Embed Size (px)
Citation preview

1
A Graph-Theoretic Approach to Webpage Segmentation
Deepayan Chakrabarti ([email protected])
Ravi Kumar ([email protected])
Kunal Punera ([email protected])
2
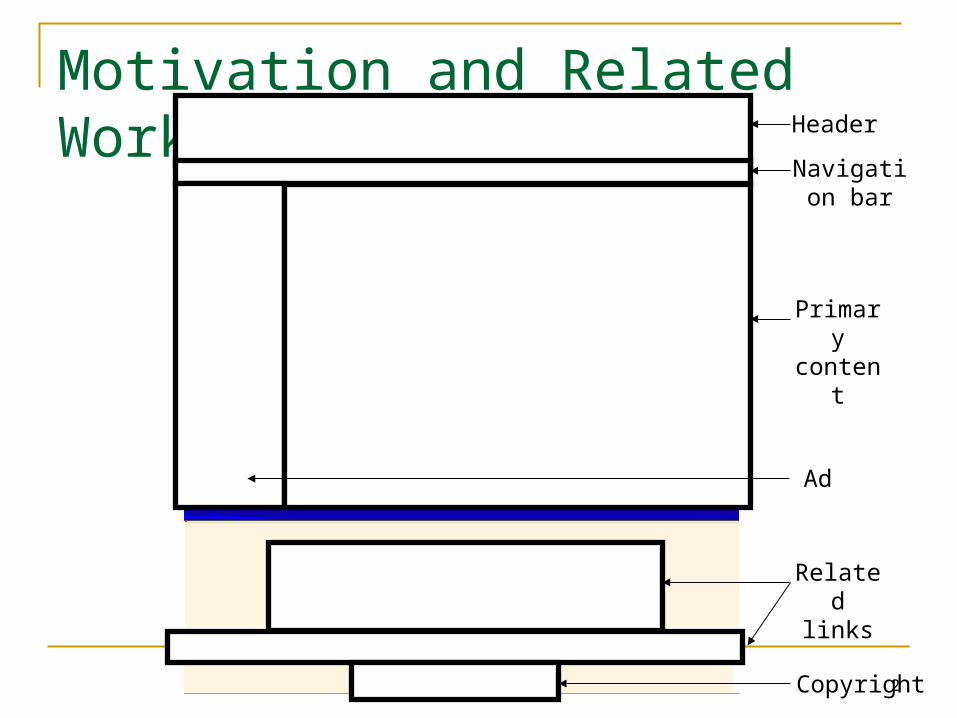
Motivation and Related WorkHeader
Navigation bar
Primary content
Related links
Copyright
Ad

3
Motivation and Related WorkHeader
Navigation bar
Primary content
Related links
Copyright
Ad
Divide a webpage into visually and semantically cohesive sections

4
Motivation and Related Work
Sectioning can be useful in: Webpage classification Displaying webpages on mobile phones and
small-screen devices Webpage ranking Duplicate detection …

5
Motivation and Related Work
A lot of recent interest Informative Structure Mining [Cai+/2003,
Kao+/2005] Displaying webpages on small screens
[Chen+/2005, Baluja/2006] Template detection: [Bar-Yossef+/2002] Topic distillation: [Chakrabarti+/2001]
Based solely on visual, or content, or DOM based clues
Mostly heuristic approaches

6
Motivation and Related Work
Our contributions Combine visual, DOM, and content based cues Propose a formal graph-based combinatorial
optimization approach Develop two instantiations, both with:
Approximation guarantees Automatic determination of the number of sections
Develop methods for automatic learning of graph weights

7
Outline
Motivation and Related Work Proposed Work Experiments Conclusions
8
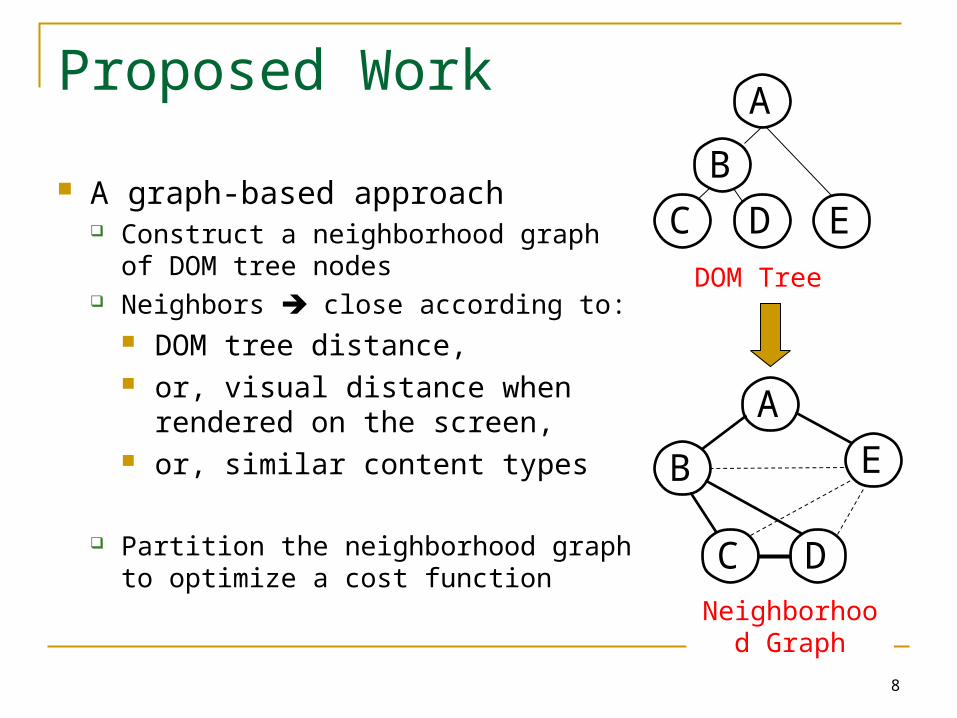
Proposed Work
A graph-based approach Construct a neighborhood graph of
DOM tree nodes Neighbors close according to:
DOM tree distance, or, visual distance when
rendered on the screen, or, similar content types
Partition the neighborhood graph to optimize a cost function
A
B
DC E
DOM Tree
A
B
C D
E
Neighborhood Graph
9
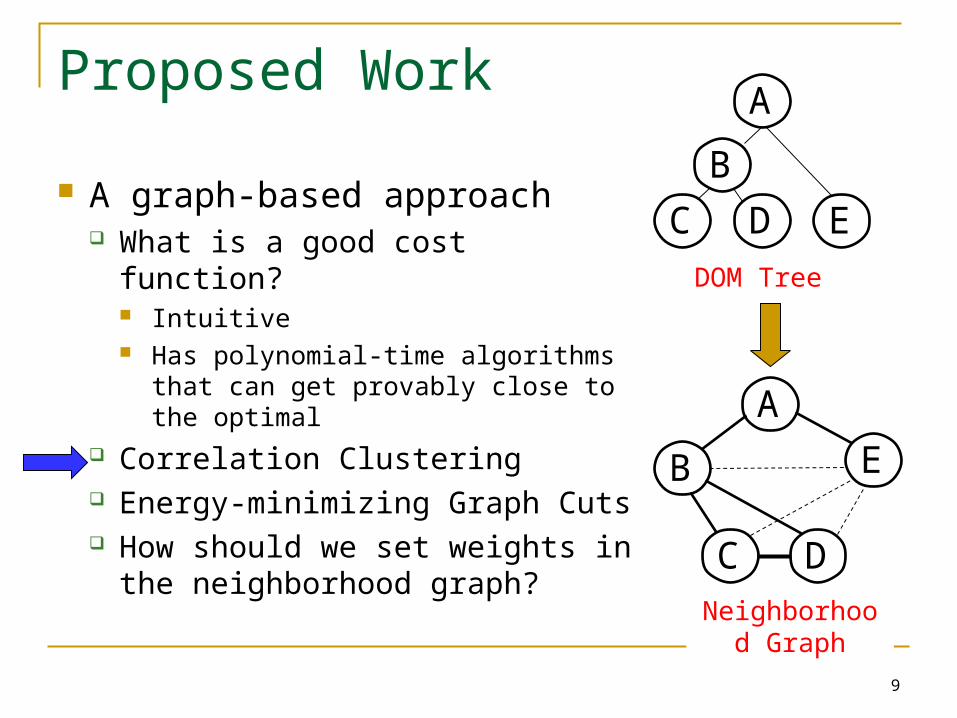
Proposed Work
A graph-based approach What is a good cost function?
Intuitive Has polynomial-time algorithms that
can get provably close to the optimal
Correlation Clustering Energy-minimizing Graph Cuts How should we set weights in
the neighborhood graph?
A
B
DC E
A
B
C D
E
DOM Tree
Neighborhood Graph
10
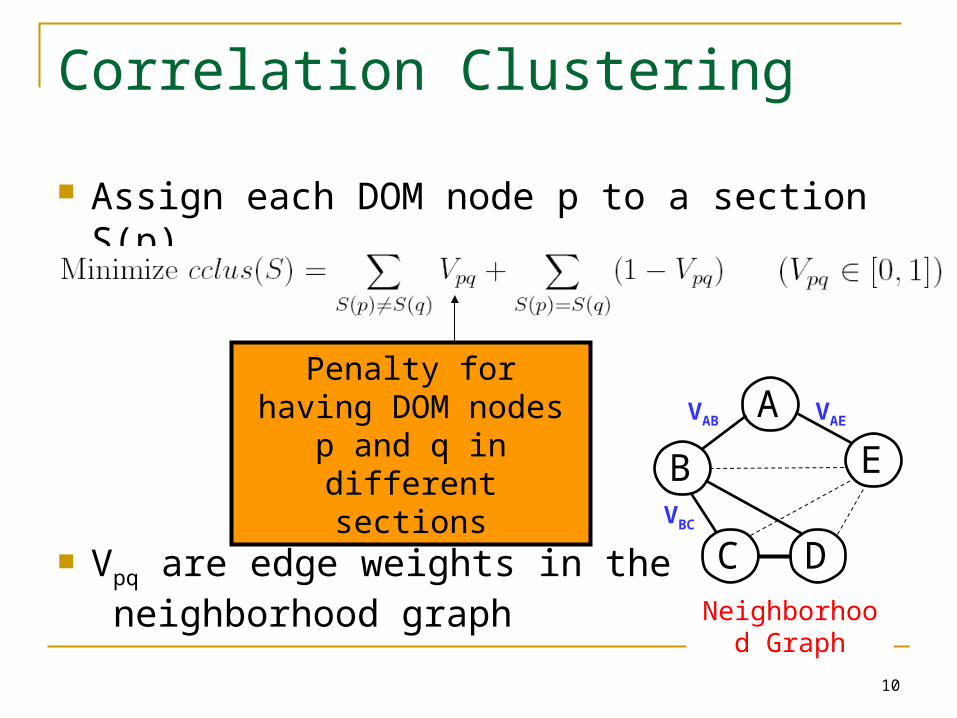
Correlation Clustering
Assign each DOM node p to a section S(p)
Vpq are edge weights in the neighborhood graph
A
B
C D
E
Neighborhood Graph
VAB VAE
VBC
Penalty for having DOM nodes p and q in different sections
11
Correlation Clustering
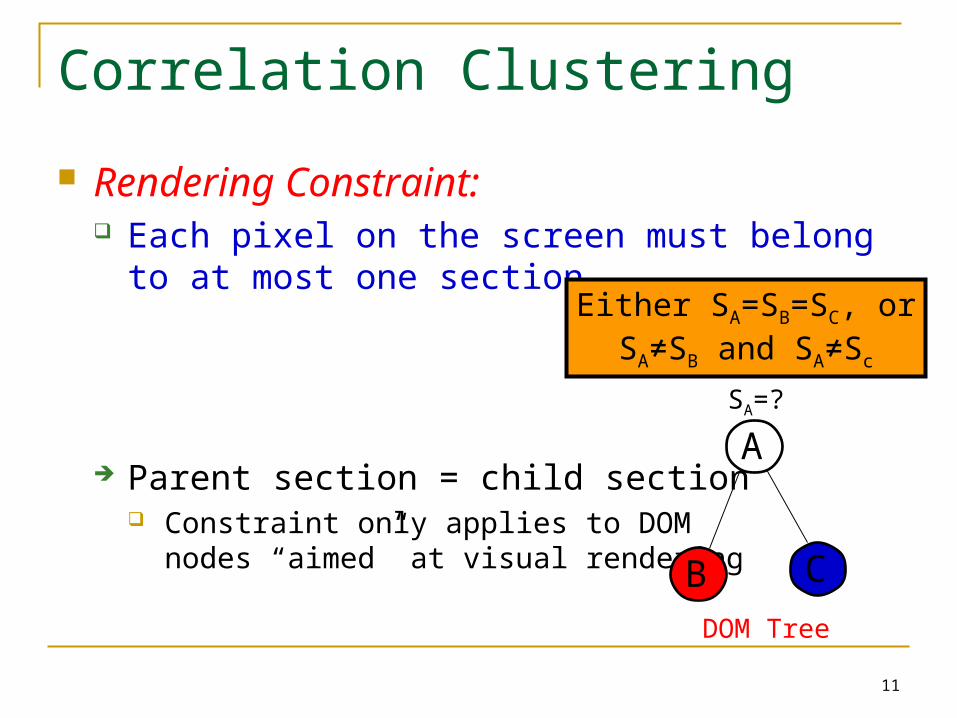
Rendering Constraint: Each pixel on the screen must belong to at most
one section
Parent section = child section Constraint only applies to DOM
nodes “aimed” at visual rendering
A
CB
SA=?
Either SA=SB=SC, or SA≠SB and SA≠Sc
DOM Tree

12
Correlation Clustering
Rendering Constraint: Each pixel on the screen must belong to at most
one section Not enforced by CCLUS
Workaround: Use only leaf nodes in the neighborhood graph But content cues may be too
noisy at the leaf level
A
CB
SA=?
Either SA=SB=SC, or SA≠SB and SA≠Sc
DOM Tree

13
Correlation Clustering
Algorithm: [Ailon+/2005] Pick a random leaf node p Create a new section of p, and all nodes q which are
strongly connected to p: Remove p and q’s from the neighborhood graph Iterate
Within a factor of 2 of the optimal Number of sections picked automatically

14
Proposed Work
A graph-based approach What is a good cost function?
Intuitive Has polynomial-time algorithms that
can get provably close to the optimal
Correlation Clustering Energy-minimizing Graph Cuts How should we set weights in
the neighborhood graph?
A
B
DC E
A
B
C D
E
DOM Tree
Neighborhood Graph
15
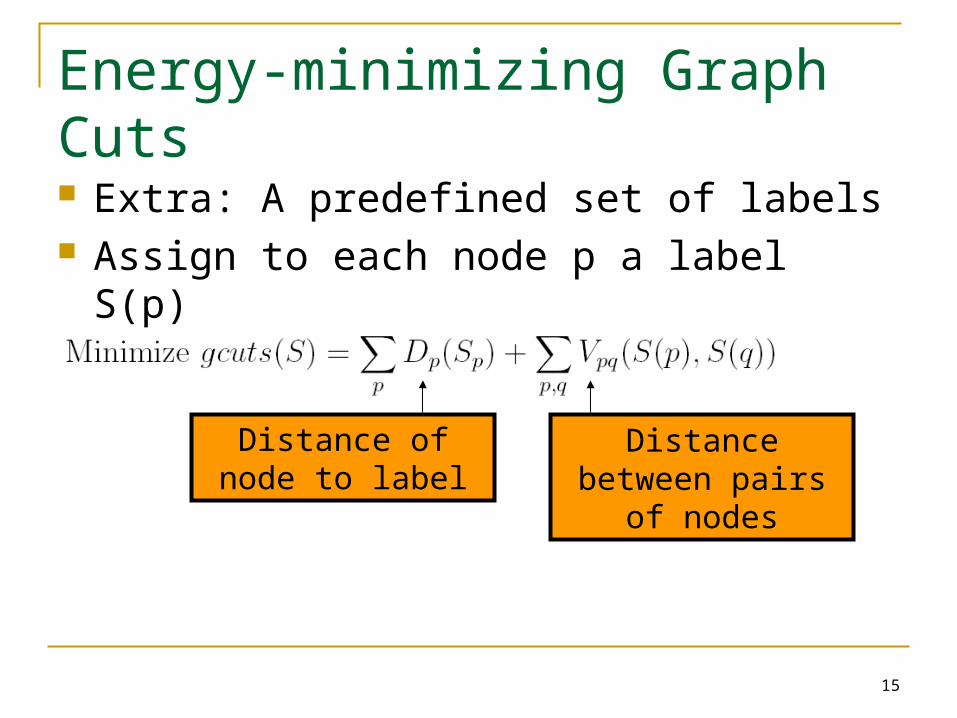
Energy-minimizing Graph Cuts Extra: A predefined set of labels Assign to each node p a label S(p)
Distance of node to label
Distance between pairs of nodes
16
Energy-minimizing Graph Cuts
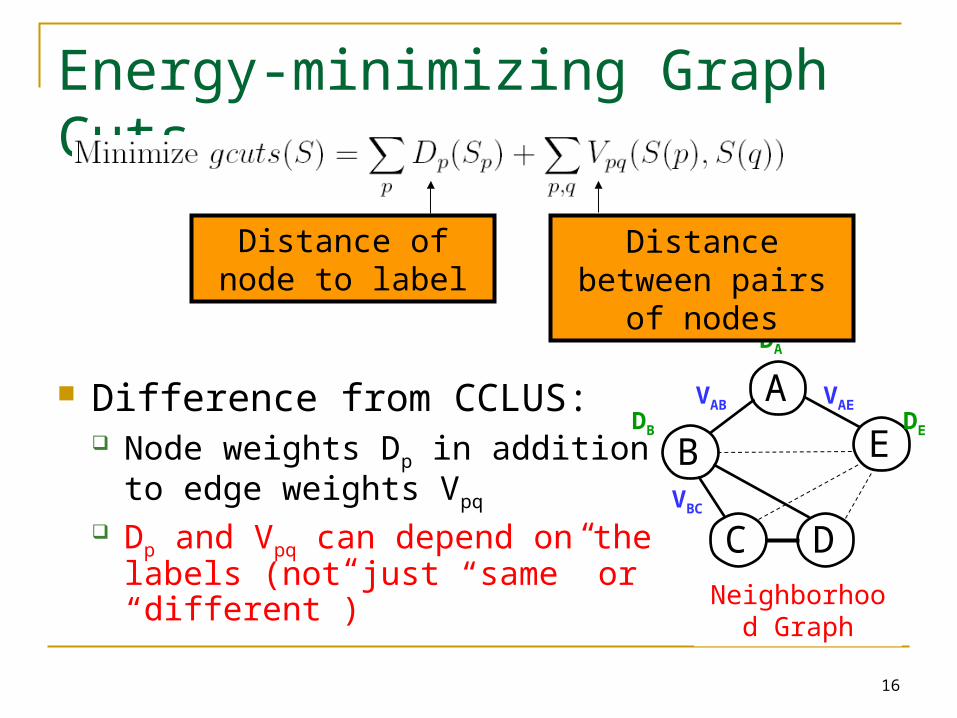
Difference from CCLUS: Node weights Dp in addition to
edge weights Vpq
Dp and Vpq can depend on the labels (not just “same” or “different”)
A
B
C D
E
Neighborhood Graph
VAB VAE
VBC
DA
DB DE
Distance of node to label
Distance between pairs of nodes

17
C
Energy-minimizing Graph Cuts
How can we fit the Rendering Constraint? Have a special “invisible” label ξ Parent is invisible, unless all
children have the same label Can set the Vpq values accordingly
A
B
SA=?ξ

18
C
Energy-minimizing Graph Cuts
How can we fit the Rendering Constraint? Have a special “invisible” label ξ Parent is invisible, unless all
children have the same label Can set the Vpq values accordingly Automatically infer “rendering”
versus “structural” DOM nodes
A
B

19
Energy-minimizing Graph Cuts Why couldn’t we use this trick in CCLUS as
well? CCLUS only asks: Are nodes p and q in the same
section or not? It cannot handle “special” sections like the
invisible section Hence, labels are giving us extra power

20
Energy-minimizing Graph Cuts
Advantages Can use all DOM nodes, while still obeying the
Rendering Constraint Better than CCLUS Factor of 2 approximation of the optimal, by
performing iterative min-cuts of specially constructed graphs We extend [Kolmogorov+/2004] Number of sections are picked automatically

21
Energy-minimizing Graph Cuts Theorem: Vpq must obey the constraint
Separation cost ≥ Merge cost
Set Vpq(different) >> Vpq(same) for nodes that are extremely close Cost minimization tries to place them in the same section

22
Energy-minimizing Graph Cuts Theorem: Vpq must obey the constraint
Separation cost ≥ Merge cost
However, we cannot use Vpq to push two nodes to be in different sections Use Dp instead

23
Energy-minimizing Graph Cuts
To separate nodes p and q: Ensure that either Dp(α) or Dq(α) is large, for any
label α So, assigning both p and q to the same label will
be too costly
Distance of node to label
24
Energy-minimizing Graph Cuts
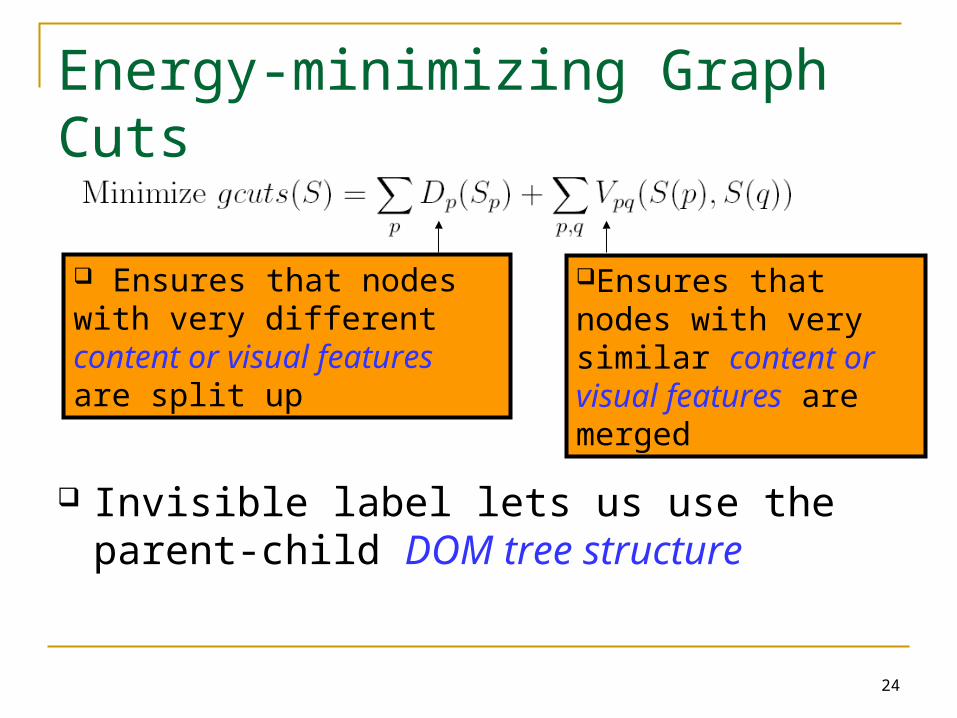
Invisible label lets us use the parent-child DOM tree structure
Ensures that nodes with very different content or visual features are split up
Ensures that nodes with very similar content or visual features are merged

25
Proposed Work
A graph-based approach What is a good cost function?
Intuitive Has polynomial-time algorithms that
can get provably close to the optimal
Correlation Clustering Energy-minimizing Graph Cuts How should we set weights in
the neighborhood graph?
A
B
DC E
A
B
C D
E
DOM Tree
Neighborhood Graph

26
Learning graph weights
Extract content and visualfeatures from training data
Learning Vpq(.) Learn a logistic regression classifier
(prob. that p and q belong to the same section)
A
B
C D
E
Neighborhood Graph
VAB VAE
VBC
DA
DBDE

27
Learning graph weights
Extract content and visualfeatures from training data
Learning Dp(.) Training data does not provide labels Set of labels = Set of DOM tree nodes in that webpage
Dp(α) = distance in some feature space
Learn a Mahalanobis distance metric between nodes(distances within section < distances across sections)
A
B
C D
E
Neighborhood Graph
VAB VAE
VBC
DA
DBDE

28
Outline
Motivation and Related Work Proposed Work Experiments Conclusions

29
Experiments
Manually sectioned 105 randomly chosen webpages to get 1088 sections
Two measures were used: Adjusted RAND: fraction of leaf node pairs which
are correctly predicted to be together or apart (over and above random sectioning)
Normalized Mutual Information Both are between 0 and 1, with higher values
indicating better results.

30
Experiments CCLUS:Only 20% of the webpages score better than 0.6
GCUTS:Almost 50% of the webpages
score better than 0.6
Adjusted RAND
% w
ebpa
ges
< s
core

31
Experiments
GCUTS is better than CCLUS
Over all webpages

32
Experiments
Application to duplicate detection on the Web Collected lyrics of the same songs from 3 different
sites (~2300 webpages) Nearly similar content Different template structures
Our approach: Section all webpages Perform duplicate detection using only the largest
section (primary content)

33
Experiments
Sectioning > No sectioning GCUTS > CCLUS

34
Outline
Motivation and Related Work Proposed Work Experiments Conclusions

35
Conclusions
Combined visual, DOM, and content based cues
Optimization on a neighborhood graph Node and edge weights are learnt from training
data Developed CCLUS and GCUTS, both with:
Approximation guarantees Automatic determination of the number of sections

36
Learning graph weights
Extract content and visualfeatures from training data
A
B
C D
E
Neighborhood Graph
VAB VAE
VBC
DA
DB DE

37
Energy-minimizing Graph Cuts
What is such a Dp(.) function? Use the set of internal DOM nodes as the set of
labels Dp(α) measures the difference in feature vectors
between node p and internal node (label) α If nodes p and q are very different, Dp(α) and Dq(α)
will differ for all α

38
Correlation Clustering
Does not enforce the Rendering Constraint: Each pixel on the screen must belong to at most
one section Parent nodes should have same section as their children
Workaround: Consider only leaf nodes in the neighborhood graph But content cues may be too noisy at the leaf level

39
Correlation Clustering
Does not enforce the Rendering Constraint Each pixel on the screen must
belong to at most one section Parent section = child section
Apply rule only for ancestors “aimed” at visual rendering
A
CB
SA=?
Either SA=SB=SC, or SA≠SB and SA≠Sc

40
Correlation Clustering
Does not enforce the Rendering Constraint
Workaround: Consider only leaf nodes in the neighborhood graph But content cues may be too
noisy at the leaf level
A
CBSB=5 SC=7
SA=?
Either SA=SB=SC, or SA≠SB and SA≠Sc

41
Energy-minimizing Graph Cuts
How can we fit the Rendering Constraint? Have a special “invisible” label ξ Parent is invisible, unless all
children have the same label Can set the Vpq values accordingly Automatically infer “rendering”
versus “structural” DOM nodes
A
CB
SB=5 SC=7
SA=?ξ
SC=5
SA=5

42
Energy-minimizing Graph Cuts
What is the set of labels? The set of internal DOM nodes
Available at the beginning of the algorithm The labels are themselves nodes, with feature vectors
Dp(α) = distance in some feature space “Tuned” to the current webpage




























