Embed Size (px)
Citation preview

Plant Genome Sequencing
Traditional Sanger Sequencing Genome Sequencing Approach
1. Create sequencing libraries of different insert sizes
• 2kb o Bulk of sequencing is performed on these libraries
• 10kb o Used for linking contigs during assembly
• 40kb o Used to link larger contigs assembly
• Bacterial artificial chromosomes o Used to link ever larger contigs assembly
2. Paired-end sequencing data collected for libraries 3. Contigs created by looking for overlapping reads 4. Contigs assembled based on homology to 10kb, 40kb and BAC sequence data; these large assemblies are called scaffolds 5. Pseudochromosomes assembled based on homology of scaffolds to the markers located on a high-density genetic map

Modern Long Read PacBio Sequencing Genome Sequencing Approach
1. Create 20kb insert libraries 2. Sequence with PacBio single molecule technology
• Reads generally 10-15 kb in length 3. Add short read (150bp) paired end data to correct for inherent PacBio errors 4. Assembly reads into contigs
• Contigs MUCH longer than with Sanger sequencing 5. Scaffolds developed by long-range scaffolding methods
• BioNano restriction enzyme mapping • Hi-C cross-linked DNA library sequencing • 10X linked read sequencing
6. Pseudochromosomes assembled based on homology of scaffolds to the markers located on a high-density genetic map
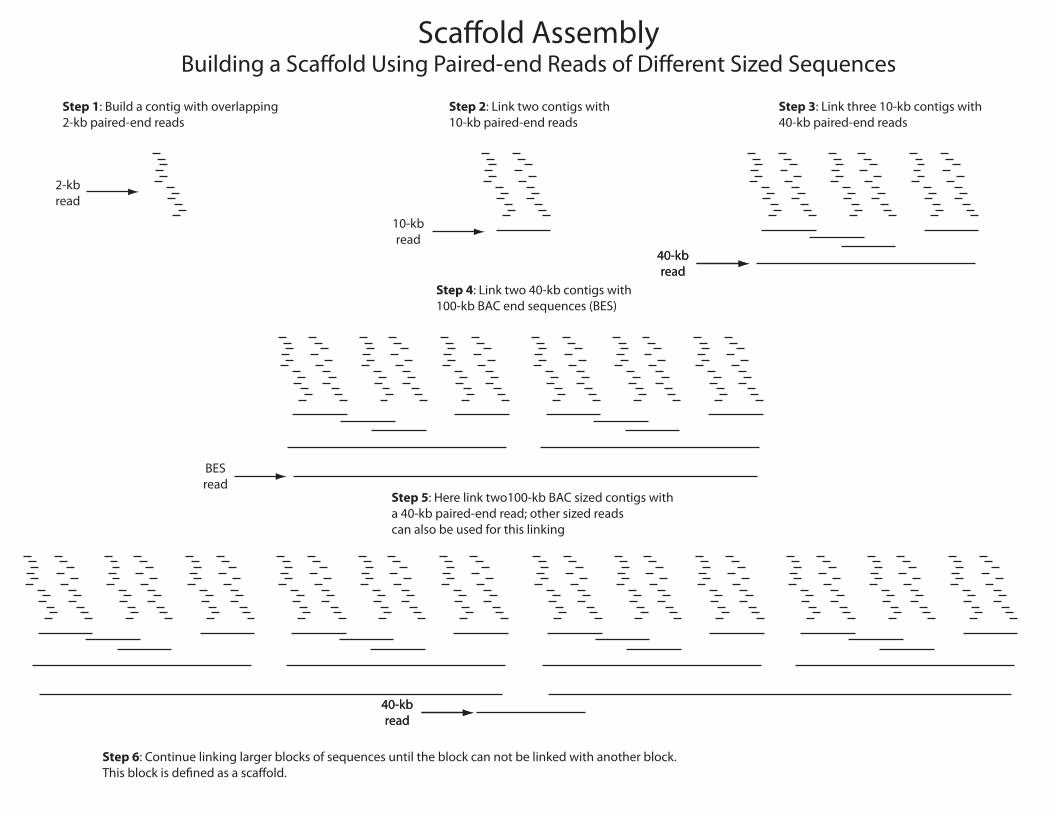
Sca�old AssemblyBuilding a Sca�old Using Paired-end Reads of Di�erent Sized Sequences
40-kbread
Step 1: Build a contig with overlapping2-kb paired-end reads
Step 2: Link two contigs with10-kb paired-end reads
Step 3: Link three 10-kb contigs with40-kb paired-end reads
Step 4: Link two 40-kb contigs with100-kb BAC end sequences (BES)
Step 5: Here link two100-kb BAC sized contigs witha 40-kb paired-end read; other sized readscan also be used for this linking
Step 6: Continue linking larger blocks of sequences until the block can not be linked with another block.This block is de�ned as a sca�old.
2-kbread
10-kbread
40-kbread
BESread
40-kbread
40-kbread
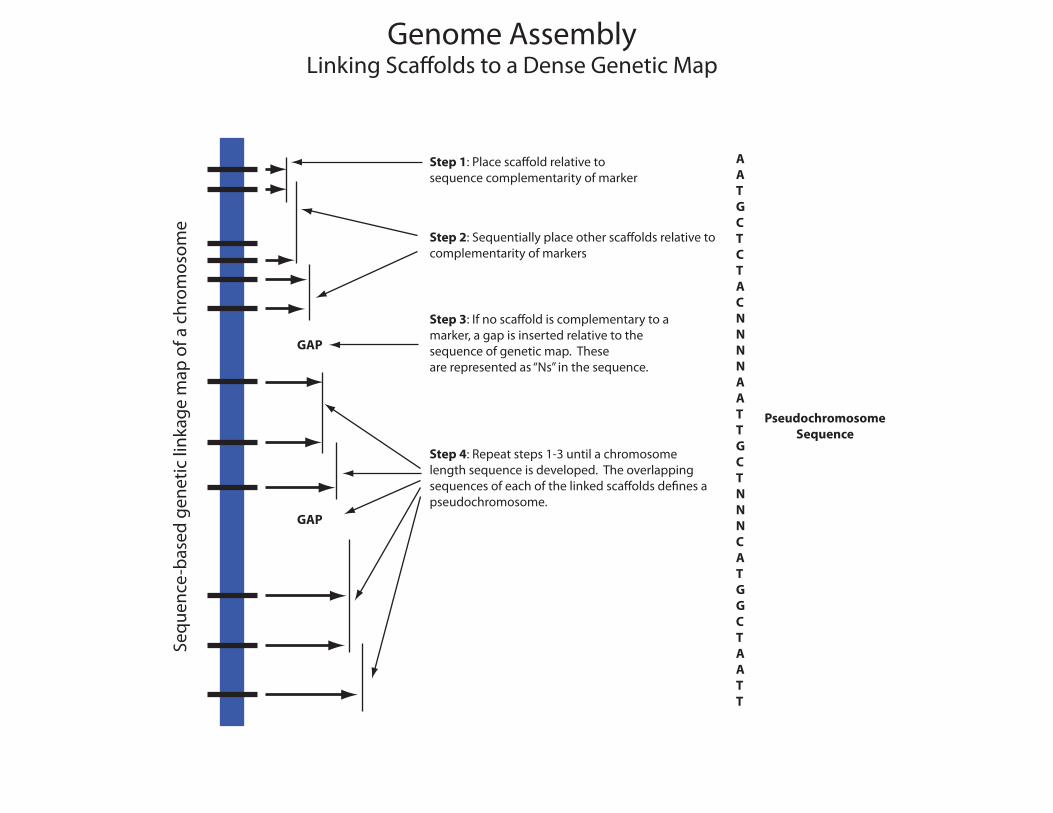
Genome AssemblyLinking Sca�olds to a Dense Genetic Map
Sequ
ence
-bas
ed g
enet
ic li
nkag
e m
ap o
f a c
hrom
osom
eStep 1: Place sca�old relative tosequence complementarity of marker
Step 2: Sequentially place other sca�olds relative tocomplementarity of markers
Step 3: If no sca�old is complementary to a marker, a gap is inserted relative to thesequence of genetic map. These are represented as “Ns” in the sequence.
Step 4: Repeat steps 1-3 until a chromosomelength sequence is developed. The overlappingsequences of each of the linked sca�olds de�nes a pseudochromosome.
GAP
GAP
AATGCTCTACNNNNAATTGCTNNNCATGGCTAATT
PseudochromosomeSequence

Phaseolus vulgaris Summary Genome Sequencing and Assembly
Short read production information
• Sequence technology: Sanger, Roche 454, Illumina • Number of libraries: 21 (15 paired, 6 unpaired) • Total Reads: 49,214,786 (10,696,722 successful paired-end reads;
2.3% failed) • Coverage: 21.02x total (18.64X linear, 3.38X paired-end)
Long read production information
• PacBio technology • 83.2x sequence coverage • Illumina data from short read project added to PacBio data

Assembly Notes
• Initial assembly o Arachne
Short read o Falcon
Long read
• Final assembly o Breaks of initial assembly
71 breaks applied to initial short read assembly 43 breaks applied to initial long read assembly
o Genetic map and soybean/common bean synteny applied to data
o Genetic map 7,015 markers used
o Soybean/common bean synteny used to detect misjoins 248 joins applied to broken assembly short read
assembly 577 joins applied to the long read assembly
o 11 pseudochromosomes assembled 98.8% of short read assembled sequence is found in
the pseudochromsomes 95.3% of long read assembled sequence is found in the
pseudochromsomes
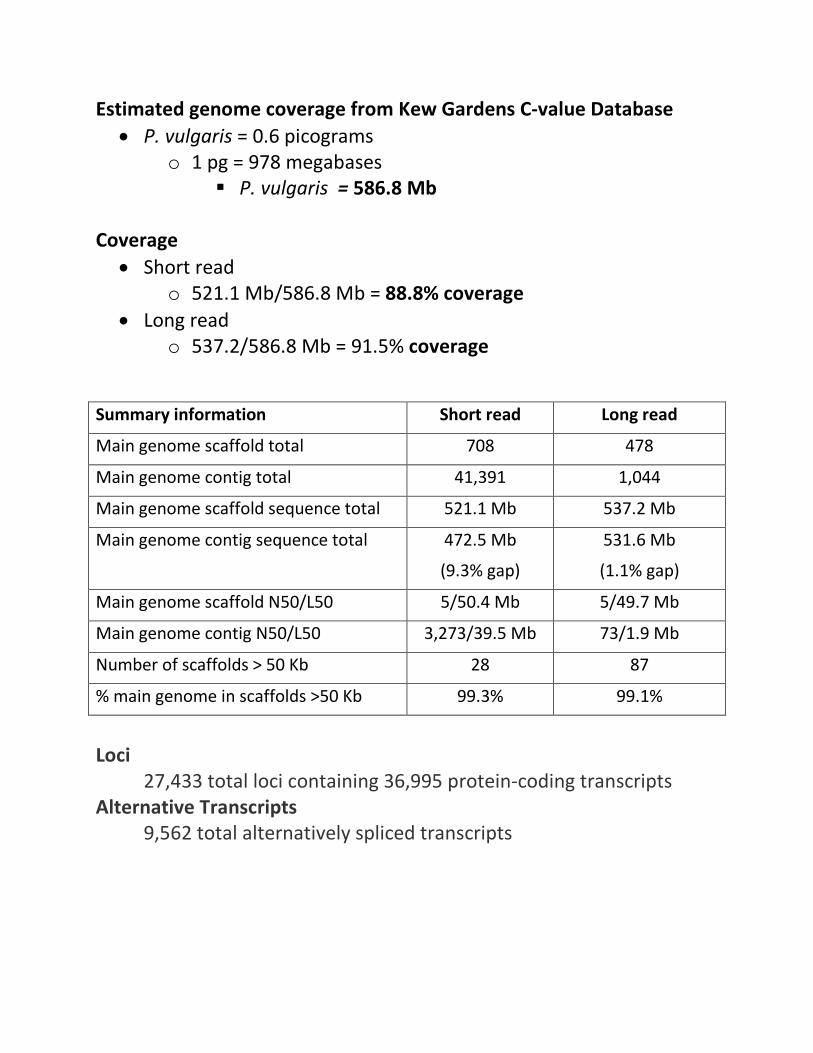
Estimated genome coverage from Kew Gardens C-value Database • P. vulgaris = 0.6 picograms
o 1 pg = 978 megabases P. vulgaris = 586.8 Mb
Coverage
• Short read o 521.1 Mb/586.8 Mb = 88.8% coverage
• Long read o 537.2/586.8 Mb = 91.5% coverage
Summary information Short read Long read
Main genome scaffold total 708 478
Main genome contig total 41,391 1,044
Main genome scaffold sequence total 521.1 Mb 537.2 Mb
Main genome contig sequence total 472.5 Mb
(9.3% gap)
531.6 Mb
(1.1% gap)
Main genome scaffold N50/L50 5/50.4 Mb 5/49.7 Mb
Main genome contig N50/L50 3,273/39.5 Mb 73/1.9 Mb
Number of scaffolds > 50 Kb 28 87
% main genome in scaffolds >50 Kb 99.3% 99.1%
Loci
27,433 total loci containing 36,995 protein-coding transcripts Alternative Transcripts
9,562 total alternatively spliced transcripts

N50 and L50: Measures of the Quality of Genomes Contig
• An aligned group of reads that represent one section of the genome o No missing sequence data
Scaffolds
• Groups of contigs that define a section of the genome o Larger than contigs o Can contain gaps (missing sequence) that are filled in with
Ns o Number of scaffolds is always smaller than the number of
contigs Pseudochromosome
• Group of scaffolds that represent one chromosome of the species N50
• The number of contigs (or scaffolds) whose collective distance equals 50% of the genome length o This is a NUMBER
L50
• The length of the smallest contig (or scaffolds), of the collection of the contigs (or scaffolds )that comprise the set of N50 contigs (or scaffolds) o This is a LENGTH
IMPORTANT NOTE Today, the L50 length is almost always reported as the N50
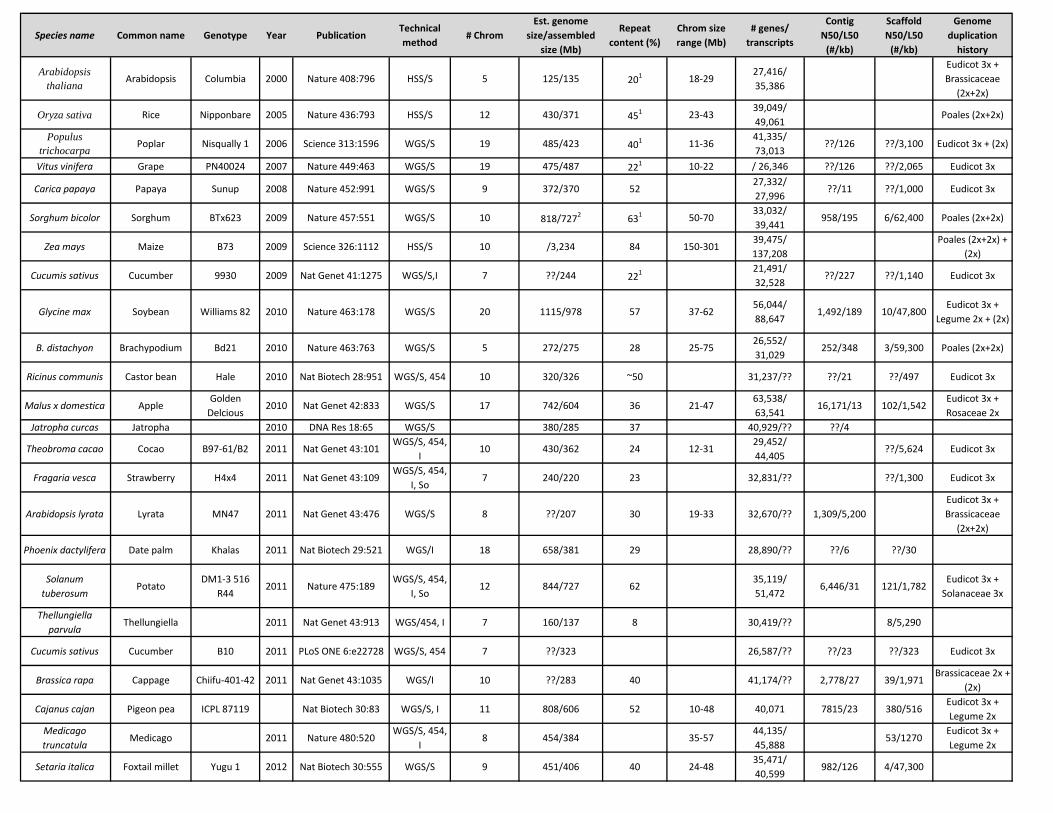
Species name Common name Genotype Year PublicationTechnical method
# ChromEst. genome
size/assembled size (Mb)
Repeat content (%)
Chrom size range (Mb)
# genes/ transcripts
Contig N50/L50
(#/kb)
Scaffold N50/L50
(#/kb)
Genome duplication
history
Arabidopsis thaliana Arabidopsis Columbia 2000 Nature 408:796 HSS/S 5 125/135 201 18-29
27,416/ 35,386
Eudicot 3x + Brassicaceae
(2x+2x)
Oryza sativa Rice Nipponbare 2005 Nature 436:793 HSS/S 12 430/371 451 23-4339,049/ 49,061
Poales (2x+2x)
Populus trichocarpa Poplar Nisqually 1 2006 Science 313:1596 WGS/S 19 485/423 401 11-36
41,335/ 73,013
??/126 ??/3,100 Eudicot 3x + (2x)
Vitus vinifera Grape PN40024 2007 Nature 449:463 WGS/S 19 475/487 221 10-22 / 26,346 ??/126 ??/2,065 Eudicot 3x
Carica papaya Papaya Sunup 2008 Nature 452:991 WGS/S 9 372/370 5227,332/ 27,996
??/11 ??/1,000 Eudicot 3x
Sorghum bicolor Sorghum BTx623 2009 Nature 457:551 WGS/S 10 818/7272 631 50-7033,032/ 39,441
958/195 6/62,400 Poales (2x+2x)
Zea mays Maize B73 2009 Science 326:1112 HSS/S 10 /3,234 84 150-30139,475/ 137,208
Poales (2x+2x) + (2x)
Cucumis sativus Cucumber 9930 2009 Nat Genet 41:1275 WGS/S,I 7 ??/244 221 21,491/ 32,528
??/227 ??/1,140 Eudicot 3x
Glycine max Soybean Williams 82 2010 Nature 463:178 WGS/S 20 1115/978 57 37-6256,044/ 88,647
1,492/189 10/47,800Eudicot 3x +
Legume 2x + (2x)
B. distachyon Brachypodium Bd21 2010 Nature 463:763 WGS/S 5 272/275 28 25-7526,552/ 31,029
252/348 3/59,300 Poales (2x+2x)
Ricinus communis Castor bean Hale 2010 Nat Biotech 28:951 WGS/S, 454 10 320/326 ~50 31,237/?? ??/21 ??/497 Eudicot 3x
Malus x domestica AppleGolden
Delcious2010 Nat Genet 42:833 WGS/S 17 742/604 36 21-47
63,538/ 63,541
16,171/13 102/1,542Eudicot 3x + Rosaceae 2x
Jatropha curcas Jatropha 2010 DNA Res 18:65 WGS/S 380/285 37 40,929/?? ??/4
Theobroma cacao Cocao B97-61/B2 2011 Nat Genet 43:101WGS/S, 454,
I10 430/362 24 12-31
29,452/ 44,405
??/5,624 Eudicot 3x
Fragaria vesca Strawberry H4x4 2011 Nat Genet 43:109WGS/S, 454,
I, So7 240/220 23 32,831/?? ??/1,300 Eudicot 3x
Arabidopsis lyrata Lyrata MN47 2011 Nat Genet 43:476 WGS/S 8 ??/207 30 19-33 32,670/?? 1,309/5,200Eudicot 3x + Brassicaceae
(2x+2x)
Phoenix dactylifera Date palm Khalas 2011 Nat Biotech 29:521 WGS/I 18 658/381 29 28,890/?? ??/6 ??/30
Solanum tuberosum
PotatoDM1-3 516
R442011 Nature 475:189
WGS/S, 454, I, So
12 844/727 6235,119/ 51,472
6,446/31 121/1,782Eudicot 3x +
Solanaceae 3x
Thellungiella parvula
Thellungiella 2011 Nat Genet 43:913 WGS/454, I 7 160/137 8 30,419/?? 8/5,290
Cucumis sativus Cucumber B10 2011 PLoS ONE 6:e22728 WGS/S, 454 7 ??/323 26,587/?? ??/23 ??/323 Eudicot 3x
Brassica rapa Cappage Chiifu-401-42 2011 Nat Genet 43:1035 WGS/I 10 ??/283 40 41,174/?? 2,778/27 39/1,971Brassicaceae 2x +
(2x)
Cajanus cajan Pigeon pea ICPL 87119 Nat Biotech 30:83 WGS/S, I 11 808/606 52 10-48 40,071 7815/23 380/516Eudicot 3x + Legume 2x
Medicago truncatula
Medicago 2011 Nature 480:520WGS/S, 454,
I8 454/384 35-57
44,135/ 45,888
53/1270Eudicot 3x + Legume 2x
Setaria italica Foxtail millet Yugu 1 2012 Nat Biotech 30:555 WGS/S 9 451/406 40 24-4835,471/ 40,599
982/126 4/47,300
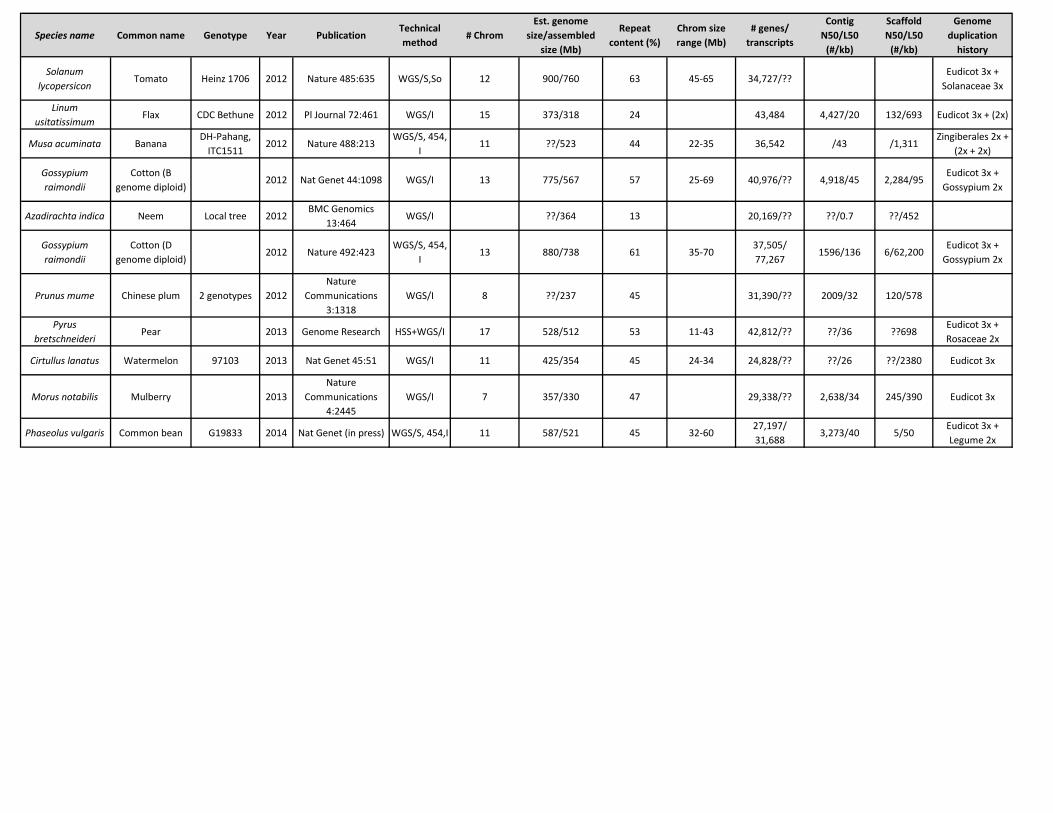
Species name Common name Genotype Year PublicationTechnical method
# ChromEst. genome
size/assembled size (Mb)
Repeat content (%)
Chrom size range (Mb)
# genes/ transcripts
Contig N50/L50
(#/kb)
Scaffold N50/L50
(#/kb)
Genome duplication
history
Solanum lycopersicon
Tomato Heinz 1706 2012 Nature 485:635 WGS/S,So 12 900/760 63 45-65 34,727/??Eudicot 3x +
Solanaceae 3x
Linum usitatissimum
Flax CDC Bethune 2012 Pl Journal 72:461 WGS/I 15 373/318 24 43,484 4,427/20 132/693 Eudicot 3x + (2x)
Musa acuminata BananaDH-Pahang,
ITC15112012 Nature 488:213
WGS/S, 454, I
11 ??/523 44 22-35 36,542 /43 /1,311Zingiberales 2x +
(2x + 2x)
Gossypium raimondii
Cotton (B genome diploid)
2012 Nat Genet 44:1098 WGS/I 13 775/567 57 25-69 40,976/?? 4,918/45 2,284/95Eudicot 3x +
Gossypium 2x
Azadirachta indica Neem Local tree 2012BMC Genomics
13:464WGS/I ??/364 13 20,169/?? ??/0.7 ??/452
Gossypium raimondii
Cotton (D genome diploid)
2012 Nature 492:423WGS/S, 454,
I13 880/738 61 35-70
37,505/ 77,267
1596/136 6/62,200Eudicot 3x +
Gossypium 2x
Prunus mume Chinese plum 2 genotypes 2012Nature
Communications 3:1318
WGS/I 8 ??/237 45 31,390/?? 2009/32 120/578
Pyrus bretschneideri
Pear 2013 Genome Research HSS+WGS/I 17 528/512 53 11-43 42,812/?? ??/36 ??698Eudicot 3x + Rosaceae 2x
Cirtullus lanatus Watermelon 97103 2013 Nat Genet 45:51 WGS/I 11 425/354 45 24-34 24,828/?? ??/26 ??/2380 Eudicot 3x
Morus notabilis Mulberry 2013Nature
Communications 4:2445
WGS/I 7 357/330 47 29,338/?? 2,638/34 245/390 Eudicot 3x
Phaseolus vulgaris Common bean G19833 2014 Nat Genet (in press) WGS/S, 454,I 11 587/521 45 32-6027,197/ 31,688
3,273/40 5/50Eudicot 3x + Legume 2x
doi: 10.1038/nature07723 SUPPLEMENTARY INFORMATION
www.nature.com/nature 34

Evolution of Plant Genomes Introduction Modern plant genomes are quite variable
~150 megabase (Mb) Arabidopsis thaliana genome. 18,000 Mb hexaploidy wheat genome.
Why understanding the evolutionary history of genomes?
Applied genetics perspective Application of comparative genomics for gene discovery.
o Arabidopsis terminal flower 1 (tfl1) Encodes a transcription factor It controls indeterminacy/determinacy phenotype Arabidopsis tfl1 as a reference gene
Homolog of this gene also controls the phenotype in other
o Dicot species Snapdragon (Antirrhinum) Pea (Pisum sativum)
o Monocot Rice (Oryza sativum)
Mutations all results in a determinate phenotype

The relevant question To what degree are functional genes in one plant species conserved in another species?
o Important to trace Evolutionary events Related to current organization of plant genomes

Polyploidy and the Construction of Plant Genomes Whole genome duplication (WGD)
Common event in the evolution of plant species o Entire genome doubles in size o Duplicates the same genome
Two related diploid species merge o During mitosis
Chromatids migrate to separate daughter cells o If they movie to only one cell
The cell will be a tetrapolid If the 2x duplicate cell is involved in reproduction
o Resulting gamete 2x the normal number of cells
If 2x gamete unites o Offspring will be tetraploid
Polyploidy
An organism that contains extra sets of chromosomes. o Tetraploids
Cultivated potato Alfalfa
For a success of any polyploidy o It must generate balanced gametes.
The same number of chromosomes as other gametes
Embryos from gametes with the same number of gametes o Successfully survive

Other Polyploids Allopolyploids
o Two species with very similar chromosomal structure and number intermate.
o After chromosomal doubling organism, genome will have Number of chromosomes equal to the sum of the
number of chromosomes from each of the parent species.
Examples of allolopolyploid species o Tetraploid durum wheat (x=14) o Hexaploid bread wheat (x=21).
Durum wheat arose from o Union of two diploid species (x=7) species
Bread wheat arose from o Diploid wheat species with the tetraploid wheat species

Constructing the A. thaliana genome as a model for eudicot genome evolution
With the whole genome sequence o Study the duplication history of the A. thaliana genome. o Ancestral duplication signatures could be inferred
Blastp analysis Protein vs. protein comparison Identifies gene pairs
o E-value < -10 used in Fig. 1 Suggests genes are ancestrally related
Duplicates are mapped relative position in the genome
Displayed using a dot blot Blocks observed
o Linear arrayed dots o Form a diagonal in the dot blot,
Signatures of a duplication event

Figure 1A Early comparison of the proteins in the A. thaliana genome
o Red and green diagonals in the upper right panel Block 3
Chromosome 1 vs. chromosome 1 block Signature of a duplicated block of genes Genes that have the same conserved order At two ends of the A. thaliana chromosome
1 Block 5
Another pairs of duplicated genes on chromosome 1
Block 8 Shared block on chromosomes 1 and 3
Block, 11 Largest block Ends of chromsomes 3 and 2
o Total 27 major duplicated blocks
Strong signals Signals of a recent duplication
So how does this relate to the mechanism of genome construction?
A. thaliana underwent a WGD o Chromosomes were broken o Rearranged into new chromosomes o New chromosomes developed
Represent blocks of DNA from the progenitor species
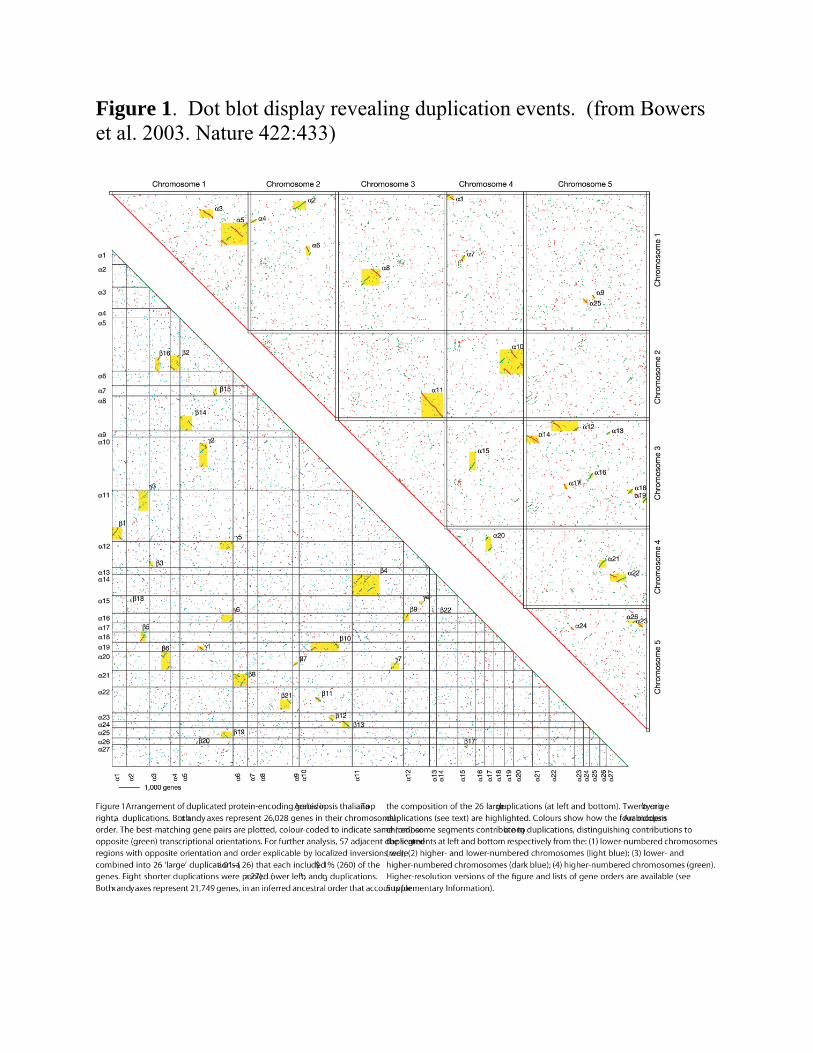
Figure 1. Dot blot display revealing duplication events. (from Bowers et al. 2003. Nature 422:433)

Progenitor Arabidopsis genome How it was modified by the duplication event Compare to species that is evolutionary close.
o A. lyrata 8 chromosomes
o A. thaliana 5 chromosomes
Genetic maps developed using shared loci were Fig. 2
Five A. thaliana chromosomes o Constructed from ancestral genome with eight
chromosomes At Chr 1
o Blocks of AlyLG1 + AlyLG2 At Chr II
o Blocks of AlyLG3 + AlyLG4. Conclusion
o Two species with different chromosome numbers consist of the same chromosomal blocks

Figure 2. Comparative physical map of A. thaliana and the genetic map of A. lyrata. (from: Yogeeswaran et al. Genome Research 15:505)

Fig. 1B – Early duplication events
Shows evidence of more ancient duplications o 27 duplications reoriented
Notice block 5 Two duplicates blocks in the same order Two in an opposite orientation
Presumed ancestral order derived from these four blocks
Same procedure that uncovered the blocks. Two types of blocks discovered.
o 22 blocks Another duplication event in the
A. thaliana lineage The 7 blocks
Controversial o Hypothesis 1
Early duplication in the angiosperm lineage o Hypothesis 2
Duplication after the split of monocots and dicots Grapevine genome sequenced
o Evidence from the genome appears to have resolved this question Grape
Ancestor of the rosids o Group of species included A. thaliana.
Blast and dot blot analysis of grape genome

Figure 3 Any genes shared with two other regions of the genome
o Grape genome has a hexaploid history How about other species
o Signal of hexaploidy is detected Figure 4
Grape and poplar genomes were compared Only triplicated regions in grape used
o Triplicated regions Two copies in poplar
o Hexaploid ancestry concept is supported o Poplar under went an additional WGD after its
divergence from the grape lineage Shared duplications in dicot and monocot analysed
Grape and rice orthologs analyzed o Hypothesis 1
Rice shared the hexaploid ancestry 3-to-3 relationship
o Not observed o Hypothesis
Rice does not share the same hexaploid ancestry 3-to-1 relationship observed
o Conclusion Monocots and dicots do not share the same
hexaploid history. (Note: See Tang et al. 2008. Genome Research18:1944 for an alternative perspective.)
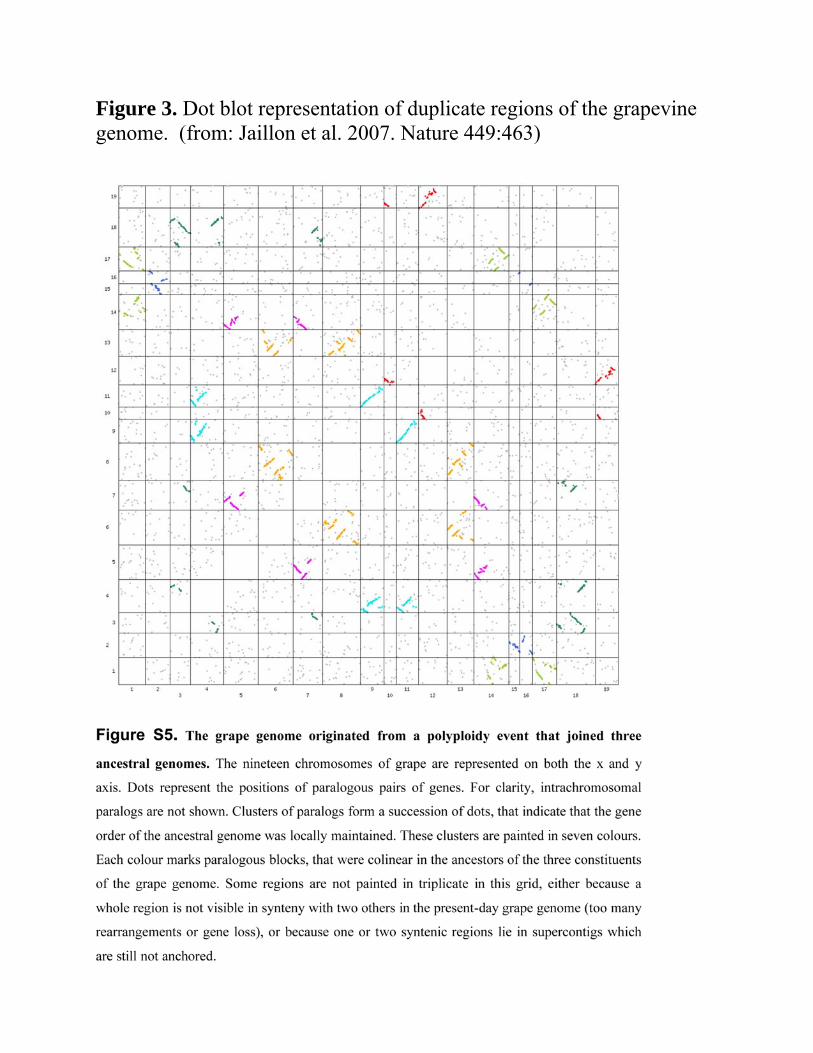
Figure 3. Dot blot representation of duplicate regions of the grapevine genome. (from: Jaillon et al. 2007. Nature 449:463)
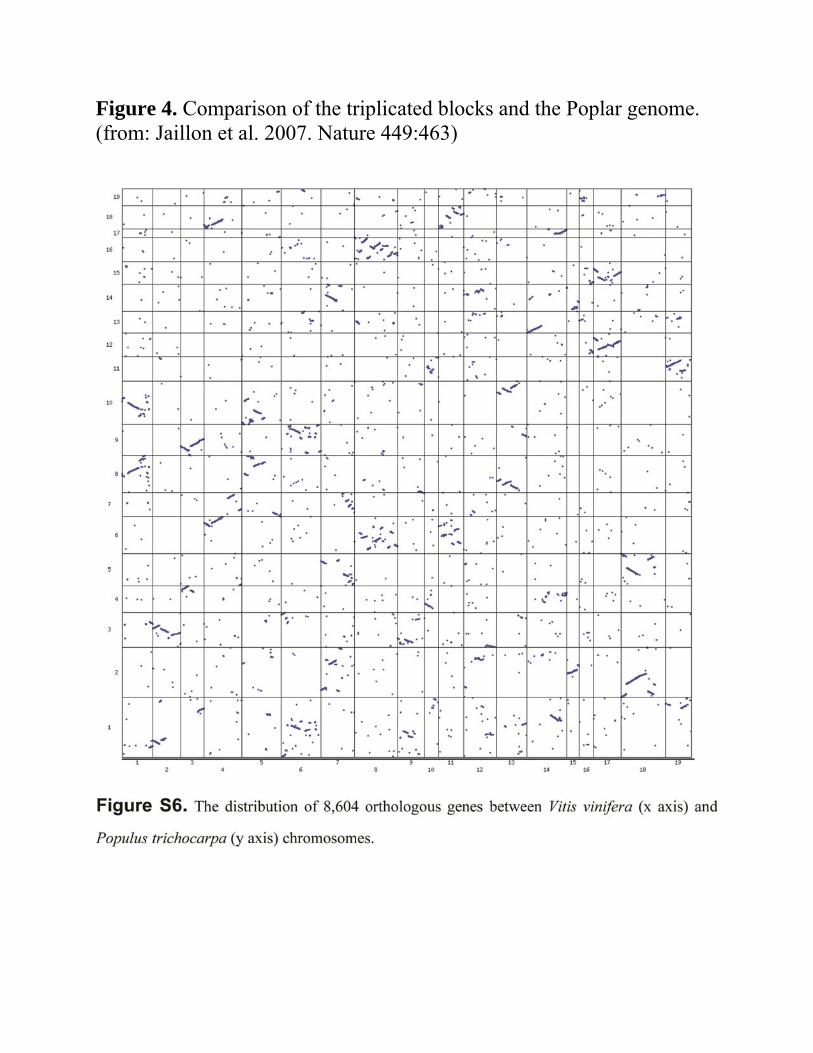
Figure 4. Comparison of the triplicated blocks and the Poplar genome. (from: Jaillon et al. 2007. Nature 449:463)

Summary of Eudicot Evolution Two diploid mate
o Tetraploid species developed Tetraploid species mated to another diploid
o Produce the ancestral hexaploid All subsequent eudicots derived from this
ancestor Signatures of the same duplications
o Should be observed in their genome history
Monocot genome evolution.
Monocots also have a duplication history. o Figure 5
Compared rice and maize. Maize chromosomes (y-axis) as the
reference o Most rice genes found in two copies
Rice chromosomes (x-axis) as the reference o Blocks found three or four times in
maize. Conclusion
WGD event in the history of monocots An additional duplication occurred in the
maize lineage.
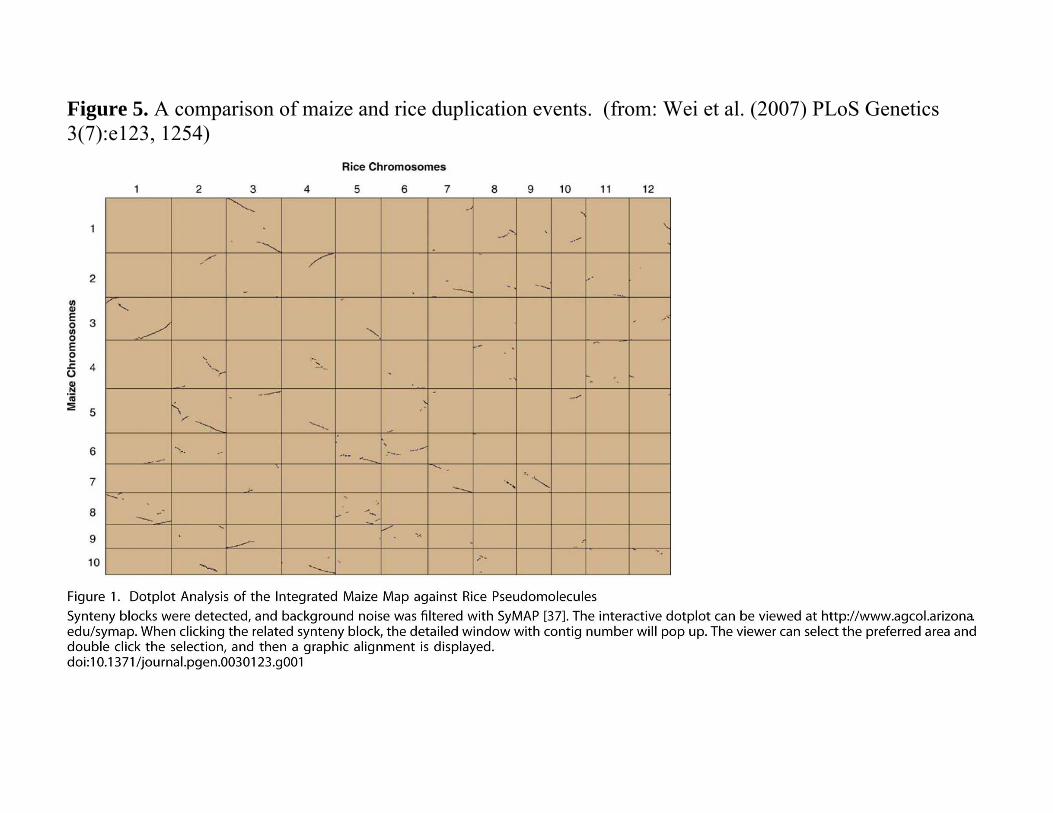
Figure 5. A comparison of maize and rice duplication events. (from: Wei et al. (2007) PLoS Genetics 3(7):e123, 1254)

Unified model of grass evolution – developing the ancestor Based on sequences of genome sequences of
o Rice o Sorghum o Brachypodium (a model grass species) o Maize
56-73 MYA o Ancestral grass species containing five chromosomes
Duplicated Genome with ten chromosomes appeared
o Then A4 and A6 fractionated
Chromosomes A4, A6, and A2 appear A7 and A10 fractionated
Chromosomes A7, A10, and A3 appear o Paleopolyploid developed
12 chromosomes Progenitor of all of the modern grasses
Unified model of grass evolution – developing the lineages
Rice genome structure o Represents the ancient paleotetraploid.
Basic set of chromosomes Building blocks for other genomes

Figure 6 Breakage/translocation/fusion events
o Involve chromosomal fragments from the n=12 ancestor. Developed
Brachypodium Poideae (representing the wheat lineage) Panicoideae (representing the
maize/sorghum lineage) Panicoideae
o Simplest history o Arose from only four breaks
Other lineages o More complex patterns of evolution
Maize genome Underwent additional
duplication Additional
breakage/translocation/fusion events
Constructed the modern maize chromosomes
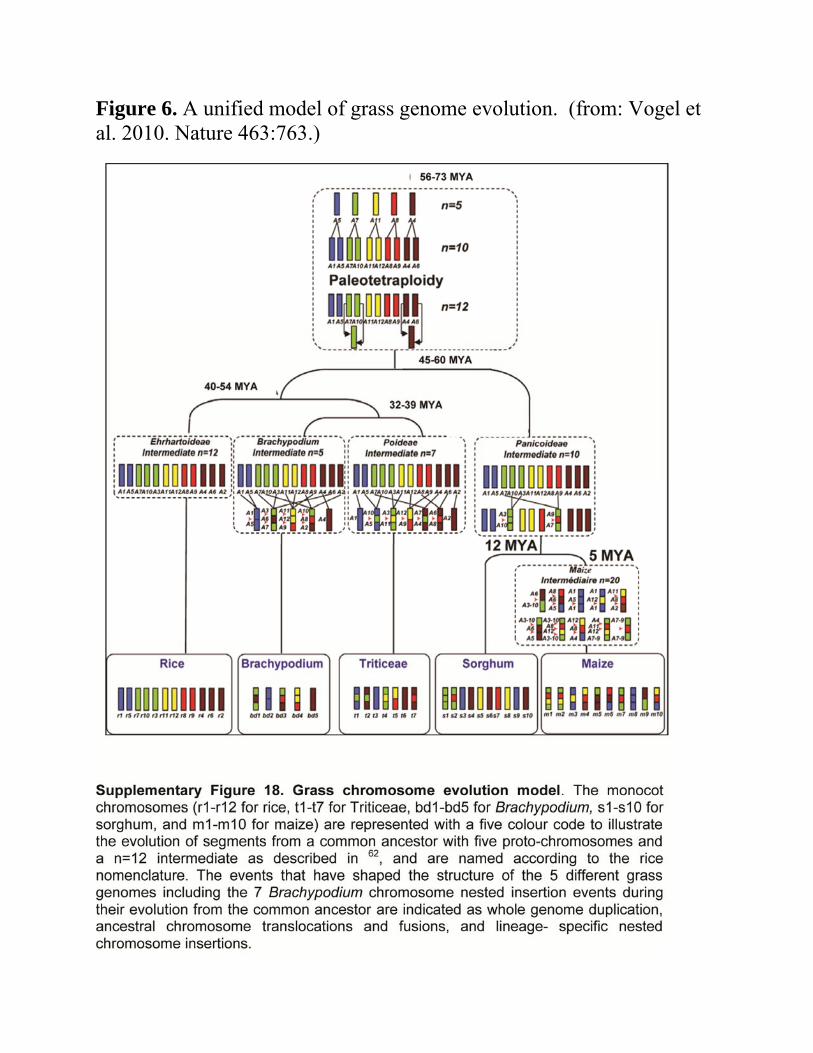
Figure 6. A unified model of grass genome evolution. (from: Vogel et al. 2010. Nature 463:763.)

Summary Plant genomes
o A long history of genome duplications Unlike animal and fungal genoemes,
Figure 7 o Illustrates the duplication history
(The event should be moved to the origin of the eudicot lineage.)
o Significant role of WGD in development of plant species Many duplications appear 55-70 MYA
Transition point o Cretaceous and Tertiary periods
Mass extinction of species Hypothesis
o Duplications gave plants the needed gene repertoire To survive this extinction Flourish on earth
(see Fawcett et al. 2009. PNAS USA 106:5737)
Figure 8 o Additional species were analyzed o Extended the analysis to deeper phylogeny o Additional duplication events determined
Ancestral seed plants ζ at ~330 MYA
Ancestral angiosperms ε at ~220 MYA
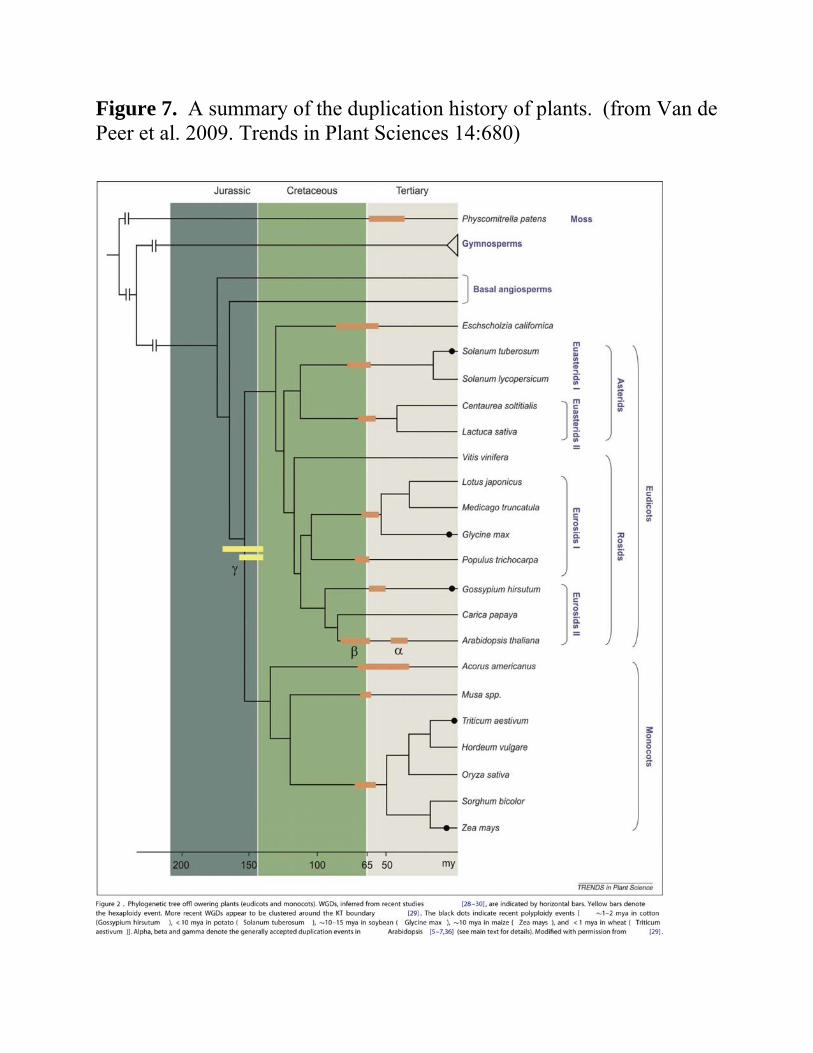
Figure 7. A summary of the duplication history of plants. (from Van de Peer et al. 2009. Trends in Plant Sciences 14:680)
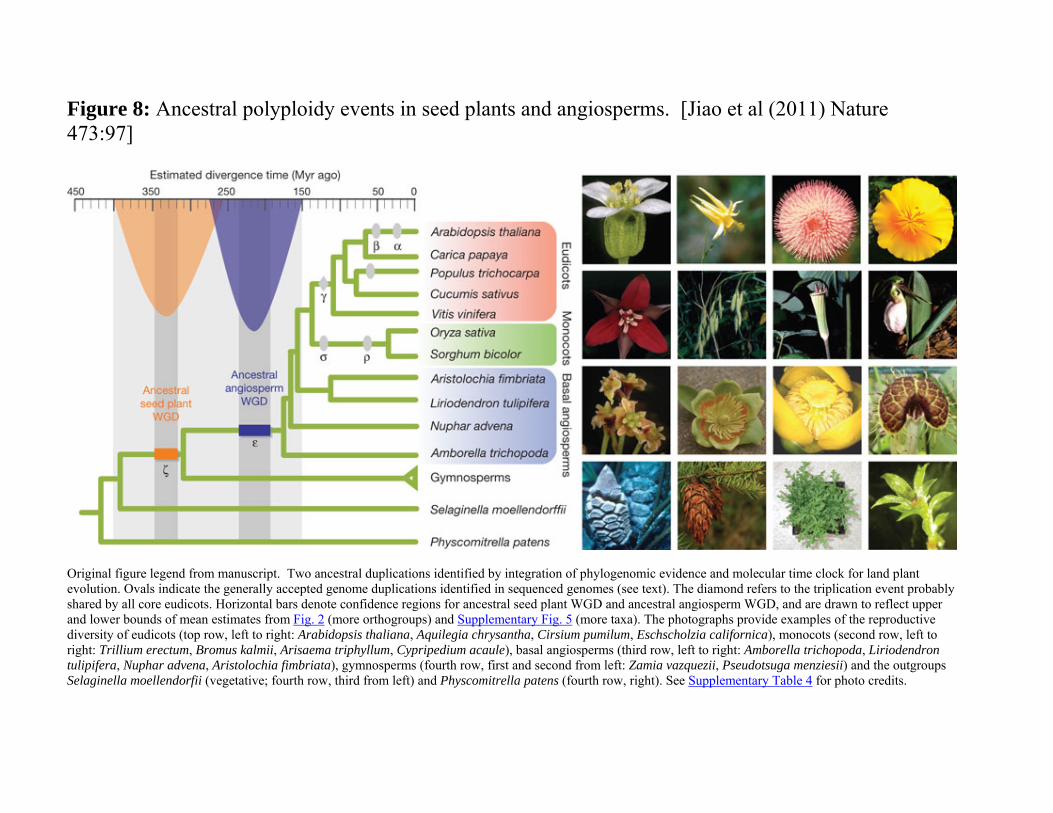
Figure 8: Ancestral polyploidy events in seed plants and angiosperms. [Jiao et al (2011) Nature 473:97]
Original figure legend from manuscript. Two ancestral duplications identified by integration of phylogenomic evidence and molecular time clock for land plant evolution. Ovals indicate the generally accepted genome duplications identified in sequenced genomes (see text). The diamond refers to the triplication event probably shared by all core eudicots. Horizontal bars denote confidence regions for ancestral seed plant WGD and ancestral angiosperm WGD, and are drawn to reflect upper and lower bounds of mean estimates from Fig. 2 (more orthogroups) and Supplementary Fig. 5 (more taxa). The photographs provide examples of the reproductive diversity of eudicots (top row, left to right: Arabidopsis thaliana, Aquilegia chrysantha, Cirsium pumilum, Eschscholzia californica), monocots (second row, left to right: Trillium erectum, Bromus kalmii, Arisaema triphyllum, Cypripedium acaule), basal angiosperms (third row, left to right: Amborella trichopoda, Liriodendron tulipifera, Nuphar advena, Aristolochia fimbriata), gymnosperms (fourth row, first and second from left: Zamia vazquezii, Pseudotsuga menziesii) and the outgroups Selaginella moellendorfii (vegetative; fourth row, third from left) and Physcomitrella patens (fourth row, right). See Supplementary Table 4 for photo credits.
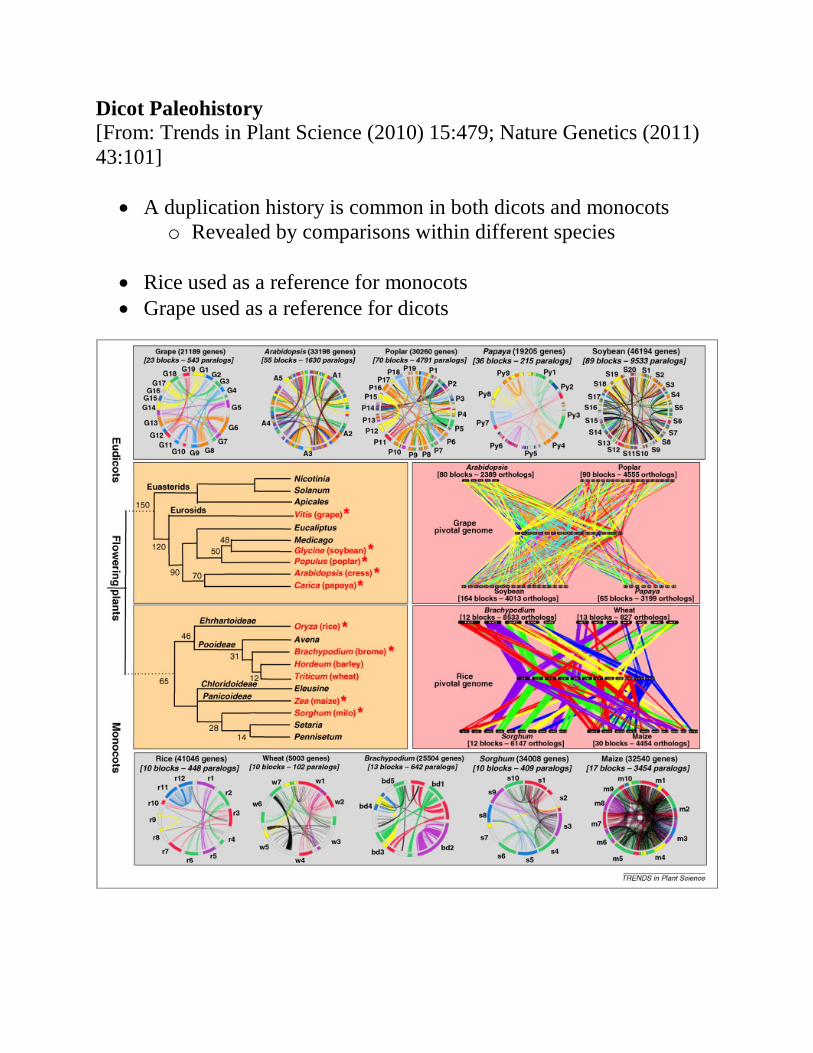
Dicot Paleohistory [From: Trends in Plant Science (2010) 15:479; Nature Genetics (2011) 43:101]
• A duplication history is common in both dicots and monocots o Revealed by comparisons within different species
• Rice used as a reference for monocots • Grape used as a reference for dicots
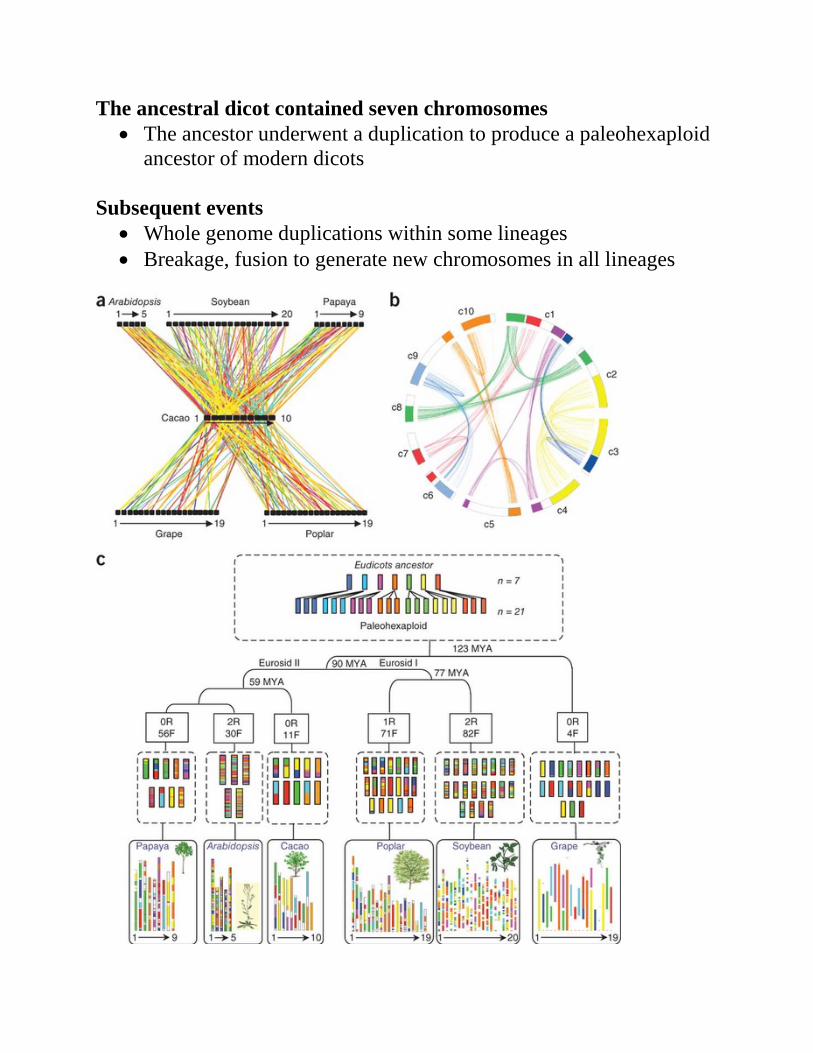
The ancestral dicot contained seven chromosomes • The ancestor underwent a duplication to produce a paleohexaploid
ancestor of modern dicots Subsequent events
• Whole genome duplications within some lineages • Breakage, fusion to generate new chromosomes in all lineages
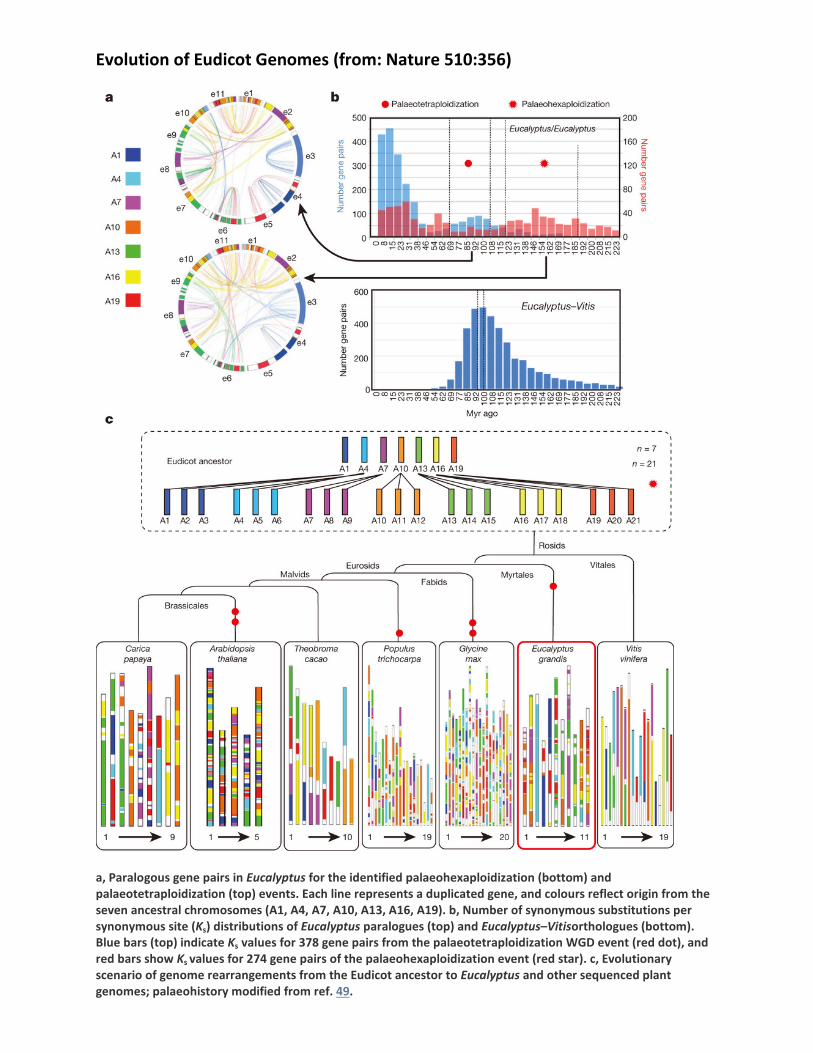
Evolution of Eudicot Genomes (from: Nature 510:356)
a, Paralogous gene pairs in Eucalyptus for the identified palaeohexaploidization (bottom) and palaeotetraploidization (top) events. Each line represents a duplicated gene, and colours reflect origin from the seven ancestral chromosomes (A1, A4, A7, A10, A13, A16, A19). b, Number of synonymous substitutions per synonymous site (Ks) distributions of Eucalyptus paralogues (top) and Eucalyptus–Vitisorthologues (bottom). Blue bars (top) indicate Ks values for 378 gene pairs from the palaeotetraploidization WGD event (red dot), and red bars show Ks values for 274 gene pairs of the palaeohexaploidization event (red star). c, Evolutionary scenario of genome rearrangements from the Eudicot ancestor to Eucalyptus and other sequenced plant genomes; palaeohistory modified from ref. 49.

The Gene-based Evolution of Duplicated Genes If duplications are a major signature of plant genomes
Copy number of genes should equal the number of rounds of duplication.
Table 1
Number of genes found within plant species o Complete genome sequence
If the hexoploidy concept is true for dicots, and Grape only contains this hexaploid event
Estimate o Ancestral dicot contains ~10,000 genes
(=30,000/30).
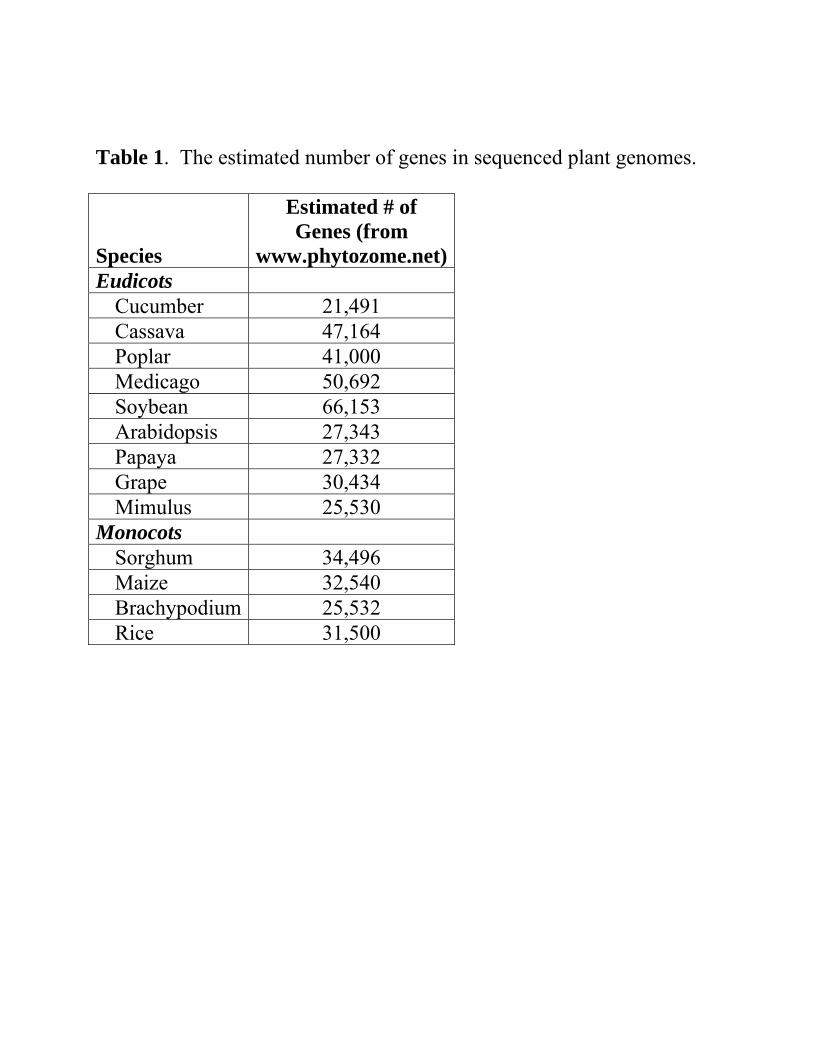
Table 1. The estimated number of genes in sequenced plant genomes. Species
Estimated # of Genes (from
www.phytozome.net)Eudicots
Cucumber 21,491 Cassava 47,164 Poplar 41,000 Medicago 50,692 Soybean 66,153 Arabidopsis 27,343 Papaya 27,332 Grape 30,434 Mimulus 25,530
Monocots Sorghum 34,496 Maize 32,540 Brachypodium 25,532 Rice 31,500

Similarily Poplar underwent an additional duplication,
o Theoretically # of genes = 60,000 genes A.thaliana underwent two duplications
o Theoretically # of genes = 120,000 genes Not observed
Monocot calculations
Rice, Brachypodium, and sorghum only contain a duplication event
o Number of ancestral monocot genes 15,000 (=30,000/2).
o Maize Additional duplication event
But has undergone a reduction to ~30,000 genes
Conclusion o Necessary to reduce the number of genes to ensure the
success of the species.

Diploidization. The polploid past history of plants
Surprising result for Arabidopsis and rice genomes o Why??
Selected for sequencing because of their small genome sizes
Consequences of polyploidy?
Doubling or tripling of the number of chromosomes o Evident for monocots.
Fate of the additional gene set from the WGD
Concept o Species cannot maintain the entire set of duplicate
chromosomes o New genes a problem
Generate deleterious mutations Compromises the fitness of a genome
o Genome must transition back to its original state. Process is called
Diploidization.

To revert back to the diploid state Many duplicate genes must be eliminated from the gene set
o But a recently duplicated genome Soybean
Withstands the extra copies Genome about 2X the basic set of 30,000
genes of hexoploid ancestral eudioct Events associated with diploidization
Duplicate genome must change its chromosome pairing pattern o After the duplications,
Four chromosomes pair Form quadravalents
o Chromosomal structure must be changed so Bivalents must be formed
Result o Doubling of the chromosome number
Seen for the monocot lineage Once bivalents are formed
o Gene sets can evolve Processes
Deletions and chromosomal rearrangements

Duplicate genes can undergo specific changes Common fate
o Gene death of new copies Loses associated with
Chromosomal breakage Rearrangements.
Result New basic set of chromosomes and genes
will have appeared Duplicate genes fate differs
Some are retained as multicopy o Up to the ploidy level for that species
Other reduced to only a single copy “Deletion resistant” genes
Not reduced to single copy o Dosage dependent
Mainly encode Transcription factors
May lead to Complex morphologies
“Duplication resistant” genes
Must be maintained as single copy o Mainly encode
Enzymes or genes of unknown function
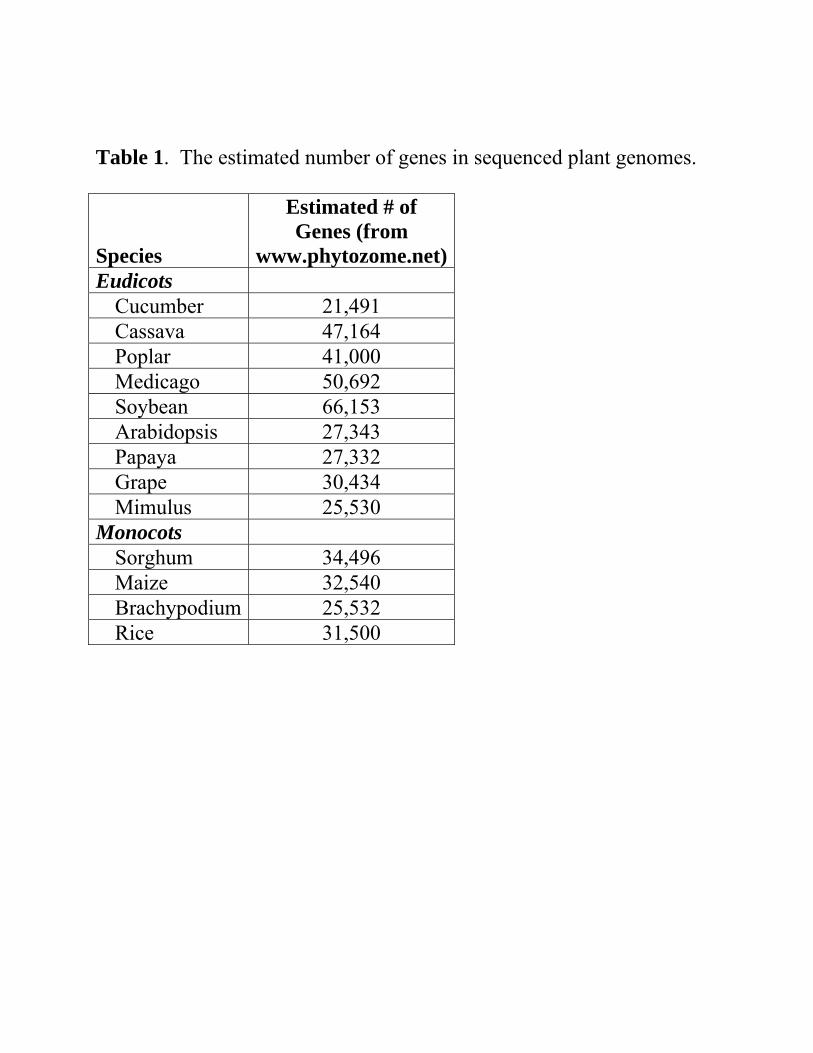
Table 1. The estimated number of genes in sequenced plant genomes. Species
Estimated # of Genes (from
www.phytozome.net)Eudicots
Cucumber 21,491 Cassava 47,164 Poplar 41,000 Medicago 50,692 Soybean 66,153 Arabidopsis 27,343 Papaya 27,332 Grape 30,434 Mimulus 25,530
Monocots Sorghum 34,496 Maize 32,540 Brachypodium 25,532 Rice 31,500

Developing new functions Duplicate set of genes cannot be maintained
Deleterious mutations can arise Duplicate genes are modified
o Changes will provide New functions Altered altered functions
o New functions may lead to the evolution of the species Higher level of fitness Evolutionary modifications of duplicate genes
Neofunctionalization.
One duplicate gene maintains its original function Second gene evolves a function
o May increase the adaptability of an individual Subfunctionalization
Modifies the duplicates Basic structure of both copies altered
o Expression pattern of the gene changes Results in a higher level of the protein production
Alternately, the function of the original gene is maintained o Structure of both copies is significantly changed.
New copies retains Part of the original function
Two genes work together Function of the original gene maintained

Synteny: The Result of WGD and Reconstructing Plant Genomes Synteny among plant species.
Major result of the duplication history o Synteny
Maintenance of gene order between two species o Classic approach to synteny
Based on shared markers mapped onto two different species.
Macrosynteny is detected by o Large scale chromosomal blocks shared
by two species. Fig. 9
Example of macrosynteny o Tomato and eggplant
Eggplant linkage group 4 Evolutionarily related to tomato
Linkage groups 10S and 4L. Highly conserved marker order over many
centimorgans of the two genomes
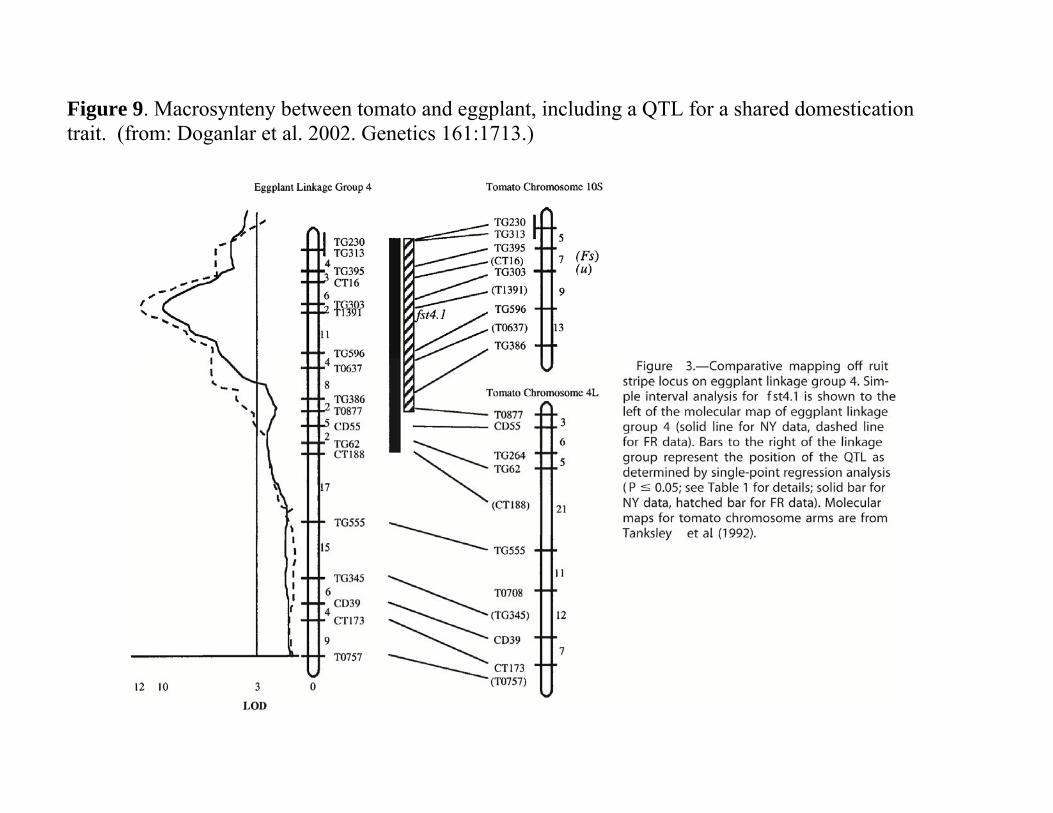
Figure 9. Macrosynteny between tomato and eggplant, including a QTL for a shared domestication trait. (from: Doganlar et al. 2002. Genetics 161:1713.)

Genetic mapping of shared genes • First method of comparing species • Only way to compare species that have not been sequenced • Many examples of synteny mapping in plants. • The power of synteny mapping
o Discovery of shared loci from two species Control the same phenotype
• Map to the same genetic location. Fig. 9 again
• Major QTL for fruit striping o Eggplant linkage 4. o Previous work with tomato
Major QTL • Linkage group 10 of tomato
o Syntenic marker and QTL observed here • Hypothesis
o Multiple loci are shared in the same macrosyntenic order Same ancestral gene is controlling this trait in these
two species.

Leveraging knowledge in one species for gene discovery in a second species
Phenotypic traits mapped extensively in one species o Points a researcher working on a second species o Likely location of a similar gene in second species. o Leverage is
Great aid for genetic discovery For species in where the discovery of
important genetic factors are limited by a lack of funding





























