Embed Size (px)
Citation preview

PipeliningPipelining
Ana Cristina Alves de OliveiraAna Cristina Alves de [email protected]@dsc.ufcg.edu.br
Arquitetura de ComputadoresArquitetura de ComputadoresMestrado em Ciências da ComputaçãoMestrado em Ciências da Computação
Depto. de Sistemas e Computação – UFCGDepto. de Sistemas e Computação – UFCG

RoteiroRoteiro
IntroduçãoIntrodução Visão Geral sobre PipeliningVisão Geral sobre Pipelining Pipeline SuperescalarPipeline Superescalar Pipeline DinâmicoPipeline Dinâmico ExemplosExemplos ResumoResumo ConclusõesConclusões ReferênciasReferências

IntroduçãoIntrodução Pipeline é uma técnica que explora o Pipeline é uma técnica que explora o
paralelismo entre as instruções, considerando paralelismo entre as instruções, considerando um fluxo de execução sequencialum fluxo de execução sequencial
É invisível ao programadorÉ invisível ao programador O pipeline começa uma instrução a cada ciclo O pipeline começa uma instrução a cada ciclo
de clockde clock Não reduz o tempo gasto para completar uma Não reduz o tempo gasto para completar uma
instruçãoinstrução Aumenta a vazão das instruções iniciadas e Aumenta a vazão das instruções iniciadas e
terminadas na unidade de tempoterminadas na unidade de tempo Estamos considerando o processador deste Estamos considerando o processador deste
trabalho como sendo o MIPStrabalho como sendo o MIPS

Tempo entre Instruções (Ti)Tempo entre Instruções (Ti)
TiTipipelinepipeline = Ti = Tinão-pipelinenão-pipeline / nº de estágios / nº de estágios
ClasseClasse BuscaBusca Leit. Leit. RegReg
Op. Op. ULAULA
Aces. Aces. DadoDado
Escr. Escr. RegReg
Tempo Tempo TotalTotal
Load Load word (lw)word (lw)
2 ns2 ns 1 ns1 ns 2 ns2 ns 2 ns2 ns 1 ns1 ns 8 ns8 ns
Store Store word (sw)word (sw)
2 ns2 ns 1 ns1 ns 2 ns2 ns 2 ns2 ns 7 ns7 ns
Add, sub, Add, sub, and, or, and, or, sltslt
2 ns2 ns 1 ns1 ns 2 ns2 ns 1 ns1 ns 6 ns6 ns
beqbeq 2 ns2 ns 1 ns1 ns 2 ns2 ns 5 ns5 ns

Conflitos do Pipeline: Conflitos do Pipeline: Estruturais e de ControleEstruturais e de Controle
Conflitos estruturaisConflitos estruturais– O hardware não pode suportar a combinação O hardware não pode suportar a combinação
de instruções no mesmo ciclo de clockde instruções no mesmo ciclo de clock– Exemplo: Suponha que exista apenas uma Exemplo: Suponha que exista apenas uma
memória para dados e instruções. Ocorrerá memória para dados e instruções. Ocorrerá este conflito se uma instrução acessar um este conflito se uma instrução acessar um dado na memória (lw), enquanto outra tenta dado na memória (lw), enquanto outra tenta escrever na memória (sw) simultaneamenteescrever na memória (sw) simultaneamente
Conflitos de controleConflitos de controle– Necessidade de tomar uma decisão com base Necessidade de tomar uma decisão com base
nos resultados de uma instrução, enquanto nos resultados de uma instrução, enquanto outras estão sendo executadasoutras estão sendo executadas

Conflitos do Pipeline:Conflitos do Pipeline: Soluções Soluções para o Conflito de Controle (1)para o Conflito de Controle (1)
Parada do Pipeline: conhecida como “bolha”Parada do Pipeline: conhecida como “bolha”– Execução sequencial com a inserção de uma instrução Execução sequencial com a inserção de uma instrução
de de nopnop após um desvio condicional após um desvio condicional– Degrada o desempenho consideravelmenteDegrada o desempenho consideravelmente
PrediçãoPredição– Em geral, é adotada para tratar os desvios condicionais Em geral, é adotada para tratar os desvios condicionais
executados em pipelineexecutados em pipeline– Não retarda o pipeline se a previsão for corretaNão retarda o pipeline se a previsão for correta– Esquema simples: sempre predizer que a condição vai Esquema simples: sempre predizer que a condição vai
falharfalhar– Preditores Preditores dinâmicosdinâmicos em hardware fazem predições em hardware fazem predições
dependendo do comportamento anterior de cada desviodependendo do comportamento anterior de cada desvio

Conflitos do PipelineConflitos do Pipeline: Soluções para : Soluções para o Conflito de Controle (2)o Conflito de Controle (2)
Decisão retardada: conhecida como Decisão retardada: conhecida como “desvio retardado” (delayed branch)“desvio retardado” (delayed branch)– Sempre executa a instrução seguinte à Sempre executa a instrução seguinte à
instrução de desvio, cuidando para que a instrução de desvio, cuidando para que a escolha seja uma instrução não afetada escolha seja uma instrução não afetada pela decisão do desviopela decisão do desvio
– Tipicamente, os compiladores preenchem Tipicamente, os compiladores preenchem cerca de 50% dos slots que seguem o cerca de 50% dos slots que seguem o desvio condicional com instruções úteisdesvio condicional com instruções úteis
– Utilizada no processador MIPSUtilizada no processador MIPS

Conflitos do Pipeline: Conflitos Conflitos do Pipeline: Conflitos por Dadospor Dados
Conflitos por dadosConflitos por dados– A execução de uma instrução depende do A execução de uma instrução depende do
resultado de outra, que ainda está no resultado de outra, que ainda está no pipelinepipeline
– Não é preciso esperar o término da Não é preciso esperar o término da instrução para tentar resolver este conflitoinstrução para tentar resolver este conflito
– SoluçãoSolução AdiantamentoAdiantamento ou ou bypass:bypass: obtenção antecipada obtenção antecipada
de determinado item faltante a uma operação, de determinado item faltante a uma operação, a partir de recursos internos da máquinaa partir de recursos internos da máquina

Conflitos do Pipeline: Conflitos do Pipeline: Reordenação do Código para Reordenação do Código para
Evitar ParadasEvitar Paradas Encontre o conflito deste Encontre o conflito deste códigocódigo::
# reg $t1 possui o end. de v[k]# reg $t1 possui o end. de v[k]lw $t0, 0($t1)lw $t0, 0($t1) # reg $t0 (temp) = v[k]# reg $t0 (temp) = v[k]lw $t2, 4($t1)lw $t2, 4($t1) # reg $t2 = v[k+1]# reg $t2 = v[k+1]sw $t2, 0($t1)sw $t2, 0($t1) # v[k] = reg $t2# v[k] = reg $t2sw $t0, 4($t1)sw $t0, 4($t1) # v[k+1] = reg $t0 (temp)# v[k+1] = reg $t0 (temp)
Reordene as instruções de modo a Reordene as instruções de modo a evitar parada do pipeline em função do evitar parada do pipeline em função do conflitoconflito
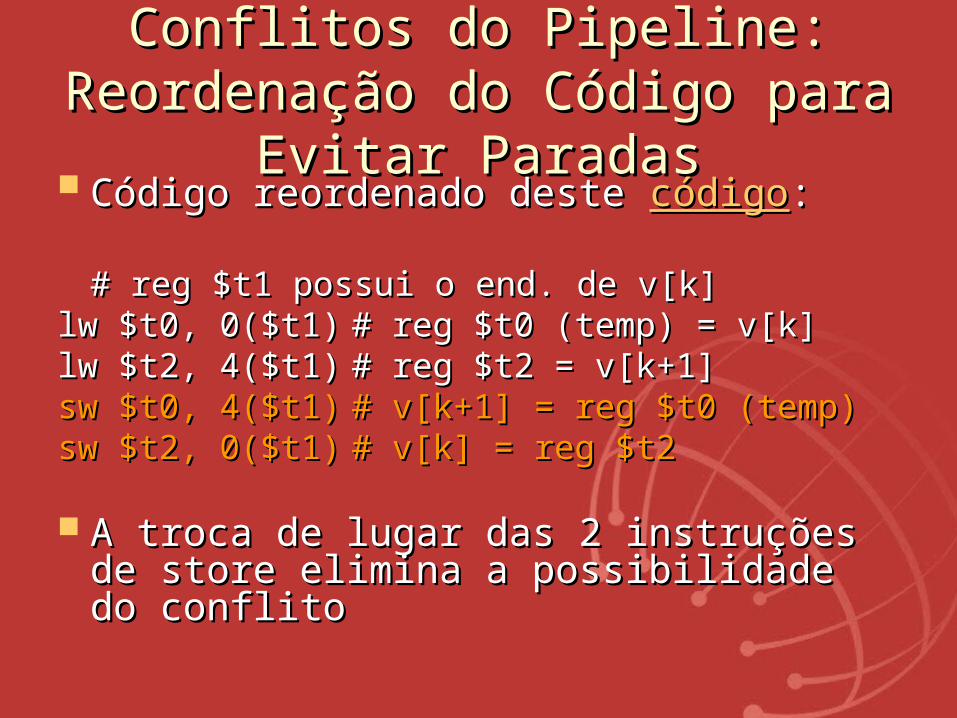
Conflitos do Pipeline: Conflitos do Pipeline: Reordenação do Código para Reordenação do Código para
Evitar ParadasEvitar Paradas Código reordenado deste Código reordenado deste códigocódigo::
# reg $t1 possui o end. de v[k]# reg $t1 possui o end. de v[k]lw $t0, 0($t1)lw $t0, 0($t1) # reg $t0 (temp) = v[k]# reg $t0 (temp) = v[k]lw $t2, 4($t1)lw $t2, 4($t1) # reg $t2 = v[k+1]# reg $t2 = v[k+1]sw $t0, 4($t1)sw $t0, 4($t1) # v[k+1] = reg $t0 (temp)# v[k+1] = reg $t0 (temp)sw $t2, 0($t1)sw $t2, 0($t1) # v[k] = reg $t2# v[k] = reg $t2
A troca de lugar das 2 instruções de A troca de lugar das 2 instruções de store elimina a possibilidade do conflitostore elimina a possibilidade do conflito

Código em C para a FunçãoCódigo em C para a Função
swap(int v[], int k) {swap(int v[], int k) {
int temp;int temp;
temp = v[k];temp = v[k];
v[k] = v[k+1];v[k] = v[k+1];
v[k+1] = temp;v[k+1] = temp;
}}

Pipeline SuperescalarPipeline Superescalar Replicação dos componentes internos do Replicação dos componentes internos do
processador para que ele possa colocar várias processador para que ele possa colocar várias instruções em cada estágio do pipelineinstruções em cada estágio do pipeline
Permite que a taxa de instruções prontas na Permite que a taxa de instruções prontas na unidade de tempo exceda à taxa do clockunidade de tempo exceda à taxa do clock
Exemplo: um processador de 1000Mhz, Exemplo: um processador de 1000Mhz, superescalar, com 4 instruções simultâneas superescalar, com 4 instruções simultâneas pode operar em uma taxa de pico de 4 bilhões pode operar em uma taxa de pico de 4 bilhões de instruções por segundode instruções por segundo
Desvantagem: trabalho extra de manutençãoDesvantagem: trabalho extra de manutenção

Pipeline DinâmicoPipeline Dinâmico
Ou Escalonamento Dinâmico do Ou Escalonamento Dinâmico do PipelinePipeline
Executado pelo hardware para evitar Executado pelo hardware para evitar conflitos no pipelineconflitos no pipeline– É normalmente associado a recursos É normalmente associado a recursos
extras de hardwareextras de hardware– As instruções posteriores podem As instruções posteriores podem
prosseguir em paraleloprosseguir em paralelo O modelo de execução de instruções O modelo de execução de instruções
é bem mais complexoé bem mais complexo

ExExemplo 1: Implementação emplo 1: Implementação Simples de PipelineSimples de Pipeline
Especificações : É como o MIPS, exceto por:
•Não modifica a ordem de execução (sem desvio retardado e sem reescalonamento por software)•Registradores não podem ser lidos e escritos em um mesmo ciclo de clock•Após um desvio, não se pode fazer uma busca por nova instrução até que a comparação seja feita•Sem adiantamento
Complete os estágios do pipeline a seguir ==>
and $4, $6, $5 IF ID AL MR WB sub $8, $6, $5 IF ID AL MR WB Or $7, $4, $8 IF n n n ID AL MR bne $5, $5, exit IF ID AL sw $3, 4($4) lw $10, 4 ($4) add$12, $10, $11
MR
IF ID
WB

Exemplo 2: Implementação de Exemplo 2: Implementação de pipeline para pipeline para MIPSMIPS
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
Estes endereços estão em octal
Desvio atrasado é tarefa do compilador:‘ori’ será uma tarefa fora da ordem
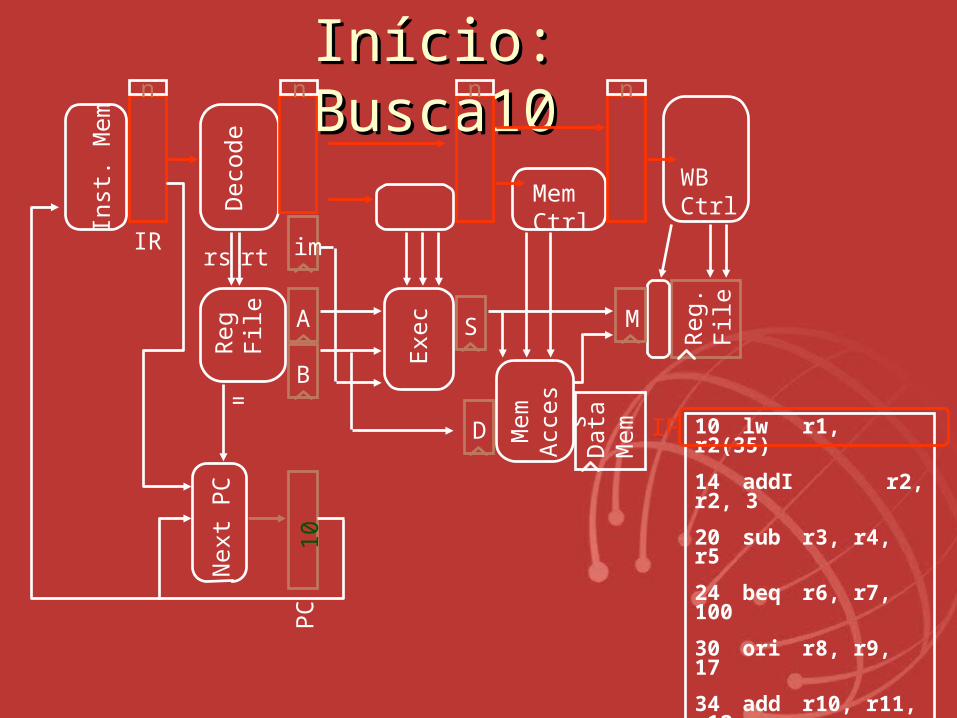
InícioInício: : BuscaBusca1010
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
rs rt im
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
IF
PC
Nex
t P
C
10
=
n n n n
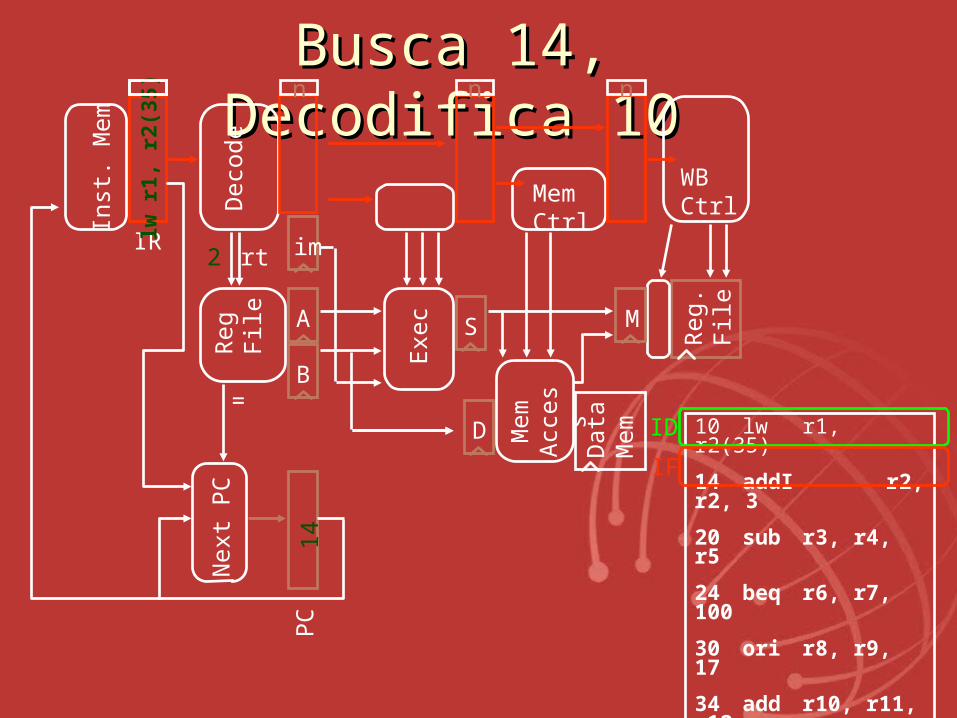
BuscaBusca 14, 14, DecodificaDecodifica 1010
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
A
B
SReg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
2 rt im
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1, r
2(35
)
ID
IF
PC
Nex
t P
C
14
=
n n n
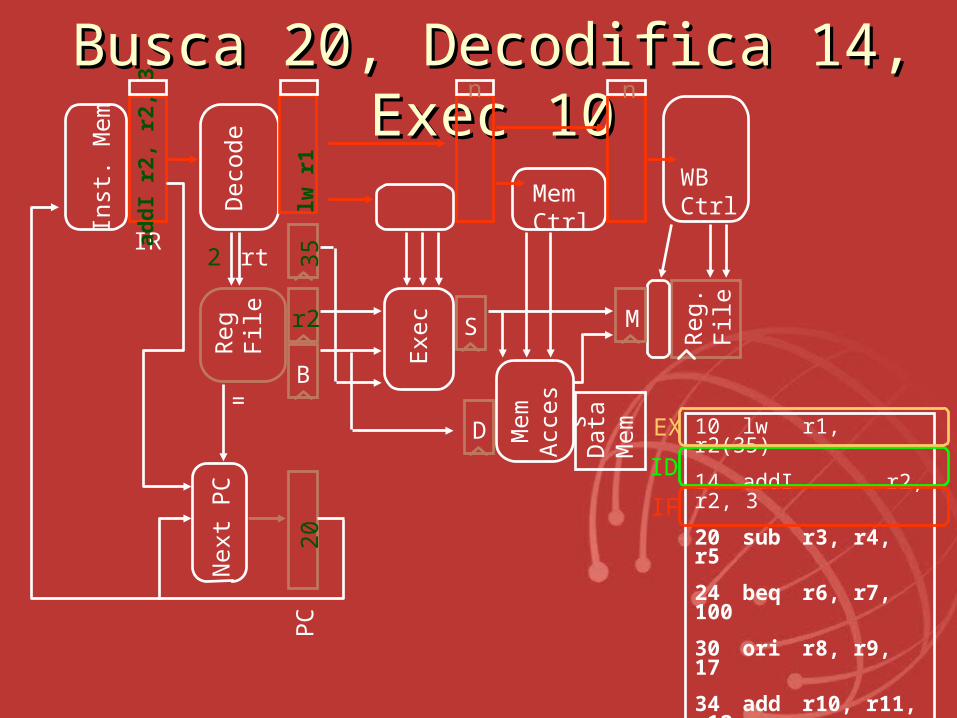
BuscaBusca 20, 20, DecodificaDecodifica 14, 14, Exec 10Exec 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r2
B
SReg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
2 rt 35
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1
add
I r2,
r2,
3
ID
IF
EX
PC
Nex
t P
C
20
=
n n
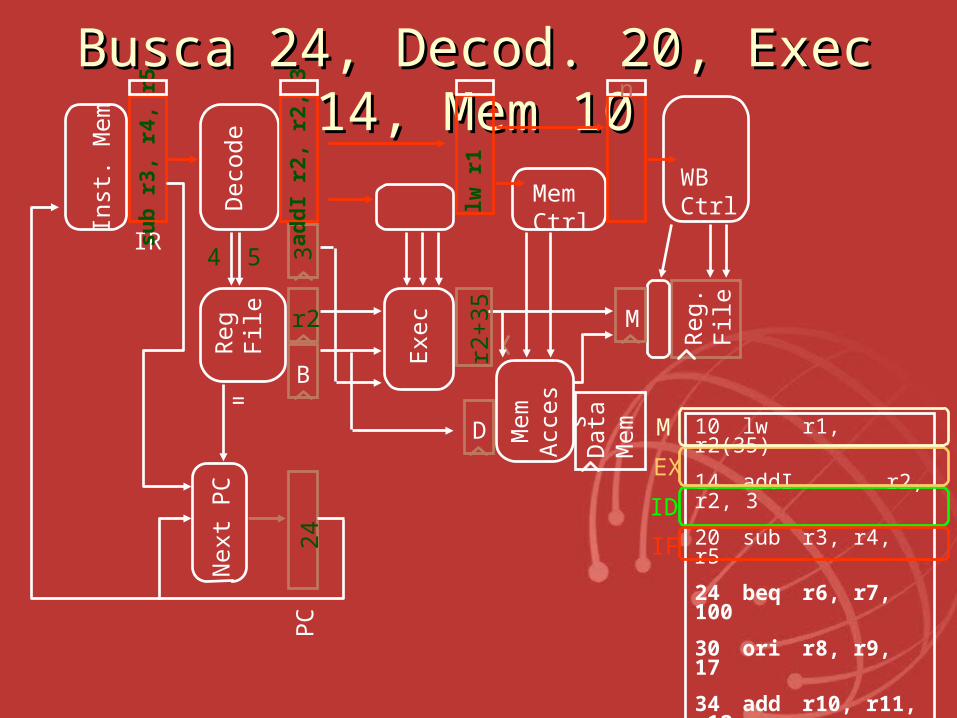
BuscaBusca 24, Decod 24, Decod.. 20, Exec 14, 20, Exec 14, Mem 10Mem 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r2
B
r2+
35
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M
4 5 3
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1
sub
r3,
r4,
r5
add
I r2,
r2,
3
ID
IF
EX
M
PC
Nex
t P
C
24
=
n
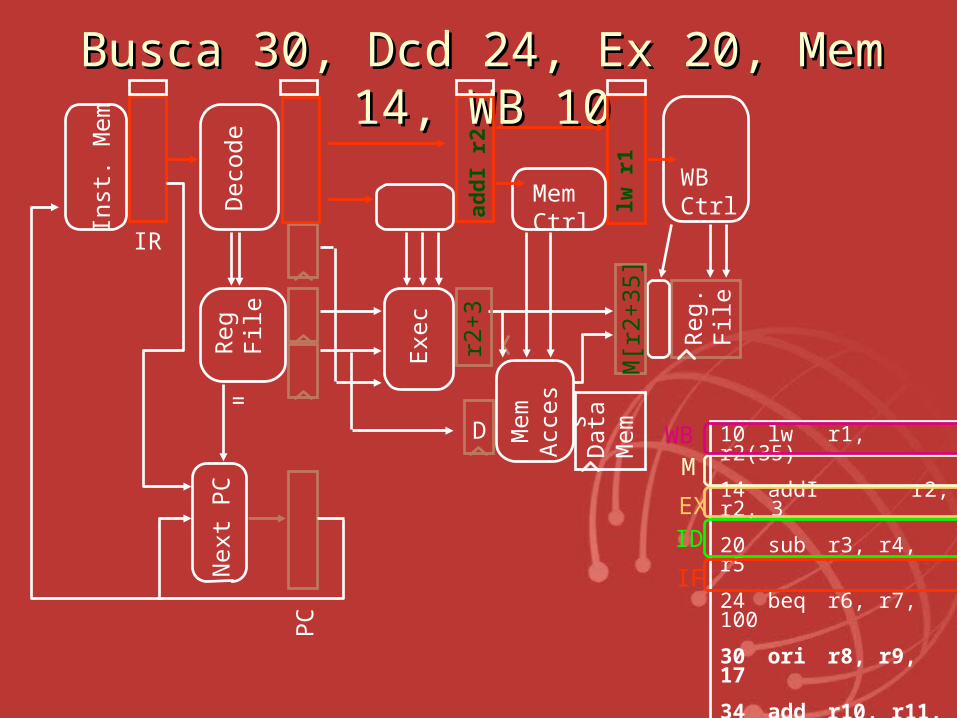
BuscaBusca 30, Dcd 24, Ex 20, Mem 14, 30, Dcd 24, Ex 20, Mem 14, WBWB 10 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r2+
3
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M[r
2+35
]
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1
add
I r2
ID
IF
EX
M WB
PC
Nex
t P
C
=

BuscaBusca 30, Dcd 24, Ex 20, Mem 14, 30, Dcd 24, Ex 20, Mem 14, WB 10WB 10
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r4
r5
r2+
3
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
M[r
2+35
]6 7
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
lw r
1
beq
r6,
r7
100
add
I r2
sub
r3
ID
IF
EX
M WB
PC
Nex
t P
C
30
=
Note que o desvio retardado: sempre executa ori após beq
sub
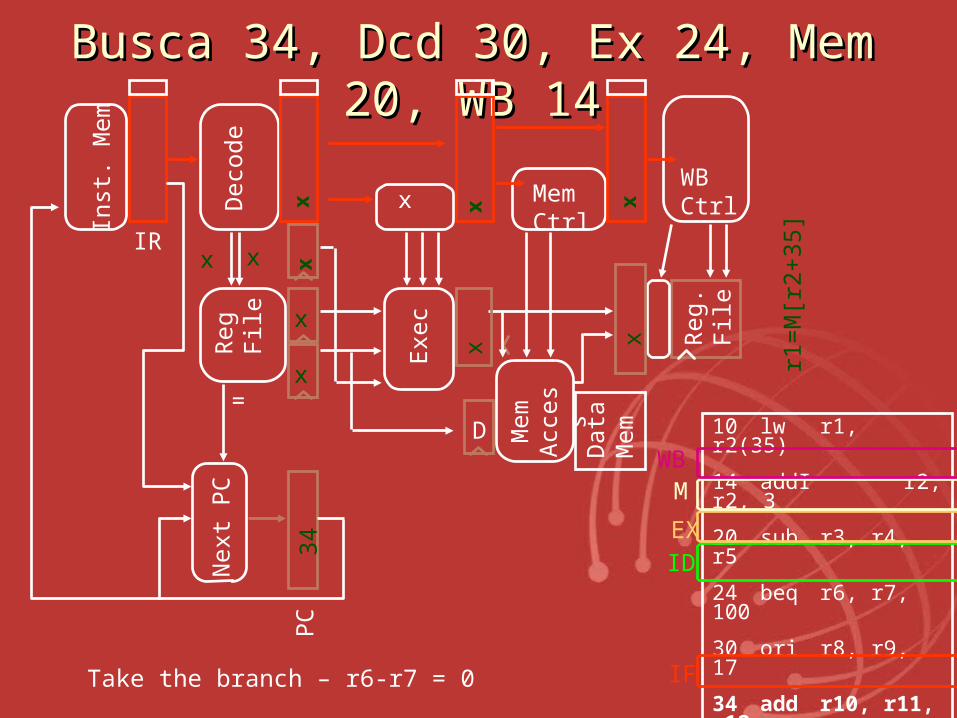
BuscaBusca 34, Dcd 30, Ex 24, Mem 20, 34, Dcd 30, Ex 24, Mem 20, WB 14WB 14
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
x
x
xReg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=
M[r
2+35
]
x
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
x xxx
x
ID
IF
EX
M WB
PC
Nex
t P
C
34
=
Take the branch – r6-r7 = 0
x
x
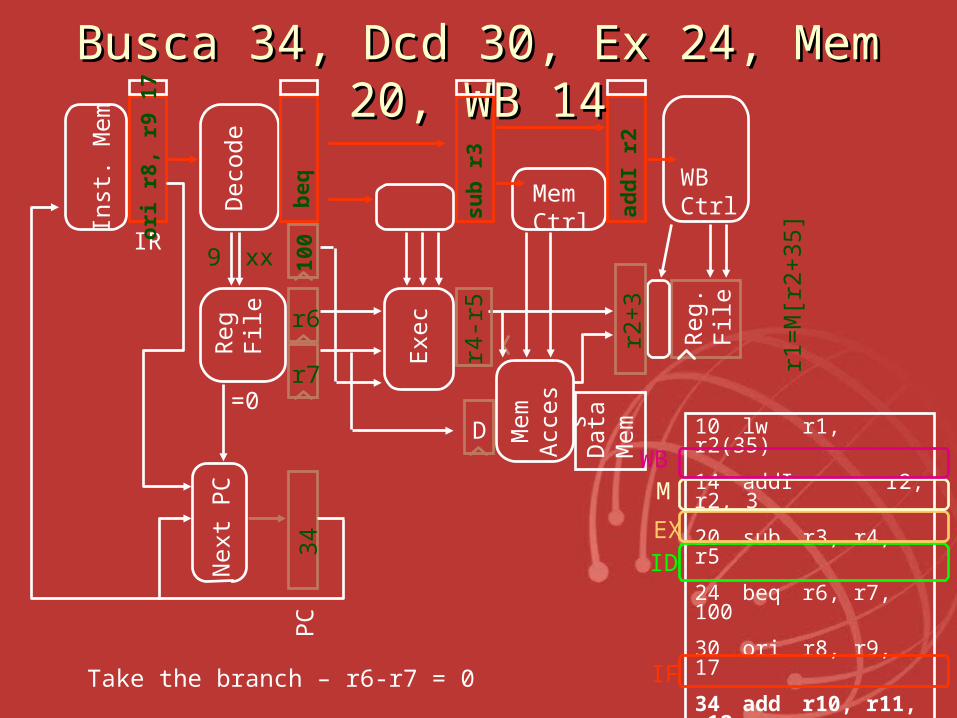
BuscaBusca 34, Dcd 30, Ex 24, Mem 20, 34, Dcd 30, Ex 24, Mem 20, WB 14WB 14
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r6
r7
r2+
3
Reg
File
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=
M[r
2+35
]
9 xx
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
beq
add
I r2
sub
r3
r4-r
5
100
ori
r8,
r9
17
ID
IF
EX
M WB
PC
Nex
t P
C
34
=0
Take the branch – r6-r7 = 0
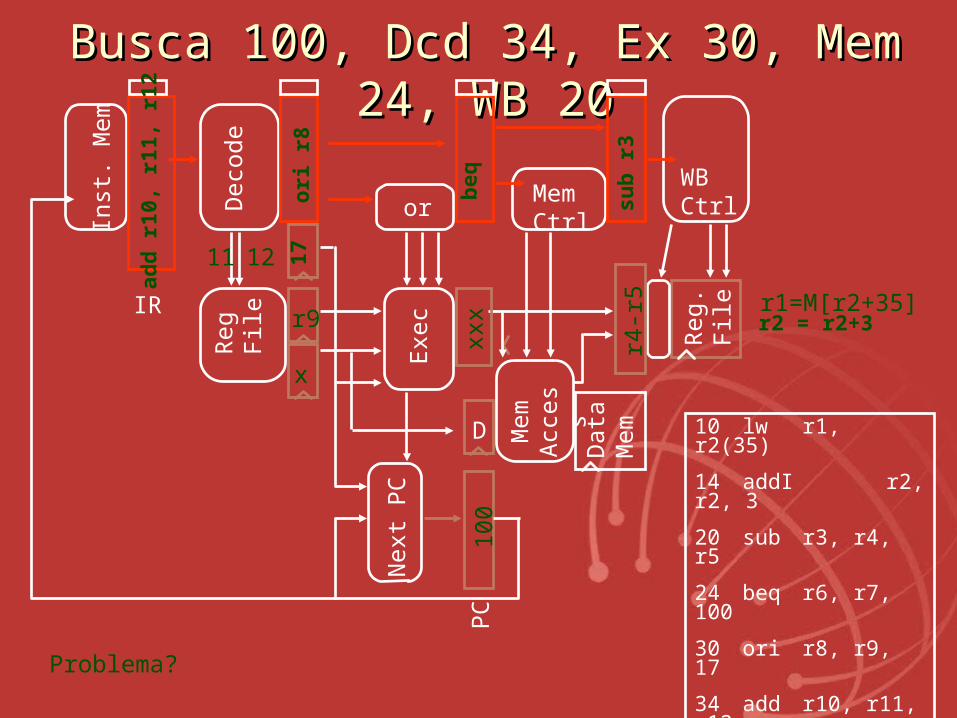
BuscaBusca 100, Dcd 34, Ex 30, Mem 24, 100, Dcd 34, Ex 30, Mem 24, WB 20WB 20
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r9
x
Reg
File
PC
Nex
t P
C
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=M[r2+35]
11 12
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
100
beq
r2 = r2+3
sub
r3
r4-r
5
17o
ri r
8
xxx
add
r10
, r11
, r12
Problema?
or
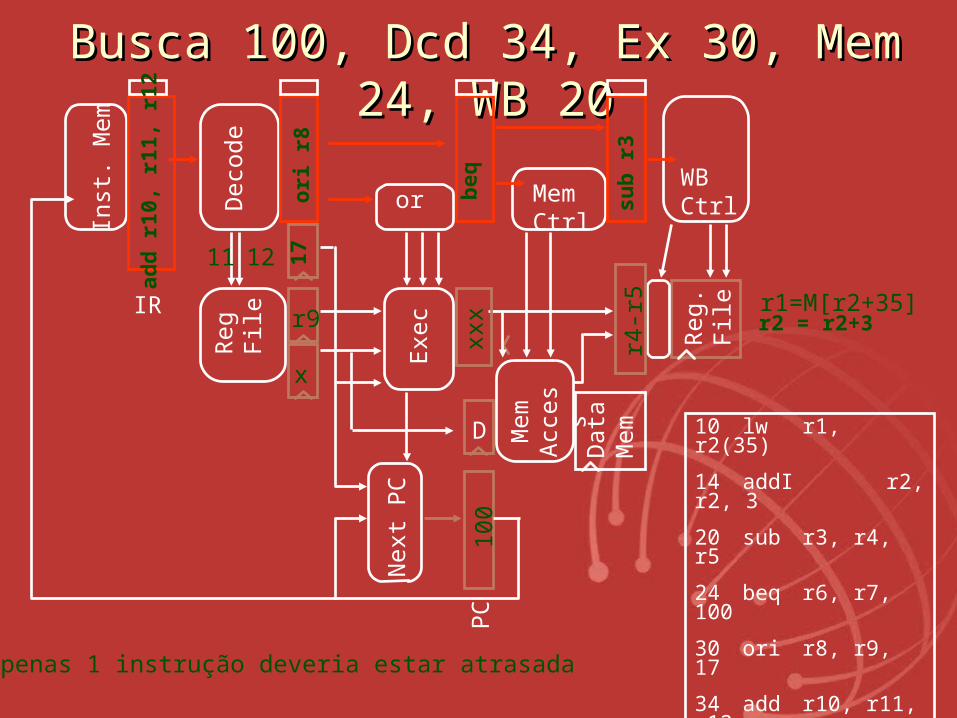
BuscaBusca 100, Dcd 34, Ex 30, Mem 24, 100, Dcd 34, Ex 30, Mem 24, WB 20WB 20
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r9
x
Reg
File
PC
Nex
t P
C
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=M[r2+35]
11 12
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
100
beq
r2 = r2+3
sub
r3
r4-r
5
17o
ri r
8
xxx
add
r10
, r11
, r12
Apenas 1 instrução deveria estar atrasada
or
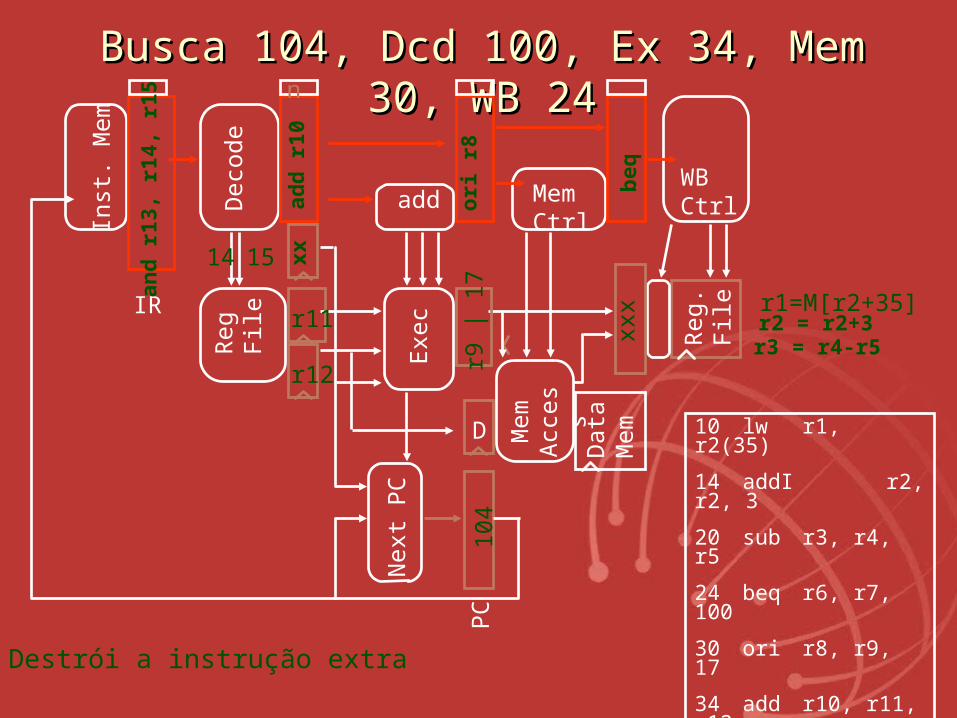
BuscaBusca 104, Dcd 100, Ex 34, Mem 30, 104, Dcd 100, Ex 34, Mem 30, WB 24WB 24
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r11
r12
Reg
File
PC
Nex
t P
C
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=M[r2+35]
14 15
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
104
beq
r2 = r2+3r3 = r4-r5
xx
ori
r8
xxx
add
r10
and
r13
, r14
, r15
n
Destrói a instrução extra
r9 |
17
add

BuscaBusca 108, Dcd 104, Ex 100, Mem 34, 108, Dcd 104, Ex 100, Mem 34, WB 30WB 30
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
r14
r15
Reg
File
PC
Nex
t P
C
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=M[r2+35]
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
108
r2 = r2+3r3 = r4-r5
xx
ori
r8
add
r10
and
r13
n
r9 |
17
r11+
r12
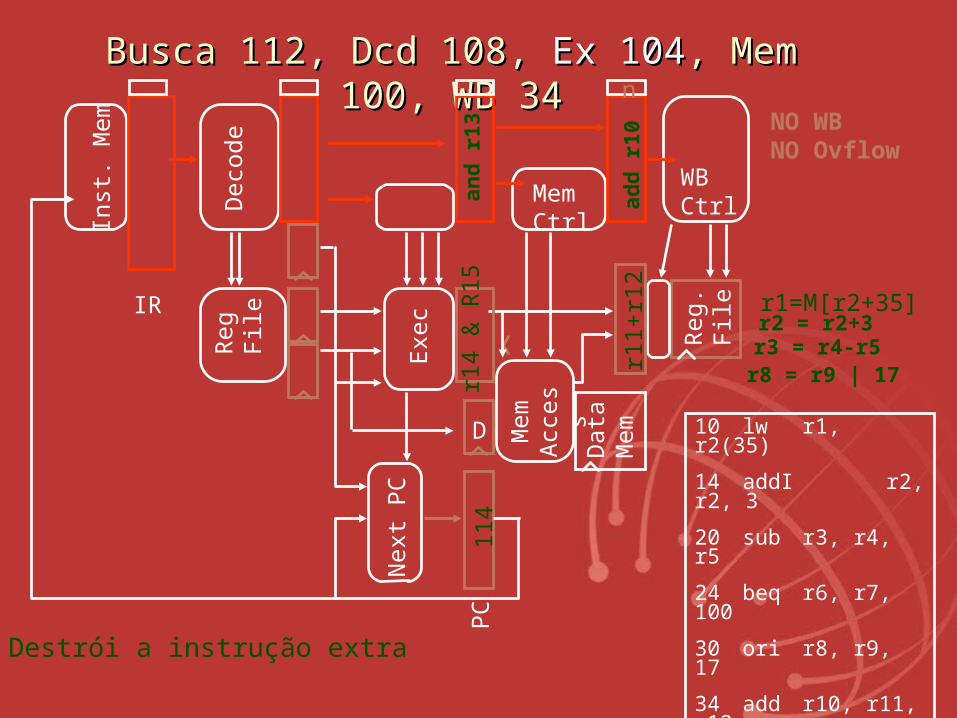
BuscaBusca 112, Dcd 108, 112, Dcd 108, Ex 104Ex 104, Mem 100, , Mem 100, WB 34WB 34
Exe
c
Reg
. F
ile
Mem
Acc
ess
Dat
aM
em
Reg
File
PC
Nex
t P
C
IR
Inst
. M
em
D
Dec
ode
MemCtrl
WB Ctrl
r1=M[r2+35]
10 lw r1, r2(35)
14 addI r2, r2, 3
20 sub r3, r4, r5
24 beq r6, r7, 100
30 ori r8, r9, 17
34 add r10, r11, r12
100 and r13, r14, 15
114
r2 = r2+3r3 = r4-r5r8 = r9 | 17
add
r10
and
r13
n
Destrói a instrução extrar1
1+r1
2
NO WBNO Ovflow
r14
& R
15

ResumoResumo O que o torna fácil o pipeline?O que o torna fácil o pipeline?
– Todas as instruções têm o mesmo tamanhoTodas as instruções têm o mesmo tamanho– Poucos formatos para a instruçãoPoucos formatos para a instrução– Operandos da memória aparecem apenas em Operandos da memória aparecem apenas em loadsloads
ee storesstores
O que o torna fácil o pipeline?O que o torna fácil o pipeline?– Conflitos estruturaisConflitos estruturais: : caso exista apenas 1 memória caso exista apenas 1 memória
para instruções e dadospara instruções e dados– Conflitos de controleConflitos de controle: : preocupação com instruções preocupação com instruções
de desviode desvio– Conflitos de dadosConflitos de dados: : instruções que depedem de instruções que depedem de
instruções anterioresinstruções anteriores

ResumResumoo5 Estágios5 Estágios::
– Busca: busca instruções na memóriaBusca: busca instruções na memória– Decodificação:Decodificação: pega o valor do registrador e decodifica as pega o valor do registrador e decodifica as
informações de controleinformações de controle– ExecuçãoExecução: : executa operações aritméticas/cálculo de executa operações aritméticas/cálculo de
endereçosendereços– MemMemóriaória: : faz operações da mémoria (load e store)faz operações da mémoria (load e store)– Escreve no registradorEscreve no registrador: : escreve resultados de volta nos escreve resultados de volta nos
registradoresregistradoresPipelines Pipelines passam o controle da informação pelo passam o controle da informação pelo
pipe assim como os dados se movem no pipepipe assim como os dados se movem no pipeBalancear o tamanho das instruções torna o Balancear o tamanho das instruções torna o
pipeline mais suavepipeline mais suaveAumentar o tamanho do pipeline, aumenta o Aumentar o tamanho do pipeline, aumenta o
impacto de conflitosimpacto de conflitos

ConclusõesConclusões O pipeline melhora o O pipeline melhora o throughputthroughput, mas não altera o , mas não altera o
tempo de execução de uma instruçãotempo de execução de uma instrução A latência introduz dificuldades devido às A latência introduz dificuldades devido às
dependências nos programasdependências nos programas Redução do custo das dependências com:Redução do custo das dependências com:
– Hardware para adiantamento de dadosHardware para adiantamento de dados– Predição de desviosPredição de desvios
Processamento superescalar e escalonamento Processamento superescalar e escalonamento dinâmico tem melhorado cerca de 60% ao ano o dinâmico tem melhorado cerca de 60% ao ano o desempenho dos processadores desde 1986desempenho dos processadores desde 1986
Com os avanços na tecnologia de processamento, Com os avanços na tecnologia de processamento, o sistema de memória é que passa a ser o gargalo o sistema de memória é que passa a ser o gargalo (lei de Amdahl)(lei de Amdahl)

ReferênciasReferências Patterson, D. A.; Hennessy, J. L. Organização e Patterson, D. A.; Hennessy, J. L. Organização e
projeto de computadores: A interface projeto de computadores: A interface HARDWARE/SOFTWARE. Rio de Janeiro, LTC, 2ª HARDWARE/SOFTWARE. Rio de Janeiro, LTC, 2ª ed., 2000.ed., 2000.
Programmed Introdution to MIPS Assembly Programmed Introdution to MIPS Assembly Language. Language. http://chortle.http://chortle.ccsuccsu..eduedu//AssemblyTutorialAssemblyTutorial//TutorialContentsTutorialContents.html.html..
SPIM - SPIM - A MIPS32 SimulatorA MIPS32 Simulator. . http://www.http://www.cscs..wiscwisc..eduedu/~/~laruslarus//spimspim.html.html
Aplicações Avançadas de Microprocessadores:Aplicações Avançadas de Microprocessadores: Colectânea de Problemas.Colectânea de Problemas. http://tahoe.inesc.pt/~aml/ist/aam98/problemas/phttp://tahoe.inesc.pt/~aml/ist/aam98/problemas/problemas.htmlroblemas.html

ContatoContato
Ana Cristina A. de OliveiraAna Cristina A. de Oliveira– [email protected]@dsc.ufcg.edu.br– www.www.dscdsc..ufcgufcg..eduedu..brbr/~/~cristinacristina
Projeto Failure SpotterProjeto Failure Spotter– www.spotter.www.spotter.lsdlsd..ufcgufcg..eduedu..brbr








![Pipelining & Parallel Processing - ics.kaist.ac.krics.kaist.ac.kr/ee878_2018f/[EE878]3 Pipelining and Parallel Processing.pdf · Pipelining processing By using pipelining latches](https://img.dokumen.tips/doc/110x75/5d40e26d88c99391748d47fb/pipelining-parallel-processing-icskaistackricskaistackree8782018fee8783.jpg)




















