Embed Size (px)
DESCRIPTION
isi mengenai spss
Citation preview

Warning # 849 in column 23. Text: in_IDThe LOCALE subcommand of the SET command has an invalid parameter. It couldnot be mapped to a valid backend locale.GET FILE='D:\Kuliah\2014\mpkuan\MPK\MPK-2015\TUGAS DISKRIMINAN.sav'.DATASET NAME DataSet1 WINDOW=FRONT.DISCRIMINANT /GROUPS=PEMBACA(0 1) /VARIABLES=LAYOUT UKURAN_HURUF CAKUPAN_BERITA AKTUALITAS_BERITA ISUE KOLOM_ANALISIS KELENGKAPAN_BERITA FREKUENSI_IKLAN FREKUENSI_TERBIT KUALITAS_CETAKAN HARGA /ANALYSIS ALL /METHOD=MAHAL /PIN=.05 /POUT=.10 /PRIORS EQUAL /HISTORY /STATISTICS=MEAN STDDEV UNIVF COEFF CROSSVALID /PLOT=CASES /CLASSIFY=NONMISSING POOLED.
Discriminant
Notes
Output Created 30-MAY-2015 15:55:06
Comments
Input
Data
D:\Kuliah\2014\mpkuan\MPK\
MPK-2015\TUGAS
DISKRIMINAN.sav
Active Dataset DataSet1
Filter <none>
Weight <none>
Split File <none>
N of Rows in Working Data
File150
Missing Value Handling Definition of Missing User-defined missing values
are treated as missing in the
analysis phase.

Cases Used
In the analysis phase, cases
with no user- or system-
missing values for any
predictor variable are used.
Cases with user-, system-
missing, or out-of-range
values for the grouping
variable are always excluded.
Notes
Syntax
DISCRIMINANT
/GROUPS=PEMBACA(0 1)
/VARIABLES=LAYOUT
UKURAN_HURUF
CAKUPAN_BERITA
AKTUALITAS_BERITA ISUE
KOLOM_ANALISIS
KELENGKAPAN_BERITA
FREKUENSI_IKLAN
FREKUENSI_TERBIT
KUALITAS_CETAKAN
HARGA
/ANALYSIS ALL
/METHOD=MAHAL
/PIN=.05
/POUT=.10
/PRIORS EQUAL
/HISTORY
/STATISTICS=MEAN
STDDEV UNIVF COEFF
CROSSVALID
/PLOT=CASES
/CLASSIFY=NONMISSING
POOLED.
ResourcesProcessor Time 00:00:00,33
Elapsed Time 00:00:00,39
[DataSet1] D:\Kuliah\2014\mpkuan\MPK\MPK-2015\TUGAS DISKRIMINAN.sav
Analysis Case Processing Summary
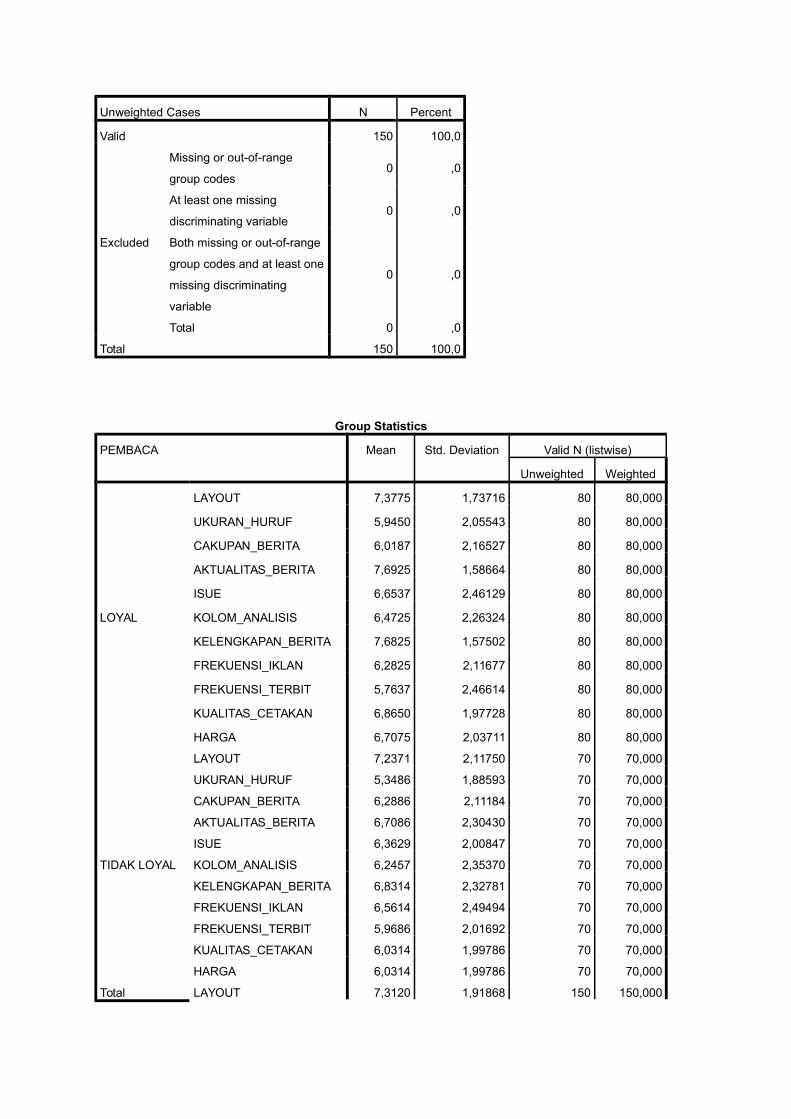
Unweighted Cases N Percent
Valid 150 100,0
Excluded
Missing or out-of-range
group codes0 ,0
At least one missing
discriminating variable0 ,0
Both missing or out-of-range
group codes and at least one
missing discriminating
variable
0 ,0
Total 0 ,0
Total 150 100,0
Group Statistics
PEMBACA Mean Std. Deviation Valid N (listwise)
Unweighted Weighted
LOYAL
LAYOUT 7,3775 1,73716 80 80,000
UKURAN_HURUF 5,9450 2,05543 80 80,000
CAKUPAN_BERITA 6,0187 2,16527 80 80,000
AKTUALITAS_BERITA 7,6925 1,58664 80 80,000
ISUE 6,6537 2,46129 80 80,000
KOLOM_ANALISIS 6,4725 2,26324 80 80,000
KELENGKAPAN_BERITA 7,6825 1,57502 80 80,000
FREKUENSI_IKLAN 6,2825 2,11677 80 80,000
FREKUENSI_TERBIT 5,7637 2,46614 80 80,000
KUALITAS_CETAKAN 6,8650 1,97728 80 80,000
HARGA 6,7075 2,03711 80 80,000
TIDAK LOYAL
LAYOUT 7,2371 2,11750 70 70,000
UKURAN_HURUF 5,3486 1,88593 70 70,000
CAKUPAN_BERITA 6,2886 2,11184 70 70,000
AKTUALITAS_BERITA 6,7086 2,30430 70 70,000
ISUE 6,3629 2,00847 70 70,000
KOLOM_ANALISIS 6,2457 2,35370 70 70,000
KELENGKAPAN_BERITA 6,8314 2,32781 70 70,000
FREKUENSI_IKLAN 6,5614 2,49494 70 70,000
FREKUENSI_TERBIT 5,9686 2,01692 70 70,000
KUALITAS_CETAKAN 6,0314 1,99786 70 70,000
HARGA 6,0314 1,99786 70 70,000
Total LAYOUT 7,3120 1,91868 150 150,000

UKURAN_HURUF 5,6667 1,99404 150 150,000
CAKUPAN_BERITA 6,1447 2,13760 150 150,000
AKTUALITAS_BERITA 7,2333 2,00903 150 150,000
ISUE 6,5180 2,25859 150 150,000
KOLOM_ANALISIS 6,3667 2,30091 150 150,000
KELENGKAPAN_BERITA 7,2853 2,00152 150 150,000
FREKUENSI_IKLAN 6,4127 2,29734 150 150,000
FREKUENSI_TERBIT 5,8593 2,26251 150 150,000
KUALITAS_CETAKAN 6,4760 2,02371 150 150,000
HARGA 6,3920 2,04038 150 150,000
Tests of Equality of Group Means
Wilks' Lambda F df1 df2 Sig.
LAYOUT ,999 ,199 1 148 ,656
UKURAN_HURUF ,978 3,394 1 148 ,067
CAKUPAN_BERITA ,996 ,593 1 148 ,442
AKTUALITAS_BERITA ,940 9,463 1 148 ,002
ISUE ,996 ,618 1 148 ,433
KOLOM_ANALISIS ,998 ,361 1 148 ,549
KELENGKAPAN_BERITA ,955 7,023 1 148 ,009
FREKUENSI_IKLAN ,996 ,549 1 148 ,460
FREKUENSI_TERBIT ,998 ,305 1 148 ,582
KUALITAS_CETAKAN ,957 6,571 1 148 ,011
HARGA ,972 4,186 1 148 ,043
Analysis 1
Stepwise Statistics
Variables Entered/Removeda,b,c,d
Step Entered Min. D Squared

Statistic Between Groups Exact F
Statistic df1 df2 Sig.
1AKTUALITAS_B
ERITA,253
LOYAL and
TIDAK LOYAL9,463 1 148,000 ,002
2 HARGA ,549LOYAL and
TIDAK LOYAL10,187 2 147,000 7,192E-005
3KELENGKAPAN
_BERITA,861
LOYAL and
TIDAK LOYAL10,564 3 146,000 2,493E-006
At each step, the variable that maximizes the Mahalanobis distance between the two closest groups is
entered.a,b,c,d
a. Maximum number of steps is 22.
b. Maximum significance of F to enter is .05.
c. Minimum significance of F to remove is .10.
d. F level, tolerance, or VIN insufficient for further computation.
Variables in the Analysis
Step Tolerance Sig. of F to
Remove
Min. D Squared Between Groups
1 AKTUALITAS_BERITA 1,000 ,002
2
AKTUALITAS_BERITA ,879 ,000 ,112LOYAL and
TIDAK LOYAL
HARGA ,879 ,002 ,253LOYAL and
TIDAK LOYAL
3
AKTUALITAS_BERITA ,865 ,000 ,334LOYAL and
TIDAK LOYAL
HARGA ,862 ,001 ,480LOYAL and
TIDAK LOYAL
KELENGKAPAN_BERITA ,974 ,002 ,549LOYAL and
TIDAK LOYAL
Variables Not in the Analysis
Step Tolerance Min. Tolerance Sig. of F to
Enter
Min. D Squared
0
LAYOUT 1,000 1,000 ,656 ,005
UKURAN_HURUF 1,000 1,000 ,067 ,091
CAKUPAN_BERITA 1,000 1,000 ,442 ,016
AKTUALITAS_BERITA 1,000 1,000 ,002 ,253
ISUE 1,000 1,000 ,433 ,017

KOLOM_ANALISIS 1,000 1,000 ,549 ,010
KELENGKAPAN_BERITA 1,000 1,000 ,009 ,188
FREKUENSI_IKLAN 1,000 1,000 ,460 ,015
FREKUENSI_TERBIT 1,000 1,000 ,582 ,008
KUALITAS_CETAKAN 1,000 1,000 ,011 ,176
HARGA 1,000 1,000 ,043 ,112
1
LAYOUT 1,000 1,000 ,649 ,259
UKURAN_HURUF 1,000 1,000 ,085 ,340
CAKUPAN_BERITA 1,000 1,000 ,448 ,270
ISUE ,998 ,998 ,540 ,264
KOLOM_ANALISIS 1,000 1,000 ,539 ,264
KELENGKAPAN_BERITA ,993 ,993 ,006 ,480
FREKUENSI_IKLAN 1,000 1,000 ,495 ,267
FREKUENSI_TERBIT ,990 ,990 ,813 ,255
KUALITAS_CETAKAN ,965 ,965 ,053 ,363
HARGA ,879 ,879 ,002 ,549
2 LAYOUT ,986 ,867 ,420 ,570
Variables Not in the Analysis
Step Between Groups
0
LAYOUT LOYAL and TIDAK LOYAL
UKURAN_HURUF LOYAL and TIDAK LOYAL
CAKUPAN_BERITA LOYAL and TIDAK LOYAL
AKTUALITAS_BERITA LOYAL and TIDAK LOYAL
ISUE LOYAL and TIDAK LOYAL
KOLOM_ANALISIS LOYAL and TIDAK LOYAL
KELENGKAPAN_BERITA LOYAL and TIDAK LOYAL
FREKUENSI_IKLAN LOYAL and TIDAK LOYAL
FREKUENSI_TERBIT LOYAL and TIDAK LOYAL
KUALITAS_CETAKAN LOYAL and TIDAK LOYAL
HARGA LOYAL and TIDAK LOYAL
1
LAYOUT LOYAL and TIDAK LOYAL
UKURAN_HURUF LOYAL and TIDAK LOYAL
CAKUPAN_BERITA LOYAL and TIDAK LOYAL
ISUE LOYAL and TIDAK LOYAL
KOLOM_ANALISIS LOYAL and TIDAK LOYAL
KELENGKAPAN_BERITA LOYAL and TIDAK LOYAL
FREKUENSI_IKLAN LOYAL and TIDAK LOYAL
FREKUENSI_TERBIT LOYAL and TIDAK LOYAL
KUALITAS_CETAKAN LOYAL and TIDAK LOYAL
HARGA LOYAL and TIDAK LOYAL

2 LAYOUT LOYAL and TIDAK LOYAL
Variables Not in the Analysis
Step Tolerance Min. Tolerance Sig. of F to
Enter
Min. D Squared
2 UKURAN_HURUF ,996 ,876 ,065 ,657
CAKUPAN_BERITA 1,000 ,879 ,492 ,564
ISUE ,994 ,876 ,436 ,568
KOLOM_ANALISIS ,984 ,865 ,842 ,551
KELENGKAPAN_BERITA ,974 ,862 ,002 ,861
FREKUENSI_IKLAN ,999 ,878 ,582 ,559
FREKUENSI_TERBIT ,949 ,843 ,684 ,555
KUALITAS_CETAKAN ,904 ,817 ,256 ,590
3
LAYOUT ,983 ,848 ,337 ,891
UKURAN_HURUF ,996 ,858 ,065 ,976
CAKUPAN_BERITA ,999 ,861 ,570 ,871
ISUE ,991 ,859 ,562 ,872
KOLOM_ANALISIS ,963 ,852 ,525 ,874
FREKUENSI_IKLAN ,996 ,860 ,708 ,865
FREKUENSI_TERBIT ,935 ,832 ,980 ,861
KUALITAS_CETAKAN ,879 ,795 ,548 ,873
Variables Not in the Analysis
Step Between Groups
2 UKURAN_HURUF LOYAL and TIDAK LOYAL
CAKUPAN_BERITA LOYAL and TIDAK LOYAL
ISUE LOYAL and TIDAK LOYAL
KOLOM_ANALISIS LOYAL and TIDAK LOYAL
KELENGKAPAN_BERITA LOYAL and TIDAK LOYAL
FREKUENSI_IKLAN LOYAL and TIDAK LOYAL
FREKUENSI_TERBIT LOYAL and TIDAK LOYAL
KUALITAS_CETAKAN LOYAL and TIDAK LOYAL
3
LAYOUT LOYAL and TIDAK LOYAL
UKURAN_HURUF LOYAL and TIDAK LOYAL
CAKUPAN_BERITA LOYAL and TIDAK LOYAL
ISUE LOYAL and TIDAK LOYAL
KOLOM_ANALISIS LOYAL and TIDAK LOYAL
FREKUENSI_IKLAN LOYAL and TIDAK LOYAL
FREKUENSI_TERBIT LOYAL and TIDAK LOYAL
KUALITAS_CETAKAN LOYAL and TIDAK LOYAL

Wilks' Lambda
Step Number of
Variables
Lambda df1 df2 df3 Exact F
Statistic df1
1 1 ,940 1 1 148 9,463 1
2 2 ,878 2 1 148 10,187 2
3 3 ,822 3 1 148 10,564 3
Wilks' Lambda
Step Exact F
df2 Sig.
1 148,000 ,002
2 147,000 ,000
3 146,000 ,000
Summary of Canonical Discriminant Functions
Eigenvalues
Function Eigenvalue % of Variance Cumulative % Canonical
Correlation
1 ,217a 100,0 100,0 ,422
a. First 1 canonical discriminant functions were used in the analysis.
Wilks' Lambda
Test of Function(s) Wilks' Lambda Chi-square df Sig.
1 ,822 28,780 3 ,000
Standardized Canonical Discriminant
Function Coefficients
Function
1
AKTUALITAS_BERITA ,841
KELENGKAPAN_BERITA ,609

HARGA ,716
Structure Matrix
Function
1
AKTUALITAS_BERITA ,543
KELENGKAPAN_BERITA ,468
HARGA ,361
KUALITAS_CETAKANa ,341
LAYOUTa -,109
FREKUENSI_TERBITa -,102
FREKUENSI_IKLANa -,057
UKURAN_HURUFa -,040
ISUEa ,025
CAKUPAN_BERITAa -,024
KOLOM_ANALISISa -,017
Pooled within-groups correlations
between discriminating variables and
standardized canonical discriminant
functions
Variables ordered by absolute size of
correlation within function.
a. This variable not used in the analysis.
Functions at Group
Centroids
PEMBACA Function
1
LOYAL ,433
TIDAK LOYAL -,495
Unstandardized canonical
discriminant functions
evaluated at group means
Classification Statistics

Classification Processing Summary
Processed 150
Excluded
Missing or out-of-range
group codes0
At least one missing
discriminating variable0
Used in Output 150
Prior Probabilities for Groups
PEMBACA Prior Cases Used in Analysis
Unweighted Weighted
LOYAL ,500 80 80,000
TIDAK LOYAL ,500 70 70,000
Total 1,000 150 150,000
Classification Function Coefficients
PEMBACA
LOYAL TIDAK LOYAL
AKTUALITAS_BERITA 3,309 2,909
KELENGKAPAN_BERITA 2,581 2,293
HARGA 3,017 2,688
(Constant) -33,453 -26,391
Fisher's linear discriminant functions
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Original 1 0 0 ,303 1
2 0 0 ,410 1
3 0 1** ,655 1
4 0 0 ,280 1
5 0 0 ,837 1
6 0 0 ,139 1
7 0 1** ,750 1
8 0 1** ,940 1
9 0 0 ,574 1
10 0 0 ,413 1
11 1 1 ,763 1
12 1 1 ,916 1
13 1 1 ,770 1
14 1 1 ,007 1
15 1 0** ,806 1
16 0 1** ,921 1
17 0 1** ,795 1
18 0 0 ,938 1
19 0 0 ,071 1
20 0 0 ,317 1
21 0 1** ,585 1
22 0 0 ,861 1
23 0 0 ,793 1
24 0 1** ,954 1
25 0 1** ,692 1
26 1 1 ,211 1
27 1 1 ,058 1
28 1 1 ,385 1
29 1 1 ,476 1
30 1 1 ,219 1
31 1 1 ,357 1
32 1 1 ,546 1
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Original 1 ,800 1,061 1 ,200
2 ,768 ,678 1 ,232
3 ,504 ,199** 0 ,496
4 ,807 1,165 1 ,193
5 ,560 ,042 1 ,440
6 ,858 2,187 1 ,142
7 ,674 ,101** 0 ,326
8 ,589 ,006** 0 ,411
9 ,721 ,315 1 ,279
10 ,767 ,670 1 ,233
11 ,538 ,091 0 ,462
12 ,629 ,011 0 ,371
13 ,540 ,085 0 ,460
14 ,948 7,163 0 ,052
15 ,659 ,061** 1 ,341
16 ,628 ,010** 0 ,372
17 ,662 ,067** 0 ,338
18 ,623 ,006 1 ,377
19 ,892 3,264 1 ,108
20 ,796 1,002 1 ,204
21 ,719 ,299** 0 ,281
22 ,567 ,031 1 ,433
23 ,662 ,069 1 ,338
24 ,593 ,003** 0 ,407
25 ,516 ,157** 0 ,484
26 ,831 1,562 0 ,169
27 ,899 3,589 0 ,101
28 ,775 ,754 0 ,225
29 ,749 ,508 0 ,251
30 ,828 1,508 0 ,172
31 ,783 ,848 0 ,217
32 ,729 ,365 0 ,271
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Original 1 3,833 1,463
2 3,067 1,256
3 ,232 -,048**
4 4,028 1,512
5 ,522 ,228
6 5,792 1,912

7 1,553 -,813**
8 ,725 -,419**
9 2,218 ,995
10 3,049 1,251
11 ,392 -,193
12 1,068 -,600
13 ,404 -,203
14 12,989 -3,171
15 1,378 ,679**
16 1,053 -,593**
17 1,409 -,754**
18 1,010 ,510
19 7,476 2,240
20 3,719 1,434
21 2,173 -1,041**
22 ,567 ,258
23 1,417 ,696
24 ,757 -,437**
25 ,283 -,099**
26 4,741 -1,744
27 7,964 -2,389
28 3,225 -1,363
29 2,691 -1,207
30 4,646 -1,723
31 3,418 -1,416
32 2,346 -1,099
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Original 33 1 1 ,842 1
34 1 1 ,935 1
35 1 1** ,038 1
36 0 0 ,766 1
37 0 0 ,852 1
38 0 0 ,846 1
39 0 0** ,499 1
40 0 0** ,300 1
41 1 1 ,931 1
42 1 1 ,238 1
43 1 1 ,938 1
44 1 0 ,928 1
45 1 0 ,726 1
46 1 1 ,520 1
47 1 0** ,736 1
48 1 0** ,881 1
49 1 0** ,550 1
50 1 1 ,113 1
51 0 0 ,975 1
52 0 0 ,360 1
53 0 1** ,766 1
54 0 1 ,700 1
55 0 0 ,453 1
56 0 0** ,945 1
57 0 0** ,724 1
58 0 0 ,842 1
59 0 1 ,758 1
60 0 0 ,621 1
61 0 0 ,683 1
62 0 0 ,135 1
63 0 1 ,676 1
64 0 0 ,440 1
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Original 33 ,649 ,040 0 ,351
34 ,624 ,007 0 ,376
35 ,913 4,284** 0 ,087
36 ,539 ,088 1 ,461
37 ,646 ,035 1 ,354
38 ,648 ,038 1 ,352
39 ,742 ,458** 1 ,258
40 ,801 1,076** 1 ,199

41 ,587 ,008 0 ,413
42 ,821 1,390 0 ,179
43 ,623 ,006 0 ,377
44 ,626 ,008 1 ,374
45 ,526 ,123 1 ,474
46 ,736 ,414 0 ,264
47 ,678 ,114** 1 ,322
48 ,572 ,022** 1 ,428
49 ,728 ,357** 1 ,272
50 ,870 2,515 0 ,130
51 ,599 ,001 1 ,401
52 ,782 ,837 1 ,218
53 ,539 ,088** 0 ,461
54 ,518 ,149 0 ,482
55 ,755 ,563 1 ,245
56 ,591 ,005** 1 ,409
57 ,526 ,125** 1 ,474
58 ,561 ,040 1 ,439
59 ,536 ,095 0 ,464
60 ,709 ,244 1 ,291
61 ,513 ,167 1 ,487
62 ,860 2,231 1 ,140
63 ,511 ,174 0 ,489
64 ,759 ,598 1 ,241
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Original 33 1,269 -,694
34 1,018 -,576
35 8,985 -2,565**
36 ,398 ,136
37 1,240 ,619
38 1,258 ,627
39 2,573 1,109**
40 3,862 1,470**
41 ,707 -,408
42 4,437 -1,674

43 1,011 -,573
44 1,036 ,523
45 ,332 ,082
46 2,468 -1,138
47 1,600 ,770**
48 ,606 ,284**
49 2,326 1,030**
50 6,318 -2,081
51 ,804 ,402
52 3,395 1,348
53 ,397 -,197**
54 ,294 -,109
55 2,816 1,183
56 ,738 ,364**
57 ,330 ,079**
58 ,530 ,233
59 ,384 -,187
60 2,020 ,927
61 ,269 ,024
62 5,862 1,926
63 ,260 -,077
64 2,892 1,206
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Original 65 0 1 ,725 1
66 1 1 ,804 1
67 1 1** ,659 1
68 1 0 ,324 1
69 1 1 ,668 1
70 1 0 ,787 1
71 1 1** ,671 1
72 1 0** ,771 1
73 1 1 ,971 1
74 1 1 ,984 1
75 1 1 ,897 1
76 0 1 ,914 1
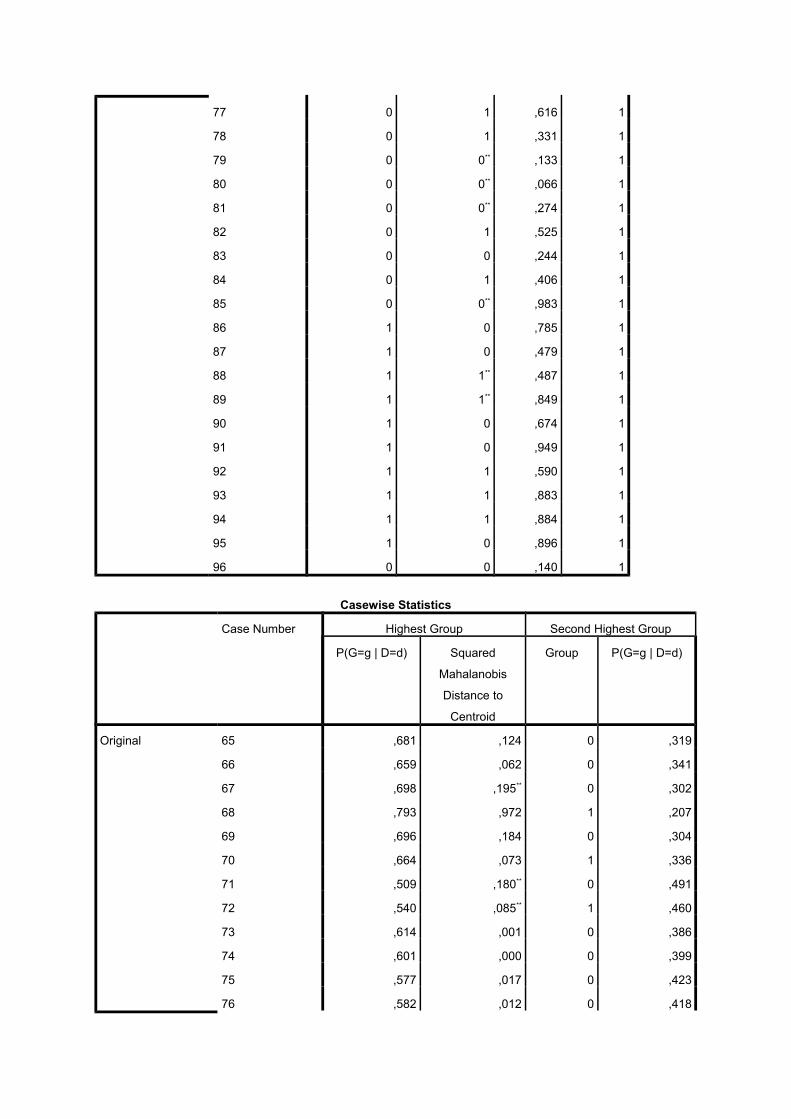
77 0 1 ,616 1
78 0 1 ,331 1
79 0 0** ,133 1
80 0 0** ,066 1
81 0 0** ,274 1
82 0 1 ,525 1
83 0 0 ,244 1
84 0 1 ,406 1
85 0 0** ,983 1
86 1 0 ,785 1
87 1 0 ,479 1
88 1 1** ,487 1
89 1 1** ,849 1
90 1 0 ,674 1
91 1 0 ,949 1
92 1 1 ,590 1
93 1 1 ,883 1
94 1 1 ,884 1
95 1 0 ,896 1
96 0 0 ,140 1
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Original 65 ,681 ,124 0 ,319
66 ,659 ,062 0 ,341
67 ,698 ,195** 0 ,302
68 ,793 ,972 1 ,207
69 ,696 ,184 0 ,304
70 ,664 ,073 1 ,336
71 ,509 ,180** 0 ,491
72 ,540 ,085** 1 ,460
73 ,614 ,001 0 ,386
74 ,601 ,000 0 ,399
75 ,577 ,017 0 ,423
76 ,582 ,012 0 ,418
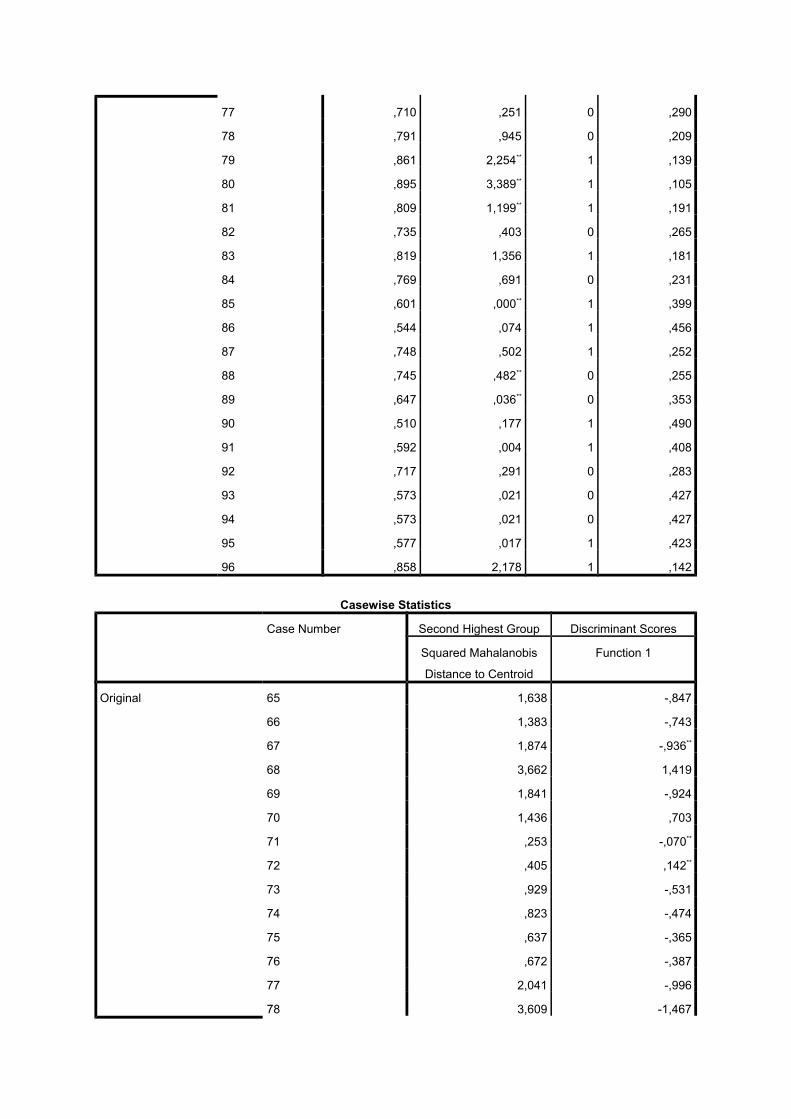
77 ,710 ,251 0 ,290
78 ,791 ,945 0 ,209
79 ,861 2,254** 1 ,139
80 ,895 3,389** 1 ,105
81 ,809 1,199** 1 ,191
82 ,735 ,403 0 ,265
83 ,819 1,356 1 ,181
84 ,769 ,691 0 ,231
85 ,601 ,000** 1 ,399
86 ,544 ,074 1 ,456
87 ,748 ,502 1 ,252
88 ,745 ,482** 0 ,255
89 ,647 ,036** 0 ,353
90 ,510 ,177 1 ,490
91 ,592 ,004 1 ,408
92 ,717 ,291 0 ,283
93 ,573 ,021 0 ,427
94 ,573 ,021 0 ,427
95 ,577 ,017 1 ,423
96 ,858 2,178 1 ,142
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Original 65 1,638 -,847
66 1,383 -,743
67 1,874 -,936**
68 3,662 1,419
69 1,841 -,924
70 1,436 ,703
71 ,253 -,070**
72 ,405 ,142**
73 ,929 -,531
74 ,823 -,474
75 ,637 -,365
76 ,672 -,387
77 2,041 -,996
78 3,609 -1,467

79 5,900 1,934**
80 7,665 2,274**
81 4,091 1,528**
82 2,442 -1,130
83 4,376 1,597
84 3,093 -1,326
85 ,822 ,412**
86 ,429 ,161
87 2,677 1,141
88 2,631 -1,189**
89 1,249 -,685**
90 ,256 ,012
91 ,747 ,370
92 2,152 -1,034
93 ,610 -,348
94 ,611 -,349
95 ,636 ,302
96 5,777 1,909
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Original 97 0 0 ,812 1
98 0 1 ,981 1
99 0 0** ,649 1
100 0 0 ,866 1
101 0 0 ,842 1
102 0 0 ,547 1
103 0 1** ,451 1
104 0 1** ,692 1
105 0 0 ,091 1
106 1 1 ,248 1
107 1 0 ,433 1
108 1 1 ,730 1
109 1 1 ,913 1
110 1 1 ,905 1
111 0 1** ,467 1
112 0 0** ,459 1
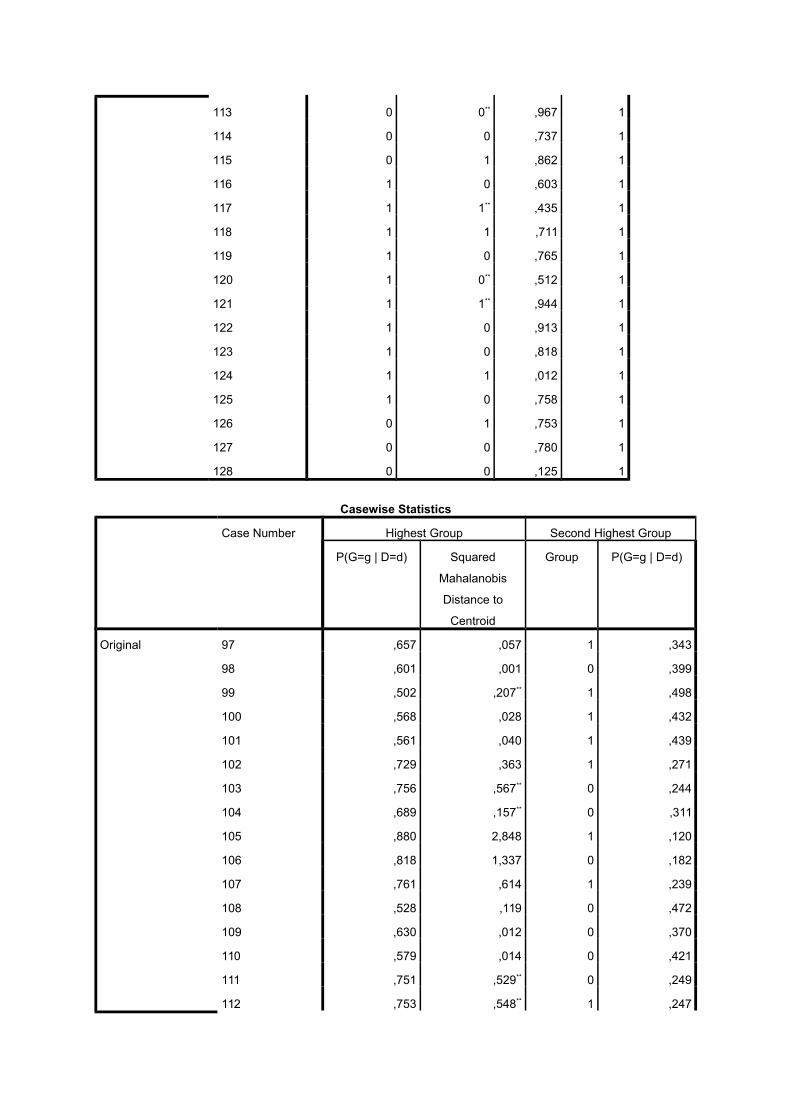
113 0 0** ,967 1
114 0 0 ,737 1
115 0 1 ,862 1
116 1 0 ,603 1
117 1 1** ,435 1
118 1 1 ,711 1
119 1 0 ,765 1
120 1 0** ,512 1
121 1 1** ,944 1
122 1 0 ,913 1
123 1 0 ,818 1
124 1 1 ,012 1
125 1 0 ,758 1
126 0 1 ,753 1
127 0 0 ,780 1
128 0 0 ,125 1
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Original 97 ,657 ,057 1 ,343
98 ,601 ,001 0 ,399
99 ,502 ,207** 1 ,498
100 ,568 ,028 1 ,432
101 ,561 ,040 1 ,439
102 ,729 ,363 1 ,271
103 ,756 ,567** 0 ,244
104 ,689 ,157** 0 ,311
105 ,880 2,848 1 ,120
106 ,818 1,337 0 ,182
107 ,761 ,614 1 ,239
108 ,528 ,119 0 ,472
109 ,630 ,012 0 ,370
110 ,579 ,014 0 ,421
111 ,751 ,529** 0 ,249
112 ,753 ,548** 1 ,247
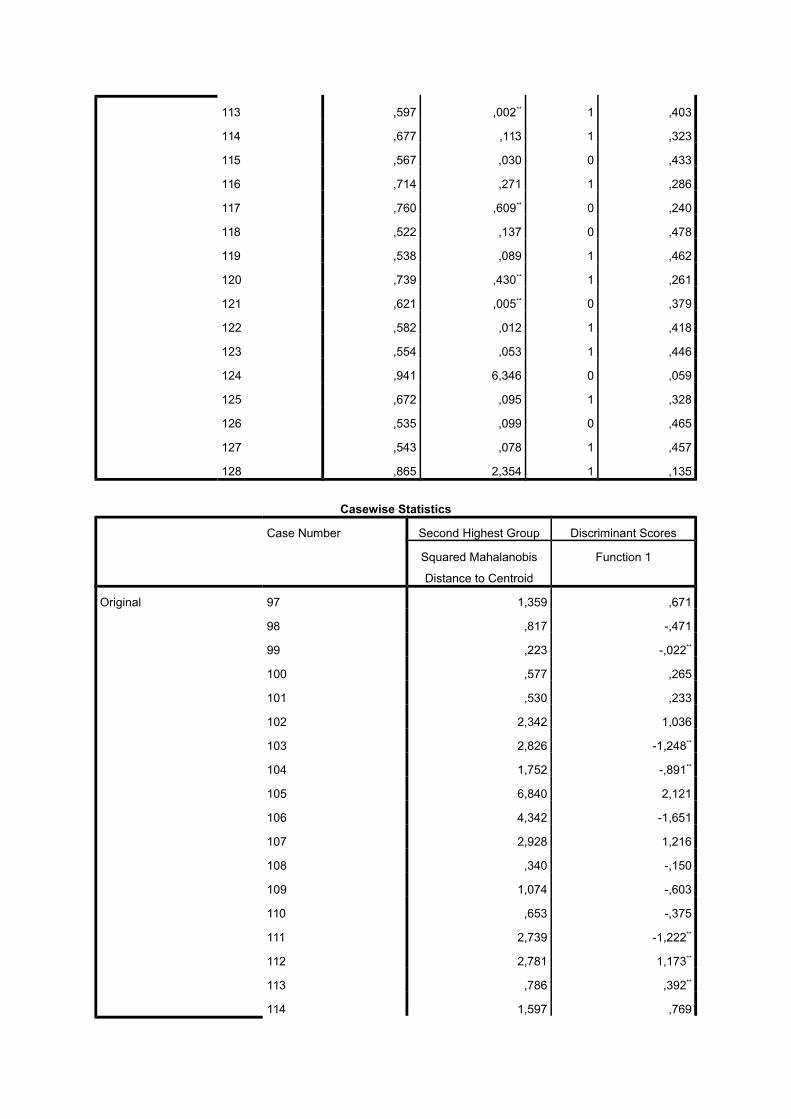
113 ,597 ,002** 1 ,403
114 ,677 ,113 1 ,323
115 ,567 ,030 0 ,433
116 ,714 ,271 1 ,286
117 ,760 ,609** 0 ,240
118 ,522 ,137 0 ,478
119 ,538 ,089 1 ,462
120 ,739 ,430** 1 ,261
121 ,621 ,005** 0 ,379
122 ,582 ,012 1 ,418
123 ,554 ,053 1 ,446
124 ,941 6,346 0 ,059
125 ,672 ,095 1 ,328
126 ,535 ,099 0 ,465
127 ,543 ,078 1 ,457
128 ,865 2,354 1 ,135
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Original 97 1,359 ,671
98 ,817 -,471
99 ,223 -,022**
100 ,577 ,265
101 ,530 ,233
102 2,342 1,036
103 2,826 -1,248**
104 1,752 -,891**
105 6,840 2,121
106 4,342 -1,651
107 2,928 1,216
108 ,340 -,150
109 1,074 -,603
110 ,653 -,375
111 2,739 -1,222**
112 2,781 1,173**
113 ,786 ,392**
114 1,597 ,769

115 ,569 -,321
116 2,098 ,954
117 2,918 -1,275**
118 ,311 -,125
119 ,395 ,134
120 2,507 1,088**
121 ,996 -,565**
122 ,670 ,324
123 ,486 ,202
124 11,881 -3,014
125 1,526 ,741
126 ,376 -,180
127 ,420 ,153
128 6,061 1,967
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Original 129 0 0 ,974 1
130 0 0 ,439 1
131 1 1** ,972 1
132 1 0 ,598 1
133 1 1 ,926 1
134 1 1 ,195 1
135 1 1** ,980 1
136 0 0** ,788 1
137 0 0 ,255 1
138 0 1 ,999 1
139 0 0 ,814 1
140 0 0 ,243 1
141 0 0 ,938 1
142 0 1 ,546 1
143 0 0** ,652 1
144 0 0** ,857 1
145 0 0** ,930 1
146 1 1 ,216 1
147 1 0 ,399 1
148 1 1 ,490 1

149 1 1** ,945 1
150 1 1 ,098 1
Cross-validated
1 0 0 ,762 3
2 0 0** ,805 3
3 0 1** ,778 3
4 0 0 ,708 3
5 0 0 ,911 3
6 0 0 ,406 3
7 0 1 ,721 3
8 0 1 ,802 3
9 0 0 ,918 3
10 0 0 ,856 3
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Original 129 ,613 ,001 1 ,387
130 ,759 ,598 1 ,241
131 ,614 ,001** 0 ,386
132 ,715 ,278 1 ,285
133 ,626 ,009 0 ,374
134 ,837 1,683 0 ,163
135 ,611 ,001** 0 ,389
136 ,664 ,072** 1 ,336
137 ,816 1,298 1 ,184
138 ,606 ,000 0 ,394
139 ,657 ,055 1 ,343
140 ,820 1,363 1 ,180
141 ,623 ,006 1 ,377
142 ,729 ,365 0 ,271
143 ,503 ,204** 1 ,497
144 ,645 ,032** 1 ,355
145 ,586 ,008** 1 ,414
146 ,829 1,532 0 ,171
147 ,771 ,712 1 ,229
148 ,745 ,475 0 ,255
149 ,591 ,005** 0 ,409

150 ,877 2,743 0 ,123
Cross-validated
1 ,798 1,161 1 ,202
2 ,765 ,985** 1 ,235
3 ,508 1,096** 0 ,492
4 ,805 1,389 1 ,195
5 ,558 ,534 1 ,442
6 ,857 2,909 1 ,143
7 ,684 1,336 0 ,316
8 ,595 ,997 0 ,405
9 ,719 ,504 1 ,281
10 ,765 ,772 1 ,235
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Original 129 ,923 ,466
130 2,894 1,206
131 ,927 -,530**
132 2,118 ,961
133 1,042 -,588
134 4,951 -1,792
135 ,907 -,520**
136 1,431 ,701**
137 4,272 1,572
138 ,857 -,493
139 1,352 ,668
140 4,389 1,600
141 1,010 ,510
142 2,347 -1,099
143 ,227 -,018**
144 1,227 ,613**
145 ,706 ,346**
146 4,689 -1,732
147 3,139 1,277
148 2,615 -1,184
149 ,738 -,426**
150 6,676 -2,151
Cross-validated 1 3,907
2 3,347
3 1,163
4 4,223
5 ,996
6 6,483
7 2,885
8 1,770
9 2,387
10 3,128
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Cross-validated 11 1 1 ,075 3
12 1 1 ,844 3
13 1 1** ,975 3
14 1 1 ,008 3
15 1 0 ,982 3
16 0 1 ,133 3
17 0 1** ,322 3
18 0 0** ,997 3
19 0 0 ,328 3
20 0 0 ,464 3
21 0 1 ,592 3
22 0 0 ,578 3
23 0 0 ,967 3
24 0 1 ,164 3
25 0 1** ,838 3
26 1 1** ,087 3
27 1 1** ,046 3
28 1 1 ,068 3
29 1 1 ,204 3
30 1 1 ,317 3
31 1 1** ,150 3
32 1 1 ,246 3
33 1 1 ,064 3
34 1 1** ,022 3
35 1 1** ,048 3
36 0 0 ,812 3

37 0 0 ,624 3
38 0 0 ,681 3
39 0 0 ,882 3
40 0 0 ,558 3
41 1 1 ,097 3
42 1 1 ,114 3
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Cross-validated 11 ,510 6,917 0 ,490
12 ,626 ,823 0 ,374
13 ,539 ,216** 0 ,461
14 ,950 11,712 0 ,050
15 ,664 ,171 1 ,336
16 ,656 5,592 0 ,344
17 ,682 3,491** 0 ,318
18 ,622 ,051** 1 ,378
19 ,891 3,443 1 ,109
20 ,792 2,565 1 ,208
21 ,733 1,905 0 ,267
22 ,560 1,973 1 ,440
23 ,661 ,264 1 ,339
24 ,618 5,110 0 ,382
25 ,519 ,848** 0 ,481
26 ,824 6,558** 0 ,176
27 ,897 8,015** 0 ,103
28 ,763 7,111 0 ,237
29 ,739 4,594 0 ,261
30 ,823 3,532 0 ,177
31 ,774 5,316** 0 ,226
32 ,719 4,142 0 ,281
33 ,626 7,273 0 ,374
34 ,592 9,642** 0 ,408
35 ,912 7,890** 0 ,088
36 ,535 ,957 1 ,465
37 ,641 1,759 1 ,359
38 ,643 1,505 1 ,357
39 ,740 ,661 1 ,260
40 ,798 2,069 1 ,202
41 ,563 6,315 0 ,437
42 ,814 5,957 0 ,186
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Cross-validated 11 6,995
12 1,850
13 ,526
14 17,599
15 1,537
16 6,881
17 5,013
18 1,047
19 7,638
20 5,239
21 3,923
22 2,453
23 1,597
24 6,071
25 1,004
26 9,641
27 12,344
28 9,445
29 6,675
30 6,612
31 7,783
32 6,026
33 8,306
34 10,383
35 12,563
36 1,237
37 2,917
38 2,683
39 2,755
40 4,817
41 6,825
42 8,910
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Cross-validated 43 1 1 ,576 3
44 1 0 ,979 3
45 1 0** ,474 3
46 1 1 ,267 3
47 1 0 ,889 3
48 1 0 ,809 3
49 1 0** ,219 3
50 1 1** ,038 3
51 0 0 ,790 3
52 0 0 ,823 3
53 0 1 ,808 3
54 0 1 ,161 3
55 0 0 ,519 3
56 0 0 ,771 3
57 0 0** ,564 3
58 0 0** ,882 3
59 0 1** ,642 3
60 0 0 ,542 3
61 0 0 ,982 3
62 0 0 ,496 3
63 0 1** ,738 3
64 0 0 ,893 3
65 0 1 ,168 3
66 1 1** ,760 3
67 1 1** ,604 3
68 1 0 ,781 3
69 1 1 ,555 3
70 1 0 ,874 3
71 1 0 ,493 3
72 1 0 ,925 3
73 1 1 ,488 3
74 1 1 ,427 3
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Cross-validated 43 ,616 1,981 0 ,384
44 ,630 ,191 1 ,370
45 ,538 2,507** 1 ,462
46 ,727 3,948 0 ,273
47 ,686 ,633 1 ,314
48 ,579 ,969 1 ,421
49 ,756 4,423** 1 ,244
50 ,865 8,443** 0 ,135
51 ,595 1,046 1 ,405
52 ,780 ,910 1 ,220
53 ,543 ,970 0 ,457
54 ,539 5,149 0 ,461
55 ,751 2,269 1 ,249
56 ,587 1,127 1 ,413
57 ,518 2,040** 1 ,482
58 ,558 ,664** 1 ,442
59 ,544 1,676** 0 ,456
60 ,703 2,151 1 ,297
61 ,512 ,174 1 ,488
62 ,858 2,387 1 ,142
63 ,516 1,261** 0 ,484
64 ,757 ,617 1 ,243
65 ,708 5,053 0 ,292
66 ,655 1,172** 0 ,345
67 ,693 1,851** 0 ,307
68 ,806 1,085 1 ,194
69 ,690 2,085 0 ,310
70 ,672 ,698 1 ,328
71 ,501 2,406 1 ,499
72 ,543 ,473 1 ,457

73 ,605 2,432 0 ,395
74 ,591 2,777 0 ,409
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Cross-validated 43 2,925
44 1,257
45 2,813
46 5,910
47 2,197
48 1,606
49 6,680
50 12,161
51 1,818
52 3,444
53 1,317
54 5,464
55 4,474
56 1,826
57 2,184
58 1,133
59 2,027
60 3,877
61 ,271
62 5,992
63 1,388
64 2,890
65 6,824
66 2,455
67 3,478
68 3,939
69 3,684
70 2,135
71 2,413
72 ,818
73 3,286
74 3,515
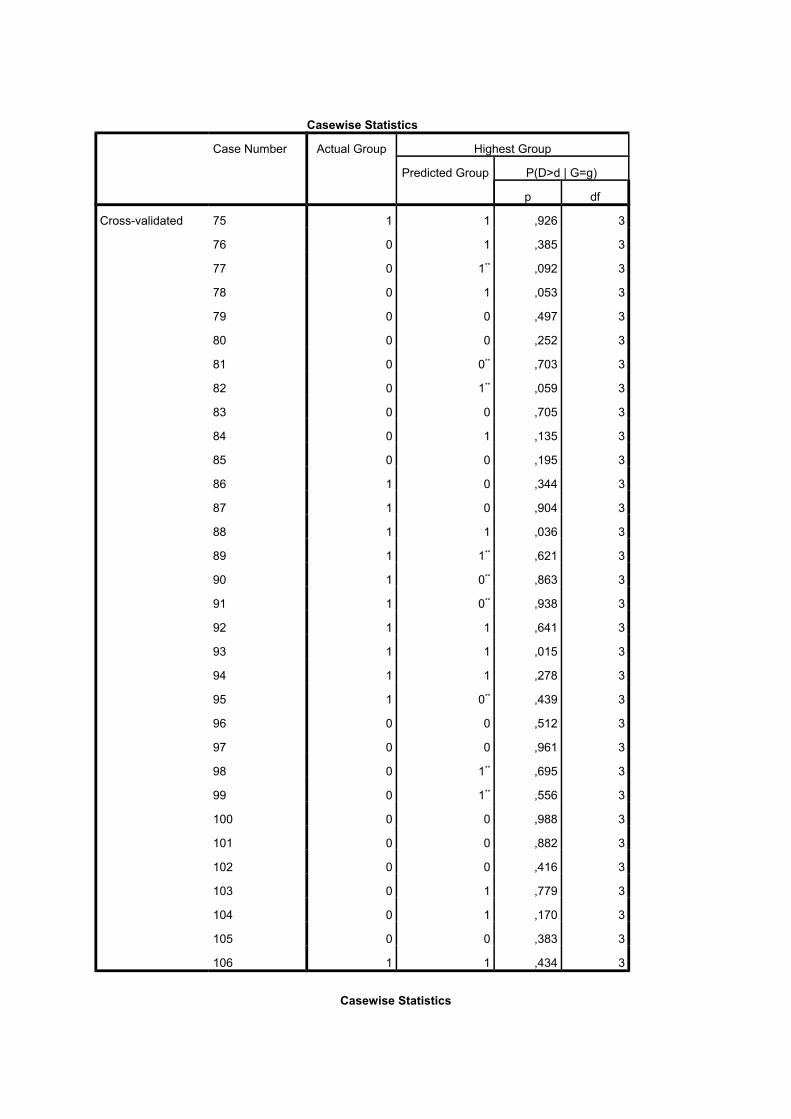
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df
Cross-validated 75 1 1 ,926 3
76 0 1 ,385 3
77 0 1** ,092 3
78 0 1 ,053 3
79 0 0 ,497 3
80 0 0 ,252 3
81 0 0** ,703 3
82 0 1** ,059 3
83 0 0 ,705 3
84 0 1 ,135 3
85 0 0 ,195 3
86 1 0 ,344 3
87 1 0 ,904 3
88 1 1 ,036 3
89 1 1** ,621 3
90 1 0** ,863 3
91 1 0** ,938 3
92 1 1 ,641 3
93 1 1 ,015 3
94 1 1 ,278 3
95 1 0** ,439 3
96 0 0 ,512 3
97 0 0 ,961 3
98 0 1** ,695 3
99 0 1** ,556 3
100 0 0 ,988 3
101 0 0 ,882 3
102 0 0 ,416 3
103 0 1 ,779 3
104 0 1 ,170 3
105 0 0 ,383 3
106 1 1 ,434 3
Casewise Statistics

Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Cross-validated 75 ,575 ,469 0 ,425
76 ,597 3,040 0 ,403
77 ,744 6,451** 0 ,256
78 ,828 7,700 0 ,172
79 ,859 2,380 1 ,141
80 ,894 4,086 1 ,106
81 ,807 1,413** 1 ,193
82 ,773 7,439** 0 ,227
83 ,817 1,402 1 ,183
84 ,799 5,568 0 ,201
85 ,586 4,701 1 ,414
86 ,561 3,323 1 ,439
87 ,758 ,566 1 ,242
88 ,728 8,574 0 ,272
89 ,641 1,771** 0 ,359
90 ,513 ,744** 1 ,487
91 ,596 ,409** 1 ,404
92 ,712 1,681 0 ,288
93 ,533 10,496 0 ,467
94 ,558 3,848 0 ,442
95 ,592 2,707** 1 ,408
96 ,856 2,305 1 ,144
97 ,656 ,292 1 ,344
98 ,609 1,444** 0 ,391
99 ,506 2,082** 0 ,494
100 ,567 ,131 1 ,433
101 ,558 ,664 1 ,442
102 ,723 2,848 1 ,277
103 ,767 1,090 0 ,233
104 ,717 5,031 0 ,283
105 ,879 3,059 1 ,121
106 ,814 2,738 0 ,186
Casewise Statistics

Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Cross-validated 75 1,071
76 3,826
77 8,581
78 10,848
79 6,000
80 8,345
81 4,276
82 9,885
83 4,395
84 8,323
85 5,399
86 3,813
87 2,849
88 10,542
89 2,930
90 ,851
91 1,189
92 3,495
93 10,764
94 4,318
95 3,449
96 5,877
97 1,580
98 2,333
99 2,130
100 ,672
101 1,133
102 4,766
103 3,475
104 6,889
105 7,029
106 5,693
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)

p df
Cross-validated 107 1 0 ,795 3
108 1 1 ,669 3
109 1 1** ,463 3
110 1 1 ,288 3
111 0 1 ,712 3
112 0 0 ,727 3
113 0 0** ,382 3
114 0 0** ,939 3
115 0 1 ,511 3
116 1 0 ,545 3
117 1 1 ,027 3
118 1 1 ,548 3
119 1 0 ,604 3
120 1 0 ,808 3
121 1 1** ,988 3
122 1 0** ,975 3
123 1 0** ,473 3
124 1 1 ,014 3
125 1 0 ,445 3
126 0 1 ,551 3
127 0 0** ,934 3
128 0 0 ,462 3
129 0 0 ,962 3
130 0 0** ,684 3
131 1 1** ,695 3
132 1 0 ,709 3
133 1 1 ,329 3
134 1 1 ,139 3
135 1 1 ,935 3
136 0 0 ,896 3
137 0 0 ,666 3
138 0 1 ,772 3
Casewise Statistics
Case Number Highest Group Second Highest Group

P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Cross-validated 107 ,773 1,026 1 ,227
108 ,521 1,557 0 ,479
109 ,621 2,569** 0 ,379
110 ,565 3,763 0 ,435
111 ,764 1,371 0 ,236
112 ,750 1,309 1 ,250
113 ,587 3,061** 1 ,413
114 ,676 ,405** 1 ,324
115 ,578 2,309 0 ,422
116 ,730 2,136 1 ,270
117 ,743 9,154 0 ,257
118 ,513 2,119 0 ,487
119 ,548 1,852 1 ,452
120 ,750 ,974 1 ,250
121 ,620 ,127** 0 ,380
122 ,585 ,218** 1 ,415
123 ,567 2,510** 1 ,433
124 ,942 10,660 0 ,058
125 ,690 2,672 1 ,310
126 ,544 2,106 0 ,456
127 ,541 ,429** 1 ,459
128 ,863 2,574 1 ,137
129 ,612 ,290 1 ,388
130 ,756 1,493** 1 ,244
131 ,608 1,446** 0 ,392
132 ,728 1,383 1 ,272
133 ,615 3,439 0 ,385
134 ,831 5,500 0 ,169
135 ,609 ,427 0 ,391
136 ,661 ,604 1 ,339
137 ,813 1,573 1 ,187
138 ,613 1,122 0 ,387
Casewise Statistics
Case Number Second Highest Group Discriminant Scores

Squared Mahalanobis
Distance to Centroid
Function 1
Cross-validated 107 3,479
108 1,727
109 3,555
110 4,285
111 3,718
112 3,511
113 3,762
114 1,872
115 2,941
116 4,129
117 11,279
118 2,223
119 2,234
120 3,173
121 1,108
122 ,903
123 3,050
124 16,226
125 4,272
126 2,459
127 ,757
128 6,255
129 1,199
130 3,753
131 2,325
132 3,353
133 4,372
134 8,688
135 1,315
136 1,941
137 4,518
138 2,042
Casewise Statistics
Case Number Actual Group Highest Group
Predicted Group P(D>d | G=g)
p df

Cross-validated 139 0 0 ,902 3
140 0 0 ,492 3
141 0 0** ,997 3
142 0 1 ,130 3
143 0 1 ,539 3
144 0 0 ,799 3
145 0 0** ,785 3
146 1 1** ,215 3
147 1 0 ,862 3
148 1 1 ,856 3
149 1 1 ,350 3
150 1 1 ,274 3
Casewise Statistics
Case Number Highest Group Second Highest Group
P(G=g | D=d) Squared
Mahalanobis
Distance to
Centroid
Group P(G=g | D=d)
Cross-validated 139 ,654 ,576 1 ,346
140 ,817 2,411 1 ,183
141 ,622 ,051** 1 ,378
142 ,760 5,653 0 ,240
143 ,505 2,166 0 ,495
144 ,641 1,011 1 ,359
145 ,583 1,065** 1 ,417
146 ,824 4,466** 0 ,176
147 ,782 ,745 1 ,218
148 ,742 ,771 0 ,258
149 ,578 3,280 0 ,422
150 ,875 3,883 0 ,125
Casewise Statistics
Case Number Second Highest Group Discriminant Scores
Squared Mahalanobis
Distance to Centroid
Function 1
Cross-validated 139 1,852
140 5,400
141 1,047
142 7,955
143 2,209
144 2,175
145 1,732
146 7,552
147 3,302
148 2,884
149 3,912
150 7,775
For the original data, squared Mahalanobis distance is based on canonical functions.
For the cross-validated data, squared Mahalanobis distance is based on observations.
**. Misclassified case
b. Cross validation is done only for those cases in the analysis. In cross validation, each case is classified by
the functions derived from all cases other than that case.
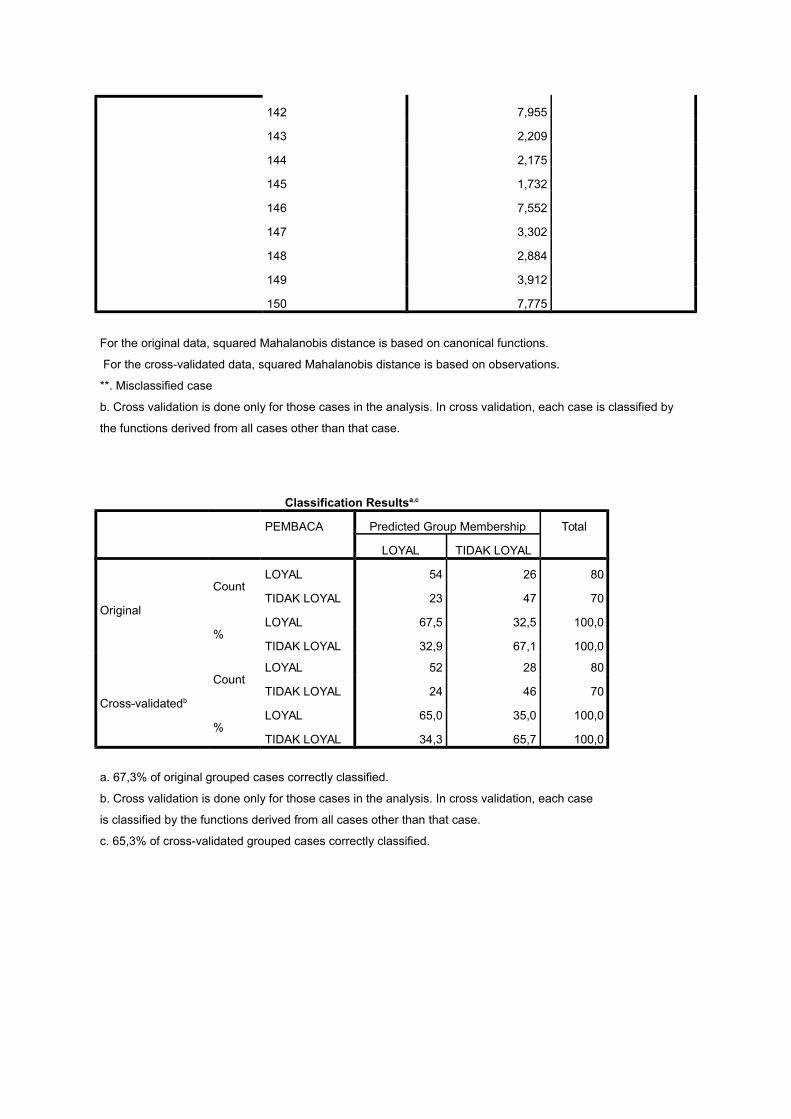
Classification Resultsa,c
PEMBACA Predicted Group Membership Total
LOYAL TIDAK LOYAL
Original
CountLOYAL 54 26 80
TIDAK LOYAL 23 47 70
%LOYAL 67,5 32,5 100,0
TIDAK LOYAL 32,9 67,1 100,0
Cross-validatedb
CountLOYAL 52 28 80
TIDAK LOYAL 24 46 70
%LOYAL 65,0 35,0 100,0
TIDAK LOYAL 34,3 65,7 100,0
a. 67,3% of original grouped cases correctly classified.
b. Cross validation is done only for those cases in the analysis. In cross validation, each case
is classified by the functions derived from all cases other than that case.
c. 65,3% of cross-validated grouped cases correctly classified.





























