Embed Size (px)
Citation preview

Parallel ComputersParallel Computers
Prof. Sin-Min LeeProf. Sin-Min Lee
Department of Computer Department of Computer ScienceScience

MultiprocessorsMultiprocessors
Systems designed to have 2 to 8 CPUsSystems designed to have 2 to 8 CPUs The CPUs all share the other parts of the The CPUs all share the other parts of the
computercomputer MemoryMemory DiskDisk System BusSystem Bus etcetc
CPUs communicate via Memory and the CPUs communicate via Memory and the System Bus System Bus

MultiProcessorsMultiProcessors
Each CPU shares memory, disks, etcEach CPU shares memory, disks, etc Cheaper than clustersCheaper than clusters Not as good performance as clustersNot as good performance as clusters
Often used forOften used for Small ServersSmall Servers High-end WorkstationsHigh-end Workstations

MultiProcessorsMultiProcessors
OS automatically shares work among OS automatically shares work among available CPUsavailable CPUs On a workstation…On a workstation…
One CPU can be running an engineering One CPU can be running an engineering design programdesign program
Another CPU can be doing complex graphics Another CPU can be doing complex graphics formattingformatting

Applications of Parallel Applications of Parallel ComputersComputers
Traditionally: government labs, Traditionally: government labs, numerically intensive applicationsnumerically intensive applications
Research InstitutionsResearch Institutions Recent Growth in Industrial ApplicationsRecent Growth in Industrial Applications
236 of the top 500236 of the top 500 Financial analysis, drug design and analysis, Financial analysis, drug design and analysis,
oil exploration, aerospace and automotive oil exploration, aerospace and automotive

1966 Flynn’s Classification1966 Flynn’s Classification
Michael Flynn,
Professor of Stanford University


Multiprocessor SystemsMultiprocessor SystemsFlynn’s ClassificationFlynn’s Classification
Single instruction multiple data (SIMD):Single instruction multiple data (SIMD):
MainMemory
ControlUnit
Processor
Processor
Processor
Memory
Memory
Memory
CommunicationsNetwork
• Executes a single instruction on multiple data values Executes a single instruction on multiple data values simultaneously using many processorssimultaneously using many processors• Since only one instruction is processed at any given time, it Since only one instruction is processed at any given time, it is not necessary for each processor to fetch and decode the is not necessary for each processor to fetch and decode the instructioninstruction• This task is handled by a single control unit that sends the This task is handled by a single control unit that sends the control signals to each processor.control signals to each processor.• Example: Array processorExample: Array processor

Why Multiprocessors?Why Multiprocessors?1.1. Microprocessors as the fastest CPUsMicroprocessors as the fastest CPUs
• Collecting several much easier than Collecting several much easier than redesigning 1redesigning 1
2.2. Complexity of current microprocessorsComplexity of current microprocessors• Do we have enough ideas to sustain Do we have enough ideas to sustain
1.5X/yr?1.5X/yr?• Can we deliver such complexity on Can we deliver such complexity on
schedule?schedule?3.3. Slow (but steady) improvement in parallel Slow (but steady) improvement in parallel
software (scientific apps, databases, OS)software (scientific apps, databases, OS)4.4. Emergence of embedded and server markets driving Emergence of embedded and server markets driving
microprocessors in addition to desktopsmicroprocessors in addition to desktops• Embedded functional parallelism, Embedded functional parallelism,
producer/consumer modelproducer/consumer model• Server figure of merit is tasks per hour vs. latencyServer figure of merit is tasks per hour vs. latency

Parallel Processing IntroParallel Processing Intro Long term goal of the field: scale number processors to size of Long term goal of the field: scale number processors to size of
budget, desired performancebudget, desired performance Machines today: Sun Enterprise 10000 (8/00)Machines today: Sun Enterprise 10000 (8/00)
64 400 MHz UltraSPARC® II CPUs,64 GB SDRAM memory, 868 64 400 MHz UltraSPARC® II CPUs,64 GB SDRAM memory, 868 18GB disk,tape 18GB disk,tape
$4,720,800 total $4,720,800 total 64 CPUs 15%,64 GB DRAM 11%, disks 55%, cabinet 16% 64 CPUs 15%,64 GB DRAM 11%, disks 55%, cabinet 16%
($10,800 per processor or ~0.2% per processor)($10,800 per processor or ~0.2% per processor) Minimal E10K - 1 CPU, 1 GB DRAM, 0 disks, tape ~$286,700Minimal E10K - 1 CPU, 1 GB DRAM, 0 disks, tape ~$286,700 $10,800 (4%) per CPU, plus $39,600 board/4 CPUs (~8%/CPU)$10,800 (4%) per CPU, plus $39,600 board/4 CPUs (~8%/CPU)
Machines today: Dell Workstation 220 (2/01)Machines today: Dell Workstation 220 (2/01) 866 MHz Intel Pentium® III (in Minitower)866 MHz Intel Pentium® III (in Minitower) 0.125 GB RDRAM memory, 1 10GB disk, 12X CD, 17” monitor, 0.125 GB RDRAM memory, 1 10GB disk, 12X CD, 17” monitor,
nVIDIA GeForce 2 GTS,32MB DDR Graphics card, 1yr servicenVIDIA GeForce 2 GTS,32MB DDR Graphics card, 1yr service $1,600; for extra processor, add $350 (~20%)$1,600; for extra processor, add $350 (~20%)

Major MIMD StylesMajor MIMD Styles
1.1. Centralized shared memory ("Uniform Centralized shared memory ("Uniform Memory Access" time or "Shared Memory Memory Access" time or "Shared Memory Processor")Processor")
2.2. Decentralized memory (memory module Decentralized memory (memory module with CPU) with CPU) • get more memory bandwidth, lower memory get more memory bandwidth, lower memory
latencylatency• Drawback: Longer communication latencyDrawback: Longer communication latency• Drawback: Software model more complexDrawback: Software model more complex


Multiprocessor SystemsMultiprocessor SystemsFlynn’s ClassificationFlynn’s Classification

MIMD computers usually have a different program running on every processor. This makes for a very complex programming environment.
What processor?Doing which task?At what time?
What’s doing what when?


Memory latency
The time between issuing a memory fetch and receiving the response.
Simply put, if execution proceeds before the memory request responds, unexpected results will occur.
What values are being used? Not the ones requested!

A similar problem can occur with instruction executions themselves.
Synchronization
The need to enforce the ordering of instruction executions according to their data dependencies.
Instruction b must occur before instruction a.

Despite potential problems, MIMD can prove larger than life.
MIMD Successes
IBM Deep Blue – Computer beats professional chess player.
Some may not consider this to be a fair example, because Deep Blue was built to beat Kasparov alone. It “knew” his play style so it could counter is projected moves. Still, Deep Blue’s win marked a major victory for computing.

IBM’s latest, a supercomputer that models nuclear explosions.
IBM Poughkeepsie built the world’s fastest supercomputer for the U. S. Department of Energy. It’s job was to model nuclear explosions.

MIMD – it’s the most complex, fastest, flexible parallel paradigm. It’s beat a world class chess player at his own game. It models things that few people understand. It is parallel processing at its finest.

Multiprocessor SystemsMultiprocessor SystemsSystem Topologies:System Topologies: The topology of a multiprocessor system refers to the pattern of The topology of a multiprocessor system refers to the pattern of
connections between its processorsconnections between its processors Quantified by standard metrics:Quantified by standard metrics:
DiameterDiameter The maximum distance The maximum distance between two between two processors in the computer processors in the computer systemsystem
BandwidthBandwidth The capacity of a The capacity of a communications link communications link multiplied by the number of multiplied by the number of such links in such links in the system (best case)the system (best case)
Bisectional BandwidthBisectional Bandwidth The total bandwidth of the links The total bandwidth of the links connecting the two halves of connecting the two halves of
the the processor split so that the processor split so that the number of number of links between the two halves links between the two halves is is minimized (worst case)minimized (worst case)


Multiprocessor SystemsMultiprocessor SystemsSystem TopologiesSystem Topologies
Six Categories of System Topologies:Six Categories of System Topologies:
• Shared bus
• Ring
• Tree
• Mesh
• Hypercube
• Completely Connected



Multiprocessor SystemsMultiprocessor SystemsSystem TopologiesSystem Topologies
Shared bus:Shared bus: The simplest topologyThe simplest topology Processors communicate Processors communicate
with each other exclusively with each other exclusively via this busvia this bus
Can handle only one data Can handle only one data transmission at a timetransmission at a time
Can be easily expanded by Can be easily expanded by connecting additional connecting additional processors to the shared processors to the shared bus, along with the bus, along with the necessary bus arbitration necessary bus arbitration circuitrycircuitry
Shared Bus
GlobalMemory
M
P
M
P
M
P




Multiprocessor SystemsMultiprocessor SystemsSystem TopologiesSystem Topologies
Ring:Ring: Uses direct dedicated Uses direct dedicated
connections between connections between processorsprocessors
Allows all Allows all communication links to communication links to be active simultaneouslybe active simultaneously
A piece of data may A piece of data may have to travel through have to travel through several processors to several processors to reach its final reach its final destinationdestination
All processors must have All processors must have two communication linkstwo communication links
P
P P
P P
P

Multiprocessor SystemsMultiprocessor SystemsSystem TopologiesSystem Topologies
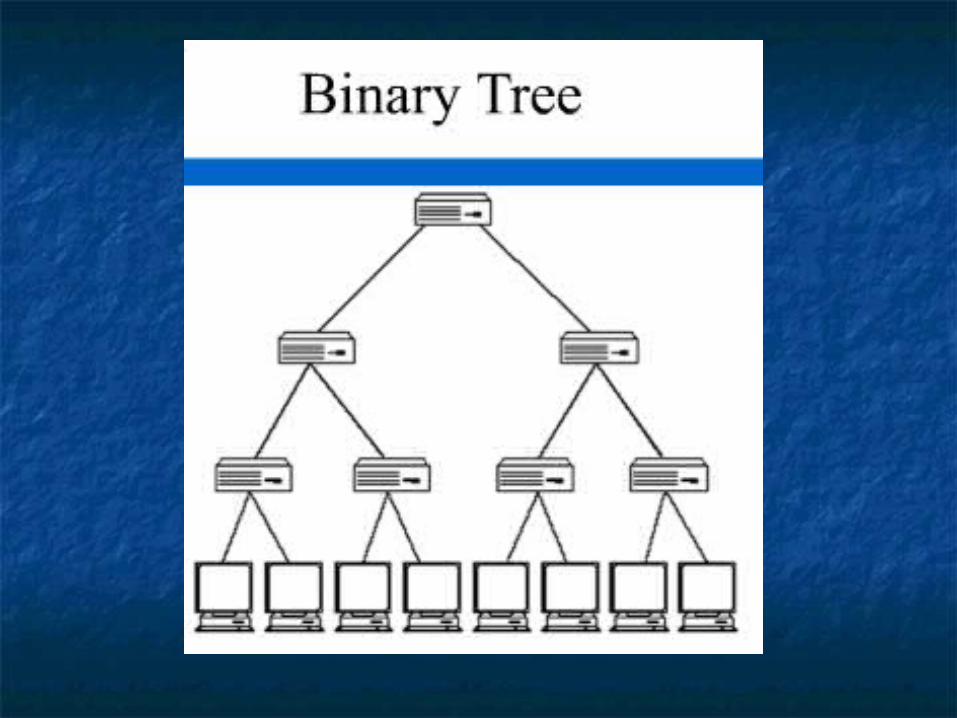
Tree topology:Tree topology: Uses direct connections Uses direct connections
between processorsbetween processors Each processor has Each processor has
three connectionsthree connections Its primary advantage Its primary advantage
is its relatively low is its relatively low diameterdiameter
Example: DADO Example: DADO ComputerComputer
P
P P
P P PP


Multiprocessor SystemsMultiprocessor SystemsSystem TopologiesSystem Topologies
Mesh topology:Mesh topology: Every processor Every processor
connects to the connects to the processors above, processors above, below, left, and rightbelow, left, and right
Left to right and top Left to right and top to bottom to bottom wraparound wraparound connections may or connections may or may not be presentmay not be present
P P P
P P P
P P P


Multiprocessor SystemsMultiprocessor SystemsSystem TopologiesSystem Topologies
Hypercube:Hypercube:
Multidimensional Multidimensional meshmesh
Has n processors, Has n processors, each with log n each with log n connectionsconnections


Multiprocessor SystemsMultiprocessor SystemsSystem TopologiesSystem Topologies
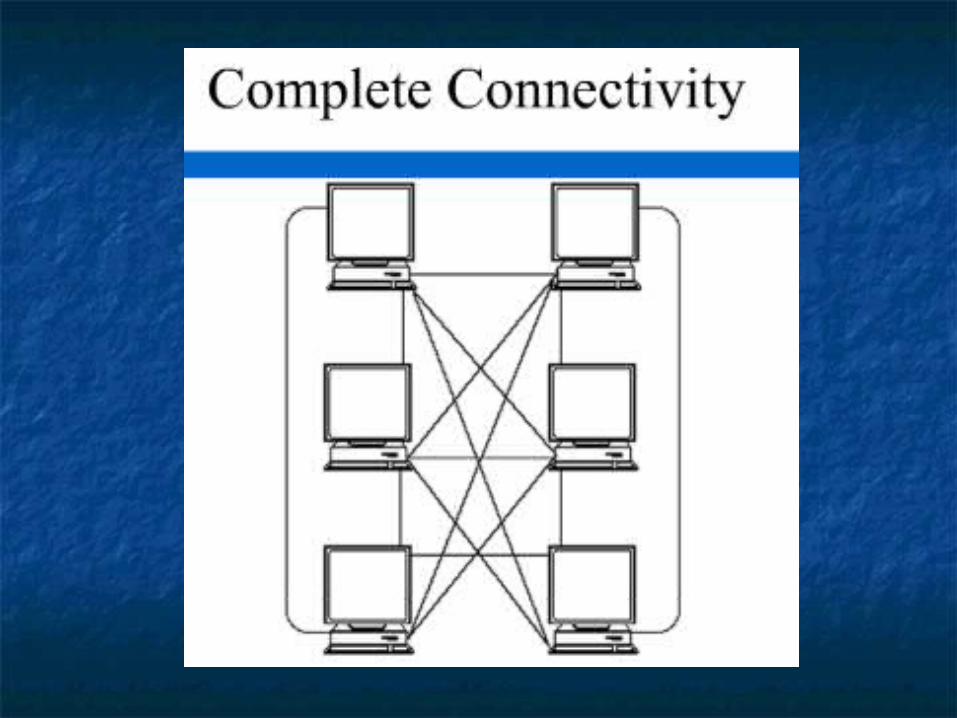
Completely Connected:Completely Connected:
• Every processor has n-1 connections, one to each of the other processors• The complexity of the processors increases as the system grows• Offers maximum communication capabilities

A Supercomputer at $5.2 million
Virginia Tech 1,100 node Macs.
G5 supercomputer

The Virginia Polytechnic Institute and State University has built a supercomputer comprised of a cluster of 1,100 dual-processor Macintosh G5 computers. Based on preliminary benchmarks, Big Mac is capable of 8.1 teraflops per second. The Mac supercomputer still is being fine tuned, and the full extent of its computing power will not be known until November. But the 8.1 teraflops figure would make the Big Mac the world's fourth fastest supercomputer

Big Mac's cost relative to similar machines is as noteworthy as its performance. The Apple supercomputer was constructed for just over US$5 million, and the cluster was assembled in about four weeks.
In contrast, the world's leading supercomputers cost well over $100 million to build and require several years to construct. The Earth Simulator, which clocked in at 38.5 teraflops in 2002, reportedly cost up to $250 million.

Srinidhi Varadarajan, Ph.D.Dr. Srinidhi Varadarajan is an Assistant Professor of Computer Science at Virginia Tech. He was honored with the NSF Career Award in 2002 for "Weaving a Code Tapestry: A Compiler Directed Framework for Scalable Network Emulation." He has focused his research on building a distributed network emulation system that can scale to emulate hundreds of thousands of virtual nodes.
October 28 2003Time: 7:30pm - 9:00pmLocation: Santa Clara Ballroom

Parallel ComputersParallel Computers
Two common typesTwo common types ClusterCluster Multi-ProcessorMulti-Processor

Cluster ComputersCluster Computers
Clusters on the Rise
Using clusters of small machines to build a supercomputer is not a new concept.
Another of the world's top machines, housed at the Lawrence Livermore National Laboratory, was constructed from 2,304 Xeon processors. The machine was build by Utah-based Linux Networx.
Clustering technology has meant that traditional big-iron leaders like Cray (Nasdaq: CRAY) and IBM have new competition from makers of smaller machines. Dell (Nasdaq: DELL) , among other companies, has sold high-powered computing clusters to research institutions.

Cluster ComputersCluster Computers
Each computer in a cluster is a Each computer in a cluster is a complete computer by itselfcomplete computer by itself CPUCPU MemoryMemory DiskDisk etcetc
Computers communicate with each Computers communicate with each other via some interconnection bus other via some interconnection bus

Cluster ComputersCluster Computers
Typically used where one computer Typically used where one computer does not have enough capacity to do does not have enough capacity to do the expected workthe expected work Large ServersLarge Servers
Cheaper than building one GIANT Cheaper than building one GIANT computercomputer

Although not new, supercomputing clustering technology still is impressive. It works by farming out chunks of data to individual machines, adding that clustering works better for some types of computing problems than others.
For example, a cluster would not be ideal to compete against IBM's Deep Blue supercomputer in a chess match; in this case, all the data must be available to one processor at the same moment -- the machine operates much in the same way as the human brain handles tasks.
However, a cluster would be ideal for the processing of seismic data for oil exploration, because that computing job can be divided into many smaller tasks.

Cluster ComputersCluster Computers
Need to break up work among the Need to break up work among the computers in the clustercomputers in the cluster
Example: Microsoft.com Search EngineExample: Microsoft.com Search Engine 6 computers running SQL Server6 computers running SQL Server
Each has a copy of the MS Knowledge BaseEach has a copy of the MS Knowledge Base Search requests come to one computerSearch requests come to one computer
Sends request to one of the 6Sends request to one of the 6 Attempts to keep all 6 busyAttempts to keep all 6 busy

The Virginia Tech Mac supercomputer should be fully functional and in use by January 2004. It will be used for research into nanoscale electronics, quantum chemistry, computational chemistry, aerodynamics, molecular statics, computational acoustics and the molecular modeling of proteins.

Supercomputers in ChinaSupercomputers in China









The previous speed leader is a The previous speed leader is a computer called computer called Cray XT5 JaguarCray XT5 Jaguar located at the Oak Ridge National located at the Oak Ridge National Laboratory of the United States. Laboratory of the United States.
China has invested billions in China has invested billions in computing in recent years, and computing in recent years, and supercomputers are being pressed supercomputers are being pressed into service for everything from into service for everything from designing aeroplanes to probing the designing aeroplanes to probing the origins of the universe. They're also origins of the universe. They're also being used all over the world to being used all over the world to model climate change scenarios. model climate change scenarios.

Tianhe-1A : China’s New Supercomputer, BeTianhe-1A : China’s New Supercomputer, Beats Cray XT5 Jaguar of USats Cray XT5 Jaguar of US

It contains a massive 7,000 graphics It contains a massive 7,000 graphics processors and 14,000 Intel chips. but processors and 14,000 Intel chips. but it was Chinese researchers who it was Chinese researchers who worked out how to wire them up to worked out how to wire them up to create the lightning-fast data transfer create the lightning-fast data transfer and computational power. and computational power.
The system is designed at the The system is designed at the National University of Defense National University of Defense Technology in China. This Technology in China. This supercompter, based in supercompter, based in China’s China’s National Center for SupercomputingNational Center for Supercomputing, , has already started working for the has already started working for the local weather service and the National local weather service and the National Offshore Oil CorporationOffshore Oil Corporation

The super computer set a performance record by The super computer set a performance record by crunching crunching 2.507 petaflops2.507 petaflops of data at once of data at once ((two-and-a-half thousand trillion operations two-and-a-half thousand trillion operations per secondper second), which is 40 percent more than the ), which is 40 percent more than the Cray XT5 Jaguar’s speed of 1.75 petaflops.Cray XT5 Jaguar’s speed of 1.75 petaflops.
The Tianhe-1A is twenty-nine million times more The Tianhe-1A is twenty-nine million times more powerful than the earliest supercomputers of the powerful than the earliest supercomputers of the 1970s 1970s

LinuxLinux operating system operating system
Tianhe-1A runs on Tianhe-1A runs on LinuxLinux operating system. While the operating system. While the thousands of individual processors used in the thousands of individual processors used in the supercomputer are made in America, the switches supercomputer are made in America, the switches that connect those computer chips are built by that connect those computer chips are built by Chinese scientists. The connection and the switches Chinese scientists. The connection and the switches are critical success factor of a super computer, as the are critical success factor of a super computer, as the faster you make the interconnect, the better your faster you make the interconnect, the better your overall computation will flow.overall computation will flow.
Milky Way is a reported 47% faster than the XT5 and Milky Way is a reported 47% faster than the XT5 and does this by uniting its thousands of Intel chips with does this by uniting its thousands of Intel chips with graphics processors made by rival firm Nvidia.graphics processors made by rival firm Nvidia.

The super computer consists of The super computer consists of 20,000 smaller 20,000 smaller computerscomputers linked together, and covers more than linked together, and covers more than a a third of an acrethird of an acre (17,000 square feet). (17,000 square feet).
It is sized more than 100 fridge-sized computer racks It is sized more than 100 fridge-sized computer racks and together these weigh more than and together these weigh more than 155 tonnes.155 tonnes.
The Tianhe-1A is powered by The Tianhe-1A is powered by 7168 Nvidia Tesla 7168 Nvidia Tesla M2050 GPUs and 14336 Intel Xeon CPUsM2050 GPUs and 14336 Intel Xeon CPUs. The . The system consumes system consumes 4.04 megawatts4.04 megawatts of electricity. of electricity.
Five new supercomputers are being built that are Five new supercomputers are being built that are supposed to be four times more powerful than China’s supposed to be four times more powerful than China’s new machine. Three are in the U.S.; two are in Japan.new machine. Three are in the U.S.; two are in Japan.

Luckily the Tianhe-1A canLuckily the Tianhe-1A can
.. The fact that China currently owns the world's The fact that China currently owns the world's
fastest supercomputer is not really relevant to an fastest supercomputer is not really relevant to an understanding of the international league tables of understanding of the international league tables of computing power. It almost goes without saying computing power. It almost goes without saying that in 18 months time even 2.507 petaflops will that in 18 months time even 2.507 petaflops will look like pocket calculator stuff. The real story here look like pocket calculator stuff. The real story here is that China's unprecedented level of investment in is that China's unprecedented level of investment in supercomputing is resulting in huge numbers of supercomputing is resulting in huge numbers of software engineers coming out of the country. It is software engineers coming out of the country. It is not the Tianhe-1A that spells the future of not the Tianhe-1A that spells the future of computing dominance, but the legions of computing computing dominance, but the legions of computing experts of the future.experts of the future.





























