Embed Size (px)
Citation preview

PIPELINESSC-0114 ARQUITETURA DE COMPUTADORES
11/09/2017

Conceitos básicos
1. A velocidade de execução dos programas é influenciada por muitos fatores
O que pode ser feito para que haja melhor desempenho?
2

Conceitos básicos
Empregar tecnologias que permitam circuitos mais rápidos em projetos de processadores e memória ?
3Quantum computer processor<https://medium.com/@n.biedrzycki/only-god-can-count-that-fast-the-world-of-quantum-computing-406a0a91fcf4>

Conceitos básicos
41945-1960: Building Beetles<http://mashable.com/2015/10/30/building-beetles/#mqzsvBk4JkqT>

Pipeline
• Uma forma de organizar atividades concorrentes– Mais operações ocorrendo ao mesmo tempo– Sobreposição temporal de fases de
processamento– Mais operações realizadas por segundo• Isso não implica que cada instrução seja executada mais rapidamente!
5
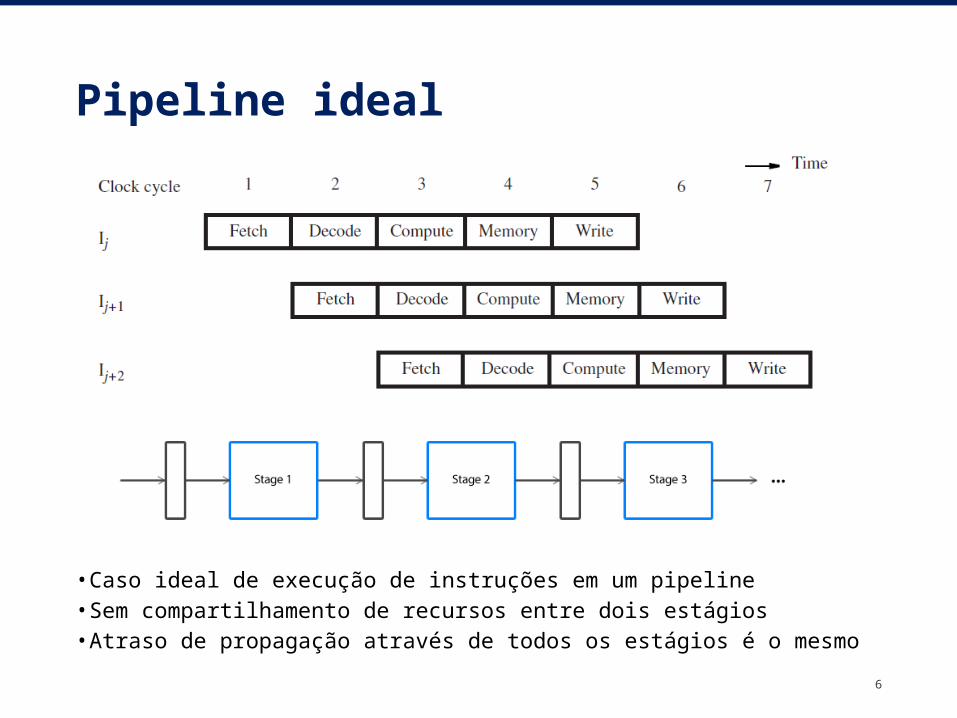
Pipeline ideal
• Caso ideal de execução de instruções em um pipeline• Sem compartilhamento de recursos entre dois estágios• Atraso de propagação através de todos os estágios é o
mesmo 6

Pipeline - Organização
7
B1: alimenta estágio de decodificação
B2: alimenta estágio de computação com operandos lidos de [*], valores imediatos da instrução, ...
B3: armazena dado da ULA e o mantém até ser salvo em memória ou ser repassado para B4B4: alimenta estágio de escrita para [*]

Pipeline – Desempenho
8
• Instruções por programa dependem do código fonte, tecnologia do compilador e ISA
• Ciclos por instruções (CPI) dependem da ISA e da microarquitetura
• Tempo por ciclo depende da microarquitetura e tecnologia de circuitos

Desempenho (exemplos)
9

Pipeline – Expectativas
• 1 ciclo de clock por estágio Tempo do ciclo de clock definido pelo estágio mais lento
• Mais estágios ~ maior desempenho• Estágios longos quebrados em tamanhos
menores• Mas...– E se operandos de entrada ou destino não estiverem disponíveis no momento em que são esperados?
10

Dependências/Conflitos (Hazards)
11Data hazard (Cache Miss de Dados)
STALL

Dependências/Conflitos (Hazards)
12Data hazard (Dependência entre D2 e W1 - Interlock)
Mul R2, R3, R4Add R5, R4, R6
I1 B 4 x AI2 C 3 + B
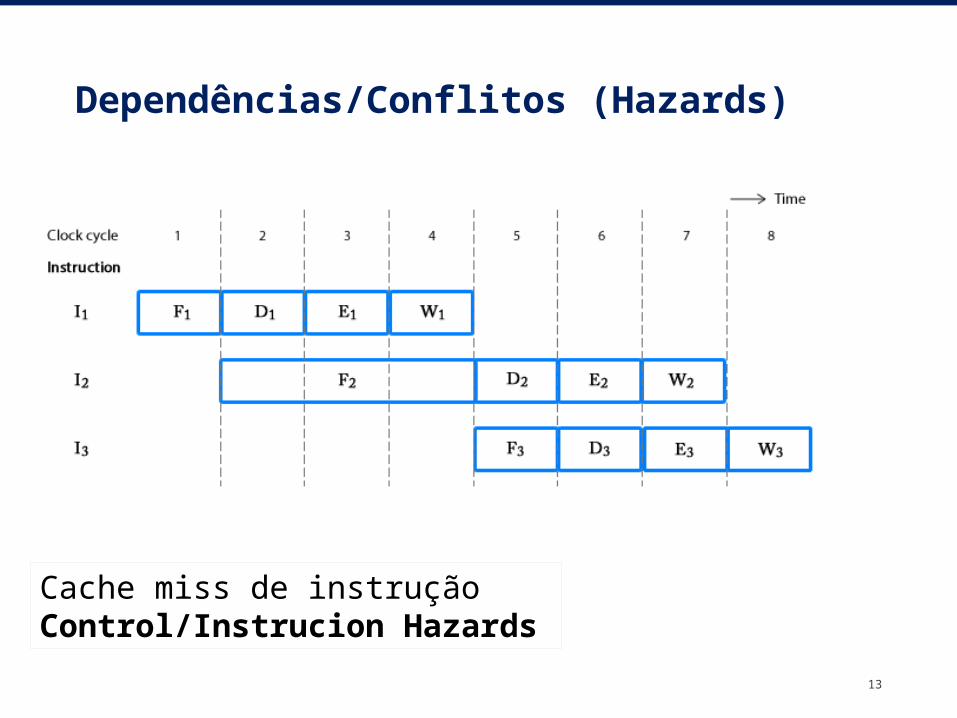
Dependências/Conflitos (Hazards)
13
Cache miss de instrução Control/Instrucion Hazards

Dependências/Conflitos (Hazards)
14
Load X(R1), R2
Tentativa de uso de um recurso compartilhado por 2 instruçõesStructural Hazard

Exemplos de CPI em Pipeline
15
Medida da finalização em sequência da primeira a última instrução

Mitigando problemas (data hazard)
16HARDWARE: Encaminhamento de operando (Forwarding operand ou Bypass)
Mul R2, R3, R4Add R5, R4, R6

Mitigando problemas (data hazard)
17
SOFTWARE: Compilador: é o responsável pela tarefa de detectar e tratar dependências
Mul R2, R3, R4
NOP
NOP
Add R5, R4, R6

Instruções de desvio (INCONDICIONAL)
18Penalidade: 2 ciclos de clock (Desvio computado no estágio E)

Instruções de desvio (INCONDICIONAL)
19Penalidade: 1 ciclo de clock (Desvio computado no estágio D)
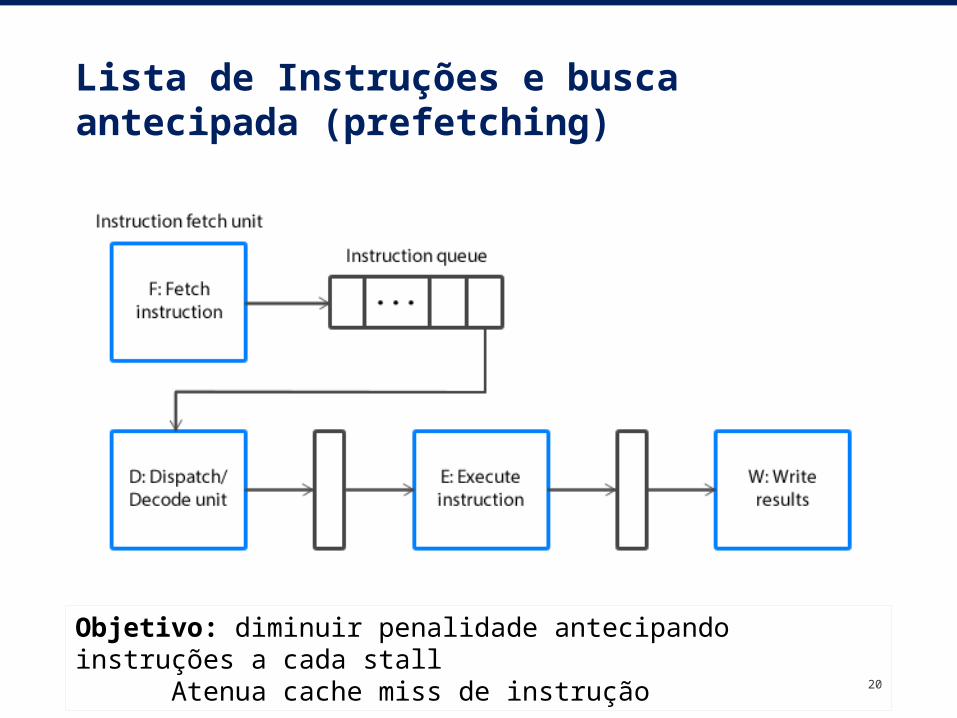
Lista de Instruções e busca antecipada (prefetching)
20
Objetivo: diminuir penalidade antecipando instruções a cada stall
Atenua cache miss de instrução
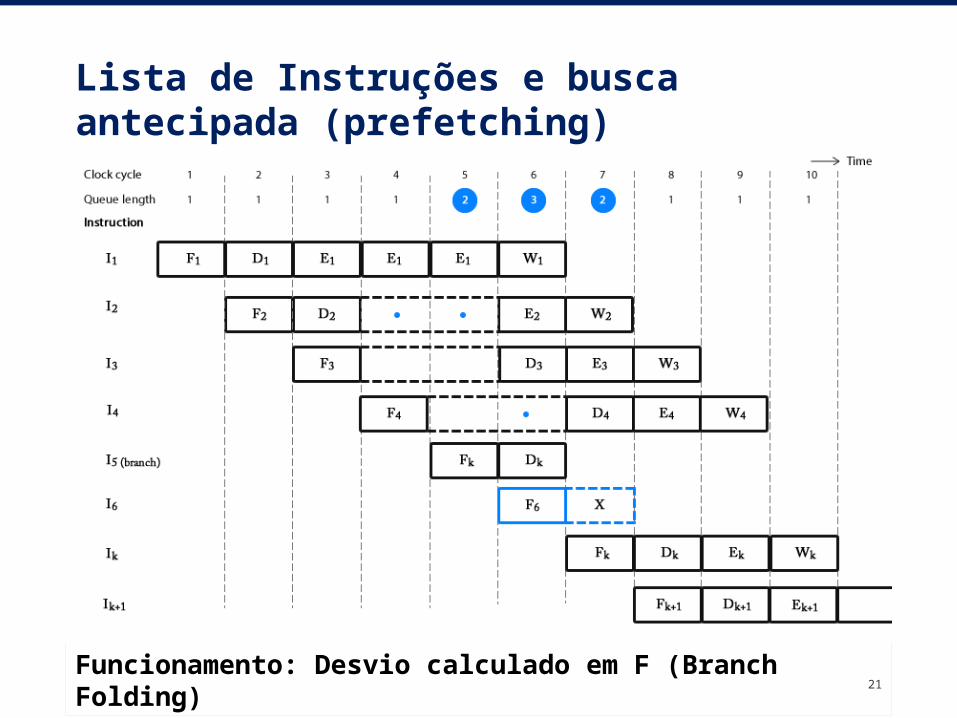
Lista de Instruções e busca antecipada (prefetching)
21Funcionamento: Desvio calculado em F (Branch Folding)

Mitigando problemas (control hazards)
22
–Software• Eliminar desvios – desenrolar loops
– Aumenta tamanho da execução (mais instruções)• Reduz tempo de resolução (agendamento de
instruções)– Desvios são computados ASAP (desvios são
frequentemente o caminho crítico através dos códigos)–Hardware• Ocupar delay slots
– Substituir bolhas do pipeline por trabalho útil (depende do compilador)
• Especular – predição de desvio

Instruções de desvio
23
– Cerca de 20% das intruções de um programa são de desvio (Hamacker et Al., 2015) – Penalidades por falhas no desvio reduzem
profundamente desempenho do pipeline
–Hazard: Dependência do resultado da instrução precedente• Decisão de desvio não pode ser tomada até a etapa de execução ser concluída• Tentar prever o desvio pode valer a pena–Predição de desvio do processadores modernos tem precisão > 95%

Instruções de desvio
24
– Técnicas para tentar diminuir penalidades com desvios:•Desvio atrasado (delayed branch)•Predição de desvio (branch prediction)•Predição de desvio dinâmico (dynamic branch prediction)

Instruções de desvio (CONDICIONAL)
25
– Desvio atrasado (delayed branch)• Instruções após desvio:- Executadas total ou parcialmente• Branch delay slots
• Esses slots podem serutilizados em instruções úteispara serem executadas independente se o desviofor feito

Instruções de desvio (CONDICIONAL)
26
– Desvio atrasado (delayed branch)
LOOP Shift_left R1Decrement R2Branch=0 LOOP
NEXT Add R1,R3
LOOP Decrement R2Branch=0 LOOPShift_left R1
NEXT Add R1,R3
– Técnica sofisticada de compilação• Reordena instruções sem que haja perda da lógica • Para 1 slot – 85% de sucesso• Para mais 1 slot – reordenar instruções sem perda de semântica decresce substancialmente

Instruções de desvio (CONDICIONAL)
27
– Predição de desvio (branch prediction)• Instruções são executadas antes de se saber o resultado do desvio– CUIDADO EXTRA: registradores e posições da memória
não podem ser atualizadas enquanto não se souber o resultado do desvio
– Se a predição foi correta: Instruções já processadas!– Se a predição for incorreta: Penalidade: instruções e
dados associados precisam ser removidos, nova instrução precisa ser escalonada

Instruções de desvio (CONDICIONAL)
28
– Predição de desvio (branch prediction)•Execução especulativa estática
1. Tratada em hardware: pode comparar endereços do PC para tomar uma decisão» Processador checa offset da instrução de desvio. Exemplo:• (offset > 0) Topo do loop: desvio pouco provável• (offset < 0) Fim do loop: desvio provável

Instruções de desvio (CONDICIONAL)
29
– Predição de desvio (branch prediction)•Execução especulativa estática

Instruções de desvio (CONDICIONAL)
30
– Predição de desvio (branch prediction)•Execução especulativa estática
2. Tratada em software: compilador faz análise do comportamento esperado do programa: e configura uma flag: branch
prediction bit (suportado pela ISA) indicando por 1 ou 0 se o desvio é provável ou loop unrolling

Instruções de desvio (CONDICIONAL)
31
– Predição de desvio dinâmico (dynamic branch prediction)– Correlação temporal: leva em consideração
os resultados dos desvios anteriores para prever o próximo desvio–Correlação espacial: desvios podem se
resolver de forma altamente correlacionada (um caminho preferido de execução)
Se a primeira condição é falsa, provavelmente a segunda também é (Yeh and Patt, 1992)

Instruções de desvio (CONDICIONAL)
32
– Predição de desvio dinâmico (dynamic branch prediction)
–Como reduzir a probabilidade de tomar uma decisão errada?• Histórico das execuções–Máquinas de estado– Tabelas ou Buffers para mapear endereço de
desvio associando: Resultado do desvio 1 ou 2 bits para o algoritmo de previsão de
desvio Instrução alvo

Instruções de desvio (CONDICIONAL)
33
– Predição de desvio dinâmico (dynamic branch prediction)
–Maquina de estado (1 bit) LT – Likely to be taken(provável que ocorra)
LNT – Likely not to be taken(provável que não ocorra)

Instruções de desvio (CONDICIONAL)
34
– Predição de desvio dinâmico (dynamic branch prediction)
ST – Strongly likely to be taken(MUITO provável que ocorra)
LT – Likely to be taken(provável que ocorra)
LNT – Likely not to be taken(provável que não ocorra)
SNT – Strongly likely not to be taken(MUITO provável que NÃO ocorra)
Maquina de estado (2 bits)
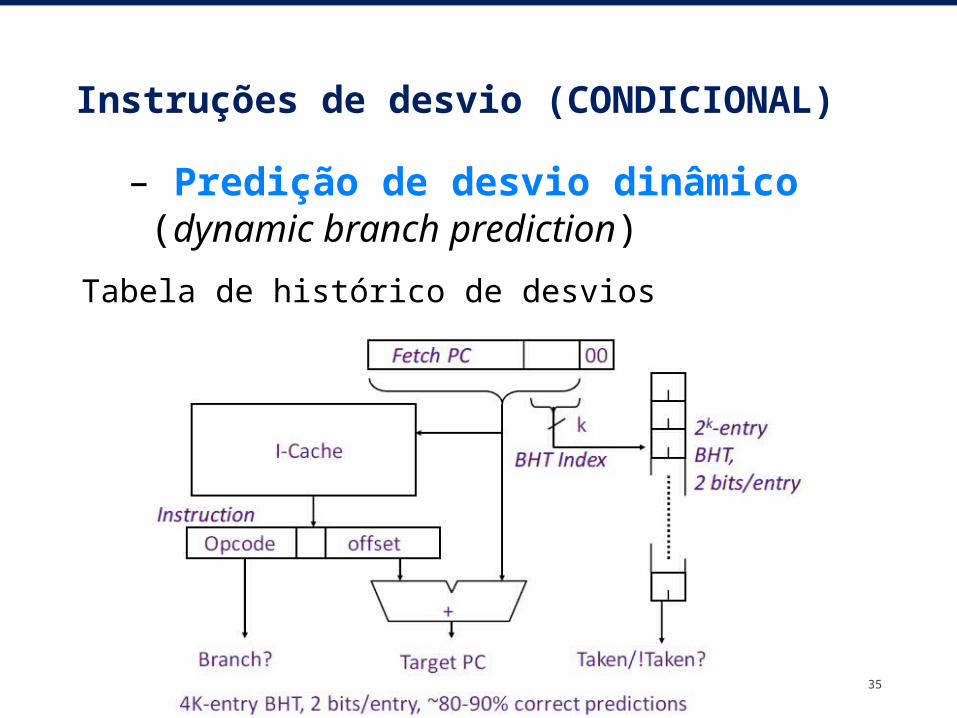
Instruções de desvio (CONDICIONAL)
35
– Predição de desvio dinâmico (dynamic branch prediction)
Tabela de histórico de desvios

Interrupções
36
Evento interno ou externo que precisa ser processado por outro programa (SO)

Interrupções (causas)
37
• Assíncrona: um evento externo– Dispositivo de entrada/saída– Tempo esgotado– Falhas de hardware
• Síncrona: evento interno (traps ou exceptions)– Opcode indefinido (instrução privilegiada)– Overflow aritmético ou exceção da FPU– Acesso à memória não alinhado– Exceções da memória virtual: falha de página, violação de
proteção– System calls (pula para kernel-space)
Interrupção: um evento que requer atenção do processador

Interrupções (tratamento)
38

DYSEAC (primeiro computador móvel)
39

Interrupções Assíncronas (tratamento)
40
–Um dispositivo de E/S reivindica atenção por meio de uma requisição de interrupção –Quando o processador decide interromper o processo•Para a execução da instrução corrente Ii, mas completa todas as anteriores Ii-1 (interrupção precisa) •Salva PC da Ii em registrador especial (EPC)•Desabilita a interrupção e transfere o controle para o gerenciador de interrupções (kernel-mode)

Gerenciamento de Interrupção
41
–Salva EPC antes de habilitar interrupções para permitir interrupções aninhadas• Precisa de uma instrução para mover EPC dentro de um GPRs
–Precisa de um registrador de estatus que indica a causa da interrupção–Usa um jump de instrução indireta (RFE
return-from-exception) que:• Habilita interrupções• Restaura o processador para o modo de usuário

Interrupções Síncronas
42

Limitações de recursos
43
–Stalls ocorrem quando não há recursos suficientes de hardware para que todos os estágios possam operar concorrentemente– Se 2 instruções precisam acessar o mesmo recurso
no mesmo ciclo de clock, uma delas deve ser interrompida (interlocked)–Exemplo:• ~25% das operações envolvem load/store–Se os estágios de Fetch e Memory acessam uma mesma
cache (dados e instrução) haverá 25% de stalls causados por essa limitação –Hardware adicional pode mitigar problema: separando
caches de dados e instrução (Harvard)

Número ideal de estágios
44
– n estágios tende a um aumento de vazão por um fator de n• CONTUDO
– Maior número de estágios leva a maior possibilidade de dependência entre instruções (mais stalls)
– A penalidade por erros de desvio é maior– Latência dos latches passa a ser considerável quanto maior for o
pipeline– A ULA costuma servir de referência para se calcular
o número de ciclos de clock para todos os estágios– Acesso à memória cache são divididos em estágios
que levam o mesmo tempo que as operações da ULA– Em processadores modernos a própria ULA pode ter
seu pipeline para aumentar a vazão de dados, diminuindo o número de ciclos de clock dos estágios

Número de estágios (Intel x ARM)
45
Microarchitecture Pipeline stages
P5 (Pentium) 5
P6 (Pentium 3) 10
P6 (Pentium Pro) 14
NetBurst (Willamette) 20
NetBurst (Northwood) 20
NetBurst (Prescott) 31
NetBurst (Cedar Mill) 31
Core 14
Bonnell 16
Sandy Bridge 14
Silvermont 14 to 17
Haswell 14
Skylake 14
Kabylake 14
Microarchitecture Pipeline stages
ARM up to 7: 3
ARM 8-9:
5
ARM 11: 8
Cortex A7: 8-10
Cortex A8: 13
Cortex A15: 15-25
Fonte: https://softwareengineering.stackexchange.com/questions/210818/how-long-is-a-typical-modern-microprocessor-pipeline

Máxima vazão
46
– Diversas instruções estão no pipeline mas em estágios de execução diferentes• Exemplo: Enquanto uma realiza uma operação na ULA, outra instrução está sendo decodificada
–Na ausência de hazards, uma instrução entra no pipeline e outra completa a sua execução em cada ciclo de clock
– (DESSA FORMA) Máxima vazão de um processador com pipeline: 1 instrução por ciclo de clock

Superscalar
47
– Um processador pode ter múltiplas unidades funcionais para gerenciar diversas instruções em paralelo em cada estágio de processamento•Várias instruções iniciam suas execuções no mesmo ciclo de clock (múltipla expedição – multiple issue)•Vazão pode ser maior que 1 instrução por ciclo de clock–Processador superscalar
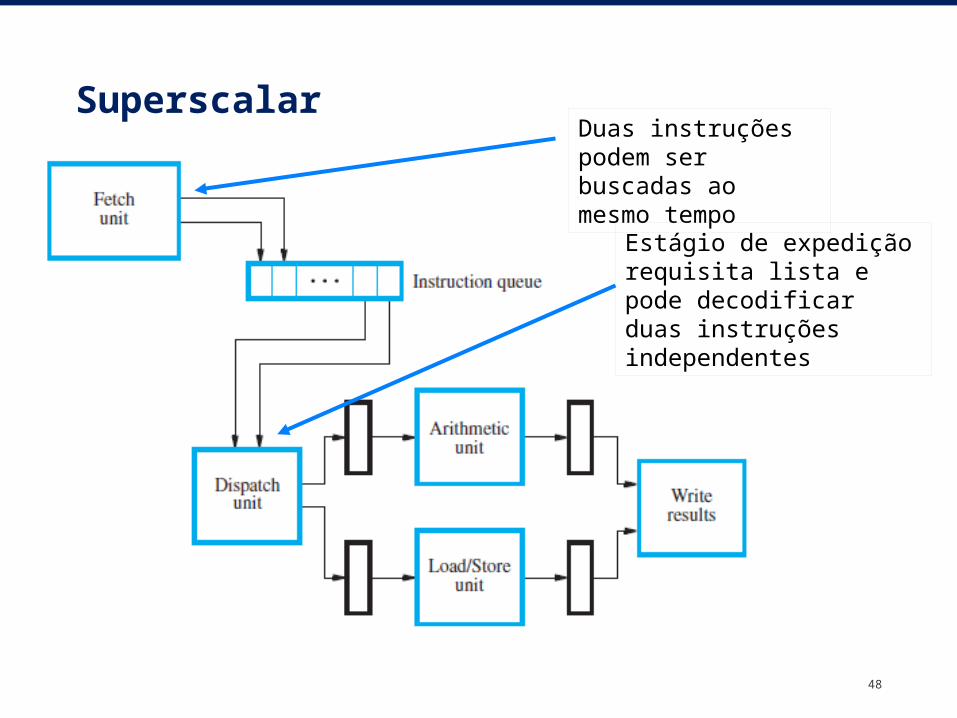
Superscalar
48
Duas instruções podem ser buscadas ao mesmo tempo
Estágio de expedição requisita lista e pode decodificar duas instruções independentes

Superscalar
49
Instruções designadas simultaneamente para uso de recursos distintos

Superscalar (considerações)
50
– Otimizar o uso de múltiplas unidades funcionais depende do compilador
–reordenar instruções a fim de intercalar as que usem diferentes unidades funcionais simultaneamente
– Desvios ou dependências de dados limitam a vazão
– Software pode gerar uma imposição de acesso sequencial para ser executado corretamente

Superscalar (considerações)
51
– Um processador superscalar precisa garantir que as instruções sejam executadas na ordem correta
– Instruções de PF são mais lentas – Atraso das memórias devido cache misses podem causar stalls nos estágios de fetch e expedição das instruções– vazão tende a ser abaixo da máxima devido as limitações

Superscalar (considerações)
52
–A unidade de fetch gerencia as instruções de desvio e determina quais instruções devem ocupar a fila de expedição
–Deve determinar a decisão de desvio e o alvo para cada instrução–A decisão de desvio pode depender de uma instrução anterior que ainda está na lista ou foi expedida. »Bolha na unidade de fetch até o resultado estar disponível pode reduzir a vazão significativamente e não é desejável
–Motiva a execução especulativa

Execução fora de ordem (Out-of-Order)
53
– A dependência entre instruções pode ser tratada com o atraso de alguma delas• I2 depende do resultado de I1– Execução de I2 é atrasada (stalled)
– E se exceções ocorrerem?• Erro ao buscar operando ou operação ilegal (divisão por zero)

Execução fora de ordem (Out-of-Order)
54
• Exceções imprecisas: – Dentro de uma sequencia de instruções, aquela que causou a exceção é identificada, mas as que se sucedem continuam sendo executadas – Execução do programa é dita em estado inconsistente

Execução fora de ordem (Out-of-Order)
55
• Exceções precisas: – Todas as instruções subsequentes a que gerou a exceção são descartadas. Exige suporte de hardware para salvar de forma temporária resultado de estágios salvos fora de ordem (reservation stations).

Conclusão da execução
56
• Uma unidade de execução pode ser ativada para executar qualquer instrução cujos os operandos estejam disponíveis
– (Porém) Instruções precisam ser completadas em ordem para gerar exceções precisas– Resultados de operações fora de ordem precisam ser salvos em registros temporários e encaminhados para uso de instruções subsequentes» Register renaming

Conclusão da execução
57
• Caso não hajam exceções, operações fora de ordem são salvas (commitement step) em ordem e os registradores temporários liberados
– Reorder buffer– A instrução é considerada completa (retired)

Resumo
58
• Pipeline permite aumento na frequência de clock, favorecendo CPI e melhorando o desempenho–Hazards são um complicador no escalonamento de
instruções nos pipelines– Estruturais (duas instruções que querem o mesmo recurso de
hardware)– Dados (instrução anterior produz valor necessário para
próxima instrução)–Controle (intruções que mudam o fluxo de execução como de
desvio e exceções)–Técnicas para gerenciar hazards
– Interlock (aguardar pelo uso de recurso e só depois continuar a execução)– Bypass (transferir o resultado da computação tão logo for
possível)–Especulação

Referências
59
• Henessy e Patterson (livro texto)• Hamacher et al. Computer Organization,
5.a. edição• Slides C152 - Computer Science 152:
Computer Architecture and Engineeringhttp://www-inst.eecs.berkeley.edu/~cs152/fa16/





























