Embed Size (px)
Citation preview

Inte
rnet
-Sca
le D
ata
Man
agem
ent
JANUARY/FEBRUARY 2012 1089-7801/12/$31.00 © 2012 IEEE Published by the IEEE Computer Society 13
D ata management for Web applications, especially stateful ones, is challenging. Applications’
popularity can grow rapidly, and application owners must be able to scale on demand while minimizing ongoing operational costs. Applications don’t typically require full transactional support, however, and they execute complex analysis tasks offline in separate systems (for instance, MapReduce platforms such as Hadoop). In recent years, these requirements have given rise to a class of Internetscale data management systems often called cloud data stores, NoSQL systems, and so on. Such systems let developers spend most of their time rapidly innovating at the application layer instead of mired in the complexities of the data layer. These systems must handle a high throughput of requests (thousands of database reads and writes per second) with low latency (tens of milliseconds).
Internetscale data management systems typically run on commodity servers and trade off more traditional systems’ query and transaction functionalities for the efficient support of scalability, elasticity, and high availability. Scalability means maintain ing system performance as the work load grows by adding resources propor tionally. Elasticity allows for allocating new resources to users on demand and augmenting system capacity by adding servers, without service interruption to existing workloads. High availability means a system uses data replication to survive failures, keep data accessible during failures, and recover quickly and automatically.
PNUTS is Yahoo’s dataserving platform, f irst described in 2008,1 around when we released and started using it within Yahoo. Since then, we’ve published several research articles on different aspects of the system and ideas we’ve prototyped on top of it.
Data management for stateful Web applications is extremely challenging.
Applications must scale as they grow in popularity, serve their content with
low latency on a global scale, and be highly available, even in the face of
hardware failures. This need has generated a new class of Internet-scale data
management systems. Yahoo has more than 100 user-facing applications and
numerous internal platforms. To meet its data management needs, it built the
PNUTS system. Here, the authors review PNUTS’ growing adoption, point to
specific applications, and detail several of PNUTS’ features.
Adam Silberstein, Jianjun Chen, David Lomax, Brad McMillen, Masood Mortazavi, P.P.S. Narayan, Raghu Ramakrishnan, and Russell Sears Yahoo
PNUTS in Flight: Web-Scale Data Serving at Yahoo
IC-16-01-Silb.indd 13 12/13/11 2:51 PM

Internet-Scale Data Management
14 www.computer.org/internet/ IEEE INTERNET COMPUTING
However, we’ve written little about PNUTS’ adoption within Yahoo. PNUTS has been in use for more than three years and, as of early 2011, hosts more than 100 applications supporting major Yahoo properties ranging from Yahoo Answers to Weather, running on thousands of servers spread across 18 data centers worldwide. Adoption and usage are growing rapidly.
Here, we briefly review PNUTS and highlight some of the unique features that separate it from competing systems. (For an overview of other systems, see the sidebar, “Related Work in LargeScale DataServing Systems.”) We also discuss what motivated our “customers” (internal Yahoo application and platform developers) to launch on or migrate to PNUTS — that is, what problems it solves for them — and how easy it is to operate and run.
PNUTS OverviewLet’s first examine PNUTS’ key requirements and how we addressed them in design and implementation.
Serving Data Globally on a Giant ScaleYahoo has 680 million customers, myriad userfacing applications, and numerous internal platforms. These own a huge amount of data and must serve numerous concurrent requests at levels that singleserver or smallscale systems can’t satisfy. PNUTS supports Yahoosized workloads through scalability and elasticity.
PNUTS is a lowlatency system and, because Yahoo is a global company, must be low latency no matter where in the world client requests originate. PNUTS has stringent latency servicelevel agreements (SLAs) so that Web applications relying on it in turn respond quickly. Our SLAs are on the order of tens of milliseconds; at Yahoo scale, if slow load times cause even a small percentage of users to browse elsewhere, we lose significant revenue. Stringent latency requirements differentiate PNUTS from batchoriented systems such as Hadoop. Batch jobs run analyses over huge amounts of data and complete in minutes, hours, or longer. Although collectively PNUTS requests access large amounts of data, each
Related Work in Large-Scale Data-Serving Systems
The past few years have seen considerable development in the number and maturity of large-scale data-serving sys-
tems. Examples include Amazon’s Dynamo,1 Google’s BigTable2 and Megastore,3 and Apache’s Cassandra (http://cassandra.apache.org) and HBase (http://hbase.apache.org). These sys-tems are roughly of the same generation as PNUTS.
PNUTS was one of the earliest systems to natively support geographic replication, using asynchronous replication to avoid long write latencies. HBase and Cassandra support synchro-nous geographic replication. Megastore uses Paxos for syn-chronous replication, even across regions.
Different systems employ different consistency models. Big-Table and HBase write synchronously to all replicas, ensuring that they’re always up to date. Dynamo and Cassandra require that writes must succeed on a quorum of servers before they return success to the client. This maintains record availability during network partitions but at the cost of consistency. Spe-cifically, the systems let conflicting writes succeed, leading to an eventual consistency model in which clients can see a ver-sion of record that might be overwritten by a concurrent write. Megastore comes closer to the consistency of traditional data-base management systems, supporting ACID (atomicity, con-sistency, isolation, durability) transactions (meant to be used on records within the same entity group). PNUTS exposes two consistency models from which clients can choose: timeline
consistency using record mastery, and eventual consistency with mastery disabled.
Comparing the performance of data-serving systems is chal-lenging. Such a study requires running each system with identi-cal workloads on identical hardware. We did just that with the Yahoo cloud-serving benchmark.4 Our results measure each system’s throughput and latency as they performed at the time of our study. The numbers reflect the system architectures. PNUTS, running buffer-page-oriented MySQL as its storage engine, excels at read-heavy workloads, whereas log-structured Cassandra and HBase excel at write-heavy workloads. Further experiments demonstrate each system’s scalability and elasticity.
References1. G. DeCandia et al., “Dynamo: Amazon’s Highly Available Key-Value
Store,” Proc. 21st ACM Symp. Operating Systems Principles, ACM Press, 2007,
pp. 205–220.
2. F. Chang et al., “Bigtable: A Distributed Storage System for Structured
Data,” Proc. Usenix Symp. Operating Systems Design and Implementation, Usenix
Assoc., 2006, pp. 205–218.
3. J. Baker et al., “Megastore: Providing Scalable, Highly Available Storage for
Interactive Services,” Proc. 5th Biennial Conf. Innovative Data Systems Research
(CIDR 11), published under Creative Commons license, 2011, pp. 223–234.
4. B.F. Cooper et al., “Benchmarking Cloud Serving Systems with YCSB,” Proc.
ACM Symp. Cloud Computing, ACM Press, 2010, pp. 143–154.
IC-16-01-Silb.indd 14 12/13/11 2:51 PM

PNUTS in Flight: Web-Scale Data Serving at Yahoo
JANUARY/FEBRUARY 2012 15
individual request touches a small portion of data and must complete quickly.
Traditional databases provide a strong consiste ncy model, serializable transactions, for handling concurrent client requests; one client’s transac tion over a set of records is isolated from other transactions. Supporting this model is extremely expensive in largescale distributed systems. Moreover, most Yahoo applications don’t need strong consistency but rather tend to write a single record at a time (for example, changing a user’s home location in their profile record), and it’s acceptable if some subsequent reads of the record (for instance, by the user’s friends) don’t immediately see the write. An alternative model, timeline consistency, makes this type of workload straightforward. PNUTS need not synchronously maintain a record and its replicas, but all follow the same timeline of states. We don’t allow records to go backward in time, nor states to appear that other concurrent writes will discard. For some applications, we can relax the second constraint with an optional eventual consistency mode in which different replicas of a record might see different sequences of states, but ultimately converge to the same value.
PNUTS must preserve some degree of consistency and availability during partition failure cases (for example, when network failures partition a data center from the rest of the system). Geographic replication makes all records always available for read from anywhere. However, anytime the system is partitioned, preserving both write consistency and availability is impossible. By providing two consistency models, we let customers choose their preference.
Although PNUTS would be quite useful as a simple keyvalue store, it enables many more applications by supporting limited traditional database functionality. In particular, it supports ordered tables that organize records physically by key to enable range scans, as well as secondary indexes.
Example ApplicationsLet’s look at three sample Yahoo applications that use PNUTS. The first customizes content on the Yahoo front page based on user profile information, browsing history, and a preferences model. The application maintains a PNUTS record for each user, reading the record when he or she arrives at the front page, and writing the record when users update their profiles, click
on links, and so on. The application is tied to frontpage traffic and is thus large on day one, in terms of disk and memory footprint, serving traffic, and global distribution. Customization can’t slow down frontpage loads, so the application must have low latency. It could deploy a standard database management system (DBMS), but would then have to provision the hardware, partition the workload, plan for growth over time, and develop disaster recovery plans. PNUTS addresses all these issues, letting even largescale application developers focus on application logic rather than infrastructure.
Linkup, in contrast, is a small, experimental social application from Yahoo Labs that lets users organize or sign up for events and see friends’ status. Although Linkup remains small and could contain all its data in a standard DBMS such as MySQL, PNUTS still provides key reliability and availability benefits. Moreover, if Linkup expands, it won’t need to scramble
to move from a traditional database to a more scalable solution. Normally, an application like this must choose between launching quickly with a nonscalable data store and delaying the launch for a more complex, scalable solution. PNUTS removes this conflict.
Our final example is another social application that stores social activities in PNUTS. Each time a user posts a status update, this application writes a new record with a key formed by concatenating the user’s ID and the current time. For example, when Alice updates her status to “at work,” the application inserts a record with the key alice_8:30AM. When a user wants to see his or her friends’ activities, for each friend, the application client scans this table for the latest activities. If Bob is connected to Alice, the client retrieves the “at work” update, and others, and presents them to Bob. This application emphasizes the importance of
Although PNUTS would be quite useful as a simple key-value store, it enables many more applications by supporting limited traditional database functionality.
IC-16-01-Silb.indd 15 12/13/11 2:51 PM
Internet-Scale Data Management
16 www.computer.org/internet/ IEEE INTERNET COMPUTING
consistency semantics. It’s fine for Bob to miss the very latest Alice updates if they happened in the past few seconds; it isn’t acceptable for Alice to miss them and assume her status update didn’t succeed. PNUTS supports both semantics. The application also shows the importance of ordered tables that cluster similar records and lets clients find them by searching for all records prefixed with “alice.” Similar applications running on simple keyvalue stores must keep all of Alice’s updates in a single record and on every query parse them all, even if clients just want the latest few.
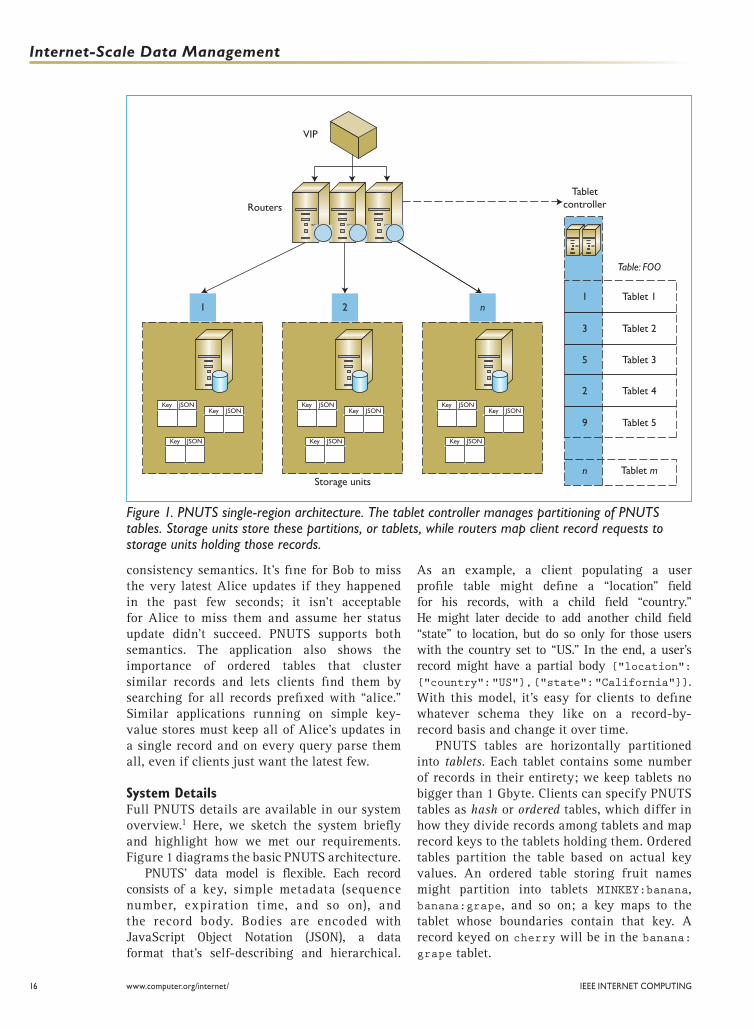
System DetailsFull PNUTS details are available in our system overview.1 Here, we sketch the system briefly and highlight how we met our requirements. Figure 1 diagrams the basic PNUTS architecture.
PNUTS’ data model is flexible. Each record consists of a key, simple metadata (sequence number, expiration time, and so on), and the record body. Bodies are encoded with JavaScript Object Notation (JSON), a data format that’s selfdescribing and hierarchical.
As an example, a client populating a user profile table might define a “location” field for his records, with a child field “country.” He might later decide to add another child field “state” to location, but do so only for those users with the country set to “US.” In the end, a user’s record might have a partial body {"location": {"country": "US"}, {"state": "California"}}. With this model, it’s easy for clients to define whatever schema they like on a recordbyrecord basis and change it over time.
PNUTS tables are horizontally partitioned into tablets. Each tablet contains some number of records in their entirety; we keep tablets no bigger than 1 Gbyte. Clients can specify PNUTS tables as hash or ordered tables, which differ in how they divide records among tablets and map record keys to the tablets holding them. Ordered tables partition the table based on actual key values. An ordered table storing fruit names might partition into tablets MINKEY:banana, banana:grape, and so on; a key maps to the tablet whose boundaries contain that key. A record keyed on cherry will be in the banana: grape tablet.
Figure 1. PNUTS single-region architecture. The tablet controller manages partitioning of PNUTS tables. Storage units store these partitions, or tablets, while routers map client record requests to storage units holding those records.
Key JSONKey JSON
Key JSON
Key JSONKey JSON
Key JSON
Storage units
Routers
Tabletcontroller
Table: FOO
Tablet 1
Tablet 2
Tablet 3
Tablet 4
Tablet 5
Tablet m
VIP
Key JSONKey JSON
Key JSON
n211
3
5
2
9
n
IC-16-01-Silb.indd 16 12/13/11 2:51 PM

PNUTS in Flight: Web-Scale Data Serving at Yahoo
JANUARY/FEBRUARY 2012 17
Hash tables partition tables by hash value. An 8byte hash space might give us tablets 0x00000000:0x10000000, 0x10000000:0x20000000, and so on. When mapping a key to a tablet, we first apply a hash function to determine the tablet to which it maps. If cherry hashes to 0x15000000, it maps to the tablet 0x10000000:0x20000000. While seemingly adding extra complexity, using hash tables when ordered table functionality isn’t needed actually makes load balancing easier.
PNUTS stores tablets in servers called storage units. A storage unit contains a diskbased persistence layer responsible for holding tablets; production PNUTS currently uses MySQL, but we can deploy it with other storage systems swapped in. The tablet controller maintains the mapping of tablets to storage units and replicates this mapping to multiple routers, which in turn contact the tablet controller to check for mapping changes.
PNUTS supports a simple set of operations against its tables: insert, update, read, and delete of single records, as well as range scans against multiple records, a feature not found in simple keyvalue stores. For reads, clients can specify fields they want returned rather than the whole record. Clients send requests to a router, which parses the specified table and key (in the case of range scans, the start key) from the client request and maps the table and key to a tablet. The mapping step varies depending on whether the specified table is ordered or hashed. The router determines which storage unit hosts the mapped tablet and forwards the client request to that unit. The storage unit itself executes the operation. For read requests, it returns a success or failure status message and the record’s body. For writes, it returns a status message.
This description covers a single region of PNUTS. As Figure 1 shows, in reality, PNUTS replicates tables across multiple regions, with each region in a single data center. We manage crossregion replication using a separate topicbased publish–subscribe system, Tribble. Each tablet maps to a Tribble topic, with all tablet replicas subscribed to that topic. When one region writes a record, the region publishes the write, and Tribble transmits it asynchronously to all subscribing regions. Tribble is proprietary to Yahoo and an interesting system in its own right, but it’s out of this article’s scope. For a basic understanding of what Tribble provides PNUTS, readers can refer
to Hedwig (https://cwiki.apache.org/ZOOKEEPER/hedwig.html), an open source system with the same semantic guarantees as Tribble.
Asynchronous geographic replication has been in PNUTS’ design from conception. This feature is especially important for a global company such as Yahoo. If we had a presence only in a single data center in the US, clients on other continents would incur long network round trips on all PNUTS operations. Asynchronous geographic replication gives us lowlatency reads and writes. Once we have geographic replication, lowlatency reads are easy; no matter where clients are, we route their requests to the nearest PNUTS region. Writes are more subtle. When we write a record in a PNUTS region, we don’t wait for that write to propagate to any other region before returning success to the user. Instead, we use Tribble as a writeahead log; on publishing to Tribble, the write persists to several disks in the local region. PNUTS considers the write durable, and immediately returns success to the user. Meanwhile, Tribble handles replication in the background; that replication will complete in a time roughly equal to the latency delay between regions.
PNUTS implements its default timeline consistency using record mastery. No matter where they originate, PNUTS forwards all writes to a record to a single region where that record is mastered. Only that region accepts writes for the record and publishes them to Tribble, which guarantees that writes to a topic made in one region are delivered to all regions in the order they’re written — that is, the record master serializes writes to the record, producing a timeline of record states. All replicas see the same timeline, although asynchrony means replicas might trail the master at times. Figure 2 illustrates timeline consistency, using our earlier social application example. Alice makes two writes to her record, first updating her status from sleeping to awake, and then updating her location from home to work. Alice cares that the writes get applied in all regions in the order she made them; in particular, she doesn’t want it to appear as if she’s sleeping at work. Alice’s writes happen to be routed to two separate regions. Her record is mastered in region 1, however, so the write to region 2 is forwarded there. Region 1 serializes the writes. Record mastery does limit record availability during failure cases; later, we discuss PNUTS’ relaxed consistency model, which prioritizes availability.
IC-16-01-Silb.indd 17 12/13/11 2:51 PM

Internet-Scale Data Management
18 www.computer.org/internet/ IEEE INTERNET COMPUTING
Most PNUTS applications can afford to serve some stale records, as long as those records are always in some valid state. For cases in which clients can’t afford to serve stale data (for instance, when users must see their own writes), we provide read-critical(required version), in which clients specify the minimum record version that they must see. We also provide test-and-set(required version) writes for singlerecord transactions. The client writes a record conditioned on it being at a specified, previously seen version.
PNUTS’ scalability comes from its ability to grow any system component in the user path. As the number and size of tables grow, we can add more storage units to increase storage and serving capacity. As individual tables grow, we split their tablets to increase the number of partitions and then distribute those tablets among more storage units. Routers replicate the tablet map, and we add more routers as the client request volume rises. Tribble scales as well; as the number of tablets rises, so does the number of topics, and we add more capacity to handle these.
Geographic replication ensures that PNUTS is available under various failure conditions. PNUTS tolerates temporary and permanent loss of individual servers and entire data centers. Data is available, but possibly readonly, during network partitions. When a region loses a storage unit, that region recovers its lost tablets by copying them from a different region.
At Yahoo, PNUTS runs as a hosted service rather than a product that individual teams install and manage. We can think of PNUTS as a private cloud system. Having a single PNUTS instance for the company has numerous advantages, including
having a single team of service engineers running it, and not having to separately provision for every customer’s peak loads.
Running on PNUTSPNUTS’ adoption has grown dramatically at Yahoo, especially in the past 18 months. As mentioned previously, as of early 2011, PNUTS hosts more than 100 applications across Yahoo, owning more than 450 tables on more than 50,000 tablets. Most of these applications deployed in 2010 and 2011. In this same time span, our deployment has grown accordingly, from tens of servers to thousands, and from four data centers to our current 18. Many data centers host hundreds of PNUTS servers, whereas some have just a few dozen. PNUTS continues to grow, with a current pipeline of 50 more applications deploying shortly.
Yahoo applications running on PNUTS include Movies, Mobile Video, Travel, Weather, Maps, An swers, Mail, Address Book, global blog search, and small experimental applications. Many applications use PNUTS alongside other technologies. One video application, for example, stores its metadata in PNUTS and the videos themselves in a specialized store for multimedia content.
Many applications have moved to PNUTS either from pure LAMP (Linux, Apache, MySQL, and PHP) stacks or from other legacy keyvalue stores at Yahoo. When moving from LAMP, developers adapt to exploit PNUTS’ scalability (scaling out their clients) and to its much simpler schema and query interface. We make this transition easy with a thorough developer guide and by supporting a series of testing environments before they launch in production.
Figure 2. Timeline consistency enforced through record mastership. Alice first updates her status from sleeping to awake, then updates her location from home to work. Record mastery ensures that her writes get applied in all regions in the order in which she made them.
(Alice, Home, Sleeping)
(Alice, Home, Sleeping)
(Alice, Home, Awake) (Alice, Work, Awake)
(Alice, Work, Awake)
(Alice, Work, Awake)
Region 1
Region 2
Awake Work
Work
IC-16-01-Silb.indd 18 12/13/11 2:51 PM

PNUTS in Flight: Web-Scale Data Serving at Yahoo
JANUARY/FEBRUARY 2012 19
PNUTS isn’t currently selfprovisioning — rather, it uses a ticketing system. We take this approach not owing to any technical limitations but to enforce a step in which we learn (internal) customers’ requirements, advise them on how to best use PNUTS, and ensure capacity to support new customers and any load spikes while continuing to meet our strict SLAs. Application developers submit a ticket that describes their requirements. We require them to submit table names and types, as well as their expected growth.
For customers who want to try out PNUTS, we offer a selfprovisioning sandbox environment without the production environment’s SLAs and data durability. Users can get running in the sandbox in a few minutes, letting them functionally test PNUTS and get familiar with the API. Making this first step easy has won over several customers that might have otherwise looked elsewhere.
In addition to our previous examples, let’s look at some additional applications that adopted PNUTS and why.
One of PNUTS’ earliest adopters is LocDrop, Yahoo’s user location platform, which captures and stores end users’ accurate normalized locations in an applicationneutral fashion. These locations are stored in PNUTS and accessed by many Yahoo properties, including the front page, Weather, News, My Yahoo, and the toolbar at the top of most Yahoo pages. LocDrop was drawn to PNUTS primarily because it doesn’t have the recordsize limitations of LocDrop’s previous system (a combination of cookies and an older proprietary data store). In today’s world of social checkins, Yahoo must be able to store and manage a large history of locations per user.
Another large PNUTS adopter is the UserGenerated Content (UGC) platform, which lets Yahoo end users leave comments on articles, rate comments and articles, post nested replies to comments, and vote on polls. UGC requires timeordered access to comments (for example, return the last 10 comments posted on a particular article) for a huge number of concurrent requests. With previous Yahoo hashedorganized technologies, these two requirements were difficult to simultaneously achieve, but ordered tables make access straightforward from UGC (by executing range scans) and efficient for PNUTS (the requested data is sequential on disk).
One key feature added to PNUTS after its initial release is notifications, which we describe in more detail later. In short, this feature lets clients see a stream of all writes done on a table. Several applications became viable on PNUTS once we released notification, all needing to feed writes to downstream systems. Common downstream systems are memorybased writebehind caches (to lower request latency), vertical search platforms (addressing rich text searches beyond PNUTS’ scope), and Hadoop (for large analytical workloads). Yahoo’s social directory platform uses notifications to manage both an external cache and keyword index.
Although these examples illustrate large internal consumer platforms, smaller groups gravitate toward PNUTS as well, because it’s a hosted multidatacenter solution. Given that each Yahoo property must procure and install new hardware in many locations, timetodelivery for these applications substantially decreases from months to days. We built shortterm experimental projects in Labs easily (in time and cost) using PNUTS precisely for this reason. Linkup, discussed previously, is one such example.
Not only is PNUTS multitenant in the sense that it hosts multiple tables on the same production cluster, but it also allows multiple groups to share the same table (when appropriate). This pattern makes enduser preferences and settings available to all Yahoo properties. There’s no reason to force every application to maintain its own basic user profile info, such as birth date and location, when PNUTS can store this information in a common profiles table. Historically, Yahoo has used a legacy system that assumes each user has as strong affinity to a single geographic region and that all writes to that user’s record will come from that region; this system doesn’t handle writes from multiple regions well. Such an assumption simply doesn’t hold anymore. PNUTS’ eventual consistency lets us replace this system by providing good latency no matter where updates originate (and
In today’s world of social check-ins, Yahoo must be able to store and manage a large history of locations per user.
IC-16-01-Silb.indd 19 12/13/11 2:51 PM

Internet-Scale Data Management
20 www.computer.org/internet/ IEEE INTERNET COMPUTING
resolving rare conflicts). PNUTS brings many other important features to user data as well, such as permissioning by table, ordered records, and selective replication.
Recent DevelopmentsThe preceding overview describes PNUTS as it’s existed for several years and should look familiar to anyone who has read our original article.1 Let’s examine some of PNUTS’ more recent developments.
Ordered Table ChallengesOrdered tables add significant management comple xity. Hash tables inherently provide nice load balancing properties. Because hashing assigns records to tablets uniformly at random, the footprint and request rates for tablets are roughly equal. As a hash table grows, all tablets grow at an even rate. We can initially build a table with a few tablets covering the whole hash range and split them into more tablets as the
table grows. In contrast, when initializing an ordered table, we must know the customer’s key distribution to choose tablet boundaries that will evenly distribute load among them. If we choose poorly (for example, splitting evenly across all ASCII characters when all of the keys are numerical), the table will quickly have hot spots, resulting in high latency and low throughput, until we repartition and move the data. To initially choose good boundaries, we use our PNUTS onboarding ticketing system. For each ordered table request, we ask clients to provide an initial expected table size and random sample of their expected keys. We sort this sample and draw tablet split points from it. For example, a customer with 100 Gbytes of data across 100 million records might send us 100,000 keys. We sort these keys and draw every 1,000th key as a split point for a table with 100 tablets of 1 Gbyte each. Prior work discusses this further.2
Once loaded, ordered tables continue to present new challenges. At any given time, certain tablets might be more popular than others. This happens when applications choose key names in ways that cause ranges to change in size and popularity at different rates. Heavily loaded storage units hurt PNUTS' ability to meet SLAs. We must either overprovision the entire system or move load from heavily loaded servers to lightly loaded ones.
We built a load balancer for PNUTS named Yak, which collects load metrics from each storage unit at the storage unit and tablet granularities. Metrics include request latencies, disk space, and so on. Yak’s main purpose is to detect overloaded storage units and take one of two balancing actions: tablet move or split. Moves shift load off from overloaded servers onto underloaded ones. Splits break apart hot tablets that aren’t good move candidates (that is, moving them immediately overloads the destination storage unit). We continually tune Yak based on surprising issues we see in production, including temporary load spikes that don’t reflect a change in workload, het erogeneous hardware (as newer servers come online), and customers’ new access patterns.
Relaxed ConsistencyIn our initial release, PNUTS provided timeline consistency, allowing only one region to insert or update each record. This consistency comes at a performance price: any writes not originating in a record’s master region must endure slow crossregion calls to that master region (although PNUTS does its best to assign mastership to the most active writing region).
Moreover, single region mastership limits availability during failures. While PNUTS can transfer record masterships to another region, the transfer is operatordriven, and all records mastered in the region remain unavailable for write until transfer is complete; even if we respond quickly, we might still have thousands of client request failures.
We added an eventual consistency table type, similar to Dynamo’s,3 that relaxes consistency but allows unmastered writes. Clients can make inserts and updates to any region at any time. PNUTS resolves conflicts using time stamps at the record body’s column level (toplevel fields of the JSON object). The latest update for each column value wins, and PNUTS discards other
Since PNUTS’ inception, we’ve believed in its ability to elegantly support materialized views and the importance of doing so.
IC-16-01-Silb.indd 20 12/13/11 2:51 PM

PNUTS in Flight: Web-Scale Data Serving at Yahoo
JANUARY/FEBRUARY 2012 21
writes. Other resolutions are possible (such as bubbling conflicting writes up to the client for their decision), but we haven’t implemented them. Although in general “latest wins” can lead records into states that no single client writer envisioned (similar to Alice sleeping at work), in reality, applications don’t typically generate conflicting simultaneous updates to records. If the application itself generates updates in a “timelineconsistent” manner, PNUTS almost never resolves conflicts.
For customers who understand and can accept the eventual consistency model, the perfor mance benefits are great. All writes are performable local to the client, greatly improving latencies. Given a server node failure, another node will always be available to accept writes.
NotificationsMost traditional databases include the concept of triggers, in which secondary actions can be performed within the database based on primary writes to database tables. PNUTS users have similar requirements; to support them, we provide notifications. Customers can subscribe to a notification stream that contains all updates made to a table. In fact, we use notifications to implement materialized views in PNUTS.
Under the covers, the notification stream actually draws from PNUTS’ messaging layer, Tribble. Unlike traditional databases, PNUTS doesn’t perform notifications “inside” the database or in any database context. Instead, customers define and operate their own notification client, and PNUTS pushes notifications to it. Because of this, notifications are well suited to maintaining a state that’s outside of the PNUTS context, such as specialty applications like caches or fulltext indexes.
Materialized ViewsSince PNUTS’ inception, we’ve believed in its ability to elegantly support materialized views and the importance of doing so. View types such as indexes help customers who must access their data via multiple attributes. Consider a shopping application that maintains a PNUTS table of items for sale. We assign each item a unique ID (such as item1234) and insert it into PNUTS; records are keyed on that unique ID and contain an “item” category as one attribute in the body. This table suffices for operations that access by primary key. Suppose, however, that
the application must support lookup by category (for instance, “show ‘bike’ items”). Scanning the base table isn’t viable. Instead, the application developers request that PNUTS construct an index on the base table, with each item keyed by the concatenation of item category and ID (bike_item1234). The application then scans only those records prefixed with a particular category.
View tables are regular PNUTS tables that PNUTS, rather than users, updates. We believe view maintenance must not lie in the user write path, increasing write latency, but instead occur asynchronously in the background. We leverage notifications: a view maintainer component listens to base table writes, transforms those writes into view updates for one or more view tables, and applies them. In our shopping application, adding item1234 with payload bike inserts bike_item1234 into the index; updating the category to motorcycle deletes bike_item1234 and inserts motorcycle_item1234.
Our detailed view architecture is available elsewhere.4
We’re currently adding view support in production and have revisited some design aspects. For example, we debated whether view tables should indeed be normal PNUTS tables. This approach replicates view tables, like base tables, across regions. Base table writes now incur crossregion traffic for themselves and for their dependent view tables. From the base updates alone, we can see that each region can independently produce identical view updates. We can achieve crossregion bandwidth savings by inventing a nonreplicated table type local to a single region. We chose for now to keep view tables as normal PNUTS tables. The primary argument is failure recovery. PNUTS’ failurerecovery design and implementation is one of
PNUTS’ failure-recovery design is one of its most complex aspects; rather than building recovery techniques for a second table type, we chose to minimize complexity and development time.
IC-16-01-Silb.indd 21 12/13/11 2:51 PM

Internet-Scale Data Management
22 www.computer.org/internet/ IEEE INTERNET COMPUTING
its most complex aspects; rather than building recovery techniques for a second table type, we chose to minimize complexity and development time by leveraging our existing solution.
Bulk OperationsAlthough PNUTS is optimized for serving workloads, many customers want a bulkload utility. In the standard serving case in which clients are userfacing webpages, we care about throughput and latency; in the bulk case, in contrast, we want the highest throughput possible for the bulk job (latency itself isn’t important), while not interfering with concurrent serving workloads. Many bulk loads originate in Hadoop. For example, some customers, such as the frontpage application, analyze user click logs to build models of user behavior. They push these models to PNUTS to access them quickly at serving time.
We built our bulk loader as a library on Hadoop. The close affinity for our customers between PNUTS and Hadoop makes this a natural choice. Hadoop brings several important properties we need, such as scalability and fault tolerance. The library includes extensions for reading from and writing to PNUTS, logging errors, and throttling PNUTS operations to avoid overloading it and hurting servingworkload latency. We added extra failure handling on top of Hadoop’s to handle and log oneoff errors (PNUTS timeouts, malformed records, and so on), shortcircuit jobs during widespread failures (such as network partitions), and reenter jobs after resolving failures.
Our library by default uses the standard PNUTS API. We also prototyped higher throughput approaches for writing to PNUTS that import tablet snapshot files directly into the underlying storage layer on the storage units. We’re also experimenting with logstructured storage layers more amenable to writeheavy workloads. More details on Hadoop integration are available elsewhere.5
Selective Record ReplicationPNUTS by default replicates records to all re gions in which a customer application runs, providing lowlatency access to records and replication against failure. Many Yahoo applications have a truly global user base, replicate to many more regions than needed for fault tolerance, and incur millions of record writes
per day. PNUTS does a tremendous amount of replication work for these applications.
Although an application might be global, its records might actually be local. Suppose a PNUTS record contains a user’s profile; such records are likely only ever written and read in one or a few geographic regions (such as the US east coast) — namely, those locations where the user and his or her friends live. Legal issues also arise at Yahoo that limit where we can replicate records; this pattern typically follows user locality as well.
We added perrecord selective replication to PNUTS. Regions that don’t have a full copy of a record still have a stub version with enough metadata to know which regions contain full copies for forwarding requests. A stub is updated only at record creation or deletion, or when the record’s replica locations change. PNUTS and Tribble coordinate to send normal data updates only to regions containing full copies of the record, saving bandwidth and disk space.
We prototyped static and dynamic placement policies,6 and currently use static ones in production. With static policies, the customer specifies for each record those regions where the record must or can’t exist. Dynamic policies monitor a record’s usage and automatically add and remove replicas based on access patterns, while also respecting any static constraints.
We’ve reached an interesting point in PNUTS’ life cycle. It has run in production for several
years, serving as the largescale geographic data store for a large and growing number of Yahoo applications and internal platforms. Even as PNUTS has become ubiquitous at Yahoo, we continue to add key features and improvements, as detailed in this article.
Building PNUTS has taught us several important lessons. It’s crucial for a large organization such as Yahoo to have a cloud data system like PNUTS. We provide a hosted infrastructure for small and large applications on shared hardware. A second lesson is that we must determine the functionality we can support well and resist expanding beyond that scope. For example, we support a limited singlerecord transaction model but not general transactions; we provide point lookups, range scans, and even indexes, but not general joins. Finally, we try to release new features quickly, but gradually. We added a load balancer, but initially
IC-16-01-Silb.indd 22 12/13/11 2:51 PM

PNUTS in Flight: Web-Scale Data Serving at Yahoo
JANUARY/FEBRUARY 2012 23
ran it in recommendation mode. We added indexes, but initially only for brand new tables. Despite its maturity and wide usage, PNUTS isn’t a finished product. We continue to add new features that add functionality for our customers and let us operate PNUTS more efficiently.
AcknowledgmentsPNUTS, known as the Sherpa system within Yahoo, is a
result of the tireless work of many people, most of whom
don’t appear as authors here. We would like to acknowledge
the contributions of the Sherpa and Tribble engineering
teams, who have done much of the heavy lifting in building,
testing, and managing PNUTS.
References1. B.F. Cooper et al., “PNUTS: Yahoo!’s Hosted Data
Serving Platform,” Proc. 34th Int’l Conf. Very Large
Databases, VLDB Endowment, 2008, pp. 1277–1288.
2. A. Silberstein et al., “Efficient Bulk Insertion into a
Distributed Ordered Table,” Proc. 2008 SIGMOD Int’l Conf.
Management of Data, ACM Press, 2008, pp. 765–778.
3. G. DeCandia et al., “Dynamo: Amazon’s Highly Available
KeyValue Store,” Proc. 21st ACM Symp. Operating
Systems Principles, ACM Press, 2007, pp. 205–220.
4. P. Agrawal et al., “Asynchronous View Maintenance
for VLSD Databases,” Proc. 35th SIGMOD Int’l
Conf. Management of Data , ACM Press, 2009,
pp. 179–192.
5. A. Silberstein et al., “A Batch of PNUTS: Experiences
Connecting Cloud Batch and Serving Systems,” Proc.
2011 SIGMOD Int’l Conf. Management of Data, ACM
Press, 2011, pp. 1101–1112.
6. S. Kadambi et al., “Where in the World Is My Data?”
Proc. 37th Int’l Conf. Very Large Databases, VLDB
Endowment, to appear, 2011.
Adam Silberstein is a staff software engineer at LinkedIn
in the Distributed Data Systems group. He was previ
ously a research scientist at Yahoo Research, where he
worked on PNUTS, among other projects. His research
focuses on largescale distributed data management in
both online data serving and offline batch analysis.
Silberstein has a PhD in computer science from Duke
University. Contact him at [email protected].
Jianjun Chen is a principal research engineer in Yahoo
Labs’ Cloud Science group, where he works on research
projects over Yahoo’s cloud infrastructure, including
PNUTS. His research focuses on various aspects of
cloud data management. Chen has a PhD in computer
science from the University of Wisconsin, Madison.
Contact him at jjchen@yahooinc.com.
David Lomax is a senior software engineer in Yahoo’s
Cloud Structured Storage and Messaging group, where
he develops features in the Sherpa/PNUTS storage
system. He has more than 20 years of experience in
software development, much of it relating to database
work. Contact him at dlomax@yahooinc.com.
Brad McMillen is a software architect in Yahoo’s Cloud Plat
form group, where he works on multiple distributed
dataserving systems. His research interests include low
latency, highavailability dataserving systems that drive
critical corporate or Internet infrastructure. McMillen
has a BS in mathematics from Pennsylvania State Uni
versity. Contact him at bradtm@yahooinc.com.
Masood Mortazavi is a senior principal architect in Yahoo’s
Cloud Platform group, where he works on designing and
evolving massively scalable storage systems for serving
application and user data. His main interests include
multitenant elasticity, distributed processing, and
massively scalable serving data stores. Mortazavi has
a PhD in computational fluid dynamics from the Uni
versity of California, Davis. Contact him at masood@
yahooinc.com.
P.P.S. Narayan (PPSN) is the senior director of engineering
for structured storage and messaging at Yahoo. His team
is responsible for the design, architecture, and engineer
ing of the NoSQL platforms that support Yahoo’s prop
erties and applications. His research interests include
transaction management, XML, and query processing.
Narayan has a BS and MS in computer science from the
Indian Institute of Technology, Bombay. Contact him at
ppsn@yahooinc.com.
Raghu Ramakrishnan is the chief scientist for search and cloud
computing at Yahoo. His research is in cloud comput
ing, database systems, and data mining. Ramakrishnan
has a PhD in computer science from the University of
Texas at Austin. He’s a fellow of IEEE and the ACM.
Russell Sears is a research scientist in Yahoo’s Systems
Research group, where he maintains the Stasis trans
actional storage library and works on scalable storage
systems. His research interests include scalable stor
age systems and programming abstractions for highly
concurrent and distributed systems. Sears has a PhD
in computer science from the University of California,
Berkeley. Contact him at sears@yahooinc.com.
Selected CS articles and columns are also available for free at http://ComputingNow.computer.org.
IC-16-01-Silb.indd 23 12/13/11 2:51 PM

For access to more content from the IEEE Computer Society, see computingnow.computer.org.
This article was featured in
Top articles, podcasts, and more.
computingnow.computer.org





























