - W SVM - E
We
kto
r za
ch
od
ni
We
kto
r w
sch
od
ni
Wektor południowy
Wektor północny
Sumowanie
głosów
Decyzja
Rys 4.11 Schemat blokowy klasyfikatora głosującego
Skuteczność klasyfikatora głosującego zależy od parametrów maszyn SVM, liczby
klasyfikatorów, oraz długości wektorów brzegowych. Wyniki testów skuteczności w
zależności od tych czynników zostały przedstawione w rozdziale 6.1.

Przenośny system detekcji i rozpoznawania znaków drogowych
46
5. Rozpoznawanie obrazów i metody klasyfikacji
wzorców
Zadanie rozpoznawania obrazów jest jednym z istotnych problemów współczesnej
techniki, które nadal jest zgłębiane przez wielu naukowców. Przez pojęcie obrazu, jak to było
wspomniane we wcześniejszych rozdziałach, należy rozumieć pewien zbiór danych
zgrupowany w wektor jednowymiarowy lub wielowymiarowy.
Rozpoznawanie jest często realizowane, jako poszukiwanie podobieństw pomiędzy
analizowanym obrazem, a zbiorem pewnych oczekiwanych obrazów –wzorców. Ponadto
definiuje się także pojęcie klasy jako swoistego zbioru wzorców wyróżniających się w pewien
sposób od pozostałych. Nie wyklucza to jednak sytuacji, w której każdy wzorzec wyznacza
swoją klasę, choć znacznie częściej do jednej klasy należy kilka wzorców. Wśród klas można
także wyznaczyć klasę bezwartościową tj. taką która nie posiada konkretnego wzorca. Obraz
należy do klasy bezwartościowej gdy nie należy do żadnej innej klasy. Obraz należy do danej
klasy jeżeli jego podobieństwo do wzorca jest wystarczające w przyjętym systemie ocen.
Przydzielanie obrazu do jednej z wyznaczonych klas określane jest mianem klasyfikacji.
W literaturze anglojęzycznej zadanie rozpoznawania nazwane jest ang. „Pattern
recognition”. Sposobów rozpoznawania obrazów jest wiele, jednak można je podzielić na
trzy podstawowe grupy
Metody bezpośredniej analizy obrazu.
–rozpoznawanie w oparciu o sieci neuronowe
–rozpoznawanie oparte o korelację wzajemną obrazu i wzorca
Metody oparte o generację i analizę wektora cech
–metody minimalno odległościowe NN i k-NN
–metody otoczeń kulistych
–SVM
Inne
Istnieje także grupa metod probabilistycznych, spośród których najistotniejszym jest
klasyfikator Bayesa. W pracy nie będą omawiane klasyfikatory tej grupy, stosowne
informacje i zastosowanie można znaleźć w literaturze oraz w [18], [19] .
Przedstawiony podział nie jest oczywiście ścisły i możliwe jest przykładowo
zastosowanie SVM bezpośrednio na obrazie, jak również użycie sieci neuronowych przy
analizowaniu cech. Przedstawiony tu podział, a także podstawowe metody klasyfikacji które
znajdują się w podrozdziale 5.2.3 zostały opracowane na podstawie [5].
5.1 Metody bezpośredniej analizy obrazu
Analiza bezpośrednia jest też często nazywana dopasowaniem wzorca
(ang. „Template maching”) gdyż przynależność obrazu do klasy jest określana na podstawie
bezpośredniego porównania obrazu i wzorca. Metoda ta nie przewiduje żadnych
przekształceń, a najczęściej stosowanym algorytmem tej grupy jest wyznaczenie wartości
korelacji wzajemnej obrazu i wzorca. Jak podaje [2] wartość korelacji wzajemnej w
dziedzinie liczb rzeczywistych dla danych w postaci macierz może być wyznaczona z
wykorzystaniem wzoru (5.1)

Przenośny system detekcji i rozpoznawania znaków drogowych
47
(5.1)
gdzie są wymiarami wzorca (rozmiar obrazu jest większy), określa
umiejscowienie wzorca na obrazie
W praktyce jednak wyznacza się wartość korelacji wzajemnej dla zerowego
przesunięcia wymaga to jednak dopasowania wymiarów obrazu i wzorca. W
takim przypadku:
Zdefiniowana wzorem (5.1) korelacja wzajemna (dla oraz gdy wielkości –w sensie ilości elementów– obrazu i wzorca są
takie same) jest iloczynem skalarnym tych dwóch wektorów i osiąga
maksimum wtedy i tylko wtedy, gdy wektory te pokrywają się.
Analizując wartości korelacji obrazu ze zdefiniowanymi wcześniej wzorcami można
wyznaczyć klasę obrazu. Najprostszą analizą tego typu jest progowanie tj. sprawdzenie, czy
wartości korelacji znajdują się ponad pewnym arbitralnie dobranym progiem oraz wybranie
klasy dla której wartość korelacji jest największa. Rozpoznawanie obrazów tą metodą mimo
swojej prostoty ma jednak duże ograniczenia związane ze sporym nakładem obliczeniowym.
Przykładowo dla 100 wzorców i rozmiarów obrazu pikseli konieczne jest
przeprowadzenie operacji MAC w procesorze sygnałowym. Ponadto wymagane
jest zapamiętanie wszystkich wzorców w szybkiej pamięci komputera, gdyż w przeciwnym
wypadku czas wykonywania operacji zostanie dodatkowo zwiększony. Z tego też powodu
rozwiązanie to stosowane jest przy rozpoznawaniu bardzo małych obrazów i jednocześnie
niewielkiej ilości wzorców oraz w przypadkach niewymagających działania w czasie
rzeczywistym.
Wraz z rozwojem układów programowalnych a w szczególności układów FPGA
możliwe było częściowe rozwiązanie problemu dużego nakładu obliczeniowego, przez
zrównoleglenie obliczeń i wykorzystanie pamięci rozproszonej charakterystycznej dla tych
układów. Przyspieszenie to najczęściej uzyskiwano implementując w układach
programowalnych sieci neuronowe. Sieci takie są w stanie zapamiętać stosunkowo dużą
liczbę wzorców w postaci współczynników wagowych. Ich dodatkową zaletą jest umiejętność
uczenia się nowych wzorców, sieć taka doskonali swoje umiejętności.
Podstawową jednostką w sieciach neuronowych są perceptrony zbudowane z wejść-
dendrytów, których sygnał jest następnie przemnażany przez wagę- synapsa. Wszystkie
sygnały wejściowe z odpowiednimi wagami są w dalszej kolejności sumowane i stanowią
pobudzenie dla aksonu generującego sygnał do następnej komórki. Neuron może być
przedstawiony jak na rysunku 5.1.
Rys 5.1 Schemat poglądowy neuronu [33].

Przenośny system detekcji i rozpoznawania znaków drogowych
48
Matematycznie pojedynczą komórkę można opisać równaniem (5.2)
(5.2)
gdzie jest funkcją aktywacji neuronu a iloczyn dla =0 jest piedestałem (ang. „bias”)
Często stosowaną funkcją aktywacji neuronu jest funkcja znaku. Jedyną pracochłonną
operacją jest kilkakrotnie powtórzona operacja MAC czyli pomnożenie wartości z wejścia
neuronu przez odpowiednią wagę a następnie zsumowanie wyników.
Sieci jednowarstwowe mają ograniczone możliwość, dlatego też częściej stosuje się
sieci wielowarstwowe zdolne realizować skomplikowane funkcje, także funkcje
rozpoznawania. W sieciach wielowarstwowych realizowane są przeróżne topologie połączeń
włączając w to sprzężenia zwrotne oraz połączenia każdy z każdym. Powoduje to, że
możliwości tych sieci są bardzo duże. Zastosowanie sieci neuronowych jest dość powszechne,
metodę tą zastosowali autorzy [22],[23]. Podstawy działania, podział i przykłady
zastosowania sieci neuronowych w różnych dziedzinach nauki przedstawione są w [6].
5.2 Metody oparte o generacje wektora cech
Obraz we wszystkich swoich elementach niesie pewne informacje, i na podstawie
części tych informacji może on być prawidłowo sklasyfikowany. Najczęściej nie można
a priori wyznaczyć elementów niosących konkretną informację, gdyż każdy element zawiera
w sobie cząstkę wielu informacji jednocześnie. Oznacza to, że w celu wydobycia z obrazu
pożądanej informacji konieczne jest przeprowadzenie wnioskowania wszystkich (lub prawie
wszystkich) elementów obrazu. Transformacje, wydobywające z obrazu najistotniejsze
informacje zapisują je w postaci tzw. wektora cech (ang. „Feature vector”). Najczęściej dąży
się do maksymalnej liczby informacji istotnych z punktu widzenia dalszego przetwarzania w
możliwie najmniejszym wektorze cech.
Przykładem obrazu i jego wektora cech może być grafika komputerowa przedstawiająca
figurę geometryczną w pewnym kolorze. Obraz taki zapisany w postaci macierzy 100 100
pikseli wykorzystujący przestrzeń RGB o 8 bitach na kolor zawiera 10000 elementów o
wielkości 24 bity i zajmuje w pamięci w sumie 234kb. Jego wektor cech składać się może
natomiast z elementów takich jak kod koloru oraz przykładowo niezmienniki momentowe lub
współczynniki kształtu. Wektor cech składał się więc będzie z zaledwie kilku elementów,
zapisanych z taką samą dokładnością reprezentacji, a zajmował będzie znikomy procent
pamięci potrzebnej na przechowanie obrazu oryginalnego.
W przypadku prostych figur geometrycznych wektorami cech mogą być bardzo prosto
wyznaczalne parametry. Niektóre z nich zostały omówione i przeanalizowane pod względem
dokładności reprezentacji i odporności na zakłócenia w dodatku umieszczonym na końcu
pracy. W przypadku bardziej skomplikowanych obrazów koniecznym jest zastosowanie
przekształcenia, które wydobędzie z obrazu wymagane cechy. Transformację należy dobrać
stosownie do wymagań stawianych wektorowi cech. Przekształcenie takie powinno spełniać
kilka dość oczywistych warunków:
dla obrazów tej samej klasy wektory cech powinny być zbliżone względem siebie, i
jednocześnie zdecydowanie różne od wektorów cech dla obrazów należących do
innych klas.
liczba liniowo zależnych względem siebie cech powinna być ograniczona

Przenośny system detekcji i rozpoznawania znaków drogowych
49
wektor cech powinien być reprezentatywny tzn. powinien zawierać wszystkie istotne z
punktu widzenia dalszego przetwarzania informacje o obrazie, z którego został
wygenerowany.
Przedstawione w podrozdziale 5.2.1 przykłady transformat mają szczególne zastosowanie
przy analizowaniu obrazów grafiki komputerowej, chociaż z powodzeniem mogą być
zastosowane w wielu innych przypadkach.
Oddzielnym zagadnieniem jest klasyfikacja wzorców, czyli sposób
przyporządkowywania wektora cech do odpowiedniej klasy. Teoretycznie możliwe jest
zastosowanie prostych metod ilościowych jak np. korelacja wzajemna. Metody te nie dają
jednak dobrych rezultatów. Stosuje się wiele sposobów klasyfikacji, spośród których w
rozdziale 5.2.2 omówione są te najbardziej podstawowe.
5.2.1 Powszechnie znane sposoby generowania wektora cech
Popularnie stosowaną transformatą jest SIFT (ang. „Scale Invariant Feature
Transform”) opisana i zastosowana w [17],[24] oraz [26]. Algorytm ten wyznacza w obrazie
punkty kluczowe (niezależne od skali, kąta i przesunięcia), a następnie opisuje otoczenie
takiego punktu. Przy wyznaczeniu punktów zainteresowania wykorzystane są różnice funkcji
Gaussa (ang. „Difference of Gaussian”) sprzężone z obrazem jak we wzorach (5.3) według
[17].
(5.3a)
(5.3b)
Zmieniające się wartości we wzorach (5.3) generują przestrzeń skal i kolejne obrazy
. Każdy piksel w obrazie jest porównywany z 8 sąsiadami w swojej skali i 9
sąsiadami w skali powyżej i poniżej jego skali. Jeżeli stanowi on maksimum lub minimum
wśród sąsiadów, to jest postrzegany jako kandydat na punkt kluczowy. Następnie
eliminowane są te punkty kluczowe, które mają zbyt mały kontrast, lub są słabo
zlokalizowane względem krawędzi. Kolejnym krokiem jest wyznaczenie gradientu (kierunku)
w punkcie kluczowym a ostatnim etapem określenie otoczenia tego punktu z uwzględnieniem
obliczonego wcześniej kierunku. Dokładny opis algorytmu znajduje się w [17] i [26].
Analogiczną do SIFT jest transformata SURF (ang. „Speeded Up Robust Features”), która
jest nieco zmodyfikowaną i w pełni dyskretną wersją SIFT. Transformata ta została opisana
w [16]. Obie transformaty są dość skomplikowane do wyznaczenia i wymagają przy tym
umiarkowanych mocy obliczeniowych, ale dają bardzo dobre rezultaty.
Inną zaawansowaną transformatą jest PCA (ang. „Principal Components Analysis”)
transformata ta de koreluje dane i umożliwia usunięcie nieistotnych czynników. Pozostałe
dane stanowią wynik działania (ang. Principal Components). W literaturze transformata ta
jest znana pod nazwą ang. Karhunen–Loève transform. Jej algorytm przewiduje w pierwszej
kolejności taką normalizację danych, tak aby ich wartość średnia wynosiła zero. Następnie
wyznaczana jest macierz kowariancji oraz wektory i wartości własne macierzy kowariancji.
Wektorami cech są wektory własne macierzy kowariancji, przy czym najistotniejszy wektor,
to ten którego wartość własna jest największa (dlatego najpierw układane są one w kolejności
malejącej). Transformata ta wykazuje największy stopień kompresji danych spośród
powszechnie znanych transformat. Wymaga ona jednak dużej mocy obliczeniowej do
wyznaczenia macierzy kowariancji, przez co jest rzadko stosowana.

Przenośny system detekcji i rozpoznawania znaków drogowych
50
Często stosowaną transformatą jest wyznaczenie histogramów (rozdział 3.2.1) oraz
histogramów fazowych zrealizowane w [4]. Stosowane są także metody, w których
utworzony na podstawie obrazu wejściowego kontur zostaje poddany analizie. Wyznaczany
jest opis konturowy tzn. obliczane są długości i nachylenia prostych z jakich składa się kontur
i to one stanowią wektor cech. Sposobów generowania wektora cech jest bardzo dużo,
najczęściej bowiem transformatę dobiera się indywidualnie do realizowanego zadania i zależy
ona głównie od pomysłowości autora. Zastosowana w pracy transformata omówiona jest w
podrozdziale 5.2.2.
5.2.2 Zastosowana metoda ekstrakcji cech
W pracy dla wyznaczenia wektora cech zastosowano metodę zbliżoną do tej użytej
w [8]. Zastosowany algorytm jest w istocie podobny do zasady działania tomografu
komputerowego.
Obraz w przestrzeni RGB jest w pierwszej kolejności zamieniany na obraz
monochromatyczny o 256 poziomach skali szarości. Następnie wyznaczany jest histogram, a
na jego podstawie próg binaryzacji według wzoru 5.41. Próg ten to w istocie środek ciężkości
histogramu.
(5.41)
gdzie jest wektorem histogramu o 256 elementach
Następnie obraz poddawany jest binaryzacji z progiem gdzie pikselom o wartościach
jasności większych od progu przypisywana jest 1 a pikselom ciemniejszym 0.
Rys. 5.2 Obraz oraz jego histogram
Wektor cech wyznaczany jest w dwojaki sposób:
Pierwsze podejście przewiduje wyznaczenie dwóch podwektorów poziomego i
pionowego, które następnie zostaną złączone w jeden wektor wynikowy. W tym rozwiązaniu
-ty element pionowego podwektora jest sumą wartości -tego wiersza obrazu binarnego,
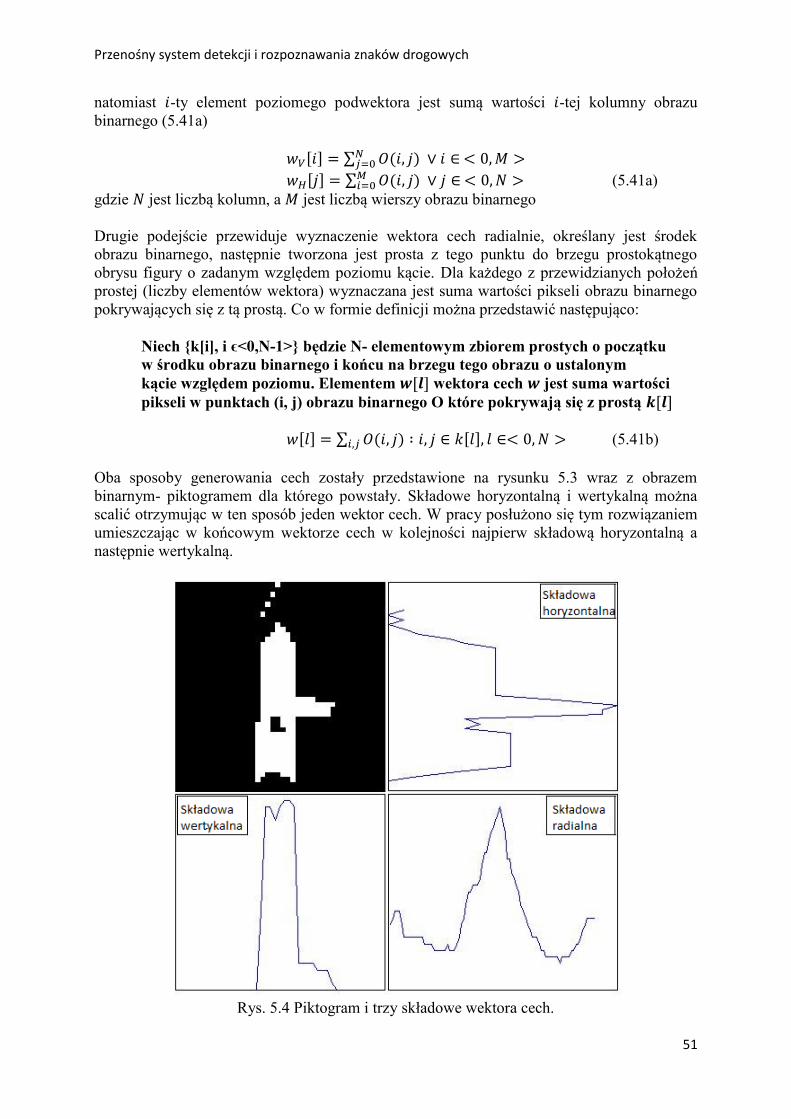
Przenośny system detekcji i rozpoznawania znaków drogowych
51
natomiast -ty element poziomego podwektora jest sumą wartości -tej kolumny obrazu
binarnego (5.41a)
(5.41a)
gdzie jest liczbą kolumn, a jest liczbą wierszy obrazu binarnego
Drugie podejście przewiduje wyznaczenie wektora cech radialnie, określany jest środek
obrazu binarnego, następnie tworzona jest prosta z tego punktu do brzegu prostokątnego
obrysu figury o zadanym względem poziomu kącie. Dla każdego z przewidzianych położeń
prostej (liczby elementów wektora) wyznaczana jest suma wartości pikseli obrazu binarnego
pokrywających się z tą prostą. Co w formie definicji można przedstawić następująco:
Niech {k[i], i ϵ<0,N-1>} będzie N- elementowym zbiorem prostych o początku
w środku obrazu binarnego i końcu na brzegu tego obrazu o ustalonym
kącie względem poziomu. Elementem wektora cech jest suma wartości
pikseli w punktach (i, j) obrazu binarnego O które pokrywają się z prostą
(5.41b)
Oba sposoby generowania cech zostały przedstawione na rysunku 5.3 wraz z obrazem
binarnym- piktogramem dla którego powstały. Składowe horyzontalną i wertykalną można
scalić otrzymując w ten sposób jeden wektor cech. W pracy posłużono się tym rozwiązaniem
umieszczając w końcowym wektorze cech w kolejności najpierw składową horyzontalną a
następnie wertykalną.
Rys. 5.4 Piktogram i trzy składowe wektora cech.

Przenośny system detekcji i rozpoznawania znaków drogowych
52
5.3 Klasyfikatory
Drugim istotnym zagadnieniem w rozpoznawaniu wzorców jest wybór metody
przyporządkowania wektora cech do zadanej klasy obrazów. Zadanie przyporządkowania w
literaturze nazwane jest klasyfikacją i może być zdefiniowane następująco:
Klasyfikatorem jest taki algorytm działania, który na podstawie pewnego
opisu obiektu przyporządkuje ten obiekt do jednej z wielu wcześniej
wyznaczonych grup. Jeżeli istnieją tylko dwie grupy, to algorytm ten
nazywany jest dyskryminatorem.
Stosowane są różnego rodzaju klasyfikatory, najpopularniejsze przedstawione poniżej
są klasyfikatorami wymagającymi nauki. Oznacza to, że klasyfikator jest sparametryzowany, i
w pierwszej kolejności należy ustawić jego parametry- nauczyć rozróżniać klasy. W procesie
nauki wymagane jest podanie co najmniej jednego wektora wzorcowego dla każdej klasy. W
praktyce jednak stosuje się kilka wektorów wzorcowych dla każdej klasy, a ich ilość jest
uzależniona od podobieństw między klasami, liczby klas i rozmiarów wektorów. W
zależności od użytego klasyfikatora wymagana ilość wektorów wzorcowych może być różna,
jednak im większa ich liczba tym większa skuteczność klasyfikacji i mniejsza skłonność do
pomyłek. Istnieje wiele rodzai klasyfikatorów, poniżej zostały przytoczone najpopularniejsze
klasyfikatory nieparametryczne. Klasyfikatory te są najprostszymi, ze stosowanych w
algorytmach rozpoznawania i zostały tu przytoczone ze względu na swoją prostotę.
Klasyfikator NN (ang. Nearest Neighbour) to klasyfikator minimalno odległościowy.
Dla każdej klasy należy zapamiętać co najmniej jeden wzorcowy wektor cech.
Klasyfikacja realizowana jest jako wybór tej klasy, dla której poddawany analizie
wektor cech jest w zadanej metryce najbliższy wektorowi wzorcowemu. W praktyce
kształt klasy w przestrzeni cech może być bardzo skomplikowany, dlatego też stosuje
się kilka wektorów wzorcowych (są to punkty w przestrzeni cech) które pokrywają
cały obszar danej klasy. Metoda ta nie jest odporna na błędy powstałe podczas
wyznaczania wzorcowych wektorów cech.
Klasyfikator k-NN (ang. k Nearest Neighbours ) jest modyfikacją metody NN,
wyznacza się w niej odległość analizowanego wektora od wszystkich wektorów
wzorcowych w klasie, a badanie przeprowadzane jest we wszystkich klasach.
Otrzymane odległości są następnie szeregowane od najmniejszej do największej, a
skojarzone z nimi klasy tworzą k głosów klasowych. Przynależność wektora cech
(obrazu) do danej klasy jest określana na podstawie większości głosów klasowych.
Metoda ta jest odporna na błędy powstałe przy uczeniu klasyfikatora (wyznaczaniu
wektorów wzorcowych) gdyż pojedynczy wektor wzorcowy ze źle przypisaną klasą
zostanie zignorowany podczas pracy klasyfikatora. Jeżeli bowiem błędny wektor
będzie pokazywał na inną klasę niż pozostałe k-1 wektorów to jego głos nie będzie
miał wpływu na klasyfikację.
Klasyfikator NM (ang. Nearest Mode). Jest kolejną ewolucją klasyfikatora NN w
którym konieczne było zapamiętanie wszystkich wzorców pokrywających
równomiernie obszar całej klasy. Klasyfikator NM wybiera kilka wektorów
wzorcowych i każdemu przypisuje kulę (kula jest zdefiniowana przez metrykę
przestrzeni) o środku w punkcie określonym przez wektor cech i promieniu
proporcjonalnym do częstości pojawiania się tego wektora (lub wektora zawierającego
się w tej kuli) w procesie nauki klasyfikatora. Następnie powstałe kule są analizowane
pod kątem zawierania się w pozostałych, jeżeli kula zawiera się w całości w innej kuli,

Przenośny system detekcji i rozpoznawania znaków drogowych
53
to ta mniejsza jest usuwana (zapominana). Efektem końcowym jest zbiór otoczeń
kulistych tworzących pewien obszar w przestrzeni cech z przypisaną do nich klasą. W
pamięci należy więc zapisać dużo mniejszą niż w metodach k-NN i NN ilość
wektorów cech. Klasyfikacja nowych wektorów cech jest dokonywana poprzez
sprawdzenie, czy analizowany wektor leży w środku kuli, czy poza nią.
Klasyfikator SVM. Maszyna SVM jest w istocie dyskryminatorem, jeżeli jednak
zostanie zebranych kilka dyskryminatorów SVM analizujących pojedynczy opis
obiektu, to powstały twór można nazwać klasyfikatorem SVM. Dokładny opis
dyskryminatora SVM przedstawiony jest w rozdziale 5.3.1.
5.3.1 Maszyna wektorów wspierających (ang. Support Vector Machine)
Maszyna wektorów wspierających jest w istocie dyskryminatorem, co oznacza, że jest
w stanie odróżnić tylko dwie klasy. Możliwe jest zbudowanie klasyfikatora w oparciu o SVM,
jednakże wymaga to wielokrotnego przyporządkowania.
Zadanie przyporządkowania obiektu do jednej z N klas prymitywnych }
można rozpatrywać jako zadanie wielokrotnego przyporządkowania tego obiektu do jednej z
dwu klas konkurencyjnych lub gdzie Możliwe
są przy tym następujące warianty [7]
Jeden przeciw wszystkim. Dwie konkurencyjne klasy biorące udział w klasyfikacji
budowane są według wzoru w ten sposób
zamiast klasyfikatora N- klasowego powstaje N dyskryminatorów. Decyzja o
przynależności wektora cech do klasy podejmowana jest na podstawie najsilniejszej
spośród N odpowiedzi.
Jeden na jednego. Dzięki przypisaniu każda para klas jest
analizowana, co pociąga za sobą konieczność zbudowania N(N-1)/2 dyskryminatorów.
Każdej zwycięskiej klasie w każdym dyskryminatorze zostaje przyznany punkt, a
decyzja o przynależności wektora cech do klasy jest podejmowana na podstawie
liczby zgromadzonych punktów.
Jeden przeciw pozostałym. Dwie konkurencyjne klasy stanowią: i a więc konieczne jest zastosowanie N-1 dyskryminatorów.
Decyzja o przynależności jest podejmowana w wyniku przejścia w drzewie decyzji
podjętych przez poszczególne dyskryminatory.
O zdolnościach algorytmu w rozpoznawaniu wzorców mówi tzw. Rozmiar Vapnika-
Czervonenkisa [7] .Wielkość ta określa ile maksymalnie klas prymitywnych można
rozgraniczyć przy użyciu dyskryminatora. Definicja rozmiaru VC według [7] i [28] jest
następująca:
Niech będzie skończonym zbiorem funkcji rozdzielających takich, że
tj. rozróżniających tylko dwie grupy. Rozmiar VC zbioru
funkcji określa maksymalną liczbę klas N (jakie można ponumerować
na sposobów), które da się rozgraniczyć przy użyciu tych funkcji .
Najprostszym przykładem funkcji rozdzielających jest zbiór zorientowanych hiperpłaszczyzn
w przestrzeni (hiperpłaszczyzna taka posiada stronę dodatnią i ujemną). Wektory cech

Przenośny system detekcji i rozpoznawania znaków drogowych
54
stanowią punkty w przestrzeni możliwa jest więc ich klasyfikacja na podstawie położenia
w tej przestrzeni za pomocą hiperpłaszczyzn. W ogólności istnieje takie ułożenie
hiperpłaszczyzny, aby po jej dodatniej stronie znajdowała się dowolna liczba wektorów,
pozostałe natomiast będą usytuowane po stronie ujemnej, co daje bardzo duże możliwości
klasyfikacji. O rozmiarze VC dla zbioru zorientowanych hiperpłaszczyzn mówi poniższe
twierdzenie:
Rozmiar Vapnika-Czervonenkisa zbioru zorientowanych hiperpłaszczyzn
w przestrzeni wynosi
Oznacza to, że dla przestrzeni można w sposób liniowy rozdzielić maksymalnie 3 klasy,
graficznie jest to przedstawione na rysunku 5.2 gdzie każda klasa prymitywna posiada tylko
jeden wzorzec.
Rys. 5.5 Przykład rozdzielności trzech punktów, oraz cztery nieseparowane liniowo punkty.
Zgodnie z definicją rozmiaru Vapnika- Czervonenkisa istnieje sposobów
numerowania, na rysunku 5.5 są przedstawione cztery przykłady rozmieszczenia klas,
pozostałe cztery przypadki powstają przy zmianie orientacji prostej. Czterech punktów
przedstawionych po prawej stronie rysunku nie da się rozdzielić w sposób liniowy, jest to
nieformalny dowód twierdzenia o rozmiarze VC.
W przypadku dyskryminowania wzorców za pomocą zbioru hiperpłaszczyzn istnieje
problem optymalnego doboru tych płaszczyzn. Należy mieć na uwadze, że wzorce
podlegające klasyfikacji są punktami w przestrzeni cech. Naturalnym rozwiązaniem wydaje
się więc takie umieszczenie hiperpłaszczyzny, aby odległość wszystkich wzorców od niej
była największa.
5.3.2 SVM liniowo separowalnego zbioru wzorców
Wzorce są liniowo separowane, gdy da się je rozdzielić zbiorem hiperpłaszczyzn. W
takim przypadku dobór optymalnej hiperpłaszczyzny może być wyznaczony zgodnie z
poniższymi wzorami przytoczonymi z [29]. Rysunek 5.6 stanowi graficzną interpretację
poszukiwanego rozwiązania dla przypadku dwuwymiarowego.

Przenośny system detekcji i rozpoznawania znaków drogowych
55
Rys.5.6 Poszukiwanie optymalnej hiperpłaszczyzny H
Dowolna hiperpłaszczyzna może być opisana wzorem (5.4)
(5.4)
gdzie: A jest wektorem normalnym do hiperpłaszczyzny,
jest odległością hiperpłaszczyzny
od środka układu współrzędnych, natomiast jest argumentem czyli wektorem w przestrzeni
cech ( )
Można wyznaczyć dwie hiperpłaszczyzny graniczne, z których każda przechodzi przez zbiór
wszystkich najbardziej wysuniętych punktów swojej klasy. Punkty graniczne nazywane są
wektorami wspierającymi (ang. „Support Vector”). Na rysunku 5.6 przedstawione to jest jako
proste H1 i H2, matematycznie zaś przez równania (5.5)
dla H1 (5.5a)
dla H2 (5.5b)
gdzie jest odzwierciedleniem klas konkurencyjnych omawianych we wstępie i oznacza
punkty będące wektorami wspierającymi. Pozostałe punkty spełniają równania (5.6)
dla (5.6a)
dla (5.6b)
Oba powyższe równania mogą być sprowadzone do pojedynczego równania:
(5.6c)
gdzie oznacza klasę konkurencyjną -tego wektora cech

Przenośny system detekcji i rozpoznawania znaków drogowych
56
Odległości pomiędzy prostymi H1 i H oraz H2 i H są oznaczone kolejno d1 i d2 Pożądanym
przypadkiem jest, aby odległości d1 i d2 były równe. wtedy d=d1=d2 znane jest w literaturze
jako margines maszyny SVM, a geometria wektorowa mówi, że (5.7):
(5.7)
Zapewnienie maksymalnej odległości d wymaga jednocześnie znalezienia najmniejszej
wartości przy zachowaniu warunku: co może być zapisane
jako (5.8):
, (5.8)
Znalezienie optymalnego rozwiązania (5.8) możliwe jest przy wykorzystaniu mnożników
Lagrange’a (ang. „Lagrange multipliers”). Jest to metoda znajdowania ekstremum
warunkowego funkcji różniczkowalnych. Metoda ta jest opisana w wielu podręcznikach
matematyki wyższej i nie jest tematem tej pracy mimo, że jej znajomość jest konieczna do
rozwiązania postawionego wyżej problemu. W związku z tym zostaną przytoczone tylko
wzory początkowe i końcowe ważniejszych etapów rozwiązania, a wszystkie niezbędne
przekształcenia zostaną pominięte. Przekształcenia te znajdują się w [28] i [29].
(5.9)
gdzie jest wagą we wzorze Lagrange’a
Żądane rozwiązanie to takie, w którym i minimalizuje wartość a tą wartość
maksymalizuje przy konieczności zachowania . W celu znalezienie takiego
rozwiązana należy przyrównać pochodne względem i a do zera.
(5.10)
Wstawiając równania (5.10) do (5.9) otrzymujemy:
(5.11)
Przedstawione równanie (5.11) jest formą dualną równania . Zadanie minimalizacji
zostało przekształcone do zadania maksymalizacji i jest to problem wypukłej
optymalizacji kwadratowej. Rozwiązanie numeryczne tego zadania daje w wyniku wartość
na podstawie której możliwe staje się wyznaczenie ze wzoru (5.10) a następnie na
podstawie (5.5). Możliwe jest także znalezienie wektorów wspierających, są to mianowicie te
wektory dla których .

Przenośny system detekcji i rozpoznawania znaków drogowych
57
Na koniec należy zauważyć, że liniowy SVM opiera się na hiperpłaszczyznach, a więc
obowiązuje go twierdzenie odnośnie rozmiaru VC i maksymalnej liczby klas jakie jest w
stanie odróżnić. Nakłada to konieczność stosowania odpowiednio dużego wektora cech.
Przedstawiona procedura wyznaczania optymalnej hiperpłaszczyzny opierała się
głównie na rozwiązaniu dość złożonego zestawu równań. Odmienne podejście jest
przedstawione w [5], autor przyjmuje że istnieje pewna ciągła funkcja rozgraniczająca klasy.
Zakłada przy tym, że funkcja ta jest funkcją o (cytat z [1]) „skończonej dziwaczności” i da się
aproksymować pewnym zbiorem funkcji o „rosnącej dziwaczności”. Pojęcie funkcji o
skończonej dziwaczności jest dalej tłumaczone jako funkcja o ograniczonej liczbie
ekstremów, analogicznie należy rozumieć rosnącą dziwaczność. Na podstawie [5] został
napisany kolejny podrozdział 5.3.2 omawiający problem nieliniowej klasyfikacji SVM.
5.3.3 SVM dla nieliniowo separowalnego zbioru wzorców
W praktyce liniowa separowalność wektorów jest rzadko spotykana, nie mniej istnieją
takie przypadki, gdzie mimo pozornej nieliniowości funkcji przynależności należy
zastosować liniową maszynę SVM. Ma to miejsce gdy wektory cech użyte do uczenia
maszyny mają źle przypisane klasy- podobny problem występował dla minimalno
odległościowych metod klasyfikacji. (Metoda k-NN jest uodpornioną wersją metody NN na
źle przypisane klasy wzorców). Maszynę SVM także można uodpornić na błędnie przypisane
klasy wektorów wzorcowych, należy wtedy równania (5.5) zmodyfikować do następującej
postaci:
(5.12)
Gdzie oznacza koszt błędu, a minimalizacji jest poddawane wyrażenie:
przy zachowaniu warunku
Gdzie jest współczynnikiem wagowym mówiącym jak bardzo koszt błędów ma wpływać
na proces nauki klasyfikatora. Mnożnik Lagrange’a przyjmuje postać:
(5.13)
i są wagami wynikającą z ogólnego wzoru mnożników Lagrange’a
Do wyznaczenia konieczne jest obliczenie trzech pochodnych:
(5.14)
Prowadzi to do tego samego równania , jak w przypadku liniowo separowanych wzorców,
tym razem jednak warunkami są:

Przenośny system detekcji i rozpoznawania znaków drogowych
58
i (5.15)
Rozwiązanie więc jest analogiczne do poprzedniego. Powstała maszyna SVM dopuszcza
istnienie błędnie przypisanych klas, ale w procesie uczenia ich liczba jest minimalizowana.
Ten algorytm wyznaczania współczynników hiperpłaszczyzn jest częściej stosowany, niż
„czysty” SVM.
Jeżeli jednak wzorce nie są liniowo separowane, to należy zastosować nieliniową
maszynę SVM. W tym przypadku praktykowany jest pewien zabieg linearyzujący dane, a
więc zmieniający dziedzinę algorytmu. Zabieg ten można także rozumieć jako zakrzywienie
przestrzeni, w taki sposób, żeby wzorce były liniowo separowane. W nowej dziedzinie można
zastosować algorytm liniowego SVM. Jak podaje autor [5] zakłada się, że istnieje pewna
funkcja rozróżniająca dwie klasy konkurencyjne i :
(5.16a)
Funkcja jest ponadto rozwijalna względem rodziny funkcji zwanej
funkcjami bazowymi lub funkcjami jądra rozwinięcia.
(5.16.b)
gdzie: jest wagą -tej funkcji rozwijającej
Przytoczony wzór (5.16b) jest uproszczoną wersją bardzo często stosowanych przekształceń
zwanych popularnie transformacjami. W transformacjach stosuje się rodzinę funkcji o
określonych właściwościach, lecz różnych wartościach tych właściwości dla każdego członka
rodziny. Przykładowo w transformacji kosinusowej rodziną funkcji jest zbiór cosinusów,
każdy o innym okresie. Ogólna postać rodziny funkcji jest nazywana jądrem transformaty
(ang. „Kernel”), dla wspomnianej transformaty kosinusowej jest to funkcja cosinus.
Współczynniki rozwinięcia transformaty mówią, w jakim stopniu funkcja podlegająca
transformacie jest podobna do danego członka rodziny. Analogicznie we wzorze 5.16b
określa jaki jest udział funkcji w rozwijanej funkcji . Sumowanie jest
przeprowadzane po wszystkich członkach rodziny funkcji rozwijających i
dlatego wynik tego sumowania może być równy funkcji klasyfikującej. W praktyce jednak
dopuszcza się istnienie pewnego błędu aproksymacyjnego związanego z sumowaniem
pierwszych M członków rodziny narzuca to jednak na tą rodzinę zachowanie pewnych
prawidłowości. Warunki jakie musi spełniać rodzina są dobrze omówione w [5], tu zostaną
one tylko wspomniane:
Rodzina musi zapewnić dobrą rozwijalność funkcji względem siebie.
Członkowie rodziny muszą być funkcjami o rosnącej liczbie ekstremów.
Najmłodszy członek rodziny musi dobrze aproksymować funkcje o małej liczbie
ekstremów, podczas gdy starsi powinni reprezentować większą liczbę ekstremów.
Warunek ten jest analogicznym do malejącego okresu cosinusów w transformacie
kosinusowej.
Najbardziej pożądanym jest aby funkcje bazowe było ortonormalne względem siebie,
a w zasadzie koniecznym jest aby były ortogonalne.
Prawidłowo dobrana rodzina funkcji rozwijających zapewnia, że klasyfikator może być
zrealizowany jako:

Przenośny system detekcji i rozpoznawania znaków drogowych
59
(5.17)
Wzór (5.17) względem (5.16) różni się zakresem sumowania, który w tym pierwszym
obejmuje także element o indeksie zero, a więc element neutralny. Wektory cech są za
pomocą funkcji rozwijających rzutowane do innej przestrzeni cech, gdzie realizowany jest
liniowy SVM. Funkcjami rzutującymi mogą być następujące funkcje
liniowe:
(5.18)
w takim przypadku liczba funkcji rozwijających, a także sumowanie we wzorze (5.17)
przyjmuje wartość co z kolei prowadzi do:
(5.19)
Wzór (5.19) jest analogicznym do (5.4) tak więc zaprezentowane w [5] podejście jest
równoważnym do podejścia przedstawionego w [28] i [29]. Na tej podstawie można
wnioskować, że wykorzystanie rodziny nieliniowych funkcji jądra będzie prowadziło do
takich samych rezultatów, jakie są przedstawione w [28] i [29]. Rodzina funkcji
przekształcających generuje wektory w nowej przestrzeni cech, zachodzi więc:
(5.20a)
Zatem:
(5.20b)
gdzie jest nowym wektorem cech
Co oznacza, że nieliniowy problem SVM został dzięki zmianie dziedziny przekształcony do
liniowej maszyny SVM. Podobne rozumowanie przeprowadzone jest w [29] gdzie warunek
wzoru (5.11) został wyprowadzony z jego ogólnej formy postaci:
(5.21)
gdzie oznacza funkcję jądra
Zaprezentowane tu jądro jest liniowe, nie mniej może to być niemalże dowolne inne
jądro. Więcej na ten temat można znaleźć w [28]. Także w tym przypadku nieliniowa funkcja
przekształcająca prowadzi do linearyzacji zadania klasyfikacji i umożliwia zastosowanie
liniowej maszyny SVM. Analiza (5.21) w kontekście przytoczonej z [5] metodyki
rozumowania po raz drugi prowadzi do wniosku, że podejścia te są równoważne. Wzór (5.17)
jest zatem istotą działania liniowego i nieliniowego SVM, który to algorytm może być
traktowany, jako pewnego rodzaju transformata.
Powszechnie stosowanymi jądrami są:

Przenośny system detekcji i rozpoznawania znaków drogowych
60
RBF (ang. “Radial Basis Function”)
Wielomianowe
Sigmoidalne
Rozmiar Vapnika-Czervonenkisa maszyny SVM stosującej jądro typu RBF jest nieskończenie
duży. Można bowiem dla każdego wektora zastosować odrębną funkcję RBF która w okolicy
tego wektora będzie przyjmowała wartości bliskie 1, a wszędzie poza tym obszarem wartości
bliskie 0 (o wielkości ww. obszaru decyduje przyjęta metryka oraz parametr we wzorze). W
nieliniowej dziedzinie będzie więc znajdował się tylko jeden punkt o wartości zbliżonej do 1 i
wiele punktów o wartościach zbliżonych do 0. Taki układ jest łatwo klasyfikowalny liniowo,
a więc każdemu wektorowi można przypisać odrębną klasę. Teoretycznie zatem klasyfikator
zbudowany na podstawie dyskryminatora z jądrem RBF jest w stanie rozróżnić
nieograniczoną liczbę klas przy skończonym wymiarze wektora cech. Jest to największą
zaletą maszyny SVM z tym jądrem.
W [5] zaprezentowana jest także metodyka wyznaczania współczynników wagowych
algorytmu. Ze względu na fakt, że nieliniowy SVM da się sprowadzić do liniowego,
przedstawiony tu plan nauki dotyczył będzie tylko przypadku liniowego. Przewiduje on, że
nowe położenie hiperpłaszczyzny jest wyznaczane jako suma dotychczasowego położenia i
pewnej poprawki. Poprawka jest obliczana na podstawie samego wektora, przypisanej klasy
docelowej, oraz klasy na jaką wskazuje ucząca się maszyna. Poprawki są wyznaczane tak,
żeby maksymalizować skuteczność klasyfikatora. Proces uczenia przeprowadza się zazwyczaj
kilku etapowo, w pierwszej części głównym celem jest osiągnięcie największej liczby
prawidłowych klasyfikacji. W drugim natomiast optymalizuje się położenie hiperpłaszczyzny,
ze względu na maksymalizację jej odległości od każdej z klas. Interpretację geometryczną
procesu uczenia przedstawia rysunek 5.7
Nowe położenie
hiperpłaszczyznyStare położenie
hiperpłaszczyzny Rys. 5.7 Interpretacja geometryczna procesu uczenia

Przenośny system detekcji i rozpoznawania znaków drogowych
61
Jeżeli jądro przekształcenia zostało prawidłowo dobrane do realizowanego zadania, oraz
maszynie zaprezentowano wystarczającą liczbę wzorców do nauki, to jest ona zdolna do klasyfikacji.
Wektory których nie stosowano do trenowania maszyny, a których przynależność do klas jest znana
stanowią zbiór trenujący. Testowanie odbywa się poprzez zastosowanie wzoru 5.22, a więc
przekształcenie do nowej przestrzeni cech i wykonanie operacji MAC.
(5.22)
gdzie oznacza znak wyrażenia będącego argumentem
Przynależność do klasy jest określana na podstawie znaku, zatem skomplikowana metodyka nauczania
klasyfikatora jest później rekompensowana prostym jego użyciem. Wyniki działania maszyny SVM
przy zastosowaniu różnych funkcji jądra zaprezentowane są w rozdziale 6.2

Przenośny system detekcji i rozpoznawania znaków drogowych
62
6. Skuteczność algorytmów
Zastosowane w pracy rozwiązanie składa się z dwóch modułów, modułu detekcji i
modułu rozpoznawania. Z tego względu badanie skuteczności zostało podzielone na dwie
części. Pierwszy podrozdział opisuje blok detektora i wpływ różnych parametrów z nim
związanych na skuteczność oraz czas jego pracy. W drugim podrozdziale analizowana jest
praca bloku rozpoznawania znaków i wpływ dostępnych parametrów na jego pracę. Ostatni
podrozdział podsumowuje uzyskane wyniki i porównuje je do uzyskiwanych przez podobne
algorytmy.
Zbiór testowy składał się ze 164 obrazów, które przedstawiały w sumie 202 znaki.
Wszystkie obrazy trenujące/testujące zostały zgromadzone przez autora pracy przez
wykonanie zdjęć znaków aparatem fotograficznym wbudowanym w telefon komórkowy.
Zdjęcia zostały wykonane w rozdzielczości 1Mpix czyli 1280×768 pikseli z automatycznym
balansem bieli oraz bez użycia doświetlającej lampy błyskowej. Zebrane zdjęcia nie były w
żaden sposób poprawiane w programach graficznych do tego służących. Tak zebrany zbiór
trenujący/testujący zdaniem autora jest najbardziej reprezentatywny gdyż przedstawia znaki w
scenerii w jakiej występują. Ze względu na trudności przy zbieraniu obrazów liczba klas
znaków została ograniczona do 23 najczęściej występujących w czasie gdy ich gromadzenie
było przeprowadzane. Najliczniejszymi grupami są znaki A7-ustąp pierwszeństwa, B20- stop
C9- nakaz jazdy z prawej strony znaku i D1- droga z pierwszeństwem przejazdu i występują
one w liczebności 10 i 11 znaków. Najmniej licznymi są klasy A5- skrzyżowanie, C12- ruch
okrężny, B33- ograniczenie do 50 km/h itp. występujące w liczebności 6 znaków. Takie
podejście zapewnia rozkład liczby znaków na klasę wahający się od 3.1% do 5.6%.
Zastosowane metody trenowania i testowania bloków detektora i rozpoznawania
przedstawiono w stosownych rozdziałach tj. odpowiednio w 6.1 i 6.2.
6.1 Skuteczność detektora
Pionowe znaki drogowe wykorzystują 6 podstawowych kształtów geometrycznych,
którymi są: okrąg, prostokąt, trójkąt z wierzchołkiem skierowanym w górę, trójkąt z
wierzchołkiem skierowanym w dół, rąb i ośmiokąt. Trenowanie/testowanie algorytmu
detektora zostało oparte o wylosowanie spośród wszystkich obrazów 6 takich, w których będą
się zawierały wszystkie 6 figur geometrycznych. Te 6 obrazów stanowi zbiór testowy,
pozostałe znaki stanowią zbiór trenujący. Operacja trenowania została powtórzona
kilkakrotnie, a po każdym jej przeprowadzeniu zapisano stosowne parametry detektora, tak
żeby możliwym było jego ponowne użycie. Jest to uproszczona wersja sprawdzianu
krzyżowego (ang. „cross-validation”).
Moduł detektora został szczegółowo opisany w rozdziale 4.3 tu należy przypomnieć,
że zastosowana metoda opiera się o analizę koloru i kształtu jednocześnie. W pierwszej
kolejności realizowane jest badanie obrazu pod względem występujących w nim kolorów, aby
następnie wybrane obszary przeanalizować pod względem kształtu za pomocą maszyny SVM.
Skuteczność detektora zależały więc od dwóch czynników, operacji realizowanych przy
analizie kolorystycznej, oraz ustawień maszyny SVM i sposobu reprezentacji kształtu jaki ta
maszyna analizuje.
Analiza koloru realizowana jest w przestrzeni HSV dzięki czemu znalezienia barw
odpowiadających barwom znaków można dokonać przy użyciu prostych funkcji
przynależności. Funkcja taka sprawdza czy kolor piksela znajduje się w jej obszarze
zainteresowania, jeżeli barwa piksela jest odpowiednia to w obrazie wyjściowym przyjmuje

Przenośny system detekcji i rozpoznawania znaków drogowych
63
on wartość 1 w przeciwnym przypadku 0. Progi funkcji przynależności zostały dobrane
sztywno i nie istnieje możliwość ich zmiany. Powstały w ten sposób obraz binarny można
poddać wielu przekształceniom, spośród których autor doświadczalnie wybrał zestaw tych,
które dawały najlepsze rezultaty podczas testów.
Na rysunku 6.1 przedstawiona została skuteczność detektora przy zastosowaniu kilku
zestawów różnych przekształceń. Na wykresach przedstawiono zdolność znalezienia znaku-
seria „znak” oraz błędne rozpoznanie kształtu który został zinterpretowany jako znak w serii
„błąd”. Można przyjąć rozumowanie, w którym zdolność znalezienia znaku będzie
ekonomicznym zyskiem, natomiast błędnie zinterpretowany kształt kosztem operacji. W tym
sensie należy dążyć do zwiększenia zysku przy jednoczesnym obniżeniu kosztów. Liczbę
znalezionych kształtów porównano z całkowitą liczbą znaków jaka znajdowała się w
testowym zbiorze obrazów.
Przez określenie operacji lokalnej autor miał na myśli trzykrotne przeprowadzenie
danej operacji, jednorazowo na każdym z trzech pod-obrazów będących wynikiem
częściowym poszukiwania kolorów. Oznacza to, że przykładowa operacja zamknięcia została
wykonana dla pod obrazu który jest wynikiem pośrednim poszukiwania znaków koloru
czerwonego. Drugie zamknięcie zostało wykonane dla pod obrazu z koloru żółtego, a trzecia
operacja dla koloru niebieskiego. Wszystkie te operacje wykorzystywały taki sam element
strukturalny. Pojęcie operacji globalnej należy rozumieć, jako wykonanie jej na obrazie
będącym sumą trzech pod obrazów składowych.
Skuteczność algorytmu w przypadku braku dodatkowych operacji (kolumny 1)
stanowią punkt odniesienia dla wszystkich przeprowadzonych przekształceń. Najlepszy
rezultat uzyskano dla lokalnego zamknięcia i globalnego otwarcia, która to operacja
przyczyniła się do wzrostu skuteczności z poziomu 69% do poziomu 79%. Jest to jednak
okupione wzrostem nieprawidłowych oznaczeń (algorytm znalazł znak w miejscu gdzie go
niema) z poziomu 30% do 50%. Koszt jest więc dwa razy większy, niż uzyskane korzyści,
niemniej jednak można w tym miejscu domniemywać, że blok rozpoznawania będzie w stanie
odrzucić taki błędnie zinterpretowany kształt. Interesującym rozwiązaniem jest też
zastosowanie lokalnego przekształcenia zamknięcia, która to operacja cechowała się
wzrostem skuteczności z 69% do 75% przy jednoczesnym wzroście kosztów z 30% do 33%.
Rozwiązanie to jest więc „ekonomicznie uzasadnione”

Przenośny system detekcji i rozpoznawania znaków drogowych
64
Rys. 6.1 Wpływ różnych przekształceń obrazów na skuteczność algorytmu detekcji.
Drugim czynnikiem mającym wpływ na skuteczność bloku detektora są ustawienia
maszyny SVM i zastosowanych w jej pracy wektorów. W pracy przewidziano jeden sposób
tworzenia wektora cech (został on opisany w rozdziale 4.3) możliwa jest natomiast zmiana
jego długości w dowolnych granicach. Nie mniej ustawienie wektora o długościach bardzo
małych jest mało zasadne, gdyż zakłócenia w obrazie oraz fakt istnienia skończonej liczby
pikseli będą miały zbyt duży wpływ na wyznaczane wektory. Ustalenie wartości zbyt dużej
skutkuje koniecznością skalowania figury do rozmiarów większych, niż te w których on
występuje, co także wiąże się z powstaniem dużych błędów binaryzacji. Duże wektory cech
wymagają także stosowania większej liczby treningów i jednocześnie większej liczby danych
trenujących. Na rysunku 6.2 przedstawiony został wpływ rozmiarów wektora na skuteczność
algorytmu detekcji. Posłużono się przy tym powszechnie znanym wykresem ROC
(ang. „Receiver Operating Characteristic”). Na osi poziomej tego wykresu znajduje się
parametr FPR (ang. „False Positive Rate”) który mówi ile obszarów zostało błędnie
sklasyfikowanych jako znaki w stosunku do wszystkich obszarów nie będących znakami. Na
osi pionowej znajduje się parametr TPR (ang. „True Positive Rate”), który z kolei mówi ile
znaków zostało prawidłowo znalezionych w stosunku do wszystkich znaków występujących
w obrazach. Wykres ROC został przedstawiony w całym zakresie możliwych wartości.
Dodatkowo w prawym dolnym rogu znajduje się zbliżenie obszaru uzyskanych wyników.
Na rysunku można zaobserwować, że najlepsze wyniki uzyskano dla wektorów o długości 50
elementów. Wynik można zinterpretować następująco: analizując zbiór obrazów przeciętnie
zostanie znalezionych 78%

Przenośny system detekcji i rozpoznawania znaków drogowych
65
znaków w nich przedstawionych i jednocześnie do grupy znaków zostanie błędnie
przydzielonych 26% pozostałych figur znajdujących się w tych obrazach. Czerwona prosta
przebiegająca skośnie przez środek wykresu jest hipotetycznym wynikiem losowania, czy
dany kształt jest znakiem czy nie. Zakłada się przy tym, że liczebność zbiorów znaków i
nie-znaków jest taka sama.
Rys. 6.2 Wpływ rozmiaru wektora na skuteczność algorytmu detekcji.
TPR – liczba znalezionych znaków w odniesieniu do wszystkich znaków w obrazie.
FPR – liczba obszarów błędnie rozpoznanych jako znaki w stosunku do liczby wszystkich
obszarów nie będących znakami.
Przy testowaniu algorytmu założono, że nieprawidłowe zinterpretowanie kształtu
(rozpoznanie trójkąta w miejscu, gdzie występuje rąb itp.) jest równoznaczne ze
zinterpretowaniem nie- znaku jako znaku. Tym samym postawiono detektorowi
rygorystyczne wymagania poprawności działania. Podejście takie podyktowane jest
wymaganiami kolejnego etapu przetwarzania- bloku rozpoznawania. Koniecznym jest
wycięcie wnętrza znaku w celu poddania go pod analizę zawartości, błędnie zinterpretowany
kształt znaku uniemożliwiłby więc poprawne działanie tego bloku.
Innym dość istotnym parametrem algorytmu był czas jego wykonania, zależał on
głównie od czasu potrzebnego na przekształcenia kolorów, w tym na dodatkowe operacje
morfologiczne. Sprawdzony więc był czas realizacji algorytmu w zależności od rozmiaru
obrazu jaki był poddawany analizie, oraz jego wpływ na skuteczność procedury. Wyniki
przedstawiono na rysunku 6.3.
Jak widać na wykresie czas realizacji w bardzo dużym stopniu zależy od rozmiarów
obrazu i może zmienić się o rząd wielkości. Algorytm zachowywał stabilność, należy bowiem
zauważyć, że zmiana rozmiarów obrazu wiąże się ze zmianą wielkości znaków, a więc i
koniecznością skalowania ich obszarów w górę. To z kolei w niewielkim stopniu może
prowadzić do zmniejszenia skuteczności algorytmu jak to zostało wykazane w poprzednim
przypadku. Zastosowanie zbyt małych obrazów wiąże się z większym wpływem dyskretnego
charakteru obrazu, a więc gorszą jakością znaków a co za tym idzie także i mniejszą

Przenośny system detekcji i rozpoznawania znaków drogowych
66
skutecznością algorytmu. Wpływ tych dwóch parametrów można zaobserwować na krzywej
skuteczności, która ma tendencję do zaginania się w dół dla coraz mniejszych rozmiarów
obrazu.
Rys.6.3 Wpływ rozmiarów obrazu na czas detekcji
Obrazy o średnich rozmiarach (0.4Mpix do 0.6Mpix) są analizowane szybko, wykres
czasu jest w dużym stopniu liniowy, można więc w prosty sposób przeliczyć wielkość obrazu
na czas jego przetwarzania. Obrazy o rozmiarach powyżej 0.6Mpix były bardzo dokładne, a
więc skuteczność ich przetwarzania zbliżyła się bardzo do maksimum. Różnica w czasie
przetwarzania obrazów o rozmiarach 0.6Mpix i 1Mpix wynosi aż 450 [ms] czyli 50% czasu
potrzebnego na analizę większego z nich. Zastosowanie bardzo dużych obrazów jest więc
bezzasadne, nie wpływa znacząco na skuteczność, a zabiera dużo czasu. Zakładając, że
algorytm może pracować w urządzeniach mobilnych bardzo istotnym staje się czas jego
realizacji, który jak widać w dużym stopniu zależy od przyjętej dokładności danych
poddawanych analizie- rozmiarowi obrazu.
Jak wykazano skuteczność przyjętego rozwiązania modułu detektora zależy od kilku
czynników spośród których najważniejszymi są zastosowane operacje morfologiczne
realizowane na obrazach częściowo przetworzonych, prawidłowy dobór rozmiarów wektora
cech, a także rozmiar samego obrazu. Ten ostatni parametr ma także bardzo duży wpływ na
czas realizacji, co jest kluczowym czynnikiem w aplikacjach pracujących w czasie
rzeczywistym. Uzyskane maksimum skuteczności nie jest największym z jakim można się
spotkać w literaturze. Wynik 80% jest zadowalający, nie mniej daleko mu do wyników
dobrych. Powodem takiego stanu rzeczy może być niedoskonały blok analizy koloru, progi
funkcji przynależności są ustawione sztywno i nie ma możliwości ich zmiany. Zastosowanie
algorytmów wielokrotnej analizy tekstury, lub metod uczących się mogłoby w dużym stopniu
poprawić znajdowanie obszarów zainteresowania. Poza tym zastosowanie bloku obracania do
prawidłowego ułożenia przekrzywionych znaków przypuszczalnie także skutkowałoby
zwiększeniem prawidłowości działania algorytmu.
Także sposób generowania wektorów cech nie jest doskonały, gdyż przysłonięty róg
prostokątnego znaku skutkuje zaburzeniem w dwóch wektorach cech. Może się tak zdarzyć,
że zaowocuje to błędnym rozpoznaniem tych wektorów i w efekcie odrzuceniem figury. Z
drugiej jednak strony przysłonięcie całego brzegu (przykładowo gałęziami drzew) przy
widocznych rogach spowoduje, że tylko jeden wektor będzie błędnym i cały znak pozostanie
prawidłowo rozpoznany. Rozwiązaniem tego problemu może być złożenie czterech wektorów

Przenośny system detekcji i rozpoznawania znaków drogowych
67
w jeden i zastosowanie jednego klasyfikatora. Rozwiązanie takie nie było jednak testowane.
Także procedura trenowania maszyny SVM ma wpływ na jej skuteczność.
6.2 Skuteczność rozpoznawania
Blok detektora przekazuje znalezione obszary o stosownym kształcie do bloku
rozpoznawania, który odpowiedzialny jest za prawidłowe zidentyfikowanie znaku. Zasada
działania bloku rozpoznawania oparta jest o ekstrakcję cech opisaną w rozdziale 5.2.2.
klasyfikacja natomiast została zrealizowana jako maszyna SVM opisana w rozdziale 5.3.
Skuteczność rozpoznawania uzależniona jest więc od dwóch czynników: wielkości i sposobu
wyznaczenia wektorów cech opisujących znak oraz parametrów maszyny, w tym
najważniejszego czynnika jakim jest typ jądra przekształcenia. Wybrany sposób generacji
cech i typ jądra przekształcenia maszyny SVM pociągają za sobą konieczność dostosowania
pozostałych parametrów klasyfikatora. Wektor cech wygenerowany w układzie kartezjańskim
jest umieszczony w innym miejscu przestrzeni niż wektor tego samego znaku
wygenerowany w układzie biegunowym. Także odległości między wektorami w układzie
kartezjańskim są inne niż odległości między analogicznymi wektorami w układzie
biegunowym. Oznacza to, że przestrzenie cech są inne, a więc inne powinny być także
parametry maszyny SVM. W każdym przypadku powinien on być dostosowany do
przestrzeni w jakiej pracuje. Wszystkie te czynniki powodują, że koniecznym jest testowanie
skuteczności w tzw. zestawach czyli parach: typ wektora cech – typ jądra przekształcenia.
Zbadane zostały konfiguracje z jądrem Liniowym i RBF, nie udało się znaleźć prawidłowych
parametrów dla jądra Sigmoidalnego. Poszukiwania prawidłowych parametrów maszyny
SVM dokonano według idei przedstawionej w [32]. Na rysunku 6.4 przedstawiono wyniki
badania.

Przenośny system detekcji i rozpoznawania znaków drogowych
68
Rys. 6.4 Skuteczność rozpoznawania dla różnych zestawów.
Na tym etapie skuteczność badano podobnie jak w detektorze tj. metodą sprawdzianu
krzyżowego losując grupę obrazów, która zawiera co najmniej po jednym znaku danej klasy.
Grupa ta stanowi wektor testowy, pozostałe obrazy stanowią wektor trenujący.
Najwyższą skuteczność uzyskano dla zestawu, w którym zastosowano kartezjański
układ współrzędnych do wyznaczenia wektora cech, a jądrem przekształcenia był RBF.
Uzyskany wynik 86% nie wyróżniał się jednak bardzo spośród wszystkich zastosowanych
rozwiązań, gdyż najgorszy wynik dla zestawu 4 to 78%. Te niewielkie rozbieżność należy
przeanalizować pod kątem zastosowanego sposobu generacji wektora cech, oraz pod kątem
typu jądra maszyny SVM.
Porównanie kolumny 1 z 4 i 2 z 3 jest w istocie porównaniem sposobu tworzenia
wektora cech. W tym przypadku wektory tworzone w układzie kartezjańskim lepiej opisują
znak. Ten sposób gwarantuje zapamiętanie każdego piksela znaku dwukrotnie, podczas
tworzenia wektora pionowego i poziomego. Natomiast tworzenie wektora cech w układzie
biegunowym skutkuje kilkakrotnym zapamiętaniem pikseli znajdujących się blisko środka
obszaru znaku i pominięciem pikseli odległych od tego środka. Szczególnie w przypadku
znaków trójkątnych sposób ten nie wydaję się być najodpowiedniejszym, gdyż w znakach
tych istotne są także brzegi obszaru w pobliżu wierzchołków trójkąta. Fakt ten objawia się
mniejszą skutecznością algorytmu niż zastosowanie układu kartezjańskiego.
Porównanie kolumn 1 z 2 oraz 3 z 4 jest analizą skuteczności rozpoznawania ze
względu na zastosowane jądro przekształcenia. Maszyna oparta o jądro radialne wykazała
większą skuteczność, niż ta w której zastosowano liniową klasyfikację. Wynika to z
właściwości przekształcenia wykorzystującego funkcje RBF, które selekcjonują wybrany
obszar w przestrzeni cech odrzucając jego otoczenie. Funkcja liniowa jest natomiast w stanie
oddzielić wybrany obszar tylko z jednej strony. Niewielka różnica w uzyskanej skuteczności

Przenośny system detekcji i rozpoznawania znaków drogowych
69
wynikła zapewne z dość jednoznacznie określonych wektorów cech oraz dużej ich odległości
między sobą. Wektory te nie były skomplikowane, dlatego też klasyfikator wykorzystujący
przekształcenie liniowe uzyskał wynik bardzo zbliżony do klasyfikatora z funkcjami RBF.
Ustalenie prawidłowych parametrów bloku rozpoznawania pozwoliło na wyznaczenie
w bardziej wiarygodny sposób skuteczności algorytmu. Na tym etapie zastosowano metodę
trenowania/testowania typu zostaw jeden poza (ang. „leave-one-out”) która zakłada, że każdy
obraz jest dokładnie jeden raz wektorem testującym i N-1 razy wektorem trenującym gdzie N
jest liczbą obrazów. Sprawdzono przy tym jak często znaki są błędnie rozpoznawane- znak
jest przyporządkowany do innej klasy, a jak często nie- znak jest błędnie rozpoznawany jako
znak. Wyniki zostały przedstawione w postaci tzw. macierzy pomyłek (ang. „confusion
matrix”). W przekątnej głównej znajdują się ilościowe wyniki prawidłowych rozpoznań, w
ostatnim wierszu znajdują się kształty nie będące znakami, które zostały błędnie
zidentyfikowane jako znaki. Ostatnia kolumna przedstawia wyniki nierozpoznania znaków, a
więc sytuacji, w której znajdujący się w obrazie znak zostaje odrzucony. Pozostałe wyniki to
przypadki błędnego rozpoznania znaku - przyporządkowania do złej klasy. Macierz pomyłek
przedstawiona jest w tabeli 6.5.
Podsumowanie wyników przedstawione jest poniżej macierzy pomyłek. Znajdują się
tam wyniki ilościowe i procentowe skuteczności rozpoznawania. Nieprawidłowe rozpoznania,
oraz brak rozpoznania są niemalże równoprawdopodobne i wynoszą odpowiednio 6.44% i
5.45%. i stanowią uzupełnienie skuteczności rozpoznawania do 100%. Prawidłowe
rozpoznania to 88.12% co jest wynikiem bardzo zbliżonym do wartości otrzymanej w
pierwszej części analizy skuteczności algorytmu. Oznacza to, że przyjęte podejście odnośnie
wykonania prostszych i szybszych testów tej części było prawidłowe, a uzyskane wyniki są
reprezentatywne. Obszary, które nie zawierają znaków, a zostały zinterpretowane jako znaki
są dość liczne i w odniesieniu do całkowitej liczby znaków jest to 14.36%. Wynik ten jest
duży i powinien być najważniejszym wyznacznikiem przy ewentualnych poprawkach
algorytmu.

Przenośny system detekcji i rozpoznawania znaków drogowych
70
Tab.6.5 Wynik skuteczności bloku rozpoznawania
Pomimo dobrze dobranego sposobu reprezentacji znaków- wektora cech, oraz dużego
nacisku na prawidłowe trenowanie klasyfikatora uzyskano stosunkowo niewielką skuteczność
bloku rozpoznawania równą 88%. Przyczyną takiego stanu rzeczy jest niedoskonałe
określenie obszaru znaku. Przykładowo lekko przekrzywiony znak zostanie w module

Przenośny system detekcji i rozpoznawania znaków drogowych
71
detektora prawidłowo rozpoznany, jego zawartość jest następnie wycinana stałą maską
zależną od wyniku pracy detektora. Przekrzywiony znak jest więc wycinany z otoczenia jako
znak ułożony prawidłowo, pociąga to za sobą utworzenie zafałszowanych wektorów cech.
Wektor taki może wpłynąć na proces uczenia bloku rozpoznawania (maszyn SVM) i zakłócić
prawidłowe obszary znaków w przestrzeni cech. Poddany analizie podczas pracy modułu
może zostać nieprawidłowo zinterpretowanym. Sposób wycinania wnętrza znaku także jest
niedoskonały, gdyż nie uwzględnia znalezionego kształtu, lecz stosuje sztywne maski co
może prowadzić do powstania błędów na brzegach znaku. Ponadto znaki w analizowanych
obrazach nie były ich głównym tematem, obrazy przedstawiały znaki w otoczeniu w jakim
występują, często były więc obserwowane perspektywicznie, odbijało się od nich światło,
były wyblakłe, pomalowane lub przesłonięte. To także wpłynęło na otrzymane wektory cech,
a w konsekwencji wpłynęło na uzyskaną skuteczność algorytmu.
6.3 Podsumowanie wyników
Test działania całej procedury poszukiwania i rozpoznawania znaków został
podzielony na dwie części zgodnie z budową tego algorytmu. Uzyskane wyniki skuteczności
detektora rzędu 80% oraz skuteczności identyfikowania 88% wskazują, że oba te moduły są
dopracowane z jednakową starannością. Oznacza to także, że ewentualne zwiększenie
skuteczności będzie pociągało za sobą konieczność modyfikacji obu tych bloków.
Skuteczność całej procedury a więc prawidłowego znalezienia i rozpoznania znaku wynosi
zaledwie 70% co nie jest wynikiem zadowalającym. Dla porównania można przytoczyć
skuteczności uzyskane w publikacjach naukowych, a przedstawionych w tabeli 6.6
Tab. 6.6 Wyniki skuteczności algorytmów detekcji i rozpoznawania uzyskiwane w innych
pracach
Uzyskany wynik 70% jest więc dużo gorszy od tych otrzymywanych przez naukowców na
świecie, należy jednak mieć na uwadze dużo mniejsze doświadczenie autora tej pracy.
Celem uskutecznienia zaprezentowanego algorytmu detekcji i rozpoznawania znaków
należałoby zdaniem autora poprawić moduł detektora kolorów i rozbudować go o możliwości
adaptacji do oświetlenia lub zmodyfikować procedurę wyznaczania obszarów
zainteresowania wykorzystując przykładowo logikę rozmytą (ang. „fuzzy logic”). Prace
powinny iść także w kierunku bloku obracania przekrzywionych znaków. Największym
problemem na jaki natrafiono, a którego nie udało się do końca skutecznie rozwiązać jest
detekcja i rozpoznawanie obszarów nie będących znakami. Na tym polu większego nakładu
pracy wymagałby detektor, który powinien odrzucić te błędne obszary. Maszyna SVM
służąca prawidłowemu rozpoznawaniu kształtów powinna być uzależniona od koloru jaki
posiada analizowany kształt. W bloku rozpoznawania poprawienia wymaga sposób wycinania
wnętrza znaku, zastosowane stałe maski należałoby wyposażyć w możliwość analizy i

Przenośny system detekcji i rozpoznawania znaków drogowych
72
dopasowania do znalezionego kształtu. Rozwiązanie sposobu klasyfikacji znaków w oparciu o
wektory cech oraz maszynę wektorów wspierających SVM jest dobre i można przypuszczać,
że tym sposobem dałoby się uzyskać skuteczność rzędu 95% lub większą.

Przenośny system detekcji i rozpoznawania znaków drogowych
73
7. Opis programu Zaprojektowany algorytm detekcji i rozpoznawania znaków został napisany w języku C++ w programie Microsoft Visual C++ 2010 Expres. Jądro programu napisane jest z wykorzystaniem biblioteki OpenCV 2.2 Jest to biblioteka wieloplatformowa typu Open source zapoczątkowana przez firmę Intel. Bibliotekę wraz z dokumentacją można ściągnąć ze strony www.opencv.willowgarage.com.
Biblioteka podzielona jest dziesięć modułów, wśród których znajdują się przykładowo bloki umożliwiające otwieranie i zapisywanie obrazów z plików o najpowszechniej stosowanych formatach. Zawiera moduł przetwarzania obrazów, w którym zaimplementowane są histogramy, przekształcenia i transformacje, analiza kształtów i inne. Ponadto biblioteka wyposażona jest w blok uczenia maszynowego, który zawiera algorytm SVM.
Interfejs użytkownika napisany został przy wykorzystaniu biblioteki Qt firmy Nokia. Biblioteka jest wieloplatformowa i zawiera w sobie wiele narzędzi umożliwiających budowę interfejsu użytkownika, a także obsługę procesów, plików, sieci, grafiki trójwymiarowej (OpenGL), baz danych (SQL), języka XML, lokalizacji, wielowątkowości, zaawansowanej obsługi napisów oraz wtyczek.
7.1 Obsługa programu
Program po uruchomieniu przedstawia rysunek 7.1.
Rys. 7.1 Okno detekcji programu

Przenośny system detekcji i rozpoznawania znaków drogowych
74
Program zgodnie ze swoją modułową budową posiada dwie zakładki. Pierwsza przedstawiona na rysunku 7.1 jest związana z modułem detektora i taką nosi nazwę. Druga związana jest z modułem rozpoznawania i będzie przedstawiona w dalszej części opisu. Działanie bloku detektora regulowane jest z kilkoma ustawieniami dostępnymi w zakładce Detektor. Znajdują się tu:
• Wczytaj obraz. Linia adresu do obrazu na którym będzie przeprowadzona detekcji i w dalszej części rozpoznawanie. Wyposażona w dodatkowy przycisk Browse uruchamiający explorera i umożliwiający interaktywne wyszukanie obrazu.
• Wybierz kolor znaku. Trzy przyciski typu zatwierdzającego (ang. Checkbox) uaktywniające funkcje przynależności odpowiadających im kolorów. Zaznaczenie przycisku spowoduje, uaktywnienie wybranej funkcji przynależności, dzięki czemu znaki odpowiadającego im koloru mogą zostać znalezione.
• Rozłączanie znaków. Rozłączanie znaków jest uruchomione bez względu na stan tego przycisku.
• Wektory cech. Ustawienia wektorów cech, ich długości i zakresu. W algorytmie sprawdzania kształtów generowane są wektory cech. W pierwszej kolejności obiekt jest skalowany do rozmiarów określonych przez licznik Istotne punkty wektora. Następnie na podstawie licznika Długość wektora wybierane są punkty dla których wyznaczany jest wektor cech. Możliwe jest zatem skalowanie obszarów do rozmiaru przykładowo 100 pikseli i wyznaczenie 50 elementowego wektora. W takim przypadku będzie brana pod uwagę co druga wyznaczona odległość.
• Wczytaj wektory cech. Przycisk ten oraz następny Utwórz nowe wektory odpowiadają ze wczytanie lub utworzenie nowych wektorów cech. Wektory te należy zatwierdzić trzecim przyciskiem Zastosuj wektory. Rozwiązanie to wprowadzone jest w celu umożliwienia zapisu i ponownego wczytania wektorów cech. Dzięki temu raz wyznaczone wektory można wykorzystać wielokrotnie.
• SVM -jądro maszyny. Trzy przyciski wykluczające określają typ stosowanego przekształcenia
• Wektory trenuj ące. Maszynę SVM detektora można wytrenować na podstawie wszystkich obiektów jakie zostały zapisane we wzorcowych wektorach cech ( w tym także nie będących figurami geometrycznymi), lub tylko tych przedstawiających figury geometryczne.
• Wektory wybrane do trenowania. Spośród wybranych wcześniej wektorów możliwe jest zastosowanie wszystkich do trenowania maszyny SVM lub wylosowanie spośród nich 70% które będą służyły do treningu. Pozostałe 30% stanowić będzie wektor testowy.
• Trenuj i zapisz SVM. Dwa przyciski kontrolujące zastosowaną maszynę wektorów wspierających. Możliwe jest wytrenowanie nowej maszyny na podstawie wszystkich dostępnych w oknie ustawień, lub wczytanie wcześniej wytrenowanej maszyny- Wczytaj SVM. Zapisanie nowej maszyny SVM jest realizowane w rzeczywistości jako zapisanie pięciu plików. Koniecznym jest więc utworzenie nowego folderu dla tych plików.
• Sprawdź SVM. Przycisk służy do testowania działania detektora. Druga zakładka programu zawiera ustawienia bloku rozpoznawania, jej widok przedstawiony jest na rysunku 7.2. Znajdują się tu następujące parametry:

Przenośny system detekcji i rozpoznawania znaków drogowych
75
Rys 7.2 Zakładka bloku rozpoznawania
• Opis znaku w układzie współrzędnych. Dwa wykluczające się przyciski
związane są ze sposobem generowania wektora cech w bloku rozpoznawania. Możliwe jest zastosowanie wektorów wyznaczanych w układzie kartezjańskim lub biegunowym.
• Długość wektora opisującego. Określa długość wektora cech przy rozpoznawaniu. Obszar znaku przed wyznaczeniem wektorów cech skalowany jest do wielkości określonej tym ustawieniem.
• Rodzaj maszyny SVM. Blok rozpoznawania zbudowany jest w oparciu o maszynę wektorów wspierających dla której można zastosować jedno z trzech jąder przekształcenia. Podczas badania skuteczności algorytmu zostały przetestowane dwa spośród tych ustawień: Liniowa i RBF
• Trenuj i zapisz. Przycisk uruchamia okno dialogowe, w którym można wybrać, czy wektory cech mają być utworzone od nowa, czy wczytane z pliku. Utworzenie nowych wektorów uruchamia podprogram, w którym opisuje się każdy znaleziony znak. Wczytanie zapisanych wcześniej wektorów wymaga podania ścieżki dostępu do odpowiedniego pliku i kończy się procedurą trenowania maszyny.
• Testuj obraz. Przycisk uruchamia algorytm główny dla obrazu do którego ścieżka została podana w linii adresowej detektora. Detekcja realizowana jest zgodnie z ustawieniami w zakładce Detektor. Następnie znalezione obszary są analizowane pod względem zawartości i klasyfikowane w bloku rozpoznawania.

Przenośny system detekcji i rozpoznawania znaków drogowych
76
Rozpoznawanie realizowane jest przez maszynę SVM której parametry zostały ustawione w zakładce Rozpoznanie.
Przycisk trenuj i zapisz spowoduje pojawienie się okna dialogowego przedstawionego
na rysunku 7.3. Umożliwia on utworzenie nowych wektorów lub wczytanie wcześniej utworzonych. Jeżeli użytkownik wybierze pierwszą możliwość, to bieżące okno ulegnie zamknięciu, a w jego miejsce pojawi się nowe pokazane na rysunku 7.4.
Rys 7.3 Okno dialogowe
Nowe okno dialogowe służy do wyznaczania nowych wektorów cech znaków.
Wektory te posłużą do wytrenowania maszyny SVM bloku rozpoznawania według ustawień dokonanych w oknie głównym programu. Zakończenie procedury spowoduje automatyczne zapisanie wyników (wektorów cech ) wraz z przypisanymi im kodami w katalogu głównym programu.
Rys. 7.4 Okno dialogowe wyznaczania nowych wektorów cech znaków
Przed przystąpieniem do wyznaczania nowych wektorów cech konieczne jest podanie pliku z listą obrazów dla których procedura ta ma być przeprowadzona. Wyznaczanie nowych wektorów cech jest w istocie ich nazywaniem, nie wymaga więc dokładniejszego omówienia. Jeżeli znalezionym kształtem nie będzie znak lecz inny obiekt, to na liście rozwijanej Typ znaku należy wybrać Brak .

Przenośny system detekcji i rozpoznawania znaków drogowych
77
Pozostałe przyciski w zakładce Rozpoznawanie oraz wybór ustawień i przyciski
menu głównego są nieaktywne i pozostają jako jeden z punktów do dalszego opracowania. Testowanie działania algorytmu po ustawieniu wszystkich parametrów typów maszyn SVM wymaga każdorazowo wprowadzenia adresu nowego obrazu. Zmiana ustawień maszyn SVM wymaga ponownego wczytania wektorów trenujących. Próby testowania skuteczności bez uprzedniego wytrenowania maszyn wektorów wspierających zakończy się błędem działania programu i spowoduje odpowiednia reakcję systemu operacyjnego.
Przetestowanie działania algorytmu w najprostszej wersji przy założeniu, że użytkownik posiada wszystkie niezbędne pliki z danymi maszyn SVM wymaga podjęcia następujących kroków.
1. W zakładce Detektor w polu adresu wybrać należy plik dla którego będzie
przeprowadzana analiza. Można się przy tym posłużyć przyciskiem Browse. 2. Wcisnąć przycisk Wczytaj SVM a następnie podać ścieżkę dostępu do stosownego
pliku z zapisanymi parametrami maszyny SVM. W wybranym katalogu powinny się także znaleźć cztery inne pliki zapisywane automatycznie przy zapisywaniu maszyny SVM.
3. Działanie detektora można sprawdzić klikając przycisk Sprawdź SVM. Ustawienia detektora są gotowe, należy przejść do ustawień bloku rozpoznawania.
4. W bloku rozpoznawania należy wybrać sposób generowania wektora cech oraz jego długość.
5. Należy wybrać tym maszyny SVM, a następnie kliknąć na Trenuj i zapisz. W nowym oknie dialogowym należy wybrać Wczytaj wektory i podać ścieżkę dostępu do pliku z zapisanymi wektorami cech.
6. Można przetestować działanie programu klikając na Testuj obraz 7.2 Ważniejsze części i funkcje programu W rozdziale zostaną przytoczone i omówione bardziej istotne części programu. Przedstawione będą fragmenty algorytmów detekcji i rozpoznawania, oraz przykład wykorzystania właściwości biblioteki Qt przy realizacji interfejsu użytkownika. Przytoczone tu fragmenty stanowią niewielką część kodu i zostały „wyrwane z kontekstu”. Nie mniej ich opis pozwolił odnieść się do zaproponowanej w poprzednich rozdziałach metodzie detekcji i rozpoznawania znaków.
Detektor koloru jest funkcją uruchamianą z czterema argumentami. Pierwszy to referencja do obrazu na którym ma zostać wykonana operacja detekcji kolorów. Jest to nieprzetwarzany obraz odczytany ze wskazanego pliku. Z obrazu tego pod koniec pracy bloku detektora zostaną wycięte fragmenty sklasyfikowane jako figury geometryczne- potencjalne znaki. Pozostałe trzy argumenty funkcji detektora koloru skojarzone są z ustawieniami wyboru koloru w zakładce Detektor. Mat Detect_Sel( Mat &RGB_image, bool R, bool Y, bool B)
{
Zmiana przestrzeni barw z RGB do HSV. Biblioteka OpenCV stosuje w istocie odwrotną przestrzeń RGB czyli pierwszym składnikiem jest kolor niebieski, stąd nazwa parametru CV_BGR2HSV.

Przenośny system detekcji i rozpoznawania znaków drogowych
78
cvtColor(RGB_image,hsv,CV_BGR2HSV); //konwersja z przestrzeni RGB do HSV
Obraz jest następnie rozdzielany na trzy obrazy składowe- monochromatyczne, aby możliwe było zastosowanie odpowiednich masek koloru.
Mat tmp[3]; split(hsv,tmp); // rozdzielanie obrazow
Kolejnym istotnym krokiem jest zbudowanie funkcji przynależności i zastosowanie ich do detekcji kolorów. Detekcja ta jest realizowana jako operacja odczytu z tablicy (ang. Look-at-table) dla składowych H i S osobno.
Mat lutH(1,256,CV_32F,Scalar(0)); Mat lutS(1,256,CV_32F,Scalar(0));
//RED – przygotowanie funkcji przynależności i realizacja operacji LUT
if (R==true)
{ lutH.colRange(0,13)=1; //Funkcje przynależności
lutH.colRange(172,180)=1;
lutS.colRange(120,255)=1; LUT(tmp[0],lutH,H); //tmp[0] -skladowa H obrazu
LUT(tmp[1],lutS,S); //lutH- tablica wartosci, S- obraz wynikowy
RED=H.mul(S,1);
Rezultat znajdowania kolorów jest wynikiem mnożenia składowych H i S, który jest dalej poddawany operacji zamknięcia elementem strukturalnym 3×3
dilate(RED,hsv,Mat::ones(3,3,CV_8U));
erode (hsv,RED,Mat::ones(3,3,CV_8U)); }
Podobnie operacja znajdowania kolorów jest przeprowadzana dla znaków w kolorach niebieskim i żółtym. Ich wyniki są ze sobą sumowane, a następnie poddawane binaryzacji, a na końcu operacji otwarcia.
hsv=RED+YELLOW+BLUE; threshold(hsv,H,0.5,1,THRESH_BINARY);
// progowanie argumenty: hsv-zrodlo, H-wynik, 0.5-prog, 1-wartosc maksymalna
// THRESH_BINARY - tryb binaryzacji- patrz opis na stronie OpenCV
morphologyEx(hsv,H,MORPH_OPEN,Mat::ones(3,3,CV_8U));
H.convertTo(hsv,CV_8UC1); return (hsv);
}
Tak przygotowany obraz zostaje w następnej kolejności przekazany do wyznaczenia wektorów brzegowych i klasyfikacji w maszynie SVM. Realizowane to jest w funkcji vector<figura> Wkontur (Mat &image, Size rozmiar, Size krok_wekt_cech, Vec<int,4>
zakr_wekt_cech )
która w pierwszej kolejności znajduje kontury obiektów, z zastosowanymi parametrami jest to operacja segmentowania i indeksacji. Indeksy przechowywane są w zmiennej hierarchy cv::findContours( image, contours, hierarchy,CV_RETR_TREE, CV_CHAIN_APPROX_NONE );

Przenośny system detekcji i rozpoznawania znaków drogowych
79
/* funkcja znajdowania obszarow, argumenty
image- obraz zrodlowy,
contours- wynik operacji,
hierarchy- hierarchia obszarow CV_RETR_CCOMP-parametr okreslajacy sposób zapamietania konturu
ostatni parametr okresla sposob zapisu- aktualnie zapisuje wszystkie piksele konturu*/
Następnie każdy obiekty jest z obrazu wycinany i analizowany pod kątem pola powierzchni i stopnia prostokątności. Dla obiektów, które przeszły weryfikacje są wyznaczane w pętli wektory brzegowe. //B- obraz zawierajacy analizowany obszar //rozmiar- obiekt klasy Size przechowujący rozmiar obrazu B
//F- obiekt klasy figura przechowujacej wektory brzegowe
for (int i=0;i<fin;i++) {
int j=0;
while(!B.at<long>(i,j++)&& j<rozmiar.width){}; F.left.push_back(j);
j=99;
while(!B.at<long>(i,j--)&& j!=0){}; F.right.push_back(rozmiar.height-j);
};
Kolejną jest funkcja rozłączania dwóch stykających się obszarów. Efektem końcowym jest zbiór wektorów brzegowych zapisanych w obiekcie F klasy figura. Przeprowadzenie tego algorytmu dla wszystkich obszarów w obrazie źródłowym daje w efekcie zbiór obiektów klasy figura. Do zarządzania tym zbiorem posłużono się klasą vector. Zbiór obiektów klasy figura stanowi argument funkcji weryfikacji kształtów, która dla każdej z czterech maszyn SVM realizuje procedurę: //M-macierz do której zostaje przepisany wektor brzegowy z domyślną zmianą typu //figury- zbiór obiektów klasy figura
//wynik- wektor wyników głosowania
M.create(1,figury[i].left.size(),CV_32FC1);
for (int j=0;j<figury[i].left.size();j++)
M.at<float>(0,j)=figury[i].left.get(j);
wynik[static_cast<int>(SVM_L.predict(M))]+=1;
Każda maszyna jako wynik analizy swojego wektora brzegowego wpisuje na
odpowiednie miejsce w wektorze swój głos. Jeżeli maszyna nie rozpoznała figury, to głosuje na klasę bezwartościową- nie reprezentującą żadnego konkretnego kształtu. Weryfikacja głosów jest realizowana w następujący sposób.
//wynik- wektor wyników głosowania
//max- zmienna tymczasowa
//ODP- odpowiedź klasyfikatora głosującego, 0- to nie jest figura geometryczna
for(int i=0;i<7;i++)
{
if(wynik[i]>max) {
max=wynik[i];

Przenośny system detekcji i rozpoznawania znaków drogowych
80
wsk=i;
}
}
ODP.push_back(wynik[wsk]>2 ? wsk : 0);
Jeżeli blok detektora rozpozna figurę geometryczną zgodną z tymi występującymi w znakach drogowych, to wycina stosowny fragment obrazu sprzed zamiany przestrzeni barw z RGB do HSV ( tego będącego argumentem funkcji Detect_Sel.) Wycięty fragment obrazu jest trafia do bloku rozpoznawania do funkcji wyznaczania wektora cech. W pierwszej kolejności obraz ten jest zamieniany na monochromatyczny i wyznaczany jest jego histogram.
//obraz- wyciety fragment obrazu sprzed zamiany przestrzeni barw //temp- wynik zmiany przestrzeni z RGB do monochromatycznej
//CV_BGR2GRAY- typ przekształcenia
cvtColor(obraz,temp,CV_BGR2GRAY);
//Przygotowanie danych do funkcji wyznaczajacej histogram int hbins = 256;
int histSize[] = {hbins};
float hranges[] = { 0, 256 };
const float* ranges[] = { hranges };
MatND hist;
int channels[] = {0};
/*&temp- wektor obrazow dla ktorych tworzony jest histogram
channels- kanaly obrazow dla ktorych beda wyznaczane histogramy Mat()- maska operacji, wpisana wartość to brak maski
hist- wielowymiarowa macierz zawierajaca histogramy
histSize- rozmiar macierzy zawieracej histogramy ranges-zakresy */
calcHist( &temp, 1, channels, Mat(),hist, 1, histSize, ranges,true, false );
Następnie na podstawie momentów bezwładności zostaje wyznaczony próg binaryzacji, a w efekcie binaryzacja obrazu. double maxVal=0; minMaxLoc(hist, 0, &maxVal, 0, 0);
float x=0,d=1; for(int i=0;i<hbins;i++)
{
x+=hist.at<float>(i)*i; //x- moment bezwladnosci I-go rzedu d+=hist.at<float>(i); //d-moment bezwladnosci 0-go rzedu
}
threshold(temp,obraz,x/d,1,CV_8UC1);
Dla obrazu binarnego są w dalszej kolejności wyznaczane wektory cech, poniżej przedstawiony jest algorytm tej procedury w układzie kartezjańskim. Wpierw jednak obraz binarny zostaje przeskalowany do wymaganej wielkości związanej z rozmiarem wektora cech. //obraz- obraz binarny po progowaniu
//temp- obraz- zmienna tymczasowa
//L_elem – docelowy rozmiar wektora cech cv::resize(obraz,temp,Size(L_elem,L_elem));

Przenośny system detekcji i rozpoznawania znaków drogowych
81
//wynik- wektor cech wynik.create(1,temp.size().width+temp.size().height,CV_32F);
for(int i=0;i<temp.size().width;i++) wynik.col(i)=sum(temp.col(i))[0];
for(int i=0;i<temp.size().height;i++) wynik.col(temp.size().width+i)=sum(temp.row(i))[0];
Tak przygotowany wektor cech jest następnie analizowany w maszynie wektorów wspierających w bloku rozpoznawania. Wynikiem tego rozpoznania jest adres linii w pliku z nazwami znaków. Stosowna nazwa zostaje odczytana i wyświetlona jako wynik działania algorytmu. Narzędzia biblioteki Qt są narzędziami obiektowymi. Do przekazywania informacji pomiędzy obiektami biblioteka ta została wyposażona w mechanizm sygnałów i slotów. Każdy obiekt, który zrealizował jakąś operację bądź nastąpiło zdarzenie związane z tym obiektem, generuje globalny sygnał w którym zamieszczone są informacje o stanie tego obiektu. Informacje te mogą być przekazane do dedykowanej do tego funkcji w innym obiekcie. Funkcja ta nosi nazwę slotu i stanowi swoisty port dla informacji, przekazywanych z jednego lub wielu obiektów. Zaobserwowanie sygnału w porcie- slocie skutkuje uruchomieniem tej funkcji na rzecz tego obiektu. Dokładnie mechanizm sygnałów i slotów opisany jest w dokumentacji biblioteki.
W niniejszej pracy autor zastosował mechanizm sygnałów i slotów w wielu miejscach. Jest on wykorzystany w przyciskach gdzie kliknięcie przycisku powoduje wysłanie odpowiedniego sygnału. Trafia on do dedykowanego slotu i uruchamia tam odpowiednie procedury. Mechanizm ten został zastosowany w najprostszej postaci i nie realizuje uruchamiania wielu slotów wieloma sygnałami. Najlepszym przykładem działania mechanizmu jest proces wyznaczania wektorów wzorcowych bloku rozpoznawania. Zastosowane rozwiązanie przedstawione jest graficznie na rysunku 7.5
W bloku okna głównego znajdują się trzy procedury, obie są w stanie wygenerować sygnał nast_znak(). Sygnał ten trafia do slotu znajdz_znak gdzie wczytywany jest nowy obraz i przeprowadzana jest detekcja kształtów jakie w nim występują,oraz wyznaczane są wektory bloku rozpoznawania. Procedura ta po wykonaniu swojego zadania generuje sygnał znajdz_znak_done(obraz). Sygnał ten trafia do slotu pokaz(obraz) w oknie dialogowym, w sygnale tym przekazywany jest obraz wyświetlany w tym oknie. Po reakcji użytkownika generowany jest sygnał dial_done(nazwa) zawierający informacje o kodzie znaku. Sygnał ten podłączony jest do procedury zapisz_wynik(nazwa) która zapisuje wyznaczony wektor cech bloku rozpoznawania wraz z przypisanym mu kodem znaku. Funkcja zapisz_wynik(nazwa) generuje nowy sygnał nast_znak(), który sprawdza, czy są jeszcze obrazy do przeanalizowania i uruchamia procedurę od nowa.

Przenośny system detekcji i rozpoznawania znaków drogowych
82
Rys 7.5 Schemat przepływu sygnałów w procedurze tworzenia nowych wektorów wzorcowych bloku rozpoznawania

Przenośny system detekcji i rozpoznawania znaków drogowych
83
Porównanie współczynników kształtu oraz
momentów geometrycznych
W pierwszej kolejności należy zdefiniować jak powinny się zmieniać wartości
idealnego współczynnika kształtu. Powinien on być niezależny od rozmiarów i obrotu figury.
Poszukiwany współczynnik powinien dobrze rozróżniać figury, tzn. jego wartość dla różnzch
obiektów powinna być zdecydowanie inna. Wymagana jest także odporność na niewielkie
zaburzenia kształtu, gdyż w rzeczywistości znaki mogą być przysłonięte przez inne nie
niewielkie obiekty, jak chociażby drzewa lub śnieg.
W tabelach 1 i 2 przedstawione są wartości współczynników kształtu oraz
niezmienników momentowych dla dwóch figur. W pierwszej kolejności analizowany jest
wpływ wielkości obiektu na wartość współczynnika na podstawie figur geometrycznych
prostokąta i trójkąta.
Tab. 1 Wartości współczynników kształtu i niezmienników momentowych dla różnych
wielkości prostokąta.
Prostokąt Rozmiar obrazu w odniesieniu do oryginału
Współczynnik 120% 100% 80% 60% 40% 20%
zawartości 1.2523 1.2482 1.242 1.2234 1.1964 1.0931
cyrkularności 136.5339 113.9663 91.3987 56.9804 36.668 15.2227
Malinowskiej 0.1191 0.1172 0.1144 0.1061 0.0938 0.0455
prostokątności 1.0167 1.0201 1.0252 1.0408 1.0645 1.1667
Fareta 1 1 1 1.0204 1.0323 1.0833
Blair -Bliss 0.9772 0.9773 0.9773 0.9773 0.9774 0.9786
Haralicka 0.994 0.994 0.994 0.994 0.9939 0.9934
Niezmiennik momentowy
M1 0.1667 0.1667 0.1666 0.1666 0.1666 0.1662
M2 0.0278 0.0278 0.0278 0.0278 0.0278 0.0276
M3*1000 0 0 0 0 0 0
M7 0.0069 0.0069 0.0069 0.0069 0.0069 0.0069
Tab. 2 Wartości współczynników kształtu i niezmienników momentowych dla różnych
wielkości trójkąta
Trójkąt Rozmiar obrazu w odniesieniu do oryginału
Współczynnik 120% 100% 80% 60% 40% 20%
zawartości 1.2931 1.2488 1.3102 1.2229 1.2274 1.2072
cyrkularności 123.7261 101.9733 81.7588 61.5975 40.5118 20.2795
Malinowskiej 0.1371 0.1175 0.1446 0.1059 0.1079 0.0987
prostokątności 0.5265 0.5325 0.5402 0.5394 0.548 0.5493
Fareta 0.763 0.7606 0.7611 0.7647 0.75 0.75
Blair –Bliss 0.9063 0.9061 0.9064 0.9065 0.9059 0.9044
Haralicka 0.9751 0.9752 0.9755 0.9754 0.9745 0.9732
Niezmiennik momentowy
M1 0.1938 0.1939 0.1937 0.1937 0.194 0.1946
M2 0.0376 0.0376 0.0375 0.0375 0.0376 0.0379
M3*1000 1.6032 1.6104 1.5963 1.5922 1.6413 1.6545
M7 0.0092 0.0092 0.0092 0.0092 0.0092 0.0093

Przenośny system detekcji i rozpoznawania znaków drogowych
84
Analizując powyższe wartości należy zauważyć, że dużą zmienność na wielkość
figury wykazuje współczynnik cyrkularności. Jest to wystarczający powód by współczynnik
ten zdyskwalifikować jako przydatny do sprawdzania kształtu. Współczynniki Fereta, BB i
Haralicka oraz niezmienniki momentowe nie zmieniają się w ogóle przy zmianie wielkości
figury, a więc są z tego punktu widzenia najbardziej interesujące. Dobrze wyniki uzyskują
również prostokątność i współczynnik Malinowskiej.
Kolejnym testem jest wpływ obrotu figury na wartości współczynników. Pomiarów
dokonano przy użyciu prostokąta, który był obracany co 150 zgodnie z ruchem wskazówek
zegara. Stosowne dane przedstawia tabela nr 3.
Tab.3 Wpływ ułożenia (obrotu) figury na wartości współczynników.
Kąt obrotu Kąt obrotu w stopniach w prawo
Współczynnik 15˚
30˚ 45˚ 60˚ 75˚
zawartości 1.1659 0.9379 0.7973 0.9379 1.1615
cyrkularności 136.1931 136.0762 136.1744 136.0715 136.1557
Malinowskiej 0.0798 -0.0316 -0.1071 -0.0315 0.0777
prostokątności 0.6788 0.5474 0.513 0.5473 0.6831
Fareta 0.9932 1 0.9941 1 0.9864
Blair -Bliss 0.9773 0.9772 0.9774 0.9772 0.9773
Haralicka 0.9942 0.9941 0.9942 0.9942 0.9942
Niezmiennik momentowy
M1 0.1666 0.1667 0.1666 0.1667 0.1666
M2 0.0278 0.0278 0.0278 0.0278 0.0278
M3*1000 0 0 0 0 0
M7 0.0069 0.0069 0.0069 0.0069 0.0069
W tym przypadku najbardziej wrażliwymi są współczynnik zawartości, Malinowskiej
oraz prostokątności. Współczynniki Fereta, BB i Haralicka a także wszystkie niezmienniki
momentowe są niewrażliwe na tego typu przekształcenia.
We współczynnikach opisujących figury ważne jest także, żeby opis ten jednoznacznie
rozróżniał obiekty. Należy więc oczekiwać jak największej zmienności współczynników dla
różnych figur. Porównanie pod tym względem jest przedstawione w tabeli 4.

Przenośny system detekcji i rozpoznawania znaków drogowych
85
Tab. 4 Wartości współczynników przy różnych figurach geometrycznych.
Współczynnik koło prostokąt trójkąt
równor.
trójkąt
prost. Gwiazda plama strzałka księżyc
Zawartości 0.8021 1.2578 1.2624 1.3354 2.6444 1.7168 1.9727 1.7545
Cyrkularności 118.0006 125.4482 104.5381 98.8862 104.5259 103.0044 54.6187 112.4649
Malinowskiej -0.1044 0.1215 0.1236 0.1556 0.6262 0.3103 0.4045 0.3246
Prostokątności 0.7989 1.0183 0.5312 0.5378 0.3899 0.5947 0.5872 0.5198
Fareta 1.0172 0.8571 0.7902 0.9917 0.9161 1.0973 2.7632 1.1308
Blair –Bliss 0.9999 0.9716 0.9084 0.849 0.8733 0.8865 0.6982 0.7795
Haralicka 1 0.9927 0.976 0.9613 0.9706 0.9677 0.9192 0.9465
Niezmiennik
M1 0.1592 0.1686 0.1929 0.2208 0.2087 0.2025 0.3264 0.2619
M2 0.0253 0.0284 0.0372 0.0608 0.0436 0.0494 0.1066 0.0705
M3*1000 0 0 1.4641 2.7939 0.0067 0.3641 0.0618 4.3565
M7 0.0063 0.0069 0.0092 0.0092 0.0109 0.0082 0.0072 0.0139
Dużą zmienność wykazują współczynnik Malinowskiej, BB oraz niezmienniki M1 i
M2. Biorąc pod uwagę także poprzednie tabele można stwierdzić, że dobrze zachowuje się
M7 oraz wsp. Haralicka mimo że ich wartości niewiele się zmieniają. Szczególną należy
zwrócić na średnice Fereta. Jego wartości wykazują dużą zmienność i niezależność od
transformacji, ponadto doskonale wykrywa on obiekty podłużne. Należy bowiem zwrócić
uwagę, że dla strzałki (która jest podłużna) wartość tego współczynnika znacznie odbiega od
pozostałych jego wartości.
W przypadku zastosowania współczynników do znajdowania znaków drogowych,
istotne jest także ich zachowanie przy nierównomiernych ich kształtach. W rzeczywistości
bowiem znak może być częściowo przesłonięty przez drzewo, obiekt na drodze, śnieg lub
inny znak. W tabeli 5 przedstawiono wyniki współczynników dla różnych imitowanych
zakłóceń.
Tab. 5 Wpływ zniekształceń figur na wartości współczynników.
Współczynnik
Zawartości 1.7096 1.2624 1.315 1.1616 2.5889 1.4531 1.2665
Cyrkularności 113.4456 104.5381 100.7612 101.3031 99.5087 96.9093 99.2781
Malinowskiej 0.3075 0.1236 0.1467 0.0778 0.609 0.2055 0.1254
prostokątności 0.48 0.5312 0.6128 0.5706 0.4813 0.4983 0.5037
Fareta 0.8654 0.7902 0.6364 0.904 0.7902 0.8626 0.8309
Blair –Bliss 0.9004 0.9084 0.9157 0.9288 0.8593 0.8935 0.9038
Haralicka 0.9724 0.976 0.9772 0.981 0.966 0.9732 0.9747
Niezmiennik momentowy
M1 0.1963 0.1929 0.1898 0.1845 0.2156 0.1993 0.1948
M2 0.0388 0.0372 0.036 0.0348 0.0465 0.0398 0.0384
M3*1000 1.0828 1.4641 1.5711 0.7032 1.7041 1.2678 1.6354
M7 0.0094 0.0092 0.0083 0.0083 0.0115 0.0099 0.0093

Przenośny system detekcji i rozpoznawania znaków drogowych
86
W tym przypadku dobrze zachowują się współczynniki: BB, Haralicka, M1, M2, słabą
odporność wykazują natomiast średnice Fereta. Współczynnik Malinowskiej wykazuje małą
odporność na tego typu zakłócenia.
Test zachowania współczynników przy tak małej liczbie danych testujących nie może
być traktowany jako decydujący. Nie mniej pozwala spojrzeć na zachowanie się
współczynników w różnych sytuacjach i wybór tych , które najlepiej rokują jako cechy figur.
Te wybrane współczynniki powinny być sprawdzone na odpowiednio dużej liczbie wektorów
testujących i przy użyciu algorytmu, który potrafiłby określić w jakim stopniu są one
przydatne. Współczynnikami, które zdaniem autora najlepiej spełniają warunki przydatności
to współczynniki: Fereta, BB, Haralick, M1, M2, M7, prostokątności i zawartości. Pozostałe
czyli cyrkularność, wsp. Malinowskiej i M3 nie spełniają stawianych im wymagań. W
literaturze przedmiotu, znajdują się obszerne porównania współczynników kształtu.

Przenośny system detekcji i rozpoznawania znaków drogowych
87
Literatura:
[1] Komputerowa analiza i przetwarzanie obrazów. Ryszard Tadeusiewicz i Przemysław
Korohoda , wyd. Fundacji postępu telekomunikacji, Kraków 1997
[2] Cyfrowe przetwarzanie sygnałów od teorii do zastosowań. Tomasz P. Zieliński,
Wydawnictwa komunikacji i łączności, Warszawa 2007
[3] Nowoczesne metody przetwarzania obrazu. Christopher D.Watkins, Alberto Sadun,
Stephen Marenka, WNT 1995
[4] Metody i algorytmy rozpoznawania obiektów w obrazach cyfrowych. Bogusław
Cyganek. Wydawnictwo AGH, Kraków 2009
[5] Rozpoznawanie obrazów. Tadeusiewicz, Ryszard (1947- ). Państwowe Wydawnictwo
Naukowe, 1991. Seria: Problemy Współczesnej Nauki i Techniki. Informatyka.
[6] Sieci neuronowe. Ryszard Tadeusiewicz Akademicka oficyna wydawnicza RM,
Warszawa 1993
[7] Rozpoznawanie obrazów i sygnałów mowy. Włodzimierz Kasprzak, Warszawa 2009
Oficyna Wydawnicza Politechniki Warszawskiej
[8] Extracting Road Signs using the Color Information. Wen-Yen Wu, Tsung-Cheng
Hsieh, and Ching-Sung Lai, World Academy of Science Engineering and Technology
http://www.waset.org/journals/waset/v32/v32-54.pdf -dostęp 10 styczeń 2011
[9] Circular road signs recognition with soft classifiers. Bogusław Cyganek AGH –
University of Science and Technology, Kraków.
[10] Color-Based Road Sign Detection and Tracking. Luis David Lopez and Olac Fuentes,
Computer Science Department University of Texas, El Paso, USA
[11] Road Sign Detection and Recognition, Michael Shneier, National Institute of
Standards and Technology, Bureau Drive, Gaithersburg
[12] Traffic Sign Detection and Classification using Colour and Shape. F.P. Senekal,
Council for Scientific and Industrial Research, South Africa
[13] Road-Sign Detection and Recognition Based on Support Vector Machines. Saturnino
Maldonado-Bascón, Member, IEEE, Sergio Lafuente-Arroyo, Pedro Gil-Jiménez,
Hilario Gómez-Moreno, Member, IEEE, and Francisco López-Ferreras
[14] Fast Shape-based Road Sign Detection for a Driver Assistance System by Gareth Loy
and Nick Barnes
[15] A Fast Radial Symmetry Transform for Detecting Points of Interest Gareth Loy and
Alexander Zelinsky Australian National University, Canberra 0200, Australia,
http://www.syseng.anu.edu.au/~gareth -dostęp 15 grudzień 2010
[16] SURF: Speeded Up Robust Features. Herbert Bay1, Tinne Tuytelaars, and Luc Van
Gool ETH Zurich, Katholieke Universiteit Leuven
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.85.2512&rep=rep1&type=p
df -dostęp 5 grudzień 2010
[17] Distinctive Image Features from Scale-Invariant Keypoints. David G. Lowe Computer
Science Department University of British Columbia Vancouver, B.C., Canada,
January 5 2004, http://www.cs.ubc.ca/~lowe/papers/ijcv04.pdf -dostęp 3 listopad 2010
[18] IBM Research Report An empirical study of the naive Bayes classifier. Irina Rish IBM
Research Division Thomas J. Watson Research Center P.O. Box 218 Yorktown
Heights, NY http://www.research.ibm.com/people/r/rish/papers/RC22230.pdf - dostęp
20 styczeń 2010
[19] Nomograms for Visualization of Naive Bayesian Classier. Martin Mozina, Janez
Demsar, Michael Kattan, and Blaz Zupan;
http://www.ailab.si/blaz/papers/2004-PKDD.pdf -dostęp 12 listopad 2010
[20] http://www.algorytm.org/index.php -dostęp 10 marzec 2011

Przenośny system detekcji i rozpoznawania znaków drogowych
88
[21] http://www.flashandmath.com/advanced/color/ - dostęp 20 kwiecień 2011
[22] Real Time Road Signs Recognition. Alberto Broggi, Pietro Cerri, Paolo Medici, Pier
Paolo Porta VisLab – Dipartimento di Ingegneria dell’Informazione Universit`a degli
Studi di Parma, ITALY
[23] Road Signs Recognition using a Dynamic Pixel Spaces. G. Pollaccia, G. Pilato and
E Sorbello
[24] Traffic Sign Recognition by Bags of Features. Kazumasa Ohgushi, Nozomu Hamada
School of Integrated Design Engineering Kio University Kanagawa Japan
[25] General Traffic Sign Recognition by Feature Matching. FeiXiang Ren, Jinsheng
Huang. The University of Auckland, New Zealand 24th International Conference
Image and Vision Computing New Zealand
[26] Object Recognition from Local Scale-Invariant Features David G. Lowe Computer
Science Department University of British Columbia Vancouver, B.C, Canada
http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.21.1181&rep=rep1&type=p
df –dostęp 10 maj 2011
[27] A tutorial on Principal Components Analysis. Lindsay Smith, February 26 2002
http://www.cs.otago.ac.nz/cosc453/student_tutorials/principal_components.pdf -
dostęp 12 pażdziernik 2010
[28] A Tutorial on Support Vector Machines for Pattern Recognition. Christopher J.C.
Burges. Bell Laboratories, Lucent Technologies
http://www.cs.brown.edu/courses/archive/2006-2007/cs195-5/extras/Burges98.pdf -
dostęp 20 wrzesień 2010
[29] Support Vector Machines Explained. Tristan Fletcher www.cs.ucl.ac.uk/sta
/T.Fletcher/ March 1, 2009
[30] Computed Tomography Its History and Technology by SIEMENS medical.
http://www.medical.siemens.com/siemens/zh_CN/gg_ct_FBAs/files/brochures/CT_Hi
story_and_Technology.pdf - dostęp 5 września 2010
[31] An Empirical Comparison of Voting Classication Algorithms: Bagging, Boosting, and
Variants. by Eric Bauer Received 3 Oct 1997; Revised 25 Sept 1998
http://ai.stanford.edu/~ronnyk/vote.pdf - dostęp 20 listopad 2010
[32] A Practical Guide to Support Vector Classifcation. Chih-Wei Hsu, Chih-Chung
Chang, and Chih-Jen Lin, Department of Computer Science National Taiwan
University, Taipei 106, Taiwan http://www.csie.ntu.edu.tw/~cjlin, Initial version: 2003
Last updated: April 15, 2010 – dostęp 24 kwiecien 2010
[33] http://commons.wikimedia.org – dostęp 15 marzec 2011





























